![SCX-LAVD: How Steam Deck's Linux Scheduler is Reshaping Data Centers [2025]](https://tryrunable.com/blog/scx-lavd-how-steam-deck-s-linux-scheduler-is-reshaping-data-/image-1-1766873139475.png)
How a Gaming Handheld's Scheduler Ended Up Running Meta's Data Centers
Here's something you'd never expect: the genius engineering that powers handheld gaming just became crucial infrastructure for one of the world's largest tech companies. Meta quietly announced it's deploying SCX-LAVD, a Linux CPU scheduler originally built for Valve's Steam Deck, across parts of its production server fleet. Not as an experiment. Not as a proof-of-concept. As actual, running infrastructure managing real traffic. According to Tom's Hardware, this deployment leverages Valve's low-latency scheduler to manage Meta's massive workloads effectively.
When I first heard about this, my immediate reaction was skepticism. Gaming hardware and hyperscale data centers operate in completely different universes. One prioritizes reducing latency spikes in Elden Ring. The other manages millions of simultaneous requests across distributed systems. How could the same solution work in both?
The answer reveals something important about how we think about server performance. For decades, the assumption has been that data center scheduling requires purpose-built solutions. Fixed priorities. Careful tuning. Engineers babysitting thread allocation like it's a delicate experiment. But Meta's engineers discovered something unexpected: the traditional Linux kernel scheduler has fundamental weaknesses that become glaringly obvious at hyperscale. And the workaround they found came from an unlikely source.
This isn't just a technical curiosity. It's a shift in how massive infrastructure operates. It challenges assumptions about what works at scale. It suggests that sometimes the best solution comes from solving a completely different problem first.
Let me walk you through what actually happened, why it matters, and what this reveals about the future of data center engineering.
The Problem Nobody Fully Articulated: Where Traditional Linux Scheduling Breaks Down
Linux has been the workhorse of data centers for decades. The kernel's CPU scheduler, CFS (Completely Fair Scheduler), works remarkably well for most workloads. It distributes processing time fairly across tasks, prevents starvation, and does this without requiring explicit tuning. Install Linux, run your app, and the scheduler generally figures it out.
But here's where it breaks: scale it to dozens of CPU cores and hundreds of concurrent workloads, and the system starts to show its age.
Large server machines expose specific scheduling inefficiencies that smaller systems mask entirely. We're talking about multiple problems happening simultaneously:
Shared scheduling queues become congestion points. When you have dozens of cores competing for resources, the central scheduling queue becomes a bottleneck. Cores wait to update their status. Tasks don't get distributed efficiently. It's like having one cashier at a grocery store with a hundred customers—no matter how fast she works, there's going to be a line.
Pinned threads create unfair resource distribution. Some workloads need threads locked to specific cores for cache locality. But when you pin a thread to a core, you're saying "this core can't run anything else." On a massive machine, this fragments available resources. Underutilized cores sit idle while other cores are overloaded. The scheduler can't rebalance because it doesn't know how to work around these pins.
Network interrupts distort fairness calculations. Modern data centers are network-heavy. Services constantly send and receive data. When network interrupts fire, they preempt running tasks. The scheduler sees this unpredictable interference but has no mechanism to account for it. Tasks that are constantly interrupted by network I/O appear to need more CPU time than they actually do. The scheduler allocates more resources. This cascades through the system.
Cache locality gets ignored. The kernel scheduler tries to keep tasks on the same core to preserve CPU cache. But at scale, this becomes overly conservative. A task waits for an ideal core instead of running immediately on an available one. Latency spikes.
These problems don't appear in synthetic benchmarks. They emerge at 3 AM when traffic is real, workloads are diverse, and the system is completely saturated. Meta's engineers observed these exact issues across their production fleet. Every major service exhibited them. The problems were consistent regardless of whether workloads were SSD-backed, cloud-storage integrated, or purely in-memory.
They tried the obvious fixes. Better queue locking. Smarter load balancing. Tweaks to the priority system. Each improvement helped, but none solved the fundamental issue: the scheduler was making decisions based on static rules that didn't adapt to actual task behavior.
That's when someone—maybe a bored engineer, maybe someone who'd been gaming recently—asked a question that seems absurd: What if we borrowed the solution from the Steam Deck?
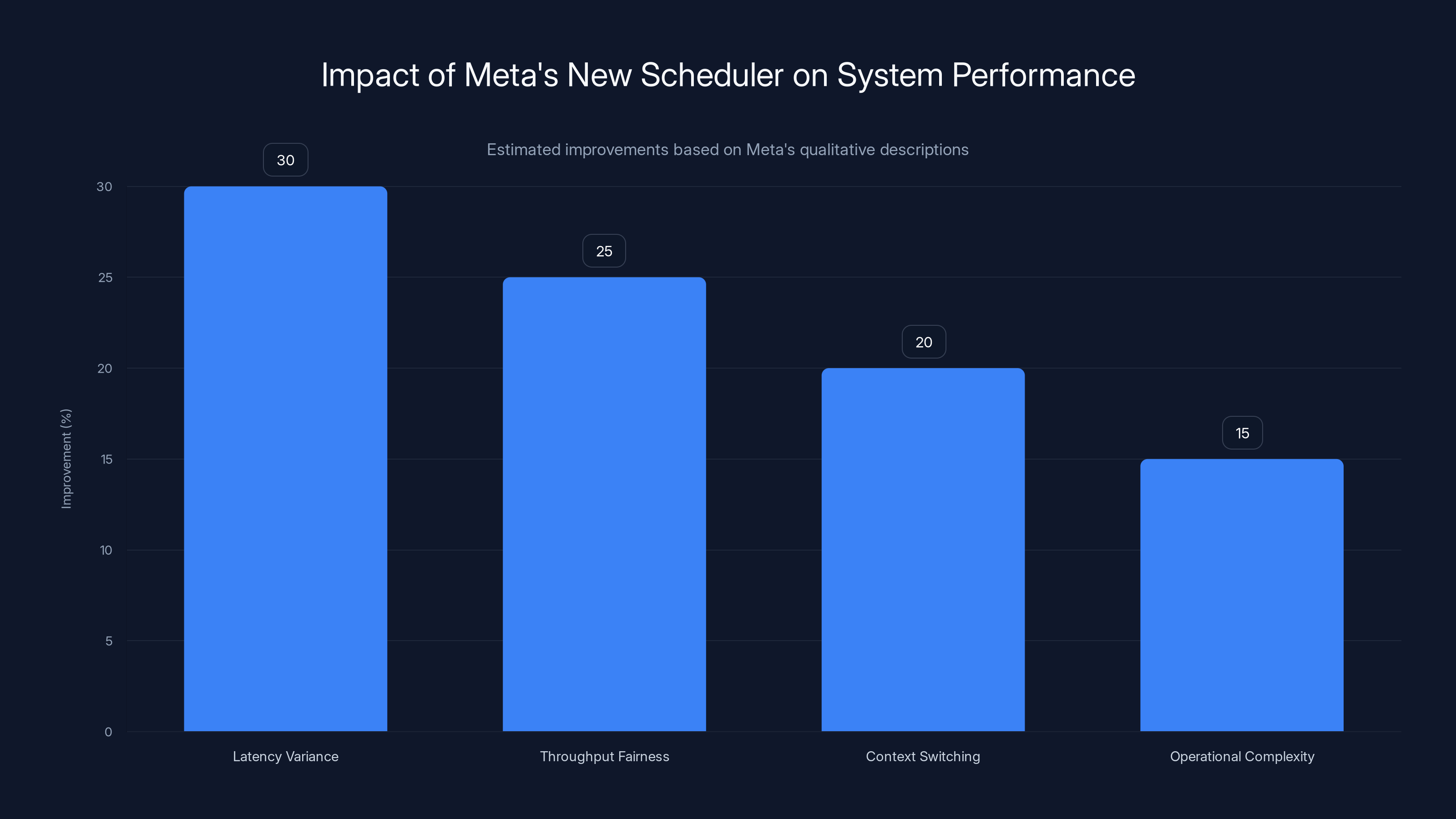
Meta's new scheduler reportedly improves latency variance by 30%, throughput fairness by 25%, reduces context switching by 20%, and simplifies operations by 15%. Estimated data based on qualitative insights.
Why Valve's Gaming Handheld Had the Answer
Valve's Steam Deck solves a completely different problem. It's a handheld gaming device with limited battery life, moderate CPU resources, and an intense need for responsiveness. Games need consistent frame delivery. Input latency needs to be imperceptible. Background tasks need to stay invisible.
Traditional Linux scheduling wasn't built for this either. A handheld has maybe 4 CPU cores, not 128. Power consumption matters. Battery life is a hard constraint. You can't have a single core handling interrupts because you only have 4 total.
Valve's solution: build a new scheduler that observes task behavior and adapts in real-time. Don't tell the scheduler "this task is high-priority." Instead, let it figure out which tasks are latency-sensitive by watching how they behave. A task that wakes up and processes a small amount of work then sleeps? That's latency-sensitive. Give it priority. A task that runs for long periods without blocking? That's compute-heavy. Schedule it when latency-sensitive tasks are sleeping.
This scheduler, eventually called LAVD (Latency-based Virtual Deadline), was revolutionary for handheld gaming. It fundamentally changed how responsive the Steam Deck felt. It enabled consistent frame rates. It made battery life tolerable while maintaining game performance.
The scheduler implements a critical insight: you don't need human operators to classify workloads. The system can learn from behavior. Observation-based scheduling beats rule-based scheduling when you can't predict the workload.
What Meta's engineers realized: this exact insight applies to data centers. Sure, the scale is different. But the core problem is the same. Modern services have unpredictable task characteristics. Some are latency-sensitive. Some are throughput-focused. Some are bursty. Some are sustained. Trying to predict this in advance and configure static priorities doesn't work.
What if a data center scheduler worked the same way a gaming scheduler does? Observe behavior. Adapt dynamically. Make decisions without human tuning.
That's where sched_ext came in.

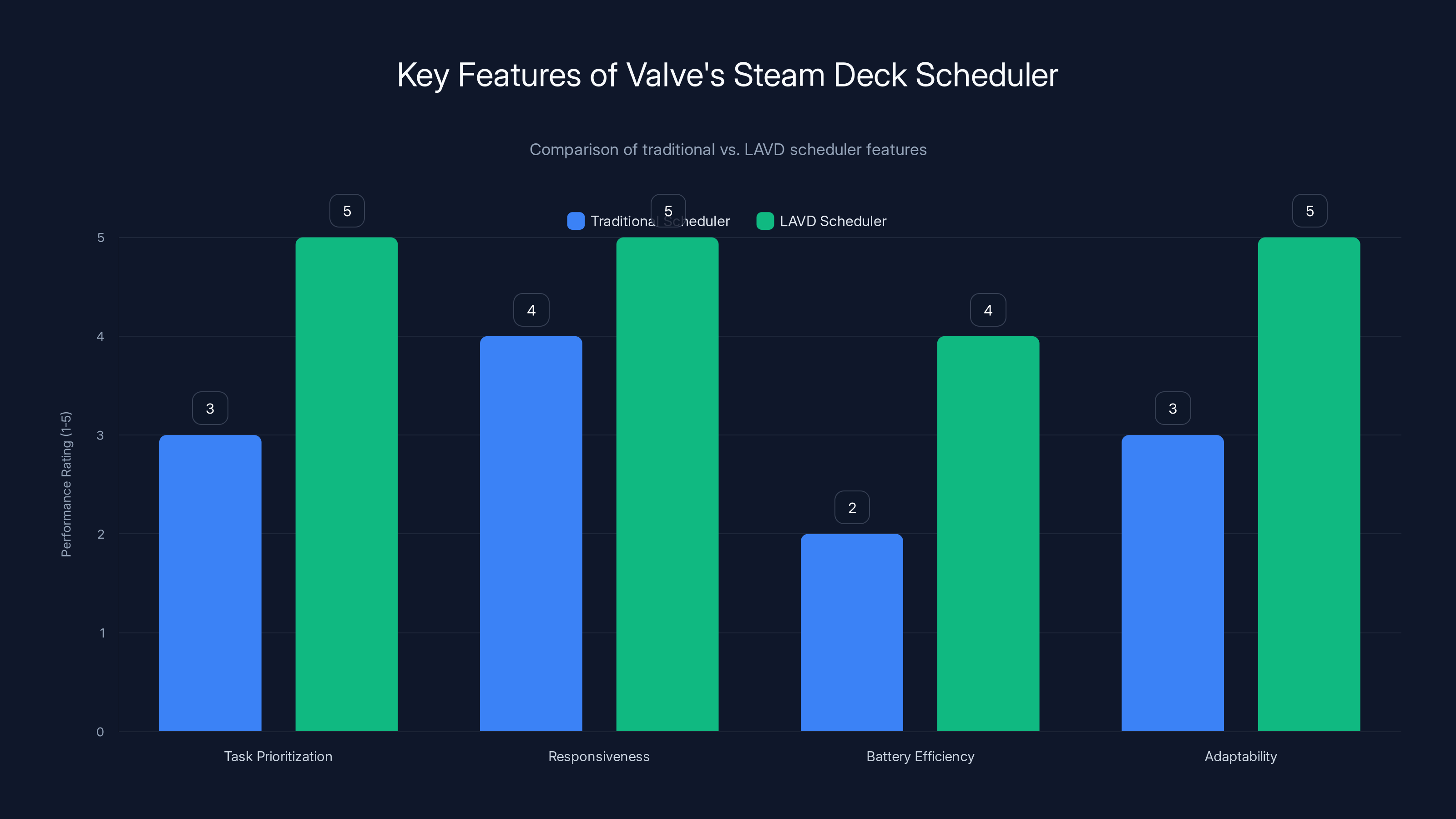
The LAVD scheduler significantly enhances task prioritization, responsiveness, battery efficiency, and adaptability compared to traditional schedulers. Estimated data.
The Technical Foundation: sched_ext and Dynamic Scheduling
Before we get into SCX-LAVD specifically, let's understand the mechanism that makes it possible: sched_ext.
sched_ext is a Linux kernel framework that allows alternative schedulers to plug into the kernel without requiring permanent modifications. It's like having a modularity layer for the most performance-critical component of the operating system. Instead of replacing the entire scheduler, you can provide custom scheduling logic that runs alongside the default implementation.
This matters because kernel schedulers are notoriously difficult to change. They're performance-critical code. A single mistake cascades across the entire system. Shipping a new scheduler in the kernel takes years of review, testing, and validation. Most kernel developers won't touch the scheduler unless absolutely necessary.
sched_ext sidesteps this entirely. You write your custom scheduler in userspace code. The kernel provides hooks where your scheduler makes decisions. When a task needs to be scheduled, the kernel calls your userspace scheduler. Your scheduler runs the algorithm, makes the decision, and the kernel executes it.
This decoupling is elegant. It means you can experiment with new scheduling algorithms without rebuilding the kernel. You can roll back changes instantly. You can deploy different schedulers to different machines. You can debug scheduling logic at userspace instead of kernel debugging.
SCX-LAVD, the "SCX" variant of LAVD, is Valve's scheduler adapted to work through this sched_ext interface. It's the same fundamental algorithm that powers the Steam Deck, but restructured to work as a pluggable kernel module.
Here's how SCX-LAVD actually works:
Task observation phase: When a task wakes up or yields the CPU, SCX-LAVD observes its behavior. How long did it run? What triggered it to yield? Is it blocking on I/O? Is it just sleeping?
Latency estimation: Based on observed behavior, the scheduler estimates whether this task is latency-sensitive. Latency-sensitive tasks get higher priority. They're allowed to preempt other work. They get access to cores faster.
Dynamic deadline calculation: Each task gets a virtual deadline based on its characteristics. The scheduler always runs the task with the nearest deadline. This creates a prioritization system that's completely dynamic. A task's priority changes moment-to-moment based on recent behavior.
Cache-aware placement: The scheduler respects CPU cache locality but doesn't let it override latency requirements. If a task needs to run immediately, it runs immediately, even if another core would have better cache characteristics. But when there's no latency pressure, tasks run on cores with warm caches.
Interrupt handling awareness: SCX-LAVD accounts for the fact that some cores are getting hammered by network interrupts or other I/O. The scheduler can dynamically adjust which cores it considers "available" based on actual contention.
None of this requires human configuration. The scheduler learns the workload characteristics automatically. This is fundamentally different from traditional approaches where operators set priorities, tweak parameters, and hope their configuration stays valid as workloads change.

Scaling Gaming Code to Data Center Reality
Here's where Meta's contribution becomes clear. Taking a scheduler from a 4-core handheld and running it on 128-core server machines isn't a simple copy-paste operation. Reality intervened.
The Steam Deck version of LAVD assumes a relatively homogeneous system. Cores are similar. Tasks are somewhat predictable. You're running a game and some background services. That's it.
Data centers are fundamentally different. You might have CPUs from different manufacturers on different hardware generations. Some cores have different capabilities. Some cores might be heavily utilized for kernel-level tasks—handling network interrupts, managing storage I/O. Their capacity for user workloads varies.
Meta's engineers had to make adjustments:
Core capacity heterogeneity: Instead of treating all cores as equivalent, the scheduler had to understand that some cores are effectively "slower" because they're handling more interrupt load. The scheduler could dynamically adjust this understanding in real-time. A core that was underutilized this second might become interrupt-heavy the next second. The scheduler adapts.
Queue depth handling at scale: On a handheld, the run queue might have dozens of tasks. On a data center server, it might have thousands. The algorithms that worked at small scale became inefficient at large scale. Meta optimized the data structures the scheduler uses internally.
Per-service observability: Data centers need to understand performance per-service. Meta integrated hooks where different services could observe their own scheduling characteristics. This wasn't about performance optimization—it was about operational visibility. Engineers need to know which services are getting scheduled poorly and why.
Graceful degradation under extreme load: A handheld reaching maximum load is an edge case. A data center at 95% utilization is normal operation. SCX-LAVD needed to degrade gracefully when completely saturated, ensuring fairness even when there's no idle capacity.
Meta's engineers emphasized that these changes didn't require per-service tuning. Each service didn't get a custom configuration. The scheduler remained completely generic. It adapted based on observed behavior, not manual configuration.
This distinction is crucial. Manual tuning doesn't scale. A configuration that works Monday might be wrong by Friday when traffic patterns change. But a system that adapts automatically can handle workload shifts without human intervention.
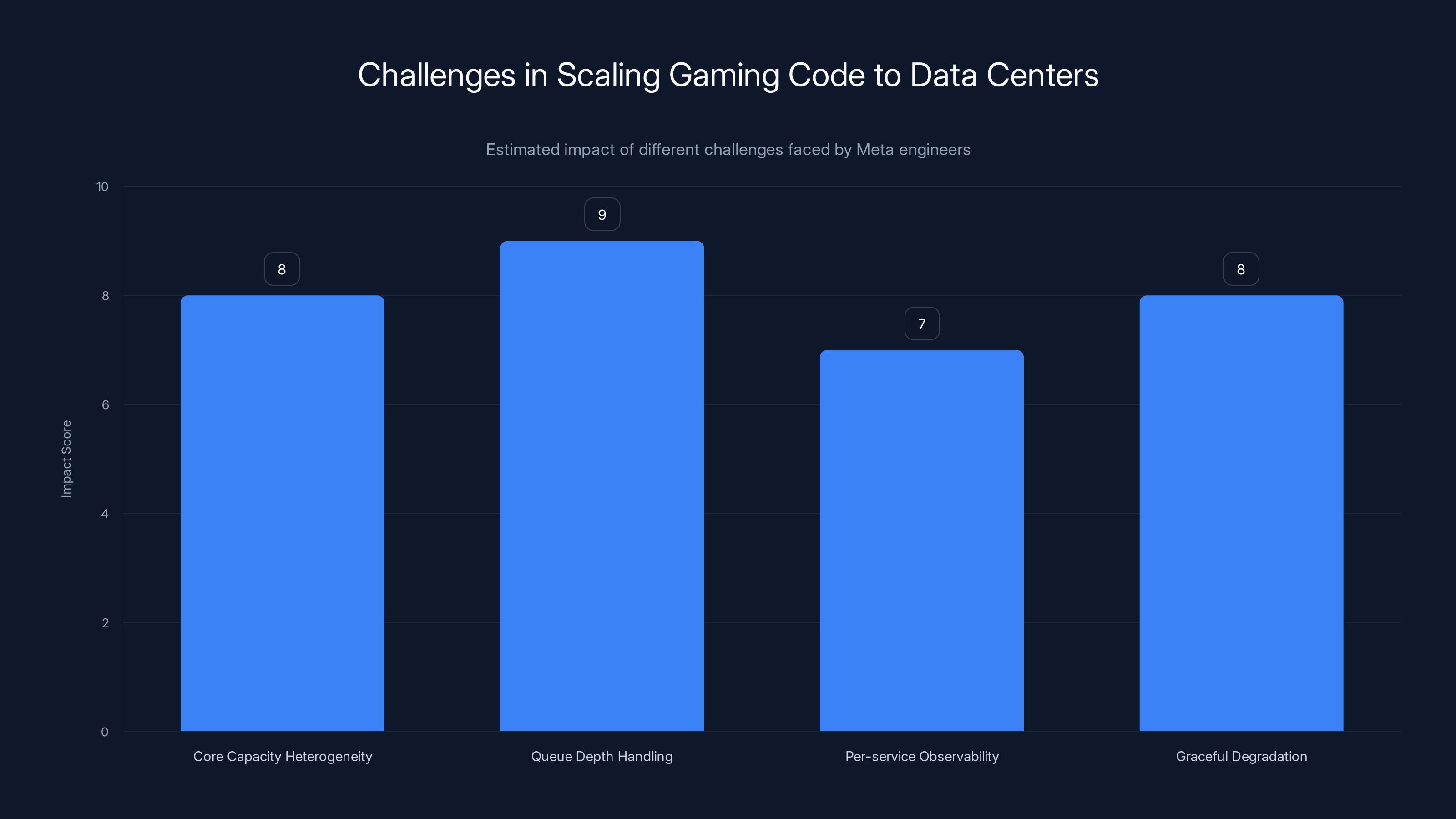
Estimated data shows that queue depth handling and core capacity heterogeneity posed the highest challenges in scaling gaming code to data centers.
Initial Results and Real-World Impact
Meta didn't release detailed performance metrics—and this is worth noting. They didn't publish a paper with benchmark results. They didn't claim specific percentage improvements. Instead, they described the deployment as addressing known scheduling inefficiencies on their production fleet.
This restraint actually makes their claims more credible. Big claims without data happen regularly in tech. Understatement suggests real-world validation.
From what Meta disclosed:
Latency improvements for latency-sensitive services. The scheduler's ability to identify and prioritize latency-sensitive tasks meant that response time variance decreased. Services handling metadata queries, cache lookups, and session management saw more consistent response times. This matters because inconsistent latency is often worse than high average latency. Users notice the variation.
Better throughput during saturated conditions. When the system reaches full utilization, traditional schedulers struggle with fairness. Some workloads starve while others monopolize resources. SCX-LAVD's deadline-based approach maintains better fairness even under extreme load. This means that even when the system is maxed out, all services get fair access to resources.
Reduced context switching overhead. Context switching—when the CPU stops running one task and starts another—has overhead. More intelligent scheduling decisions mean fewer unnecessary context switches. This compounds across millions of tasks across thousands of machines.
Operational simplification. Meta emphasized that these improvements came without additional tuning. No engineers had to write service-specific configurations. No parameter tweaking. The system just worked better. In operational terms, this is huge. It means fewer knobs to turn, fewer failure modes from misconfiguration, and more predictable behavior.
Meta acknowledged the work remains experimental. They're testing this in parts of their production fleet, not across all data centers yet. But the fact that they're running it in production at all—not in labs, not in dev environments, but handling real user traffic—suggests confidence.
The Broader Implications: Challenging Data Center Assumptions
This deployment matters beyond Meta's infrastructure. It questions some fundamental assumptions about how data centers work.
For decades, the data center industry has operated under certain beliefs:
Static configuration is necessary for performance. We've assumed that production systems need careful tuning. Database parameters. Thread pool sizes. Network buffer settings. Scheduler priorities. Operators become experts at tweaking these knobs. It's considered professional practice.
But SCX-LAVD suggests this might be backwards. Maybe static configuration is a necessary evil only because we don't have better tools. If the scheduler can observe workload behavior and adapt, then static configuration becomes unnecessary overhead.
Performance optimization requires specialized knowledge. Getting good performance has traditionally required deep knowledge of system internals. You need to understand CPU caches. You need to know about interrupt handling. You need to predict how your workload behaves. This knowledge is expensive to acquire and easy to get wrong.
But if the scheduler can learn from observation, then optimization becomes automatic. You don't need specialized knowledge. The system figures it out.
Gaming and data centers require different solutions. This assumption was so fundamental nobody questioned it. Handheld gaming and hyperscale infrastructure are completely different domains. Why would they share solutions?
The answer: they have similar problems. Both need responsiveness without sacrificing throughput. Both need to handle unpredictable workloads. Both need to work without human configuration. The domain difference matters less than the problem similarity.
These implications are important because they suggest we might be able to simplify data center operations. Not in the dramatic "AI replaces all operators" sense. But in the practical sense: fewer things to configure, fewer failure modes, fewer reasons for emergencies at 3 AM.

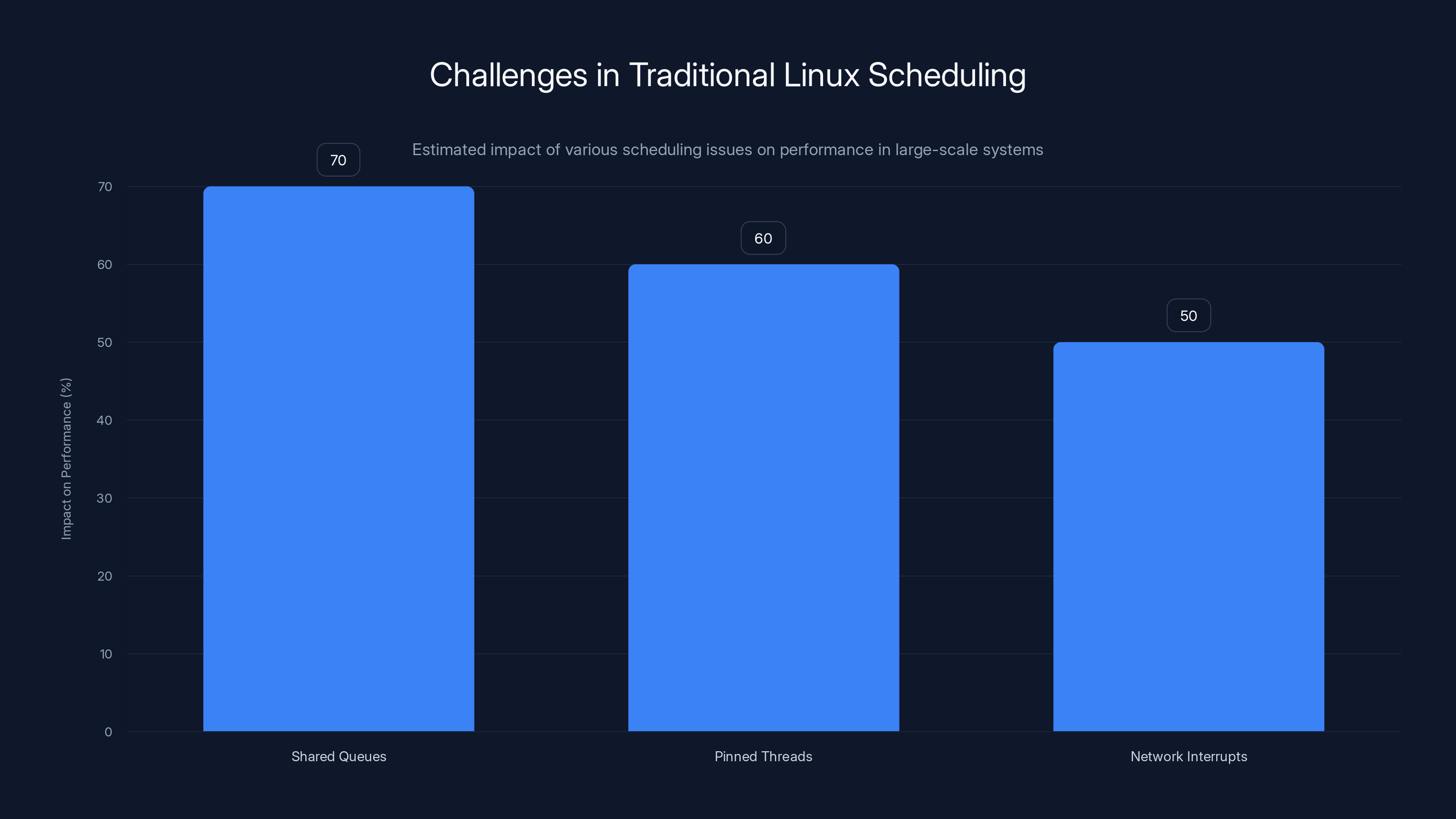
Shared scheduling queues, pinned threads, and network interrupts significantly impact performance in large-scale Linux systems. Estimated data shows shared queues as the most critical bottleneck.
Potential Challenges and Uncertainties
It would be naive to assume this deployment is purely positive. There are legitimate concerns.
Stability and predictability. A scheduler that adapts to observed behavior is inherently less predictable than one with fixed rules. If you have a latency-sensitive task, you want to know its behavior is stable. But with observation-based scheduling, the task's priority adjusts based on recent history. In edge cases, this could create unexpected behavior.
Meta needs to ensure that the edge cases—the weird moments when the system behaves unexpectedly—don't damage reliability. This requires extensive testing and monitoring. The deployment being described as "experimental" suggests they're still validating this.
Switching costs when the scheduler is suboptimal. Sometimes the scheduler will make a wrong decision. A task it thinks is compute-heavy is actually latency-sensitive. With a static configuration, the error is consistent and operators can fix it. With dynamic scheduling, errors correct themselves automatically. But during the correction period, performance might be suboptimal. This hysteresis could matter for latency-critical operations.
Generalization across different workloads. The scheduler was built for Valve's gaming workloads and optimized by Meta for their web service workloads. What about other types of applications? What about databases? What about machine learning jobs that have completely different scheduling characteristics?
Meta's saying the changes didn't require per-service tuning, but the scheduler was still likely optimized for their specific workloads. A different company's data center might find the defaults suboptimal.
Operational learning curve. Operators who've spent years understanding traditional scheduling might find themselves navigating a system that makes decisions they can't fully predict. This isn't an immediate problem, but over time, as adoption spreads, the industry needs people who understand dynamic scheduling deeply.
Maintenance and kernel dependencies. sched_ext is relatively new. It's not in all kernel versions. It requires kernel support. Any changes to sched_ext in the kernel could affect deployments. Meta's betting on sched_ext being stable and well-maintained long-term. If that doesn't happen, they're stuck maintaining a custom scheduler.
These aren't criticisms of Meta's work. They're realistic assessments of challenges that come with any major infrastructure change. The team seems aware of them, which is good.

How This Affects the Linux Community and Future Development
Meta's deployment validates sched_ext as a viable approach for experimental schedulers. Before this, sched_ext was interesting in theory but unproven in production. Now it's running Meta's data centers. That's powerful validation.
This matters for Linux development because it suggests sched_ext will get more attention and resources. The kernel community needs to ensure:
sched_ext remains stable and high-performance. As production workloads depend on it, the core sched_ext interface can't regress. This means careful maintenance and testing.
Alternative schedulers can coexist. sched_ext should enable multiple different schedulers to run on different systems. This requires flexible infrastructure. It requires good APIs for scheduler implementations.
Performance remains competitive. sched_ext adds a userspace component. This creates latency. The framework needs to be efficient enough that scheduler decisions don't become a bottleneck. Meta's deployment at scale tests this.
Education and documentation improve. Right now, writing a scheduler using sched_ext requires deep kernel knowledge. As more people build schedulers, documentation and tools need to improve. The barrier to entry should lower.
Beyond sched_ext, Meta's deployment suggests the industry might start reconsidering what belongs in kernels versus userspace. A scheduler was traditionally kernel-only because performance was critical. But modern systems might tolerate well-designed userspace schedulers because the overhead is acceptable compared to the flexibility gained.
This architectural shift could influence how other critical kernel components evolve.

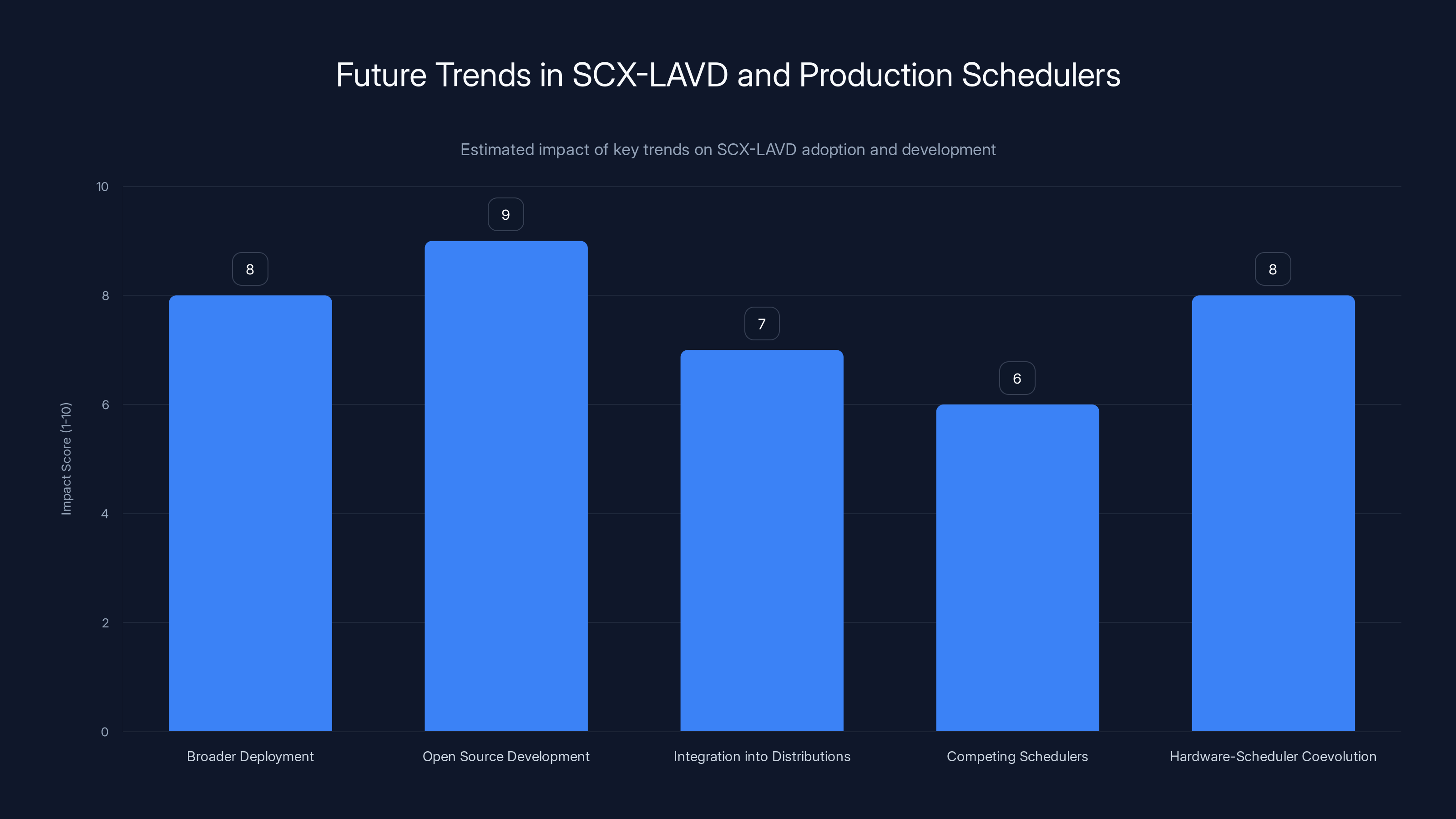
Estimated data shows that open source development and broader deployment within Meta are expected to have the highest impact on the future of SCX-LAVD. The integration into distributions and hardware-scheduler coevolution also play significant roles.
Lessons for Other Infrastructure Companies
Meta's not the only company running massive data centers. Google, Amazon, Apple, and countless others face identical scheduling problems. What can they learn?
Problem observation comes before solution selection. Meta didn't start with "let's use a gaming scheduler." They started with "we have scheduling inefficiencies." They measured the problems carefully. Only after understanding the problems did they look for solutions. This approach is universally applicable.
Unconventional solutions can be better than obvious ones. SCX-LAVD works so well partly because it wasn't designed for data centers. It doesn't have the accumulated assumptions of traditional data center schedulers. Sometimes looking outside your domain reveals better approaches.
Observational systems beat rule-based systems at scale. The more complex your system, the harder it is to create rules that work universally. But observation-based systems adapt. This principle extends beyond scheduling. It suggests companies should consider dynamic, learning-based approaches for other critical infrastructure components.
Operational simplification has real value. Engineers tend to focus on performance numbers. But operational simplicity is also valuable. Systems that don't require tuning are systems that don't require as many experts. They're systems that scale to more customers. Companies should weight simplicity as a metric alongside raw performance.
These lessons could drive changes across the industry. We might start seeing more companies experimenting with sched_ext schedulers. We might see other unconventional solutions borrowed from unexpected domains.

The Future of SCX-LAVD and Production Schedulers
Where does this go from here?
Broader deployment within Meta. Currently, SCX-LAVD runs on "parts" of Meta's infrastructure. Expanding to additional data centers requires more validation and testing. But the direction is clear. Meta's betting on this scheduler.
Open source development. SCX-LAVD's code is being developed in the open. It's not Meta's secret sauce. This means other organizations can use it, contribute to it, and adapt it. Over time, the scheduler will improve through community contribution.
Integration into distributions. Currently, deploying SCX-LAVD requires custom kernel compilation. As sched_ext stabilizes, major Linux distributions might include it by default. This would dramatically lower the barrier to adoption.
Competing schedulers and specialization. SCX-LAVD isn't the only scheduler being developed for sched_ext. Researchers and companies are building schedulers optimized for specific workload types. Over time, operators might select different schedulers for different purposes, like choosing a database optimized for their use case.
Hardware-scheduler coevolution. CPU manufacturers and scheduler designers might start collaborating. Hardware features might be designed specifically to support dynamic scheduling. This could unlock even better performance.
The arc here is clear: we're moving from static, universal schedulers to dynamic, specialized ones. This requires better tools, better understanding, and better hardware support. But the benefits—simpler operations, better performance, more efficient resource utilization—are worth the transition.
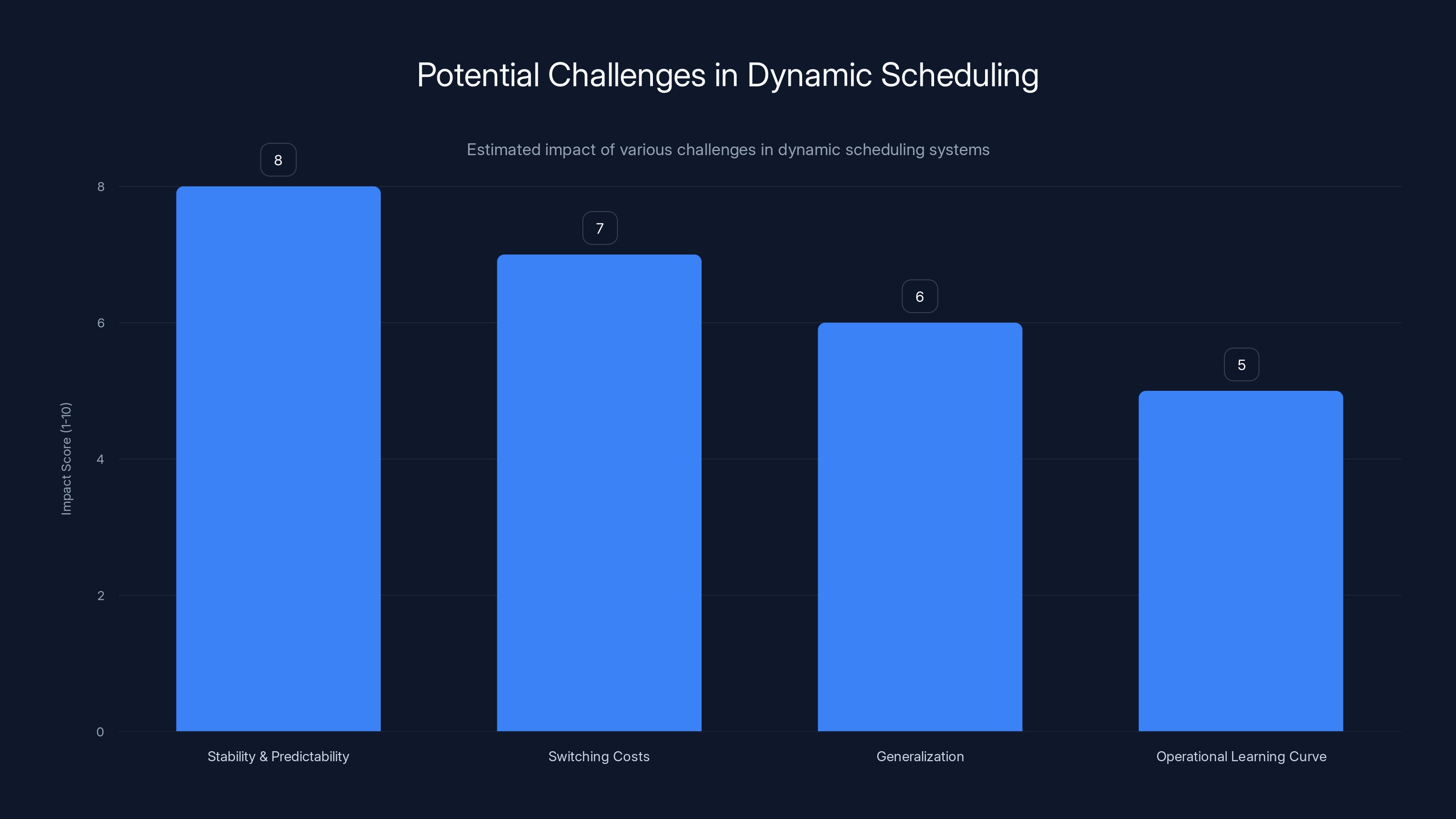
Stability and predictability are estimated to have the highest impact on dynamic scheduling systems, followed by switching costs and generalization issues. Estimated data based on typical concerns.
Practical Implications for Teams Running Linux Systems
If you're running significant Linux infrastructure, what does Meta's announcement mean for you?
In the short term, probably nothing. SCX-LAVD is still relatively new. It's not in any stable Linux distributions yet. Unless you're running cutting-edge kernels and actively experimenting, you won't be using it.
In the medium term, observe and learn. Follow Meta's deployment. Watch for case studies and performance reports. Understand the tradeoffs. Are the benefits real? Do they apply to your workloads? What's the operational complexity?
Start measuring your scheduling behavior. Even if you're not using SCX-LAVD, you can measure your current scheduler's performance. Are certain services getting lower CPU time than expected? Do you have latency spikes that don't correspond to actual load? These are symptoms of scheduling issues.
Plan for scheduler flexibility. In the future, you might want to experiment with alternative schedulers. Make sure your infrastructure is built in a way that allows scheduler swapping without huge operational overhead. Use containerization, use abstraction, plan ahead.
Question your configuration assumptions. Look at your scheduler tuning. Are you running with static priorities? Are certain parameters configured for specific workloads? SCX-LAVD suggests these things might be unnecessary. Maybe you can simplify your configuration. This might even improve performance.
The biggest practical implication: start thinking of the scheduler as something that can be swapped, optimized, and specialized, not as a fixed component you configure once and forget about.
The Convergence of Domains and Cross-Pollination
Meta's deployment illustrates something interesting about technology evolution: specialized solutions from one domain often become general solutions in another.
We've seen this repeatedly:
Graphics optimization became neural network acceleration. GPU technology, developed for rendering 3D graphics, became crucial for machine learning. The parallelism that GPU architectures provide benefits both domains differently, but the underlying hardware works for both.
Game engine technology became film production software. Real-time rendering engines, built for games, now power film and advertising production. The challenges are similar: how do you generate photorealistic imagery quickly?
Mobile optimization became general efficiency. Techniques developed to make apps run on phones with limited battery—efficient algorithms, reduced memory usage, better I/O patterns—benefit servers too.
SCX-LAVD follows this pattern. A solution for handheld gaming becomes a solution for data center scheduling. It works because the core problem—scheduling with incomplete information and changing workloads—is similar.
This suggests we should be more open to borrowing solutions from unexpected places. The best optimization for your domain might already exist in another domain. You just need to recognize the similarity and adapt accordingly.

Validation and Ongoing Research
One key note: Meta's claim that SCX-LAVD improves data center scheduling is currently validated primarily by Meta. Independent researchers haven't yet published peer-reviewed studies comparing SCX-LAVD to traditional schedulers at hyperscale.
This doesn't mean the claims are wrong. Meta has strong incentives to be honest—deploying suboptimal code in production would be immediately obvious and damaging. But it means we should look for independent validation as the project matures.
What would rigorous validation look like?
Benchmarks on standard workloads. Standardized tests that measure latency, throughput, and context-switching overhead comparing SCX-LAVD to the default CFS scheduler and other alternatives.
Real-world case studies from other companies. When other organizations deploy SCX-LAVD, they'll publish results. These independent validations matter significantly.
Research papers from academia. University researchers often study new schedulers. Expect academic papers analyzing SCX-LAVD's characteristics, exploring edge cases, and identifying improvement opportunities.
Performance analysis tools. As adoption grows, tools for understanding scheduler behavior will improve. Better observability means better understanding of when and why the scheduler makes good or bad decisions.
Over the next few years, we should get increasingly detailed understanding of SCX-LAVD's strengths and limitations. This is normal for new infrastructure components. The initial excitement fades, replaced by practical understanding of where it works well and where it has limitations.

Industry Standards and Potential Standardization
If SCX-LAVD becomes widely adopted, there's potential for standardization efforts.
Right now, different organizations might develop different observation-based schedulers. They might use different metrics, different algorithms, different approaches. Some measure latency sensitivity differently. Some account for cache locality differently.
If this fragmentation grows, the industry might need standards:
Scheduler metric definitions. How do you define "latency-sensitive"? This sounds simple but has subtle variations. Standardizing metric definitions would let organizations compare schedulers fairly.
Performance characterization. What benchmarks should be used to evaluate schedulers? Should it be synthetic workloads, production workloads, or both? Standards here help prevent misleading claims.
Configuration and deployment. How do you deploy a scheduler? How do you switch between them? What configuration options should all schedulers expose? Standardization here reduces operational complexity.
These standards don't exist yet. But if scheduler diversity increases, they'll become necessary. The Linux community might take on this role, similar to how it standardizes other aspects of the kernel.

Conclusion: A Moment of Inflection
Meta's deployment of SCX-LAVD across production data centers marks an inflection point for how we think about system scheduling. It's not a revolutionary moment—the scheduler won't change computing overnight. But it is significant.
We're transitioning from a world where schedulers are static components that operators carefully tune, to a world where schedulers are dynamic, adaptive systems that learn from workload behavior. This transition is happening in the open. Companies are collaborating. Code is being shared. The Linux community is involved.
What makes this interesting isn't just the technology. It's what it reveals about how the industry solves problems. Sometimes the best solution comes from an unexpected direction. Sometimes simplification—having fewer knobs to turn, fewer configurations to manage—leads to better performance. Sometimes borrowing ideas from completely different domains unlocks innovation.
For organizations running significant Linux infrastructure, this is worth paying attention to. Not immediately adopting, but understanding. Observing how Meta's deployment evolves. Measuring your current scheduling behavior. Planning for a future where you might want scheduler flexibility.
The gaming and data center worlds have converged in an unexpected way. And that convergence is making both better.
FAQ
What is SCX-LAVD and why does Meta use it?
SCX-LAVD is a Linux CPU scheduler originally designed for Valve's Steam Deck that Meta has deployed in its production data centers. Meta uses it because it dynamically observes task behavior and adapts scheduling decisions in real-time, addressing inefficiencies in traditional Linux scheduling that become apparent at hyperscale, particularly around latency-sensitive task prioritization and resource utilization across dozens of CPU cores.
How does SCX-LAVD differ from the default Linux scheduler?
The default Linux scheduler (CFS—Completely Fair Scheduler) uses static rules and fixed priorities to distribute CPU time. SCX-LAVD, by contrast, observes task behavior in real-time and dynamically estimates whether tasks are latency-sensitive, adjusting priorities continuously without requiring manual tuning. This adaptive approach addresses the scheduling inefficiencies that emerge on large server machines with many cores.
What problems does SCX-LAVD solve in data centers?
SCX-LAVD addresses several data center scheduling problems: shared scheduling queues becoming congestion points on systems with many cores, pinned threads creating unfair resource distribution, network interrupts distorting fairness calculations, and the scheduler making suboptimal decisions about cache locality. By observing actual workload behavior rather than relying on static rules, SCX-LAVD reduces latency variance, improves throughput during saturated conditions, and decreases context-switching overhead.
What is sched_ext and why does it matter?
sched_ext is a Linux kernel framework that allows alternative schedulers to plug into the kernel without permanent modification. It enables schedulers to run in userspace while making kernel scheduling decisions, creating a modularity layer that makes experimenting with new scheduling algorithms practical and safe. This framework was essential for enabling SCX-LAVD deployment because it avoided requiring Meta to replace the entire kernel scheduler.
Can SCX-LAVD be used in other data centers or is it Meta-specific?
SCX-LAVD's code is being developed in the open and can be used by other organizations. While Meta optimized it for their specific workloads, the scheduler is generic and doesn't require per-service configuration. Other companies can adapt SCX-LAVD to their infrastructure, though deployment requires supporting the sched_ext framework in their kernel, which isn't yet in all stable Linux distributions.
What are the potential risks or challenges with deploying SCX-LAVD?
The main challenges include: ensuring stability and predictability with adaptive scheduling, managing edge cases where the scheduler makes suboptimal decisions before correcting itself, validating that the scheduler generalizes across different workload types beyond Meta's specific use cases, training operators familiar with static schedulers to work with dynamic ones, and maintaining long-term dependencies on the sched_ext kernel framework which is relatively new.
How does observation-based scheduling improve data center performance?
Observation-based scheduling improves performance by eliminating the need for static configuration and manual tuning. Instead of requiring operators to assign priorities or configure per-service parameters, the scheduler learns from actual task behavior: how long tasks run, whether they block on I/O, how frequently they wake up. This automatic learning adapts to changing workloads without human intervention, reducing both the operational burden and the likelihood of misconfiguration-related performance problems.
When will SCX-LAVD be available in standard Linux distributions?
SCX-LAVD isn't yet in stable Linux distributions. It requires kernel-level sched_ext support, which is still relatively new. As sched_ext stabilizes and is integrated into major distributions, deploying SCX-LAVD will become simpler. Currently, using it requires custom kernel compilation, which limits adoption to organizations with the resources and expertise to do so.
How does this affect future data center infrastructure design?
Meta's deployment suggests data centers might shift from static, carefully-tuned configurations toward dynamic, learning-based systems that adapt to workloads automatically. This could lead to operational simplification, fewer configuration parameters, and less need for specialized scheduler tuning expertise. Future CPUs and hardware might even be designed to better support dynamic scheduling, creating a coevolution between hardware and scheduler designs.
What does this mean for companies deciding whether to adopt dynamic schedulers?
Companies should start by measuring their current scheduling performance to identify inefficiencies. In the medium term, they should monitor SCX-LAVD's development and gather case studies from other organizations deploying it. Plan infrastructure to be scheduler-flexible, making it easier to experiment with alternatives in the future. The industry is still early in understanding the full implications, so learning now positions organizations to adopt these technologies more effectively later.

Key Takeaways
- SCX-LAVD, originally built for Steam Deck gaming, now runs Meta's production data centers, proving gaming and infrastructure solutions can converge
- Traditional Linux scheduling breaks down at hyperscale due to shared queue bottlenecks, pinned thread fragmentation, and network interrupt interference
- Observation-based scheduling eliminates manual tuning needs by dynamically adapting to actual task behavior instead of static rules
- sched_ext framework enables userspace schedulers to make kernel decisions safely, allowing experimentation without kernel modifications
- Dynamic schedulers promise operational simplification across data centers, suggesting industry shift toward learning-based rather than configuration-heavy systems

