![The Legal Battle of AI: Dictionaries vs. OpenAI [2025]](https://tryrunable.com/blog/the-legal-battle-of-ai-dictionaries-vs-openai-2025/image-1-1773684544620.jpg)
The Legal Battle of AI: Dictionaries vs. Open AI [2025]
The digital age has ushered in an era where artificial intelligence (AI) is not just a tool but a transformative force across various industries. One of the most captivating stories in this evolving landscape is the legal battle between traditional knowledge repositories and AI giants. At the forefront of this clash is the lawsuit filed by Encyclopedia Britannica and Merriam-Webster against OpenAI, alleging massive copyright infringement. This article delves into the complexities of this case, the legal arguments involved, and its broader implications for AI and intellectual property rights.
TL; DR
- AI's Legal Challenges: The lawsuit highlights the legal complexities AI faces in terms of copyright and intellectual property.
- Implications for AI Development: This case could set significant precedents for how AI companies develop and train their models.
- Ethical Considerations: The ethical implications of using copyrighted material for AI training are under scrutiny.
- Future of Content Creation: There are potential changes in how content creators protect and monetize their work.
- Industry Impact: The outcome could reshape the relationship between AI developers and traditional content publishers.

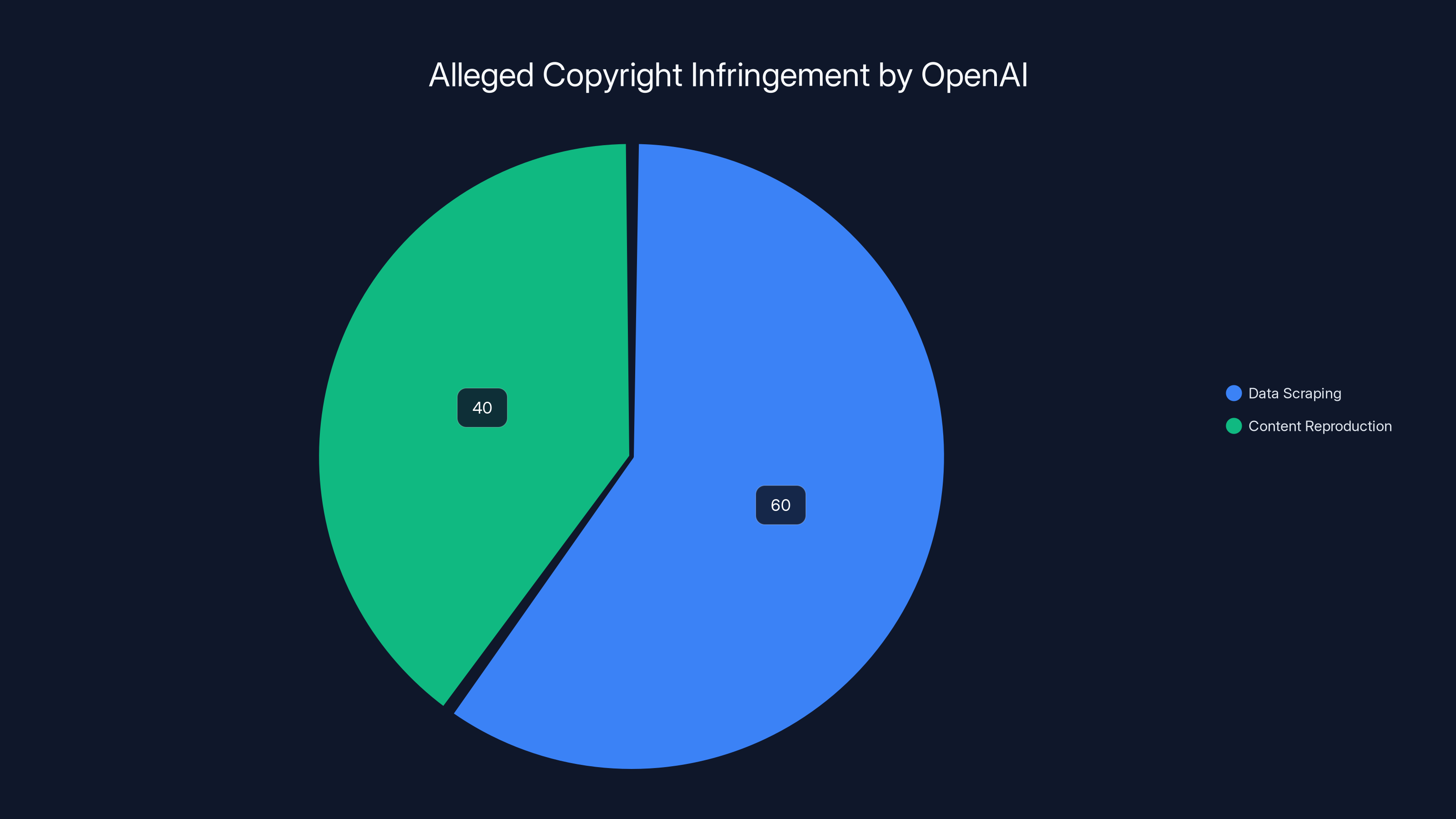
The lawsuit against OpenAI highlights two main types of copyright infringement: data scraping (60%) and content reproduction (40%). Estimated data.
The Genesis of the Conflict
At the heart of the legal dispute is the accusation that OpenAI used copyrighted content from Encyclopedia Britannica and Merriam-Webster to train its large language models (LLMs) without permission. Britannica alleges that nearly 100,000 articles were unlawfully scraped and utilized in OpenAI's model training processes, as reported by Courthouse News.
Understanding LLMs and Training Data
Large language models, such as those developed by OpenAI, rely on extensive datasets to learn and generate human-like text. These datasets often include a wide range of publicly available online content. However, the inclusion of copyrighted material without explicit permission raises legal and ethical questions, as discussed in UConn Today.
Copyright Infringement Allegations
The lawsuit accuses OpenAI of two primary forms of copyright infringement:
- Data Scraping: The unauthorized extraction of content from Britannica's online articles.
- Content Reproduction: Generating outputs that contain verbatim or partially reproduced copyrighted content.
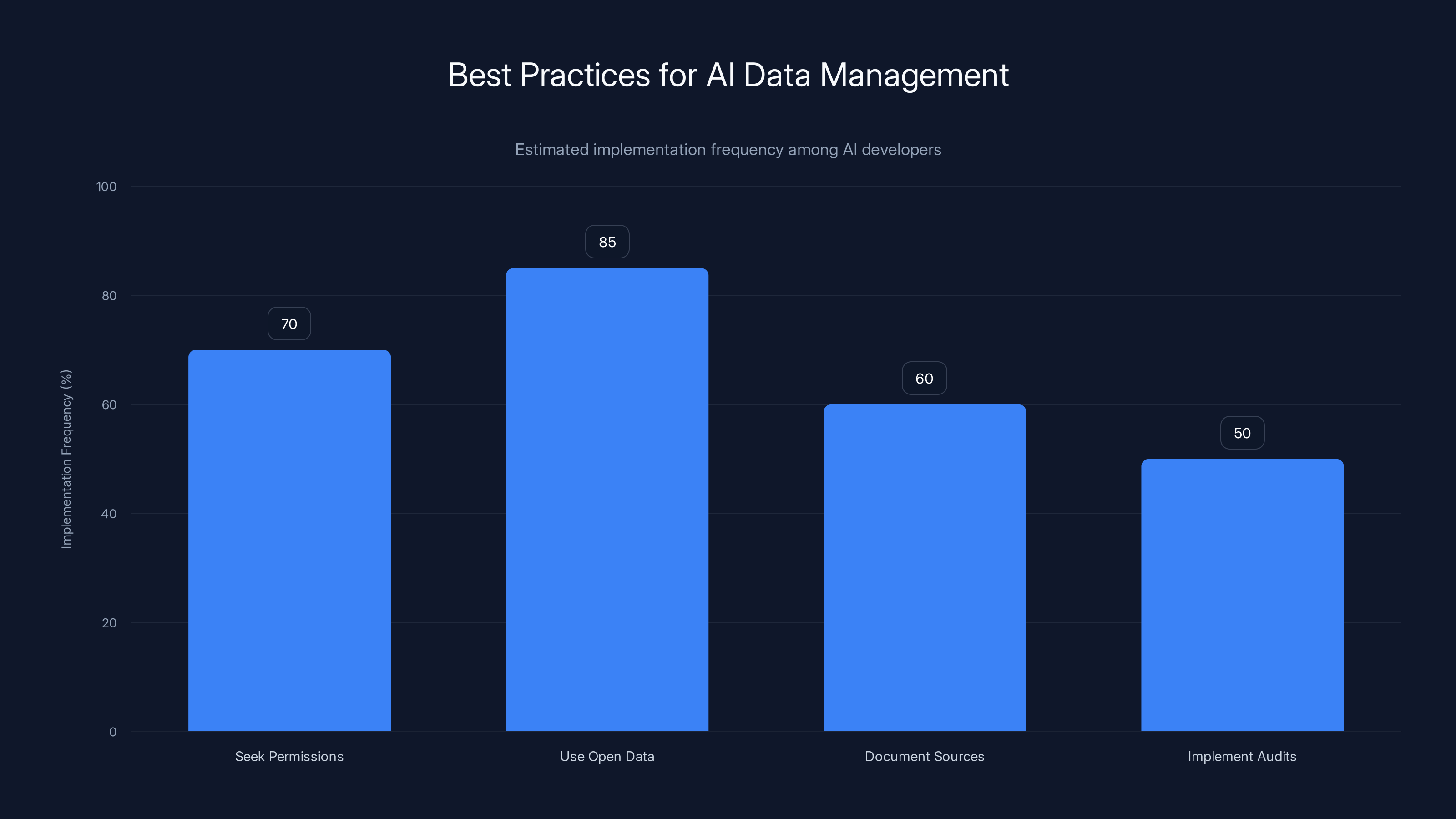
Using open data is the most frequently implemented practice among AI developers, with an estimated 85% adoption rate. Estimated data.
Legal Framework and Arguments
To understand the legal implications of this case, it's crucial to examine the relevant legal frameworks governing copyright and intellectual property rights.
Copyright Law
Copyright law grants creators exclusive rights to their original works, including reproduction and distribution. Britannica's lawsuit asserts that OpenAI violated these rights by using its content without authorization, as noted in Norton Rose Fulbright's publication.
The Lanham Act
In addition to copyright infringement, Britannica also alleges violations of the Lanham Act, a U.S. trademark statute. This claim centers on OpenAI's generation of "hallucinations"—false or misleading outputs attributed to Britannica's content, as highlighted by Courthouse News.
Fair Use Doctrine
A pivotal aspect of this case is whether OpenAI's use of Britannica's content qualifies as "fair use." This doctrine allows limited use of copyrighted material without permission for purposes such as criticism, comment, news reporting, teaching, scholarship, or research, as discussed in Morgan Lewis' analysis.

Technical Aspects and AI Training
For AI developers and technologists, understanding the technical nuances of AI model training is essential.
The Role of Data in AI Training
AI models, particularly LLMs, require vast amounts of data to learn language patterns and generate text. This data is often collected from a variety of sources, including publicly available websites, proprietary databases, and user-generated content, as explained in Nature's article.
Retrieval Augmented Generation (RAG)
OpenAI's use of retrieval augmented generation (RAG) is a key point in the lawsuit. RAG is a technique that enhances AI models by allowing them to retrieve and incorporate external information during text generation. Britannica argues that this process involves unauthorized use of its content, as reported by Press Gazette.

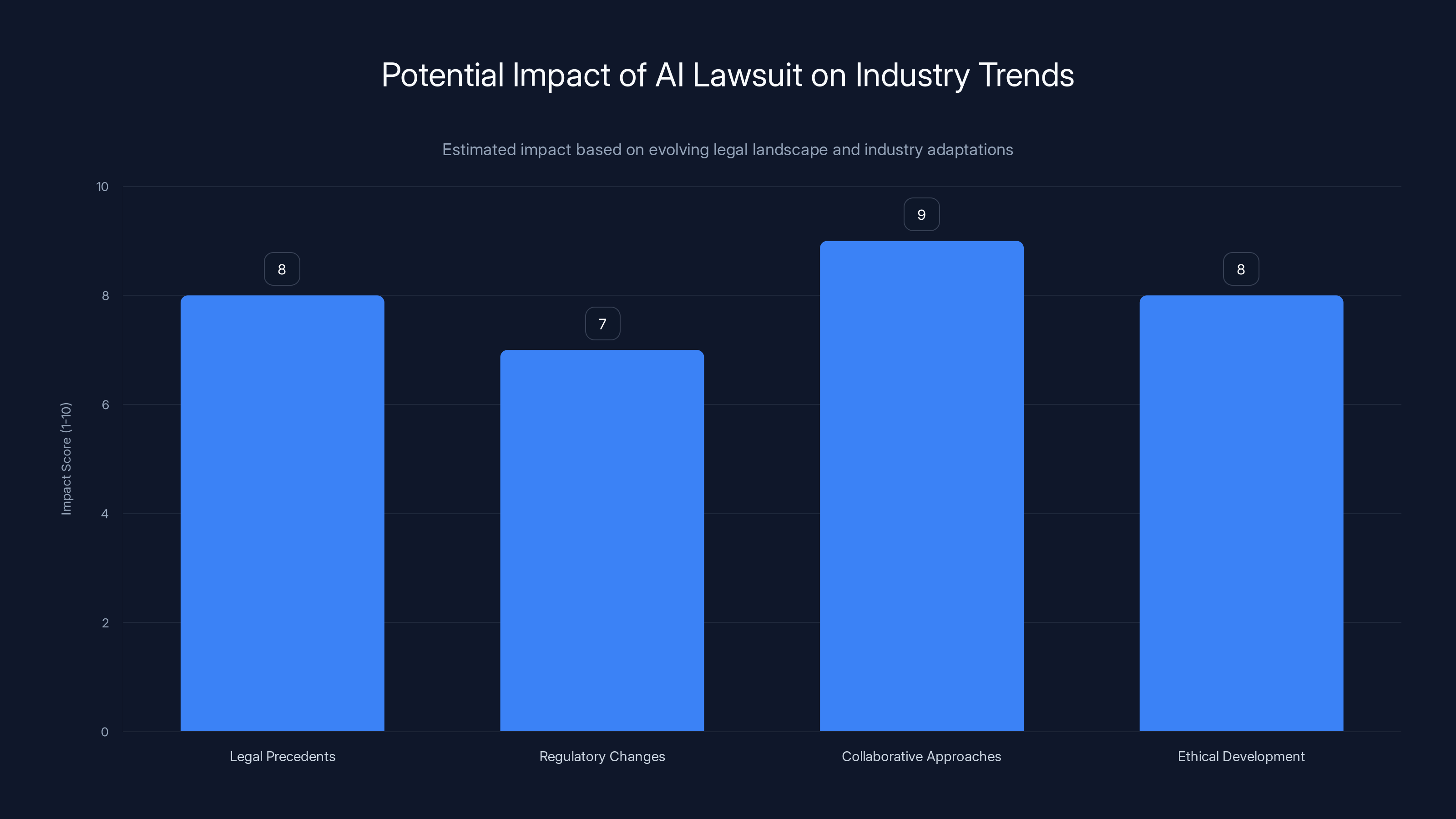
Estimated data suggests that the lawsuit could significantly influence legal precedents and encourage collaboration and ethical practices in AI development.
Practical Implementation Guides and Best Practices
For AI developers and companies, navigating the legal landscape requires implementing best practices to mitigate risks associated with copyright infringement.
Data Licensing and Permissions
- Seek Permissions: Obtain explicit permissions or licenses for using copyrighted content in AI training, as advised by Business Wire.
- Use Open Data: Prioritize datasets with clear licensing terms, such as those available under Creative Commons licenses.
Transparent Data Usage
- Document Sources: Maintain comprehensive records of data sources and usage to demonstrate compliance with copyright laws.
- Implement Audits: Regularly audit datasets to ensure compliance with legal and ethical standards, as recommended by Mendo Voice.
Common Pitfalls and Solutions
Navigating copyright issues in AI development can be challenging. Here are some common pitfalls and solutions.
Pitfall: Assumption of Public Domain
Solution: Verify the copyright status of content before use and consult legal experts for guidance.
Pitfall: Inadequate Documentation
Solution: Implement robust documentation practices to track data sources, usage, and permissions.
Future Trends and Recommendations
The outcome of this lawsuit could have far-reaching implications for AI development and intellectual property rights.
Evolving Legal Landscape
- Precedent Setting: The case could set legal precedents for AI training practices and copyright enforcement.
- Regulatory Changes: Anticipate potential regulatory changes to address AI-specific copyright issues, as discussed in Press Gazette.
Industry Adaptations
- Collaborative Approaches: Encourage collaboration between AI developers and content creators to establish fair compensation models.
- Ethical AI Development: Prioritize ethical considerations in AI development, including transparency and accountability.
Conclusion
The legal battle between Encyclopedia Britannica and OpenAI underscores the complex relationship between AI technology and traditional content publishers. As AI continues to evolve, navigating the legal, ethical, and practical challenges of using copyrighted content will be crucial for developers and companies alike. The outcome of this case could reshape the landscape of AI development and intellectual property rights, influencing how AI models are trained and how content creators protect and monetize their work.
Key Takeaways
- AI legal challenges highlight the complexities of copyright in the digital age.
- The lawsuit could set precedents for AI training practices and copyright enforcement.
- Ethical considerations are crucial in AI development, including transparency and accountability.
- Industry adaptations may include collaborative approaches and regulatory changes.
- The outcome could reshape the relationship between AI developers and content creators.
- Future trends may involve evolving legal landscapes and fair compensation models.
Related Articles
- AI and the Ethics of Mimicking Expertise: The Grammarly Controversy [2025]
- Understanding the Legal Challenges Facing Grammarly's AI 'Expert Review' Feature [2025]
- The Illusion of AI: Why Machines Aren't Conscious [2025]
- Navigating Turbulence: The Challenges and Future of xAI Amidst Constant Upheaval [2025]
- Rebuilding from Scratch: The Trials and Tribulations of xAI's Second Act [2025]
- Beyond AI Wrappers: The Future of Startup Innovation in India [2025]
FAQ
What is The Legal Battle of AI: Dictionaries vs OpenAI [2025]?
The digital age has ushered in an era where artificial intelligence (AI) is not just a tool but a transformative force across various industries.
What does tl; dr mean?
One of the most captivating stories in this evolving landscape is the legal battle between traditional knowledge repositories and AI giants.
Why is The Legal Battle of AI: Dictionaries vs OpenAI [2025] important in 2025?
At the forefront of this clash is the lawsuit filed by Encyclopedia Britannica and Merriam-Webster against OpenAI, alleging massive copyright infringement.
How can I get started with The Legal Battle of AI: Dictionaries vs OpenAI [2025]?
This article delves into the complexities of this case, the legal arguments involved, and its broader implications for AI and intellectual property rights.
What are the key benefits of The Legal Battle of AI: Dictionaries vs OpenAI [2025]?
- AI's Legal Challenges: The lawsuit highlights the legal complexities AI faces in terms of copyright and intellectual property.
What challenges should I expect?
- Implications for AI Development: This case could set significant precedents for how AI companies develop and train their models.

