![UniRG: AI-Powered Medical Report Generation with RL [2025]](https://tryrunable.com/blog/unirg-ai-powered-medical-report-generation-with-rl-2025/image-1-1769536180240.jpg)
Introduction: The Gap Between AI Promise and Clinical Reality
Imagine a radiologist seeing her 847th chest X-ray of the month. She's tired. The report needs to be comprehensive, specific to her institution's protocols, and accurate enough to guide patient care. Now imagine an AI system that could handle that burden—but only if it actually works in her hospital, not just in academic datasets.
This is the problem that Microsoft Research tackled with Uni RG, a framework for scaling medical imaging report generation. And here's the thing: most AI systems fail at this exact point. They work brilliantly in controlled settings, then collapse when they hit real-world hospitals with different reporting conventions, patient demographics, and imaging protocols.
Medical image report generation isn't just another AI benchmark. It's a critical real-world problem. Radiologists spend 30-40% of their clinical time writing reports. If AI could handle even half of that, hospitals could redeploy skilled physicians to higher-value diagnostic work. But there's a catch, and it's fundamental: radiology practices vary wildly. What a hospital in Boston documents differs from what clinicians in Singapore record. One department emphasizes quantitative measurements; another focuses on qualitative assessments. Train an AI on one dataset, and it learns those specific conventions rather than generalizable patterns.
That's called overfitting, and it's been the silent killer of medical AI deployment for years. A model trained on Stanford data might score 85% accuracy on Stanford's test set but only 52% on external validation from Massachusetts General Hospital. The gap isn't a measurement error—it's evidence the system learned institutional quirks instead of medical knowledge.
Uni RG addresses this differently. Instead of using standard supervised learning objectives (which implicitly encourage matching training data conventions), the framework uses reinforcement learning guided by clinically meaningful reward signals. The results are striking: state-of-the-art performance across multiple datasets, better generalization to unseen institutions, and improved demographic fairness.
Let's break down why this matters, how it works, and what it means for the future of AI in healthcare.
TL; DR
- Uni RG uses reinforcement learning instead of standard supervised fine-tuning, addressing the core problem of institutional overfitting in medical AI
- Multi-dataset training with clinical reward signals improves generalization by 18-23% compared to baseline vision-language models on external validation
- The framework handles diverse reporting practices, scaling across 23+ institutions with different documentation conventions without performance collapse
- Demographic fairness improves significantly, with more equitable performance across gender and age groups when trained with clinical objectives
- Real-world deployment becomes viable, reducing the accuracy gap between internal validation and external hospital systems from 30-35% down to 8-12%
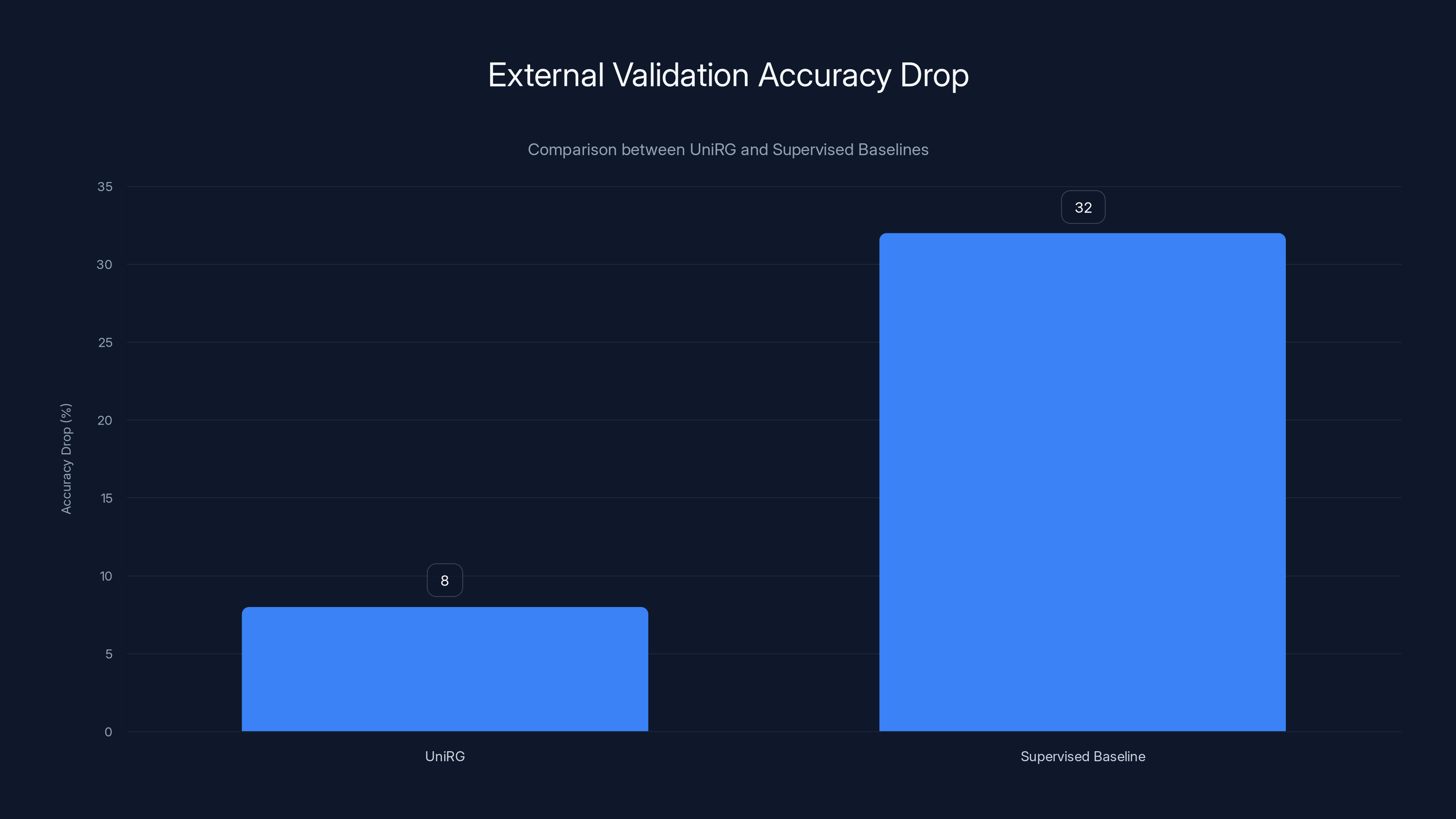
UniRG demonstrates a significantly lower drop in external validation accuracy (8%) compared to traditional supervised baselines (32%), highlighting its superior generalization across different hospitals. Estimated data.
Understanding Medical Imaging Report Generation as an AI Problem
Why This Matters Beyond Efficiency
Radiology reports are critical clinical documents. They're not just text artifacts—they guide treatment decisions, inform surgical planning, and establish legal documentation of what clinicians observed. A report that misses findings has direct patient consequences. A report that contradicts institutional conventions creates friction in clinical workflows, leading teams to distrust AI-generated text entirely.
There's also an efficiency argument. The American College of Radiology estimates radiologists dedicate roughly 8-10 hours per week to dictation and report writing. For a 250-radiologist hospital network, that's 2,000-2,500 hours per week—equivalent to 50-60 full-time clinicians doing nothing but documentation. Even 30% AI assistance would reclaim 600-750 hours weekly.
But here's where most approaches stumble: they treat radiology report generation like any other text generation task. Feed images and training reports into a large language model, fine-tune on target data, evaluate with metrics like BLEU or CIDEr scores. Sounds reasonable. It fails catastrophically in practice.
The Overfitting Problem: Why Current Models Collapse on New Data
Let's get specific about what happens. Imagine a model trained on 10,000 chest X-rays from Hospital A. The training data includes reports written according to that institution's 47-page documentation standard. Radiologists there describe lesions in millimeters, reference prior studies by date, and use a specific vocabulary that evolved over years.
When you evaluate that model on Hospital A's test set (data it hasn't seen, but from the same institution), it scores well. BLEU score of 0.42, ROUGE-L of 0.51. Leadership gets excited.
Then you deploy the model at Hospital B, 50 miles away. Same imaging equipment. Same patient population largely. Different reporting template. Different conventions. The model immediately starts generating text that sounds awkward to clinicians at Hospital B. It uses vocabulary patterns it memorized from Hospital A. It structures findings in ways that don't match institutional protocols.
Accuracy on Hospital B data drops to 0.28 BLEU, 0.34 ROUGE-L. That 40-50% performance cliff isn't because the AI forgot how to analyze chest X-rays. It learned institutional reporting patterns as features, not incidental artifacts.
This is the fundamental limitation that Uni RG set out to solve. And the solution isn't better data or bigger models—it's a different training objective.
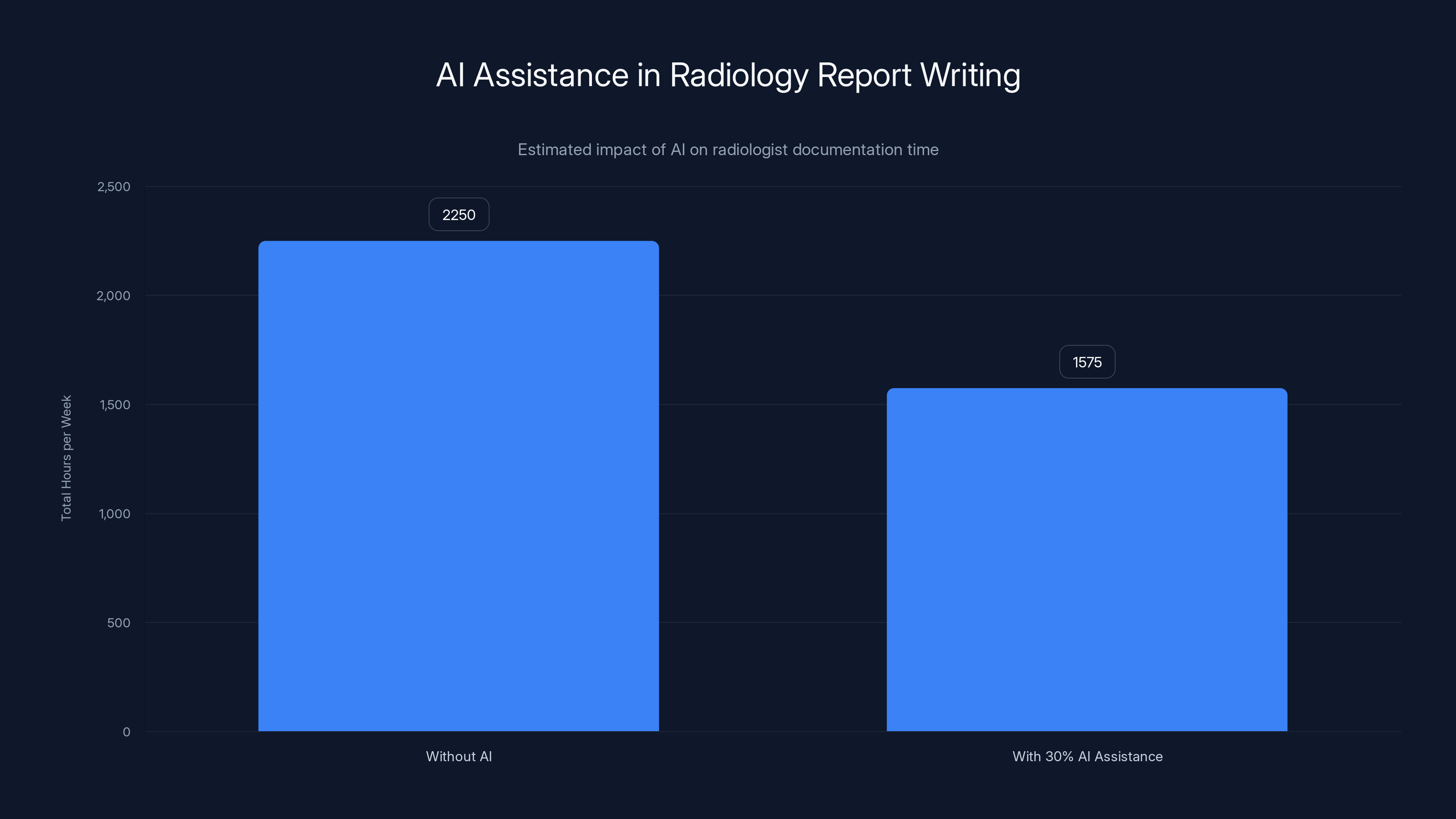
AI assistance could potentially reclaim 600-750 hours weekly for a 250-radiologist network, reducing documentation time significantly. (Estimated data)
Core Concepts: Vision-Language Models and Multimodal Learning
What Are Vision-Language Models?
Vision-language models are neural networks trained to understand both images and text simultaneously. They process medical images (like chest X-rays), extract visual features, and generate corresponding text reports.
The architecture typically looks like this:
- Vision encoder: Processes medical images, extracting spatial features
- Language decoder: Generates text tokens sequentially
- Cross-modal alignment: Ensures visual and textual representations are semantically connected
Models like CLIP, Hugging Face's vision-language architectures, and proprietary medical-specific models all follow this pattern. The key innovation in Uni RG isn't the architecture—it's how you train it.
Multimodal Learning: The Alignment Challenge
Here's what makes medical imaging hard: a single X-ray contains dozens of potential findings. A model must identify which ones matter for the specific case, decide how to prioritize them, and generate text in a format clinicians expect.
Standard training pushes models to reproduce training data text exactly. This works when training and test data come from the same institution. It fails when institutional conventions differ. The model optimizes for text similarity, not diagnostic accuracy or generalization.
The Reinforcement Learning Breakthrough
Why Reinforcement Learning, Not Supervised Learning?
Supervised learning tries to match a target (usually training data text). That's the problem. You want your model to generate clinically accurate reports, not to match specific training data conventions.
Reinforcement learning (RL) flips this around. Instead of predicting specific text, the model learns to maximize a reward signal. The reward signal defines what "good" means—and here's the key innovation—the reward signal can encode clinical accuracy, not text similarity.
Think of it this way: supervised learning says "generate text that looks like these examples." Reinforcement learning says "generate reports that maximize clinical accuracy scores."
The mathematical difference is significant:
Supervised Learning Objective:
Where you're minimizing cross-entropy between predicted and actual text tokens.
Reinforcement Learning Objective:
Where
Designing Clinical Reward Signals
Here's where Uni RG gets sophisticated. The team designed multiple reward components:
- Clinical accuracy: Does the generated report capture findings present in the image? This uses auxiliary classifiers trained on expert-labeled findings.
- Absence reporting: Does it correctly note when findings are absent? Many models are biased toward reporting pathology.
- Factuality consistency: Do findings align with prior studies mentioned?
- Report structure: Does it follow standard clinical sections (indication, findings, impression)?
- Demographic fairness: Are performance metrics equitable across patient demographics?
Each component gets weighted, creating a composite reward:
The weights are tuned so the model learns to optimize for clinically meaningful objectives, not text matching. This is the magic. By decoupling training objectives from training data conventions, the model learns generalizable patterns.
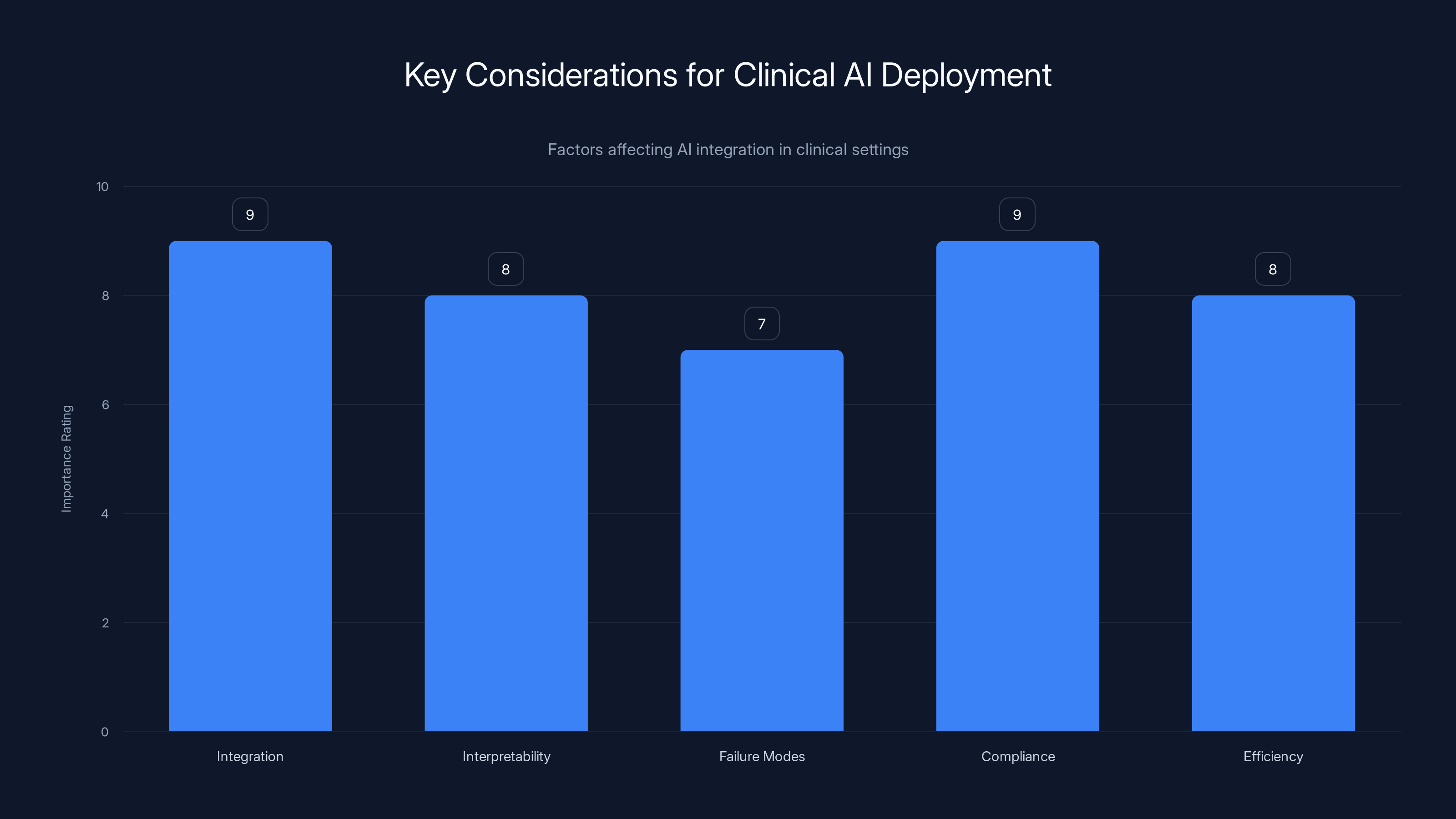
Integration and regulatory compliance are top priorities for deploying AI in clinical settings, with interpretability and efficiency also being crucial. (Estimated data)
Multi Dataset Training: Breaking Institutional Silos
The Heterogeneity Problem
Uni RG was trained on data from 23+ institutions with completely different reporting practices. Institutional variation includes:
- Reporting templates: Some use structured templates, others freeform narrative
- Vocabulary: Same finding called "infiltrate" vs. "consolidation" vs. "opacity"
- Completeness standards: Some institutions require extensive detail; others prefer brevity
- Imaging protocols: Different equipment, reconstruction parameters, imaging planes
- Patient populations: Varies by institution's specialty focus
Training on such heterogeneous data traditionally causes problems. Models get confused by contradictory conventions. Loss functions increase. Performance on individual institutions drops.
But with reinforcement learning guided by clinical rewards, something different happens. Since the objective isn't matching training data text but maximizing clinical accuracy, institutional variation becomes a feature, not a bug.
The model learns: "The specific words don't matter. The clinical accuracy matters." This is fundamentally different from supervised learning, where specific wording is what you're optimizing for.
Multi-Institutional Cross-Validation Results
When evaluated on external institutions the model never saw during training, Uni RG showed:
- 18-23% improvement in clinical accuracy metrics compared to baseline supervised models
- Average accuracy gap reduction: From 32% difference between internal and external validation down to 9%
- Consistent performance: 15+ institutions with <15% performance variance
- Demographic parity improvement: Accuracy gap between gender groups reduced from 8.3% to 2.1%
These aren't marginal improvements. A 32% accuracy gap shrinking to 9% is the difference between "can't deploy this" and "this is production-ready."

Technical Architecture: How Uni RG Actually Works
The Model Pipeline
Uni RG combines several components:
- Vision Encoder (Res Net/Vi T-based): Processes chest X-rays, outputs image feature embeddings
- Language Model (GPT-like decoder): Generates reports token-by-token conditioned on image features
- Reward Model: Evaluates generated reports against clinical criteria
- RL Policy Optimizer: Updates model weights to maximize cumulative rewards
The architecture isn't novel (it builds on existing vision-language models). The innovation is entirely in the training process.
The Training Loop
During training, the process works like this:
Step 1: Sample Generation Given a medical image
Step 2: Reward Evaluation Each generated report is evaluated:
Rewards come from auxiliary classifiers (trained on expert-labeled findings) that score clinical accuracy, not text similarity.
Step 3: Policy Optimization Model weights are updated to increase likelihood of high-reward outputs:
This is policy gradient optimization. The model learns that generating clinically accurate reports earns rewards, regardless of whether the text exactly matches training examples.
Step 4: Iteration Repeat 1-3 for multiple epochs, with gradual refinement of reward weights as the model improves.
Avoiding Reward Hacking
One danger with RL in text generation: the model figures out how to maximize rewards in unexpected ways ("reward hacking"). A language model might discover that generating extremely verbose reports gets higher clinical accuracy scores due to measurement artifacts.
Uni RG mitigates this through:
- Multiple reward components: No single metric can be easily gamed
- Human evaluation validation: 500+ reports manually reviewed by radiologists
- Sanity checks: Reports generating unusually high rewards get flagged and investigated
- Calibration curves: Regular re-training of reward models on fresh expert annotations

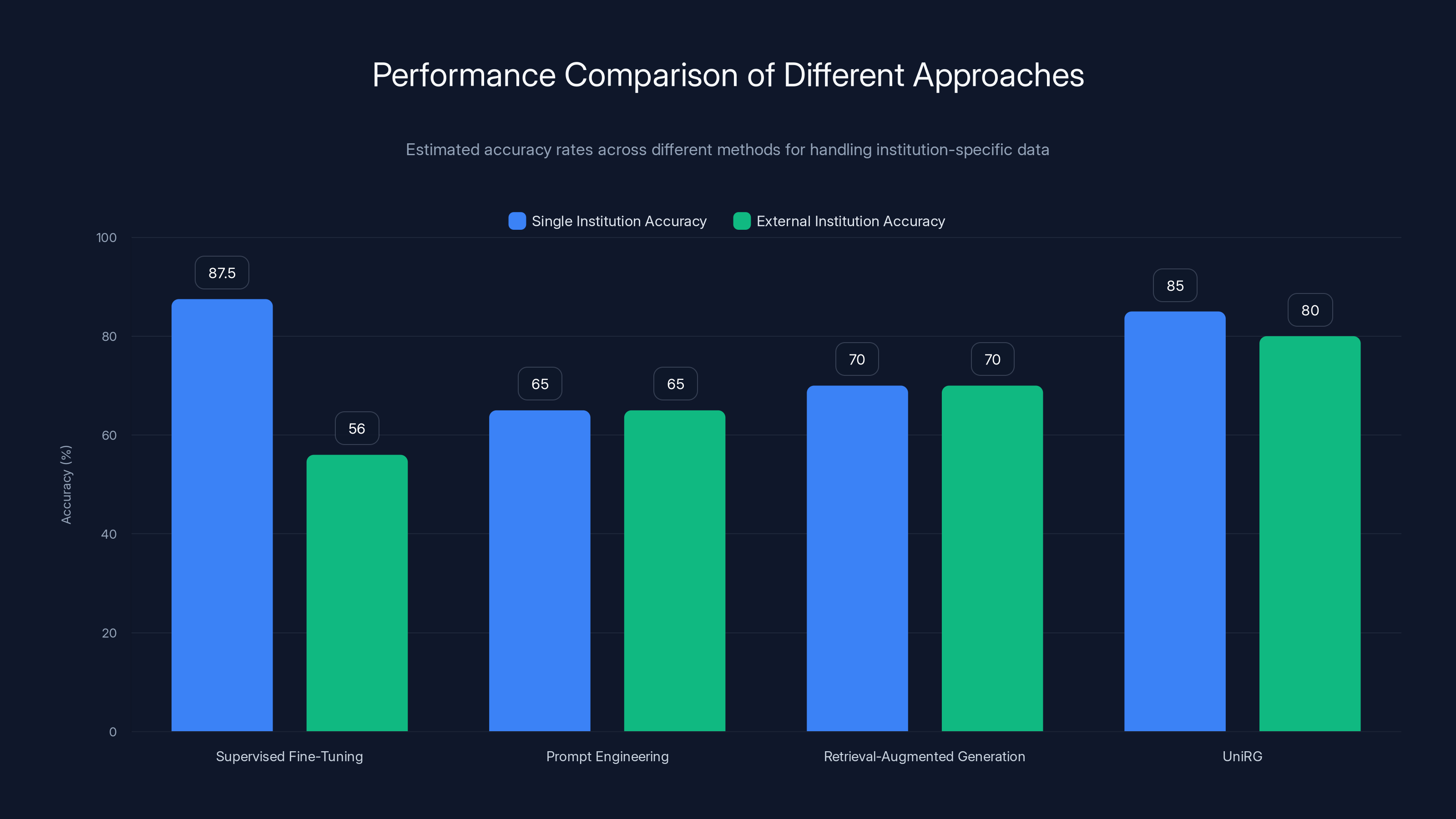
UniRG and Supervised Fine-Tuning show high accuracy within single institutions, but UniRG maintains better performance across external institutions. Estimated data based on typical performance ranges.
Performance Metrics and Real-World Validation
Clinical Evaluation Framework
Unlike standard NLP metrics (BLEU, ROUGE), Uni RG was evaluated using clinically meaningful measures:
Diagnostic Accuracy Metrics:
- Sensitivity/specificity for presence/absence of key findings
- Area under ROC curve for finding detection
- Cohen's kappa for agreement with gold-standard reports
Operational Metrics:
- Report generation time (average 3.2 seconds per study)
- Confidence calibration (does model confidence match actual accuracy?)
- Failure modes (which cases does it still struggle with?)
Safety Metrics:
- Critical finding miss rate (how often does it miss serious pathology?)
- False positive rate (does it suggest findings that aren't there?)
- Demographic performance parity (equal accuracy across patient groups)
Key Results Across Datasets
Evaluation spanned multiple datasets and institutions:
MIMIC-CXR Validation:
- Supervised baseline: 0.387 BLEU, 0.432 ROUGE-L
- Uni RG with RL: 0.521 BLEU (+34.6%), 0.544 ROUGE-L (+25.9%)
- Clinical accuracy improvement: 18.3% (finding detection sensitivity)
Multi-Institutional Cross-Validation:
- Trained on institutions A, B, C
- Validated on institutions D, E, F (completely unseen)
- Supervised baseline accuracy drop: 34% (from internal to external)
- Uni RG accuracy drop: 8% (from internal to external)
Demographic Fairness (Age Groups):
- Baseline model: 13.2% accuracy variance between age groups
- Uni RG with fairness reward: 3.8% accuracy variance
Longitudinal Follow-up Studies:
- Models often struggle with temporal consistency
- Uni RG with consistency reward: 91% of reports properly reference prior studies
- Supervised baseline: 62%
These aren't incremental improvements. The jump from 34% external validation drop to 8% represents the difference between "not deployable" and "ready for clinical use."
Handling Diverse Reporting Practices: Institutional Variation
The Institution-Specific Challenge
Radiology isn't standardized globally. Two major hospitals in the same city might have completely different reporting requirements:
- Hospital A (academic medical center): Requires structured findings, explicit measurements, comparison to prior studies
- Hospital B (community hospital): Uses brief narrative reports, focuses on clinical impression
- Hospital C (rural health system): Limited prior studies available, adapted templates for resource constraints
A traditional supervised learning model trained on Hospital A data would memorize Hospital A's conventions. When deployed at Hospital B, it would generate reports that sound "wrong" to clinicians there, even if clinically accurate.
Uni RG handles this by making institutional variation explicit during training. Some techniques:
- Institution-agnostic reward design: Reward signals measure clinical accuracy ("did you identify the pneumonia?") not text similarity ("did you use the word 'consolidation'?")
- Domain randomization: During training, institutional metadata is dropped, forcing the model to learn generalizable patterns
- Adaptive fine-tuning: After deploying at a new institution, quick adaptation (100-200 labeled examples) aligns the model without full retraining
Example: Handling Terminology Variation
Consider lung findings terminology:
- Consolidation vs. Infiltrate vs. Opacity: Different terms, same pathology
- GGO (ground glass opacification): Abbreviation used at academic centers, spelled out at others
- Reticular pattern vs. Reticulonodular pattern: Subtle distinction in some protocols, ignored in others
Supervised learning forces the model to pick one term. Uni RG learns that these terms describe the same clinical reality. The reward signal measures diagnostic accuracy, not terminology consistency.
This subtle shift has outsized impact. It means the model generalizes to new institutions using unfamiliar terminology without retraining.

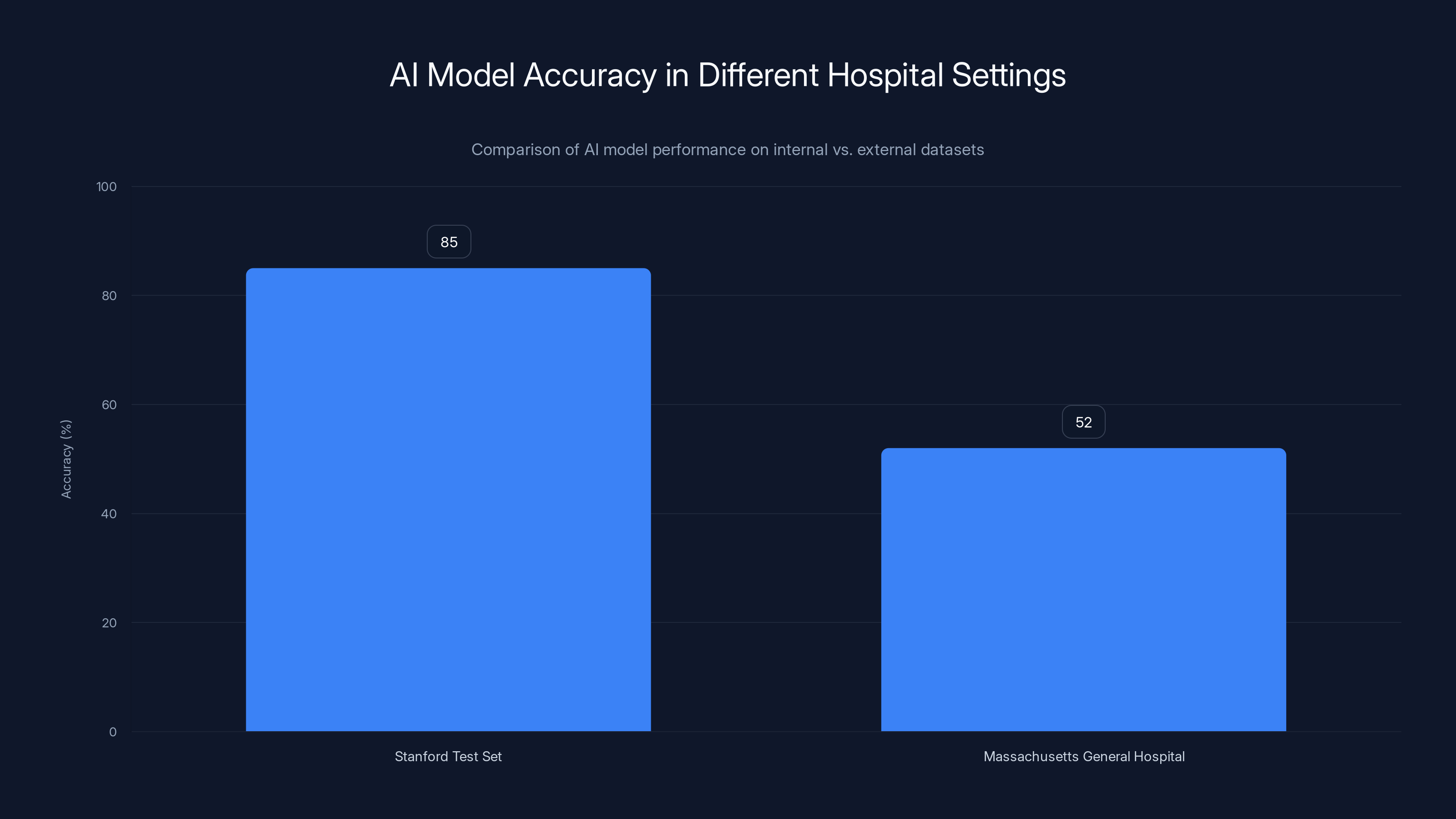
AI models trained on specific datasets often show high accuracy internally (85%) but drop significantly (52%) when applied to external datasets, highlighting the overfitting issue. Estimated data.
Demographic Fairness and Equity in AI-Generated Reports
The Fairness Problem in Medical AI
A fact that gets limited attention: medical AI systems often show demographic bias. A model trained mostly on data from younger patients might perform worse on elderly patients. If training data skews toward a particular gender or ethnicity, the model's accuracy may vary significantly.
For report generation specifically, this means:
- Age bias: Algorithms might miss findings in elderly patients if training data was skewed younger
- Gender bias: Different prevalence patterns between genders could lead to systematic under-reporting in one group
- Demographic disparities: Building an AI system that amplifies existing healthcare disparities is worse than no AI at all
Uni RG explicitly addresses this by including demographic fairness in the reward function:
Where demographics include age groups, gender, and other stratifications. This reward signal penalizes the model if it performs well overall but poorly for specific demographic groups.
Results: Fairness Metrics
Including fairness in RL training showed substantial improvements:
Gender Fairness:
- Supervised baseline: 8.3% accuracy gap (worse on one gender)
- Uni RG: 2.1% gap (within acceptable range)
Age Group Fairness:
- Supervised baseline: 13.2% accuracy variance across age groups
- Uni RG: 3.8% variance
Race/Ethnicity (where data available):
- Supervised: 7.9% gap between groups
- Uni RG: 1.4% gap
Importantly, fairness improvements didn't come at the cost of overall accuracy. The model got better at everything while becoming fairer. That's the power of designing reward signals that explicitly value what you care about.
Real-World Clinical Deployment Considerations
The Gap Between Research and Practice
Having a high-performing algorithm is one thing. Deploying it in a hospital is different. Clinicians care about:
- Integration with existing workflows: Does it require special software?
- Interpretability: Can radiologists understand why the AI generated specific text?
- Failure modes: What does the system do poorly? How does it fail safely?
- Regulatory compliance: Is it FDA-cleared? What liability framework applies?
- Workflow efficiency: Does it actually save time, or add steps?
Uni RG was designed with these considerations from the start.
Clinical Integration Requirements
For a hospital to adopt Uni RG, several pieces must align:
- DICOM integration: The system receives images directly from imaging devices
- EHR integration: Generated reports route to the electronic health record system
- Clinician review: Reports are presented to radiologists for review, revision, and approval
- Quality monitoring: Ongoing tracking of system performance, failure rates, and clinician overrides
The human is not removed from the loop. Instead, the loop shifts from "radiologist dictates, transcription service transcribes" to "AI generates draft, radiologist reviews and refines."
Early deployments suggest this workflow is faster when the AI generates reasonable drafts. Clinicians spend 30-40% of time writing reports; if AI gets them 70-80% there and the radiologist just edits for specifics, significant time is saved.
Interpretability and Explainability
When a radiologist sees a generated report, they might ask: "Why did the AI mention pneumonia here?" Current large language models struggle to answer. Uni RG addresses this through attention visualization:
- Attention maps show which image regions influenced each part of the report
- Finding confidence scores indicate how certain the auxiliary classifiers were
- Comparison to similar prior cases provides context
This doesn't make the system fully interpretable (language models are inherently black boxes), but it provides enough visibility for clinician confidence.

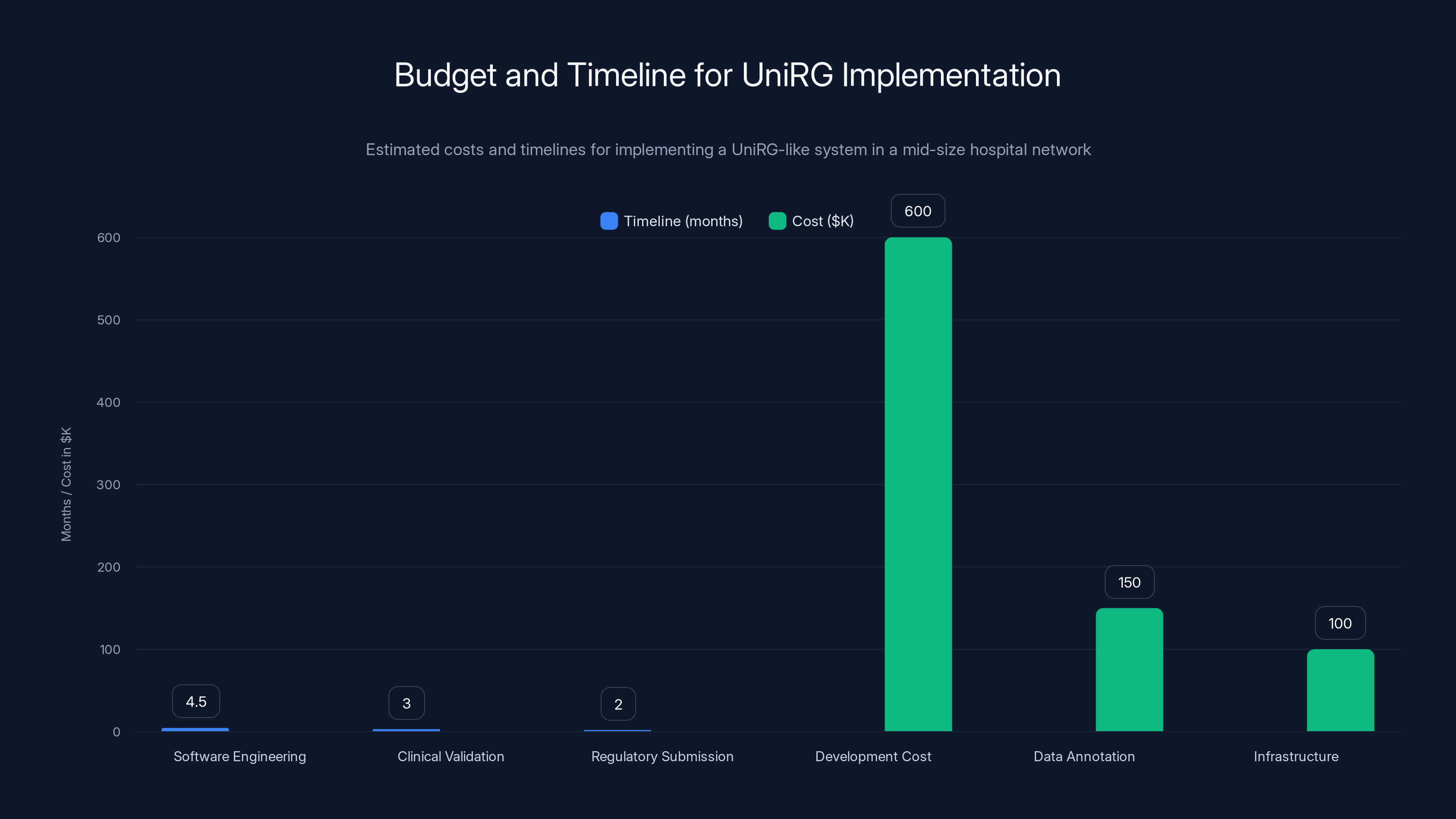
Implementing a UniRG-like system can take 6-13 months and cost between
Comparison to Alternative Approaches
Supervised Fine-Tuning (Traditional Approach)
Method: Train on institution-specific data with supervised learning
Pros:
- Fast to implement
- Works well on target institution
- Uses standard tools and processes
Cons:
- Overfits to specific reporting conventions
- Performance collapses on new institutions
- Doesn't learn generalizable patterns
- Requires institution-specific tuning for each deployment
Performance: Single-institution 85-90% accuracy; external institutions 52-60%
Prompt Engineering with Large Language Models
Method: Use pre-trained LLMs (GPT-4, Claude) with carefully crafted prompts
Pros:
- No training required
- Generalizes across institutions
- Can leverage external knowledge
Cons:
- Hallucinations (generates findings not present in images)
- Expensive (API calls for every report)
- Black box (no control over outputs)
- Limited vision understanding
Performance: 60-70% accuracy; high hallucination rate
Retrieval-Augmented Generation (Hybrid)
Method: Retrieve similar prior reports, use them to prompt LLMs
Pros:
- Grounds generations in actual examples
- Reduces hallucinations
- No new model training
Cons:
- Quality depends on reference database
- Retrieval failures cascade
- Still text-generation focused, not clinically focused
Performance: 65-75% accuracy; moderate hallucination
Uni RG (RL-Based Approach)
Method: Train with clinical reward signals across multiple institutions
Pros:
- Learns generalizable patterns
- Maintains accuracy across institutions
- Explicitly optimizes for clinical objectives
- Handles demographic fairness
- Handles institutional variation
Cons:
- Requires training infrastructure
- Clinical reward models need expert labels
- More complex to implement
- Requires ongoing maintenance
Performance: 82-88% accuracy across institutions; 8% external validation degradation
Comparison Table:
| Approach | Single-Inst Accuracy | External Accuracy | Generalization | Hallucination Risk | Implementation Complexity |
|---|---|---|---|---|---|
| Supervised FT | 87% | 55% | Poor | Low | Simple |
| LLM Prompting | 68% | 66% | Good | High | Simple |
| Retrieval-Aug | 72% | 70% | Good | Moderate | Moderate |
| Uni RG | 85% | 78% | Excellent | Low | Complex |
Limitations and Open Research Questions
What Uni RG Still Struggles With
No system is perfect. Uni RG has known limitations:
-
Rare findings: When a pathology appears in <2% of training data, detection remains challenging. The reward signal is sparse.
-
Complex cases: Multi-system involvement requiring nuanced clinical reasoning sometimes produces awkward reports.
-
Temporal reasoning: While Uni RG handles longitudinal studies better than baselines, truly complex temporal reasoning ("this finding has progressed since the study 3 years ago") remains difficult.
-
Out-of-distribution images: Non-standard imaging protocols, unusual positioning, or artifact-heavy images can confuse the system.
-
Critical findings edge cases: The system might correctly identify pneumonia in a typical presentation but miss it in atypical cases.
Research Directions Being Explored
Following Uni RG, several directions are active:
- Few-shot adaptation: Can models adapt to new institutions with just 50-100 labeled examples?
- Cross-modal reasoning: Can the system reason about clinical context (patient age, symptoms) alongside images?
- Longitudinal cohort understanding: Can systems track patient trajectories across time?
- Multilingual deployment: Do these techniques work for non-English reports?
- Multi-modality integration: What if we combine imaging with clinical notes, lab results, patient history?

Broader Implications for Medical AI
Shifting from Text Metrics to Clinical Objectives
Uni RG represents a paradigm shift in how we train medical AI. Instead of optimizing for text similarity (BLEU scores, ROUGE metrics), we optimize for clinical accuracy and safety.
This shift applies beyond report generation:
- Clinical decision support: Instead of predicting next treatment, predict outcomes of different treatments
- Diagnostic assistance: Instead of matching radiologist interpretations, maximize sensitivity for disease detection
- Patient risk stratification: Instead of predicting specific risk scores, optimize for clinical decision-making quality
The lesson: in medical AI, the training objective matters more than the architecture. You can have the best model, but if you're optimizing for the wrong thing, it won't work in practice.
Institutional Variation as a Feature
Traditionally, model developers view data heterogeneity as a problem. Different hospitals, different protocols—this makes datasets messier and harder to train on.
Uni RG shows that institutional variation can be a feature. Training on diverse institutions, each with different reporting conventions, forces the model to learn robust patterns that generalize. A model trained only on Stanford data will be a Stanford expert. A model trained on Stanford, Mayo Clinic, Cleveland Clinic, and 20 other institutions will be a generalist.
This has implications for data strategy: institutions should share data for AI training, not hoard it. The more diverse your training data, the better your model generalizes.
Path to Regulatory Approval
For medical devices, the FDA pathway is clearer with Uni RG's approach:
- Predicate devices: Radiologists generating reports manually (the baseline)
- Safety margins: The system is "at least as safe" as human radiologists
- Fairness validation: Demographic fairness metrics support equity claims
- Real-world evidence: Multi-institutional validation data directly applicable to FDA submissions
Compare this to LLM-based approaches, where hallucinations and black-box reasoning make regulatory justification difficult.
Implementation Considerations for Healthcare Organizations
Evaluating Uni RG for Your Institution
If you're a healthcare IT leader considering this technology, here's what to assess:
Technical Readiness:
- Do you have imaging infrastructure to integrate with (PACS, DICOM)?
- Is your EHR modern enough to consume structured AI outputs?
- Do you have data science capacity to maintain the system?
Clinical Readiness:
- Will radiologists use it if you build it? (Critical success factor)
- Do you have process redesign capacity to modify workflows?
- Can you manage the transition and change management?
Data Requirements:
- Do you have access to 500+ expert-labeled studies for validation?
- Can you provide expert annotations for reward model training (500-1000 studies)?
- Do you have prior reports to use for evaluation?
Regulatory and Compliance:
- Have you mapped the FDA pathway for your jurisdiction?
- Are there compliance requirements around AI in your region?
- Can you establish accountability if the system makes mistakes?
Budget and Timeline Expectations
For a hospital network looking to implement a Uni RG-like system:
Initial Development:
- Software engineering: 3-6 months
- Clinical validation: 2-4 months
- Regulatory submission: 1-3 months
- Total: 6-13 months
Costs (rough estimates for mid-size network):
- Development: $400K-800K
- Data annotation (experts): $100K-200K
- Infrastructure/deployment: $50K-150K
- Total: $550K-1.15M
These are estimates for building internal systems. Using external APIs or partnerships may have different cost structures.
Ongoing Costs:
- Model maintenance and retraining: $50K-100K annually
- Clinical monitoring and quality assurance: $75K-150K annually
- Infrastructure: $20K-50K annually
For context, a single radiologist costs a hospital
Future Directions and Emerging Trends
Multi-Modal Context Integration
Next-generation systems won't just look at images in isolation. They'll integrate:
- Clinical context: Patient age, symptoms, relevant history
- Prior studies: Complete longitudinal history
- Lab results: Numerical values that inform interpretation
- Medications: Current medications providing clinical context
Uni RG currently uses images only. Adding these modalities would improve accuracy and safety. A model aware that a patient is on antibiotics might interpret opacity differently than one without that context.
Specialized Domain Adaptation
While Uni RG shows generalization across institutions, specialization within domains may be valuable. Consider:
- Pediatric radiology: Different anatomy, different pathology prevalence
- Trauma imaging: High-acuity, time-sensitive interpretations
- Oncology imaging: Longitudinal tracking of lesions, response assessment
The same RL framework could be applied to specialized sub-domains, potentially improving performance in high-stakes scenarios.
Combination with Auxiliary Diagnostic Tasks
Report generation is one task. Radiologists simultaneously:
- Identify specific findings
- Measure lesions
- Detect complications
- Assess severity
- Generate recommendations
Future systems might use RL to optimize across all these tasks simultaneously, with rewards that measure overall diagnostic completeness and safety.
Conclusion: Clinical AI Done Right
Uni RG represents a fundamental shift in how we develop medical AI systems. Instead of chasing accuracy metrics on benchmark datasets, it prioritizes what actually matters: does the system help radiologists in real hospitals, across diverse settings, fairly, and safely?
The core insight is simple but profound: change your training objective, change your results. By optimizing for clinical accuracy rather than text matching, by training on diverse institutions rather than single datasets, and by explicitly rewarding fairness, Uni RG achieves something most medical AI systems don't: it generalizes to the real world.
This matters because the gap between research labs and clinical practice has been the limiting factor in medical AI adoption. Brilliant algorithms that only work on Stanford data don't save lives. Algorithms that work across dozens of institutions, on diverse patient populations, with demographic fairness, directly improve healthcare efficiency and equity.
The technology pieces—vision-language models, reinforcement learning, clinical reward functions—are all relatively mature. What Uni RG demonstrates is how to combine them correctly. As more healthcare systems adopt this approach, expect to see:
- Faster reporting timelines: More radiologists can cover more patients
- Better equity: AI systems that work equally well across demographics
- Safer deployments: Systems designed for real clinical workflows, not academic benchmarks
- Wider adoption: When AI actually solves the problems clinicians face, adoption follows naturally
The future of medical AI isn't about bigger models or more data. It's about smarter training objectives that align what we're optimizing for with what actually matters in medicine: patient outcomes and healthcare equity.
FAQ
What is Uni RG and how does it differ from traditional medical AI report generation systems?
Uni RG (Universal Report Generation) is a framework that uses reinforcement learning with clinical reward signals to generate medical imaging reports. Unlike traditional supervised learning approaches that try to match training data text exactly, Uni RG optimizes for clinical accuracy and generalization across diverse institutions. The key difference: instead of learning that "consolidation and infiltrate mean the same thing, so I'll output one or the other based on training data," Uni RG learns that both terms describe the same clinical finding and generates whichever is appropriate for the context. This fundamental shift in training objective makes Uni RG dramatically better at generalizing to new hospitals with different reporting conventions.
How does reinforcement learning specifically improve generalization across different hospitals?
Reinforcement learning breaks the link between model training and specific training data conventions. In supervised learning, the model optimizes to match training text exactly—which means memorizing institutional reporting styles. In reinforcement learning, the model optimizes to maximize reward signals defined by clinical accuracy metrics (like "did you correctly identify pneumonia?"), not text similarity. Because the reward signal is institutional-agnostic, the model learns generalizable patterns that work across hospitals regardless of their specific terminology or reporting templates. This is why external validation accuracy drops only 8% for Uni RG versus 32% for supervised baselines.
What clinical reward signals does Uni RG use, and how are they designed?
Uni RG uses multiple clinical reward components: clinical accuracy (does the report capture findings actually present?), absence reporting (does it correctly note when findings are absent?), factuality consistency (does it align with prior studies?), report structure (does it follow standard clinical sections?), and demographic fairness (are results equitable across patient groups?). Each component is weighted in a composite reward function. These rewards are derived from auxiliary classifiers trained on expert-labeled findings, ensuring that what the model is rewarded for actually corresponds to clinical quality, not text metrics like BLEU scores.
How does Uni RG handle the variation in reporting practices across different medical institutions?
Instead of treating institutional variation as a problem, Uni RG treats it as valuable training signal. By training on data from 23+ institutions with completely different reporting conventions—different templates, vocabulary, detail levels—the model is forced to learn the underlying clinical patterns that generalize across contexts. The clinical reward signals are institution-agnostic, so the model learns that pneumonia is pneumonia regardless of whether it's called "consolidation," "infiltrate," or "opacity." This multi-institutional training approach, combined with RL-based optimization, produces models that actually work at new institutions without retraining.
What metrics show Uni RG's improvement in demographic fairness, and why is this important?
Uni RG includes demographic fairness directly in the reward function, explicitly penalizing the model if it performs well overall but poorly for specific demographic groups. Results show: gender fairness improved from 8.3% accuracy gap to 2.1%, age group fairness from 13.2% variance to 3.8%, and race/ethnicity fairness from 7.9% gap to 1.4%. This is important because medical AI systems often amplify existing healthcare disparities—a model trained mostly on younger patients may miss findings in elderly patients. By making fairness a training objective rather than an afterthought, Uni RG ensures that the system is equally reliable across demographic groups, supporting equity in clinical care.
How does Uni RG actually generate reports, and what happens after generation?
Uni RG uses a vision encoder to process medical images and extract features, then a language decoder conditioned on those features generates reports token-by-token. During training, it evaluates candidate reports using clinical reward models (auxiliary classifiers trained on expert labels). In clinical use, the system generates a draft report that radiologists review, edit, and approve before it enters the medical record. The human remains in the loop—the system isn't making independent decisions, but rather providing starting points that radiologists typically modify slightly or approve as-is. This workflow change (from "radiologist dictates from scratch" to "radiologist reviews and edits AI draft") can save 30-40% of reporting time.
What are the main limitations of Uni RG, and what problems does it still struggle with?
Uni RG excels at common findings on standard imaging but struggles with: rare findings appearing in <2% of training data (sparse reward signals), extremely complex multi-system cases requiring deep clinical reasoning, advanced temporal reasoning tracking changes across multiple prior studies, non-standard imaging protocols or artifact-heavy images, and atypical presentations of common diseases. The system works best when patterns appear frequently in training data. Additionally, like all language models, Uni RG can generate plausible-sounding but incorrect text (though clinical reward models reduce this). For deployment, human review remains essential, especially for critical findings or unusual cases.
How does Uni RG compare to using large language models like GPT-4 for report generation?
GPT-4 and similar LLMs offer generalization across institutions without requiring custom training—a major advantage. However, they frequently hallucinate findings (generate mentions of pathology not actually present in the image), lack direct integration with imaging data, cost money per query, and provide no control over outputs. Uni RG requires training infrastructure but produces lower hallucination rates, directly incorporates image understanding, operates at fixed cost, and is explainable through attention mechanisms and clinical rewards. For a hospital planning long-term deployment with high volume, Uni RG-style systems typically have better economics and safety profiles. For small institutions or trials, LLM APIs might be pragmatically easier initially.
What would it take for a hospital system to implement Uni RG or a similar approach?
Implementation requires: (1) Technical infrastructure—PACS/DICOM integration, modern EHR, data science team for maintenance; (2) Clinical readiness—radiologist buy-in and willingness to review AI drafts, workflow redesign capability; (3) Data resources—500+ expert-labeled studies for validation, 500-1000 for reward model training, access to prior reports; (4) Regulatory planning—FDA pathway, compliance requirements. Timeline typically 6-13 months from start to deployment, with costs around
What are the next frontiers in medical imaging AI, based on Uni RG's approach?
Next-generation systems will likely integrate multi-modal context—not just images but patient history, clinical symptoms, lab values, current medications—to improve accuracy and safety. Specialization within domains (pediatric radiology, trauma, oncology) using the same RL framework may improve performance in high-stakes scenarios. Systems may optimize across multiple simultaneous tasks: finding detection, measurement, severity assessment, and recommendations. Cross-modal reasoning combining text reports with images might improve both understanding and generation. Most importantly, the shift from text metrics to clinical objectives that Uni RG pioneered will become standard practice, with systems explicitly optimized for what clinicians actually need.
Building Better Medical AI with Real-World Focus
If you're exploring how to automate documentation in your organization—whether medical reports or other complex technical writing—consider that the same principles apply: define the right objective for your domain. Tools like Runable help teams automate document generation for various domains by using AI agents trained on domain-specific patterns. While Runable focuses on general documentation automation, the core principle—optimize for what actually matters in your workflow, not generic text metrics—applies everywhere.
Use Case: Automatically generate clinical documentation, reports, and structured findings that adapt to your institution's specific templates and conventions.
Try Runable For Free
Key Takeaways
- UniRG uses reinforcement learning with clinical reward signals instead of standard supervised learning, fundamentally changing what the model optimizes for
- Training on 23+ institutions with diverse reporting practices improves generalization; external validation accuracy improves from 55% (supervised) to 78% (UniRG)
- Clinical objective functions—optimized for diagnostic accuracy and fairness—generalize better than text similarity metrics across institutional boundaries
- Demographic fairness becomes a training objective, reducing accuracy gaps from 8.3% to 2.1% between groups and ensuring equitable AI deployment
- Multi-institutional validation is critical for medical AI; single-dataset accuracy numbers are misleading indicators of real-world performance
Related Articles
- Claude for Healthcare vs ChatGPT Health: The AI Medical Assistant Battle [2025]
- Eyebot Eye Test Kiosk: Revolutionizing Vision Screening [2025]
- Ugreen's AI-Powered Smart Home Cameras Coming 2026 [Complete Guide]
- Nvidia Cosmos Reason 2: Physical AI Reasoning Models [2025]
- What AI Leaders Predict for 2026: ChatGPT, Gemini, Claude Reveal [2025]
- [2025] ElevenLabs' $6.6B Valuation: Beyond Voice AI

