![Unmasking Pseudonymous Users: How LLMs Are Changing Privacy Dynamics [2025]](https://tryrunable.com/blog/unmasking-pseudonymous-users-how-llms-are-changing-privacy-d/image-1-1772543220716.jpg)
Introduction
In the digital age, privacy often feels like a distant memory. With the rise of large language models (LLMs), the veil of pseudonymity that many internet users rely on is becoming increasingly transparent. These models leverage vast amounts of data and advanced algorithms to identify individuals behind pseudonymous accounts with surprising accuracy. This article explores the mechanics behind this phenomenon, its implications for privacy, and what the future may hold.

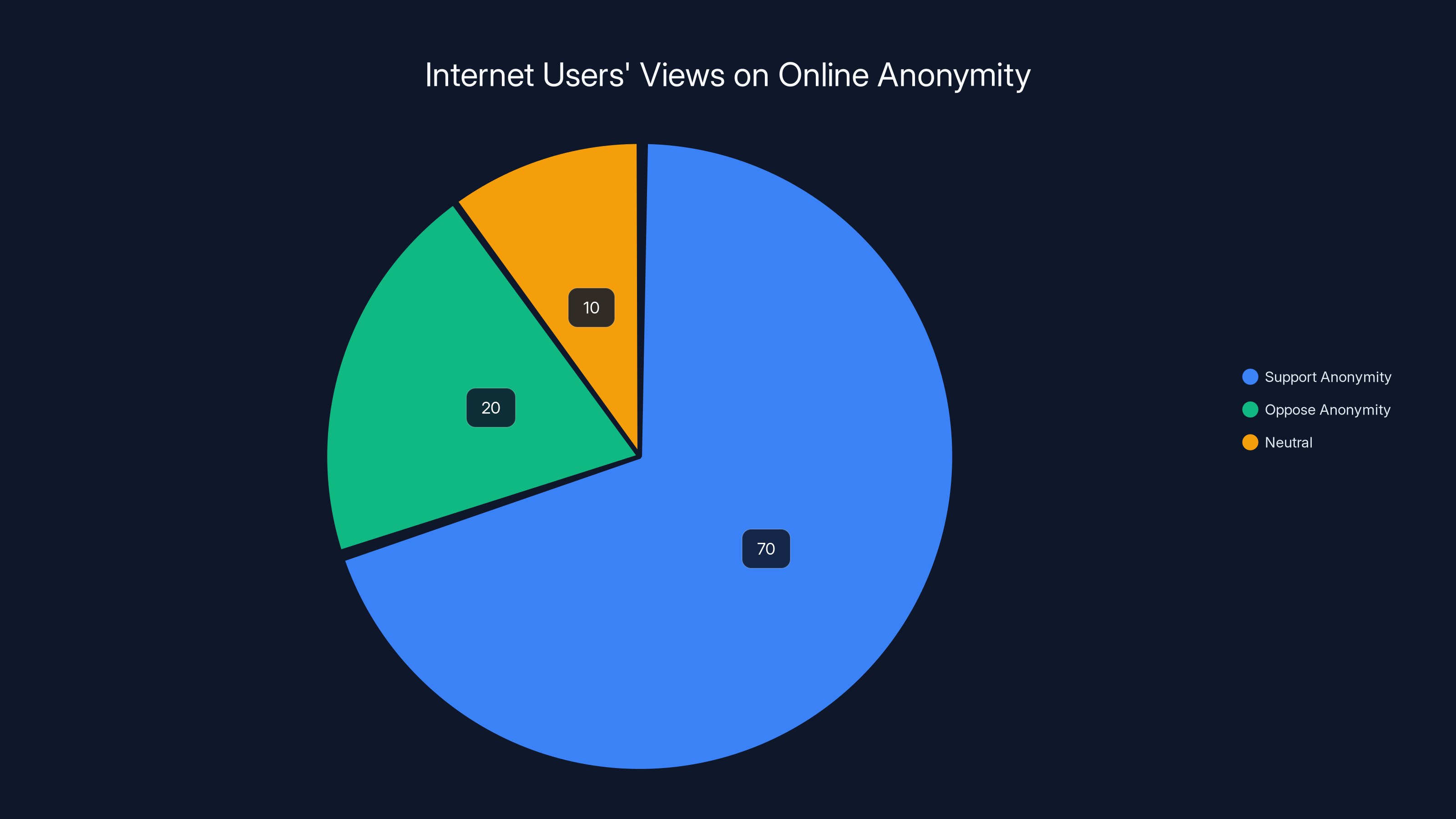
A 2023 survey reveals that 70% of internet users support maintaining online anonymity unless a crime is involved, highlighting the importance of privacy in digital spaces.
TL; DR
- LLMs can identify pseudonymous users with up to 90% precision, raising significant privacy concerns, as detailed in a recent report.
- Cross-platform analysis allows LLMs to correlate user activity across different social media sites.
- Textual fingerprints are key to deanonymization, as unique language patterns reveal identities.
- Privacy-preserving techniques are evolving but struggle to keep pace with AI advancements, according to market research.
- Regulatory frameworks need urgent updates to address these new privacy challenges, as highlighted by Eurostat.
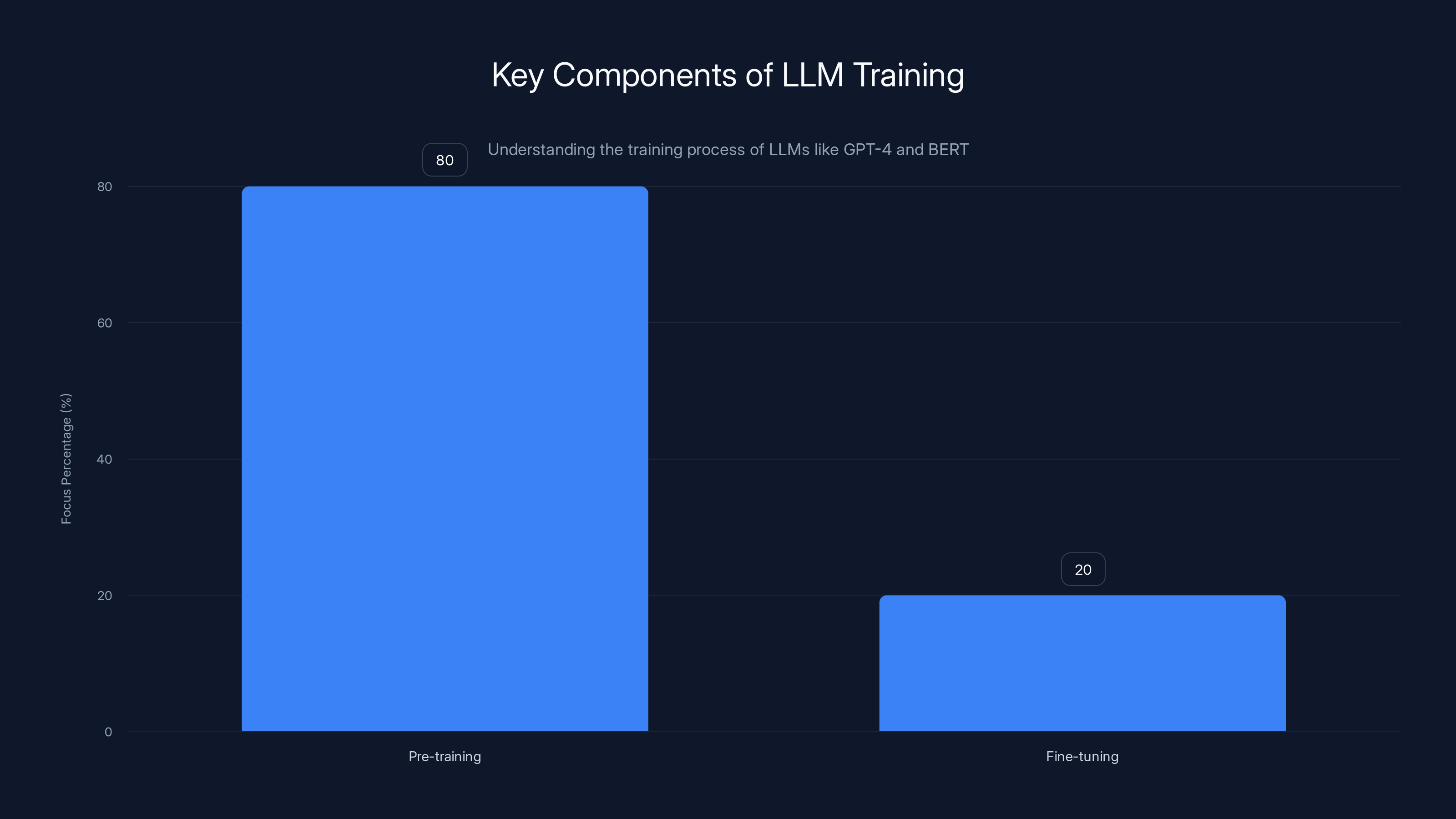
LLMs dedicate approximately 80% of their training to pre-training on vast text corpora, while 20% focuses on fine-tuning for specific tasks. Estimated data based on typical LLM training processes.
The Mechanics of Deanonymization
At the heart of LLMs' ability to unmask users is their capacity to analyze vast datasets for patterns. These models process textual data, identifying unique language patterns that serve as digital fingerprints. Every individual has a distinct way of using language, whether through vocabulary, syntax, or even the frequency of emojis. By training on large datasets, LLMs learn to recognize these patterns across different platforms.
How LLMs Work
LLMs, such as OpenAI's GPT-4 and Google's BERT, are designed to understand and generate human-like text. They are trained on diverse internet data, which enables them to capture the nuances of language. This training process involves two key components:
- Pre-training: Models are exposed to vast text corpora, learning grammar, facts about the world, and some reasoning abilities.
- Fine-tuning: Models are adapted to specific tasks, such as text classification or summarization, using smaller, task-specific datasets.
These models are adept at recognizing subtle language cues, making them powerful tools for identifying users based on their writing style.
Case Studies: LLMs in Action
Example 1: Social Media Analysis
Imagine a user who maintains pseudonymous accounts on Twitter and Reddit. This user frequently discusses topics like technology and gaming. By analyzing the user's language patterns—such as specific jargon used, sentence structure, and even common misspellings—LLMs can correlate posts from both platforms to a single identity.
Example 2: Forum Participation
Consider a developer active on various coding forums under different aliases. The developer's use of certain programming terminologies, coupled with a preference for specific languages like Python over Java, forms a unique textual fingerprint. LLMs can cross-reference these patterns against known public profiles, potentially revealing the user's real identity.

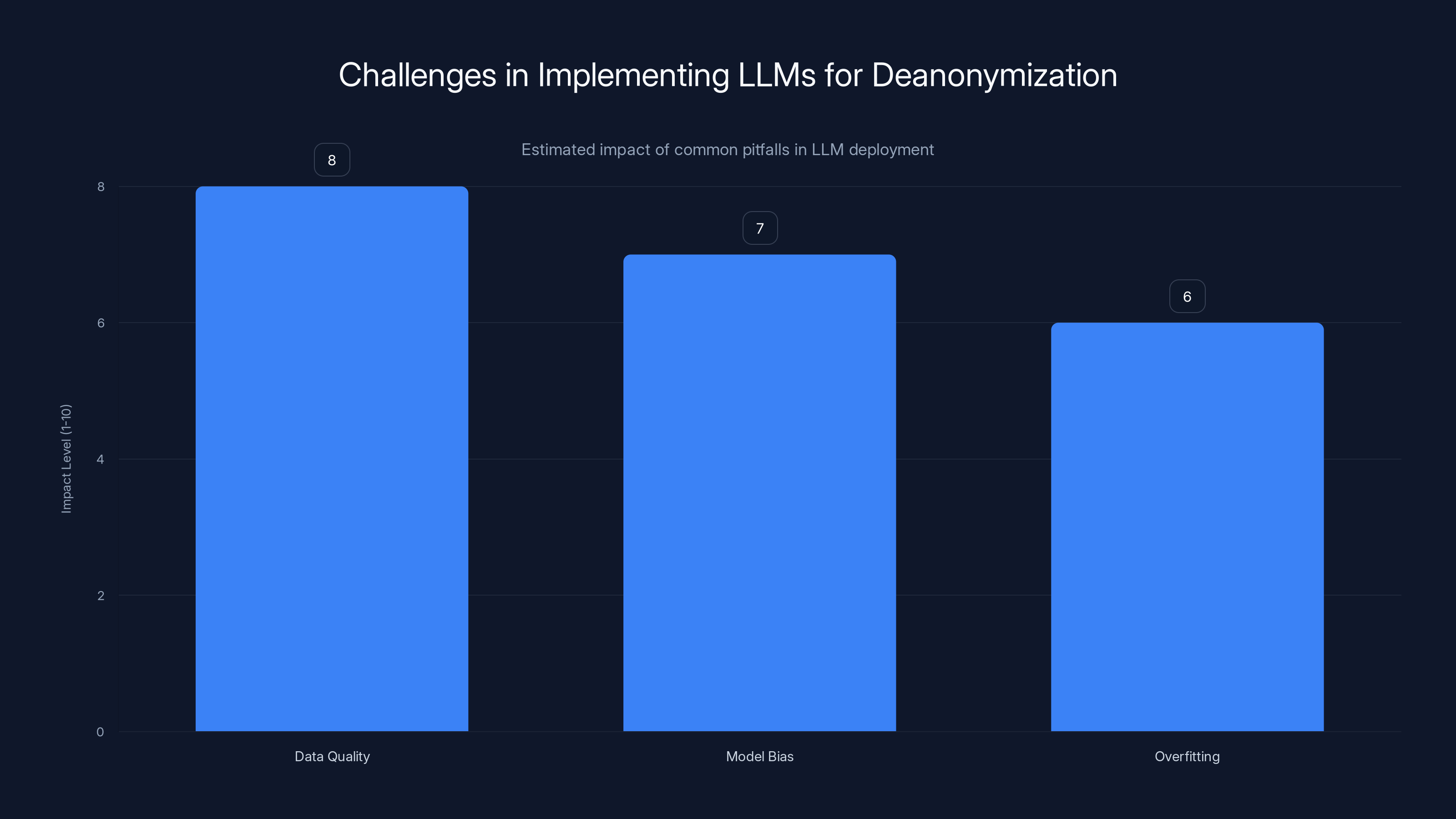
Data quality poses the highest challenge in LLM deployment for deanonymization, followed by model bias and overfitting. Estimated data based on common pitfalls.
Technical Details and Best Practices
Implementing LLMs for Deanonymization
To effectively use LLMs for deanonymization, several technical steps are involved:
- Data Collection: Gather text data from various platforms where the target user is active.
- Pre-processing: Clean and normalize the data to remove noise, such as irrelevant symbols or non-textual elements.
- Model Training: Use a pre-trained LLM, fine-tuned on the specific dataset to enhance recognition accuracy.
- Pattern Analysis: Implement algorithms to detect unique language patterns across different datasets.
Common Pitfalls and Solutions
- Data Quality: Poor quality data can lead to inaccurate results. Ensure that the data is comprehensive and representative of the user's typical language use.
- Bias in Models: LLMs can inherit biases present in training data. Regularly update training datasets to minimize bias and improve fairness.
- Overfitting: Fine-tuning models too aggressively on small datasets can lead to overfitting. Use techniques like dropout and cross-validation to avoid this.
Privacy Implications
Eroding Anonymity
The ability of LLMs to deanonymize users poses significant privacy challenges. As these models become more accurate, the concept of pseudonymity—once a cornerstone of internet privacy—is being undermined. Users who rely on pseudonyms to express opinions without fear of retribution may find themselves exposed.
Legal and Ethical Considerations
The use of LLMs for deanonymization raises important legal and ethical questions. For instance, is it ethical to unmask users who wish to remain anonymous for their safety? How should the law balance the right to privacy against the need for accountability?
Practical Implementation Guides
Tools and Frameworks
Several tools and frameworks can assist in implementing LLMs for user identification:
- Transformers Library: This open-source library by Hugging Face provides pre-trained models and tools for fine-tuning.
- OpenAI API: Offers access to advanced language models for text analysis and generation.
- TensorFlow: A popular framework for building and deploying machine learning models, including LLMs.
Step-by-Step Guide
-
Install Required Libraries
bashpip install transformers openai tensorflow -
Prepare Your Dataset
- Collect text samples from different platforms.
- Use Python scripts to clean and organize the data.
-
Fine-Tune the Model
pythonfrom transformers import GPT2LMHeadModel, GPT2Tokenizer model = GPT2LMHeadModel.from_pretrained('gpt2') tokenizer = GPT2Tokenizer.from_pretrained('gpt2') # Fine-tuning steps here -
Analyze Patterns
- Use the fine-tuned model to analyze language patterns and identify potential matches.
Future Trends and Recommendations
Advancements in Privacy-Preserving AI
As LLMs continue to evolve, so too do privacy-preserving technologies. Techniques like differential privacy and federated learning are being integrated into AI models to enhance user privacy, as discussed in a recent analysis.
Regulatory Developments
Governments and regulatory bodies are beginning to recognize the impact of AI on privacy. Updated regulations, such as the GDPR in Europe, are setting new standards for data protection and user privacy.
Best Practices for Users
- Use Multiple Pseudonyms: Vary your language patterns across platforms to make deanonymization more difficult.
- Limit Personal Information: Avoid sharing identifiable information in public forums.
- Stay Informed: Keep up to date with the latest privacy tools and practices.
Conclusion
The capabilities of LLMs to unmask pseudonymous users are a double-edged sword. While they offer powerful tools for accountability and security, they also pose significant threats to privacy. As these technologies continue to advance, it is crucial for individuals, organizations, and governments to navigate the balance between transparency and privacy responsibly.
FAQ
What are LLMs?
LLMs, or large language models, are advanced AI models designed to understand and generate human-like text. They are trained on vast datasets and can perform various language-related tasks.
How do LLMs deanonymize users?
LLMs analyze language patterns across different platforms to identify unique textual fingerprints. By correlating these patterns, they can unmask pseudonymous users.
Why is deanonymization a privacy concern?
Deanonymization erodes the privacy of individuals who rely on pseudonyms to express themselves freely. It can expose users to risks such as harassment or legal repercussions.
How can I protect my online anonymity?
Use multiple pseudonyms, limit personal information shared online, and stay informed about privacy-preserving technologies and practices.
What legal frameworks address privacy in the context of AI?
Regulations like the GDPR set standards for data protection and privacy. However, ongoing updates are necessary to address the challenges posed by advanced AI technologies.
Are there ethical considerations in using LLMs for deanonymization?
Yes, ethical considerations include balancing the right to privacy with the need for accountability. It is crucial to consider the potential harm and benefits of unmasking users.
What future trends are expected in AI and privacy?
Advancements in privacy-preserving technologies, updated regulations, and increased awareness of privacy issues are expected to shape the future of AI and privacy.
How can organizations use LLMs responsibly?
Organizations should implement privacy-preserving techniques, comply with regulations, and consider the ethical implications of using LLMs for deanonymization.

Key Takeaways
- LLMs can achieve up to 90% precision in identifying pseudonymous users.
- Textual fingerprints are crucial for deanonymization.
- Cross-platform analysis enhances identification accuracy.
- Privacy-preserving techniques must evolve alongside AI advancements.
- Regulatory frameworks need urgent updates to address AI privacy challenges.
- Users should adopt privacy best practices to protect anonymity.
- Ethical considerations are vital in balancing privacy and accountability.
- Future trends include privacy-preserving AI and updated regulations.
Related Articles
- How Mastodon's New Content Sharing Button Changes Social Media Dynamics [2025]
- Making the Switch from ChatGPT to Claude: A Comprehensive Guide [2025]
- We're Still Early to AI — And Your Team Needs More Help Than You Think [2025]
- Navigating the Surveillance Frontier: AI, Ethics, and Government Collaboration [2025]
- Unmasking the Latest Phishing Threat: Fake Google Security Pages [2025]
- How Palantir, Microsoft, Amazon, and Google Power Trump’s Immigration Crackdown | WIRED

