![Voice: The Next AI Interface Reshaping Human-Computer Interaction [2025]](https://tryrunable.com/blog/voice-the-next-ai-interface-reshaping-human-computer-interac/image-1-1770304155485.png)
Introduction: The Shift From Screens to Sound
Your phone's screen is about to become irrelevant. Not immediately. Not completely. But gradually, inevitably, voice is going to become the dominant way you interact with artificial intelligence. This isn't hype. This is happening right now, and the implications are massive.
We've spent the last fifteen years optimizing for touchscreens. Every interaction designed around fingers, every app architected around visual interfaces. But here's what's changing: AI models are getting better at understanding context, emotion, and nuance in human speech. They're no longer just converting audio to text and back again. They're reasoning with voice, understanding tone, and responding conversationally in ways that feel natural.
The numbers backing this shift are staggering. Major AI companies like OpenAI and Google have made voice interaction central to their next-generation systems. Apple is quietly building voice-adjacent, always-on technologies through strategic acquisitions. And companies like Eleven Labs, which recently raised
But this transition isn't just about convenience. It's about fundamentally changing how humans engage with machines. It's about moving technology out of your hands and into the ambient environment around you. Instead of reaching for your phone to check the weather, you'll ask your glasses. Instead of typing commands into your laptop, you'll describe what you want to a device you can't even see.
This shift is happening because voice solves real problems that screens can't. Voice doesn't require your hands. It doesn't drain battery as fast. It works while you're driving, cooking, or walking. It bridges the gap between digital and physical worlds in ways that make technology feel less intrusive and more like a natural extension of how humans actually communicate.
The implications stretch far beyond convenience. Voice-first AI changes accessibility for people with motor disabilities. It changes how we multitask. It changes what devices need to look like and where AI can actually exist in our daily lives. And it opens entirely new frontiers for surveillance, privacy concerns, and data collection that we're only beginning to grapple with.
TL; DR
- Voice is becoming the dominant AI interface: Companies are shifting from text and screens to conversational, voice-based interactions as the primary way users control AI systems
- Hardware makers are betting big: Wearables, smart glasses, and always-on devices are pushing voice to the center, with Apple, Meta, and others building voice-first products
- Technical breakthroughs are enabling this shift: Modern voice models now combine emotion, intonation, and contextual reasoning rather than simple speech-to-text conversion
- Agentic AI changes the interaction model: Future systems will use persistent memory and context to understand user intent without explicit prompting
- Privacy and surveillance concerns are massive: As voice systems get closer to users' daily lives, data collection and storage raise serious questions about consent and security
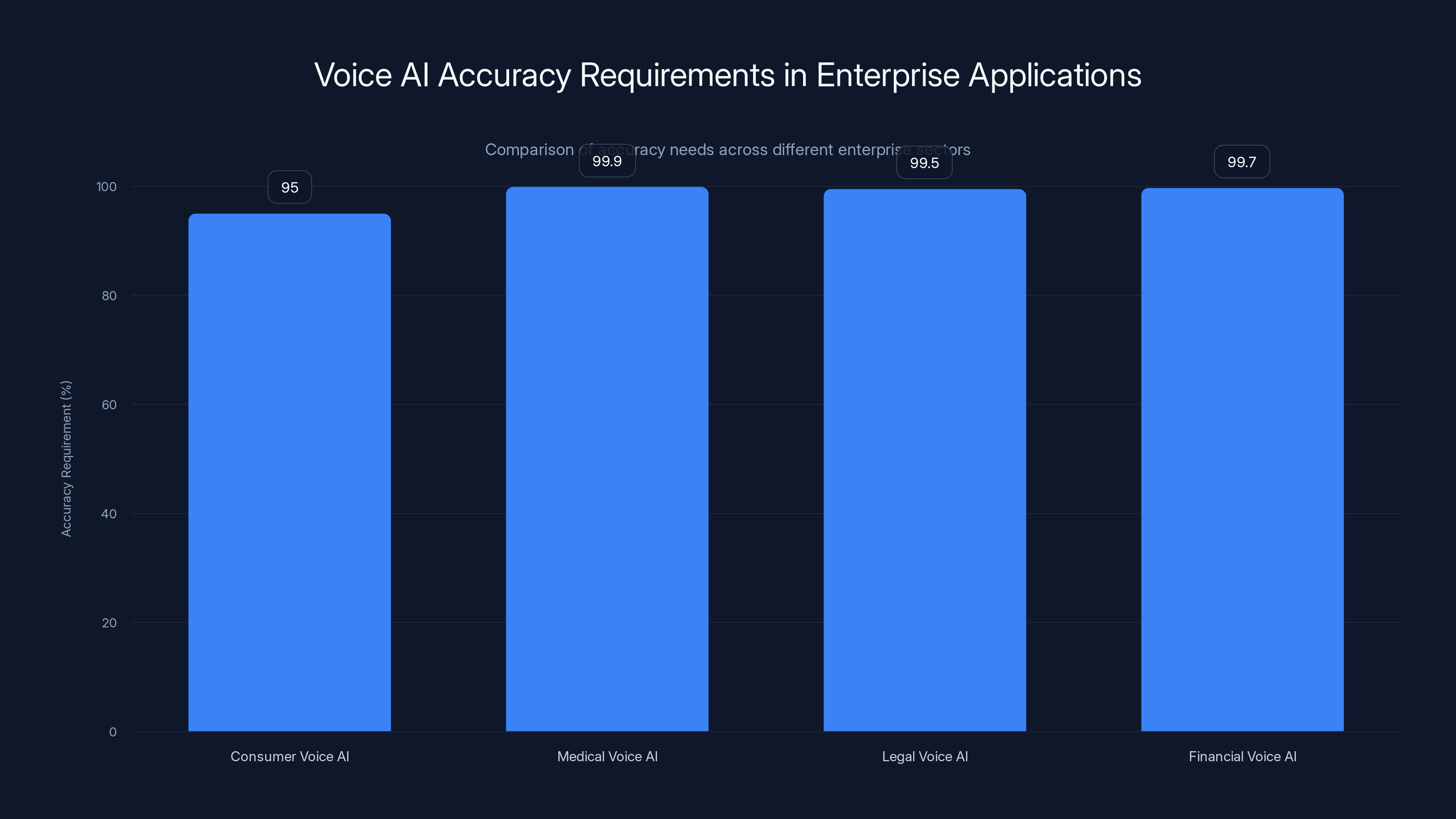
Enterprise voice AI systems require significantly higher accuracy compared to consumer applications, with medical systems needing over 99.9% accuracy to ensure compliance and safety. Estimated data.
Why Voice Becomes the Natural Human-Computer Interface
Let's start with something obvious that we often overlook: humans have been communicating with voice for roughly 100,000 years. Writing came along maybe 5,000 years ago. Keyboards arrived about 150 years ago. Touchscreens? About 20 years ago.
When you think about human communication on that timeline, voice isn't new. It's the default. Everything else is an adaptation.
That matters because it means voice interfaces require less cognitive overhead. You don't need to learn gestures or memorize keyboard shortcuts. You just talk, the way you talk to anyone else. This is why voice AI adoption has been surprisingly high even when the technology was mediocre. People will tolerate buggy voice systems because the interaction model itself feels right.
But the real reason voice is becoming dominant now isn't nostalgia or natural preference. It's because of what modern AI models can actually do with voice data.
Older speech recognition systems treated voice as an input problem. Take audio, convert to text, process the text. This created a bottleneck because a lot of human meaning lives in tone, pacing, emotion, and context that gets stripped away in transcription. You can say "That's great" with complete sincerity or with heavy sarcasm, and those mean opposite things. Text alone can't capture that.
Modern voice models are different. They process voice as voice, not as a proxy for text. They understand that a hesitation might indicate uncertainty, that a rising tone might signal a question even when the grammar says statement, that the emotional weight of what someone's saying matters as much as the literal words.
Combine that with large language models that can reason about context, maintain conversation history, and understand implication, and suddenly voice becomes genuinely powerful. You don't need to say "Check my calendar for Tuesday afternoon between 2 and 4 PM." You can say "Do I have anything before that meeting I mentioned yesterday?" The system understands history, context, and implication.
This is why agentic AI matters so much in this conversation. An agentic system doesn't just respond to what you say. It understands what you're trying to accomplish, remembers previous context, and can take actions without explicit instruction. Voice becomes the control interface for a system that's smart enough to need less explicit control.
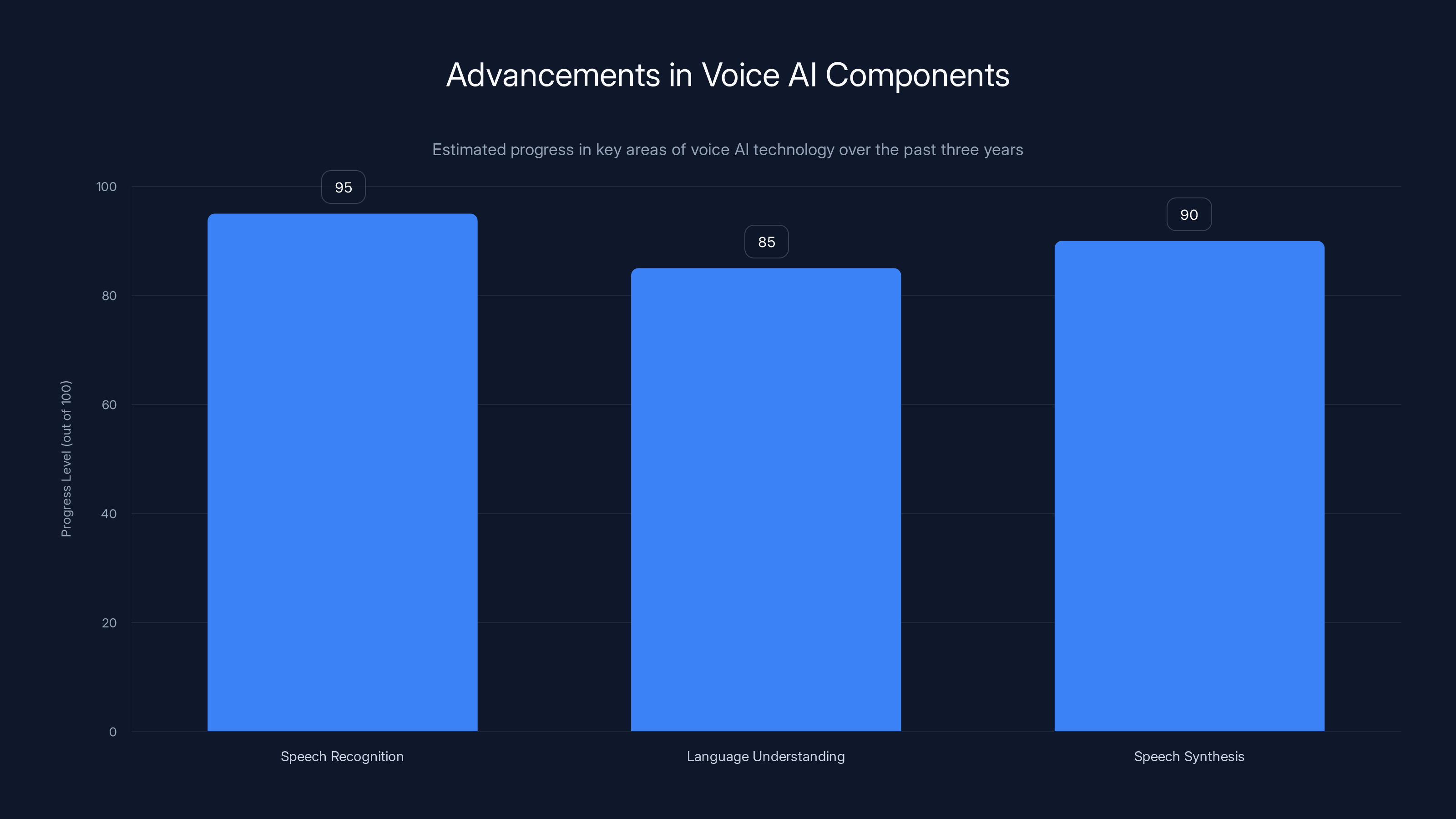
Speech recognition has achieved near-perfect accuracy in clean environments, while language understanding and speech synthesis have made significant strides towards natural interaction. Estimated data.
The Current State of Voice AI Technology
We're at an interesting moment in voice AI development. The technology is good enough to be genuinely useful, but not so mature that it's invisible. You notice when voice systems work well. You also notice when they fail.
Three main components make up modern voice AI systems: speech recognition, language understanding, and speech synthesis. Each has made huge advances in the last three years.
Speech recognition accuracy has basically hit the wall at around 95-97% in clean audio environments. That's good enough for most purposes. The remaining 3-5% of errors are usually edge cases that would confuse humans too, like heavily accented speech or highly technical jargon. The real improvement now comes in handling interruptions, background noise, and multiple speakers simultaneously.
Language understanding is where the biggest innovations are happening. Rather than treating voice input as a special case of text, the best systems now process voice and text differently, preserving information that transcription would lose. A system that understands "I'll pass" versus "I'll pass on that" versus the sarcastic version of "I'll pass" needs to work with acoustic data, not just text.
Speech synthesis has moved past the robotic "text-to-speech" era into something closer to natural speech. Modern systems can generate speech that includes emotion, pacing variations, and even personality quirks. The uncanny valley has mostly disappeared. Synthesized speech now sounds like a person, not a simulation of a person.
The breakthrough that's enabling voice as a primary interface is the integration of these three components with agentic reasoning. Previous systems were designed like a phone tree: you speak, the system transcribes and processes, the system generates a response, the system speaks back. Latency was often a second or more, which made the interaction feel clunky.
New systems are reducing latency dramatically. Some now respond in under 500 milliseconds, which approaches the latency of a human conversation. This is partly because of faster hardware, but mostly because of architectural changes that let the system start generating a response before you finish speaking.
Think about how humans have conversations. You don't wait for someone to finish their entire sentence before you start thinking about what to say. You're thinking and predicting in parallel. Modern voice AI systems now work similarly. This makes conversations feel natural instead of mechanical.

Hardware Innovation: Voice Enters Wearables and Ambient Computing
Voice interfaces are only useful if you have a device to speak to. This is why the explosion of voice AI is happening alongside a parallel boom in new hardware categories.
Smartphones revolutionized computing by putting a powerful computer in your pocket. But they also locked you into a specific interaction model: looking at a screen, tapping with your fingers. That's great for certain tasks. It's terrible for others.
Voice-first hardware solves that problem. Smart glasses let you access information and control devices without looking at a screen at all. Earbuds become command centers. Smartwatches become interfaces for complex tasks, not just notifications. Even your car dashboard becomes less about visual displays and more about voice commands.
Apple's acquisition of Shazam and other voice-adjacent companies suggests they're building an ecosystem where voice becomes the primary interface for their devices. Meta's partnership with Eleven Labs for Instagram and Horizon Worlds shows they're thinking about voice in social and immersive contexts. Google's push toward conversational search is fundamentally about making voice the entry point.
But here's what's really interesting: these aren't voice features added to existing hardware. These are devices designed from the ground up assuming voice will be the primary input method.
Ray-Ban smart glasses, for example, are useful with taps and swipes, but they're genuinely powerful with voice commands. "Show me directions to the restaurant I mentioned yesterday." "Who is this person?" "Record a video for my team." All of these work better with voice than with tiny screen taps.
Wearables are particularly interesting because they're always with you. A smartphone is something you carry. Headphones or glasses are things you wear. Your watch is on your wrist. These devices become extensions of your body in a way phones never quite did. Voice interaction is more natural at that level of integration.
The hardware category that's going to matter most over the next five years isn't any single device. It's the ecosystem. You need your glasses to talk to your earbuds to talk to your car to talk to your home. The voice AI that integrates these disparate devices into a coherent system is what creates real value.
This is why companies like Eleven Labs are pushing toward hybrid approaches that combine cloud and on-device processing. Cloud processing gives you access to the most powerful models with the best reasoning. On-device processing gives you privacy, latency, and the ability to work offline. The future of voice hardware needs both.

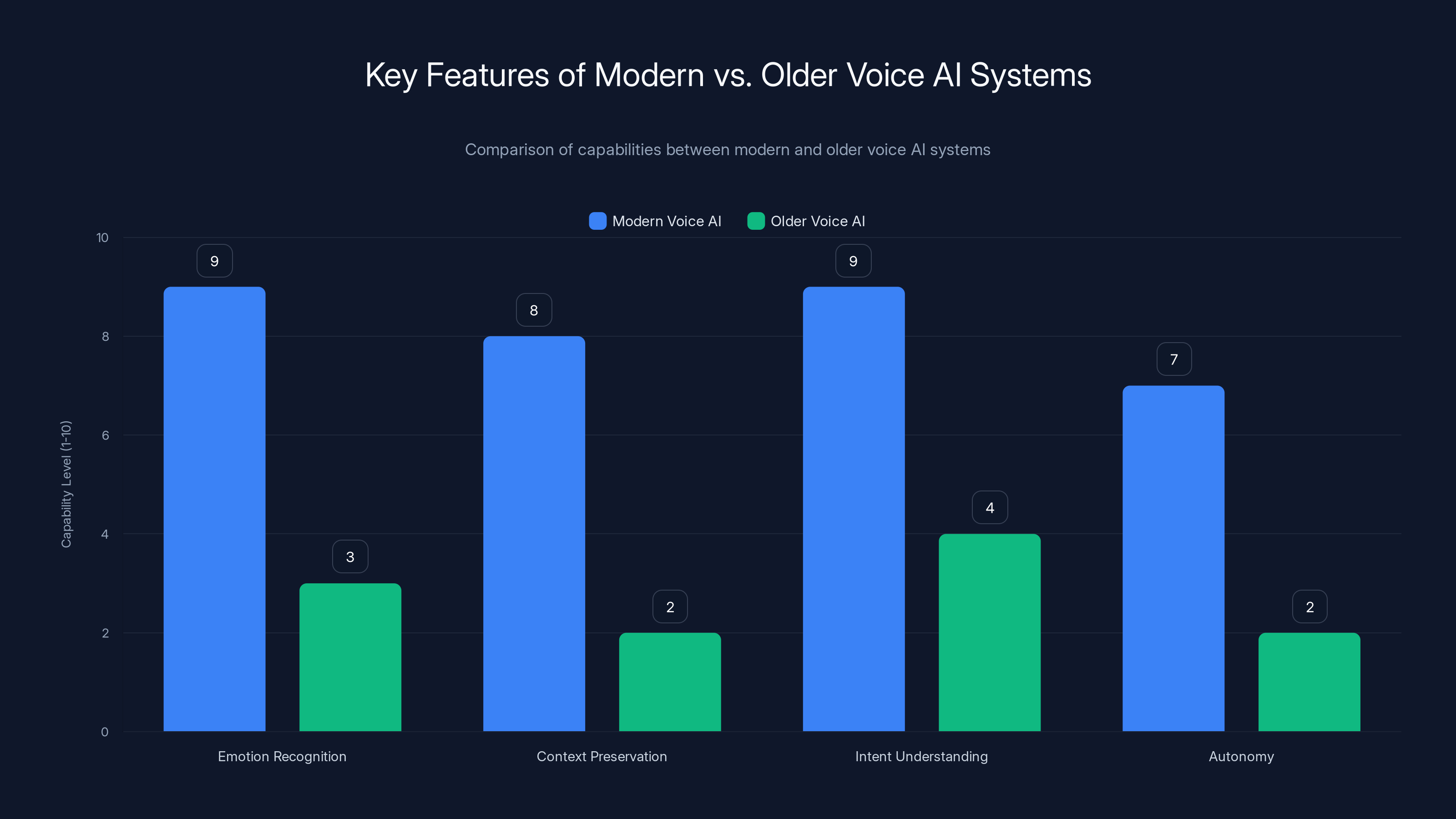
Modern voice AI systems significantly outperform older systems in emotion recognition, context preservation, and understanding user intent, offering a more autonomous interaction experience.
The Agentic Shift: Voice Moves Beyond Commands to Conversation
Traditional voice interfaces work like a telephone tree. You speak a command, the system processes it, executes an action, and responds. "What's the weather?" System checks weather, tells you it's sunny. Transaction complete.
Agentic voice AI works completely differently. Instead of waiting for explicit commands, the system is actively maintaining context, remembering previous conversations, understanding your goals, and proactively suggesting actions.
Let's say you tell your voice assistant "I have a meeting with Sarah tomorrow." A traditional system notes this fact and stops. An agentic system notes the fact, but also understands that this means you might want to:
- Review previous conversations with Sarah
- Check what preparation materials she might need
- Look for scheduling conflicts
- Pull up relevant project files
- Block off travel time before the meeting
- Set reminders for action items
None of that was explicitly requested. The system is reasoning about your intent and what might be helpful.
This is where persistent memory becomes critical. Previous voice systems started fresh with each interaction. You'd repeat context multiple times: "Remember when I said I was thinking about switching jobs?" "Yes, I remember you mentioning that." But if the system restarted, that context was gone.
Agentic systems maintain persistent memory. They remember previous conversations, your preferences, your patterns, your goals. Over time, they become more useful because they understand more about who you are and what you're trying to accomplish.
The shift from commands to conversation is subtle but profound. With commands, the user is entirely in control. The user knows what they want, articulates it clearly, and the system executes. With conversation, the system has agency. The system can ask clarifying questions. The system can suggest alternatives. The system can push back if something doesn't make sense.
This requires guardrails and integrations that traditional voice systems didn't need. An agentic system that can take actions on your behalf needs to understand boundaries. It needs to know what it's allowed to do without asking permission. It needs to know what requires explicit approval before proceeding.
These guardrails are still being figured out. How much should an AI system be allowed to do without explicit user authorization? If your voice assistant is connected to your email, should it send messages without asking first? If it's connected to your bank account, should it make purchases? These aren't technical questions. They're policy questions that different companies will answer differently.
But the direction is clear: voice AI is moving from simple command execution toward genuine assistance that understands context, maintains memory, and reasons about what might be helpful.

How Voice Models Now Integrate Emotion and Reasoning
One of the biggest breakthroughs in voice AI is the realization that emotion and reasoning can't be separated. They're deeply intertwined.
When you tell someone "I'm fine," they understand a lot based on how you say it. If you say it cheerfully, you're fine. If you say it flatly, they know something's wrong. If you say it sarcastically, you're indicating the opposite. The literal words are identical. The meaning is completely different.
Old speech-to-text systems would transcribe "I'm fine" every time, losing all that emotional and contextual information. Modern voice models preserve and understand that information.
This matters because emotional context changes how an AI system should respond. If someone says "I don't know how to fix this" with frustration in their voice, that's different from saying it with calm curiosity. The first might need empathy and encouragement. The second might benefit from technical depth.
The integration of emotion into reasoning is relatively new. It requires that voice models and language models work together rather than sequentially. The traditional pipeline was: audio → transcription → language model → response. The new pipeline is more like: audio → integrated processing → language model with emotional context → response generation.
This sounds technical, but the user experience is what matters. A voice system that understands emotion feels more natural because it responds appropriately to how you say things, not just what you say.
There's also something interesting happening with reasoning and voice. Text-based AI systems have become very good at chain-of-thought reasoning, where the system shows its work: "First, I'll check your calendar. Then I'll look at your inbox. Then I'll prioritize based on deadlines." This explicit reasoning helps users understand how the system arrived at conclusions.
Voice-based reasoning is different. You can't really listen to a system's entire chain of thought while you're waiting for an answer. That would make conversations tedious. Instead, voice systems are learning to do reasoning internally and present only the conclusion conversationally. "You should probably reply to Sarah's email before your meeting" rather than "I checked your email, found Sarah's message from 2 hours ago about the budget review, checked your calendar, saw you have a meeting in 3 hours, and determined that replying would be good."
But internally, the system might be doing complex multi-step reasoning. Voice models are getting better at this kind of internal reasoning without making the conversation feel stilted.

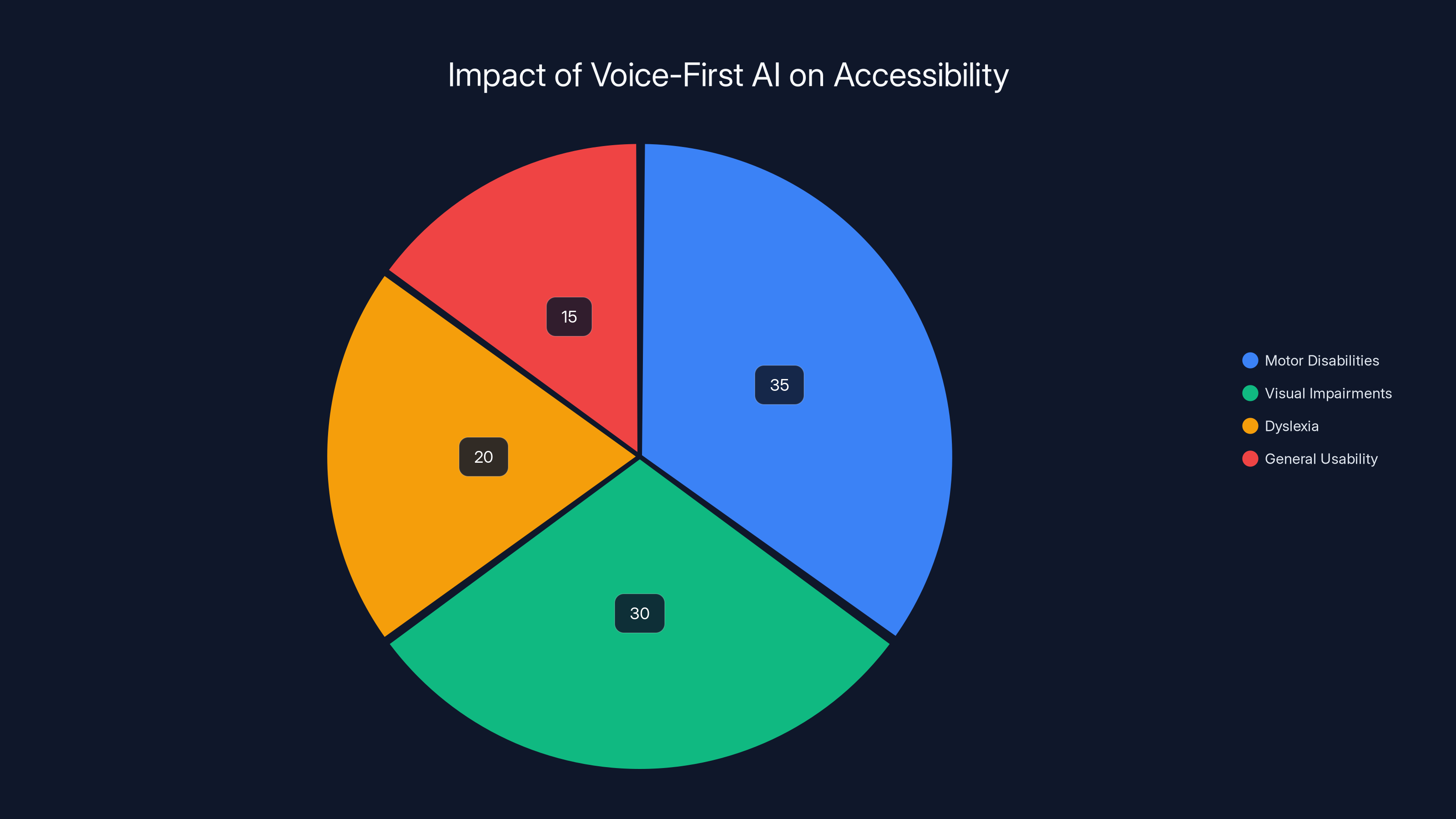
Voice-first AI significantly enhances accessibility, with the greatest impact on motor disabilities and visual impairments. (Estimated data)
Privacy Concerns: The Dark Side of Always-On Voice
Here's the thing nobody wants to talk about: more voice data collection means more opportunities for surveillance, abuse, and privacy violations.
When voice AI lives on your phone and you activate it with a wake word, there's at least a conscious interaction. You know the system is listening because you said "Hey Siri" or "Okay Google." It's explicit.
But as voice moves into wearables, ambient devices, and always-on systems, the line between listening and recording gets blurry. If your glasses have a microphone for voice interaction, how do you know when it's recording? If your headphones are constantly ready to respond to voice commands, are they always listening to some degree?
Google has already been caught paying contractors to listen to audio recorded by voice assistants. Apple was discovered doing similar things. Amazon had to disclose that humans listen to Alexa recordings. The technology companies will argue that this is necessary for improving the systems, that it's done with privacy protections, that users agree to it in terms of service.
But here's the core problem: users don't really understand what they're agreeing to. Most people don't read terms of service. Most people don't understand the difference between what's processed on-device and what's sent to company servers. And most people don't realize how voice data can be used to build profiles of who they are, what they care about, who they talk to, and what they might do next.
Voice data is particularly sensitive because it reveals so much. Transcripts show not just what you said, but when you said it, who you were talking to, your emotional state based on tone analysis, your location based on context, and your relationships based on who you're communicating with. Companies that aggregate this data can predict behavior with unsettling accuracy.
The regulatory response is still figuring out how to address this. GDPR in Europe has given people rights to their data and requires transparency about collection. But there's no unified international standard, and many countries have minimal privacy protections.
On the device side, the push toward hybrid processing (some on-device, some in cloud) is partly a technical choice about latency and performance, but it's also partly driven by privacy concerns. If you can do voice processing locally without sending everything to company servers, that's inherently more private.
But "more private" doesn't mean "actually private." Device-local processing still requires microphones listening all the time. Local processing still creates data trails. And it doesn't solve the problem of bad actors or government surveillance.
What's required is a fundamental shift in how we think about voice AI and privacy. Some possibilities:
- Requiring explicit opt-in for voice recording and storage, rather than burying it in terms of service
- Limiting how long voice data can be stored and requiring regular deletion
- Prohibiting voice data from being used for purposes other than what the user explicitly agreed to
- Creating technical standards for local processing that actually preserve privacy
- Giving users genuine control over when and how their voice is being captured
None of these are being implemented broadly yet. Most companies are moving in the opposite direction: collecting more data, storing it longer, and using it for more purposes.

Enterprise Applications: Voice in Business and Knowledge Work
While consumer applications of voice AI get most of the attention, the real impact might be in enterprise and knowledge work.
Imagine a radiologist who no longer needs to type reports. They examine medical images and speak notes, and a voice AI system generates formatted, compliant reports in real-time. The radiologist stays focused on the images instead of toggling between imaging software and reporting systems. This isn't hypothetical. This is happening now.
Law firms are experimenting with voice AI for legal research and brief writing. Consultants are using voice to analyze data and generate presentations. Customer service teams are using voice AI to handle initial interactions and route complex issues to human agents. The productivity gains are significant.
What makes enterprise voice different from consumer voice is the emphasis on accuracy, compliance, and integration with existing systems. A consumer voice assistant can be 95% accurate and it's fine. A medical voice system needs to be 99.9%+ accurate because mistakes matter. A legal voice system needs to handle specialized terminology. A financial voice system needs to generate compliant documentation.
This has created a market opportunity for specialized voice AI systems. General-purpose voice AI trained on internet data isn't going to be as good as domain-specific voice AI trained on actual enterprise data.
There's also something interesting happening with voice as a debugging and documentation tool. Instead of writing code comments, developers can speak them. Instead of typing documentation, teams can speak it. Instead of writing emails, people can voice them and have them transcribed and formatted.
This might sound like a minor efficiency gain, but it actually changes how people work. Typing is a bottleneck. It's something you have to consciously do. Speaking is something you're already doing. Making speech the input method for documentation and analysis removes a bottleneck.
The challenge in enterprise is getting voice AI to understand context and terminology specific to each organization. A voice AI trained on general English might not understand your internal acronyms, your specialized tools, or your company culture. This is driving a market for customizable voice AI systems that can be trained on your specific data and terminology.

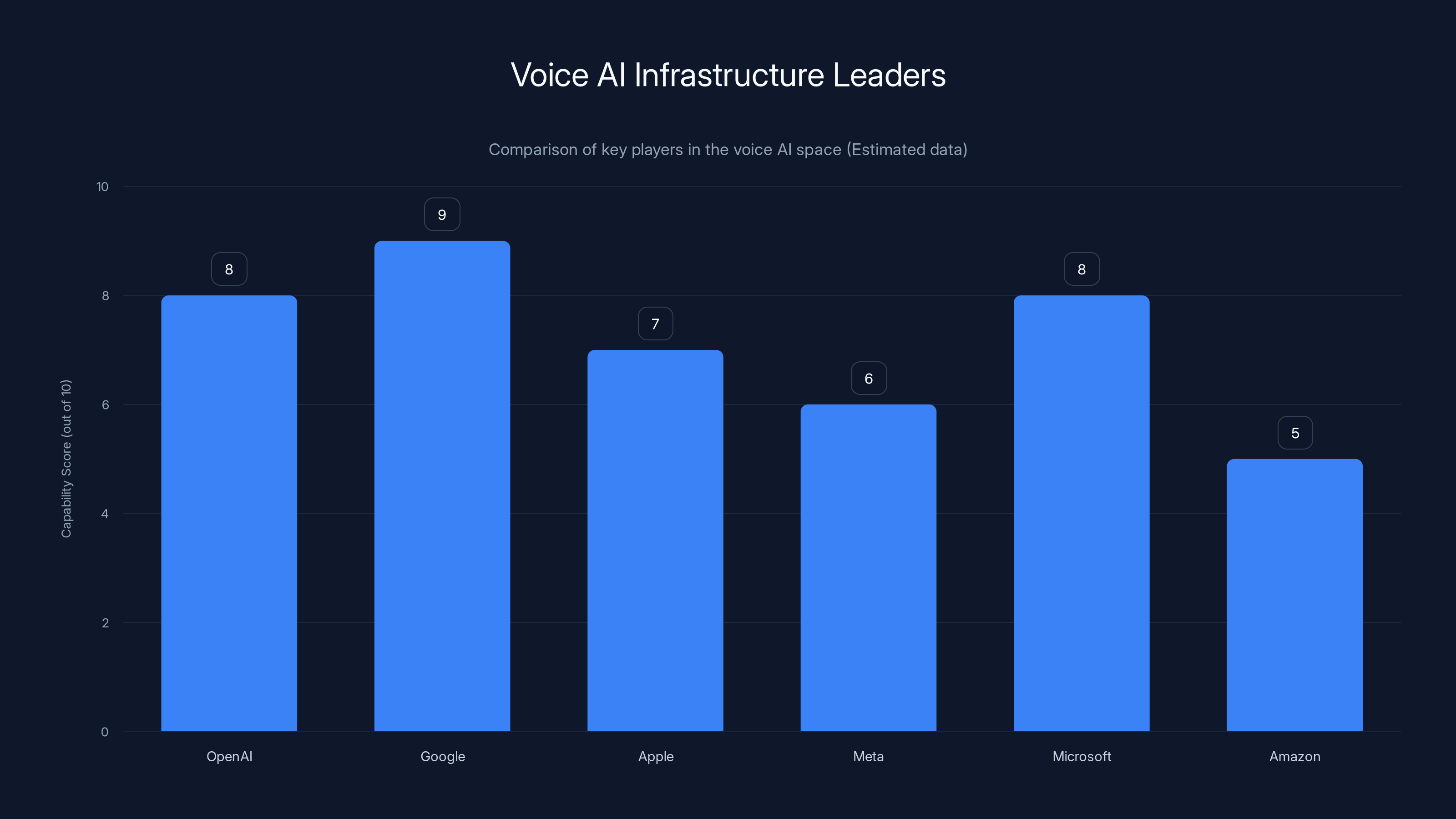
Google leads in voice AI capabilities due to extensive data and integration, while Amazon's Alexa needs improvement to catch up. Estimated data.
The Accessibility Argument: Voice as Equalizer
One of the strongest arguments for voice-first AI is accessibility. For people with motor disabilities, visual impairments, or other conditions that make traditional interfaces difficult, voice can be genuinely transformative.
A person with limited hand mobility who can't comfortably use a keyboard or mouse suddenly has full access to computing through voice. Someone who is blind can use voice to control their environment in ways that visual interfaces never enabled. Someone with dyslexia can interact with written information through voice without the friction that written text creates.
This isn't just a nice-to-have feature. For millions of people, it's the difference between functional and non-functional computing.
But here's where it gets complicated: accessibility features are often treated as afterthoughts or niche features rather than central design considerations. Voice-first design that prioritizes voice from day one is more likely to create genuinely accessible systems than voice features bolted onto visual-first systems.
The companies that take accessibility seriously in voice AI will create systems that work better for everyone. A voice interface that works well for someone who is blind will likely work better for someone driving a car too. A voice system designed for someone with motor disabilities will probably be more efficient for someone with their hands full.
The problem is that accessibility often requires more research, testing, and iteration. It's more expensive to build right. Many companies skip these steps to get products to market faster.
What's needed is a mindset shift where voice accessibility isn't a feature, it's a fundamental design principle. Build for voice first, with the assumption that many users will rely entirely on voice. Design for people with varying abilities. Test with actual users who depend on accessibility features.
Companies that do this will likely create better voice AI systems overall, not just better accessibility. There's a reason that Apple's accessibility focus has made their products generally easier to use for everyone.

Integration Challenges: Getting Devices to Work Together
Here's a problem that nobody talks about enough: voice AI is useless if it can only control one device.
You have a phone, a car, a home, a computer, a watch, and earbuds. These are all separate ecosystems with separate voice assistants. "Hey Siri, play music" works on your phone. But does it work in your car? Does it work in your home? Does it integrate with your smart lights, your smart thermostat, your smart door lock?
The answer is usually "kind of" or "sometimes" or "not really." Integration is a nightmare.
This is why the companies that can control multiple device categories have an advantage. Apple can make Siri work across iPhone, iPad, Mac, Watch, HomePod, and CarPlay because they control the software stack on all of them. Google can do something similar across Android devices, Homes, Pixels, and Wear OS. Meta can theoretically do it with Instagram, Quest headsets, Ray-Bans, and their apps.
But even within these ecosystems, integration isn't seamless. Switching between devices often feels clunky. Continuing a conversation from your phone to your car to your home requires explicit handoff.
The dream scenario is seamless continuity. You're talking to your voice assistant in your car. You pull into your driveway. The conversation continues on your home speakers without interruption or explicit switching. You walk inside, and your lights adjust automatically based on what you were just discussing.
This requires:
- Cross-device awareness (the system knows you've moved from car to home)
- Context preservation (the system remembers what you were talking about)
- Coordinated hardware (multiple devices aware of each other)
- Universal standards (or at least compatible standards)
- User preferences (you've configured which devices handle which types of requests)
None of these are trivial. They require cooperation between companies, standardization that doesn't exist, and technical infrastructure that's still being built.
There's also the fundamental question of what "integrating" means. Does it mean different devices from different companies talking to each other? Or does it mean you're locked into one ecosystem? Right now, it's largely the latter. You pick Apple or Google or Amazon and live in that world. Mixing and matching creates friction.
The future probably involves some combination: dominant ecosystems (Apple, Google) that integrate tightly, plus open standards that let other companies' devices participate at the edges. It's messy, but it's more likely than perfect integration.

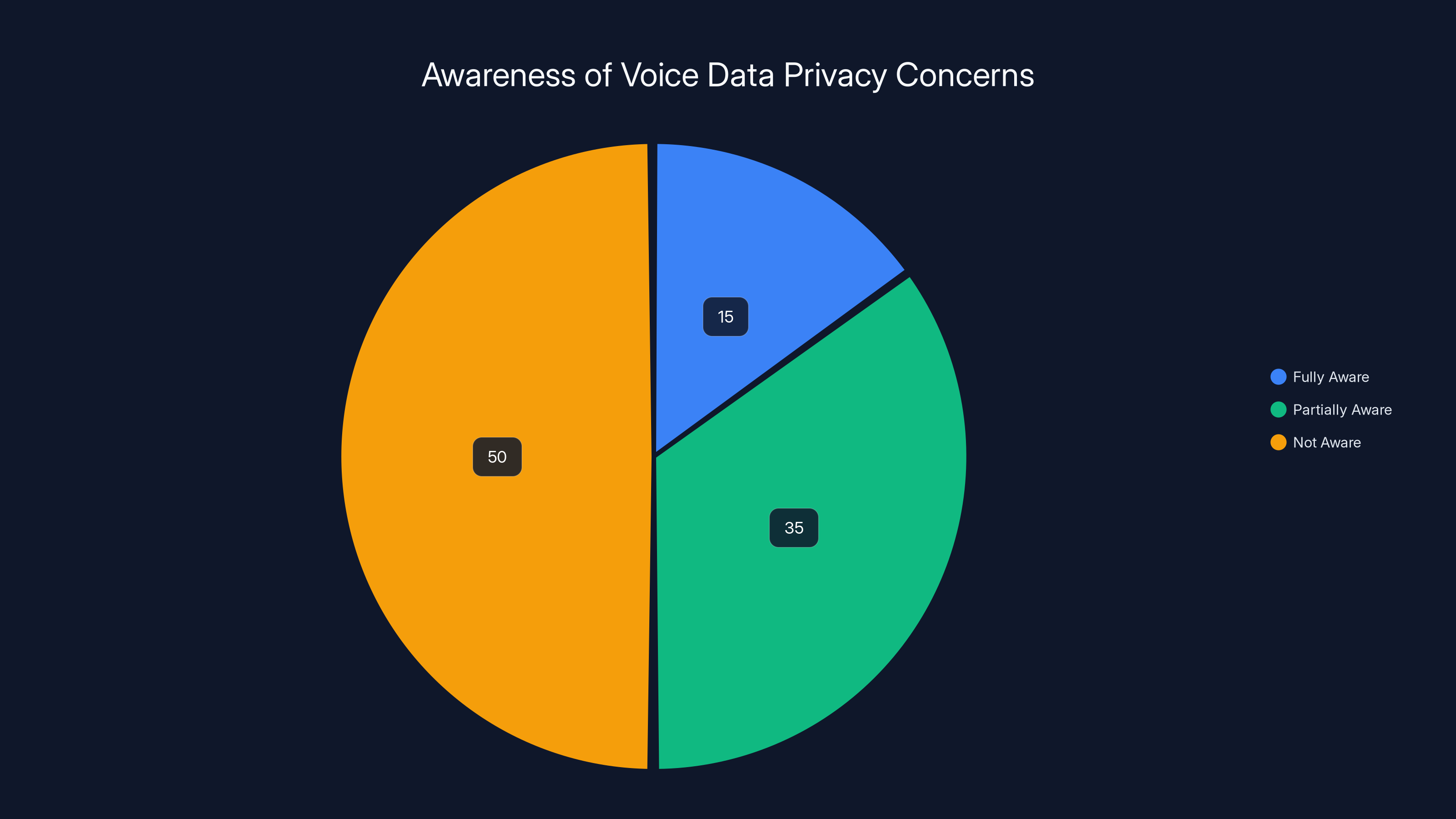
Estimated data shows that only 15% of users are fully aware of voice data privacy concerns, while 50% are not aware at all.
Competitive Landscape: Who's Building Voice AI Infrastructure
The voice AI space is surprisingly concentrated. A few companies are making the big moves.
OpenAI has integrated voice directly into ChatGPT. You can speak to the system and it responds conversationally. It's not the most feature-complete voice system, but it benefits from being attached to the most powerful language models. The reasoning capabilities are excellent.
Google is pushing voice through multiple channels: Google Assistant on phones and smart homes, voice search in mainstream Google, and specialized voice AI in Workspace products. Google's advantage is data. They have more speech data than anyone else, which historically meant better speech recognition. Whether that advantage persists with neural approaches is unclear.
Apple is building voice into Siri across all their devices, plus pushing Siri into increasingly complex tasks. Their approach is different: more on-device processing, more privacy-focused, more integrated with their ecosystem. Siri has a reputation for being less capable than Google Assistant or ChatGPT, but Apple is investing heavily in improving this.
Meta is integrating voice into Instagram, WhatsApp, Ray-Ban smart glasses, and Quest VR headsets. Meta's advantage is ubiquity. Voice in social media contexts could be powerful if they execute well. They're also partnering with Eleven Labs for voice quality.
Microsoft has integrated voice deeply into their productivity suite and is investing in voice-enabled Copilot experiences. For enterprise and knowledge workers, Microsoft's approach might matter more than consumer-focused systems.
Amazon's Alexa was first to market with voice assistants, but it's been somewhat stagnant. Alexa is good at smart home control and simple tasks, but less capable at reasoning and complex conversations. Amazon is integrating generative AI into Alexa to improve this, but they're playing catch-up.
Eleven Labs is a specialized player. They're not building a full voice assistant. They're building the voice quality layer. They do voice synthesis (text-to-speech) and are expanding into speech-to-text and voice cloning. Their partnership with Meta suggests they'll be a critical infrastructure layer for multiple companies' voice systems.
There are also specialized players: Anthropic (through Claude), Cohere, and others building voice into their models. But the landscape is increasingly dominated by the major technology companies that can afford massive compute and have distribution channels.
For most users, the choice is essentially: which ecosystem do you live in? Apple users get Siri. Android users get Google Assistant. Meta users get Meta's voice systems. And increasingly, everyone can access ChatGPT's voice interface.
The competitive advantage isn't pure technical capability anymore. It's ecosystem integration, ease of use, and how deeply voice is woven into the system. The company that makes voice so natural and frictionless that it becomes the default way you interact with their devices will win the most users.

The Battery Problem: Can Voice AI Run on Wearables?
There's a practical constraint that doesn't get discussed enough: batteries.
Wearables are small. They have limited power. Running powerful voice AI models is computationally expensive. Traditional approach: do heavy processing in the cloud, send only the essential data over the network. But this creates latency and requires constant connectivity.
Modern approach: do some processing on the device, some in the cloud. Decide what needs to be done locally for latency and what can be deferred to the cloud for accuracy.
This is the hybrid approach that Eleven Labs and others are developing. It's not just about splitting processing arbitrarily. It's about understanding which operations are latency-sensitive and which are quality-sensitive.
Speech recognition is interesting because you can do a first pass locally (good enough for basic wake words and simple commands) and refine it in the cloud if needed. Voice synthesis can happen locally for common cases and fall back to cloud for more complex generation. Voice understanding can be local for straightforward tasks and cloud-backed for complex reasoning.
The battery constraint also drives innovation in model compression. Can you run a capable model on a tiny processor? Can you reduce model size without losing much capability? This is an active area of research.
Longer term, the answer might be specialized hardware. Your phone already has a Neural Engine. Your future glasses might have a specialized voice processing chip. Your earbuds might have an AI accelerator. The idea is to make voice processing efficient enough that it doesn't drain battery significantly.
For voice to truly succeed in wearables, the battery question has to be solved. An earbud that needs charging every few hours because it's running voice AI isn't much better than a phone. Real wearables need multi-day or multi-week battery life while still running capable voice AI.
This is why on-device processing matters. It's not primarily a privacy choice, though that's a benefit. It's because on-device processing can be more efficient than constantly communicating with servers.

The Future: Voice in a Decade
Fast-forward ten years. What does voice-first computing look like?
Your primary computing interface is voice. You don't carry a phone in your pocket much anymore. You wear glasses, earbuds, or a watch. You speak to them, and they respond conversationally. They understand context from your previous conversations, your calendar, your patterns, your goals.
Your environment is voice-responsive. Your car understands complex instructions without you looking at screens. Your home anticipates your needs based on voice patterns. Your workplace integrates voice into every task.
Privacy is either comprehensively solved or comprehensively violated, depending on regulatory choices made today. If governments enforce strong privacy standards, voice AI becomes genuinely private. If companies are allowed to monetize voice data freely, privacy disappears.
AI systems are more agentic and proactive. They're not waiting for you to ask questions. They're offering suggestions, proposing actions, managing your time and attention. Your voice assistant is less of a tool and more of a collaborator.
But here's what will probably still exist: specialized interfaces for specialized tasks. Screens aren't going away. Keyboards aren't going away. They'll still be the best way to do certain things. Writing long documents, visual design, gaming, and detailed visual work will probably still prefer traditional interfaces.
Voice will be dominant for information retrieval, decision-making, task management, and communication. It will be the default interface for interactions that don't require visual output.
The transition won't be smooth. There will be false starts. Some use cases will adopt voice faster than others. Some companies will succeed where others fail. But the direction is clear: voice is becoming the primary interface for AI systems.
What's less clear is whether we solve the privacy and surveillance problems that come with voice-first computing. That depends less on technology and more on choices we make about regulation, ethics, and what kind of relationship we want with technology companies.

Runable: Automating Your Workflow with Voice-Enabled AI
While major tech companies are building voice interfaces, there's a parallel opportunity in automating complex workflows without needing to speak every command.
Use Case: Create presentation slides from voice notes automatically, without manually typing content or designing layouts
Try Runable For FreePlatforms like Runable are bridging the gap between voice input and structured output. Instead of manually typing, you describe what you want, and AI generates it. For teams that need to create presentations, documents, and reports, this approach combines voice convenience with structured output quality.
Voice-first workflows are particularly valuable for rapid ideation and documentation. Speak your ideas, get AI-generated content, refine and polish. The friction of typing disappears, but you still get professional output.

FAQ
What makes voice the next interface for AI?
Voice is becoming the next interface because it's the most natural way humans communicate, requires no special training, works without hands, and modern AI can now preserve emotional context and reasoning alongside the words themselves. As AI moves into wearables and always-on devices, voice becomes more practical than screens that require looking and tapping.
How do modern voice AI systems differ from older voice assistants?
Older systems transcribed speech to text and processed the text. Modern voice AI processes audio directly, preserving emotion, tone, and context. They also integrate with language models that can reason about intent, maintain conversation history, and understand what you're trying to accomplish rather than just executing explicit commands.
What is agentic voice AI?
Agentic voice AI systems operate with some autonomy, maintaining context and memory across conversations, understanding user goals, and taking actions without constant explicit instruction. Rather than a command-response model, agentic systems understand intent and can proactively suggest or execute actions aligned with your objectives.
Why are companies investing so heavily in voice AI right now?
Companies are investing because voice AI has reached a maturity point where it's genuinely useful. Technical breakthroughs in emotion recognition, low-latency response, and on-device processing have made voice practical for real applications. Additionally, the shift toward wearables and ambient computing makes voice the most natural interface for devices that don't have screens.
What are the major privacy concerns with voice AI?
The main concerns are that companies collect vast amounts of voice data that reveals sensitive information about your life, relationships, emotional states, and habits. This data can be used for surveillance, behavioral prediction, and monetization. As voice moves into always-on wearables, it becomes harder for users to know when they're being recorded and what happens to that data.
How can individuals protect their privacy with voice AI?
You can limit voice assistant permissions, regularly delete recording history, disable voice processing when not needed, and understand what each company does with voice data. Longer-term solutions require government regulation requiring transparency, limiting data retention, and preventing voice data from being used for purposes beyond what users explicitly consent to.
Will voice completely replace screens and keyboards?
No. Voice will become the dominant interface for many tasks, but screens and keyboards will remain the best choice for visual work, detailed content creation, gaming, and visual design. The future is probably 70-80% voice interaction with screens and keyboards for specialized tasks that genuinely require them.
What does voice integration look like across different devices?
Currently, integration is limited and often requires explicit ecosystem choice. Apple's Siri works across Apple devices. Google Assistant works across Android and Google devices. Seamless cross-ecosystem voice is rare. Future integration will likely mean choosing a dominant platform or accepting friction when moving between devices.
How does on-device voice processing improve on cloud processing?
On-device processing reduces latency (responses are faster), improves privacy (data doesn't leave your device), works offline, and is more efficient with battery (less data transmission). Cloud processing enables more powerful models and better learning over time. The future uses both: on-device for responsiveness and privacy, cloud for complex reasoning.
What role will voice AI play in enterprise and business?
Voice AI will significantly impact knowledge work by enabling hands-free documentation, faster information retrieval, and voice-based analysis. Radiologists speaking reports, lawyers researching cases, consultants analyzing data, and teams documenting processes will all benefit from voice input. Specialized domain-specific voice AI will emerge for specific industries and professional contexts.

Key Takeaways
- Voice is becoming the dominant AI interface because it's the most natural way humans communicate and works better for wearables and ambient computing than screens
- Modern voice AI combines emotion recognition, low-latency response, and integration with reasoning models, making conversations feel genuinely natural
- Agentic systems that maintain memory, understand context, and proactively suggest actions represent the next evolution beyond simple command-response voice assistants
- Hardware innovation in wearables, smart glasses, and always-on devices is driving the shift toward voice-first interfaces
- Significant privacy and surveillance concerns exist as voice systems move into constantly-listening devices, but technical solutions for privacy-preserving on-device processing are emerging
- Enterprise applications show significant productivity gains when voice becomes the primary input for documentation, analysis, and knowledge work
- Accessibility benefits are substantial, particularly for people with motor or visual disabilities for whom voice can be genuinely transformative
- Device integration remains a major challenge, with most users locked into single ecosystems rather than experiencing seamless cross-platform voice control
- Battery constraints on wearables require efficient voice processing and hybrid cloud-device approaches to remain practical
- The next decade will see voice become the primary interface for most interactions, though specialized tasks will still benefit from visual interfaces and keyboards

Related Articles
- Amazon Alexa+ Free on Prime: Full Review & Early User Warnings [2025]
- Alexa+: Amazon's AI Assistant Now Available to Everyone [2025]
- AMD Ryzen AI Max+ 395 All-in-One PC: Game-Changing Desktop Power [2025]
- Paza: Speech Recognition for Low-Resource Languages [2025]
- Google Hits $400B Revenue Milestone in 2025 [Full Analysis]
- Alexa+ Nationwide Launch: Amazon's Next-Gen AI Assistant [2025]

