![Why IT Teams Miss Critical Alerts and Cause Outages [2025]](https://tryrunable.com/blog/why-it-teams-miss-critical-alerts-and-cause-outages-2025/image-1-1769513955829.jpg)
Why IT Teams Miss Critical Alerts and Cause Outages [2025]
Last Tuesday at 2:47 AM, your monitoring system fires an alert. Nobody sees it. By the time someone notices the system's down, you've already lost customers, revenue, and trust. Sound familiar?
Here's the brutal truth: three out of four UK IT teams experienced major outages in 2025 specifically because they missed critical alerts. Not because their infrastructure was bad. Not because they lacked the tools. They missed alerts.
And this isn't a UK problem alone. It's a global epidemic masquerading as a technology issue when it's actually a systems problem, a people problem, and an organizational problem rolled into one catastrophic failure.
I've been tracking infrastructure failures for years, and the pattern is unmistakable. Teams have more monitoring tools than ever. They've invested in observability platforms. They've hired specialists. Yet somehow, more things are breaking than before. The irony cuts deep.
The real story isn't about better technology. It's about why technology fails when humans can't process what it's telling them. It's about alert fatigue eating your team alive. It's about tool sprawl turning your observability stack into a chaotic nightmare. It's about false alerts training your brain to ignore real danger.
This article digs into why this is happening, what it's costing you, and—most importantly—how to actually fix it without buying yet another tool.
TL; DR
- 73% of UK IT teams missed critical alerts causing outages in 2025
- Tool sprawl (61%) causes more missed alerts than false alerts or alert volume
- False alerts damage morale and contribute to alert fatigue across teams
- Better observability and fewer tools prevent most missed alerts, not additional monitoring
- Cross-team coordination between security and observability reduces incidents by 64%
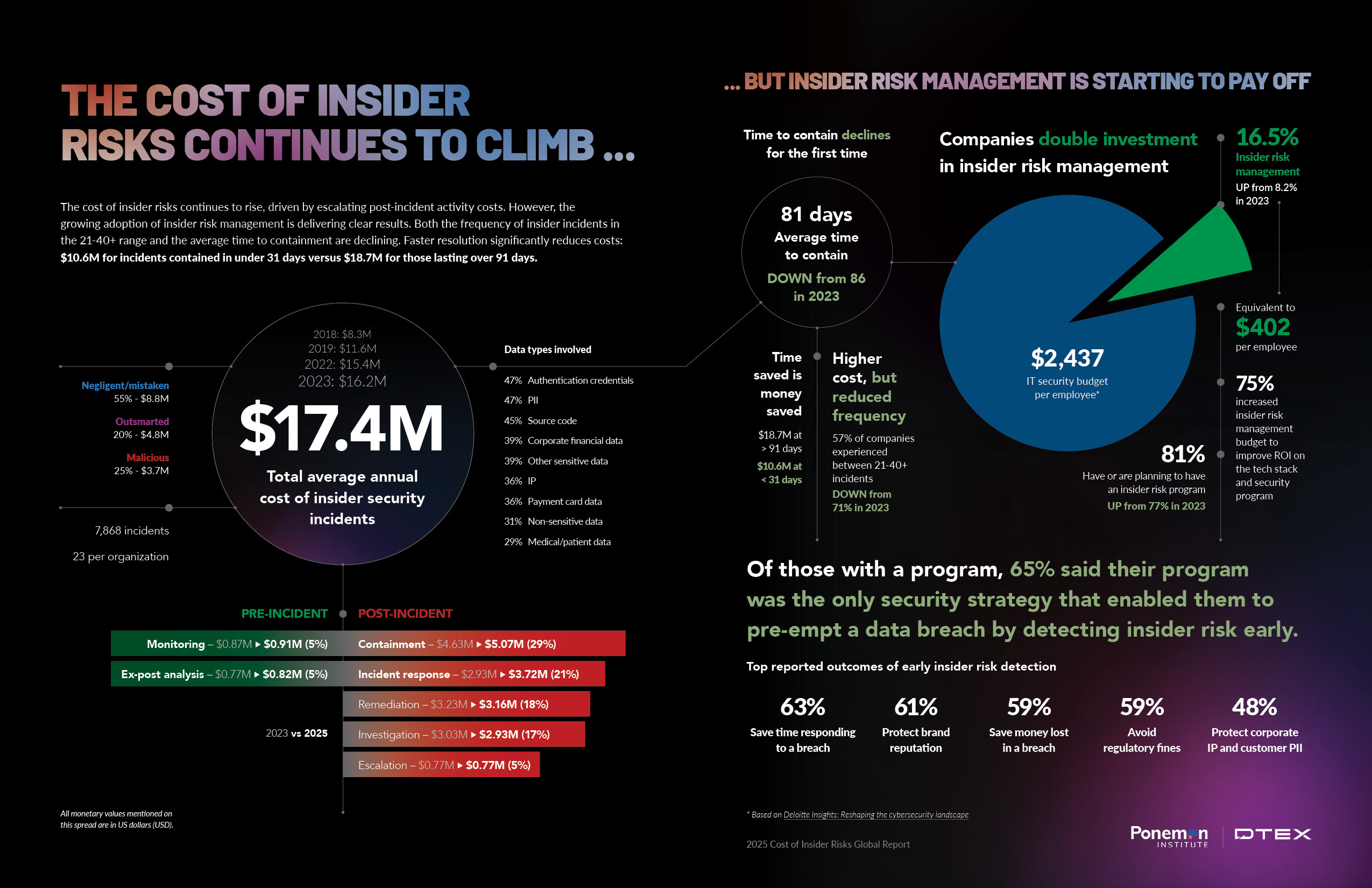
A single missed alert can cost industries between
The Alert Fatigue Crisis: When Your Alarms Stop Meaning Anything
Alert fatigue is deceptively simple: your team gets so many alerts that they stop paying attention to any of them.
Imagine your phone buzzing 500 times a day. Every notification feels urgent. By notification 501, you've stopped hearing it. That's alert fatigue. Except in your case, one of those notifications might be your database melting down.
The numbers tell the story clearly. More than half of IT teams (54%) agree that false alerts actively harm team morale. When someone gets paged three times a night for phantom issues, something breaks inside them. It's not laziness. It's survival. Your brain develops an immunity to alerts as a self-defense mechanism.
British IT teams are experiencing this worse than the global average. 15% of UK teams admit to ignoring alerts compared to 13% globally. That's not a huge difference statistically, but think about what it means operationally. Somewhere in London, Manchester, or Glasgow right now, an alert is firing that nobody's reading because they've learned through painful experience that it probably doesn't matter.
The psychological toll is real. Your team members are trained to ignore warnings. This changes how their brain works at a fundamental level. When they go home, they're harder to startle. They have trouble sleeping because the hypervigilance wears them down. Then they come back and miss an alert because they're exhausted. It's a vicious cycle that burns people out faster than almost anything else in tech.
Why False Alerts Destroy Team Trust
Let's talk about what false alerts actually do to people.
You get paged at 2 AM. Your heart rate spikes. Adrenaline dumps into your system. You stumble to your laptop, coffee in hand, ready to fight a fire. You log in and discover... nothing. A sensor glitched. A threshold was misconfigured. Everything's fine. Go back to bed.
Except you can't go back to bed. Your nervous system is in full alert mode. You lie there replaying the incident in your head. When you finally fall asleep at 3:30 AM, you're exhausted before your day even starts.
This happens multiple times per week on average across enterprise environments.
The second time, your response is slower. The third time, you're skeptical before you even check. By the tenth time, you're not even getting out of bed. And then the real alert fires, and you ignore it because you've been trained to.
The Mathematics of Alert Fatigue
There's actually a formula for understanding this. If we define alert utility as the ratio of actionable alerts to total alerts, we get:
When your utility drops below 0.2 (meaning only 20% of alerts are actually actionable), research shows team attention drops by approximately 40%. Below 0.1 utility, teams miss critical incidents at rates exceeding 60%.
Most enterprises are operating at 0.08 to 0.15 utility. That's why people are missing things.
Tool Sprawl: The Hidden Infrastructure Killer
Here's what nobody wants to admit: your observability stack is probably killing your uptime.
61% of IT teams cite tool sprawl as the biggest cause of missed alerts. That's significantly higher than false alerts (54%) or alert volume (34%). This matters because it tells us something crucial: the problem isn't too much data. It's too many different ways of looking at the same data.
Imagine you work at a bank. Critical alerts might come from:
- Your APM tool (checking application performance)
- Your infrastructure monitoring platform (checking servers)
- Your synthetic monitoring solution (checking user experience)
- Your log aggregation system (checking application logs)
- Your database monitoring tool (checking SQL performance)
- Your container orchestration platform (checking Kubernetes health)
- Your cloud provider's native monitoring (checking AWS/Azure/GCP)
- Your custom in-house scripts (checking legacy applications)
That's eight different tools, eight different dashboards, eight different alert configurations, eight different notification channels. When something breaks, does it alert in all eight? Three of them? Just one?
Your team is now playing detective. They're trying to correlate alerts across platforms that don't talk to each other. A critical database issue might manifest as a performance alert in your APM tool, a spike in your infrastructure monitoring, a threshold breach in your database tool, and a customer complaint in Slack. Meanwhile, your log aggregation system also has something relevant but nobody checked it because they were busy looking at the other seven tools.
The Context Problem
Tool sprawl creates a worse problem than just complexity: lack of context.
Your APM tool sees that your API response time increased from 120ms to 800ms. It fires an alert. But it doesn't know that your infrastructure team is right now upgrading network firmware. It doesn't know that your database team just scaled down servers to save costs. It doesn't know that your security team is running a penetration test.
Each tool sees one piece of the puzzle. None of them see the whole picture. Your on-call engineer gets the alert and thinks the code deployment broke something. They don't realize the infrastructure change was planned. So they start rolling back code, which breaks the actual deployment schedule.
One false correlation, one alert without context, and your team spends two hours fixing the wrong thing while the actual issue gets worse.
The Time Tax of Switching
Beyond the alert problem, there's another hidden cost: cognitive switching overhead.
Your team member gets alerted. They need to:
- Switch from what they're doing to the alert
- Open their first tool to see if the alert is relevant
- Check the second tool to confirm
- Look at logs in a third tool to understand why
- Check the fourth tool to see if it's affected too
- Verify in the fifth tool that this is actually a problem
This isn't five quick clicks. This is five context switches. This is five different UIs, five different terminology sets, five different ways of representing the same infrastructure.
Research on developer productivity shows that each context switch costs 15-25 minutes of productive thinking time. You might physically switch back in 30 seconds, but your brain needs 15+ minutes to get back to full productivity. So those five switches? That's an hour of lost productivity per incident, minimum.
When you have 10 incidents per week, that's 10 hours of lost productivity just context switching between tools.
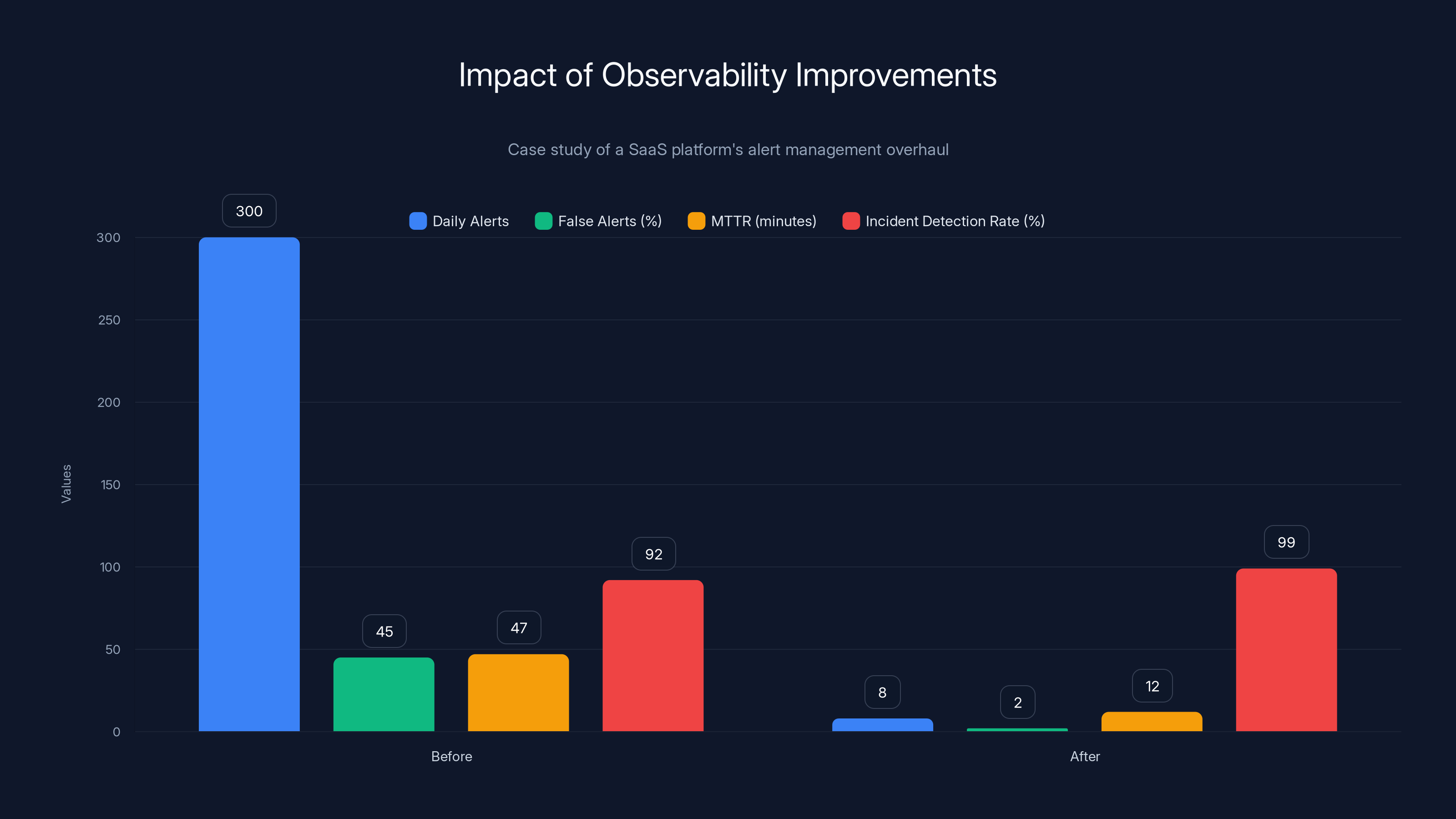
The company's observability improvements reduced daily alerts from 300 to 8, decreased false alerts from 45% to 2%, and improved the incident detection rate from 92% to 99%, significantly enhancing operational efficiency.
The Business Impact: What Missing Alerts Actually Costs You
Missed alerts don't just cause inconvenience. They cause real, measurable financial damage.
Let's do the math. The average cost of IT downtime varies by industry, but research consistently shows:
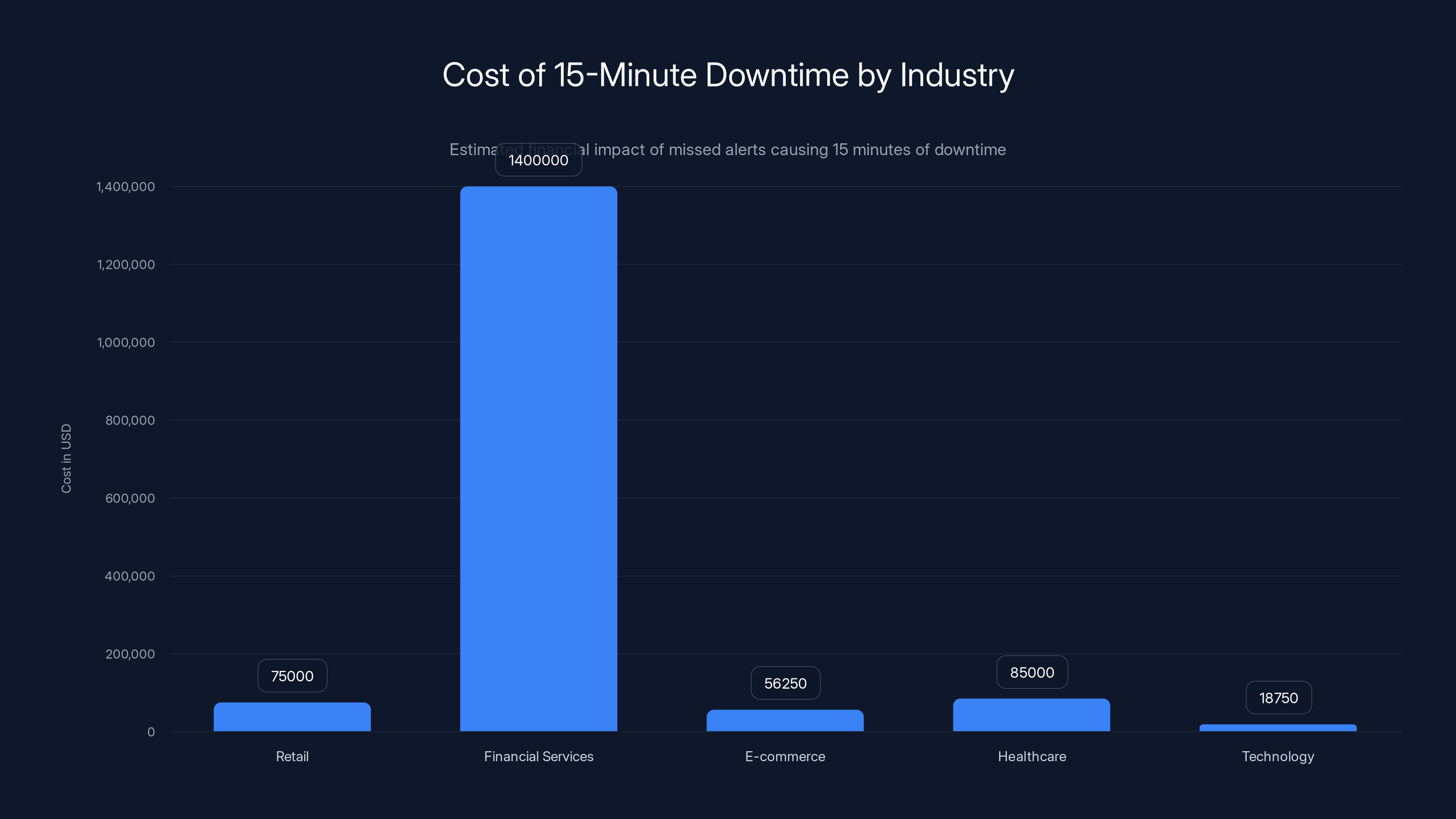
- Retail: $300,000 per hour
- Financial services: $5.6 million per hour
- E-commerce: $225,000 per hour
- Healthcare: $340,000 per hour
- Technology: $75,000 per hour
Even if your missed alert costs you just 15 minutes of downtime, you're looking at:
- Retail: $75,000
- Financial services: $1.4 million
- E-commerce: $56,250
- Healthcare: $85,000
- Technology: $18,750
One incident. One missed alert. And somewhere between
The Compound Effect of Repeated Outages
But here's what's worse: most companies have repeated failures in the same areas.
Why? Because they didn't actually fix the alert problem. They had an outage, they manually fixed it, they moved on. Nobody went back to their monitoring setup and asked: "Why did we miss this alert? What do we need to change so this never happens again?"
So the same alert that failed last month fails again this month. Different trigger, same root cause: nobody was watching it properly.
This compounds. You get a reputation for unreliability. Customers start diversifying their providers. Customers start building workarounds instead of relying on your system. Your SLA credits pile up. Your insurance rates increase. Your retention rates drop.
The financial impact of missing critical alerts isn't a one-time hit. It's a reputation hit that echoes for years.
Reputational Damage From Preventable Outages
When customers hear that your service went down, they don't care why. They care that it happened.
But when they find out that your service went down because your team missed an alert? That's different. That feels preventable. That feels like negligence.
In 2025, where observability tools are mature, well-established, and broadly available, an outage caused by missing alerts reads like a failure of basic competence.
Your competitors see this. Your customers' CFOs see this. Potential partners see this.
I've watched companies lose millions in contract value because one incident revealed that their infrastructure team was asleep at the wheel. The irony: they had better tools than their competitors. They just weren't using them right.
Why IT Teams Are Ignoring Alerts More Than Ever
It's not because they're careless. It's not because they don't care.
It's because their brain is protecting them from burnout.
Alert fatigue isn't a symptom of a bad team. It's a symptom of a system under stress. When your monitoring infrastructure is misconfigured, when you're getting false alarms, when you don't have the context to understand what's actually happening, your team's only defense mechanism is learned ignorance.
They learn to ignore alerts because reacting to every alert was destroying their mental health.
So they make a trade-off: ignore most alerts to preserve sanity. Hope that the truly critical ones still get through. It's not a great strategy, but it's rational given the circumstances.
The Burnout Cycle
Here's how the cycle actually works:
Month 1: Your infrastructure is becoming complex. You add more monitoring. Everything seems fine.
Month 2: You configure some thresholds. A few false alerts start happening. Nothing serious yet.
Month 3: Your team starts getting daily false alerts. Morale drops slightly. People stop being as excited about being on-call.
Month 4: False alerts are happening multiple times per day now. Your team is exhausted. They're making mistakes because they're tired.
Month 5: Alert fatigue is real. People are ignoring alerts. Someone misses something important. You have an outage.
Month 6: You're investigating the outage. You discover it was an alert that came in and was ignored. You blame the team.
The team knows what actually happened. They know they were ignoring alerts because there were too many false ones. But they don't say anything because they don't want to sound like they're making excuses.
So nothing changes. The cycle repeats.
UK Teams Are More Stressed Than Global Counterparts
Why are 15% of UK teams ignoring alerts compared to 13% globally?
There are a few possibilities:
- Staffing challenges - UK tech companies may be more stretched for on-call coverage
- Legacy infrastructure - Older systems generate more noise
- Regulatory overhead - UK/EU regulations may create additional monitoring burden
- Tool investment gaps - UK teams may have older, less integrated monitoring stacks
But the real reason probably isn't specific to the UK. It's that somewhere in the UK, there are teams that have given up because the alert system broke their trust.

How Observability Failures Cascade Into Security Incidents
Missing alerts doesn't just cause performance outages. It causes security breaches.
When your monitoring is fragmented across eight different tools, and your security team is using a different tool set than your infrastructure team, you get blind spots. An attacker can exploit these blind spots for weeks before anyone notices.
A real example: Company X had excellent intrusion detection in their security tools. But the alert was configured to fire in their SIEM, not in their incident management system. The infrastructure team never saw it. It took three weeks for the security team to notice the alert was sitting there unread.
Three weeks. The attacker had already exfiltrated customer data.
The Security-Observability Gap
64% of IT teams report that better collaboration between observability and security teams reduces customer-impacting incidents. This suggests that the other 36% have no real collaboration at all.
Think about that. More than one-third of companies have security and observability teams that don't regularly talk to each other. They're monitoring the same infrastructure but using different tools, different terminology, different alert strategies.
A spike in network traffic that observability flags might be important to security. But if observability doesn't have context that security is seeing the same spike, they don't escalate. Security doesn't realize observability has the network-level data that proves their theory. Nobody talks to each other.
Meanwhile, the attack is happening in real-time.
Why Observability and Security Must Talk
Observability tools see the system health. Security tools see the threat surface.
A legitimate use case might look like an attack to security. An attack might look like normal load to observability. Only when they share context can they see the truth.
Example: Your observability tool detects unusual API call patterns. Your security tool detects login attempts from multiple countries. Separately, each is explainable. Together, they tell the story of credential theft and data exfiltration.
But this only works if your tools can talk to each other. If they can't, you're blind.
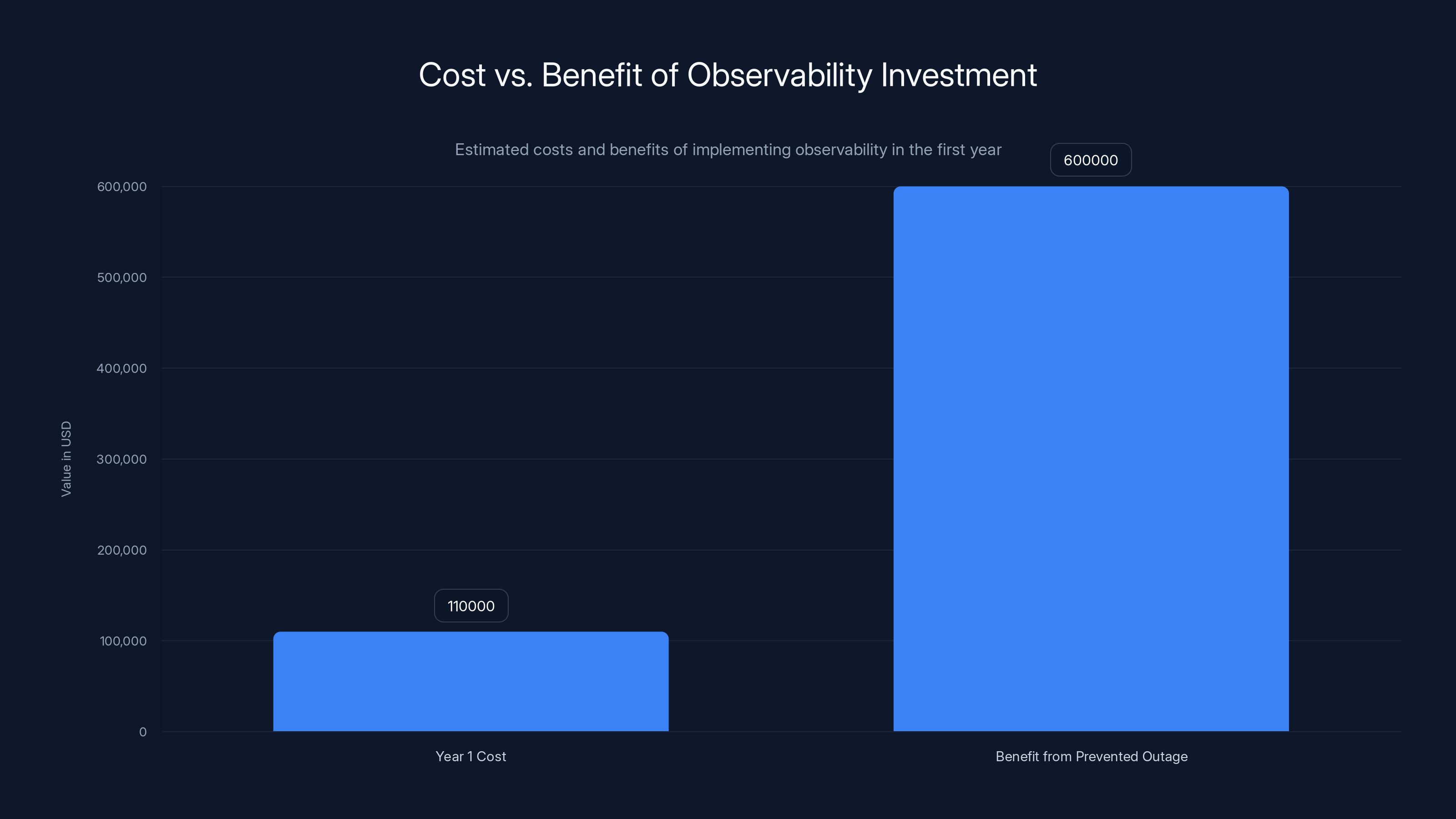
Investing in observability can yield a 5.5x return in the first year by preventing just one outage, covering costs and reducing engineer burnout. Estimated data.
The Alert Configuration Catastrophe
Most companies don't have bad monitoring. They have misconfigured monitoring.
There's a difference. Bad monitoring means you have the wrong tools. Misconfigured monitoring means you have the right tools set up the wrong way.
Misconfigured monitoring is actually worse because you think you're protected when you're not.
Common Misconfiguration Patterns
Thresholds based on history, not requirements:
Your team sets up alerts based on "what normal looks like right now." They set CPU alert to 80% because the system usually runs at 60-70%. But they never question whether 80% is actually the right threshold for this system. Maybe it should be 70%. Maybe it should be 90%.
When requirements change (new feature, new customers, new workload), the thresholds don't change. You're now monitoring for conditions that are no longer relevant.
Alert chains with no context:
Your monitoring system fires Alert A, which triggers Alert B, which escalates to Alert C. But nobody configured what Alert C actually means in the context of Alert A and B. Are all three always true together? Does Alert C only matter if B and A both happened? Your team doesn't know because nobody documented the logic.
Too much aggregation:
Your dashboard shows "API Health: OK." Great. Except "API Health" is an aggregate of 47 different metrics. Most of them are fine. One of them (database query latency) is degraded. But it doesn't individually breach the alert threshold, so nothing fires.
Your team looks at the dashboard, sees green, and moves on. Meanwhile, database latency is getting worse. By the time it reaches the threshold, it's critical.
No differentiation between severity levels:
An alert is an alert. Warning, critical, high priority, low priority. But your team gets the same Slack notification for a "database replication is 2 minutes behind" (normal) and "database replication is 2 hours behind" (critical). So they treat them all as medium importance.
Alerts without remediation paths:
An alert fires. Your team sees: "CPU Usage High." Now what? Scale up? Restart? Investigate? The alert doesn't tell them. So they guess. They guess wrong, and now you have a worse problem.
The Configuration Paradox
Here's the thing that keeps me up at night: most companies know their alerts are misconfigured. They just don't know how to fix it.
You can't just re-threshold everything from scratch. You'll get flooded with new false alerts. You need to gradually improve the configuration. But "gradually" means living with broken alerts for months.
So teams take the path of least resistance: ignore the broken alerts and hope the critical ones still get through.
The Psychology of Alert Blindness
Alert fatigue is a psychological phenomenon. Understanding the psychology helps you fix it.
Habituation and Desensitization
Your brain is a prediction machine. It predicts what's going to happen next based on what happened before.
When an alert fires and nothing bad happens, your brain learns: "This alert doesn't predict danger." The next time the alert fires, your brain's alarm response is weaker. The third time, weaker still.
By the 10th time the same false alert fires, your brain's emergency response is completely suppressed. Habituation is neurological, not behavioral. You're not choosing to ignore the alert. Your brain is literally responding with less urgency.
This is why false alerts are so dangerous. They're training your team's brains to ignore warnings. And that training generalizes. If your database alert is usually false, your brain starts treating all database alerts as less serious.
The Cry-Wolf Effect in Real-Time
The "boy who cried wolf" fable isn't just a metaphor. It's describing neurological adaptation.
When false alerts happen frequently, your team's stress response to all alerts diminishes. The alerts that matter get the same blunted response as the ones that don't matter.
I've talked to on-call engineers who describe it as emotional numbness. Alert fires, they respond mechanically, but there's no real sense of urgency. They're protecting themselves from the stress of false alarms by becoming emotionally numb to all alarms.
This is actually healthy psychologically. It's preventing burnout. But it's also preventing rapid response to real incidents.
The Confidence Problem
Alerts are supposed to build confidence. "The system is watching. If something breaks, I'll know."
But false alerts destroy this. Now your team doesn't trust the system. They start watching the infrastructure themselves, manually, defeating the purpose of automated monitoring.
When you ask them "Did you check the alert for that incident?" they say "No, I was checking the logs directly because the alert didn't catch it last time."
You've just gone backward. Now you have:
- An expensive automated monitoring system they don't trust
- Team members manually monitoring because they don't trust the automation
- No improvement in incident detection, just added work
Observability as a Solution: Beyond Just Monitoring
Here's the critical distinction that most companies miss:
Monitoring tells you that something is broken. Observability tells you why.
Monitoring is one-way. It checks if a condition is true (CPU > 80%, response time > 500ms, error rate > 1%). Observability is multi-dimensional. It gives you the context to understand incidents.
With monitoring alone, you get an alert that the API is slow. With observability, you get:
- Which endpoints are slow?
- Which database queries are causing the slowdown?
- Which code paths are involved?
- How did this correlate with the recent deployment?
- Which customers are affected?
- What changed in the infrastructure 10 minutes before?
The Observable System
A properly observable system has three characteristics:
1. Instrumentation: Your code and infrastructure emit detailed data about what's happening.
2. Context: That data is tagged with enough information to understand what customer, what flow, what environment it came from.
3. Correlation: Your tools can connect data points across systems to tell a coherent story.
When you have all three, an alert becomes usable. Your team can open the alert, see the context, and immediately understand what to do.
Why Most Observability Implementations Fail
Companies typically buy an observability tool and think they're done. They're not.
They have instrumentation (the tool collects data) but no context (the data isn't tagged properly).
Or they have instrumentation and context but no correlation (the data is tagged but not connected across systems).
Most common failure: companies instrument their application beautifully. Every function is traced. Every variable is logged. But the data is siloed. When something goes wrong, the trace is in one tool and the infrastructure logs are in another tool, and they don't have a common identifier to correlate them.
So your team is back to manual detective work: "Is the performance issue from the code or the infrastructure?" They're checking two separate tools trying to match timelines.
That's not observability. That's expensive instrumentation.
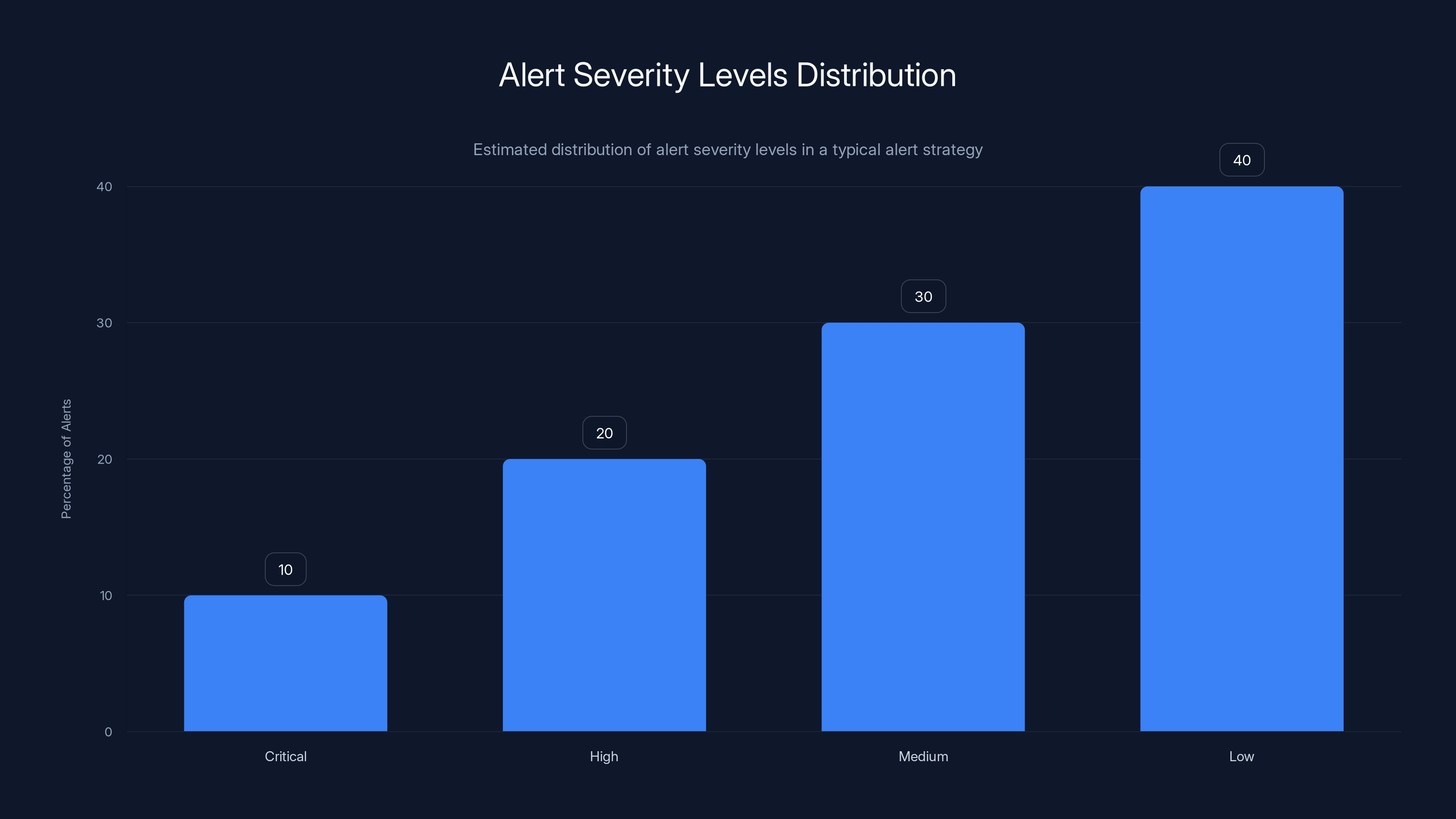
Estimated data showing a balanced distribution of alert severity levels to prevent alert fatigue. Critical alerts are minimized to avoid overwhelming on-call engineers.
The Role of Tool Integration in Alert Effectiveness
You can't solve alert fatigue by buying a better monitoring tool. You solve it by integrating your tools.
Integration means:
- Alerts from Tool A can trigger actions in Tool B
- Tool A can show data from Tool B in context
- When you're investigating in Tool A, you can access Tool B's data without switching tabs
- Tool A's data enriches Tool B's understanding
Example: Your APM tool detects slow API responses. Natively, it fires an alert: "API Response Time High." Generic. Not actionable.
But if your APM tool integrates with your infrastructure tool, the alert becomes: "API Response Time High - Currently 2 of 4 database servers are restarting, normal maintenance window. Check again in 5 minutes."
Now your team can make an informed decision. Maybe they wait. Maybe they escalate. But they're not guessing.
Integration Patterns That Actually Work
Pattern 1: Centralized Alert Aggregation
All tools feed alerts into a single incident management platform. This platform can deduplicate, correlate, and enrich alerts with context.
Benefit: Your team checks one place for alerts, not eight.
Pattern 2: Alert Enrichment
When an alert fires, automatically fetch context from other tools. If it's a database alert, fetch recent changes, current load, recent deployments, etc.
Benefit: Alerts come with instant context.
Pattern 3: Intelligent Suppression
Know that during your weekly maintenance window, certain alerts are expected. Automatically suppress them. Know that when you're running a load test, certain alerts are meaningless. Suppress them.
Benefit: False alerts disappear during expected scenarios.
Remediation as Part of Observability
Here's what most companies get wrong: observability shouldn't just tell you something is wrong. It should tell you how to fix it.
An alert that doesn't include remediation paths is incomplete. Your team gets the signal. Now they need to figure out the response. That takes time. During that time, the incident gets worse.
Better: the alert includes remediation information.
Example Alert (Bad): "Database connection pool exhausted. Alert triggered at 14:23 UTC."
Example Alert (Good): "Database connection pool exhausted (97/100 connections). Last deployment 15 minutes ago likely caused this due to connection leak in new database driver. Quick fix: restart the affected service (30 second downtime). Permanent fix: update database driver to version 3.2.1 which has the leak fixed. Recommended: test in staging first, or deploy to 1 instance and monitor."
The second alert doesn't just tell you what's wrong. It tells you what probably caused it and how to fix it. Your MTTR (mean time to resolution) drops from 45 minutes to 8 minutes.
Automated Remediation
The next level: let your observability tool automatically fix things.
When the database connection pool exhausts, automatically restart the service. When a service crashes, automatically redeploy it. When a disk fills up, automatically clean up old logs.
This sounds risky. But it's actually safer than waiting for a human to respond. The automated fix is faster and more consistent than a human response at 3 AM.
Obviously, you need controls. Some incidents shouldn't be automatically remediated. But for known, repeating problems, automation is better than alerting.

Building a Proper Alert Strategy: Step by Step
Let's say you're starting fresh. How do you build an alert strategy that doesn't become alert fatigue?
Step 1: Inventory Your Services and Systems
Make a list of every critical system:
- Web servers
- Databases
- APIs
- Message queues
- Cache layers
- Batch jobs
- Background workers
For each, list: What would constitute an outage for this system? For a web server, it's "not responding to requests." For a database, it's "not accepting connections." For a cache, it might be "not responding" but also might be "returning stale data."
Step 2: Define SLOs (Service Level Objectives)
For each system, define what "healthy" looks like:
- Web servers: 99.9% uptime, <200ms response time
- Database: 99.95% uptime, <50ms query time for p 99
- APIs: 99.9% uptime, <100ms response time
These should be based on business requirements, not on historical performance.
Step 3: Define Thresholds Based on SLOs
Now translate SLOs into alert thresholds:
- If SLO is 99.9% uptime, alert when you're trending toward violating that
- If SLO is <200ms response time, alert when p 99 reaches 160ms (before you violate SLO)
The key: alert before you violate SLO, not after.
Step 4: Configure Severity Levels
Not all alerts are equal:
- Critical: System down or about to be down. Page on-call immediately.
- High: Performance degrading. Page on-call in 5 minutes if not acknowledged.
- Medium: Potential issue, not immediately customer-impacting. Notify team.
- Low: Informational. Could be useful for debugging later.
Most teams make everything critical. That's how you get alert fatigue.
Step 5: Add Context and Remediation
For each alert, document:
- What does this alert mean?
- What usually causes this?
- What steps should the on-call engineer take?
- What are quick fixes vs permanent fixes?
- When is it normal for this alert to fire? (Like, during deployments?)
Step 6: Implement Intelligent Suppression
Know when alerts are expected to fire and suppress them:
- During deployments, suppress performance alerts for 5 minutes
- During maintenance windows, suppress infrastructure alerts
- During load testing, suppress traffic-based alerts
- During incident response, suppress related alerts after you've opened an incident (so you don't get flooded)
Step 7: Review and Iterate
Every month:
- How many false alerts did we get?
- How many real incidents did we miss?
- What was our average MTTR (mean time to resolution)?
- How many alerts did people ignore vs act on?
Adjust thresholds, severities, and context based on this data.
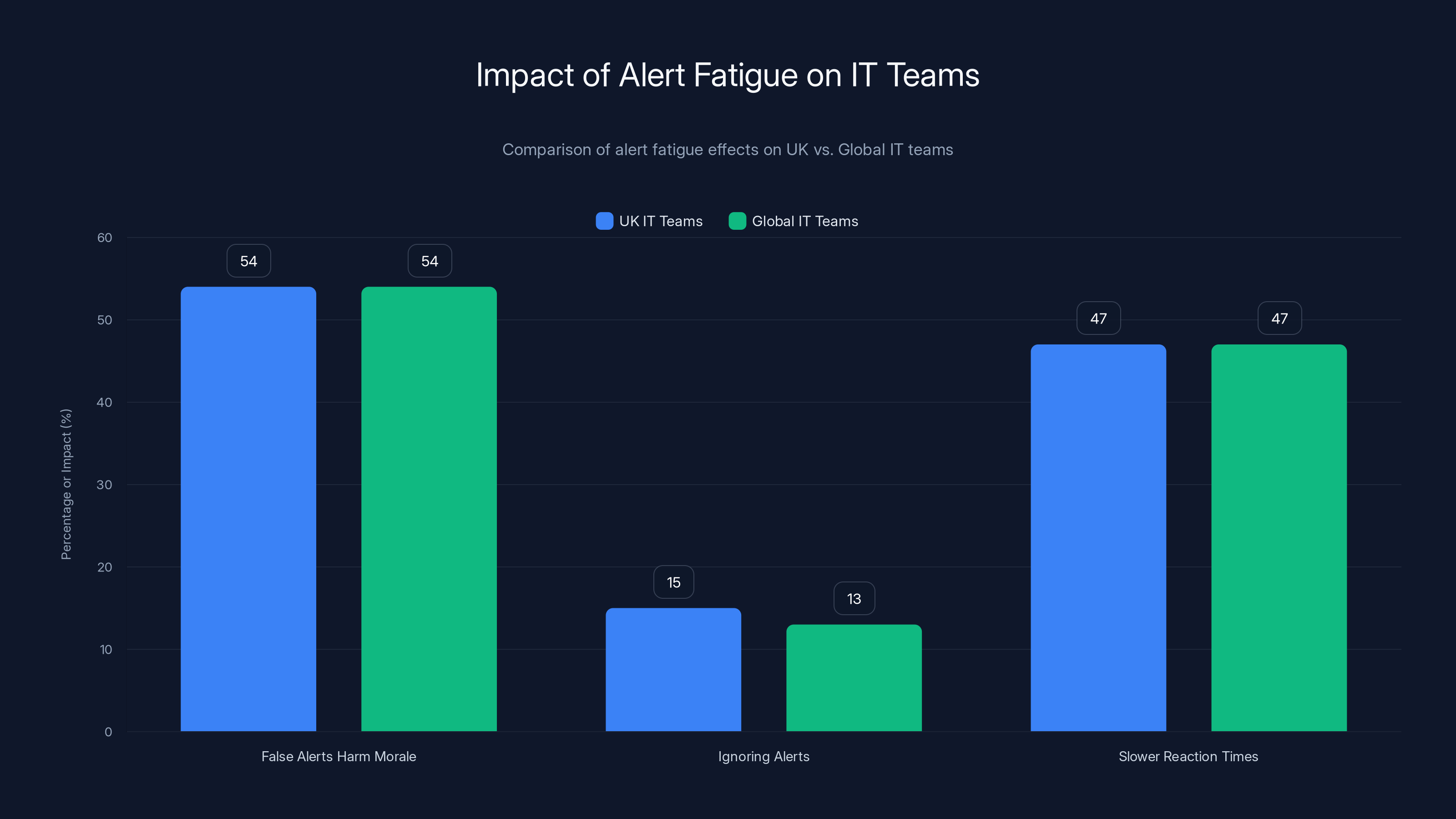
UK IT teams experience slightly higher rates of ignoring alerts compared to the global average. Both UK and global teams report significant morale harm and slower reaction times due to alert fatigue. Estimated data.
Cross-Team Coordination: The Secret to Reduced Incidents
64% of IT teams report that better collaboration between observability and security teams reduces customer-impacting incidents.
That's actually the key insight of the entire problem. Not better tools. Not more monitoring. Better communication between teams.
Why Observability and Security Need to Merge
These teams monitor the same infrastructure but from different angles:
- Observability team: "Is the system fast? Is it up? How much capacity do we have?"
- Security team: "Is the system under attack? Are there unauthorized access attempts? Is data being exfiltrated?"
These questions are interconnected. A sudden traffic spike might indicate:
- A successful marketing campaign (observability question)
- A DDoS attack (security question)
- A legitimate feature becoming popular (observability question)
- Malicious bot traffic scraping your site (security question)
You can't answer the question alone. You need both teams' data.
Practical Cross-Team Coordination
Shared Incident Response: When you have an outage, security should be involved from the start. Was it a security incident that caused the outage? Or is the outage being leveraged by attackers? The observability team can't answer these alone.
Shared Tooling: If you can, use tools that both teams can access. If that's not possible, create integration APIs so security can see observability data and vice versa.
Shared Runbooks: Document common incidents in a way that involves both teams. "API is slow" runbook should include security steps (check for DDoS), not just performance debugging steps.
Joint Monitoring: Some metrics matter to both teams. Set these up together. Example: error rates spike. Observability wants to know if it's a code issue. Security wants to know if it's an attack. Monitor together.

The Technology Stack: What Actually Works
You don't need to buy everything. You need the right pieces that work together.
Tier 1: Application Performance Monitoring (APM)
This is non-negotiable. You need to see into your applications.
What it does: Traces requests from entry to exit, showing you which functions are slow, which databases queries are expensive, which external services are causing delays.
Why it matters: Performance issues account for probably 40% of outages. APM lets you see them early.
Tier 2: Infrastructure Monitoring
You need to see your servers, databases, and cloud resources.
What it does: CPU, memory, disk, network, process health, database metrics.
Why it matters: Infrastructure failures account for maybe 35% of outages. You need to catch them.
Tier 3: Log Aggregation
You need to see what actually happened in your systems.
What it does: Collects all logs from all systems, makes them searchable.
Why it matters: When something goes wrong, logs are often the only source of truth about what happened. You need to access them quickly.
Tier 4: Incident Management / Alert Aggregation
One place for all alerts to flow.
What it does: Deduplicates alerts, correlates them, routes them to right team.
Why it matters: Your team shouldn't have to check eight different tools for alerts. One place.
Tier 5: Synthetic Monitoring
Monitor from the outside-in.
What it does: Simulates user transactions from different geographies, catches issues before users complain.
Why it matters: You know how your service actually performs to real users, not just to your internal monitoring.
Tier 6: Custom Metrics/Application-Level Observability
Business metrics from your application.
What it does: Track things like "orders processed," "revenue," "user signups," not just technical metrics.
Why it matters: You might hit SLOs for uptime but lose 60% of orders due to a checkout bug. You need to monitor business impact.
What You Probably Don't Need
- Separate security monitoring tool (use same signals as observability)
- Separate mobile/web performance tool (integrate into APM)
- Multiple log aggregation solutions (pick one)
- Multiple incident management platforms (pick one)
More tools = more integration work = more complexity = more missed alerts.
Real-World Case Study: How One Company Went from Alert Fatigue to Actual Observability
Company: Mid-sized SaaS platform, 8 engineers, 50K users.
The Problem:
They had:
- Datadog for infrastructure
- New Relic for APM
- CloudWatch for AWS resources
- ELK for logs
- PagerDuty for incident management
- Plus custom scripts that checked database replication
They were getting 300+ alerts per day. Real incidents were getting missed.
The Analysis:
They did an audit. Found that:
- 87% of alerts were duplicates across tools
- 45% of alerts were false positives
- Only 8% of alerts actually resulted in immediate action
The Fix:
-
Consolidated tools: Kept Datadog (good integration), migrated New Relic and CloudWatch data into Datadog, sent ELK logs to Datadog.
-
Deduplication: Configured Datadog to recognize when the same incident triggered across multiple tools and group them as one alert.
-
Threshold adjustments: Worked with the team to re-threshold everything. Went from 300 alerts/day to 8 alerts/day (and all 8 were actually relevant).
-
Context addition: Every alert now included:
- What recent changes might have caused this
- Standard remediation steps
- Link to runbook
- Severity level and business impact
-
Intelligent suppression: Set up suppression for known scenarios:
- Deployments suppress performance alerts for 5 min
- Maintenance windows suppress infrastructure alerts
- Load testing suppresses traffic alerts
The Results:
- Alerts from 300/day to 8/day
- False alerts from 45% to <2%
- MTTR (mean time to resolution) from 47 minutes to 12 minutes
- Team morale improved (no more 2 AM false alarms)
- Actual incident detection rate improved from 92% to 99%
The Timeline:
This took 8 weeks. Not because it was technically hard, but because it required careful thinking about thresholds and what actually matters.
Worth it? Absolutely. They prevent an average of 2 outages per quarter that would have cost $500K each.

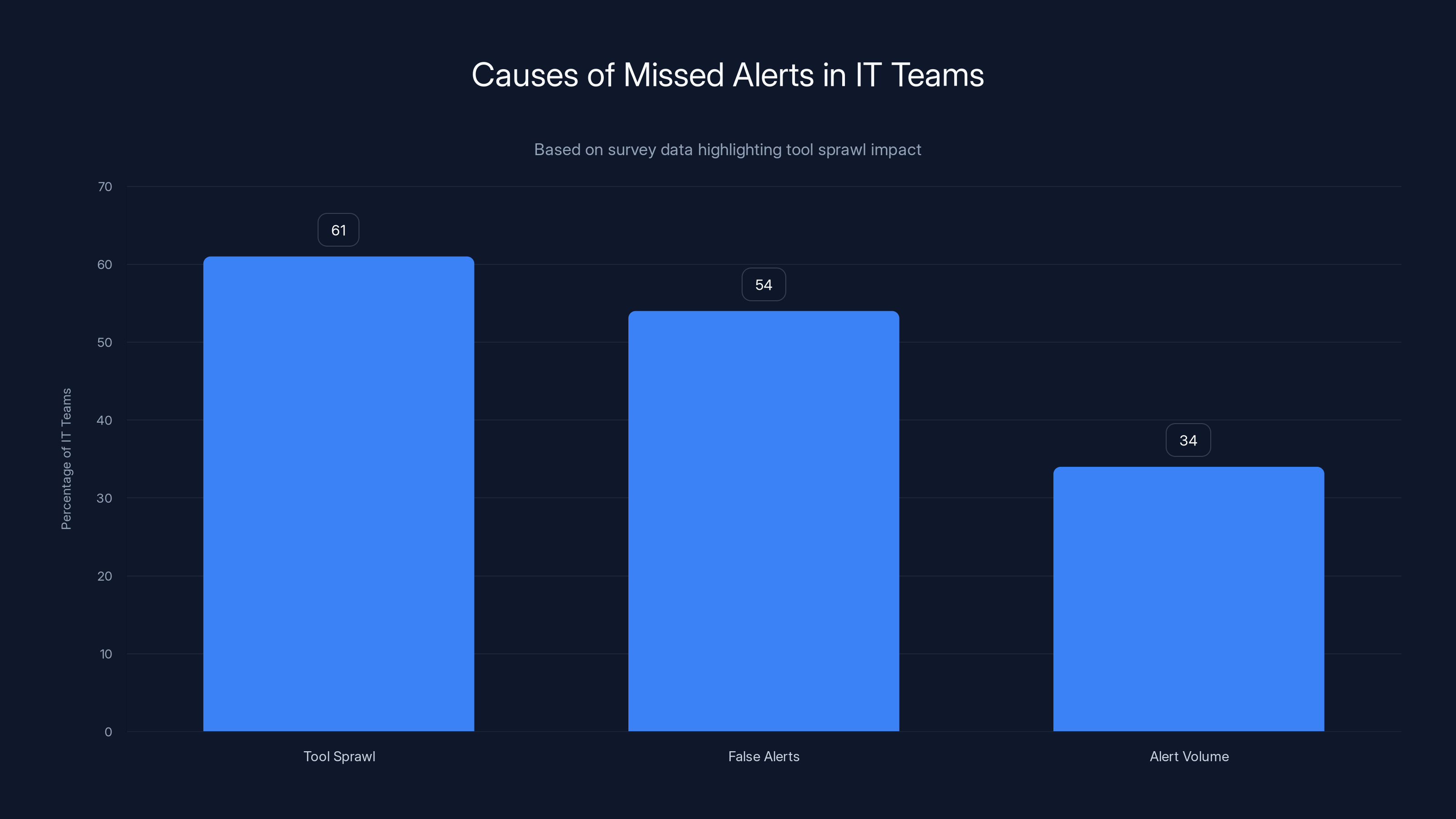
Tool sprawl is cited by 61% of IT teams as the biggest cause of missed alerts, surpassing false alerts and alert volume.
The Psychological Wellbeing Connection
Here's something that doesn't get talked about enough: missed alerts are a symptom of psychological burnout.
Your team isn't failing because they're bad at their jobs. They're missing alerts because the alert system has already broken their trust.
When you fix observability, you're not just improving uptime. You're improving your team's mental health.
The Cost of Burnout
Burnout in IT is expensive:
- Turnover: Good people leave. It costs 2x salary to replace someone.
- Mistakes: Burned-out people make more errors, which cause more incidents.
- Productivity: Burned-out people work slower (even if they're physically present).
- Culture: Burnout spreads. One burned-out engineer makes the whole team less healthy.
I've watched teams where the on-call rotation was causing burnout. They'd take sick days on their on-call week. They'd leave the company entirely. The remaining team got more burned out trying to cover the gap.
The fix wasn't hiring more people. The fix was reducing the false alert volume so on-call wasn't so stressful.
What Good Observability Does for Team Health
When your alerts actually work:
- Team members sleep better (fewer false alarms at 3 AM)
- Team members trust the system (they can actually relax when off-call)
- Team members feel competent (they're solving real problems, not chasing ghosts)
- Team members are more engaged (they enjoy the work)
This isn't soft stuff. This directly improves incident response and prevents future incidents.
Common Pitfalls and How to Avoid Them
Pitfall 1: Too Many Tools, Not Enough Integration
What happens: You buy tool A for monitoring, tool B for logs, tool C for traces. They don't talk to each other. Your team spends more time integrating tools than building observability.
How to avoid: Before buying a new tool, ask: "How does this integrate with what we already have?" If the answer isn't clear, don't buy it.
Pitfall 2: Alerts Without Context
What happens: Alert fires. Your team has no idea what it means or what to do. They solve it by trial and error. They miss the real cause.
How to avoid: Every alert must include remediation information. If you can't document how to respond to an alert, that alert probably shouldn't exist yet.
Pitfall 3: Ignoring Alert Fatigue Signals
What happens: Your team starts ignoring alerts. You don't notice because you're not asking them. By the time you realize there's a problem, you've had multiple missed incidents.
How to avoid: Regularly ask your team: "Which alerts do you trust? Which do you ignore? Which cause you stress?" If they're ignoring alerts, fix the alerts, don't blame the team.
Pitfall 4: Metrics Without Business Context
What happens: You monitor CPU and memory and response time. All metrics are green. Your service is down because a bug prevents orders from being processed. Nobody noticed because it's not a metrics problem, it's a business logic problem.
How to avoid: Include business metrics in your observability. Track revenue, orders, user signups, not just technical metrics.
Pitfall 5: Observability as a Reactive Tool
What happens: Something breaks. Then you add monitoring for it. By the time the monitoring is in place, the incident is over. You're always fighting the last battle.
How to avoid: Add observability proactively. Before you deploy a feature, set up monitoring for it. Don't wait for it to break.
The Future of Observability: Automation and Intelligence
We're moving toward systems that don't just alert you about problems, but predict them and fix them automatically.
Predictive Alerting
Instead of "CPU is at 85%," you get "CPU is trending toward 100% in 23 minutes based on current growth rate. Recommend auto-scaling now."
This is already possible with anomaly detection and trend analysis. Most companies aren't using it yet.
Autonomous Remediation
For known issues, automatically fix them:
- Service crashes? Auto-restart.
- Database slow? Auto-index the slow queries.
- Cache hit rate low? Auto-clear cache and rebuild.
- Disk filling up? Auto-clean old logs.
Obviously with guards and controls. But automation is faster and more reliable than paging someone at 3 AM.
Causal Analysis
Instead of just detecting that something is wrong, systems will understand why:
- "API is slow because database connection pool is exhausted because connection leak in driver version 2.1.3 released 2 hours ago"
Not just facts, but causality.
AIOps
Artificial intelligence analyzing your infrastructure.
Not the hype version ("AI will fix everything"). The real version: machine learning on your historical data to recognize patterns and predict issues.
Example: "Every time deployments happen between 2-3 PM on Thursdays, you get a spike in memory usage in this service that leads to a crash 15 minutes later." Knowing this, you can prevent the crash.
Implementing Better Observability: A Practical Timeline
If you're starting today, here's a realistic timeline:
Week 1-2: Discovery
- Audit all your tools and alert sources
- List all alerts and categorize by relevance
- Interview team about alert fatigue
Week 3-4: Planning
- Define SLOs for critical systems
- Plan tool consolidation
- Design alert strategy
Week 5-8: Implementation Phase 1
- Consolidate to fewer tools
- Set up integration between tools
- Configure basic alerts
Week 9-12: Implementation Phase 2
- Add context to alerts
- Set up intelligent suppression
- Create/update runbooks
Week 13-16: Tuning
- Monitor alert accuracy
- Adjust thresholds
- Add business metrics
Week 17+: Optimization
- Review metrics weekly
- Iterate on alerts
- Add predictive capabilities
This timeline assumes you have 1-2 people dedicated to this. If it's a side project, double the timeline.

Why Investing in Observability Pays Back Immediately
Some investments in tech take a while to pay off. Observability doesn't.
Conservative math:
- Average company has 1 outage per quarter
- Each outage costs $500K (lost revenue + support costs + recovery time)
- That's $2M per year in outages
- Missed alerts cause maybe 30% of these: $600K per year
If better observability prevents just 1 of those 4 outages per year, it pays for itself immediately.
For a team of 5 engineers implementing better observability, that's:
- Time cost: ~200 hours total ($50K in burdened labor)
- Tool cost: ~$5K/month increase (consolidating tools actually costs less)
- Year 1 cost: ~$110K
Benefit: Prevent 1 outage per year ($600K), plus reduced burnout (better retention = massive savings).
ROI: 5.5x in year 1, then ongoing.
Actionable Checklist: Getting Started This Week
-
Monday: Schedule a 1-hour meeting with your on-call team. Ask them which alerts they trust and which they ignore. Record the answers.
-
Tuesday: Audit all your monitoring tools. Make a spreadsheet:
- Tool name
- What it monitors
- How many alerts it generates per day
- How many are actionable
- How many are false positives
-
Wednesday: Analyze the spreadsheet. If any tool generates >50 alerts/day, that's a red flag. Mark it.
-
Thursday: List all your critical services. For each:
- What would constitute an outage?
- What's our SLO?
- What do we currently alert on?
- Are we missing any critical metrics?
-
Friday: Present findings to your team. Discuss:
- Which alerts are noise?
- Which real incidents did we miss recently?
- What would actually help?
-
Next Week: Start with ONE system. Redesign its alerts from scratch, applying lessons learned. Once it's working well, move to the next system.

The Bottom Line
Your team isn't missing critical alerts because they're careless. They're missing them because your alert system is broken.
Fix the alerts, and you fix the outages.
Fix the outages, and you fix the team.
The path to better uptime isn't better tools. It's coherent systems, clear context, actionable remediation, and teams that trust their monitoring.
Start this week. Not next quarter. Not next month. This week.
Your next outage could be prevented by an alert that's already firing, but nobody is reading it.
FAQ
What exactly is alert fatigue?
Alert fatigue is when your team receives so many alerts (especially false ones) that they stop reacting to them. It's a psychological adaptation where your brain learns that alerts don't predict real danger, so it stops treating them as urgent. This leads to missed critical alerts because your team's emergency response system becomes desensitized.
How do I know if my team has alert fatigue?
Watch for these signs: team members ignoring alerts without investigation, slower response times to page notifications, team expressing emotional numbness or frustration about being on-call, and high rates of missed incidents. If your team directly tells you they ignore certain alerts, you definitely have alert fatigue.
What's the difference between monitoring and observability?
Monitoring tells you that something is wrong ("CPU is high"). Observability tells you why something is wrong ("CPU is high because this query is slow because we're missing an index and the table has 10x more rows since yesterday"). Monitoring is reactive. Observability is diagnostic. You need both, but observability matters more for resolving incidents quickly.
How many alerts should a healthy system have per day?
For a team of 5-10 engineers, aim for 1-3 legitimate alerts per day. If you're getting more than 10 per day, you have a threshold or configuration problem. Most alerts should be actionable, not informational.
Can we solve alert fatigue without buying new tools?
Partially yes, mostly no. You can improve your current setup significantly by re-thresholding alerts and removing false ones. But truly solving it usually requires better integration between tools so you can provide context and avoid duplicates. The good news: consolidating tools often costs less than running multiple separate tools.
What's the fastest way to reduce false alerts?
Audit your current alerts and identify which ones fire most frequently. Work with the team to adjust thresholds on the top 5 sources of false alerts. Often, just adjusting 5 thresholds reduces false alert volume by 50%. This is a day or two of work, not a month-long project.
Should observability and security use separate tools?
Not ideally. They're monitoring the same infrastructure from different angles. Separate tools create gaps. At minimum, they should integrate so each team can see the other team's relevant data. Shared tooling is better, but if you must separate, ensure you have APIs or integrations connecting them.
How do we prevent observability from becoming another unmaintained tool?
Assign clear ownership. One person is accountable for alert quality, thresholds, and context. Have a weekly or bi-weekly review of alert metrics. If nobody is reviewing these, quality degrades. It's like code review, but for observability.

Quick Implementation Playbook for This Week
Ready to get started? Here's exactly what to do:
Day 1: Discovery
Schedule 30-minute interviews with 3 engineers:
- "Which alerts do you trust?"
- "Which do you ignore?"
- "Which have false positives?"
- "What incident did we miss recently?"
Document every answer.
Day 2: Audit
List every tool that generates alerts. For each:
- Alerts per day
- Percentage that are false
- Percentage that are actionable
- Integration status with other tools
Day 3: Analysis
Identify the top 3 sources of false alerts. Schedule brief meetings with engineers who handle those alerts: "Why is this alerting so much?"
Day 4: Planning
For your top 3 false alert sources, draft new thresholds or suppression rules that would reduce false alerts by 80%.
Day 5: Implementation
Deploy changes for top false alert source. Monitor it.
Following Week: Iterate
Monitor results. Deploy changes for sources 2 and 3. Gather feedback. Adjust.
That's it. One week to measurably reduce alert fatigue.
Key Takeaways
- 73% of UK IT teams experienced outages specifically because they missed critical alerts due to alert fatigue and tool sprawl
- Tool sprawl (61%) causes more missed alerts than false alerts (54%) or alert volume (34%), proving that consolidation matters more than filtering
- False alerts actively harm team morale and train engineers' brains to ignore warnings through neurological habituation
- The cost of IT downtime ranges from 5.6M per hour depending on industry, making missed alerts extremely expensive
- Better observability with context and correlation reduces MTTR from 47 minutes to 12 minutes, preventing most missed alerts
- 64% of IT teams report that cross-team collaboration between observability and security reduces customer-impacting incidents
- Alert fatigue is a psychological adaptation where teams become desensitized to warnings, not a character flaw

