![Threat Hunting With Real Observability: Stop Breaches Before They Spread [2025]](https://tryrunable.com/blog/threat-hunting-with-real-observability-stop-breaches-before-/image-1-1768923579252.jpg)
Threat Hunting With Real Observability: Stop Breaches Before They Spread [2025]
You're sitting at your desk on a Tuesday morning when the alert fires. A user account accessed files in three different departments within the span of 40 minutes. Normal? Maybe. Suspicious? Possibly. But without the right observability tools, you're left guessing.
This is the reality for thousands of security teams right now. They're drowning in alerts (we're talking 2,000+ per day), burning out their analysts on false positives, and missing the actual attacks happening inside their networks. The problem isn't that they lack data. It's that they lack clarity.
Here's the thing: prevention is dead. Or at least, prevention alone is dead. The most sophisticated attackers don't get stopped at the perimeter. They slip through, establish a foothold, and then spend days or weeks quietly moving laterally through your infrastructure, probing systems, escalating privileges, and hunting for crown jewels. That time between entry and detection? That's where breaches become crises.
The good news is that real observability changes the game. Not the kind that just collects more logs. The kind that connects signals, reveals patterns, and shows threat hunters exactly what they're looking for: how an attacker is actually moving through your environment.
Let's dig into why observability matters so much for threat hunting, how it works in practice, and what modern security teams need to implement it effectively.
TL; DR
- Alert fatigue is crushing detection: Security teams face 2,000+ daily alerts with 14+ hours spent weekly on false positives, making it nearly impossible to spot real threats.
- Lateral movement is the silent killer: Nearly 9 in 10 organizations experienced lateral movement attacks last year, with breaches resulting in 7+ hours of downtime and weeks of recovery.
- Visibility isn't enough—context is everything: 40% of east-west traffic lacks meaningful context, allowing attackers to move freely while defenders remain uncertain.
- Security graphs and correlation are game-changers: Connecting scattered alerts through contextual models reveals attack pathways and enables rapid containment before spread.
- AI and automation scale human judgment: Machine learning identifies patterns humans would miss, reducing alert volume and letting analysts focus on real threats.

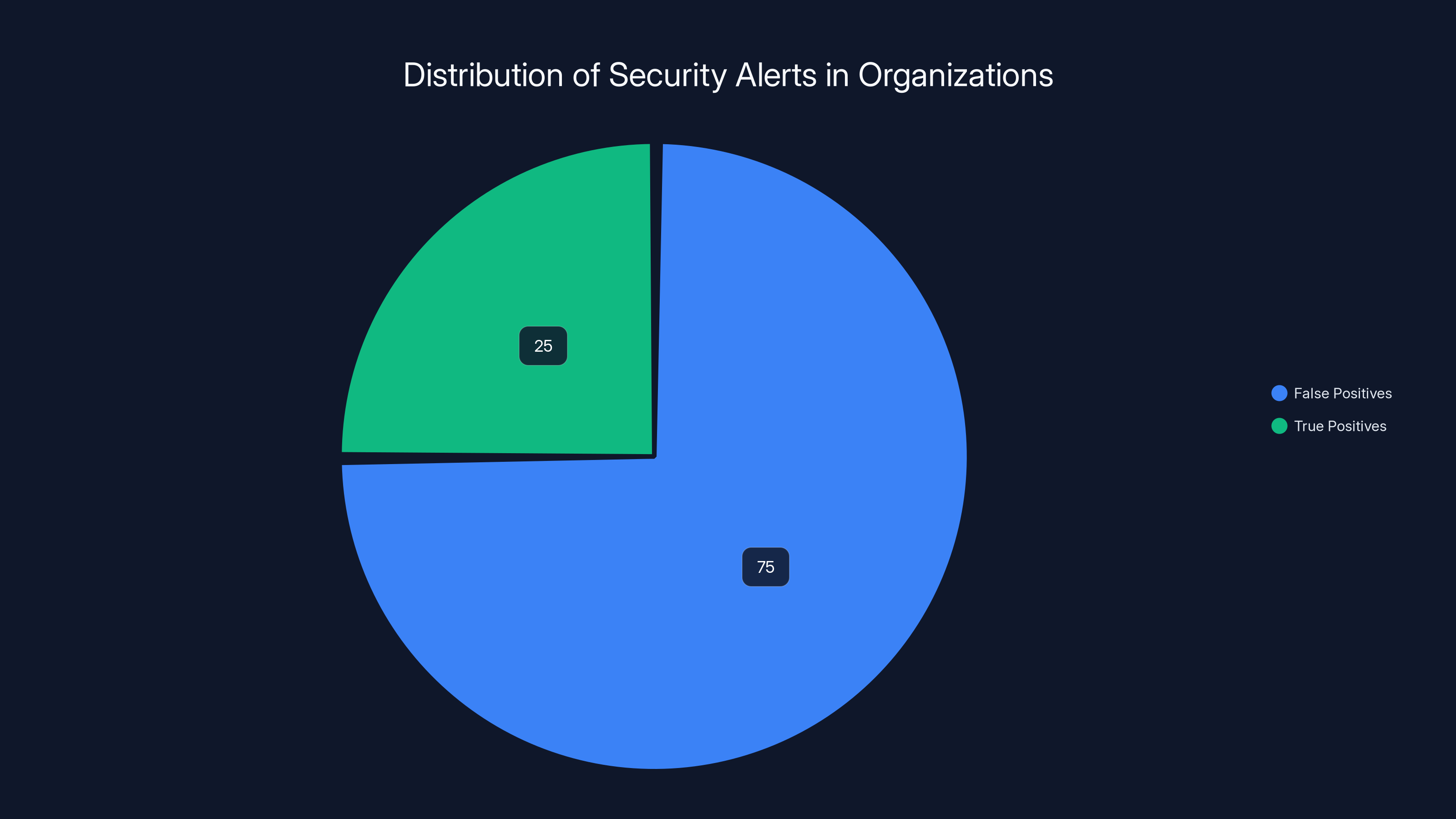
Estimated data shows that 75% of security alerts are false positives, leading to significant analyst fatigue and missed detections.
The Breach That Went Undetected: Why Prevention Alone Fails
Most security breaches don't announce themselves. There's no warning klaxon. No red text on a black background. Instead, they quietly slip past your defenses and settle in.
Consider this scenario: An attacker gains access through a compromised credential. Maybe it's a phishing email, maybe it's a password reused across services. They're in. And then they stop. They don't immediately exfiltrate data or lock files. That would raise alarms. Instead, they observe. They move carefully through the network, escalating privileges step by step, understanding the environment, finding the systems that matter.
This is lateral movement. And it's where small intrusions transform into enterprise-wide disasters.
The challenge is staggering: nearly 9 in 10 organizations have experienced lateral movement incidents in the past year. On average, these breaches resulted in over seven hours of downtime. But here's the kicker: the actual attack could have been detected and contained in hours if teams had the right observability.
Instead, what typically happens is this: An alert fires. Maybe it's a privilege escalation attempt. Maybe it's unusual network traffic. But in an environment generating 2,000+ alerts daily, this signal gets buried. It's one of hundreds. Analysts spend 14+ hours each week chasing false positives, and by the time they get around to investigating, the attacker has already moved three systems deeper into the network.
Two-thirds of security leaders admit their teams simply cannot keep up. That's not a failure of tools. That's a failure of visibility.
The root cause? Organizations are collecting mountains of data but drowning in noise. They have multiple detection platforms running in parallel, each generating alerts independently. There's no context connecting these signals. It's like having security cameras on every corner of a building but no way to track a person's actual path through it. You see them in Camera 1, then Camera 3, then Camera 5, but you don't know if they're the same person or where they're going.
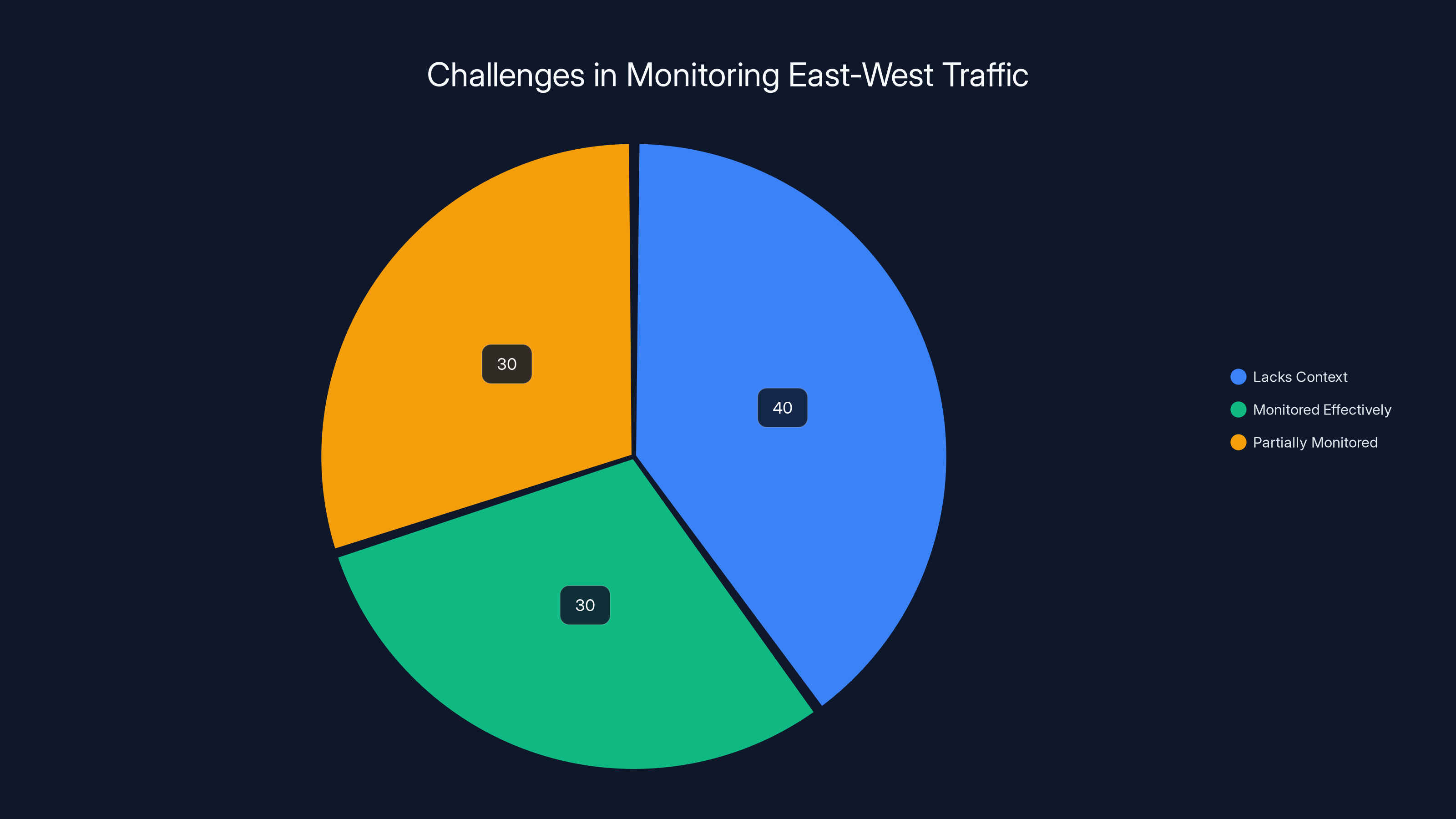
Estimated data shows that nearly 40% of east-west traffic lacks context for confident analysis, highlighting a significant challenge in detecting lateral movement within networks.
The Alert Fatigue Crisis: Why More Data Isn't Better
Let's talk numbers, because the statistics are sobering.
A typical mid-sized organization faces over 2,000 security alerts every single day. That's not a typo. Two thousand. For a security team with maybe 10-15 analysts, that's roughly 150-200 alerts per person per day.
How many of those are actually important? Research consistently shows that 60-90% of security alerts are false positives. That means analysts are spending the vast majority of their time investigating things that don't matter. And when 60-90% of your caseload is noise, you're statistically guaranteed to miss real threats.
Here's the human factor that tool vendors don't love to mention: analysts get tired. They get cynical. After investigating 50 false positives, that 51st alert—which might be a real attack—feels like just another cry wolf. Studies show that analyst fatigue directly correlates with missed detections. When people are exhausted, they make mistakes. They skip steps. They miss context.
The typical analyst spends more than 14 hours each week—that's nearly two full workdays—chasing alerts that go nowhere. Multiply that across your entire security team, and you're burning thousands of hours on noise instead of detection.
Most organizations now use multiple cloud detection and response platforms (CDRS) in hopes that more tools mean better coverage. But the research shows the opposite: 92% of organizations report significant capability gaps despite running multiple detection platforms. Overlapping systems create conflicting information and fragmented visibility. Instead of getting a clearer picture, teams get contradictory signals.
The problem compounds when you realize that more data doesn't equal better detection. A system generating 2,000 alerts might actually provide worse security than one generating 500 high-confidence alerts. Why? Because the human element can't scale infinitely. There's a ceiling to how many alerts an analyst can effectively investigate in a day. Once you hit that ceiling, the marginal value of additional alerts drops to zero—and in many cases, goes negative because the noise increases the miss rate.
This is why observability is different from traditional logging. Observability isn't about collecting more data. It's about making sense of the data you already have.

Lateral Movement: The Attacker's Playground in Your Network
Now let's talk about why lateral movement is so dangerous and why organizations struggle to detect it.
Once an attacker is inside your network, the game shifts from "how do I get in" to "how do I move around without getting caught." This lateral movement is what transforms a single compromised account into a full-blown breach.
Here's a typical lateral movement chain:
- Attacker compromises a standard user account (low-privilege entry point)
- They discover a database server on the same network segment
- They move from the user workstation to a neighboring system
- They find admin credentials stored in plaintext in a config file
- They escalate privileges using those credentials
- They move to the sensitive systems they were actually after
- They establish persistence and begin exfiltrating data
Each step in this chain generates some kind of signal. A login from an unusual location. Network traffic to an unusual destination. A process spawning with elevated privileges. But each signal, in isolation, looks routine.
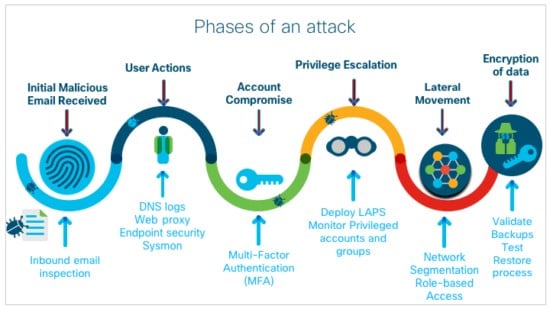
The problem is east-west traffic. That's the term for traffic between systems inside your network (as opposed to north-south traffic, which crosses the perimeter). Traditional security infrastructure was designed to monitor north-south traffic heavily. Firewalls inspect traffic coming in and going out. But east-west traffic? That happens inside your network. And many organizations trust internal traffic implicitly.
The statistics are damning: nearly 40% of east-west traffic lacks the context required for confident analysis. That means organizations can't reliably tell the difference between legitimate internal communication and an attacker moving through the network. It's like having lights on every highway exit but no way to see who's driving down the side roads.
This is especially problematic in hybrid environments where workloads span on-premises data centers and cloud infrastructure. A server in AWS might communicate with a server in your data center, and that traffic might flow through multiple network segments. The attack path becomes exponentially harder to track.
The research backs this up: nearly 9 in 10 organizations experienced at least one incident involving lateral movement in the past year. These weren't edge cases. They were the norm. And the consequences were significant: more than seven hours of downtime per breach, with full recovery stretching weeks or even months.
Why does it take so long to detect and contain lateral movement? Because defenders are looking for known indicators. They're checking for malware signatures, looking for known C2 (command and control) domains, monitoring for processes that are known to be malicious. But sophisticated attackers use living-off-the-land techniques: they use legitimate system tools (Power Shell, Windows Management Instrumentation, legitimate cloud APIs) to accomplish their objectives. These tools are so normal that detecting their malicious use requires understanding context and intent.
An attacker might use the same commands that a systems administrator uses during routine maintenance. The difference is in the pattern, the frequency, the accounts involved, and the systems targeted. Without observability that tracks these behavioral patterns, defenders can't distinguish legitimate activity from attack activity.
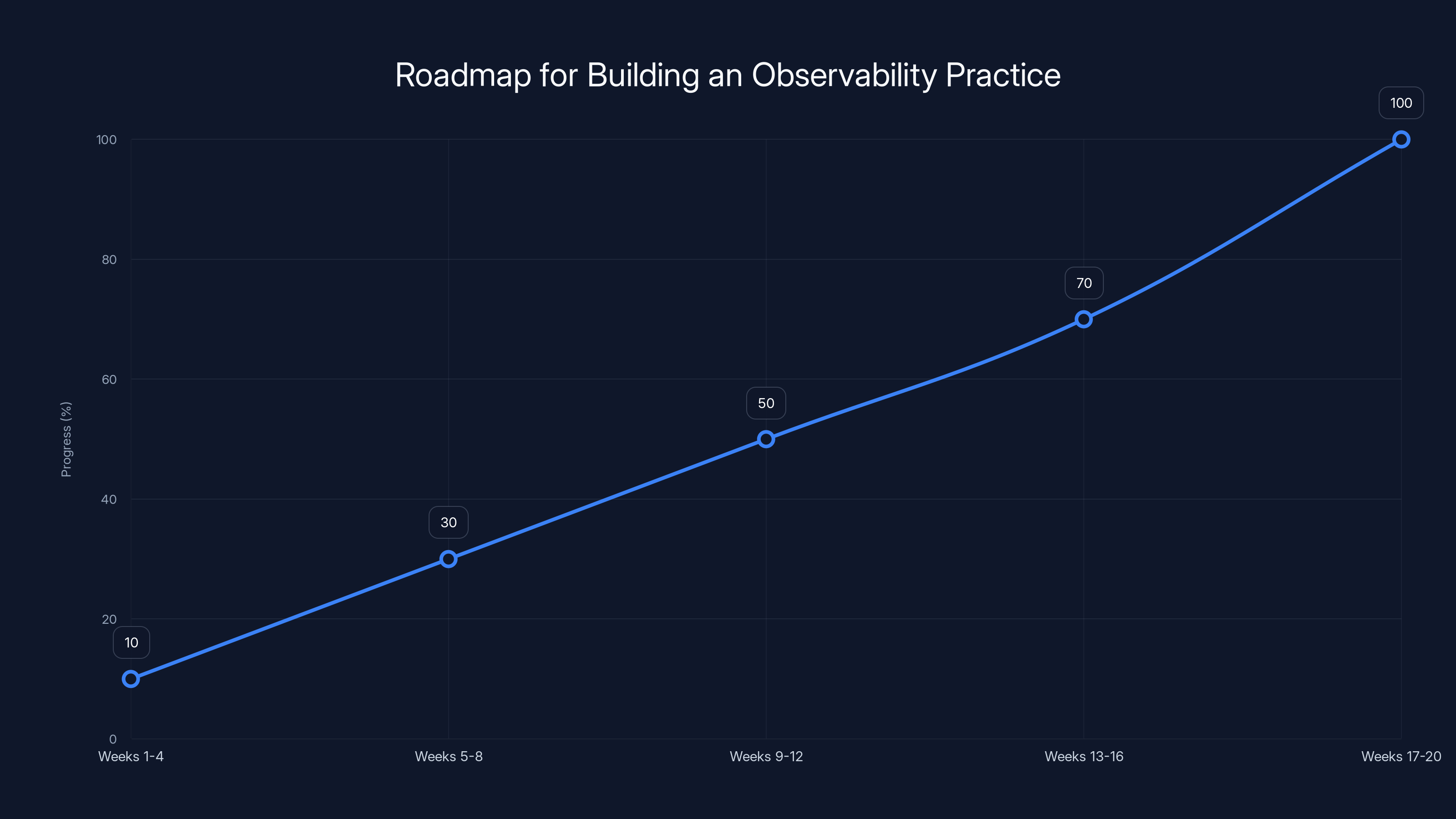
This chart outlines a typical timeline for implementing an observability practice, progressing from initial assessment to closing critical gaps. Estimated data based on typical project phases.
What Real Observability Actually Means
Observability is one of those terms that's been so overused and vaguely defined that it's almost lost its meaning. Vendors slap "observability" on everything from basic monitoring dashboards to full-stack visibility platforms.
Let's clarify what observability actually means in the context of threat hunting and security operations.
Traditional monitoring tells you the current state of a system. Is the CPU above 80%? Is the service running? Has the disk filled up? Monitoring answers "what is happening right now."
Observability goes deeper. It's the ability to ask arbitrary questions about your systems and get answers, even for events you didn't anticipate monitoring. Observability enables you to understand not just what's happening, but why it's happening.
In security terms, observability means:
- Behavioral tracking: Understanding how systems, users, and applications normally behave, and detecting when behavior deviates from the baseline
- Relationship mapping: Knowing which systems communicate with which, which users access which resources, how workloads interact
- Historical context: Maintaining enough historical data to detect slow, low-and-slow attacks that unfold over weeks
- Cross-domain correlation: Connecting signals from different sources (network, endpoint, cloud, identity) into a coherent picture
- Actionable insights: Presenting data in ways that help analysts understand attacker intent rather than just isolated anomalies
This is fundamentally different from a Security Information and Event Management (SIEM) system that collects logs from various sources and provides search and alerting capabilities. A SIEM is a tool. Observability is an outcome.
Real observability requires three things:
1. Comprehensive data collection across all the places attackers move. That includes network traffic, endpoint activities, cloud API calls, identity and access events, and application behavior. You can't have blind spots because that's where attackers hide.
2. Intelligent correlation that connects these data sources. A single login anomaly might mean nothing. But that same login combined with unusual file access on three different servers, preceded by a privilege escalation, suddenly tells a story.
3. Clear presentation that reduces cognitive load on analysts. The data needs to be summarized, prioritized, and contextualized in ways that help humans make faster decisions.
The security guidance has shifted in this direction too. The UK's National Cyber Security Centre (NCSC), for example, recently emphasized that organizations cannot hunt for threats they cannot see. Traditional indicators of compromise are necessary but insufficient. Defenders need visibility into behaviors, patterns, identities, workloads, and internal traffic flows to catch attackers in motion.
This aligns perfectly with threat hunting methodology. A threat hunter isn't waiting for alerts to fire. They're actively searching for evidence of compromise based on behavioral hypotheses. "What if an attacker is using this lateral movement technique?" "What systems might they target?" "What would that look like in our logs?" Observability is what makes these questions answerable.
The Context Problem: Why 40% of Internal Traffic Goes Unanalyzed
Here's a counterintuitive finding: organizations often report high confidence in their internal traffic monitoring while simultaneously admitting they can't analyze 40% of that traffic with confidence.
What's going on here?
The issue is the difference between visibility and understanding. Many organizations have network visibility: they can see that traffic is happening. But they lack context: they can't interpret what that traffic means.
Consider this scenario: A server sends a request to another server at 3 AM. The request uses a legitimate protocol (HTTP or DNS). The destination is a valid internal IP address. By every measure, this looks fine. But without context, you can't answer critical questions:
- Does this server normally communicate with that destination?
- Does this server normally communicate at 3 AM?
- Is this traffic coming from a compromised system?
- Is this a reconnaissance probe?
- Is this an internal threat?
Each of those questions requires context. And context is expensive to maintain. It requires understanding baseline behavior for thousands or millions of traffic flows. It requires storing historical data. It requires computational resources to correlate events.
Traditional network monitoring tools focus on throughput, latency, and basic anomalies. "This server is sending 1000x more traffic than usual." That's visibility. But many internal reconnaissance attacks don't generate unusual traffic volumes. They're quiet. They're specifically designed not to stand out.
This is where behavioral analysis becomes critical. Instead of asking "is this traffic unusual in volume," threat hunters need to ask "is this traffic unusual for this system at this time from this user." That requires maintaining behavioral baselines and comparing current activity against historical patterns.
In hybrid environments (mixing on-premises and cloud), this problem amplifies. Traffic patterns might be legitimate and expected within one domain but suspicious when crossing domain boundaries. A user might normally access a file server during business hours, but accessing it from a cloud system at 2 AM suggests compromise. Correlating across domains is where most organizations fail.
The solution isn't to try to analyze every single piece of traffic. That's impossible and would create more noise. Instead, organizations need to:
- Identify high-risk traffic patterns (based on user behavior, system roles, data sensitivity)
- Establish behavioral baselines for these high-risk patterns
- Alert on significant deviations from baseline
- Provide context for analysts to quickly assess whether an alert represents a real threat
This is iterative. Early detections will have higher false positive rates. But as the system learns normal behavior, accuracy improves. And critically, as analysts provide feedback on whether detections were true or false positives, the system can refine its models.

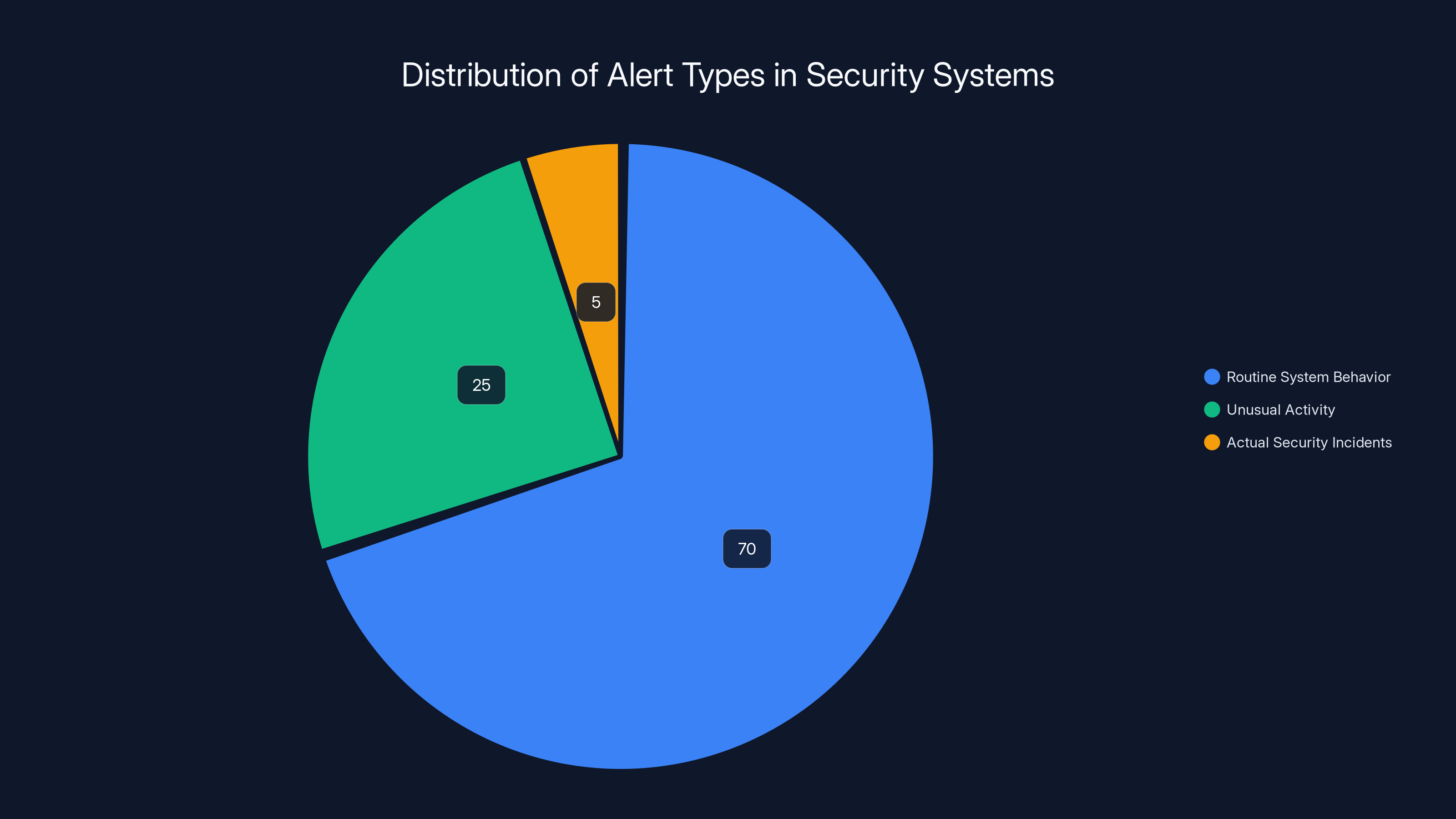
Estimated data shows that most alerts (70%) are routine system behaviors, while actual security incidents make up only 5% of alerts, highlighting the challenge of distinguishing real threats from noise.
Security Graphs: Turning Fragments Into a Complete Picture
Imagine trying to solve a jigsaw puzzle where someone hands you one piece at a time, and you have to make a decision about each piece before seeing the next one. That's what current alert-driven security operations feel like.
A security graph takes a different approach. Instead of processing alerts in isolation, it maps the relationships between all the entities in your environment: users, workloads, systems, accounts, data flows, and devices. Then it tracks how these entities interact and change over time.
In practice, a security graph might look like this:
User A
├── Account A (High privilege)
├── Accessed File Server 1
│ ├── Downloaded sensitive files
│ └── Connected to System B (Database)
│ └── System B has access to System C (Data warehouse)
└── Account B (Standard privilege)
├── Accessed File Server 2
└── Attempted privilege escalation (Failed)
Now, a single low-level alert on Account B attempting privilege escalation might not trigger investigation. It's routine for users to sometimes try things that require elevated permissions. But when that alert is correlated with User A's activities—accessing sensitive files and then accessing database systems that store similar data—a pattern emerges. The alerts that seemed routine in isolation suddenly look suspicious when connected.
This is the power of correlation. Low-confidence alerts become high-confidence indicators when you understand the broader context.
Security graphs work because they answer the questions threat hunters actually need answered:
- Which systems can this compromised account reach? (Showing actual paths, not just theoretical permissions)
- What sensitive data would this attack path expose? (Prioritizing by business impact)
- What other systems might be affected? (Understanding blast radius)
- Where can we stop the attacker? (Identifying chokepoints for rapid containment)
Implementing security graphs is non-trivial. It requires:
- Comprehensive inventory of all systems, accounts, and users
- Mapping of permissions and access rights (including inherited permissions)
- Understanding of data flows and dependencies
- Historical tracking of changes to detect lateral movement paths
- Regular updates as infrastructure changes
But once implemented, security graphs become force multipliers for threat hunters. Instead of investigating hundreds of alerts, hunters can focus on the few that represent real attack paths through sensitive systems.
The business value is significant. Organizations using security graph approaches report:
- 3-5x faster incident investigation
- 50-70% reduction in false positives
- Earlier detection of lateral movement (sometimes by days)
- Faster containment once attacks are detected
- Better risk prioritization (focusing on threats that actually matter)

Alert Fatigue vs. Real Threats: Winning the Signal-to-Noise Battle
Let's address the elephant in the room: how do you keep alert volumes low while maintaining detection coverage?
This is where most security tools fail. They're designed to be sensitive, which means they catch real attacks. But sensitivity and false positive rate are inversely related. A tool that catches 95% of attacks will generate lots of noise. A tool that generates no false positives will miss attacks.
The solution isn't finding perfect balance. It's prioritization.
Not all alerts are equally important. In a given day:
- Most alerts represent routine system behavior (false positives)
- Some alerts represent unusual activity but not security-relevant (system errors, misconfigurations, legitimate unexpected changes)
- A tiny fraction represent actual security incidents
Traditional approaches try to reduce the volume at the source. Set thresholds higher, use more specific detection rules, add more manual review gates. But this inevitably means missing real attacks because the specificity has to be so high to avoid false positives.
Better approaches use machine learning to learn what normal looks like, then alert only on significant deviations. But even ML-based approaches struggle because "normal" is contextual. Normal for a system administrator at 2 PM on a Wednesday is different from normal for the same person at 2 AM on a Saturday.
The state-of-the-art approach combines multiple strategies:
Behavioral profiling learns what normal activity looks like for each user, system, and service. When activity deviates significantly from historical patterns, it becomes more likely to generate an alert.
Risk scoring weights alerts based on context. An unusual login by an admin might be risky. An unusual login by a regular user to a low-sensitivity system might be routine. But an unusual login by a regular user to a system containing customer credit card data is definitely risky.
Correlated detection looks for patterns across multiple data sources. A single unusual event might be routine, but multiple unusual events from the same source within a time window suggests coordinated attack activity.
Analyst feedback continuously improves detection as analysts mark alerts as true or false positives. ML systems learn from these feedback loops and adjust thresholds accordingly.
The result is a hybrid approach: algorithmic detection and correlation handle the heavy lifting, reducing noise and prioritizing threats. Analysts focus on the highest-risk alerts, investigating with context provided by the security graph and historical data.
Organizations implementing this hybrid approach see dramatic improvements:
- Alert volume drops 60-80% when correlated and de-duplicated
- Alert quality improves because remaining alerts have higher priority
- Analyst productivity increases because they're investigating higher-confidence alerts
- Detection capability actually improves despite lower alert volume because real threats are prioritized
The key insight: fewer, better alerts beat more alerts every time.

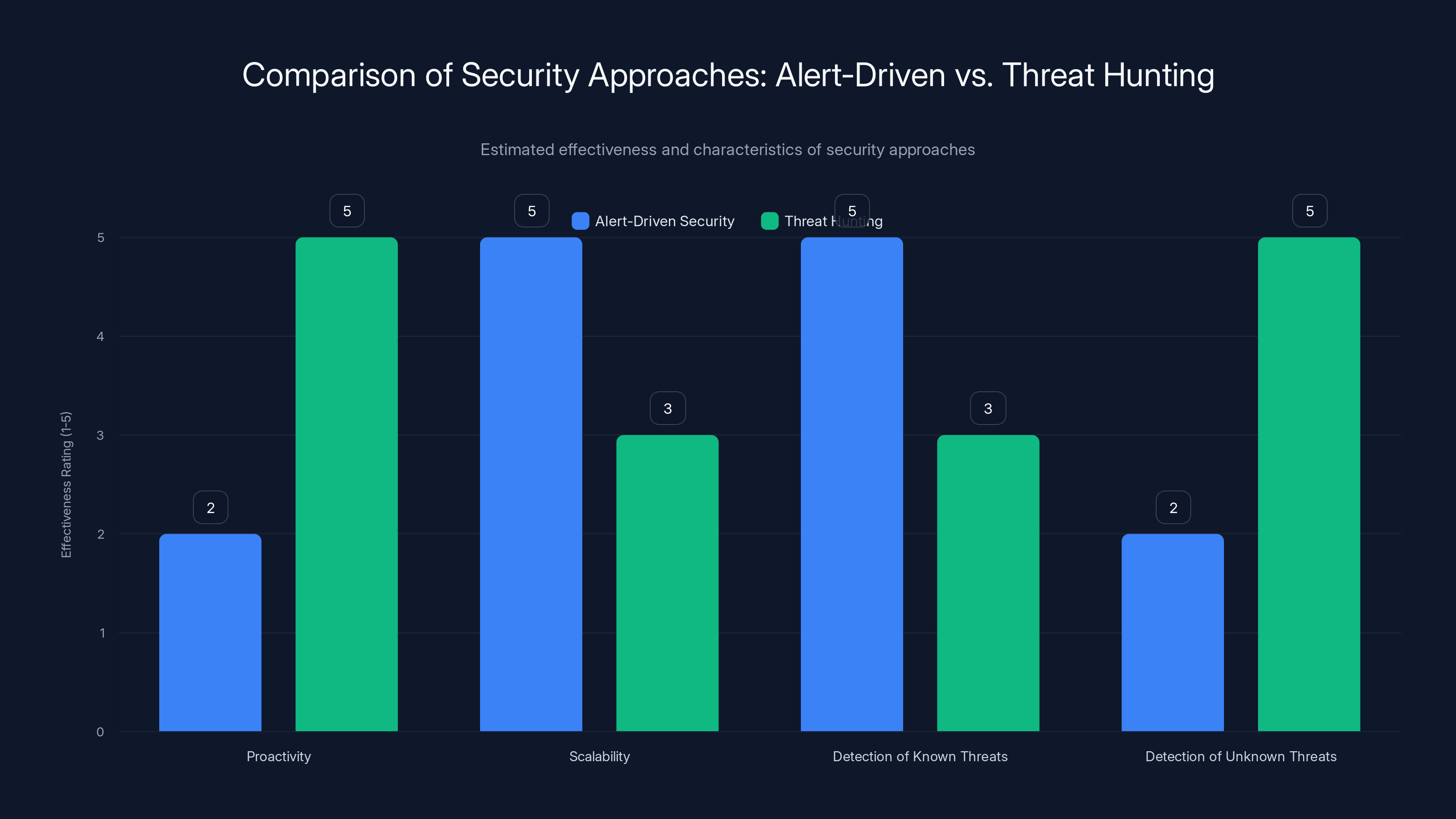
Threat hunting is more proactive and better at detecting unknown threats, while alert-driven security excels in scalability and known threat detection. Estimated data based on typical characteristics.
From Alert Hunting to Threat Hunting: A Fundamental Mindset Shift
There's an important distinction between alert-driven security and threat hunting. Organizations often confuse the two, and it shows in their security operations results.
Alert-driven security is reactive. A system generates an alert, an analyst investigates it, closes it or escalates it. This happens all day, every day. Analysts are in a perpetual reactive cycle, handling whatever comes next.
Threat hunting is proactive. Hunters examine data with specific hypotheses about what attackers might be doing. They search for evidence of attacks that haven't yet triggered alerts. They explore the data with the mindset of "what would this attack look like if it happened here?"
These require completely different tools and approaches.
Alert-driven security thrives with traditional SIEM: store logs, define rules, fire alerts. It's scalable and systematic, but it's capped by the quality of the rules. You can only detect attacks you've thought to create rules for.
Threat hunting requires observability. Hunters need to ask ad-hoc questions of the data. "Show me all instances where a user accessed files they've never accessed before." "Show me all outbound connections to rare IP addresses from systems in this network segment." "Show me anomalous process chains on these servers." These aren't predefined rules. They're dynamic queries based on current threat intelligence and hypotheses.
The best security programs do both. Alert-driven detection provides constant coverage and baseline detection. Threat hunting teams surface the sophisticated attacks that evade baseline detection.
The shift requires organizational change too:
- Different skillsets: Alert engineers focus on writing detection rules. Threat hunters focus on understanding attack techniques and analyzing complex data.
- Different tools: Alert systems need to be deterministic and fast. Hunting systems need flexibility and depth, even if they're slower.
- Different metrics: Alert-driven teams measure alert count and closure rate. Threat hunting teams measure investigation depth and findings rate.
- Different culture: Alert teams execute procedures. Threat hunting teams ask questions and follow leads.
Organizations that successfully implement both operating models see significantly better security outcomes. They catch the obvious stuff with alerts, and they catch the sophisticated stuff with hunting. Attackers don't have anywhere to hide.
For Runable users looking to document their threat hunting processes and create reports on findings, Runable's AI-powered document and report generation can help threat hunting teams scale their documentation and share findings across the organization more efficiently.

Observability in Hybrid Environments: The Multi-Domain Challenge
Implementing observability is hard enough in a traditional data center. Add cloud infrastructure, and complexity explodes.
Hybrid environments introduce visibility challenges that on-premises-only or cloud-only environments don't face:
Domain boundary crossing is the first problem. When workloads span multiple cloud providers, on-premises data centers, and potentially even third-party hosting, network traffic crosses domain boundaries. The network operators in your data center can't see traffic once it leaves for AWS. AWS Cloud Trail shows API activity in AWS but not what happens when that workload talks to an on-premises database.
Inconsistent identity systems compound the problem. Your on-premises systems might use Active Directory. AWS workloads might use IAM roles. Kubernetes uses service accounts. When an attacker moves from one domain to another, they need to establish new credentials in that domain. But because identity systems are decoupled, it's easy for defenders to lose track of the attacker's path.
Inconsistent monitoring tools are inevitable in hybrid environments. Organizations use native tools: Active Directory audit logs, AWS Cloud Trail, Kubernetes audit logs, cloud security posture management tools. Each tool provides data in different formats, with different retention periods, different search capabilities, and different query languages. Correlating across tools is painful.
Architectural assumptions that break are probably the worst part. A system designed for on-premises environments might assume that internal network traffic is trustworthy. But in a hybrid world, internal traffic crosses the internet. Systems designed for cloud environments might assume resources are ephemeral and identities are short-lived. But in hybrid environments, on-premises systems might keep the same identities for years.
Building observability across these domains requires:
-
Centralized data collection: Aggregate logs and metrics from all domains into a central location (could be a cloud service or on-premises infrastructure). Use standardized formats and ensure consistent timestamps.
-
Identity unification: Create mappings between identity systems so that you can track a user or service across domain boundaries. This is harder than it sounds when identity systems have different lifecycles and different permission models.
-
Behavioral baselining across domains: Understand normal behavior within each domain and across domain boundaries. An internal-only system might have completely different traffic patterns than a system that regularly communicates across domains.
-
Incident response coordination: Design IR processes that account for multi-domain scope. An attack might start in on-premises but move to cloud, requiring coordination between teams that typically operate separately.
Organizations that successfully implement hybrid observability gain significant competitive advantages in incident detection and response. They can track attackers across infrastructure boundaries and contain threats before they spread across the entire environment.
The investment is substantial, but so is the risk of not doing it. Hybrid attacks—where the attacker exploits inconsistent monitoring to move between domains—are increasingly common. And they're hard to detect if you're only monitoring within single domains.
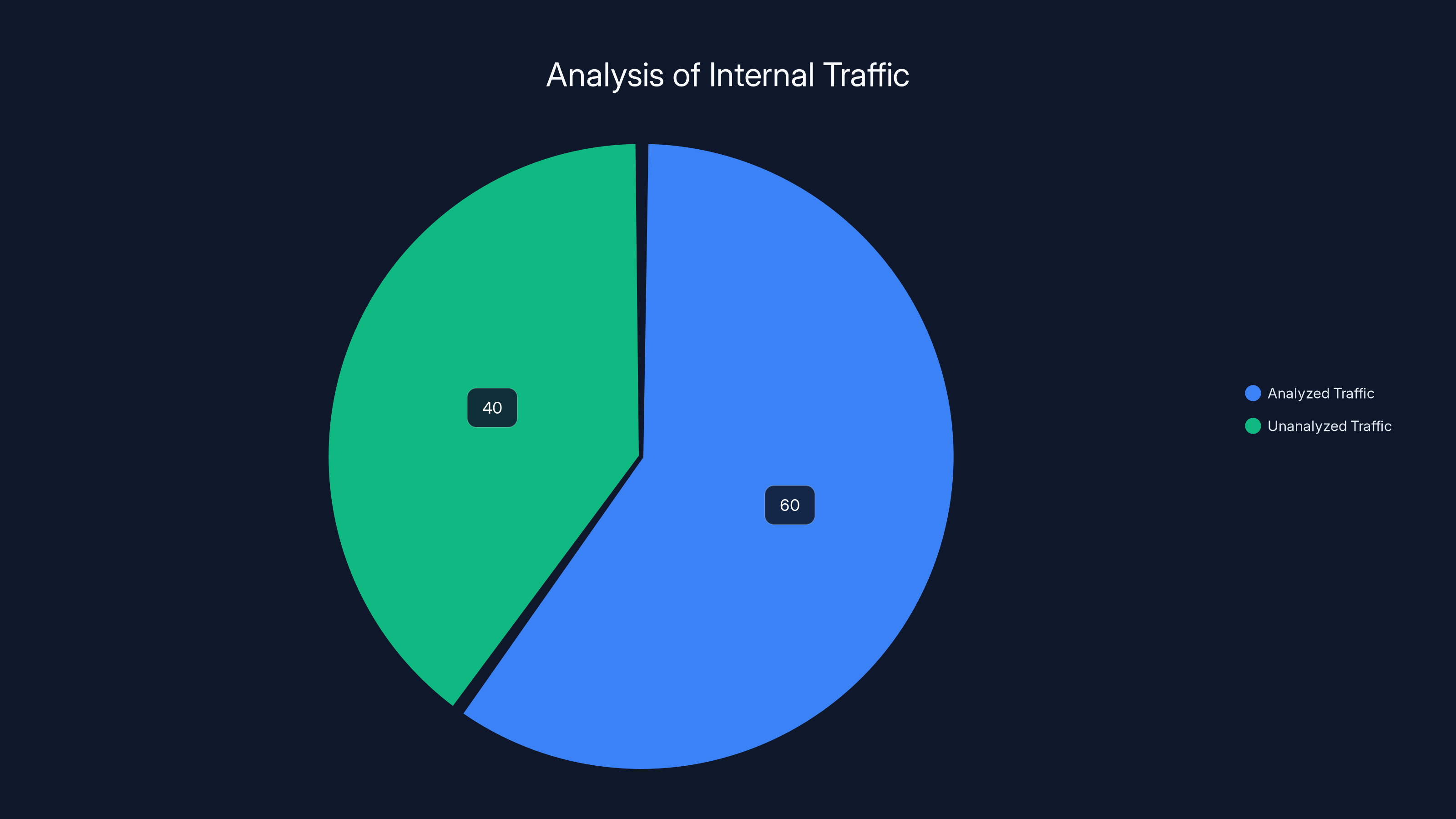
An estimated 40% of internal traffic remains unanalyzed due to lack of context, highlighting a significant gap in network monitoring capabilities.
AI and Machine Learning: Scaling Threat Hunting Beyond Human Limits
Here's the reality: there aren't enough skilled threat hunters to manually hunt threats in every organization. The human time required to analyze terabytes of log data and network traffic simply doesn't scale.
Machine learning changes that equation. ML can process vast quantities of data, identify patterns humans would miss, and flag the tiny percentage of data worth human attention.
But here's what's important: ML doesn't replace threat hunters. It amplifies them. The best security programs use ML to do what computers are good at (processing massive datasets and identifying anomalies) and reserve human analysts for what humans are good at (understanding context, reasoning through complex scenarios, and making judgment calls).
ML's role in observability includes:
Unsupervised anomaly detection identifies unusual patterns without needing predefined rules. The system learns what normal behavior looks like, then flags significant deviations. This works well for detecting novel attacks that don't match known signatures.
Supervised classification learns from labeled examples (attack vs. normal activity) to classify new activities. This is more accurate than unsupervised approaches but requires training data.
Behavioral clustering groups similar activities together, making it easier to spot when a user or system behaves differently from peers in similar roles.
Predictive modeling forecasts future behavior based on historical patterns. If a system never accessed a particular data store before, and suddenly attempts access, that's a strong signal of compromise.
The challenge with ML in security is the false positive problem. ML systems can generate predictions at massive scale, but if 90% of those predictions are false positives, you haven't solved the alert fatigue problem—you've made it worse.
Effective ML-based observability addresses this through:
- Ensemble methods combining multiple ML models to reduce individual model biases
- Confidence scoring so analysts know which predictions to trust
- Feedback loops where analyst feedback on predictions continuously improves the models
- Human-in-the-loop design where the system asks for clarification on borderline cases rather than making binary decisions
Organizations should expect ML-based observability tools to require 6-12 months of tuning before they reach optimal effectiveness. That's not a flaw—it's a feature. It means the system is learning your environment and adapting to your specific threat landscape.
Once tuned, ML-enabled observability delivers remarkable improvements in threat detection speed and accuracy. Analysts report that they can investigate more threats with higher confidence, and the most dangerous attacks (which generate unusual but subtle signals) are caught earlier.

Response and Containment: Making Observability Actionable
Observability without action is just data. Real value comes from observability that enables rapid response and containment.
When a threat hunter identifies evidence of compromise through observability, the next step is containment. This is where most organizations struggle.
Typical containment happens like this:
- Analyst identifies compromised system
- Analyst notifies operations/infrastructure team
- Operations team reviews the alert and understands the issue
- Operations team isolates the system (hopefully)
- Meanwhile, the attacker may have already moved to other systems
This manual process is slow. Even if each step takes only 30 minutes, you've lost two hours where the attacker can keep moving.
State-of-the-art observability enables automated or semi-automated response:
Automated isolation immediately blocks network traffic to/from compromised systems before notifying teams. The system continues to collect data (for forensics) but cannot spread infection or exfiltrate data.
Hunting-informed automation uses the security graph to identify all potentially-exposed systems and preemptively isolates those too, not just the confirmed-compromised system.
Staged automation with human approval gates provides automation for common scenarios (isolate endpoint, revoke credentials, block IPs) but requires human approval for more invasive actions.
Automated investigation instantly collects additional data from other systems to understand the scope of compromise (which accounts were accessed, which data was touched, which other systems might be affected).
The key is that this happens in seconds or minutes, not hours. By the time senior leadership is notified, the active threat has already been contained. Remaining work is forensic analysis and recovery, not crisis response.
Organizations using orchestrated response (observability + automated action) see containment times drop from hours to minutes. The difference in breach impact is enormous. A threat contained in 15 minutes versus a threat that spreads for two hours is the difference between a minor incident and a catastrophic breach.
Implementing automated response requires trust. Security teams need to be confident that the observable system is accurately identifying compromises. This comes back to the earlier points about reducing false positives through correlation and context. If automation is going to block network access (affecting business operations), it needs to be very confident in its detections.
The approach is to start conservative:
- First implement automated data collection on suspected compromise. Gather forensic data automatically.
- Then implement notification acceleration. Immediately notify relevant teams instead of waiting for manual validation.
- Then implement reversible actions. Reset credentials, force reauthentication, but don't isolate systems yet.
- Finally implement containment only after systems are tuned and confidence is high.
Organizations that successfully implement this progression see dramatic improvements in their ability to contain threats before they become crises.
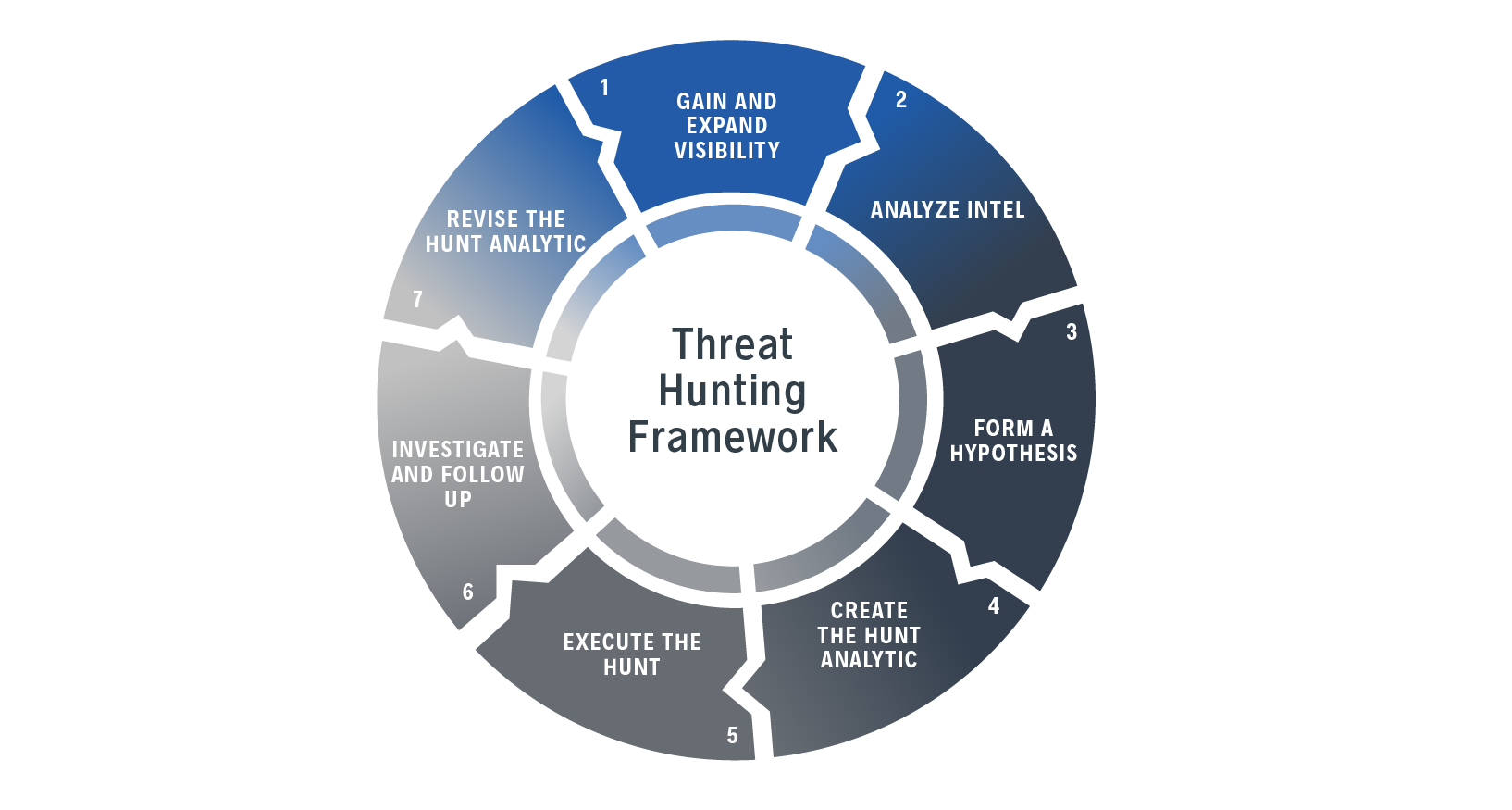
Building an Observability Practice: Roadmap and Implementation
Observability isn't something you buy. It's something you build.
Vendors will tell you that their product is the observability solution. What they really mean is that their product is a tool that can contribute to observability if properly implemented. Real observability is the outcome of combining multiple tools, processes, and organizational capabilities.
Here's a realistic roadmap for building observability:
Phase 1: Assess Current State (Weeks 1-4)
Start by understanding what visibility you already have. Audit your existing tools:
- What data sources are you currently collecting? (Endpoint logs, network logs, cloud API logs, application logs, identity events)
- What's the retention period for each data source?
- How quickly can you search and query these sources?
- How well do these sources correlate?
- What blind spots exist? (Which systems or domains have no monitoring)
Document the gaps. Where is monitoring thin? Where are there blind spots?
Phase 2: Define Use Cases (Weeks 5-8)
Observability shouldn't be built for its own sake. Define specific security use cases that observability will enable:
- "Detect lateral movement within 15 minutes of initial system compromise"
- "Identify which systems a compromised account accessed"
- "Detect privilege escalation attempts across the environment"
- "Track data exfiltration patterns"
For each use case, define what data would be needed and what patterns would indicate compromise.
Phase 3: Close Critical Gaps (Weeks 9-20)
Prioritize data collection gaps by security impact. Typically:
- Start with identity and access events (easiest to implement, highest value)
- Add endpoint monitoring for critical systems
- Add network monitoring for traffic between high-value systems
- Add cloud API logging and application monitoring
Don't try to get everything at once. Pick the highest-impact gaps and close them first.
Phase 4: Implement Correlation and Context (Weeks 21-36)
Once data is being collected, build correlation rules and context. This is where you create the security graph:
- Map user-to-system access patterns
- Map system-to-system communication patterns
- Create behavioral baselines for critical systems
- Define risk scores based on system criticality and data sensitivity
Phase 5: Operationalize Threat Hunting (Weeks 37+)
Once observability infrastructure exists, staff threat hunting. Threat hunters use the observability infrastructure to proactively search for evidence of compromise.
Start with documented attack patterns (from threat intelligence, incident history, industry reports). Have hunters search for evidence that these patterns are occurring in your environment. As hunters gain experience, they expand investigations to novel patterns.
This roadmap typically takes 6-12 months for a mature implementation. But value starts accruing earlier. By Phase 3, you should already be seeing improvements in detection capabilities.
Budget expectations vary widely based on environment size and existing infrastructure, but a typical mid-sized organization should expect:
- Tooling and infrastructure: 2M (often can be built on cloud infrastructure for lower upfront costs)
- Personnel: 3-5 security engineers to implement and maintain, plus 2-3 threat hunters for operations
- Ongoing operational costs: $100-300K annually for cloud infrastructure, training, and tool licenses
The ROI is strong though. Organizations that successfully implement observability report:
- 50-80% reduction in incident response time
- 60-90% reduction in false positive investigation load
- Earlier detection of threats (dwell time drops from weeks to days)
- Better prioritization of security investments based on actual threat evidence
- Improved security culture as teams gain evidence-based confidence in their detection capabilities

Observability and Compliance: Alignment as a Side Effect
Here's a pleasant surprise: observability that's built for threat detection also satisfies many compliance requirements.
Regulatory frameworks like HIPAA, PCI-DSS, SOX, and GDPR all require organizations to log and monitor access to sensitive data and critical systems. They require demonstration of detective controls. They require rapid notification of breaches.
Observability infrastructure naturally provides these capabilities:
- Comprehensive logging (required for compliance) feeds threat detection
- Access monitoring (required for compliance) enables behavioral analysis
- Audit trails (required for compliance) provide the data for forensic investigation
- Incident response playbooks (required for compliance) leverage the observability infrastructure
Organizations that build observability for security purposes find that compliance becomes much easier. The data is already being collected and retained. The systems for alerting on suspicious activity are already in place. The incident response processes are already operational.
In fact, organizations that treat observability as a compliance checkbox tend to do it poorly. They collect data just to satisfy the requirement, without thinking about whether that data actually helps with threat detection. Organizations that build observability for threat hunting find that compliance falls out naturally as a side effect.
This creates a virtuous cycle: security investment drives better threat detection, which naturally improves compliance posture. Leadership funding security initiatives sees both security and compliance benefits.

The Future of Observability: Where the Field Is Heading
Observability as a security discipline is still relatively young. The field is evolving rapidly, and several trends are emerging:
Autonomous threat hunting is the direction AI research is moving. Instead of threat hunters asking questions of the data, AI systems proactively hunt for threats using hypotheses generated from threat intelligence. The human threat hunter becomes more of a supervisor who validates findings and decides on response, rather than someone doing manual investigation.
Real-time response is moving from theoretical to practical. Current observability systems detect threats within seconds or minutes. Response lags by hours. The goal is to close that gap: detect and contain in real-time, with human oversight.
Supply chain observability is becoming critical. Breaches increasingly come through compromised vendors and dependencies. Organizations are building observability that extends beyond their own infrastructure to track behavior of vendors, third-party code, and dependencies.
Cross-organization threat sharing is improving. Industry information sharing organizations are making it easier for organizations to share threat intelligence and observability insights. Better threat intelligence means better threat hunting hypotheses.
Decentralized observability for managed services and serverless architectures is an ongoing challenge. As workloads become more ephemeral and distributed, traditional observability approaches break down. New approaches are needed.
The organizations that invest in observability infrastructure now are building competitive advantages that will last for years. Early adopters will have mature threat detection capabilities while laggards are still struggling with alert fatigue.
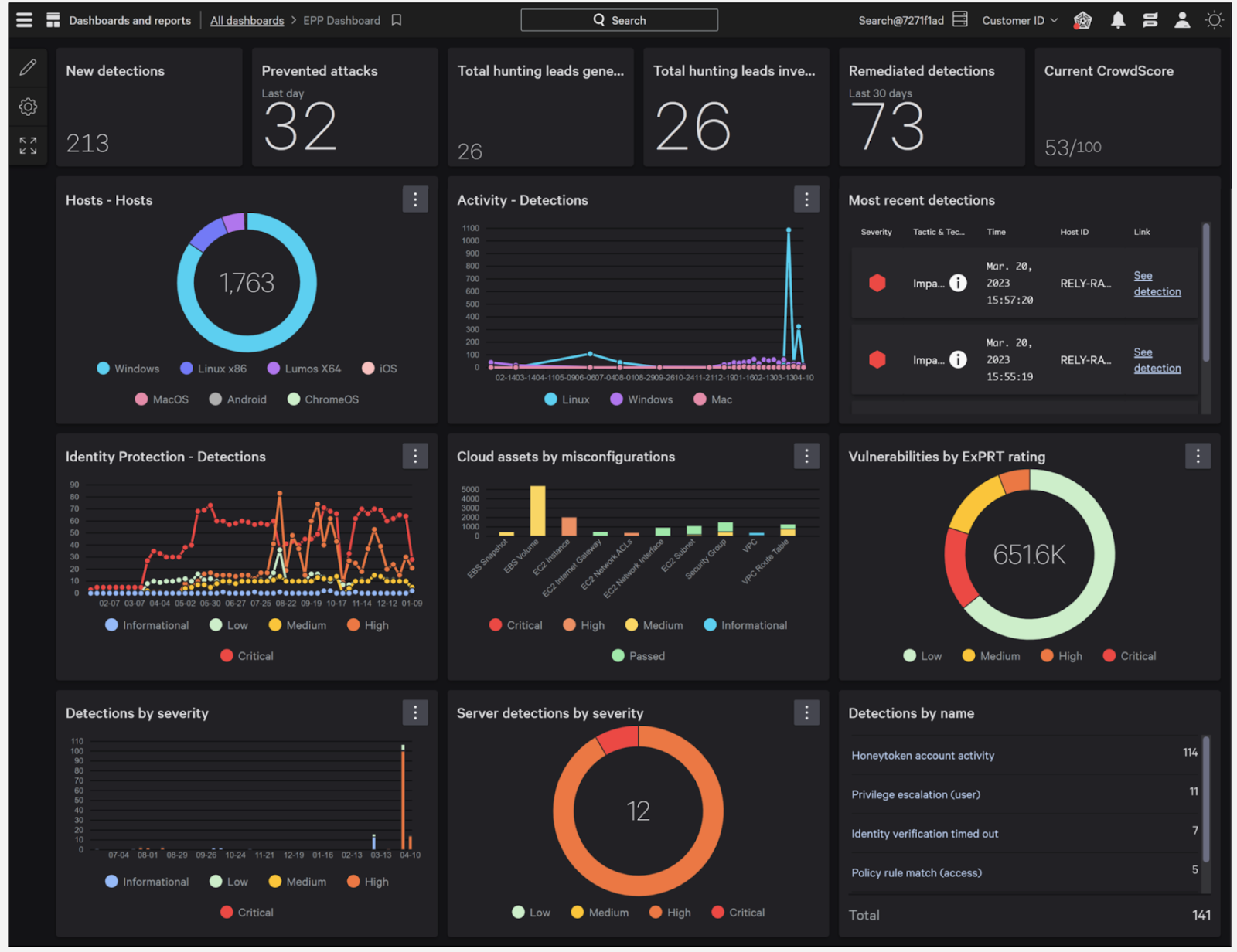
Putting Observability Into Practice: Starting Points
Let's get concrete. If you're responsible for security at your organization and you want to implement observability, where do you start?
Week 1: Audit existing tools Make a list of every security tool you have. For each one, document: what data it collects, how long data is retained, how quickly it can be searched, whether it integrates with other tools.
Week 2-3: Identify gaps Based on the tools you have, identify what data you're missing. Is endpoint activity monitored? Is cloud activity monitored? Are internal network flows monitored? Where are the blind spots?
Week 4: Calculate impact For each gap, estimate the business impact if that area was compromised. Focus on high-impact gaps first.
Week 5: Build a business case Determine what data collection and tools would be needed to close the highest-impact gaps. Get cost estimates. Calculate the potential cost of a breach in those areas (use breach cost calculators based on your industry). Present the ROI to leadership.
Weeks 6+: Pilot and expand Start with the highest-priority gaps. Pilot new tools or data sources. Build correlation rules and alert thresholds. Once you have a working pilot, expand to the next priority.
For teams looking to create detailed roadmap documents, implementation plans, or breach impact assessments, Runable offers AI-powered document generation that can help teams create comprehensive security strategy documents quickly. At $9/month, it's a cost-effective way to accelerate security documentation and planning.

The Human Element: Team Composition and Skills
Observability is technology, but it's also human. You need the right people with the right skills.
Traditional security operations centers are staffed with alert responders: junior analysts who respond to alerts generated by detection systems. These roles are important but are being increasingly automated. The future security team needs different skillsets.
Threat hunters need deep knowledge of attacker techniques, good intuition about what attacks look like in data, and comfort with ambiguity. They're comfortable asking questions that don't have obvious answers. They follow leads.
Detection engineers need software engineering skills and security knowledge. They build the detection rules, correlation logic, and alert systems that feed threat hunters. They work at the intersection of security and engineering.
Security engineers work on infrastructure and tooling. They make sure observability systems are scalable, reliable, and integrated with incident response workflows.
Data analysts understand how to work with large datasets, build queries, and create visualizations that help analysts understand what the data is saying.
Incident responders take the findings from threat hunters and execute the response. They need deep knowledge of system architecture, incident response procedures, and evidence handling.
Organizations don't need to hire all of these roles at once. Start with threat hunters and one security engineer. As you mature, add roles based on bottlenecks.
The big challenge is finding people with threat hunting skills. This is a high-demand, relatively scarce skillset. Options:
- Hire experienced threat hunters from larger organizations (expensive)
- Train existing security staff in threat hunting (takes time but leverages existing knowledge of your environment)
- Partner with external threat hunting firms (expensive but can be good short-term while building internal capabilities)
- Hire threat intelligence analysts and train them in threat hunting (related skillset)
Most organizations do a combination of these.
FAQ
What is observability in the context of security?
Observability in security is the ability to ask arbitrary questions about your systems and get answers that help you understand attacker behavior and detect threats. It goes beyond traditional monitoring by providing behavioral context, relationships between systems, and historical data that enables threat hunters to proactively search for evidence of compromise rather than just reacting to alerts.
How does observability differ from traditional SIEM?
Traditional SIEM systems collect logs and provide alerting based on predefined rules. Observability requires those capabilities plus behavioral baselines, behavioral analysis, correlation across multiple data sources, and the ability to run ad-hoc queries that answer arbitrary questions about system behavior. A SIEM is a tool for alert generation. Observability is the broader capability of understanding what's happening in your environment.
What data sources are essential for observability?
The essential data sources are identity and access events (who accessed what), endpoint activity (processes, file access, network connections), network traffic (especially east-west internal traffic), and cloud API calls. Additional sources like application logs and database access logs become valuable once the basics are in place. The exact mix depends on your threat landscape and architecture.
How long does it take to implement observability?
A basic observability infrastructure (identity and access logging, endpoint monitoring, some correlation) can be implemented in 3-6 months. A mature implementation with behavioral baselines, threat hunting operations, and automated response takes 12-18 months. The timeline depends heavily on your existing infrastructure and how much data you're already collecting.
How much does observability cost?
Costs vary widely based on environment size, existing tools, and whether you build in-house or use vendor solutions. A typical mid-sized organization might spend
Can observability be implemented gradually?
Absolutely. The recommended approach is to start with the highest-impact gaps and build observability incrementally. Start with identity and access monitoring, then add endpoint monitoring, then network monitoring. Each phase provides immediate value and informs what to focus on next. This approach is less risky and easier to fund than trying to implement everything at once.
What's the relationship between observability and threat hunting?
Observability is the foundation that makes threat hunting possible. Threat hunters use observability infrastructure (comprehensive logging, behavioral baselines, correlation systems) to proactively search for evidence of attacks that haven't yet triggered alerts. Threat hunting requires observability, but observability alone doesn't constitute threat hunting—you also need skilled analysts asking the right questions.
How does observability help with incident response?
Observability enables faster incident response by providing immediate context about compromise scope (which systems were accessed, which data might be exposed, which other systems are at risk), speed of investigation (analysts can correlate signals across data sources instead of manually tracing attack paths), and speed of containment (security graph and observed attack paths inform which systems need immediate isolation). These improvements can reduce incident response time from days to hours.
What's the biggest challenge in implementing observability?
The biggest challenge isn't technical—it's organizational. Observability requires cross-team coordination (security, infrastructure, cloud operations), sustained investment over many months, skilled personnel who are in high demand, and a commitment to threat hunting as an ongoing practice rather than a project. Organizations that successfully implement observability typically have strong executive sponsorship and clear security strategy.
How does observability reduce false positives?
Observability reduces false positives by providing context for alerts. An isolated alert might look suspicious—an unusual login, for example. But when correlated with other context (is the user accessing normal systems, is the login pattern consistent with their history, are other accounts from the same user doing normal things), the same alert might be clearly benign. Observability systems use this context to deprioritize low-confidence alerts so analysts focus on high-confidence threats.
Conclusion: Why Observability Is No Longer Optional
The security landscape has shifted fundamentally. Attackers no longer try to avoid detection entirely. Instead, they're banking on the reality that defenders can't see everything, that analysts are overwhelmed by noise, that once they're inside, they can move slowly and quietly until they find what they want.
Traditional security approaches—prevention-focused, alert-driven, reactive—are failing at scale. Organizations are collecting thousands of alerts daily and missing the actual attacks. Security teams are burning out chasing false positives. Breaches are reaching critical severity because lateral movement goes undetected for days or weeks.
Observability changes the game. Not by collecting more data—we already have too much data. But by making sense of the data we have, revealing patterns humans can't see, and enabling threat hunters to proactively search for evidence of compromise.
The best-defended organizations today share a common characteristic: they have strong observability. They can see how their systems are behaving. They understand normal activity well enough to detect abnormal activity. They can track attackers as they move through the network. They can contain threats in hours instead of weeks.
Building observability isn't trivial. It requires investment in tools and infrastructure. It requires skilled personnel. It requires organizational commitment. But for any organization handling sensitive data or operating critical systems, it's not optional. It's the foundation of modern security.
The threat landscape isn't getting easier. Attackers are getting more sophisticated, patient, and resourceful. The defenders who win are the ones who can see what's happening in their environment and act faster than attackers can adapt. Observability is what makes that possible.
Start somewhere. Audit your existing visibility. Identify your biggest gaps. Pick the highest-impact one and close it. Then iterate. Build observability not as a project but as an ongoing practice. Hire and develop threat hunters. Make threat hunting core to your security operations.
The breach that changes your organization isn't the one you see coming. It's the one that creeps in quietly while you're not watching. Real observability means you're always watching. You won't catch every attack, but you'll catch the ones that matter before they become crises.
That's what separates leading security organizations from the rest: not more tools, but better visibility. Not more alerts, but clearer signals. Not more data, but smarter analysis. That's observability.

Key Takeaways
- Observability is foundational to modern threat detection—traditional prevention-only security leaves attackers free to move laterally once inside
- Alert fatigue (2,000+ daily alerts) cripples security teams; real observability reduces noise through context and correlation, not more data
- Lateral movement attacks succeed because 40% of internal traffic lacks meaningful context; security graphs solve this by mapping system relationships
- Threat hunting requires observability infrastructure; alert-driven security and proactive hunting are complementary, not competing approaches
- Organizations implementing observability report 50-80% faster incident response times and earlier detection of sophisticated attacks
Related Articles
- VoidLink: The Advanced Linux Malware Reshaping Cloud Security [2025]
- N8n Ni8mare Vulnerability: What 60,000 Exposed Instances Need to Know [2025]
- Ingram Micro Ransomware Attack: 42,000 Affected, SafePay Claims Responsibility [2025]
- Malicious Chrome Extensions Spoofing Workday & NetSuite [2025]
- How to Disable Chrome's On-Device AI Scam Detection [2025]
- Cisco CVE-2025-20393 Critical Vulnerability Finally Patched [2025]

