![Wikipedia AI Licensing Deals: How Big Tech Is Paying for Knowledge [2025]](https://tryrunable.com/blog/wikipedia-ai-licensing-deals-how-big-tech-is-paying-for-know/image-1-1768491420194.jpg)
Introduction: When Free Knowledge Becomes Expensive
For over two decades, Wikipedia operated on a simple promise: the world's largest encyclopedia, entirely free and written by volunteers. But something shifted in late 2024 and early 2025 that forced the Wikimedia Foundation to confront an uncomfortable reality: the companies training the most sophisticated AI systems on the planet were extracting billions of dollars' worth of curated knowledge without contributing a dime.
Then came Thursday's announcement that changed everything. The Wikimedia Foundation revealed that it had signed commercial licensing agreements with Microsoft, Meta, Amazon, Perplexity AI, and Mistral AI. These weren't small deals negotiated quietly—they represented the foundation getting nearly every major player in the AI industry to flip a switch from free scraping to paid access. Google had already signed in 2022. Now the dominoes were falling.
What makes this moment significant isn't just that Wikipedia is finally getting paid. It's that the entire economics of AI training are shifting. For years, the AI boom was built partly on a foundation of free data. Wikipedia articles, open-source datasets, scraped web pages—all of it fueled the training of models that are now worth hundreds of billions of dollars. But that free ride is ending, and the implications ripple across every part of the AI ecosystem.
This shift matters for several reasons. First, it establishes a precedent: companies training AI models should pay for valuable training data. Second, it threatens to make AI development more expensive at a moment when margins are already razor-thin for startups. Third, it raises fundamental questions about who owns knowledge, how it should be monetized, and whether current licensing models are even sustainable.
In this comprehensive guide, we'll walk through the Wikipedia licensing deals from multiple angles: what they mean financially, how they change AI development, what they reveal about the future of knowledge as a commodity, and why this moment might be a turning point for how we think about data, copyright, and AI.
TL; DR
- Major AI Companies Now Paying: Microsoft, Meta, Amazon, Perplexity, and Mistral AI signed paid licensing deals with Wikimedia Enterprise, joining Google from 2022
- The Scale of the Problem: Wikipedia bandwidth usage for bot downloads grew 50% from January 2024 to April 2025, with bots accounting for 65% of the most expensive infrastructure requests
- Financial Pressure: The nonprofit foundation faces rising infrastructure costs and discovered that 27% of traffic was actually automated scrapers, not human visitors
- The Precedent Being Set: Wikipedia's move establishes that AI training data has real monetary value and companies should pay for access rather than scrape for free
- What's at Stake: If major AI companies are now paying Wikipedia, what about smaller news outlets, artists, and other content creators whose work trains these same models?

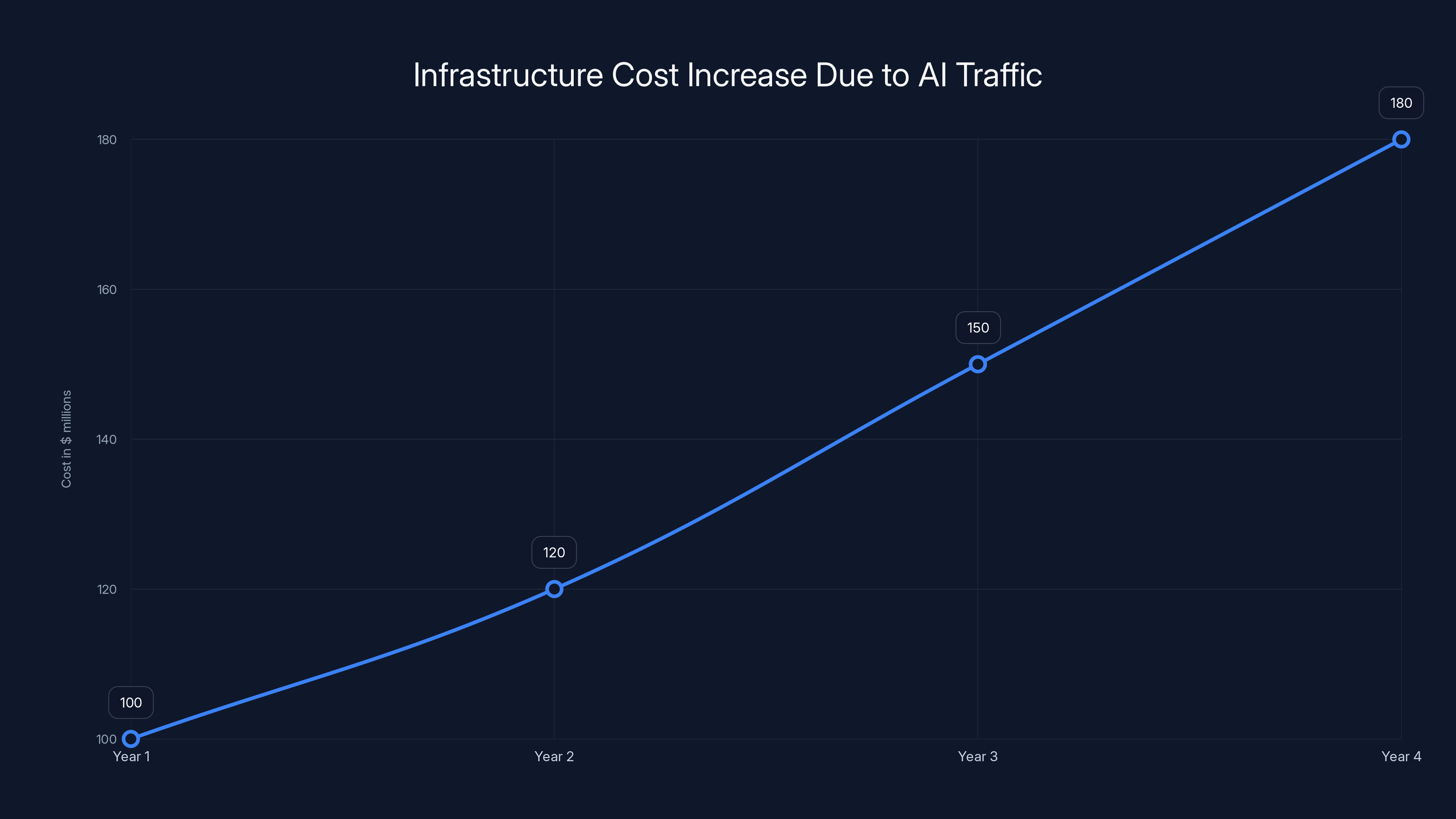
Estimated data shows a significant increase in Wikimedia's infrastructure costs due to AI-related traffic, with a projected rise from
The Economics of Free Knowledge in the AI Era
For most of Wikipedia's existence, the word "free" was sacred. Free to read. Free to edit. Free from corporate influence. The foundation's business model was straightforward: ask readers for donations, keep servers running, and let volunteer editors do the work.
This model held steady for years. Yes, servers cost money, but Wikipedia's infrastructure needs were modest compared to commercial platforms. A few million dollars a year in donations could keep everything running. The foundation even had a certain purity to it: they didn't sell user data, they didn't run ads, they didn't compromise on their mission.
But then something changed around 2022 and 2023. AI companies started scraping Wikipedia at an industrial scale. Not individual articles. Not even batches of thousands. We're talking about automated systems that would pull down massive chunks of the entire encyclopedia, every word, every reference, every data point. These bots would hammer Wikipedia's servers constantly, looking for new updates, changed passages, entire rewrites.
The foundation didn't realize how bad it was getting until they looked at the numbers. In April 2025, they published a report that stopped people in their tracks: bandwidth used for downloading multimedia content had surged 50 percent in just 16 months. That's not gradual growth. That's explosive. And most of it came from bots.
Worse, these weren't bots that identified themselves clearly. They were designed to evade detection. When the foundation finally updated its bot-detection systems and analyzed traffic patterns properly, they discovered something sobering: roughly 27 percent of what appeared to be human visitors were actually automated scrapers. The real number of humans visiting Wikipedia had actually fallen about 8 percent year-over-year.
Think about what that means for a moment. Wikipedia's core feedback loop—readers visit, some become donors or editors, content improves—was breaking down. Humans were leaving. Bots were multiplying.
Meanwhile, the infrastructure costs kept climbing. Every bot request that downloads Wikipedia content consumes bandwidth, CPU cycles, and storage. That's not free. Someone has to pay for it. And until recently, that someone was entirely the nonprofit foundation, funded by small donations from a tiny fraction of Wikipedia's users.
So when you do the math, it's clear: companies worth hundreds of billions of dollars were using Wikipedia content to train models that generate enormous economic value, and Wikipedia was essentially eating the infrastructure costs. It's as if someone showed up at your restaurant, ate meals for free every single day, and then went out and made billions of dollars partly because of how good the food was. And you still haven't covered payroll.
That's the economic paradox that created the pressure for licensing deals in the first place.
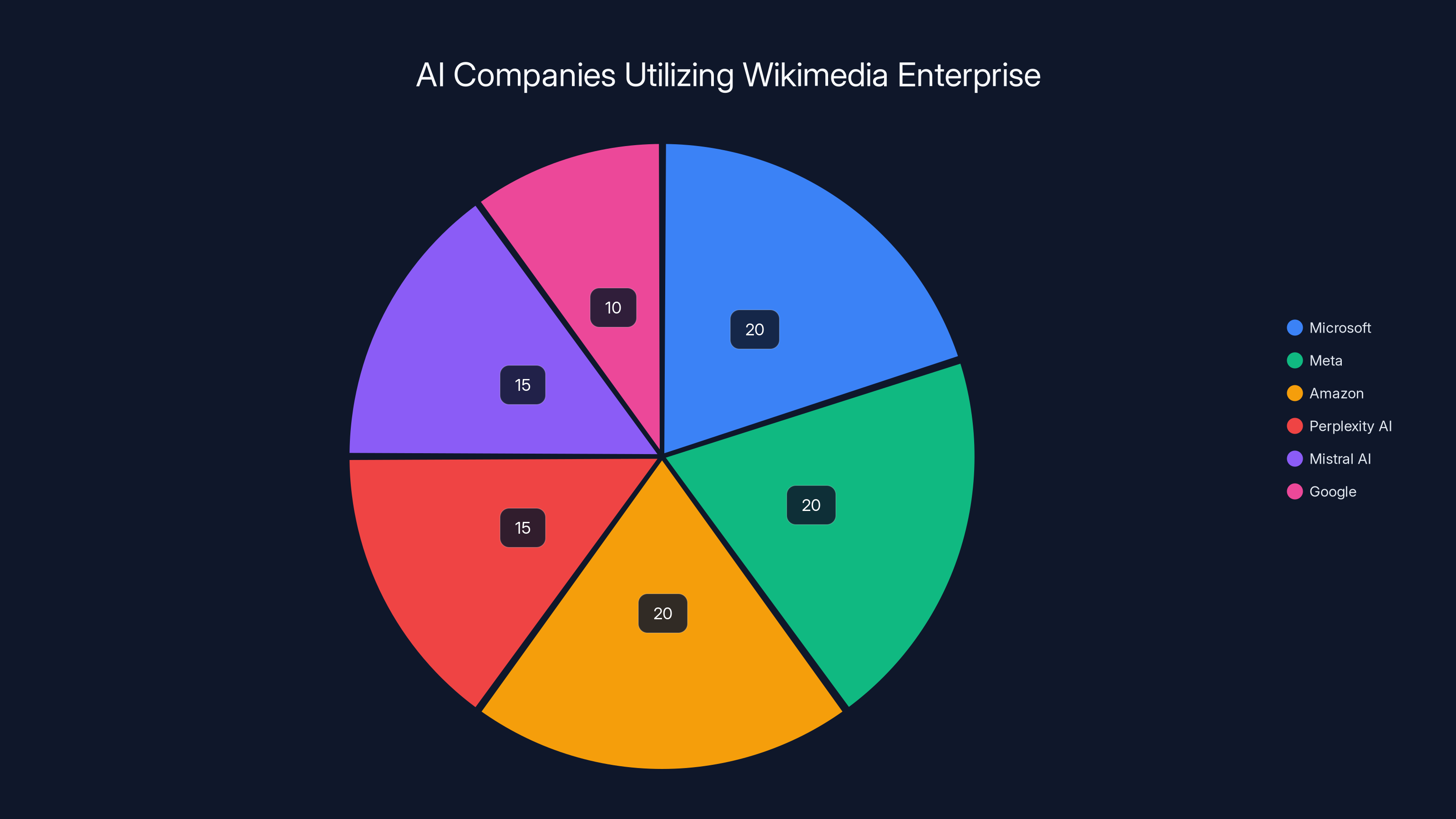
The chart illustrates the distribution of major AI companies utilizing Wikimedia Enterprise for high-volume data access. Microsoft, Meta, and Amazon each represent 20% of the major users.
Understanding the Wikimedia Enterprise Model
Wikimedia Enterprise isn't Wikipedia. That's an important distinction that often gets muddled in coverage. Wikipedia remains free, open, and available to everyone. Wikimedia Enterprise is a separate commercial subsidiary created specifically to sell API access to Wikipedia's content to large organizations.
The difference matters because the free Wikipedia API still exists. Anyone can still build applications on top of Wikipedia. Students can still research. Nonprofits can still access content. The philosophical core of Wikipedia—free knowledge for everyone—remains intact.
But Wikimedia Enterprise offers something different. It's essentially a premium tier. Instead of the standard Wikipedia API with its rate limits and modest bandwidth, Wikimedia Enterprise provides:
- Higher API speeds: Faster response times for data retrieval
- Larger bandwidth allowances: Ability to download more data simultaneously
- Higher volume access: Permission to query the API far more aggressively
- Enhanced documentation: Better integration guides and support
- Priority processing: Your requests get processed before generic free API requests
- Direct support: Contact someone at Wikimedia if something breaks
For a startup or small company, the free API is fine. They don't need massive bandwidth. For an AI company training models on Wikipedia's 65 million articles, the free API would take forever. You'd be constantly hitting rate limits. Your training pipeline would stall. That's where Wikimedia Enterprise comes in.
The foundation didn't invent this model from scratch. Google signed the first major deal in 2022, proving that large tech companies would pay. Since then, the foundation has also brought on smaller players like Ecosia (the privacy-focused search engine), Nomic (an open-source data company), Pleias, Pro Rata, and Reef Media.
But the announcements in January 2025 were different. These were the mega-companies that power AI. Microsoft has Copilot and deep investments in AI. Meta is pushing Llama. Amazon has AWS and Q. Perplexity is a search startup that explicitly uses AI to synthesize information. Mistral is Europe's answer to Open AI. If these companies are all signing up, it signals that paid licensing for training data is becoming the norm.
Lane Becker, president of Wikimedia Enterprise, put it plainly: "It took us a little while to understand the right set of features and functionality to offer if we're going to move these companies from our free platform to a commercial platform. But all our Big Tech partners really see the need for them to commit to sustaining Wikipedia's work."
That language is interesting. Not "commit to Wikipedia's mission" or "commit to supporting open knowledge." Commit to sustaining the work. It's acknowledging a reality: if Wikipedia stops running, these AI companies lose access to 65 million articles of carefully curated, fact-checked, sourced knowledge. They can't replace it. They need Wikipedia to exist.
The Scale of Infrastructure Costs and Why They Matter
Most people have no idea how expensive it is to run Wikipedia. The Wikimedia Foundation is a nonprofit, so they publish financial reports. In recent years, they've spent roughly $100+ million annually across all their projects. That's not enormous by tech standards, but for a nonprofit funded by donations, it's substantial.
Infrastructure itself is a major piece: servers, bandwidth, storage, redundancy, backups, security, maintenance. Wikipedia needs to be up 24/7. It needs to handle traffic spikes. It needs to keep data safe. It needs to process millions of edits. That infrastructure has a real cost.
Now add in what's happened since AI boomed. When a bot downloads Wikipedia's entire database to train an AI model, that's:
- Bandwidth cost to transfer the data
- Computational cost to serve those requests
- Storage cost because the bot is constantly checking for updates
- Network overhead from the sheer volume of requests
Say a major AI company downloads Wikipedia data once a month. That's one large spike in infrastructure usage. But multiple companies downloading continuously, running bots that check for updates daily or hourly, and other AI companies training different models? You're looking at a massive, sustained increase in infrastructure load.
The 50 percent increase in multimedia bandwidth in 16 months is just one metric, but it shows the scale of the problem. And it's growing. As more AI models train on Wikipedia, as competition in AI intensifies and companies want the latest data, that bot traffic will likely keep climbing.
Without licensing deals and revenue from Wikimedia Enterprise, the foundation would have to either:
- Cut costs by reducing infrastructure (slower Wikipedia, less reliable service)
- Ask donors to fund the bot-driven infrastructure costs (not realistic)
- Implement stricter rate limiting and bot detection (but AI companies would just work around it)
- Start running ads or selling user data (violates Wikipedia's mission)
Licensing deals solve the problem elegantly: the companies driving the infrastructure costs pay for them. It's straightforward economics.
But there's another angle here. Wikipedia's data is incredibly valuable. Not just because it's comprehensive, but because it's human-curated and fact-checked. When you train an AI model on Wikipedia data, you're not just getting words. You're getting the collective knowledge of millions of editors who have spent decades building and maintaining articles. That curation has real value.
Wikipedia founder Jimmy Wales understands this. In interviews, he's made the point clear: if you're using our data to build billion-dollar products, you should pay. He even said he's "very happy personally that AI models are training on Wikipedia data because it's human curated." But he also said bluntly: "You should probably chip in and pay for your fair share of the cost that you're putting on us."
It's not about greed. It's about sustainability. If Wikipedia stops existing because the foundation can't afford to keep the servers running, everyone loses.
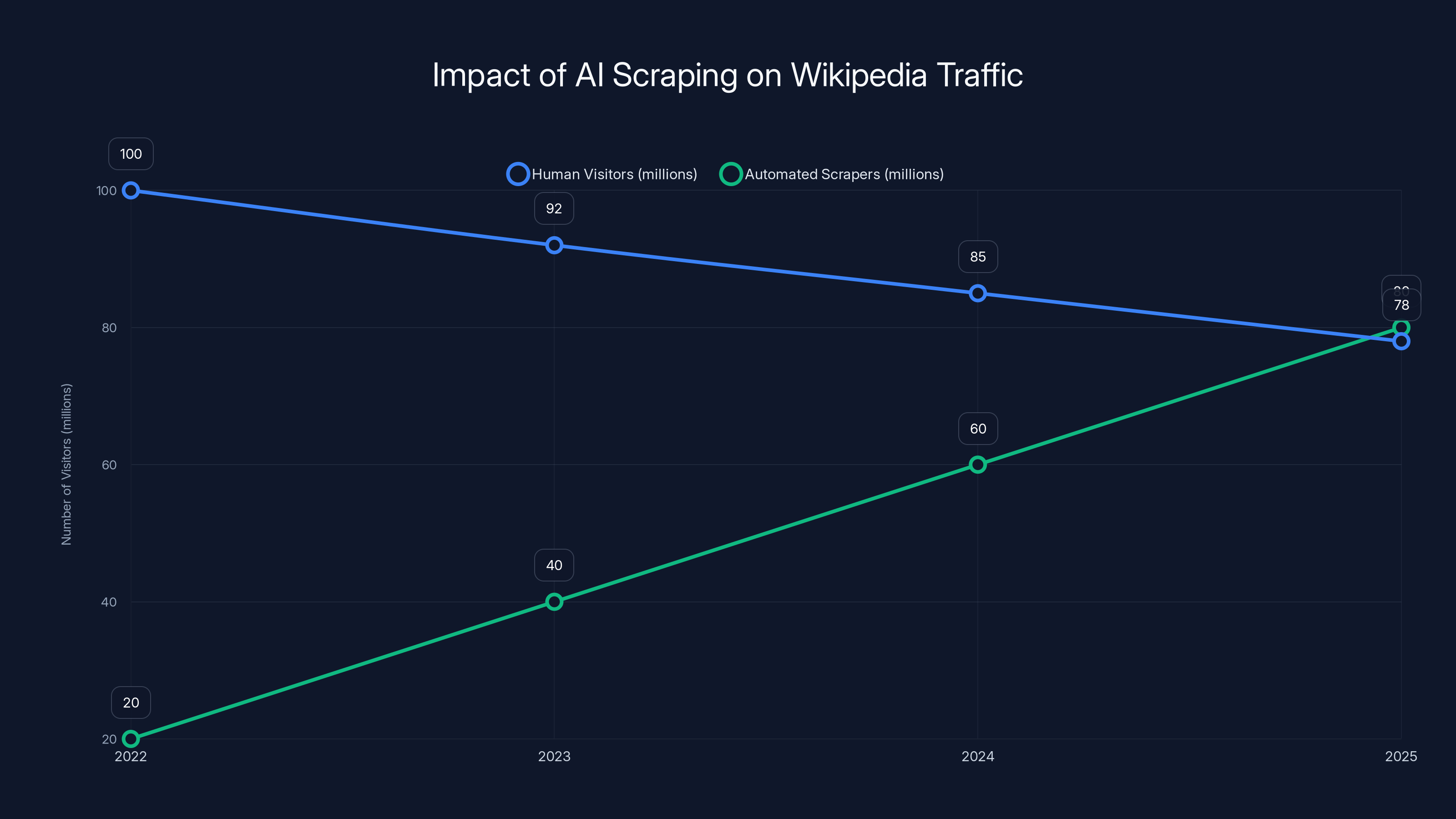
From 2022 to 2025, human visitors to Wikipedia decreased by approximately 8% annually, while automated scrapers surged, highlighting the growing impact of AI on web traffic. Estimated data.
What Wikipedia Gets from the Deals (Beyond Money)
The Wikimedia Foundation hasn't disclosed the financial terms of the deals. Microsoft, Meta, Amazon, Perplexity, and Mistral all kept quiet about what they're paying. That's typical for licensing agreements—both sides usually prefer privacy.
But the deals offer benefits to Wikipedia beyond just money. Let's think through them.
First, there's legitimacy and precedent. When Microsoft signs a licensing deal with Wikipedia, it signals to Microsoft's shareholders and competitors that Wikipedia is a valuable asset worthy of investment. That makes it easier for Wikipedia to approach other companies. It proves that the model works, that companies are willing to pay.
Second, there's the feedback loop. Companies using Wikimedia Enterprise might provide better data about which articles are most useful for AI training. They might flag errors or outdated information. They might even contribute back—some licensing deals include provisions where the company helps improve Wikipedia articles in their area of expertise. That can improve content quality.
Third, there's sustainability and momentum. Revenue from licensing deals helps the foundation plan long-term. They can invest in better infrastructure, hire more staff, improve the editing experience, and develop new tools. That strengthens Wikipedia overall.
Fourth, there's the principle. Once major companies start paying, others feel pressure to do the same. It changes the norm from "scrape for free" to "license from the source." That's significant culturally and practically.
But I want to flag something important: the foundation also paused an AI-generated article summaries pilot program in June 2024 after volunteer editors called it a "ghastly idea" and worried it could damage trust in the platform. This shows tension. While leadership welcomes revenue from AI licensing, the editors who actually build Wikipedia are more cautious about AI. They worry that AI-generated content on Wikipedia itself could confuse readers or reduce quality.
That's not a problem the licensing deals solve. That's a cultural and community challenge that Wikipedia will need to navigate separately.

The Broader Market Implications: Who Else Gets Paid?
Here's the million-dollar question: if Wikipedia is now getting paid by AI companies, what about everyone else?
Think about artists. Millions of images on the internet are used to train image generation models like DALL-E, Midjourney, and Stable Diffusion. Some of those images are copyrighted. Should artists get paid? Many say yes. Some are suing.
Think about news publishers. Perplexity AI, one of the companies signing with Wikipedia, builds its search results partly by summarizing content from news sites. Should journalists and news organizations get paid? The New York Times sued Open AI arguing they should.
Think about books. Google trained its Gemini model partly on copyrighted books. Authors say they should have been compensated.
Think about social media. Elon Musk's X (formerly Twitter) has changed its terms to charge companies for API access to posts, partly to offset the cost of bot scraping.
Wikipedia's licensing deals matter because they set a precedent. They say that if your content is valuable enough to train a major AI model, you deserve compensation. That precedent could ripple outward.
It might also create a problem. If Wikipedia can charge for licensing, and news publishers demand payment, and book authors demand payment, and artists demand payment, then the cost of training AI models goes up. That means:
- Startups training custom models have higher costs
- Big companies with large R&D budgets have an advantage over smaller competitors
- The consolidation of AI power in big tech companies accelerates
Or, companies find ways around it. They scrape more carefully to avoid licensing obligations. They train on older data that's in the public domain. They use synthetic data they generate themselves. They acquire companies with pre-existing training data.
Either way, the market for training data is changing. And Wikipedia's deals are just the beginning.
Estimated data suggests Wikipedia could earn between
The Technical Side: How Wikimedia Enterprise Works
For developers and companies actually using Wikimedia Enterprise, it's worth understanding how the technical side works.
At its core, Wikimedia Enterprise provides API access to the same Wikipedia data that the free API provides. The difference is in the terms of service and the capacity. The free Wikipedia API has rate limits: you can make a certain number of requests per second. If you exceed that, your requests get throttled. That's intentional—it prevents any single user from overwhelming Wikipedia's servers.
Wikimedia Enterprise removes or greatly increases those rate limits. A company training an AI model might need to download millions of articles, each with all their revision history, metadata, and references. With the free API, that would take weeks or months. With Wikimedia Enterprise, it might take days.
The enterprise API also likely includes better stability guarantees. If Wikipedia's infrastructure is under load, the free API gets deprioritized. Enterprise clients get priority. That matters when you're running a training pipeline that costs thousands of dollars per hour.
There might also be custom endpoints or data formats that aren't available through the free API. For example, an AI company might want access to Wikipedia data in a specific format optimized for their training pipeline, or they might want metadata about article quality and reliability.
From a technical architecture perspective, this isn't complicated. It's still the same Wikipedia data. But packaging it for commercial use requires different infrastructure: separate rate-limited pools, different authentication, better monitoring and support.
What's interesting from a business model perspective is that this doesn't require Wikimedia to change Wikipedia itself. The free version stays free. The open API stays open. They've simply created a premium tier for companies with high-volume needs.
That's actually a pretty elegant solution. It preserves the open mission while generating revenue. Not every company can do this—it requires that your product (Wikipedia) is genuinely valuable enough that some customers will pay for better access.

What Perplexity and Mistral Get from This Deal
Perplexity and Mistral are interesting players in this story because they're not as established as Microsoft or Meta, yet they still warrant licensing deals. That tells us something about how the market values them.
Perplexity is a search startup that uses AI to directly answer questions rather than returning a list of links. It's built on top of language models (initially Chat GPT, now increasingly their own models), and it relies heavily on being able to fetch and synthesize current information from the internet. Wikipedia is a natural fit—it's a curated source of reliable information that works well in a search-and-synthesis workflow.
For Perplexity, the Wikimedia Enterprise deal gives them guaranteed access to high-quality data with better performance. It also provides legitimacy. When you're a startup challenging Google's dominance in search, having licensing agreements with major content sources signals that you're serious and will respect intellectual property.
Mistral is Europe's leading AI company, often compared to Open AI but with a different approach: they've focused on smaller, more efficient models that are easier to deploy and fine-tune. Mistral's customers include governments, enterprises, and other companies building AI applications. For them, having access to high-quality training data through Wikimedia Enterprise helps them build better models and offer more value to their customers.
Both companies also benefit from the PR angle. Announcing a licensing deal with Wikipedia is positive coverage. It says "we're doing the right thing" when it comes to respecting intellectual property and supporting important institutions.
That said, I wonder about the practical implications for smaller AI companies. If Microsoft and Meta and Perplexity are all paying for Wikimedia Enterprise access, does that create pressure on everyone else to do the same? Or does the free API still suffice for most use cases? That's a question that will probably play out over the next year or two.
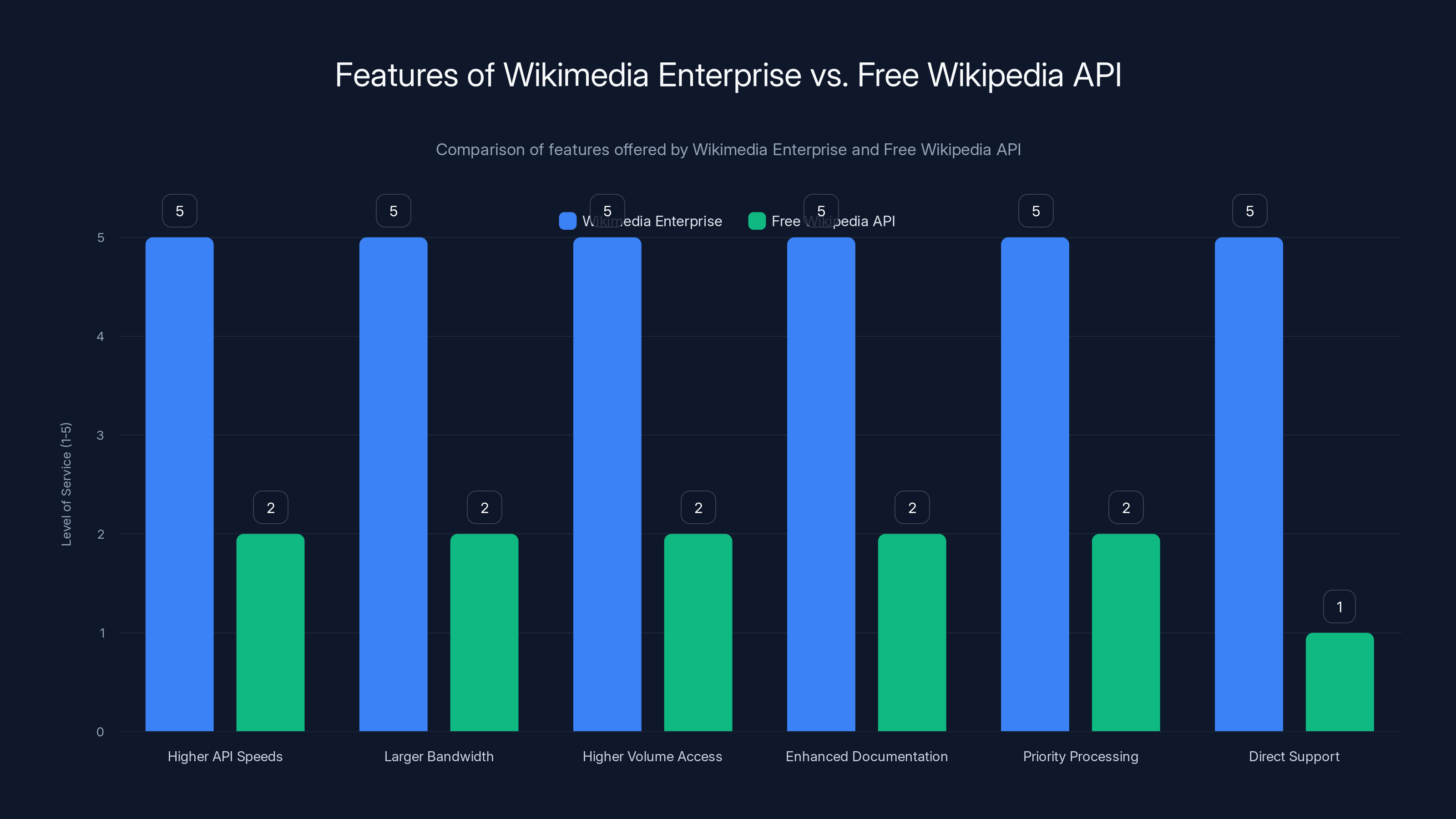
Wikimedia Enterprise offers significantly enhanced features compared to the free Wikipedia API, catering to high-demand users with higher speeds, bandwidth, and support. Estimated data.
The Volunteer Editor Problem: How AI Affects Wikipedia's Community
Here's something that doesn't get enough attention in coverage of Wikipedia's licensing deals: the people who actually build Wikipedia care about this stuff, and they have concerns.
Wikipedia is built by volunteers. Millions of them over the years, though these days there are probably tens of thousands of active editors. Some edit one article once and disappear. Others dedicate their lives to improving Wikipedia, handling vandalism, writing new articles, and keeping everything organized.
When Wikipedia paused its AI-generated article summaries pilot program in June 2024, it was because editors thought it was a bad idea. The feedback was strong: editors worried that AI-generated content could reduce trust, that it might contain errors, that it could undermine the care and attention that human editors pour into articles.
But the foundation is now licensing Wikipedia data to AI companies. Some editors probably think: "Wait, if we pause AI on Wikipedia itself because we're worried about quality, why are we licensing data to other AI companies?" It's a fair question.
The foundation's position would probably be: AI-generated summaries on Wikipedia articles could confuse readers about authorship and quality. Licensing data to companies training general AI models is different—it doesn't affect Wikipedia's content directly.
But I think editors would reasonably ask: If this data is good enough for training AI models that millions of people will rely on, wouldn't it be good enough for Wikipedia summaries?
Or inversely: If we're worried about AI-generated content on Wikipedia, should we really be licensing data to companies building AI systems that the entire world will depend on?
These are genuinely hard questions that pit Wikipedia's mission (free knowledge for everyone) against its economic pressures (need revenue to keep servers running) and practical reality (AI is going to use this data anyway, might as well be paid for it).
I don't have a clean answer. But I think it's worth acknowledging that there's real tension here that the licensing deals don't fully resolve.

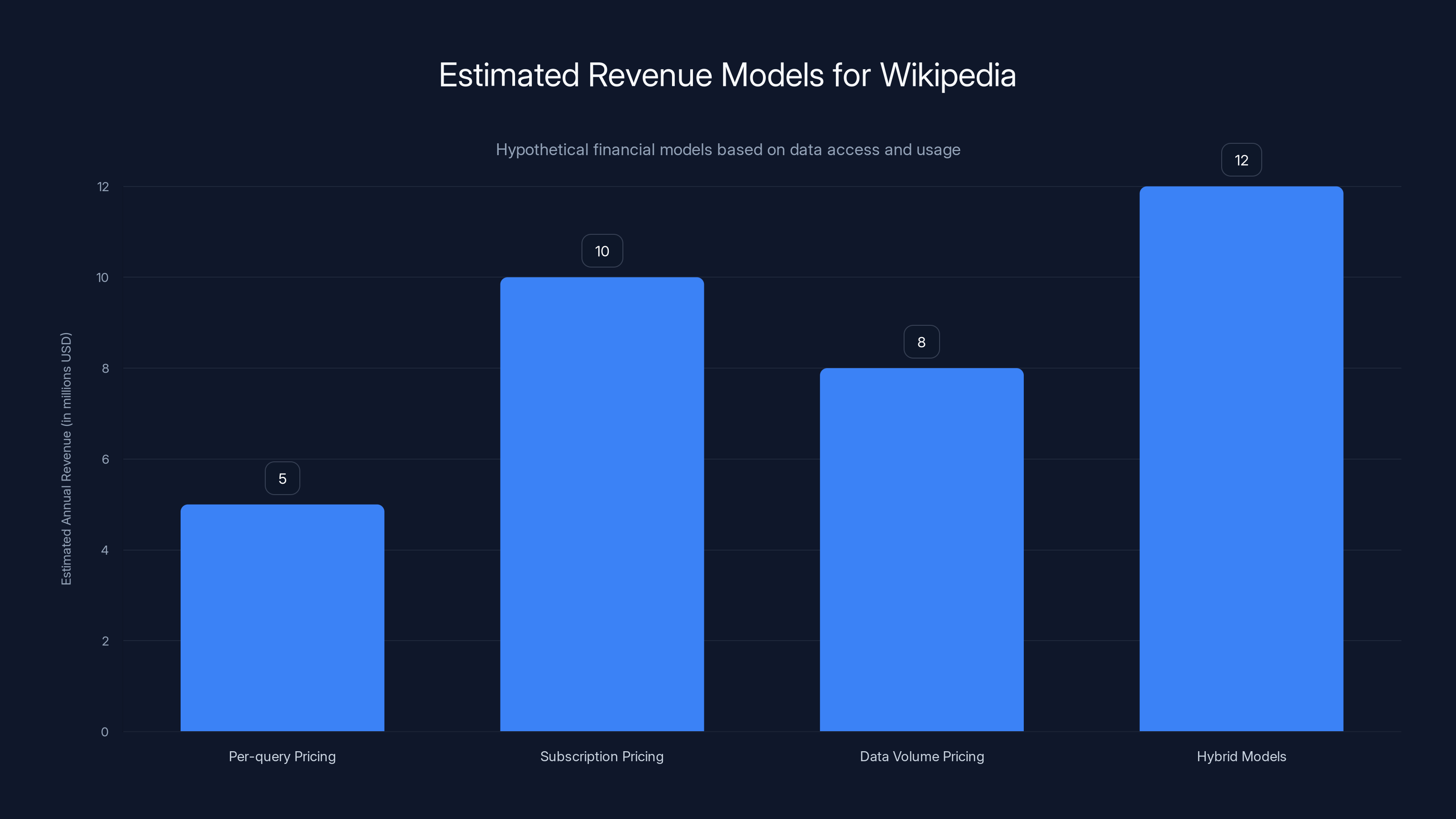
Financial Models: What Wikipedia Might Be Earning
The foundation won't disclose terms, but we can make some educated guesses about the financial scale.
Wikipedia has 65 million articles. If we assume a licensing deal based partly on volume of data accessed, the pricing might work something like:
- Per-query pricing: A small fee per API request, e.g., 0.01 per request
- Subscription pricing: A monthly fee based on expected usage tier
- Data volume pricing: A fee based on how much data is accessed annually
- Hybrid models: Some combination of the above
If Microsoft alone is training multiple AI models on Wikipedia data, they might easily make hundreds of millions of API requests. Even at a tiny per-request fee, that adds up.
Alternatively, the deals might be flat-fee subscription deals. Microsoft pays $X per month for unlimited access to Wikimedia Enterprise during the contract term.
Without knowing the actual terms, we're in the dark. But the scale of value suggests these deals could be worth millions of dollars annually to Wikipedia. Not hundreds of millions, probably, but enough to meaningfully help with infrastructure costs and fund strategic initiatives.
Here's a useful way to think about it: if the deals generate even $10 million per year for Wikipedia, that's 10 percent of the foundation's annual budget. That's significant.
For the companies paying, the costs are likely trivial relative to their AI R&D budgets. Microsoft spends billions on AI research. A few million for licensing high-quality training data is pocket change. The real value isn't the cost—it's the legitimacy and access.
From a financial modeling perspective, this is interesting because it shows how AI development costs might actually change. For years, AI training was cheap because data was free. But as quality data becomes licensed, training costs will rise. That will change which companies can afford to build frontier AI models.
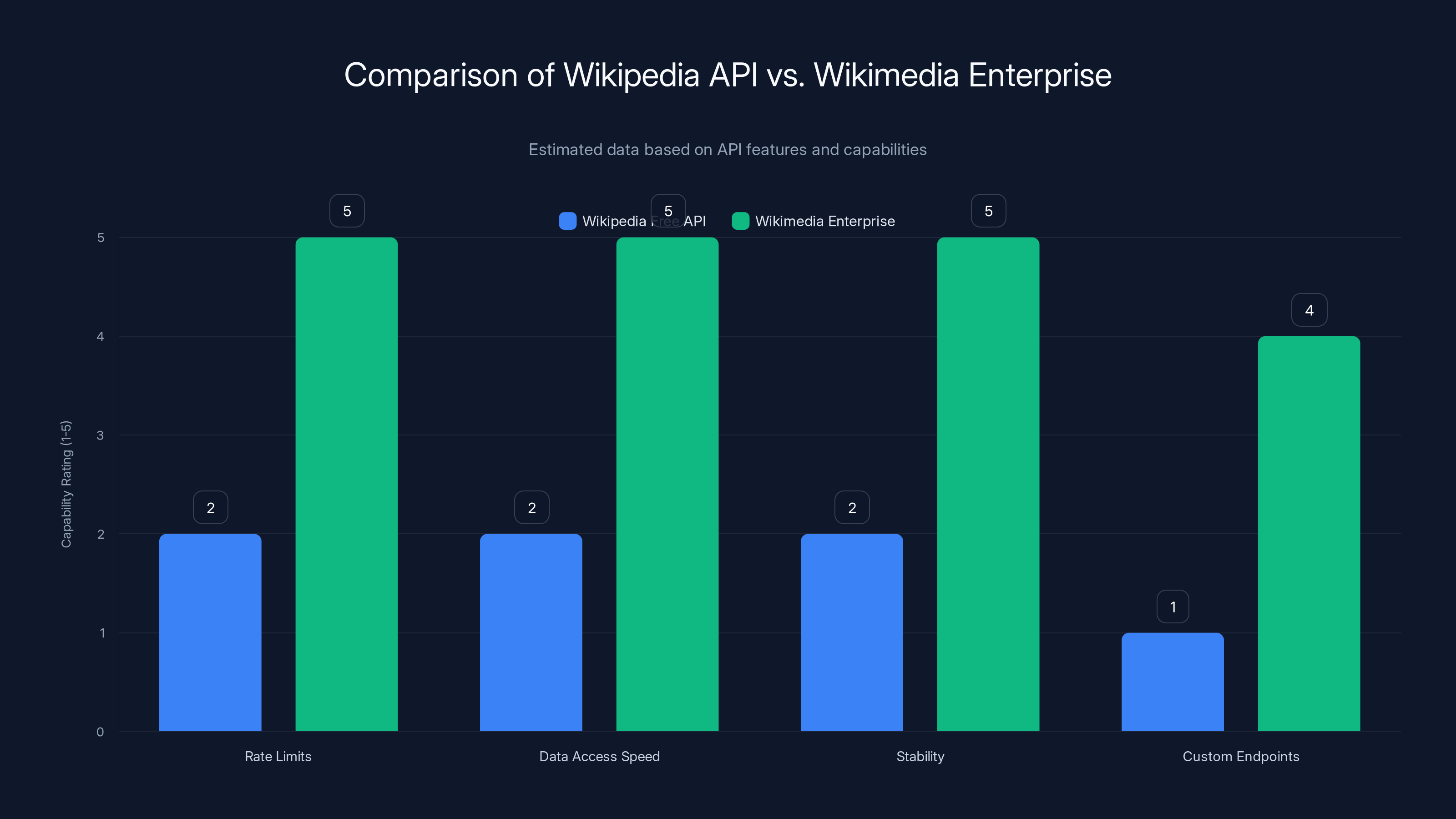
Wikimedia Enterprise offers significantly higher rate limits, faster data access, improved stability, and potential custom endpoints compared to the free Wikipedia API. Estimated data.
The Precedent: What This Means for Other Content Creators
Let's think about the broader implications. Wikipedia's licensing deals set a precedent that's already shaping conversations across the media and creative industries.
News publishers are now asking themselves: "Why isn't Perplexity paying us for content that appears in their search results?" Some are demanding payment. Others are blocking AI crawlers.
Artists are asking: "Why isn't Stable Diffusion paying royalties to artists whose work trained the image model?" Some are suing.
Authors are asking: "Why isn't Open AI paying us for books that trained Chat GPT?" The New York Times sued.
All of these conversations would be different if Wikipedia had simply caved and allowed unlimited scraping for free. By insisting on licensing agreements, Wikipedia created proof of concept. It showed that it's possible to charge for training data. It legitimized the idea that content creators deserve compensation.
Now, does that mean everyone will get paid? Probably not. News publishers might not have the leverage that Wikipedia has. There's competing news available for free everywhere. But Wikipedia is singular—there's no real alternative to it.
Still, the precedent shifts expectations. Companies in the AI industry can no longer claim that they should have unlimited free access to high-quality content. Wikipedia proved that's not how it works.
That said, there's a risk that this creates a chilling effect on AI development for smaller companies. If licensing fees become standard, training custom models becomes more expensive. That benefits well-funded companies and potentially slows innovation from startups.
There's also the question of what happens with public domain content, open-source datasets, and other content that's legally available for free use. Will companies still use that, or will they increasingly rely on licensed sources? Probably some mix of both.

How This Affects AI Model Training Pipelines
On the technical side, having a licensed data pipeline changes how companies build AI models.
With the free API, you'd need to manage rate limiting, retries, and potentially long waits for data. Your training pipeline has to be fault-tolerant because requests might timeout or get throttled. You might cache data locally to avoid repeated requests.
With Wikimedia Enterprise, you get more reliable, faster access. That simplifies your training infrastructure. You can fetch data on-demand more efficiently. You can update your training data more frequently if needed.
This matters because AI training is complex and expensive. The infrastructure needs to be robust. If you're spending $50,000 per hour on GPU time, you don't want your data pipeline failing. Licensed access is more reliable.
It also matters for data freshness. Wikipedia is constantly being edited. New articles are added. Old ones are updated. If you license access, you might be able to get fresher data more efficiently. That could mean your AI models are trained on more current information.
For companies training models, this likely streamlines their workflows. It's a small efficiency gain, but across a large training pipeline, small efficiencies compound.
From a business model perspective, it also changes the economics. Instead of treating data as free, companies now budget for it. That's a real cost, though probably small relative to other training costs like compute and researcher salaries.
What About Attribution and Citation?
One thing that's not entirely clear from the public announcements: do the licensing deals include requirements for attribution or citation?
When you use Wikipedia content in a paper or project, best practice is to cite it. But when you're training an AI model on Wikipedia data, you're not citing individual articles in the training set—you're just feeding data into neural networks.
Does the licensing agreement require companies to acknowledge that their models were trained on Wikipedia? Does it require them to maintain a list of articles used in training? These are technical and legal questions that matter but aren't being publicly discussed.
It's possible that the licensing agreements include provisions about attribution—perhaps requiring companies to disclose that their models were trained on Wikipedia data. Or it might not. The deals are private.
This matters because it affects Wikipedia's reputation and reach. If Microsoft says "Copilot was trained on Wikipedia," that's great for Wikipedia. It showcases the value of their content. If Microsoft trains on Wikipedia but never mentions it, that's less valuable from a PR perspective.
For context, some other training datasets do require attribution. The COCO dataset, for example, has specific citation requirements. Other datasets are released under licenses like Creative Commons that specify how attribution should work.
I'd guess the Wikipedia licensing deals probably include some attribution requirement, but without seeing the actual contracts, that's speculation.
It's also worth considering: if companies are required to disclose that models were trained on Wikipedia, does that affect user trust? Does knowing that your AI assistant's knowledge comes from a crowdsourced, volunteer-edited encyclopedia change how you think about it? Probably somewhat, but hard to say.

The Revenue Model Question: Is It Sustainable?
Licensing content to AI companies is a revenue model, but is it sustainable long-term?
Some considerations:
Bargaining power: Right now, Wikipedia has leverage. There's no alternative to Wikipedia, so companies have to license from them if they want that data. But what if that changes? What if a competing encyclopedia emerges? What if some other source of curated knowledge becomes equally valuable? Then Wikipedia's bargaining power declines. They might need to lower prices to stay competitive.
Market saturation: There's a limited number of major AI companies. Microsoft, Meta, Amazon, Perplexity, Mistral. That's mostly it. You can only sell licenses to so many customers. Once everyone's signed up, where's the next revenue growth coming from? Startups? But startups might use the free API.
Technological change: What if AI companies eventually train models on better sources of data? What if they develop synthetic data that's more useful than Wikipedia? Then demand for Wikipedia licensing might decline.
Regulation: Future regulations might require companies to open-source training data or restrict what data can be used to train models. That could change the market.
Crowdsourced content evolution: Wikipedia's value comes from volunteer editors. If the volunteer editing community shrinks or becomes less active, Wikipedia's quality could decline. Then licensing becomes less valuable.
I'm not saying any of these are likely to happen soon. But I'm flagging them as longer-term uncertainties. The Wikipedia licensing model works right now because Wikipedia is uniquely valuable and in high demand. But sustaining that long-term requires maintaining the value of the platform.
That's partly why the decision to pause AI-generated summaries was strategically sound. It signals that Wikipedia cares about quality and trusts its volunteer editors. That's what keeps Wikipedia valuable. A Wikipedia that's 50 percent AI-generated content would be less valuable and less licensable.
Implications for Open Source and Open Data Movements
There's a tension here worth acknowledging: Wikipedia is open source. The content is open. The database is downloadable. Yet the foundation is now licensing access through Wikimedia Enterprise.
Isn't that contradictory? Not really. Open source doesn't mean free for commercial use without paying. Open source means transparent, auditable, and available. You can still charge for access or services built on open source.
Redhat built a billion-dollar company offering services around Linux, which is open source. Canonical does the same with Ubuntu. O'Reilly publishes books about open-source software. The Linux Foundation funds open-source projects. Open source and commercial licensing aren't mutually exclusive.
But there is a cultural tension. The open-source community values free access. Charging for API access to open data feels a bit against that spirit, even if it's not technically violating the license terms.
Wikipedia's approach is actually sophisticated: the data itself remains open. You can download the entire Wikipedia database for free. You can run your own instance. You can use it however you want, within the license terms (Creative Commons Attribution-Share Alike).
But if you want enterprise-grade API access with good performance and support, you pay Wikimedia Enterprise. That's not restricting access to the data—it's providing a service layer on top of it.
That model might become more common in the open-source and open-data world as companies realize that providing services around free/open data can be quite profitable.
Global Implications: How This Plays Out in Different Countries
Wikipedia is global, so let's consider international dimensions.
Wikipedia exists in over 300 languages. But the majority of traffic and editing activity is concentrated in a few languages: English, German, French, Spanish, Portuguese. Other language editions are smaller and often have fewer resources.
The licensing deals the foundation announced are probably mostly in English, serving companies based in the US. But these same companies operate globally. When they train models on Wikipedia data, they're probably ingesting all language versions.
Does that create equity issues? Are editors in less-resourced language editions getting fairly compensated? Probably not directly—the licensing revenue flows to the foundation, not to individual editors. But you could argue that revenue from licensing should be reinvested in supporting all language editions, including the smaller ones.
There's also a question of sovereignty and culture. Some countries view their language and knowledge bases as strategic resources. They might be uncomfortable with foreign companies licensing access to Wikipedia content in their language and using it to train AI models that will be deployed globally.
Europe has GDPR and has been more aggressive about regulating AI. Some European countries might require different licensing terms for AI companies operating in their jurisdiction.
Mistral, one of the companies signing with Wikipedia, is French. That might signal European regulatory approval or comfort with the model. But I'd expect more nuance to emerge as different countries think about how to regulate AI training data.
What Happens to the Free Tier? Will Wikipedia Users Feel the Change?
Important reassurance: the free Wikipedia experience should remain unchanged. Wikipedia will stay free to read, edit, and use. The licensing deals don't affect that.
But there's a longer-term question: as Wikipedia relies more on licensing revenue, does that shift priorities?
If licensing to AI companies becomes a significant revenue source, the foundation might naturally invest more in features and infrastructure that support those customers. Better API performance, more detailed data, faster updates. Those investments benefit the paying customers more than regular Wikipedia users.
There's also a subtle cultural shift. When your primary customer is volunteers, you're accountable to them. When your primary revenue source is tech companies, you're accountable to them. That changes decision-making.
Wikipedia's foundation is nonprofit and mission-driven, so hopefully that alignment to the mission stays strong. But economic pressures are real. They matter over time.
I think the key indicator to watch is whether Wikipedia continues investing in the editing community, tools for editors, and quality control. If licensing revenue leads to better support for volunteer editors, that's a win. If it's purely extracted to cover infrastructure costs while editing infrastructure withers, that's concerning.

The Future: What's Next for Wikipedia and AI
Looking ahead, I see several possibilities:
Scenario 1: Expansion of licensing deals. The foundation approaches other AI companies, data providers, and researchers to expand licensing revenue. Eventually, licensing could represent 20-30 percent of the foundation's budget, providing more stability.
Scenario 2: Licensing becomes competitive. Other platforms realize they have valuable data and start licensing it to AI companies. Wikipedia's unique advantage fades. Competition drives down licensing prices.
Scenario 3: Regulation changes the model. Governments mandate transparency about training data or restrict AI training on certain copyrighted content. That could either help Wikipedia (making licensing mandatory) or hurt it (restricting access).
Scenario 4: Wikipedia becomes more integrated with AI. Instead of just licensing data, Wikipedia becomes a data partner for AI companies in deeper ways. Partnerships on quality assurance, fact-checking, knowledge verification. That could be significant.
Scenario 5: Community backlash. Volunteer editors become uncomfortable with commercial licensing and reduce their contributions. Wikipedia's quality declines, making it less valuable for licensing.
I think the most likely scenario is a mix of these. Licensing does expand, but competitive pressure and regulation shape how. The community stays involved but becomes more aware of commercialization. Wikipedia remains valuable and free while also becoming a more significant commercial player.
The philosophical question that remains: should knowledge be a freely available common good, or is it reasonable to charge for access to curated knowledge? Wikipedia's answer seems to be: it should be free for individuals and nonprofits, but companies that profit from it should share in the costs. That seems like a reasonable middle ground.
FAQ
What exactly is Wikimedia Enterprise, and how is it different from regular Wikipedia?
Wikimedia Enterprise is a commercial subsidiary of the Wikimedia Foundation that provides premium API access to Wikipedia's 65 million articles. While regular Wikipedia remains completely free and open to everyone, Wikimedia Enterprise offers higher bandwidth, faster response times, larger API rate limits, priority processing, and dedicated support. The distinction is important: it allows Wikipedia to keep its core mission intact while generating revenue from large commercial users who have high-volume data needs.
Why did Wikipedia suddenly need to charge AI companies for data?
Wikipedia didn't suddenly decide to charge. Rather, the foundation gradually realized that AI companies were scraping Wikipedia at industrial scale, creating massive infrastructure costs. In 2024 and early 2025, they discovered that bot traffic had grown 50% in 16 months and was consuming 65% of their most expensive infrastructure resources. Rather than absorb these costs through donations, the foundation created a licensing model where the companies driving the costs help pay for them.
Which AI companies are now paying Wikipedia for data, and are there others?
The announced companies are Microsoft, Meta, Amazon, Perplexity AI, Mistral AI, and Google (which signed in 2022). Smaller companies like Ecosia, Nomic, Pleias, Pro Rata, and Reef Media have also signed. These companies represent most of the major players in AI, though many smaller startups likely still use the free API.
Does Wikipedia content remain free to the public under these licensing deals?
Yes, absolutely. The licensing deals do not change Wikipedia's free access model. Regular readers can still read Wikipedia for free. Editors can still contribute for free. The deals only affect commercial companies that need high-volume API access, which must now use Wikimedia Enterprise instead of the free API.
How much money is Wikipedia making from these licensing deals?
The Wikimedia Foundation has not disclosed the financial terms of the deals, so the exact revenue is unknown. However, given that the foundation's annual budget is around $100+ million and licensing represents a new revenue stream from major tech companies, estimates suggest the deals could generate millions of dollars annually, potentially 5-10% of the foundation's total budget.
What does this mean for other content creators like news publishers and artists whose work is used to train AI?
Wikipedia's licensing deals set an important precedent: if your content is valuable enough to train major AI models, you potentially deserve compensation. This is already influencing conversations across media and creative industries. News publishers are demanding payment from AI search tools, artists are suing image model companies, and authors are suing language model companies. The precedent Wikipedia established makes these arguments stronger.
Will the licensing deals affect the quality or speed of Wikipedia for regular users?
Probably not. The licensing revenue actually helps Wikipedia maintain and improve infrastructure. The deals provide funding to cover costs that were previously absorbed by donations. In fact, this revenue model might help Wikipedia invest more in editing tools and quality control, benefiting all users.
How do the licensing deals align with Wikipedia's open-source mission?
There's no contradiction. The Wikipedia data remains open and downloadable for free. Wikimedia Enterprise simply provides a commercial service layer—fast, reliable API access with support. This is similar to how Red Hat profits from Linux or how Canonical profits from Ubuntu, both open-source projects. You can use the open source for free, or pay for enterprise services.
Are there any concerns about Wikipedia's reliance on AI company licensing revenue?
Some editors worry that commercial licensing might shift Wikipedia's priorities away from the volunteer community. There's also the long-term question of whether this model is sustainable if AI companies find alternative data sources or if regulation changes how AI training works. The foundation needs to be careful that licensing revenue doesn't undermine the editorial community that makes Wikipedia valuable.

Conclusion: A Turning Point for Knowledge and AI
The Wikipedia licensing deals announced in January 2025 represent more than just a new revenue stream for a nonprofit. They signal a fundamental shift in how the world thinks about data, knowledge, and artificial intelligence.
For years, the AI boom was built partly on free data. Companies could scrape, download, and train on public content without asking permission or paying. That era is ending. Wikipedia proved it's possible to charge for high-value training data, and that precedent is reshaping entire industries.
For Wikipedia itself, the deals are a pragmatic solution to a real problem. Infrastructure costs from bot traffic were unsustainable on a donation-based model alone. Licensing to companies using that infrastructure makes economic sense. The foundation gets funding to maintain the platform that everyone relies on. The companies get reliable, fast access to valuable data. It's a fair exchange.
But it also raises deeper questions about the future. As more content creators demand payment for data used in AI training, will AI development become more expensive and concentrated among well-funded companies? Will startups be priced out of training custom models? Will innovation slow? Or will licensing become so normalized that it's just another cost of doing business in AI?
There's also the cultural question. Jimmy Wales said he's happy that AI models train on Wikipedia because it's human-curated. But does that hold true as Wikipedia becomes more commercial? Can a platform remain mission-driven while increasingly dependent on tech company revenue? These aren't rhetorical questions. They matter for Wikipedia's future.
What's clear is that we're at an inflection point. The free-data era of AI development is ending. What replaces it will shape the next decade of AI innovation. Wikipedia's deals might be the first domino in a much larger transformation.
If you're building in AI or relying on data for any kind of AI application, these deals should be on your radar. They signal that licensing costs are becoming normal. They prove that premium data access has value. They suggest that open access and commercial licensing can coexist. And they raise hard questions about sustainability, fairness, and who should profit from knowledge.
The full implications won't be clear for years. But the Wikipedia licensing deals are definitely a turning point worth understanding.
Key Takeaways
- Wikipedia signed paid licensing deals with Microsoft, Meta, Amazon, Perplexity, and Mistral AI—establishing that high-quality training data commands real value
- Bot traffic for AI training grew 50% in 16 months, with automated scrapers consuming 65% of Wikipedia's most expensive infrastructure costs despite being only 35% of total traffic
- The deals create a precedent that ripples across industries: news publishers, artists, and authors are now demanding compensation for data used in AI training
- Wikimedia Enterprise provides enterprise-grade API access with higher speeds and volumes, while free Wikipedia remains unchanged for regular users and nonprofits
- Revenue from licensing helps Wikipedia sustain infrastructure costs and fund operations while maintaining its free, open-source mission for the public

