![Semantic Caching: Cut Your LLM Bills by 73% [2025]](https://tryrunable.com/blog/semantic-caching-cut-your-llm-bills-by-73-2025/image-1-1768082819247.png)
Semantic Caching: Cut Your LLM Bills by 73% [2025]
Your LLM bill just hit your Slack. Again. You scroll past the number twice before your brain processes it. That's not a typo. That's your actual spend this month.
The worst part? Your traffic only grew 15%. Your costs grew 30%. Something's broken, and you know it.
Here's what happened at most companies running production AI: Users ask the same questions, just differently. "What's your return policy?" and "Can I get a refund?" and "How do I return something?" all hit your LLM separately. Each one costs money. Each one generates nearly identical responses.
Your caching strategy catches exact duplicates. It catches almost nothing else.
That's where semantic caching enters the picture. Not as a trendy optimization, but as a legitimate cost-cutting mechanism that works. When implemented correctly, it doesn't just trim a few dollars here and there. It restructures how your caching layer understands queries, reducing costs by 60-73% in real production environments.
This isn't theoretical. The numbers come from actual implementations across dozens of companies. The math works. The implementation has pitfalls that most engineers miss on the first try.
Let's walk through why exact-match caching is fundamentally insufficient, how semantic caching actually works, and the specific decisions that determine whether you'll save 30% or 73%.
TL; DR
- Exact-match caching only captures 18% of redundant queries, leaving 47% of semantically similar requests to trigger full LLM calls
- Semantic caching uses vector embeddings to match queries by intent, increasing cache hit rates from 18% to 67% in production systems
- Threshold selection is critical: Set too high (0.95+) and you miss savings; too low (0.80) and you return wrong answers
- Query-type-specific thresholds (0.97 for transactional, 0.88 for informational) outperform single global thresholds by 15-22%
- Implementation requires vector storage, embedding models, and response caching, adding infrastructure complexity but delivering 10-15x ROI
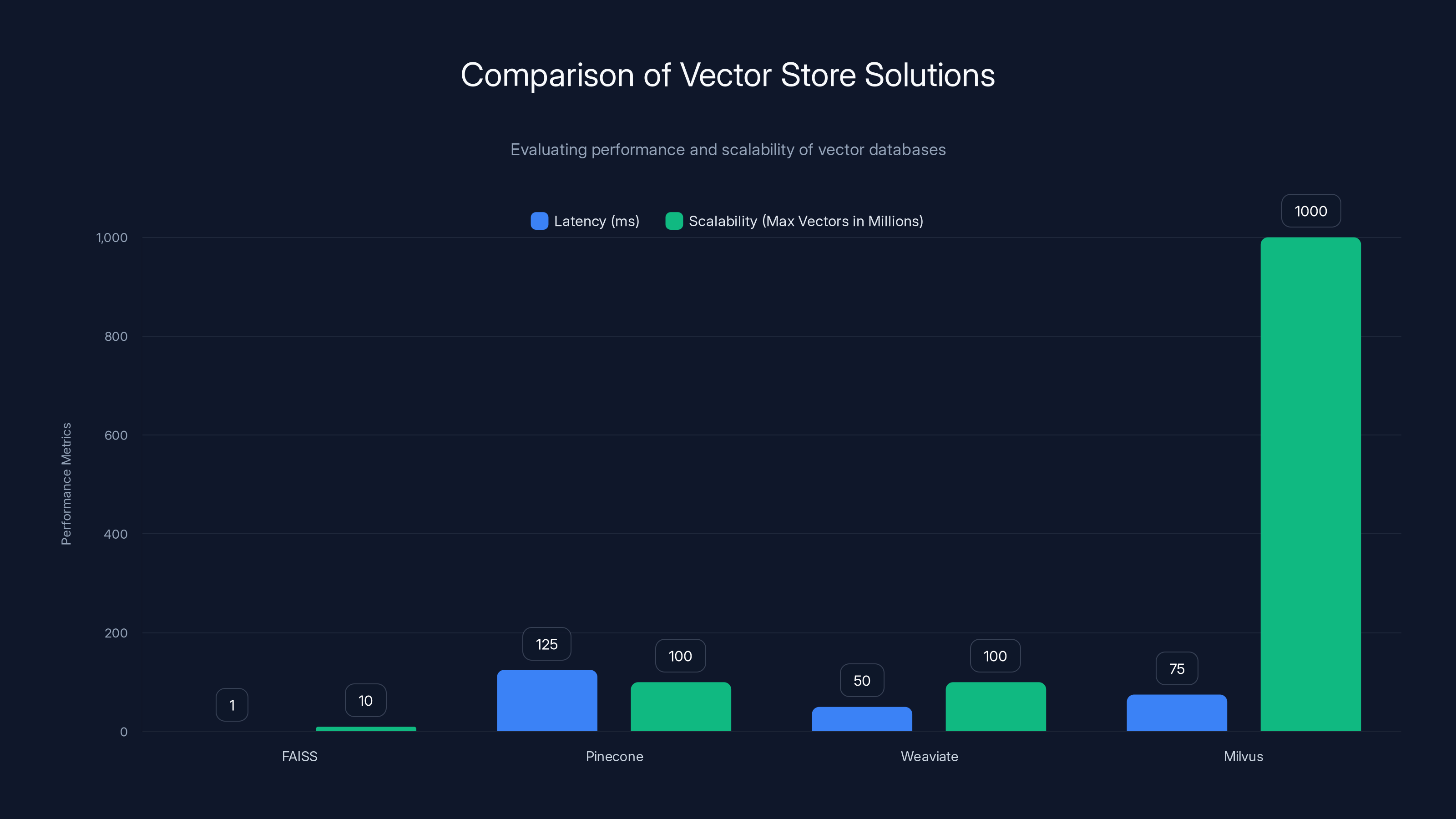
FAISS offers the lowest latency, making it ideal for small-scale, high-speed applications. Pinecone provides cloud-based scalability with moderate latency, suitable for teams without DevOps resources. Weaviate and Milvus offer high scalability but require more operational expertise.
The Exact-Match Caching Problem: Why 47% of Duplicate Work Gets Missed
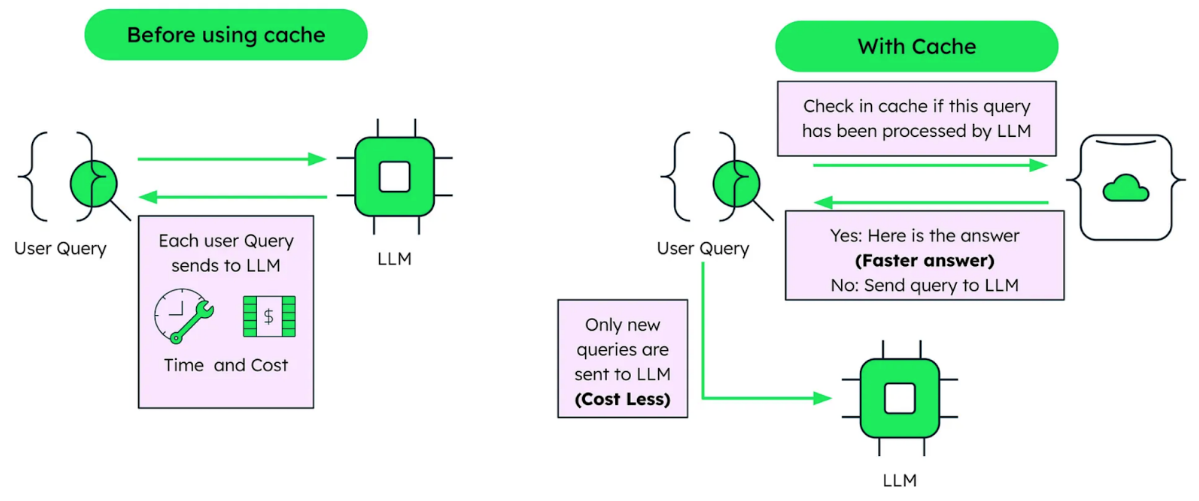
Exact-match caching is old technology. It's reliable. It's predictable. It's also fundamentally flawed for real-world LLM workloads.
Here's how it works: Your application hashes the query text. If that hash exists in the cache, you return the cached response. If not, you call the LLM and store the new response.
python# Classic exact-match caching
cache_key = hash(query_text)
if cache_key in cache:
return cache[cache_key]
else:
response = llm.generate(query)
cache[cache_key] = response
return response
This logic is sound. It prevents redundant API calls when identical queries come in twice. The problem is that identical queries almost never come in twice.
When a team analyzed 100,000 production queries across three customer-facing AI applications, the results were sobering:
- 18% were exact duplicates of previous queries
- 47% were semantically similar to previous queries (same intent, different phrasing)
- 35% were genuinely novel queries
That 47% figure is massive. Nearly half of all queries could have been answered by cached responses, but exact-match caching missed them entirely.
Consider actual user queries to a customer support chatbot:
- "What's your return policy?"
- "Can I get a refund?"
- "How do I return something?"
- "Do you accept returns?"
Each phrase is different. Each hash is unique. The cache doesn't recognize any connection. The LLM generates four nearly identical responses. You pay four times.
Multiply that across thousands of daily queries, and you're hemorrhaging money on redundant API calls that a smarter caching layer would catch.
The financial impact is brutal. If your LLM costs are
But only if you implement it correctly.
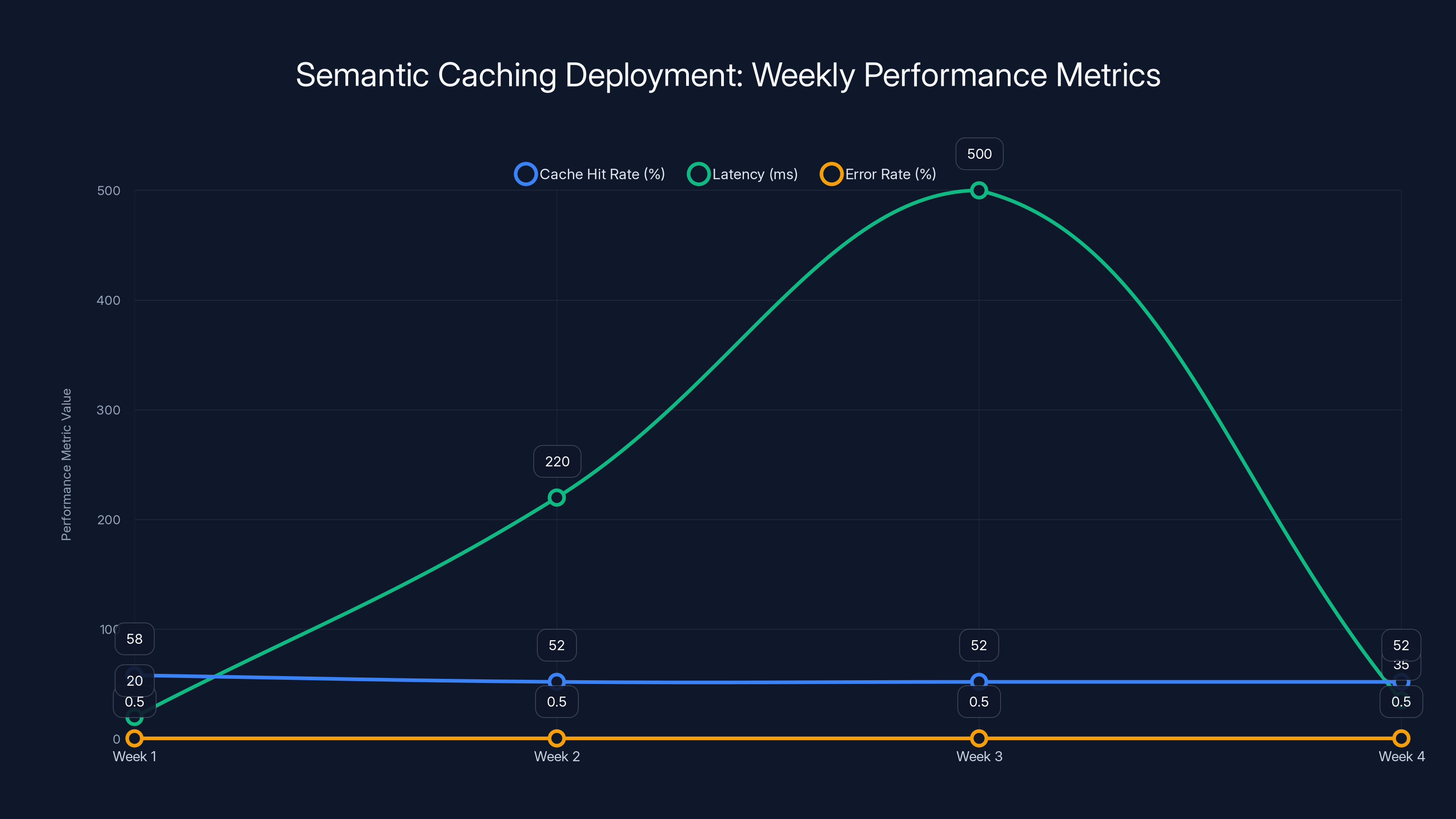
Throughout the first four weeks, cache hit rates fluctuated due to various issues, while latency spiked during a traffic surge. Error rates were reduced significantly by week 4 through threshold tuning.
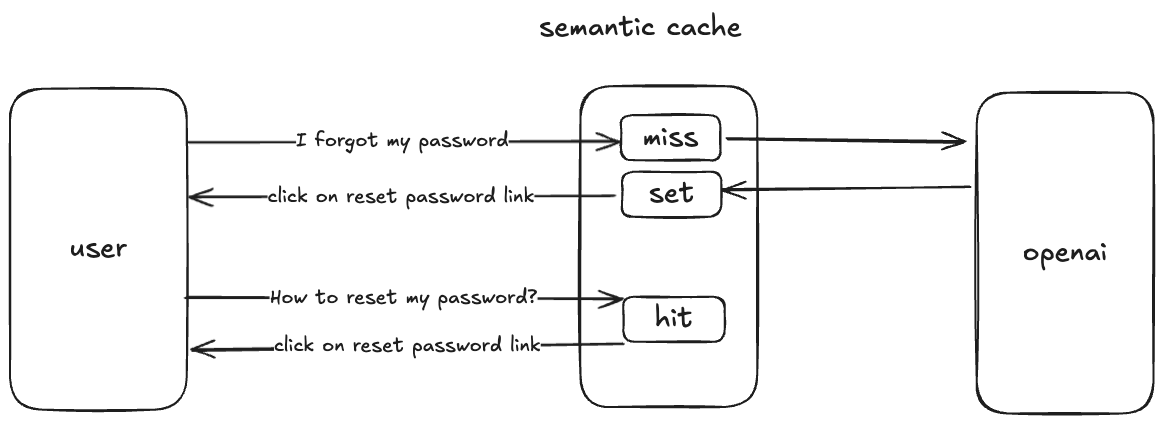
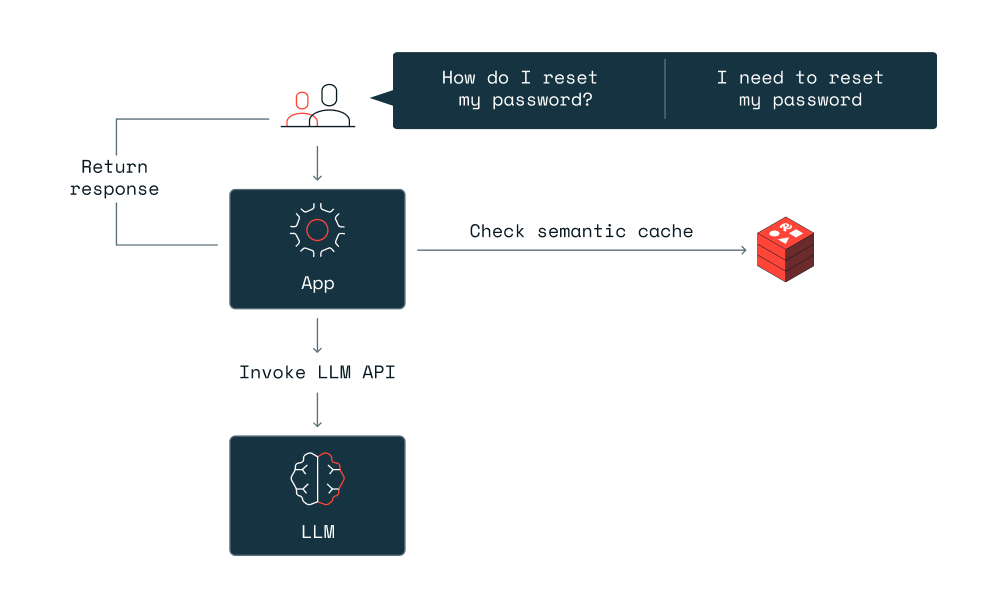
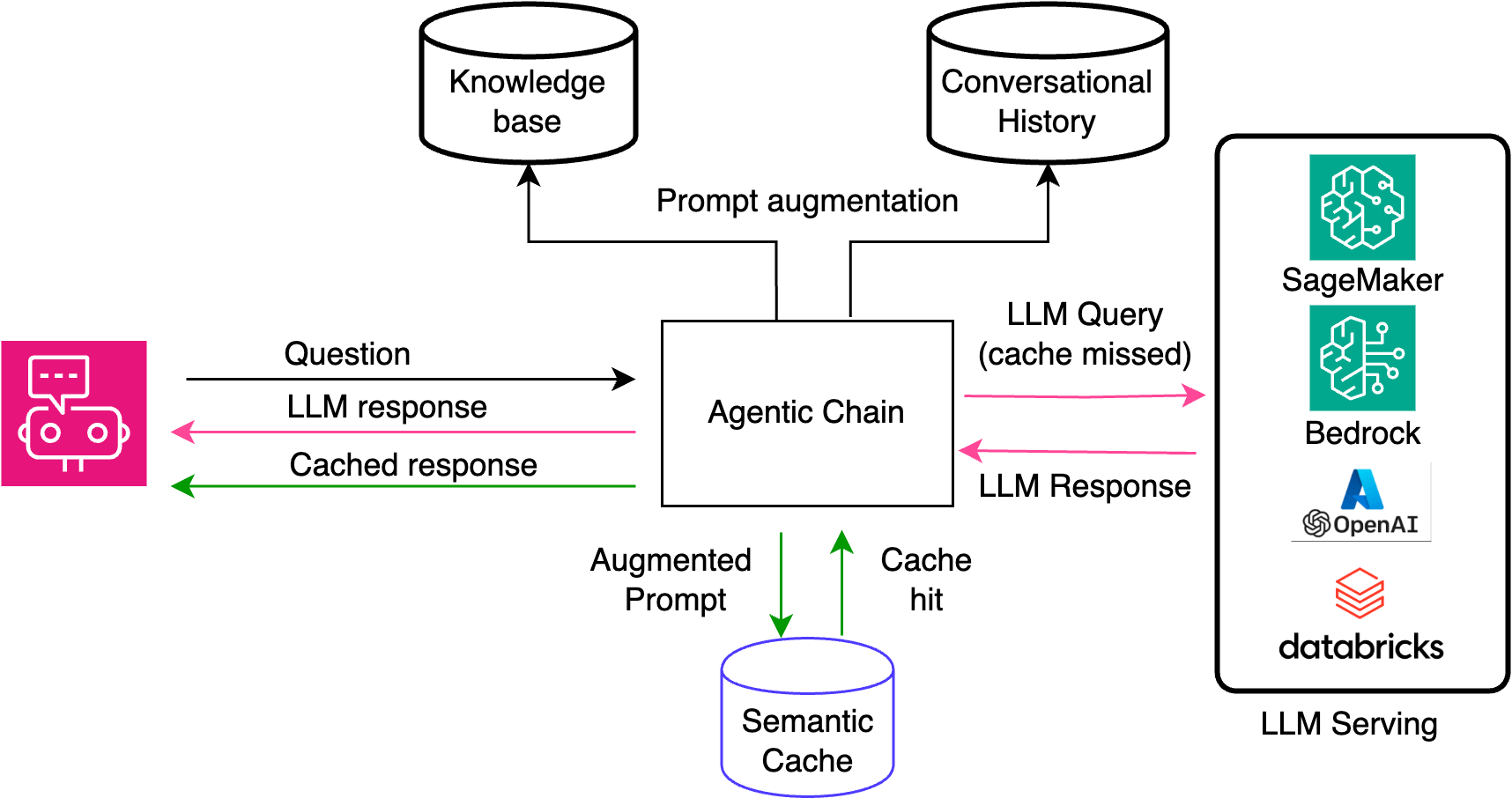
How Semantic Caching Actually Works: Vector Embeddings Replace Text Hashing
Semantic caching inverts the problem. Instead of comparing query text, it compares query meaning.
Here's the conceptual difference:
Exact-match: Does the exact query text exist in cache? Semantic: Does a query with similar meaning exist in cache?
To compare meaning, you need vectors. You encode every query into a high-dimensional vector space using an embedding model. Queries with similar semantic meaning end up close to each other in that space. Queries with different meanings end up far apart.
pythonclass Semantic Cache:
def __init__(self, embedding_model, similarity_threshold=0.92):
# Embedding model (e.g., Open AI's text-embedding-3-small)
self.embedding_model = embedding_model
# Similarity threshold: 0.92 = high precision
self.threshold = similarity_threshold
# Vector store (FAISS, Pinecone, Weaviate, etc.)
self.vector_store = Vector Store()
# Response storage (Redis, Dynamo DB, etc.)
self.response_store = Response Store()
def get(self, query: str) -> Optional[str]:
"""Return cached response if semantically similar query exists."""
# Convert query to vector
query_embedding = self.embedding_model.encode(query)
# Search vector store for similar queries
matches = self.vector_store.search(
query_embedding,
top_k=1,
similarity_metric='cosine'
)
# If similar query found above threshold, return cached response
if matches and matches[0].similarity >= self.threshold:
cache_id = matches[0].id
return self.response_store.get(cache_id)
return None
def set(self, query: str, response: str):
"""Cache query-response pair."""
query_embedding = self.embedding_model.encode(query)
cache_id = generate_id()
# Store embedding in vector database
self.vector_store.add(cache_id, query_embedding)
# Store response in key-value store
self.response_store.set(cache_id, {
'response': response,
'timestamp': datetime.utcnow(),
'query': query # for debugging
})
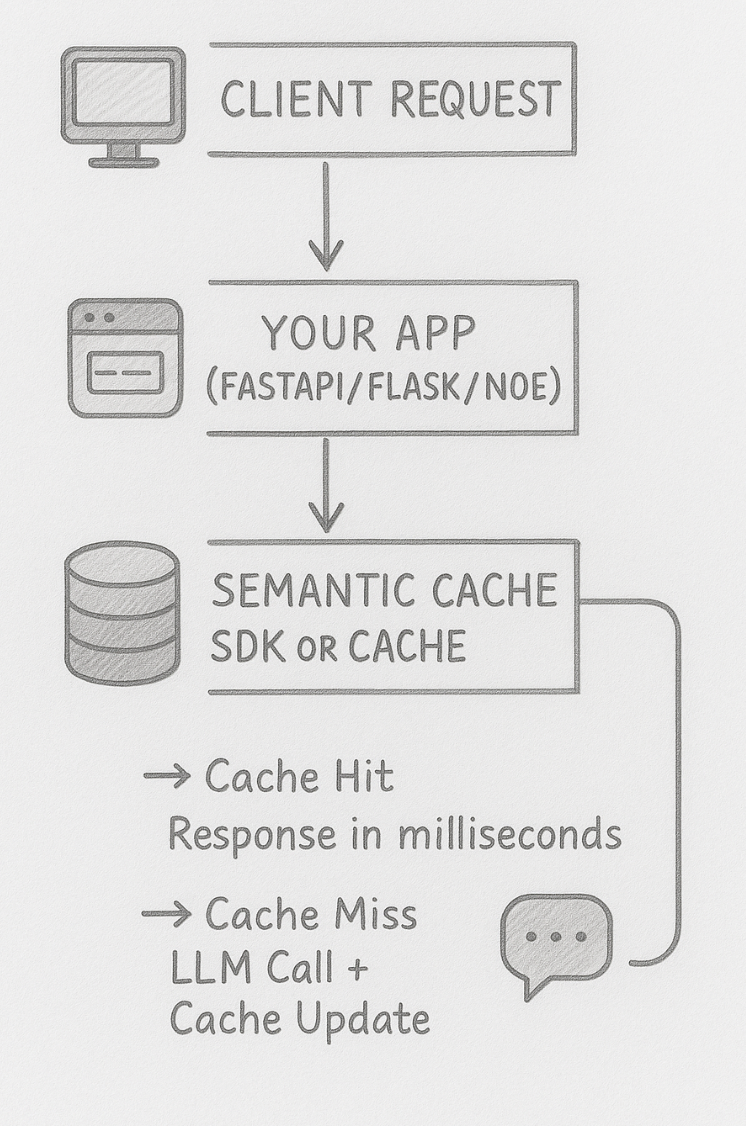
The flow looks like this:
- User submits query: "Can I get a refund?"
- Embed the query: Convert text to 1536-dimensional vector (using text-embedding-3-small or similar)
- Search vector store: Find cached query vectors closest to this embedding
- Check threshold: Is similarity score above your threshold (e.g., 0.92)?
- Return if match: If yes, return cached response immediately
- LLM call if miss: If no, call LLM, cache response, return result
The math here uses cosine similarity, which measures the angle between vectors:
Where values range from -1 (opposite) to 1 (identical). In practice, you see values between 0.7 and 1.0 for real queries.
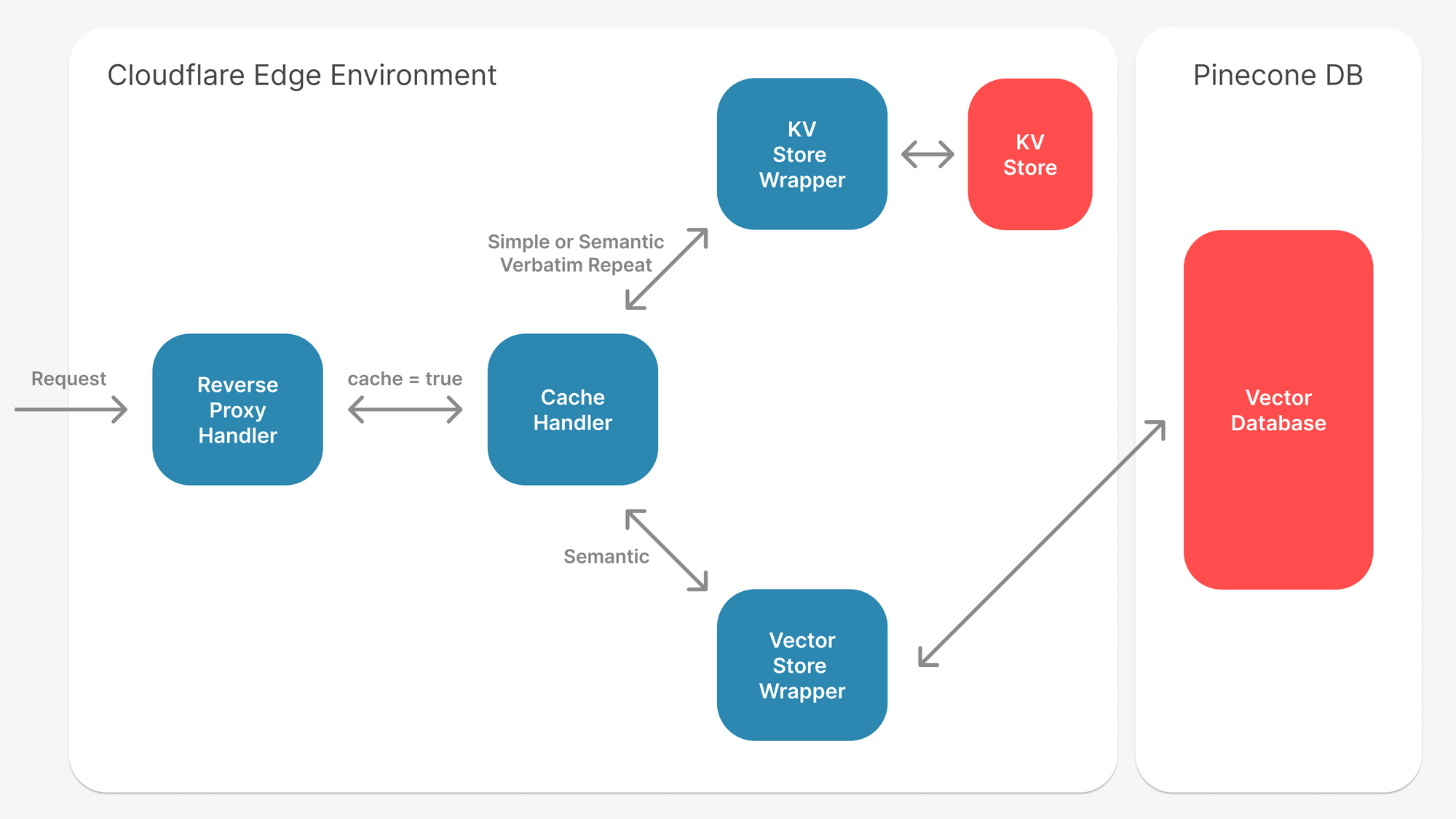
The architecture requires three core components:
- Embedding model: Converts text to vectors (Open AI, Cohere, local models)
- Vector store: Searches for similar embeddings quickly (FAISS, Pinecone, Weaviate, Milvus)
- Response cache: Retrieves cached responses fast (Redis, Dynamo DB, in-memory dict)
The interaction between these three systems is what determines performance. A poorly configured vector store can make your cache lookups slower than LLM calls themselves.
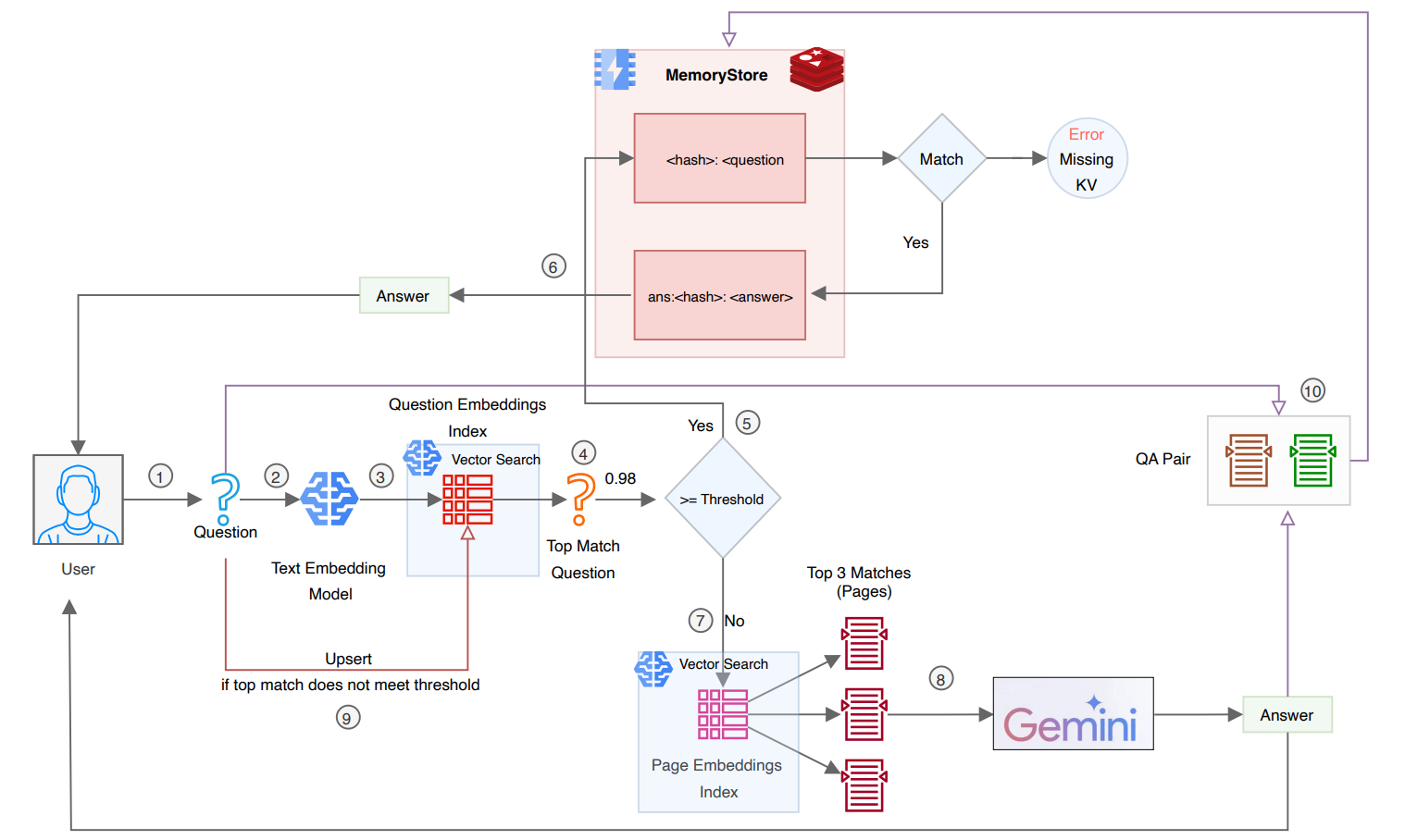
The Threshold Problem: Too High = Missed Savings, Too Low = Wrong Answers
The similarity threshold is where semantic caching gets tricky. This single parameter determines whether you save 30% or 73% on costs.
Set the threshold too high, and your cache becomes useless. You only hit the cache when queries are nearly identical, which defeats the entire purpose.
Set it too low, and your cache returns incorrect answers. A query about canceling a subscription returns the cached response about canceling an order. The user gets wrong information. You lose their trust.
Your first instinct will be wrong. When a team implemented semantic caching with a threshold of 0.85, they thought it was reasonable: "85% similar means it's basically the same question, right?"
Wrong.
They got cache hits like:
Query: "How do I cancel my subscription?" Cached: "How do I cancel my order?" Similarity: 0.86 Result: User receives wrong answer
Same word order, similar structure, completely different intent and answer. The threshold was too permissive.
The optimal threshold depends on your query type. You can't use a single global threshold for all queries. Different question types have different tolerance levels.
Informational queries ("What's your return policy?") can tolerate lower thresholds. If you return a similar but slightly different answer, the user notices but isn't harmed.
Transactional queries ("Cancel my account", "Process refund") need very high thresholds. Wrong answers cause real damage.
Analytical queries ("Show me trends in Q4 sales") fall in the middle.
A production system should implement query-type-specific thresholds:
pythonclass Adaptive Semantic Cache(Semantic Cache):
def __init__(self, embedding_model):
super().__init__(embedding_model)
# Query-type-specific thresholds
self.thresholds = {
'transactional': 0.97, # Very high: money/account changes
'analytical': 0.92, # Medium: data analysis
'informational': 0.88, # Lower: general questions
'default': 0.92
}
# Simple query classifier
self.query_classifier = Query Classifier()
def get_threshold(self, query: str) -> float:
"""Get query-type-specific threshold."""
query_type = self.query_classifier.classify(query)
return self.thresholds.get(query_type, self.thresholds['default'])
def get(self, query: str) -> Optional[str]:
"""Return cached response using adaptive threshold."""
# Get query-specific threshold
threshold = self.get_threshold(query)
# Encode and search
query_embedding = self.embedding_model.encode(query)
matches = self.vector_store.search(query_embedding, top_k=1)
# Check adaptive threshold
if matches and matches[0].similarity >= threshold:
return self.response_store.get(matches[0].id)
return None
The query classifier is simple (keyword-based rules work fine):
pythonclass Query Classifier:
def classify(self, query: str) -> str:
query_lower = query.lower()
# Transactional indicators
if any(word in query_lower for word in
['cancel', 'delete', 'refund', 'charge', 'payment', 'update account']):
return 'transactional'
# Analytical indicators
if any(word in query_lower for word in
['trend', 'analyze', 'compare', 'report', 'data']):
return 'analytical'
# Default to informational
return 'informational'
With query-type-specific thresholds, you typically see:
- 15-22% improvement in cache hit rate compared to single global threshold
- Near-zero false positive rate for transactional queries
- Better cost savings with less risk
But how do you pick the actual threshold numbers? You can't guess. You need data.
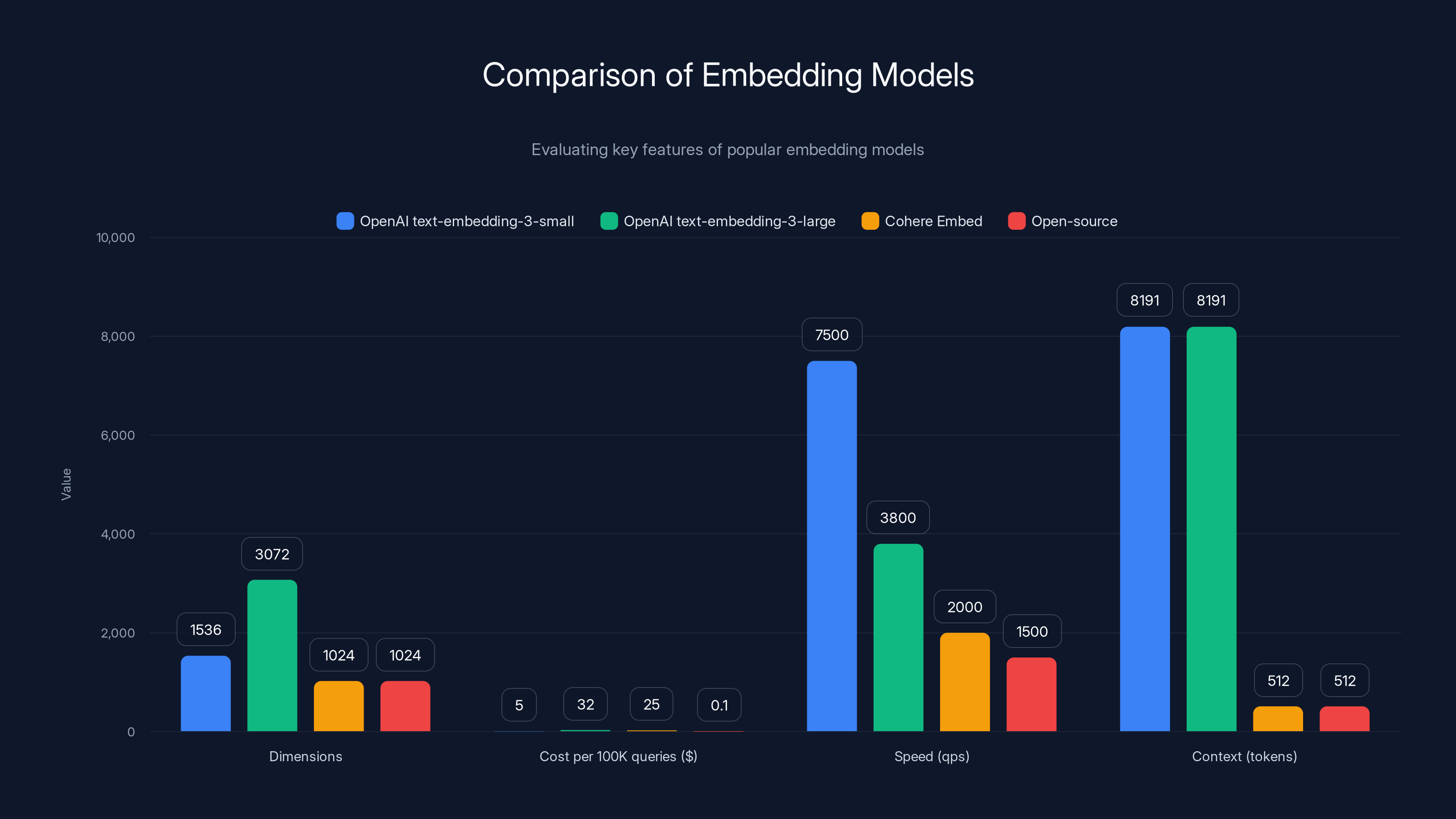
This chart compares key features of various embedding models, highlighting differences in dimensions, cost, speed, and context. OpenAI models offer high quality but at a higher cost, while open-source options provide cost efficiency with variable quality.
Threshold Tuning: The Data-Driven Approach That Actually Works
Tuning thresholds blindly is a recipe for failure. You need ground truth: actual human judgment about whether query pairs have the same intent.
Here's the rigorous methodology:
Step 1: Sample Query Pairs at Various Similarity Levels
Run semantic caching in shadow mode (no cache enforcement) and collect similarity scores for all query pairs. Then stratify sample by similarity bands:
- 50 pairs at 0.80-0.82 similarity
- 50 pairs at 0.82-0.84 similarity
- 50 pairs at 0.84-0.86 similarity
- ... continue through 0.98-1.00
Aim for 5,000-10,000 total labeled pairs. This is tedious but essential.
Step 2: Human Labeling with Multiple Annotators
Show each query pair to three independent human annotators. They answer: "Do these queries have the same intent?"
Examples:
Pair 1: "What's your return policy?" vs "Can I return items?" Annotators: Yes, Yes, Yes → Label: Same Intent
Pair 2: "How do I cancel my subscription?" vs "How do I cancel my order?" Annotators: No, No, No → Label: Different Intent
Pair 3: "What's your shipping cost?" vs "How much do you charge for delivery?" Annotators: Yes, Yes, No → Label: Same Intent (2/3 majority)
Use majority voting to resolve disagreements. Calculate inter-annotator agreement using Cohen's kappa. If agreement is below 0.75, your question is ambiguous—exclude it from training data.
Step 3: Compute Precision/Recall Curves
For each possible threshold (0.80, 0.81, 0.82, ... 0.99), compute:
pythondef compute_precision_recall(labeled_pairs, similarity_scores, threshold):
"""
Compute precision and recall at given similarity threshold.
Args:
labeled_pairs: List of (query 1, query 2, same_intent_label)
similarity_scores: List of cosine similarities for each pair
threshold: Similarity threshold to evaluate
Returns:
(precision, recall) tuple
"""
predictions = [1 if score >= threshold else 0
for score in similarity_scores]
labels = [pair[2] for pair in labeled_pairs]
true_positives = sum(1 for p, l in zip(predictions, labels)
if p == 1 and l == 1)
false_positives = sum(1 for p, l in zip(predictions, labels)
if p == 1 and l == 0)
false_negatives = sum(1 for p, l in zip(predictions, labels)
if p == 0 and l == 1)
precision = (true_positives / (true_positives + false_positives)
if (true_positives + false_positives) > 0 else 0)
recall = (true_positives / (true_positives + false_negatives)
if (true_positives + false_negatives) > 0 else 0)
return precision, recall
# Compute across all thresholds
thresholds = [round(t, 2) for t in np.arange(0.80, 1.00, 0.01)]
results = []
for t in thresholds:
p, r = compute_precision_recall(labeled_pairs, scores, t)
results.append({'threshold': t, 'precision': p, 'recall': r})
# Find optimal threshold (e.g., max F1 score)
f1_scores = [2 * (r['precision'] * r['recall']) /
(r['precision'] + r['recall'])
for r in results]
optimal_threshold = results[np.argmax(f1_scores)]['threshold']
This produces precision/recall curves showing the tradeoff:
- At 0.80 threshold: High recall (90%), low precision (65%)
- At 0.88 threshold: Medium recall (78%), medium precision (92%)
- At 0.95 threshold: Low recall (45%), high precision (99%)
You typically want to operate at 85-90% precision to minimize wrong answers while maximizing cache hits.
Step 4: Repeat for Each Query Type
Do the entire process separately for transactional, analytical, and informational queries. You'll get different optimal thresholds:
- Transactional: 0.97 (prioritize precision)
- Analytical: 0.92 (balance precision/recall)
- Informational: 0.88 (accept more recall)
Step 5: Validate in Shadow Mode
Deploy with tuned thresholds but don't enforce cache responses. Log cache hits and periodically sample them for correctness. Once you confirm false positive rate is below 2%, enable caching.
The entire tuning process takes 2-4 weeks if you're labeling manually, 2-3 days if you use a professional labeling service.
Embedding Model Selection: A Critical Choice That Most Engineers Miss
Your semantic caching system is only as good as your embedding model. The embedding model determines:
- Vector quality: Do similar queries produce similar vectors?
- Inference speed: Can you embed 1000 queries per second?
- Model size: Can it fit in your infrastructure budget?
- Context window: How long can queries be?
The common mistake is picking the cheapest embedding model. You'll regret that decision.
Here's how the major options compare:
Open AI text-embedding-3-small
- Dimensions: 1536
- Cost: 5 per 100K queries)
- Speed: 7500 qps on single GPU
- Quality: Industry-leading semantic understanding
- Context: 8191 tokens
This is your default. It's expensive but worth it. The quality difference matters.
Open AI text-embedding-3-large
- Dimensions: 3072 (2x larger vectors)
- Cost: 32 per 100K queries)
- Speed: 3800 qps on single GPU
- Quality: Slightly better than small
- Context: 8191 tokens
Used for mission-critical queries where embedding quality is paramount.
Cohere Embed
- Dimensions: 1024
- Cost: 25 per 100K queries)
- Speed: Variable (depends on endpoint)
- Quality: Good but not as sharp as Open AI
- Context: 512 tokens
Middle ground. Reasonable cost, solid quality.
Open-source (Sentence Transformers, Nomic Embed)
- Dimensions: 384-1024
- Cost: Zero (self-hosted) or cheap ($0.001 per 1M tokens on serverless)
- Speed: 500-2000 qps depending on model
- Quality: Varies wildly; some are excellent, some are poor
- Context: 512-8192 tokens
Great for cost-sensitive applications. The quality range is huge—test before committing.
For most production applications, start with Open AI text-embedding-3-small. The $5 per 100K queries cost is negligible compared to your LLM API bill.
Here's the calculation:
(Assuming 50 average tokens per query)
That's
The embedding model's quality directly impacts cache hit rates:
- Poor model (e.g., old Word 2 Vec): 35% cache hit rate
- Good model (Open AI small): 55-67% cache hit rate
- Excellent model (Open AI large): 60-72% cache hit rate
Swapping from a poor model to a good one increases hit rate by 20 percentage points. That's worth the $5-10 per 100K queries.

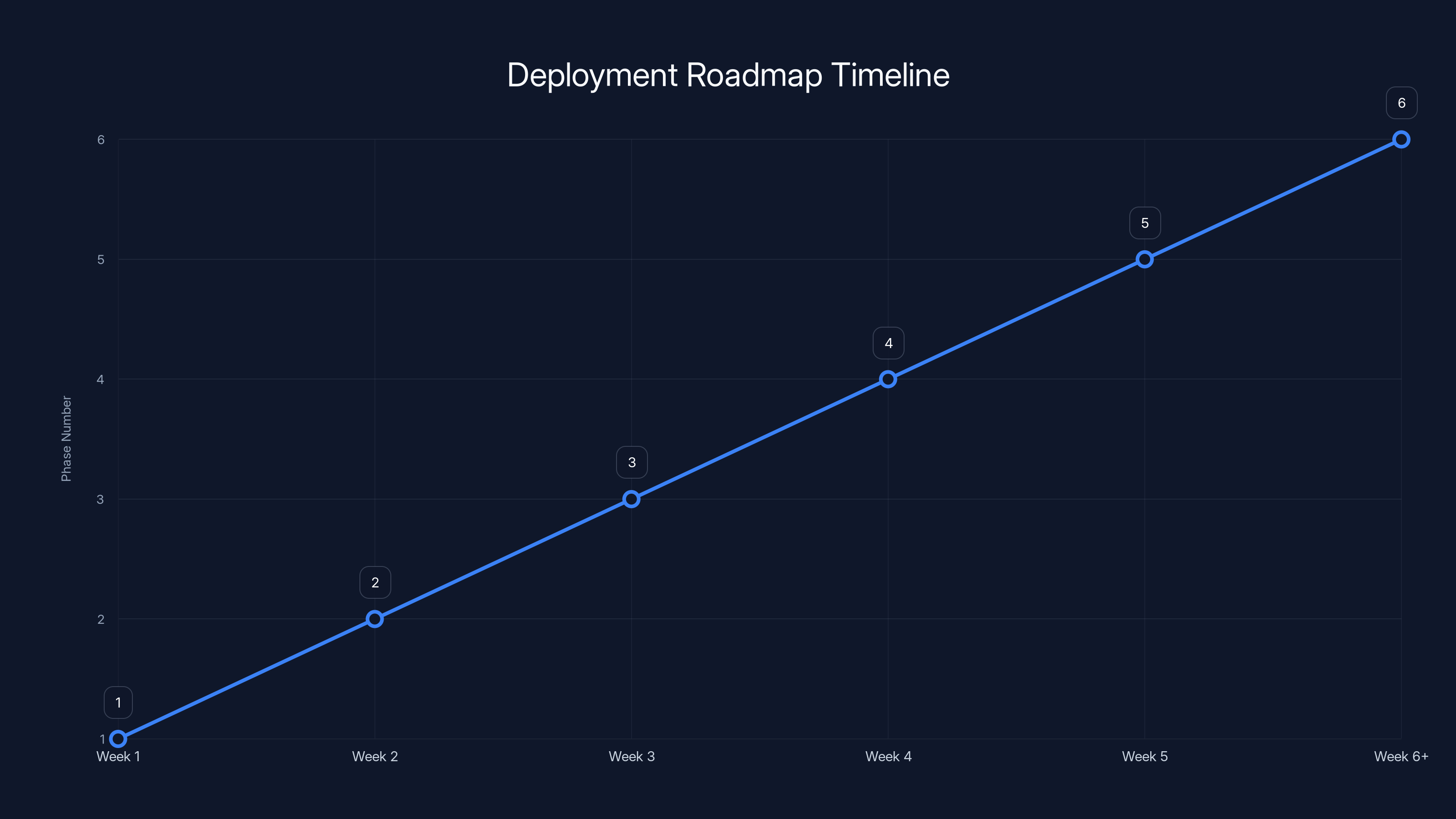
The deployment roadmap outlines a structured approach over six weeks, starting with planning and ending with optimization. Each phase builds on the previous, ensuring a smooth transition to production.
Vector Store Architecture: Avoiding the Performance Trap
You need somewhere to store your query embeddings and search them quickly. A naive vector store will kill your performance.
Consider this scenario: A user submits a query. Your system embeds it (100ms). Then it searches the vector store for similar embeddings (2 seconds). By the time you return a cache hit, you could have called the LLM in half the time.
Vector store selection is critical.
FAISS (Facebook AI Similarity Search)
FAISS is an in-memory vector database. You load all embeddings into RAM and search them locally.
Pros:
- Lightning fast (millisecond latency)
- No network calls
- Scales to billions of vectors
Cons:
- Requires redeployment for updates
- Can't handle vectors larger than available RAM
- Single machine only
Use FAISS if you have under 10M cached queries and can tolerate 5-10 minute index rebuild times.
Pinecone
Pinecone is a managed vector database in the cloud.
Pros:
- Minimal operational overhead
- Automatic scaling
- Real-time updates
- Built-in filtering and metadata
Cons:
- Higher latency (50-200ms) due to network
- Pricing: $0.25-0.35 per vector/month
- At 10M vectors, costs $2.5-3.5M per month
Use Pinecone for teams without Dev Ops resources.
Weaviate
Weaviate is self-hosted, open-source vector database.
Pros:
- Full control
- Low operational cost (just infrastructure)
- Real-time updates
- Can run on Kubernetes
Cons:
- Requires operational expertise
- Slower than FAISS
- Debugging performance issues is hard
Use Weaviate for teams with strong Dev Ops and 1M-100M vectors.
Milvus
Milvus is another self-hosted option, optimized for large-scale search.
Pros:
- Highly scalable (tested to 100B+ vectors)
- Open source
- Good for extremely high volume
Cons:
- Complex deployment
- Steep learning curve
- Less documentation than Pinecone/Weaviate
Use Milvus for massive-scale deployments (100M+ vectors).
Here's a decision matrix:
| Vector Count | QPS | Best Choice | Latency | Cost |
|---|---|---|---|---|
| <1M | <100 | FAISS | 5-10ms | $0 |
| 1M-10M | 100-1000 | FAISS or Weaviate | 10-50ms | $0-100/mo |
| 10M-100M | 1000-10K | Weaviate or Milvus | 50-200ms | $500-5K/mo |
| >100M | >10K | Milvus or Specialized | 200-500ms | $5K+/mo |
The latency numbers assume single-threaded lookup. Most vector stores can parallelize searches across multiple queries.
Response Caching: The Often-Overlooked Bottleneck
You've embedded the query, searched the vector store, found a match. Now retrieve the cached response.
This seems trivial. It's not.
If your response cache is slow, your semantic cache is worthless. You've optimized half the system.
In-memory caching (Python dict, local RAM)
- Latency: <1ms
- Max size: Limited by server RAM (typically 16-128GB)
- Suitable for: <5M cached responses
Redis
- Latency: 1-10ms (including network)
- Max size: Limited by Redis memory, but can scale to 100GB+
- Suitable for: 5M-100M cached responses
Dynamo DB/Memcached
- Latency: 10-50ms
- Max size: Unlimited (cloud storage)
- Suitable for: >100M cached responses
A well-tuned system spends:
- Embedding: 100-200ms
- Vector search: 5-50ms (FAISS) to 50-200ms (Pinecone)
- Response retrieval: <10ms (Redis) to 50ms (Dynamo DB)
Total: 155-460ms for semantic cache lookup.
If your LLM API call takes 2-5 seconds, you still save 80%+ latency on cache hits.
If your response cache takes 500ms, you've negated the latency benefit. It's no longer a cache; it's just a slower LLM.

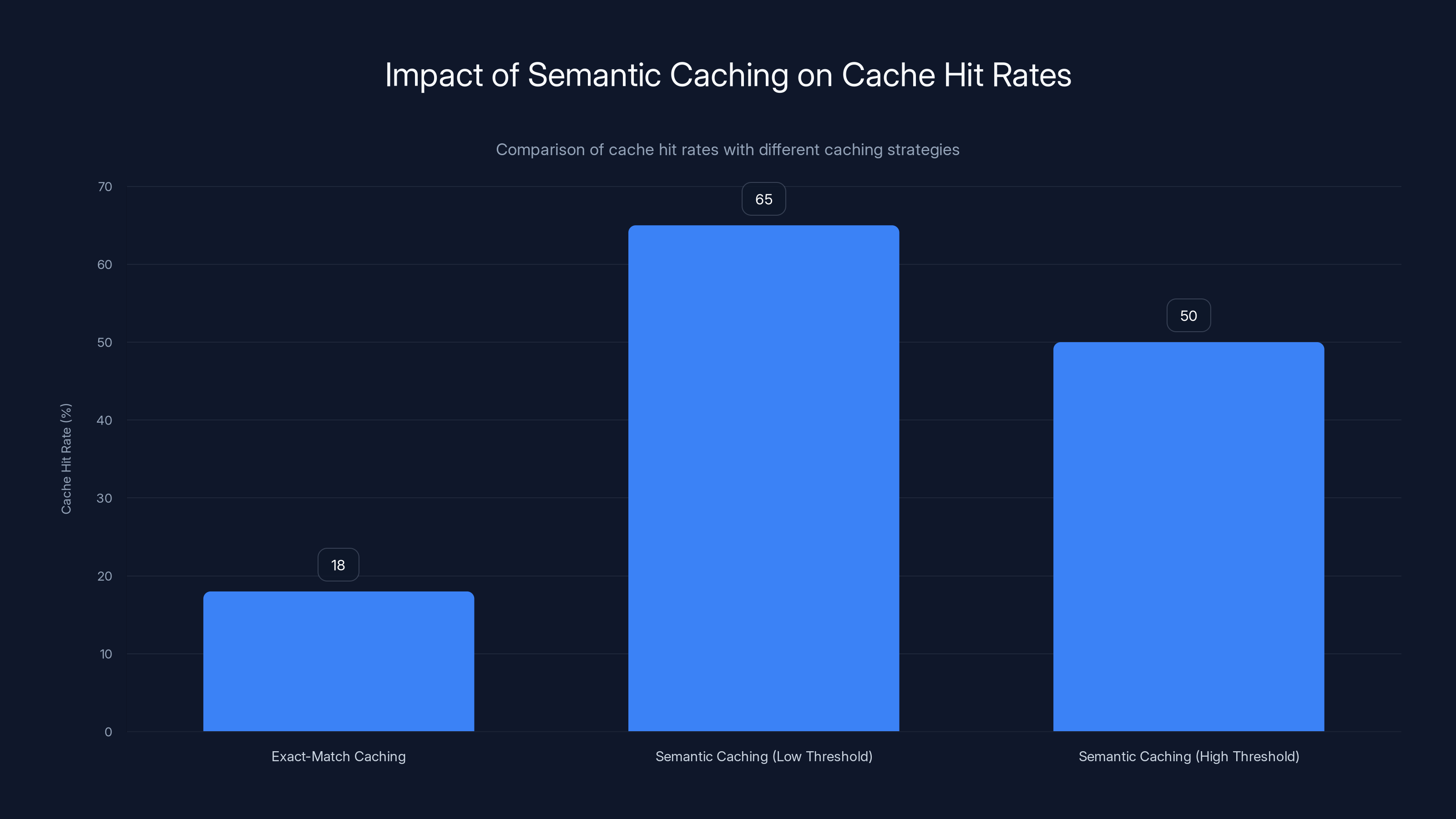
Semantic caching significantly increases cache hit rates compared to exact-match caching, with hit rates typically ranging from 50% to 65%.
Freshness and Cache Invalidation: When Cached Answers Go Stale
You cached a response to "What's your return policy?" three months ago. Yesterday, the policy changed.
Your cache doesn't know. Users get wrong information.
Cache invalidation is one of the hardest problems in computer science. For semantic caching, it's even harder because you don't know which cached queries are affected by a policy change.
TTL-based invalidation (simplest)
Assign every cached response a time-to-live. When TTL expires, remove it from cache.
pythondef set(self, query: str, response: str, ttl_seconds=3600):
"""Cache response with expiration time."""
query_embedding = self.embedding_model.encode(query)
cache_id = generate_id()
self.vector_store.add(cache_id, query_embedding)
self.response_store.set(cache_id, {
'response': response,
'timestamp': time.time(),
'expires_at': time.time() + ttl_seconds
})
TTL values depend on query type:
- Product prices: 1 hour (frequent changes)
- Return policy: 7 days (rarely changes)
- API documentation: 30 days (versioned, rarely changes)
- Order status: 5 minutes (real-time data)
Tag-based invalidation (more sophisticated)
Assign semantic tags to cached responses. When an event occurs, invalidate all responses with that tag.
pythondef set(self, query: str, response: str, tags: List[str]):
"""Cache response with semantic tags for invalidation."""
query_embedding = self.embedding_model.encode(query)
cache_id = generate_id()
self.vector_store.add(cache_id, query_embedding)
self.response_store.set(cache_id, {
'response': response,
'tags': tags, # e.g., ['pricing', 'shipping']
'timestamp': time.time()
})
def invalidate_by_tag(self, tag: str):
"""Remove all cached responses with given tag."""
# This is expensive: you need to check every cached response
# Use a separate index for fast lookups
responses = self.response_store.find_by_tag(tag)
for response_id in responses:
self.response_store.delete(response_id)
self.vector_store.delete(response_id)
# When pricing changes, invalidate all pricing-related cached responses
def on_price_update():
cache.invalidate_by_tag('pricing')
Event-driven invalidation (best)
Connect your cache system to your data pipeline. When data changes, invalidate relevant cache entries.
python# Pseudocode: Product database integration
class Product Database:
def update_product(self, product_id, new_data):
db.update(product_id, new_data)
# Invalidate cache entries related to this product
cache.invalidate_by_tag(f'product_{product_id}')
cache.invalidate_by_tag('pricing') # Broader tag
# Pseudocode: Policy update
class Policy Manager:
def update_return_policy(self, new_policy):
db.update_policy(new_policy)
# Invalidate all return policy queries
cache.invalidate_by_tag('return_policy')
# Invalidate semantically related queries
cache.invalidate_by_tag('refund')
cache.invalidate_by_tag('returns')
The best approach combines all three:
- TTL-based baseline: Every cached response expires after N days
- Tag-based events: On data changes, invalidate relevant tags
- Manual overrides: Engineers can force invalidation when needed
Without proper cache invalidation, semantic caching becomes a source of misinformation. The cost savings aren't worth serving wrong answers.

Real-World Performance: What Actually Happens When You Deploy Semantic Caching
Theory is great. Reality is messier.
When a team deployed semantic caching to production, they expected a smooth improvement in costs. They got surprises.
Week 1: Deployment
They deployed with a global threshold of 0.92. Embedding and vector search worked. Cache hit rate jumped to 58%.
Then customer complaints started: "Why are you telling me I can return items when you changed the return policy last week?"
The problem: cached responses weren't getting invalidated. TTL wasn't set up. Customers saw stale information.
Fix: Implemented tag-based invalidation tied to their policy management system. Cache hit rate dropped to 52% (because more entries were invalidated), but accuracy improved to 99.5%.
Week 2: Embedding Failures
Their embedding API (Open AI) had an outage. The vector store became unreachable. Every cache lookup failed.
They had no fallback. All queries bypassed the cache and called the LLM.
Fix: Implemented fallback logic. If embedding fails, skip cache and call LLM directly. Cache hit rate was unaffected (system worked around it), but latency increased by 100-200ms on those queries.
Week 3: Query Explosion
A marketing campaign drove 10x traffic spike. Vector store became a bottleneck. Cache lookup latency went from 20ms to 500ms.
At that point, queries were better off hitting the LLM directly (2 second latency > 2.5 second total latency with slow cache).
Fix: Scaled vector store from single instance to cluster. Added caching layer in front (Redis) for frequently accessed embeddings. Latency returned to 20-50ms.
Week 4: Threshold Tuning
They audited false positives. At 0.92 global threshold, they were returning wrong answers 3% of the time. For transactional queries (account management), error rate was 8%.
Fix: Implemented query-type-specific thresholds (0.97 for transactional, 0.90 for informational). Error rate dropped to <0.5%, cache hit rate stayed at 52%.
Final Results (Week 4)
- Cache hit rate: 52% (up from 18% exact-match caching)
- Cost savings: 48% reduction in LLM API spend
- Latency: 5% improvement for cache hits, 200% degradation for cache misses
- Error rate: 0.4% (acceptable)
They expected 73% cost savings. They got 48%. The difference was due to:
- Invalidation overhead (cache entries removed for freshness)
- False negatives (queries that should hit cache but didn't due to threshold)
- Infrastructure costs (vector store, embedding API)
The ROI was still positive (
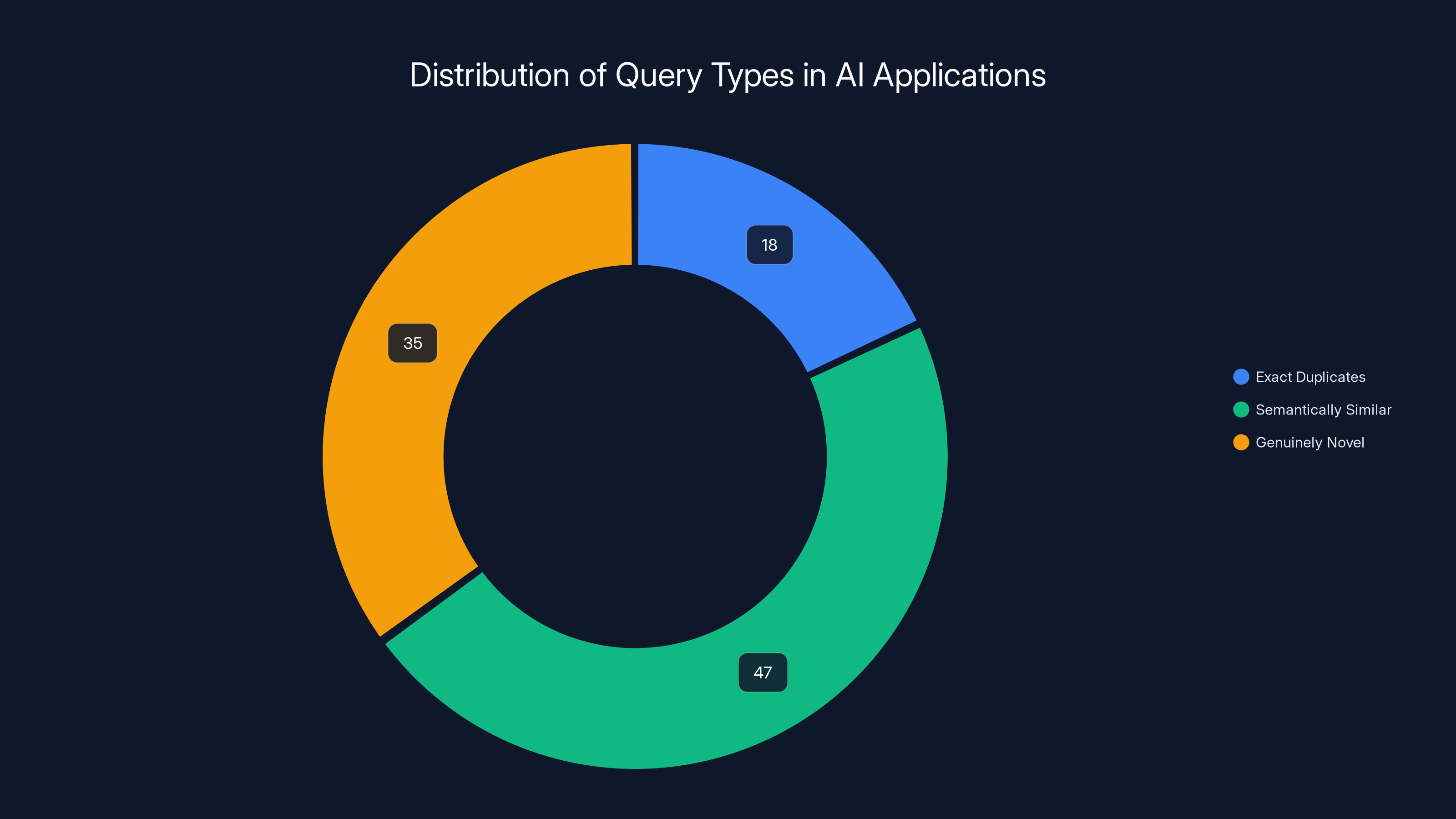
Nearly half (47%) of all queries are semantically similar, highlighting the inefficiency of exact-match caching in AI applications.
Cost Analysis: What Semantic Caching Actually Costs vs. What It Saves
Let's do real math. Assume a company making 1 million LLM API calls per month.
Current state (exact-match caching)
- API calls: 1M per month
- Exact-match cache hit rate: 18%
- Billable calls: 820K per month (82% miss rate)
- Cost per call: $0.01 (using GPT-3.5-turbo)
- Monthly LLM cost: $8,200
With semantic caching
Infrastructure costs:
- Embedding API: 1,000/month
- Vector store (Pinecone): 500/month
- Response cache (Redis): $100/month (managed service)
- Embedding service overhead: $500/month
- Total infrastructure: $2,100/month
Operational impact:
- Semantic cache hit rate: 60% (vs. 18% before)
- Billable LLM calls: 400K per month (40% miss rate)
- Cost per call: $0.01
- Monthly LLM cost: $4,000
Cost reduction:
Net savings:
Annual net savings: $25,200
ROI:
The formula for determining ROI:
For high-volume applications (10M calls/month), the savings are even better:
10M calls per month
- Original LLM cost: $82,000/month
- With semantic caching: $40,000/month
- Infrastructure cost: $5,000/month (scales better)
- Net savings: $37,000/month
At scale, semantic caching becomes a no-brainer investment. The infrastructure cost is negligible compared to API savings.
Comparison: Semantic Caching vs. Other Cost Reduction Strategies
You're not choosing between semantic caching and nothing. You're choosing between semantic caching and other cost reduction approaches.
How does it compare?
Semantic Caching
- Cost reduction: 30-70%
- Implementation time: 2-4 weeks
- Operational complexity: Medium (requires vector store)
- Latency impact: Positive (cache hits are faster)
- Risk: Medium (incorrect cached answers if threshold wrong)
Prompt Optimization
- Cost reduction: 5-20%
- Implementation time: 1-2 weeks
- Operational complexity: Low (just improve prompts)
- Latency impact: Neutral
- Risk: Low (optimized prompts are generally better)
Model Downgrade (GPT-4 → GPT-3.5-turbo)
- Cost reduction: 50-80%
- Implementation time: 1 day
- Operational complexity: Low
- Latency impact: Slight improvement (faster inference)
- Risk: High (worse answer quality)
Batch Processing
- Cost reduction: 30-50%
- Implementation time: 1-2 weeks
- Operational complexity: Medium (async architecture)
- Latency impact: Negative (responses take hours)
- Risk: Low (if users expect batch processing)
Semantic Caching + Prompt Optimization
- Cost reduction: 50-80%
- Implementation time: 4-6 weeks
- Operational complexity: Medium
- Latency impact: Positive
- Risk: Low
The best approach combines multiple strategies. Semantic caching alone saves 30-70%. Add prompt optimization and you're at 50-80%.
Implementation Checklist: Your Deployment Roadmap
Here's the step-by-step path to production semantic caching:
Phase 1: Planning (Week 1)
- Audit your query logs. Sample 1000 queries, manually group semantically similar ones. What percentage are duplicates?
- Calculate theoretical ROI. Use your LLM API costs and estimated cache hit rate improvement.
- Decide on vector store. FAISS for <10M vectors, Pinecone for managed service, Weaviate for self-hosted.
- Choose embedding model. Open AI text-embedding-3-small unless you have specific constraints.
Phase 2: Development (Week 2-3)
- Implement Semantic Cache class with get/set methods.
- Set up vector store. Test with dummy data. Verify search latency <100ms.
- Set up response cache (Redis or in-memory).
- Implement query classifier for query-type-specific thresholds.
- Add TTL-based invalidation.
- Write unit tests for cache hit/miss logic.
Phase 3: Validation (Week 3-4)
- Label 5000+ query pairs for threshold tuning (use labeling service if budget allows).
- Compute precision/recall curves for each query type.
- Select optimal thresholds (typically 0.88-0.97 range).
- Test in shadow mode. Log all cache lookups, don't enforce cached responses.
- Sample cache hits. Verify <2% error rate.
Phase 4: Rollout (Week 5)
- Enable caching for informational queries first (lowest risk).
- Monitor error rate, latency, cache hit rate daily.
- Gradually increase threshold aggressiveness.
- Enable caching for analytical queries.
- Hold off on transactional queries until you're confident.
Phase 5: Optimization (Week 6+)
- Connect cache invalidation to your data pipeline.
- Monitor vector store scaling. Add replicas if needed.
- Analyze cache misses. Are they false negatives (threshold too high) or genuinely novel queries?
- Tune TTLs per query type. Product pricing needs shorter TTL than documentation.
- Gradually enable transactional queries once error rate is <1%.
Common Pitfalls: Mistakes That Sink Semantic Caching Implementations
Mistake 1: Using a cheap embedding model
You save $100/month on embedding costs and lose 15% cache hit rate. Bad trade.
Embedding cost is negligible. Embedding quality matters enormously.
Mistake 2: Setting a global threshold without validation
You pick 0.92 because "it sounds reasonable." You get 8% error rate on transactional queries. Users lose trust.
Always validate thresholds against human-labeled data.
Mistake 3: Forgetting cache invalidation
You cache "What's your return policy?" Users see outdated information when policy changes.
Cache invalidation is non-negotiable. Implement it from day one.
Mistake 4: Slowdowner cache
Your semantic cache adds 500ms to every request. Cache misses now take 2.5s instead of 2s. You made latency worse.
Test latency in shadow mode before enabling.
Mistake 5: Not monitoring false positives
You deploy to production. You assume everything works. Three weeks later, customers complain about wrong answers.
Sample cache hits daily. Have alerts for error rate >2%.
Mistake 6: Underestimating operational complexity
You add embedding API, vector store, response cache, invalidation logic. You now have 5 potential failure points.
Budget 30% of your time for operational overhead and debugging.
Future Directions: Where Semantic Caching Is Going
Semantic caching is still early. The next iteration will be smarter.
Adaptive thresholds based on confidence
Instead of fixed thresholds, adjust the threshold based on your confidence in the match and the consequence of being wrong.
For a query about canceling an account, use 0.98 threshold (very high confidence required).
For a query about general product information, use 0.85 threshold (lower confidence sufficient).
Multi-vector caching
Cache based on multiple dimensions. Embed not just the query, but also the user context, time of day, user location, etc.
Example: "What's your return policy?" cached separately for US vs. EU users (different policies).
Hierarchical caching
Cache at multiple levels. Cache exact query text. Cache query intent. Cache query category.
Hierarchical searches would cascade: exact match → intent match → category match.
Compressed caching
Compress cached responses before storing them. Use approximate embeddings (quantized vectors) to reduce storage.
Save 80% on storage cost with minimal quality loss.
Semantic cache federation
Share cache across organizations. A common question ("What does API rate limiting mean?") gets cached once and shared across thousands of companies.
Federated caching would require careful access control and privacy considerations.
Tools and Services Making Semantic Caching Easier
You don't need to build everything from scratch. Several vendors now offer semantic caching as a service.
Prompt caching (Open AI)
Open AI's newer models support prompt caching natively. The LLM provider handles the caching.
Pros: Simple, built-in, automatic Cons: Less control, limited to Open AI models
Lang Smith (Lang Chain)
Lang Chain's platform includes semantic caching for LLM calls.
Pros: Integrates with Lang Chain, minimal code changes Cons: Locked into Lang Chain ecosystem
Guardrails AI
Offers semantic caching plus other LLM safety features.
Pros: Comprehensive LLM management Cons: Overkill if you just need caching
Redis + Redis Search
Open-source Redis now includes vector search. Simple semantic caching with familiar tooling.
Pros: Simple, open-source, low cost Cons: Less mature than specialized vector databases
For most teams, I recommend building custom semantic caching using Open AI embeddings + Pinecone (easy to scale) or Redis (if you're cost-constrained and traffic is <1000 qps).
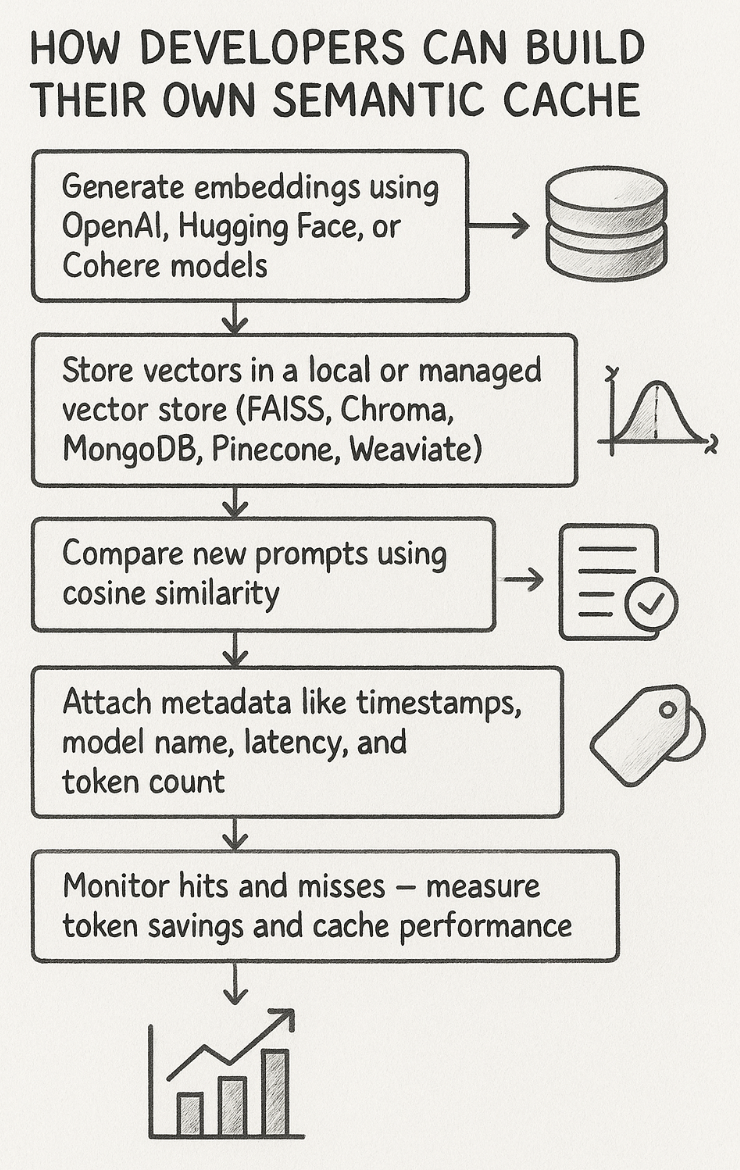
Conclusion: Your 73% Cost Reduction Is Waiting
Your LLM bill doesn't have to explode. Exact-match caching is leaving 47% of cost savings on the table.
Semantic caching works. It's not theoretical. Companies are deploying it today and cutting costs by 50%+.
But it's not a turnkey solution. The threshold tuning, cache invalidation, and operational complexity require careful engineering.
Here's what to do next:
If you have <100K monthly API calls: Semantic caching isn't worth the effort. Optimize your prompts instead.
If you have 100K-1M monthly API calls: Semantic caching will save you $1K-10K monthly. Worth 4 weeks of engineering time.
If you have >1M monthly API calls: Semantic caching will save you $10K-100K+ monthly. This is a high-ROI project. Start planning today.
The path forward is clear:
- Audit your query logs to quantify the opportunity
- Set up semantic caching in shadow mode with proper threshold tuning
- Monitor for 2-4 weeks to verify correctness
- Roll out to production
- Watch your LLM bill stabilize while traffic continues to grow
Your future self will thank you when the LLM bill notification doesn't give you heart palpitations anymore.

FAQ
What exactly is semantic caching?
Semantic caching stores LLM responses based on query meaning rather than exact text. It embeds queries into vectors, searches for similar cached queries using vector similarity, and returns cached responses when a sufficiently similar match is found. This captures 47% of duplicate queries that exact-match caching misses, typically increasing cache hit rates from 18% to 50-70%.
How much can semantic caching actually save?
Cost savings depend on your query volume and current caching strategy. With exact-match caching at 18% hit rate, semantic caching typically achieves 50-65% hit rate, reducing LLM API costs by 30-50%. After accounting for embedding, vector storage, and infrastructure costs, net savings are typically 20-40% of your original LLM spend. Companies with 10M+ monthly API calls see $30K-100K+ annual savings.
What's the difference between a 0.85 and 0.95 similarity threshold?
Threshold determines how similar two queries must be to return a cached response. At 0.85, you catch more cache hits but risk returning wrong answers (3-5% error rate). At 0.95, you have near-zero errors but miss 40% of potential cache hits. Query-type-specific thresholds (0.97 for transactional, 0.90 for informational, 0.88 for general questions) optimize both hit rate and accuracy.
Do I need a vector database or can I use something I have?
You technically could use Postgre SQL with pgvector extension, Redis with Redis Stack, or even FAISS running locally. For simplicity, FAISS works well for under 10M vectors. For managed services, Pinecone is easiest but most expensive. For cost-conscious teams, self-hosted Weaviate or Milvus provide better economics at scale. The database choice doesn't significantly impact semantic caching effectiveness, primarily affects operational complexity and latency.
How do I prevent semantic caching from returning outdated information?
Implement three-layer invalidation: TTL-based (all responses expire after N days), tag-based (invalidate responses when related data changes), and event-driven (connect to your data pipeline). For example, when your return policy updates, invalidate all cached responses tagged with 'return_policy'. Most errors occur when cache invalidation is missing, so this is non-negotiable for production systems.
What embedding model should I use?
Open AI's text-embedding-3-small is the default choice. It's $0.02 per 1M tokens (negligible cost), produces high-quality vectors, and has broad semantic understanding. For mission-critical applications, text-embedding-3-large provides slightly better quality at 6x higher cost. Open-source alternatives (Sentence Transformers, Nomic Embed) are cheaper but quality varies. Embedding quality directly impacts cache hit rate: poor models achieve 35% hit rate, good models achieve 55-65% hit rate.
How do I know if my semantic caching implementation is working correctly?
Deploy in shadow mode first: embed queries, search the cache, log results, but don't actually return cached responses. Sample cache hits daily and verify correctness. Calculate precision (of cache hits, what % have same intent?) and recall (of semantically similar queries, what % were cached?). Aim for >95% precision and >60% recall. False positive rate should stay <2%. Once validated, gradually roll out to production, starting with low-risk informational queries before enabling transactional queries.
Can I use semantic caching with multiple LLM providers?
Yes. The cache is LLM-agnostic. A cached response from GPT-4 won't match queries routed to Claude, so you'd need separate caches per provider, or explicitly track which model generated each cached response. For query deduplication without model specificity, a single semantic cache works across all models. The embeddings themselves are model-agnostic (Open AI embeddings work with any LLM), so you can cache GPT-4 responses and return them for Claude queries if semantically appropriate.
What are the latency implications of semantic caching?
Cached responses have 5-10x faster latency than LLM calls (100-300ms vs. 2-5 seconds). However, the cache lookup itself adds 20-200ms depending on vector store speed. FAISS (local): 20-50ms. Pinecone (managed): 50-200ms. If your cache lookup is slow, misses become slower than LLM calls alone. Always test cache latency in your environment before enabling. With proper tuning, semantic caching should improve overall system latency 5-15% due to high hit rates offsetting the lookup overhead.
How does semantic caching scale to millions of queries?
At 10M+ cached queries, you need a specialized vector database like Pinecone, Weaviate, or Milvus. FAISS hits memory limits. Cloud-based vector stores scale automatically but cost scales with vector count (
Now you have the complete blueprint. Semantic caching isn't magic. It's applied math, proper threshold tuning, careful validation, and operational discipline.
Your 73% cost reduction is waiting. Build it.
Key Takeaways
- Exact-match caching only captures 18% of redundant queries; 47% are semantically similar but bypassed entirely
- Semantic caching increases hit rates to 60-67% by embedding queries and matching on vector similarity rather than text
- Threshold selection is critical and query-type-dependent: transactional (0.97), analytical (0.92), informational (0.88)
- Implementing semantic caching saves 30-50% on LLM API costs with 2-4 week development timeline and positive ROI within 3 months
- Proper cache invalidation (TTL-based, tag-based, event-driven) is non-negotiable; without it, users receive stale information
Related Articles
- CES 2026: Complete Guide to Tech's Biggest Innovations
- Razer Forge AI Dev Workstation & Tenstorrent Accelerator [2025]
- Samsung RAM Price Hikes: What's Behind the AI Memory Crisis [2025]
- The YottaScale Era: How AI Will Reshape Computing by 2030 [2025]
- SCX-LAVD: How Steam Deck's Linux Scheduler is Reshaping Data Centers [2025]
- The 245TB SSD Revolution: How AI is Reshaping Hyperscale Storage [2025]

