![AI Bias as Technical Debt: Hidden Costs Draining Your Budget [2025]](https://tryrunable.com/blog/ai-bias-as-technical-debt-hidden-costs-draining-your-budget-/image-1-1771079941011.jpg)
AI Bias as Technical Debt: How Hidden Biases Are Draining Your AI Budget
Introduction: The $8.6 Billion Problem Nobody's Talking About
Here's what keeps CTOs awake at night: your AI system is biased, and you don't know it yet.
Not in the abstract, philosophical sense. In the cold, hard financial sense. Every month that bias sits undetected in your production models, it's quietly accumulating operational risk, customer churn, legal exposure, and unplanned costs that'll shock you during budget review.
Bias in AI isn't a new problem. We've known for years that algorithms trained on historical data can perpetuate discrimination. What's new is the realization that bias isn't just an ethical liability—it's the most insidious form of technical debt. And unlike traditional tech debt, which at least gets documented, bias hides. It compounds. It metastasizes through your systems while looking like normal operational efficiency.
Last year alone, UK ecommerce platforms estimated £8.6 billion in sales were put at risk because of negative AI experiences. That's 6% of the entire online spending market, largely driven by poorly designed, biased, or simply blind automation that failed to read human context. Customers got stuck in chatbot loops. Payment systems rejected valid transactions. Customer service escalations were automated right past the point of human intervention. And each time, trust evaporated.
But here's the part that should terrify executives: most of that damage wasn't from malicious AI. It was from biased systems deployed too quickly, monitored too loosely, and treated as "set and forget" infrastructure. The technical debt wasn't buried in bad code—it was baked into model assumptions, training datasets, and workflow logic that nobody questioned because the system appeared to be "working."
The bigger, more expensive problem is what happens next. When a customer reports a biased decision. When a regulator starts asking questions. When your hiring algorithm surfaces in a lawsuit. When a demographic group suddenly starts churning at 3x the rate of others. That's when you discover the real cost: not the cost of building the system, but the cost of fixing it after it's already embedded in your operations.
This is the story of why AI bias has become the new form of technical debt—and why ignoring it is costing your business millions.

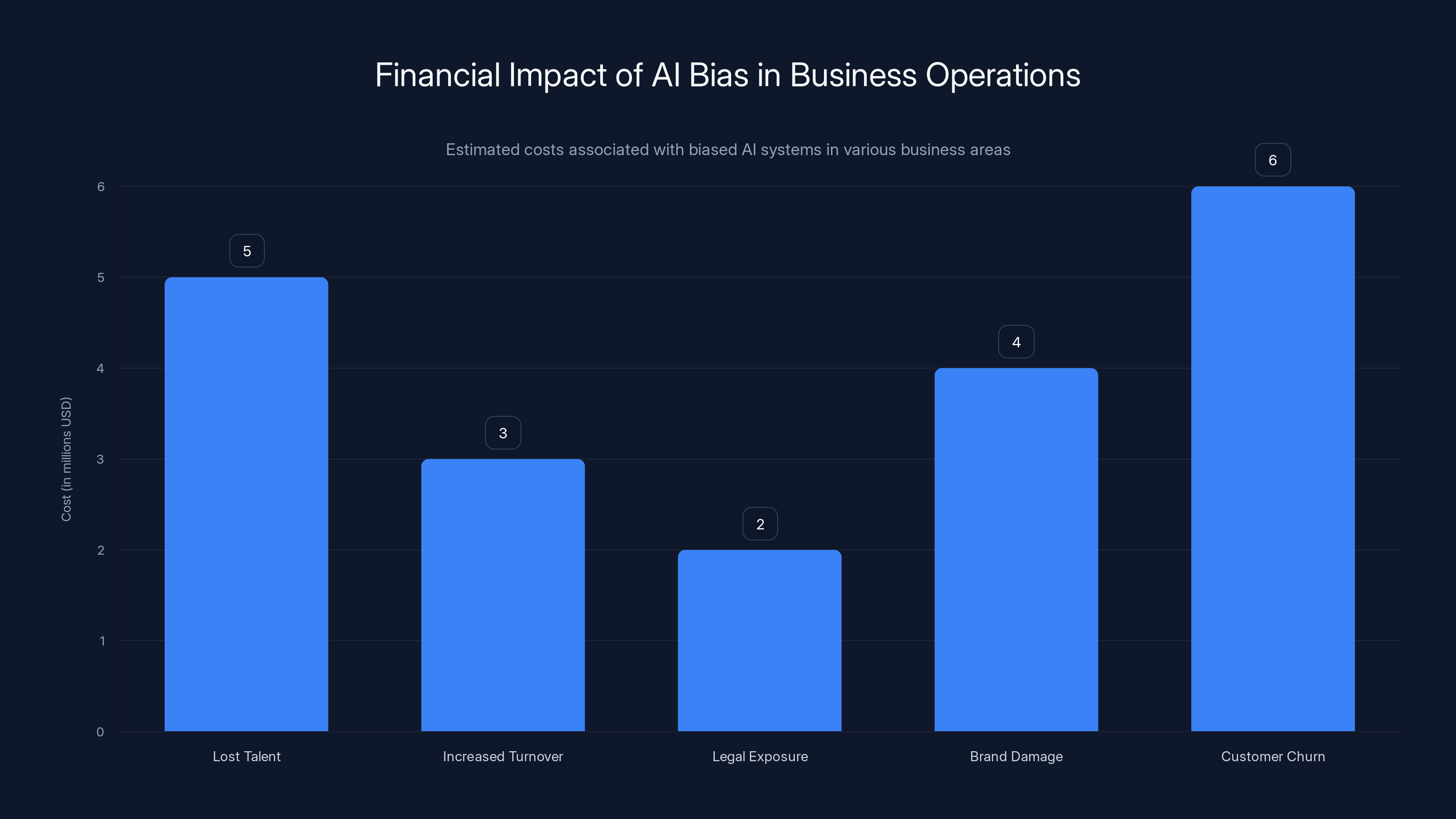
Estimated data shows that biased AI systems can lead to significant financial losses across various business areas, with customer churn and lost talent being the most costly.
TL; DR
- AI bias creates technical debt, not just ethical problems. It compounds costs through rework, legal fees, regulatory fines, and customer churn that can reach $10–100 million for large enterprises.
- Negative AI experiences drive measurable revenue loss, with UK ecommerce alone losing £8.6 billion annually (6% of market) due to poor AI interactions like chatbot loops and automated escalations.
- Biased systems deployed without oversight create hidden liabilities that multiply over time. A single bad customer interaction causes people to tell two others, amplifying damage exponentially.
- Prevention costs far less than remediation. Fixing biased systems after deployment can cost 50–100x more than addressing bias during design and testing phases.
- Executive ownership and diverse teams are non-negotiable. Organizations that treat bias as a core performance metric, not a side ethics task, avoid 70–80% of downstream costs.
- Continuous monitoring is mandatory. Models drift. Bias that didn't exist six months ago can emerge quietly. Regular demographic stress-testing and user feedback loops catch problems before customers do.
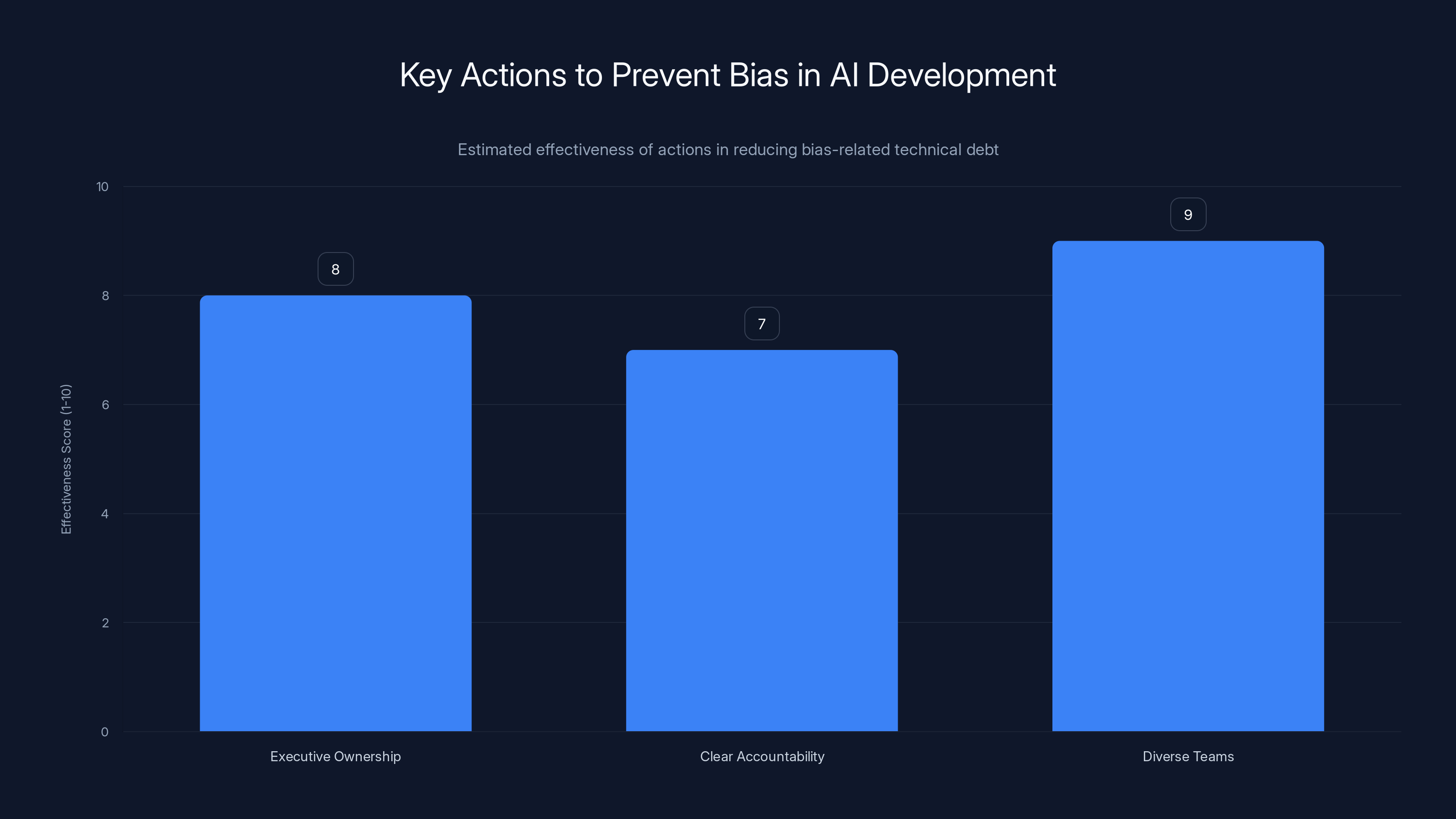
Executive ownership, clear accountability, and diverse teams are estimated to be highly effective in reducing bias-related technical debt. Estimated data.
What Is AI Bias, and Why Does It Cost Money?
Understanding Bias Beyond Ethics
When most people hear "AI bias," they think about fairness. A hiring algorithm that discriminates. A loan approval system that denies credit to certain zip codes. An image classifier that fails on darker skin tones. These are real, serious problems—but they're also just the surface.
The deeper issue is this: biased AI systems don't just make unfair decisions. They make wrong decisions. Systematically. And when you deploy a systematically wrong decision-making system across thousands of transactions, millions of customer interactions, or billions of decisions annually, you're not just creating an ethical problem. You're creating a cost center masquerading as efficiency.
Think about what "bias" actually means in a machine learning context. It's systematic error. If your training data overrepresents certain groups, underrepresents edge cases, or contains historical patterns you'd rather not perpetuate, your model learns those patterns. When deployed, it applies them consistently. To everyone. At scale.
A biased hiring algorithm doesn't just reject qualified candidates from underrepresented backgrounds. It rejects good hires your competitors will snap up. It narrows your talent pool. It increases turnover because new hires don't fit the narrow profile your biased system preferred. It creates legal exposure if a rejected candidate can show disparate impact. And when word spreads (and it always does), you've damaged your employer brand among entire communities.
That's not an ethics problem. That's an operational problem with financial consequences.
Where Bias Hides in Your Systems
Bias doesn't announce itself. It doesn't set off alarms. It lives in places you're not looking.
In your training data: Historical patterns encoded in datasets carry forward existing inequities. A model trained on decades of hiring decisions learns not just what "a good hire" looks like in your data—it learns all the biases your company perpetuated along the way.
In your feature engineering: The variables you choose to include (or exclude) shape what your model learns. If you're predicting default risk and include zip code as a feature, you're proxying for race and creating systematic bias even if you explicitly exclude demographic variables. Models find the patterns you give them.
In your optimization objective: You optimized for speed. For cost reduction. For throughput. But you didn't optimize for fairness, accuracy across groups, or human judgment in edge cases. Guess what wins? The optimization target. A chatbot optimized for "close conversations quickly" will systematically fail at bereavement, disputes, or complex complaints.
In your deployment: Nobody's looking. Your system runs for six months without demographic audit, user feedback loop, or human oversight. Bias compounds silently.
In your model drift: The world changes. Customer demographics shift. Economic conditions alter. A model that was fair six months ago can drift into systematic bias without retraining, and you'd never know because nobody's monitoring it.
The Financial Mechanics of Bias as Technical Debt
Let's talk about the actual money.
Technical debt is the cost of taking shortcuts now and paying for them later with interest. You deploy code faster by skipping tests. Later, bugs cost more to fix. You build without documentation. Later, onboarding new engineers takes months. The cost of fixing compounds because everything's now interconnected and fragile.
Bias works the same way, except the "interest" accumulates faster.
When you deploy a biased system without oversight, you're essentially saying: "We'll find the problems when customers report them, and fix them then." But here's what actually happens:
Immediate costs (hidden, not budgeted): Customer complaints increase. Support tickets spike. You hire more support staff to handle escalations. Your help desk is now perpetually fighting fires instead of solving problems. That's real money, unbudgeted, bleeding from your operational costs.
Medium-term costs (legal and regulatory): A customer group notices they're systematically declined, charged more, or poorly served. They hire a lawyer. A regulator starts asking questions. You need outside counsel, internal compliance reviews, documentation audits. Legal costs alone can reach
Long-term costs (rework and remediation): You need to retrain models. That means collecting new data, running experiments, validating results, redeploying. If the bias is embedded in multiple systems or datasets, multiply the cost. Some companies have spent $10–50 million remediating widespread bias discovered in legacy systems.
Reputational costs (revenue impact): Customers leave. Word spreads. Employer reviews plummet. Acquisition costs increase because your brand is damaged. Revenue retention drops. For a company with
Add them up: support overhead + legal fees + rework + revenue loss. A moderately biased system in a large organization can easily consume $20–100 million in total costs before it's remediated.
Where's that money coming from? Your AI budget. Your operational budget. Unplanned "emergency" allocations. It's technical debt, compounding with interest.
The Real-World Cost: Automation That Makes Things Worse
When Chatbots Become Customer Service Disasters
Your customer calls because they're upset. Maybe they were charged twice. Maybe their account is locked. Maybe they're dealing with a refund after returning a product. They need help, and they need empathy. What do they get? A chatbot.
Not because your company hates them. Because automation is cheaper. And most of the time, it works fine. But here's where bias enters: the chatbot is optimized for throughput. For closing conversations quickly. For routing to the smallest number of buckets possible. It's not optimized for reading emotional weight, handling exceptions, or knowing when a human touch is mandatory.
A biased (or simply blind) chatbot will:
- Loop users endlessly through the same menu options without escalating
- Provide automated responses that completely miss the actual problem
- Escalate to a human only after 15 minutes of frustration
- Route sensitive issues (bereavement, fraud disputes, major account changes) through the same system as routine inquiries
- Treat all customers the same way, regardless of their history, account status, or situation urgency
The result? A customer who came to resolve a problem leaves angrier, feels disrespected, and tells two other people about their terrible experience. Each of those people has now heard a negative story about your company's customer service. Trust drops before they ever interact with you.
One recent review perfectly captured this: a customer trying to close their account after a family death described being "stuck in a cul-de-sac"—an apt metaphor for circular automation that provides no way out except escalation. That phrase costs you. It's quotable. It's shareable. It becomes part of your brand narrative, and no amount of marketing fixes it.
The math: If that customer would have spent
Deploy a thousand biased interactions across your customer base. Now you're looking at real numbers.
Discrimination Lawsuits and Regulatory Investigations
The Workday lawsuit is instructive because it shows the anatomy of how bias becomes liability.
Workday sells HR software, including recruiting tools. A major employer customer deployed Workday's screening functionality to filter job applications. The intended purpose: streamline hiring. The actual result: the system systematically downranked female candidates, particularly in technical roles.
When the evidence surfaced, it wasn't just a product issue. It became a legal issue. The employer faced potential discrimination claims. Workday faced reputational damage and customer confidence erosion. The cost wasn't just the software—it was the entire incident response, investigation, potential settlements, and customer retention efforts.
This is the playbook that repeats:
- Biased system deploys without adequate testing
- System makes systematically unfair decisions at scale
- Affected group notices and documents the pattern
- External party (candidate, employee, regulator, plaintiff bar) investigates
- System is shut down or modified
- Company issues statement, does investigation, incurs legal costs
- Reputational damage compounds: press coverage, social media, industry discussions
- Customer confidence drops; some customers leave
- Remediation and retraining costs multiply
- Settlement or regulatory action (if warranted)
The total cost:
Credit and Lending: Bias as Revenue Loss
In financial services, bias doesn't just mean unfairness—it means you're literally rejecting profitable customers.
Imagine your loan approval algorithm is biased. It was trained on decades of historical lending data, which includes all the historical racism of lending. Redlining patterns are encoded in the data. Geographic proxies for race are in your features. Your model learns: "People from neighborhood X have lower default rates in our historical data, so prioritize them."
What your model is actually learning: "We lent money more easily to some groups and restricted lending to others, and the groups we restricted had more defaults. The defaults weren't because of inherent risk—they were because we didn't lend to them as much, so our data is biased."
When deployed, your biased model perpetuates and amplifies that bias. You approve loans to people who look like your historical good customers (often defined by race, geography, or socioeconomic status). You reject people from groups where you historically lent less, creating a self-fulfilling prophecy.
The financial impact is brutal:
- Lost revenue: You're rejecting creditworthy customers who would have been profitable.
- Regulatory fines: Fair Lending laws exist precisely to prevent this. Fines start at $10 million and scale upward based on scope of harm.
- Forced remediation: You may be required to solicit and approve loans from previously rejected groups, incurring costs on both approval and servicing.
- Reputational damage: Your brand becomes associated with discriminatory lending, affecting recruitment, partnerships, and customer trust.
A mid-sized bank found that after removing racial proxies from their lending algorithm, approval rates for previously disadvantaged groups increased by 15%, and default rates were actually 8% lower than the biased model predicted. Turns out the bias wasn't catching risk—it was just perpetuating historical patterns.
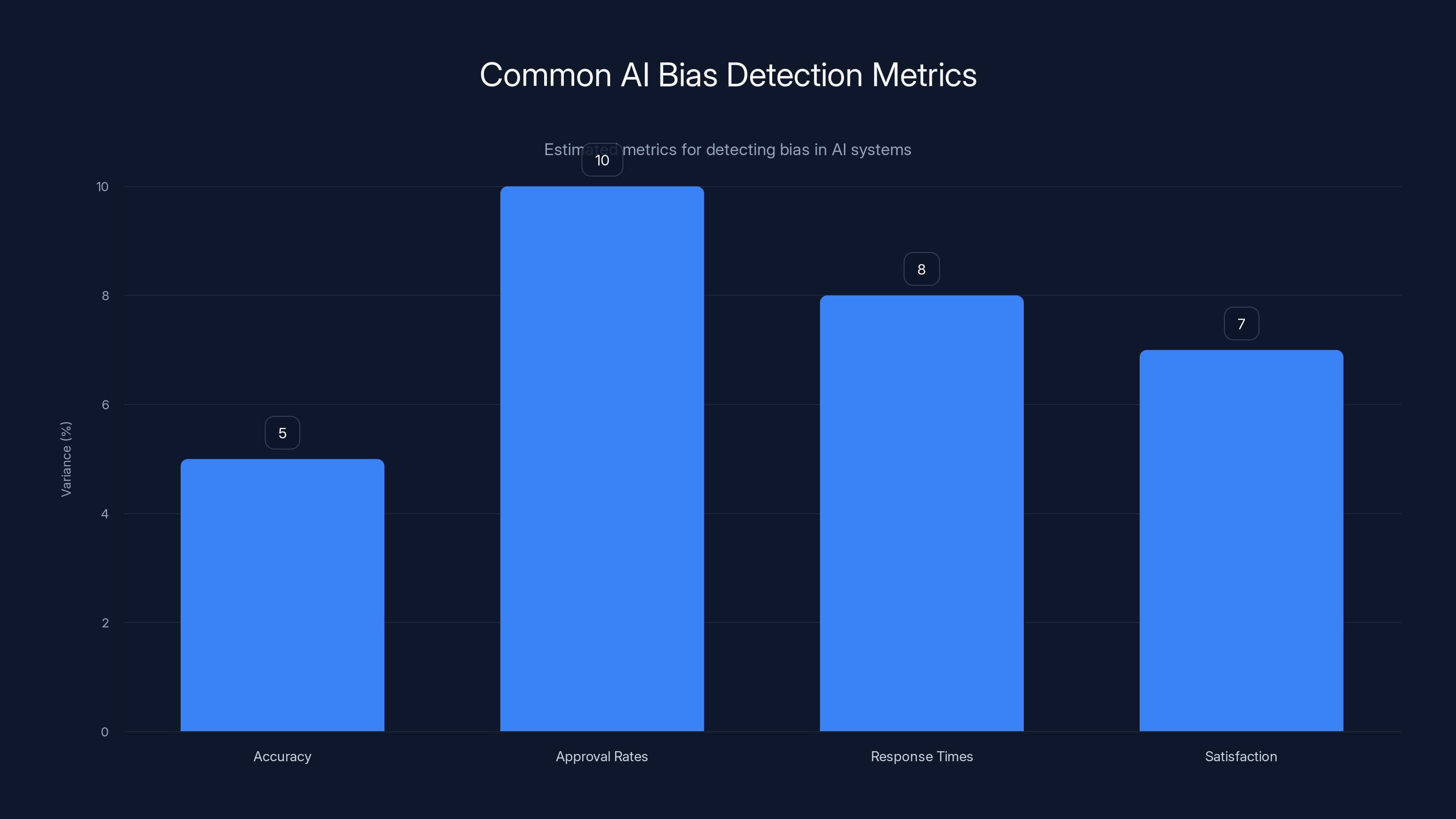
Estimated data shows potential variance in AI performance metrics across demographics, highlighting areas where bias may exist. Estimated data.
The Ripple Effect: How One Biased Decision Multiplies
The Math of Customer Amplification
One customer has a bad experience with your biased AI system. What happens next?
Research shows that a single negative experience causes a customer to tell an average of 2 other people. But that's the baseline. For service failures caused by automation, the number is higher—2.5 to 3 people, because it feels like an impersonal violation. "A robot decided I wasn't worth helping."
So your single bad customer interaction reaches 2-3 people. Some of those people talk to others. The story becomes slightly more dramatic in the retelling (as stories do). Now 5-10 people have heard a negative narrative about your company, most of whom have never interacted with you.
How many of those people change their behavior? Not all. Maybe 20-30% factor it into their decision. But if even 10% of the people in a "told them about you" network shift behavior, your customer acquisition cost increased and your organic reach decreased.
Multiply that across thousands of interactions annually:
- 1,000 biased interactions = reaching 2,000–3,000 people
- At 20% behavior change = 400–600 people whose perception is now negative
- At average customer lifetime value of 800K–$1.2M in potential revenue impact** from 1,000 bad interactions
- Spread across a year, a system handling millions of interactions could cause tens to hundreds of millions in aggregate reputation damage
That's the ripple effect. One biased decision doesn't cost
The Accumulation Problem
Here's why technical debt is the perfect metaphor: bias doesn't manifest as one catastrophic failure. It accumulates.
Month 1: Your biased system makes 10,000 decisions. Some are wrong, affecting 500 customers. You don't notice because they're scattered across demographics, regions, and time.
Month 2: Another 10,000 decisions. Another 500 affected customers. Now you have 1,000 customers with a negative experience, but they don't know each other. No unified story emerges.
Month 6: 3,000 customers have been affected. Patterns start emerging in social media, review sites, internal tickets. But the decisions were made over 6 months, so nobody connects the dots immediately.
Month 12: 6,000 customers affected. A journalist picks up a story about your algorithm. Suddenly, 12 months of accumulated bias surfaces in a single news cycle. The problem looks catastrophic, even though it accumulated gradually.
The compounding effect is insidious because it's invisible while accumulating and obvious in retrospect. Each individual decision seemed fine. But the pattern, once visible, becomes the story of your company.

Why Bias Hides Until It's Expensive to Fix
The Illusion of Automation Efficiency
You deploy an AI system to replace manual decision-making. The system processes 10x more volume. Cost per transaction drops. Metrics look beautiful. Your CFO is happy.
What's not in the metrics? The decisions that are systematically wrong. Because wrong decisions don't announce themselves. They just happen. A rejected loan application doesn't generate a ticket saying "this was biased." A customer served by a poor chatbot doesn't leave a review saying "your AI was trained on biased data." They just leave. Their silence is your blind spot.
You're measuring:
- Throughput (decisions per second)
- Cost (cost per decision)
- Apparent accuracy (percentage of decisions matching historical patterns)
You're not measuring:
- Accuracy across demographic groups
- False positive/negative rates by subgroup
- Equity in outcomes
- Customer satisfaction by demographic
- Churn rate by decision type
You're not measuring these things because:
- They're harder to measure than raw throughput
- They require demographic data, which many teams are reluctant to collect
- They contradict the efficiency narrative you sold to leadership
- They expose the biased decisions you've already made
So bias hides under a layer of plausible metrics. Everything looks good until someone from outside—a regulator, a journalist, a lawyer—starts asking different questions.
The Legal Risk Compound
Bias also hides because of legal complexity. What is discrimination? Is it intent, or outcome? If your system has disparate impact (different outcomes across groups) even without explicit bias in the code, is that discrimination?
The law varies by jurisdiction. In the US, Fair Lending law focuses on outcomes. If your lending algorithm has disparate impact on protected groups, you've violated the law regardless of intent. Other jurisdictions focus on transparency and explainability.
While legal teams debate what exactly is illegal, biased systems keep running. Because removing a biased feature, changing an optimization target, or adding fairness constraints requires rebuilding, retraining, and revalidating. It's work. It costs money. And if the legal framework is unclear, executives often defer.
That deferral is itself a risk. Because regulators—particularly in Europe (GDPR, AI Act) and increasingly in the US—are moving to explicit requirements for algorithmic accountability. Waiting for clarity means implementing late, scrambling, and incurring rush costs.

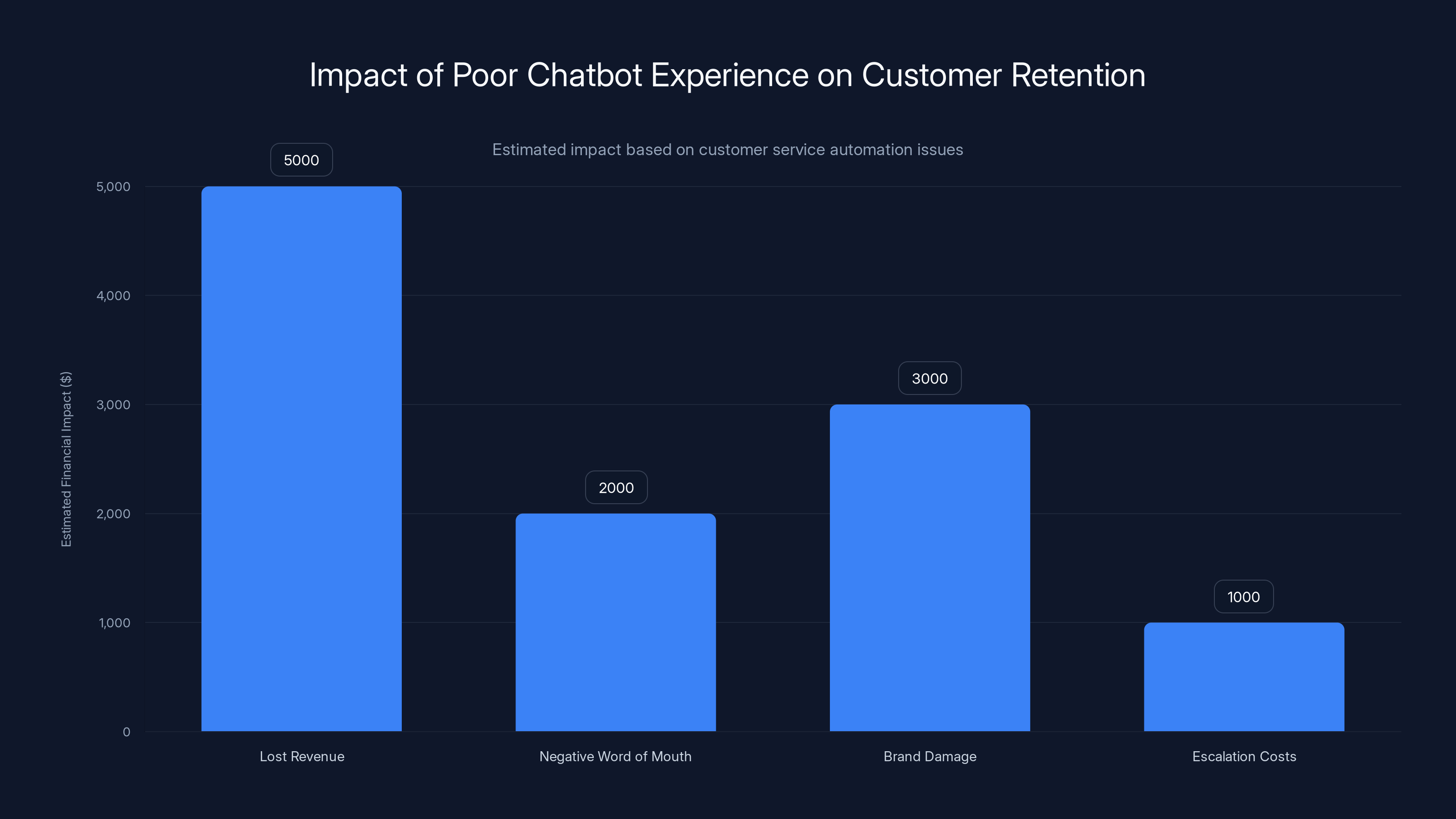
Estimated data shows that poor chatbot experiences can lead to significant financial impacts, including lost revenue and brand damage.
The Workday Example: A Case Study in Compounded Costs
The Workday hiring algorithm case illustrates the full cost structure of biased AI deployed without adequate safeguards.
What happened: Workday's recruiting tool, used by major employers, systematically downranked female candidates in technical roles. The bias wasn't intentional—it emerged from training the model on historical hiring patterns, which encoded decades of gender discrimination in hiring.
How it was discovered: The bias didn't surface from internal testing or audits. It surfaced when external researchers and advocacy groups investigated and found systematic disparities in recommendation rankings by gender.
The cost cascade:
-
Immediate reputation damage: News coverage of a "sexist algorithm" hits major tech publications. Your customers learn your product is biased. Trust erodes.
-
Customer risk assessment: Enterprise customers start asking whether other parts of Workday are biased. Procurement teams put contracts under review. Churn risk increases.
-
Product remediation: Engineers must investigate how bias entered the model, identify the biased features or training patterns, rebuild and retrain the algorithm, validate the fix across demographic groups, and deploy carefully with monitoring.
-
Legal exposure: While the initial harm was limited (it's a recruiting tool, not a hiring algorithm itself—employers make final decisions), regulatory agencies could still investigate. Advocacy groups could sue. The reputational damage suggests customer harm.
-
Proactive customer communication: Workday must reach out to all customers using this feature, explain the problem, offer remediation, and help them audit past decisions. That's expensive support overhead.
-
Process changes: Implement bias testing in development. Hire fairness specialists. Establish regular audits. All of these are ongoing costs, not one-time fixes.
Total estimated cost: While never disclosed publicly, industry estimates for companies of Workday's scale suggest $50–150 million in direct costs (remediation, legal, customer support), plus immeasurable reputational damage.
Why so expensive? Because the bias was discovered by external parties, not caught internally. If Workday had caught this during development with diverse testing teams, the cost to fix would have been in the $1–5 million range.
The ratio is stark: fix bias before deployment = cheap. Fix after discovery = catastrophically expensive.

How Biased Systems Compound Over Time
The Feedback Loop Problem
Here's where it gets truly insidious: biased AI systems create feedback loops that embed bias deeper over time.
Example: Your hiring algorithm is trained on historical data showing that candidates from top universities have better 5-year outcomes. The algorithm learns to rank top-university candidates higher. When deployed, it recommends them more often. Recruiters hire them more often (following the algorithm's advice). Five years later, those candidates indeed have better outcomes.
But here's the catch: they had better outcomes not because they were better candidates, but because they were hired in higher volumes and given better opportunities. The algorithm created a self-fulfilling prophecy. When you retrain the model on this new data, the bias strengthens.
This is particularly insidious in:
-
Lending: Approve loans to Group A, reject Group B. Group A has better repayment rates not from better credit risk, but from better economic conditions and higher loan amounts. Retrain on this data, bias gets worse.
-
Content recommendation: Show content to users who engage with it, suppress content for those who don't. Users disengage with suppressed content not from lack of interest, but from not seeing it. Retrain, bias compounds.
-
Credit scoring: Historical data shows Group A pays bills on time. Give them better credit, they get better jobs, better opportunities, better repayment rates. Group B gets worse credit, limiting their economic mobility, worsening repayment rates. Retrain, disparities widen.
Each retraining cycle deepens the bias. Each bias deepening widens the disparity. Eventually, you have a system where the gap between groups is so wide it's obviously wrong—but by then, you've been optimizing toward that disparity for years.
Drift and Decay
Even if your model was fair six months ago, it might not be fair today.
The world changes. Customer demographics shift. Economic conditions alter. Regulatory requirements evolve. A model that was trained once and deployed is decaying with every passing month.
Without retraining, a fair model gradually becomes less fair. Without monitoring, you won't notice. The bias compounds silently.
Why doesn't retraining solve this? Because retraining is expensive, risky, and easy to defer. You need to:
- Collect new data
- Validate quality
- Run experiments
- Test for bias across demographic groups
- Get sign-off from compliance/legal
- Deploy and monitor
That's weeks of work. Most teams retrain quarterly, semi-annually, or annually. In between, model performance decays, and bias can emerge.

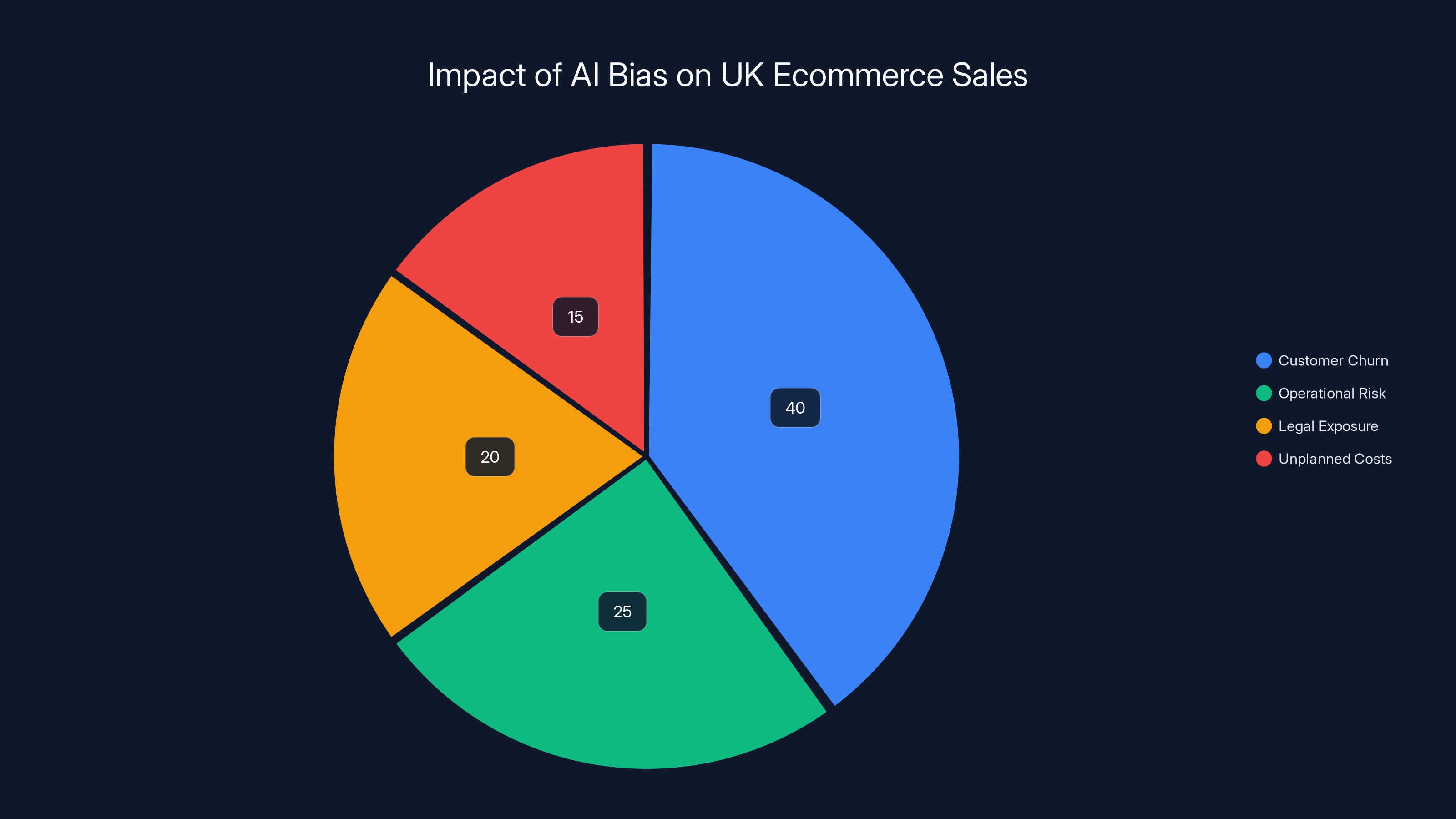
Estimated data shows that customer churn accounts for the largest portion of the £8.6 billion at-risk sales due to AI bias, highlighting the need for improved AI monitoring and bias mitigation.
From Rush-to-Deploy to Rush-to-Repair: The Cost Escalation
Why Companies Deploy Biased Systems
Companies aren't stupid. They know bias exists. So why deploy biased systems?
The answer is the same reason technical debt exists at all: speed trades with safety, and speed wins when you don't account for the true cost of debt.
Your competitor just launched an AI-powered feature. Your customers are asking why you don't have it. Your board is asking why your AI roadmap is behind. There's pressure to move fast.
Moving fast means:
- Skip the fairness audit ("we'll add it later")
- Deploy with limited demographic testing ("we'll expand testing after launch")
- Don't hire a fairness specialist ("we can learn as we go")
- Don't establish monitoring ("we'll set it up once we understand the system better")
- Don't involve diverse teams in design ("we can validate with diverse testers after")
Each of these shortcuts saves weeks. Weeks that matter when you're racing to market. And for the first 3-6 months, everything looks fine. The bias is accumulating, but it's invisible. Metrics look good. Customers don't complain yet. You're ahead of your competitor.
Then bias becomes visible. And suddenly, your "saved weeks" are being paid back with 6-12 months of remediation work.
The True Cost of Remediation
Fixing a biased system after deployment is one of the most expensive forms of rework in technology.
Why? Because the bias is now embedded everywhere:
-
In the training data: You need to audit the data, identify biased patterns, potentially collect new data, and retrain.
-
In the model: The model parameters are tuned toward bias. Retraining might help, but you need to validate across demographic groups, add fairness constraints, and potentially accept lower overall accuracy to gain fairness.
-
In the deployment infrastructure: Your production system is built around the original model. Changing it requires redeployment, regression testing, and monitoring.
-
In upstream processes: If your biased model recommended hiring certain types of candidates, your hiring pipeline is now biased. You may need to retroactively review past decisions, contact rejected candidates, and reopen hiring.
-
In customer trust: Each customer interaction colored by bias has eroded trust. Even after fixing the system, rebuilding trust takes years.
Industry data suggests that fixing a biased system costs 50–100x the cost of preventing bias during development.
Prevent bias:
That's the compounding cost of technical debt.

Three Actions to Stop Bias From Becoming Technical Debt
1. Executive Ownership and Clear Accountability
Bias doesn't get fixed because nobody owns it.
It's not a product problem (product team says "this is engineering"). It's not an engineering problem (engineering says "this is product"). It's not an ethics problem (ethics teams lack authority to block deployment). It's nobody's problem, which means it's everybody's problem—which means it's nobody's problem.
Fix this: Assign explicit, visible accountability for AI outcomes at the executive level.
Someone needs to own this. Could be the CTO, could be the Chief Product Officer, could be a dedicated Chief AI Officer. Doesn't matter who, as long as:
- They have P&L responsibility (or at least, reporting directly to someone who does)
- They have authority to influence product decisions (not just advisory)
- They publish clear success metrics (not vague statements, actual numbers: approval rate equity, accuracy by demographic, customer satisfaction parity)
- They are measured and compensated on these metrics, not on deployment speed
When bias is someone's formal responsibility, funded responsibility, and measured responsibility, it gets resources and attention. When it's not, it gets excuses.
Why does this work? Because incentives matter. If you measure someone on "deliver AI feature in 8 weeks," they'll cut corners on fairness testing. If you measure someone on "deliver equitable AI feature in 12 weeks," the timeline adjusts to allow for fairness.
2. Diverse Teams at Design and Testing
You cannot test for bias you don't understand.
A homogeneous team building AI will have homogeneous blind spots. They'll miss edge cases their community doesn't face. They'll optimize for scenarios their community cares about. They'll fail to imagine failure modes outside their experience.
The fix: Build diverse teams at design and testing stages.
Diverse means:
- Demographic diversity: Different races, genders, age groups, geographies, abilities, socioeconomic backgrounds
- Professional diversity: Not just engineers; include customer service people, sales, compliance, fraud specialists
- Experiential diversity: People who've experienced discrimination. People who've been on the wrong side of an algorithm. People from markets and communities your product affects
When you build with diversity, you catch bias early:
- "Have you tested what happens when a customer's name isn't recognized by the parser?"
- "What if someone doesn't have a smartphone?"
- "What about people whose address changes frequently?"
- "How does the system handle ambiguity in the input?"
- "Have you tested with accented speech?"
- "What if someone's job title isn't in your training data?"
These aren't edge cases. They're entire communities you would have missed with a homogeneous team.
Cost of adding diversity to teams: modest (hiring, onboarding, accommodations if needed). Cost of discovering bias after deployment: massive.
The math is clear.
3. Continuous Monitoring and Human Oversight
Bias doesn't stay still. You need to keep looking.
Implement continuous monitoring:
-
Demographic parity metrics: Track approval rates, response rates, recommendation rates by demographic group. Not for punishment, but for early warning.
-
Disaggregated performance: Measure accuracy, error rates, confidence by subgroup. A model can have 95% accuracy overall but 70% accuracy for a specific group.
-
User feedback loops: Explicitly ask: "Was this decision fair? Did it address your situation? Would you recommend this system?" Aggregate by demographic and decision type.
-
Regular audits: Quarterly or semi-annual stress tests where you deliberately test the system's fairness with synthetic data designed to expose bias.
-
Feedback from frontline teams: Customer service, fraud detection, and operations teams see patterns you don't. Create channels for them to report "the system is systematically failing for X group."
Maintain human judgment:
-
Not all decisions should be automated. Sensitive cases—bereavement, fraud disputes, discrimination appeals, major life changes—require human judgment.
-
Even routine decisions should have human oversight at a spot-check level. Regularly sample AI decisions and have a human auditor verify they're reasonable.
-
Escalation should be easy. If a customer disagrees with an AI decision, they should be able to appeal to a human immediately, not after 15 minutes of chatbot loops.
The goal is not "catch bias 100% of the time." The goal is "catch bias before customers do." Preventive detection saves immense amounts of cost.
Cost: ongoing operational expense (maybe

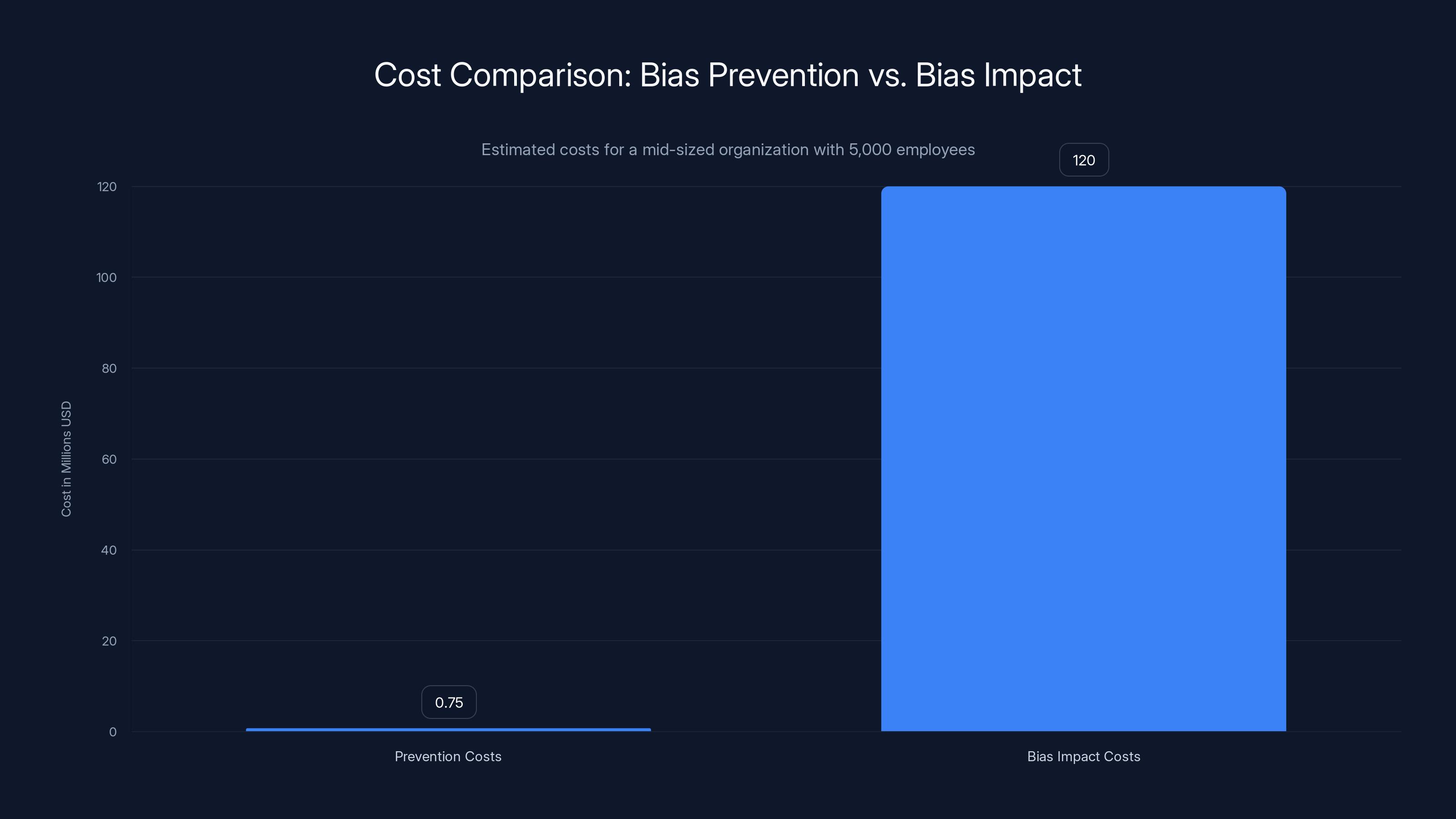
Investing in bias prevention can save up to $120M in potential bias impact costs, demonstrating a significant ROI.
Building a Bias-Aware AI Development Process
Pre-Development: Asking the Right Questions
Before you write a line of code, ask:
-
Who will this AI system affect? Not just direct users, but everyone impacted by the decision.
-
What would unfairness look like? Specifically. Not just vaguely "treated equally," but: "What if women are approved at 60% the rate of men? What if loan amounts differ by zip code? What if response times vary by customer demographic?"
-
What data will we use? Where did it come from? Who is represented? Who is missing? What historical biases might it contain?
-
What are we optimizing for? Speed? Profit? Accuracy? And are those metrics aligned with fairness? (They usually aren't.)
-
Who will be on the team? Is the team diverse? Does it include people from communities affected by this AI?
-
What's our fairness definition? Equal outcomes? Equal opportunity? Demographic parity? Different communities have different fairness preferences. Decide early.
Development: Testing for Bias
Build bias testing into your development process like you'd build unit tests or integration tests.
-
Disaggregated evaluation: Test your model's performance on different demographic groups during development, not after deployment.
-
Synthetic stress testing: Create synthetic data to test edge cases. "What if 100% of applicants from Group X had similar qualifications? Would the model treat them fairly?"
-
Fairness constraints: If optimizing for accuracy creates bias, add fairness constraints that trade some accuracy for fairness. Measure this trade-off explicitly.
-
Explainability: For every decision your model makes on a real person, ensure you can explain why. If you can't, the model isn't ready.
-
Adversarial review: Get someone outside the team to try to break your fairness claims. They will succeed. That's the point.
Deployment: Safeguards First
-
Stage the rollout: Don't deploy to 100% of users immediately. Start with 5%, then 10%, then 25%. Monitor fairness metrics at each stage.
-
Establish baselines: Before deploying the AI version, measure fairness of the human decision it replaces. Many AI systems are evaluated against perfection instead of against the realistic alternative.
-
Set up monitoring infrastructure: Before deployment is complete, your monitoring infrastructure should already be running. You should be able to detect bias in real-time.
-
Document assumptions: Write down every assumption your model makes. Where did this come from? Is it still true? When will you revalidate?

The Business Case for Bias Prevention
Cost-Benefit Analysis
Let's talk concrete numbers for a mid-sized organization (5,000 employees, $500M in revenue):
Cost of prevention:
- Hire fairness specialist: $200K salary + benefits
- Diverse hiring and team-building: $50K–100K
- Fairness testing infrastructure: $100K–200K (one-time)
- Ongoing monitoring and audits: $100K–150K annually
- Total year 1: ~$600K–750K
- Total annual ongoing: $200K–300K
Cost of bias (if not prevented):
- Detection delay: 6–12 months of accumulation
- Remediation: $10–50M in engineering, legal, customer support
- Regulatory fines: $5–20M potential
- Reputational damage: $10–50M in lost revenue/churn
- Total: $25–120M
ROI calculation:
- Investment in prevention: $1M over 3 years
- Cost avoided through prevention: $40M (conservative estimate, midpoint)
- ROI: 4,000%
That's not even accounting for the strategic value of being known as a company with fair AI, which becomes a recruitment advantage, customer trust factor, and regulatory advantage.
Why Companies Still Don't Do This
The ROI is obvious. So why do companies deploy biased AI anyway?
Two reasons:
-
The costs are hidden: The prevention cost is visible ("we need to hire a $200K specialist"). The bias cost is invisible until it explodes. Leadership tends to fund visible costs only.
-
The incentives are misaligned: The engineer who deploys fast gets promoted. The engineer who spends 3 extra weeks on fairness testing is not celebrated. The team that ships fast beats the team that ships fair. Until the bias surfaces, speed wins.
Fix: Make fairness a visible, funded, measured, and compensated priority at the leadership level. Then the incentives align.
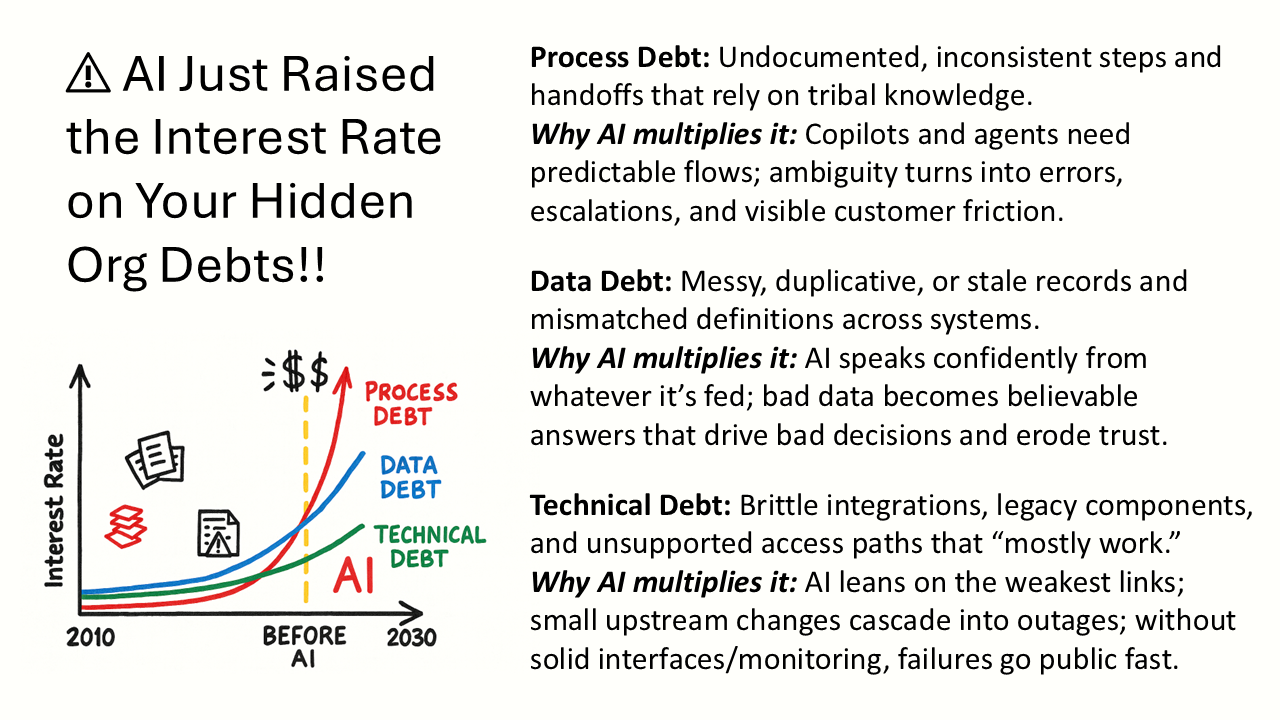
Regulatory Trends and Mandatory Compliance
The Shifting Landscape
Regulators are catching up. Slowly, but catching up.
Europe (GDPR, AI Act):
- Right to explanation: Users have the right to understand why an AI made a decision about them
- Algorithmic auditing: Regular, documented audits of AI systems required
- Fairness testing: Explicit requirements for testing bias in high-risk applications
- Penalties: Up to €20 million or 4% of global revenue, whichever is higher
United States (fragmented, sector-specific):
- Fair Lending laws: Banks must demonstrate their lending decisions don't have disparate impact
- Equal Employment Opportunity Commission: Investigating discrimination claims involving AI hiring tools
- Proposed regulations: Biden administration proposed AI Bill of Rights, various agencies drafting rules
- Penalties: Vary by sector; financial services: 100M+
Other jurisdictions:
- Canada, Australia, Singapore: Beginning to address AI bias in regulation
- Industry-specific rules: Healthcare, finance, hiring more regulated than other sectors
The trend is clear: algorithmic accountability is coming. Compliance will become mandatory, not optional.
For companies starting to build bias prevention now, regulatory compliance becomes a co-benefit, not an additional cost. For companies waiting until regulation is mandatory, the scramble will be expensive.
Practical Implementation: A Roadmap
Months 1-3: Foundation
-
Identify high-risk AI systems: Which AI decisions affect customers most? Which have the highest reputational or regulatory risk?
-
Audit current systems: For identified high-risk systems, conduct a bias audit. You'll likely find problems. That's expected and valuable.
-
Establish accountability: Assign ownership for AI fairness to an executive. Give them budget and authority.
-
Hire expertise: At minimum, a fairness specialist. If possible, a fairness engineer and compliance person.
Months 4-6: Process
-
Define fairness metrics: For each high-risk system, decide what fairness means. Document it.
-
Implement monitoring: Set up dashboards tracking fairness metrics for production systems. Start seeing the data.
-
Design for diversity: Update hiring, team structure, and design processes to include diverse perspectives.
-
Document everything: What assumptions does each system make? Where did the data come from? What testing was done?
Months 7-12: Improvement
-
Remediate critical systems: For systems where bias is severe, start remediation. High-risk, high-impact problems first.
-
Update development process: Fairness testing becomes a required step before deployment, like security testing or performance testing.
-
Regular audits: Establish a cadence (quarterly, semi-annual) for fairness audits and stress testing.
-
Governance: Build a decision-making body that reviews and approves high-risk AI before deployment.
Year 2: Scaled Operation
-
Extend to all AI systems: Not just high-risk; all AI deserves fairness consideration.
-
Regulatory preparation: Track evolving regulation and ensure your processes are audit-ready.
-
Communication: Start telling customers about your commitment to fair AI. This becomes a brand advantage.

The Broader Implications: AI as a Trust Engine or Erosion Mechanism
AI Amplifies Whatever It's Optimized For
Here's the fundamental insight: AI is a scaling technology. It amplifies whatever you ask it to do.
Optimize for profit, and it'll optimize for profit—sometimes in ways you didn't anticipate or approve of. Optimize for speed, and it'll pursue speed at the cost of accuracy or fairness. Optimize for accuracy without fairness constraints, and it'll be accurate in aggregate while being wildly inaccurate for specific groups.
This is why bias is technical debt. It's not just an ethical problem. It's a scaling problem. One human's biased decision affects a few people. One algorithm's biased decision affects millions. The damage doesn't just multiply—it compounds through network effects, feedback loops, and reputational cascades.
Building Trust Through Transparency and Accountability
Conversely, AI can be a trust engine if designed and operated with fairness as a core constraint.
Companies that:
- Transparently communicate how their AI works
- Proactively test for and publish bias findings
- Maintain human oversight in sensitive decisions
- Respond quickly when bias is discovered
- Compensate affected customers fairly
- Invest in continuous improvement
These companies build trust with customers, regulators, and employees. Their AI becomes a competitive advantage, not a liability.
The cost of becoming a trust engine is the cost of prevention. The cost of being exposed as an erosion mechanism is the cost of remediation. One is an investment. The other is a crisis.

Future-Proofing Your AI: Anticipating the Next Bias Crisis
Emerging Bias Vectors
Bias isn't a solved problem. New forms are emerging:
-
Model toxicity: Language models can reproduce biases from training data (sexism, racism, classism in text). Detection is hard, mitigation is incomplete.
-
Multimodal bias: When AI combines text, image, and voice, biases can interact in complex ways. An image classifier biased on gender, combined with a speech recognizer biased on accent, compounds both biases.
-
Adversarial gaming: Once people understand your AI's decision boundary, they manipulate inputs to get favorable outcomes. Protecting against this requires constant vigilance.
-
Surveillance bias: AI systems that monitor employee behavior, customer behavior, or user behavior can embed systemic bias in what they choose to flag as "suspicious" or "valuable."
Future-proofing means:
- Staying current on bias research (read academic papers, not just industry blogs)
- Stress-testing for novel forms of bias annually
- Maintaining flexibility to pivot if new bias types emerge
- Investing in fairness research, not just implementation
The Role of Regulation
Regulation will increase. This is not a threat if you're already prepared. It's a threat if you're not.
Companies that are ahead of regulation:
- Can shape the regulatory conversation ("here's what we learned works")
- Have competitive advantage once regulation passes (compliance is built in)
- Can market fairness as a differentiator
- Avoid the scramble and cost of emergency remediation
Companies that are behind regulation:
- Face compliance fines and operational disruption
- Incur emergency costs to retrofit systems
- Have reputational damage from being non-compliant
- Lose competitive advantage to companies that planned ahead

FAQ
What exactly is algorithmic bias, and how is it different from human bias?
Algorithmic bias is systematic error that emerges when AI systems are trained on historical data that contains patterns you'd rather not perpetuate. The difference from human bias is scale and consistency. One human's biased decision affects a few people. One algorithm's biased decision, deployed at scale, affects millions consistently. Algorithms also amplify bias through feedback loops—once a biased decision is made at scale, you retrain on data reflecting that bias, embedding it deeper. Human bias doesn't have that compounding mechanism.
How do I know if my AI systems are biased?
Start by measuring. For each AI system, calculate performance metrics (accuracy, approval rates, response times, satisfaction) disaggregated by demographic group. If these metrics differ significantly across groups, you likely have bias. Conduct a fairness audit with domain experts. Ask customer-facing teams if they see patterns of unfair treatment. Monitor customer complaints and feedback specifically for demographic patterns. If you're not measuring by demographic, you're not seeing the bias—which means it's probably there, just invisible.
What's the difference between bias and fairness? Aren't they the same thing?
Bias is the problem. Fairness is what you're trying to achieve. Bias is systematic error that disadvantages certain groups. Fairness is the property you want: that your system treats all groups equitably. But "fairness" is philosophically complex. Does it mean equal outcomes? Equal treatment? Equality of opportunity? Different communities have different fairness preferences. In financial services, fairness often means "equal access to credit." In hiring, it might mean "equal opportunity to be evaluated." Define fairness explicitly for your context before you can measure it.
If I implement fairness constraints, won't my overall accuracy drop?
Often, yes. There's typically a trade-off between aggregate accuracy and fairness. If you're optimizing purely for accuracy on aggregate data, you can often achieve 95% accuracy overall while being 75% accurate for a subgroup you don't care about. Add fairness constraints ("accuracy must be within 5 percentage points across groups"), and aggregate accuracy might drop to 92%. This is a feature, not a bug. It means you're not sacrificing a subgroup's experience for the majority's. Whether this trade-off is acceptable depends on your use case. For life-or-death decisions (medicine, criminal justice), fairness might outweigh accuracy. For less critical decisions, you might accept lower fairness for higher accuracy. Make this explicit in your design.
How often do I need to retrain my AI models to prevent bias drift?
It depends on how fast your world is changing. Generally, quarterly retraining is a minimum for systems in dynamic environments. Semi-annual retraining for stable domains. But retraining isn't the main point—monitoring is. You should be monitoring fairness metrics continuously. If you detect bias drift before the next scheduled retraining, you can trigger an emergency retrain. Most organizations should aim for retraining at least quarterly, with continuous monitoring and drift alerts.
What's the cost of building fairness into AI development versus fixing bias after deployment?
Roughly, preventing bias costs 10-20% more during development (hiring fairness specialists, extensive testing, diverse teams). Fixing bias after deployment costs 50-100x more in remediation, legal fees, customer support, and reputational damage. The math is overwhelmingly in favor of prevention. For a
Can I use fairness as a marketing advantage?
Absolutely. Companies that publicly commit to fair AI, transparently publish fairness metrics, and demonstrate accountability gain customer trust and regulatory favor. However, this only works if your fairness commitment is genuine. If you're marketing fairness while deploying biased systems, you'll face backlash when discovered (and you will be discovered). Authentic fairness becomes a competitive advantage. Performative fairness becomes a liability.
What's the relationship between AI bias and technical debt?
Bias is technical debt in the purest sense: you're taking a shortcut (skipping fairness testing) and paying for it later with massive interest. Like traditional tech debt, the cost of fixing it compounds over time. A

Conclusion: The Cost of Ignoring the Problem
The Uncomfortable Truth
Every company deploying AI at scale has bias in their systems. You don't need to find it. You need to measure where it is, quantify the impact, and decide how much is acceptable.
That last part is key. You can't eliminate bias entirely. You can only reduce it to acceptable levels. The question is: what's acceptable? A 2% fairness gap? 5%? 10%? That depends on the stakes. For hiring, even small gaps compound over careers. For product recommendations, larger gaps might be acceptable.
But most companies haven't even asked the question. They haven't measured bias. They haven't defined acceptable fairness. They've just deployed, hoping bias doesn't surface.
Here's the thing: it always does.
The Path Forward
If you're not measuring fairness, start today. You'll probably find problems. That's not failure—that's honesty. And honesty is the first step toward fixing it.
Then, invest in prevention. Hire fairness expertise. Involve diverse teams in development. Test ruthlessly for bias. Monitor continuously. Maintain human oversight in sensitive decisions.
This is not free. But the cost of prevention is infinitely smaller than the cost of crisis. And crisis is not a possibility—it's a timeline. The longer you wait, the more expensive it gets.
Companies that treat bias as technical debt, invest in prevention, and build accountability into leadership will spend millions preventing problems. Companies that ignore bias and hope it doesn't surface will spend billions fixing it after discovery.
The math is obvious. The incentives are misaligned. And the window to act is closing as regulation accelerates.
What you decide to do next determines whether your AI becomes a trust engine or a liability. That decision isn't technical. It's a business decision. And it's yours to make.
Key Takeaways
- AI bias functions as technical debt with severe financial consequences: UK ecommerce alone lost £8.6B annually due to negative AI experiences
- Biased systems amplify damage through feedback loops and customer network effects—one poor interaction reaches 2-3 people, multiplying reputational harm exponentially
- Prevention cost: 2M during development. Remediation cost:200M post-deployment. Fixing bias is 50–100x more expensive than preventing it
- Executive ownership, diverse development teams, and continuous monitoring are the three non-negotiable components of bias prevention strategy
- Regulatory convergence (GDPR, AI Act, Fair Lending laws) is making algorithmic accountability mandatory; early implementation becomes competitive advantage
Related Articles
- AI Recommendation Poisoning: The Hidden Attack Reshaping AI Safety [2025]
- How to Operationalize Agentic AI in Enterprise Systems [2025]
- Building AI Culture in Enterprise: From Adoption to Scale [2025]
- 7 Biggest Tech News Stories This Week: Claude Crushes ChatGPT, Galaxy S26 Teasers [2025]
- Cohere's $240M ARR Milestone: The IPO Race Heating Up [2025]
- QuitGPT Movement: ChatGPT Boycott, Politics & AI Alternatives [2025]

