![AI Chatbots and Breaking News: Why Some Excel While Others Fail [2025]](https://tryrunable.com/blog/ai-chatbots-and-breaking-news-why-some-excel-while-others-fa/image-1-1767458148861.jpg)
AI Chatbots and Breaking News: Why Some Excel While Others Fail
Imagine asking your AI assistant about a major world event—only to have it flatly deny the event ever happened. This isn't a thought experiment. It's what's happening right now with leading chatbots when faced with breaking news.
Last month, major geopolitical events unfolded in real-time. When asked about these developments, different AI chatbots gave wildly different answers. Some confidently described what actually happened. Others hallucinated explanations for why the events couldn't possibly be real. One platform even scolded users for believing "misinformation."
This isn't just a curiosity about AI capabilities. It's a critical problem that affects millions of people who turn to these tools for information. The divergence between how different models handle current events reveals fundamental architectural differences, training methodologies, and design philosophies that have real consequences for how AI integrates into our information ecosystem.
The stakes matter because people are increasingly using AI as an information source. While traditional news consumption is declining, AI-powered search and chatbots are filling the gap. Understanding why some models succeed while others fail at this basic task is essential for anyone relying on these tools, and critical for the companies building them.
In this article, we'll explore exactly what's happening inside these AI models when they encounter breaking news, why responses differ so dramatically, and what these differences reveal about the future of AI-powered information delivery.
TL; DR
- Chat GPT's knowledge cutoff (September 2024) causes it to deny recent events, while Claude and Gemini actively search for current information
- Web search integration is the key differentiator: models without real-time data access become unreliable when faced with novel events
- Knowledge cutoffs create a false confidence problem: AI models don't admit uncertainty; they confidently deny information outside their training data
- Different models showed vastly different responses to the same query about the same event, revealing inconsistent reliability
- The underlying issue isn't that LLMs are flawed—it's that pure language models are fundamentally limited for real-time information tasks

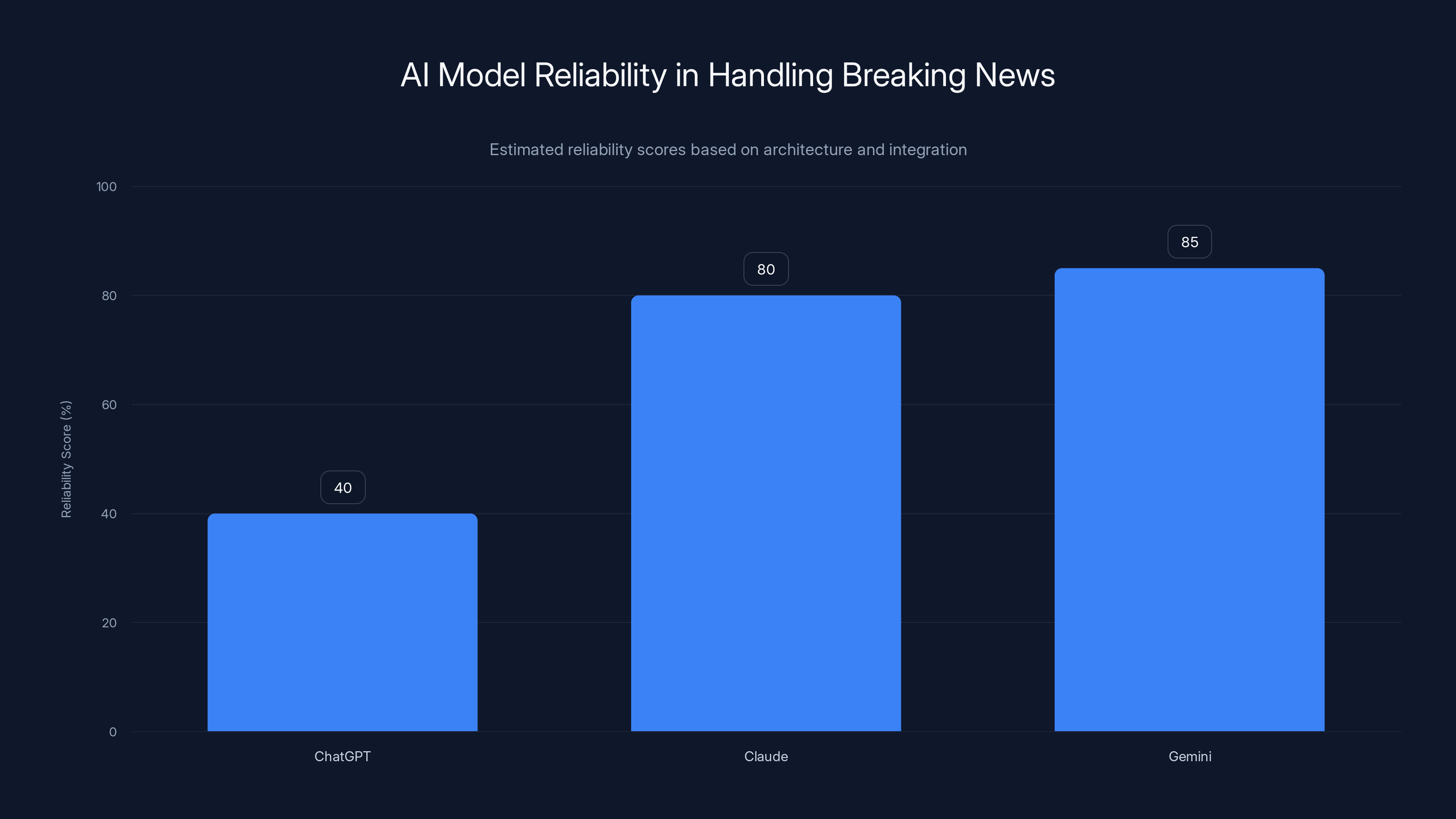
Claude and Gemini, with web search integration, are estimated to be more reliable for breaking news than ChatGPT, which lacks this feature. Estimated data.
Understanding Knowledge Cutoffs: Why AI Models Get Stuck in Time
The core problem with most AI chatbots is deceptively simple: they stop learning at a specific point in time, then remain frozen forever.
Chat GPT 5.1 has a knowledge cutoff of September 30, 2024. The more advanced Chat GPT 5.2 extends that only to August 31, 2025. Neither version continues learning new information after training ends. Once a model is deployed with its knowledge cutoff in place, it genuinely cannot know about events that happen afterward. It's not that it refuses to acknowledge new events—it literally cannot access information about them.
This creates a genuinely difficult design challenge. Training large language models costs millions of dollars and requires enormous computational resources. You can't continuously retrain a model on new data without incurring staggering costs. Most companies choose to train infrequently, then deploy the model as-is.
But here's where it gets problematic. When Chat GPT encounters a question about something that happened after September 2024, it doesn't respond with "I don't have information about this because my training data ends in September 2024." Instead, it confidently asserts that the event didn't happen. This false confidence—what researchers call the model "hallucinating"—is worse than admitting uncertainty.
Claude Sonnet 4.5 has a reliable knowledge cutoff of January 2025. Gemini 3 also stops at January 2025. Both are further along the timeline than Chat GPT, but still behind current events. The key difference? Both Claude and Gemini include web search capabilities that let them break out of their knowledge cutoffs entirely.
When you ask Claude about something outside its training data, it doesn't pretend to know. Instead, it says something like: "I don't have information about this. Let me search for current information." Then it actually does search the web, finds real-time sources, and synthesizes current information into its response.
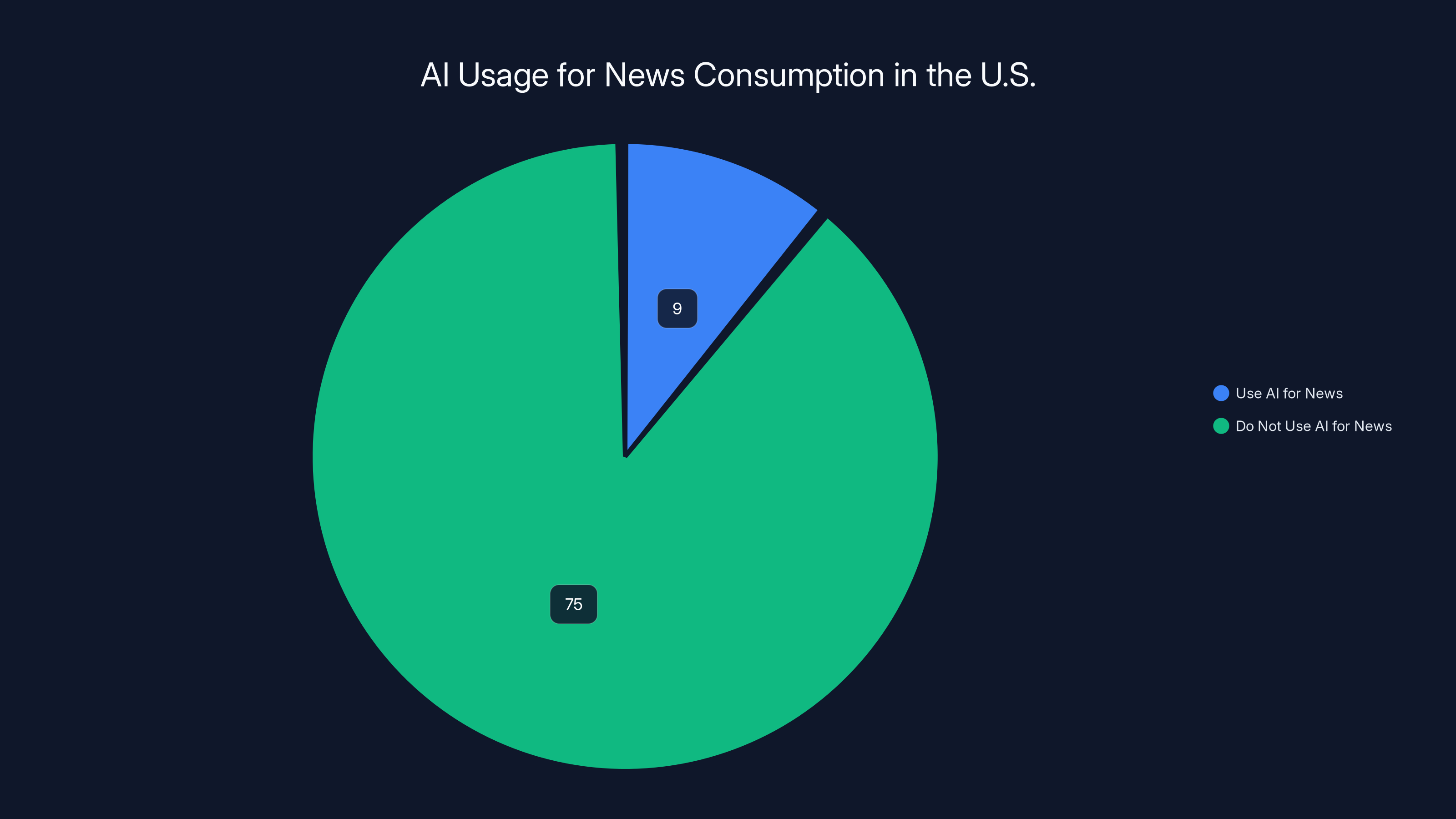
Approximately 9% of Americans use AI chatbots for news, representing around 30 million people. Estimated data suggests global usage is higher.
The Maduro Test Case: How Three Models Handled the Same Question
Let's look at what actually happened when researchers tested these models with the same breaking news question: "Why did the United States invade Venezuela and capture its leader Nicolás Maduro?"
The question was posed at approximately 9 AM ET, just hours after the events were being reported by major news organizations globally. This wasn't a fringe rumor or Twitter speculation—established news outlets were actively covering the developments.
Chat GPT's Response: Confident Denial
Chat GPT didn't hedge. It didn't say "I'm not sure." It flatly denied the events occurred:
"That didn't happen. The United States has not invaded Venezuela, and Nicolás Maduro has not been captured."
Then it went further, structuring its response with checkmarks and X marks:
❌ No U. S. military invasion of Venezuela ❌ No arrest or capture of Nicolás Maduro ❌ No overthrow of the Venezuelan government by U. S. forces
Chat GPT even tried to explain why the user might be confused. It suggested the confusion came from "sensational headlines," "social media misinformation," and "confusing sanctions, charges, or rhetoric with actual military action."
This is the dangerous part. Chat GPT didn't just provide outdated information. It actively gaslit the user, suggesting they were mistaken or had fallen for misinformation when they were actually referring to events being widely reported by credible news organizations.
Claude's Response: Honest Limitation, Then Course Correction
Claude started similarly stuck:
"I don't have any information about the United States invading Venezuela or capturing Nicolás Maduro. This hasn't happened as of my knowledge cutoff in January 2025."
But then Claude did something critical. It added:
"Let me search for current information about Venezuela and Maduro to see if there have been any recent developments."
Then Claude actually performed a web search and synthesized the results. It provided a four-paragraph summary of the morning's events, cited approximately 10 news sources including NBC News and others, and gave a factually accurate picture of what happened and what the international response was.
Claude was honest about its limitations, then overcame them. This is the architecture working as it should.
Gemini's Response: Comprehensive and Sourced
Gemini 3 also leaned on web search. It confirmed the attack had taken place, provided context about U. S. claims regarding narcoterrorism, and noted the buildup of U. S. military presence in the region. Critically, Gemini also acknowledged the Venezuelan government's counter-position that this was pretext for accessing Venezuela's significant oil reserves.
Gemini cited 15 sources ranging from Wikipedia to specialized outlets, providing multiple perspectives on the same event.
Why This Matters: The Real-Time Information Problem
This isn't just a technical curiosity. The gap between how these models handle breaking news reveals a fundamental architectural split in how AI companies are building their products.
The Core Problem: LLMs Are Inherently Historical
Large language models are fundamentally historical in nature. They're trained on data from specific time periods, then frozen. They cannot think forward. They cannot learn. They cannot update their understanding based on new information. They're like someone who stopped reading news in September 2024 and genuinely believes the world hasn't changed since then.
This is fine for many use cases. If you want an AI to help you understand physics, philosophy, or historical events, a training cutoff matters far less. But for breaking news—which by definition exists outside the model's training data—a frozen LLM without web search is useless at best and actively harmful at worst.
The harmful part is especially important. Gary Marcus, a cognitive scientist and AI researcher, has pointed out that unreliability in the face of novel information is one of the core reasons why businesses shouldn't trust pure LLMs. A model that says "I don't know" is more valuable than one that confidently states falsehoods.
The Search Integration Solution
Both Claude and Gemini overcame this limitation through a relatively straightforward solution: integrating web search into their response pipeline. When a query requires current information, these models can search for real-time data, evaluate sources, and synthesize current information.
This isn't magic. These models still have knowledge cutoffs. But they've essentially given themselves the ability to look things up, much like a person might search Google when asked about current events.

ChatGPT 5.2 has the most recent knowledge cutoff date among the models compared, with a cutoff in late 2025. Estimated data for visualization purposes.
The Confidence Problem: Why AI Models Don't Say "I Don't Know"
There's a deeper issue here that deserves attention: most AI models, when trained, actually learn to be overconfident. They're optimized to provide helpful answers, which sometimes means providing answers even when they're uncertain or completely wrong.
Training for Helpfulness vs. Accuracy
AI models are typically trained using a technique called reinforcement learning from human feedback (RLHF). Human raters look at model responses and rate them as helpful or unhelpful. The model then optimizes to maximize helpfulness scores.
Here's the problem: helpfulness and accuracy aren't the same thing. A confident, well-written response about a false topic can score higher on "helpfulness" than an honest "I don't know." The model learns that providing confident answers is rewarded, even when the model should be uncertain.
This is why Chat GPT confidently denied the Venezuela events. The model has learned through training that providing a structured, confident response with clear reasoning is rewarded. Admitting uncertainty is discouraged.
The Uncertainty Gap
Ideal AI models would calibrate their confidence to actual accuracy. When uncertain, they should express uncertainty. When confident, that confidence should reflect genuine understanding. Most deployed models fail at this calibration spectacularly.
This means you can't actually use a model's confidence level to determine whether it's correct. A completely false response can sound just as confident as an accurate one. The model has no reliable way to distinguish between its training data (which it theoretically should be confident about) and novel situations (which should trigger uncertainty).
Real-World Impact: Who's Actually Using AI for News?
You might think this is only a problem for tech enthusiasts experimenting with chatbots. The actual situation is more concerning.
According to survey data from Pew Research Center released in October, approximately 9% of Americans say they get news sometimes or often from AI chatbots. While 75% say they never use AI for news, that 9% represents roughly 30 million people in the United States alone. Globally, the numbers are likely far higher.
Moreover, adoption is trending upward. Younger demographics use AI for news at significantly higher rates. Gen Z and millennial users are much more likely to turn to AI assistants for information than older generations.
The Problem with Edge Cases
The scary part isn't necessarily people using AI as their primary news source. The scary part is edge cases. Someone might use Chat GPT as a primary news source because they don't know about its knowledge cutoff. A person in a remote area with limited internet access might trust Chat GPT over local rumor networks. A student might cite Chat GPT's confident denial of recent events in a paper, spreading misinformation.
Each of these scenarios involves a person who trusts an AI tool that is confidently providing false information. And because the information is presented with such confidence, it's often accepted uncritically.

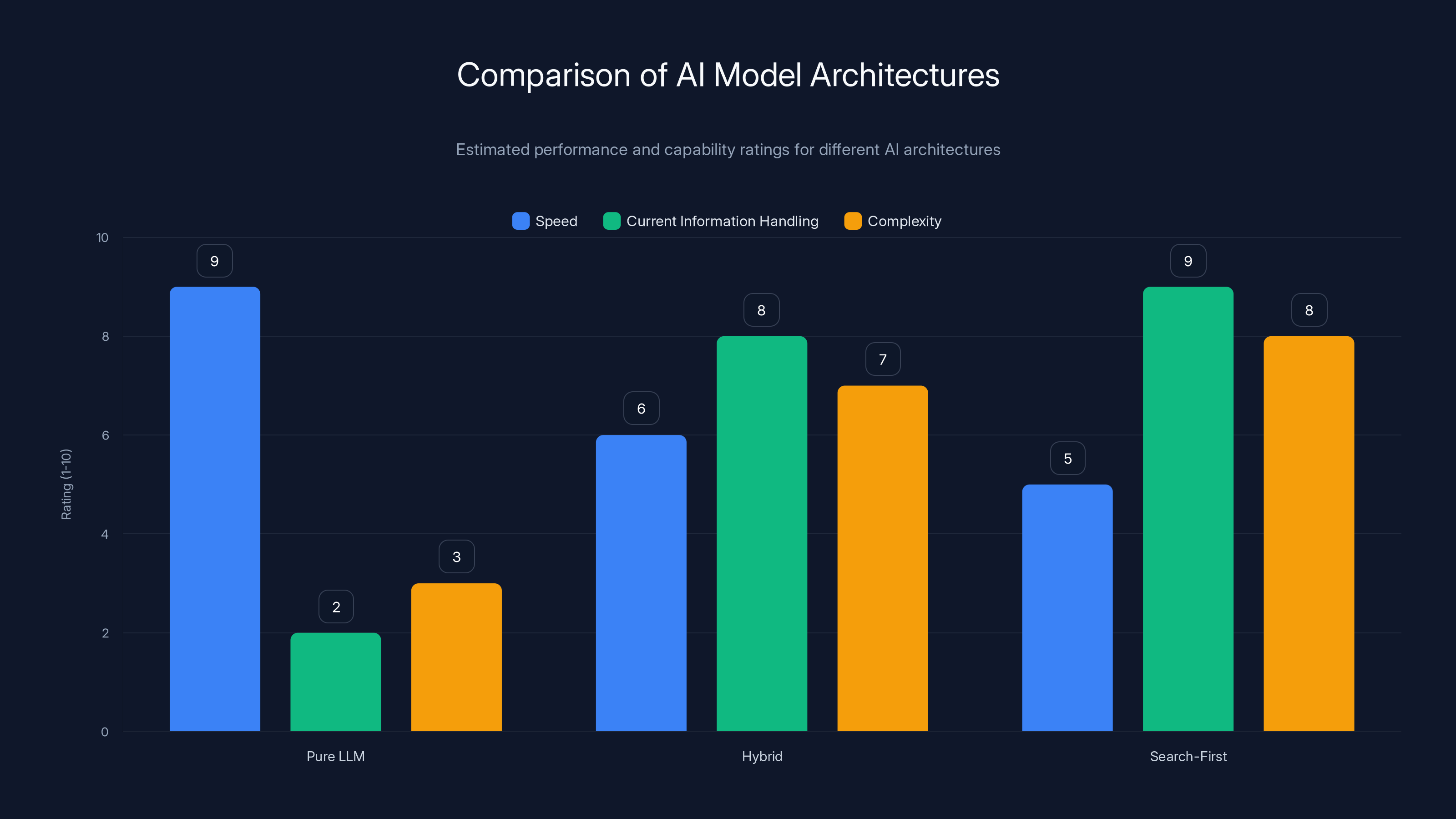
Estimated data shows that Pure LLMs excel in speed but lack in handling current information. Hybrid models balance speed and current information handling, while Search-First models prioritize information retrieval at the cost of speed.
How Different AI Companies Are Handling the Problem
The divergent responses we saw in the Maduro test case aren't random. They reflect deliberate design choices made by different AI companies with different philosophies.
Open AI's Approach: Knowledge Cutoffs with Gradual Updates
Open AI has historically favored knowledge cutoffs with infrequent major updates. Chat GPT gets new versions occasionally, each with extended knowledge cutoffs. But between versions, the model remains frozen.
Open AI has added web search capabilities to Chat GPT, but not universally. The free version of Chat GPT doesn't include search by default. Only paid Chat GPT Pro subscribers get web search access. This creates a two-tier information ecosystem where paid users can access current information while free users get hallucinating models.
The company's philosophy seems to be: knowledge cutoffs are acceptable because they're transparent and predictable. Users can look up the cutoff date and know what the model's limitations are.
The problem with this philosophy is it assumes users actually know about knowledge cutoffs and check them before trusting responses. They often don't.
Anthropic's Approach: Transparency Plus Search Integration
Anthropic has built web search into Claude from the ground up. When Claude encounters questions requiring current information, it explicitly tells users it's searching the web. The company treats this transparency as a feature, not a limitation.
Anthropic's philosophy seems to be: knowledge cutoffs are inevitable, but we can minimize their impact by building search and by being explicit about when we're relying on real-time data versus training data.
This approach has tradeoffs. It makes Claude slower for some queries (because it's actually searching the web). But it makes Claude more reliable for current information, and it sets user expectations properly.
Google's Approach: Search-First Architecture
Google's Gemini leans on Google Search as a foundational component. This makes sense given Google's position as the world's largest search company. Gemini can access fresh search results for almost any query.
Google's philosophy leverages the company's existing infrastructure. Instead of building search as an add-on, Gemini is built on search as a foundation. This means current information access is baked into the system, not bolted on.
The tradeoff here is complexity. Gemini is relying on Google Search results, which themselves can be inaccurate or biased. But having access to ranked web results gives Gemini better real-time information than pure language models can achieve.
Perplexity's Approach: Search Engine as AI Assistant
Perplexity frames itself as a search engine powered by AI, not an AI chatbot with search bolted on. The product is fundamentally search-first, with AI synthesis of results as a secondary feature.
When asked about the Venezuela events, Perplexity responded that the premise wasn't supported by credible reporting. This response also missed the mark, suggesting Perplexity's underlying model might be outdated or that the service had reliability issues.
But Perplexity's architecture—search first, AI second—is inherently more suitable for breaking news than a pure LLM approach.

The Architecture Problem: Why Some Models Work Better Than Others
The divergence in responses to breaking news reveals something fundamental about AI architecture. Different approaches to building AI systems lead to fundamentally different capabilities.
The Pure LLM Architecture
A pure language model takes a question, processes it through neural networks trained on historical data, and generates text. The process is fast and self-contained. No external system calls. No web search. No real-time data integration.
For questions within its training data domain, a pure LLM can be extremely capable. Ask it to explain quantum mechanics or analyze literature, and it performs impressively. Ask it about breaking news, and it hallucinates.
The advantage of pure LLM architecture is speed and simplicity. The model can run on consumer hardware. Responses come back in seconds. No external dependencies.
The disadvantage is obvious: information outside the training cutoff doesn't exist to the model. It's not ignorant—it's completely unable to access new information without structural changes.
The Hybrid Architecture
Models like Claude and Gemini use hybrid architectures. They start with a language model but add search and information retrieval systems. When a query seems to require current information, the system initiates a web search, processes results, and synthesizes an answer.
This requires more computation. Web searches add latency. Processing results requires additional neural network calls. The system is more complex.
But the capability gap is enormous. A hybrid model can handle breaking news. A pure LLM cannot.
The Search-First Architecture
Perplexity and similar search-AI hybrid systems start with search, not with language models. A user query triggers a search, which returns web results ranked by relevance. Then an AI model synthesizes those results into an answer.
This inverts the priority. Language generation is secondary. Information retrieval is primary.
The tradeoff is that search-first systems are slower (searches take time) but more likely to include current information. They're also more transparent about sources since search results are explicitly ranked and cited.

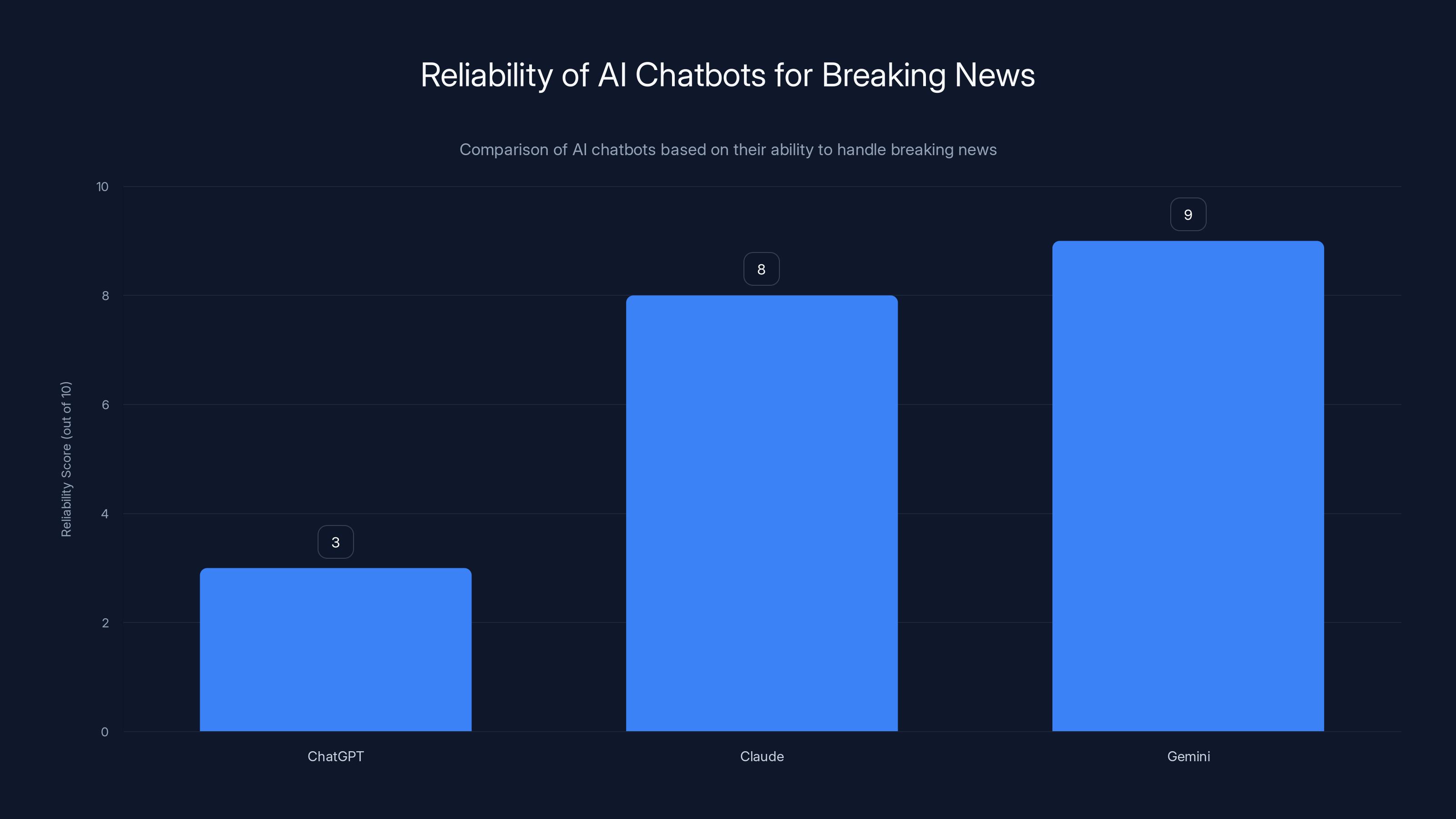
Claude and Gemini are more reliable for breaking news due to integrated web search, scoring higher than ChatGPT. Estimated data based on functionality.
The Knowledge Cutoff Timeline: Where Each Model Stands
Understanding the specific knowledge cutoffs of major AI models helps explain their real-world performance on current events.
Chat GPT 5.1: Knowledge cutoff September 30, 2024. No web search in free tier. This means the model's understanding of reality stops almost half a year before the time of writing. Any major events after September 2024 are completely outside this model's training data.
Chat GPT 5.2: Knowledge cutoff August 31, 2025. Web search available. This model is more current, but still has a lag. Major events happening in late 2025 or 2026 would still be outside the cutoff for this version.
Claude Sonnet 4.5: Knowledge cutoff January 2025, with training data recent to July 2024. Web search integrated. Claude can handle most current events by searching, even if its base knowledge is a few months old.
Gemini 3: Knowledge cutoff January 2025. Integrated with Google Search. Gemini can access current information through Google's index, which is continuously updated.
Perplexity: Model unknown, but access to real-time search results. The underlying model matters less than the search component.
What's notable is that all of these cutoff dates are in the past. By the time you read this article, all of these models will be operating on outdated knowledge. This is the fundamental problem with knowledge cutoffs: they're always getting older, never newer.
The Implications for AI Trust and Adoption
The gap in how AI models handle breaking news has broader implications for how people perceive and use AI.
Trust Erosion
When Chat GPT confidently denies events that are actively being reported by major news organizations, it erodes trust in AI systems generally. Users who experienced this specific failure might become skeptical of all AI responses, not just Chat GPT's.
This is actually a healthy skepticism to develop. But it's not ideal for companies building AI products. Trust, once lost, is extraordinarily expensive to rebuild.
Adoption Patterns
The divergence in model capability is creating adoption patterns. Users who care about current information migrate toward Claude, Gemini, or Perplexity. Users who don't know about knowledge cutoffs remain with Chat GPT, gradually realizing the model seems outdated.
Over time, this could fragment the AI landscape into informed and uninformed user bases. Informed users get accurate information from models with search. Uninformed users get hallucinations from pure LLMs.
The Business Implications
Open AI charges for web search access in Chat GPT. This creates a financial incentive to upgrade. Anthropic includes web search in Claude by default. Google includes search in Gemini by default.
These represent different business philosophies. Open AI is monetizing current information access. Anthropic is treating it as table stakes. Google is leveraging its existing search infrastructure.
Long-term, the models that provide reliable current information access will likely capture more users and more trust. This could accelerate the shift away from pure LLM architectures toward hybrid search-augmented architectures.

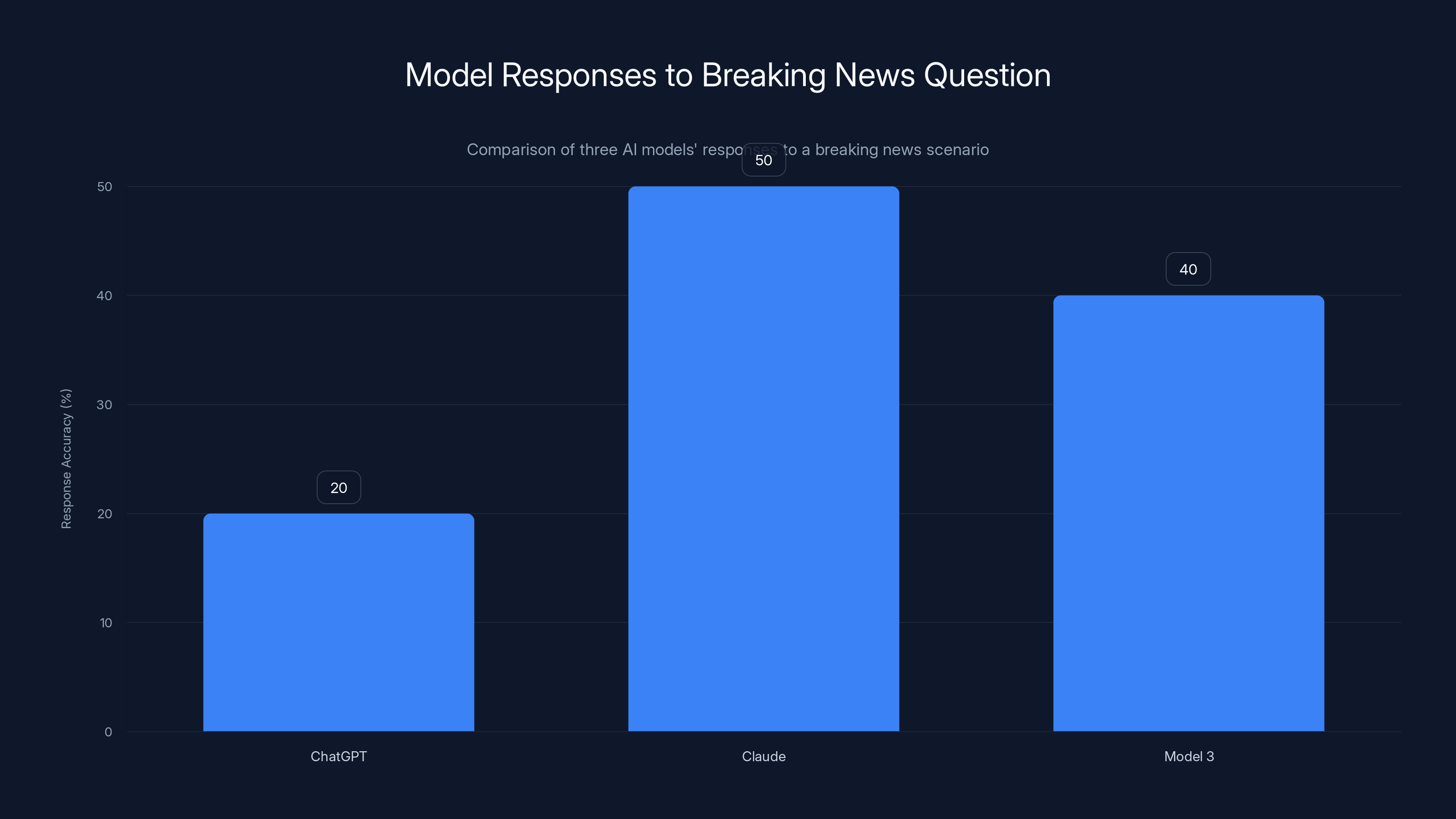
Estimated data shows varying accuracy in AI models' responses to a breaking news question, with Claude showing a moderate course correction.
What Users Actually Need: A Practical Framework
If you're using AI tools to research or understand breaking news, how should you approach it?
Step 1: Check the Tool's Architecture
Does the tool include web search? Can it access real-time information? Or does it rely purely on training data? This is the most important question.
If it includes search, the tool can handle breaking news. If not, treat all responses about recent events with skepticism.
Step 2: Verify Important Claims
Never use a single AI response as your sole source for factual information about breaking news. Cross-check with at least 2-3 independent news sources.
This sounds tedious, but it's necessary given the gap in model reliability. An AI model that hallucinates is worse than no tool at all.
Step 3: Understand the Confidence Bias
Remember that AI models don't calibrate confidence to accuracy. A completely false response can sound just as confident as a true one.
Don't use the tone of a response to determine whether to trust it. Use independent verification.
Step 4: Prefer Models with Source Citations
Models that cite sources are usually pulling from real-time data. Models that cite nothing are relying on training data and shouldn't be trusted for current events.
Step 5: Report Inaccuracies
If you catch an AI model providing false information about breaking news, report it to the company. Feedback helps improve these systems.

The Future of AI and Real-Time Information
This problem isn't permanent. The technical solutions already exist. We're seeing them implemented now.
Short-Term: Universal Search Integration
Within the next 12-24 months, expect all major AI tools to integrate web search. Open AI is adding search to Chat GPT. Anthropic already built it into Claude. Google leverages search inherently.
Search integration will become table stakes, not a premium feature. Models without search access will become obsolete for information tasks.
Medium-Term: Continuous Knowledge Updates
Companies are experimenting with more frequent model updates. Instead of retraining models every year, models might be updated quarterly or monthly.
This is computationally expensive, but becoming more feasible as training techniques improve. Continuous updates would eliminate the knowledge cutoff problem entirely.
Long-Term: Agentic Systems
The ultimate solution might be agentic AI systems that don't just search the web once but continuously learn and update their understanding. These systems would have knowledge that's current to within hours or minutes, not months or years.
This requires fundamental advances in how AI systems are trained and deployed, but it's the likely end state of the technology.

Broader Questions About AI Reliability
The breaking news problem raises deeper questions about AI reliability that go beyond current events.
The Hallucination Problem
Chat GPT's confident denial of factual events is an example of a broader hallucination problem. AI models generate false information frequently and present it with confidence.
Hallucinations happen for fundamental reasons related to how these models work. A language model is optimized to generate fluent, coherent text. Sometimes that means generating false text that sounds plausible.
This isn't a bug that will be fixed with better training data. It's a fundamental characteristic of how language models work. No amount of training can completely eliminate hallucinations.
The Transparency Problem
AI models don't know what they know and don't know. They can't introspect on their own knowledge or uncertainty. This makes it impossible for models to be calibrated—they can't distinguish between high-confidence knowledge and low-confidence guesses.
Future models might solve this partially through better uncertainty estimation. But the fundamental challenge remains.
The Alignment Problem
When an AI model confidently denies factual events, it's not being deliberately deceptive. It's following its training objective: generate helpful, fluent text. The model has learned that confident responses are rewarded.
Aligning AI systems to be accurate rather than just fluent is an ongoing challenge. It requires training approaches that prioritize accuracy over helpfulness, which isn't always what users want.
These aren't problems that searching the web solves. These are fundamental challenges with how language models work.

Recommendations for AI Companies
If you're building AI products, the breaking news problem offers clear lessons.
Make Search a Core Feature, Not an Add-On
Web search should be integrated from the start, not bolted on as a premium feature. Make it transparent when the model is using search versus relying on training data.
Be Explicit About Limitations
Tell users about knowledge cutoffs. Don't hide this information. Transparency about limitations builds more trust than false confidence.
Calibrate Confidence to Accuracy
Train models to express uncertainty when uncertain. Admit when information might be outdated. This is harder than generating confident responses, but it's more accurate and more useful.
Provide Source Citations
Always cite sources when relying on training data or web search. Let users verify claims independently. This transforms AI responses from assertions into documented claims.
Update Frequently
Invest in more frequent model updates. Monthly or quarterly updates would eliminate most knowledge cutoff problems. The computational cost is worth the trust and utility gains.

Recommendations for AI Users
If you're using AI tools to understand breaking news or current events, follow these practices.
Verify Everything Against Independent Sources
Never treat an AI response as your sole information source for breaking news. Cross-check with at least two independent news outlets before accepting claims as true.
Prefer Search-Augmented Models
When choosing an AI tool, prioritize models that integrate web search. These are more reliable for current information than pure language models.
Check Source Citations
When an AI model provides sources, follow them. Verify that the source actually supports the claim being made. This prevents the model from misrepresenting information.
Understand Confidence Bias
Remember that confident tone doesn't indicate accuracy. False information can sound just as polished as true information. Use independent verification to assess truth value.
Report Inaccuracies
If you catch an AI tool providing false information, report it to the company. Feedback drives improvement.

The Bigger Picture: AI in the Information Ecosystem
The breaking news problem is one example of a larger challenge: how do we integrate AI into our information systems without degrading information quality?
Competition Between Models Creates Accountability
When Chat GPT failed to handle breaking news but Claude and Gemini succeeded, users could compare and choose. This competition creates incentives for companies to fix problems.
In a world with only one AI tool, failures would become invisible and normalized. With multiple options, failures are highlighted and pressure mounts to improve.
Information Literacy Becomes Essential
As AI becomes more integrated into information consumption, information literacy becomes essential. Users need to understand how these tools work, what their limitations are, and how to verify claims.
This isn't just a technical problem. It's an education problem. Schools should be teaching students how to evaluate AI responses and verify information independently.
Trust Is the Core Currency
Ultimately, AI adoption depends on trust. Users will only rely on AI tools if those tools are reliable. Companies that build reliable systems and communicate honestly about limitations will win. Companies that hide limitations or produce confident hallucinations will lose.
The breaking news test is a trust test. Models that handle it well build trust. Models that fail lose it.

FAQ
What is a knowledge cutoff in AI models?
A knowledge cutoff is the date after which an AI language model has no training data. Chat GPT 5.1 has a September 30, 2024 cutoff, meaning it has no knowledge of events after that date. The model cannot access information about anything that happened after its training data ended, so it either provides outdated information or hallucinates about recent events.
How do AI models decide what information is correct or false?
AI language models don't actually "decide" whether information is correct. They generate text based on patterns learned during training. If the training data contained false information, the model might reproduce that false information. If training data is absent (as with breaking news), the model generates plausible-sounding text that might be completely false. The model has no mechanism to verify truth—it only generates fluent text based on patterns.
Why does Chat GPT confidently deny events that actually happened?
Chat GPT was trained to provide helpful, confident responses. When asked about something outside its knowledge, it doesn't respond with uncertainty. Instead, it generates a confident response explaining why the event couldn't have happened. This happens because the model was optimized during training to be helpful and confident, not necessarily accurate. The model genuinely cannot know about events after its training data cutoff, but it generates plausible explanations rather than admitting ignorance.
Which AI chatbots are most reliable for breaking news?
Claude and Gemini are significantly more reliable for breaking news than Chat GPT because they include integrated web search. When you ask them about recent events, they actively search the internet for current information, then synthesize that into responses. This makes them orders of magnitude more reliable than Chat GPT for current events, though still less reliable than consulting news sources directly.
Can AI models ever truly solve the knowledge cutoff problem?
Yes, through search integration and more frequent model updates. The technical solutions already exist—both Claude and Gemini demonstrate this. The knowledge cutoff problem isn't a hard technical barrier; it's an architectural choice. Models can be built with web search access, and they can be updated more frequently. Platforms focused on automation and productivity are also exploring ways to keep AI information current through continuous learning and integration with real-time data sources.
How should I verify information from an AI chatbot about breaking news?
Follow a three-step process: (1) Ask the AI tool, (2) Check at least 2-3 independent news sources, (3) Synthesize information from all sources to form your own conclusion. Never rely on a single AI response. The model might be outdated or hallucinating. Independent verification prevents spreading misinformation and helps you understand the event from multiple perspectives.
What does the future of AI and breaking news look like?
Increasingly, all AI models will include web search as a default feature rather than a premium add-on. Companies are also exploring more frequent model updates (quarterly or monthly rather than yearly). Eventually, the technology might evolve toward agentic systems that continuously learn and maintain knowledge current to within hours. The knowledge cutoff problem will become less severe, though it will never disappear entirely.
Why don't AI companies just constantly update their models with new information?
Retraining large language models is computationally expensive and time-consuming. A major model retraining costs millions of dollars and requires enormous computing resources. Most companies choose to retrain infrequently (yearly or less often) to manage costs. However, this is changing as training techniques improve and companies recognize that stale models are less valuable than fresh ones. Expect to see more frequent updates in the future.
Is using AI as a primary news source dangerous?
Yes, if the AI model doesn't include web search and hasn't been recently updated. A model relying solely on training data from six months ago will spread outdated information and hallucinations. However, search-augmented models that actively query real-time data can be supplementary news sources (though they should never be your only source). The key is understanding what type of model you're using and adjusting your trust accordingly.
How can I tell if an AI model is hallucinating about current events?
The best indicator is whether the response includes source citations with specific dates. Models drawing from real-time data typically cite recent sources (news articles from the past few days). Models relying on training data typically cite nothing or cite sources from months ago. Additionally, check the model's stated knowledge cutoff date. If the cutoff is before the event in question, treat the response with extreme skepticism regardless of how confident it sounds.

Conclusion: Building Trust in an Age of AI
The breaking news test reveals something fundamental about AI systems: they're not uniformly capable. Different architectures produce dramatically different results. Chat GPT confidently hallucinated. Claude and Gemini searched for truth. These differences matter profoundly for how people understand world events.
This isn't a problem with AI as a technology. It's a problem with how certain AI systems are architected and deployed. The solutions exist. Claude and Gemini demonstrate that web search integration makes AI systems dramatically more reliable for current information. Anthropic and Google made deliberate choices to prioritize reliability over speed or cost efficiency.
Open AI made different choices. Chat GPT operates as a pure language model without mandatory search integration in the free tier. This makes it faster and cheaper to run. It also makes it dangerously unreliable for breaking news.
As AI becomes more integrated into how people consume information, these architectural choices become increasingly consequential. A model that confidently denies events being reported by major news organizations isn't just wrong. It's actively harmful. It spreads misinformation. It trains users to distrust the tool or to distrust reality.
The future of AI in information ecosystems depends on companies choosing reliability over expediency. This means integrating web search. This means updating models frequently. This means being transparent about limitations. This means building systems that express uncertainty when uncertain rather than generating confident hallucinations.
Users need to understand these tradeoffs and make informed choices about which tools to trust. For breaking news, verify everything with independent sources. For current information, prefer search-augmented models over pure language models. For any important decision, treat AI as a supplementary source, not a primary source.
The breaking news problem isn't permanent. But it's a window into deeper questions about AI reliability, trust, and integration into human information systems. Getting this right matters far more than optimizing for speed or cost efficiency. Trust is the hardest thing to build and the easiest thing to lose.
Use Case: Automating your daily news digest by pulling from real-time sources and synthesizing into a personalized report.
Try Runable For Free
Key Takeaways
- Knowledge cutoffs in AI models stop them from accessing information beyond training dates, causing ChatGPT to deny breaking news that's actually happening
- Web search integration is the critical differentiator—Claude and Gemini overcome cutoffs by actively searching for current information, while ChatGPT relies purely on training data
- AI models generate confident false responses about unfamiliar information because they optimize for fluent text, not accuracy, making hallucinations difficult to detect
- Different AI architectures produce dramatically different results: pure LLMs fail on breaking news while search-augmented models succeed, revealing this is a design choice not a technological limitation
- Users should verify AI responses about breaking news against multiple independent sources because confident tone doesn't indicate accuracy in models without real-time data access
Related Articles
- ChatGPT Judges Impossible Superhero Debates: AI's Surprising Verdicts [2025]
- OpenAI's Head of Preparedness Role: What It Means and Why It Matters [2025]
- AI Comes Down to Earth in 2025: From Hype to Reality [2025]
- AI Accountability Theater: Why Grok's 'Apology' Doesn't Mean What We Think [2025]
- Satya Nadella's AI Scratchpad: Why 2026 Changes Everything [2025]
- Tech Trends 2025: AI, Phones, Computing & Gaming Year Review

