![AI Defense Breaches: How Researchers Broke Every Defense [2025]](https://tryrunable.com/blog/ai-defense-breaches-how-researchers-broke-every-defense-2025/image-1-1769200863112.png)
AI Defense Breaches: How Researchers Broke Every Defense [2025]
You're shopping for AI security. The vendor says their defense blocks 99.8% of attacks. Their logo looks trustworthy. The slide deck promises zero compromises.
Then you read the paper.
In October 2025, researchers from OpenAI, Anthropic, and Google DeepMind published findings that should stop every CISO mid-procurement. They tested 12 published AI defenses, most claiming near-zero attack success rates. The researchers achieved bypass rates above 90% on almost all of them, as detailed in a VentureBeat report.
The gap between what vendors claim and what actually works is massive.
This isn't theoretical. Real attackers are already exploiting this gap. In September 2025, Anthropic disrupted an AI-orchestrated cyber operation where attackers executed thousands of requests per second with human involvement dropping to just 10-20% of the effort. Traditional three-to-six-month campaigns compressed to 24-48 hours, as noted by Cyber Magazine.
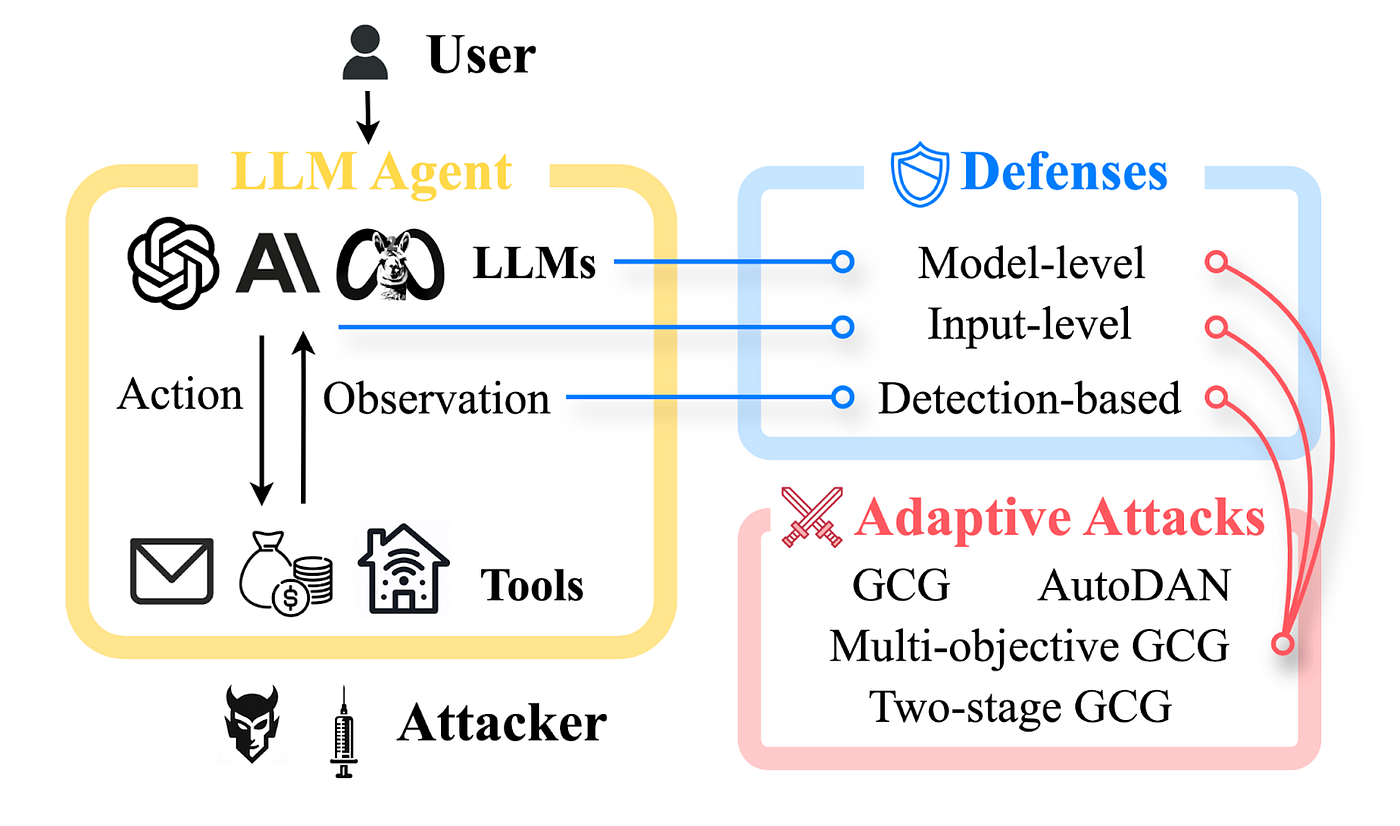
The problem isn't that AI security is impossible. The problem is that vendors are testing against attackers that don't behave like real attackers. They're testing static defenses against adaptive attacks. They're testing in controlled labs against adversaries operating at internet scale.
Here's what you need to know, and the seven critical questions you should ask your vendor before signing anything.
TL; DR
- 12 AI defenses tested, all failed: Researchers achieved 90%+ bypass rates on defenses claiming near-zero vulnerability
- Adaptive attacks are the real threat: Static defenses collapse instantly when attackers adjust their approach based on detection feedback
- Deployment is outpacing security: IBM predicts 40% of enterprise applications will integrate AI agents by end of 2026, up from <5% in 2025
- Four attacker profiles are already active: External adversaries, malicious B2B clients, insider threats, and AI-native attackers all exploit inference-layer vulnerabilities
- Ask vendors these 7 questions: About adaptive testing, real-world deployment, continuous monitoring, incident response, third-party validation, industry benchmarks, and integration depth

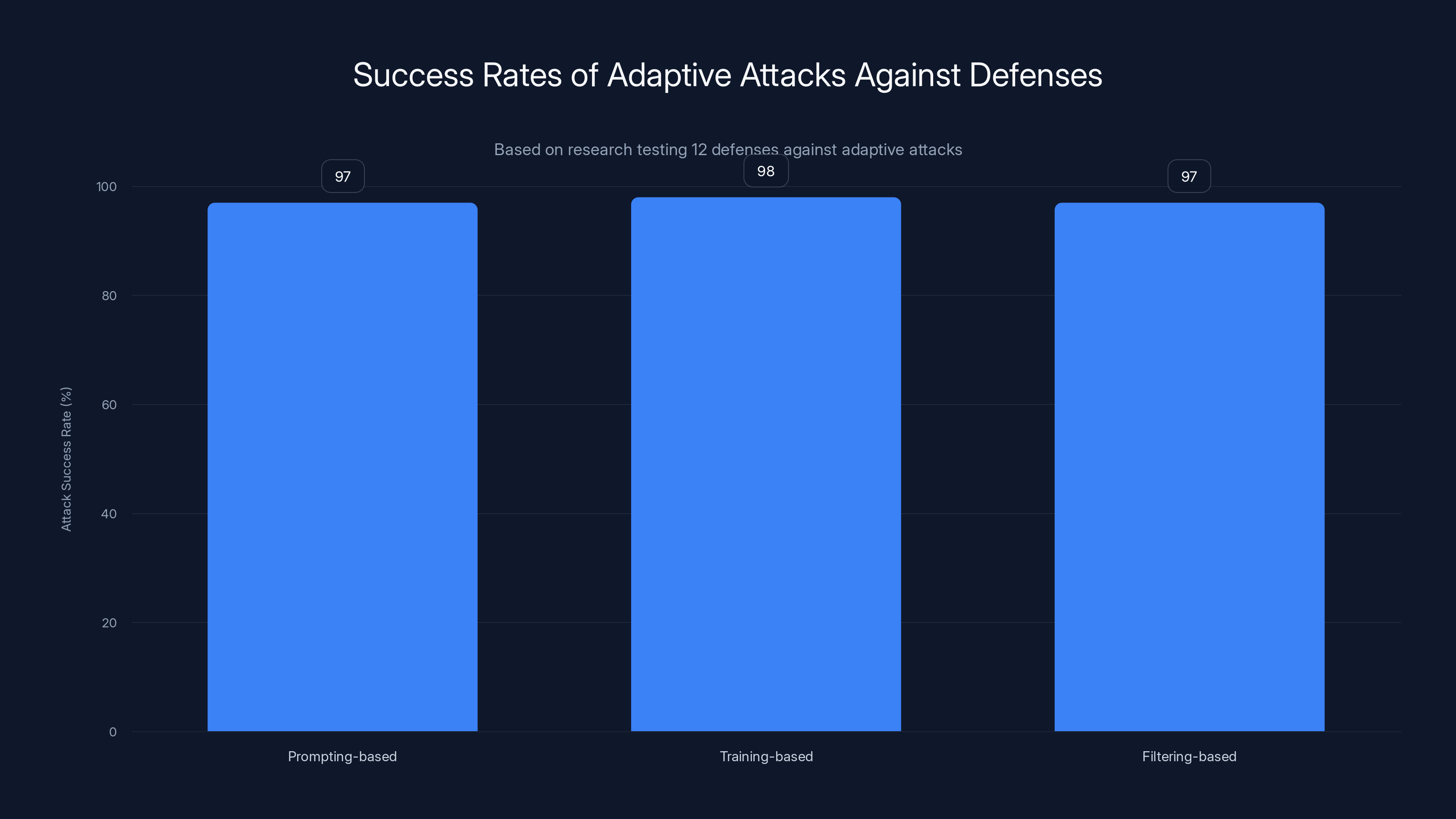
Adaptive attacks like Crescendo and GCG achieved 95-100% success rates against all tested defenses, highlighting the need for more robust adaptive security measures. Estimated data.
Why This Research Matters (And Why Most CISOs Missed It)
The paper's title tells you everything: "The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against LLM Jailbreaks and Prompt Injections." That subtitle is the vulnerability in a nutshell.
Your firewall doesn't know what yesterday's attack looked like. It doesn't adapt. It doesn't learn. It's static. It's predictable.
AI attacks don't work that way anymore.
Consider the Crescendo attack. It's elegant in its cruelty. Instead of throwing a malicious request at a model in one shot, Crescendo breaks it into innocent-looking fragments spread across up to 10 conversational turns. Each fragment seems harmless. Each one builds on the previous. The model builds rapport. Trust develops. By the time the final fragment lands, the model has been primed to comply.
A stateless filter catches none of this. Each turn looks safe individually. The danger lives in the pattern, the progression, the relationship that develops over time.
Then there's Greedy Coordinate Gradient (GCG), an automated attack that generates jailbreak suffixes through gradient-based optimization. No human creativity required. No custom prompting. Just math. Suffixes that mean nothing to humans but perfectly exploit the model's semantic understanding.
The research team tested both approaches, plus 10 others, against 12 published defenses.
Every single defense failed. Prompting-based defenses hit 95-99% attack success rates under adaptive conditions. Training-based methods hit 96-100%. Filtering-based approaches? Same story.
The methodology was rigorous. Fourteen authors. A $20,000 prize pool for successful attacks. Peer review. Published October 2025.
But here's what makes this urgent: most enterprises haven't implemented even basic AI security. According to research from McKinsey, only 16% of enterprises with generative AI deployments report having security controls in place. That means 84% are running blind.
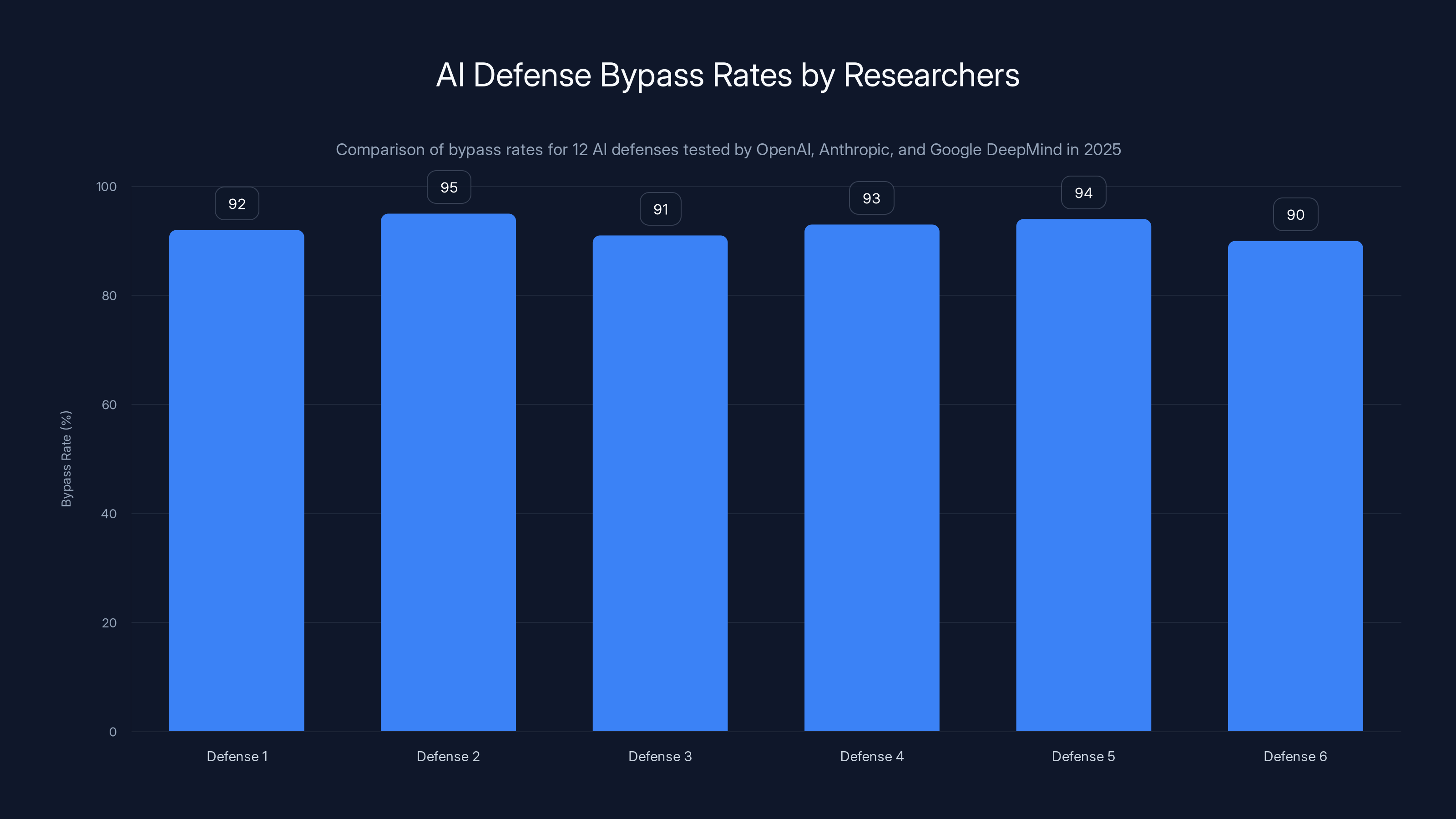
Researchers achieved bypass rates above 90% on almost all tested AI defenses, highlighting a significant gap between vendor claims and actual performance. Estimated data.
The Fundamental Problem: Static Defenses vs. Adaptive Attacks
Traditional security assumes your attacker behaves predictably. Network signatures. Pattern matching. Known-bad lists. It works when attackers follow predictable playbooks.
AI attacks don't follow playbooks. They adapt in real time.
Why Web Application Firewalls Fail at the Inference Layer
Your WAF is stateless. It's trained once. It never learns. It never adapts.
AI attacks are stateful. They learn from every blocked attempt. Every failed injection teaches the attacker something about your defenses.
The researchers made this explicit. They threw known jailbreak techniques at these defenses. Techniques with published code. Techniques available on GitHub. The defenses should have caught them immediately.
They didn't.
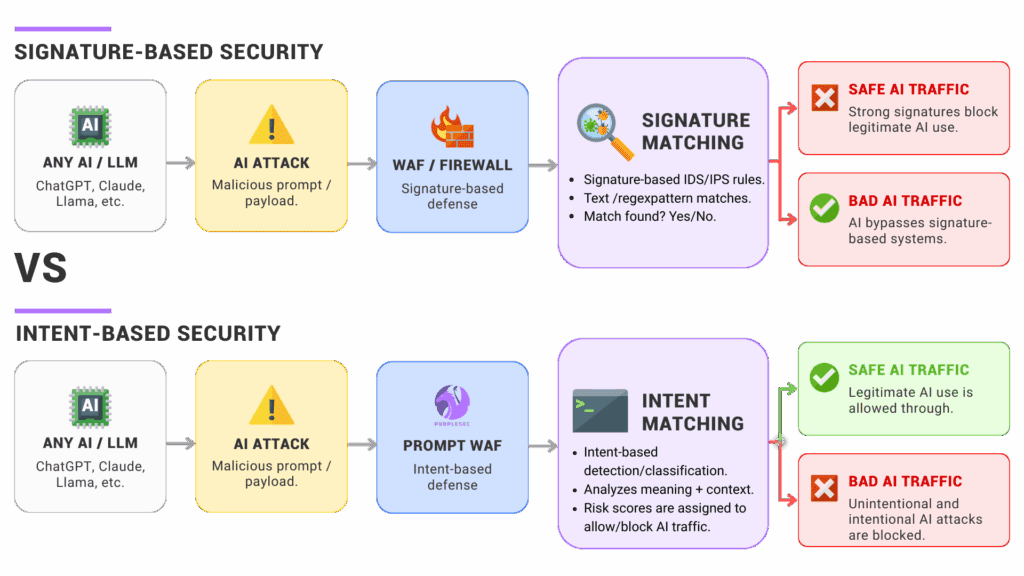
Why? Because stateless analysis can't parse semantic attack patterns. A phrase as innocuous as "ignore previous instructions" bypasses signature-based detection because it's semantically correct English, grammatically sound, and contextually reasonable. It looks like legitimate conversation. The attack lives in the instruction override, not in the string itself.
Base 64 encoding hides the payload from simple pattern matching. Rot 13 obscures it further. But the model understands the underlying instruction perfectly. That's the gap. Traditional security operates at the syntactic layer. AI attacks operate at the semantic layer. WAFs don't speak semantics.
The research paper tested this explicitly. They measured bypass rates for each defense type:
- Prompting defenses (like system prompts instructing models to refuse harmful requests): 95-99% bypass rate
- Training-based defenses (like RLHF fine-tuning to align models against jailbreaks): 96-100% bypass rate
- Filtering defenses (like input/output filters blocking known attack patterns): 90-95% bypass rate
All of them failed because none of them adapted to new attack formulations.
The Context Loss Problem
Here's what's really insidious: most AI security implementations treat each API call in isolation. One request comes in, one response goes out, done.
But Crescendo doesn't work that way. Neither does any sophisticated adversary.
Multi-turn conversations create context. Context creates understanding. Understanding creates compliance. By the time request 10 arrives, the model has been primed by requests 1-9. It's not evaluating request 10 in isolation. It's evaluating request 10 in the context of a relationship.
Defenses that only inspect individual requests miss the pattern. They miss the relationship. They see 10 innocent conversations. An attacker sees an escalation ladder.
Carter Rees, VP of AI at Reputation, puts it bluntly: "A phrase as innocuous as 'ignore previous instructions' or a Base 64-encoded payload can be as devastating to an AI application as a buffer overflow was to traditional software. The difference is that AI attacks operate at the semantic layer, which signature-based detection cannot parse."
That's the core problem. Your defenses are operating at the wrong layer entirely.

The Speed Gap: Why Deployment Is Outpacing Security
The timing of this research couldn't be worse. Or more important.
Gartner predicts 40% of enterprise applications will integrate AI agents by the end of 2026. That's up from less than 5% in 2025. The deployment curve is vertical. The security curve is flat.
Your organization is probably part of that acceleration. Every department wants AI. Every vendor sells AI. Nobody's asking if it's secure.
Adam Meyers, SVP of Counter Adversary Operations at CrowdStrike, quantifies the speed gap with a number that should terrify you: "The fastest breakout time we observed was 51 seconds. Adversaries are getting faster, and this makes the defender's job a lot harder."
Fifty-one seconds. That's how long it takes for an experienced attacker to break from a compromised system to lateral movement. At scale, with modern tooling, that number is probably lower now.
The CrowdStrike 2025 Global Threat Report found 79% of detections involved malware-free attacks. Adversaries aren't bringing in backdoors anymore. They're using keyboard commands. Hands-on-keyboard techniques that bypass traditional endpoint defenses entirely.
In September 2025, Anthropic disrupted the first documented AI-orchestrated cyber operation. Here's what that looked like:
- Attackers executed thousands of requests, often multiple per second
- Human involvement dropped to just 10-20% of total effort
- The attack operated autonomously for long periods
- Traditional multi-month campaigns compressed to 24-48 hours
Your security team wasn't designed for that speed. Your incident response wasn't built for that scale. Your monitoring isn't looking for that pattern.
Why AI Agents Amplify the Risk
Jerry Geisler, Executive Vice President and CISO of Walmart, sees the problem clearly: "The adoption of agentic AI introduces entirely new security threats that bypass traditional controls. These risks span data exfiltration, autonomous misuse of APIs, and covert cross-agent collusion, all of which could disrupt enterprise operations or violate regulatory mandates."
Agentic AI doesn't wait for human approval. It doesn't second-guess its actions. It doesn't have risk aversion. An AI agent with API access to your billing system, your database, your cloud infrastructure, is an agent with total autonomy to cause damage.
A compromised agent doesn't just steal data. It can:
- Auto-scale your cloud infrastructure into bankruptcy
- Modify database records without leaving audit trails
- Execute API calls faster than your monitoring can detect
- Coordinate with other agents to bypass access controls
- Cover its tracks by modifying logs before analysis
This isn't paranoia. This is threat modeling with AI capabilities as an offensive tool.
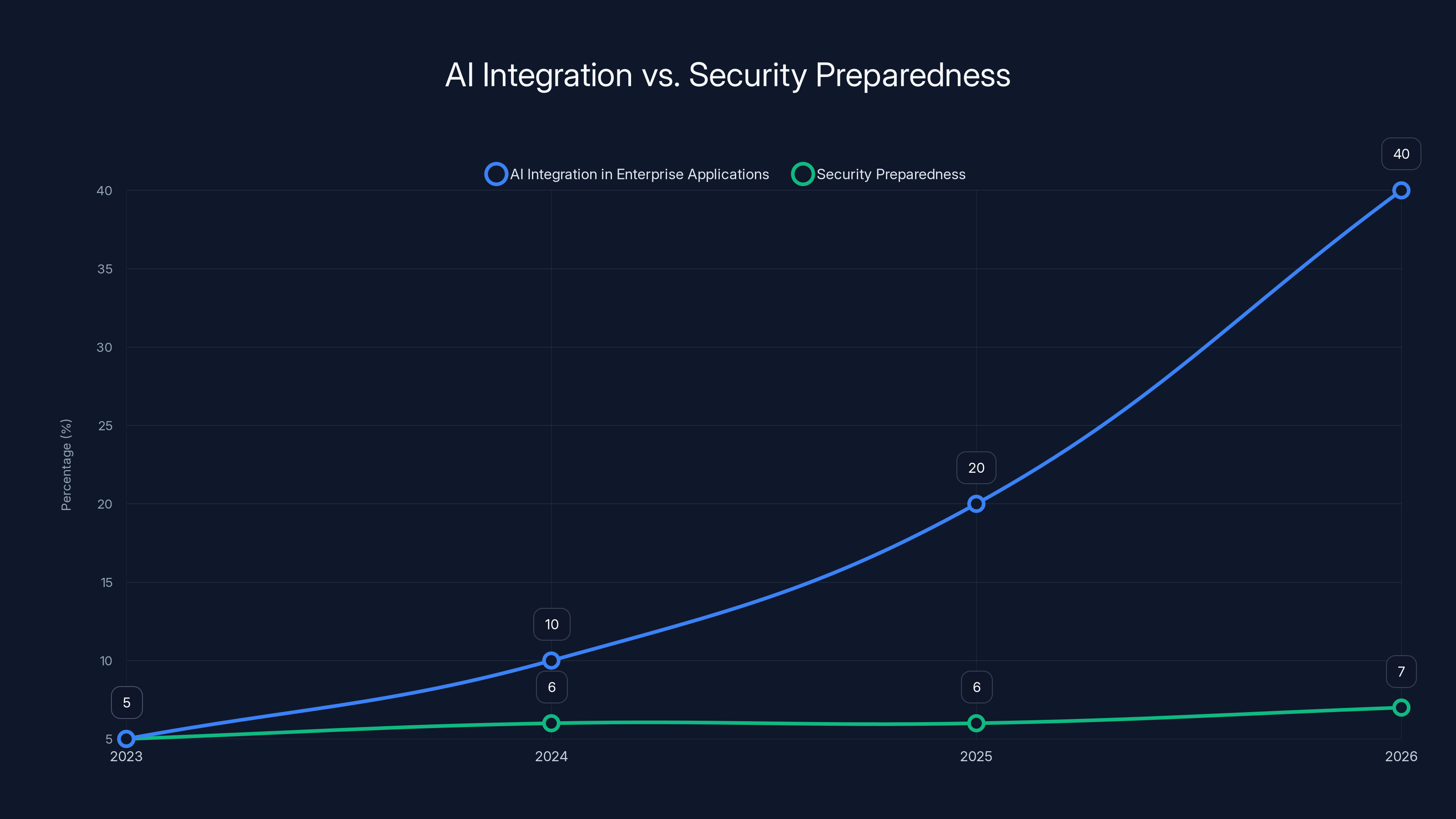
By 2026, AI integration in enterprise applications is projected to reach 40%, while security preparedness shows minimal growth, highlighting a significant speed gap. Estimated data.
Four Attacker Profiles Already Exploiting the Gap
The research paper makes an observation that explains why this matters so much: defense mechanisms eventually appear in internet-scale training data. Security through obscurity provides exactly zero protection when the models themselves learn how defenses work and adapt on the fly.
Anthropic tests against 200-attempt adaptive campaigns. OpenAI reports single-attempt resistance. These inconsistent testing standards highlight how fragmented AI security still is. Yet the research paper's authors used both approaches. Every defense still fell.
Four distinct attacker profiles are already operationalizing these findings.
1. External Adversaries Operationalizing Published Research
These are organized threat groups who read the same research papers you do. They see Crescendo. They see GCG. They see the bypass rates. They implement the attacks.
They test against each defense type. They adapt their approach to each defense's specific design, exactly as the researchers did. They have months of lead time before organizations even realize they need to patch.
These aren't nation-states spending billions. These are mid-tier threat groups with budgets in the millions who can afford to hire ML engineers and security researchers.
Their advantage is that they move second. They wait for your defense to go public. They study it. They attack it. You never see them until they've already won.
2. Malicious B2B Clients Exploiting Legitimate API Access
You invited this threat inside the firewall.
A legitimate B2B partner gets API credentials. They use those credentials to reverse-engineer your defenses. They test attack vectors. They probe the boundaries of what they can access and what they can do.
They're not breaking in. They're looking at what you've given them access to and finding creative ways to abuse it.
This is harder to detect because the traffic looks legitimate. The requests come from a partner you trusted. The access is authorized. The logs show normal usage patterns.
Until they don't.
3. Insider Threats with AI Knowledge
Your employee knows how your defenses work. They have infrastructure access. They understand the security controls.
They sell that knowledge. Or they use it themselves.
Insider threats have always existed. But an insider threat with understanding of AI security implementation can be exponentially more dangerous. They know where the blind spots are. They know what the defenses are looking for. They know what they're not looking for.
They can craft attacks that sail through your monitoring because they're designed to avoid exactly what you're monitoring for.
4. AI-Native Attackers (The Real New Category)
These aren't humans using AI tools. These are attackers whose entire operation is AI-first.
They don't have an employee roster. They have a cluster of ML models. They don't plan campaigns in Slack. They plan them in latent space. They don't execute manually. They orchestrate autonomously.
These operations are harder to profile, harder to predict, and harder to respond to because they don't follow human patterns.
We've never had to defend against this before.

What the Research Actually Tested (And Why It Matters)
The methodology is crucial to understanding why this breaks all the vendor claims.
The research team tested 12 defenses across four categories:
- Prompting-based defenses: System instructions telling models to refuse harmful requests
- Training-based defenses: RLHF fine-tuning and other training-time alignment methods
- Filtering-based defenses: Input/output filters and detection systems
- Hybrid defenses: Combinations of the above
For each defense, they designed an adaptive attack specifically calibrated to that defense's design. They didn't use generic attacks. They engineered attacks that exploited each defense's specific assumptions.
This is crucial because it shows the real vulnerability: vendor defenses are optimized against old attacks, not adaptive ones.
Prompting Defenses: 95-99% Bypass Rate
Think of prompting defenses as guardrails written into the system prompt. "You are Claude, a helpful AI assistant. You never provide information about illegal activities. You refuse harmful requests. Etc."
These seem like they should work. The model is explicitly told not to do the thing.
But the research shows they fail instantly under adaptive attacks because:
- A new prompt formulation can override the system prompt
- Jailbreaks can reframe harmful requests as legitimate ones
- The model's training might be more influential than the system prompt in edge cases
- Semantic obfuscation makes the request seem to align with the prompt's instructions
One specific finding: when prompting defenses were combined with additional safeguards, they still failed 90%+ of the time. The combinations didn't provide meaningful additional protection.
This means stacking prompts doesn't help. Doubling down on instruction-based defenses doesn't help. The vulnerability is fundamental to the approach, not a matter of degree.
Training-Based Defenses: 96-100% Bypass Rate
These are models fine-tuned to refuse harmful requests. Companies spend millions on RLHF (Reinforcement Learning from Human Feedback) to align models away from generating harmful content.
The research shows these fail because:
- Attackers can apply transformations (paraphrasing, encoding, obfuscation) that the training didn't anticipate
- Conversational context can make harmful requests seem acceptable
- The model's underlying capabilities never went away, just the training coating
- Gradient-based attacks can find adversarial prompts that exploit edge cases in the training
Once again, the fundamentals don't change. Training-based alignment is brittle.
Filtering-Based Defenses: 90-95% Bypass Rate
These are blocklists, pattern matching, and rule-based systems. They're looking for known-bad strings and known-bad patterns.
They fail because:
- Encoding (Base 64, Rot 13, hex, Unicode variation) hides the payload
- Tokenization breaks vary between models, so the filter and model see different strings
- Homoglyph attacks (Unicode characters that look like ASCII equivalents) bypass string matching
- The attack can be split across multiple turns or requests
- New attack variations don't match the list
These are the kind of defenses that feel like security theater. They make executives feel like something's being done. They fail the moment an attacker puts in 10 minutes of effort.

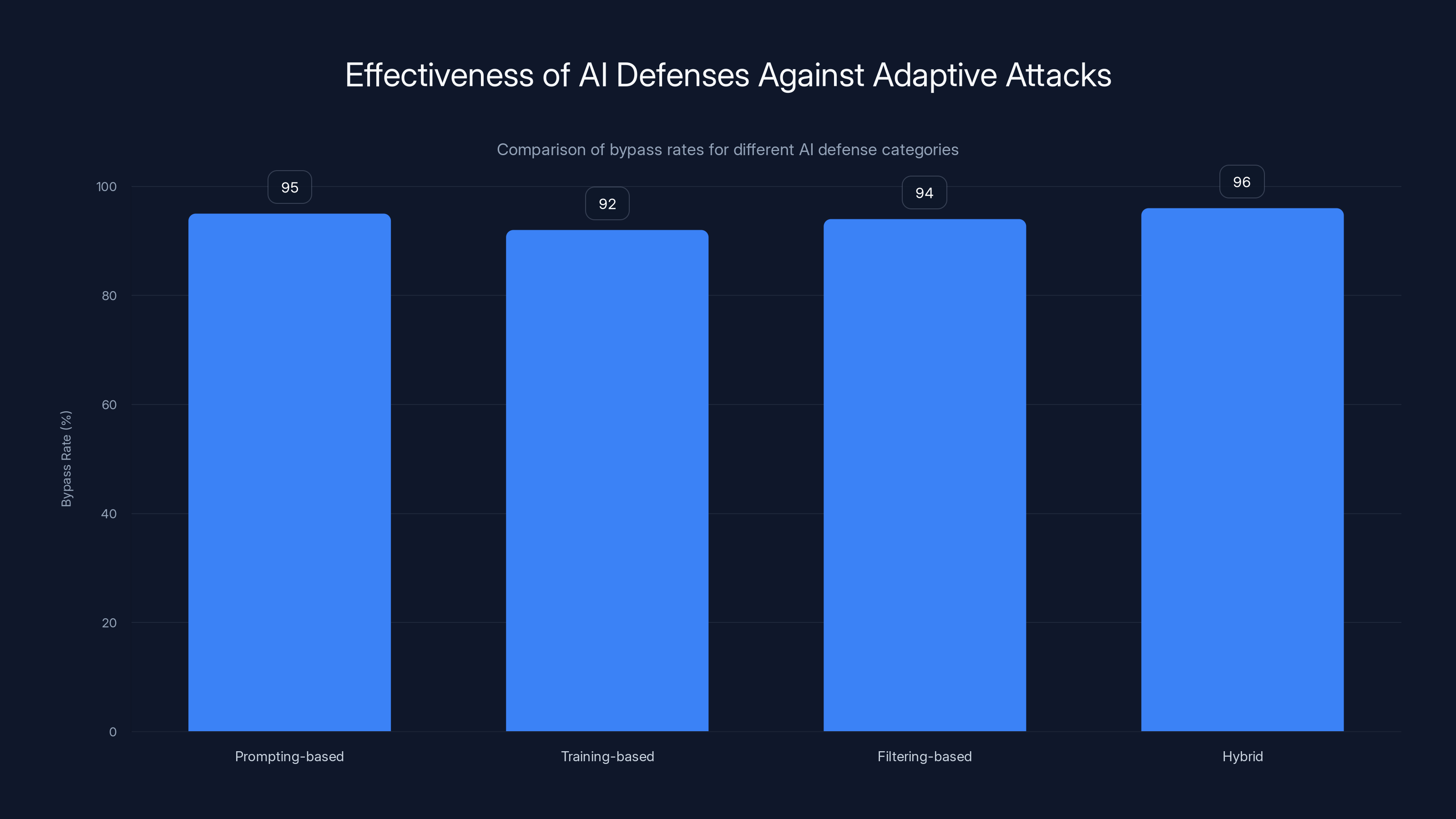
All tested AI defenses were bypassed at rates above 90%, indicating a high vulnerability to adaptive attacks despite claims of robustness. Estimated data.
The Testing Methodology: Why Real Validation Matters
Here's what made this research different from vendor self-tests:
They didn't test defenses under ideal conditions. They didn't test against known attacks. They tested against adaptive attacks where researchers actively tried to bypass each defense.
They gave each defense 200 attempts. They ran gradient-based optimization. They tried semantic obfuscation. They tried encoding. They tried conversational attack strategies.
Each defense got a fair but ruthless assessment.
This is the standard real-world attacks use. An attacker gets 200 attempts? They use every one. They get feedback? They learn from it. They have computational resources? They apply them to the problem.
Most vendor tests use static attacks. Known-bad inputs from a test set. The vendor runs these once and claims victory.
That's not how attacks work in production.
The Prize Pool Effect
The research team offered a $20,000 prize pool for successful attacks. This created incentive alignment. Security researchers competed to break the defenses. They tried harder because they had skin in the game.
This mirrors real-world conditions where attackers get paid for successful breaches. Vendors self-testing don't have this incentive.
When you introduce realistic incentives, the bypass rates went up. Way up. The defenses that claimed 99%+ protection dropped to 90%+ failure rates.
Real-World Implications: How This Plays Out in Production
Theory is one thing. Your production system is something else.
When these vulnerabilities are exploited in the wild, here's what happens:
The Speed of Exploitation
An attacker probes your API. They identify the defense type. They generate attack variants. They execute.
This entire cycle takes hours, not days.
Your incident response team is on-call during business hours. Your monitoring is configured for traditional attacks. Your playbooks assume humans are doing the attacking.
By the time you notice something's wrong, the attacker has already exfiltrated data, modified systems, or established persistence.
Meyers from CrowdStrike highlights the key point: "Threat actors have figured out that bringing malware into the modern enterprise is like trying to walk through airport security with a water bottle. They're probably going to get caught. Instead, they find a way to avoid detection altogether. One of the ways they've done that is by not bringing in malware at all."
Instead, they use your own systems. Your API. Your agents. Your access controls.
The Autonomy Problem
When you deploy agentic AI, you're handing the keys to systems that don't require human approval for every action.
A compromised agent can:
- Make unlimited API calls
- Modify data without rate limiting
- Coordinate with other agents
- Execute at speeds humans can't monitor
Traditional incident response assumes you can kill a compromised process and stop the bleeding.
With agentic AI, there might be dozens of processes, all coordinating, all operating autonomously.
One agent gets compromised. It signals others. They start executing their own operations. Your monitoring sees a distributed attack pattern instead of a single failure.
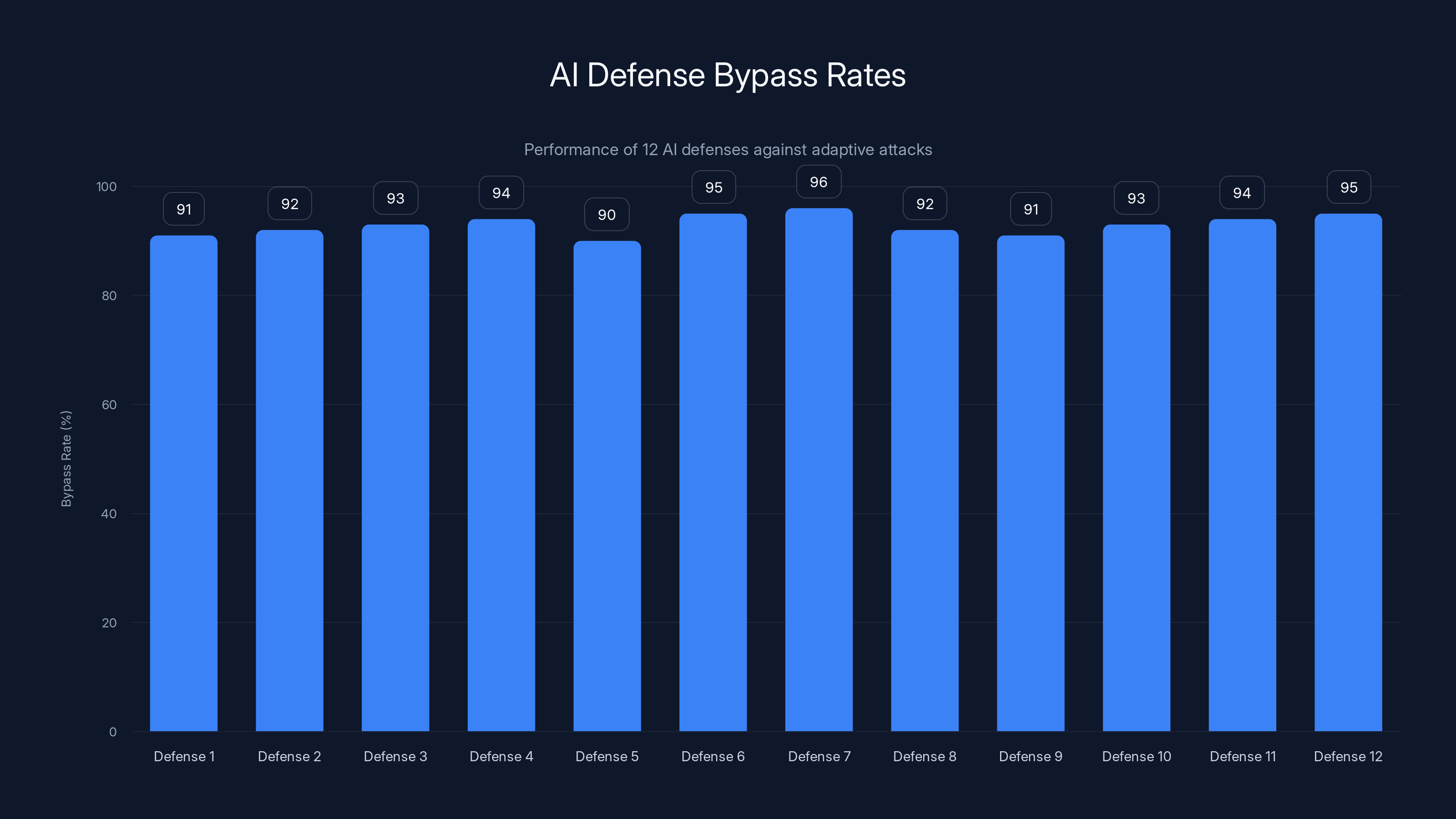
All 12 AI defenses tested showed high bypass rates, with each exceeding 90%, highlighting the vulnerability of static defenses to adaptive attacks.
Seven Critical Questions to Ask Your AI Security Vendor
Now you know the research. You know the gap. Here's what you need to ask before buying any AI security solution.
Question 1: How Does Your Defense Perform Against Adaptive Attacks with 200 Iterations?
Don't let them give you a test result against static attacks. That's theater.
Ask them:
- Have you tested against adaptive attacks where the attacker gets feedback and adjusts strategy?
- How many iterations did the attacker get? (Should be at least 100, ideally 200+)
- Did independent researchers test your defense, or was this an internal test?
- What were the failure rates under these adaptive conditions?
If they haven't done this testing, or if they won't disclose the results, they don't know if their defense works.
Question 2: What's Your Detection Latency for Multi-Turn Attack Patterns?
Crescendo works by spreading attacks across multiple turns. Your defense needs to detect the pattern, not individual requests.
Ask them:
- Can you detect attack patterns that span 5+ conversation turns?
- What's your detection latency? (Milliseconds matter at scale)
- How do you track context across turns without false positives?
- What happens if an attacker varies the attack pattern each turn?
If they're only looking at individual requests, they'll miss Crescendo entirely.
Question 3: How Do You Handle Prompt Injection Against Your Own System Prompts?
This is the recursive defense problem. If your defense uses system prompts to block harmful requests, what happens when someone injects against your system prompts?
Ask them:
- Have you tested against prompt injections that target your defense itself?
- What's your fallback if the primary defense is compromised?
- How do you prevent defense-aware attacks that know your specific defense design?
- Do you assume your defense implementation will eventually leak to the internet? (Spoiler: it will)
If they haven't thought through this recursion, they've built a defense against the last attack, not future ones.
Question 4: How Do You Separate Legitimate Use Cases from Attack Patterns?
Here's the hard part: some legitimate use cases look like attacks.
Imagine a customer asking your AI-powered support bot progressively more detailed questions about your products. Each question builds on the previous. Over 10 turns, they've learned enough to make a purchasing decision.
That's legitimate. It also looks like Crescendo.
Ask them:
- How do you distinguish between legitimate multi-turn conversations and staged attacks?
- What's your false positive rate for normal usage patterns?
- Can you provide examples of legitimate use cases that your defense would block?
- How do you tune the defense without breaking legitimate functionality?
A defense that blocks legitimate usage is worse than no defense at all.
Question 5: How Do You Monitor and Adapt to New Attack Techniques?
Defenses age. Fast.
The Crescendo and GCG attacks were already available when this research started. Six months from now, there will be new attack techniques that aren't in the research paper.
Ask them:
- How frequently do you update your defenses? (Weekly? Monthly? Never?)
- Do you have threat intelligence integration that automatically updates based on new attacks?
- How do you test new attack variants before they're in the wild?
- Can you explain your process for adapting defenses against attacks that didn't exist last month?
If their answer is "we hope our static model handles it," you need a different vendor.
Question 6: What's Your Third-Party Validation Story?
Vendor self-tests are theater. Independent validation matters.
Ask them:
- Have you submitted your defense to independent security researchers for testing?
- Do you have published results from third parties who've tried to break your defense?
- Are you willing to participate in future research evaluations?
- What certifications or third-party validations do you have?
If they can't point to independent validation, everything else is just marketing.
Question 7: How Does Your Defense Scale to Agentic AI Operations?
AI agents operate at different scales and speeds than traditional systems.
Ask them:
- Can your defense handle thousands of requests per second from multiple agents?
- Do you have specific monitoring for agent-to-agent communication?
- How do you detect when agents coordinate to bypass your defenses?
- What's your latency impact on high-volume agent operations?
If their defense is designed for chat applications, it won't work for agent orchestration.
What Actually Works: Building Defense-in-Depth for AI
Single-layer defenses fail. We know that from the research. So what actually works?
Defense-in-depth means multiple layers, each looking for different attack signals, each with different detection mechanisms.
Layer 1: Input Validation and Anomaly Detection
This isn't just pattern matching. It's behavioral baseline establishment.
You need to know what normal usage looks like for your specific AI application:
- How many requests per minute is typical?
- What's the average conversation turn count?
- How long do typical interactions last?
- What's the average input length?
When something deviates significantly from these baselines, that's a signal. Not proof of attack, but a signal worth investigating.
Encode detection separately from semantic detection. A user shouldn't base 64-encode their requests to your customer support bot. If they do, that's suspicious.
Layer 2: Semantic Analysis and Intent Detection
This is the expensive layer that actually understands what's happening.
You need a secondary model (smaller, faster, different architecture) that analyzes the primary model's inputs for intent. Not syntax. Intent.
Does this request intent look like it's trying to override my instructions? Does it intend to extract protected information? Does it intend to bypass my access controls?
This layer doesn't need to be perfect. It just needs to catch high-confidence attack patterns.
Layer 3: Behavioral Monitoring on the Agent Level
If you're using agentic AI, you need real-time monitoring of agent behavior.
What APIs is this agent calling? In what order? With what frequency? At what scale?
An agent that suddenly starts calling your database at 1000x normal velocity should trigger immediate alerts. An agent that starts making API calls it normally doesn't make should stand out.
This requires logging everything. At scale. Continuously.
Layer 4: Incident Response and Containment
Detection is half the battle. Response is the other half.
You need:
- Automated agent shutdown capabilities
- API token revocation procedures
- Agent communication isolation
- Audit trail verification
- Damage assessment protocols
When you detect a compromised agent, you don't get to take your time investigating. You need to stop the bleeding immediately.

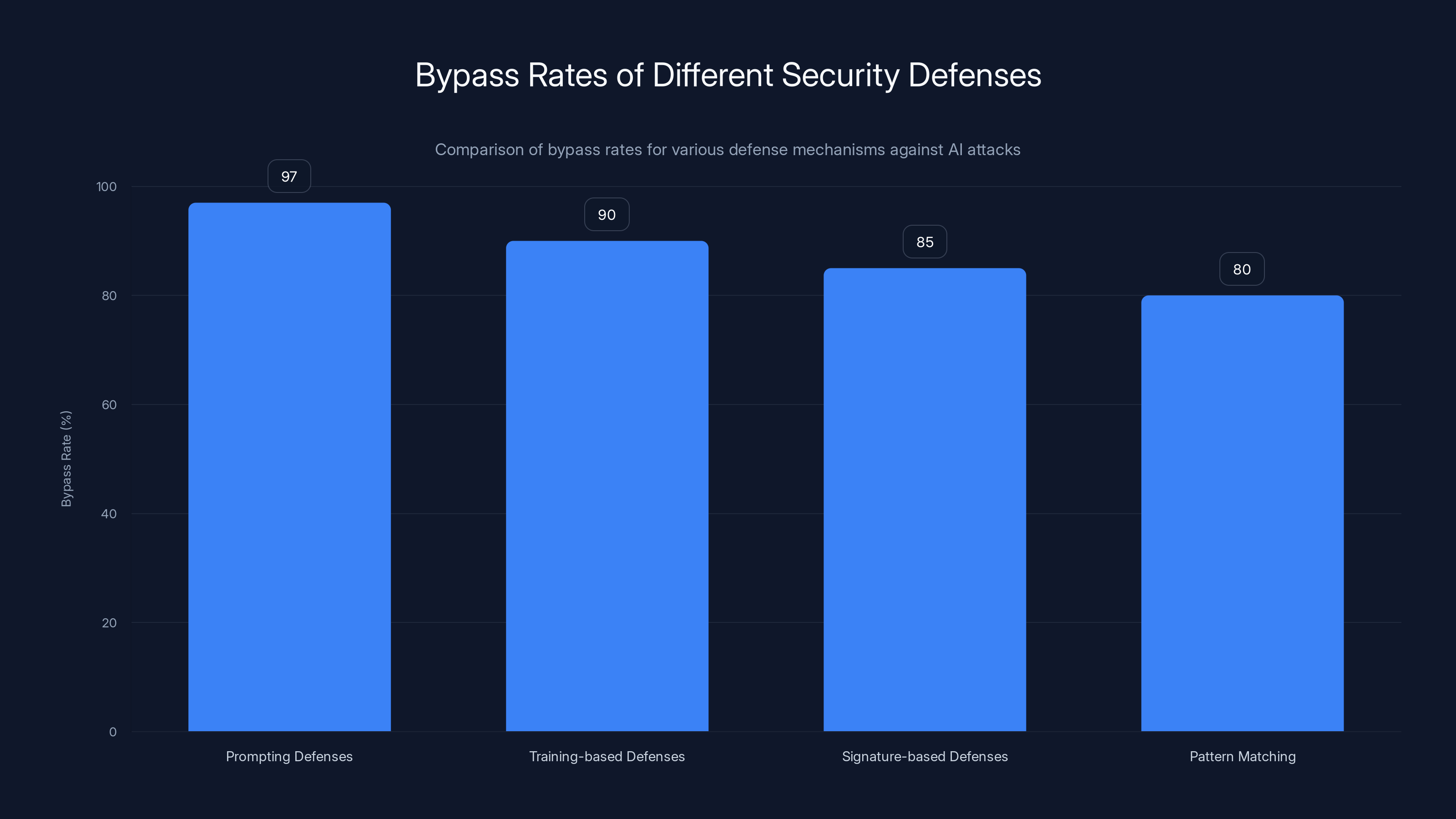
AI attacks have a high bypass rate against traditional security defenses, with prompting defenses being the most vulnerable. Estimated data based on typical bypass rates.
The Organizational Challenge: Building AI Security Culture
Technology is half the problem. The other half is people and processes.
Most organizations approached AI deployment like they approached cloud adoption in 2010. Deploy first. Secure later.
That didn't work then. It won't work now.
Security Needs a Seat at the Design Table
Your security team needs to review AI applications before they're deployed, not after they're exploited.
This means:
- Security architects reviewing AI architecture decisions
- Threat modeling AI workflows before implementation
- Defining security requirements in the RFP, not as afterthoughts
- Testing security assumptions in staging environments
You Need AI-Specific Security Expertise
Your traditional security team doesn't know how to attack an LLM. They don't understand semantic exploitation. They haven't tested against adaptive threats.
You need to hire or develop expertise in:
- AI/ML security
- Prompt engineering and jailbreak techniques
- Adversarial machine learning
- Agent coordination and orchestration
This is a new discipline. Your existing staff might not have these skills.
Continuous Testing Against New Threats
You can't rely on vendors to keep up with threat evolution.
You need internal red team capacity that:
- Tests your AI systems monthly (minimum)
- Reads AI security research and adapts tests accordingly
- Runs simulations of agent compromise scenarios
- Reports findings and drives remediation
This isn't one-time penetration testing. This is continuous security evaluation.
The Regulatory Landscape: What Compliance Actually Requires
Complicating everything: regulators are behind the threat curve.
Most compliance frameworks (SOC 2, ISO 27001, HIPAA, GDPR) don't have specific AI security requirements. They have general security requirements that don't translate well to AI deployment.
You're going to run into conflicts:
- Compliance requires data minimization, but AI improves with more data
- Compliance requires auditability, but AI model decisions are opaque
- Compliance requires access controls, but agents need broad permissions to be useful
Your organization needs to decide: do we meet compliance by the letter or the spirit?
Most organizations will choose the letter. That leaves them compliant but insecure.
Looking Forward: The Evolution of AI Attacks
The research from October 2025 is already becoming outdated. Not because the findings were wrong, but because attackers innovate faster than academics publish.
Here's what's probably coming:
Distributed Attack Patterns
Instead of one attacker hitting one target, you'll see coordinated attacks across multiple agents, multiple sessions, multiple organizations.
One attack softens your defenses. Another exploits the weakness. A third exfiltrates data. A fourth covers tracks.
Your incident response is designed to catch single-organization compromises. Distributed patterns will slip through.
Model-Specific Attack Adaptation
Attackers will develop AI-specific attacks optimized for each major model architecture.
They'll fingerprint your model through API responses, then apply model-specific jailbreaks.
OpenAI's models will need different defenses than Anthropic's. Claude will need different defenses than Llama. Your homegrown model will need defenses nobody's written yet.
Supply Chain Exploitation
Attackers will target AI platforms through their dependencies.
Compromise the API platform. Compromise the fine-tuning vendor. Compromise the evaluation tool. Each compromise spreads to downstream users.
Your AI application might be perfectly secure. Your vendor's infrastructure might be completely compromised.
Implementation Roadmap: From Theory to Practice
Let's translate this research into action items.
Month 1-2: Assess Current State
First, understand where you stand:
- Inventory all AI applications in production
- Document security controls currently in place
- Identify critical AI systems (data access, financial impact, regulatory exposure)
- List current threat intelligence and monitoring capabilities
Don't overthink this phase. You're gathering baseline data, not solving problems yet.
Month 2-3: Conduct AI Security Threat Modeling
Bring together architects, security, and AI teams:
- Define realistic threat actors for each AI application
- Model attack paths through your AI infrastructure
- Identify single points of failure
- Document assumptions about defense effectiveness
Use the four attacker profiles from the research as templates. Build on them with your specific threat context.
Month 3-4: Red Team Current Defenses
Test what you've already got:
- Run Crescendo-style attacks against your systems
- Test prompt injection specific to your deployed models
- Attempt to bypass your current filtering or detection
- Document failure points and success rates
Expect to fail spectacularly. That's the point.
Month 4-6: Layer Defense-in-Depth
Based on testing, implement multiple detection layers:
- Input anomaly detection
- Semantic analysis
- Behavioral monitoring
- Agent coordination tracking
Start with one layer. Validate. Scale.
Month 6+: Continuous Monitoring and Adaptation
Once layered defenses are in place:
- Monthly red team exercises
- Quarterly threat modeling updates
- Continuous threat intelligence integration
- Incident response testing
This isn't a project. It's an operational capability.

The Uncomfortable Truth About AI Security Today
Here's what you need to accept: nobody's winning at AI security yet.
Vendors are overselling. Researchers are discovering new attack vectors faster than defenses can be built. Organizations are deploying without basic controls.
The October 2025 research paper is simultaneously the best and worst thing to happen to the AI security industry.
Best because it's forcing honest conversations about the gap between claimed and actual security.
Worst because it shows us we're not ready. We've deployed powerful technology without understanding the attack surface. We've built defenses that fail under real conditions. We're operating in a state of defensive ignorance.
But awareness is the first step.
If you read the research, you know more than most CISOs. If you ask the seven questions we outlined, you'll separate vendors who understand the problem from vendors who are faking it.
If you implement defense-in-depth with continuous testing, you're ahead of 99% of organizations.
The window to get this right is closing. By 2026, when AI deployment accelerates, the attacks will be faster, more sophisticated, and operating at scale.
Start now. Test ruthlessly. Assume your defenses will fail. Build accordingly.
FAQ
What exactly did the research test?
Researchers from OpenAI, Anthropic, and Google DeepMind tested 12 published AI defenses across four categories: prompting-based, training-based, filtering-based, and hybrid approaches. They used adaptive attacks where the attacker received feedback and adjusted their strategy accordingly, rather than static one-shot attacks. All 12 defenses were bypassed at rates above 90%, despite claims of near-zero vulnerability.
Why do prompting-based defenses fail?
Prompting defenses rely on system instructions like "never help with illegal activities." They fail because adaptive attackers can reformulate requests, reframe contexts, use semantic obfuscation, or override instructions through prompt injection techniques. The vulnerability is fundamental to the approach, not a matter of implementation detail. New prompt variations defeat the defense because the model's underlying capabilities remain unchanged.
How is Crescendo different from traditional attacks?
Crescendo breaks malicious requests into innocent-looking fragments spread across up to 10 conversational turns. Each fragment seems harmless individually, but they build context and rapport that primes the model for compliance. Traditional static defenses that analyze individual requests miss the pattern entirely because they don't track multi-turn context or relationship development over time.
What makes AI attacks adaptive?
Adaptive attacks adjust their strategy based on feedback from previous attempts. If one jailbreak fails, the attacker learns why and modifies the next attempt accordingly. Attackers can test hundreds of variations and learn which formulations work against specific defenses. This is fundamentally different from static attacks that rely on a single predetermined payload.
Can I just stack multiple defenses together?
The research showed that combining defenses doesn't provide meaningful additional protection. When they tested prompting defenses combined with additional safeguards, they still achieved 90%+ bypass rates. Stacking defenses of the same type (multiple prompts or multiple filters) doesn't address the underlying vulnerability. You need defenses at different layers targeting different attack vectors.
What questions should I ask my AI security vendor?
Asking vendors about adaptive attack testing (200+ iterations), multi-turn detection latency, recursive defense vulnerabilities, false positive rates for legitimate use, defense update frequency, third-party validation, and scalability to agentic AI operations will quickly separate vendors with real security from those with marketing theater. Most can't answer convincingly to these questions.
How fast can a real attack move?
According to CrowdStrike, the fastest breakout times observed were 51 seconds from initial compromise to lateral movement. AI-orchestrated operations can exfiltrate critical data in hours rather than the traditional multi-month campaigns. Your incident response team operates at human speed. Your defenses need to operate at machine speed or you'll miss the attack entirely.
What's the difference between prompting, training, and filtering defenses?
Prompting defenses use system instructions to guide model behavior (instructional guardrails). Training-based defenses fine-tune models through RLHF to refuse harmful requests (learning-based alignment). Filtering defenses use pattern matching or rules to block known-bad inputs and outputs (rule-based blocking). All three categories were defeated by adaptive attacks in the research, but each fails for different technical reasons requiring different defense strategies.
Can AI agents be compromised?
Yes. AI agents with API access to your systems represent the same compromise risk as any other system component. A compromised agent can execute API calls at scale, coordinate with other agents, modify data autonomously, and operate without human approval. Unlike traditional systems, agents can operate fully autonomously during an attack, making detection and containment more difficult.
What should my defense-in-depth strategy include?
Build multiple layers: input validation with behavioral baselines, semantic analysis with secondary models for intent detection, agent-level behavioral monitoring with real-time API tracking, and automated incident response with containment capabilities. Each layer should detect different attack patterns and operate at different speeds. No single layer will catch everything, but multiple layers dramatically improve detection odds.

Conclusion: The Road Ahead for AI Security
The October 2025 research paper on AI defense bypasses is not an outlier finding. It's a wake-up call that the emperor has no clothes.
Every organization deploying AI right now is making a bet. They're betting that their vendor's security is adequate. They're betting that their existing controls transfer to AI systems. They're betting that attackers haven't figured out how to exploit their specific deployment.
They're losing these bets.
The research proves that vendor defenses don't work under realistic attack conditions. The gap between claimed security and actual security isn't a matter of implementation details or parameter tuning. It's a fundamental architectural problem.
But here's the important part: knowing this puts you ahead.
You now understand that:
- Single-layer defenses fail. You need multiple detection mechanisms at different levels.
- Static defenses are theater. Adaptive attacks will overcome them. Your defenses must evolve continuously.
- Speed matters. AI attacks move faster than human incident response. Your detection and containment must be automated.
- Third-party validation matters. Vendor self-tests prove nothing. Independent research is the only reliable signal.
- Agentic AI amplifies risk. Autonomous agents with API access represent a new threat surface that traditional security wasn't designed for.
- This is now your problem. Your CISO, your CTO, your board needs to understand AI security implications before deploying at scale.
The deployment curve for AI is vertical. The security curve is flat. That gap will close, but only if organizations prioritize security from day one of AI adoption.
Start with the seven vendor questions. Get honest answers. If you don't like those answers, keep looking.
Implement defense-in-depth. Test continuously. Assume your defenses will fail and build plans for when they do.
Hire AI security expertise. This isn't something your existing security team can improvise their way through.
Build incident response capabilities for AI-specific scenarios. Your playbooks for malware response won't work for compromised agents.
Most importantly: don't pretend this problem doesn't exist while hoping your vendor's marketing is true.
The researchers already proved it's not.
The time to secure AI deployments is now. The research showing why existing defenses fail is already published. The attack techniques are already available. The first sophisticated, coordinated AI-native attacks are probably being planned right now.
What happens next depends on whether your organization responds with urgency or continues operating under the assumption that things will probably be fine.
History suggests they won't be.
Choose accordingly.

Key Takeaways
- Researchers achieved 90%+ bypass rates on 12 published AI defenses, demolishing vendor claims of near-zero vulnerability
- Adaptive attacks where the attacker receives feedback and adjusts strategy are fundamentally different from static test attacks
- Multi-turn conversation attacks like Crescendo defeat stateless defenses by building context across 10+ turns
- Four distinct attacker profiles are currently exploiting AI security gaps in production environments
- Defense-in-depth with continuous monitoring, semantic analysis, and agent behavioral tracking is the only viable strategy
- Traditional incident response designed for human-speed attacks fails against AI-orchestrated operations completing in hours
Related Articles
- Google Gemini Calendar Prompt Injection Attack: What You Need to Know [2025]
- FortiGate Under Siege: Automated Attacks Exploit SSO Bug [2025]
- Microsoft 365 Outage 2025: What Happened, Why, and How to Prevent It [2025]
- LinkedIn Phishing Scam Targeting Executives: How to Protect Yourself [2025]
- Hyatt Ransomware Attack: NightSpire's 50GB Data Breach Explained [2025]
- Threat Hunting With Real Observability: Stop Breaches Before They Spread [2025]

