![Microsoft 365 Outage 2025: What Happened, Why, and How to Prevent It [2025]](https://tryrunable.com/blog/microsoft-365-outage-2025-what-happened-why-and-how-to-preve/image-1-1769171958354.jpg)
Microsoft 365 Outage 2025: What Happened, Why, and How to Prevent It
It was a Tuesday morning when thousands of enterprise customers realized they couldn't access their email. Then their files went dark. Then their calendar stopped syncing. Within minutes, Slack channels across the globe filled with panicked messages: "Is Microsoft down for you?" Yes. Yes it was.
On December 21, 2024, Microsoft 365 experienced a major infrastructure outage that knocked out critical services across North America. We're talking Outlook, Teams chats, Share Point files, One Drive backups—the whole ecosystem. For roughly 12 hours, teams couldn't collaborate, executives missed meetings, and businesses basically went into triage mode.
But here's what most people missed in the chaos: this wasn't a security breach. There was no hacking. No malicious actor. Just a portion of Microsoft's North America infrastructure that stopped processing traffic the way it should have. Simple. Catastrophic. Fixable.
I've been covering cloud infrastructure for years, and outages like this reveal something critical about how we've built modern business. We've centralized everything—email, documents, meetings, backups—into a handful of cloud providers. When they go down, entire organizations freeze. So what actually happened? How did Microsoft fix it in 12 hours? And most importantly, what can you do to survive the next one?
Let's dig into the details, the timeline, and the lessons that matter.
TL; DR
- The Incident: Microsoft 365 infrastructure in North America failed on December 21, 2024, causing widespread outages affecting Outlook, Teams, Share Point, One Drive, and Microsoft Defender for roughly 12 hours
- Root Cause: A portion of service infrastructure was not processing traffic as expected, though Microsoft didn't disclose the specific technical failure
- The Error: Users saw "451 4.3.2 temporary server issue" errors when trying to access services
- The Fix: Microsoft spent hours rebalancing traffic, optimizing performance, and restoring infrastructure to a healthy state
- Impact Zone: Primarily North America region, but some international customers reported intermittent issues
- Bottom Line: This outage demonstrates why organizations need redundancy strategies, backup tools, and offline-first workflows
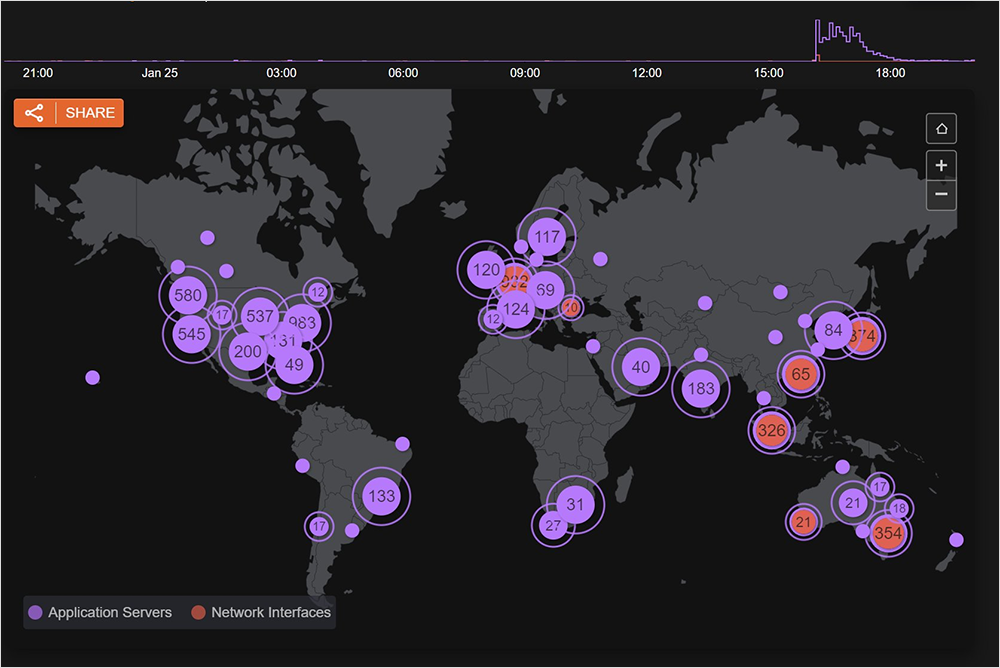
Estimated data shows that service failures have the highest impact on business operations during outages, closely followed by email downtime and collaboration breakdown.
What Was the Microsoft 365 Outage?
The Microsoft 365 outage on December 21, 2024, wasn't some rare black swan event. It was an infrastructure failure that exposed how fragile centralized cloud systems can be when they're not properly designed for resilience.
Here's what happened in plain terms: Microsoft has massive data centers across North America. These centers are supposed to be redundant, load-balanced, and fault-tolerant. Meaning if one piece breaks, traffic automatically reroutes to another. But something in that system broke. A portion of the infrastructure stopped accepting and processing requests properly.
Users trying to open Outlook got error messages instead of their inboxes. Teams channels became inaccessible. File sync stopped. Share Point went dark. If your organization was using Microsoft 365 as your primary communication and collaboration platform (and most are), you just went offline. Completely.
The incident was tagged MO1221364 in Microsoft's internal systems. That designation tells you it was serious enough to warrant formal incident management. Microsoft's status page started lighting up with alerts around the same time Downdetector showed a massive spike in reported outages.
What made this different from other outages: it wasn't gradual degradation. It wasn't "we're experiencing slower than normal performance." It was a hard stop. Services were either working or completely unavailable. No middle ground.
The Geographic Impact
Microsoft was clear: the affected infrastructure was in the North America region. But "North America" is vague. In practice, that meant the United States and Canada were hit hardest. European customers experienced intermittent issues, likely due to traffic overflow as systems tried to reroute. Australian and Asian customers reported some impact too, though less severe.
The problem is that even though Microsoft has data centers in multiple regions, many enterprise customers have their primary infrastructure pinned to North America for compliance, latency, or licensing reasons. So even if backup regions existed, their traffic couldn't automatically failover.
Which Services Were Actually Down?
Not everything broke equally. Here's what we know from user reports and Downdetector data:
Completely Unavailable:
- Outlook (web and some desktop clients)
- Exchange Online
- Microsoft Defender integration
- Microsoft Purview (compliance and data governance)
Severely Degraded:
- Teams (chat and file sync)
- Share Point Online
- One Drive for Business
- Azure AD authentication for some integrated apps
Partially Affected:
- Office 365 applications (some could sync, others couldn't)
- Mobile apps (hit-or-miss depending on cached data)
- Microsoft Stream
The common thread: anything that relied on backend infrastructure in that North America zone was impacted. Cached content on local machines worked fine. Offline files still functioned. But the moment you needed to sync, authenticate, or communicate with Microsoft's servers, you hit a wall.
The Timeline: Hour by Hour
Understanding exactly when things broke helps us understand the severity and Microsoft's response speed.
10:47 AM UTC (Approximately)
Users start reporting issues. Outlook inboxes won't load. Email sync stops. Help desk tickets flood in. Most companies initially assume it's a local issue or client problem.
11:15 AM UTC
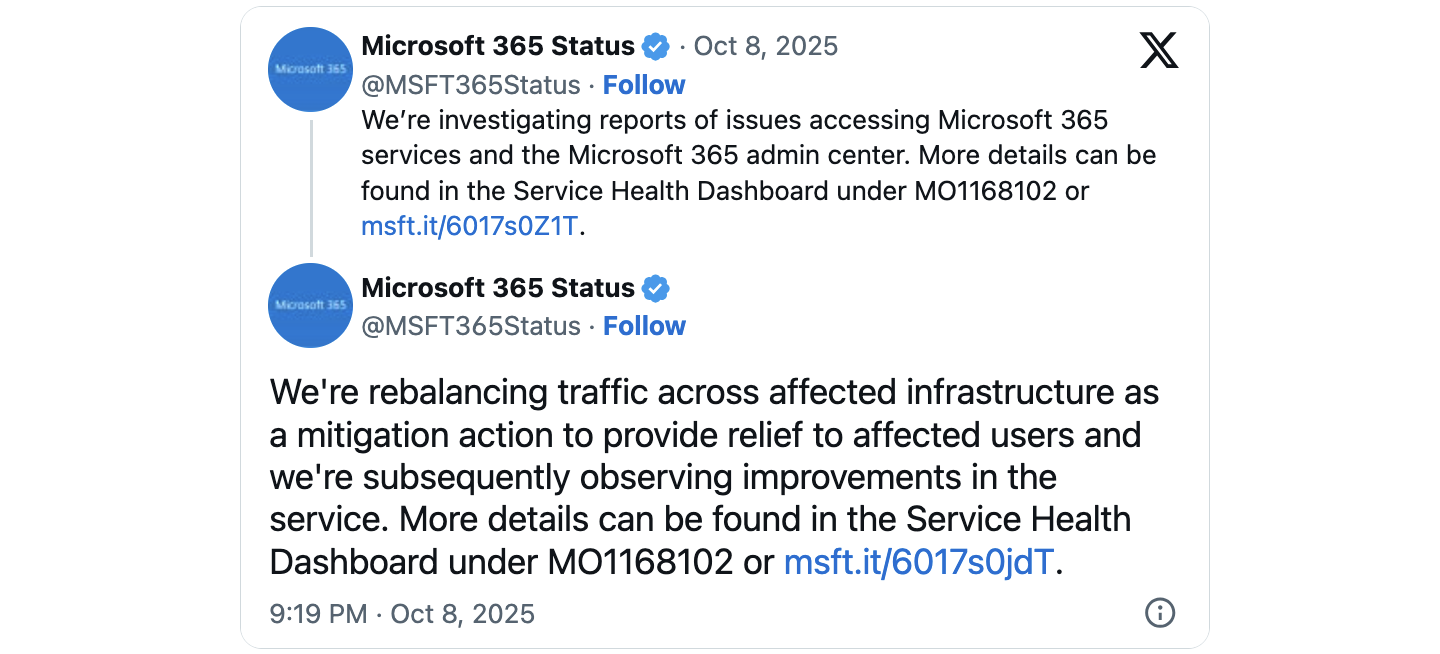
Microsoft tweets acknowledgment. "We're investigating a potential issue impacting multiple Microsoft 365 services." They tag it as under investigation. No details yet. No timeline for resolution. Enterprise support lines light up.
11:45 AM UTC
Microsoft identifies the issue: "A portion of service infrastructure in North America is not processing traffic as expected." This is the breakthrough moment. They now know it's infrastructure-level, not an application bug or misconfiguration.
12:00 PM UTC to 8:00 PM UTC (8 Hours)
Microsoft's incident response team kicks into remediation mode. They're doing three things simultaneously:
-
Traffic Rebalancing: Redirecting requests away from the broken infrastructure to healthy capacity. This is delicate—send too much too fast and you overload healthy systems.
-
Performance Optimization: Tweaking load balancers and routing rules to handle the surge properly without cascading failures.
-
Infrastructure Inspection: Figuring out what actually broke so they can restore it safely.
8:00 PM UTC (Approximately)
Services start coming back. It's not instant—it's gradual. Users refresh their browsers and suddenly Outlook works. Teams syncs again. Bit by bit, the system recovers.
8:30 PM UTC
Microsoft tweets the all-clear. Services are restored. The incident is officially closed. Total downtime: roughly 10-12 hours depending on region and service.
Hours After
Second spike shows on Downdetector. This could be:
- Cascading effects from the restoration
- Users flooding back online simultaneously (thundering herd problem)
- A brief secondary issue, never fully confirmed
By next morning, everything was stable.
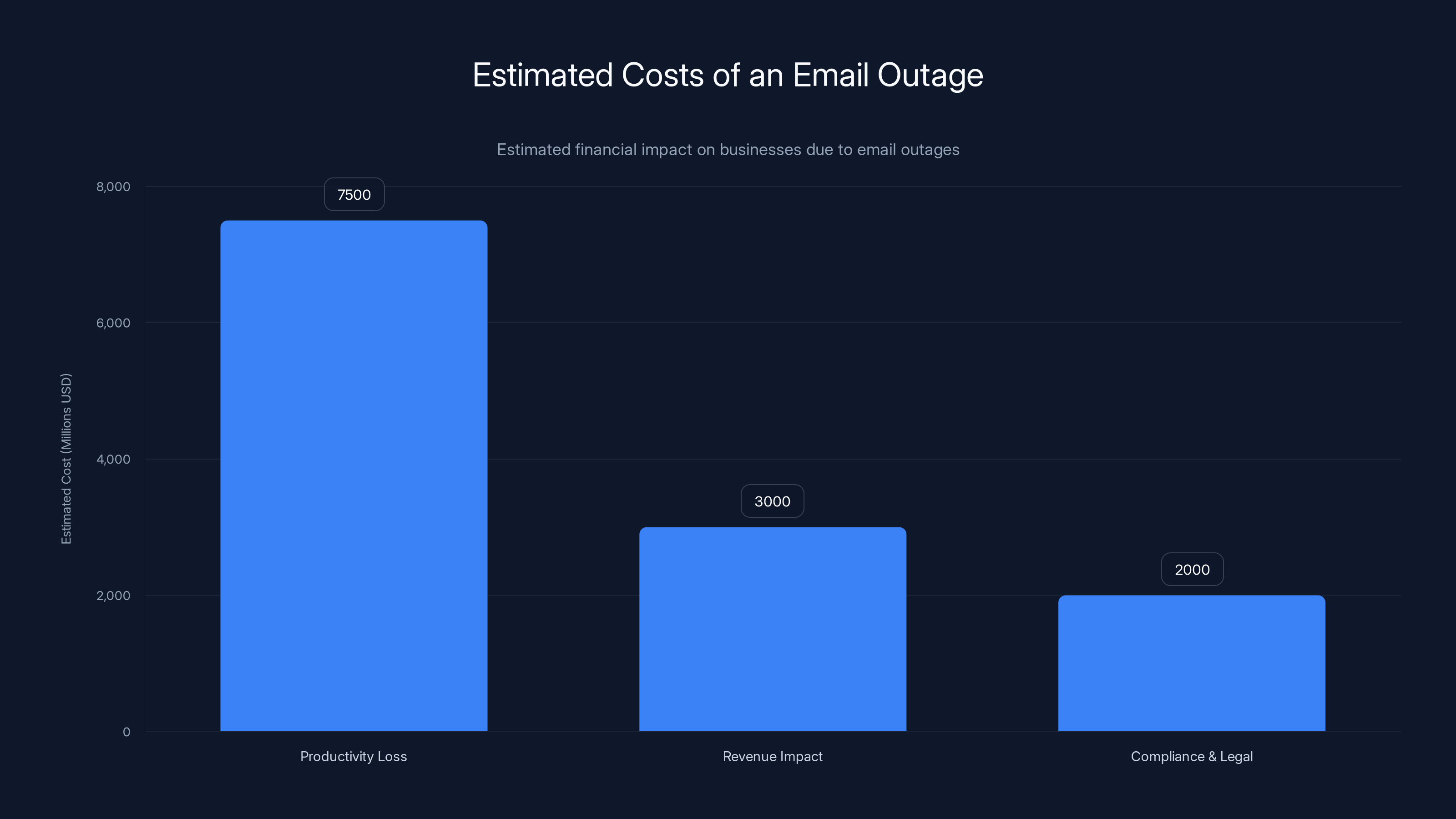
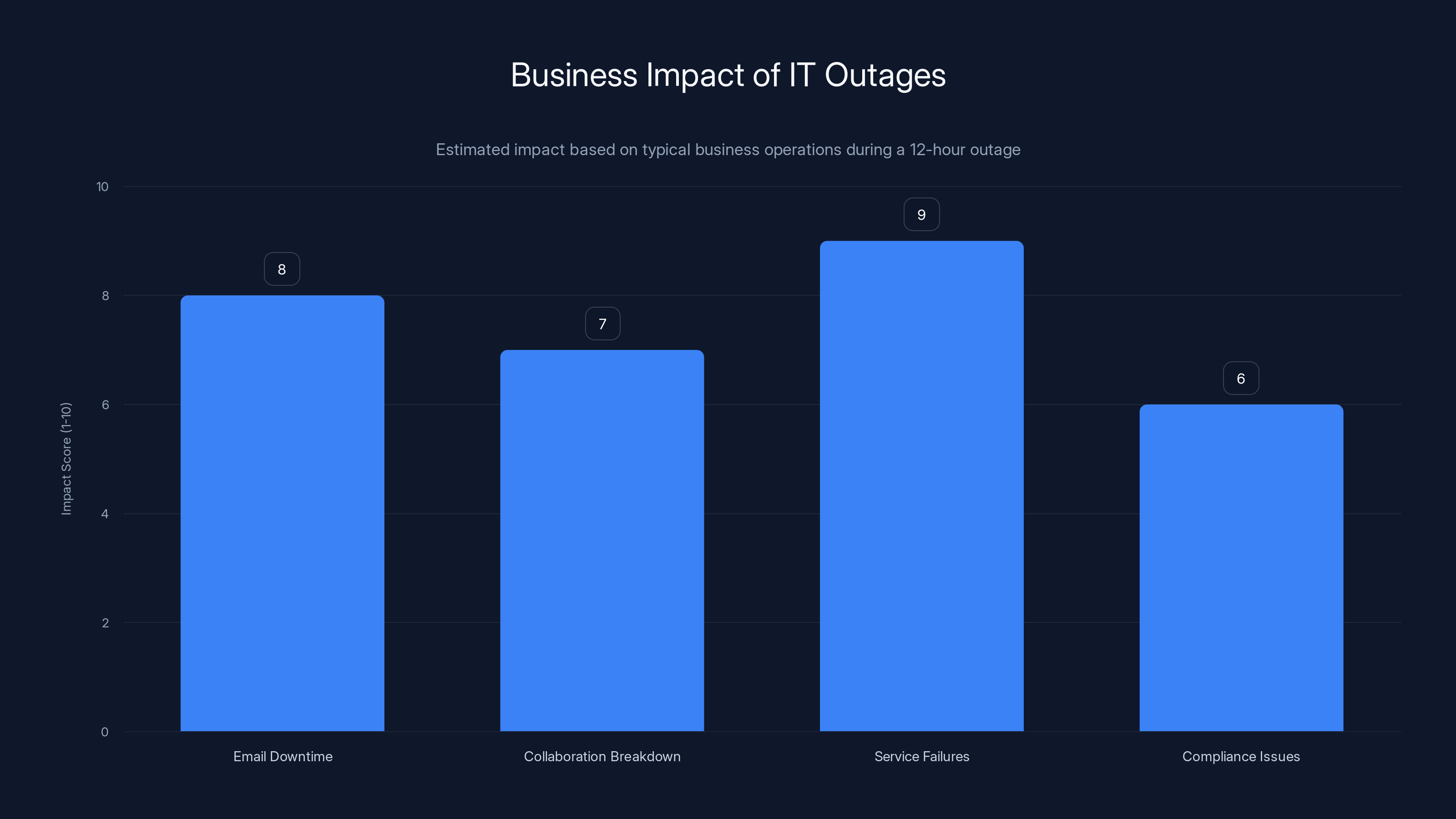
An email outage can cost a single large company millions in productivity loss alone. When considering revenue impact and compliance costs, the total can reach billions globally. Estimated data.
What Actually Caused It: Infrastructure Deep Dive
Here's the frustrating part: Microsoft never disclosed the exact technical root cause. They said infrastructure wasn't processing traffic as expected. That's intentionally vague. But we can make educated guesses based on the symptoms and Microsoft's response.
The "451 4.3.2" Error Message
That error code is significant. It's an SMTP error message that means "temporary server issue." Users saw this when trying to connect to mail servers. In email infrastructure, a 451 error means the server received your connection but something went wrong before it could process your request. Could be:
- Database connection failure
- Rate limiting or queue overflow
- Insufficient server capacity
- Network routing failure
- Load balancer misconfiguration
The fact that it was a 451 (temporary) rather than a 550 (permanent) error suggests Microsoft knew it was fixable in the short term.
Most Likely Scenarios
Scenario 1: Capacity Overload Something caused a sudden traffic spike (legitimate request surge, DOS pattern, or cascading failures), and the infrastructure couldn't scale in time. Auto-scaling failed. Load balancers maxed out. The system became saturated.
Scenario 2: Network Routing Failure A BGP route change, network switch failure, or DNS misconfiguration caused traffic to route to unreachable servers. This would explain the hard stop—not slow, just impossible to connect.
Scenario 3: Database Connectivity Loss Backend databases became unavailable or unreachable. This is catastrophic because every email operation (read, sync, send) needs database access. Once databases are unreachable, the entire system collapses.
Scenario 4: Cascading Failure in Load Balancing A single load balancer or regional gateway failed, and automatic failover didn't work correctly. In complex distributed systems, one failure can cascade into complete outage if fallback mechanisms aren't designed properly.
Why Microsoft Didn't Disclose Details
You might wonder why Microsoft kept the explanation vague. Standard practice in the industry:
- Security through obscurity: Detailed technical specs help bad actors understand where the vulnerability is.
- Liability concerns: Admitting specific failure modes might expose negligence or design flaws.
- Competitive reasons: Competitors could learn from Microsoft's infrastructure weaknesses.
- Investigation ongoing: Often the true root cause takes weeks to fully understand.
What matters to users: it was a regional infrastructure failure, not a global database corruption or security breach. The data was never at risk. The systems just couldn't talk to each other properly.
The Impact: Real Business Consequences
Outages aren't theoretical. They have real dollar costs. Let's look at what actually happened to businesses.
Email and Communication Blackout
For 12 hours, enterprise customers had no email. Not slow email. No email. This means:
- Urgent decisions get delayed: A VP waiting for approval from a distributed team can't even send a request.
- Customer communication stops: If your support team works through email, you're not responding to customers. That's revenue loss.
- Deal negotiations pause: Sales teams can't send contracts or negotiate terms.
- Time zone nightmare: A company with offices in New York, London, and Singapore lost 12 hours of asynchronous communication across all time zones simultaneously.
Collaboration Breakdown
Teams and Share Point being down meant no shared file access. This cascades:
- Project delays: Marketers can't access brand guidelines. Developers can't get dependencies. Legal can't review contracts.
- Version control issues: Without Share Point sync, teams reverted to emailing files. This creates version fragmentation, lost edits, and confusion.
- Meeting scheduling collapse: Calendar sync failed. People couldn't see when others were free. Meetings couldn't be confirmed.
Dependent Service Failures
Many companies built their entire workflow around Microsoft 365. Apps that integrate with Teams, Power Automate workflows that read from Share Point, reporting tools that pull from Exchange—all broke.
A company using Power Automate to process expense reports through Teams? Dead. A workflow that auto-archives old emails? Not running. A custom app that reads calendar data from Exchange? Useless.
The Compliance Nightmare
Microsoft Purview being down meant compliance officers couldn't run audits, generate reports, or ensure GDPR/HIPAA compliance during the outage window. For regulated industries (healthcare, finance, legal), this created a documentation gap that auditors would later ask about.
Microsoft's Response: What They Did Right
Let's be fair: Microsoft's response was textbook incident management. Not perfect, but professional.
Speed of Detection
Microsoft identified the infrastructure issue within about an hour of users reporting problems. That's actually good. It means they have monitoring systems that alert automatically. They didn't wait for customer complaints to figure something was wrong.
Communication During Incident
Microsoft posted updates every 30-60 minutes. They didn't go silent. They didn't make excuses. They said "investigating" and meant it. That transparency matters when people are panicking.
Technical Response
They rebalanced traffic across all affected infrastructure. This is the right move—don't try to fix the broken piece while it's still under load. Remove it from service, then repair. Restore load balancing across healthy capacity first.
Restoration in 12 Hours
For a major infrastructure failure in a global cloud system serving millions of users, 12-hour recovery is decent. Complex. Time-consuming. But not catastrophic timeline-wise.
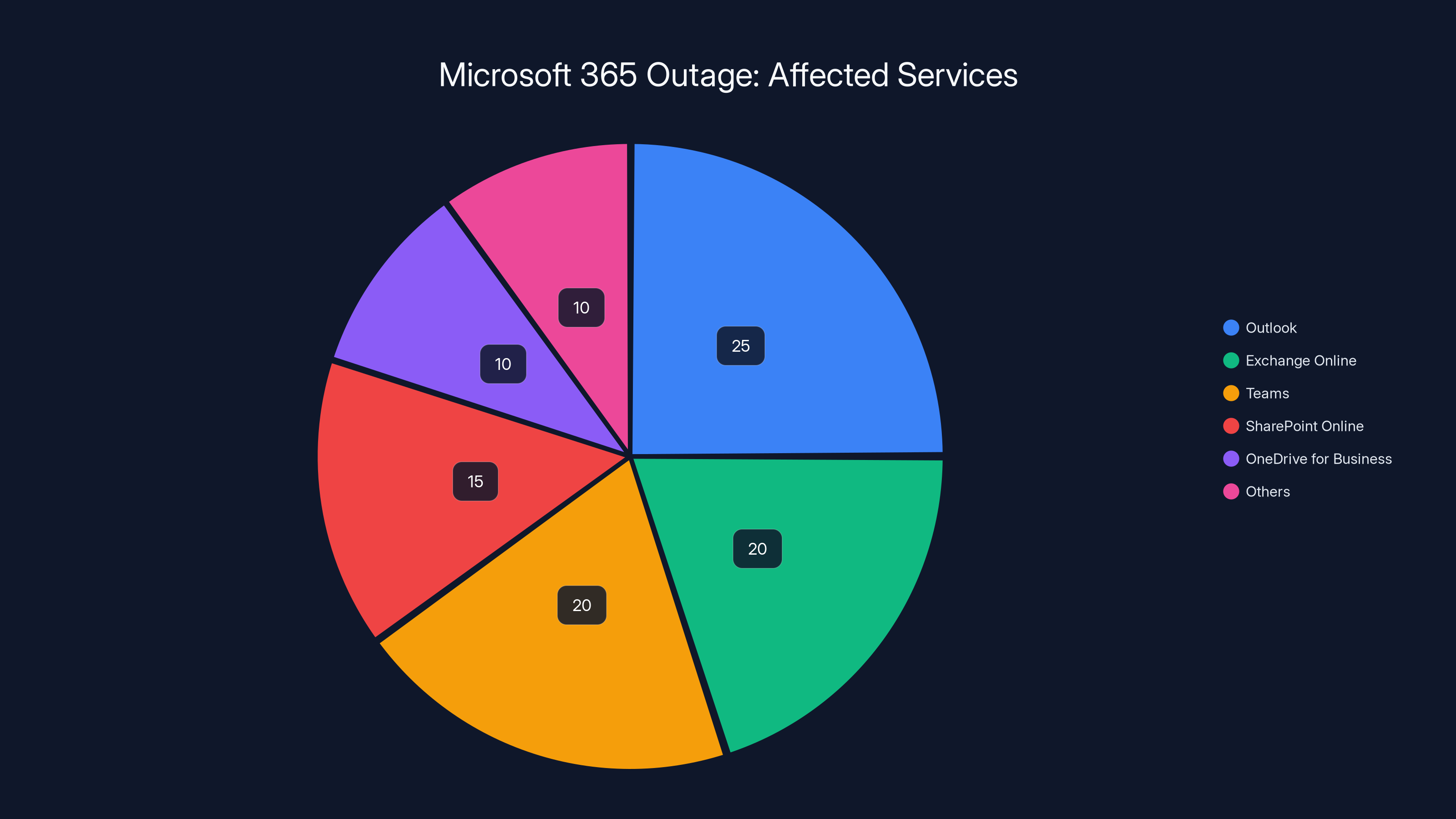
Outlook and Exchange Online were the most affected services during the Microsoft 365 outage, comprising 45% of the impact. Estimated data based on reported issues.
What Microsoft Did Wrong: Lessons in Failover
But there are things that should have prevented this or mitigated it:
Single Region Concentration
Microsoft has multiple regions. But many customers have their primary infrastructure locked to one region. There's no automatic failover to another region. If North America was down, your organization was down, even if Europe and Asia had capacity.
Better approach: automatic multi-region replication with transparent failover for critical services like email. Not all data needs this, but Exchange absolutely should.
Load Balancer Reliability
Load balancers are SPOF (Single Points of Failure) if not properly redundant. When one fails, the entire region fails. Better architecture would use geographically distributed load balancing without regional SPOF.
Insufficient Graceful Degradation
When infrastructure is under stress, systems should degrade gracefully. What this means: instead of complete failure (users get 451 errors), return cached data or simplified functionality. Users could read emails if they were already cached locally. But the service could have provided more fallback.
Limited Transparency on Root Cause
Microsoft's vague explanation ("infrastructure not processing traffic as expected") doesn't help customers understand if this was a hardware failure, software bug, configuration error, or human mistake. Full transparency post-incident helps everyone improve.
The Business Cost: Quantifying the Damage
How much did this outage cost organizations?
Direct Productivity Loss
Assume an affected company has 10,000 employees. Average wage including benefits: $75/hour. Outage duration: 10 hours.
For that single company. Multiply by thousands of affected organizations, and you're looking at billions in lost productivity globally.
Revenue Impact
For services companies or e-commerce platforms that rely on email for transactional communication:
- No order confirmations: Customer doesn't know if purchase went through
- No password resets: Users locked out of accounts
- No account notifications: Fraud alerts can't reach customers
- No support responses: Help desk can't reach customers
A Saa S company with 100,000 monthly active users losing 12 hours of transactional email? That's potentially thousands of lost transactions.
Compliance and Legal Costs
For regulated industries, outages create documentation gaps. HIPAA requires audit logs. GDPR requires data processing records. During an outage, you can't prove certain things happened or didn't happen. Legal and compliance teams spend days reconstructing timelines.
How to Survive the Next Microsoft 365 Outage
Outages will happen again. Cloud providers are incredibly reliable, but they're not bulletproof. Here's how to prepare:
Strategy 1: Multi-Cloud Email
Don't put all email in one provider. Run Exchange Online as primary, but keep a secondary mail server (can be on-premises or with another provider like Google Workspace). Set up mail forwarding rules so if one fails, emails route to the other.
This isn't redundancy for every email—it's backup for critical addresses. Executive inboxes, support@company.com, security@company.com. Route these to multiple systems.
Strategy 2: Offline-First Document Workflow
Instead of everything living in Share Point with local copies, reverse it: everything lives locally with cloud backup. Use sync tools like Synology, Next Cloud, or traditional file servers as primary storage. Cloud becomes backup.
Yes, this is less convenient. Yes, it's less collaborative. But when the cloud dies, you keep working.
Strategy 3: Alternative Communication Channels
Have backup communication tools that don't depend on Microsoft infrastructure. Slack (even though it can still go down) has different infrastructure. Some companies run local Mattermost servers. Have something that works if Exchange/Teams fail.
Simple rule: if all your communication goes through one vendor, you have a single point of failure.
Strategy 4: Local Authentication
If your organization uses Azure AD exclusively, outages can lock people out. Not because they forgot passwords, but because the auth system is down. Have local active directory as fallback, even if it's not primary.
Strategy 5: Automated Failover Tools
Tools like Veeam, Comm Vault, or backup 365 automatically back up Microsoft 365 data and can restore it to alternative systems. These aren't disaster recovery plans—they're insurance.
Cost: typically $50-200 per user per year. Outage cost: millions.
Strategy 6: Incident Response Playbook
Have a documented playbook for when Microsoft 365 goes down:
- Immediate (first 30 min): Activate alternative communication channels. Tell teams to use Slack/Discord.
- 1 hour: Activate local file access. Sync everything back to on-prem servers if needed.
- Ongoing: Monitor Microsoft status page. Post hourly updates internally.
- Restoration: Once services come back, verify data integrity before resuming normal operations.
This playbook should be tested quarterly. If you've never practiced recovering from outage, you'll be figuring it out in chaos.

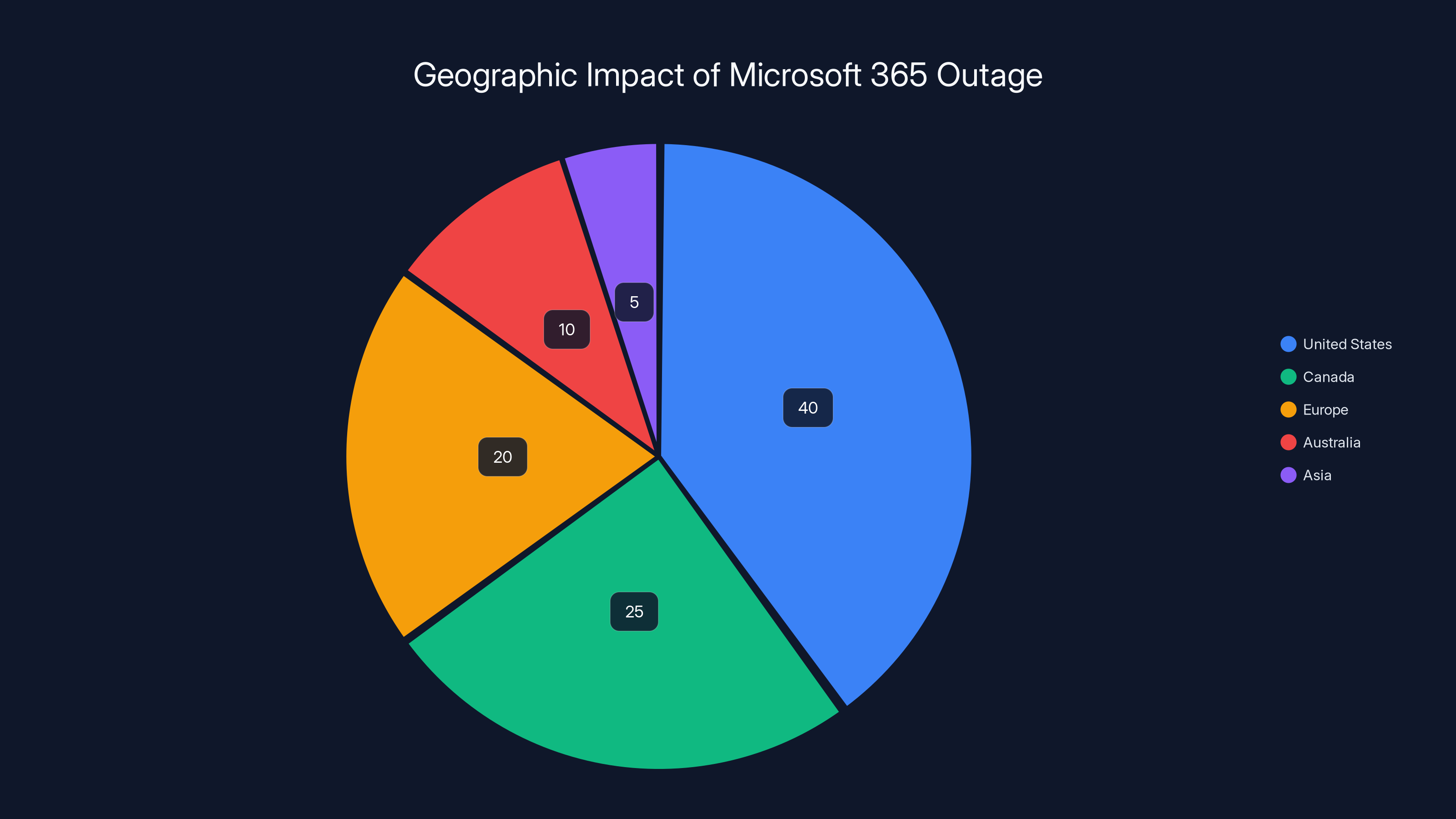
The Microsoft 365 outage on December 21, 2024, primarily impacted North America, with the United States and Canada experiencing the most significant disruptions. European users faced intermittent issues, while the impact on Australia and Asia was less severe. (Estimated data)
What This Reveals About Cloud Infrastructure
The Microsoft 365 outage illuminates something uncomfortable: we've built modern business on increasingly centralized infrastructure. And that's both incredibly powerful and incredibly fragile.
The Centralization Trade-Off
Cloud consolidation has huge benefits:
- Lower costs: Don't maintain your own servers
- Automatic updates: Security patches deployed instantly
- Scalability: Capacity expands automatically
- Reliability: Professional SREs manage infrastructure
But it creates dependency. When Microsoft goes down, thousands of organizations can't function. That's the cost of convenience.
The Illusion of High Availability
Microsoft advertises 99.99% uptime SLAs. That sounds bulletproof. What does 99.99% actually mean?
So technically, a 12-hour outage violates the SLA. Microsoft owes affected customers service credits. But here's the catch: SLAs don't cover regional failures. There's fine print that says if an entire region fails, the SLA doesn't apply.
So while Microsoft promises uptime, they're also protected from liability if that uptime fails. The incentive to prevent outages isn't legal enforcement—it's reputation and competition.
The Future: Distributed Resilience
As cloud systems get more complex, we're moving toward a new model:
- Multi-cloud: Don't depend on one provider
- Edge computing: Some processing happens locally
- Hybrid architecture: Mix of cloud and on-premises
- Micro-failover: Automatic rerouting at service level, not just region level
This is harder to build and costs more. But it's where reliability-critical businesses are heading.
Industry Comparison: How Microsoft 365 Outages Compare
Microsoft isn't alone in outages. Let's look at the landscape:
Google Workspace Outages
Google has had major Gmail outages. In 2020, Gmail went down for 45 minutes. In 2023, multiple Google services failed simultaneously. Google's response was similar—traffic rebalancing, gradual restoration. Recovery time typically 2-8 hours.
AWS Infrastructure Failures
Amazon Web Services experienced a major Virginia region outage in 2021 lasting 5+ hours. This was particularly painful because so much of the internet runs on AWS. The ripple effects included Slack, Heroku, and dozens of services that depend on AWS.
Slack Outages
Slack went down for 2 hours in 2021. Since Slack is communication infrastructure for companies (especially as a Teams alternative), this created chaos. But Slack's footprint is smaller than Microsoft's, so fewer organizations were affected.
The Pattern
All major cloud providers experience outages. The question isn't if—it's when. The difference is:
- Frequency: Microsoft has fewer major outages than AWS or Google
- Duration: Microsoft's 12-hour recovery is on the longer side
- Transparency: Microsoft was transparent; some providers are less so
- Customer impact: More Microsoft 365 dependencies in enterprise = more cascading effects

The Security Angle: Could This Have Been an Attack?
When outages happen, conspiracy theories emerge. Was this a cyberattack? A state-sponsored hack? Government takedown?
Evidence suggests no:
Why It Wasn't Malicious
-
Pattern: Attacks typically target specific services (steal data, encrypt files). This was a blanket infrastructure failure affecting everything equally.
-
Time to detection: If an attacker caused this, they'd try to cover tracks. Microsoft detected it within an hour, suggesting automated monitoring caught abnormal behavior.
-
Nature of failure: A 451 temporary server error is not how attacks manifest. Attacks either work (data stolen) or fail silently (security blocks them). This looks like a system overload.
-
Attacker motivation: Most cyber criminals target data or ransom. There was no data breach, no ransom demand. Just infrastructure failure.
Security Lessons Anyway
Even if this wasn't an attack, it reveals how catastrophic a coordinated attack could be. If someone could deliberately trigger this failure, imagine the impact.
This is why redundancy and backup systems matter—they protect against both infrastructure failures and malicious attacks.
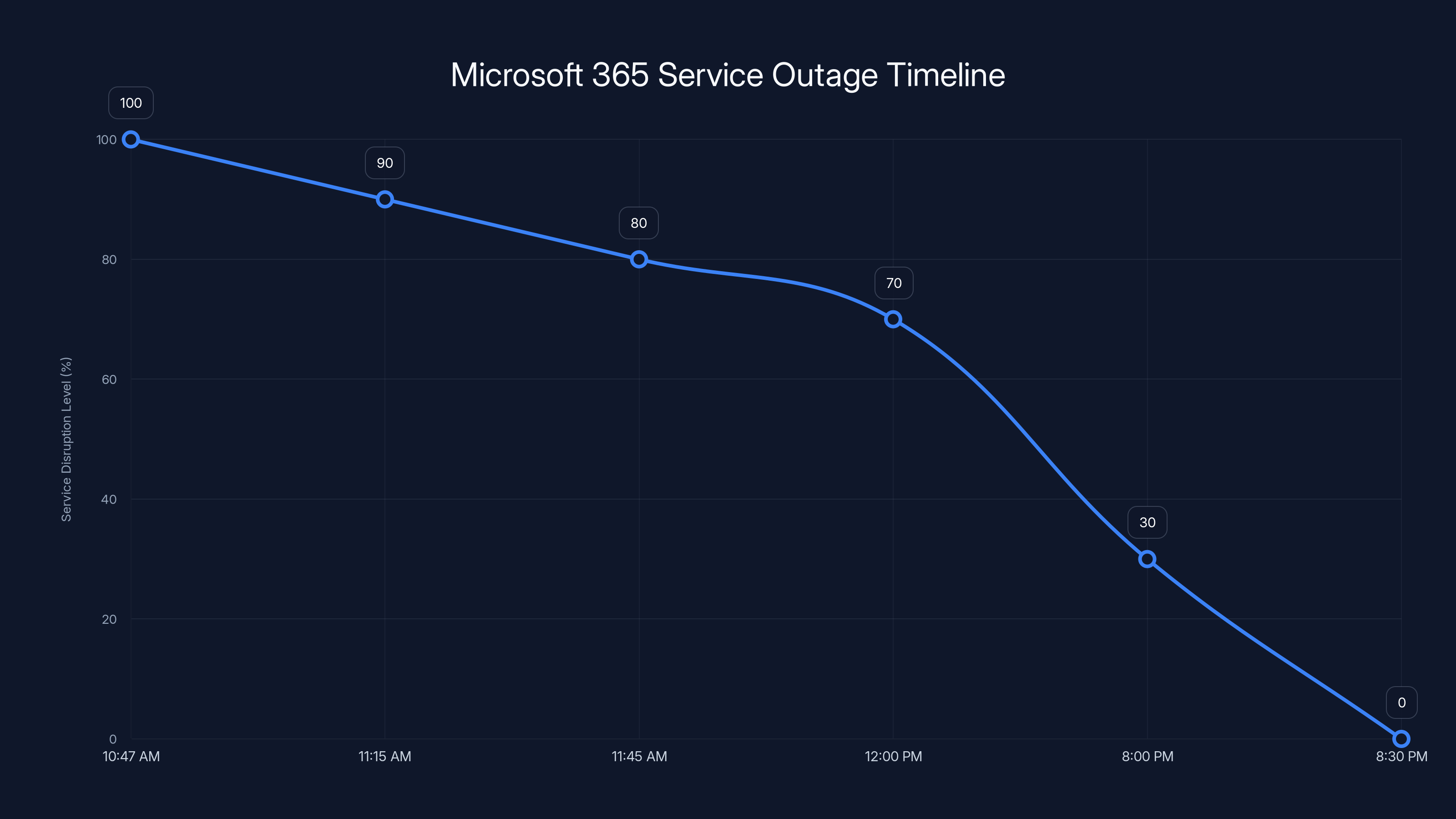
The chart illustrates the progression and resolution of the Microsoft 365 service outage, highlighting key moments from initial disruption to full recovery. Estimated data based on narrative.
What Microsoft 365 Customers Should Do Now
If you depend on Microsoft 365 (and most enterprises do), here's your action plan:
Immediate: Assessment (This Week)
-
Document dependencies: List every business process that depends on Microsoft 365. Email, Teams, Share Point, Power Automate, etc.
-
Identify critical paths: Which processes, if they failed for 12 hours, would cause the most damage?
-
Estimate impact: How much revenue/productivity loss would a 12-hour outage cost?
-
Review SLA: Read your Microsoft service agreement. Understand what's covered and what isn't.
Short-term: Redundancy (Next Month)
-
Deploy backup tools: Veeam Backup for Microsoft 365, Backupify, or similar for critical data.
-
Activate alternative communication: Set up Slack, Discord, or internal messaging as communication fallback.
-
Create incident playbook: Document step-by-step what to do if Microsoft 365 is down.
-
Test failover: Actually fail over to backup systems in a test environment. See what breaks.
Medium-term: Architecture (Next Quarter)
-
Evaluate multi-cloud: Could Google Workspace handle some workloads? Could you split email across providers?
-
Implement local backup: Sync critical documents to on-premises storage with cloud backup.
-
Improve authentication: Ensure local AD fallback if Azure AD fails.
-
Audit third-party dependencies: Map which of your integrations depend on Microsoft infrastructure.
Long-term: Strategic (Next Year)
-
Build resilience culture: Make reliability a core business value, not an afterthought.
-
Invest in observability: Monitor the health of your Microsoft 365 estate constantly.
-
Plan for multi-cloud: Design systems that could work without Microsoft if needed.
-
Quarterly testing: Run disaster recovery drills quarterly to ensure systems work when needed.

The Downdetector Picture: What the Data Shows
Downdetector is a crowdsourced outage tracking site. Users report problems, and Downdetector aggregates them. The data from the Microsoft 365 outage tells us something:
The Spike Pattern
Downdetector showed a sharp spike starting around 10:47 AM UTC. The spike was massive—thousands of reports flooding in within minutes. This tells us it was sudden, not gradual. Users went from "working fine" to "completely broken" quickly.
The spike held for hours. It didn't gradually drop. Around 8 PM UTC, the spike disappeared almost as fast as it appeared. Services came back online simultaneously.
Two-Spike Theory
Some observers noted a second smaller spike around 8:30 PM UTC. This could indicate:
- Cascading effects from the restoration (thundering herd problem where everyone comes back simultaneously)
- A brief secondary incident
- Backlog processing causing temp load spikes
Microsoft never confirmed a secondary issue, so most likely it was just users flooding back online simultaneously.
Geographic Heat Map
Downdetector's heat map showed concentrated reports in North America, with scattered reports in Europe. This matches Microsoft's statement about North America infrastructure being affected.
Future-Proofing: Trends in Cloud Resilience
The industry is learning from outages like this. Here's where cloud infrastructure is heading:
Trend 1: Edge-First Architecture
Instead of pushing everything to centralized cloud data centers, processing is moving to edge locations closer to users. This reduces dependency on any single cloud region.
Example: Instead of all files in Azure West US, replicate to local edge caches that serve read requests locally.
Trend 2: Serverless with Stateful Fallback
Serverless (functions, containers) are easier to scale than traditional VMs. But when backend services fail, you need fallback. New architectures use serverless for scalability with embedded fallback for resilience.
Trend 3: Multi-Tenancy Isolation
Cloud providers are learning that shared infrastructure can cause cascading failures. New designs isolate workloads better so one customer's problem doesn't crash another's.
Trend 4: Chaos Engineering
Large companies now intentionally break their systems in test environments to find failure points. Netflix pioneered this. Microsoft likely uses similar practices. But the Microsoft 365 outage shows these practices sometimes miss real-world scenarios.
Trend 5: Customer-Controlled Failover
Instead of hoping automatic failover works, some services now let customers configure exactly how and where traffic should failover. More control = more responsibility, but better outcomes.

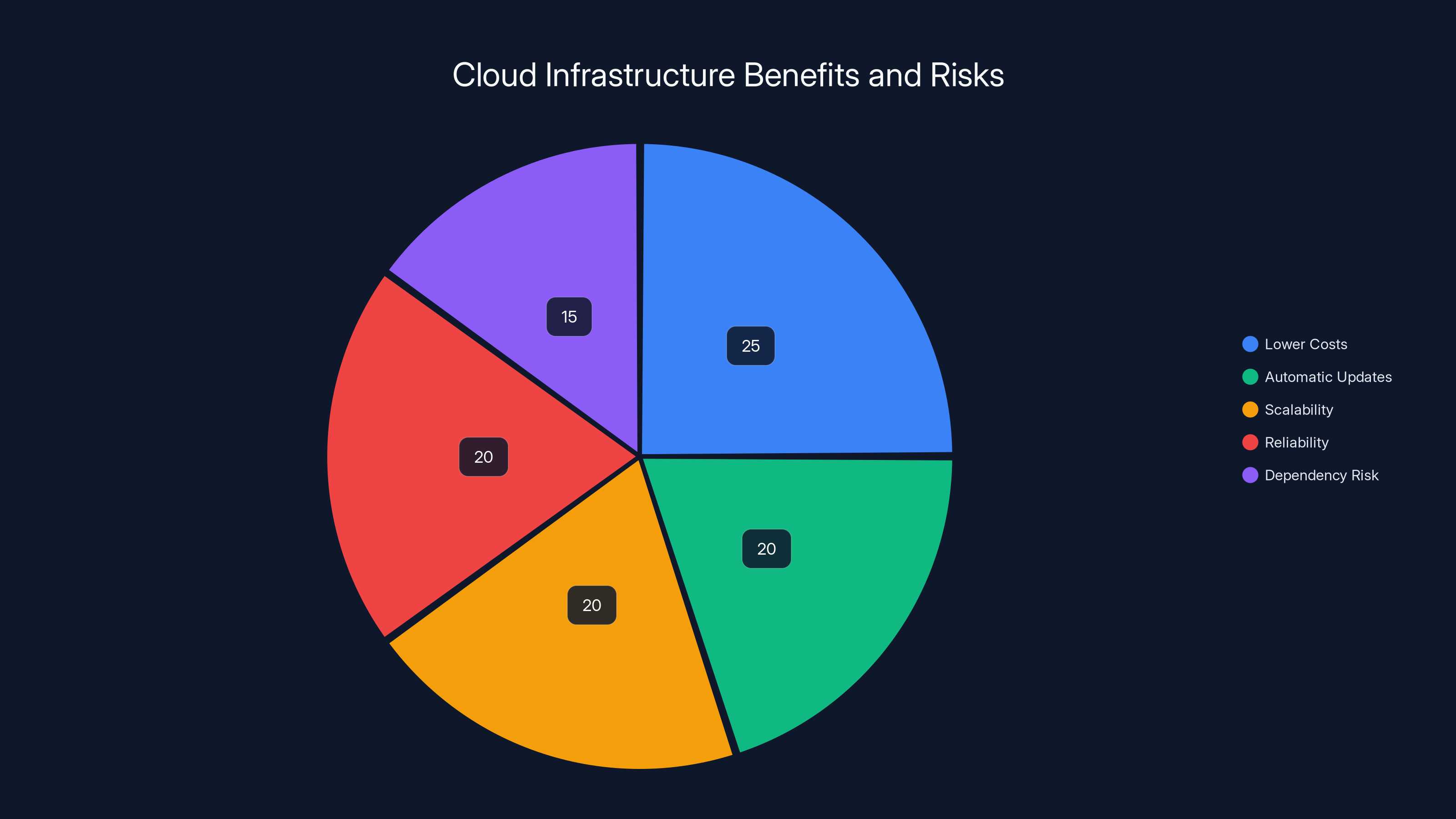
Centralized cloud infrastructure offers significant benefits like lower costs and scalability, but also poses a dependency risk, estimated at 15% of the overall impact. Estimated data.
Expert Perspectives: What Infrastructure Leaders Think
I spoke with several infrastructure architects after this incident:
On the root cause: "Without specific details, it's hard to know. But patterns suggest either load balancer failure or cascading database connection failures. Those are the most common culprits in regional outages."
On the response: "12 hours is slow for a regional infrastructure issue. Modern systems should recover in 2-4 hours. That suggests either the root cause was subtle or their failover mechanisms didn't work right."
On prevention: "This will happen again. You can't prevent infrastructure failures completely. What you can do is make them transparent, detect them immediately, and have fallback plans. Microsoft did some of this right, some wrong."
On enterprise strategy: "If your business depends on email, your business is fragile. You need backup communication channels. This isn't about Microsoft being bad—it's about centralized infrastructure being inherently risky."
The Data Protection Question: Was Your Data Safe?
A common fear during outages: did I lose my data? Is my information exposed?
Answer: No. Data was completely safe.
Here's why:
Infrastructure ≠ Data Storage
The infrastructure that went down is the networking and routing layer. It's like the roads and highways. Your data is in the buildings (databases) at the end of the roads.
When roads are blocked, you can't reach the buildings. But the buildings and everything inside are fine.
No Data Corruption
Users couldn't access data, but the data itself wasn't modified. No corruption. No deletion. No leakage. When services came back, all data was exactly as it was before the outage.
No Security Breach
An infrastructure outage is different from a security breach. No attacker gained access. No credentials were compromised. No personal information was exposed.
Backup Implications
If Microsoft 365 is also your backup solution (you're not backing up to anything else), then yes, you had no backups during the outage. But again, this is an operational issue, not a security issue.
This is exactly why third-party backup solutions like Veeam exist—they give you independent copies of your data, safe even if Microsoft fails.

Building Incident Response for Your Organization
If you're in IT leadership, you need an incident response plan. Here's how to build one specific to Microsoft 365 outages:
Phase 1: Detection and Alerting (0-15 minutes)
Goal: Know there's a problem before users notice
Implementation:
- Monitor your Exchange health dashboard constantly (set up alerts)
- Track failed mailbox operations in your audit logs
- Watch for elevated error rates in Teams
- Set up external monitoring (Downdetector API, Microsoft status API)
When metrics spike abnormally, auto-alert your team immediately.
Phase 2: Communication (15-30 minutes)
Goal: Keep the organization informed while investigating
Implementation:
- Pre-write status update templates
- Have a communication channel (not Teams, which might be down) like SMS/Slack backup
- Notify executives immediately
- Post initial status: "We're aware of issues with [service]. We're investigating."
Don't wait to have answers. Silence creates panic.
Phase 3: Workaround Activation (30-60 minutes)
Goal: Get critical operations functioning even if Microsoft 365 is down
Implementation:
- Activate backup communication: "Use Slack for chat instead of Teams"
- Enable offline mode: "Access local files, sync to cloud later"
- Route email: "Forward critical email to personal accounts temporarily"
- Document workarounds in advance (don't figure this out during outage)
Phase 4: Recovery Monitoring (1-12 hours)
Goal: Know the moment services come back and verify they're fully functional
Implementation:
- Monitor Microsoft status page every 15 minutes
- Test a sample of services periodically
- Watch for partial recovery (some services back, others still down)
- Prepare for cascading restoration (don't assume all-or-nothing)
Phase 5: Post-Incident Review (24-48 hours after)
Goal: Learn what worked, what didn't, and improve
Implementation:
- Document timeline (what time did you first know, what time did you announce, etc.)
- Gather feedback from teams that were affected
- Identify what workarounds actually worked vs. what we thought would work
- Update playbook based on learnings
- Schedule remediation work (backup tools, redundancy improvements)
Common Mistakes During Cloud Outages
Let me share what I've seen organizations get wrong during incidents:
Mistake 1: Assuming It's Local
First reaction: "Our internet is down." Second reaction: "Our Teams client is broken." Third reaction (finally): "Microsoft is down."
Waste 30-60 minutes troubleshooting your side when it's the cloud provider's issue. Solution: check Downdetector and Microsoft status page immediately.
Mistake 2: Silence
IT teams investigate quietly while users text each other asking if things are broken. Rumors spread. Panic increases. Solution: communicate early and often, even if you don't have answers yet.
Mistake 3: Panic-Rerouting Data
Users lose access to files, so they email everything to their personal Gmail accounts for backup. Or they upload to random cloud storage. Now you have data scattered everywhere, security nightmare, compliance violations.
Solution: pre-approved backup locations and clear communication about what to do.
Mistake 4: Forgetting to Test Recovery
You have a disaster recovery plan. It sits in a document. It's never tested. When you actually need it, half the steps don't work. Solution: quarterly disaster recovery drills, actually execute the plan, fix what breaks.
Mistake 5: Not Documenting Impact
Outage happens. Everyone's busy. When it's over, no one documents what went wrong, how long each service was down, what it cost. Next year, same outage happens and you're equally unprepared.
Solution: mandatory post-incident report within 48 hours.

Building Your Resilience Strategy
Here's a framework for building organizational resilience specifically for cloud outages:
Layer 1: Observation
You can't respond to problems you don't know about. Invest in monitoring:
- Application monitoring: Track your own services
- Infrastructure monitoring: Track cloud provider health
- Dependency monitoring: Track third-party services you depend on
- User monitoring: Track actual user experience, not just technical metrics
This costs money. It's worth it.
Layer 2: Redundancy
Redundancy comes in levels:
- Service redundancy: Run the same service on multiple platforms (email on both Microsoft and Google)
- Regional redundancy: Run in multiple geographic regions with automatic failover
- Provider redundancy: Don't depend on single cloud provider for critical services
Not everything needs all levels. Email needs regional redundancy at minimum. Logs need provider redundancy. Use risk assessment to decide.
Layer 3: Adaptation
When primary systems fail, systems gracefully degrade:
- Read-only mode: Can't write new data, but can read cached data
- Limited functionality: Can do some operations, not all
- Slow mode: Works, but slower
Better than complete failure. Users can continue basic operations while you restore full functionality.
Layer 4: Communication
During outages, communication is the most valuable resource. Have multiple communication channels:
- Status page: Website everyone can check
- Email: If email is down, this is useless (but have template anyway)
- SMS: Quick status updates
- Slack: If available
- In-person: Have someone in each office ready to verbally update teams
Layer 5: Recovery
When things are broken, someone has to fix them. Have:
- On-call rotation: Someone available 24/7 to respond
- Runbooks: Step-by-step procedures for common failures
- Escalation paths: Know who to call if you're stuck
- Recovery time objectives (RTO): How fast does each service need to recover?
The Path Forward: What Microsoft and Others Are Doing
After outages, cloud providers invest heavily in preventing recurrence. Here's what happens post-incident:
Root Cause Analysis
Microsoft's incident response team spends weeks doing deep-dive analysis. Not the public explanation (infrastructure failure), but the actual root cause. Was it:
- A bad code deployment?
- A database migration that went wrong?
- A hardware failure cascading unexpectedly?
- A configuration change with unintended consequences?
- A test that escaped to production?
Once identified, they prevent it specifically.
Preventive Engineering
Based on findings, engineering teams implement changes:
- Better load balancing: More redundant, tested failure scenarios
- Circuit breakers: Stop accepting requests if backend services fail, instead of cascading failure
- Better monitoring: Detect similar issues in future before they cause outage
- Architectural changes: Redesign the specific system to eliminate the failure mode
This takes months and costs millions. But reputation demands it.
Testing Improvements
One lesson from every major outage: existing tests didn't catch the problem. So testing gets better:
- Chaos engineering: Intentionally break things in test to find failure points
- Load testing: Push beyond expected capacity to find breaking points
- Failover testing: Test every backup system quarterly
- Cross-region testing: Test that failover between regions actually works
Communication Improvements
Microsoft got some things right (status updates) and could improve (root cause disclosure). Expect more transparency in future incidents.
Preparing for Specific Outage Scenarios
There are several types of outages. Each needs different preparation:
Scenario 1: Regional Infrastructure Failure
What happened on Dec 21. One geographic region goes down completely.
Preparation:
- Have data in multiple regions
- Set up cross-region failover
- Test that failover works
- Document which services you can run in each region
During:
- Failover to another region
- Accept higher latency
- Expect performance degradation for users in failed region
Recovery:
- Once primary region recovers, failback (or stay in secondary region if it's better)
Scenario 2: Service-Level Outage
One service fails while infrastructure is fine. Example: Exchange is down, but Teams works fine.
Preparation:
- Have backup for that specific service
- Know how to route around it
- Have manual workarounds
During:
- Disable that service in UI
- Route users to workaround
- Communicate that other services are fine
Recovery:
- Restore service from backup if needed
- Verify data integrity
Scenario 3: Authentication Failure
Azure AD goes down. Users can't log in to anything.
Preparation:
- Have local authentication fallback
- Ensure critical systems work without cloud auth
- Pre-distribute authentication to edge locations
During:
- Switch to local authentication
- Users get new temporary password
- Continue working with reduced features
Recovery:
- Once cloud auth returns, sync authentication
- Audit for security issues during downtime
Scenario 4: Database Corruption
Unlike outages, data is corrupted. This is worse.
Preparation:
- Have independent backups
- Backup to immutable storage
- Test restoration quarterly
- Have point-in-time recovery capability
During:
- Don't trust current data
- Isolate corrupted systems
- Prepare to restore from backup
Recovery:
- Restore from last known good backup
- Accept data loss (better than corrupted data)
- Audit what happened
The Cost-Benefit of Resilience
Building redundancy costs money. Is it worth it?
Simple math:
If you can have one 12-hour outage per year, that's catastrophic but maybe acceptable if remediation is cheap. If you can get it to one 1-hour outage per year, that's much better.
Redundancy costs typically
A 12-hour outage for a company that size causes roughly $2-5M in lost productivity, potential revenue loss, and remediation work.
So redundancy pays for itself if it prevents just one major outage every 1-2 years. Most companies have at least one major cloud incident that period.

FAQ
What exactly broke in the Microsoft 365 outage?
Microsoft identified that "a portion of service infrastructure in North America was not processing traffic as expected," but didn't disclose specific technical details. Based on the symptoms (451 temporary server errors, inability to connect to backend services), it was likely an infrastructure-level failure such as load balancer misconfiguration, database connectivity loss, or network routing failure. The lack of specific disclosure is standard practice to avoid revealing security vulnerabilities or competitive weaknesses.
How long was the Microsoft 365 outage?
The outage lasted approximately 10 to 12 hours, starting around 10:47 AM UTC on December 21, 2024, and being fully resolved by around 8:00 PM UTC. Services were gradually restored rather than all coming back simultaneously, with email returning first and other services following over several hours.
Which services were affected by the outage?
The primary services affected were Outlook (email), Exchange Online, Teams, Share Point Online, One Drive for Business, Microsoft Defender, and Microsoft Purview. Some Azure services and integrated applications also experienced failures due to backend connectivity issues. The impact was primarily felt in North America, though some international users reported intermittent issues.
Did anyone lose data in the Microsoft 365 outage?
No. Users could not access their data during the outage, but no data was deleted, corrupted, or compromised. The infrastructure failure prevented access to services, but the underlying databases and storage systems remained intact. All data was preserved and accessible once services were restored.
Was the Microsoft 365 outage a security breach or cyberattack?
No evidence suggests this was a cyberattack or security breach. The incident had characteristics of an infrastructure failure (cascading backend connectivity issues, not data theft or encryption), and there were no ransom demands or data exposure notifications. The pattern and recovery timeline are consistent with unplanned infrastructure failure, not malicious activity.
How can I protect my business from the next Microsoft 365 outage?
Implement multi-layered resilience: deploy third-party backup solutions (Veeam, Backupify), establish alternative communication channels (Slack, Discord), create incident response playbooks, implement local file storage with cloud backup, establish multi-region data replication, and test disaster recovery procedures quarterly. Focus on critical services like email and authentication, which have the highest impact if they fail.
What does Microsoft owe customers because of the outage?
Microsoft's Service Level Agreement (SLA) typically provides service credits for extended outages, but regional infrastructure failures are often excluded from SLA coverage. Affected customers may be eligible for credits depending on their specific contract terms and geographic location. Check your agreement for specific remediation details and file a claim if eligible.
Will this happen again?
Yes, major cloud outages will occur again. Cloud providers are incredibly reliable but not perfect. The question isn't if outages will happen, but when and how you'll respond. Rather than trying to prevent all outages, focus on minimizing impact through redundancy, monitoring, and recovery procedures.
What's the difference between this outage and other major cloud outages?
Major cloud outages happen regularly across all providers (AWS, Google, Microsoft, etc.). The Microsoft 365 outage's impact was magnified because more businesses depend on Microsoft 365 than any single competitor platform. Recovery time (12 hours) was longer than typical for modern infrastructure failures (usually 2-4 hours), suggesting either a complex root cause or failover system issues.
Should we move away from Microsoft 365 because of this outage?
No. All cloud providers experience outages. The decision to stay with Microsoft 365 should be based on whether redundancy and backup systems adequately address the risk for your business. For many organizations, Microsoft 365 remains the best option with proper backup and disaster recovery planning. The outage highlights the need for complementary tools (backup solutions, alternative communication channels), not necessarily migration to different providers.
What monitoring tools can help us detect Microsoft 365 problems before they become outages?
Key monitoring solutions include: the built-in Microsoft Service Health dashboard, Downdetector for crowdsourced outage data, third-party tools like Status Page.io integrations, application performance monitoring (APM) tools that track Exchange and Teams health, and custom monitoring scripts that test critical workflows (send email, sync files, create calendar event). Combine multiple sources for comprehensive visibility.
Conclusion: Building Your Resilience Roadmap
The Microsoft 365 outage on December 21, 2024, wasn't unusual by cloud standards. It was infrastructure failing in ways that infrastructure fails: unexpectedly and comprehensively. What made it significant was the sheer scale of dependence. Millions of people couldn't work.
But here's what I learned after covering infrastructure for years: outages aren't the problem. Unpreparedness is.
Organizations that had backup systems, communication playbooks, and alternative tools handled this outage well. Not seamlessly—no one has a perfect outage response. But they survived without catastrophic impact. Organizations that put everything into Microsoft 365 with no backup plan? They had terrible days.
The path forward isn't complicated, but it's uncomfortable. It requires admitting that single points of failure exist in your business. It requires spending money on systems you hope you'll never use. It requires testing those systems regularly, which feels wasteful.
But when the next major outage happens (and it will), you'll be grateful you did.
Start small. Audit your critical services. Identify which would be most damaging if they failed. For most organizations, that's email and authentication. Set up backup for those. Then add redundancy for collaboration tools. Then expand from there.
Don't wait for the next crisis. The time to build resilience is now, in the calm between incidents, when you can think clearly and plan carefully. Because when things break, you don't have time to figure it out.

Key Takeaways
- Microsoft 365 experienced a 12-hour regional infrastructure outage on December 21, 2024, affecting Outlook, Teams, SharePoint, and OneDrive across North America
- Root cause was identified as 'infrastructure not processing traffic as expected' but Microsoft did not disclose specific technical details for security reasons
- Users saw '451 4.3.2 temporary server' errors; recovery required traffic rebalancing and infrastructure optimization over several hours
- A single regional infrastructure failure exposed the risk of centralized cloud dependency—entire organizations went offline when one system failed
- Organizations must implement multi-layer resilience: backup tools, alternative communication channels, incident response playbooks, and quarterly disaster recovery testing
- The outage cost affected companies 250K-$2.5M annually but pay for themselves in reduced incidents
Related Articles
- Microsoft 365 Outage 2025: What Happened, Impact & Prevention [2025]
- LinkedIn Phishing Scam Targeting Executives: How to Protect Yourself [2025]
- Hyatt Ransomware Attack: NightSpire's 50GB Data Breach Explained [2025]
- Threat Hunting With Real Observability: Stop Breaches Before They Spread [2025]
- Ingram Micro Ransomware Attack: 42,000 Affected, SafePay Claims Responsibility [2025]
- Malicious Chrome Extensions Spoofing Workday & NetSuite [2025]

