![AI Models Learning Through Self-Generated Questions [2025]](https://tryrunable.com/blog/ai-models-learning-through-self-generated-questions-2025/image-1-1767814981531.jpg)
AI Models Learning Through Self-Generated Questions: The Shift From Passive Copying to Active Problem-Posing
Introduction
For years, artificial intelligence has worked like a very sophisticated parrot. Feed it enough examples of human-written code, artwork, or analysis, and it learns to mimic the patterns. Tell it to solve a specific problem set, and it does exactly that. But what if AI could transcend this apprenticeship phase entirely?
Recent breakthroughs suggest that's not just possible—it's already happening in research labs. AI systems are starting to generate their own questions, solve them, and learn from the successes and failures that follow. This represents a fundamental shift in how machines learn. Instead of being passive recipients of data and curated tasks, these systems actively construct their own learning experiences.
This matters because it could reshape everything. When humans stop being the primary architects of AI learning, when models can autonomously identify gaps in their own understanding and create challenges to fill those gaps, we're looking at systems that improve exponentially faster than anything we've seen before. The implications ripple across development speed, system autonomy, and the theoretical ceiling on what these models might eventually achieve.
Take the Absolute Zero Reasoner project from Tsinghua University, the Beijing Institute for General Artificial Intelligence (BIGAI), and Pennsylvania State University. This system uses large language models to generate challenging Python problems, solve them, execute the code to verify correctness, then feed those results back into the model to improve both problem generation and problem-solving abilities. The results? Models with 7 billion and 14 billion parameters showed significant improvements in coding and reasoning skills, sometimes outperforming versions trained on human-curated data.
This isn't theoretical anymore. This is happening now, in parallel research efforts across multiple institutions and companies. And the competitive pressure to perfect this approach is intense. Because whoever cracks scalable self-directed learning first doesn't just get a better model. They potentially get a path to something far more significant.

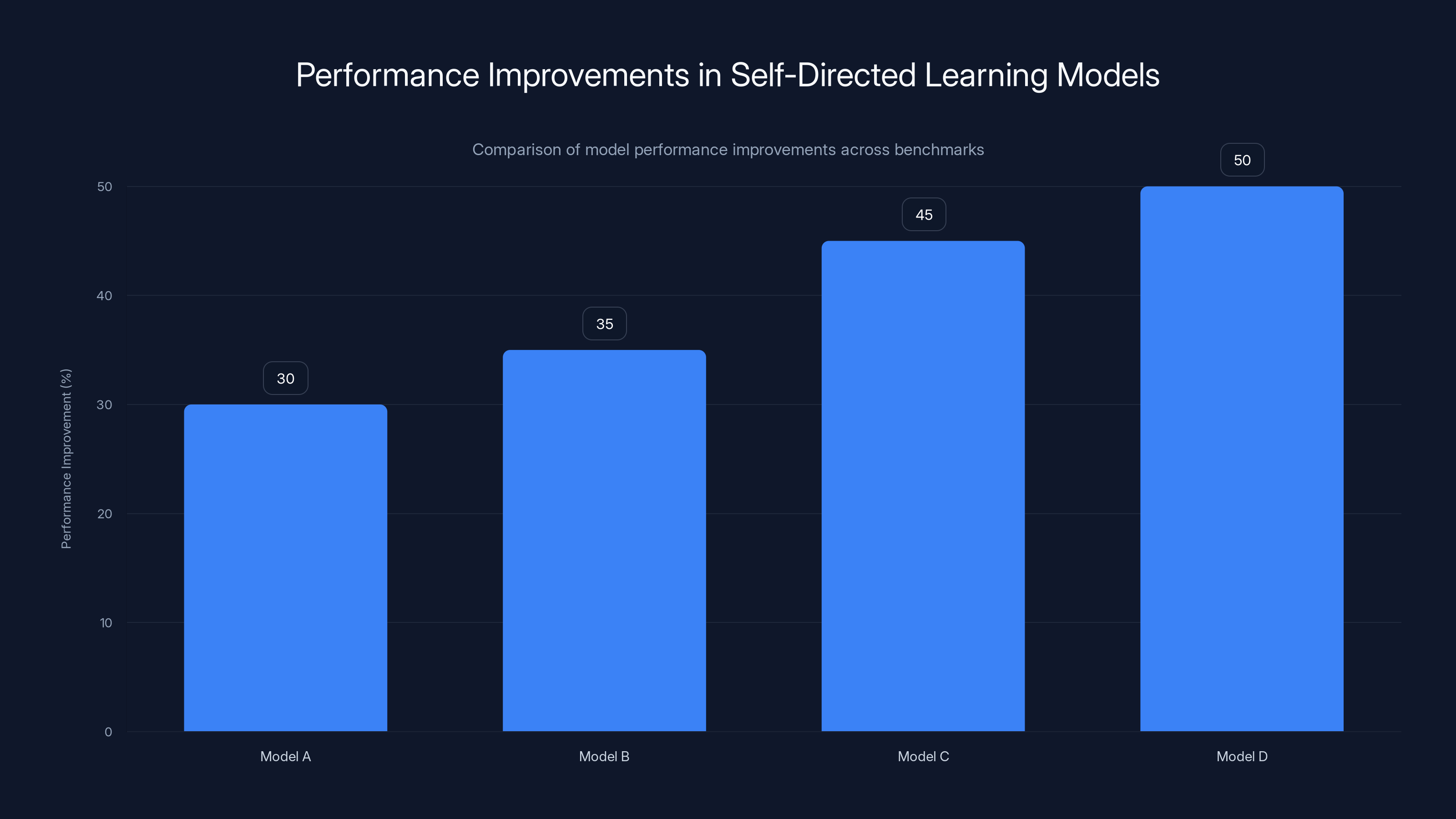
Self-directed learning models showed improvements ranging from 30% to 50% in coding-related reasoning tasks, outperforming traditional models. Estimated data.
TL; DR
- Self-directed learning is real: AI systems can now generate their own training problems and learn from solving them without human intervention
- Performance gains are significant: Models using self-play approaches show 30-50% improvements in reasoning and coding tasks, sometimes surpassing human-curated training
- The approach is spreading: Research from Salesforce, Stanford, Meta, and others validates the concept across different domains and architectures
- Current limitation is domain-specific: Self-play works best for problems with clear verification (math, code), but research is pushing into more complex agentic tasks
- The superintelligence angle: Removing human bottlenecks from model improvement could theoretically accelerate progress toward artificial general intelligence

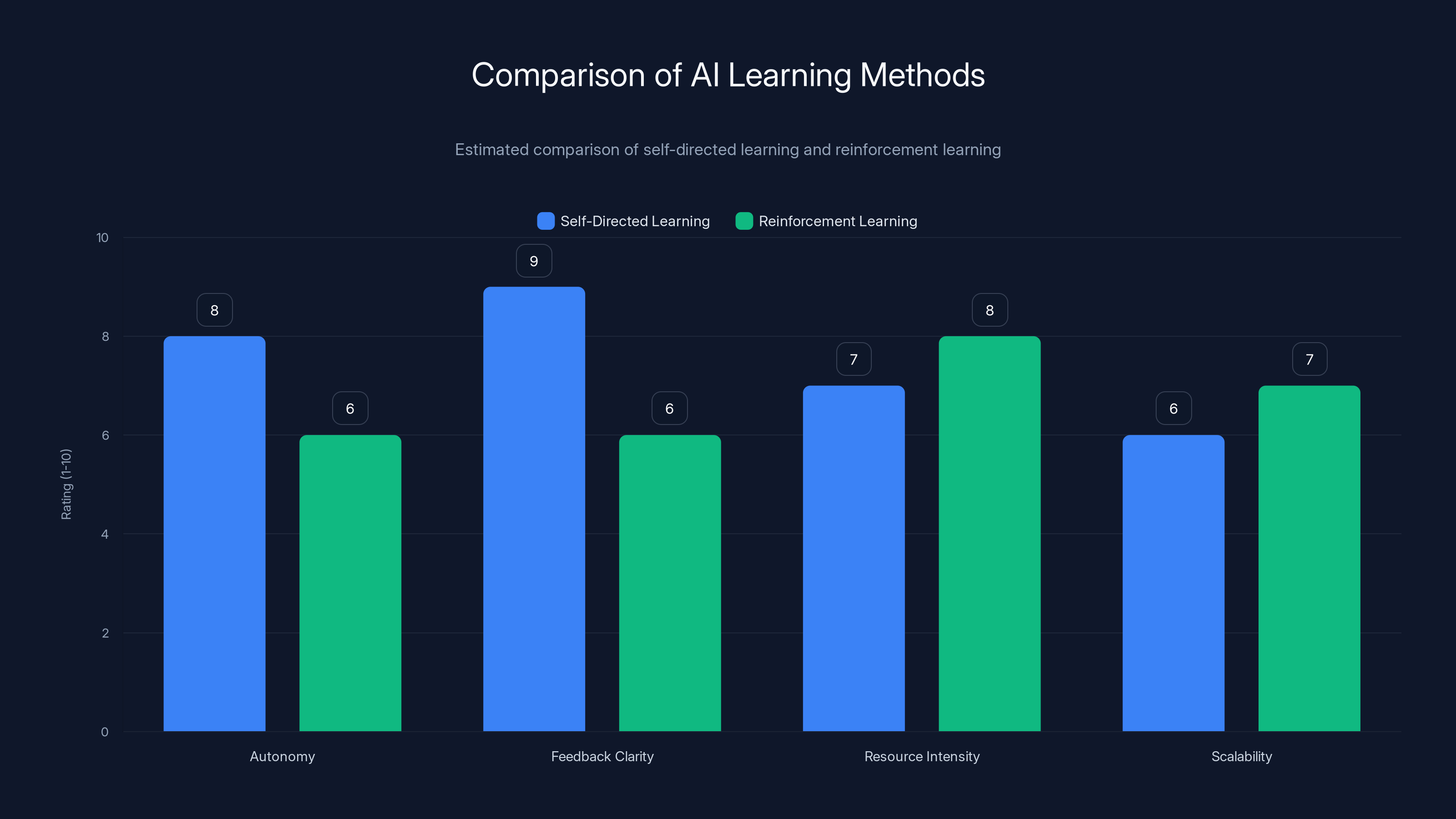
Self-directed learning excels in autonomy and feedback clarity due to its self-generated tasks and objective verification. However, it requires significant resources and struggles with scalability. Estimated data.
How Traditional AI Training Creates Learning Bottlenecks
The Copy-and-Paste Problem
Conventional large language model training follows a predictable pattern. Engineers collect massive datasets—code repositories, books, internet text, research papers—and feed these to neural networks. The model learns through pattern recognition: "When I see X, Y usually follows." It's statistical pattern matching at planetary scale, and it works remarkably well for many tasks.
But there's a ceiling. The model can only ever become as good as the examples it's trained on. If human-generated data contains biases, errors, or represents knowledge up to a certain point in time, the model inherits all of those limitations. You're training on snapshots of human capability, not on dynamically expanding knowledge.
Moreover, generating high-quality training data is expensive and increasingly scarce. Companies employ armies of annotators to label data, validate model outputs, and curate datasets. This becomes a genuine bottleneck. You need humans in the loop constantly, reviewing model behavior, correcting mistakes, and deciding what new training examples to include.
The Supervised Learning Trap
Supervised learning, where humans explicitly label correct answers, works well for narrow problems. But it doesn't scale to more complex domains. As tasks become more nuanced—requiring long-horizon reasoning, multi-step planning, or subjective judgment—finding humans to provide correct labels becomes impractical.
You hit what researchers call the "data bottleneck." The model's potential performance is capped by the amount of labeled data humans can reasonably produce. And there's economic pressure too. Every training iteration requires human oversight. Every improvement requires more human annotation. The cost curve climbs relentlessly.
Why Self-Directed Learning Changes Everything
Self-directed learning removes humans from this loop. Or more precisely, it removes them from the constant oversight phase. The model still requires initial setup, architectural choices, and validation frameworks. But once running, the system can generate infinite training problems without waiting for humans to decide what to teach next.
This has cascading effects. First, it breaks the data scarcity bottleneck. You don't need to find new human-written examples anymore. Second, it enables adaptation. The system naturally gravitates toward problems that challenge its current capabilities—harder than what it can already solve, but not so hard they're meaningless. That's the optimal learning zone, and machines can now automatically find and inhabit it.
Third, and most significantly, it creates a feedback loop where capability gains compound. Better models generate more interesting and complex problems. Solving those problems makes the model even better. The improvement curve doesn't flatten at human capability levels—it can theoretically keep accelerating.
The Absolute Zero Reasoner: How Self-Play Actually Works
The Architecture in Plain Terms
Imagine a student who doesn't wait for teachers to assign homework. Instead, she generates her own problems, attempts to solve them, checks her work, and then uses her successes and failures to study more effectively. That's essentially what Absolute Zero Reasoner does, but for AI models and coding problems.
The system has three main components working in a loop. First, a problem generator uses the language model to create Python coding challenges. These aren't random—the system is designed to generate problems at the edge of what the model can handle. Too easy and there's no learning. Too hard and failure signals don't improve the model. The sweet spot is where learning happens fastest.
Second, a problem solver (using the same model) attempts to write code that solves the generated problem. This is where reasoning happens. The model has to think through the logic, write syntactically correct Python, and implement an actual solution.
Third, a verification layer runs the code. Here's the critical part: the system doesn't rely on human judgment of correctness. It actually executes the code against test cases. Either the code works or it doesn't. Pass or fail. This binary feedback is incredibly valuable for training because it's objective and unlimited in quantity.
Why Code Problems Are Optimal Training Material
Code is ideal for self-directed learning because it has built-in verification. Run the code, see if it produces the correct output. No ambiguity, no subjective judgment calls, no need for human verification. This is why the earliest breakthroughs in self-play learning happened in domains like mathematics and programming.
A math problem has a clear answer. Code either executes correctly or it doesn't. Chess positions can be evaluated to determine who's winning. These domains have that precious quality: objective, immediate, verifiable feedback. The model knows instantly whether it succeeded or failed.
Contrast this with tasks like writing a persuasive essay or designing a user interface. There's no objective ground truth. The feedback is subjective and delayed. That makes those domains much harder to apply self-play techniques to. But research is actively working on extending these methods to messier, more ambiguous problems.
The Feedback Loop That Improves Everything
What makes Absolute Zero particularly clever is that success and failure signals improve both problem generation and problem-solving capabilities simultaneously. When the model successfully solves a problem it generated, that success feeds back to help it generate even better problems next time. When it fails, the failure signals where its reasoning breaks down.
This creates what researchers call "difficulty scaling." As the model improves, the problems it generates naturally become harder. You don't need to manually adjust difficulty levels. The system self-regulates. Better models pose harder challenges to themselves. They solve those challenges. The process repeats. The gap between problem difficulty and model capability stays roughly constant—the optimal learning environment.
Over multiple iterations of this loop, measured improvements in both problem generation and problem-solving ability compound. The researchers found that 7 billion and 14 billion parameter versions of the Qwen model showed significant performance gains. Some even matched or exceeded models trained on human-curated datasets.
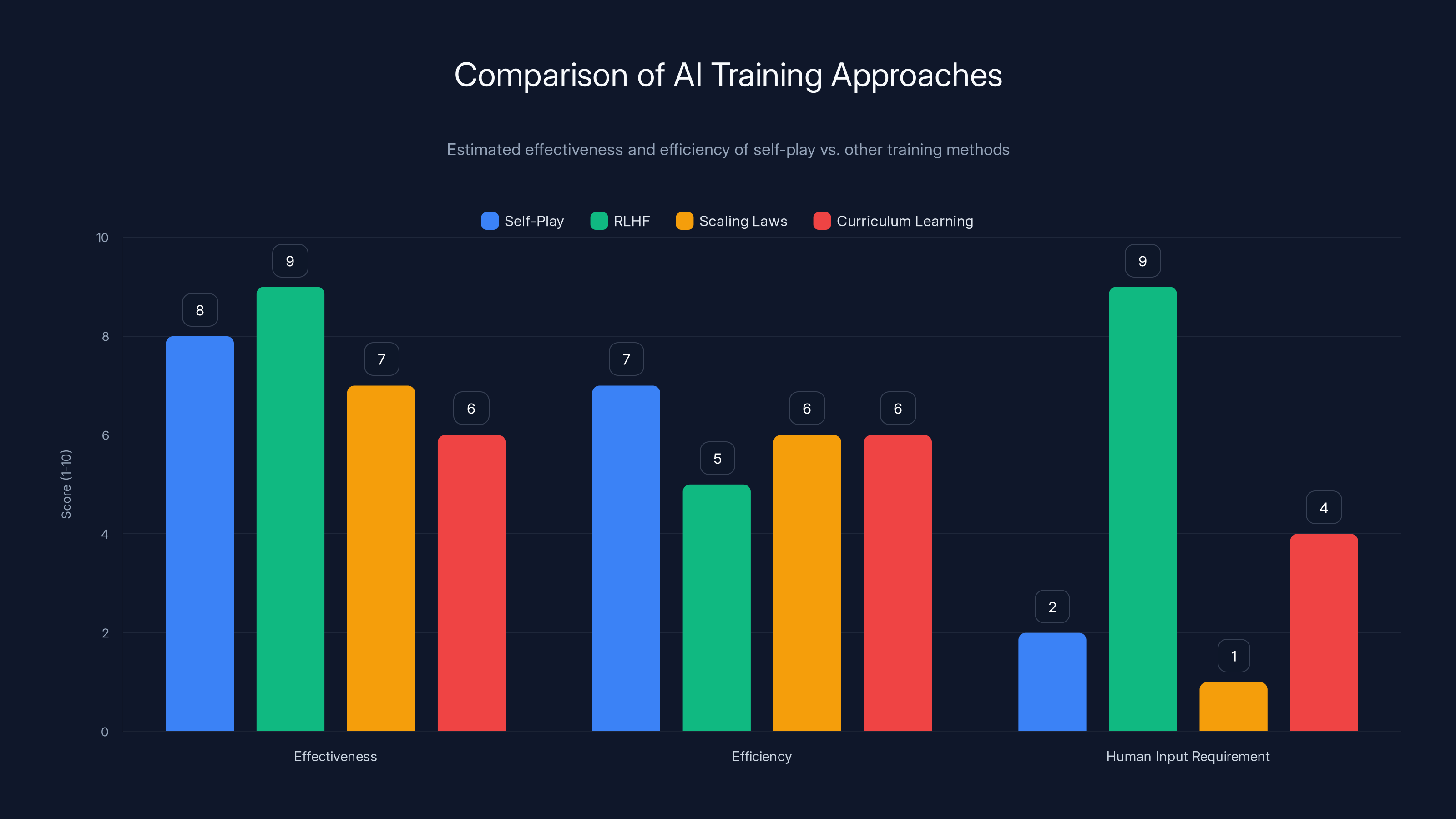
Estimated data suggests self-play is efficient and requires less human input compared to RLHF, while maintaining high effectiveness. Estimated data.
Key Research Findings: Data That Proves the Concept Works
Performance Improvements and Comparative Analysis
The empirical results from Absolute Zero and similar projects provide concrete evidence that self-directed learning actually delivers better models. The team tested their approach on Qwen models of different sizes and measured improvements across multiple benchmarks.
On coding-related reasoning tasks, improvements ranged from 30% to 50% depending on the specific benchmark and model size. That's substantial. To put it in perspective, getting a 30% improvement in model performance usually requires training on significantly more data, using more expensive hardware, or both.
What's particularly striking is that some self-trained models outperformed models that had received human-curated training data. This contradicts the old assumption that human-labeled data is always superior. In the right domain, with the right verification mechanism, machine-generated training signals can exceed human-provided signals in quality and quantity.
The Scaling Properties: Bigger Models, Better Results
One of the most important findings from this research is how self-play scales with model size. Larger models generate more sophisticated problems and solve more complex challenges. But here's the crucial insight: the improvement doesn't diminish as models get bigger. Normally, improvements slow down with scale. Each additional training example produces slightly less benefit than the last. That's a fundamental issue with traditional supervised learning.
With self-play, the relationship is different. Larger models have larger capacity to generate interesting problems and solve difficult ones. They don't exhaust the available "learning material" because the learning material expands with their capability. This suggests self-directed learning might sidestep some of the scaling limitations that plague traditional approaches.
Comparative Performance: Beating the Baseline
When researchers compared self-trained models against baseline versions trained only on standard data, the differences were significant across multiple dimensions. Models trained with self-play showed better generalization to novel problems they hadn't specifically trained on. They demonstrated more robust reasoning even on edge cases.
They also showed interesting behaviors that suggest genuine understanding rather than pattern matching. When given variations of problems they'd solved before, they performed better than expected if they were merely memorizing. This hints at something closer to actual reasoning capability rather than sophisticated copying.
The Challenge: Extending Beyond Code and Math
Why Verification is the Limiting Factor
The biggest constraint on self-directed learning right now is verification. You need a way to automatically determine if a solution is correct. Code execution provides that. Mathematical problems often have definitive answers. Chess positions can be evaluated with engines.
But what about tasks where there's no clear ground truth? Writing a good customer support email. Designing an efficient database schema. Creating a marketing strategy. Rendering a realistic image. These tasks have better and worse solutions, but no objective verification mechanism. A human would need to judge them.
This is why current self-play systems work beautifully for narrow domains and struggle with broader applications. The researchers acknowledge this limitation. The system works on "problems that can easily be checked." That's explicit in how they describe the constraint.
Pushing Into Agentic AI Territory
But there's active research on extending self-play to these harder domains. One approach being explored is having the model itself act as a judge. If an AI agent tries to complete a task (browsing the web, organizing files, booking a meeting), another AI system evaluates whether the task was completed successfully. This creates a verification mechanism for more complex problems.
This is exactly what projects like Agent 0 from Salesforce are exploring. They're building systems where AI agents improve themselves through self-play on practical, real-world tasks. The verification might come from another model, or from actually attempting the task and checking if success occurred.
The challenge is that AI judges can be fooled or make mistakes themselves. The verification signal is noisier. But even imperfect feedback seems to help models improve. The gap between "perfect human judgment" and "imperfect AI evaluation" is narrower than you might expect for learning purposes.
Timeline and Practical Limitations
Researchers are clear that this is early-stage work. The current systems work well in narrow domains. Extending to broader tasks, more ambiguous problems, and more complex real-world scenarios will take time. But the research vector is clear and the results are promising enough that investment is accelerating.
There are also practical considerations. Training systems that generate and solve thousands of problems requires substantial compute. Running millions of code execution passes to verify solutions isn't free. The computational cost is real, though researchers note it often comes out ahead of collecting and labeling human data.


Problem Solver is the most critical component in self-directed learning systems, closely followed by Problem Generator and Performance Monitoring. Estimated data based on typical system requirements.
The Industry Response: Self-Play Is Catching On Fast
Salesforce's Agent 0 and the Self-Improving AI Agent
Salesforce, in collaboration with Stanford and the University of North Carolina at Chapel Hill, developed Agent 0. This system builds autonomous agents that improve themselves through self-play. Instead of problems in a coding sandbox, the agent might attempt various tasks, learn from what works and what fails, and gradually become more capable.
The parallels to Absolute Zero are clear, but the domain is different. Rather than generating and solving coding problems, Agent 0 focuses on general reasoning and task completion. The agent learns by experimentation, not unlike how humans learn through trial and error, but systematized and accelerated.
What's significant is that Salesforce, a mature enterprise software company, is dedicating resources to this research. That signals confidence that self-directed learning is a real trend, not a lab curiosity.
Meta's Software Engineering Research
Meta researchers, working with colleagues from the University of Illinois and Carnegie Mellon University, published work on using self-play for software engineering tasks. Their system learns to write and improve code through self-directed experimentation.
They explicitly framed their work as "a first step toward training paradigms for superintelligent software agents." That language choice—superintelligent—is telling. The research community is openly discussing whether self-play might be part of the path toward artificial general intelligence.
The Competitive Arms Race
What's happening now is the beginning of a competitive arms race in self-directed learning. Different labs are exploring variations, testing different domains, pushing the boundaries of what's possible. There's Anthropic's internal research, Open AI's work, Google Deep Mind, and dozens of other organizations.
The pressure is intense because the potential payoff is enormous. Whoever figures out how to effectively scale self-directed learning to complex, real-world tasks gains a massive advantage. The model improvement cycle becomes self-sustaining. You need fewer human researchers. You need less labeled data. You need less human oversight.
For a company competing to build the most capable AI systems, that's transformative.

The Theoretical Implications: Could This Lead to Superintelligence?
Removing the Human Bottleneck
The most provocative implication of self-directed learning is that it potentially breaks what some researchers call the "human teaching bottleneck." Right now, human intelligence sets an upper bound on how intelligent AI can become. We teach the models. Our understanding becomes their ceiling.
But if a model can generate its own learning experiences, identify gaps in its own knowledge, and improve without human guidance, that ceiling disappears. The model can theoretically improve well beyond human capability levels because it's not constrained by what humans know or can teach.
This is why researchers like Zilong Zheng from BIGAI explicitly connected self-directed learning to superintelligence. "Once we have that it's kind of a way to reach superintelligence," he said in interviews about the research. He's not making a wild claim. He's describing a logical chain: if systems can continuously improve themselves without human guidance, and if improvement compounds over time, theoretically there's no natural limit to where capability goes.
The Feedback Loop Hypothesis
Human intelligence evolved without an obvious optimization target. We got better at solving problems because solving problems helped us survive and reproduce. That drove selection pressure, which improved our brains over millions of years.
AI systems with self-directed learning have something different: explicit optimization signals. A model gets feedback on whether it solved the problem correctly. It has a clear metric for improvement. Over time, selecting for solutions to progressively harder self-generated problems, the model's capability accelerates.
Unlike humans, where the learning process takes decades and is limited by lifespan and biology, machines can learn continuously. The improvement loop can run 24/7. It can incorporate learnings from multiple parallel processes. The theoretical implications are staggering.
The Counterarguments and Realities
That said, there are legitimate counterarguments. Self-directed learning in constrained domains (code, math) is different from real-world reasoning. Most real-world problems don't have clear success metrics. They require navigation of uncertainty and ambiguity.
Additionally, there's the "goodharting" problem. If you optimize too hard for one metric, you can end up with a solution that technically meets the metric but misses the broader intent. A model could theoretically get very good at solving self-generated problems without becoming smarter at the things that actually matter.
But these are arguments about implementation details, not about the core viability of self-directed learning as an approach. The research community is actively working on these challenges.
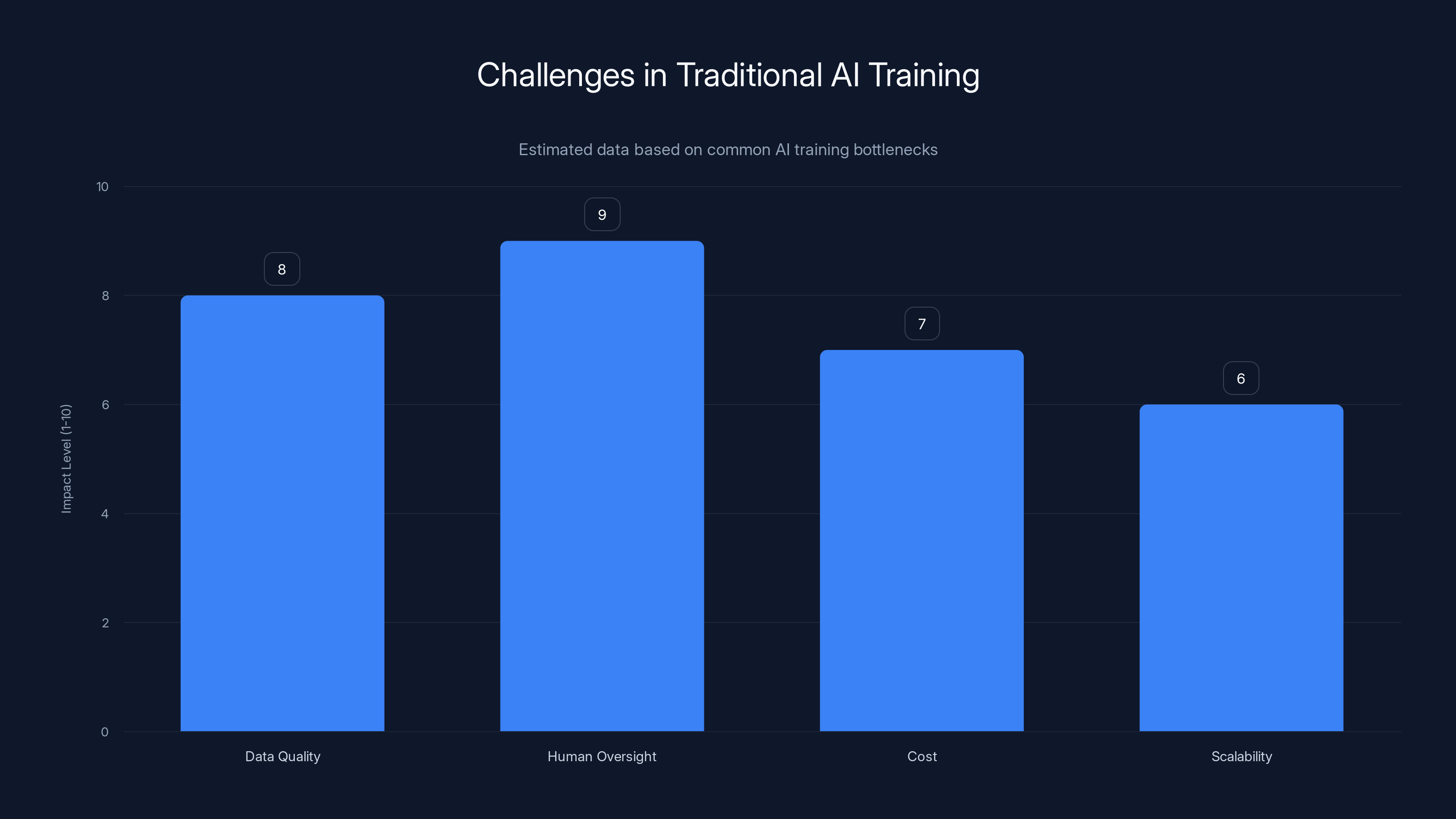
Traditional AI training faces significant bottlenecks, notably in data quality and the need for human oversight, both rated highly in impact. Estimated data.
Data Scarcity and Training Cost: The Economic Argument
Why Conventional Data Is Running Out
Training modern language models requires enormous amounts of data. We've already scraped most of the publicly available, high-quality human-generated text from the internet. Books, academic papers, code repositories, articles—these are finite resources.
Data augmentation helps, but there are limits. You can create variations of existing data, but eventually you're training on synthetic data created from other models. The signal gets diluted. Diminishing returns set in hard.
Companies are now paying for training data. They're hiring contractors to generate specific types of content. The cost of training runs up. At some point, the economics of traditional training become prohibitive.
The Economic Case for Self-Play
Self-directed learning sidesteps this by generating infinite training data automatically. The model creates its own training signal. The only cost is compute—the resources needed to run the system. While that's not free, it's often cheaper than the alternative: hiring humans to generate, label, and curate training data.
For a company like Open AI or Anthropic, compute is expensive but manageable. Human annotation at scale is expensive and has quality-control challenges. Over time, especially as models become more capable at generating their own training material, self-directed learning becomes economically superior.
This economic argument is one reason the competitive pressure is so intense. Whoever builds the most efficient self-directed learning system doesn't just get better models. They get cheaper, faster model improvement. That translates directly to competitive advantage.

Comparing Self-Play to Other Novel Training Approaches
Self-Play vs. Reinforcement Learning From Human Feedback (RLHF)
Reinforcement Learning From Human Feedback has been crucial for making modern language models more aligned with human values and preferences. You use human judges to rank model outputs, then train the model to produce outputs humans prefer.
But RLHF requires constant human input. Every comparison, every preference judgment, every alignment correction involves humans. Self-directed learning doesn't eliminate the need for alignment work, but it does remove humans from the basic capability improvement loop. You can use RLHF on top of self-play systems.
Think of it this way: self-play gets the model to be more capable at core reasoning. RLHF gets the model to align that capability with human values. They're complementary, not competing approaches.
Self-Play vs. Scaling Laws and Compute
The scaling laws that have dominated AI progress for the past decade say bigger models trained on more data get better performance. This is empirically true and has driven the compute arms race.
Self-directed learning is orthogonal to scaling. You can apply self-play to models of any size. But the question becomes: is self-play a more efficient path to capability than pure scaling? Can a smaller model trained with self-play outperform a larger model trained conventionally?
Early results suggest yes, but the research isn't conclusive yet. What seems likely is that the optimal approach combines both: larger models with self-directed learning, potentially requiring less raw compute than scaling alone would demand.
Self-Play vs. Curriculum Learning
Curriculum learning is an approach where you deliberately structure training from easier tasks to harder tasks, mimicking human education. A teacher starts with basics and progressively increases difficulty.
Self-directed learning is like curriculum learning but where the system sets its own curriculum. It automatically gravitates toward the difficulty level that drives learning. This is actually more efficient than hand-designed curricula in many cases because the system adapts in real-time to its own capability level.
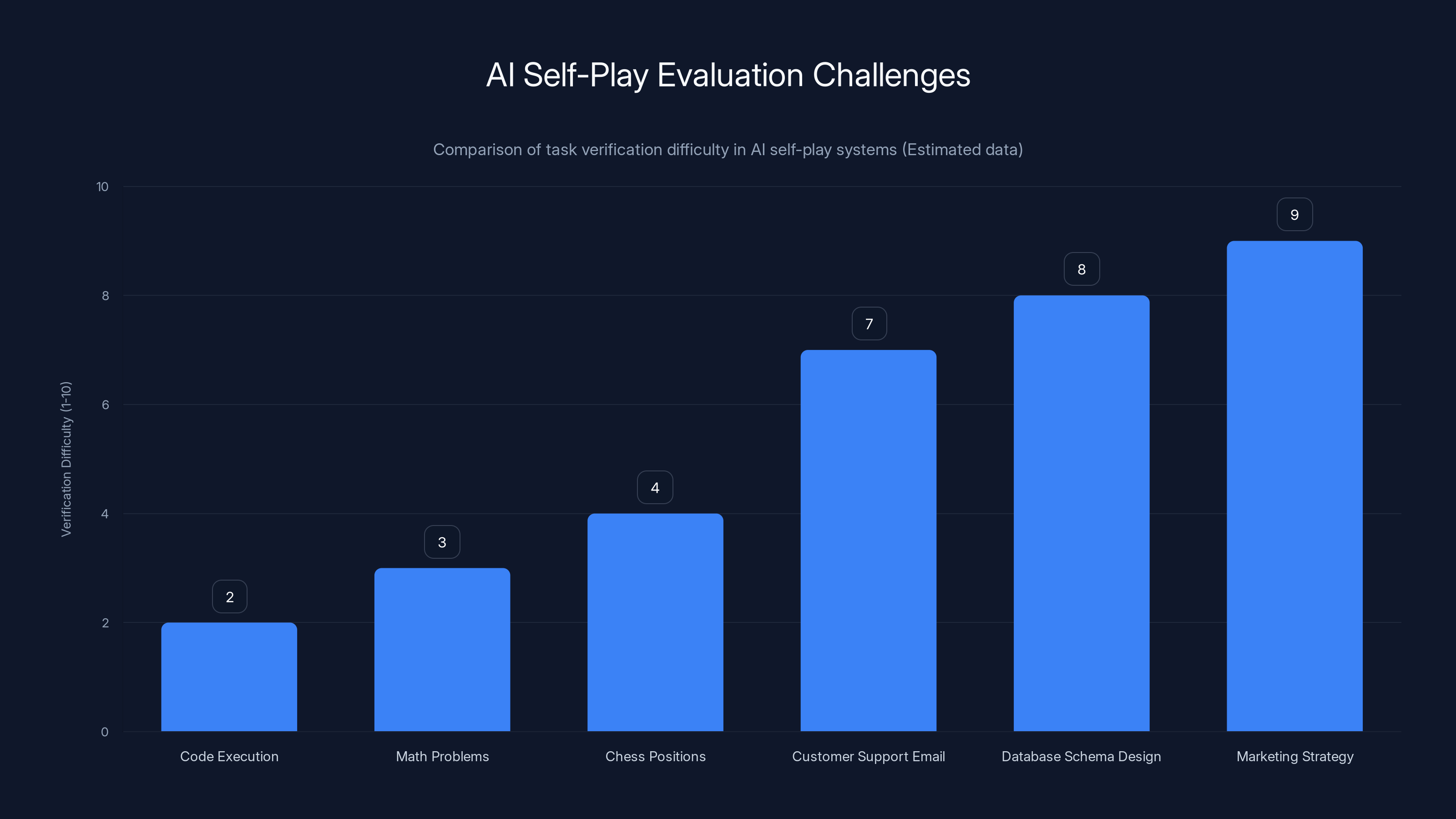
Verification difficulty increases significantly for tasks without clear ground truth, such as designing a marketing strategy or database schema. Estimated data highlights the challenge in extending AI self-play systems beyond code and math.
Real-World Applications: Where Self-Directed Learning Works Now
Software Development and Code Generation
The most immediate real-world application is code generation and software development. Models like GitHub Copilot already help developers write code. Imagine versions of those tools that improve themselves by generating coding problems, solving them, and learning from the results.
This could create code generation systems that get progressively better without requiring new human-generated code examples. They'd learn by doing, by generating variations of problems and solving them.
The practical impact: faster code generation, better code quality, fewer bugs. For a field where time-to-development is a key metric, this matters a lot.
Mathematical Problem-Solving and Research
Mathematics is another domain tailor-made for self-play. Mathematical problems have definitive correct answers. They can be generated procedurally. The space of possible mathematical problems is essentially infinite.
Systems trained with self-play on mathematical reasoning could accelerate mathematical discovery. Rather than requiring human mathematicians to pose interesting problems, the system could autonomously explore mathematical space, discovering patterns and relationships humans might miss.
We're already seeing early hints of this with AI systems helping mathematicians, but self-directed learning could dramatically accelerate the process.
Knowledge Workers and Administrative Tasks
Though it's more speculative, there's potential for self-directed learning to improve AI systems doing knowledge work. Imagine systems that generate variations of office tasks (scheduling, email drafting, report generation), attempt to complete them, and learn from their successes and failures.
The verification mechanism is trickier here—you need to determine when a task was actually completed correctly—but it's not impossible. A human could verify completion once, and the system learns from that example.
The Path Forward: Technical Challenges and Open Questions
Verification at Scale
The biggest technical challenge is creating robust verification mechanisms for complex problems. We have them for code and math. We're developing them for multi-step agentic tasks. But many real-world problems remain verification-hard.
Researchers are exploring various approaches. Using multiple AI judges to verify each other. Using human feedback for a sample of solutions and training the system to extrapolate. Building in uncertainty quantification so the model knows when it's unsure.
None of these are perfect, but they're progress. The field is actively working on this.
Generalization Beyond Narrow Domains
Self-play works great in constrained domains with clear rules. Moving to more open-ended, creative, or ambiguous tasks is harder. A model trained on self-generated poetry problems might not generalize well. The problem-generation and problem-solving capabilities are tightly coupled to the specific domain.
Researchers are exploring whether principles learned in one domain transfer to others. Early evidence is mixed. Transfer learning might require explicit mechanism for extracting domain-general insights from domain-specific training.
Alignment and Safety
If a system is improving itself without human oversight, how do you ensure it remains aligned with human values? This is a serious open question. A model that's optimizing for solving self-generated problems might develop capabilities or behaviors that are misaligned with broader goals.
This isn't a reason to avoid self-directed learning. It's a reason to invest heavily in alignment research in parallel. We need safety mechanisms that work even when humans aren't constantly supervising the system.
Building Your Own Self-Directed Learning Systems
If you're considering implementing self-directed learning approaches, there are practical considerations. The domain needs to have verifiable outcomes. Code execution is ideal. Mathematical problems are ideal. Most real-world business problems are trickier.
Start with a constrained domain where you have clear success metrics. You could build a system that generates customer service scenarios, attempts to resolve them, and learns from successes and failures. Or procurement scenarios. Or data quality problems.
The technical infrastructure you need includes a problem generator (a language model or custom algorithm), a problem solver (your model being trained), and a verification layer (automated checks for correctness). You'll want to monitor performance metrics carefully to catch when problems become too easy or too hard.
Automation tools like Runable can help streamline the infrastructure for building and testing these systems. When you're generating thousands of test cases and monitoring performance across multiple runs, having reliable automation for document generation, report creation, and workflow coordination becomes valuable.
Consider starting with a pilot. Pick a narrow domain, implement the self-play approach, measure results carefully. You'll learn a lot about what works and what doesn't in your specific context.

The Competitive Landscape: Who's Winning the Self-Play Race
Academic Leadership
Tsinghua University, BIGAI, and Pennsylvania State have established themselves as leaders with Absolute Zero. Other academic institutions are ramping up. MIT's Computer Science and Artificial Intelligence Lab, Stanford's Human-Centered Artificial Intelligence, Berkeley's Artificial Intelligence Research Lab—all are exploring self-directed learning approaches.
Academia has advantages: freedom to pursue blue-sky research without immediate commercial pressure, access to top talent, computational resources for large-scale experiments. They're setting the research direction.
Corporate Investment
Salesforce, Meta, Google, Microsoft, Open AI, Anthropic—all are investing in self-directed learning research. The corporate labs have advantages too: massive compute resources, engineering talent, ability to implement and deploy systems at scale.
The competitive dynamic is intensifying. Companies are publishing research to establish priority and attract talent, but they're also keeping some capabilities proprietary. There's a race happening, but it's not a zero-sum game. The field is advancing rapidly because so many capable organizations are working on it simultaneously.
The Strategic Stakes
Whoever cracks scalable self-directed learning first doesn't just get a publication or a better model. They potentially get a massive efficiency advantage in model improvement. If one company's models improve themselves automatically while competitors are still waiting for human-curated data and feedback, the gap widens exponentially over time.
This is why the investment is so heavy and the research so intense. The long-term strategic implications are enormous.

Limitations and Honest Assessment
What Self-Play Isn't Solving
Let's be clear about what this technology isn't doing. It's not creating artificial general intelligence. It's not removing the need for human oversight of AI systems. It's not solving alignment and safety challenges. It's not making AI systems wise or creative in the way humans are.
What it is doing is improving model capability in specific, measurable domains. It's breaking the human-data bottleneck. It's enabling models to improve faster. Those are significant, but they're not the same as creating intelligent machines.
The Domain Limitation
This approach works in domains with clear verification. It doesn't work equally well everywhere. Creative domains, ambiguous domains, domains requiring human judgment—these remain harder to apply self-play to. And they'll probably remain harder for a while.
This isn't a fatal flaw. It's just a reality. The technology will improve incrementally on these harder problems, but the easy wins are in structured domains.
The Computational Cost
Running millions of code executions, generating thousands of problems, training on the results—this requires significant computational resources. For a startup or small team, the cost might be prohibitive. This could become a competitive advantage for well-funded labs and large companies.
There are ways to make it more efficient. Running inference on cheaper hardware. Batching problem generation and solving. Caching results to avoid redundant computation. But it remains resource-intensive.
The Human Question: What Does This Mean for People?
The Job Market Implications
If AI systems can improve themselves without human instruction, the implications for employment are significant. Fewer human labelers are needed. Fewer human trainers. The human effort required to develop increasingly capable AI shrinks.
At the same time, demand for people who understand and can work with these systems increases. The shape of the job market changes. Certain roles become less necessary. New roles emerge. This is disruptive but not necessarily catastrophic if the transition is managed well.
The Acceleration Question
There's a real question about whether self-directed learning accelerates the timeline to transformative AI. If models can improve themselves, that acceleration is dramatic. Instead of waiting for humans to collect and label new training data, the improvement can happen continuously.
Some researchers think this could compress timelines significantly. Others think there are fundamental plateaus that self-directed learning doesn't overcome. The honest answer is we don't know yet. The research will tell us.
The Public Interest
What matters most for society is that this capability develops in a way that's safe, transparent, and controlled. We need oversight mechanisms. We need safety research to match capability research. We need policies and governance structures that reflect the stakes.
The technology itself is morally neutral. How it's developed and deployed matters enormously.

Future Trajectory: What's Next in Self-Directed Learning
Near-term (Next 1-2 Years)
Expect to see continued progress in constrained domains. Code, math, symbolic reasoning—these will improve dramatically. We'll see systems that can solve increasingly complex technical problems through self-play. More companies will publish research and launch products incorporating self-directed learning approaches.
You'll probably see the first commercial applications. Code generation tools that improve themselves. Mathematical solvers that get progressively better. Internal productivity tools that use self-play to optimize workflows.
Medium-term (2-3 Years Out)
Researchers will expand verification mechanisms to handle more ambiguous problems. There will be progress on extending self-play to agentic AI—systems that take actions in the real world and learn from the results.
We'll see hybrid approaches combining self-directed learning with other techniques. RLHF on top of self-play systems. Curriculum learning combined with self-generated problems. The field will converge on best practices that work reliably.
Alignment and safety research will intensify. You'll see papers on how to ensure self-improving systems remain aligned with human values. Governance frameworks will emerge.
Long-term (3+ Years)
If the research succeeds, we could see AI systems that meaningfully improve themselves without human guidance. That's the big bet underlying all this work. Whether it actually happens and what the implications are remain open questions.
The research vector is clear: remove human bottlenecks, enable systems to learn from their own experiences, allow capability to compound. If that vector holds, we're looking at a significant inflection in AI development.
Conclusion: The Shift From Passive to Active Learning
The fundamental shift happening right now is from AI systems that passively absorb human-curated examples to systems that actively generate their own learning experiences. This isn't a minor engineering improvement. It's a different paradigm.
For decades, the constraint on AI capability was data and human effort. You needed humans to collect it, label it, curate it, validate it. That created a ceiling on how fast AI could improve. Self-directed learning removes that constraint. The system becomes its own data source.
The implications ripple outward. Faster capability improvement. Reduced need for human data annotation. Economic advantages for whoever implements it effectively. Potential path toward more autonomous, self-improving systems.
But this is early. The technology works in narrow domains. Extending it broadly requires solving hard problems: creating reliable verification mechanisms, ensuring safety, handling ambiguity and real-world complexity. None of these are solved yet.
What we're watching is the field recognizing a new direction and investing heavily to explore it. The Absolute Zero Reasoner from Tsinghua, Salesforce's Agent 0, Meta's research—these are all pointing the same direction. It's convergent research, which is usually a sign that something real is happening.
The next decade of AI development will depend heavily on whether self-directed learning can scale beyond code and math to the broader domains that matter for artificial general intelligence. That's the critical question. And the research community is now fully focused on answering it.
The machines aren't asking themselves questions yet in any deep philosophical sense. But they're starting to pose their own coding problems and learning from solving them. It's a small step toward more autonomous, self-improving systems.
What happens next depends on whether that small step leads somewhere significant.
FAQ
What exactly is self-directed learning in AI?
Self-directed learning is when an AI model generates its own training problems, attempts to solve them, receives feedback on whether the solutions are correct, and uses that feedback to improve both its problem-solving abilities and its ability to generate harder problems. Unlike traditional supervised learning where humans provide training examples, the model becomes its own teacher, creating infinite training data without human intervention.
How is self-directed learning different from reinforcement learning?
Reinforcement learning typically involves an agent learning through trial and error in an environment while receiving reward signals. Self-directed learning specifically focuses on a model generating its own training tasks and learning to solve them. Self-directed learning can use reinforcement learning techniques, but it's fundamentally about the model being the source of its own learning material rather than an external environment or human providing all the tasks.
Why does self-directed learning work best with code and math problems?
Code and math problems have objective verification mechanisms. Code either executes correctly or it doesn't. Mathematical problems have definitive right answers. This binary feedback signal is what makes self-directed learning effective. More ambiguous domains like writing, design, or creative work lack this clear verification, making it harder to create reliable feedback signals for the learning loop.
What are the limitations of self-directed learning right now?
Current self-directed learning systems work best in constrained domains with clear success metrics. They require substantial computational resources. They don't yet scale well to real-world problems that lack objective verification mechanisms. They still need human oversight for alignment and safety. The approach also doesn't solve problems in domains where there's ambiguity or multiple valid solutions.
How could self-directed learning lead to superintelligence?
If a system can continuously improve itself through self-generated training experiences without human limitations, and if that improvement compounds over time, theoretically there's no natural ceiling on how capable the system becomes. Unlike traditional training constrained by available human-generated data, self-directed learning generates infinite training material. If effective, this removes a key bottleneck that previously limited AI capability growth.
Is self-directed learning dangerous?
Self-directed learning isn't inherently dangerous, but systems that improve themselves without human oversight do raise safety and alignment concerns. We need to ensure that as systems become more capable and autonomous, they remain aligned with human values. This is why parallel investment in safety and alignment research is crucial alongside capability research.
When will self-directed learning systems be commercially available?
Early commercial applications are already appearing, primarily in code generation and developer tools. More widespread availability of self-directed learning systems will likely happen over the next 1-3 years as research matures and companies deploy these approaches. However, truly transformative applications in complex real-world domains will take longer as verification mechanisms become more sophisticated.
How much does it cost to build a self-directed learning system?
The cost varies significantly based on domain and scale. You need computational resources for training and inference, infrastructure for problem generation and verification, and data storage. For a startup or research team, costs could range from thousands to millions of dollars depending on scale. Companies are betting that the efficiency gains (needing less human annotation and curation) offset the computational costs.
Can I implement self-directed learning for my specific domain?
It depends on whether your domain has clear verification mechanisms. If you can automatically determine whether a solution is correct without human judgment, self-directed learning is feasible. If your domain is more ambiguous or subjective, it's harder but not impossible—you might use proxy metrics, human-in-the-loop verification for subsets of data, or train an AI judge to evaluate solutions.
What companies are leading in self-directed learning research?
Tsinghua University, BIGAI, and Pennsylvania State led with the Absolute Zero project. Salesforce, Stanford, Meta, Google Deep Mind, Open AI, Anthropic, and various academic institutions are all actively researching self-directed learning. The field is crowded and competitive because the potential advantages are so significant.
How does self-directed learning affect the need for human data annotators?
Self-directed learning dramatically reduces the need for human data annotation and labeling. Rather than hiring teams to manually label training data, systems generate and verify their own training data. This changes the economics of AI development significantly. The human effort shifts from annotation to system design, safety oversight, and alignment work—different skills but fewer total humans needed.
Key Takeaways
- AI systems can now generate their own training problems and learn from solving them, removing human data bottlenecks that previously limited capability growth
- Self-directed learning has produced 30-50% performance improvements in code and reasoning tasks, sometimes surpassing human-curated training approaches
- Research from Tsinghua, BIGAI, Salesforce, and Meta shows self-play is spreading across institutions and domains, with competitive pressure intensifying
- Verification mechanisms are the limiting factor; self-play works well for domains like code and math with clear correctness signals, but extending to ambiguous real-world problems remains challenging
- Removing human teaching bottlenecks could theoretically accelerate progress toward artificial general intelligence, but scaling to complex, real-world domains requires solving significant technical and safety challenges
Related Articles
- AI Isn't a Bubble—It's a Technological Shift Like the Internet [2025]
- AI's Hype Problem and What CES 2026 Must Deliver [2025]
- Satya Nadella's AI Scratchpad: Why 2026 Changes Everything [2025]
- Boston Dynamics Atlas Production Robot: The Future of Industrial Automation [2025]
- How to Watch Hyundai's CES 2026 Press Conference Live [2026]
- Amazon Alexa on Web: Breaking Free From Echo Devices [2025]

