![AI PC Crossover 2026: Why This Is the Year Everything Changes [2025]](https://tryrunable.com/blog/ai-pc-crossover-2026-why-this-is-the-year-everything-changes/image-1-1768329583344.jpg)
Introduction: The Year AI PCs Stop Being a Buzzword
For the past few years, "AI PC" has been the tech industry's favorite vaporware promise. Every keynote, every conference, every earnings call promised that AI-powered personal computers were coming. And technically, they were always there. But here's the thing: nobody was actually using the AI part.
That's about to change completely in 2026.
We're at a genuine inflection point. This isn't hype from a vendor trying to sell you something you don't need. This is a fundamental shift in how computing hardware meets software architecture, triggered by three things coming together at exactly the right moment: mature neural processing units (NPUs), actually useful AI experiences beyond chatbots, and developers finally building applications that take advantage of local processing.
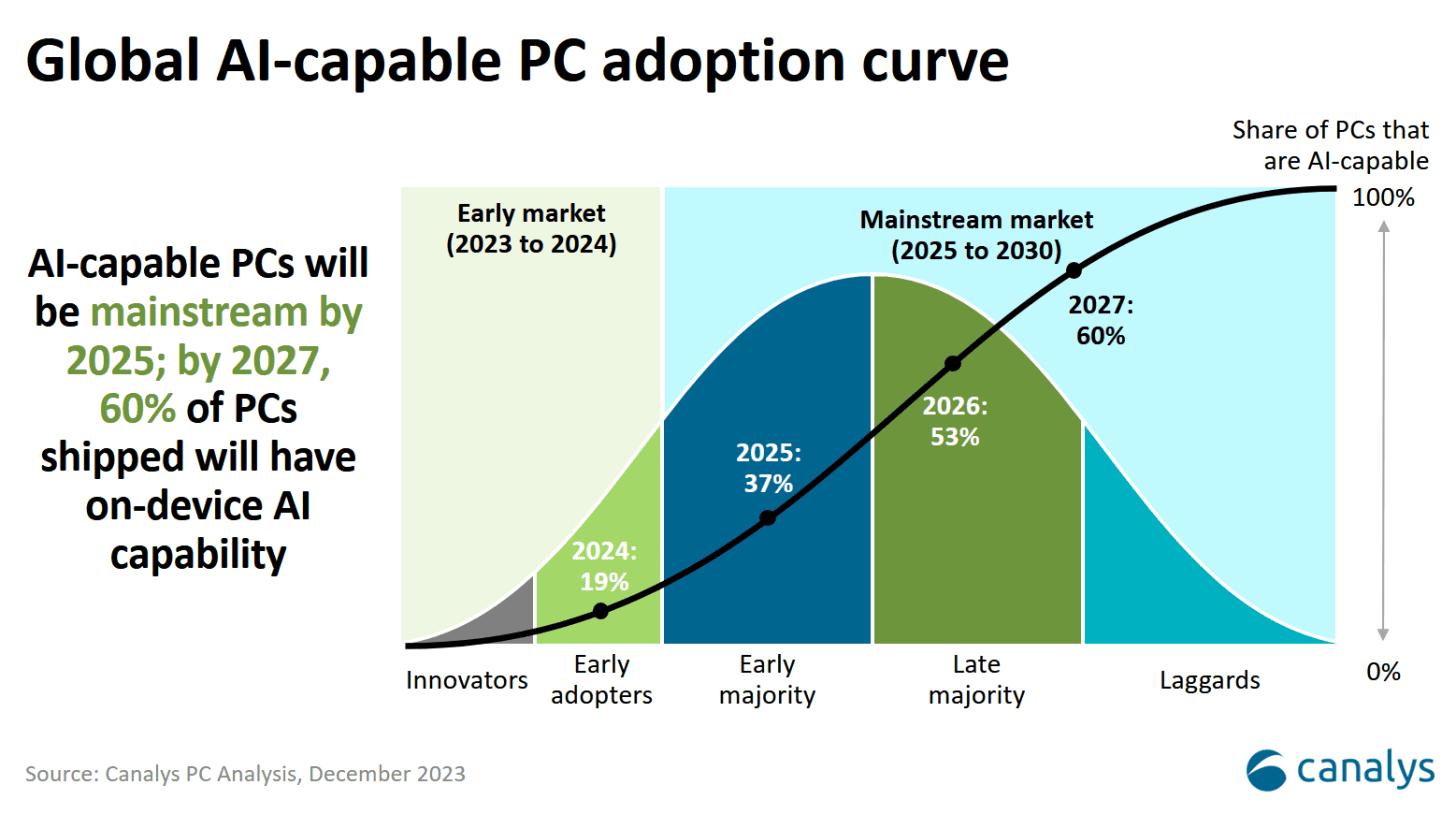
According to industry leaders speaking publicly at major tech conferences, 2026 will be the year when more AI-enabled PCs ship than traditional PCs without AI capabilities. That's the crossover point. That's when something goes from "early adopter enthusiasm" to "the baseline expectation."
But before you think this is just about slapping a Copilot button on your laptop, understand what's actually happening. We're talking about a complete rearchitecture of how computing works locally, how data flows, and how applications process information. The implications touch everything from privacy to development practices to what "offline computing" even means in 2026 and beyond.
This deep dive explores what's driving the AI PC moment, why mini PCs are becoming the unexpected hero in this transition, what developers absolutely need to understand, and what this means for the broader computing landscape. Because unlike the last decade of AI hype, this time the infrastructure is actually ready.
TL; DR
- 2026 is the inflection point: More AI PCs will ship than traditional PCs for the first time, marking genuine mainstream adoption rather than early adopter interest
- The crossover matters for developers: When the user base reaches critical mass, it becomes economically sensible to build applications leveraging local AI capabilities and neural processing
- Mini PCs are the surprising catalyst: Ultra-compact form factors are growing faster than traditional desktops, offering users the performance of both notebooks and desktops without trade-offs
- Local AI changes the game: NPUs enable private, offline AI processing without cloud dependency, reducing latency, costs, and data exposure concerns
- The software ecosystem is finally maturing: Tools like Microsoft Copilot, third-party developer frameworks, and enterprise applications are creating the actual use cases that drive hardware adoption
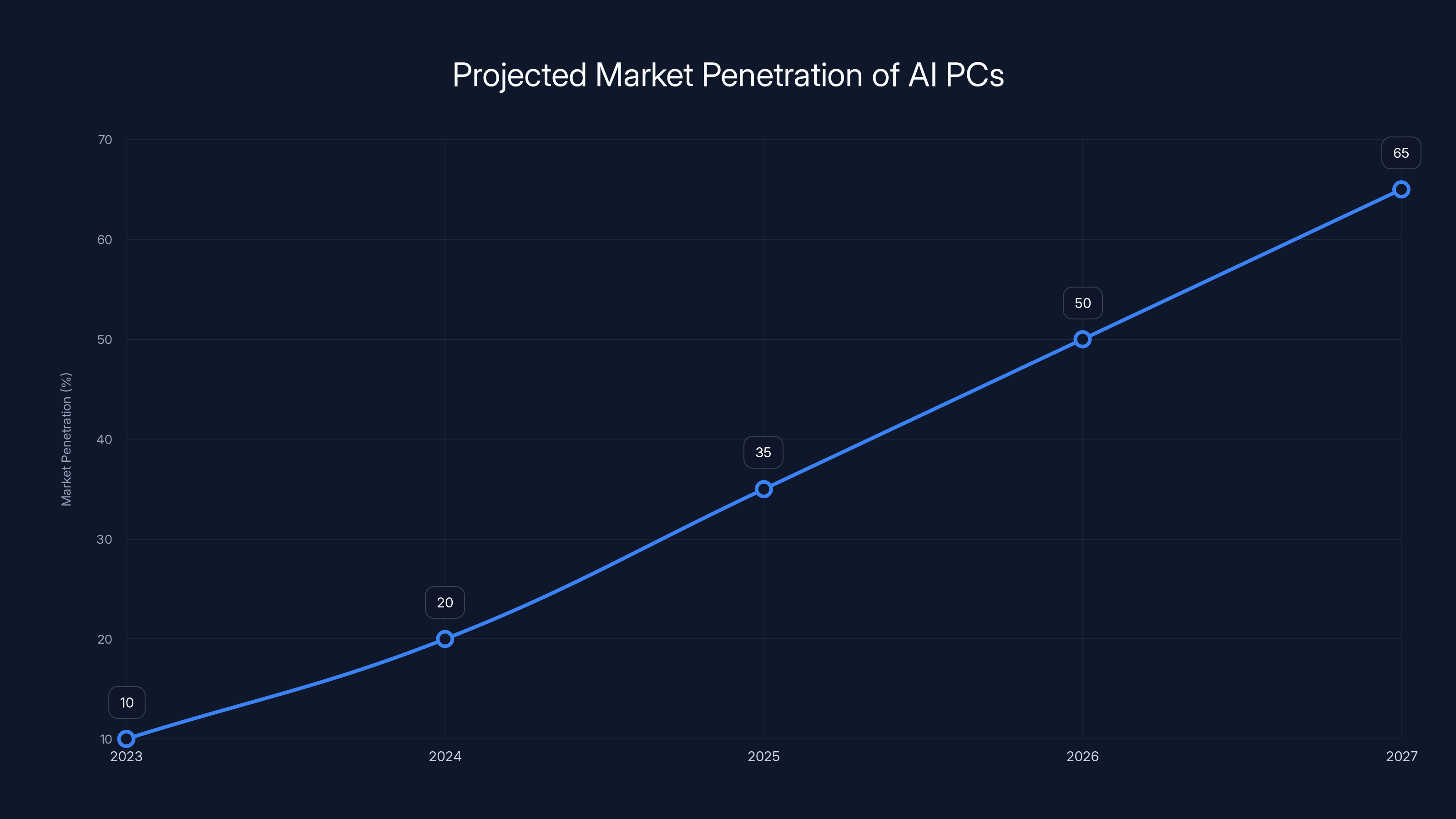
The market penetration of AI PCs is projected to reach 50% by 2026, making AI-optimized software development economically viable for mainstream developers. Estimated data.
The AI PC Inflection Point: What 2026 Actually Means
Understanding the Crossover Moment
When industry executives talk about a "crossover point," they're describing something specific in technology adoption. It's the moment when the minority technology becomes the majority. Think about smartphones overtaking feature phones, or SSDs replacing mechanical hard drives. The crossover doesn't mean everyone switches immediately. It means the trajectory is now irreversible, and the baseline expectation has shifted.
For AI PCs, crossing that 50% threshold in 2026 is significant because it fundamentally changes developer incentives. Until now, building applications optimized for neural processing units (NPUs) was a nice-to-have. Supporting Windows, macOS, and Linux was mandatory. Supporting NPU acceleration was a curiosity for people building AI research tools or specialized applications.
Once the installed base of AI PCs exceeds traditional PCs, the economics flip. A software developer can now reach more potential users by optimizing for NPUs than by ignoring them. That's when third-party applications explode. That's when your productivity suite starts using local AI for real-time spell-checking and grammar analysis instead of cloud API calls. That's when photo editors process multiple filters in parallel using neural processing instead of taxing the main CPU.
This isn't speculative. Look at what's already happening: major software vendors are quietly building NPU support into their applications. Design software, content creation tools, productivity suites. They're not announcing it loudly because the user base isn't large enough to matter yet. But they're building it. And in 2026, when that user base crosses into majority territory, those investments pay off.
Why the Timing Works Now
Three factors converged to make 2026 the realistic crossover year instead of 2024 or 2025.
First, the hardware is finally mature. The current generation of NPUs in mainstream processors actually works reliably. Early iterations had limited instruction sets, poor memory hierarchies, and driver issues that made them more of a liability than an advantage. Today's NPUs can execute actual workloads at meaningful speeds. Latency dropped from seconds to milliseconds for many tasks.
Second, the software maturity caught up. Microsoft's Copilot integration into Windows became genuinely useful rather than a forced addition. Third-party developers started shipping real applications that leverage NPU capabilities. The experience gap—that period where the hardware was faster but the software had nothing interesting to do with that speed—is closing.
Third, the cost structure became viable. AI PCs that are actually competitive on price with traditional computers exist now. For most buyers, the AI PC premium has shrunk to a negligible amount. That removes the friction point that limited adoption in 2024 and 2025.
What This Means for Hardware Adoption
The crossover point creates a self-reinforcing cycle. More units shipped means more developers build optimized applications. More optimized applications mean more compelling reasons to buy AI PCs. More compelling reasons mean faster adoption, which accelerates the cycle further.
Historically, this cycle takes 18-24 months to really mature. The first-generation of applications is rough. They don't fully utilize the hardware capabilities. But by the second and third generation, developers understand the architecture, design patterns emerge, and you get software that actually feels like it's been engineered for the platform rather than ported.
In 2026, we're looking at the bottom of the S-curve for that adoption. By 2028-2029, AI PCs might be 70-80% of the market. By 2030, you might have to actively search for a PC without NPU support, much like you can't easily find a laptop without an SSD today.
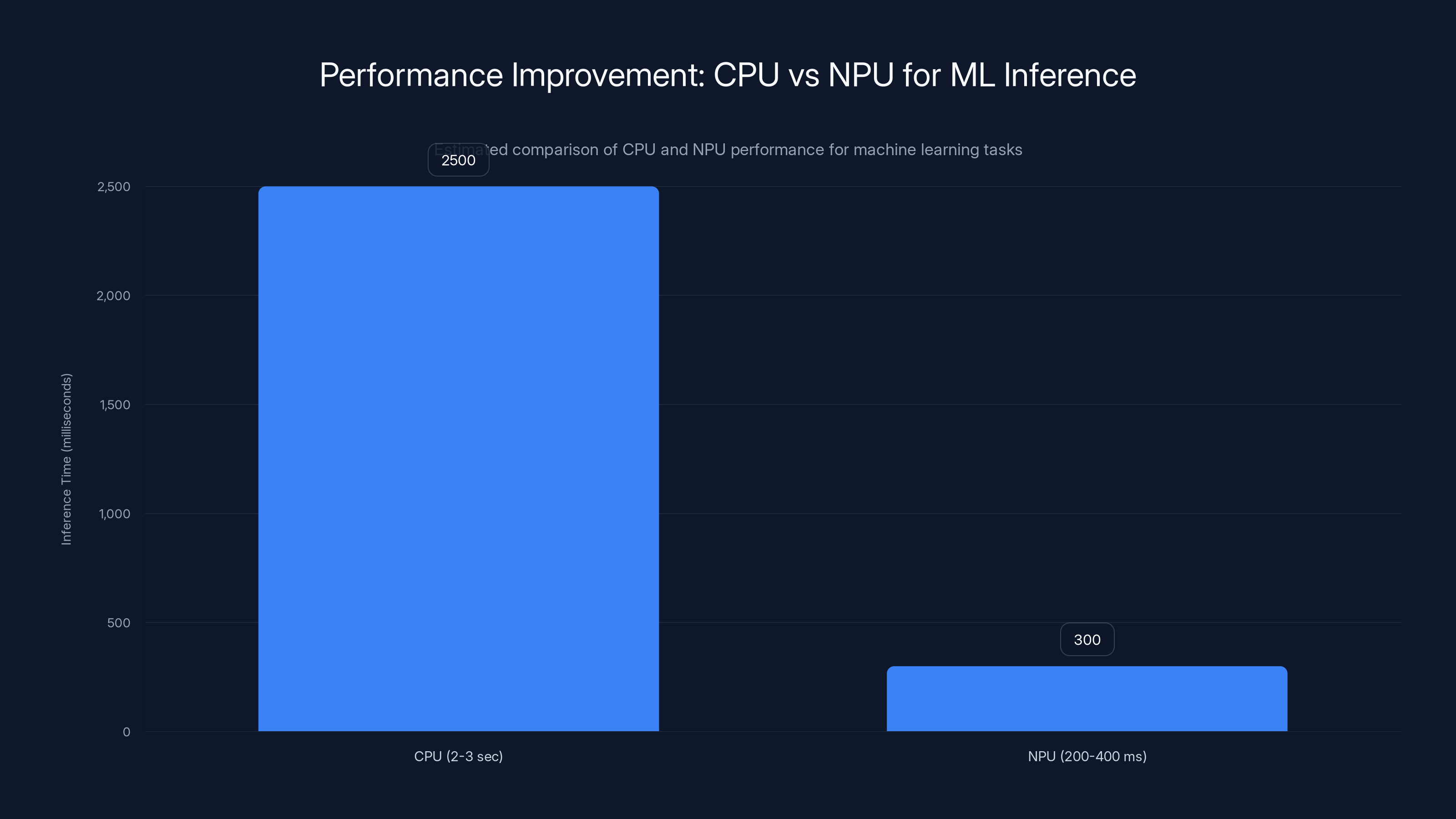
Estimated data shows NPUs significantly reduce inference time from 2-3 seconds on CPUs to 200-400 milliseconds, enhancing responsiveness for AI tasks.
Mini PCs: The Unexpected Driving Force Behind AI PC Adoption
Why Mini PCs Are Growing Faster Than Anyone Expected
Here's something that surprised the industry: mini PCs are the form factor that's driving adoption more aggressively than traditional laptops or desktops. This wasn't obvious. Most people assumed the AI PC story would be dominated by the traditional laptop market—that made intuitive sense. But the actual data tells a different story.
Mini PCs are growing faster than laptops, faster than traditional desktops, and faster than tablets. The reasons are fundamental, and they explain a broader shift happening in how people actually work.
For years, the computing landscape seemed locked into three tiers: notebooks (portable but with trade-offs on performance), desktops (maximum performance but no mobility), and tablets (portable but limited capability). Mini PCs occupy a fourth space that didn't previously make sense. They're small enough to sit on any desk without dominating the space. They're compact enough to move between offices easily. They deliver nearly the same performance as a full-size desktop. And with modern wireless peripherals, the cable tangle that used to be necessary is gone.
That fourth tier suddenly became extremely valuable post-pandemic, when hybrid work became the norm. Workers needed to be productive in office and at home, but didn't want to maintain two full desktop setups. Mini PCs solved that problem elegantly. Take your mini PC from office to home, drop it on a desk, connect to peripherals you already have, and continue working. No performance compromise. No setup hassle.
But there's a deeper reason mini PCs are accelerating specifically in the AI era: they're small enough to make people feel comfortable putting genuine computing power on their desks, but powerful enough that the local AI processing actually matters. A laptop with an NPU running local AI is interesting. But a mini PC with an NPU running local AI workloads while connected to a larger display, better speakers, and professional peripherals? That's a complete productivity system.
The Performance-to-Size Equation
When you look at raw specifications, modern mini PCs are delivering something previously unthinkable: you can get 85-95% of the performance of a full-size desktop in a form factor that fits in a small backpack.
This changes the decision tree for anyone buying a new system. Previously, if you needed performance, you bought a desktop and accepted the immobility. If you wanted mobility, you bought a laptop and accepted performance limitations. Mini PCs collapse that trade-off. You get mobility and performance and the ability to use a real display, keyboard, and mouse setup.
Add in local AI processing on an NPU, and the value proposition becomes even more compelling. You can run inference on large language models locally, process images or video locally, and handle data processing without any cloud connectivity. For privacy-conscious users, for people in regions with expensive data plans, for enterprise security teams—mini PCs with NPU processing become genuinely strategic hardware choices.
The form factor advantage compounds in the AI PC era. Mini PCs don't waste thermal capacity on cooling a large chassis—all that cooling power goes to the processor and NPU. The power efficiency is excellent because everything is tightly integrated. The upgrade path is often better because you're not locked into a laptop's form factor constraints.
Desktop Replacement or Supplemental System?
Here's where the market data gets interesting. Mini PCs aren't necessarily replacing traditional desktops wholesale. Instead, they're replacing laptops in many workflows and supplementing desktops in others.
For professionals who work remotely or travel frequently, a mini PC becomes your complete computing setup. You don't carry a laptop. You carry the mini PC and a lightweight peripherals kit. On-site, you connect to an external display and peripherals. At home, you connect to a different external display and peripherals. Everything stays in the cloud or on the mini PC itself—nothing sits on local laptops that get left behind.
For desk-based workers, mini PCs are becoming supplemental systems. Your primary compute stays at your desk (the mini PC setup), but you can also work on secondary tasks using a tablet or laptop when away from the office. This distributes compute in a way that previous generation hardware made inefficient, but modern form factors make elegant.
The key insight: mini PCs work best when you have control over the entire setup. Someone buying a mini PC is usually making a deliberate choice about their desk arrangement. They're not trying to force a compromise like laptop users typically do. They're not locked into software licensing assumptions like traditional desktop buyers. They're building out a computing system deliberately.
That deliberate approach appeals especially to people who care about AI capabilities, because local AI processing benefits enormously from being able to configure your entire system around that workload. You want specific NPU support, enough RAM, fast storage, and cooling capacity. Mini PCs make those choices straightforward.
The Hardware Foundation: Neural Processing Units and What They Actually Enable
From Promise to Performance: How NPUs Finally Matured
Neural Processing Units have been a buzzword in computing since around 2017. Every processor manufacturer claimed their NPU was the future. And technically, they existed. But for years, they were marketing fiction—hardware that existed but had almost no software that could use it effectively.
That changed somewhere around 2023-2024, when two things happened simultaneously. First, the instruction set maturity reached a critical point. Modern NPUs support a broad enough range of operations to handle real machine learning inference workloads without constantly falling back to the main CPU. Second, software frameworks caught up. TensorFlow, PyTorch, and newer frameworks could compile models to run efficiently on actual NPUs instead of requiring custom optimization work.
The performance improvements are substantial once you're actually using them. A machine learning inference task that takes 2-3 seconds on the main CPU might complete in 200-400 milliseconds on the NPU. That difference matters enormously. It means local AI processing feels responsive. It means you can run things like real-time video effects, on-device language models, or image processing without the constant latency that would otherwise make the experience painful.
But here's the nuance that matters: not all workloads benefit from NPU processing. Simple inference tasks on small models? Absolutely, NPUs win decisively. Complex, branching inference chains? Sometimes the main CPU is better because modern CPUs have more sophisticated control flow handling. Mixed workloads that switch between different types of operations? Often a cooperative approach works best, where the main CPU handles coordination and the NPU handles the actual neural operations.
This is why software maturity is the actual bottleneck, not hardware capability. The hardware is capable enough. What's needed is sophisticated software that understands when to use NPU processing versus CPU processing, how to keep data flowing efficiently between them, and how to handle the different data type requirements of each.
Privacy and Latency: The Local Processing Revolution
Two benefits of local NPU processing are creating genuine competitive advantage for AI PCs, and they're not the ones you see in marketing material.
Privacy first. When you run inference locally on your machine's NPU, your data never leaves your machine. It doesn't go to cloud servers. It doesn't get stored in any database. It doesn't get logged for training future models. For users handling sensitive information—financial data, health records, proprietary business information, anything personal—local processing isn't just a convenience, it's a legal and ethical requirement.
This matters more in 2026 because more applications are using AI for core workflows. If your email client runs a spam filter using AI, that spam filter trained on your email data is a privacy concern if it's cloud-based. If it runs locally on your machine's NPU, it's completely private. Same with document analysis, image editing, or anything that touches personal information.
Latency second. Cloud-based AI has inherent latency. Your data has to go to the server, be processed, and come back. That's typically 100-500ms of round-trip time at minimum, often more. Local processing on an NPU might be 50-200ms, and more importantly, it's consistent and doesn't depend on network conditions. For interactive applications—design tools, video editors, anything with real-time feedback—that latency difference is the difference between an intuitive tool and a frustrating one.
These aren't marginal benefits. They're foundational advantages that make local AI processing essential for certain applications, rather than optional optimization.
The Thermal and Power Efficiency Story
One thing most marketing materials get wrong about NPU processing is the power efficiency narrative. They make it sound like NPUs are magical and use almost no power.
That's misleading. NPUs are power efficient relative to the main CPU for the same task. They use less power than running the same inference on general-purpose cores. But they still use meaningful power. Running heavy inference workloads continuously on an NPU will impact battery life on mobile devices, and will impact thermals on laptops and mini PCs.
However, power efficiency is relative. If your main CPU would drain a laptop battery in 2 hours running a heavy workload, and your NPU can do the same work with 70% less power, suddenly the laptop runs for 3+ hours. That's the actual value proposition. Not "NPUs use no power," but "NPUs use less power than the alternative."
For mini PCs and desktops with consistent power supply, this matters less. But the thermal aspect matters significantly. A desktop or mini PC can incorporate its NPU into overall thermal design. If the NPU is producing heat, you're already accounting for it in your cooling solution. The power efficiency benefit here is that you can handle more compute without more heat generation, which means you don't need massive cooling solutions.
This becomes relevant when you're talking about running multiple workloads in parallel. On a laptop, everything competes for the same thermal budget. On a mini PC with integrated NPU and proper thermal management, you can have the main CPU doing one task while the NPU handles another without either one overheating. That's where the form factor advantage of mini PCs really shines in the AI PC era.
By 2026, AI PCs are projected to make up 50% of the market, highlighting the importance of developing applications that support both AI and traditional PCs. Estimated data.
The Software Ecosystem: Why Experiences Drive Adoption More Than Specifications
Microsoft Copilot and the Baseline Experience
When Microsoft integrated Copilot deeply into Windows in 2024, it marked a turning point. Suddenly, "AI PC" wasn't just a specification. It was an actual feature people could use. You open Copilot, you ask questions, you get answers. It was available, it worked, and it required no configuration.
That baseline experience matters enormously for adoption. Before Copilot integration, an AI PC was something you owned but never actually used. The AI capabilities existed, but accessing them required opening a web browser, logging into a service, and paying for API credits. Most people didn't bother. The friction was too high relative to the value.
Copilot changed that equation. The experience is now built into the operating system. It's free (as a baseline—premium features cost money). It's always available. It works with your local files and settings. Crucially, it works partially offline for basic tasks, though it still connects to cloud services for complex operations.
For 2026, the Copilot experience is expected to deepen considerably. More capabilities shifting to local processing on the NPU. More integration with third-party applications. Better context awareness because more apps share data with Copilot. It becomes the obvious next step after the taskbar and system settings in terms of things you interact with on your machine.
The key insight: Copilot isn't necessarily the AI experience that will matter most long-term. Instead, it's the proof point that AI can be integrated into computing experiences seamlessly. It's showing developers that AI integration is viable. It's showing users that AI capabilities are practical, not theoretical. That's driving developer investment in other applications.
Third-Party Applications Getting Serious About AI Integration
While Microsoft is integrating Copilot systemwide, the real explosion is happening in third-party applications. Productivity suites are adding AI-powered writing assistants. Design tools are adding generative image capabilities. Video editors are adding AI-powered effects and corrections. Spreadsheet applications are adding predictive analytics.
Most of these features currently require cloud connectivity. But the architectural groundwork is being laid for local NPU processing. Developers are building applications with the assumption that some AI workloads will eventually run locally. They're not all migrating to local processing in 2025 or early 2026, but they're building the infrastructure to make that transition straightforward.
This is where the crossover point becomes self-reinforcing. In 2025, these features work fine running on cloud services for most users. But in 2026, when millions of users suddenly have AI PCs with local NPU processing, developers will start publishing optimized versions. "Now 10x faster with local AI processing" becomes a feature differentiator. Early adopters of local processing will see real benefits. That attracts more users to buy AI PCs specifically for those applications.
Enterprise applications are taking this seriously. Security software, data management tools, business intelligence platforms. These applications handle sensitive data that enterprises are reluctant to send to the cloud. Local AI processing on an NPU is incredibly valuable. It means the AI features the vendor wants to add—anomaly detection, threat analysis, pattern recognition—can run entirely on the customer's hardware.
This is less visible than consumer applications, but potentially more important for driving adoption. IT departments buying enterprise hardware are increasingly specifying AI PC capabilities because the business applications they deploy can actually use them.
Developer Tools and Frameworks Finally Maturing
For developers to build applications that use local AI processing, they need the right tools. And for years, those tools didn't really exist. You could technically write code to invoke an NPU, but it required low-level programming, had platform-specific quirks, and offered limited performance gains because the software overhead was substantial.
That's changing in 2025-2026. Frameworks like TensorFlow and PyTorch now have NPU backends that make deploying models much more straightforward. Development tools provide NPU optimization as an explicit step in the build pipeline. Performance profiling tools can show developers exactly which workloads benefit from NPU acceleration and which don't.
More importantly, higher-level frameworks are abstracting away the NPU complexity. You don't necessarily need to know the specific NPU architecture. You write code targeting a standard interface, and the framework figures out how to optimize it for the available hardware. This dramatically lowers the barrier to entry for developers.
By 2026, expecting an application to "just work" on AI PCs with local NPU processing becomes reasonable. Developers aren't all going to build native NPU code—many will use cloud APIs. But the ones who do build locally will have mature tooling, clear examples, and established best practices to draw on.
Understanding Local AI Models: What Actually Runs on NPUs
The Model Landscape: From Gigantic Cloud Models to Compact Local Models
When people think about AI, they often think about the largest possible models. GPT-4 with 1+ trillion parameters. Or Llama with 70+ billion parameters. These models are extraordinarily capable, and they require data centers to run effectively.
But local NPU processing is suited to a very different category of models: compact models optimized for efficient inference. These aren't smaller versions of the huge models—they're different architectures altogether, designed from the ground up for deployment on consumer hardware.
Think models with a few million parameters rather than billions. They're not "general purpose" AI assistants. They're specialized. A model trained specifically to understand financial documents. Another trained specifically for image classification on medical scans. Another trained specifically for natural language processing in specific domains.
These models can run in milliseconds on an NPU. They use very little memory. They don't need constant cloud connectivity. They can be updated or customized locally. For enterprise applications particularly, they're genuinely more valuable than connecting to a massive general-purpose model.
This is where the economics of 2026 get interesting. Right now, if you want AI capabilities in your application, you typically connect to an API. That costs money per request, requires network connectivity, and creates potential privacy issues with sensitive data. In 2026, you're increasingly going to see applications ship with a local model compiled for local NPU processing. No API costs. No network dependency. No privacy concerns. Just instant local inference.
The model quality story is important to understand realistically. A compact model optimized for local inference won't be as generally capable as a massive cloud model. But it can be orders of magnitude better at specific tasks because it's specialized. It's the same reason a car is worse than a truck at hauling cargo, but better at commuting. Different tool for different jobs.
Model Compression and Quantization: The Engineering Behind Local AI
Getting a model small enough and fast enough to run locally on an NPU requires significant engineering work. This isn't transparent to end users, but it's happening constantly.
Quantization is the primary technique. Most AI models are trained using 32-bit or 16-bit floating point numbers. But NPUs can often work with 8-bit or even lower precision numbers without significant accuracy loss. Converting a model from 32-bit to 8-bit reduces its size by 75% and makes it proportionally faster to run. The accuracy loss is often minimal—less than 1% in many cases, which is well below perceptual thresholds for applications like image classification or natural language processing.
Pruning is another technique. AI models have redundant connections. You can remove the redundant paths without much impact on accuracy. This reduces model size and computation requirements further.
Knowledge distillation is a third approach. You train a small model to mimic a large model's behavior. The small model is much faster and more efficient, while maintaining most of the original model's accuracy. This is how you get models that are genuinely useful but small enough for local inference.
By 2026, these techniques are mature and largely automated. Developers don't necessarily need deep expertise in quantization to deploy efficient models. Tools handle much of it. But understanding that these trade-offs exist—that "smaller model" often means "less general capability, more task-specific focus"—is important context for why local AI models and cloud AI models coexist rather than one replacing the other.
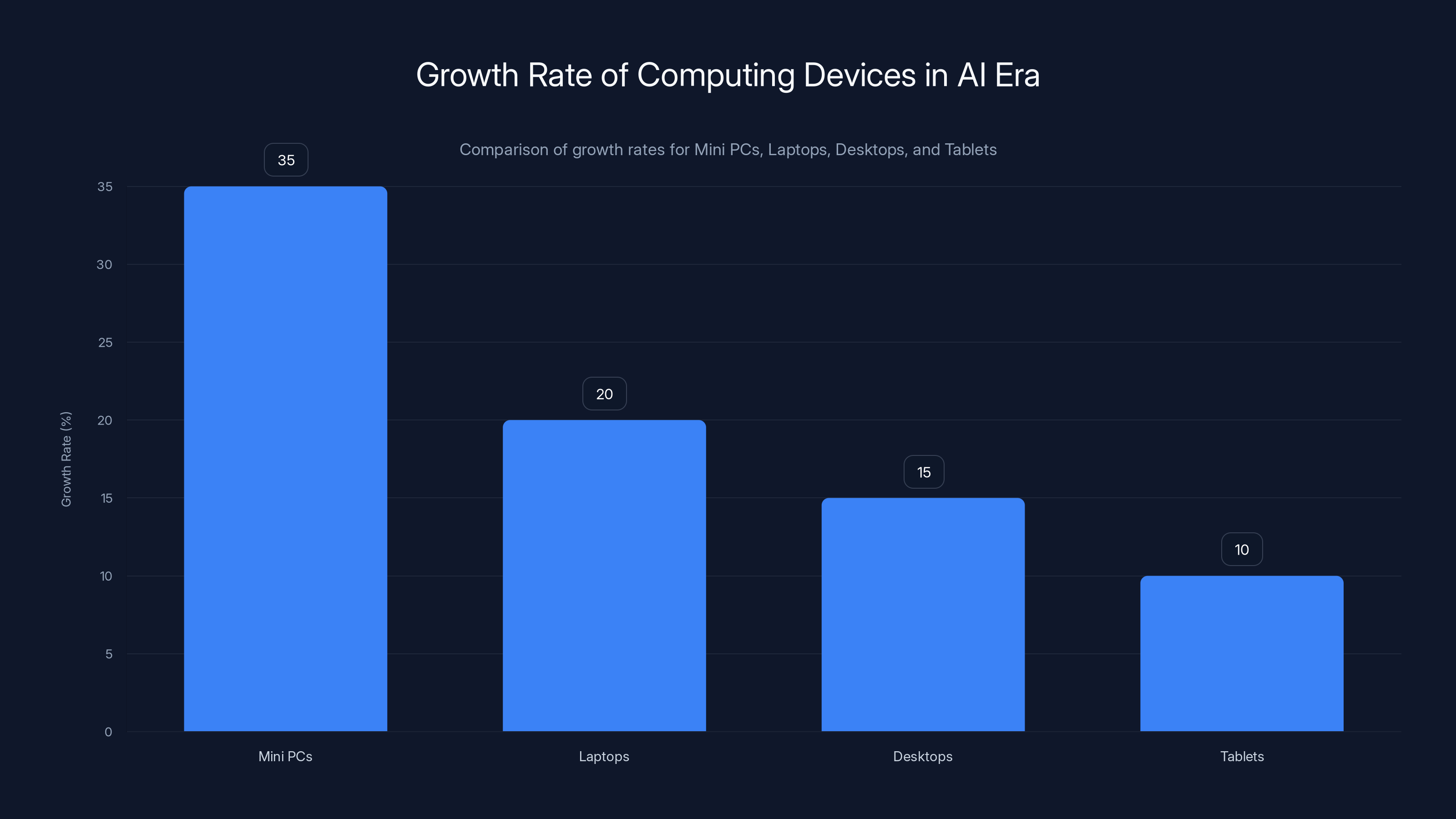
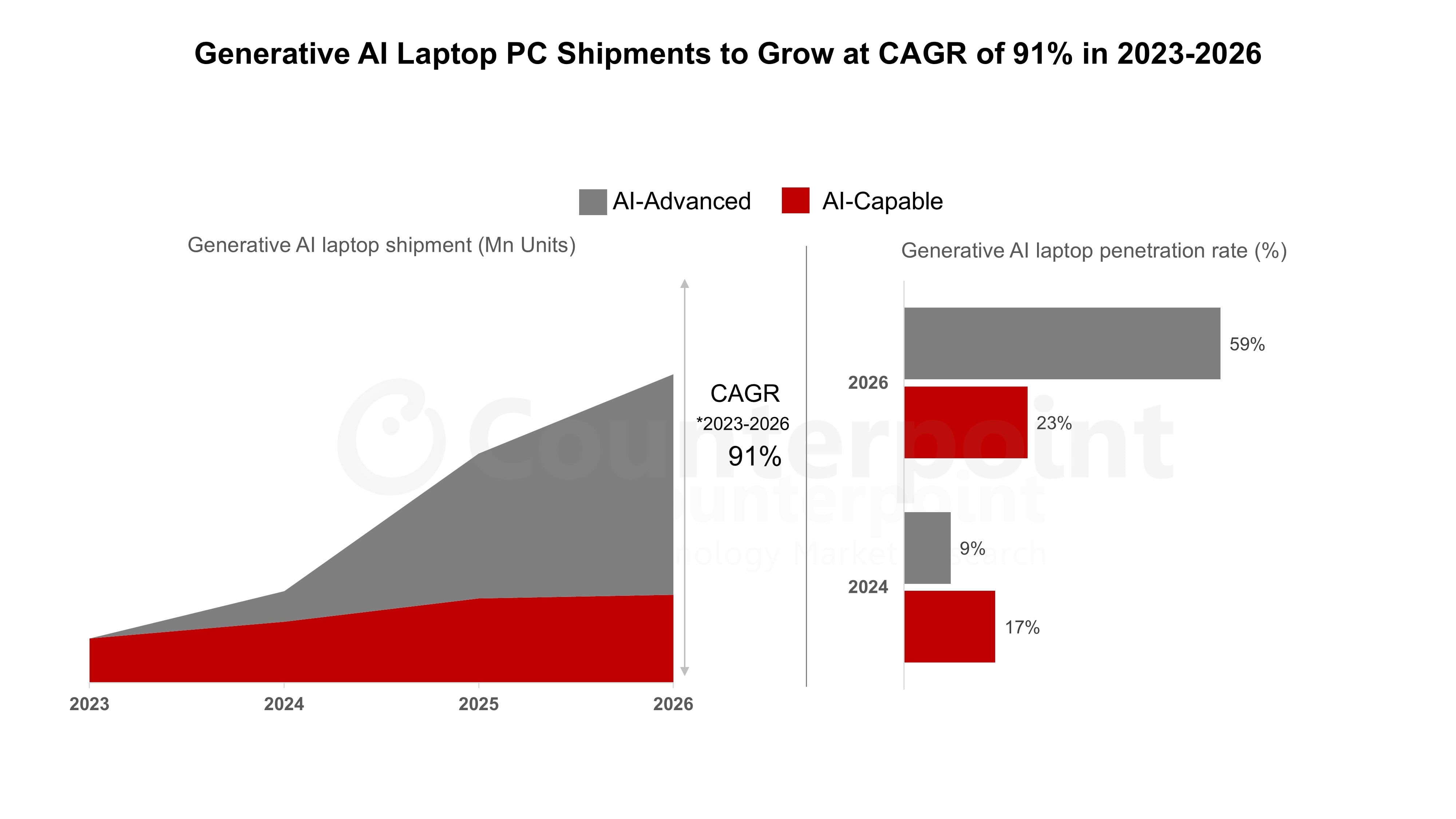
Mini PCs are experiencing the highest growth rate at 35%, outpacing laptops, desktops, and tablets in the AI era. Estimated data.
Developer Considerations: How to Build for AI PCs in 2026
NPU Detection and Graceful Degradation
When 2026 rolls around and AI PCs are mainstream, developers can't assume every machine has the same NPU architecture. Even within a single vendor like AMD or Intel, there are multiple generations of NPUs with different capabilities. Add in ARM-based machines, specialized hardware accelerators, and the landscape gets complex quickly.
The approach that's emerging is NPU detection at runtime. Your application probes what hardware is available and makes decisions accordingly. If the machine has a capable NPU, you use optimized code paths that leverage it. If it doesn't, you fall back to standard CPU computation. Everything still works, but performance differs.
Graceful degradation is critical. You can't ship an application that requires a specific NPU and just fails on machines without it. That was acceptable for specialized applications in 2024-2025. It's not acceptable for mainstream applications in 2026 when AI PC adoption is climbing toward 50% of the market but hasn't reached it yet.
This means writing your application to work well on both AI PCs and traditional machines. You might have two code paths: one optimized for NPU processing, one for CPU processing. Or you might have a single code path that dynamically adapts to available hardware. Both approaches have trade-offs.
The framework you choose for AI integration matters significantly here. Higher-level frameworks often handle hardware detection and fallback automatically. Lower-level frameworks give you more control but require more careful engineering to handle different hardware configurations.
Data Preparation and Model Serving
Getting a machine learning model from research to production is never straightforward, but local NPU deployment adds specific constraints.
Your model needs to be in a format that your NPU and its associated software stack can actually execute. This sounds obvious, but it's where much complexity lurks. A model trained in PyTorch might need conversion to ONNX format, then potentially to another vendor-specific format, before it can run on a specific NPU. Each conversion step introduces potential for bugs or performance degradation.
Data preparation is equally critical. An NPU might require input data in a specific format or range. Your image data needs to be resized, normalized, and formatted correctly. Any mismatch and your inference fails or produces garbage output. This often isn't obvious until you test on actual hardware.
Model serving—the infrastructure around executing the model—is often where developers stumble. You need to handle concurrent requests to your model while respecting resource constraints. If your NPU can only handle one inference at a time, concurrent requests need to be queued. If your NPU can handle multiple inference tasks in parallel, you need to partition the workload appropriately. This requires actual testing on target hardware, not just theoretical analysis.
Optimization Workflows and Performance Profiling
Building for NPUs requires different profiling and optimization approaches than traditional CPU or GPU optimization.
You need to measure where time is actually being spent. Is it the data transfer to the NPU that's slow? Is it the actual inference? Is it post-processing? Are you bottlenecking on memory bandwidth or computation?
Different bottlenecks require different optimization strategies. If data transfer is the bottleneck, you reduce the amount of data you move. If inference is the bottleneck, you optimize the model itself. If memory bandwidth is the bottleneck, you restructure your algorithm to reuse cached data more effectively.
NPU profiling tools are improving rapidly in 2025-2026, but they're still not as mature as CPU profiling tools. You often need vendor-specific tools. You might need to instrument your code manually. Real profiling on actual hardware is essential—simulation and theoretical analysis are not sufficient.

Enterprise Adoption: Why Businesses Are Taking AI PCs Seriously
Security and Data Privacy in Enterprise Contexts
Enterprise IT teams have been skeptical of consumer-focused AI computing because it typically involves sending sensitive data to cloud services. That's been a non-starter for many organizations. You can't send patient health records to cloud AI services. You can't send proprietary designs to cloud AI services. You can't send financial data to cloud AI services. The compliance and liability implications are massive.
Local AI processing on enterprise AI PCs changes that calculus entirely. The sensitive data never leaves the organization's hardware. The inference happens locally. The organization retains full control over the model, the data, and the results. For regulated industries—healthcare, finance, legal, government—this is transformative.
This is driving enterprise adoption faster than consumer adoption, even though enterprise technology typically lags consumer technology. The security advantage of local processing is too significant to ignore. IT teams are actively evaluating AI PC platforms specifically because they enable AI capabilities that were previously impossible to deploy in sensitive environments.
The encryption story is equally important. An enterprise can encrypt sensitive data on disk, decrypt it locally for processing on the NPU, and keep everything encrypted in memory. The NPU processing happens on decrypted data, but the overall system architecture ensures no unencrypted sensitive data ever leaves the machine. This is technically more complex than standard processing, but it's becoming standard practice in security-conscious organizations.
Productivity and Custom Application Development
Beyond security, enterprises are finding productivity value in AI PCs that justifies the hardware investment.
Consider customer service. A customer service representative using an AI-enabled system can leverage local AI processing to analyze customer inquiries in real-time, suggest relevant knowledge base articles, and draft responses automatically. If this processing happens locally, it's fast and private. If it happens via cloud API, each request costs money and introduces latency. At scale, the local processing approach is both faster and cheaper.
Consider document processing. Legal departments, financial organizations, and any organization handling large volumes of documents can leverage local AI to extract structured information from unstructured documents. Again, local processing means sensitive data stays private, processing happens instantly, and there's no per-request API cost.
Consider software development. Developers using AI-assisted coding tools benefit from local processing that understands their codebase, suggests relevant code snippets, and handles complex refactoring tasks. If the AI processing happens locally, it can leverage the developer's entire local codebase for context. If it's cloud-based, you need to explicitly upload the context, creating friction and potential security concerns.
Enterprise development teams are actively building custom applications that leverage local AI processing specifically to get these productivity benefits. As of 2025, many of these applications are still in development or pilot phases. But in 2026, when enough machines have AI capabilities, they're going into production.
Hardware Specification and Procurement
Enterprise IT teams typically specify hardware based on specific workload requirements. You buy servers, desktops, and laptops configured for the work your team does.
In 2025-2026, AI PC specifications are becoming standard enterprise configurations. When IT teams procure new desktops or laptops, they're increasingly specifying machines with capable NPUs, sufficient RAM to run local inference workloads, and fast storage for model caching.
This isn't happening uniformly across all organizations. But it's happening in organizations that have identified productivity use cases for AI. Finance teams. Customer service organizations. Development teams. Marketing teams doing content creation. Legal teams doing document analysis.
The interesting wrinkle is that enterprise procurement often lags consumer availability. It takes time for organizations to test hardware, deploy it, train users, and handle inevitable support issues. A technology that's mainstream consumer hardware in 2026 might not reach widespread enterprise deployment until 2027-2028. But the decision-making is happening now.

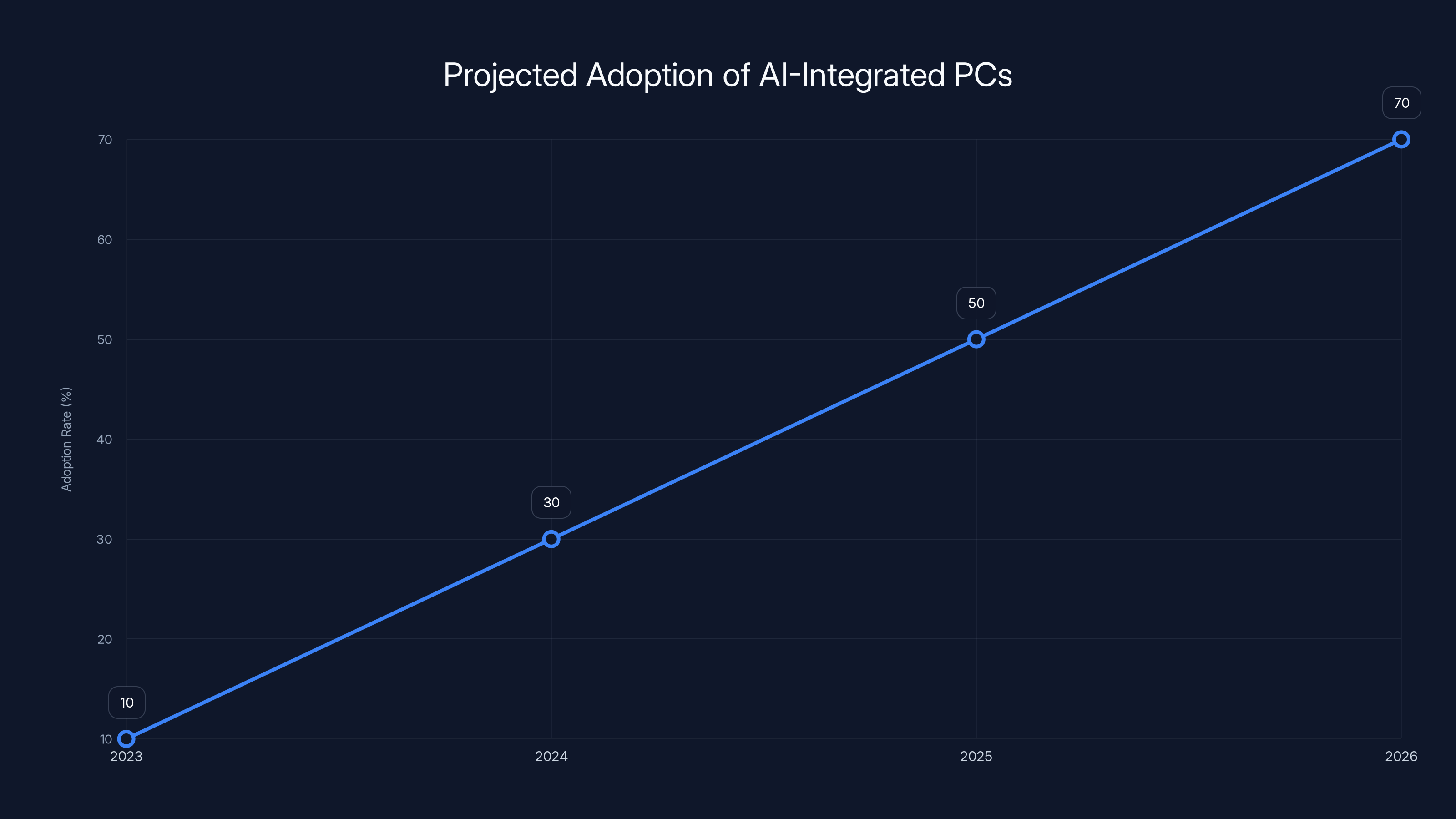
The integration of AI like Microsoft Copilot is projected to significantly increase the adoption of AI-integrated PCs from 2023 to 2026. Estimated data.
The Competitive Landscape: AMD, Intel, and Nvidia's Roles in 2026
AMD's AI PC Strategy and Ryzen AI Architecture
AMD entered the AI PC market with Ryzen AI processors, integrating NPUs directly into mainstream consumer and business processors. The strategy is straightforward: make AI capabilities standard in every processor, rather than optional or specialized.
Ryzen AI NPUs support a broad range of inference workloads and are designed with reasonable power efficiency. AMD's focus is on making AI processing accessible without requiring specialized developer knowledge. Their software stack and optimization tools are targeted at making it straightforward for developers to use the NPU.
The competitive advantage for AMD is integration. Because the NPU is on the same die as the CPU, the memory bandwidth between them is very high and latency is very low. This enables workloads that require frequent data movement between CPU and NPU to perform well. For complex inference chains that involve CPU and NPU working together, this is significant.
For 2026, AMD is expecting massive Ryzen AI volume because the processors are shipping in mainstream laptops and desktops. They're not a premium feature—they're the default. This gives AMD a volume advantage that's valuable for driving software ecosystem development.
Intel's Arc and Iris XE AI Processing
Intel's approach is similar in some ways—integrate NPU capabilities into mainstream processors—but their execution timeline has been different. Intel's AI processing capabilities shipped in their latest generation processors but with a different architecture and software stack compared to AMD.
Intel is investing heavily in software frameworks and developer tools to make their AI processing capabilities accessible. Their Arc ecosystem tools are sophisticated, and their commitment to standardizing on ONNX and other cross-platform formats is reducing vendor lock-in.
The competitive dynamic between AMD and Intel on AI processing is actually healthy for the ecosystem. Because they have different architectures, developers are forced to build applications that work across different platforms. This creates more robust software. Whoever wins the market share battle, the winner is probably the software ecosystem that's forced to be more platform-agnostic.
Nvidia's DGX Spark and Premium Positioning
Nvidia's approach is different. Rather than compete for the mainstream consumer market with integrated NPU solutions, Nvidia is positioning their discrete mini PCs and specialized AI hardware for users who need maximum capability.
DGX Spark is a mini PC that combines Nvidia GPUs with Nvidia's software stack. It's not cheap—it's positioned as premium hardware for professionals who need maximum AI computing capability. The target market is different: researchers, developers, and professionals doing heavy AI workloads.
This actually complementary to AMD and Intel's approach. The consumer market with integrated AI processing goes one direction. The premium professional market with discrete AI accelerators goes another. Both can thrive without directly competing.
However, Nvidia is also shipping integrated AI processing in ARM-based processors through their acquisition of ARM holdings and continued development of ARM ecosystem. This creates interesting competitive dynamics in emerging markets and specific segments where ARM dominates.
The interesting wild card is that Nvidia's software ecosystem—CUDA—has been the industry standard for AI development for over a decade. Even as AMD and Intel add NPU capabilities, developers often prefer writing code for CUDA because it's familiar and well-optimized. This creates a software moat for Nvidia that's separate from their hardware market share. Watch for 2026-2027 to see whether CUDA dominance persists even as AMD and Intel gain hardware market share.

Use Cases Coming to Life in 2026
Creative Professionals and Real-Time Effects
Design software, video editors, and creative applications have been the early adopters of AI because the use cases are obvious and compelling.
A video editor using local AI processing can render complex effects in real-time. Traditional rendering is slow—you make changes, wait for the renderer, see the result. With local AI processing, effects render instantly, making the creative workflow much more intuitive.
Image editors can use local AI for things like intelligent object removal, background replacement, and style transfer. Again, when these operations happen locally, they feel instant and responsive rather than requiring a cloud round-trip.
Design tools can use local AI to understand design intent, suggest color palettes, recommend layout adjustments, and assist with repetitive design tasks. All of this is more valuable when it happens locally because it can be context-aware and responsive.
In 2026, expect a wave of creative application updates adding local AI support. Not just as nice-to-have features, but as core workflow enhancements.
Knowledge Workers and Productivity Augmentation
People who work with documents, data, and information are getting some of the first practical AI benefits from local processing.
A knowledge worker can leverage local AI to automatically categorize documents, extract structured information, summarize content, and find relevant information across large document collections. Traditional approaches require sending sensitive documents to cloud services. Local processing makes the approach viable.
Spreadsheet and database users can leverage local AI to identify patterns in data, predict values, suggest relevant calculations, and automate repetitive data preparation tasks. Again, local processing means the organization's data never leaves their control.
People writing reports, proposals, and documents can leverage local AI for suggestions on structure, tone, clarity, and completeness. This is particularly valuable for people writing in non-native languages or for audiences they're unfamiliar with.
In 2026, expect mainstream productivity applications to start shipping with these capabilities turned on by default for users with AI PC hardware.
Software Developers and Development Tools
Software developers using AI-assisted development tools (GitHub Copilot, JetBrains AI Assistant, etc.) are getting significant productivity benefits. But these tools often run on cloud services, which creates latency and costs.
Local AI processing enables offline development. If your AI development assistant has relevant code context, it can generate suggestions without cloud connectivity. This is valuable for developers working on sensitive code, developers in areas with unreliable internet connectivity, and simply for the speed improvement of not needing cloud round-trips.
Test generation, documentation generation, and code refactoring are all candidates for local AI processing. These tasks work well when the AI system has full context about the codebase, which local processing provides naturally.
In 2026, expect development tools to offer local AI processing options alongside cloud-based options. Developers will choose based on their specific needs.
Data Analysis and Business Intelligence
Data analysts and business intelligence professionals work with large datasets and need to derive insights quickly. This is another area where local AI processing is valuable.
Local AI can help identify relevant patterns in data, suggest appropriate visualizations, recommend statistical analyses, and help generate narratives describing what the data shows. If the analysis happens locally, it's fast, it's private, and it can incorporate the analyst's full understanding of the data's context and limitations.
Data scientists can use local AI for initial exploration and prototyping before moving to larger cloud-based systems for serious computation. This speeds up the iteration cycle.
In 2026, expect business intelligence and analytics tools to start integrating local AI capabilities for initial data exploration and analysis.

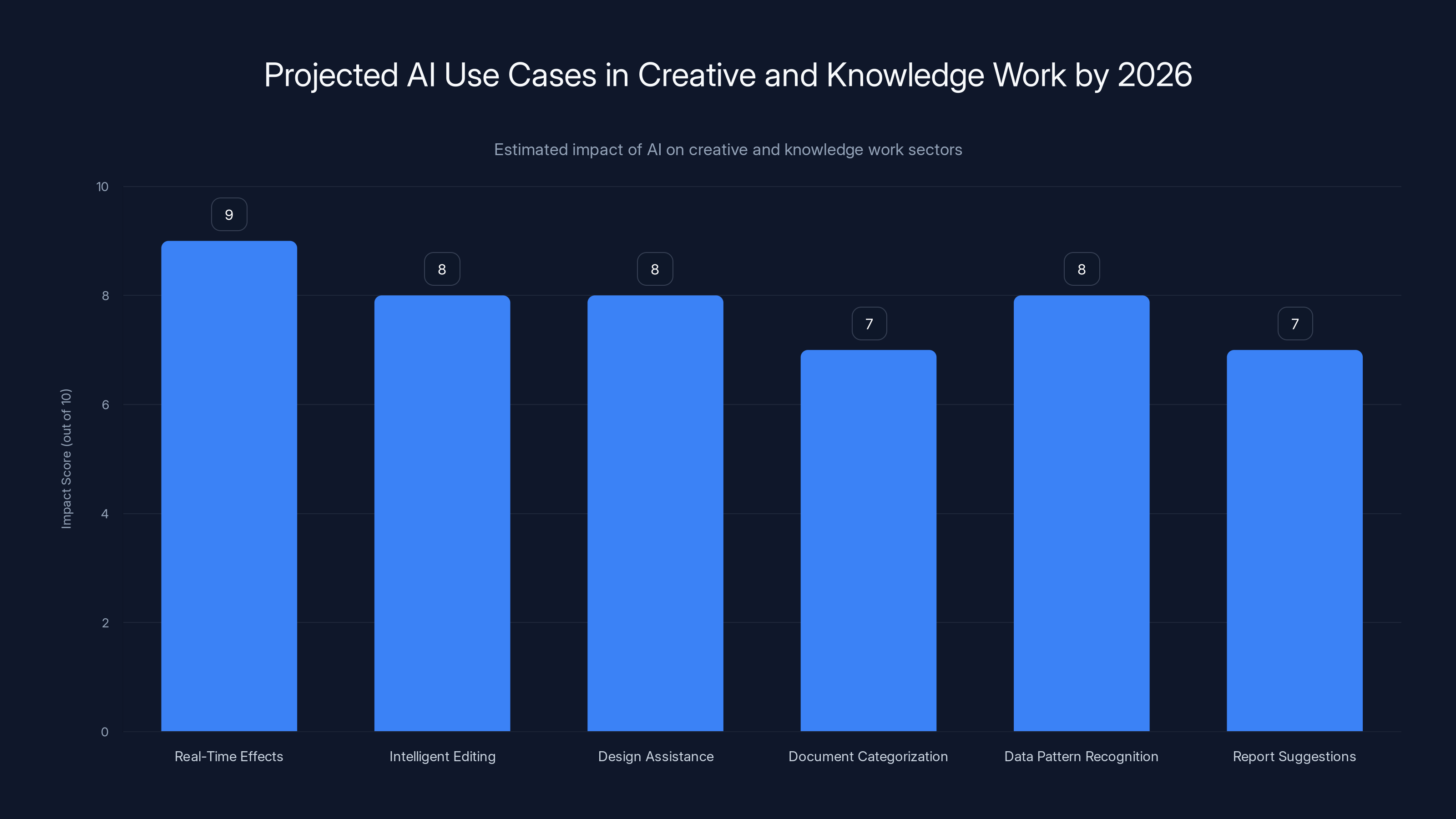
Estimated data suggests that real-time effects and intelligent editing will have the highest impact on creative professionals by 2026, with scores of 9 and 8 respectively.
Challenges and Realistic Limitations of AI PC Adoption
The Reality of Model Quality and Limitations
While local AI processing is powerful, it's important to be realistic about its limitations. Compact models optimized for local inference are not as generally capable as large cloud-based models. They're specialized and task-focused.
For tasks they're designed for, they excel. For unexpected use cases, they often fail gracefully or produce mediocre results. This is a trade-off: better performance and privacy for specific tasks, versus flexibility and capability for general-purpose tasks.
Developers need to manage user expectations carefully. If your user expects general-purpose AI assistance, a locally-running specialized model is going to disappoint. But if your user has specific, well-defined tasks they need AI assistance with, local processing can be superior.
This also means developers need to carefully evaluate whether local AI processing is actually beneficial for their use case, or whether they're just adopting it because it's trendy. Not every application benefits from local processing. Cloud-based AI makes more sense for some tasks, despite the latency and cost implications.
Integration Complexity and Software Maturity
Integrating local AI processing into applications is getting easier, but it's still not trivial. You need to handle model deployment, updates, versioning, and fallback strategies when hardware doesn't support local processing.
Models can be surprisingly large. Even compressed models might be 50MB to several hundred MB. This creates challenges for application distribution, update management, and storage concerns on constrained devices.
Different NPUs have different characteristics. Optimizing for one NPU might make your application slower on another. Cross-platform optimization is non-trivial.
These are solvable problems, but they require engineering sophistication. In 2026, some applications will handle these challenges well. Others will have rough edges. Users will notice the difference.
Privacy Claims vs. Reality
One of the big selling points of local AI processing is privacy. Your data stays on your machine. This is true, but it's not the complete picture.
First, other applications on the same machine can potentially access the data. If your AI processing app handles sensitive data in memory, another app on your system might be able to read it. This requires system-level security (proper memory isolation, which modern operating systems provide), but it's not automatic.
Second, operating system telemetry and updates can potentially expose data. Windows Update, macOS Security Updates, and Linux package management all involve system-level access. A sophisticated attacker could potentially extract data. For most users and most threat models, this is theoretical. But for organizations handling extremely sensitive data, the concern is legitimate.
Third, the model itself might encode information about its training data. If your local model was trained on sensitive information, that information might be recoverable from the model weights through inference attacks. This is a known concern in machine learning security.
None of this invalidates the privacy benefits of local processing. But it means privacy is a spectrum, not an absolute. Local processing is vastly more private than cloud processing for most use cases, but it's not perfectly private.
Vendor Lock-In and Ecosystem Fragmentation
Without standardization, local AI processing could become fragmented, with different vendors supporting different models, frameworks, and hardware capabilities.
The ONNX format is helping with this—it's a vendor-neutral format for machine learning models. But not everything supports ONNX yet, and ONNX itself doesn't guarantee portability across all platforms.
Developers might find themselves building separate code paths for AMD NPUs, Intel NPUs, Nvidia GPUs, and potentially ARM-based processors. This is similar to the fragmentation that happened in the GPU computing space before CUDA dominated, and it creates friction that slows adoption.
The industry seems aware of this risk. Major players are investing in standardized frameworks and cross-platform compatibility. But fragmentation is a real possibility if those efforts don't succeed.

The Competitive Advantage Shift: From Hardware to Software
Why Margin Wars Are Coming to AI PC Hardware
When a technology crosses into mainstream adoption (which is what the 2026 crossover point represents), hardware features become commoditized. This has happened in every computing transition: smartphone processors, GPU computing, cloud infrastructure.
In 2025-2026, there's still meaningful differentiation between different vendors' NPU implementations. But by 2028-2029, the performance and capability differences will compress. The competitive advantage will shift from hardware specifications to software ecosystem.
This means hardware margins compress. Vendors competing primarily on raw NPU performance will see their advantages erode as competitors catch up. But vendors with strong software ecosystems, developer tools, and software partnerships will maintain pricing power.
Intel learned this lesson in CPUs: processor performance only matters if the market cares about performance. When performance is "good enough," other factors dominate. AMD is learning this with their Ryzen processors. Nvidia learned the opposite lesson: when you have CUDA dominance, hardware can stay premium.
For AI PCs, watch to see which vendor (or vendors) builds the strongest software ecosystem. That's likely to be the long-term winner, regardless of who has the best hardware in 2026.
Developer Ecosystem as Competitive Moat
This is why both AMD and Intel are investing heavily in developer tools and software frameworks. Whoever builds the most productive developer ecosystem wins long-term, not the hardware race.
A developer who learns to optimize for AMD's NPU infrastructure is likely to continue optimizing for AMD. Not because they're locked in, but because they've invested in learning the architecture, building tools, and establishing best practices. Switching to Intel's infrastructure means relearning everything.
This is why Nvidia's CUDA dominance is so powerful in cloud AI. Not because CUDA's hardware is necessarily the best, but because developers know CUDA, prefer CUDA, and have invested their expertise in CUDA. Hardware alone can't displace that.
For consumer AI PCs, the developer ecosystem is still forming. Whoever wins the developer mindshare in 2026-2027 is likely to maintain dominance well into the 2030s.

Predictions and Trends for AI PC Evolution Beyond 2026
2027-2029: The Consolidation Phase
Once AI PC adoption crosses the 50% threshold in 2026, the next phase is consolidation. Vendors that can't maintain competitive positioning will exit the market or merge with others. This is normal in any mature technology.
Expect to see fewer vendors with meaningful market share by 2029. The remaining vendors will have strong software ecosystems, established developer communities, and compelling use cases. Hobbyists and niche players will either specialize (focusing on specific verticals) or disappear.
2029-2032: The Specialization Phase
As the market matures, expect increasing specialization. Generic AI PCs for general consumers will be one category. But specialized categories will emerge: AI PCs for creative professionals, AI PCs for data scientists, AI PCs for content creators, etc.
Each specialized category will have specific hardware configurations, software bundles, and optimizations for its target use case. Generic AI PCs will still exist for people without specific needs, but the most exciting developments will be in specialized categories.
The Wild Card: Breakthrough Capabilities
One thing that could accelerate adoption beyond current projections is a breakthrough capability that makes local AI genuinely necessary rather than just convenient.
Imagine if a future version of AI could do something that's impossible with cloud-based AI: real-time translation, simultaneous language processing for dozens of languages, or something we haven't even thought of yet. If that becomes possible only with local processing, adoption accelerates dramatically.
Alternatively, if privacy regulations (EU AI Act, etc.) make cloud-based AI processing significantly less viable, organizations might be forced to adopt local AI processing. Regulatory mandates can drive adoption faster than technical capability.
These aren't guaranteed, but they're possible trajectories worth considering. The 2026 crossover is based on current trajectory. But trajectories can change.

What You Actually Need to Know About AI PCs in 2026
For Consumers: Should You Buy an AI PC?
If you're considering a new computer in 2026, an AI PC is worth serious consideration. It's not premium-priced anymore. The hardware is mature and reliable. The software is actually useful, not just theoretical.
But don't buy it just for the AI features. Buy it because it's a good computer that happens to have AI capabilities. Evaluate it on the same basis you'd evaluate any computer: performance, build quality, software, support, and value for money.
If you're creative professional, data analyst, developer, or knowledge worker, the AI capabilities will probably be relevant to your work. If you're a casual user who just needs email and web browsing, the AI features are nice-to-have but not essential.
The mini PC form factor is worth special consideration if you do hybrid work or want a compact system. Mini PCs with AI capabilities are legitimately good computing platforms, not compromises.
For Developers: The Opportunity Window
If you're a developer considering building applications for local AI processing, 2026 is the window to establish expertise and build products before the space becomes saturated.
The software ecosystem is still forming. Standards are still being established. Developer who establish strong positions now will have significant advantages as the market grows.
Start small. Pick a specific use case where local AI processing genuinely solves a problem. Build for that problem. Once you've successfully shipped one application, expand to adjacent problems.
Don't try to be everything to everyone. Focus on specific use cases where local AI processing provides clear value over cloud-based alternatives. The differentiation will come from understanding your specific users' needs, not from generic AI features.
For Enterprises: Integration Opportunities
If your organization is evaluating enterprise AI capabilities, local processing on AI PCs is worth serious consideration for specific use cases.
Start with a pilot. Identify a department or team where local AI processing provides clear value: security, privacy, latency, or cost benefits. Run a pilot with that team, measure results, and iterate based on what you learn.
Don't assume local AI processing is the right answer for all use cases. Some applications genuinely work better with cloud-based AI. But for sensitive data, high-frequency processing, or low-latency requirements, local processing might be superior.
Invest in training and support. New technology requires people to understand how to use it effectively. Organizations that invest in user training and support see better adoption and better outcomes than organizations that just deploy hardware.

Conclusion: The Year Everything Shifts
When industry leaders talk about 2026 being the AI PC crossover year, they're describing a genuine inflection point. Not hype. Not speculation. But a realistic inflection point based on convergence of mature hardware, useful software, and changing market dynamics.
Three specific things need to happen for this prediction to be correct: AI PC shipments need to exceed traditional PC shipments, the installed base of AI PCs needs to create economic incentives for developers to build locally-optimized software, and the user experience of AI integration needs to be seamless enough that people forget they're using a specialized feature.
All three are on track for 2026. Hardware is ready. The installed base is approaching critical mass. The software is getting there. Mini PCs are unexpectedly catalyzing adoption by offering a form factor that neither laptops nor traditional desktops provide.
This doesn't mean AI PCs are suddenly perfect or that every user will immediately love them. Adoption curves are never vertical. But by some point in 2026, more new PCs shipped will have AI processing capabilities than won't. That crossover is the moment when the technology stops being optional and starts being expected.
For consumers, it means you'll have compelling reasons to buy an AI PC that go beyond pure marketing. For developers, it means building AI-optimized applications makes business sense. For enterprises, it means you can deploy AI capabilities in ways that were impossible before.
The year of the AI PC isn't some future promise anymore. It's 2026, and it's upon us.

FAQ
What exactly is an AI PC?
An AI PC is a personal computer with a dedicated Neural Processing Unit (NPU) designed to accelerate machine learning inference tasks locally on the device. Unlike traditional PCs that rely solely on CPUs for computation, AI PCs can offload specific workloads to the NPU, enabling faster processing, reduced latency, and the ability to run AI models without cloud connectivity. This means applications can analyze data, generate content, and perform complex computations directly on your machine while keeping your data private and avoiding internet dependency.
How does the crossover point change things for developers?
The crossover point in 2026 makes building AI-optimized software economically viable for mainstream developers. Before reaching 50% market penetration, supporting AI PC capabilities was optional—a niche optimization for early adopters. Once more machines have AI capabilities than don't, developers can justify the engineering effort to optimize for local AI processing because the potential user base becomes massive. This creates a self-reinforcing cycle where more optimized applications attract more AI PC purchases, which then justifies further optimization investments.
Why are mini PCs growing faster than traditional laptops?
Mini PCs are growing faster because they solve a problem that neither traditional laptops nor desktops perfectly address: they deliver near-desktop performance in a form factor small enough to move between office and home easily. In the hybrid work era, this combination is extremely valuable. They're compact enough to fit anywhere, powerful enough to handle demanding workloads, and flexible enough to work as a primary system or supplemental compute when combined with remote work setups. For AI processing specifically, mini PCs have excellent thermal management and power efficiency because their compact design concentrates cooling resources efficiently.
What's the difference between cloud AI and local AI processing?
Cloud AI processes data on remote servers, requiring internet connectivity and introducing latency (typically 100-500ms for a round-trip). Local AI processing using your computer's NPU processes data on your device in 50-200ms, keeps your data private, and works offline. Cloud AI excels at complex tasks requiring massive models and unlimited compute resources. Local AI excels at specific, well-defined tasks where speed, privacy, and reliability matter more than maximum capability. They're complementary, not competitive—most applications will use both strategically.
How much does local AI processing actually improve performance?
Performance improvements vary dramatically depending on the specific task. Simple image classification might be 5-10x faster on an NPU versus a CPU. Complex language model inference might be 2-3x faster. Some workloads actually perform better on the CPU because NPUs have specific architecture requirements that don't suit all computation patterns. The real benefit isn't just raw speed—it's the combination of speed, reduced latency, offline capability, and privacy. A task that feels sluggish over cloud APIs feels instant locally, which transforms the user experience even if the raw performance improvement is modest.
Are mini PCs actually powerful enough for real work?
Yes, absolutely. Modern mini PCs with high-end processors deliver 90-95% of the performance of full-size desktops. The form factor constrains them slightly on thermal capacity and component selection, but for most professional work—development, design, analysis, content creation—mini PCs are fully capable. They excel when paired with external displays, keyboards, and mice, creating a setup that's functionally equivalent to a traditional desktop but with the flexibility to move the computing core between locations easily.
Will AI PCs make traditional computers obsolete?
No. Some computing tasks don't benefit from local AI processing and don't need it. Gaming, for instance, might benefit from NPU acceleration for specific features, but NPUs aren't the primary driver of gaming performance. Large-scale data processing, simulation, and computation-intensive tasks might still require cloud compute or high-end servers. AI PCs will become the standard baseline for general-purpose computing, but specialized use cases will still drive different hardware choices.
What should developers learn in 2025 to prepare for 2026?
Developers should familiarize themselves with frameworks like ONNX, TensorFlow, and PyTorch that support NPU deployment. Understanding model quantization, inference optimization, and hardware detection is valuable. Learning how to profile applications on actual hardware to understand bottlenecks will be essential. Start small—pick a specific use case, build a prototype, measure performance, and iterate. The developers who establish expertise early will have significant advantages as the market grows and more organizations demand AI-optimized applications.
How does data security work with local AI processing?
Local AI processing is more secure than cloud-based processing because sensitive data doesn't need to leave your device. However, "local" doesn't mean "perfectly secure." Your operating system, other applications on the same machine, and sophisticated attackers with deep system access can potentially access data. For most users and most threat models, local processing is dramatically more secure than cloud processing. For organizations handling extremely sensitive data, additional security measures (encryption, hardware-level isolation, air-gapped systems) may be necessary depending on regulatory requirements and specific threat models.
What happens if my application needs to support both AI PCs and traditional computers?
This is the standard approach. You build your application to work on both AI PCs and traditional computers, with separate code paths or runtime detection to identify available hardware. If an NPU is available, you use optimized code paths. If not, you fall back to standard CPU computation. Everything still works on traditional computers, but performs significantly better on AI PCs. This approach requires careful engineering to ensure graceful degradation and to avoid false assumptions about hardware capabilities, but it's the right strategy until AI PCs reach near-universal adoption.

Key Takeaways
- 2026 is the year when AI PC shipments will exceed traditional PC shipments for the first time, marking genuine mainstream adoption rather than niche enthusiasm
- Mini PCs are unexpectedly driving AI PC adoption faster than traditional laptops because they combine desktop performance with portability ideal for hybrid work
- Neural Processing Units (NPUs) have finally matured enough to provide meaningful performance advantages for specific AI workloads without requiring specialized developer expertise
- Local AI processing eliminates cloud dependency, enabling privacy-focused applications and reducing latency for time-sensitive workloads critical in creative and enterprise environments
- The software ecosystem is the competitive differentiator—hardware features will commoditize, but developers and organizations with strong optimization ecosystems will maintain long-term advantages
Related Articles
- Salesforce's New Slackbot AI Agent: The Workplace AI Battle [2025]
- Khadas Mind Pro Mini PC: RTX 5060 Ti in 0.43L [2025]
- AI PCs Are Reshaping Enterprise Work: Here's What You Need to Know [2025]
- 7 Biggest Tech Stories: CES 2026 & ChatGPT Medical Update [2025]
- CES 2026: Complete Guide to Tech's Biggest Innovations
- AI Operating Systems: The Next Platform Battle & App Ecosystem

