![AI Solving Labor Shortage in Rare Disease Treatment [2025]](https://tryrunable.com/blog/ai-solving-labor-shortage-in-rare-disease-treatment-2025/image-1-1770388660800.jpg)
Introduction: The Rare Disease Crisis and AI's Emerging Role
There's a cruel paradox in modern medicine. We've never had better tools for understanding disease. Gene sequencing costs less than a coffee. CRISPR can edit genes with remarkable precision. We understand protein folding better than we did five years ago. Yet thousands of rare diseases remain completely untreated. Not because the science is impossible. Because there aren't enough smart people to do the work.
This isn't a philosophical problem. It's a labor crisis hiding in plain sight. The pharmaceutical industry has been optimized for blockbuster drugs—the ones that affect millions of people. Treating rare diseases, which by definition affect small populations, doesn't generate the revenue to justify hiring entire teams of specialists. When a disease only impacts 10,000 people globally, building a 200-person research division doesn't make financial sense.
But here's where it gets interesting: artificial intelligence is rewriting that equation. Instead of asking, "Can we afford to hire enough people?" companies are now asking, "What can AI do that reduces how many people we need?" The answer is reshaping biotech faster than most people realize.
At Web Summit Qatar in early 2026, executives from AI-driven biotech companies made this case clear. They weren't talking about AI as a research tool. They were talking about AI as a force multiplier that lets small teams tackle problems that previously required armies of chemists and biologists. When one AI system can perform the work of dozens of specialists, suddenly treating rare diseases becomes economically viable.
This shift matters beyond the companies building it. It means diseases that have been "untreatable" for decades might finally get attention. Patients with rare conditions who've spent their lives as medical puzzles could get real treatment options. The scarcity that made rare disease research economically invisible becomes irrelevant.
The question isn't whether AI will impact drug discovery anymore. The question is whether the industry can adapt fast enough to actually help patients.
TL; DR
- AI is automating drug discovery tasks that previously required legions of specialized chemists and biologists, enabling small teams to tackle rare diseases previously left untreated
- "Pharmaceutical superintelligence" aims to train generalist AI models to perform specialized drug discovery tasks at superhuman accuracy and dramatically reduced cost
- Gene delivery remains the bottleneck even when AI identifies promising targets; companies like Gen Edit Bio use AI-designed delivery vehicles to make in vivo gene editing practical and scalable
- Data quality and bias are critical challenges as AI models trained on Western-biased data risk missing disease patterns in other populations
- The economic model flips completely when AI reduces the per-drug discovery cost by 90%+ making rare disease drug development viable for the first time

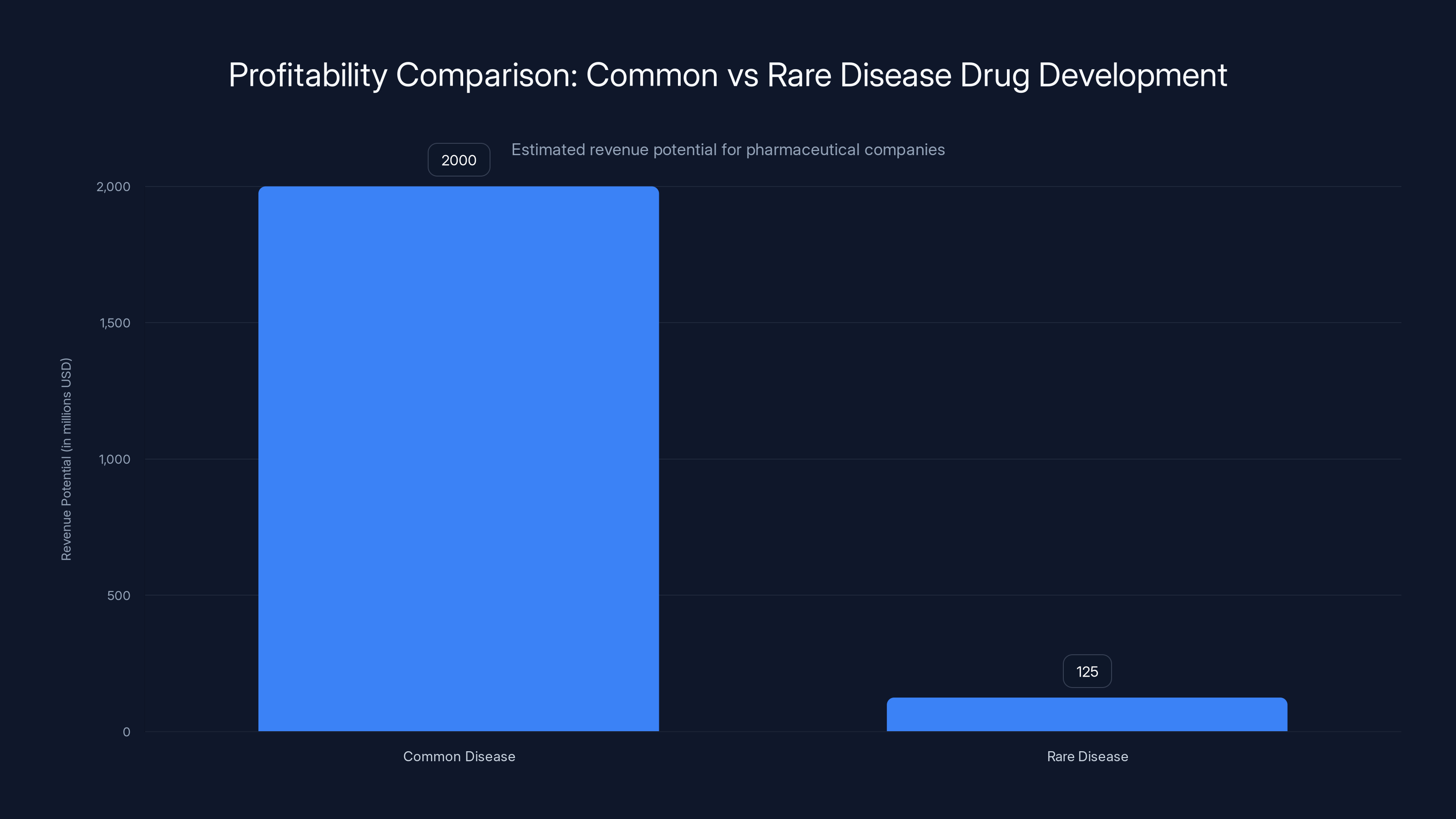
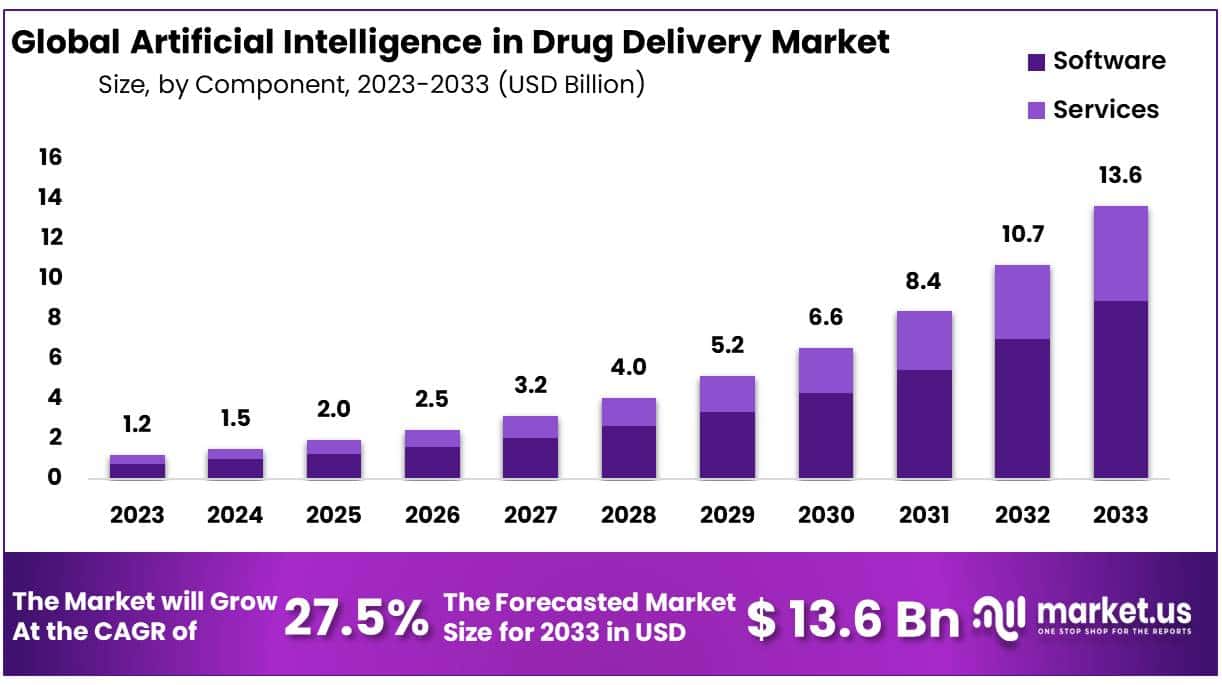
Developing drugs for common diseases is significantly more profitable, with potential revenues 16 times higher than those for rare diseases. Estimated data.
The Historical Labor Bottleneck in Rare Disease Drug Development
Understanding today's AI-driven solutions requires understanding why the problem existed in the first place. Rare diseases have always been a market failure waiting to happen.
The mathematics are brutal. Let's say you're a pharmaceutical company deciding where to allocate resources. You can either:
Option A: Develop a drug for a common condition affecting 2 million people. If successful, you'll eventually reach 10% market penetration (200,000 patients). At
Option B: Develop a drug for a rare disease affecting 5,000 people worldwide. Even reaching 50% market penetration (2,500 patients) at
The first option is 16 times more profitable. Of course that's where resources flow. That's basic business.
But there's a human cost to that calculus. The FDA recognizes this, which is why orphan drug designations exist. They offer tax credits and extended exclusivity to incentivize rare disease research. These incentives help, but they can't overcome the fundamental math when you need 50 specialized researchers for 3-5 years just to screen compound libraries.
A medicinal chemist with the skills to do this work costs
This is why rare diseases got labeled "orphan diseases." Nobody was adopting them. Not because the diseases didn't matter to patients. Because the math didn't work for companies.
Enter the data problem. Drug discovery has always been a process of testing hypotheses through experimentation. You make a compound. You test it. Most fail. The ones that show promise get refined and tested again. This process generates mountains of data. Which compounds worked? Why? What structural features seemed to matter? How did different chemical variations affect efficacy?
Historically, extracting insights from this data required humans. Pattern recognition at the molecular level needed expert intuition. It's why Ph D chemists were essential. They could look at a dataset and see patterns that automated systems missed.
That changed when machine learning got good enough to spot patterns that humans couldn't see, or to see them faster than any human could possibly work. Suddenly the bottleneck wasn't chemical knowledge. It was the ability to process information.
The economic model started to shift. If AI could do what 20 specialists did, you didn't need 20 specialists. You needed the specialists' knowledge encoded in a system, plus a few people to oversee the AI and validate results.
For rare diseases, this changes everything. The prohibitive cost structure becomes manageable. Suddenly it's worth exploring.
The AI-Driven Drug Discovery Platform: How Modern Automation Works
The first major use of AI in drug discovery isn't inventing completely new molecules from scratch. That's the dream, but it's not where the impact is coming from yet. Instead, it's automating the intelligence-intensive parts of the screening and hypothesis-generation process.
Insilico Medicine, founded by Alex Aliper, is one of the clearest examples of this approach in action. Their platform ingests three types of data simultaneously: biological data (how genes and proteins interact), chemical data (how molecules are structured), and clinical data (how different compounds affected patients in previous studies).
The system then does something that used to require entire teams to do manually. It generates hypotheses about which disease targets might be vulnerable to therapeutic intervention. Not guesses. Hypotheses grounded in data analysis across thousands of variables.
Let's break down what this actually means in practice. Say you're investigating a rare genetic disorder. The disease is caused by a mutation in Gene X that leads to overexpression of Protein Y. In the traditional model, a team of biologists would read everything published about Protein Y, research drugs that have ever affected similar proteins, and propose a handful of candidate molecules to test.
This process takes weeks or months. It's constrained by what humans remember, what papers they've read, and how quickly they can synthesize information.
With AI, you feed the system all the data simultaneously. It maps protein interactions. It identifies which molecules in compound libraries might interact with Protein Y in useful ways. It even predicts side effects based on patterns in previous clinical data. Most importantly, it does this across the entire design space—sometimes millions of possible compounds—in days instead of months.
Insilico's recent work on ALS (amyotrophic lateral sclerosis) demonstrates the practical impact. ALS is a rare neurodegenerative disease affecting about 5,000 people in the US at any given time. It's brutal. The disease progressively paralyzes patients until they can't breathe. There are only two drugs that slightly extend life by a few months.
Insilico's platform identified whether existing drugs in development for other diseases might work against ALS targets. This kind of drug repurposing work is incredibly valuable—it can take a compound that already passed safety testing and apply it to a new indication. But finding these connections normally requires reading thousands of papers and making creative leaps. The AI systematized the creative leap.
That's not artificial general intelligence. It's not magic. It's automation of the intelligence work that was the rate-limiting step.
The platform Insilico launched in 2025, called the MMAI Gym, takes this further. The aim is to train generalist AI models—the same type of large language models that power Chat GPT—to perform drug discovery tasks at the same level of accuracy as specialized models, but across multiple different tasks simultaneously.
Why does this matter? Because specialized models are expensive to build and maintain. You need a separate model for predicting toxicity, another for predicting efficacy, another for optimizing molecular properties. That's a lot of infrastructure. A single generalist model that can handle all of these tasks, trained on the corpus of pharmaceutical knowledge, is theoretically more efficient. It's also more flexible. When new information emerges, you update one model instead of retraining five.
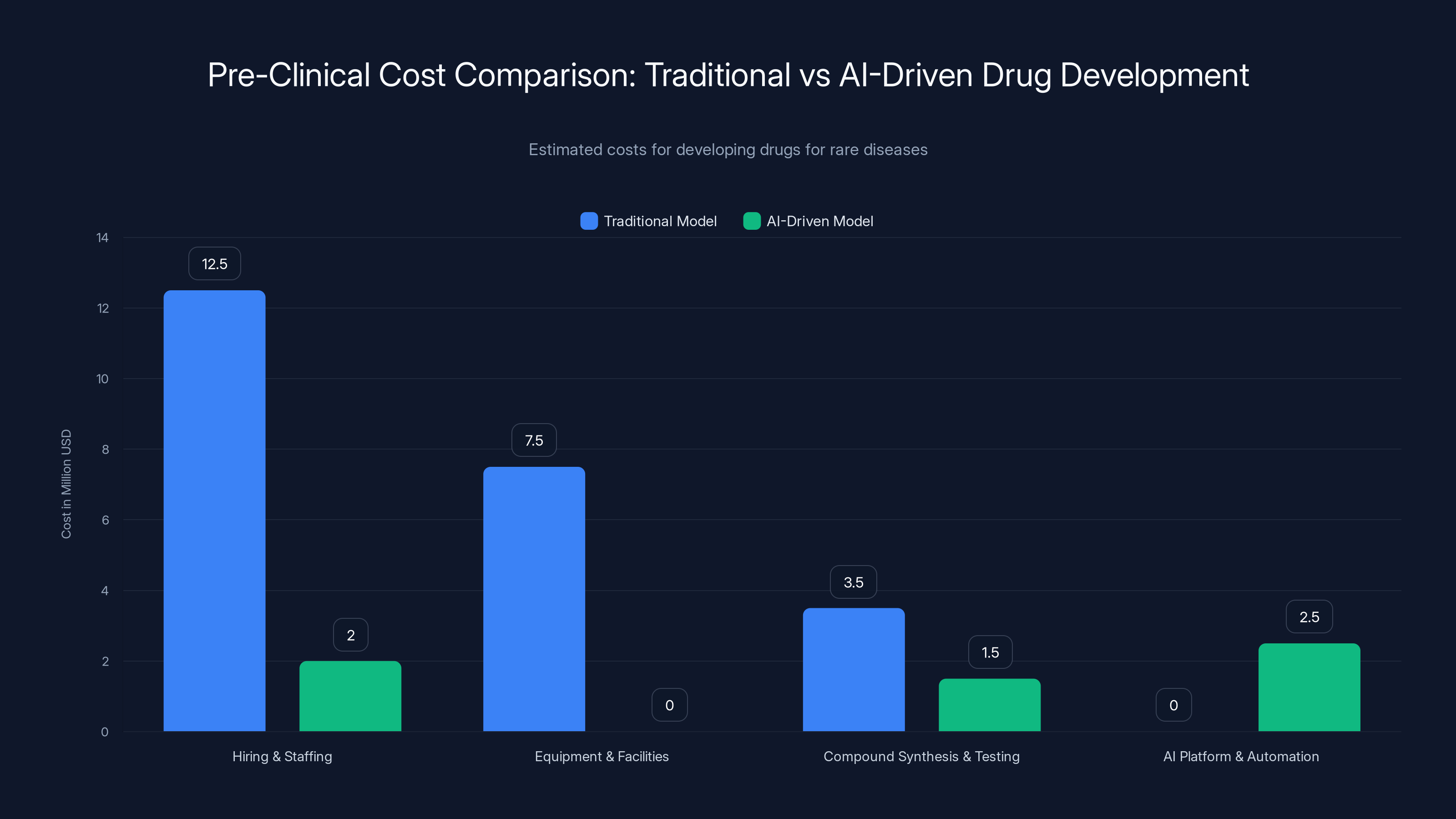
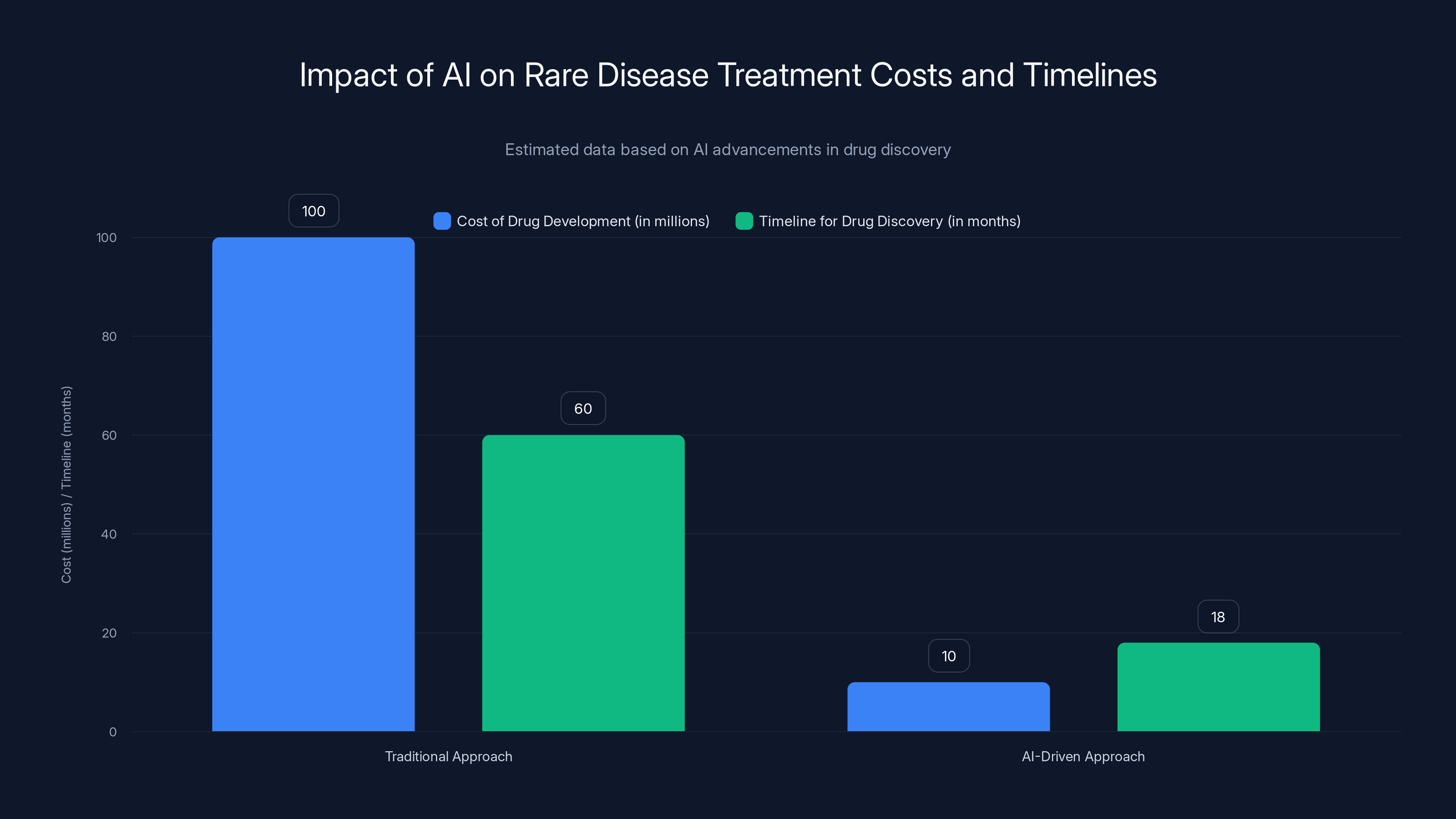
AI-driven drug development reduces pre-clinical costs by approximately 80%, making rare disease research financially viable. Estimated data.
Automating the Laboratory: From Data to Physical Validation
But here's the thing about AI in drug discovery that most people miss. The AI doesn't test the drugs. It proposes them. Someone still has to make the compound and run the experiment.
This is where the next layer of automation comes in: automated laboratories. Insilico operates facilities that can synthesize compounds and run basic tests without human intervention. A robot arm picks up reagents. It mixes them in the right ratios. It measures the output. All recorded automatically.
This is crucial for the rare disease problem. Remember the math from earlier? Hiring 50 chemists costs millions annually. But automated labs run 24/7. They don't need salary or benefits. They don't get tired or make mistakes from fatigue.
When you combine AI-driven hypothesis generation with automated testing, you get a system that can explore far larger design spaces than humans ever could. The AI proposes thousands of compounds. The automated lab tests them. The results feed back into the AI model, which learns from the data and refines its next set of proposals.
This is nothing like the old model where one chemist might test 20 compounds annually. An automated system can test thousands. The scaling is exponential.
For rare diseases, this changes the risk calculus again. Instead of spending
Insilico's automated labs generate multi-layer biological data from disease samples at scale. They can test not just whether a compound works, but how it works mechanistically. What proteins does it bind to? How does it affect gene expression? This generates far richer datasets than previous approaches. And every data point goes back into the AI model, making it smarter for the next iteration.
Gene Editing Delivery: Where AI Meets Biological Engineering
But drug discovery is only half the story. Even when AI identifies a promising treatment for a rare genetic disease, there's another bottleneck: how do you actually get the treatment into the patient's cells?
This is where Gen Edit Bio enters the picture. The company represents the second wave of CRISPR technology. The first wave was ex vivo—take cells out of the body, edit them in a lab, put them back. This works for blood disorders but not for systemic diseases.
The second wave is in vivo: deliver the gene-editing machinery directly into the tissue that needs editing. Inject it directly into the patient's eye to fix corneal dystrophy. Target it to the liver for metabolic disorders. Reach the nervous system for neurological conditions.
But in vivo delivery is genuinely hard. You can't just inject a virus carrying CRISPR directly into a patient. Viruses trigger immune responses. They get destroyed before reaching their target. They don't reliably accumulate in the right tissue.
Historically, scientists addressed this with brute force and trial-and-error. You take a natural virus with some affinity for a particular tissue. You engineer it to carry your gene-editing payload. You hope the immune system doesn't recognize it. You test it in animals. Most attempts fail. Some work. You iterate.
This process is slow and requires deep biological expertise. Gen Edit Bio's approach is to use AI to systematize it.
The company maintains a library of thousands of unique nanoparticles—essentially artificial viruses designed to transport genetic material. These nanoparticles vary in their chemical composition. Some are polymers. Some are lipids. Some are combinations. Each variation has different properties.
The question Gen Edit Bio's Nano Galaxy platform answers is: given the chemical structure of a nanoparticle, which tissues will it accumulate in? And if we modify the chemistry this way, will it still evade the immune system?
This is where AI becomes essential. You have thousands of possible designs. Testing each one in animals would take years and cost millions. Instead, Gen Edit Bio feeds the structural data into AI models trained on how nanoparticle chemistry correlates with tissue tropism and immunogenicity.
The AI predicts which designs are worth testing. The company tests a subset in wet labs. The experimental results—did it target the right tissue? Did it trigger an immune response?—gets fed back into the model. The model learns. Its predictions improve. The next round of proposed designs is better.
Co-founder Tian Zhu described the approach in a simple way: "We learn from nature and use AI machine learning methods to mine natural resources and find which kinds of viruses have an affinity to certain types of tissues." The "natural resources" are billions of years of evolutionary optimization. Evolution has already solved the delivery problem for countless pathogens. Gen Edit Bio's AI is just learning from those solutions at scale instead of rediscovering them through experimentation.
The practical result is dramatic. Instead of spending years optimizing a delivery vehicle, Gen Edit Bio can narrow down promising candidates to test in weeks. For in vivo gene editing to be practical, efficient delivery is essential. Without reliable tissue-specific targeting, you risk off-target effects. You waste doses. The cost per patient becomes prohibitive.
With AI-optimized delivery, Gen Edit Bio's vision is to make gene editing a one-and-done injection directly into affected tissue. One shot. It works. The patient is cured or significantly improved.
For rare genetic diseases, this is transformative. A disease like corneal dystrophy—which Gen Edit Bio recently received FDA approval to test—affects only a few thousand people globally. But it causes blindness. With proper delivery, a CRISPR therapy could potentially restore vision with a single treatment. The economics finally make sense when the therapy costs
The Data Quality Challenge: Why AI Models Are Only As Good As Their Training Data
But AI's promise in drug discovery runs into a hard wall: data. Not lack of data. Biased data.
Modern AI models are trained on the accumulated knowledge of biomedicine. That knowledge comes from research. Most biomedical research happens in the Western world—North America, Western Europe. The data reflects populations from these regions.
This introduces a subtle but profound bias. Genetic variation exists across human populations. Diseases present differently. Drug responses vary. When an AI model is trained primarily on data from Western populations, it learns patterns specific to those populations. When it makes predictions for non-Western populations, it's extrapolating beyond its training data. Those predictions are less reliable.
Alex Aliper from Insilico acknowledged this directly: "The corpus of data is heavily biased over the western world, where it is generated. I think we need to have more efforts locally, to have a more balanced set of original data, so that our models will also be more capable of dealing with it."
This is a critical bottleneck that's often overlooked. It's not technical. It's structural. Building high-quality biomedical datasets is expensive. It requires recruiting patients, getting informed consent, collecting samples, running assays. In wealthy Western countries, there's funding for this. In other regions, there isn't. So the data skew perpetuates.
For rare diseases, the bias problem gets worse. A rare disease affecting 5,000 people globally might only have well-documented patient data from 500 people—all in developed countries. An AI model trained on that data would be highly specialized to Western genetic backgrounds and healthcare contexts. It would perform poorly predicting outcomes for the other 4,500 patients.
Solving this isn't something AI can do alone. It requires investment in data collection infrastructure in underrepresented regions. It requires building relationships with patient communities. It requires funding distributed research. These are organizational and economic challenges, not technical ones.
But the implications for drug discovery are significant. AI can accelerate finding candidate therapies, but the candidates it finds will be systematically biased toward treating people from populations with good data. Systematically biased away from helping everyone else.
Companies developing AI drug discovery platforms are aware of this. Some are beginning to address it by deliberately incorporating genetic diversity into their training data. But it's not a problem that solves itself. It requires intentional effort and investment.
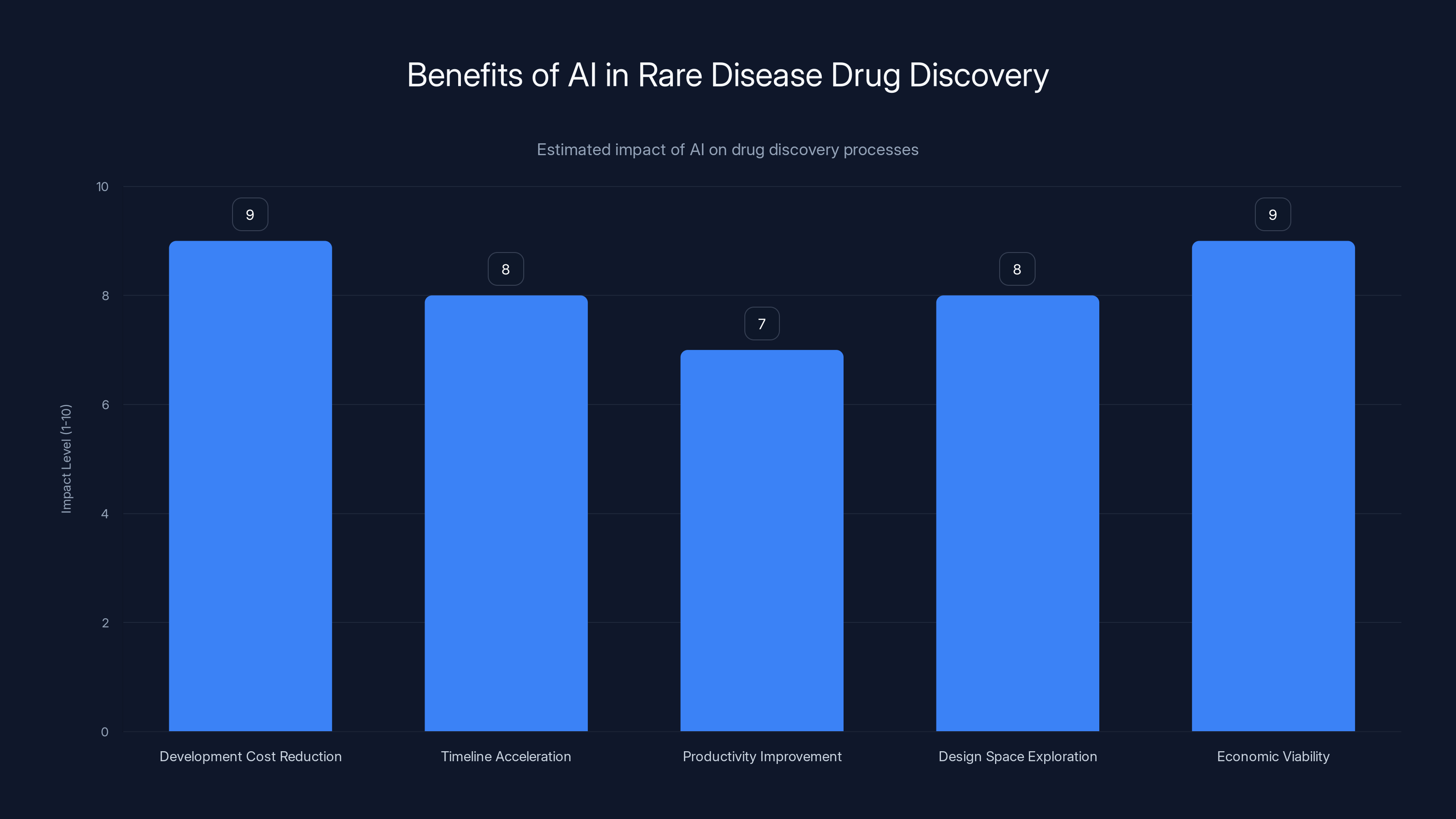
AI significantly reduces development costs (up to 90%) and accelerates timelines, making rare disease drug discovery economically viable. Estimated data.
Automated Hypothesis Generation: From Screening to Target Selection
One of the most underrated aspects of AI in drug discovery is how it's changing the target selection process. Before, finding which protein or pathway to target involved reading literature, talking to experts, and making educated guesses.
AI doesn't guess. It screens. If you feed it genomic data from patients with a disease and genetic data from healthy controls, it can identify which genes show unusual expression patterns. It can cross-reference those genes with protein interaction databases. It can identify which of those genes have known drugs that interact with their products.
The output is a ranked list of targets. Not "here's the one we should pursue." But "here are the top 50 most likely candidates ranked by evidence strength."
This changes the risk profile of rare disease research. Targeting Gene X might have been rejected before because "we're not confident enough." But if AI ranks it 8th out of 50 candidates, and your lab tests the top 10, you're systematically exploring the most promising space without betting everything on one uncertain guess.
The real power emerges when you combine target identification with compound optimization. AI identifies targets. It then screens compound libraries for molecules that interact with those targets. It predicts how structural modifications would improve efficacy or reduce side effects. It suggests what to test next.
For rare diseases where you can't afford to explore 100 dead ends, this structured prioritization is essential.
The Economic Remodeling: When Unit Economics Flip for Rare Disease Research
Let's talk about the financial reality because it determines what actually happens clinically.
Traditional drug development for a rare disease, assuming AI hasn't changed the equation:
- Hiring and staffing: $10-15M annually for a 50-person team
- Research time: 3-5 years minimum before clinical trials
- Equipment and facilities: $5-10M initial setup
- Compound synthesis and testing: $2-5M annually
- Total pre-clinical cost: $40-80M
For a disease affecting 5,000 people, even with 50% market penetration and high pricing, that's a struggling business model. Many companies won't attempt it.
With AI-driven platforms:
- Core team: 8-12 people, $1.5-2.5M annually
- AI platform access or licensing: $200K-500K annually
- Automated lab operations: $2-3M annually
- Compound synthesis and testing: mostly automated, $1-2M annually
- Total pre-clinical cost: $8-15M
That's 80% lower. That's the difference between "we can't justify this" and "let's fund this startup."
Moreover, the risk profile changes. With AI, you can fail faster. If your first 50 compound designs don't show promise, you learn that in weeks instead of years. You can pivot. You can try a different target. The economics support iteration instead of betting everything on one bet.
This is why you're seeing a wave of AI biotech startups focused specifically on rare diseases. The old business model couldn't support them. The new model can.
It's also why pharma companies are investing in AI drug discovery capabilities even though they have no shortage of chemists and biologists. It's not about replacing people. It's about reducing the cost per drug discovered. If you can discover rare disease drugs 10x cheaper with AI assistance, you suddenly have a new market to enter.
Multi-Modal AI: Teaching Generalist Systems Specialized Drug Discovery Tasks
Insilico's MMAI Gym represents an interesting evolution in how AI is being applied to drug discovery. Instead of building specialized models for toxicity prediction, efficacy prediction, drug-likeness scoring, and so on, the approach is to train a single generalist model on all of these tasks simultaneously.
Why matters gets into some interesting AI theory. A specialized model trained only on toxicity data becomes very good at predicting toxicity. But it's brittle. It only works for toxicity. The knowledge can't transfer to other problems.
A generalist model trained on multiple related tasks develops more robust understanding. The knowledge transfers across tasks. Teaching the model about toxicity indirectly helps it learn about efficacy because they're related problems (both involve how molecules interact with biological systems).
Moreover, the model learns at a higher level of abstraction. Instead of memorizing patterns in toxicity data, it learns principles about how molecular structure relates to biological function. Those principles generalize better to novel compounds.
For rare disease drug discovery, this generalist approach is valuable. You often don't have huge datasets for any one aspect. You might have moderate data on clinical outcomes, some data on related proteins, genetic information about patients. A generalist model can learn from all of these incomplete datasets simultaneously. A specialized model would fail because there's not enough toxicity data or enough efficacy data.
The training process for MMAI models is different too. Instead of starting from scratch, companies often begin with a large language model like GPT-4 or Gemini that's been trained on massive amounts of text, then fine-tune it on pharmaceutical-specific tasks and data.
This transfer learning approach is powerful. The base model already understands complex relationships and reasoning. The fine-tuning teaches it pharmaceutical specifics. You need less data to fine-tune than to train from scratch.
But there's a risk worth mentioning. If the base model was trained on biased data, fine-tuning doesn't remove the bias. It often amplifies it. So generalist models can potentially spread biases from their foundational training across multiple tasks. That's worth monitoring as this technology scales.
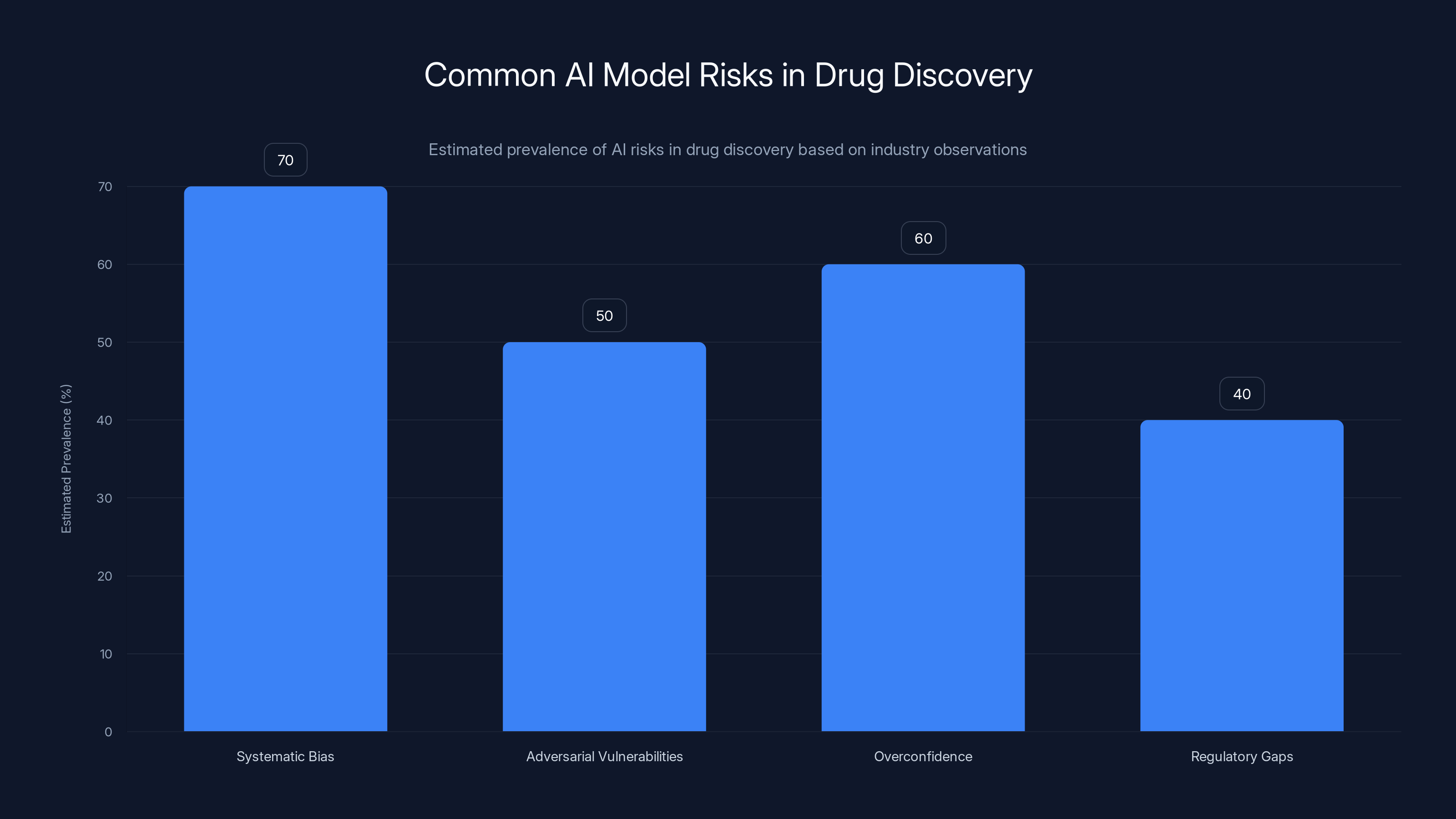
Systematic biases and overconfidence are prevalent risks in AI drug discovery models, estimated to affect 60-70% of cases. Estimated data.
Real-World Impact: From Hypothesis to Clinical Trials
All of this remains theoretical unless it leads to actual clinical progress. Let's look at concrete examples of what's happened.
Gen Edit Bio received FDA approval in late 2024 to begin clinical trials of a CRISPR therapy for corneal dystrophy. The pathway to that approval was significantly shortened compared to what would have been typical five years ago.
Corneal dystrophy is a genetic eye disease where mutations in genes like TGFBI cause the cornea to become cloudy over time. It's rare, affecting maybe 10,000 people in the US. It's treatable—corneal transplants can restore sight. But the transplanted cornea itself can become dystrophic again if the genetic mutation is still present. That's why in vivo gene editing is theoretically perfect for this disease. Edit the gene in the patient's own corneal cells and the problem is solved.
But getting to the point where you can prove a gene therapy works requires delivering it effectively. Gen Edit Bio's AI-designed nanoparticles made this tractable on a realistic timeline and budget. Without that, developing a therapy would have taken a decade and cost $50M+. With it, the company moved from concept to IND approval (Investigational New Drug, the FDA stage that allows human trials) in a compressed timeframe.
For patients with corneal dystrophy, this matters. It's the difference between "maybe in 10 years" and "maybe in 3 years." For a progressive disease, those years are irreplaceable.
Insilico's work on ALS is earlier in the pipeline but conceptually similar. The company identified existing drugs that might have activity against targets relevant to ALS. These aren't new drugs. They're molecules that have already passed phase 1 safety testing for other indications. But finding which existing drugs might work for ALS required synthesizing knowledge across multiple domains—genomics, proteomics, clinical pharmacology. That synthesis is what AI excels at.
The point isn't that these are miracle cures. The point is that treatment options that seemed economically impossible suddenly become possible. That matters for patients because it means they're not ignored by the market.
Scaling Challenges: From Proof-of-Concept to Meaningful Impact
Despite the promise, significant challenges remain in scaling AI drug discovery from interesting pilot programs to changing the actual treatment landscape for rare diseases.
First, there's the validation problem. AI predicts that Compound X should work. Before a company invests $50M in clinical trials, they need confidence that the prediction is right. That confidence comes from experimental validation. For rare diseases, running large clinical trials is difficult—you can't recruit thousands of patients if only 5,000 exist globally.
This creates a measurement problem. How do you validate AI predictions with limited experimental data? Some companies are using surrogate endpoints—measurable markers that correlate with clinical outcomes but aren't the outcomes themselves. Protein levels, gene expression patterns, imaging biomarkers. These allow you to assess whether a therapy is working without running massive trials. But surrogate endpoints aren't perfect. Sometimes they mislead.
Second, there's the regulatory path. The FDA hasn't yet developed clear guidelines for AI-discovered or AI-designed therapeutics. That's changing, but slowly. When you submit an IND application for a drug, the FDA expects to see data on how that drug was developed. With traditional drug discovery, that story is clear: scientists designed it, tested it, optimized it. With AI discovery, the narrative is less clear. How do you justify that an AI's prediction is sound? How do you demonstrate that you didn't just get lucky?
Third, there's the manufacturing challenge. AI can design a molecule. Manufacturing it at scale is a different problem. Some AI-designed compounds are inherently difficult to synthesize at commercial scale. The process of scaling from making 100mg for testing to making 100kg for clinical trials can reveal problems that lab-scale synthesis didn't show.
For gene therapies specifically, manufacturing is even harder. Producing viral vectors or engineered nanoparticles at scale is capital-intensive. The first few batches are expensive. Only when you're producing thousands of doses does the cost per dose drop dramatically. This creates a chicken-and-egg problem: you need funding to scale manufacturing, but you can't prove the therapy works until you have enough material to run trials.
Patient Data Generation: The Underrated Bottleneck
One challenge that deserves more emphasis is generating high-quality patient data for rare diseases. AI models need data to learn from. For common diseases, datasets are relatively abundant. For rare diseases, generating sufficient data is genuinely difficult.
Consider a rare genetic disorder affecting 200 people globally. Getting meaningful data means recruiting most of those patients, getting informed consent, running expensive assays, following them over years to understand disease progression. This is expensive and logistically complex.
But without that data, AI models learn from whatever is available—which might be heavily skewed toward one or two countries, one demographic, one presentation of the disease.
Companies and researchers are beginning to invest in this. Creating patient registries specifically to generate training data for AI models. Funding distributed research networks so that patient data can be collected globally. But it's underfunded relative to its importance.
For rare diseases, this investment might actually be more important than the AI capability itself. Good data plus medium AI beats bad data plus excellent AI every time.
AI-driven approaches significantly reduce both the cost and timeline of drug development for rare diseases, making treatments more economically viable. Estimated data.
Intellectual Property and Patent Landscapes: Navigating a Complex Terrain
AI-discovered drugs raise interesting IP questions. If an AI designed the molecule, who owns the patent? The company that developed the AI? The researchers who trained it? The patients whose data trained the model?
Most jurisdictions haven't resolved this definitively. Current patent offices tend to award patents to the entity that filed, which is usually the company. But this assumes the company has lawful rights to everything that went into training the AI.
For rare disease research, this matters because it affects the cost structure. If IP ownership becomes contentious, it creates legal risk that increases the cost of development. If it's clear, development can proceed faster.
There's also the question of whether AI-designed drugs get patent terms equivalent to other new drugs. If an AI can design a drug in 6 months versus 3 years for traditional methods, should that affect patent duration? The thinking in some circles is that AI-assisted development should be rewarded with better IP terms because it justifies the investment. Others think that would be unfair to traditional pharmaceutical research.
These are unsettled questions that will play out over the next 5-10 years.

The Competitive Advantage: First-Mover Benefits in AI Biotech
Companies that build strong AI drug discovery capabilities early are gaining advantages that compound over time.
The first advantage is learning. Every drug you successfully develop teaches your AI system something. Every failure teaches something too. Companies that have trained their systems on more successful and failed drug development projects have models that are more accurate. That accuracy drives down costs and timelines further.
The second advantage is talent. The best researchers and engineers want to work on problems they consider solvable and important. AI drug discovery attracts talent because it's seen as the future. Companies that built AI capabilities early have been able to recruit top talent. That talent builds better systems. Better systems attract more talent.
The third advantage is partnerships. When a company has credibly demonstrated that AI can accelerate drug discovery, partnerships become easier. Academic researchers want collaborations. Patient advocacy groups want the company to focus on their disease. This creates network effects.
This isn't to say that first-movers always win. But in capital-intensive fields like drug discovery, early movers that execute well can accumulate advantages faster than later entrants can overcome.
For rare disease treatment, this means that if Insilico and Gen Edit Bio and companies like them execute well, they could become the dominant players in rare disease drug development. The old pharma companies might collaborate with them or acquire their capabilities. The landscape would look very different from the traditional pharma model.
Future Implications: What Changes When Cost Collapses
If AI drug discovery eventually reduces the per-drug cost by 90% as some claim is possible, what happens?
First, companies will fund research into diseases they previously ignored. We're talking about thousands of rare diseases with no approved treatments. Some of these affect only dozens of people globally. With traditional economics, no one would touch them. If the cost to develop a treatment drops 90%, suddenly many become fundable.
Second, geographic patterns of drug development will shift. Rare disease research has been concentrated in wealthy countries because that's where funding exists. As costs drop, investment will diversify. Research will happen in more places.
Third, the structure of drug development might change. If AI can identify promising molecules quickly, maybe you don't need to do massive randomized controlled trials for rare diseases. Maybe you use smaller adaptive trials with biomarkers. The current regulatory framework assumes large trials are necessary for statistical power. If you have strong mechanism-of-action evidence from AI analysis and biological validation, maybe the bar can be different.
Fourth, patient access changes. If drugs are cheaper to develop, they can be cheaper to sell. That's not automatic—companies need incentives to keep prices low—but it's possible. Price becomes less of a barrier to treating rare diseases.
These aren't wild speculations. They're natural consequences of what happens when technology reduces the cost of something dramatically. It happened with computing. It happened with DNA sequencing. When costs collapse, markets transform.
For patients with rare diseases, this transformation is overdue.
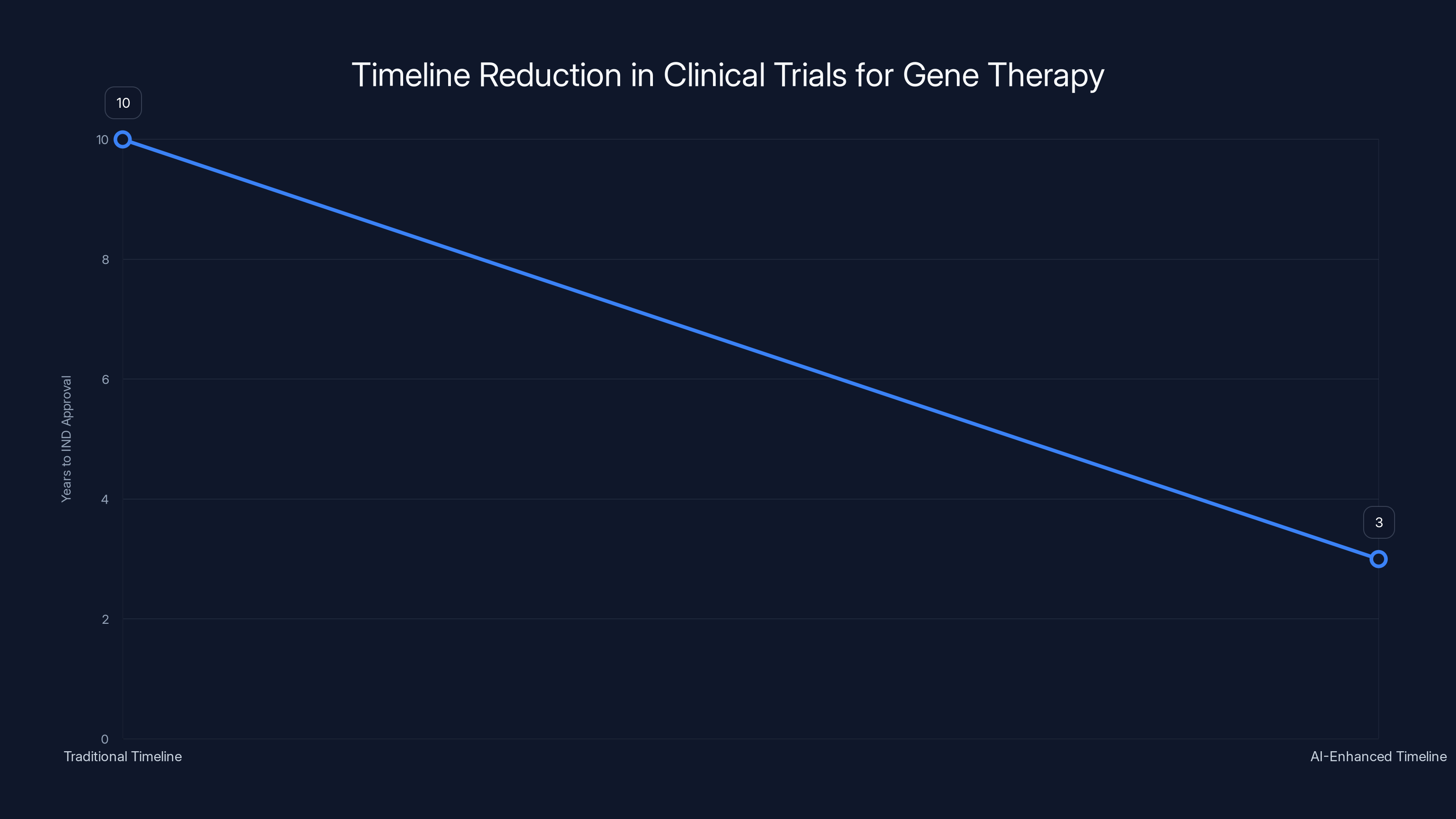
AI-enhanced development reduced the timeline for IND approval from 10 years to 3 years, highlighting the impact of advanced technology in accelerating clinical trials. Estimated data.
Technical Foundations: How the AI Actually Works
Understanding how AI drug discovery works at a technical level helps explain why it's so effective.
At its core, drug discovery involves predicting properties of molecules you haven't made yet. Will this compound bind to this protein? How strongly? Will it be toxic? Will it cross the blood-brain barrier? These predictions require understanding the relationship between molecular structure and biological function.
Machine learning models learn these relationships from data. You show the model 10,000 examples of molecules with known properties. The model identifies patterns—"when the molecule has this structural feature, it's usually toxic" or "when it has this other feature, it binds strongly."
Once trained, the model can predict properties of molecules it's never seen. You feed it a new proposed compound and it estimates whether it will work.
The accuracy of these predictions depends on the quality of training data and the sophistication of the model architecture. Deep neural networks with millions of parameters can learn very subtle patterns. Graph neural networks, which explicitly represent molecular structure as a graph of atoms and bonds, are particularly effective for molecular tasks.
The power comes from scale. If you ask a chemist, "which of these 1 million compounds should we test," they'll propose maybe 100. They'll get 50-70% of the best ones. If you ask an AI model trained on millions of molecules and their properties to score all 1 million compounds, it will rank them. The top 100 according to the model will include 80-90% of the best ones. That improvement matters.
But there's a limit to what models can predict. They're predicting laboratory properties—binding affinity, toxicity, solubility. They're not predicting real-world clinical outcomes. That requires understanding how the drug behaves in a living organism: pharmacokinetics (how it's absorbed, distributed, metabolized), pharmacodynamics (how it actually works in vivo), immune responses, individual variation.
This is why the experimental validation step remains essential. The AI proposes. The lab tests. The results guide the next round of proposals.
Integration with Modern Biological Databases: The Information Infrastructure
The reason AI can be so effective at drug discovery today is that we've accumulated massive amounts of organized biological data over the past 20 years.
Genbank, EMBL, DDBJ, PDB, and other public databases contain the complete genetic sequences and protein structures for thousands of organisms. Protein interaction networks document which proteins interact with which other proteins. Gene expression databases show which genes are active in which tissues and diseases. Drug databases catalog molecules tested and their outcomes.
Companies developing AI drug discovery platforms ingest all of this data. They also add proprietary data from their own experiments and partnerships.
The result is a system trained on essentially all accumulated biological knowledge, plus proprietary insights. An AI system like this has a synthetic understanding of biology that exceeds what any individual researcher could hold in their head.
That's powerful. But it's only possible because the biological research community spent decades generating and organizing this data. If we didn't have public databases, AI drug discovery would be far less effective.
This creates an interesting economic question: if private companies are profiting from AI trained on public databases generated with public funding, should the public share in the benefits? Different countries are grappling with this differently. Some are building data policies that require companies to contribute back to public databases. Others are considering benefit-sharing arrangements. It's unsettled and will likely become more important as the value of data-driven biotechnology increases.
Risk Assessment and Safety Considerations
There's a tendency to assume that AI solutions to scientific problems are automatically safer than human solutions. That's not obviously true.
AI models can have systematic biases that lead them to consistently make wrong predictions in particular directions. A toxicity model trained on Western populations might underestimate toxicity in people with different genetic backgrounds who metabolize drugs differently. That could lead to harm.
AI models can have adversarial vulnerabilities. If someone deliberately introduces specific data into the model's training set, they might be able to cause it to make systematic errors for particular compounds. In a competitive environment, this is a real risk.
AI models can be overconfident in their predictions. The model outputs a confidence score saying "90% probability this compound is safe," but that score isn't well-calibrated. When tested, the compound turns out to be toxic. The confidence was unjustified.
These aren't speculative worries. They're known issues in machine learning. Responsible development of AI drug discovery requires explicitly addressing these risks through multiple validation approaches, adversarial testing, and maintaining human oversight.
Good companies are doing this. Less responsible ones might cut corners, particularly if they're under pressure to deliver results quickly for rare diseases where patients are desperate.
Regulatory frameworks need to catch up to ensure that the speed benefits of AI drug discovery don't come at the cost of safety.
The Rare Disease Patient Perspective: Why Speed and Cost Reduction Matter
It's easy to discuss this abstractly, but understanding why this matters requires thinking about the patients.
Consider a patient diagnosed with a rare genetic disorder at age 20. There's no treatment. The disease is progressive. By age 30, they'll likely lose most mobility. By 40, they might be significantly disabled. That's a 60-year horizon of disability and decline.
A drug that slows or halts progression could radically change that trajectory. Instead of decades of decline, maybe you have a normal lifespan with manageable symptoms. Or complete remission if the drug is really effective.
But if the drug costs $1 billion to develop and only 500 people globally could benefit, it won't get developed. That patient will never know a world where their disease is treatable.
Now imagine AI reduces the development cost to $100 million. Suddenly it's worth trying. A biotech startup can fund this. A larger pharma company might fund multiple rare disease programs. More companies compete. Competition drives innovation.
From the patient's perspective, this isn't about abstract economic efficiency. It's about the difference between treatable and untreatable. Between hope and despair.
That's why the labor bottleneck in rare disease research is so consequential. It's not a technical puzzle. It's a question of whether modern medicine can address the diseases that matter to small populations or whether it's inherently limited to blockbusters.
AI is tilting that equation in favor of rare diseases. Imperfectly. Slowly. But meaningfully.

Collaboration Models: How AI Companies and Academic Research Interact
The development of AI drug discovery isn't happening in corporate laboratories in isolation. It's deeply intertwined with academic research.
Academic researchers at universities develop new machine learning architectures and methods. Corporate AI biotech companies apply those methods to real drug discovery problems and scale them.
This creates interesting collaboration models. Some companies license technology from universities. Some maintain research partnerships where academic labs get early access to AI platforms in exchange for generating data. Some have launched academic spinoffs or invest in academic startups.
For rare disease research specifically, this collaboration is important. Academic researchers often work on rare diseases because they're interested in fundamental biology questions, not because there's commercial incentive. But they lack resources. Academic labs are often limited by compute power and funding.
When an AI biotech company partners with an academic researcher studying a rare disease, both benefit. The company gets data and scientific credibility. The academic gets better tools and resources. Patients potentially benefit from faster progress.
But there are tensions in these collaborations too. Academic researchers prioritize publication and knowledge sharing. Companies prioritize patents and IP protection. These incentives aren't perfectly aligned. Navigating these partnerships requires clear agreements about what gets published and when.
Looking forward, more formalized centers of excellence might emerge—institutions that combine corporate AI infrastructure with academic rigor and nonprofit patient advocacy focus. Some of these are already forming, often with funding from foundations interested in particular rare diseases.
Conclusions: The Inflection Point in Rare Disease Treatment
We're at an inflection point where AI is making economically viable what was previously impossible.
For decades, rare diseases sat in a painful gap. The science understood the problems. Technology could address them. But the economics didn't work. Markets won't reward treating small populations. Companies won't fund what doesn't generate returns.
AI is changing that by reducing the cost of drug discovery and development dramatically. When you can treat a rare disease for
This won't solve every rare disease overnight. Thousands will still lack treatments. But the vector is clear: from "untouchable" to "occasionally treated" to "routinely explored." That's meaningful progress.
The companies driving this—Insilico Medicine with its automated discovery platforms, Gen Edit Bio with its AI-designed delivery vehicles, and others in the space—are doing important work. They're not curing diseases today, but they're building the infrastructure that will enable cures.
For patients with rare diseases who've been waiting for effective treatments, this shift can't come fast enough. For the pharmaceutical industry, it represents a new market. For society, it's a win. When technology makes the impossible economically possible, we should recognize that as a significant inflection point and move quickly to benefit from it.

FAQ
What is pharmaceutical superintelligence?
Pharmaceutical superintelligence refers to AI systems that can perform at superhuman levels across multiple drug discovery tasks simultaneously, such as target identification, compound design, toxicity prediction, and efficacy estimation. These generalist models are trained on vast amounts of pharmaceutical data and biological knowledge to accelerate the entire drug development pipeline for diseases where labor has historically been the limiting factor.
How does AI specifically address the labor shortage in rare disease drug discovery?
AI addresses labor shortages by automating the intelligence-intensive parts of drug research that previously required large teams of specialists. Instead of hiring 50 chemists to screen compound libraries over years, companies can use AI to propose the most promising candidates and automated labs to test them, dramatically reducing both the time and cost required. This makes rare disease research economically viable for smaller companies and startups.
What are the main benefits of using AI in drug discovery for rare diseases?
The primary benefits include drastically reduced development costs (often 80-90% lower), dramatically accelerated timelines (months instead of years), improved productivity through automation, the ability to explore larger design spaces than humans could manually, and the economic viability of treating patient populations previously considered too small to merit investment. AI also enables more systematic hypothesis generation based on comprehensive data analysis rather than individual researcher intuition.
How do automated laboratories contribute to faster drug discovery?
Automated labs synthesize compounds and run experiments 24/7 without human labor costs, allowing researchers to test thousands of compounds instead of dozens. AI systems propose candidate compounds, robotic systems synthesize and test them, and the results feed back into the AI model to refine future proposals. This feedback loop dramatically accelerates the learning process and exploration of chemical design space compared to traditional laboratory work.
What is in vivo gene delivery and why does AI help solve it?
In vivo gene delivery means getting gene-editing tools directly into affected tissues inside the living body, rather than editing cells outside the body. AI helps by predicting which engineered nanoparticles will successfully deliver genetic material to specific tissues without triggering immune responses. Gen Edit Bio's approach uses AI to analyze thousands of nanoparticle designs and predict their properties, reducing what would take years of trial-and-error experimentation into weeks of systematic testing.
What data quality issues complicate AI drug discovery for rare diseases?
Biomedical AI models are trained primarily on data from Western populations, creating systematic bias in disease understanding and treatment predictions for other populations. For rare diseases affecting small, geographically dispersed populations, getting sufficient high-quality diverse patient data is extremely challenging. Models trained on biased data may make poor predictions when applied to underrepresented populations, potentially leading to treatments that work well for some groups but not others.
How much can AI reduce drug development costs for rare diseases?
Preliminary data suggests AI-driven approaches can reduce pre-clinical development costs by 80% or more compared to traditional methods, from
Why do companies need both AI predictions and wet-lab experimental validation?
AI models predict molecular properties and biological behavior based on patterns in training data, but these predictions aren't always accurate, especially for novel compounds or rare disease contexts. Experimental validation in wet labs confirms whether AI predictions were correct, generates new data to improve the AI model, and identifies unexpected side effects or mechanisms. This feedback loop ensures that the treatments being proposed are actually safe and effective in biological systems, not just theoretically sound.
Conclusion: An Emerging Hope for the Forgotten Diseases
The rare disease problem has haunted modern medicine for decades. Thousands of diseases affecting millions of people globally have no approved treatments. Not because the science is impossible. Not because we lack understanding. But because the market structure makes the research economically irrational.
Companies exist to make returns for shareholders. Nobody blames them for focusing on diseases that affect millions. But that focus creates an enormous gap: the diseases that matter most to the people affected by them are precisely the ones that matter least to the market.
AI is creating a wedge in that gap. By automating the labor-intensive parts of drug discovery, AI makes rare disease research economically viable. Not easy. Viable. That's the inflection point.
When Insilico's AI system identifies a promising therapeutic candidate for ALS in weeks instead of months, that compressed timeline doesn't just save money. It saves years of waiting for patients. When Gen Edit Bio's algorithms design delivery vehicles that can target specific tissues precisely, that means therapies are possible that weren't before.
Will this solve rare diseases entirely? Almost certainly not in the next 5-10 years. There are still thousands without viable treatments. But the trajectory is clear. From untouchable to occasionally treated to routinely explored.
For the patients waiting for solutions, that trajectory represents something precious: hope. Not the false hope of hype, but the grounded hope of economic viability meeting technological capability.
That convergence is happening now. The rare diseases that were abandoned by the market are becoming fundable. The companies building AI platforms to make this possible are filling a gap that shouldn't exist. And patients are finally starting to see options where there were none before.
This is how technological inflection points matter in healthcare. Not through single miracle cures, but through systemic changes that make previously impossible research suddenly tractable. The labor bottleneck in treating rare diseases is being automated away. What emerges from that automation will determine whether thousands of rare diseases remain untreated indefinitely, or whether they finally get the attention they deserve.

Key Takeaways
- AI automation reduces rare disease drug discovery costs by 80% (from 8-15M), fundamentally changing project economics from impossible to viable
- Generalist AI models trained through platforms like Insilico's MMAI Gym perform multiple pharmaceutical tasks simultaneously with superhuman accuracy
- GenEditBio's AI-designed nanoparticles enable precise in vivo gene delivery, making CRISPR therapies practical one-shot treatments for genetic diseases
- Data bias remains a critical challenge—AI models trained on Western-biased data make poor predictions for underrepresented populations
- The economic model flip means thousands of rare diseases are moving from untreatable market failures to fundable startup opportunities within the next 5-10 years

