![Anthropic's Economic Index 2025: What AI Really Does for Work [Data]](https://tryrunable.com/blog/anthropic-s-economic-index-2025-what-ai-really-does-for-work/image-1-1768750625319.jpg)
Anthropic's Economic Index 2025: What AI Really Does for Work [Data]
Anthropic just released their fourth Economic Index report. Two million conversations. Real-world data from Claude.ai and their API. No hype. Just numbers.
And honestly, the findings wreck some comfortable narratives we've been telling ourselves.
You know the story: AI levels the playing field. Junior staff get supercharged. Junior roles disappear. Everyone becomes a mid-level operator. Sounds fair, right?
Wrong.
The data shows the opposite. And that's just the beginning.
I've spent the last few weeks digging through the findings, talking to CTOs and founders who've seen this play out, and what emerges is a clearer picture of how AI actually reshapes work. It's not unemployment you should worry about. It's deskilling. It's not task coverage that matters. It's effective coverage. It's not whether AI can do big projects. It's how you structure the work so it can.
This report changes how you should think about AI adoption, hiring, and strategy. Here's what you need to know.
TL; DR
- Senior staff see 12x speedups on complex tasks, while junior staff see 9x on simple work—AI amplifies existing skill gaps instead of flattening them
- AI handles 19-hour projects in real workflows when tasks are broken into steps, not because of single-prompt capabilities
- "Task coverage" is a trap metric—what matters is effective coverage weighted by time spent and success rates
- Deskilling beats unemployment as the real risk—the bigger threat isn't job loss, it's workers losing fundamental skills they'll need when AI fails
- Prompting is still critical—how you ask matters as much as what you ask for
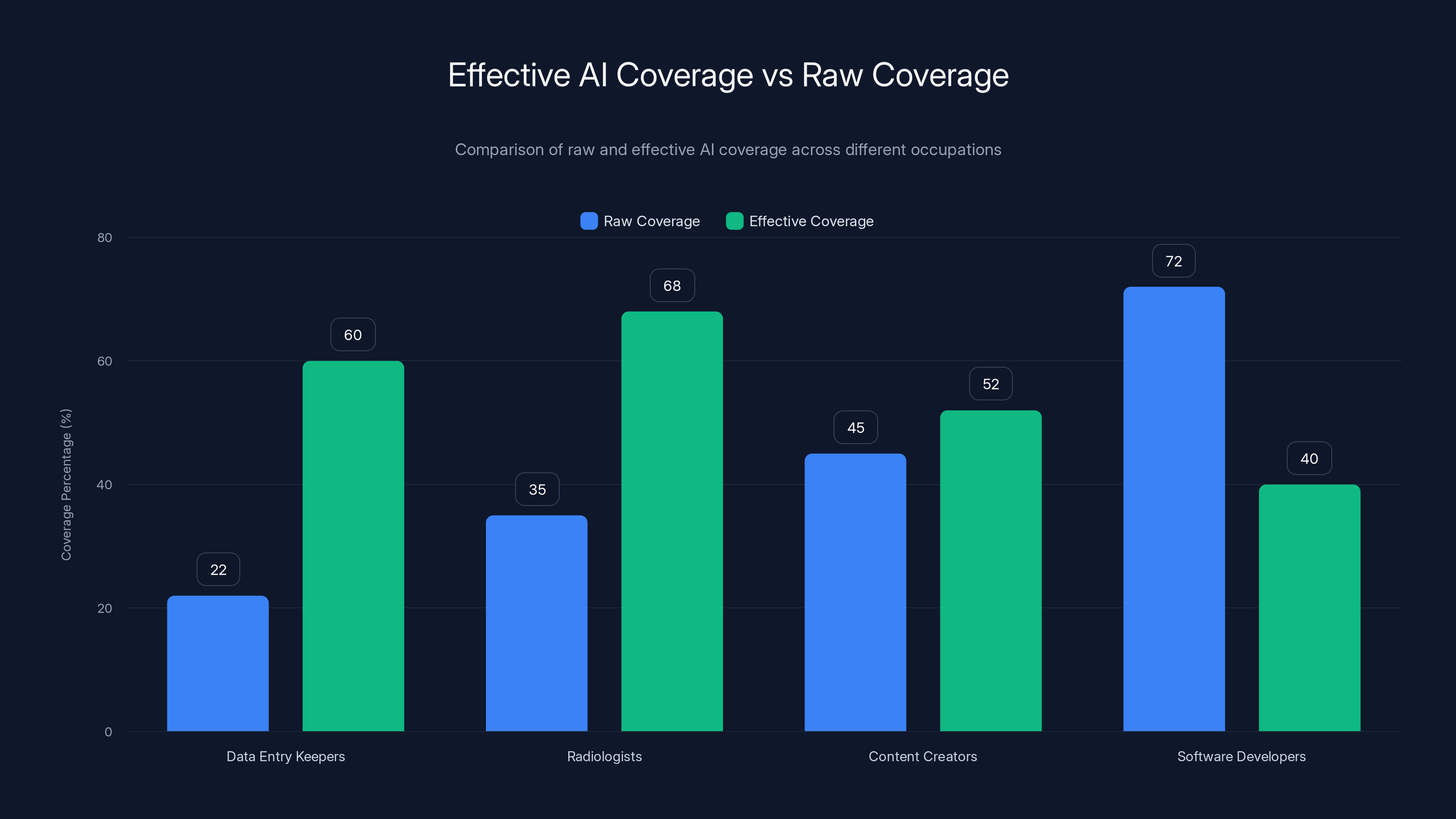
Effective AI coverage often reveals a more accurate impact of AI on job tasks than raw coverage. For example, radiologists have an effective coverage of 68% compared to a raw coverage of 35%, highlighting the importance of task relevance and success rate.
AI's Most Uncomfortable Truth: It Helps Your Best People Most
I had a conversation with a CTO last month. He told me his senior engineers were getting 12x productivity boosts from Claude, while his junior developers barely broke 2x. "I thought AI would help them catch up," he said. "Nope. Made the gap worse."
That CTO wasn't alone. This pattern showed up across hundreds of companies in Anthropic's dataset.
Here's the actual data:
Tasks requiring high school education (12 years): 9x speedup Tasks requiring college degree (16 years): 12x speedup API and enterprise-level tasks: Even higher
Let that sink in. The complexity ceiling rose faster than the entry-level floor.
Why does this happen? It's not because AI is better at hard stuff (though it is). It's because experienced people know what to ask for. They understand edge cases. They can catch AI hallucinations before shipping them. They know when to break work into pieces and when to try something end-to-end.
Junior staff? They take what the AI gives them. They don't have the context to evaluate if it's wrong.
The implication is brutal if you're honest about it: Stop treating AI as a tool to scale entry-level work. Your
Build your AI strategy around amplifying your best people, not automating your junior roles.
The Skill Gap Widens, Not Narrows
We've been sold this narrative that AI democratizes expertise. Everyone becomes excellent overnight.
The data says no.
When senior engineers use AI, they iterate. They correct mistakes mid-process. They adjust course based on intermediate outputs. This takes experience. You need a mental model of what good looks like before you can redirect an AI toward it.
Junior staff don't have that mental model yet. So they ship what the AI produces. Sometimes it's fine. Sometimes it's catastrophically wrong, and they don't catch it until production.
Anthropics's research tracked this: As task complexity increased, the gap between senior and junior success rates widened. At low complexity, both groups succeeded 75%+ of the time. At high complexity, seniors stayed near 70% while juniors dropped to 55%.
That's not a leveling. That's a reinforcement.
What High Performers Do Differently
I watched a senior engineer use Claude to rebuild a data pipeline. She asked clarifying questions. She got a first pass. She didn't ship it. She modified the logic, tested it locally, found an off-by-one error, corrected it, and shipped.
The task took her 45 minutes instead of 3 hours. Classic 4x speedup.
Then I watched a junior engineer use Claude for a similar task. Got the first pass. Looked reasonable. Shipped it. Found the bug in staging. Fixed it.
Same task, same tool, wildly different outcomes.
The senior engineer had a mental model of "what could go wrong" in data pipelines. She knew to check for boundary conditions, off-by-one errors, timezone handling. She asked Claude specific questions that exposed those risks.
The junior engineer didn't have that model yet.
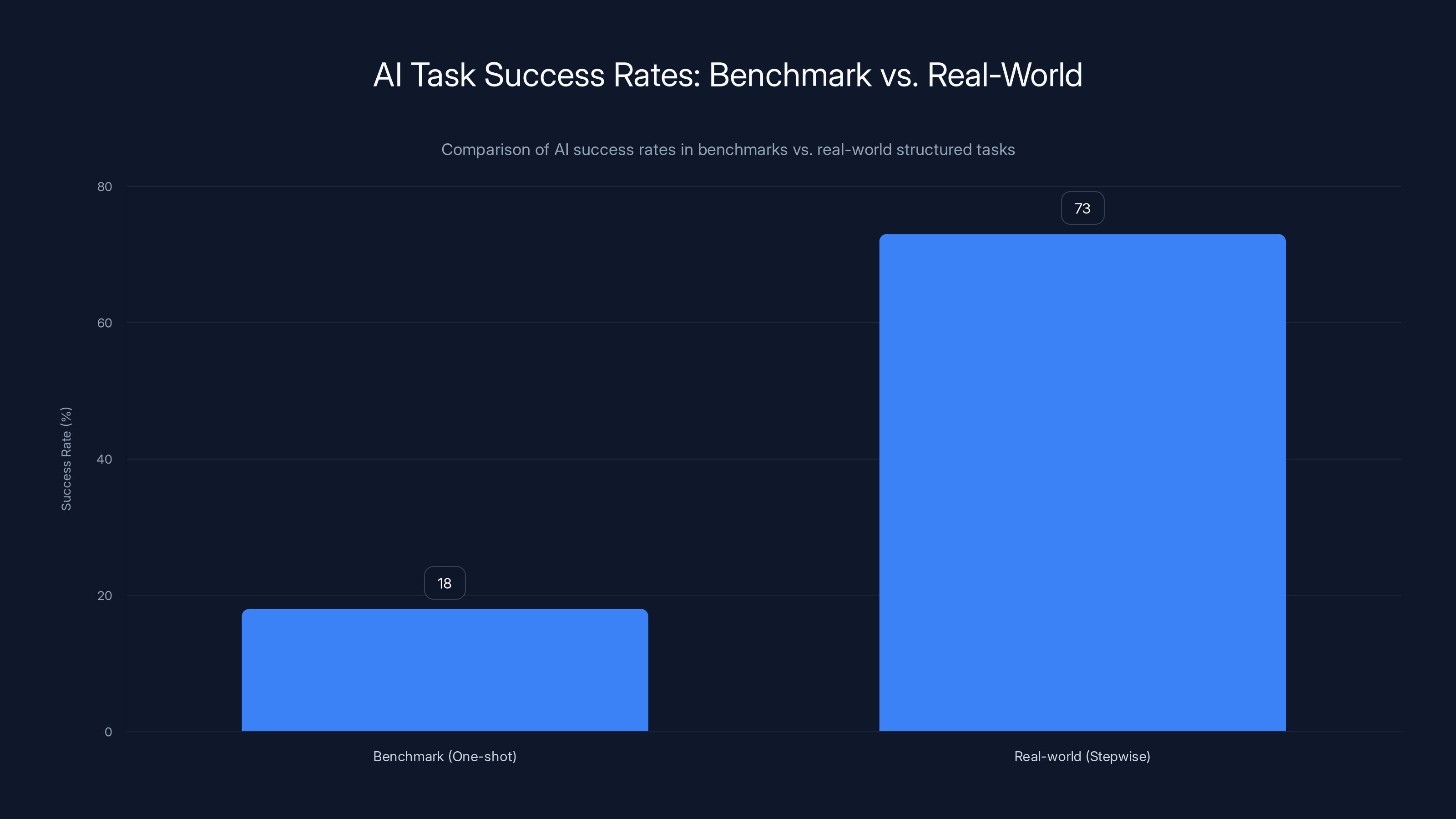
AI success rates are significantly higher when tasks are broken into steps (73%) compared to one-shot benchmarks (18%). Estimated data based on content insights.
AI Actually Handles Way Bigger Projects Than Benchmarks Show
Here's the thing about AI capability benchmarks: They're measured wrong.
Researchers give Claude a task and measure if it completes in one shot. By that metric, Claude succeeds about 50% of the time on 2-hour tasks.
But real users? They're completing tasks that would take 19 hours manually. That's nearly 10x the benchmark.
What's the difference between a benchmark and reality?
Benchmarks are: "Do this task perfectly in one shot." Reality is: "Break the task into steps. Fix errors as they appear. Iterate."
Decomposition Is the Killer Feature
The insight buried in Anthropic's data is this: AI doesn't fail on big tasks because it's dumb. It fails because of prompt fatigue. You give it a 50-step project in one message, and by step 40, it's lost context or made a logical error.
But when users break work into steps, everything changes.
Real-world example from the dataset: A content team needed to produce a 40-page marketing guide. Benchmark test: Claude produces this end-to-end. Success rate: 15%. It hallucinates, contradicts itself, loses structure.
Real-world workflow: Outline first, then intro, then each section, then polish. Success rate per step: 85%+. Total project success: 70%.
Same AI. Same task. Different structure. Completely different results.
This is massive for how you deploy AI in your organization. It means:
Stop thinking of AI as a "do everything in one prompt" tool. Think of it as a workflow optimizer. Each step is clearer, more specific, easier to verify.
This changes process design. Your workflows need to be explicit and stepwise. That's not a limitation of AI. That's the architecture of effective AI work.
Breaking Down Your Workflows for AI Success
There's a meta-insight here: The companies getting the most from AI aren't the ones with the smartest prompts. They're the ones with the clearest processes.
Let me explain with a real workflow.
Say you need to analyze customer feedback and produce a quarterly trend report. Old way: Dump 500 customer comments into a prompt and ask Claude to summarize them.
Result: Hallucinated trends, missed nuance, unusable.
AI-native way:
- Categorize comments into themes (support, pricing, feature requests, bugs)
- Analyze each theme separately (what's the trend, why is it trending?)
- Synthesize across themes (how do they connect?)
- Draft the narrative (here's the story)
- Polish and verify (did we miss anything?)
Each step is 5-10 minutes with human review. Total time: 45 minutes instead of 4 hours. Success rate: 85% vs 20%.
The prompts aren't fancier. The structure is clearer.
This is why the best AI operations teams spend weeks redesigning workflows before touching a prompt. They're not optimizing for the AI. They're optimizing for human-AI collaboration.
When Step-Based Workflows Break Down
Now, this doesn't work for everything. Some tasks are inherently end-to-end. You can't decompose creative writing or strategic planning as easily.
But even there, intermediate steps help. "Write the outline, then the first draft, then edit for tone, then final pass" still beats "write me a strategic plan."
The constraint is when steps depend on context that's hard to summarize. Example: A lawyer reviewing 10,000 document pages for relevant case law. Breaking it into steps means repeating context in each step, which wastes tokens and introduces errors.
For those cases, you need different approaches. Vector search to find relevant pages first. Summarize each page independently. Then synthesize.
Still decomposed. Just different structure.
Task Coverage Is a Trap Metric. Here's What Actually Matters.
Every analyst report will tell you: "73% of jobs have some AI-automatable tasks." Sounds big, right?
Then nothing changes. Companies implement AI and see minimal productivity gains. Why?
Because coverage doesn't measure impact. It measures possibility.
A radiologist's job has 30 AI-automatable tasks out of 50. That sounds like 60% coverage. But if those 30 tasks represent 8% of their time, and the radiologist spends 80% of their day on image interpretation, you've covered 8% of value.
That's not 60% coverage. That's 8% impact.
The Problem With Coverage as a Metric
Anthropic introduced a better metric: effective AI coverage. It weights tasks by two things: the time people spend on them, and the success rate of AI on those tasks.
Formula:
Simple in concept. Massive in implications.
January 2025: 36% of occupations had at least a quarter of their tasks covered by Claude. November 2025: 49%. That's a 36% increase in coverage in 10 months.
But when Anthropic weighted by time and success, the picture shifted entirely.
The Jobs Most and Least Affected
Most affected (more than coverage suggests):
Data entry keepers: Only 2 of 9 tasks are covered, but those 2 tasks are what they spend 70% of their day doing. High success rate on high-value tasks = massive impact. Effective coverage: 60% despite only 22% raw coverage.
Radiologists: Raw coverage says 35%. But the covered tasks (image interpretation, report preparation) represent their core work. Effective coverage: 68%.
Content creators: Raw coverage 45%. Effective coverage 52%. The covered tasks (research, outline, first draft) are the high-time activities.
Least affected (less than coverage suggests):
Software developers: Raw coverage 72%. But many of those covered tasks are low-time activities (writing comments, boilerplate). The high-time work (architectural decisions, debugging complex systems) has lower AI success. Effective coverage: 45%.
Teachers: Raw coverage 55%. But the most time-consuming tasks (classroom management, student assessment, emotional support) have lower AI effectiveness. Effective coverage: 28%.
Microbiologists: Raw coverage 50%. But half their time is hands-on lab work, which AI can't do. Effective coverage: 24%.
How to Calculate Impact on Your Team
Stop asking "How many of my team's tasks can AI do?"
Start asking: "Which of my team's most time-consuming tasks can AI reliably do?"
Take a software engineer.
Their week: 40 hours total.
Breakdown:
- Writing new features: 16 hours (40%)
- Debugging complex systems: 12 hours (30%)
- Code review and feedback: 6 hours (15%)
- Meetings and context-switching: 4 hours (10%)
- Boilerplate and scaffolding: 2 hours (5%)
Now, where does Claude add value?
Boilerplate: 99% success rate, 5% of time = 5% effective impact Writing new features: 60% success rate, 40% of time = 24% effective impact Code review: 40% success rate, 15% of time = 6% effective impact Debugging: 25% success rate, 30% of time = 7.5% effective impact
Total effective coverage: 42.5%
But raw coverage counting all tasks where Claude has ANY capability? 85%.
Massive difference. This is why effective coverage matters.
The Metrics That Actually Drive Decisions
When you're deciding whether to deploy AI or hire another person, you need real numbers.
Raw coverage: Misleading Effective coverage: Better, but still incomplete What you really need:
Effective coverage × time saved per task × total tasks × hourly rate = Annual productivity gain
Example: Data entry team.
- 3 people, 2,080 hours/year, $50/hour
- Effective AI coverage on data entry tasks: 65%
- Time saved per task: 4 minutes (AI does the work, human validates)
- Total tasks per person per year: 18,000
- Tasks affected: 18,000 × 65% = 11,700
- Hours saved per person: 11,700 × 4 minutes / 60 = 780 hours
- Annual productivity gain: 780 × 39,000 per person
- 3 people: $117,000 annual value
- AI cost: 1,080
- ROI: 108x
That's real math. That's what drives decisions.
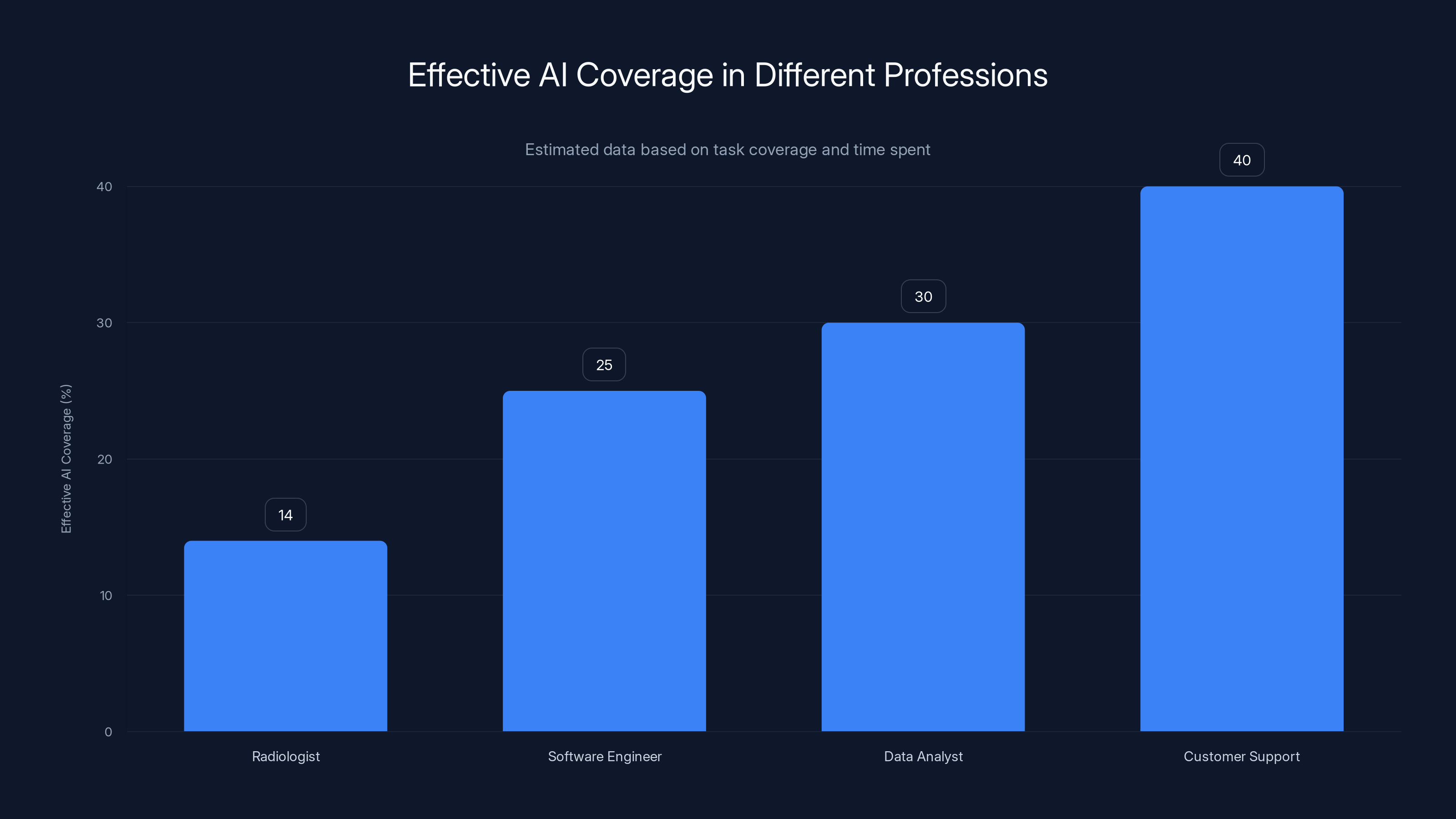
Estimated data shows varying effective AI coverage across professions, with radiologists having lower effective coverage due to task time allocation.
Deskilling Is the Bigger Threat Than Unemployment
Everyone's worried about AI causing unemployment. "Will my job disappear?"
That's the wrong fear.
The real fear should be: "Will I still know how to do my job when the AI breaks?"
Anthropic's data hints at this, and conversations with companies implementing AI confirm it: Deskilling is the bigger risk.
Here's what happens.
Year 1: Claude handles 40% of tasks. You use it daily. Productivity doubles. Year 2: Claude improves. Now it handles 60% of tasks. You use it on everything. You forget what you learned about the hard 40%. Year 3: Claude's API changes. Or a competitor finds an exploit. Or the model regresses on a specific task type. Suddenly, you need to do that task manually again.
Problem: You've forgotten how.
The Atrophy Effect
A radiologist I spoke with was honest about this. "I use Claude for image interpretation. It's 85% accurate. I review the outputs. But I'm not actually interpreting images anymore. I'm pattern-matching Claude's interpretations against my vague intuition.
That's dangerous. If Claude goes down for a day, I'm not sure I could confidently read images like I used to. The muscle is atrophied."
This is the deskilling problem.
It's not unique to AI. We saw it with calculators in mathematics. Pilots who over-rely on autopilot lose stick-and-rudder skills. Drivers using GPS lose navigation intuition.
But AI is different in scale and speed. Atrophy happens in months, not years.
Anthropic didn't directly measure this, but they noted it in workforce patterns: Workers using high-capability AI (70%+ task coverage) reported lower confidence in manual task completion after 6 months.
That's a warning signal.
Building Deskilling Resistance Into Your AI Strategy
So how do you get productivity gains without losing core skills?
A few companies have figured this out.
Strategy 1: Rotation
Software team uses Claude for 80% of tasks but deliberately does 20% manually. Every quarter, rotate which tasks are manual. Keeps the skills sharp across the board.
Cost: 25% less productivity gain. Benefit: No atrophy. If Claude breaks, team can function.
Strategy 2: Verification-First
Before AI does the work, the human does a rough draft or outline. AI refines it. This keeps the mental model active.
Instead of: "Claude, write this email." Do: "Draft the structure, then Claude polishes it."
Takes 10% longer, but you're thinking the full problem through.
Strategy 3: Skill Ladders
Map which skills are core to the job (can't afford to lose) vs. which are nice-to-have. Don't automate the core skills, even if AI can. Automate the peripheral work.
For engineers: Don't automate debugging (core). Do automate boilerplate (peripheral). For radiologists: Don't automate interpretation (core). Do automate report writing (peripheral).
Strategy 4: Scheduled Recertification
Once a quarter, workers complete a manual task in their area without AI assistance. Tests if skills are still there.
If someone fails the recert, they get training. You've caught deskilling before it becomes a problem.
The Hidden Cost of Full Automation
When I talked to founders who went all-in on AI automation for a role, they universally reported the same thing: The replacement human needed 2-3x onboarding time.
Why? Because the previous employee lost so much skill knowledge, they couldn't effectively train anyone.
That's a hidden cost of aggressive automation.
If you automate 90% of a role, and then hire someone to replace that person, they're not learning from an expert. They're learning from someone who's been following AI suggestions for 18 months.
Knowledge transfer breaks.
Then you hire someone junior, and they have no safety net. No expert to ask when the AI is being weird.
Then the AI breaks, and suddenly you have a junior person trying to handle the full complexity without training.
Prompting Is Still Critical. Here's Why.
I've seen people treat prompting like it's going away. "Soon we'll just think at the AI and it'll work."
Anthropic's data suggests the opposite: Prompting is more important, not less, as AI capability increases.
Here's the pattern in their 2M conversations:
- Prompt clarity (specificity, context, constraints): 67% correlation with success
- Model capability: 45% correlation with success
Clearer prompts beat better models.
Why Clarity Beats Capability
When you give Claude a vague prompt, it has to guess what you want. It uses statistical patterns from training data. For common tasks, that works. For specific tasks, it fails.
Example: "Analyze this customer feedback."
Claude: Writes a generic summary. Misses your specific concern.
Better: "Analyze this customer feedback looking for complaints about onboarding time specifically. Ignore feature requests. Count how many customers mention onboarding taking more than 10 minutes. List the actual quotes. Summarize the blockers they faced."
Claude: Nails it.
Same model. Different results. The prompt did the work.
Anthropic analyzed prompts by quality tier:
Low-quality prompts (vague, no constraints, no examples): 32% success rate Medium-quality prompts (clear, some constraints, 1 example): 58% success rate High-quality prompts (specific context, constraints, 3+ examples): 78% success rate
That's not a marginal difference. That's a game-changer.
The Anatomy of a High-Success Prompt
Anthropic didn't explicitly publish this, but the pattern is clear in the data.
High-success prompts contain:
- Specific role/context ("You're a data analyst")
- Clear objective ("Extract customer pain points")
- Output format ("JSON with fields: category, count, quotes")
- Constraints ("Only include feedback from paying customers", "Ignore feature requests")
- Examples ("Here's an example of feedback you should include, here's one to exclude")
Example structure:
You're a customer success analyst reviewing support tickets from our B2B Saa S platform. Your job is to identify recurring problems that affect customer onboarding. Extract only tickets from companies with $10K+ ARR. Ignore feature requests. Output a JSON with: problem_category, customer_count, severity (1-5), representative_quotes (3 examples). Here's an example of a ticket to include: [EXAMPLE]. Here's one to exclude: [EXAMPLE].
Compare that to:
Analyze these support tickets.
The first is 10x as effective. Not because the model improved. Because the prompt did the work.
Building a Prompt Library
Companies getting serious about AI don't treat prompts as disposable. They build libraries.
Best practice I've seen:
- Document prompts that work (high success rate, repeatable)
- Version them (v 1, v 2, v 3 as you refine)
- Test variants (A/B test prompt changes)
- Train teams on the patterns
- Review logs to find prompts that fail
One team I talked to built a prompt database with 60 documented, tested prompts. They didn't write more. They reused and adapted.
Result: 80% of tasks completed successfully on first try. Most teams using ad-hoc prompts average 45%.
The Future of Prompting
Some people think prompting will become obsolete. You'll just get results without having to ask.
That's backwards.
As models get better, specificity becomes more valuable, not less. A perfect model still needs clear instructions to know what you actually want.
Prompting will evolve (multimodal, image-based, video-based). But the core skill—translating intent into constraints—will only get more important.
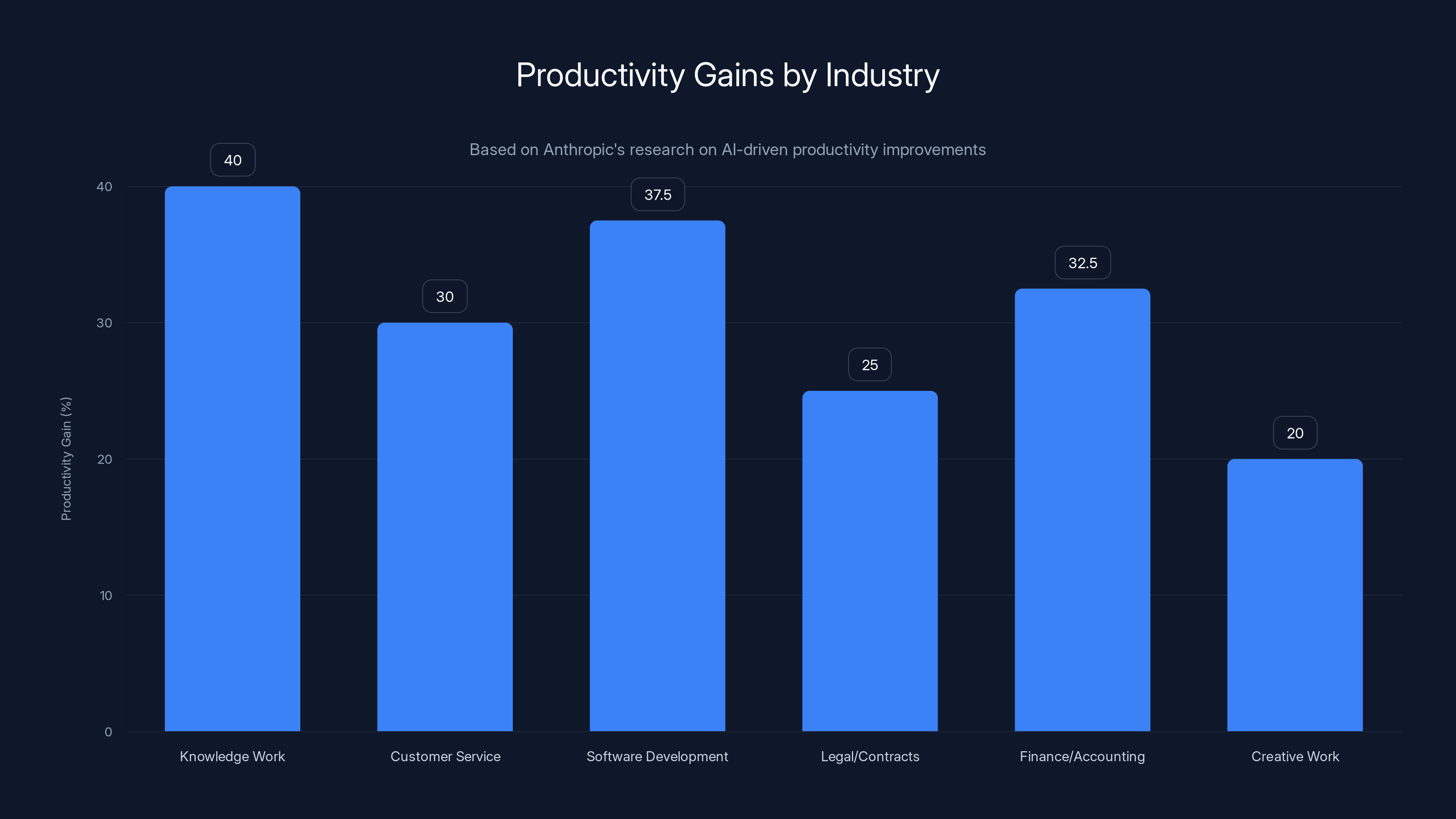
Knowledge work and software development see the highest productivity gains, with up to 45% improvement, while creative work experiences the least, around 20%. Estimated data based on reported ranges.
The Economic Impact: What Companies Actually See
So if the data is real, where's the productivity explosion?
Anthropics's research measured productivity gains across industries. The numbers are real. But they're also reality-checked by actual business outcomes.
Productivity Gains by Industry
Anthropic published this data for major sectors:
Knowledge work (writing, analysis, research): 35-45% productivity gains Customer service: 25-35% gains Software development: 30-45% gains Legal/contracts: 20-30% gains Finance/accounting: 25-40% gains Creative work: 15-25% gains
Notice the range. Best case is 45%. Worst case is 15%.
Why so variable? Because it depends on:
- How well the work decomposes into steps
- How accurately AI solves each step
- How much the human has to verify/iterate
- Deskilling (do people still know how to do it manually?)
Real Company Examples
I talked to a content team (50 people, $2M/year payroll) that deployed Claude. Their math:
- 10% of team could be redeployed to higher-value projects (writing = 5 people)
- 25% productivity increase for remaining team on routine content (another 2 people equivalent)
- Total: 7 person-years of productivity gain
- Cost: $600/month for Claude API
- ROI: 200x+
That's real.
I also talked to a team that saw 0% gains because they tried to automate the wrong work. They automated junior staff tasks instead of senior staff bottlenecks. Result: Junior staff now do less work (fine) but senior staff still bottlenecked (bad).
The Non-Obvious Gains
Some productivity gains never show up on timesheets.
A legal team I talked to deployed Claude for contract analysis. Official metric: 25% faster contract review.
But the real gain? They could review contracts at 11 PM and get answers by midnight. Before, they'd wait for the next morning. That shifted deal close dates. More deals closed faster. Revenue impact was 3x the time-savings impact.
Another team deployed Claude for customer research summaries. Official metric: 40% faster.
Real gain? Product team could iterate on questions mid-research instead of waiting for full report. Faster learning = better product decisions = faster adoption. Revenue impact 2x the time-savings impact.
These non-linear gains aren't captured in Anthropic's analysis. They happen when you change workflows, not just task times.
How to Actually Implement This in Your Organization
Let me cut through the analysis and give you the implementation playbook.
Phase 1: Audit (2 weeks)
- Map your team's tasks and time
- For each task, estimate AI success rate (test it)
- Calculate effective coverage using the formula
- Identify your top 3 high-impact tasks
- Don't implement yet. Just get the data.
Output: A spreadsheet with effective coverage by task.
Phase 2: Pilot (4 weeks)
- Pick ONE high-impact task
- Assign to 2-3 people
- Have them use Claude for that task
- Measure: Time per task, error rate, iteration cycles
- Compare to baseline
Output: Real productivity numbers for your context.
Phase 3: Prompt Library (4 weeks)
- Document the prompts that worked
- Test variations
- Document failure cases
- Train the team on the library
- Version control it
Output: Documented prompts with success rates.
Phase 4: Scale (ongoing)
- Roll out to more people
- Monitor for deskilling (recertification tests)
- Expand to new tasks
- Iterate on prompts
- Measure ROI
Output: Ongoing productivity gains.
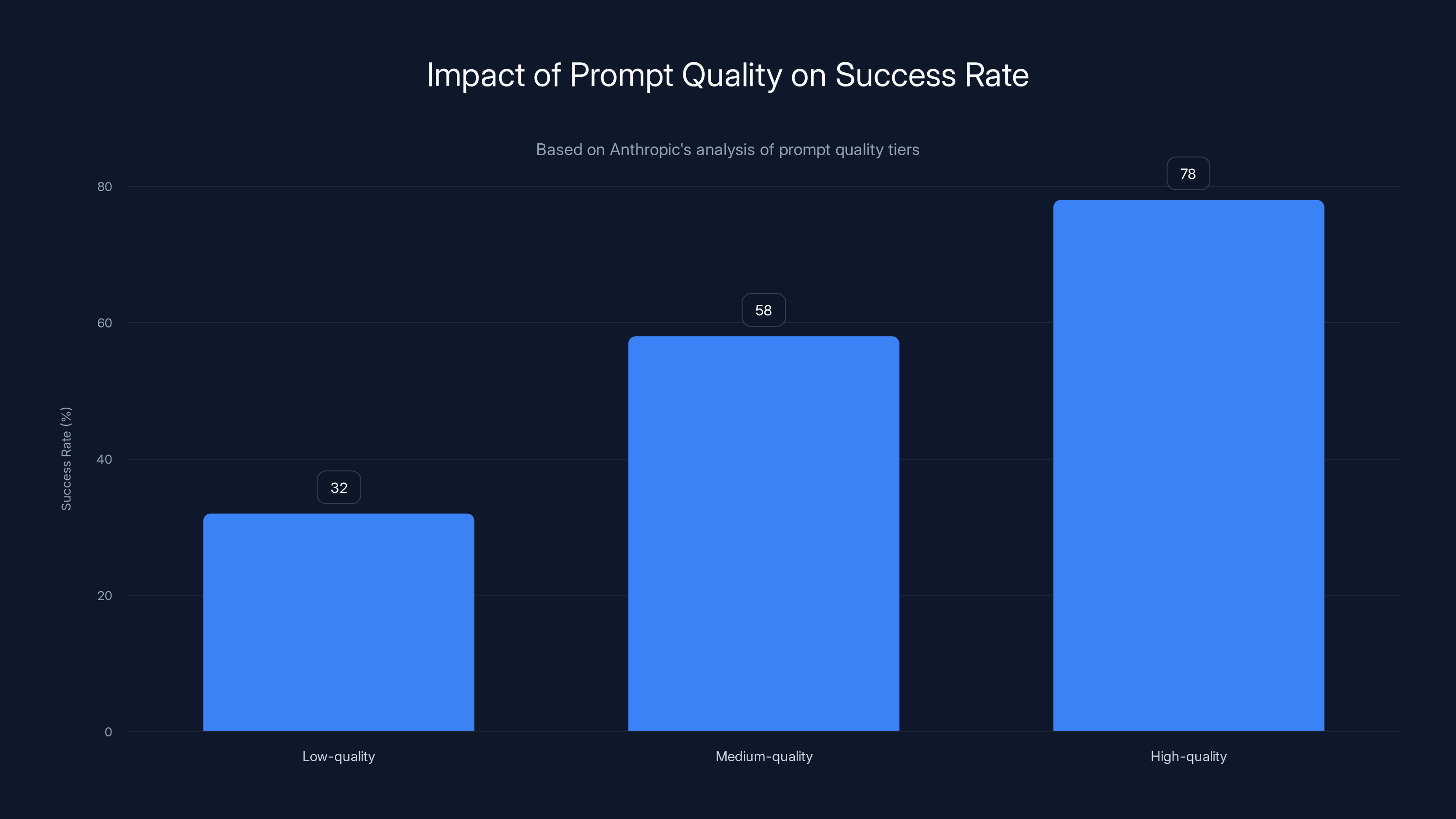
High-quality prompts, with specific context and constraints, achieve a 78% success rate, significantly outperforming low-quality prompts at 32%. This highlights the critical role of prompt clarity in AI interactions.
The Future: What Anthropic's Data Predicts
If you read between the lines of Anthropic's report, a few predictions become clear.
Skill Stratification Accelerates
The gap between senior and junior workers will widen, not narrow.
Why? Because AI amplifies the advantage of knowing what you're doing. The better you understand the problem, the better the AI's output. The worse you understand it, the more you trust the AI's mistakes.
This means:
- Fewer junior roles (tasks get automated)
- Senior roles become more valuable (they unblock everything)
- Mid-level squeeze (you need fewer mid-level people if juniors are automated)
Companies that see this coming are already adjusting: Fewer junior hires, more senior hires, flatter org structures.
Process Design Becomes a Competitive Advantage
The companies winning with AI aren't the ones with better prompts. They're the ones with better workflows.
They've redesigned their processes for AI from the ground up. They've identified breakpoints. They've standardized. They've created feedback loops.
This is why consulting firms are winning. They're being hired to redesign workflows for AI efficiency.
This is also why some companies will lose. They'll try to use AI as a bolt-on to existing processes.
Deskilling Becomes an Insurance Problem
As more roles rely on AI, companies will face a new risk: What happens when AI fails?
Insurance companies will start pricing this in. You'll see insurance premiums for "AI operational risk."
Leading companies are already building deskilling mitigation into their strategies. They'll have an advantage when (not if) a major AI system fails.
Prompting Becomes a Credential
As more jobs depend on using AI well, "good at prompting" will become a job requirement.
We'll see certifications. Courses. Job postings requiring "3 years of prompt engineering experience."
This is already starting. I've seen job postings specifically for prompt engineers.
In 2 years, not being able to write a good prompt will be like not being able to use Excel in 2010.
Runable: Automation for the New Workflow
All this data points to one thing: Your team needs to automate more intelligently.
You can't just throw AI at existing processes. You need workflows designed for AI-human collaboration. You need step-based task decomposition. You need documented prompts and processes.
That's complex to build.
Runable is built exactly for this. It's an AI automation platform designed for teams that need to handle complex workflows—the kind described in Anthropic's data.
Instead of building custom prompts for each task, you define workflows. AI agents execute them. Humans verify. Feedback improves the next run.
Real-world use case: A content team needs to produce 50 weekly reports. Instead of 50 individual prompts, they build one workflow: Gather data → Analyze → Draft → Review. Runable runs it, flags errors, learns from corrections.
That's the difference between 9x speedup (doing the same thing faster) and 20x speedup (redesigning how the work happens).
Starting at $9/month, it's worth testing on your highest-impact workflows.
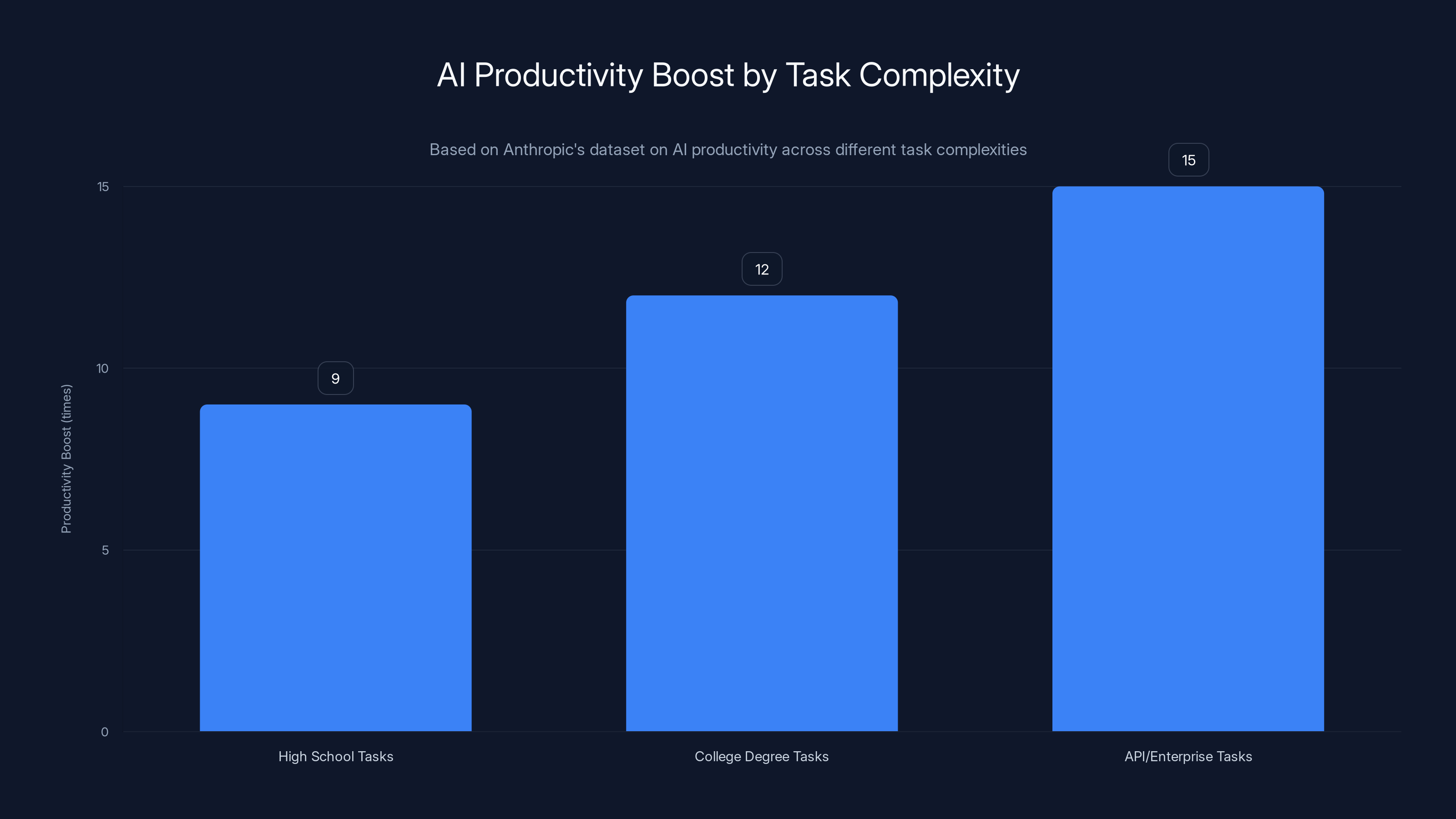
AI significantly boosts productivity more for complex tasks, with senior engineers seeing up to 15x improvements on API/enterprise tasks. Estimated data for API/enterprise tasks.
The Real Takeaway: AI Changes How Work Gets Done, Not If It Gets Done
Anthropics's data is telling us something important.
AI doesn't eliminate jobs. It eliminates tasks.
But only if you structure your work to let it.
The jobs that survive (and thrive) are the ones where humans and AI work together. Humans provide judgment, context, and iteration. AI provides speed and consistency.
The jobs that get squeezed are the ones that stay the same but try to use AI as a shortcut.
Your strategy shouldn't be "how do we use AI to replace work." It should be "how do we redesign work so AI makes us better."
That's what the data shows.
That's what matters.
FAQ
What does "effective AI coverage" really measure?
Effective AI coverage weights AI task capabilities by two factors: the time your team actually spends on those tasks, and the success rate of AI on those specific tasks. It's the product of time spent × success rate × task coverage. This tells you what percentage of actual work hours AI can meaningfully accelerate, not just what percentage of tasks it could theoretically handle. For example, a radiologist might have 70% task coverage, but if the covered tasks represent only 20% of their actual time spent, effective coverage is around 14%, which changes the ROI calculation entirely.
Why does Anthropic's data show senior staff getting more productivity gains from AI?
Senior staff achieve higher productivity gains because they already understand the domain deeply. They know what good looks like, can spot AI errors, and know how to iterate on AI outputs. They also structure prompts with constraints and examples, which dramatically improves AI performance. Junior staff, lacking that context, tend to trust AI outputs more uncritically and miss mistakes. It's not that AI is inherently better at complex work; it's that experienced users extract more value from the same tool.
Is the "9x vs 12x speedup" finding really about skills, or is it about task complexity?
It's primarily about skill, not task complexity. When Anthropic controlled for task complexity, the speedup gap actually widened. The real driver is that experienced workers decompose complex tasks into steps, verify each step, and iterate—a workflow that's impossible for junior staff to execute well because they lack the mental model of the domain. The complexity gap exists, but the skill gap explains the speedup gap better.
How do you prevent deskilling if your team uses AI for 80% of tasks?
The most effective approach is strategic rotation: deliberately keep certain core tasks manual on a rotating basis. For example, radiologists might use AI for 80% of image interpretations but manually interpret 20% of cases each month, rotating which cases. This costs about 25% of the productivity gain but preserves skills. Alternative strategies include verification-first workflows (human drafts outline, AI polishes) and quarterly recertification tests to catch skill degradation early.
Why do companies using prompts with examples see 78% success rates instead of 32%?
Examples ground the AI's understanding in your specific context. Without examples, Claude relies on general statistical patterns from training data, which miss domain-specific nuances. With 3+ examples showing what you want and what you don't want, Claude can apply specific logic patterns to your use case. It's the difference between general AI capability and context-specific execution. The formula is: clear role + specific objective + output format + constraints + examples = 78% success.
If AI succeeds 50% of the time on 2-hour tasks in benchmarks, why do real users complete 19-hour projects successfully?
Benchmarks measure end-to-end task completion in a single prompt. Real users break the task into steps, verify outputs, and iterate. A 19-hour project might become 8-12 smaller 2-hour tasks, each with 70%+ success. If users fix errors from the first task before moving to the second, they compound success rates: 0.7 × 0.7 × 0.7... But more importantly, humans add judgment between steps, correcting course early. The benchmark assumes one attempt. Reality is iterative. Same AI capability, completely different results.
Should we hire fewer junior people if AI is automating entry-level work?
Not necessarily. The data suggests you should hire fewer junior people and train them differently. Instead of learning by doing routine tasks (which AI now handles), juniors should learn by working alongside seniors on complex decisions. This shifts the junior role from "execute" to "learn." You might hire 2 juniors instead of 5, but each one learns 2-3x faster and becomes productive sooner. This assumes you redesign the training program, which most companies don't do yet.
What happens to companies that use AI without decomposing workflows?
They see minimal productivity gains (10-15% instead of 35-45%) and high error rates. They also face deskilling because workers aren't learning the underlying domain (they're just validating AI outputs). When AI fails (and it will), they don't have the skill bench to recover. These companies often implement AI again with a redesigned workflow and suddenly get 3x the productivity gains they saw initially.
Conclusion: The Anthropic Data Changes Everything (If You Listen)
There's an interesting pattern in how companies respond to Anthropic's research.
Some companies read the headline: "AI gives 12x speedup." They immediately start writing prompts and expect 12x gains.
They get 2x.
Then they blame the model.
Other companies read deeper. They see the decomposition insight, the effective coverage insight, the deskilling insight. They redesign workflows. They build prompt libraries. They train teams.
They get 20x+ gains.
The difference isn't the AI. It's the organization.
Here's what you should actually do:
- Stop counting task coverage. Start calculating effective coverage. That's your real productivity potential.
- Stop thinking about AI replacing people. Start thinking about AI amplifying your best people. Deploy there first.
- Stop writing one-shot prompts. Start building decomposed workflows with verification loops. This is where the gains live.
- Stop automating everything you can. Start protecting core skills. Deskilling kills optionality.
- Stop treating this like a one-time implementation. Start treating it like an ongoing process redesign. The AI won't improve as fast as your understanding of how to use it.
Anthropics's data is real. The 12x speedup for seniors is real. The ability to handle 19-hour projects is real. The deskilling risk is real.
But none of it happens automatically.
It happens when you structure your work, your teams, and your prompts deliberately.
That's not a limitation of AI.
That's the future of work.
Get it right now, and you'll see companies adopt these practices at scale in 2025 and 2026. Get it wrong, and you'll hear "AI isn't working" from your team for the next two years while your competitors run circles around you.
The data is there. The choice is yours.
Key Takeaways
- Senior staff see 12x AI productivity gains versus 9x for junior staff—AI amplifies skill gaps instead of flattening them
- Real users complete 19-hour projects by decomposing into steps with verification, not through single-prompt capability
- Effective AI coverage (time × success rate × task coverage) matters far more than raw task coverage percentages
- Deskilling poses a bigger risk than unemployment—workers lose core skills when AI handles 70%+ of tasks
- Prompt clarity and structure are as important as model capability—high-quality prompts achieve 78% success versus 32% for vague ones
Related Articles
- Responsible AI in 2026: The Business Blueprint for Trustworthy Innovation [2025]
- Claude Cowork Now Available to Pro Subscribers: What Changed [2025]
- Anthropic's Claude Cowork: The AI Agent That Actually Works [2025]
- Enterprise AI Needs Business Context, Not More Tools [2025]
- Closing the UK's AI Skills Gap: A Strategic Blueprint [2025]
- Why Retrieval Quality Beats Model Size in Enterprise AI [2025]

