![ChatGPT Citing Grokipedia: The AI Data Crisis [2025]](https://tryrunable.com/blog/chatgpt-citing-grokipedia-the-ai-data-crisis-2025/image-1-1769382416144.jpg)
The Moment AI Stopped Being Neutral
Imagine asking your AI assistant a straightforward question and getting an answer pulled directly from an encyclopedia you've never heard of. That's what's happening right now with Chat GPT and Grokipedia.
This isn't just a technical glitch or a minor integration issue. This is a fundamental crack in how we think about artificial intelligence, bias, and the sources that train our most powerful models. When The Guardian started digging into Chat GPT's responses, they discovered something that should concern anyone relying on these tools: Open AI's flagship model is citing Grokipedia—Elon Musk's ideologically driven, AI-generated encyclopedia—when answering user questions.
Here's what makes this genuinely alarming. Grokipedia launched in October after Musk complained that Wikipedia exhibited bias against conservative viewpoints. That complaint might have merit in some contexts, but the solution Musk built came with its own set of serious problems. Reporters found that Grokipedia articles contained false claims about HIV/AIDS, offered justifications for slavery, and used outdated or offensive terminology for transgender people. Some articles appeared to be direct copies from Wikipedia, raising questions about whether this was even legitimate original work.
Yet somehow, this content is now flowing into Chat GPT responses. Not on topics where Grokipedia's bias has been proven wrong—like January 6th insurrection coverage or scientific facts. Instead, it's cited on obscure topics where users wouldn't think to verify the source. On a question about Sir Richard Evans, for instance, Chat GPT confidently cited information The Guardian had already debunked months earlier.
The deeper problem isn't just that one bad encyclopedia is getting cited. It's what this reveals about how AI training data works, who controls the narrative, and whether we've actually solved the bias problem or just reshuffled it into new configurations.
Let me walk you through what's actually happening here, why it matters more than the headlines suggest, and what it tells us about where AI is heading in 2025.
TL; DR
- Grokipedia citations in Chat GPT: Open AI's GPT-5.2 model cited Musk's conservative encyclopedia at least 9 times across different questions, introducing ideological bias into supposedly neutral AI responses.
- The bias problem didn't disappear: Grokipedia contains factually inaccurate claims, offensive language, and ideological justifications that would fail basic fact-checking.
- Silent integration of biased sources: Chat GPT isn't flagging Grokipedia as a source in obvious ways, meaning users get misinformation without realizing where it came from.
- Broader training data crisis: This reveals how little transparency exists in how AI models select and prioritize information sources during training.
- Competition between AI ecosystems: Musk's x AI and Open AI are now competing for data dominance, and Open AI appears willing to integrate competing platforms' content without proper vetting.

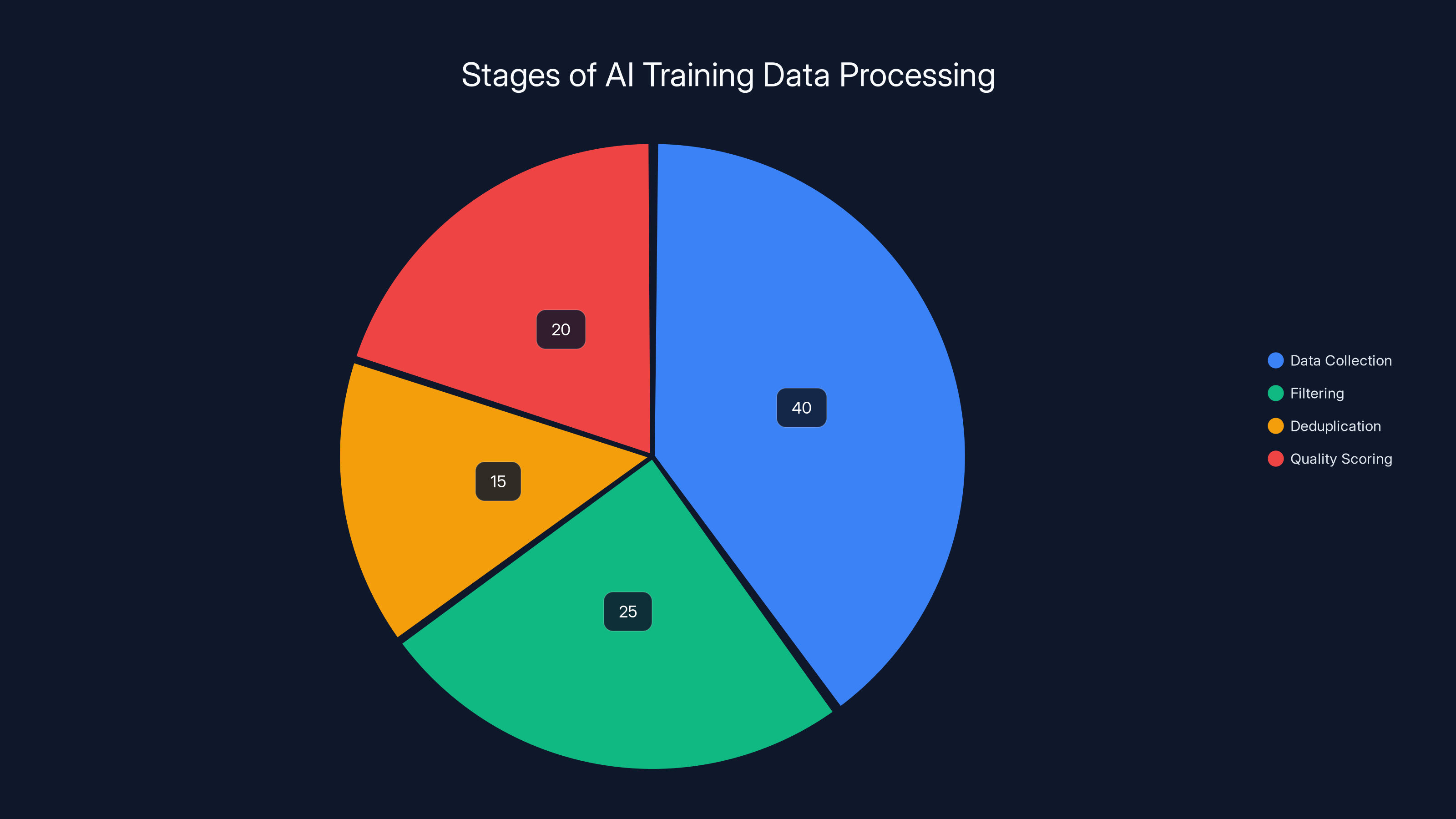
Estimated data shows that the majority of effort in AI training data preparation is spent on data collection, with significant portions also dedicated to filtering and quality scoring. (Estimated data)
Understanding Grokipedia: Why Musk Built It
You can't understand what's happening with Chat GPT without knowing why Grokipedia exists in the first place.
Elon Musk has spent years complaining that Wikipedia is biased. That Wikipedia has a political lean—particularly on certain cultural and political topics—is defensible. Wikipedia's volunteer editor base does skew toward particular demographics and viewpoints. But Musk didn't just complain on X. He funded x AI and greenlit Grokipedia as the solution.
The pitch was simple: build an AI-generated encyclopedia that offered alternative perspectives. Counter the bias. Give conservative viewpoints fair representation.
Except that's not what happened.
When Grokipedia launched in October 2024, journalists immediately started testing it. What they found was a mess. Some articles were nearly identical to Wikipedia entries—copy-paste plagiarism with different formatting. Other articles contained claims that were simply false or outdated. On topics like the AIDS crisis, Grokipedia suggested pornography was a contributing factor, which contradicts decades of epidemiological research. On slavery, it offered what could generously be called "alternative perspectives" that read like ideological justifications.
Grokipedia also had a serious language problem. It used denigrating terms for transgender people. It offered cultural commentary that would make most editorial boards wince.
None of this was hidden. It was public. Anyone could access it and verify these issues. Yet somehow, this content is being pulled into Chat GPT's training data and response generation.
The question isn't whether Grokipedia has problems. It clearly does. The question is: why would Open AI allow it into the system at all?
How Grokipedia Ended Up in Chat GPT
This is where the mechanics of AI training become relevant.
Large language models like Chat GPT aren't manually written. They're trained on vast datasets scraped from the internet. Open AI uses common crawl data, academic papers, books, websites, and other publicly available information. The model learns patterns from this data and generates responses based on those patterns.
Grokipedia is public. It's indexed by search engines. It's available for crawling. So at some point—likely when Open AI updated their training data for newer versions of the model—Grokipedia got included.
The mechanism isn't surprising. What's surprising is that Open AI didn't filter it out.
When you train an AI model on diverse internet data, bias is inevitable. The internet contains bias. Wikipedia contains bias. News sites contain bias. Ideological perspectives from across the spectrum are present in training data. The question AI companies claim to grapple with is: how do you balance these perspectives?
Open AI's stated approach is to "draw from a broad range of publicly available sources and viewpoints." That's their official position. On its surface, it sounds reasonable. Don't exclude perspectives based on ideology. Include diverse voices.
But there's a difference between including diverse perspectives and including demonstrably false information. There's a difference between representing different viewpoints and platforming content that fails basic fact-checking.
Grokipedia doesn't represent a legitimate alternative perspective. It represents an ideologically motivated project that prioritizes narrative over accuracy.
And that's now being baked into the responses millions of people get from Chat GPT every day.
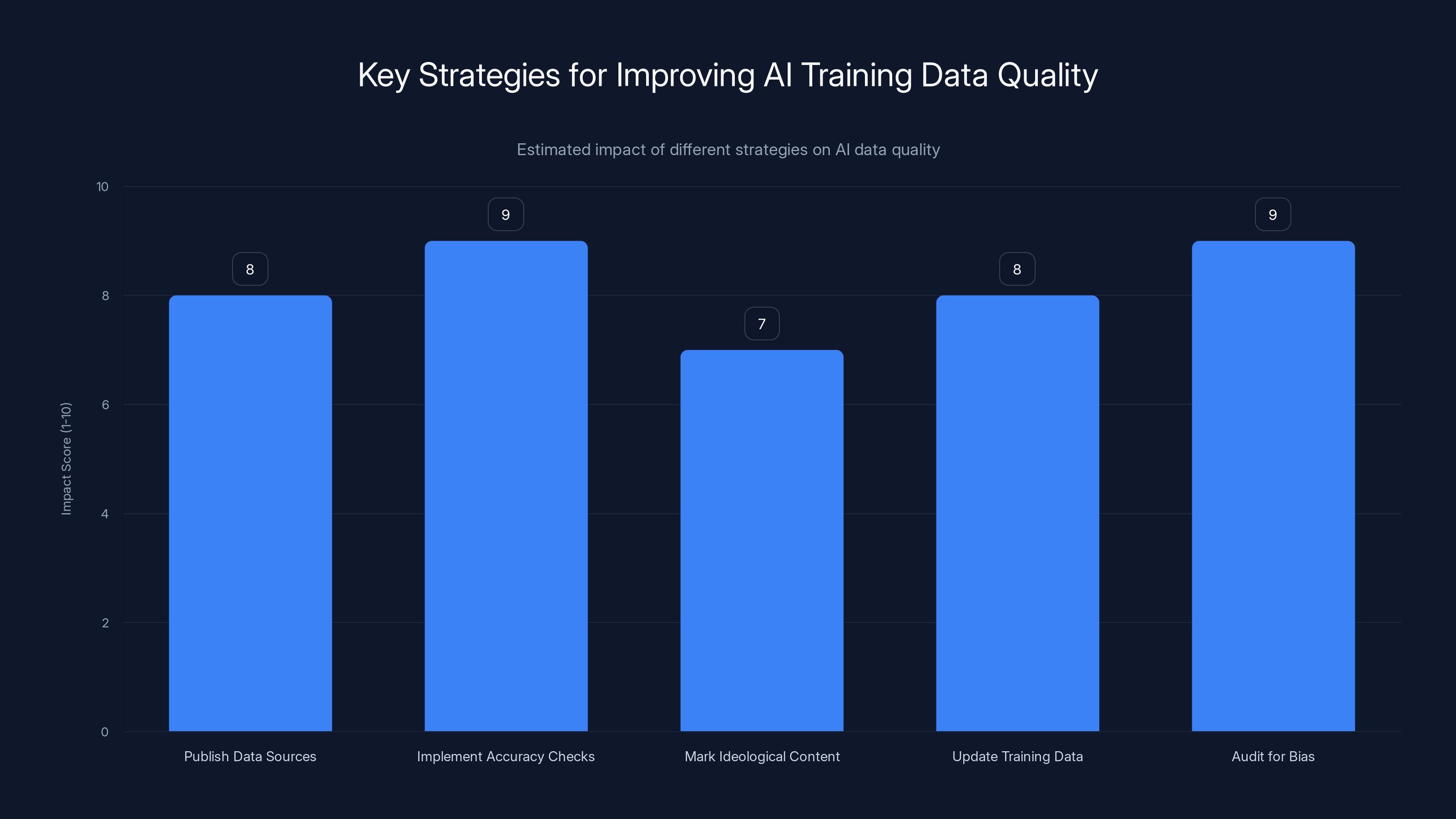
Implementing accuracy checks and auditing for bias are estimated to have the highest impact on improving AI training data quality. Estimated data.
The Guardian's Investigation: What They Found
The Guardian started investigating after noticing GPT-5.2 citing sources they couldn't verify. Once they dug deeper, they realized those sources were often from Grokipedia.
Their methodology was straightforward. They asked Chat GPT questions across different topic areas and examined the sources it cited. When they compared those citations to the original sources, they found discrepancies.
One example: a question about historian Richard Evans. Chat GPT cited Grokipedia as the source for a claim about Evans. When The Guardian checked, they found they'd already debunked that exact claim months earlier. So Chat GPT was citing information that was known to be false.
This is critical. Chat GPT wasn't just citing a conservative-leaning source. It was citing information that had already been publicly demonstrated to be inaccurate.
The Guardian also tested whether Chat GPT avoided citing Grokipedia on topics where its bias has been widely documented and criticized. On January 6th—a topic where Grokipedia's coverage is particularly problematic—Chat GPT didn't cite Grokipedia. Same with topics about the AIDS epidemic.
That's interesting because it suggests Open AI knows which topics are politically sensitive. Yet on obscure topics where users wouldn't think to fact-check, Grokipedia citations appeared regularly.
The pattern suggests something more troubling than simple data inclusion. It suggests either Open AI's systems flagged certain topics as problematic but not others, or the model learned from training data which topics would attract criticism. Either way, users are getting misinformation without knowing it.
The Bias Problem Wasn't Solved, Just Redistributed
Here's the philosophical problem underlying all of this.
When Musk complained that Wikipedia was biased, he wasn't entirely wrong. Wikipedia does have bias. Its structure—volunteer editors, community voting, edit wars between people with different ideologies—creates systematic biases. On certain topics, Wikipedia skews left. On others, it's inconsistent.
But Musk's solution created a different set of biases. Instead of addressing Wikipedia's bias by making it more rigorous and transparent, he created a parallel encyclopedia with its own, arguably more severe biases.
The irony is that both encyclopedias are now being used to train the same AI models. So instead of solving the bias problem, the AI ecosystem now has multiple bias sources pulling in different directions.
For users, this is worse than having a single biased source. At least with Wikipedia, bias is somewhat predictable and community-driven corrections happen over time. With Grokipedia integrated into Chat GPT, users get biased information without transparency about where it came from or knowing they should fact-check it.
The real issue is this: we haven't solved the question of how to build neutral AI. We've just created a system where multiple ideological perspectives are baked in, and users have no way to know which answer came from which source.
When Chat GPT cites Grokipedia on an obscure topic, the user sees a confident answer backed by a source. They don't know that source is ideologically motivated and factually problematic. They assume Chat GPT has found legitimate information.
How AI Training Data Gets Contaminated
Understanding how Grokipedia ended up in Chat GPT requires understanding how AI training data actually works in practice.
Open AI doesn't manually curate every piece of information going into their models. That would be impossible at scale. Instead, they use automated systems to scrape, filter, and prepare data. The process involves multiple stages:
First, data collection. Models are trained on massive datasets scraped from the internet. Common Crawl is a common source—it's a publicly available index of most of the internet. Academic papers, books, websites all get included.
Second, filtering. Not everything on the internet goes into training. Open AI applies filters to remove obviously problematic content. NSFW material, copyright-protected documents, certain types of harmful content get excluded.
Third, deduplication. When the same content appears multiple times across the internet, it's consolidated so it doesn't disproportionately influence the model.
Fourth, quality scoring. Different sources get weighted differently. Academic papers might be weighted higher than random blogs. News from established outlets might be weighted higher than fringe sources.
Grokipedia fits into this pipeline as public content. It's not copyright-protected. It's not overtly NSFW. It's not obviously harmful in a way automated filters catch. It's a website with encyclopedia entries, so it passes initial screening.
Where it should have been caught is in quality scoring. If Open AI's systems included checks for factual accuracy, they should have identified Grokipedia as problematic. But either those checks don't work well, or Open AI deliberately chose to include it despite knowing its problems.
The more likely explanation is that quality checks are imperfect. Fact-checking content at internet scale is genuinely hard. You can't have humans verify every source. Automated fact-checking catches obvious problems but misses subtle ones.
Grokipedia's claims are sometimes factually false (the AIDS claims) but often just ideologically biased. Detecting ideological bias automatically is much harder than detecting factual falsity. An automated system might flag "2+2=5" but might not catch a source that's technically accurate but presented through a particular ideological lens.
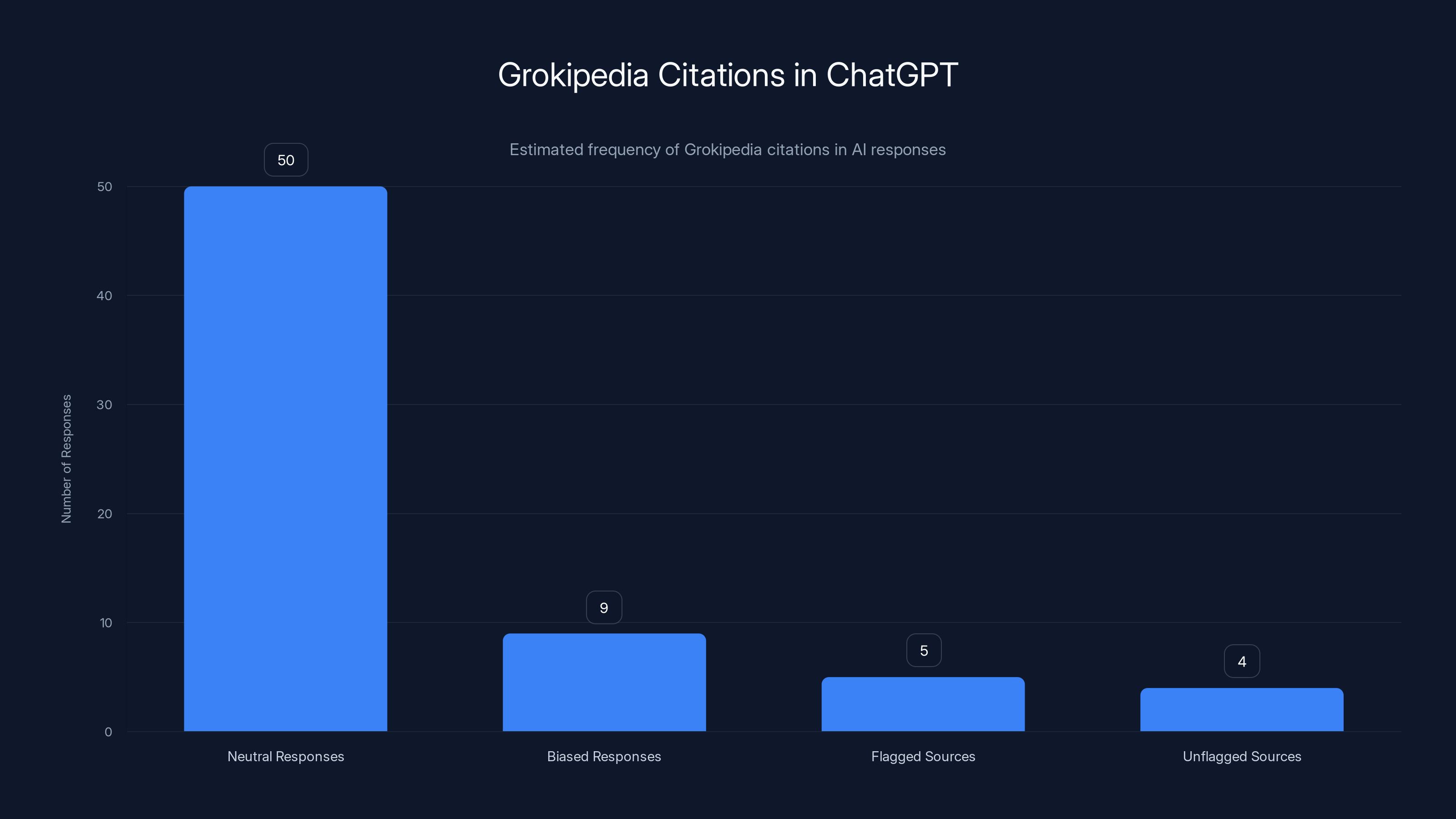
Estimated data shows that Grokipedia was cited in 9 biased responses, highlighting integration issues with unflagged sources.
The Anthropic Connection: Claude Has the Same Problem
The Guardian also found that Anthropic's Claude is citing Grokipedia to answer some queries.
This is important because it suggests the problem isn't unique to Open AI. If multiple AI companies are pulling Grokipedia into their systems, that indicates broader issues with how training data is sourced and validated across the industry.
Anthropic positions itself as more ethical than Open AI. They talk about alignment, safety, and careful data sourcing. Yet Claude is also pulling from Grokipedia.
That suggests either Anthropic faces the same data quality challenges as Open AI, or they're making deliberate choices about source inclusion that we don't fully understand.
We know less about Anthropic's training data process than Open AI's. Open AI has published some information about their data sourcing. Anthropic has been more secretive, citing safety concerns about revealing exactly how their models are trained.
But the Grokipedia citations in Claude suggest that whatever Anthropic's process is, it's also including problematic sources.
This points to a systemic issue across the AI industry. Companies aren't properly vetting the sources that go into their training data. They're applying filters for copyright and NSFW content, but they're not effectively filtering for accuracy or ideological bias.

Why This Matters: The Trust Problem
Most people don't realize Chat GPT isn't a search engine with transparent sourcing. It's a language model that generates responses based on patterns in training data.
When Chat GPT cites a source, that citation should theoretically indicate that the model found information in that source during training. But the connection between what's in the training data and what gets cited in a response isn't perfectly traceable. The model learns patterns from thousands of sources and synthesizes responses without explicitly consulting each source.
So when Chat GPT cites Grokipedia, it's not necessarily because it pulled the exact citation from a database. It's because patterns learned from Grokipedia influenced the response.
This is subtle but important. It means users get information influenced by biased sources without knowing the influence is happening.
The trust problem is massive. People use Chat GPT for research, for learning, for fact-checking. They assume the model has been trained on reliable sources. If Grokipedia is influencing responses, that assumption is violated.
And if Grokipedia is in there, what else is? What other ideological projects have made their way into training data? What other sources with hidden agendas are influencing the model's responses?
Open AI could address this. They could be transparent about which sources are included in training data. They could publish an audit of sources and their biases. They could implement stronger filters for factual accuracy.
They haven't. And that's a choice.
The Ideology Wars: Why This Is Happening Now
Grokipedia exists because Musk wanted an alternative to Wikipedia. That's not a secret. Musk has been explicit about his frustrations with what he sees as Wikipedia's bias.
But there's a deeper story here about competition between AI ecosystems.
Open AI and x AI are competitors. Open AI is dominant, but x AI is building alternative models (Grok) that position themselves as less censored, more politically neutral, and more aligned with conservative perspectives.
If Musk can get Grokipedia into Chat GPT's training data, that serves x AI's interests. It means his content shapes how Open AI's models respond. It means Grok doesn't have to be objectively better—x AI just has to make sure their perspective gets into everyone's model.
From Open AI's perspective, including diverse sources—even controversial ones—is politically safer than explicitly excluding certain perspectives. If Open AI said "we're not using Grokipedia because it's ideologically biased," they'd face criticism from Musk and conservatives who'd claim they were silencing alternative viewpoints.
But by including Grokipedia without highlighting that they're doing so, Open AI gets the worst of both worlds. They get accused of bias anyway (by conservatives who say they're excluding right-wing perspectives) AND they accidentally give credibility to factually problematic sources.
It's a no-win situation created by the polarized media landscape and the competition for AI dominance.
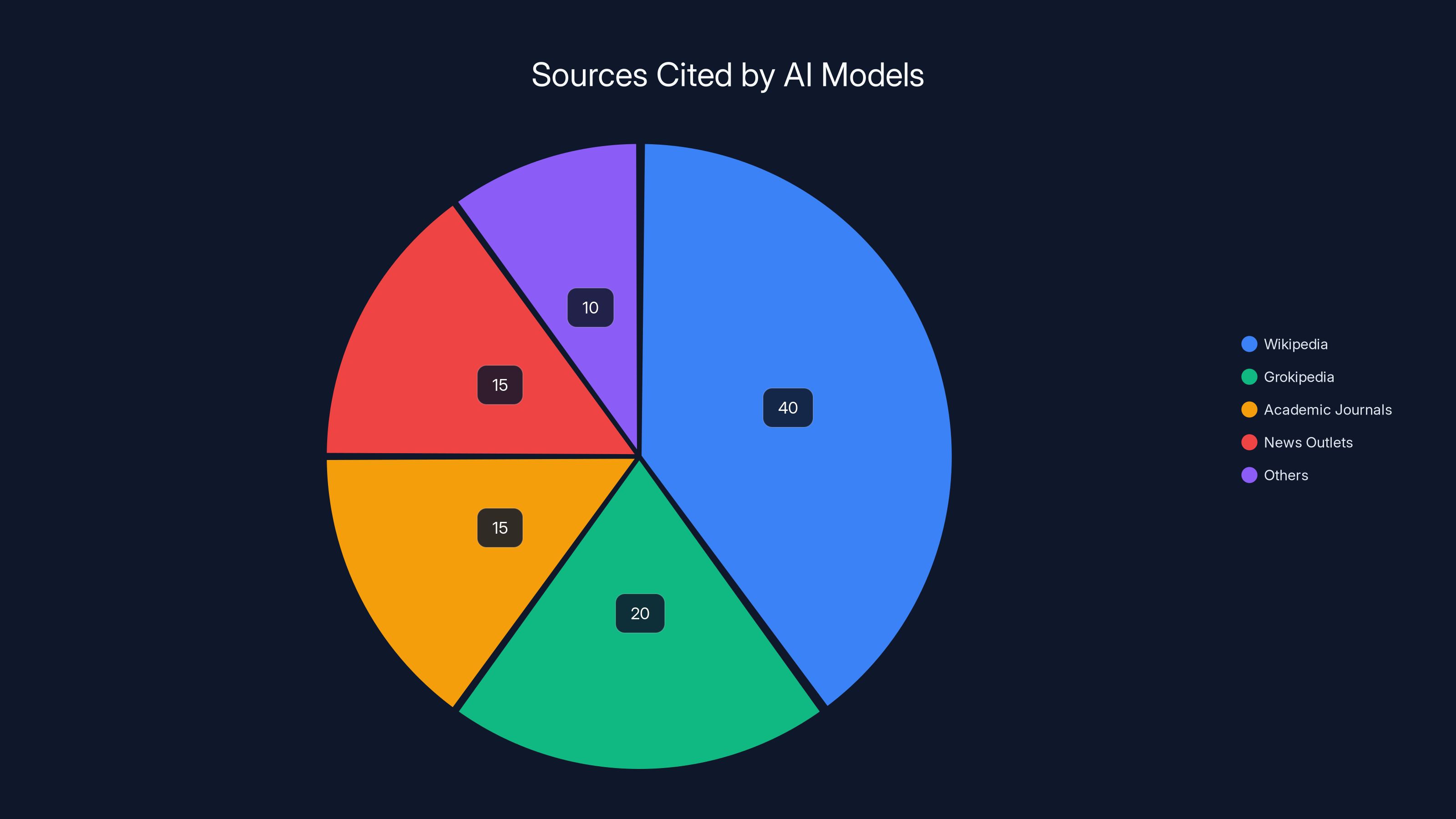
Estimated data suggests that while Wikipedia remains a primary source, new entries like Grokipedia are gaining traction, raising concerns about bias and accuracy.
The Broader Data Sourcing Crisis
Grokipedia isn't the only problematic source in AI training data. It's just the one that got caught.
Consider all the data that goes into these models. Academic papers are included, but so are blog posts from people with no expertise. News articles from reputable outlets are included, but so are opinion pieces that read like journalism. Reddit threads with thousands of upvotes influence the model's understanding because upvotes signal importance, not accuracy.
Wikipedia is included, which means its biases are baked in. But so is content from ideologically motivated websites on both sides of the political spectrum. Some of that content is factually wrong. Some is technically accurate but presented through a lens designed to influence.
AI companies don't have perfect ways to distinguish between legitimate alternative perspectives and ideological misinformation. So they default to inclusion. Better to include diverse viewpoints than to risk accusations of censorship.
But that approach means AI models end up as Frankenstein repositories of everything on the internet, good and bad, true and false, accurate and misleading.
The solution isn't to exclude all biased sources. Everything is somewhat biased. The solution is transparency and quality standards.
Companies should:
-
Publish their data sources: Users deserve to know what's in training data. If Grokipedia is included, say so explicitly.
-
Implement accuracy checks: Before including sources, verify their factual claims. Flag sources with known inaccuracies.
-
Clearly mark ideological content: If a source presents a particular perspective, label it as such. Let models learn from it, but distinguish it from neutral reporting.
-
Update training data regularly: As sources are debunked or updated, training data should be refreshed. Old, inaccurate information shouldn't influence new models.
-
Audit for bias systematically: Don't wait for journalists to find problems. Proactively test models across sensitive topics and adjust training data accordingly.
None of this is happening at scale. Most AI companies treat their training data as proprietary secrets. They don't publish audits. They don't systematically test for bias. They react to criticism after the fact.
The Grok Factor: Is This Intentional?
Here's a question that deserves serious attention: did Open AI knowingly integrate Grokipedia into their training data?
The cynical answer is yes. Musk is on the board of Open AI... wait, actually he left the board years ago and has been publicly feuding with the company. So there's no insider connection driving this.
But there could be market pressure. If Grokipedia is public and widely accessed, it naturally ends up in common crawl. If common crawl is a major source for training data, Grokipedia gets included almost automatically.
The more charitable interpretation is that this happened unintentionally. Open AI's systems aren't sophisticated enough to distinguish between Grokipedia and other encyclopedia sources. They treated it like any other website and included it.
But that's not really a defense. Even if unintentional, the result is the same: factually problematic content is influencing Chat GPT's responses.
Open AI could have prevented this by being more selective about which encyclopedia-style sources go into training data. They could have excluded Grokipedia after learning about its quality issues. They could have de-weighted it after The Guardian's reporting.
They didn't. That suggests either incompetence (they don't have good systems for managing source quality) or indifference (they included it and didn't care about the implications).
Neither is good.

What This Means for AI Users
If you use Chat GPT regularly, what should you do with this information?
First, don't panic. Chat GPT is still useful. Having some biased sources in training data doesn't make the model useless. It makes it less reliable than you probably thought, but still functional.
Second, be skeptical. Treat Chat GPT's citations the same way you'd treat citations in any source. Verify them. Check whether the cited source actually supports the claim. Look for corroboration from other sources.
Third, understand the limitations. Chat GPT is trained on data up to a certain date and reflects biases present in that data. It's not neutral. It's not a truth oracle. It's a language model that generates plausible-sounding responses based on patterns in training data.
Fourth, use multiple sources. Don't rely on Chat GPT alone for important information. Cross-reference with other tools, publications, and experts.
Fifth, ask about sources. When Chat GPT cites something, ask follow-up questions about where that source came from and whether other sources agree.
Finally, push back on the companies. Contact Open AI and Anthropic. Tell them you want transparency about training data. Tell them you want better source vetting. Tell them you want models trained on explicitly verified, high-quality information rather than everything on the internet.
Companies respond to user pressure. If enough people demand better data sourcing practices, companies will implement them.
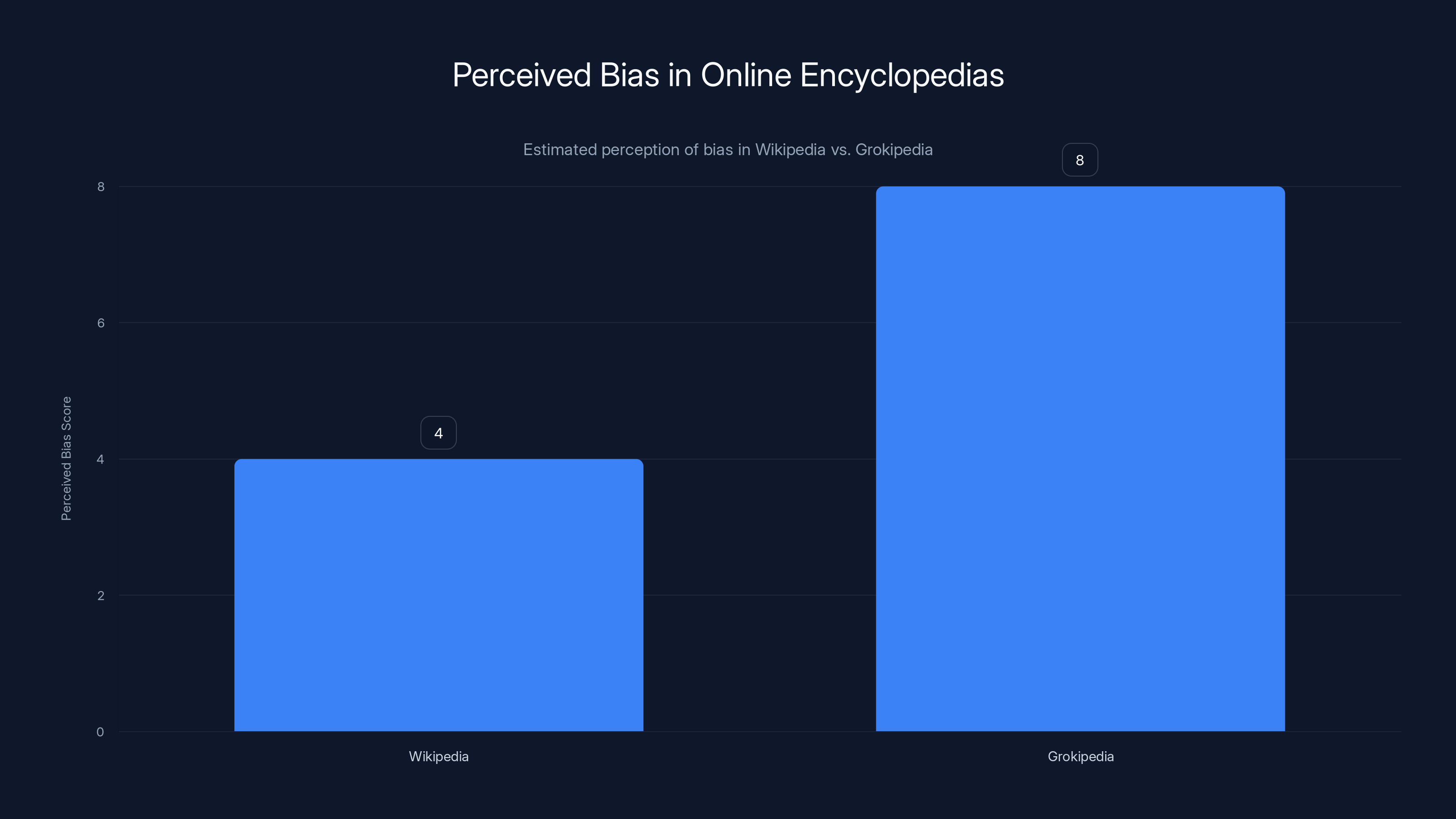
Grokipedia is perceived to have a higher bias compared to Wikipedia, with a score of 8 versus 4. Estimated data based on narrative descriptions.
The Competitive Landscape: Open AI vs. x AI vs. Anthropic
To understand why Grokipedia matters, you need to understand the competitive dynamics in AI.
Open AI dominates the consumer AI market. Chat GPT has hundreds of millions of users. But Open AI faces competition from multiple directions.
Google is building Gemini and has the advantage of owning the search infrastructure everyone uses. Meta is building Llama. Amazon is investing heavily in AI. But the most interesting competitor right now is Elon Musk's x AI.
x AI is building Grok, a chatbot positioned as an alternative to Chat GPT. Grok's pitch is different. It's less censored. It's more willing to engage with controversial topics. It's positioned as truth-seeking rather than politically correct.
Grokipedia supports this narrative. By having their own encyclopedia that includes perspectives not found in Wikipedia, Musk can claim Grok has access to different information than Chat GPT.
But here's where it gets interesting. If Grokipedia ends up in Chat GPT's training data, that undermines Grok's differentiation. Why use Grok if Chat GPT has access to the same sources?
From x AI's perspective, the goal is probably different. By getting Grokipedia cited in Chat GPT, Musk is essentially getting free distribution of his content. His perspective gets into millions of conversations happening with Open AI's model.
It's a form of soft power. You don't need to beat Chat GPT if you can influence what Chat GPT says.
Meanwhile, Anthropic is trying to position themselves as the ethical player. They emphasize safety, alignment, and responsible AI. But they're also citing Grokipedia, which suggests their ethics don't extend to careful source curation.
The lesson is that competition in AI is being fought at multiple levels. At the surface level, it's about model capability. Deeper down, it's about training data, sources, and influence over what information gets prioritized.
Grokipedia is a manifestation of that deeper competition.

The Verification Problem: How Do We Know What's True?
This whole situation highlights a fundamental problem in the age of AI: how do we verify what's true?
When information came from newspapers, you could evaluate the publication's credibility. When it came from textbooks, you could check the author's credentials. When it came from experts, you could verify their expertise.
But when information comes from an AI model trained on billions of sources, how do you know whether it's reliable?
You don't. Not directly. You have to trace it back to the original source. But AI models don't always make that tracing easy. Sometimes they cite sources, sometimes they don't. Sometimes the citations are wrong.
And even if citations are accurate, you still need to evaluate the source. Is it a primary source or secondary source? Is the author an expert or an opinion-haver? Was the information published recently or is it outdated?
AI companies are betting that users will just trust the model. That's the easiest outcome for them. But it's dangerous for everyone else.
The better approach is what The Guardian did: verify everything. Test the model with questions where you know the right answer. See whether it gets those right. If it does sometimes and fails other times, you've learned something about its reliability.
But most users don't have the expertise or time to do that. They just ask Chat GPT a question and assume the answer is right.
That's the real danger here. Not that Grokipedia is included in training data, but that millions of people will cite Chat GPT responses without ever verifying them.
Technical Solutions: How AI Companies Can Do Better
If AI companies wanted to address the Grokipedia problem, they could.
There are technical approaches that would make AI training data more transparent and reliable:
Source attribution: Instead of training on undifferentiated text, models could learn which information came from which source. Then when generating responses, they could transparently show which sources influenced their answer. This requires changing how models are trained, but it's possible.
Fact-checking layers: Companies could build systems that check claims made by the model against known facts before presenting them to users. If a claim doesn't match verified information, the model could flag it or adjust confidence levels.
Dynamic training data: Rather than training models once on a fixed dataset, companies could update training data continuously. When sources are debunked or new information emerges, training data gets updated. Models trained on fresher data would be more accurate.
Credibility scoring: Training data could be weighted by source credibility. Academic papers might count more than blog posts. Peer-reviewed research more than opinion pieces. This isn't perfect, but it's better than treating all sources equally.
Adversarial testing: Before releasing models, companies could systematically test them on topics where they're likely to encounter biased training data. They could identify problem areas and either fix the training data or add explicit corrections to the model.
Transparency reports: Companies could publish regular reports on what's in their training data, where bias has been detected, and what they're doing to address it. This would let researchers and users understand the limitations of the model.
None of these are technically impossible. They're mostly engineering challenges. The reason they're not being implemented is probably because they're expensive and companies don't want to invest in them unless forced.
But if enough users and researchers demanded better practices, companies would implement them.

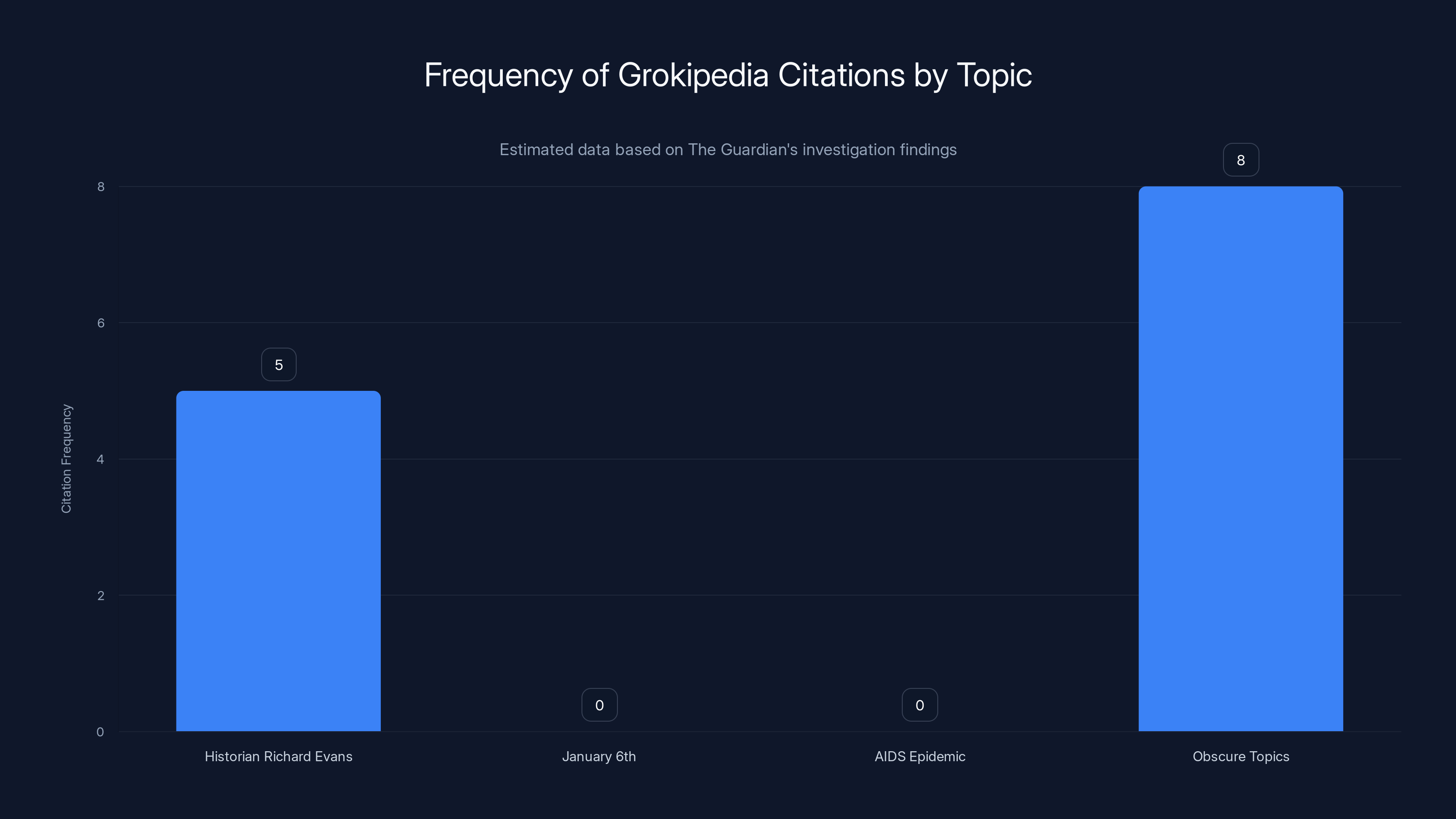
The Guardian found Grokipedia citations were frequent in obscure topics but absent in politically sensitive areas like January 6th and the AIDS epidemic. (Estimated data)
The Broader Implications: What This Means for AI Governance
The Grokipedia situation is a symptom of a larger problem: AI companies operate with minimal oversight.
They're free to choose which sources to use for training data. They're free to apply whatever filtering they want. They're free to change their practices whenever they choose. There's no regulator checking their work. There's no industry standard they have to meet.
This is starting to change. Governments around the world are developing AI regulations. The EU has the AI Act. The US is working on various proposals. Other countries are developing their own frameworks.
But most of these regulations focus on obvious harms: bias in hiring systems, discrimination in lending, deepfakes. They don't directly address the quality of training data in large language models.
They should.
Regulators should require:
-
Transparency about training data: Companies should disclose which sources are used, their relative weights, and known problems.
-
Data quality standards: Training data should meet minimum accuracy and reliability standards. Demonstrably false information should be excluded.
-
Bias audits: Models should be systematically tested for bias across sensitive topics. Results should be public.
-
Correction mechanisms: When errors or biases are discovered, companies should have clear processes for addressing them.
-
User disclaimers: Users should be informed about the limitations of the technology and the need to verify important information.
-
Researcher access: Independent researchers should be able to audit training data and model behavior without permission from the company.
These aren't radical proposals. They're basic good practices for any technology with significant social impact.
But implementing them requires cooperation from AI companies. And right now, they have no incentive to cooperate beyond what's minimally necessary to avoid criticism.
What Happens Next: The Future of AI Training Data
Grokipedia won't be the last problematic source to end up in AI training data.
As AI companies scale their models and expand their training data, they'll increasingly encounter sources that are biased, inaccurate, or ideologically motivated.
The question isn't whether this will keep happening. It will. The question is whether companies will get better at handling it.
Three scenarios seem plausible:
Scenario 1: The problem gets worse. Companies continue including diverse sources without proper vetting. More ideologically motivated projects like Grokipedia end up in training data. AI models become increasingly unreliable for factual questions because they're trained on too much misinformation.
Scenario 2: Companies tighten up voluntarily. Facing criticism and competition, AI companies improve their data sourcing practices. They implement better filtering, fact-checking, and transparency. Models become more reliable as companies filter out obviously problematic sources.
Scenario 3: Regulation forces improvement. Governments mandate data transparency and quality standards. Companies implement better practices because they have to, not because they want to. Standards improve across the industry.
My guess is we'll see a mix of Scenarios 2 and 3. Some companies will improve voluntarily to gain competitive advantage. Regulators will eventually establish standards that force others to improve.
But the next few years will probably see continued problems as training data quality lags behind model capability.
Users should adjust their expectations accordingly. AI is useful, but it's not reliable enough to trust completely. Verify important information. Cross-reference sources. Think critically about what AI tells you.
The technology is advancing faster than our ability to ensure it's trustworthy. That's a problem we're all going to have to navigate.
The Specific Harms of Grokipedia in Training Data
Let's get concrete about what it means that Grokipedia is influencing Chat GPT's responses.
Grokipedia contains false claims about public health. If someone uses Chat GPT to research HIV/AIDS transmission, they might get influenced by Grokipedia's false claims about pornography's role in the epidemic. That's not just inaccurate—it could influence health decisions.
Grokipedia contains outdated or offensive language about gender identity. If someone researches transgender topics through Chat GPT and gets influenced by Grokipedia's framing, they might internalize problematic language or concepts. That affects how they think about and treat transgender people.
Grokipedia's framing of slavery includes what could charitably be called "alternative perspectives" that function as ideological justifications. If that framing influences how Chat GPT discusses slavery and its historical context, it distorts understanding of American history.
These aren't abstract concerns. They're concrete harms that affect how people understand important topics.
The problem is they happen silently. A user researches a topic, gets an answer influenced by Grokipedia, and has no idea. They might cite that answer to others. They might base decisions on it. They might change their beliefs based on false information without realizing where it came from.
How to Evaluate AI Reliability: A Framework
Given these issues, how should you approach using AI tools?
Consider building a personal evaluation framework:
Trust level assessment: Start by asking whether this is a topic where AI models typically perform well. Factual questions with clear right answers (math, science facts) are usually better than subjective or ideologically contested topics.
Source cross-reference: When the AI cites sources, verify those citations. Check whether the source actually supports the claim. Look for corroboration from other sources.
Expert consultation: For important decisions, consult actual experts. An AI can summarize expert consensus, but it can't replace genuine expert judgment.
Recency check: Understand what date the model's training data goes through. If the topic has been heavily discussed since then, the model might be missing recent information.
Confidence calibration: Pay attention to how confident the AI sounds. Sometimes it's confident about wrong things. That overconfidence is dangerous.
Bias awareness: Understand that the AI model is trained on data that reflects particular worldviews and ideological perspectives. It's not neutral, even if it sounds neutral.
Alternative perspectives: Ask the AI to present multiple perspectives on contested topics. Compare how it frames different viewpoints. That reveals biases.
No single factor is sufficient. But together, they help you develop a more realistic understanding of when AI is helpful and when you should be skeptical.
The Bigger Picture: Trust in an Age of AI
The Grokipedia situation is part of a larger challenge we're all facing: how do we maintain trust in information systems when they're increasingly mediated by AI?
For centuries, our information infrastructure was built on institutions: newspapers, universities, libraries, governments. These institutions had credibility because they had reputations to protect. They had editorial standards. They had accountability structures.
AI models don't have those. They're trained on everything and accountable to no one. They're powerful information sources, but they lack the institutional structures that created trust in traditional information systems.
We're at an inflection point. We can either develop new institutional structures around AI—regulators, standards, transparency practices—or we accept that AI-generated information will be less trustworthy than information from traditional sources.
Right now, we seem to be trending toward accepting lower trustworthiness. That's concerning because as AI becomes more integrated into how we get information, the stakes get higher.
The solution requires action from multiple groups:
From AI companies: Implement better data sourcing practices, increase transparency, and build verification systems.
From regulators: Develop standards for AI training data and require transparency about model limitations.
From researchers: Audit AI models, identify problems, and publish findings.
From users: Be skeptical, verify important information, and push back on companies that don't meet reasonable standards.
None of this will happen automatically. It requires collective action.
But the alternative—accepting unreliable AI without complaint—is worse. The Grokipedia situation shows what happens when we're passive about AI reliability. Biased, factually problematic sources end up in our most important information systems. Users get misinformation without realizing it.
We can do better. We should demand better.
Recommendations for Moving Forward
If you care about this issue, here's what you can actually do:
Hold companies accountable: Contact Open AI, Anthropic, Google, and other AI companies. Tell them you want transparency about training data and better source vetting. Companies respond to user feedback.
Support regulatory efforts: Contact your elected representatives. Tell them you support AI regulations that require data transparency and quality standards.
Fund research: Support researchers auditing AI models and investigating data sourcing practices. Research organizations like the AI Safety Institute, Partnership on AI, and academic labs doing this work deserve funding and attention.
Improve media literacy: Help others understand AI limitations. Share information about the Grokipedia situation. Teach people to verify information from AI sources.
Use alternatives: When possible, use AI tools that are more transparent about their data sources. Support companies building AI with better practices.
Contribute to better sources: If you're an expert in something, contribute to reliable information sources. Wikipedia, peer-reviewed journals, and other institutions rely on expert contributions. By participating in these systems, you're helping build better training data for the future.
Be a critical consumer: Most importantly, think critically about the information you get from AI. Ask questions. Verify claims. Don't assume AI is right just because it sounds confident.
These individual actions matter. Collectively, they create pressure on companies and shape the incentive structures that drive how AI gets developed.
FAQ
What exactly is Grokipedia and who created it?
Grokipedia is an AI-generated encyclopedia launched by Elon Musk's x AI company in October 2024. Musk created it after complaining that Wikipedia exhibited bias against conservative perspectives. The encyclopedia is generated by artificial intelligence and contains entries on various topics, though quality and accuracy vary significantly across articles. Some entries were found to contain false claims, outdated information, and offensive language about transgender people.
How did Grokipedia content end up in Chat GPT's training data?
Grokipedia is public and indexed by search engines, which means it gets included in Common Crawl, the public internet archive used by AI companies to source training data. Open AI likely incorporated Grokipedia into their training data automatically through their data pipeline without specifically vetting it as a source. The company's data sourcing process appears to include any publicly available content unless explicitly filtered out for other reasons.
What are the main problems with Grokipedia's accuracy and content?
The Guardian and other journalists identified several serious issues with Grokipedia. The encyclopedia contains false claims about how HIV/AIDS spreads, offers what could be framed as justifications for slavery, uses offensive and outdated terminology for transgender people, and includes entries that appear to be plagiarized from Wikipedia. Some information in Grokipedia had already been debunked by fact-checkers before it was cited by Chat GPT.
Is Anthropic's Claude also affected by Grokipedia in its training data?
Yes, The Guardian's investigation found that Claude, developed by Anthropic, also cites Grokipedia in response to user queries. This suggests the problem isn't unique to Open AI but reflects broader issues across the AI industry with how training data is sourced and validated before being used to train large language models.
Why didn't Open AI filter out Grokipedia if they knew about its problems?
Open AI likely included Grokipedia either unintentionally through automated data collection processes or deliberately because they claim to "draw from a broad range of publicly available sources and viewpoints." The company may have avoided excluding it explicitly to avoid accusations of censoring conservative-leaning content, even though Grokipedia's problems go beyond ideology to include factual inaccuracy.
How can I know when Chat GPT is citing Grokipedia?
There's no automatic way to know which parts of a Chat GPT response were influenced by Grokipedia unless the model explicitly cites it as a source. The best approach is to verify important claims by checking cited sources directly. Look for corroboration from multiple sources, especially on contested or sensitive topics. If you're researching something where accuracy is critical, don't rely solely on Chat GPT.
What does this mean for the trustworthiness of Chat GPT?
The Grokipedia situation suggests that Chat GPT contains some influence from unreliable sources, particularly on obscure topics where users might not fact-check responses. While Chat GPT remains useful for many purposes, it should not be trusted completely on important matters without verification. The model is trained on diverse sources that reflect various biases and levels of accuracy from the internet.
Are there other problematic sources in AI training data besides Grokipedia?
Almost certainly. AI models are trained on billions of pieces of content from across the internet, including blog posts from unqualified authors, opinion pieces presented as fact, fringe websites with niche perspectives, and other sources with varying levels of reliability. Grokipedia is notable because it was discovered and publicized, but systematic audits would likely reveal many other problematic sources influencing model behavior.
What should AI companies do to prevent this from happening?
AI companies should implement several practices including publishing transparency reports about training data sources, conducting systematic accuracy checks on sources before including them, implementing fact-checking layers that flag claims contradicting verified information, maintaining credibility scoring systems that weight reliable sources more heavily, and conducting regular bias audits of model behavior. They should also build mechanisms to update or correct training data when sources are found to be problematic.
Could regulation help solve the AI data quality problem?
Yes, government regulation could establish standards requiring AI companies to disclose their training data sources, meet minimum data quality standards, conduct public bias audits, and implement correction mechanisms when problems are discovered. However, such regulations don't currently exist in most places, and developing them requires cooperation between regulators who don't yet fully understand AI systems and companies that prefer minimal oversight.
The Path Forward
The Grokipedia situation is a wake-up call. It reveals that the AI systems we're increasingly relying on for information are trained on sources we don't fully understand or control. Some of those sources are biased. Some are factually wrong. And we have no good way to know which responses were influenced by which sources.
That's not a sustainable situation. As AI becomes more integrated into how we work, learn, and make decisions, the stakes only get higher.
The good news is that this is fixable. It requires investment, regulation, and cultural change, but the technical problems are solvable. We know how to build better systems. We just need to decide it matters enough to implement them.
The bad news is that without pressure from users and regulators, AI companies probably won't implement these improvements. They're expensive, and they reduce the company's freedom to train on anything available.
So change depends on us. On whether we demand better. On whether we hold companies accountable. On whether we support researchers investigating these issues. On whether we vote for regulations requiring transparency and quality standards.
The Grokipedia moment is a choice point. We can treat it as a technical problem to solve, a business issue to manage, or a sign that we need systemic change in how AI gets developed.
I think we need systemic change. And I think we need it now, while AI is still developing rapidly and we have a chance to build better foundations.
The alternative is accepting AI systems that are increasingly unreliable, biased, and opaque. That's not acceptable. We deserve better. We can build better.
The question is whether we will.
Key Takeaways
- ChatGPT cites Grokipedia, an ideologically-driven encyclopedia, as a source in responses to user queries, introducing unreliable information into AI outputs.
- Grokipedia contains false claims about public health, offensive language, and ideological framings that influence how ChatGPT presents information to millions of users.
- AI training data lacks transparency and quality controls—sources are included based on automated processes without systematic fact-checking or bias detection.
- The problem extends beyond OpenAI: Anthropic's Claude also cites Grokipedia, revealing industry-wide issues with training data sourcing and vetting.
- Users have no reliable way to verify which responses were influenced by problematic sources, making critical thinking and source cross-referencing essential.
Related Articles
- Google's Hume AI Acquisition: The Future of Emotionally Intelligent Voice Assistants [2025]
- ServiceNow and OpenAI: Enterprise AI Shifts From Advice to Execution [2025]
- Agentic AI Demands a Data Constitution, Not Better Prompts [2025]
- The AI Adoption Gap: Why Some Countries Are Leaving Others Behind [2025]
- ChatGPT Creativity Settings: Master Advanced Prompting Techniques [2025]
- Why AI Agents Keep Failing: The Math Problem Nobody Wants to Discuss [2025]

