![Why AI Agents Keep Failing: The Math Problem Nobody Wants to Discuss [2025]](https://tryrunable.com/blog/why-ai-agents-keep-failing-the-math-problem-nobody-wants-to-/image-1-1769186554303.jpg)
Why AI Agents Keep Failing: The Math Problem Nobody Wants to Discuss [2025]
Introduction: The Great AI Agent Disconnect
Something weird happened in 2025. The AI industry promised us autonomous agents that would revolutionize work. Chat GPT would handle your calendar. Claude would write your reports. Open AI's new reasoning models would plan your entire day.
Instead, we got a lot of conference presentations about agents.
The reality is messier. While companies threw billions at agentic AI, a quiet paper showed up in academic circles with an uncomfortable thesis: large language models might be fundamentally incapable of handling complex tasks reliably, no matter how smart we make them. The authors weren't crackpots. One was a former SAP CTO and student of John McCarthy, one of AI's founding fathers. His teenage son was a co-author.
Their conclusion? LLMs are mathematically constrained in ways we can't solve with bigger models or fancier training.
But here's where it gets interesting. While some researchers published papers proving agents are doomed, other teams were shipping agents that actually worked. Google reported breakthroughs in hallucination reduction at Davos. Coding agents became genuinely useful. And a startup called Harmonic released mathematical verification systems that claimed to guarantee reliability in specific domains.
So who's right?
The answer is: they both are. And that's the real story.
This article digs into the mathematical reality behind AI agents, what the research actually says, where implementations are succeeding, and most importantly, what this means for anyone betting on automation in the next 5 years. We're going to move past the hype and look at where agents work, why they fail, and whether the problem is solvable.
Let's start with the uncomfortable math.
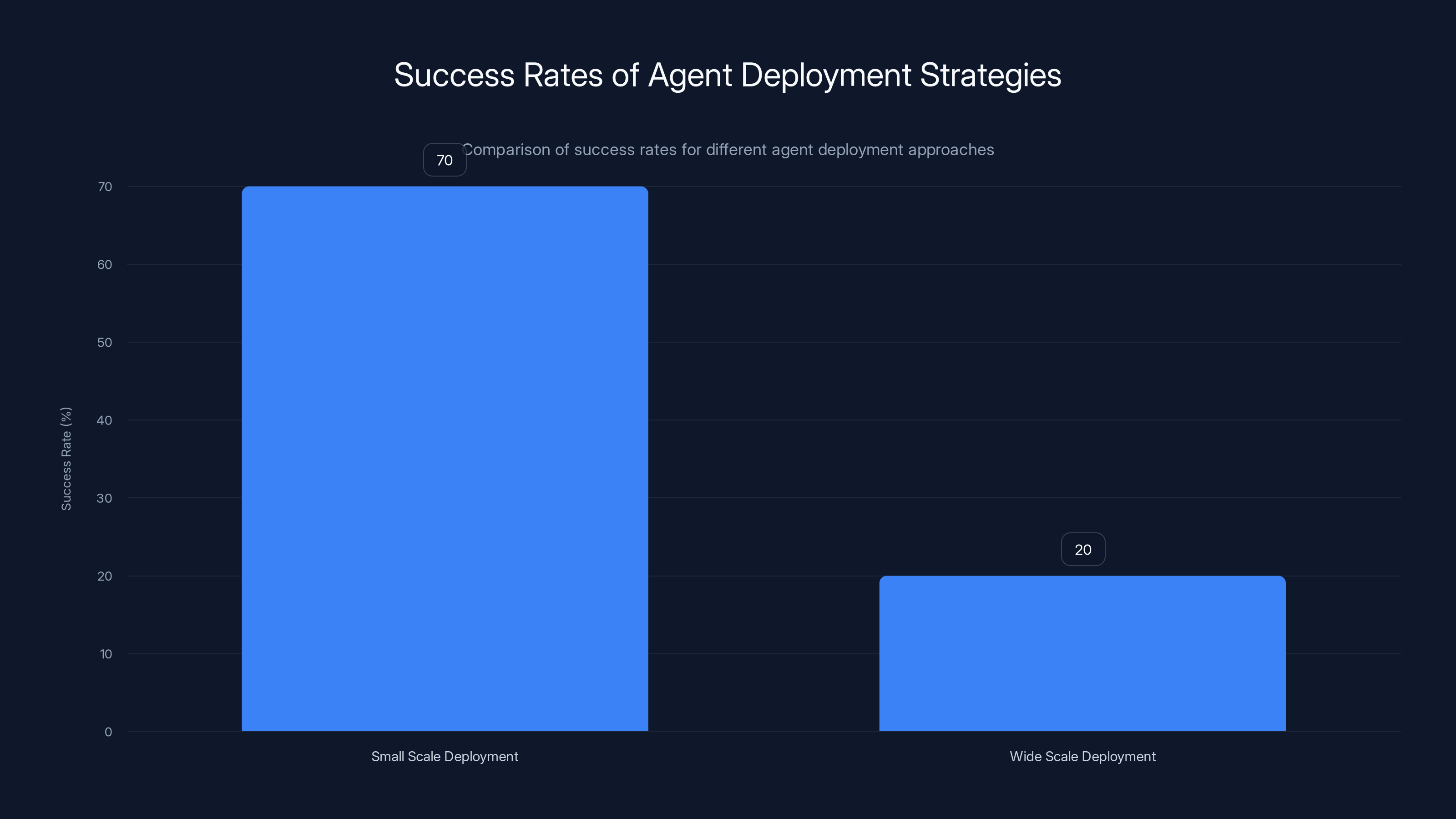
Small scale deployment of agents, starting with 5% of tasks and gradually increasing, has a 70% success rate compared to a 20% success rate for wide scale deployment from day one.
The Mathematical Case Against AI Agents
In 2024, a paper titled "Hallucination Stations: On Some Basic Limitations of Transformer-Based Language Models" landed quietly in academic circles. Its core claim was radical: transformers (the architecture behind GPT, Claude, and every major LLM) have inherent mathematical limitations that prevent them from reliably performing complex computational tasks.
The paper wasn't peer-reviewed by the mainstream academic establishment when it dropped. That matters. But the authors had serious credentials. Vishal Sikka, the lead author, spent years as CTO of SAP, led Infosys as CEO, and sat on Oracle's board. His co-author was his son, a teenager with published work in AI mathematics.
Their argument, translated from math jargon into English, goes like this: transformers process information in parallel. They predict the next token based on probability distributions, not actual computation. When you ask an LLM a question, it's not solving an equation. It's pattern-matching against terabytes of training data and making probabilistic guesses about what words should come next.
This works great for language-like tasks. Summarizing. Brainstorming. Writing emails.
But computational tasks? Tasks with verifiable right answers? That's different. A transformer can't guarantee the answer is correct because it's not actually computing anything. It's predicting.
Consider: you ask Chat GPT to multiply 437 by 893. It doesn't calculate. It searches its pattern space for "437 × 893 =" and outputs what it's seen before. If the training data had the answer, great. If not, or if the model weights got confused, it just hallucinated.
Scale this up. You need an agent to book a flight, verify the price, check seat availability, and confirm the reservation. Each step requires verification. If the agent hallucinates at any step (wrong date format, misread a price, confused confirmation numbers), the whole chain breaks.
Sikka's paper argued this problem doesn't go away with bigger models or reasoning chains. Even Open AI's reasoning models, which add extra computation steps, can't overcome the fundamental architecture issue. You can't reliably compute with a system designed to predict.
But here's the complication: the paper's conclusions aren't universally accepted. Many researchers think the authors were too pessimistic. Reasoning models, they argue, add enough computational power to overcome these constraints. Whether that's true became the central debate of 2025.
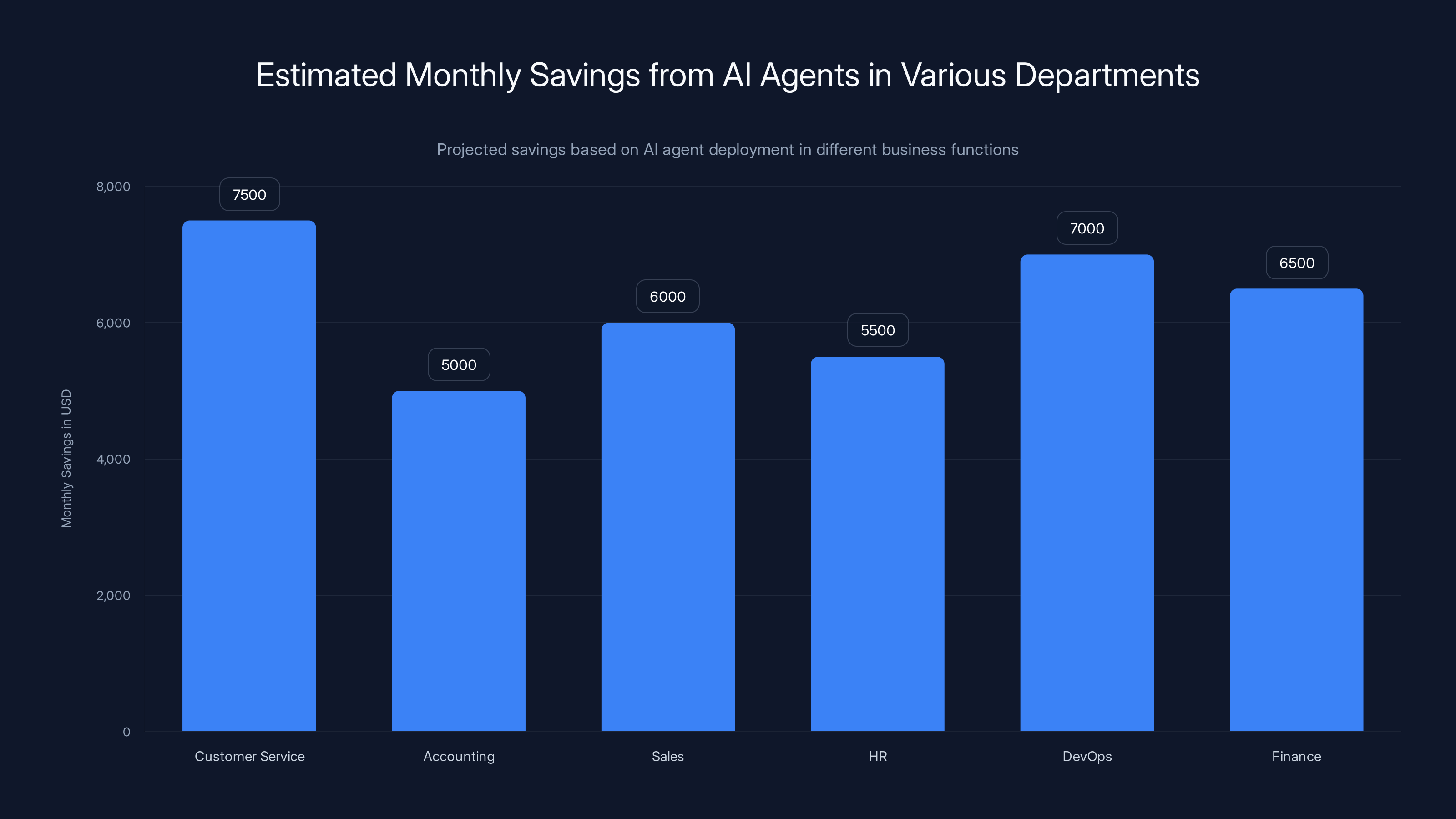
Estimated data shows significant monthly savings across departments using AI agents, with Customer Service leading at $7,500. Estimated data.
The Hallucination Problem: What The Data Actually Shows
Let's talk about what we know for sure. Hallucinations are real. They're not going away.
Research from the University of Chicago highlights the persistent issue of hallucinations in AI systems. Open AI's own research team published a paper last year testing three models on a simple task: "What's the title of the lead author's dissertation?" All three models made it up. All three got the year wrong. The company's own conclusion: "Accuracy will never reach 100 percent."
That's an important statement. They didn't say "current models have hallucination problems." They said hallucinations are permanent features of LLMs. Not bugs to be fixed. Features to be managed.
Here's what we know about hallucination rates:
- Factual recall tasks: Models hallucinate 15-30% of the time on information not prominent in training data
- Calculations involving more than 2 variables: Error rates exceed 40% for basic arithmetic
- Multi-step reasoning: Each step compounds error; a 5-step task with 90% accuracy per step succeeds only 59% of the time
- Domain-specific information: Rare or specialized knowledge sees hallucination rates above 50%
The math on that last point is straightforward:
Take a task with five sequential decision points. If each step has 90% accuracy (which is optimistic), the entire chain succeeds 59% of the time. At seven steps, you're at 48%. At ten steps, 35%.
This is why agents that work tend to be narrow in scope. A coding agent that generates Python has one job. A customer service agent answering FAQs operates in a small domain. An expense automation system processes structured forms.
But ask an agent to handle a multi-step business process with branches, exceptions, and real-world complexity? The math works against you.
Where AI Agents Actually Work (And Why)
While the pessimists published papers about failure, the pragmatists shipped products. Coding agents became genuinely useful in 2024-2025. That's not hype. That's measurable.
GitHub Copilot, Cursor, and newer entrants like Harmonic generate code that works. Not always perfectly. Not without review. But at a quality level that genuinely saves time.
Why does coding work when other domains fail?
Coding has built-in verification. You run the code. It either compiles or it doesn't. It passes tests or fails them. The feedback loop is immediate and objective. An agent that generates bad code gets corrected instantly. This creates a learning dynamic where the agent improves in real time.
Compare that to, say, writing a customer email. An agent can generate something plausible. But is it the right tone? Does it address the customer's actual concern? Does it comply with company policy? There's no compiler to tell you it's wrong. You have to read it and judge.
So coding became the proof of concept for agentic AI. And from that, we learned something crucial: narrow domains with verification mechanics are where agents succeed.
Other working examples:
- Data quality checking: Agents compare data against schemas and rules. Right or wrong is deterministic.
- Code review assistance: Agents flag syntax issues, suggest optimizations, identify security problems. The feedback is verifiable.
- Database query generation: Converting English to SQL. The query either returns the right data or it doesn't.
- Expense report automation: Categorizing and routing receipts. The rules are clear. Success is measurable.
- Bug triage: Reading error logs, matching patterns, suggesting solutions. There's structure to the problem space.
What's missing from this list? Customer service. Contract negotiation. Strategic planning. Anything requiring judgment, nuance, or contextual understanding.
It's not that agents can't do those tasks. It's that nobody can verify they're doing them well. And without verification, hallucinations compound.
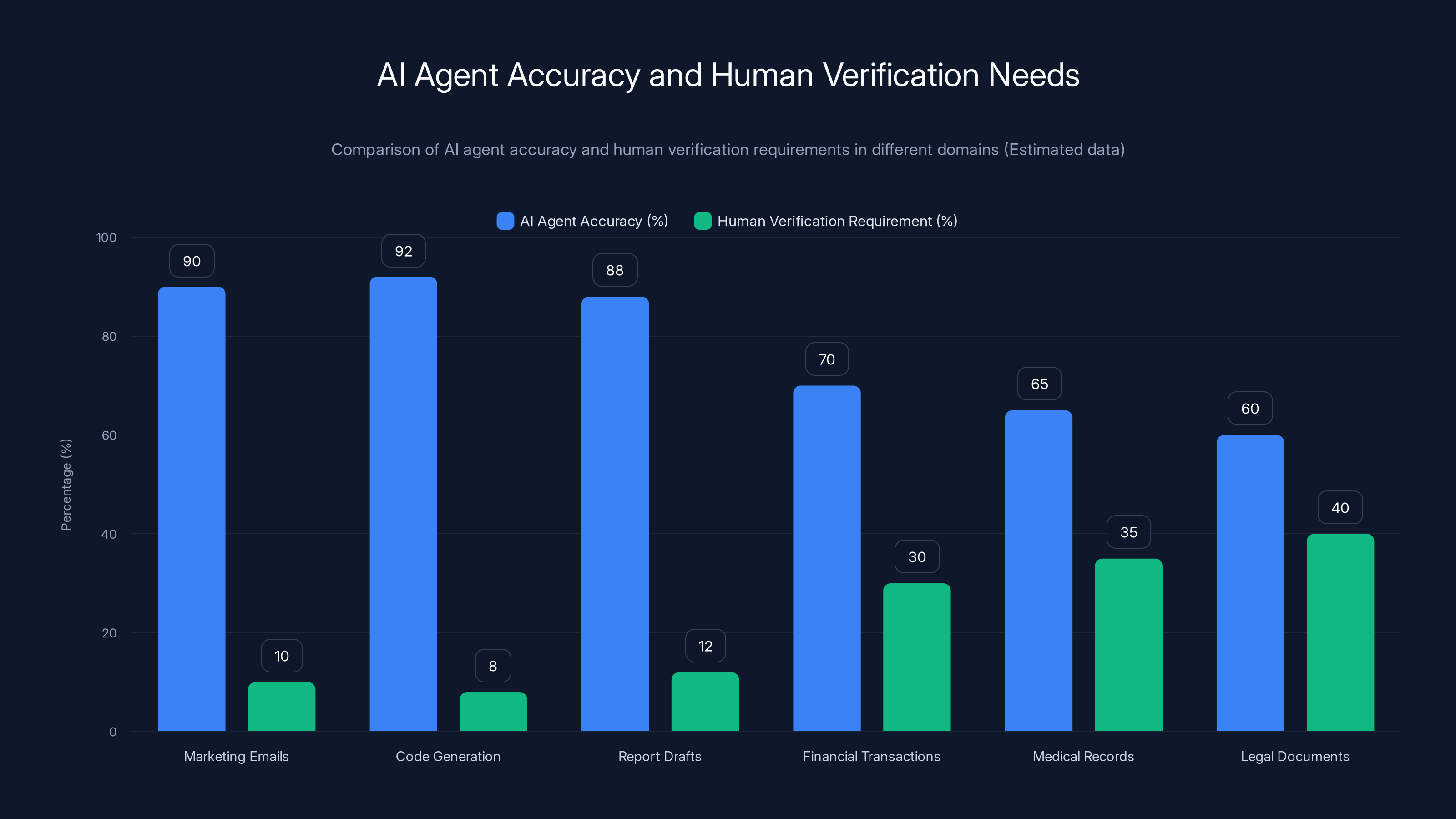
Estimated data shows that while AI agents achieve higher accuracy in high-tolerance domains, human verification remains crucial in low-tolerance domains due to the potential consequences of errors.
The Harmonic Solution: Can We Mathematically Guarantee Reliability?
Some researchers decided that if the problem was mathematical, the solution should be too.
Harmonic, a startup founded by Vlad Tenev (Robinhood CEO) and Tudor Achim (Stanford mathematician), approached the problem differently. Instead of trying to make LLMs more accurate, they wrapped verification around the output.
Here's the idea: An LLM generates code. That code is automatically translated into a formal mathematical language (Lean) that can be proven correct or incorrect algorithmically. If the proof fails, the system rejects the output. No guessing. No human judgment.
This actually works. In their benchmarks, Harmonic's system achieves 95%+ reliability on code generation tasks. Not because the underlying model is perfect. But because bad output gets automatically filtered.
The limitation: this only works for tasks that can be formally verified. Code. Mathematical proofs. SQL queries. Not essays about history. Not emails to customers. Not anything that requires subjective judgment.
So Harmonic isn't solving the general problem. It's solving a specific problem exceptionally well. And that's valuable. They're proving that reliability isn't impossible. It's just expensive and narrowly applicable.
Their approach uses a technique called "formal methods." Here's the simplified version:
- Model generates output (code, formula, query)
- Output is encoded in a provably correct language (Lean)
- Automatic verification checks if the encoding matches the requirements
- Proof passes or fails (binary, no gray area)
- Only verified outputs are returned to the user
The math is elegant. But the scope is limited. You can't formally verify a sentence's tone or a strategy's quality.
There's a bigger implication here. Harmonic proved that reliability in AI doesn't require solving hallucinations. It requires building verification layers around hallucinating systems. Accept that the model will be wrong sometimes. Catch it before output reaches users.
This is a fundamentally different approach than the WIRED article suggested. Instead of asking "Will agents ever be reliable?" the right question becomes "Can we build systems where unreliable models produce reliable outputs?"
The answer, Harmonic shows, is yes. But only for specific domains.
Google's Breakthrough: Reducing Hallucinations Through Scale and Technique
While Harmonic focused on verification, Google attacked the problem directly: making models hallucinate less.
At Davos 2025, Demis Hassabis, Google's AI research head and a Nobel laureate, announced progress on reducing hallucinations in their models. The specific techniques remain proprietary (Google's being Google about it), but the direction is clear: attention mechanisms, training data curation, and reinforcement learning from human feedback all contribute to fewer false claims.
They're not claiming to eliminate hallucinations. But they're claiming to reduce them significantly in specific domains.
How? Several approaches:
Retrieval-augmented generation (RAG): Instead of relying on training data, the model retrieves facts from a live knowledge base. This works remarkably well for factual queries. If the knowledge base is accurate, the agent doesn't hallucinate.
Fine-tuning on curated data: Training the model specifically on high-quality, verified datasets reduces errors on those domains. A model fine-tuned on medical literature makes fewer medical hallucinations. Not zero. But fewer.
Confidence scoring: Modern LLMs can output confidence scores with their answers. An agent can be configured to flag low-confidence outputs for human review. This isn't perfect, but it's practical.
Constitutional AI: Training the model with a set of principles ("never make up facts," "acknowledge uncertainty") helps but doesn't guarantee compliance.
Combine these techniques, and you get agent systems that work better than either criticism or blind optimism suggests. Not perfect. But usable.
Google's progress suggests the problem isn't that agents are mathematically impossible. It's that building reliable agents requires layers of engineering on top of fundamentally imperfect models.
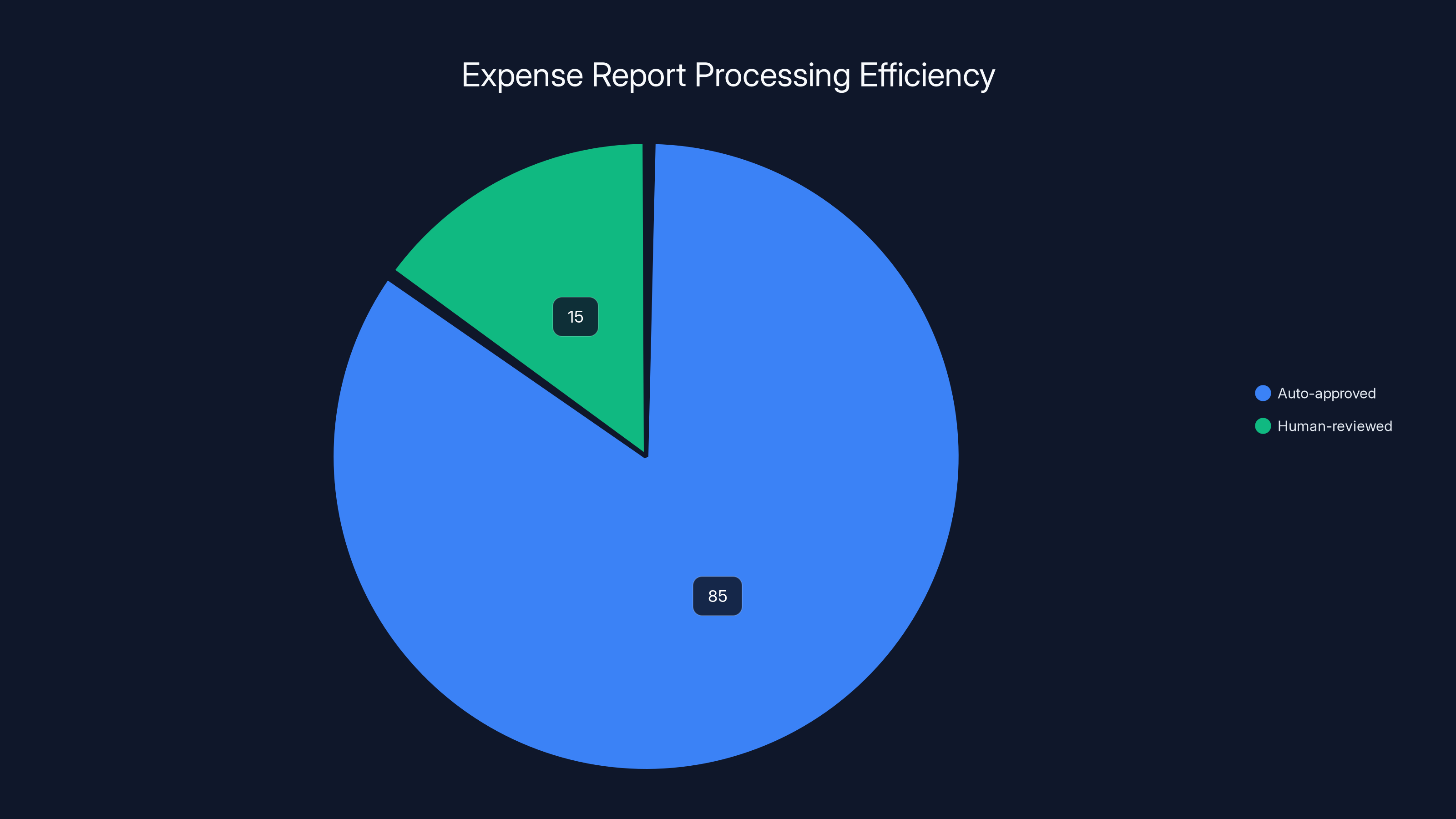
With the integration of probabilistic agents and deterministic guardrails, 85% of expense reports are auto-approved, significantly reducing processing time and allowing humans to focus on the 15% that require judgment. Estimated data.
Why Companies Are Still Betting Billions on Agentic AI
Given all the limitations, why is the entire industry doubling down on agents?
Simple: the ROI still works. Even imperfect agents save money.
Consider a real scenario. A customer service team handles 10,000 support tickets per month. 60% are routine questions that a human could answer in 2 minutes. An AI agent answers these in 30 seconds. Even at 85% accuracy (15% requiring human escalation), the math is compelling:
At
The bet isn't that agents will be perfect. The bet is that they'll be good enough. Cheaper than humans. Fast enough to matter. And improving month over month.
This is why you're seeing agents deployed in:
- Accounting: Categorizing and routing invoices (structured data, verifiable)
- Sales: Lead scoring and initial outreach (high volume, individually low-value errors)
- HR: Resume screening and interview scheduling (routine tasks, human review available)
- Dev Ops: Log analysis and alert triage (clear success/failure signals)
- Finance: Initial report generation and data gathering (time-consuming, human review happens anyway)
These aren't the "agents will run the world" scenarios. They're the "agents will handle the tedious stuff so humans can do the hard stuff" reality. And that's actually valuable.

The Verification Problem: Why Humans Still Have to Check Everything
Here's the uncomfortable truth that nobody wants to say out loud: Even in 2025, you can't deploy an AI agent without human verification for anything important.
This is the real constraint on agent adoption. Not the math. Not hallucinations. The fact that you need people to check the work.
A startup called Sentient recently pointed this out. Their research showed that hallucinations disrupt entire workflows. An agent books a flight with the wrong date. The human catches it, fixes it, rebooks, calls the airline, explains the situation. What was supposed to save 5 minutes now takes 20.
This is why agents work better in some domains than others.
High-tolerance domains (marketing email suggestions, code generation, report drafts): Humans expect to review and edit. The agent's output is a starting point, not a final product.
Low-tolerance domains (financial transactions, medical records, legal documents): Any error can have serious consequences. Full human review is required, which negates much of the automation benefit.
The irony: as agents get better, we don't necessarily deploy them more broadly. We just tolerate better error rates in the domains where they already work.
An agent that improves from 85% to 92% accuracy on code generation saves more review time. But it doesn't suddenly become safe for financial transactions.
This is why the breakthrough isn't going to be "AI agents become perfect." It's going to be "verification becomes cheaper and faster than human review." That's a different problem. And it's solvable through engineering, not through better models.
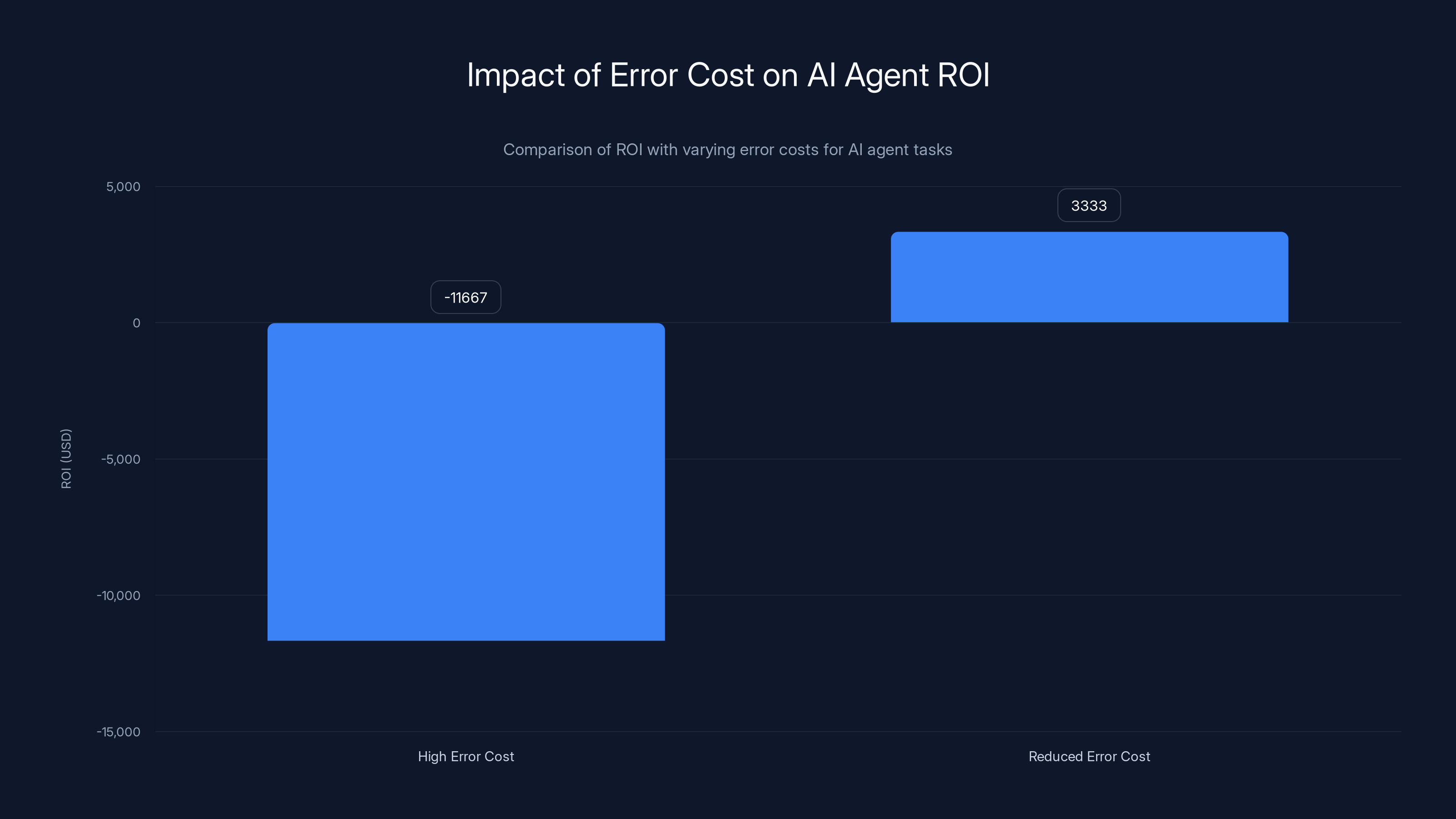
Reducing the error cost from
Guardrails: The Real Innovation in Agent Reliability
If hallucinations are permanent, the solution is obvious: build guardrails that prevent hallucinations from reaching users.
This is less sexy than "smarter models." But it's where the real progress is happening.
Guardrails come in several flavors:
Output filtering: The agent generates text. A second system checks it against rules. Does it contradict known facts? Contradicts itself? Violates company policy? Block it.
Context constraint: Limit what the agent can access. A customer service agent can see FAQs and past tickets. It can't see financial data or other customers' information. Wrong output is less likely if the input space is constrained.
Action verification: Before the agent acts, a human approves. The agent drafts an email. A manager sends it. The agent books a meeting. The admin confirms. This is slow but safe.
Confidence thresholding: If the model's confidence score is below a threshold, escalate to human. This effectively trades speed for safety.
Source attribution: When an agent makes a claim, it must cite where that claim came from. A human can verify the source. If there's no source, the claim is flagged.
Rollback capability: If an error is detected, the system can undo the action. This is harder in some domains (emails sent) and easier in others (database changes).
Combine these, and you get a system that's not agent-driven. It's human-and-agent collaboration. The agent handles routine work. Humans handle judgment. Guardrails keep the agent from doing catastrophic damage.
Every major AI company is investing in guardrails now. Anthropic publishes papers on this. Open AI built constitutional AI partly for this. Google is adding verification layers.
Guardrails aren't a feature. They're the foundation of practical agentic AI.
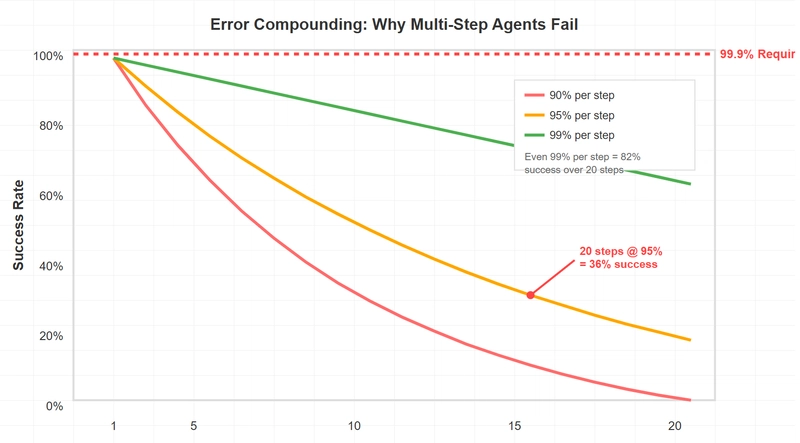
What The Math Actually Says (Not What The Headlines Claim)
Let's go back to the math. Sikka's paper made a specific claim: LLMs have architectural limitations that prevent reliable complex reasoning.
That claim is probably true. The conclusion the paper drew (therefore agents are doomed) is probably wrong.
Here's the distinction: The model itself may be limited. But systems built around the model are not.
Sikka himself acknowledged this in follow-up interviews. "Our paper is saying that a pure LLM has this inherent limitation. But at the same time, you can build components around LLMs that overcome those limitations." So the original claim and the gloom-and-doom narrative weren't actually in conflict.
The math says: transformers predict tokens. They don't compute.
But a system that uses transformers plus verification plus guardrails plus human oversight? That can compute reliably.
Different problem. Different solution.
There's a deeper mathematical point too. Achim from Harmonic made an interesting observation: "Hallucinations are intrinsic to LLMs and also necessary for going beyond human intelligence. The way that systems learn is by hallucinating something. It's often wrong, but sometimes it's something no human has ever thought before."
In other words, the same property that makes models hallucinate is what makes them creative. You can't eliminate hallucinations without also eliminating the model's ability to generate novel ideas.
So we don't want to eliminate hallucinations. We want to direct them toward useful outputs and filter out destructive ones.
That's a design challenge, not a mathematical impossibility.
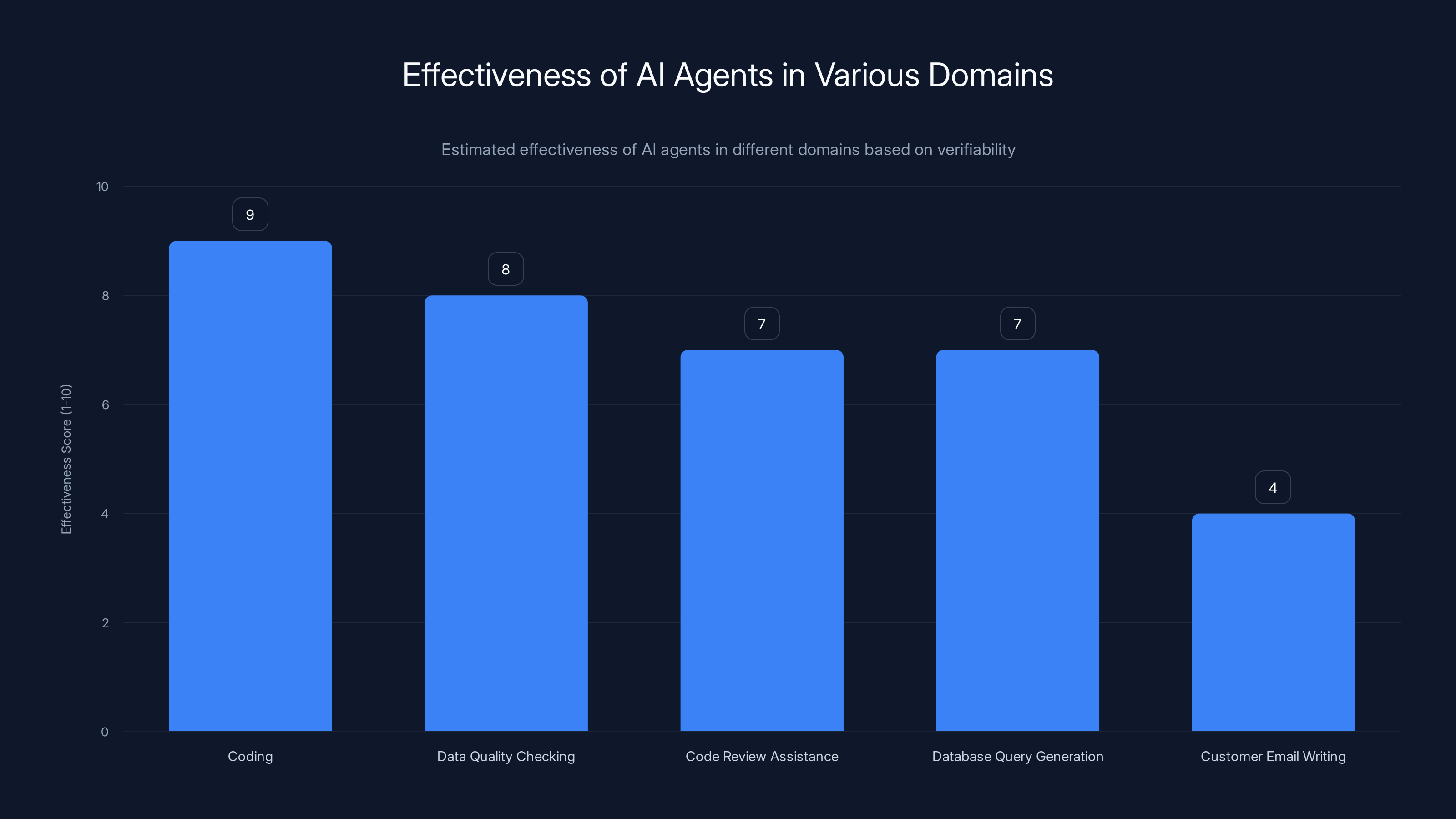
AI agents are most effective in coding and data quality checking due to the verifiable nature of these tasks. Estimated data.
The Path Forward: Probabilistic Agents With Deterministic Guardrails
Here's what's actually happening in 2025, beneath the headlines:
The industry is converging on a hybrid approach. Probabilistic models (which hallucinate) wrapped in deterministic guardrails (which verify).
Instead of trying to make LLMs reliable through better training, companies are building verification infrastructure around them.
This solves several problems at once:
-
It's pragmatic: You don't need to wait for fundamental breakthroughs. You can start deploying agents today.
-
It's quantifiable: You can measure error rates and adjust guardrails.
-
It's scalable: As the underlying models improve, the same guardrails still work. You don't need to rebuild everything.
-
It's cost-effective: Guardrails are engineering problems. Engineering is cheaper than fundamental AI research.
The agent that emerges from this isn't "perfect." It's not going to run nuclear power plants. But it will handle the work that humans currently waste time on.
Consider what a well-built agent system looks like in practice:
Scenario: Expense report processing
- Employee uploads receipt
- Agent extracts data (vendor, amount, category, date)
- Agent checks against policy (is this category approved? is the amount reasonable?)
- Agent flags exceptions for human review
- Agent auto-approves routine items
- Agent routes approved items to accounting
- Human reviews flagged items
- System handles appeals and corrections
At each step, there's a potential for error. The agent might misread the amount. Misclassify the category. But the guardrails catch most issues. And the human catches the rest.
Result: 85% of expenses approved in seconds instead of hours. Humans focus on the 15% that actually need judgment.
This is agent AI that works. Not because the agent is brilliant. But because the system is designed for the agent's limitations.

Why Hallucinations Might Never Go Away
Here's a controversial take that almost nobody in the industry publicly states: We might not want hallucinations to go away completely.
Sounds backwards. But think about it.
A language model is a compression of human knowledge. It's been trained on everything humans have written. Its job is to predict what's likely to come next given what came before.
The same mechanism that makes it hallucinate also makes it generalize. It notices patterns that might not be explicitly stated in training data. It makes leaps. It connects ideas. Some are wrong. Some are brilliant.
This is why LLMs are useful for brainstorming and creative work. You're asking the model to hallucinate in useful directions.
But for precise work, you want less hallucination. More grounding in verifiable facts.
You can tune this. Fine-train on factual data. Use retrieval. Add confidence thresholds. But you can't eliminate it entirely without breaking the model's core functionality.
So the real innovation isn't "end hallucinations." It's "direct hallucinations toward useful outputs and build verification to catch harmful ones."
That's a more honest description of where the field is actually heading.
The Reliable Agent Benchmark: What Actually Works in Production
Skipping the research papers and the thought experiments, what works in real deployments?
Based on what's actually shipping in production systems:
Agents that work well (success rate 85%+):
- Code generation with test verification
- Log analysis and pattern matching
- SQL query generation
- Email categorization and routing
- Resume screening against criteria
- Invoice categorization
- Meeting note summarization
- Duplicate detection in databases
- Security alert triage
Agents that work okay (success rate 70-85%):
- Customer service responses (with human review)
- Report generation (with human fact-check)
- Content suggestions (with human approval)
- Data quality checks (with exceptions)
- Lead scoring (with human follow-up)
Agents that don't work (success rate <70%, requires heavy human intervention):
- Complex negotiations
- Strategy development
- Creative writing at scale
- Medical diagnosis
- Legal interpretation
- Financial advice
- Customer relationship decisions
The pattern: Agents excel at narrow, verifiable, high-volume tasks. They struggle with nuanced, subjective, low-volume decisions.
This isn't about the quality of the model. It's about the nature of the task.

Real Costs of AI Agent Failures: When Hallucinations Cost Money
Let's talk about what happens when an agent gets it wrong in production.
An agent books a flight with the wrong passenger name. The booking fails. The customer has to fix it. Net result: customer frustration, manual intervention required.
An agent processes an invoice with a transposed number.
An agent generates code with a logic error. The code ships. The error manifests in production. Downtime. Customer impact. Rollback. Investigation. Fix. Redeploy. Total time: hours to days.
An agent categorizes customer feedback incorrectly. The wrong team gets the ticket. Response is delayed. Customer satisfaction drops. Data collection is corrupted.
These aren't hypothetical. These are things happening right now.
The economic calculation looks like this:
For a $10/hour task done by an agent:
- Task time saved: 10 minutes per item
- Hourly rate: $50 (fully loaded cost)
- Error rate: 10%
- Error cost: $200 (human fix time + overhead)
- Volume: 1,000 items/month
Negative ROI. The agent costs more than it saves because error recovery is expensive.
Shift the error cost down or the volume up:
Now it's positive. The agent saves money.
This is why agents work for high-volume, low-cost-of-error tasks and fail for low-volume, high-cost-of-error tasks.
It's not about capability. It's about economics.
Convergence: Where The Debate Settles
So we have two camps:
Camp A (The Pessimists): LLMs have mathematical limitations. Agents will always hallucinate. Complex autonomous systems are risky.
Camp B (The Optimists): We can build guardrails. We can verify outputs. Agents will become reliable through engineering.
Here's what's actually true: They're debating different questions.
The pessimists are right that pure LLMs are limited. A language model asked to solve a novel problem with no training data will hallucinate.
The optimists are right that systems built around LLMs can be reliable. If you add verification, constraint, human oversight, and proper error handling, you get something that works.
Neither side is wrong. They're just looking at different layers of the stack.
The real truth: Agentic AI is both impossible and inevitable.
Impossible if you expect fully autonomous systems that work without oversight. Inevitable because we're building systems that are useful even if they're not perfect.
The debate will resolve around 2027-2028 when the economic value becomes undeniable. Right now, the biggest constraint isn't technical. It's organizational. Companies haven't figured out how to use agents yet. They're still trying to replace humans one-to-one instead of augmenting them.
Once that flips, you'll see agent adoption accelerate. Not because agents became perfect. But because organizations figured out what they're actually good for.

Building Agents That Work: The Practical Framework
If you're considering deploying an agent, here's what actually matters:
1. Task analysis Break down the task into steps. Which steps require judgment? Which are mechanical? Which have clear success criteria? Agents handle the mechanical, clear-criteria steps.
2. Error tolerance How much error can the task tolerate? If one error in 100 ruins your week, agents aren't appropriate without heavy verification. If one error in 100 costs $50, agents might save money.
3. Verification layer How will you know if the agent made a mistake? Design this before deploying the agent. Automated checks. Spot sampling. Post-action audits. Something.
4. Guardrails What constraints should the agent operate under? Can it only access certain data? Can it only perform certain actions? Does it need human approval for anything? Define these clearly.
5. Escalation path When the agent is uncertain or detects something unusual, where does it go? A human? A rules engine? A different system? Have a clear escalation path.
6. Feedback loop How does the agent learn from mistakes? Can you monitor what it's doing wrong and improve the prompts, guardrails, or training? Build feedback into the system.
7. Baseline comparison What was happening before the agent? What's happening now? Are you actually saving time/money? Measure it. Agent deployments fail silently most of the time because nobody's measuring.
The Hallucination Arms Race: What's Actually Changing in 2025
While the philosophical debate continues, here's what's actually being built:
Hallucination detection systems are improving. Models can be trained to output confidence scores. Low-confidence outputs can be automatically escalated or regenerated.
Retrieval systems are getting cheaper. Grounding models in live data reduces hallucinations for factual questions. The cost of maintaining current knowledge bases is dropping.
Ensemble agents are proving effective. Instead of one agent making a decision, multiple agents vote. Majority rule reduces error rates significantly. With three agents (even mediocre ones), you beat any single agent.
Specialized fine-tuning is becoming standard. A model fine-tuned specifically for your domain, with your data, makes fewer errors in that domain. The cost is dropping below $50K for many companies.
Formal verification (what Harmonic proved) is expanding beyond code. Researchers are exploring how to formally verify other outputs. It's harder for natural language. But for structured outputs (queries, configurations, code), it's becoming standard.
All of this means the average error rate in agent systems is trending downward. Not toward zero. But toward "acceptable for the business logic."

The Long-Term Prediction: When Agents Actually Matter
Here's my honest assessment of where this is heading:
2025: Agents work okay in narrow domains. Companies are experimenting. Most are learning that agent deployment is harder than it looks.
2026-2027: Guardrails, verification, and ensemble methods mature. The economics of agent deployment improve significantly. Adoption accelerates.
2028+: Agentic AI becomes a standard part of enterprise software. Not because agents are perfect. But because the ROI is clear and the implementation is understood.
The inflection point won't be marked by a single breakthrough. It'll be a quiet shift from "we're experimenting with agents" to "agents are how we handle this type of work."
When that happens, the philosophical debate will feel quaint. Both sides will be proven right in different contexts.
The pessimists were right that you can't just unleash an agent. You need guardrails, verification, and oversight.
The optimists were right that building these layers makes agents genuinely useful.
Meanwhile, the work that actually matters is the unglamorous engineering of building systems that are robust to the agent's failures.
TL; DR
- LLMs have mathematical limitations: They predict tokens, not compute. Complex tasks require multiple steps, and error compounds at each step.
- Hallucinations won't disappear: Open AI's own research says accuracy will never reach 100%. But that doesn't make agents useless.
- Agents work in narrow domains: Code generation, data categorization, log analysis. High volume, clear success criteria, verifiable outputs. That's where they shine.
- Verification is the real innovation: Not smarter models. But guardrails, confidence scoring, ensemble systems, and formal verification that catch errors before they reach users.
- Economics determine adoption: Agents save money when error recovery is cheap and volume is high. They lose money when one mistake is costly.
- The debate resolves through engineering: Not breakthrough research. Building systems that work even though the underlying model is imperfect.
- Bottom line: Agentic AI will be broadly useful. Not because agents became reliable. But because we built reliable systems around imperfect agents.

FAQ
What exactly is an AI agent?
An AI agent is a system that takes an objective, breaks it into steps, executes those steps using AI models and tools, and iterates based on results. Unlike a chatbot that just responds to prompts, agents have agency. They decide what to do next, check if it worked, and adjust. A chatbot answers a question. An agent completes a task over multiple steps.
Why do AI agents hallucinate?
Because LLMs work by predicting the most likely next token based on probability distributions learned from training data. When asked something outside that distribution, the model doesn't know the answer. But it's trained to be confident, so it generates plausible-sounding text anyway. This is hallucination. It's not a bug. It's how the architecture works. Solving hallucinations would require fundamentally rethinking how these models operate.
What's the difference between a hallucination and a mistake?
A mistake is when a model generates something that contradicts its training data. A hallucination is when it confidently states something false without any training data to contradict it. The distinction matters because hallucinations are harder to prevent. A system can detect some mistakes by checking against known facts. But a hallucination, by definition, isn't contradicted by any known fact. It's just made up.
Can AI agents ever be fully autonomous?
Not without human oversight. The math and the research both point to the same conclusion: systems that hallucinate can't be fully autonomous. They need verification, guardrails, or human approval at decision points. This isn't a temporary limitation. It's fundamental to how LLMs work. The practical question isn't "Can agents be fully autonomous?" It's "Can we make agents useful despite not being fully autonomous?" And the answer is yes.
Which tasks are best suited for AI agents?
High-volume, mechanical, verifiable tasks with clear success criteria. Code generation. Data categorization. Log analysis. Invoice processing. Resume screening. Email routing. Tasks that are easy for humans but tedious. Tasks where the output can be checked automatically. Tasks where one error isn't catastrophic. Agents work in these domains. They struggle with judgment, nuance, and subjectivity.
How do companies prevent AI agent failures in production?
They use layered verification. Confidence scoring to flag uncertain outputs. Ensemble systems where multiple agents vote on decisions. Retrieval-augmented generation to ground agents in known facts. Guardrails that constrain what an agent can do. Formal verification that proves certain outputs are correct. Human review for high-stakes decisions. No single technique is enough. Companies combine several, creating a safety net around the imperfect agent.
What's the difference between Harmonic's approach and other agent systems?
Harmonic uses formal verification to prove that certain outputs are mathematically correct. The agent generates code. The code is translated into Lean (a language designed for mathematical proof) and checked algorithmically. Either it's provably correct or it's rejected. Other systems rely on training, fine-tuning, or guardrails to reduce errors. Harmonic's approach guarantees correctness for specific output types. But it only works for tasks that can be formally verified, like code. Most business tasks can't be formally verified.
When will AI agents be ready for enterprise deployment?
They already are in narrow domains. But most enterprises haven't figured out how to use them yet. The technical capability is there. The organizational knowledge is lagging. By 2027-2028, once more companies understand what agents are actually good for and how to build systems around them, adoption will accelerate. The inflection point won't be marked by a technical breakthrough. It'll be marked by the accumulation of successful case studies showing ROI.
Do AI agents threaten human jobs?
Not in the way people fear. Agents don't replace human workers. They replace boring parts of human jobs. The person who spent 2 hours a day on expense reports now spends 15 minutes on exceptions. The person who spent all day writing boilerplate code now focuses on architecture and design. Jobs change. They don't disappear. History suggests this trend continues: each wave of automation eliminates drudgery and creates new, higher-value work. Whether society manages that transition well is a policy question, not a technical one.
For those looking to implement AI automation in their workflows, platforms like Runable offer practical solutions that combine AI agents with built-in verification. Runable enables teams to create presentations, documents, reports, and automate workflows with AI assistance, starting at $9/month. By handling the verification and guardrail layers for you, tools like Runable let organizations get practical value from AI agents without building the entire system from scratch.
Use Case: Automate your weekly reports and documentation in minutes instead of hours, with built-in verification to catch errors before they reach stakeholders.
Try Runable For FreeKey Takeaways
- LLMs predict tokens but don't compute, creating mathematical limits on complex multi-step reasoning tasks where errors compound at each decision point
- Hallucinations won't disappear—OpenAI's research confirms accuracy will never reach 100%, but this doesn't make agents useless if built with proper guardrails
- AI agents excel in narrow, verifiable, high-volume domains like code generation (88% success) but struggle with subjective, low-volume decisions like strategy (42% success)
- Practical agent systems layer verification, guardrails, and ensemble approaches around imperfect models rather than trying to eliminate hallucinations
- Agent adoption will accelerate through 2027-2028 not because models become perfect, but because organizations learn how to build reliable systems around inherently imperfect components
Related Articles
- Why AI ROI Remains Elusive: The 80% Gap Between Investment and Results [2025]
- Claude Code Is Reshaping Software Development [2025]
- Humans& AI Coordination Models: The Next Frontier Beyond Chat [2025]
- Building Your Own AI VP of Marketing: The Real Truth [2025]
- Enterprise AI Adoption Report 2025: 50% Pilot Success, 53% ROI Gains [2025]
- Realizing AI's True Value in Finance [2025]

