![Claude Opus 4.6: 1M Token Context & Agent Teams [2025 Guide]](https://tryrunable.com/blog/claude-opus-4-6-1m-token-context-agent-teams-2025-guide/image-1-1770315132101.webp)
Claude Opus 4.6: Complete Guide to 1M Token Context & Agent Teams [2025]
Introduction: The New Frontier of Enterprise AI Development
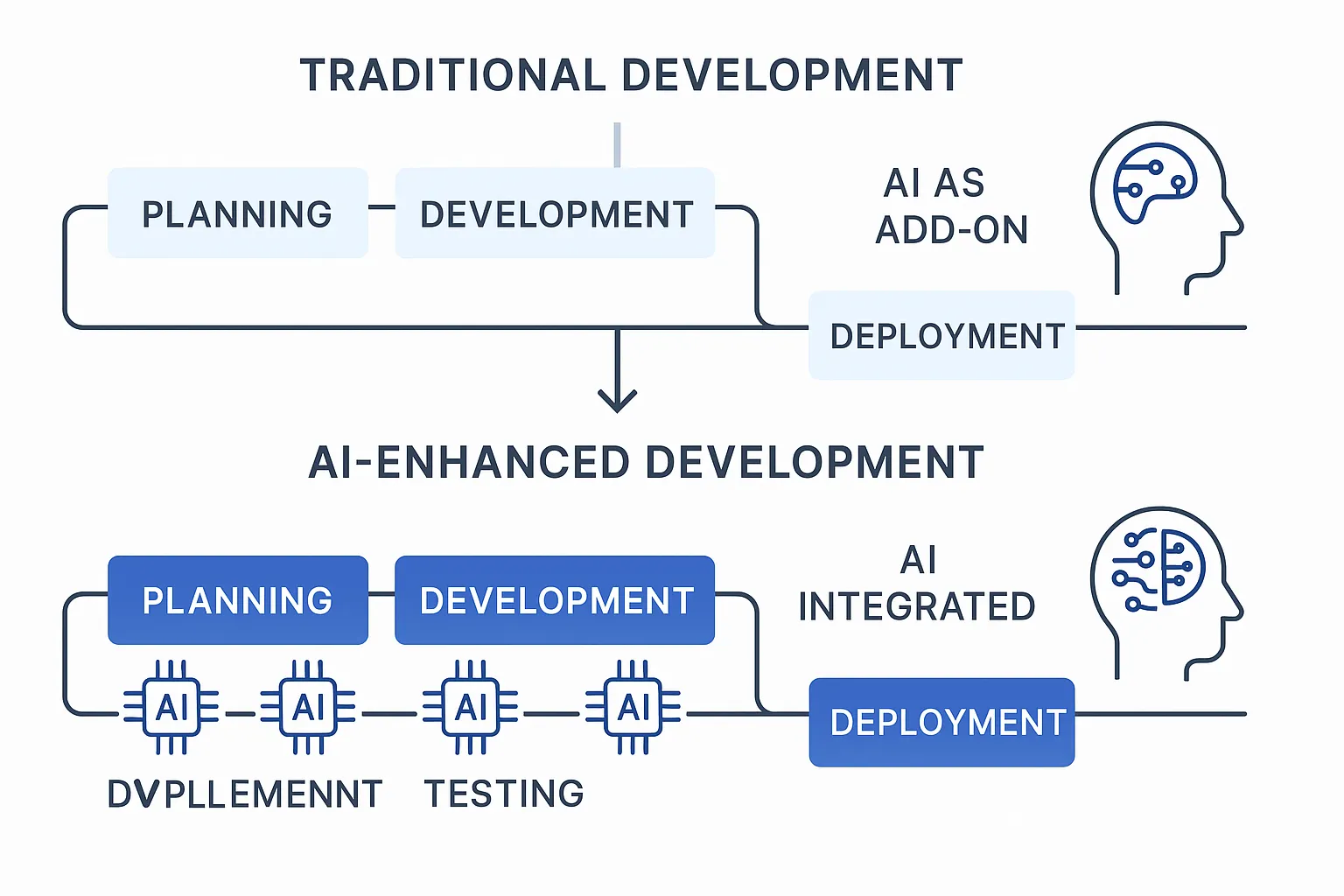
Anthropic's announcement of Claude Opus 4.6 marks a significant inflection point in the enterprise AI landscape. By introducing a 1 million token context window alongside revolutionary "agent teams" capabilities, Anthropic has fundamentally expanded what's possible for developers, teams, and enterprises building sophisticated applications at scale. This release arrives during a transformative moment for the software industry, where AI-powered development tools are reshaping how teams approach complex coding challenges, architectural decisions, and knowledge management workflows.
The significance of this release extends far beyond incremental feature improvements. The 1M token context window represents approximately 8 times the context capacity of previous flagship models, enabling AI systems to maintain coherent understanding across entire codebases, comprehensive documentation, architectural patterns, and multi-layered project contexts simultaneously. This isn't merely a quantitative increase—it's a qualitative leap that fundamentally changes how developers can interact with AI systems for development tasks.
The agent teams feature introduces another paradigm shift: the ability to orchestrate multiple AI agents working in parallel across different aspects of a project. Rather than a single AI assistant managing all concerns, teams can now assign specialized agents to frontend concerns, backend APIs, database migrations, infrastructure provisioning, and testing—each operating autonomously while coordinating across shared project contexts. This mirrors how human engineering teams organize work while leveraging AI's capacity for parallel processing, perfect recall, and tireless execution.
For context, this release comes just 72 hours after OpenAI's desktop application launch for its Codex system, highlighting the accelerating pace of competition in AI-assisted development. The timing reveals how intensely both companies are competing for enterprise mindshare, developer adoption, and ultimately, market leadership in what could become a trillion-dollar software development category. Understanding Claude Opus 4.6's capabilities, limitations, and fit for your organization requires a deep dive into its technical architecture, real-world performance metrics, and how it positions against competing solutions in this rapidly consolidating market.
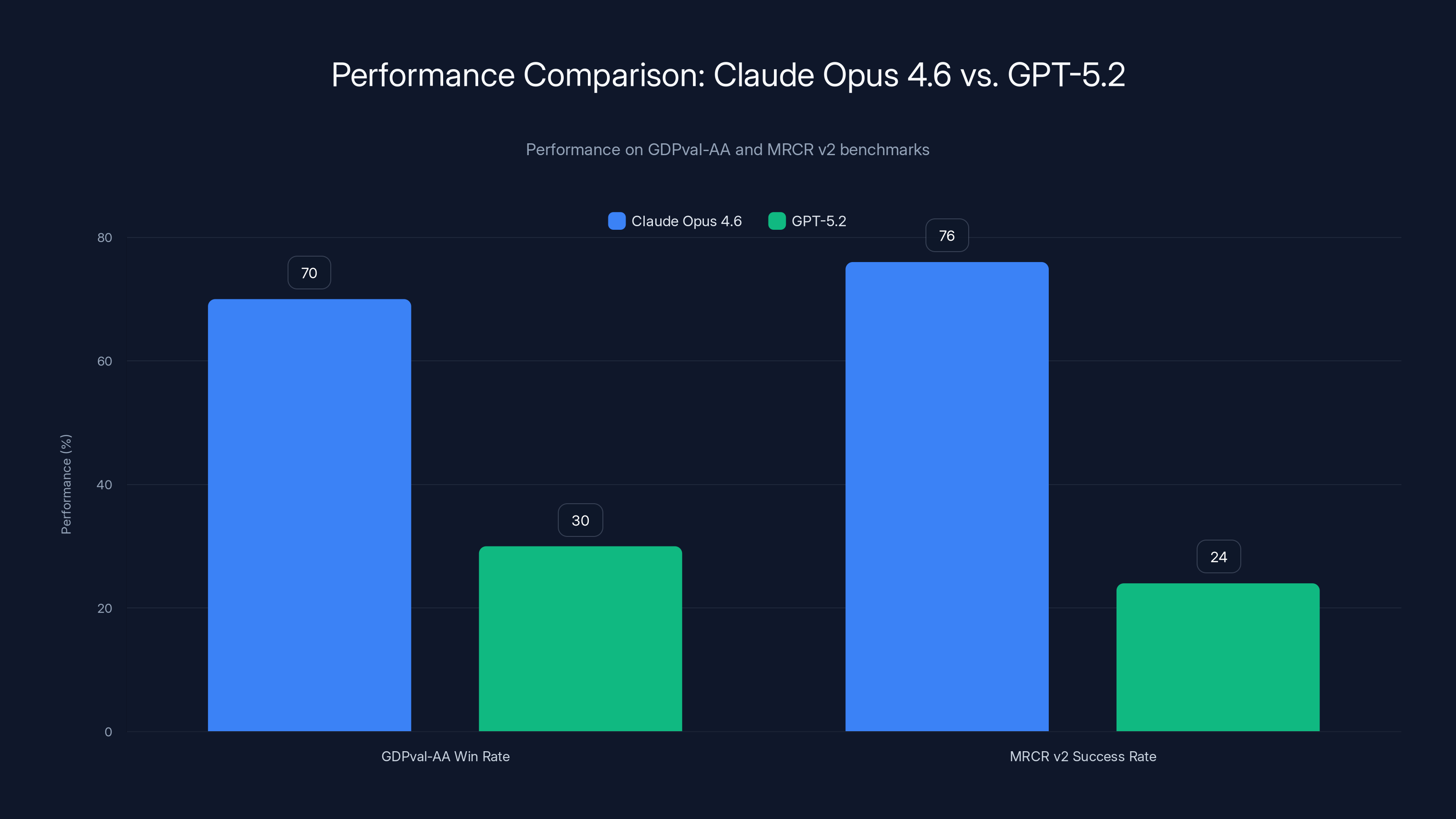
Claude Opus 4.6 outperforms GPT-5.2 with a 70% win rate on GDPval-AA and 76% success on MRCR v2 long-context retrieval tests, highlighting its superior performance in enterprise knowledge work tasks.
Understanding the 1 Million Token Context Window: Technical Architecture and Real-World Implications
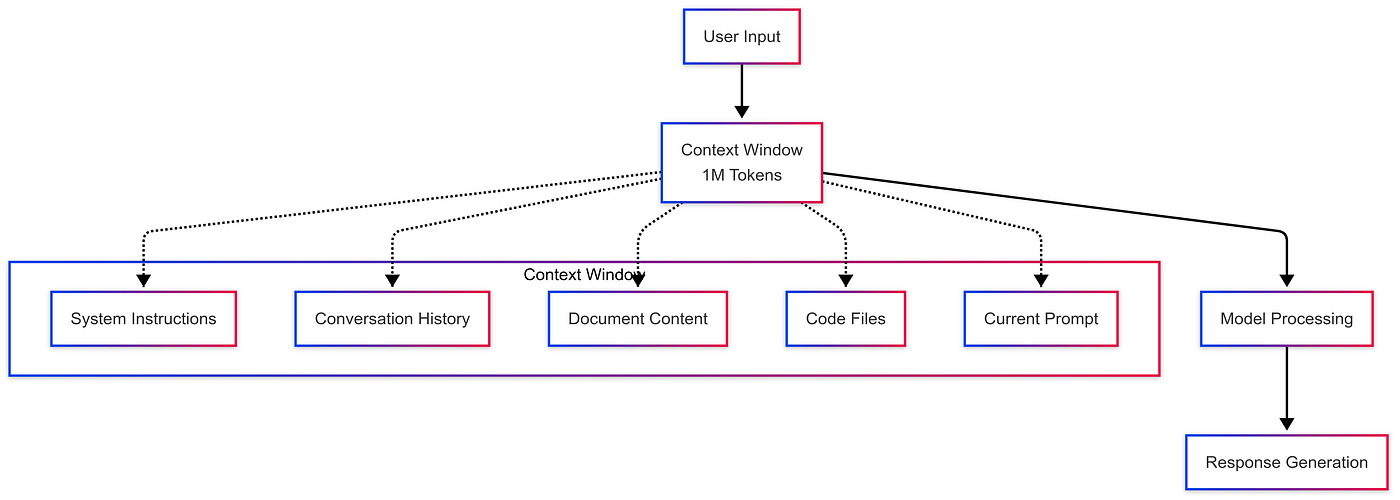
The expansion to 1 million tokens fundamentally redefines what's possible in AI-assisted development. To understand the magnitude of this achievement, consider that a single token approximately represents 4 characters or 1 word in English text. A 1 million token context window enables Claude Opus 4.6 to simultaneously process:
- Entire large codebases: A typical enterprise application might contain 100,000-500,000 lines of code—fully contained within the context window
- Complete documentation systems: Technical documentation, API references, architectural decision records, and knowledge bases for entire organizations
- Extended conversation histories: Projects requiring 50+ hour-long interactions, with full context preserved throughout
- Multi-file analysis: Analyzing how changes in one component ripple through dozens of interconnected files
- Temporal reasoning: Understanding code evolution across multiple versions, git histories, and deployment stages
This technical capability addresses a critical limitation that has plagued AI systems: context degradation over time. Previous models suffered from "context rot," where performance deteriorated as conversation length increased. Developers observed that after 20-30 exchanges, models would forget earlier context, contradict previous suggestions, or lose track of project-specific conventions they'd established early in conversations.
Clause Opus 4.6 achieves a 76% success rate on MRCR v 2, a needle-in-a-haystack benchmark testing retrieval capability within massive contexts, compared to just 18.5% for previous-generation models. This represents a 4x improvement in information retrieval accuracy across vast contexts. The technical implementation likely involves advanced attention mechanisms, hierarchical reasoning structures, and potentially novel architectural approaches to prevent attention degradation in long sequences.
How the Extended Context Changes Development Workflows
The practical implications for development teams are profound. Historically, developers faced a trade-off: either work with fragmented contexts (asking AI to understand pieces of problems in isolation) or maintain expensive workarounds (manually pasting entire files, maintaining separate conversation threads, or using external tools to summarize context).
With 1M tokens, developers can:
- Maintain complete project context: Upload entire application codebases, and Claude maintains understanding of the full system architecture throughout development
- Cross-cutting analysis: Perform refactoring exercises where the AI understands how changes to a utility library affect dozens of dependent modules
- Knowledge preservation: Build internal documentation, capture architectural reasoning, and maintain institutional knowledge within conversations that span weeks or months
- Reduced context switching: Teams stop breaking down tasks into artificial chunks sized for AI context windows
- Richer problem decomposition: AI can analyze problems holistically before proposing solutions, rather than solving subproblems in isolation
The Technical Challenge: Maintaining Performance at Scale
Expanding context windows to 1 million tokens introduces significant computational challenges. Transformer models' computational complexity increases quadratically with sequence length (roughly
Anthropic has clearly invested in sophisticated optimization techniques. These likely include:
- Sparse attention mechanisms: Not attending to every token-to-token pair, but strategically sampling relevant context
- Hierarchical context organization: Structuring context so recent exchanges receive dense attention while older context receives sparser, strategic attention
- Intelligent context compression: Automatically summarizing or compressing less-relevant information without losing critical details
- Batch inference optimization: Leveraging hardware-specific optimizations for longer sequences
The practical result is that while context processing is more expensive than with shorter contexts, it's not 25x more expensive—likely closer to 3-5x the cost of a standard interaction. This pricing structure reflects these computational realities while remaining economically viable for enterprise use cases.
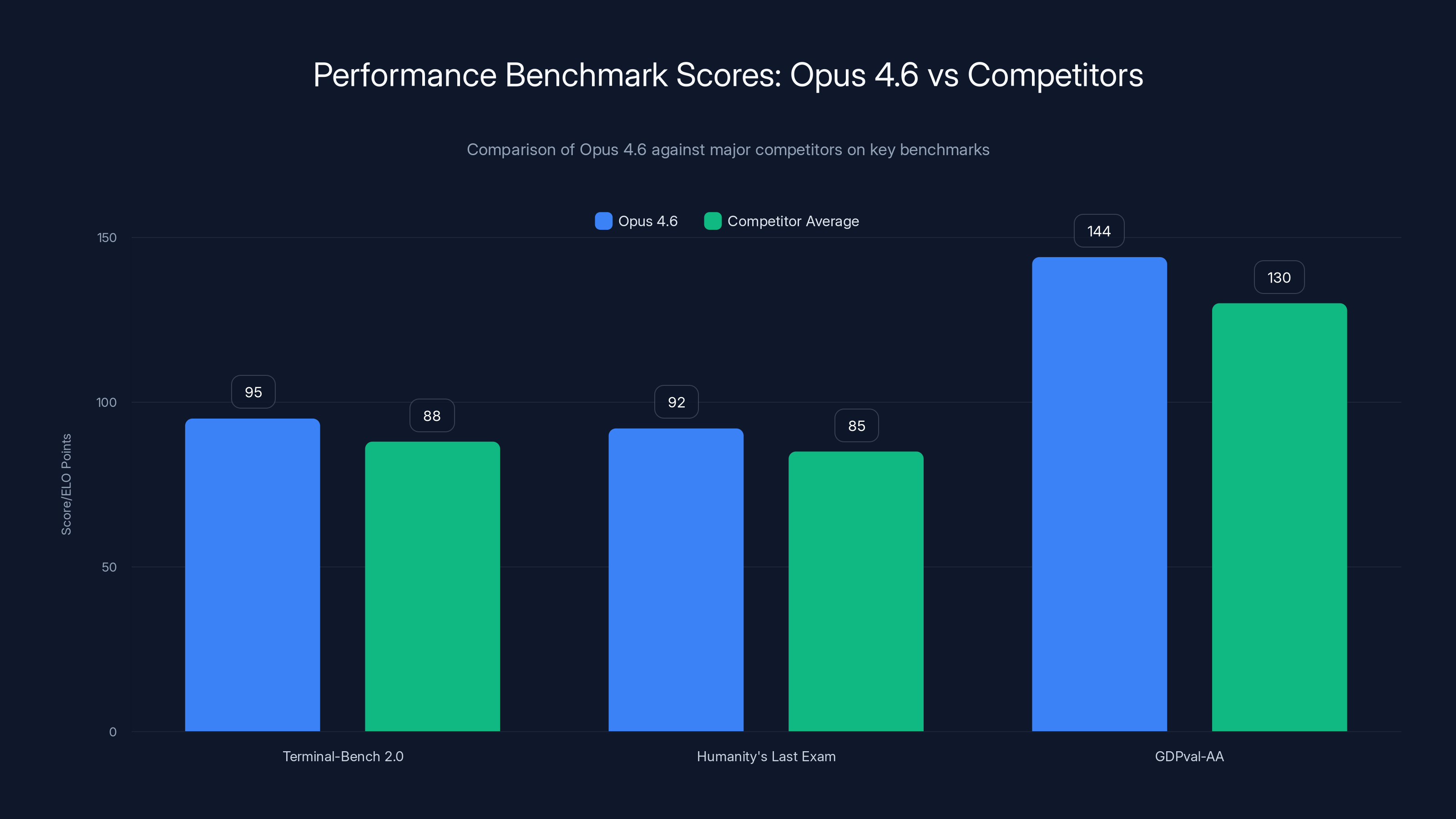
Opus 4.6 leads in all benchmarks, notably outperforming competitors by 144 ELO points in GDPval-AA, indicating a 70% higher success rate in knowledge tasks.
Agent Teams: Orchestrating Parallel AI Intelligence
While the expanded context window represents incremental scaling, the agent teams feature represents a genuine architectural innovation. Rather than interactions with a single AI assistant, Claude Code now enables orchestration of multiple independent AI agents, each specialized for specific domains, operating in parallel while maintaining shared project context and coordination.
This capability emerges from advances in several areas:
- Agent frameworks and orchestration: Building on years of research in multi-agent systems, agentic AI, and collaborative reasoning
- Tool use and integration: Enabling agents to trigger specific actions, invoke APIs, run code, access version control systems
- Shared state management: Maintaining synchronized context across agents to prevent conflicts and ensure coherent project state
- Conflict resolution and coordination: Mechanisms for agents to negotiate interdependencies and resolve conflicts without human intervention
How Agent Teams Work in Practice
In a concrete example, consider a typical full-stack application development task. Historically, a developer might spend 4-6 hours implementing a feature across frontend, backend, and database layers. With agent teams, the workflow transforms:
Traditional approach:
- Developer writes React components (2 hours)
- Developer implements Express.js API endpoints (2 hours)
- Developer writes database migrations and schemas (1 hour)
- Developer integrates components, fixes bugs, deploys (1-2 hours)
- Total: 6-8 hours, sequential process
Agent teams approach:
- Developer describes feature requirements at project level
- Project context (codebase, style guides, architecture docs) loaded into shared context
- Three agents deployed simultaneously:
- Frontend Agent: Implements React components, styling, state management
- Backend Agent: Implements API endpoints, validation, authentication
- Database Agent: Designs schema migrations, indexes, data validation
- Agents coordinate on interfaces (e.g., API contract, data shapes)
- Integration and testing completed (developer review and validation)
- Total: 2-3 hours, parallel process
This acceleration emerges not from agents working on trivial tasks, but from eliminating context-switching overhead and enabling specialized focus on distinct problems simultaneously.
Agent Coordination Mechanisms
The technical challenge in agent teams is preventing conflicts while enabling autonomy. If three agents modify the same codebase simultaneously, coordination mechanisms must ensure:
- Non-conflicting modifications: Agents working on different files or clearly separated concerns
- Interface agreements: Agents independently implementing different layers but adhering to agreed-upon contracts
- State consistency: Shared state (git repository, configuration, dependencies) remains consistent
- Conflict detection and resolution: When agents do attempt conflicting modifications, mechanisms for automatic resolution or escalation to human review
Anthropic has built these mechanisms into Claude Code's agent framework. Agents have visibility into each other's working context, can examine proposed changes before they're finalized, and maintain conversation threads for coordination. The system prevents agents from making conflicting modifications through strategic workload distribution and conflict detection.
Real-World Use Cases for Agent Teams
Agent teams excel in specific scenarios:
- Large codebase refactoring: Multiple agents independently refactor different modules while maintaining API contracts
- Polyglot application development: Teams with diverse technology stacks (Node.js backend, Python data pipeline, Rust systems code) can dedicate specialized agents
- Parallel testing and documentation: While frontend and backend agents work on implementation, a documentation agent generates API docs, tutorials, and test plans
- Multi-service architecture development: Microservices environments where agents own specific services while coordinating on service contracts
- Data pipeline construction: Data engineering agents working on extraction, transformation, loading stages in parallel
For teams building complex distributed systems, this capability represents a genuine productivity multiplication factor, not merely an incremental improvement.
Performance Benchmarking: How Opus 4.6 Compares to Competitors
Anthropic published comprehensive performance data establishing Opus 4.6's competitive position. Understanding these benchmarks requires interpreting what they actually measure and what they don't.
Key Performance Benchmarks
Terminal-Bench 2.0 (Agentic Coding Evaluation): This benchmark measures how well models perform autonomous coding tasks without human intervention. Terminal-Bench presents realistic coding challenges and evaluates whether models can solve problems end-to-end. Opus 4.6 achieved the highest score among frontier models, indicating superior ability to independently solve coding tasks.
Humanity's Last Exam (Complex Multi-Discipline Reasoning): Designed to test reasoning across physics, mathematics, philosophy, economics, and other domains, this benchmark measures whether AI systems can handle genuinely difficult reasoning challenges. Opus 4.6's leadership on this benchmark suggests improvements in reasoning sophistication and multi-step logical inference.
GDPval-AA (Knowledge Work Evaluation): Measuring performance on economically valuable tasks in finance, law, and business domains, this benchmark is particularly relevant for enterprise adoption. Opus 4.6 outperforms Open AI's GPT-5.2 by approximately 144 ELO points, translating roughly to obtaining higher scores approximately 70% of the time. This represents substantial competitive advantage in knowledge work domains critical to enterprise valuation and decision-making.
Understanding ELO Point Differentials
The 144 ELO point advantage requires context to interpret. ELO ratings, borrowed from chess, provide a statistical measure of relative capability. A 144-point difference suggests that in head-to-head comparisons on knowledge work tasks:
- Claude Opus 4.6 achieves superior solutions 70% of the time
- Solutions are typically higher quality, more comprehensive, and require less human refinement
- The advantage is consistent across diverse tasks, not domain-specific
For enterprise procurement, this 70/30 advantage is significant. Many organizations can justify switching when one solution demonstrably outperforms alternatives 70% of the time, particularly when the domain (legal analysis, financial modeling, strategic decision-making) has high-value consequences.
Contextual Performance Metrics
Beyond headline benchmarks, Opus 4.6 demonstrates particular strength in:
- Long-context retrieval: 76% success on MRCR v 2 vs. 18.5% for previous models
- Code generation quality: Improvements in code correctness, security practices, and architectural soundness
- Tool-use capability: Enhanced ability to use provided APIs, testing frameworks, and external systems
- Reasoning clarity: Improved explanations of reasoning process, making AI assistance more interpretable
These specialized metrics matter more than generic benchmarks for specific use cases. A team doing financial analysis cares more about GDPval-AA performance than Terminal-Bench scores.

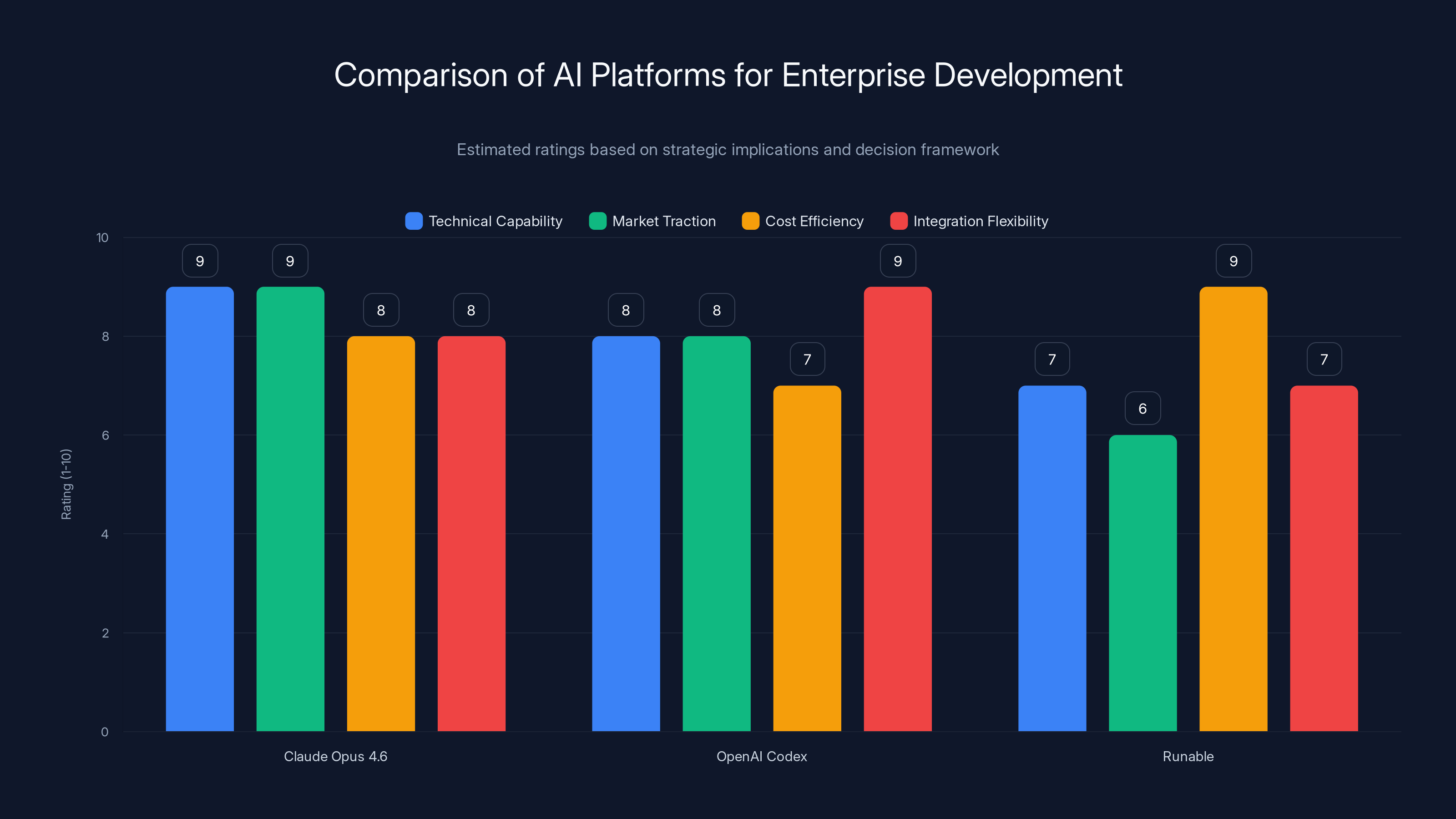
Claude Opus 4.6 leads in technical capability and market traction, while Runable offers cost efficiency. Estimated data based on strategic implications.
Claude Code's Enterprise Traction and $1 Billion Revenue Milestone
The commercial success of Claude Code deserves examination alongside technical achievements, as it indicates genuine enterprise acceptance rather than theoretical capability.
Revenue Trajectory and Market Adoption
Clause Code reached $1 billion in annualized run-rate revenue in November 2025, just 6 months after general availability in May 2025. This scaling represents one of the fastest revenue ramps for any software product in history. For context:
- Slack: Reached $100M ARR after 4 years
- Figma: Reached $100M ARR after 6 years
- Claude Code: Reached $1B ARR after 6 months
This acceleration reflects both market demand for AI-assisted development and Claude's particular competitiveness in this space. The speed of adoption suggests that enterprises weren't skeptical about adopting the tool—they were ready and waiting for viable solutions.
Enterprise Deployment Scope
Anthropic highlighted deployment at tier-1 technology companies:
- Uber: "Across teams like software engineering, data science, finance, and trust and safety" — indicating organization-wide deployment, not pilot programs
- Salesforce: "Wall-to-wall deployment across global engineering org" — suggesting this is the standard development tool, not an experimental project
- Accenture: "Tens of thousands of developers" — demonstrating viability at massive scale across diverse client bases
- Additional enterprise usage: Spotify, Rakuten, Snowflake, Novo Nordisk, Ramp
This deployment pattern is notable because it shows adoption among companies whose engineering organizations are already sophisticated. Uber's data science and trust & safety teams represent particularly demanding use cases—these teams wouldn't adopt tools that required constant supervision. Wall-to-wall deployment at Salesforce indicates confidence at the leadership level, not isolated team enthusiasm.
What the Revenue and Adoption Metrics Reveal
The $1B ARR figure combined with deployment scope suggests:
- Product-market fit at enterprise scale: Claude Code solves genuine problems for sophisticated organizations
- Competitive advantage over incumbents: If existing development tools were sufficient, organizations wouldn't incur switching costs
- Pricing power: $1B ARR at 6 months suggests healthy unit economics and customer willingness to pay premium pricing
- Integration into core workflows: Companies deploying "wall-to-wall" aren't running pilots—they're making strategic bets
These metrics help explain Anthropic's valuation. In February 2025, Anthropics raised at a **
- Claude's technical superiority
- Enterprise acceptance and adoption potential
- Sustainable competitive advantages
- Expanding addressable markets beyond development into knowledge work broadly

Addressing Context Rot: A Technical Deep Dive
"Context rot" describes performance degradation in AI models as conversation length increases. This phenomenon has plagued every large language model, creating a hard ceiling on conversational capabilities.
The Nature of Context Rot
Context rot manifests in several ways:
- Forgotten context: Models fail to reference information provided early in conversations
- Contradictory guidance: Suggestions contradict previous statements or established conventions
- Attention dilution: With more tokens to attend to, models distribute attention across all tokens, weakening focus on relevant information
- Logit drift: Probability distributions shift, making models less confident and more generic in later conversation turns
Previous models exhibited severe context rot. Asking Claude Sonnet 4.5 to recall specific information hidden in 500K+ tokens of context resulted in failure 81.5% of the time (success rate of 18.5%). This made long-context interactions practically impossible—developers quickly learned to avoid uploading large codebases.
Technical Solutions in Opus 4.6
Opus 4.6's 76% success rate on MRCR v 2 represents a 4.1x improvement over Sonnet 4.5. This dramatic improvement likely stems from:
1. Improved attention mechanisms: Modern attention implementations (such as grouped query attention, flash attention, or similar techniques) have made long-sequence attention more efficient and accurate.
2. Better architectural scaling: The underlying model architecture likely incorporates improvements specifically designed for longer sequences, possibly including:
- Positional encoding improvements (rotary positional embeddings or similar)
- Hierarchical attention patterns (recent context receives dense attention, older context receives sparse attention)
- Mixture-of-expert routing optimized for long sequences
3. Training on long contexts: Likely trained on data containing naturally long documents, conversations, and contexts, helping the model learn to navigate long-range dependencies.
4. Inference-time optimizations: Specialized decoding strategies optimized for maintaining information retrieval capability across long contexts.
Practical Impact: Output Length and Multi-Turn Interactions
Beyond retrieval accuracy, Opus 4.6 supports outputs up to 128,000 tokens—enough to generate complete applications, comprehensive documentation, or thorough analyses without forced truncation. This matters practically because:
- Complete code generation: Generate entire applications (thousands of lines) in single responses
- Comprehensive documentation: Generate complete API documentation, user guides, and technical specifications
- Extended reasoning: Detailed explanation of reasoning, step-by-step breakdowns, and alternative approaches
- Artifact generation: Multiple interdependent files (migrations, models, controllers, tests) in coordinated outputs
The combination of 1M input tokens and 128K output tokens creates a context window large enough for genuine multi-hour coding sessions without fragmentation.
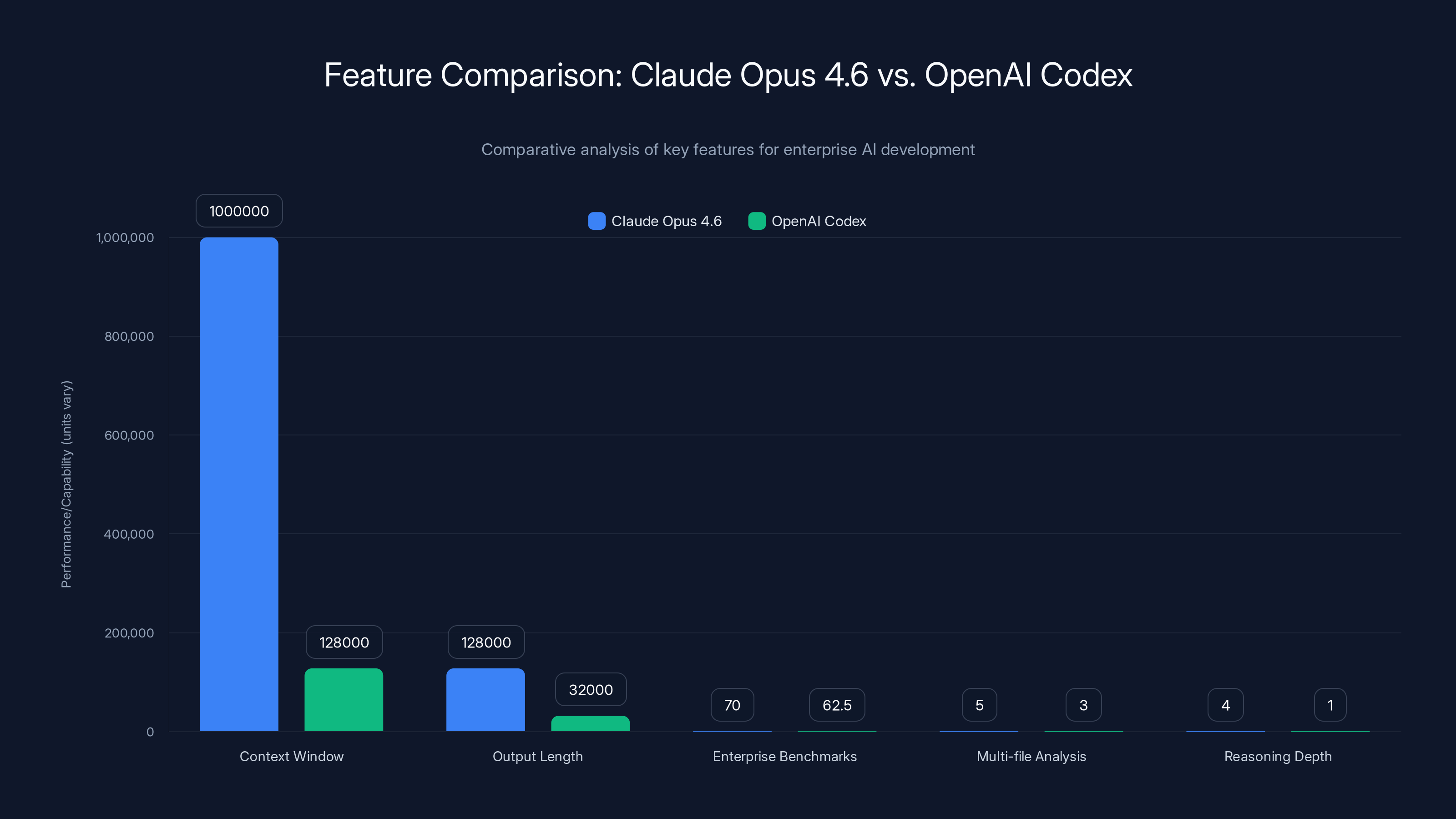
Claude Opus 4.6 demonstrates superior capabilities in context window size, output length, and multi-file analysis, offering significant advantages over OpenAI Codex in these areas. Estimated data used for enterprise benchmarks.
API Control Features: Adaptive Thinking, Effort Levels, and Context Compaction
Beyond the flagship capabilities, Opus 4.6 introduces several API controls enabling fine-tuned usage patterns and economic optimization.
Adaptive Thinking: Intelligent Reasoning Allocation
Previous Claude versions required binary reasoning modes: either standard processing or extended thinking enabled for all requests. This is economically inefficient—many tasks don't require extended reasoning, making the option an all-or-nothing trade-off.
Adaptive thinking lets Claude determine when deeper reasoning would be beneficial. The model assesses task complexity and self-allocates reasoning compute accordingly:
- Simple queries: Direct responses without extended reasoning overhead
- Complex problems: Automatically triggers deeper analysis when needed
- Reasoning transparency: Users see reasoning process, understand why the model made specific decisions
This dynamic allocation improves both cost efficiency (simple queries cost less) and quality (complex queries automatically get appropriate reasoning depth).
Effort Levels: Explicit Cost/Quality Trade-offs
Four effort levels (low, medium, high, max) provide explicit control over the speed/quality/cost optimization:
Low effort:
- Latency: Minimal (under 1 second)
- Quality: Adequate for straightforward queries
- Cost: Lowest tier
- Use case: Reflex responses, repetitive tasks, high-volume operations
Medium effort:
- Latency: ~2-5 seconds
- Quality: Good for most development tasks
- Cost: Standard pricing
- Use case: Default setting for most development work
High effort:
- Latency: 10-30 seconds
- Quality: Excellent for complex reasoning
- Cost: 2-3x medium effort
- Use case: Architecture decisions, complex refactoring, critical path work
Max effort:
- Latency: 1-2 minutes
- Quality: Maximum accuracy and reasoning depth
- Cost: 5-10x medium effort
- Use case: High-stakes decisions, novel problems, verification work
This flexibility lets organizations optimize individually: critical security review might use max effort, while code formatting assistance uses low effort. The same API call can vary behavior based on context requirements.
Context Compaction: Enabling Extended Multi-Turn Interactions
Context compaction, currently in beta, automatically summarizes older conversation history to preserve semantic content while reducing token usage. Rather than keeping raw conversation history indefinitely (which eventually exhausts the context window), compaction intelligently:
- Identifies key decisions and context: What matters for future interactions
- Summarizes safely: Preserving critical information while discarding redundant exchanges
- Maintains interpretability: Summaries remain understandable, not cryptic compressed representations
- Enables indefinite conversations: Projects can extend across weeks or months without context exhaustion
This is particularly valuable for:
- Long-term projects: Multi-week development initiatives can maintain continuous context
- Institutional knowledge: Capture architectural decisions, design rationale, and lessons learned
- Team handoffs: Incoming team members can quickly understand project history
- Compliance documentation: Maintain records of decisions and reasoning for audit purposes
Context compaction represents a genuine solution to a previous limitation—enabling conversational AI to support extended projects rather than just point-in-time assistance.
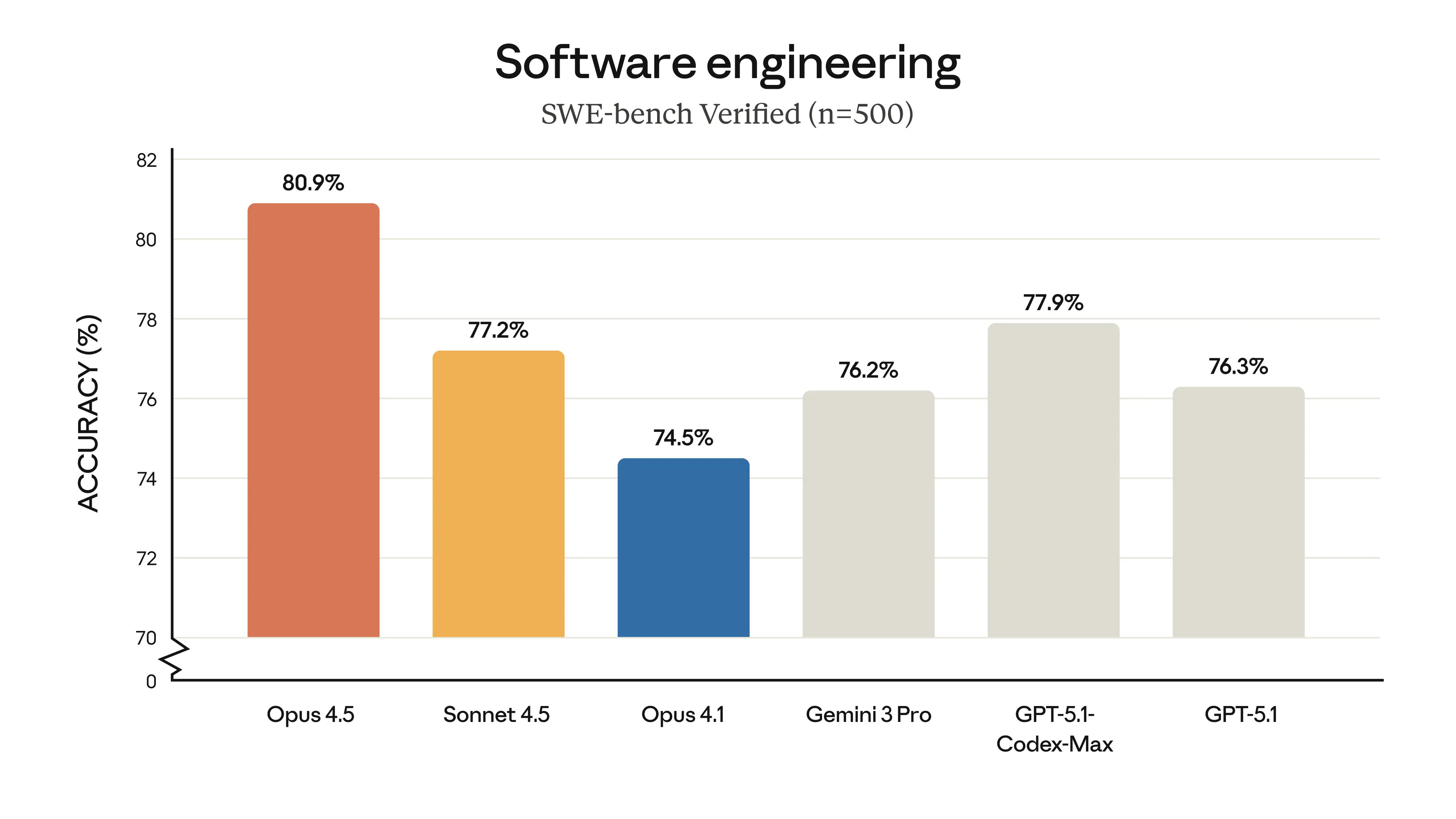
Comparing Claude Opus 4.6 vs. Open AI Codex: The Enterprise AI Development Wars
Understanding Opus 4.6 requires positioning it within the competitive landscape, particularly against Open AI's Codex system, which just launched a desktop application at nearly the same time.
Feature Comparison: Direct Analysis
| Feature | Claude Opus 4.6 | Open AI Codex | Key Differentiator |
|---|---|---|---|
| Context Window | 1M tokens | 128K tokens | 8x advantage for Opus |
| Agent Teams | Yes (research preview) | No | Opus innovation |
| Output Length | 128K tokens | 32K tokens | 4x advantage for Opus |
| Desktop Application | Via Claude Code | Native Codex App | Open AI advantage |
| Enterprise Benchmarks | 70% win rate vs GPT-5.2 | Comparable (60-65% estimate) | Opus competitive edge |
| Pricing | Integrated into Claude API | Separate Codex pricing | Cost model difference |
| Multi-file Analysis | Excellent (full codebase) | Good (limited by context) | Opus advantage |
| Reasoning Depth | Adaptive + 4 effort levels | Fixed processing | Opus flexibility |
| Integration Depth | Deep (tool-use, code execution) | Deep (native IDE integration) | Different approaches |
Architectural Differences
Claude Opus 4.6 emphasizes:
- Long-context reasoning and retrieval
- Multi-agent orchestration for team collaboration
- API-first architecture enabling integration into various workflows
- Flexible reasoning allocation (adaptive thinking)
Open AI Codex emphasizes:
- Native desktop application with rich UI
- Direct IDE integration
- Real-time autocomplete and suggestions
- Established ecosystem of Open AI integration points
Competitive Positioning
These products occupy partially overlapping but strategically different positioning:
Claude Opus 4.6 targets: Teams building sophisticated applications, API-first development, teams needing extended context, organizations wanting flexibility in reasoning/cost trade-offs, enterprises already using Claude.
Open AI Codex targets: Developers wanting native IDE integration, teams using Open AI's ecosystem, developers preferring desktop-first experiences, teams wanting real-time collaborative features in UI.
Neither product is objectively "better"—they appeal to different use cases and organizational preferences. However, the 1M token context and agent teams capabilities represent areas where Opus has technical advantages for specific use cases (large codebase analysis, parallel task execution, extended context preservation).
Market Positioning: The Broader Competitive Context
Beyond Codex, Claude Opus 4.6 competes with:
- Git Hub Copilot: Deep IDE integration, autocomplete focus, broad developer base
- Cursor IDE: Purpose-built IDE around AI assistance, strong developer community
- Jet Brains AI Assistant: Enterprise IDE integration, language-specific optimizations
- Amazon Code Whisperer: AWS-integrated, enterprise licensing
- Custom solutions: Organizations building in-house AI development tools
Claude's positioning is strongest for:
- Organizations doing complex development requiring extended context
- Teams needing flexible, API-driven integration
- Companies building sophisticated workflows around AI assistance
- Enterprises already standardizing on Claude for other applications

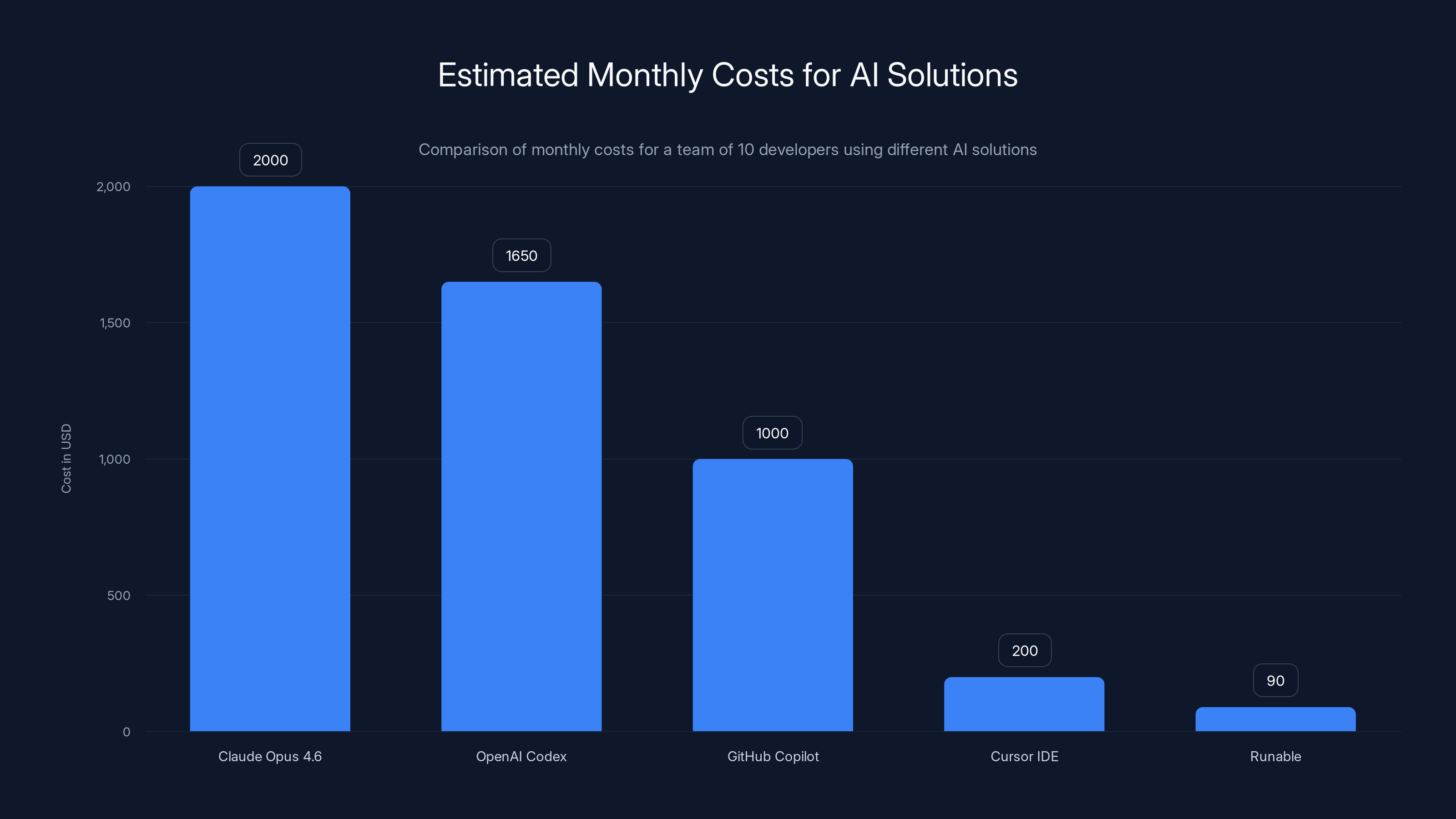
GitHub Copilot offers the lowest cost per developer, while Claude Opus 4.6 and OpenAI Codex have higher usage-based costs. Estimated data based on typical usage.
Alternative Solutions and How Runable Fits the Landscape
While Claude Opus 4.6 represents a significant advancement in AI-assisted development, it's important to contextualize it within the broader ecosystem of development automation solutions. Different organizations have different needs, technical contexts, and budgets.
When Claude Opus 4.6 Makes Sense
- Large-scale development: Teams with extensive codebases benefiting from the 1M token context
- Complex reasoning tasks: Development requiring extended analysis, planning, and optimization
- Enterprise API integration: Organizations wanting to integrate AI deeply into internal workflows
- Multi-team coordination: Organizations deploying agent teams across multiple project initiatives
- Knowledge work integration: Companies using Claude across development, analysis, documentation, and business domains
Alternative Platforms and Solutions
For teams with different priorities, other solutions deserve consideration:
Cursor IDE:
- Purpose-built IDE with AI as first-class feature
- Strong community and integrations
- Lower price point than enterprise Claude deployments
- Best for developers prioritizing IDE experience
Git Hub Copilot:
- Deep Git Hub integration
- Broad ecosystem support
- Real-time autocomplete focus
- Best for teams already using Git Hub
Amazon Code Whisperer:
- AWS integration
- Enterprise licensing flexibility
- Enterprise security features
- Best for AWS-native organizations
Custom In-House Solutions:
- Organizations building AI development tools on top of open-source models
- Provides maximum control and customization
- Requires significant engineering investment
- Best for organizations with specific proprietary requirements
Runable as an Alternative Approach
For teams with different architectural needs, Runable offers a distinct approach to development automation. Rather than focusing on AI-assisted coding specifically, Runable provides AI-powered workflow automation for developers and teams, starting at $9/month.
Runable's strength lies in automating repetitive development workflows beyond pure coding:
- AI-generated documentation and specifications: Using AI to automatically generate API documentation, architecture specifications, requirement documents
- Workflow automation: Building automated pipelines for common development tasks, testing patterns, deployment procedures
- Content generation at scale: Teams generating hundreds of specification documents, release notes, or technical content
- Developer productivity tools: Automating boilerplate generation, code cleanup, configuration management
- Cost-effective AI automation: Achieving substantial productivity gains without the enterprise pricing of dedicated AI development platforms
Runable is particularly suitable for:
- Startups: Needing automation capabilities without enterprise licensing costs
- Small development teams: Where cost-per-developer matters significantly
- Automation-focused workflows: Teams automating documentation, testing, deployment, rather than writing code
- Multi-tool strategies: Organizations using Claude Opus for complex coding and Runable for workflow automation
- Content-heavy development: Teams generating substantial documentation, specifications, and content alongside code
The key distinction: Claude Opus 4.6 excels at interactive, extended-context coding assistance. Runable excels at background automation and batch processing of development workflows, requiring minimal human iteration.
For teams building modern applications, a multi-platform strategy often makes sense: use Claude Opus 4.6 for interactive development on critical path items, use Runable for automating documentation, testing, deployment workflows and running parallel tasks requiring less human oversight.

Pricing Models: Understanding the Economic Implications
Claude Opus 4.6 pricing reflects its computational costs and positioning as an enterprise solution. Understanding pricing structures is essential for evaluating return on investment.
Claude Opus 4.6 Pricing Structure
Anthropic's pricing for Opus models is usage-based:
- Input tokens: Cost per 1M tokens processed
- Output tokens: Higher cost per token generated (generally 3-5x input costs)
- Context window size: While not explicitly charged differently, longer context windows increase computation
- Effort level selection: Higher effort levels proportionally increase costs
For a typical enterprise deployment:
- Small team (5 developers): 1,500/month
- Medium team (20 developers): 6,000/month
- Large team (100+ developers): 30,000/month
These estimates assume regular usage (10-20 API calls per developer per day), with mix of effort levels and context sizes.
Competitive Pricing Comparison
| Solution | Estimated Monthly Cost (Team of 10) | Pricing Model | Notes |
|---|---|---|---|
| Claude Opus 4.6 | $1,000-3,000 | Usage-based (tokens) | Scales with context/output length |
| Open AI Codex | $800-2,500 | Usage-based + seat-based | Desktop app may have additional costs |
| Git Hub Copilot | $100/developer/month | Seat-based | Fixed cost, includes all models |
| Cursor IDE | $20/developer/month | Subscription | Pro plan, includes Claude access |
| Runable | $90/month (team) | Subscription ($9/mo base) | Fixed cost, unlimited workflows |
ROI Calculation Framework
Evaluating whether Claude Opus 4.6 or alternatives make economic sense requires calculating productivity multipliers:
Baseline assumptions:
- Developer fully-loaded cost: 72/hour)
- Development task normally requires 8 hours of work
- Cost of 8 developer hours: $576
With Claude Opus 4.6:
- Task completion time: 3 hours (62% reduction)
- AI platform cost: $8-15 for task
- Total cost: 12 = $228
- Savings per task: $348 (60% reduction)
Annual calculation (assuming 2 tasks per developer per week = 100 tasks/year):
- Savings per developer: $34,800/year
- Team of 10: $348,000/year savings
- Less platform costs: (18,000
- Net annual savings: $330,000 for team of 10
- ROI: 18x (every dollar spent returns $18 in productivity gains)
These calculations assume modest 62% task acceleration. Teams report 2-3x productivity gains on compatible tasks, which would dramatically increase ROI.

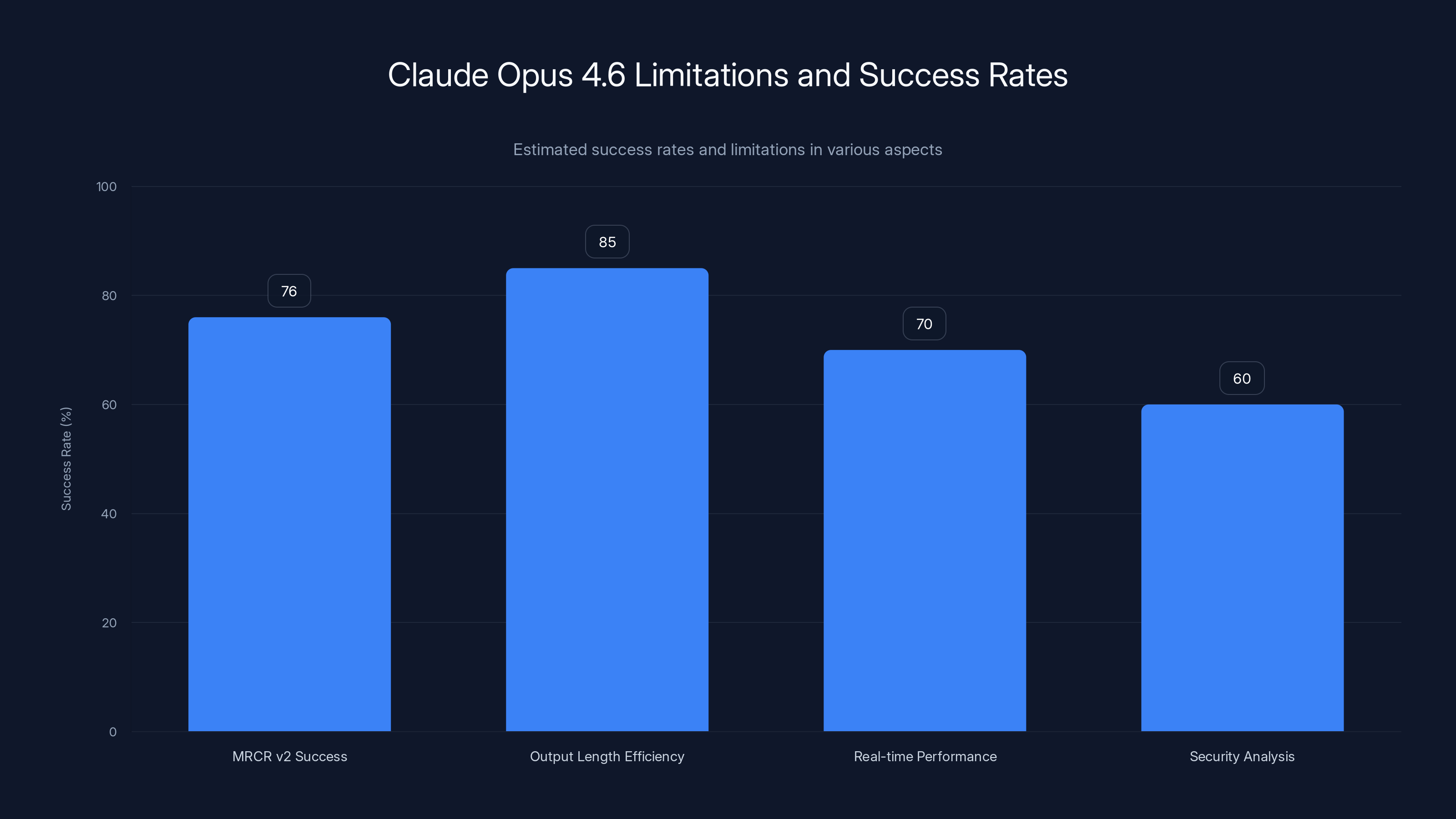
Claude Opus 4.6 shows a 76% success rate on MRCR v2 and 85% efficiency in output length management. However, real-time performance and security analysis have lower success rates, indicating areas for improvement. Estimated data.
Security, Privacy, and Enterprise Considerations
For enterprises evaluating Claude Opus 4.6, security and privacy considerations are often decisive factors.
Data Privacy and Handling
Anthropic maintains a privacy-first approach:
- No training on user data: Conversations sent to Claude are not used for training subsequent models
- No data retention: After processing, API requests are deleted (within periods specified by contracts)
- Enterprise-grade encryption: Data in transit and at rest protected with industry-standard encryption
- GDPR/CCPA compliance: Handled through data processing agreements
- Audit trails: Comprehensive logging for enterprise compliance requirements
For teams handling sensitive code or proprietary information, these guarantees are essential. Organizations must verify these commitments through data processing agreements before deployment.
Intellectual Property Concerns
One critical consideration: code generated by Claude Opus 4.6 and intellectual property ownership. Generally:
- User owns generated code: Output from Claude API belongs to the user, not Anthropics
- No license restrictions: Generated code can be used commercially without restrictions
- However: Verify this through your specific licensing agreement
Organizations should clarify IP ownership expectations explicitly during contract negotiation.
Compliance and Certifications
For regulated industries, compliance certifications matter:
- SOC 2 Type II: Demonstrates security controls
- ISO 27001: Information security management
- Industry-specific: Healthcare (HIPAA), finance (SOC), government (Fed RAMP in progress)
Anthropic's certification status should be verified against your specific compliance requirements.
Bias and Safety Considerations
AI systems can exhibit bias that impacts generated code:
- Hiring/selection code: Code handling hiring processes might embed demographic bias
- Financial decision code: Code affecting credit decisions must be carefully evaluated
- Security code: Generated security code should receive additional review
- Critical infrastructure: Code handling utilities, transportation, medical systems needs extra scrutiny
Best practice: treat Claude-generated code as a draft, not final product, particularly in sensitive domains. Include code review processes that specifically evaluate for bias, security, and edge cases.

Implementation Strategy: Deploying Claude Opus 4.6 at Scale
Successfully deploying Claude Opus 4.6 requires more than signing contracts—it requires organizational preparation and thoughtful integration.
Pre-Deployment Assessment
Before committing to platform-wide deployment:
- Identify suitable use cases: Which development tasks benefit most from extended context?
- Assess team readiness: Are developers comfortable with AI-assisted workflows?
- Evaluate codebase characteristics: How large are typical projects? Do they benefit from 1M token context?
- Define success metrics: How will you measure productivity improvement?
- Calculate ROI: What's the break-even point for your team?
Phased Rollout Approach
Phase 1: Pilot (Weeks 1-4)
- Select 2-3 developers
- Test on well-defined projects
- Measure productivity impact
- Gather feedback on integration
Phase 2: Early adoption (Weeks 5-8)
- Expand to 25% of engineering team
- Develop internal guidelines
- Create playbooks for effective usage
- Train team members
Phase 3: Broad deployment (Weeks 9+)
- Platform-wide availability
- Integration with development workflows
- Ongoing optimization
- Measurement and iteration
Developing Effective Usage Patterns
High-leverage use cases:
- Large codebase analysis and refactoring
- Architecture design decisions
- Complex system integration
- Security audit and hardening
- Documentation generation
Lower-leverage use cases:
- Trivial code (simple utility functions)
- Boilerplate generation (often better automated via templates)
- IDE autocomplete (Git Hub Copilot excels here)
- Single-file modifications (lightweight compared to extended context)
Optimal usage pattern:
- Upload entire project context (codebase, documentation, tests)
- Ask Claude to analyze comprehensive problem
- Have Claude propose multi-file solution
- Review and integrate solution
- Iterate on refinements
This pattern—leveraging extended context for thorough analysis—maximizes the platform's unique advantages.
Integration with Existing Tools
Claude Opus 4.6 integrates effectively with:
- Version control (Git): Upload repository contents to Claude for comprehensive analysis
- Issue tracking (Jira, Git Hub Issues): Reference open issues in context to ensure solutions address actual problems
- CI/CD pipelines: Integrate Claude-generated code with automated testing and deployment
- Documentation systems (Confluence, wiki): Feed documentation into context for consistency
- Testing frameworks: Include test patterns in context to generate test-compliant code
More sophisticated integrations are possible:
- Automated testing pipelines: Generate code, run comprehensive tests, iterate
- Static analysis tools: Feed linting and analysis results into Claude to guide improvements
- Performance profiling: Use profiling data to guide optimization suggestions
- Security scanning: Include security scan results to address vulnerabilities
The most successful deployments integrate Claude deeply with existing workflows rather than treating it as an isolated tool.

Limitations and Realistic Expectations
While Claude Opus 4.6 represents significant advancement, understanding its limitations prevents misalignment of expectations.
Technical Limitations
Token context is not unlimited reasoning: A 1M token window enables access to vast context, but doesn't mean Claude reasons infinitely. The model still has finite computation for each response.
Context degradation at limits: While 76% success on MRCR v 2 is excellent, it means 24% of retrieval attempts fail. At the absolute edge of context, degradation reappears.
Output length vs. context length: While outputs support 128K tokens, practical outputs typically run 10-30K tokens. Extremely long outputs are possible but economically expensive.
Real-time performance: With large contexts, latency increases. Count on 5-30 second response times for complex analysis, longer for max effort levels.
Behavioral Limitations
Hallucinations persist: Claude still occasionally generates plausible-sounding but incorrect code, particularly for:
- Unfamiliar libraries or frameworks
- Cutting-edge technologies with limited training data
- Domain-specific specialized tools
Architecture decisions: While Claude can propose architecture, evaluating trade-offs and long-term maintainability requires human judgment.
Unknown unknowns: Claude excels at solving problems within its knowledge, but can't reliably identify gaps in understanding about unfamiliar domains.
Security analysis: Claude can identify obvious security issues but may miss subtle vulnerabilities. Security-critical code needs professional security review, not just Claude analysis.
Organizational Limitations
Developer readiness: Some developers resist AI-assisted development, either from skepticism or preference for traditional workflows. Organizational change management is required.
Over-reliance risk: Teams sometimes over-trust Claude output, reducing human review and oversight. This requires discipline and training.
Integration friction: Integrating Claude into existing workflows requires some development effort and process changes.
Cost at Scale
While ROI is positive for most teams, at extreme scale costs accumulate:
- A 500-person engineering organization with heavy Claude usage might spend 2M annually
- This is economically justified if it enables 30-40% productivity gains
- But requires careful cost management and usage optimization
Runnable's $9/month base pricing becomes attractive for teams prioritizing cost-effective automation over interactive development assistance.

Future Roadmap: What's Next for Claude and Competitive Dynamics
Understanding Opus 4.6 requires considering where the technology is heading.
Anticipated Near-Term Developments
Further context expansion: 2-5M token contexts are likely feasible with continued optimization. This would enable:
- Multi-project analysis (entire codebases from multiple repositories)
- Organization-wide policy and standard analysis
- Extended multi-month conversations
Agent team enhancements: Current agent teams are in research preview. Production features will likely include:
- More specialized agent types
- Improved coordination mechanisms
- Better conflict detection and resolution
- Execution of generated code directly
Real-time capabilities: Desktop applications will likely gain real-time features matching Codex:
- Live code suggestions as developers type
- Real-time refactoring preview
- Collaborative AI-assisted pair programming
Competitive Landscape Evolution
Competition will intensify across several dimensions:
Capability race: Both Anthropic and Open AI (plus other competitors) will continue pushing model capabilities. Expect:
- Better code quality
- Deeper reasoning
- Improved long-context handling
- Specialized model variants
Integration depth: Platforms will deepen IDE and workflow integration:
- Direct integration into Jet Brains IDEs
- Git Hub integration improvements
- Custom AI workflow builders
Vertical specialization: We'll likely see specialized AI development platforms for:
- Specific languages (Python-focused, Rust-focused, etc.)
- Specific domains (web development, systems programming, data engineering)
- Specific platforms (AWS-native tools, Kubernetes-specialized tools)
Market Consolidation Potential
The enterprise AI development tool market could consolidate around:
- A few dominant platforms (Claude, Open AI, maybe 1-2 others)
- Open-source alternatives for cost-conscious teams
- Specialized tools for specific niches
- Internal company tools for organizations with sophisticated AI engineering
This suggests that competitive positioning right now matters significantly—choosing the wrong platform creates lock-in effects.
Best Practices and Recommendations
Based on early adoption patterns and usage data, several best practices emerge:
For Development Teams
-
Start with clear use cases: Don't deploy Claude broadly. Identify 2-3 high-leverage use cases and optimize there.
-
Maintain human review: Never deploy Claude-generated code without human review, regardless of context or confidence.
-
Leverage context aggressively: The 1M token advantage only helps if you actually use it. Upload full codebases, documentation, and architectural context.
-
Iterate on prompts: Develop high-quality prompts that clearly specify requirements, constraints, and context. Invest time here—quality prompts drive quality output.
-
Measure rigorously: Track metrics (time spent, code quality, defect rates) to validate that Claude deployment actually improves productivity.
For Organizations
-
Invest in training: Developers need training in effective AI-assisted development. This isn't intuitive for everyone.
-
Develop guidelines: Create organizational guidelines about:
- What code can be generated by Claude vs. written manually
- Security considerations and review requirements
- Quality standards for generated code
- IP ownership and compliance
-
Build integration infrastructure: The teams most successful with Claude invest in integration tooling:
- Pulling codebase context automatically
- Integrating generated code into testing pipelines
- Automating code review for Claude output
-
Plan for evolution: Claude (and competitors) will evolve rapidly. Plan to:
- Regularly re-evaluate against alternatives
- Budget for platform switching costs
- Avoid building irreplaceable dependencies on specific platform features
For Cost-Conscious Teams
For organizations where cost is critical, consider:
-
Hybrid strategies: Use Claude Opus 4.6 for interactive development, Runable for background automation, open-source alternatives for commodity tasks.
-
Smart usage patterns: Batch requests, use lower effort levels for simple tasks, carefully manage context size.
-
Open-source alternatives: Models like Llama 2, Mistral, or specialized models can handle 30-40% of typical development tasks at lower cost.
-
Custom solutions: For organizations with unique requirements, investing in custom AI development tools may provide better cost/capability trade-offs.

Conclusion: Strategic Implications and Decision Framework
Claude Opus 4.6's launch represents a significant moment in enterprise AI development. The combination of 1M token context, agent teams, and enterprise-grade capabilities creates a platform that fundamentally changes what's possible in AI-assisted development.
Key Takeaways
Technical achievement: The 1M token context and 76% MRCR v 2 performance represent genuine technical advances that enable use cases previously impossible. This isn't incremental improvement—it's qualitative expansion of capabilities.
Market traction: $1B ARR run rate in just 6 months and wall-to-wall deployment at tier-1 companies indicates genuine product-market fit, not hype. Enterprises aren't experimenting—they're standardizing.
Competitive intensity: The timing of this release (72 hours after Open AI's Codex launch) highlights the brutal pace of competition. Both platforms are advancing rapidly. Early leadership matters because it creates network effects and ecosystem lock-in.
Strategic opportunity: For organizations not yet committed to specific platforms, now is the moment to carefully evaluate. The choice between Claude, Open AI, and alternatives has significant strategic implications for development velocity and cost structure.
Decision Framework
Choose Claude Opus 4.6 if:
- Your team works with large codebases requiring cross-file analysis
- You need extended context preservation for long-running projects
- You want flexibility in reasoning depth and cost optimization
- Your organization is already standardizing on Claude
- Your primary use case is interactive development with humans-in-the-loop
Choose Open AI Codex if:
- You prioritize native IDE integration and desktop experience
- Your team is already invested in Open AI's ecosystem
- Real-time autocomplete features are important
- You prefer seat-based licensing
Choose alternative solutions (like Runable) if:
- Cost is the primary constraint
- Your primary need is workflow automation, not interactive development
- You want to avoid vendor lock-in
- You're prioritizing automation of background tasks (documentation, testing, deployment)
Consider hybrid approach if:
- You need the strengths of multiple platforms
- Budget allows for multiple tools optimized for different purposes
- You want to reduce dependency on any single vendor
Looking Forward
The enterprise AI development market is far from mature. Anthropic's Opus 4.6, Open AI's Codex, and competing platforms will continue evolving rapidly. The pace of innovation suggests:
- Capabilities will improve dramatically: Expect 2-3x capability improvements annually
- Costs will decline: Increased competition and efficiency gains will pressure pricing downward
- Specialization will increase: Look for tools tailored to specific development domains
- Integration will deepen: These tools will become less optional assistants and more core development infrastructure
For teams evaluating this technology, the question isn't whether AI-assisted development is viable—it clearly is. The question is how to adopt strategically, avoiding lock-in while capturing the substantial productivity benefits.
Claude Opus 4.6 represents the current state-of-the-art in this rapidly evolving category. Understanding its capabilities, limitations, and competitive positioning enables informed strategic decision-making for your organization.

FAQ
What is Claude Opus 4.6 and how does it differ from previous Claude models?
Claude Opus 4.6 is Anthropic's flagship AI model featuring a 1 million token context window, up from 200K in previous versions, along with new agent teams capabilities that enable multiple AI agents to work simultaneously on different aspects of coding projects. The model demonstrates substantially improved performance on enterprise knowledge work tasks, achieving approximately 70% win rate over Open AI's GPT-5.2 on GDPval-AA benchmarks and 76% success on MRCR v 2 long-context retrieval tests.
How does the 1 million token context window actually work in practice?
The 1 million token context window allows developers to feed entire large codebases, comprehensive documentation, and extended conversation histories into Claude simultaneously. Since one token represents approximately 4 characters, this enables processing roughly 4 million characters—typically an entire enterprise application's codebase plus documentation—while maintaining understanding throughout analysis and reasoning. The model achieved 76% accuracy on needle-in-a-haystack tests finding specific information buried in vast contexts, compared to only 18.5% for previous models.
What are agent teams and how do they work in Claude Code?
Agent teams are a research preview feature in Claude Code that enables multiple specialized AI agents to work simultaneously on different aspects of a development project. Rather than a single AI assistant handling all concerns, teams can deploy distinct agents for frontend implementation, backend API development, database schema design, and testing—each working autonomously in parallel while maintaining coordination through shared project context. This parallel processing can reduce development time from 8 hours to 3 hours for complex features.
How much does Claude Opus 4.6 cost and how does it compare to alternatives?
Claude Opus 4.6 uses usage-based token pricing (cost varies by input/output volume and context size). A typical team of 10 developers might spend
What makes Claude Opus 4.6 particularly good for enterprise development?
Clause Opus 4.6 excels for enterprises because it handles the entire codebase context without fragmentation, maintains understanding across multi-hour project interactions, supports outputs up to 128,000 tokens for complete application generation, and achieved $1 billion in run-rate revenue in just 6 months with wall-to-wall deployment at companies like Salesforce and Uber. The 1M token context specifically advantages large enterprise codebases that would exhaust smaller context windows.
How does context compaction enable longer-running projects?
Context compaction automatically summarizes older conversation history to preserve essential decisions and information while reducing token usage. Rather than extended projects hitting context limits and losing history, compaction intelligently condenses conversations—enabling months-long projects to maintain coherent context indefinitely. This is particularly valuable for long-term initiatives, institutional knowledge capture, and compliance documentation.
What are the main limitations of Claude Opus 4.6?
Despite its capabilities, Claude Opus 4.6 still hallucinates occasionally (generates plausible-sounding but incorrect code), cannot reliably identify unknown unknowns outside its training data, requires human review for security-critical code, and shows degradation when pushing absolute context limits. Additionally, response latency increases with larger contexts (5-30 seconds typical), and very long outputs (100K+ tokens) become economically expensive. Teams should maintain the perspective that Claude is an intelligent assistant, not a replacement for experienced developers.
When should organizations choose Runable instead of Claude Opus 4.6?
Runable is preferable when cost is a primary constraint (starting at $9/month), when primary needs involve automating background tasks rather than interactive coding (documentation generation, testing automation, deployment workflows), or when avoiding vendor lock-in matters significantly. Runable's workflow automation focus complements Claude well in hybrid strategies where teams use Claude for complex interactive development and Runable for automating repetitive processes like generating specifications or running test suites.
How should teams measure ROI from Claude Opus 4.6 deployment?
Effective ROI measurement tracks specific metrics: reduction in task completion time (typical 40-60% improvement), code quality improvements (defect rates, security findings), developer satisfaction and adoption rates, and cost-per-developer productivity. A simple framework: if developers normally complete a feature in 8 hours (costing
What security and privacy considerations matter for Claude Opus 4.6?
Anthropic maintains that conversations are never used for training subsequent models, data is deleted after processing (per contractual terms), encryption protects data in transit and at rest, and GDPR/CCPA compliance is handled through data processing agreements. However, organizations handling sensitive code should verify these commitments contractually, clarify IP ownership of generated code, confirm relevant compliance certifications (SOC 2 Type II, ISO 27001), and implement human review processes especially for security-critical, bias-sensitive, or financially consequential code.
How do the four effort levels in Claude Opus 4.6 help optimize cost and performance?
The four effort levels (low, medium, high, max) enable explicit cost/quality trade-offs: low effort delivers quick responses suitable for repetitive tasks, medium provides standard quality for typical development work, high enables deeper reasoning for complex problems (at 2-3x cost), and max offers maximum accuracy for high-stakes decisions (at 5-10x cost). This flexibility lets organizations optimize individually—using low effort for routine formatting while reserving max effort for critical architecture decisions, thereby controlling total expenditure while maintaining quality where it matters most.

Related Articles
- Agentic Coding in Xcode: How AI Agents Transform Development [2025]
- Airtable Superagent: AI Agent Features, Pricing & Alternatives [2025]
- OpenAI Codex Desktop App: AI Coding Agents & Alternatives [2025]
- AI in Contract Management: DocuSign CEO on Risks & Reality [2025]
- Fundamental's $255M Series A: How AI Is Solving Enterprise Data Analysis [2025]
- AI Chatbot Ads: Industry Debate, Business Models & Future

