![Cohere's Tiny Aya Models: Open Multilingual AI for 70+ Languages [2025]](https://tryrunable.com/blog/cohere-s-tiny-aya-models-open-multilingual-ai-for-70-languag/image-1-1771319427501.jpg)
Introduction: The Quiet Revolution in Multilingual AI
When you think about the major AI breakthroughs of the past few years, what comes to mind? Probably Chat GPT. Maybe Claude. Perhaps those massive foundation models that companies dump billions into training. But here's what nobody talks about: the vast majority of the world's population doesn't speak English.
That's where things get interesting. Cohere, an enterprise AI company that's been quietly building infrastructure for developers and organizations, just changed the game with something called Tiny Aya. It's not flashy. It won't beat GPT-4 at coding challenges. But for over 2 billion people who speak languages outside the English-dominant AI bubble, it might be the most important model release in years.
Tiny Aya is a family of open-weight multilingual models that support over 70 languages, including South Asian languages like Bengali, Hindi, Punjabi, Urdu, Gujarati, Tamil, Telugu, and Marathi. More importantly, they can run directly on your laptop. No internet required. No API calls. No expensive cloud infrastructure. Just raw, on-device AI that actually understands your language.
Let's think about what that actually means. In India—where the AI Summit where Cohere announced these models was taking place—millions of people live in areas with spotty internet connectivity. The ability to run a sophisticated AI model offline isn't just convenient. It's transformative. It means translation without latency. It means support systems that work in villages without reliable power grids. It means developers can build applications for their own communities without begging for access to proprietary APIs controlled by companies thousands of miles away.
This article digs into what Cohere actually built, why it matters, how it compares to what else exists out there, and what it means for the future of AI accessibility globally.
TL; DR
- What it is: Cohere launched open-weight Tiny Aya models supporting 70+ languages with strong performance on South Asian languages
- Key advantage: Runs completely offline on everyday devices like laptops without internet dependency
- Technical efficiency: Trained on just 64 H100 GPUs using modest computing resources for accessibility
- Availability: Free and open-source on Hugging Face, Kaggle, and Ollama for local deployment
- Business context: Cohere reported $240 million ARR with 50% Qo Q growth at end of 2025, positioning for potential IPO
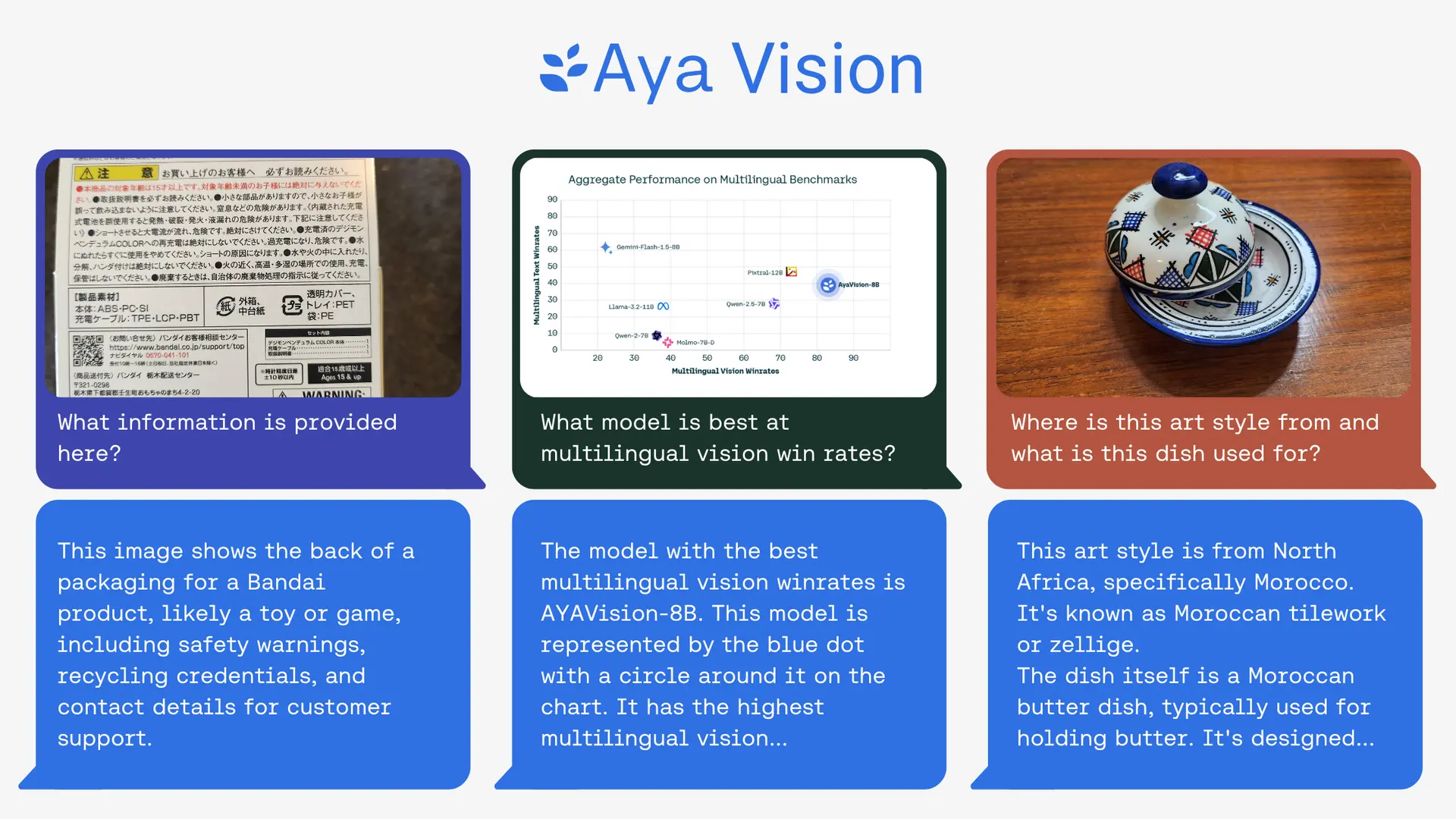
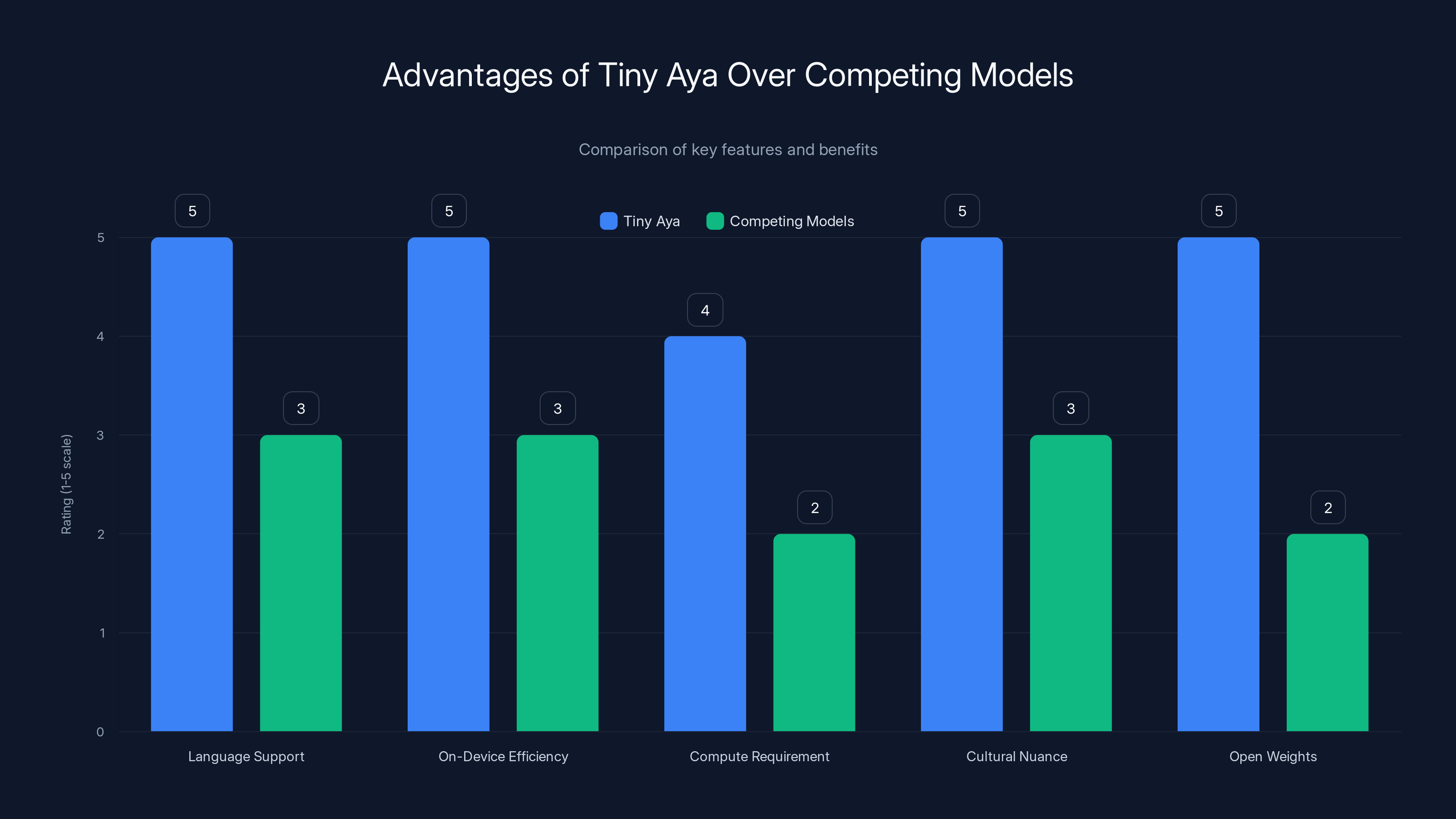
Tiny Aya excels in language support, on-device efficiency, and cultural nuance, offering open weights for free use and modification. Estimated data based on described advantages.
Understanding Cohere's Business Model and Market Position
Before diving into the technical details of Tiny Aya, it's worth understanding where Cohere sits in the AI landscape. The company isn't trying to be Open AI. It's not chasing the GPT-4 crown or building consumer chat interfaces. Instead, Cohere built itself around enterprise AI, focusing on companies that need language models for specific, mission-critical applications.
This is a fundamentally different play than the consumer-facing giants. While Open AI was busy making headlines with Chat GPT, Cohere was helping enterprises do things like generate product descriptions at scale, power customer support bots, extract information from documents, and build semantic search systems. Less flashy. Much more profitable.
The company's CEO, Aidan Gomez, publicly stated the company plans to go public "soon," and the numbers back up the confidence. By the end of 2025, Cohere hit $240 million in annual recurring revenue with 50% quarter-over-quarter growth throughout the year. Those aren't startup numbers anymore. Those are scale-up numbers that venture capital firms dream about.
But here's the interesting part: releasing Tiny Aya as open-source, freely available models seems like the opposite of a profit-maximizing move. Why would a company gunning for an IPO give away valuable technology?
The answer reveals Cohere's actual strategy. By releasing open-weight models, Cohere is essentially seeding an ecosystem. Developers and researchers around the world start building with Tiny Aya. Some of those builds become successful applications. Those applications eventually need enterprise versions, fine-tuning services, custom training, or integration with Cohere's commercial platform. It's the same playbook Meta used with Llama, and it works.
Plus, there's genuine mission alignment here. Cohere was co-founded by researchers from the University of Toronto who spent years in academia. The idea of democratizing access to AI technology, particularly for underrepresented languages and communities, isn't a cynical marketing angle. It's baked into the company's DNA.
The timing of the announcement at India's AI Summit is deliberate, too. India is a massive market. It's also a market where the English-first approach of most AI companies has created real friction. Developers there have been asking for tools that work with Hindi, Tamil, Telugu, Marathi, and other Indian languages for years. Cohere just delivered.

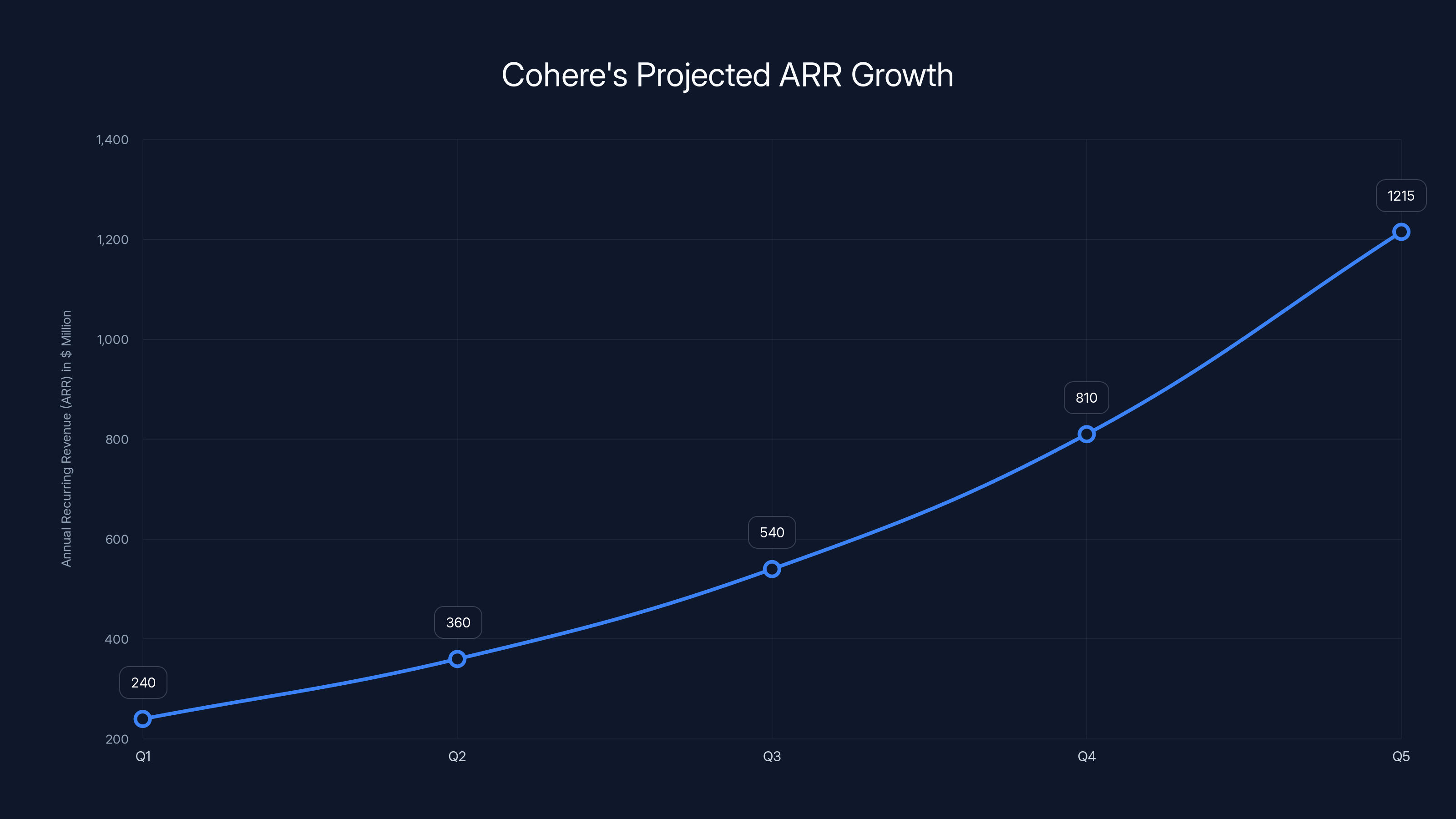
Cohere's ARR is projected to grow from
What Tiny Aya Actually Is: Architecture and Design Philosophy
Now let's get into the technical meat. Tiny Aya isn't just a single model. It's a family of models. That's important because different use cases require different size and capability tradeoffs.
The Tiny Aya family includes models of varying sizes, each optimized for different hardware constraints. The smallest versions are designed to run on smartphones and embedded devices. The larger versions still fit comfortably on a laptop without requiring GPUs. This is the opposite of the industry trend toward bigger, more resource-intensive models.
The core innovation is how Cohere structured the training to maintain strong multilingual performance while keeping the models small. This is genuinely hard. Most multilingual models either maintain decent performance across many languages but perform poorly on any single language, or they perform well on a few major languages while struggling with others.
Cohere's approach was different. They built models that develop stronger linguistic grounding and cultural nuance. Rather than training a single model on data from 70 languages mixed together (which tends to create a lowest-common-denominator effect), Cohere structured the training so that each language gets specialized attention. The result is a model that understands not just the words in Hindi or Tamil, but the context, idioms, and cultural references embedded in those languages.
This matters more than it might seem. A translation model that just maps words might turn a Hindi idiom into a literal English phrase that makes no sense. A model with better linguistic grounding understands the actual meaning and translates the intent, not just the words.
The training process is also notable for its efficiency. Cohere trained the Tiny Aya models on a single cluster of 64 H100 GPUs. That might sound like a lot, but for training a multilingual model in 2025, it's actually modest. For context, Open AI spent orders of magnitude more compute training GPT-4. Cohere's point is clear: you don't need unlimited resources to build genuinely capable AI models. You need smart architecture and good training practices.
The models are based on a transformer architecture (the same foundation that underlies most modern language models) but with optimizations for on-device inference. The software was specifically built to run efficiently on CPUs, not just GPUs. That's a deliberate design choice that most companies skip because their business models depend on users running models on their cloud infrastructure.
The 70+ Language Support: Which Languages and Why It Matters
Let's talk specifics. Cohere supports over 70 languages in the Tiny Aya family, but the distribution of support isn't random. The company prioritized South Asian languages—Bengali, Hindi, Punjabi, Urdu, Gujarati, Tamil, Telugu, and Marathi—while maintaining broad coverage across Southeast Asian, European, and African languages.
Why prioritize South Asia? Demographics and opportunity. South Asia has nearly 2 billion people. Of that, roughly 1.4 billion speak one of the languages Tiny Aya specifically supports. That's larger than the entire English-speaking population of Earth. Yet the AI industry has historically treated these languages as afterthoughts.
The gap is real. Ask most AI companies about their multilingual support, and they'll mention support for Spanish, French, German, maybe Japanese. But Hindi? Bengali? Urdu? Crickets. Not because these companies are malicious, but because of pure economics. English-speaking markets are more profitable. The training data for English is more abundant. The pressure from investors is to maximize addressable market in wealthy countries first.
Cohere's move inverts that calculus. By prioritizing Indian languages, they're betting that the future of AI adoption is in emerging markets, not saturated ones. They're also betting that building genuine capability in these languages—not just surface-level support—is an actual competitive advantage.
Here's something else that matters: the cultural nuance piece. Bengali isn't just a collection of sounds that can be tokenized and processed like any other language. Bengali has its own grammar, its own word order, its own way of expressing causality and relationships. Modern Standard Hindi uses Devanagari script, but Urdu uses a Persian-influenced script. Tamil uses its own script entirely. A model built to understand these real linguistic differences will produce better results than a model trained on tokenized data from 70 languages dumped together.
The coverage extends beyond South Asia, of course. Tiny Aya supports major European languages like English, German, French, and Spanish. It supports East Asian languages like Mandarin and Japanese. It supports African languages including Swahili and Yoruba. The breadth is genuine.
But here's the honest assessment: not all 70+ languages are equally well-supported. The top-tier support goes to languages with more training data available and larger developer communities. That's just how machine learning works. The gap between a language with 100 billion tokens of training data and a language with 1 billion tokens is significant. What Cohere did is make sure that gap doesn't turn into a cliff. Even lower-resourced languages in the family get meaningful support and functional capability.
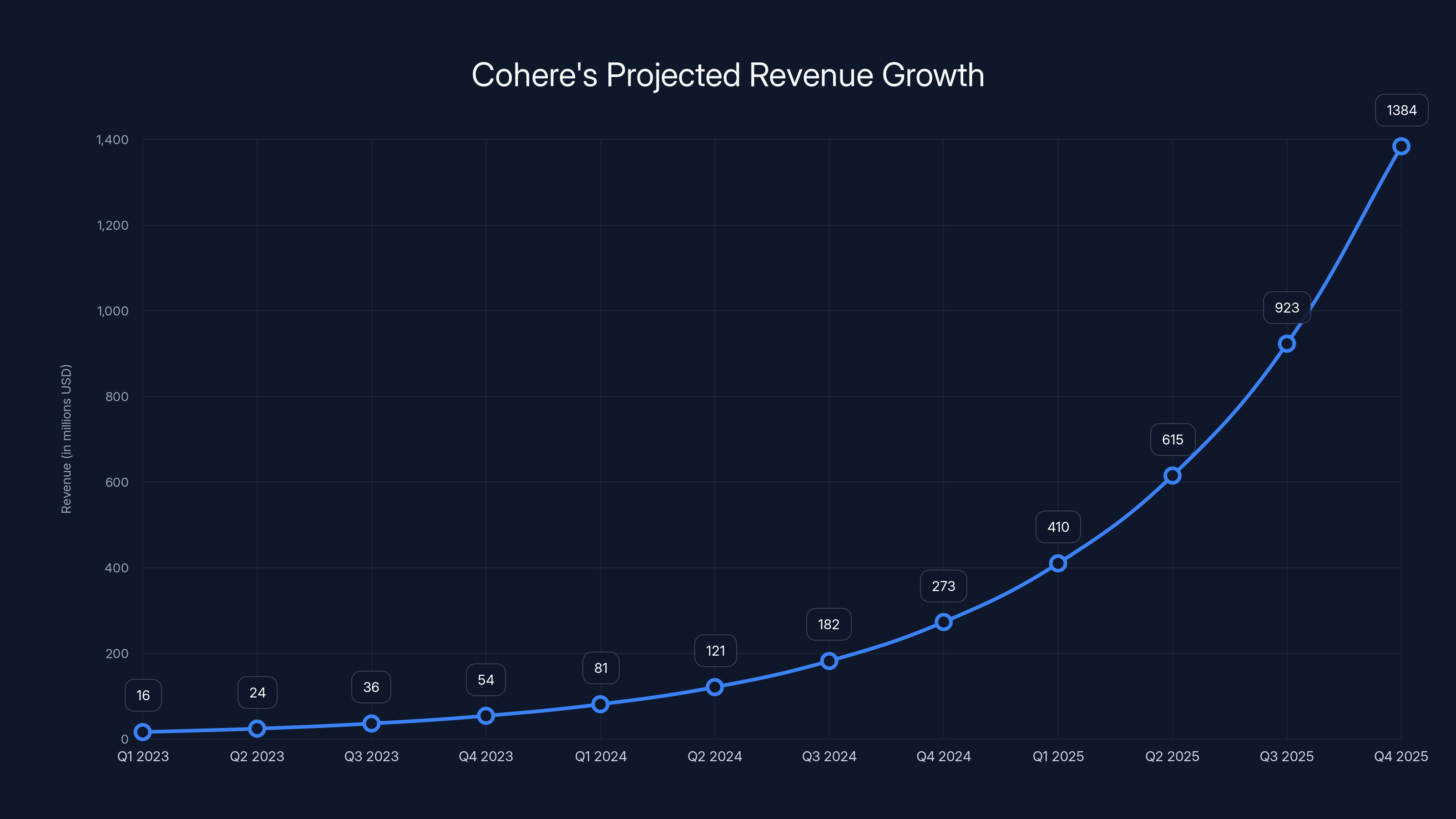
Cohere's revenue is projected to grow significantly, reaching $240 million by the end of 2025, driven by a 50% quarter-over-quarter growth rate. Estimated data.
On-Device Inference: Why Running AI Offline Changes Everything
Here's the feature that actually gets developers excited: on-device inference. Tiny Aya runs natively on your laptop. No internet connection required. No API calls. No latency waiting for responses from cloud servers. This isn't just convenient. It fundamentally changes what's possible.
Conventional cloud-based AI has serious limitations for many real-world applications. First, there's latency. Every API call means a network round trip. In some cases, that's a 200-500ms delay just waiting for a response. For translation, summarization, or other batch operations, that's manageable. For real-time interactive systems, it kills the user experience.
Second, there's cost. Every API call costs money. Companies running millions of inference operations per day face massive bills. Anthropic recently raised API prices in response to usage explosion. Open AI's API costs have been a limiting factor for many developers. Running a model locally eliminates this cost entirely after the initial download.
Third, there's privacy. When you send text to a cloud API, that text leaves your device. It goes to someone else's servers. It gets logged. It's used to train future models. It's discoverable in legal proceedings. For healthcare applications, legal documents, financial data, or anything containing personal information, this is unacceptable. On-device inference keeps your data on your device.
Fourth, there's reliability and connectivity. Many parts of the world don't have consistent, reliable internet access. Rural areas, regions with infrastructure gaps, places affected by natural disasters—these areas struggle with cloud-dependent AI. On-device models work whether you have bandwidth or not.
Cohere specifically optimized Tiny Aya for on-device deployment by building the software stack from the ground up for CPU inference efficiency. Most models are optimized for GPU servers where speed is measured in how many tokens per second the model produces. Tiny Aya is optimized for CPU efficiency, meaning less power consumption, faster response times on consumer hardware, and the ability to run on older machines that don't have modern GPUs.
The practical implication is massive. Developers can now build applications that were previously impossible or impractical. An app that translates documents from English to Hindi and runs entirely offline? Previously, you'd need to make API calls to something like Google Translate. Now you can embed Tiny Aya directly in your app.
Consider a customer support chatbot for an Indian e-commerce company. Previously, they'd need to run this on cloud infrastructure, paying for every interaction, dealing with latency issues, and managing privacy concerns. Now they can run Tiny Aya locally, responding instantly to customer queries in their native language, while keeping all customer data on-premise.
Or think about agricultural applications. Indian farmers often lack consistent internet but might have smartphones. An app that helps identify crop diseases, recommends treatments, and provides weather information—all in the farmer's local language, all working offline—could be transformative. With Tiny Aya, this becomes buildable.
Training Efficiency: How Cohere Achieved This With Modest Resources
Let's talk about the elephant in the room: how did Cohere train a 70-language model using just 64 H100 GPUs?
For context, modern large language models require staggering compute resources. Open AI, Google, and Meta all use thousands of high-end GPUs for weeks or months to train single models. Microsoft and Open AI combined resources to achieve economies of scale that smaller companies simply can't match. The conventional wisdom is that you need massive compute to build capable models.
Cohere proved that conventional wisdom is outdated. The key is efficiency, not brute force.
First, the Tiny Aya models are genuinely small. They're not competing with GPT-4 on capability, so they don't need to be trained to the same scale. Cohere created models that are fine-tuned for specific tasks and languages rather than trying to be universal solvers. This is a smarter design choice than throwing more compute at a generic problem.
Second, Cohere used advanced training techniques to maximize the learning from each compute dollar spent. Techniques like knowledge distillation (training a small model to mimic a larger, more capable model) and curriculum learning (organizing training data in a smart sequence so the model learns progressively) both help squeeze more capability out of less compute.
Third, and this is crucial, Cohere didn't start from scratch. The company had existing model architectures, training frameworks, and architectural knowledge from previous work. Building on top of previous knowledge is far more efficient than starting from first principles each time.
The efficiency message is important for the broader AI industry. Right now, there's a dangerous narrative that capability scales monotonically with compute spend. Bigger model, more GPUs, better results. It's true up to a point, but it's not the whole story. Smart architecture, efficient training, and focused scope can achieve remarkable capability on modest budgets.
For Cohere, this efficiency also matters for their business story. It proves they can build frontier-quality models without needing the venture capital war chest of a Open AI or Anthropic. That's a selling point for IPO investors and future customers alike.

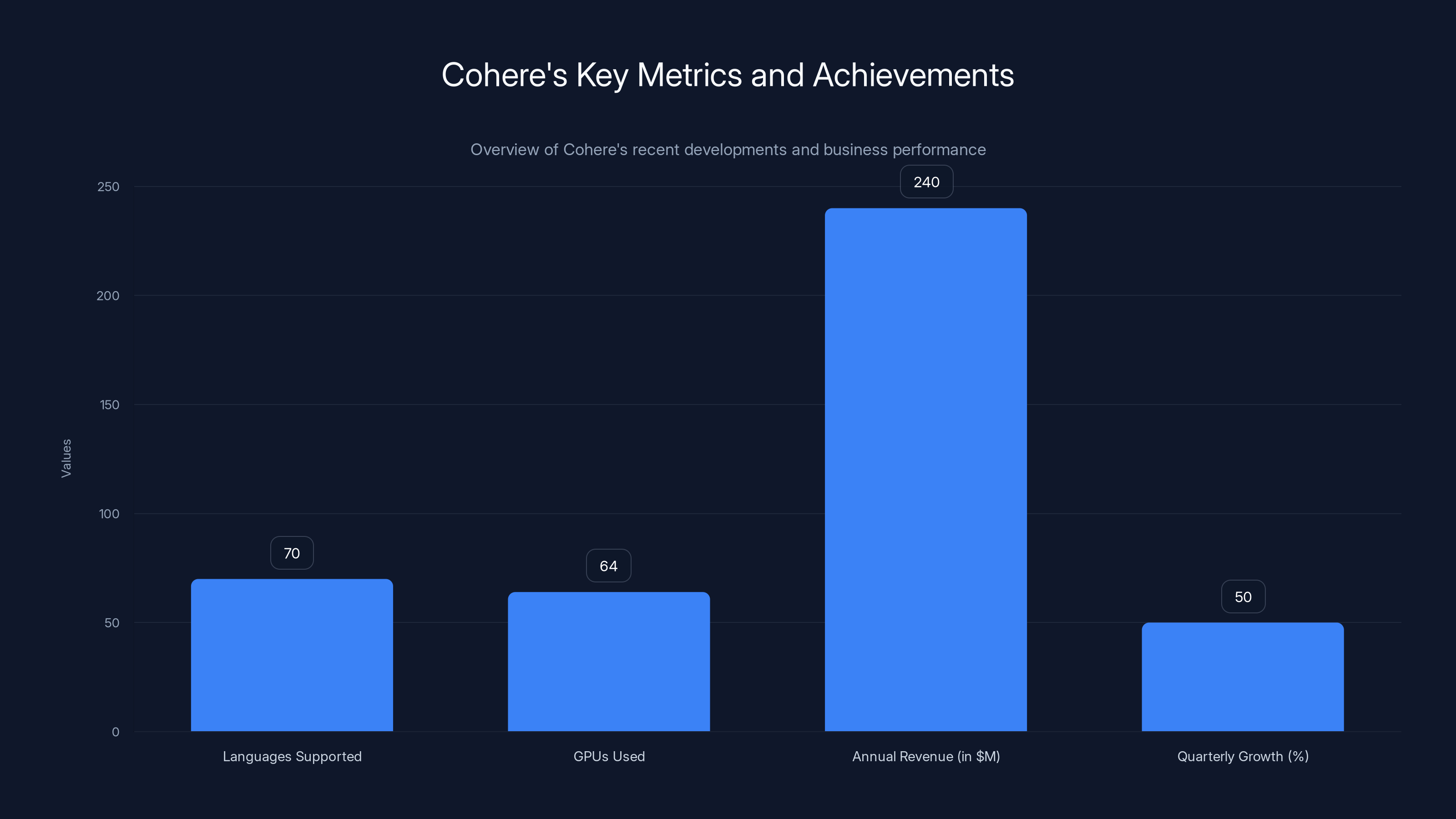
Cohere supports over 70 languages and achieved $240 million ARR with 50% QoQ growth, using just 64 GPUs for model training.
The Open-Weight Decision: Strategic Implications
Why did Cohere release these models as open-weight instead of keeping them proprietary?
Open-weight means the model weights are publicly available. Anyone can download them. Anyone can run them. Anyone can fine-tune them for their own purposes. Cohere isn't maintaining control or creating lock-in. They're distributing the technology freely.
On the surface, this seems counterintuitive for a company targeting an IPO. Why give away valuable technology? The answer lies in understanding the different value chains in AI.
There are two ways to monetize AI models. First, sell API access. You build a model, host it on servers, charge users per query. This is what Open AI does with Chat GPT. It's how Amazon Bedrock sells access to third-party models. This model has massive advantages: predictable recurring revenue, lock-in through API dependencies, and you maintain control.
Second, build infrastructure and services around models. You release the models freely, but developers need tools to fine-tune them, integrate them, deploy them, monitor them, and optimize them. You profit from the entire ecosystem that forms around the base technology. This is what Meta did with Llama and what many open-source companies do.
Cohere is pursuing the second model because it aligns with their enterprise positioning. Enterprise customers don't want to pay per API call forever. They want to own and control their models. They want to fine-tune models on proprietary data. They want to host models on their own infrastructure. By releasing Tiny Aya as open-weight, Cohere is saying: "We're not trying to be your model provider forever. We're trying to be your AI partner."
This also plays into the broader industry trend toward open-source and open-weight models. The narrative that "closed models are always better" was starting to crack. Llama 2 and Llama 3 proved you could release capable models openly and still maintain competitive advantage through superior infrastructure and commercial offerings. Mistral built an entire company around open models. The market is shifting.
For Cohere specifically, the open-weight decision also helps with recruiting and reputation. Top researchers want to work on problems that impact the world, not just maximize shareholder value. Publishing research, releasing open models, and building community goodwill attracts talent. That talent is worth more than the short-term revenue from keeping models proprietary.

Where to Get Tiny Aya: Availability and Deployment Options
Cohere made Tiny Aya available through multiple channels, which is strategically smart. Different developers have different preferences for how they access and deploy models.
Hugging Face is the primary distribution point. Hugging Face is essentially Git Hub for machine learning models. It's where researchers and developers go to find, share, and discuss models. The Tiny Aya models are available there with documentation, usage examples, and license information. For researchers and hobbyists, this is the natural home.
The Cohere Platform offers Tiny Aya for developers who want the convenience of cloud-hosted versions. You get API access if you want it, but you can also download weights for local deployment. This sits in the middle: more convenience than pure open-source, but more flexibility than pure API-based access.
Kaggle is another distribution point. Kaggle is where data scientists go for competitions, datasets, and notebooks. Having Tiny Aya there makes it easily accessible to the competitive data science community and Kaggle users.
Ollama is maybe the most important for developers wanting on-device deployment. Ollama is a tool that makes it stupid-simple to run language models locally. Download Ollama, type a single command, and boom, you're running Tiny Aya on your laptop. It handles model downloading, optimization, and optimization for your hardware. This is the path of least resistance for developers.
Cohere is also releasing training and evaluation datasets on Hugging Face. This is huge for researchers and companies wanting to fine-tune Tiny Aya on their own data. Dataset availability is often the bottleneck in machine learning projects. Cohere releasing datasets removes that barrier.
The company also promised a technical report detailing the training methodology. This is academic-style transparency. Other companies release trained models but keep training details proprietary. Cohere is publishing the research so the broader community can learn from and build on their work.

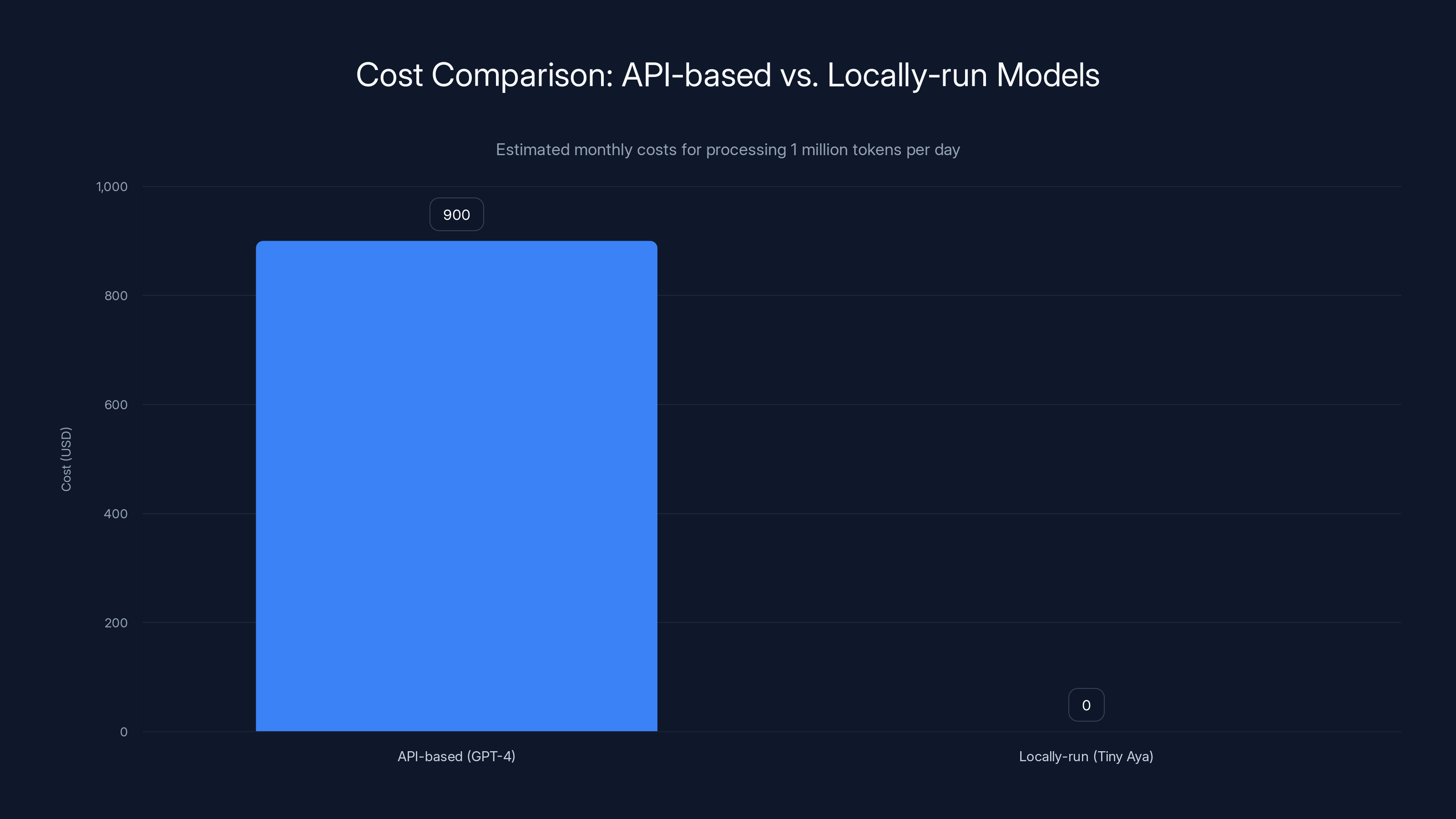
API-based models like GPT-4 can cost $900/month for 1 million tokens daily, while locally-run models like Tiny Aya have zero API costs, highlighting significant savings for high-volume processing. Estimated data.
Comparing Tiny Aya to Competing Multilingual Models
Tiny Aya doesn't exist in a vacuum. There are other multilingual models and approaches worth understanding.
Google Translate is the incumbent that most people interact with. It's incredibly convenient: point at text, get translation, move on. It supports 130+ languages and has been refined for decades. But it's also a closed system. You can't fine-tune it. You can't inspect how it works. You pay per request. For many use cases, it's still the right choice. Google has invested enormous resources in translation quality.
Llama 2 and Llama 3 support many languages and are open-weight, similar to Tiny Aya. The advantage is massive community and existing tooling. More developers know Llama. More optimization work exists for Llama. The disadvantage is that Llama wasn't specifically optimized for South Asian languages or on-device deployment the way Tiny Aya was.
Mistral models are smaller and more efficient than Llama but have less explicit focus on multilingual support. They're excellent for constrained deployment scenarios but less specifically targeted at language diversity.
Bloom is a model specifically designed for multilingual support, covering 46 languages. It was released by Big Science, a nonprofit research initiative. It's genuinely impressive, but it's also larger and more compute-hungry than Tiny Aya. For on-device deployment, Tiny Aya is a better fit.
Microsoft's Phi series focuses on efficiency and small size, similar to Tiny Aya, but doesn't emphasize multilingual support the same way.
The comparison reveals Tiny Aya's specific niche: small, efficient, multilingual (especially for underrepresented languages), and optimized for on-device deployment. It's not the most capable model for any single dimension, but it's the best integrated package for the specific use case of bringing AI to emerging markets and offline-dependent applications.
| Model | Supported Languages | On-Device Optimized | Primary Use Case | Commercial Model |
|---|---|---|---|---|
| Tiny Aya | 70+ (South Asia prioritized) | Yes | On-device, emerging markets | Open-weight |
| Llama 3 | 8+ explicitly | No | General-purpose language tasks | Open-weight |
| Mistral | Limited | Yes | Efficiency-focused tasks | Open-weight |
| Bloom | 46 | Partially | Research, multilingual tasks | Open-weight |
| Google Translate | 130+ | API-based | Production translation | Proprietary |
| Claude | 10+ | No | Advanced reasoning, knowledge | Proprietary |
The table makes clear that Tiny Aya fills a specific gap. You want multilingual support without sacrificing on-device efficiency. Tiny Aya is purpose-built for that.

Real-World Applications and Use Cases
Here's where the theory becomes practical. What can developers actually build with Tiny Aya?
Customer Support and Chatbots Companies serving Indian markets can build customer support systems that respond in Hindi, Tamil, Bengali, or other native languages. No latency waiting for cloud API responses. No expensive per-interaction costs. The chatbot understands context and cultural nuance, not just pattern-matching keywords. A company like Flipkart or Swiggy could integrate Tiny Aya directly into their app and support customer queries in native languages offline.
Document Translation and Processing Legal firms, medical offices, and government organizations often need to translate documents. Tiny Aya can run locally, maintaining document privacy while providing translation. A lawyer could translate a contract from English to Hindi entirely on their laptop without uploading anything to cloud services. A hospital could translate patient forms between languages without sending health data to third-party services.
Offline Content Recommendations Mobile applications in emerging markets can use Tiny Aya to understand user intent and recommend relevant content, all without internet connectivity. An educational app could understand student questions in their local language and recommend relevant lessons or resources.
Real-Time Speech-to-Text and Transcription Combine Tiny Aya with speech recognition tools, and you get offline voice interfaces. A farmer could speak a query in Gujarati, and the app transcribes and processes it locally. A truck driver could get navigation instructions in Marathi read aloud by the app.
Agricultural Decision Support Systems Building on the farming example: agricultural extension workers could use apps powered by Tiny Aya to diagnose crop diseases, recommend treatments, and provide weather information in local languages. Farmers can access this without reliable internet, which is critical in rural India.
Content Creation and Localization Developers can use Tiny Aya to help localize content into multiple languages programmatically. A software company releasing an app in India could use Tiny Aya to generate translations of UI strings and help text in multiple South Asian languages, then refine them with human review.
Educational Technology An Ed Tech startup could build a tutoring system that understands student questions in their native language and provides explanations also in that language. The system could work offline in schools with poor connectivity, using locally-run Tiny Aya.
Accessibility and Inclusive Technology People with visual impairments could use apps powered by Tiny Aya for information retrieval and navigation in their native language, all running locally without depending on external connectivity.
The common thread: these are applications that either need offline capability, require privacy, depend on low latency, or serve underserved language communities. Tiny Aya is purpose-built for exactly this problem space.

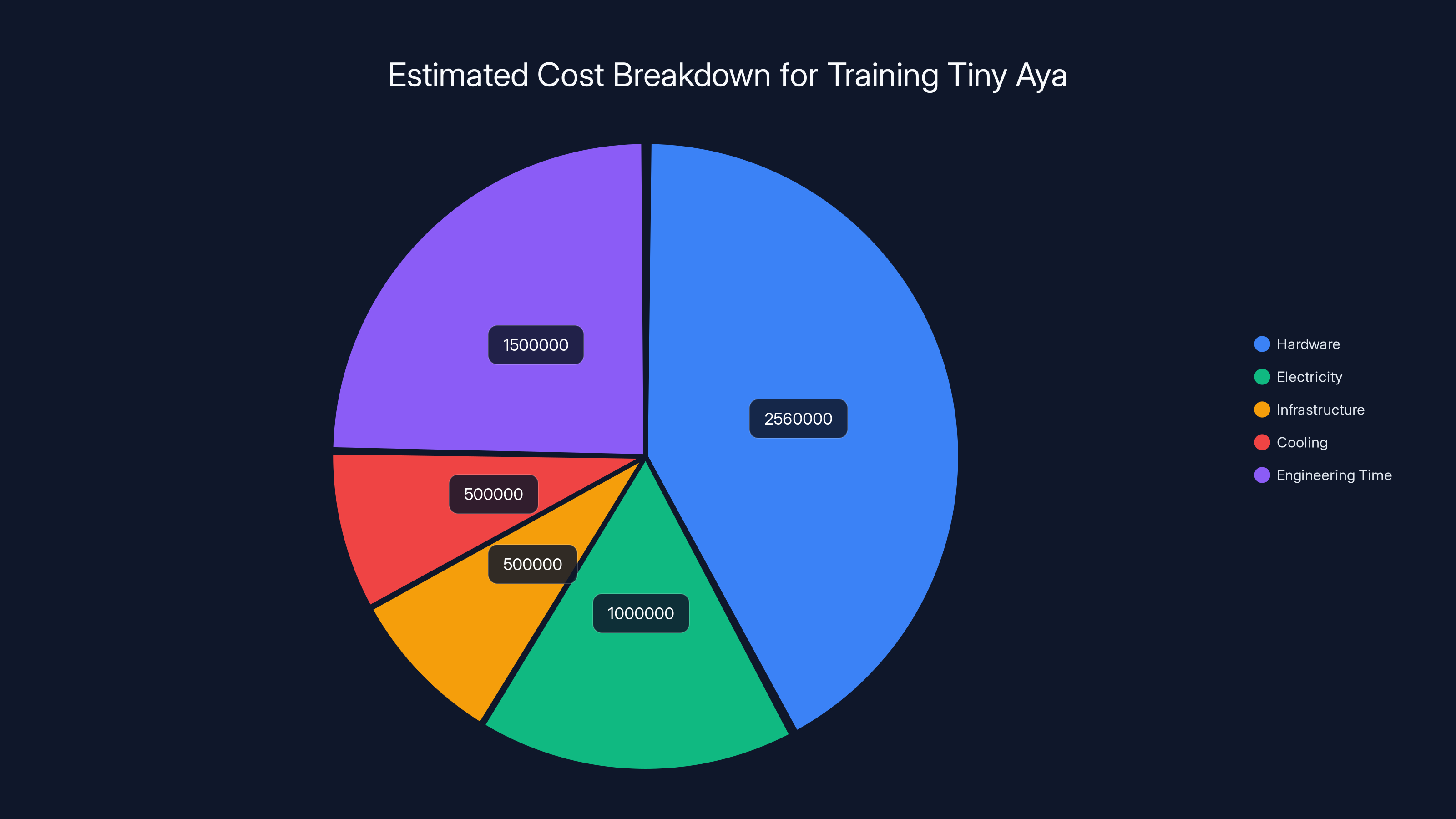
Hardware costs dominate the budget at $2.56 million, followed by engineering time. Estimated data based on typical AI development costs.
Technical Integration: How Developers Actually Use Tiny Aya
Let's get practical. How do you actually integrate Tiny Aya into an application?
For Python Developers The simplest path is using the Hugging Face transformers library. A developer can load Tiny Aya with just a few lines of code:
pythonfrom transformers import Auto Tokenizer, Auto Model For Causal LM
tokenizer = Auto Tokenizer.from_pretrained("Cohere For AI/Aya-Tiny")
model = Auto Model For Causal LM.from_pretrained("Cohere For AI/Aya-Tiny")
inputs = tokenizer.encode("Translate to Hindi: Hello world", return_tensors="pt")
outputs = model.generate(inputs, max_length=100)
result = tokenizer.decode(outputs[0])
That's it. A few imports, load the model, tokenize your input, generate output, decode the result. The barrier to entry is genuinely low.
For Desktop Applications Using Ollama For developers who don't want to deal with Python dependencies, Ollama abstracts all the complexity away. Install Ollama, run a single command, and you have a local model server:
bashollama run aya-tiny
Then any application can make HTTP requests to localhost and get responses. Your app doesn't need to know anything about machine learning. It just sends text and receives responses.
For Web Applications Developers can use projects like llama.cpp or ONNX Runtime to run models in web browsers. This is cutting-edge stuff—models running directly in Java Script in the browser—but it's getting more feasible. A web app could potentially run Tiny Aya client-side, with all processing happening in the user's browser.
For Mobile Applications Mobile integration is trickier but possible. Projects like Tensor Flow Lite and Core ML can run models on i OS and Android. Tiny Aya's small size makes it more feasible than larger models, though you'd still need to optimize carefully for mobile constraints.
Fine-tuning for Specific Domains For production applications, you'll often want to fine-tune Tiny Aya on your own data. If you're building a customer support system, you fine-tune on your actual customer interactions. If you're building a medical translation system, you fine-tune on medical texts. Fine-tuning takes the general model and adapts it to your specific domain.
pythonfrom transformers import Trainer, Training Arguments
training_args = Training Arguments(
output_dir="./aya-finetuned",
num_train_epochs=3,
per_device_train_batch_size=4,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=your_custom_dataset,
)
trainer.train()
Again, straightforward. The barrier to experimentation is low.
Optimization for Speed For production deployments, you'll want to optimize Tiny Aya for speed and memory efficiency. Techniques include quantization (reducing the precision of model weights to smaller data types), pruning (removing weights that aren't contributing meaningfully), and distillation (creating a smaller model that mimics the larger one). Libraries like ONNX, v LLM, and others handle these optimizations.
The Economics of Open Models: Why This Matters for Developers and Companies
Let's talk money, because ultimately that's what drives adoption.
If you're using an API-based model like GPT-4 or Claude, you pay per request. Let's say you're building a translation app and need to translate 10,000 documents containing 1 million tokens total. At Open AI's API pricing (around
With Tiny Aya running locally, that cost drops to zero. You download the model once. You pay for the compute hardware to run it, but you amortize that cost across unlimited requests.
For a company processing millions of documents, millions of user queries, or millions of translation requests, the cost difference is staggering. An enterprise could save $100,000+ per month switching from API-based translation to locally-run Tiny Aya.
But there's a tradeoff. With open models, you're responsible for infrastructure. You need servers to run the models. You need engineers to maintain them. You need to monitor performance and handle failures. With API-based services, you pay for convenience and someone else's problem becomes your problem.
For startups and small companies, API-based models often make sense. You're not at scale yet, and the ease of use is worth the cost. For mid-market and enterprise companies processing significant volume, open models become economical.
Cohere understands this tradeoff well. That's why they offer both paths: free open-weight models for developers who want to build their own infrastructure, and commercial services for companies that prefer to outsource infrastructure management.

The Broader Implications for AI Accessibility Globally
Tiny Aya isn't just a technical achievement. It's a statement about who gets to build AI and who gets excluded.
For the past five years, the AI industry has been dominated by massive technology companies in wealthy countries. Open AI, Google, Meta, Microsoft—these companies have the capital to train billion-parameter models on the best hardware. They set the agenda. They define what's possible. And because they're primarily English-speaking companies, they build English-first.
This creates a two-tier world: English speakers have access to best-in-class AI. Everyone else gets... less. Sometimes much less. If you speak Bengali or Tamil or Urdu, your AI options are significantly more limited. This has real consequences for education, economic opportunity, and access to information.
Tiny Aya cracks that open slightly. It's not a complete solution. Tiny Aya isn't going to outperform GPT-4 on complex reasoning. But for the 95% of real-world use cases in emerging markets—translation, information retrieval, content generation, customer support—Tiny Aya is genuinely sufficient. And it's available to anyone.
This has knock-on effects. Developers in India can now build businesses around AI without needing to pay fees to Silicon Valley companies. Students can study machine learning without being locked into studying how English-language models work. Researchers can publish work on multilingual AI using freely available models.
Longer term, this might actually be more important than incremental improvements to the biggest models. The biggest models are approaching diminishing returns. Making GPT-5 0.5% better on benchmarks matters less than making GPT-3.5 quality AI available to 2 billion new users.

Market Adoption Projections and Future Trends
What's the adoption trajectory for Tiny Aya and models like it?
Looking at comparable releases, adoption tends to follow a curve. Meta's Llama 2 was widely adopted within months of release. Mistral took off rapidly. These models achieve critical mass when they hit a few key thresholds: good enough quality, easy to use, permissive licensing, and clear use cases.
Tiny Aya hits all those boxes. Expect rapid adoption in emerging markets, particularly India, where the language support and offline capability are most valuable. Enterprise adoption will likely accelerate as companies realize the cost savings from local deployment.
Regional models will probably emerge. Developers will fine-tune Tiny Aya specifically for Hindi, Tamil, or Telugu. They'll create specialized versions for specific industries: medical, legal, financial. This specialization will drive quality improvements and broader adoption.
The bigger trend: open-weight models are becoming the norm, not the exception. Companies are realizing that releasing models openly doesn't destroy competitive advantage if you have better infrastructure, better integration, better support, or better fine-tuned versions. This benefits the entire ecosystem. More models available freely means more developers can experiment, more research can happen, and innovation accelerates.
For companies like Cohere, this is actually good news for business. As the open-model ecosystem grows, the demand for services around those models grows too. Fine-tuning services. Integration help. Deployment infrastructure. Cohere is positioning itself to serve that ecosystem.

Cohere's Long-Term Strategy and Competitive Position
So where is Cohere actually going with this?
The company's enterprise positioning is clear. They're not trying to be the consumer chatbot company. They're building infrastructure for enterprises. Tiny Aya serves that strategy by demonstrating they can build genuinely capable models without needing to compete on scale with Open AI or Google. They can compete on efficiency, on language support, on understanding enterprise needs.
The public statements about going public "soon" suggest confidence in the business fundamentals.
For investors in a potential IPO, Tiny Aya demonstrates a few things: First, Cohere can innovate and release competitive products. Second, the company isn't dependent on proprietary moats if they can execute better on service and integration. Third, there's a path to serving global markets that most of the AI industry is still ignoring.
The long-term opportunity is massive. If Tiny Aya drives adoption in India, Indonesia, Bangladesh, Pakistan, and other emerging markets, that opens entirely new revenue streams. Enterprise customers in these countries will eventually want paid services—custom fine-tuning, hosted inference, priority support, integration assistance. Cohere is seeding these markets now.
The competitive landscape matters too. As more companies release open models, proprietary moats erode. Cohere's strategy of being the best-integrated partner to enterprise customers, not the best model builder, is sound. It's a lesson from enterprise software: you don't necessarily win by building the best product. You win by being the easiest to deploy and most aligned with customer needs.

Challenges and Limitations to Acknowledge
Let's be honest about where Tiny Aya falls short.
Quality Gaps: While Tiny Aya is genuinely capable, it's not going to outperform specialized models or larger foundation models on complex tasks. If you need state-of-the-art machine translation quality, Google Translate might still be better. If you need complex reasoning or detailed knowledge synthesis, GPT-4 is still superior.
Language Distribution Unevenness: While Tiny Aya supports 70+ languages, support is uneven. Languages with more training data available get better results. Lower-resource languages get functional support but not optimal performance. This is a fundamental constraint of current machine learning—you can't get excellent results for a language without enough training data.
Deployment Complexity: Yes, running open models is easier than it used to be, but it's still more complex than making an API call. You need infrastructure. You need monitoring. You need to manage updates and security patches. For some teams, this overhead isn't worth the cost savings.
Cold Start Problem: When first deploying Tiny Aya, there's an initial download and optimization period. Depending on your hardware, this could take minutes. Once running, performance is great. But that initial friction can be a problem in some scenarios.
Customization and Fine-tuning: While you can fine-tune Tiny Aya, the process isn't trivial. You need labeled data in your domain. You need compute resources for fine-tuning. You need expertise to optimize hyperparameters. For small companies, this might be prohibitive.
Data Availability: Training good models requires data. For many specialized domains in emerging markets (medical terminology in Tamil, legal language in Gujarati, technical documentation in Bengali), sufficient labeled datasets don't exist yet. This limits what you can build.
These aren't reasons not to use Tiny Aya. They're just constraints to understand. Choose the right tool for the right problem.

How Runable Fits Into the Broader AI Ecosystem
While Tiny Aya focuses on language understanding and generation, there's a complementary need in the AI tooling space for enterprise automation and content generation. Platforms like Runable are addressing the challenge of turning AI models into production applications across multiple formats.
Runable provides AI-powered automation for creating presentations, documents, reports, images, and videos—complementing Tiny Aya's language capabilities with a full workflow automation layer. For teams building applications using Tiny Aya, integrating with workflow automation tools becomes the next logical step in their stack.
Use Case: Automate the generation of multilingual reports and presentations from Tiny Aya translations, creating localized business documentation in seconds instead of hours.
Try Runable For Free
The Research Behind Tiny Aya: Technical Depth
Cohere committed to releasing technical documentation and research about Tiny Aya. This transparency matters because it allows the broader research community to understand and build on the work.
The key innovations appear to be in training methodology. Rather than training a single 70-language model, Cohere structured the training to balance multilingual capability with specific language optimization. This probably involved techniques like:
Language-Specific Tokens: Creating separate token vocabularies for different language families so that each language's specific characteristics are preserved rather than compressed into a shared tokenizer.
Curriculum Learning: Training on data from major languages first, then progressively incorporating lower-resource languages so the model learns meaningful representations rather than just memorizing.
Language Adaptation Layers: Adding language-specific adaptation layers on top of shared representations, so the model can develop both general capabilities and language-specific nuance.
Instruction Tuning: Fine-tuning on instructions in multiple languages so the model understands how to follow directions in any of its supported languages.
The efficiency comes partly from model architecture (probably based on proven transformer designs), partly from data curation and quality (ensuring training data is representative and clean), and partly from training technique optimization.
Cohere was explicit that they trained on a single cluster of 64 H100 GPUs. For context, H100 GPUs cost roughly
The fact that Cohere can build competitive models at this price point is important. It suggests that frontier AI isn't exclusively the domain of trillion-dollar companies. With smart engineering and focused scope, mid-size companies can compete.

Conclusion: The Significance of Tiny Aya in the Evolving AI Landscape
Tiny Aya matters not because it's the most capable model ever built (it's not), but because it's a concrete demonstration that the future of AI doesn't have to be centralized and English-first.
The release represents several important trends converging: the move toward open-weight models, the focus on efficiency over raw scale, the recognition that underrepresented languages represent massive opportunity, and the understanding that on-device deployment is increasingly important.
For developers, Tiny Aya opens possibilities that didn't exist before. Building applications in native languages without API dependency. Serving users in areas with poor connectivity. Protecting privacy by keeping data local. The capability was theoretically possible but practically inaccessible before. Now it's free and easy.
For enterprises in emerging markets, Tiny Aya changes the economics of AI adoption. Instead of paying per request to cloud APIs, they can invest in infrastructure and reduce marginal costs to near-zero. This makes AI accessible to smaller companies that previously couldn't afford it.
For Cohere specifically, the release demonstrates maturity and strategic confidence. The company isn't trying to compete head-to-head with Open AI on model capability. They're winning by serving different needs, understanding their customers deeply, and building products that solve real problems.
The broader industry implication: don't expect centralized AI gatekeeping to persist. The tools for building capable AI models are democratizing. Compute costs are falling. The barrier to entry is lowering. In a few years, we'll look back at this moment as the inflection point where AI became genuinely global rather than Western-company-first.
Tiny Aya is a meaningful step in that direction. It won't single-handedly transform AI accessibility globally. But it shows the path forward: smaller models, better efficiency, genuine multilingual support, and free access for anyone who wants to build.
That's worth paying attention to.

FAQ
What is Tiny Aya and why was it released?
Tiny Aya is a family of open-weight multilingual language models released by Cohere Labs that supports over 70 languages with specific optimization for South Asian languages like Hindi, Bengali, Tamil, and Urdu. The models were released to democratize access to capable AI technology for developers and communities in emerging markets, particularly those requiring offline functionality and native language support without the expense of cloud-based API services.
How does on-device inference work with Tiny Aya compared to cloud-based APIs?
On-device inference runs the entire model locally on your computer or device without requiring internet connectivity or sending data to external servers. This eliminates latency from network requests (typically 200-500ms per API call), reduces per-operation costs from API pricing to zero after the initial model download, enhances privacy by keeping all data local, and enables functionality in areas with unreliable internet. Cloud-based APIs like those from Open AI offer convenience and instant access to the latest models but require constant connectivity and incur per-request costs that accumulate quickly at scale.
What are the main advantages of Tiny Aya over competing multilingual models?
Tiny Aya's primary advantages include specific optimization for South Asian languages (more languages have dedicated support than in models like Llama), efficiency for on-device deployment requiring less compute than comparable alternatives, training on modest computing resources (64 H100 GPUs) demonstrating the models are achievable without massive capital, strong cultural and linguistic nuance in supported languages, and completely open weights allowing free use and modification. Unlike closed systems like Google Translate, you maintain full control over the model and can fine-tune it for your specific domain.
How much technical expertise is needed to deploy and use Tiny Aya?
Basic usage requires minimal expertise with tools like Ollama handling all technical complexity automatically. For Python developers, integration takes just a few lines of code using the Hugging Face transformers library. For production deployment and optimization (quantization, pruning, fine-tuning), more machine learning expertise becomes valuable but isn't strictly necessary thanks to numerous open-source tools and frameworks that abstract the complexity. Small teams without dedicated ML engineers can successfully deploy Tiny Aya using pre-built optimization packages.
What practical applications are companies building with Tiny Aya right now?
Real-world applications include customer support systems in native languages (Flipkart, Swiggy using Hindi or Tamil), offline document translation for legal and medical records, agricultural decision support for farmers in rural areas without reliable internet, mobile apps providing content recommendations in local languages, educational technology serving students in their native language, and voice interfaces combining speech recognition with Tiny Aya for accessibility. The common factor is applications requiring native language support, offline capability, or privacy-first architecture where cloud API dependency is impractical.
How does Tiny Aya's performance compare to GPT-4 and other frontier models?
For general reasoning, complex coding challenges, and nuanced knowledge synthesis, frontier models like Anthropic's Claude and Open AI's GPT-4 maintain advantages. For practical applications in emerging markets including translation, information retrieval, customer support, content generation, and basic reasoning, Tiny Aya delivers sufficient quality at a fraction of the cost and complexity. The models represent a tradeoff between raw capability and practical accessibility, focused on serving 90% of real-world needs rather than pushing 1% of frontier benchmarks.
What does Cohere's open-weight strategy mean for their business and profitability?
Releasing open weights appears counterintuitive for a company targeting IPO, but it reflects Cohere's enterprise-focused strategy rather than API-centric monetization. The model creates ecosystem effects where developers build businesses on top of Tiny Aya, eventually requiring services like custom fine-tuning, hosting, integration support, and enterprise SLAs that Cohere provides at premium pricing. This approach proved successful for Meta with Llama, generating value through ecosystem services rather than proprietary model access. For Cohere, currently posting $240 million ARR with 50% Qo Q growth, this strategy aligns with enterprise positioning and long-term sustainability.
What are the limitations and challenges with deploying Tiny Aya?
Key limitations include uneven quality across languages depending on training data availability, need for initial infrastructure setup and maintenance that API services handle automatically, no guarantee that Tiny Aya outperforms specialized models for complex domain-specific tasks, requirement for labeled data to fine-tune effectively, and the responsibility for managing updates and security patches falling entirely on deploying organizations. Additionally, while 70+ language support is broad, it's not comprehensive, and languages with less training data show correspondingly lower capability.
Where can developers access and deploy Tiny Aya models?
Tiny Aya is available through multiple channels: Hugging Face provides the primary model repository with documentation and community discussion, Cohere's Platform offers cloud-hosted and downloadable versions, Kaggle makes models accessible to data scientists, and Ollama provides the simplest local deployment path requiring just a single command. Associated training and evaluation datasets are released on Hugging Face, and Cohere committed to publishing a technical report detailing training methodology for research purposes.
Key Takeaways
- Cohere's Tiny Aya family supports 70+ languages with specific optimization for South Asian languages like Hindi, Tamil, and Bengali
- On-device inference eliminates API costs, latency, privacy concerns, and internet dependency—critical for emerging markets
- Trained efficiently on just 64 H100 GPUs, proving frontier AI capability doesn't require trillion-dollar budgets
- Open-weight release strategy seeds developer ecosystem while creating long-term enterprise service opportunities
- Real-world applications include customer support, translation, agricultural tech, education, and accessibility—all offline-capable
Related Articles
- OpenClaw Founder Joins OpenAI: The Future of Multi-Agent AI [2025]
- AI Backdoors in Language Models: Detection and Enterprise Security [2025]
- AI Agent Social Networks: The Rise of Moltbook and OpenClaw [2025]
- OpenClaw AI Agent: Complete Guide to the Trending Tool [2025]
- Razer Forge AI Dev Workstation & Tenstorrent Accelerator [2025]
- Gemini on Google TV: Nano Banana, Veo, and Voice Controls [2025]

