![Razer Forge AI Dev Workstation & Tenstorrent Accelerator [2025]](https://tryrunable.com/blog/razer-forge-ai-dev-workstation-tenstorrent-accelerator-2025/image-1-1767821950401.jpg)
Razer Enters the AI Hardware Game with Local Development Solutions
Razer just made a move nobody expected. The gaming peripherals company, best known for mechanical keyboards and RGB mice, announced something completely different at CES 2026: a serious play in AI infrastructure.
The announcement caught me off guard because it signals a fundamental shift in how developers are approaching AI workloads. For years, the cloud dominated everything. You had your model, you shipped it to AWS or Google Cloud, and let someone else's data center handle the heavy lifting. But there's a massive problem with that approach nobody talks about openly: cost, latency, and control.
Razer's new Forge AI Dev Workstation and the accompanying Tenstorrent external accelerator directly address these pain points. This isn't about Razer suddenly pivoting to enterprise hardware. It's about recognizing that developers building AI applications need hardware that actually works the way they work. They want to iterate locally, test on their own datasets, and avoid the ridiculous cloud bills that stack up when you're experimenting with large language models.
What makes this particularly interesting is the timing. We're at an inflection point where local AI inference is becoming not just feasible but preferable for certain workflows. The rise of open-source models like Llama 3, Mistral, and others has made on-premise deployment viable. Razer is betting that developers will choose hardware they can touch and control over subscription-based cloud services.
Let me break down exactly what Razer is offering, why it matters, and whether this actually solves real problems developers face.
The Forge AI Dev Workstation: Raw Power for Local Workloads
The Razer Forge AI Dev Workstation isn't a laptop. It's a tower system designed specifically for AI development, training, and inference work without requiring cloud connectivity. Think of it as the opposite of cloud-first architecture.
The specs tell you everything about the intended use case. You can configure this workstation with up to four professional graphics cards from either NVIDIA or AMD. That's a pooled VRAM situation that lets you handle genuinely massive models. If you're working with models larger than a single GPU's memory can handle, this setup becomes essential. The multi-GPU architecture means you can train on larger datasets, run inference on bigger models, and experiment faster.
Processor options matter here too. You're looking at AMD Ryzen Threadripper PRO or Intel Xeon W chips. Both of these are workstation-class processors, not gaming chips. The Threadripper line is particularly interesting because it offers up to 64 cores, which translates to serious parallelization capabilities. For AI work, that core count means you can preprocess data, serve inference requests, and handle training operations simultaneously without bottlenecking.
Memory configuration supports eight DDR5 RDIMM slots, which is genuinely massive. We're talking potential capacities in the terabyte range depending on DIMM availability. For context, large language models are increasingly memory-hungry. Running a 70-billion parameter model requires serious RAM, and that's before you add your batch of incoming inference requests or your training dataset. This workstation doesn't make you choose between speed and capacity.
Storage and networking complete the picture. You get up to four PCIe Gen 5 M.2 NVMe drives for your models and datasets, plus eight SATA bays for bulk storage. Dual 10 Gb Ethernet ports let you connect to your network without creating a bandwidth bottleneck. For teams running distributed inference or wanting to pool their workstations into a mini cluster, that networking becomes critical.
Cooling is where the engineering discipline shows. This isn't a gaming PC with RGB fans. Razer designed the thermal system for sustained loads. When you're training a model for days or running continuous inference, you need cooling that doesn't throttle your hardware. The multiple high-pressure fans maintain consistent airflow across dense internal components, which sounds simple but actually requires careful case design and component placement.
Here's what genuinely matters though: the workstation can operate as a standalone tower on your desk or transition into rack environments. That flexibility is huge. A developer working solo can keep it compact. A team running a small cluster can rack-mount multiple units. The same hardware works for both scenarios. Most enterprise solutions force you to choose upfront.

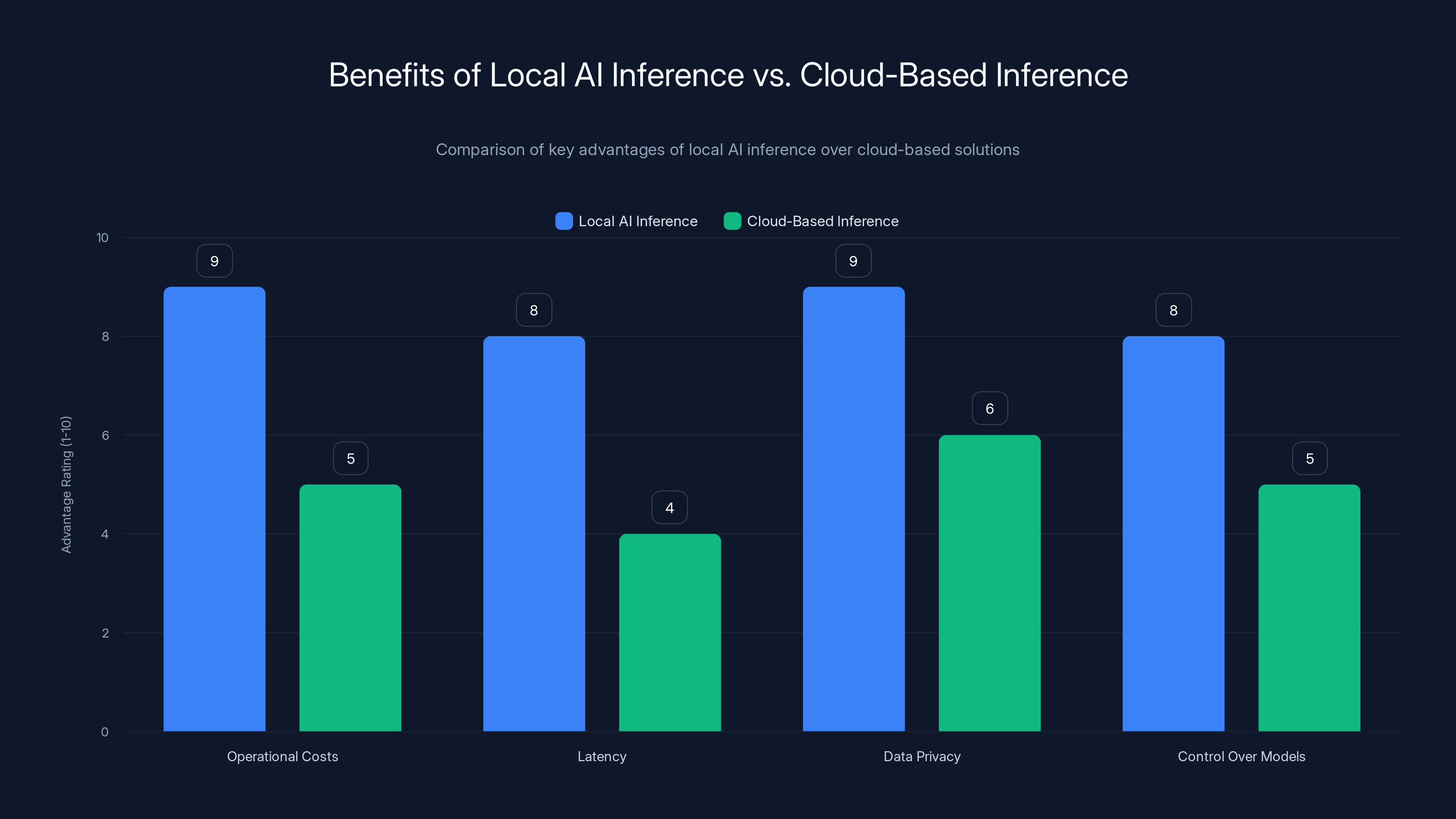
Local AI inference offers significant advantages in operational costs, latency, data privacy, and control over models compared to cloud-based inference. Estimated data based on typical benefits.
The Tenstorrent Accelerator: Portable AI Compute via Thunderbolt
Now here's where it gets interesting. Razer is also working with Tenstorrent on a compact external AI accelerator. This device connects via Thunderbolt 4 or Thunderbolt 5 and plugs directly into your laptop.
Let that sink in for a moment. Your laptop, which might have an integrated GPU or a modest discrete one, suddenly gains access to serious accelerator hardware. This fundamentally changes what's possible for local development. You can run inference on larger models on your laptop. You can test applications before deploying them to the bigger workstation. You can iterate faster because you're not waiting for cloud API responses.
Tenstorrent is led by Jim Keller, which is worth understanding. Keller's resume includes founding work on AMD's Zen CPU architecture and early autonomous driving silicon at Tesla. He's not some startup guy throwing darts at a board. This accelerator uses Tenstorrent's Wormhole architecture, which is purpose-built for running LLMs and AI workloads at scale.
The open-source software stack matters significantly here. Tenstorrent provides tools for running LLMs, image generation models, and other AI workloads. You're not locked into a proprietary ecosystem. This is crucial for developers who want flexibility in their model choices and frameworks.
Multiple units can daisy-chain together. You can connect up to four devices to create a small local cluster. For developers or small teams, this flexibility is transformative. You start with one accelerator, see how it performs, then add more if you need additional capacity. Compare this to cloud pricing, where you're either paying for resources you don't use or scrambling to scale up when demand exceeds capacity.
The Thunderbolt connection is clever. Modern Thunderbolt 5 supports up to 240 Gbps of bandwidth, which is substantial. It's fast enough that the accelerator doesn't become a bottleneck for most inference workloads. Your laptop can actually offload computation to the accelerator without waiting for data transfer to become the limiting factor.

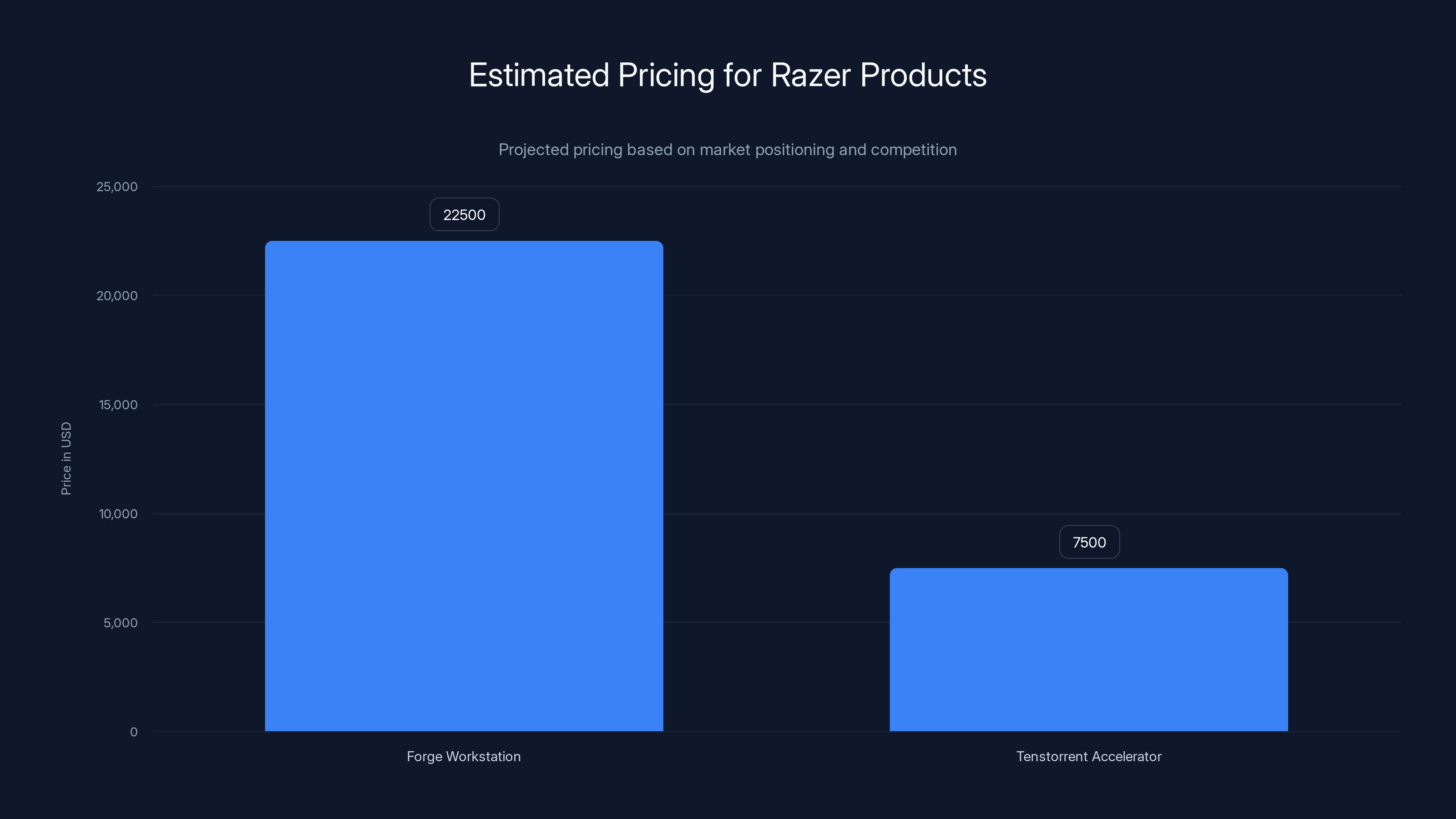
Estimated data suggests the Forge Workstation could be priced between
Why Local AI Matters: The Cloud Isn't Actually the Answer
Understanding the Forge and Tenstorrent announcements requires understanding why developers are pushing back against cloud-only architectures.
Cloud cost is the obvious problem. Running inference on large models through API calls can cost dollars per thousand tokens. If you're building an application that makes thousands of inference requests daily, those costs compound fast. A development team at a Series A startup spending $10K per month on API calls is money that should go toward hiring or product development. Local inference costs money once through hardware acquisition, then scales based on electricity.
Latency matters more than people acknowledge. When you call a cloud API, you're waiting for network roundtrips, queue time, and the actual inference computation. For real-time applications like chatbots, search applications, or decision systems, that added latency creates poor user experiences. Local inference eliminates network latency entirely. Your response time is just computation time.
Data privacy is the third factor that's rarely discussed publicly but concerns enterprises heavily. If your model processes confidential customer data, health information, or proprietary business intelligence, shipping that data to cloud providers creates compliance headaches. HIPAA, GDPR, and internal security policies often require data to remain on your own infrastructure. Local inference solves this by design.
Model control is underrated. With local deployment, you decide when to update your models, how to fine-tune them, and what data to train on. Cloud providers control the model versions they serve, the data they use for training, and when they sunset older versions. For applications where model behavior consistency matters, local control is essential.
The economics shift when you factor in these considerations. A developer might spend

Hardware Configuration Deep Dive: Building Your Setup
Let's get practical about what these systems actually enable. The configuration options matter because AI workloads vary significantly.
For a developer primarily doing inference, you might choose a mid-range GPU setup. An RTX 6000 or RTX 5880 gives you plenty of VRAM for running models like Llama 70B without needing multiple GPUs. Pair that with a Ryzen Threadripper PRO 7900 and 256GB of RAM. This configuration runs inference efficiently, costs less than four high-end GPUs, and still fits on a developer's desk.
For training work, you're looking at different priorities. Four high-end GPUs like RTX 6000 Ada cards make sense. You want maximum compute power for faster training cycles. The Threadripper PRO 7980 with 64 cores helps with data loading and preprocessing, which becomes a bottleneck with large training datasets. You probably want 512GB of RAM here.
For teams running a mixed workload, a middle ground works. Two RTX 6000s plus the Tenstorrent accelerator lets you train smaller models locally while using the accelerator for serving inference to your team. The Tenstorrent unit can handle actual user requests while the main workstation trains your next model iteration.
The key is that the Forge lets you make these choices. A fixed cloud setup doesn't adapt to your workload changing over time. You either over-provision and waste money or under-provision and get poor performance. Local hardware adjusts to your needs.
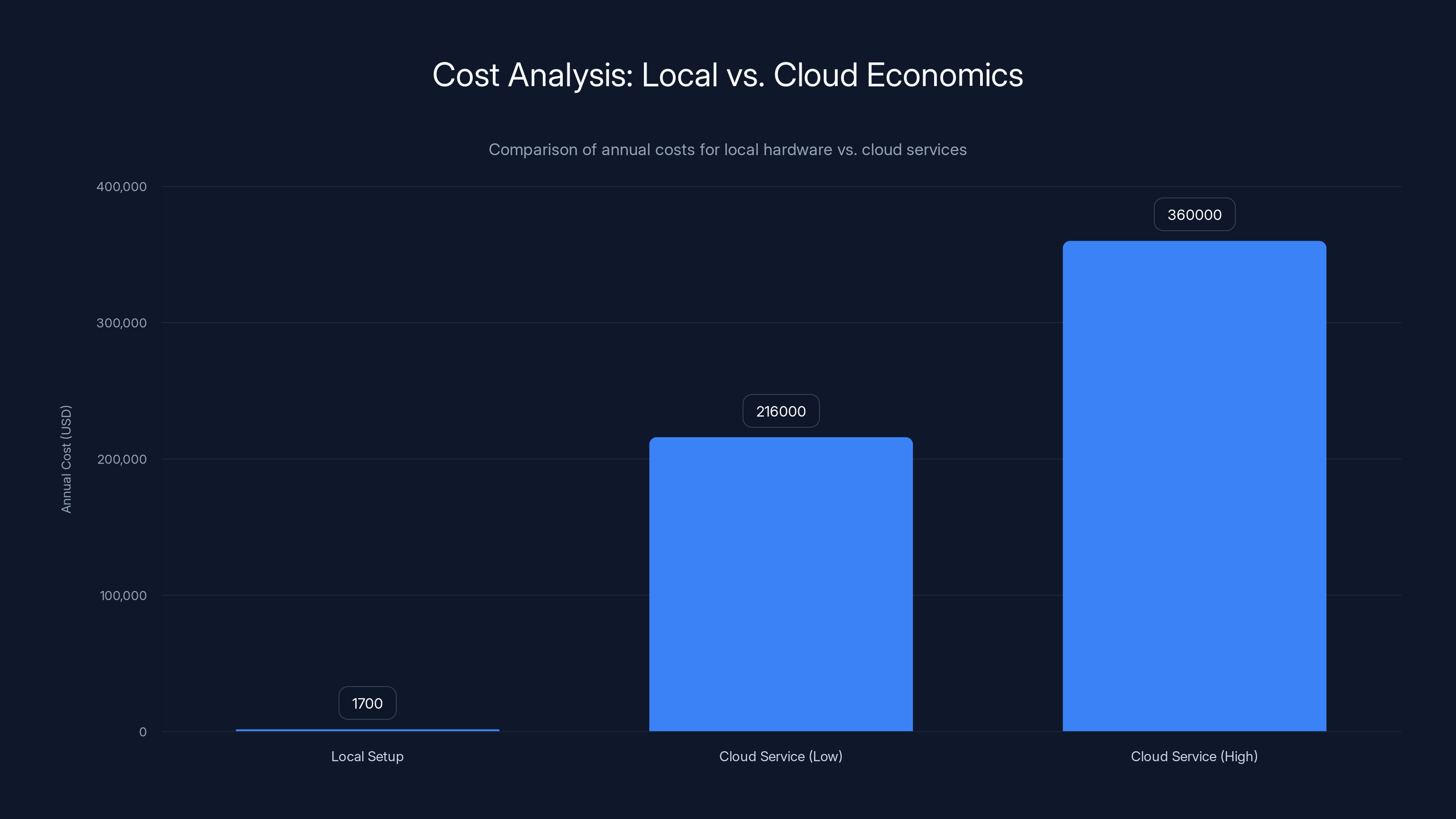
Local setups have significantly lower annual operating costs compared to cloud services, with a breakeven point within 1-2 months for inference-heavy applications. Estimated data for cloud services.
The Tenstorrent Software Ecosystem: More Than Just Hardware
Accelerators are only half the equation. The software stack determines whether the hardware becomes actually useful or sits gathering dust.
Tenstorrent's open-source approach is philosophically different from proprietary accelerator makers. You're not locked into their tools or their framework integrations. The Wormhole architecture runs models from any major framework: PyTorch, TensorFlow, JAX, or proprietary custom implementations.
The software abstraction layer handles the complexity of multi-accelerator coordination. When you connect four Tenstorrent units together, the software automatically distributes computation across them. You don't manually manage which model layer goes to which device. The system figures it out based on the model structure and available compute.
Debugging is where most hardware platforms fail developers. It's easy to make a feature but hard to let developers understand why performance is worse than expected. Tenstorrent provides profiling tools that show you exactly where computation spends time. You can see whether your bottleneck is GPU compute, memory bandwidth, or communication between devices.
Model optimization for the Wormhole architecture involves quantization, kernel fusion, and compute scheduling optimizations. Tenstorrent provides pre-optimized kernels for common operations like matrix multiplications and convolutions. If you're running standard models, these optimizations apply automatically. For custom operations, the system compiles them on the fly.
This is important: the software stack enables the hardware to reach its actual performance potential. Raw compute doesn't matter if developers can't access it efficiently. Tenstorrent understands this, which is why Jim Keller's involvement signals serious engineering discipline.
Daisy-Chaining Multiple Accelerators: Building a Home Lab
The ability to connect up to four Tenstorrent accelerators together is genuinely transformative for certain developers.
Imagine you're a researcher experimenting with distributed inference strategies. You start with one Tenstorrent unit plugged into your laptop. You test serving inference across it, optimize your serving strategy, measure latency. Then you add a second unit. The system now distributes load across both devices. You measure how communication overhead affects your latency profile.
With four units, you're running infrastructure equivalent to a small cloud instance fleet, but under your desk. You're not paying per-minute costs. You're not waiting for cloud infrastructure to scale. You're iterating on distributed systems in your actual environment.
For teams building AI applications, this matters enormously. A three-person startup can build a prototype AI service on local hardware, launch it, and prove unit economics work before spending serious money on cloud infrastructure. If it doesn't work, you lose your hardware investment, not thousands in cloud bills.
The coordination overhead for distributed Tenstorrent units is minimal compared to cloud, where network latency and API overhead dominate. Multiple local units communicate over Thunderbolt or standard networking, which is orders of magnitude faster than cloud infrastructure.
This also solves a testing problem most developers face. You want to test your application behavior when running on distributed hardware, but setting up actual cloud clusters for testing is expensive. With local Tenstorrent units, you test with real distributed infrastructure without the cost penalty.

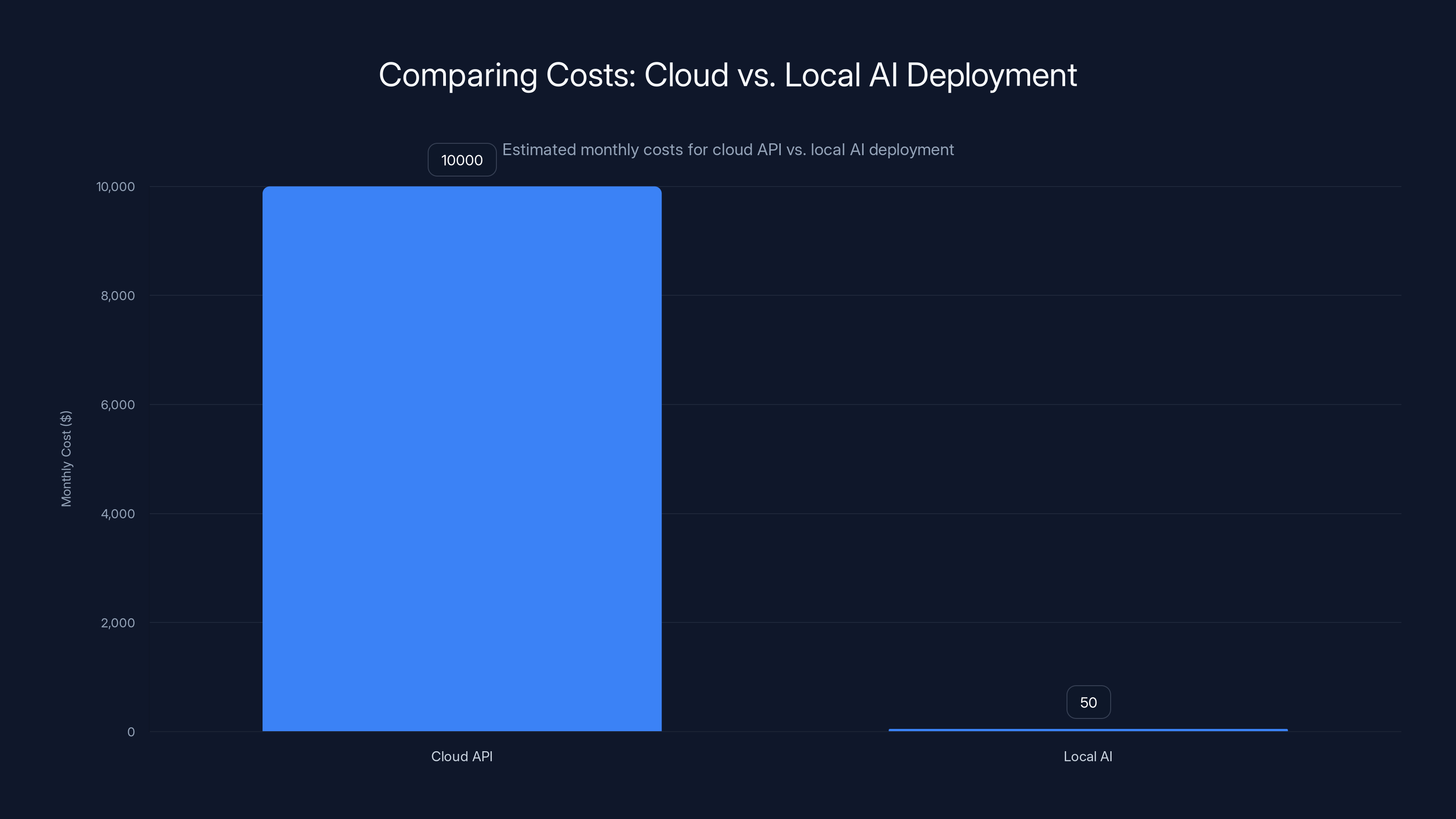
Estimated data: Cloud API deployment can cost significantly more monthly compared to local AI, which primarily incurs a one-time hardware cost.
Integration with Existing Developer Workflows
Here's what actually matters for adoption: does this integrate with how developers actually work?
Razer specifically positioned the Forge as developer-friendly, not as a new ecosystem requiring retraining. The workstation runs standard operating systems. You install PyTorch or TensorFlow the normal way. You write code in your existing editors. The hardware is transparent infrastructure underneath.
For the Tenstorrent accelerator, the same principle applies. It appears as a compute device. Your framework detects it and offers it as a target for computation. You don't need to rewrite applications to use it. Frameworks handle the acceleration automatically.
This contrasts sharply with some accelerator ecosystems where you need specialized compilers, custom frameworks, or significant refactoring. Tenstorrent's approach recognizes that developers have existing code, existing workflows, and existing skills. The accelerator should integrate into that environment, not force you to adapt to it.
The open-source software stack supports this philosophy. If something isn't working optimally, developers can dig into the code, understand what's happening, and optimize. They're not dependent on vendor support tickets.

Cost Analysis: Local vs. Cloud Economics
Let's run the math on actual costs, because that's what determines whether developers actually adopt this hardware.
A configured Forge AI Dev Workstation with dual RTX 6000 cards, Threadripper PRO processor, and 512GB RAM costs approximately
Annual operating costs primarily depend on electricity. A dual-GPU workstation consuming 1200 watts continuously at
Now compare to cloud. Running a model like Llama 70B through API inference costs roughly
Breakeven occurs within 1 to 2 months for any inference-heavy application. After that, you're operating at a massive cost advantage. Even accounting for hardware depreciation, electricity, and maintenance, local inference becomes economically dominant.
For development teams, this completely changes financial planning. Instead of scaling cloud costs with usage, you scale hardware costs with team size. A ten-person team can share a small cluster of Forge workstations more economically than running cloud infrastructure.
The ROI calculation is straightforward:

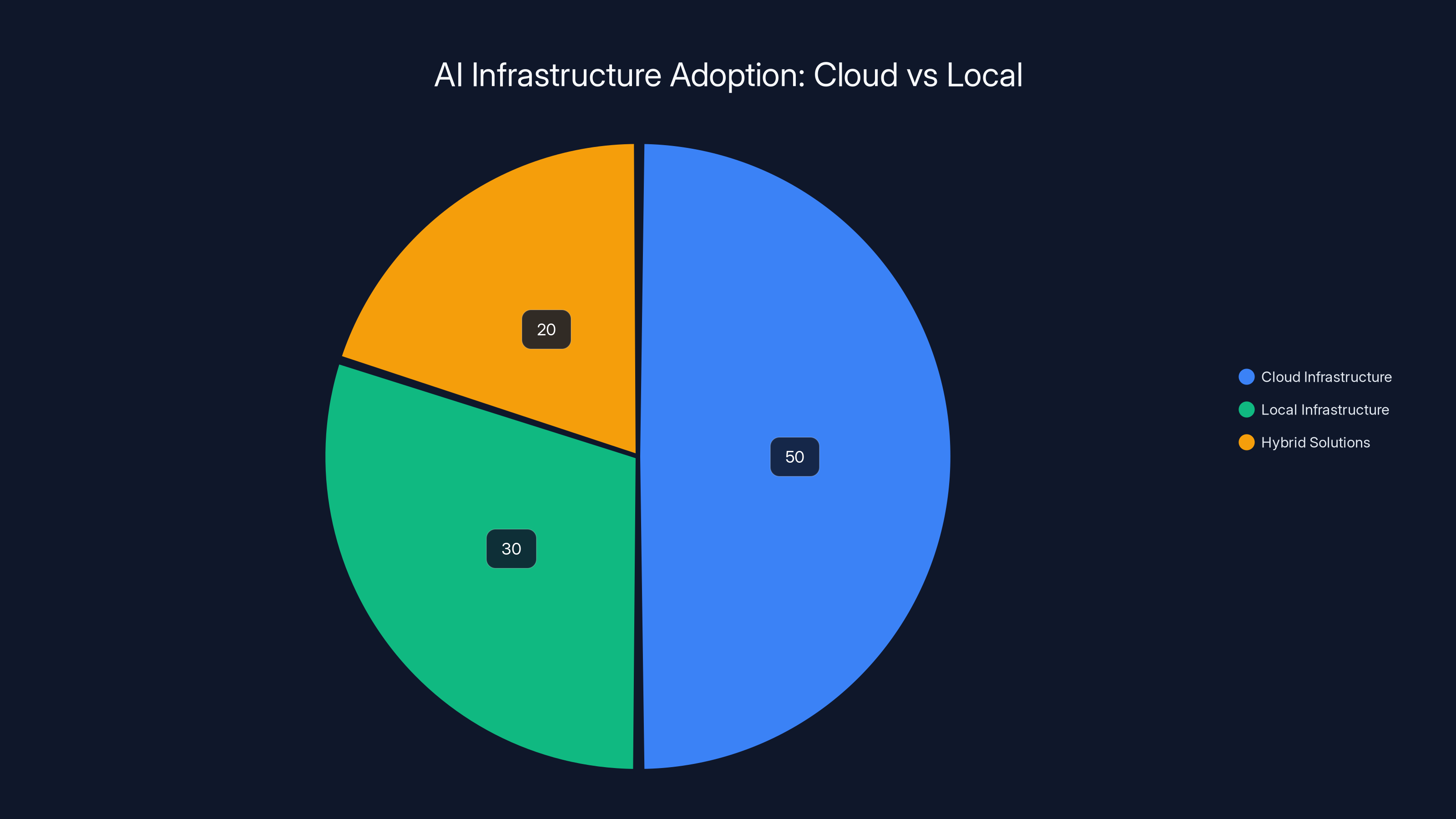
Estimated data shows a growing trend towards local AI infrastructure, with 30% adoption, as developers seek more control over their resources.
The Partnership: Why Razer and Tenstorrent Make Sense Together
The announcement mentioned it casually, but Razer and Tenstorrent's partnership actually reveals something important about where hardware is heading.
Razer brings design expertise and manufacturing capability. They know how to build products that developers actually want to use. Their reputation in gaming peripherals doesn't immediately translate to enterprise hardware, but the design philosophy does. Razer builds products that are optimized for user experience, not just features.
Tenstorrent brings the AI expertise. Jim Keller has designed chips that matter. The Wormhole architecture is purpose-built for modern AI workloads. Tenstorrent understands the compute requirements better than gaming hardware companies ever could.
Together, they're solving a gap that cloud providers actively don't want to solve. Major cloud providers make money on usage. They want you dependent on their APIs. They have zero incentive to provide you tools to run inference locally. This partnership fills that gap by combining accelerator expertise with manufacturing and design capability.
The quote from Tenstorrent's Christine Blizzard is telling: "Our goal is to make AI more accessible." Accessible means not just technically feasible but practically affordable and integrated into normal developer workflows. Razer brings the "practically integrated" part. Tenstorrent brings the technology.
This partnership also signals something about the future of specialized hardware. Rather than each company building every component of the stack, specialized companies partner. Razer doesn't need to invent accelerator architecture. Tenstorrent doesn't need to master industrial design. They collaborate and deliver better products than either could alone.

Real-World Use Cases: Where This Hardware Actually Solves Problems
Let me make this concrete. These aren't academic products. Real developers have real use cases.
Use Case 1: Fine-Tuning Proprietary Models
You're a healthcare startup building a diagnostic assistant. You have proprietary patient data. You want to fine-tune a model on this data without sending it to cloud providers. HIPAA compliance makes that complicated. Local fine-tuning on a Forge workstation becomes your only option. You load Llama 13B, fine-tune on your proprietary dataset, and keep everything on-premise. The multi-GPU setup lets you fine-tune efficiently. The ROI math works because you're not paying for cloud GPU hours.
Use Case 2: Interactive Development and Iteration
You're building an AI feature for your application. You want to iterate quickly: adjust model parameters, test on your data, see results immediately. Cloud APIs introduce delay between changes and feedback. A local Forge workstation eliminates that delay. You modify your serving code, run it against the local model, measure performance, repeat. Development velocity increases dramatically.
Use Case 3: Building a Local Search Application
You're building a customer support system that searches through company documentation to answer questions. You want low latency responses. You want privacy because the search queries include customer context. A Tenstorrent accelerator plugged into your infrastructure gives you sub-100ms responses while keeping everything on your servers. Cloud-based search would have longer latencies and privacy implications.
Use Case 4: Competing with Larger Companies
You're a smaller team competing against better-funded competitors. You can't match their cloud infrastructure budgets. But you can deploy smarter model choices, better optimization, and local inference to achieve better cost efficiency. A team using local Tenstorrent units might serve inference 10 times cheaper than competitors using cloud APIs. That cost advantage translates to better product economics and better margins.
Use Case 5: Offline-First Applications
You're building applications for regions with poor internet connectivity or applications that need to function offline. Cloud APIs don't work. You need to bundle models with your application. A laptop with a Tenstorrent accelerator becomes your development environment for testing how applications behave in offline mode. You ensure your application works before shipping to users without connectivity.

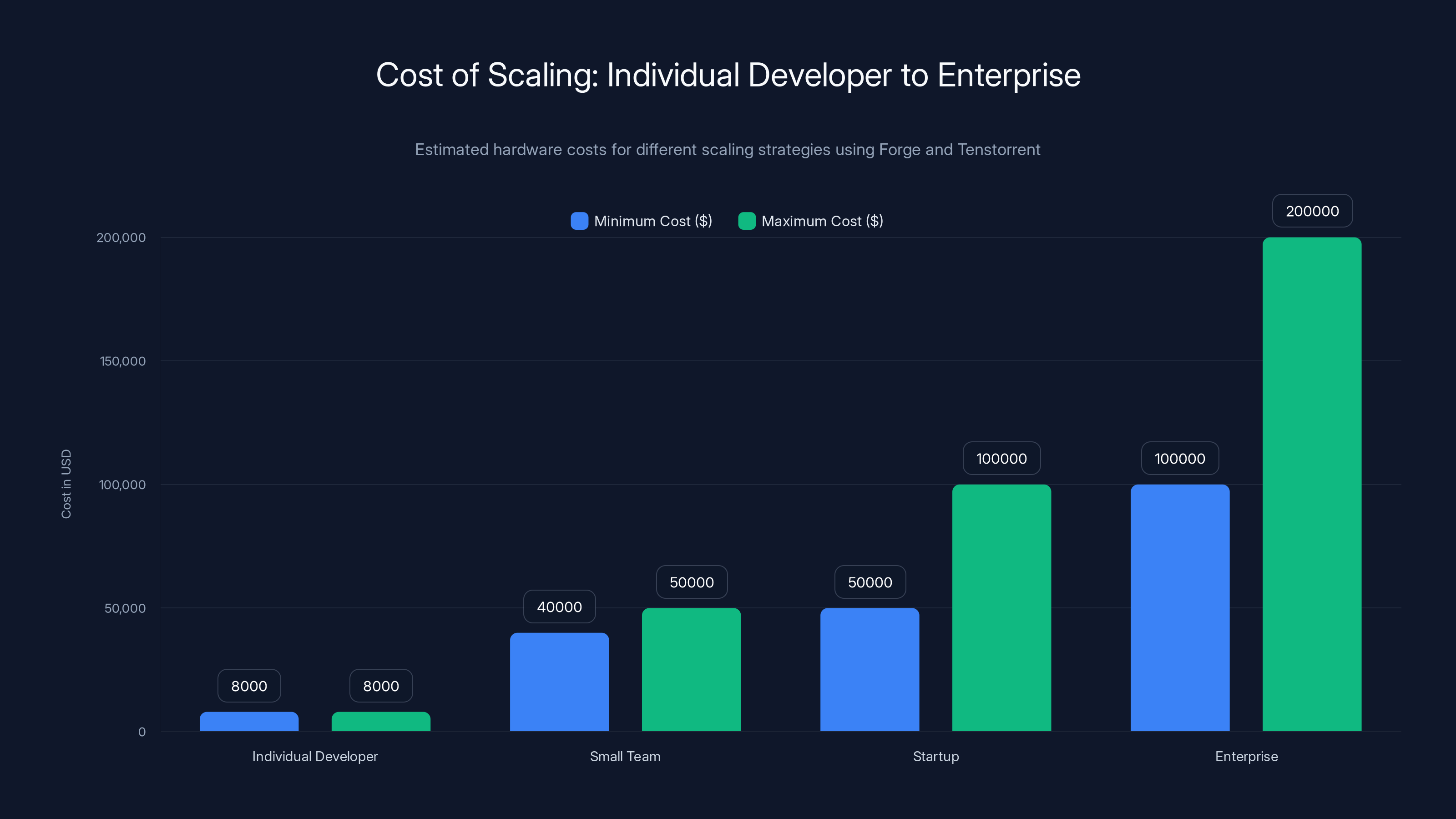
Estimated costs for scaling from an individual developer to an enterprise using Forge and Tenstorrent range from
Competitive Landscape: Where This Fits
Understanding Razer's positioning requires looking at what competitors are doing.
NVIDIA dominates GPU infrastructure but doesn't position hardware for developers. They sell GPUs to cloud providers and enterprises. They don't prioritize the developer experience of someone running inference locally. Their software stack assumes you're an enterprise with dedicated infrastructure teams.
Apple's neural engine and MacBook Pro with M-series chips offer local inference capabilities, but the compute is modest. You can run small models efficiently, but you can't fine-tune models or handle serious inference workloads. It's local, but not powerful enough for serious AI development.
Intel has invested in AI accelerators but hasn't achieved hardware momentum. Their strategy has been scattered between Gaudi accelerators, Xeon integration, and partnerships. They haven't delivered a cohesive developer experience like Razer and Tenstorrent are attempting.
Cloud providers like AWS, Google Cloud, and Azure offer excellent infrastructure but actively work against local alternatives. They want you dependent on their services. They'll discount GPUs and accelerators to keep you in their ecosystem. They don't benefit from developers running inference locally.
The Razer and Tenstorrent positioning fits a specific gap: developers who want powerful, affordable local inference without being locked into cloud ecosystems. That's a substantial market that's been underserved.

Scaling Strategies: From Individual Developer to Enterprise
The beauty of the Forge and Tenstorrent combo is the flexibility in scaling.
A solo developer starts with a laptop and one Tenstorrent accelerator. Total cost: maybe $8000. They develop locally, test their applications, optimize their models. If their application works, they add another Tenstorrent unit to handle more traffic or run multiple models in parallel.
A small team of 3-4 developers can share a single Forge workstation with multiple Tenstorrent accelerators. The workstation runs training and experimentation. The accelerators handle inference serving for development and testing. Total cost:
A larger startup with 10-20 people might run a cluster of 3-4 Forge workstations plus a bunch of Tenstorrent accelerators. Some workstations handle training work. Others serve inference. The setup becomes genuinely scalable without encountering cost explosions.
Enterprises can scale this further by running rack-mounted configurations. Multiple Forge workstations in racks provide serious compute density. The flexibility to move between tower and rack configurations means the hardware adapts to organizational growth.
The key advantage over cloud is predictable economics. You know your maximum monthly cost because you know your hardware. Cloud scaling introduces surprise bills. Local scaling is capital expense, which is budgetable and depreciable.

The Open-Source Advantage: No Vendor Lock-In
One detail that's easy to miss but profoundly important: Tenstorrent's open-source software stack means you're not locked into their ecosystem.
If you build an application using Tenstorrent acceleration, you can theoretically switch to different hardware later. The model is still in PyTorch or TensorFlow. Your application code is still portable. You might need to re-optimize for different hardware, but the transition isn't impossible.
Compare this to proprietary accelerator stacks where switching vendors requires rewriting huge portions of your application. Open-source stacks reduce switching costs, which gives developers confidence to commit to the platform.
This matters because hardware companies come and go. A team betting their inference infrastructure on a startup's accelerator architecture runs real risk. Open-source stacks mitigate that risk. Even if Tenstorrent pivots or faces challenges, their open-source work remains usable.
Tenstorrent's design also enables the community to contribute optimizations. If someone discovers a more efficient way to schedule computation across the Wormhole architecture, they can contribute that optimization. The entire ecosystem benefits. This is fundamentally different from black-box proprietary accelerators where optimization is limited to the vendor's engineering team.

Challenges and Limitations: This Isn't Perfect
Realistically, this isn't a cloud killer. There are significant limitations.
Capital cost is substantial. You need
Operational complexity increases. You now manage hardware: cooling, electricity, maintenance, potential failures. Cloud abstracts all this away. You pay for convenience and stability. For solo developers, that convenience is often worth the cost premium.
Scaling beyond a certain point becomes impractical. If you need massive inference capacity serving millions of users, local infrastructure requires massive capital investment and dedicated operations teams. Cloud scales elastically and adds redundancy automatically. Large-scale applications still favor cloud.
Model updates and distribution are more complex. With cloud, the provider updates models globally. You just re-point your API calls. With local infrastructure, you manage updates manually across your hardware fleet. This is operational overhead that's easy to underestimate.
Developers familiar with cloud infrastructure sometimes struggle with hardware-level details. What kind of cooling is adequate? What power supply capacity do you need? These questions require different expertise than cloud deployment.

Future Trajectory: Where This Hardware Is Heading
If Razer and Tenstorrent succeed, we'll see several developments.
First, other companies will create similar offerings. The success of this partnership signals opportunity. Expect desktop manufacturers, gaming companies, and hardware specialists to build competing local AI solutions. More options drive down prices and increase feature diversity.
Second, more frameworks will optimize for Tenstorrent and similar accelerators. Framework teams at PyTorch and TensorFlow will prioritize performance on popular accelerators. Community members will contribute optimized kernels. The software ecosystem matures.
Third, model compression techniques will advance to make this hardware more practical. Quantization, knowledge distillation, and pruning let you run models with less compute. Smaller models mean fewer GPUs needed, which lowers costs further.
Fourth, distributed inference will become standard. Running models across multiple accelerators for parallel inference will be as normal as distributed training is now. Frameworks will provide this automatically.
Fifth, specialized models for local inference will emerge. Just as mobile deep learning created mobile-specific models optimized for phones, we'll see models designed specifically for Wormhole architecture and similar accelerators.
Eventually, we might see a shift in how AI applications are architected. Instead of assuming cloud-first, the default becomes local-with-cloud-overflow. You run inference locally until you exhaust local capacity, then overflow to cloud for spike handling. This hybrid approach combines cost efficiency with elasticity.

Practical Implementation: How to Actually Use This
Let's get specific about implementation for a developer considering adopting this hardware.
Step 1: Define Your Workload
Determine whether you're training, inference, or both. Calculate expected throughput: how many inference requests daily? How long should training iterations take? This defines your hardware requirements.
Step 2: Start Small
Begin with a single GPU and one Tenstorrent accelerator rather than maxing out the configuration. Understand your actual requirements before committing to maximum hardware.
Step 3: Optimize Serving Strategy
Batch inference requests aggressively. Run models on quantized versions initially. Profile actual performance on your hardware. Optimize model serving code to utilize accelerators efficiently.
Step 4: Implement Monitoring
Set up GPU memory monitoring, compute utilization tracking, and latency measurements. Understand whether your bottleneck is compute, memory, or communication.
Step 5: Add Capacity Incrementally
Once you understand your workload, add GPUs or accelerators as needed. Scaling incrementally is far cheaper than buying everything upfront and discovering you overprovisioned.
Step 6: Consider Hybrid Deployment
Don't assume all inference runs locally. Use local hardware for latency-sensitive operations and most common queries. Overflow less common requests to cloud if necessary. This hybrid approach balances cost and reliability.

Industry Impact and Implications
Beyond the specific products, this announcement signals a broader industry shift.
Cloud providers built their dominance by centralizing AI compute. Forcing everyone to use their APIs meant recurring revenue and lock-in. Razer and Tenstorrent's announcement suggests cloud centralization faces real competition from distributed local inference.
This creates pressure on cloud pricing. If local inference becomes economically dominant, cloud providers must either lower prices or differentiate through services and features beyond just compute access. We're already seeing this: cloud providers bundling managed MLOps tools, fine-tuning services, and domain-specific solutions to justify their pricing.
It also impacts how startups approach AI infrastructure decisions. Previously, startups defaulted to cloud because alternatives were immature or expensive. Now they have viable local options. This leads to more sophisticated infrastructure decisions earlier in startup development.
For enterprises, this creates optionality. You can mix cloud and local infrastructure based on specific workload characteristics rather than defaulting everything to cloud. This heterogeneous approach often delivers better cost efficiency than single-vendor strategies.
The announcement also validates open-source AI frameworks. PyTorch, TensorFlow, and Ollama's success depended on these frameworks being framework-agnostic. Tenstorrent's decision to support multiple frameworks rather than forcing a proprietary stack reinforces this direction. The future likely involves multiple frameworks coexisting, each with different strengths.

Pricing Expectations and Market Positioning
Razer hasn't announced final pricing for these products, but we can infer from competitive positioning.
The Forge workstation will likely start around
The Tenstorrent accelerator pricing remains mysterious, but based on comparable hardware (NVIDIA DGX, Cerebras, etc.), expect somewhere in the
These price points position both products clearly. They're not consumer products. They're business tools for professionals and teams. The value proposition depends on inferencing volume. If you're serving millions of requests monthly, the ROI is massive. For light usage, cloud APIs remain cheaper.
Razer's brand creates pricing advantages over startups offering similar hardware. Their reputation means customers trust them for support and future products. They can command premium pricing based on brand confidence, not just specifications.

Conclusion: Local AI Is Going Mainstream
Razer's entry into AI infrastructure hardware signals that local AI development and inference are transitioning from niche to mainstream.
The Forge AI Dev Workstation isn't revolutionary technology. It's well-engineered conventional hardware targeted at a specific need. The Tenstorrent accelerator is technically impressive but operating in established accelerator markets. What's remarkable is that a gaming company saw the opportunity and executed.
This signals that AI development is becoming accessible to more developers. Cloud infrastructure democratized AI in one direction—enabling people without hardware access to experiment. Local infrastructure democratizes in another direction—enabling teams to own their infrastructure and control their costs.
Developers choosing between cloud and local will increasingly make informed tradeoffs rather than defaulting to cloud. That's genuinely different from where we were two years ago.
The partnership between Razer and Tenstorrent demonstrates that specialized companies collaborating deliver better outcomes than trying to own every layer of the stack. This model likely extends to other hardware categories: keyboards, cooling systems, power supplies, software tools. The best AI infrastructure will combine components from specialists rather than monolithic vendors.
For developers working on AI applications, this is good news. You have options. The competitive pressure between cloud providers and local infrastructure keeps everyone honest about pricing and features. You can make choices based on your specific technical requirements rather than accepting a single vendor's one-size-fits-all approach.
The hardware landscape for AI development is becoming more diverse, more accessible, and more specialized. The Forge and Tenstorrent represent important steps in that direction.

FAQ
What is the Razer Forge AI Dev Workstation?
The Razer Forge AI Dev Workstation is a purpose-built tower system designed for AI development, training, and inference work without cloud dependencies. It supports up to four professional graphics cards from NVIDIA or AMD, professional-grade processors like AMD Ryzen Threadripper PRO or Intel Xeon W, up to eight DDR5 memory slots, and multiple PCIe Gen 5 storage drives. The workstation can operate as a standalone tower or be rack-mounted for enterprise deployments.
How does the Tenstorrent external accelerator connect to devices?
The Tenstorrent accelerator connects directly to compatible devices via Thunderbolt 4 or Thunderbolt 5. This enables laptops and other systems to offload AI inference computation to the accelerator hardware. Multiple units can daisy-chain together, with support for up to four devices forming a local cluster for larger model workloads. The Thunderbolt connection provides substantial bandwidth, up to 240 Gbps with Thunderbolt 5, reducing communication overhead.
What are the main benefits of local AI inference versus cloud-based inference?
Local AI inference offers several advantages: dramatically lower operational costs after initial hardware investment, reduced latency since data doesn't travel over networks, improved data privacy since sensitive information stays on your infrastructure, and full control over model versions and updates. For applications making thousands of daily inference requests, local inference costs significantly less than cloud APIs despite higher upfront capital expenses.
What models can run on the Tenstorrent accelerator?
The Tenstorrent accelerator supports any major machine learning framework including PyTorch, TensorFlow, and JAX. It's designed to run LLMs like Llama, Mistral, and similar models, as well as image generation models and other AI workloads. The open-source software stack means you're not limited to proprietary models or specific framework versions.
How much does the Razer Forge AI Dev Workstation cost?
Razer hasn't announced final pricing, but entry-level configurations are expected to start around
Can you really save money using local AI hardware instead of cloud APIs?
Yes, for inference-heavy applications. A workstation costing
Is the Tenstorrent accelerator compatible with my laptop?
If your laptop has a Thunderbolt 4 or Thunderbolt 5 port, the Tenstorrent accelerator should be compatible. Thunderbolt ports are increasingly common on modern laptops from manufacturers like Apple, Dell, Lenovo, and others. You should check your specific laptop model to confirm Thunderbolt support before purchasing. The accelerator adds significant compute capability to any compatible device.
Why is open-source software important for the Tenstorrent accelerator?
Open-source software means you're not locked into proprietary ecosystems. Your models and applications remain portable to other hardware or frameworks. The community can contribute optimizations and improvements rather than being limited to vendor development. This reduces risk if the company pivots or faces challenges, and it enables competitive pressure to drive improvements in the software stack.
How does the Razer Forge workstation scale from individual developers to enterprises?
The workstation scales flexibly. A solo developer starts with modest GPU configuration. Small teams share a single workstation with Tenstorrent accelerators. Larger organizations run multiple workstations in rack configurations. The same underlying hardware adapts from tower to rack form factors, enabling scaling without replacing equipment. This flexibility is difficult to achieve with cloud infrastructure, which remains static regardless of organizational scale.
What's the difference between using Tenstorrent for inference versus training?
Inference involves running pre-trained models to generate predictions or outputs, while training involves updating model weights using data. Tenstorrent accelerators optimize for inference workloads, delivering fast response times with lower power consumption. Training typically requires GPU hardware like those in the Forge workstation for faster throughput. Most organizations do training on powerful GPU systems and serve inference using more efficient accelerators, splitting compute responsibilities between hardware types.

Key Takeaways
- Razer's Forge AI Dev Workstation enables local AI development with multi-GPU configurations and professional processors for developers wanting to avoid cloud dependencies
- The Tenstorrent accelerator provides portable AI compute via Thunderbolt, allowing laptop-based developers to run serious inference workloads locally
- Local AI infrastructure achieves break-even costs within 2-4 months compared to cloud APIs for typical inference-heavy applications
- Open-source Tenstorrent software stack prevents vendor lock-in and enables flexibility across frameworks like PyTorch, TensorFlow, and JAX
- Multiple Tenstorrent units daisy-chain together for distributed inference, letting small teams build local clusters rivaling cloud infrastructure at lower costs
Related Articles
- The YottaScale Era: How AI Will Reshape Computing by 2030 [2025]
- Gemini on Google TV: Nano Banana, Veo, and Voice Controls [2025]
- AI in B2B: Why 2026 Is When the Real Transformation Begins [2025]
- Thunderobot Station with Ryzen AI Max+ 395: The Cube Desktop Revolution [2025]
- Olares One Mini PC: Desktop AI Power in Compact Form [2025]

