![Gemini vs ChatGPT: Which AI Model Is Actually Better? [2025]](https://tryrunable.com/blog/gemini-vs-chatgpt-which-ai-model-is-actually-better-2025/image-1-1769009932835.jpg)
Gemini vs Chat GPT: Which AI Model Is Actually Better? [2025]
There's been a lot of noise lately about whether Google's Gemini has finally caught up to OpenAI's Chat GPT. Apple's decision to integrate Gemini into Siri certainly suggests something shifted in the competitive landscape. But the real question isn't whether one model is objectively "better"—it's whether one model better solves the specific problems you're trying to solve.
I've been testing both these AI models side-by-side for weeks now, and what I found might surprise you. Neither one is definitively superior. Instead, they're genuinely different tools that excel in different domains. One model keeps producing laughably bad dad jokes while crushing at explanatory writing. The other handles math with crystal clarity but struggles with creative flair. The choice between them matters more than people realize, especially if you're integrating AI into your workflow.
Here's the thing: the last time the industry did a comprehensive comparison like this, Google's offering was still called Bard. That was late 2023. In roughly two years, the AI world has evolved dramatically. Models have become smarter, faster, and increasingly specialized. Training datasets have expanded. Architecture improvements have compounded. Both companies have had time to iterate, learn from mistakes, and refine their approaches.
What we're about to explore is how these two models actually perform when you put them to real work. Not marketing claims. Not benchmark scores you read about online. Actual, side-by-side testing with the same prompts, the same evaluation criteria, and honest assessment of what worked and what didn't.
The stakes of this comparison are bigger than they appear. Apple's Siri partnership with Google represents one of the most significant technology decisions in recent mobile history. It signals that Google's AI capabilities have reached a threshold where Apple—a company that fiercely guards its technology partnerships—trusts them to represent Apple's brand in Siri responses. That's not a small vote of confidence.
But is it the right choice? And more importantly, which model should you actually be using for your own work? Let's find out.
TL; DR
- Chat GPT wins on originality and creative writing, but both models struggle with truly original content
- Gemini excels at mathematical clarity and structured explanations, avoiding confusing notation shifts
- Conversation quality varies dramatically by topic, with Chat GPT showing more natural charm in storytelling
- Chat GPT hallucinates specific details (dates, book subtitles) while Gemini tends to be vaguer
- The winner depends entirely on your use case, not on objective AI superiority

Gemini excels in math clarity and explanatory writing, while ChatGPT shows strength in creative flair and joke quality. Estimated data based on 2025 capabilities.
The Real Competition: Beyond the Hype
When two companies claim they've built the most advanced AI on the planet, skepticism is warranted. Both OpenAI and Google have strong financial incentives to claim superiority. Both have invested billions into training infrastructure. Both have released marketing materials suggesting their model is the intelligent choice.
But here's what actually matters: How do these models perform when asked to do real work?
The testing methodology we used tries to isolate specific capabilities. We're not running benchmark suites—those have their own biases and often measure things that don't reflect real-world usage. Instead, we're using a series of increasingly complex prompts that require different types of reasoning, creativity, and accuracy.
The prompts themselves have evolved from previous testing cycles. Where earlier comparisons used relatively straightforward requests, we're now using more sophisticated scenarios that better reflect how people actually use AI in their work. This matters because it prevents the models from pattern-matching to simple prompt templates.
One critical insight before we dive into specific tests: neither model is being shown the other's responses during testing. This prevents contamination where one model might be influenced by seeing the other model's output. Each model works independently, and we evaluate each response on its own merits.
The evaluation criteria blend objective and subjective measures. For mathematical problems, correctness is measurable. For creative writing, we're assessing originality, coherence, and charm—qualities that are inherently subjective. We're transparent about which category each test falls into, so you can weight the results according to what matters to you.
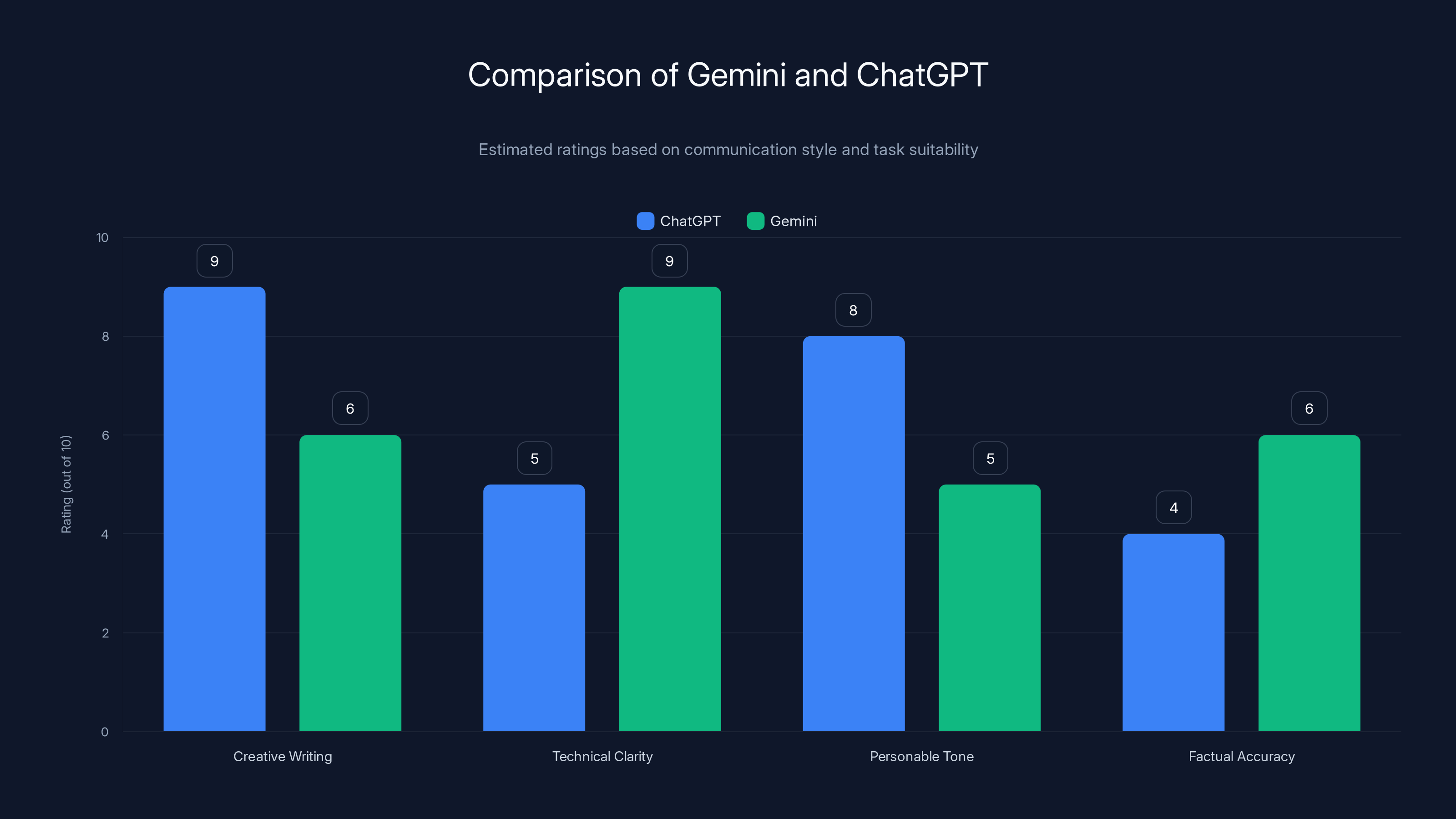
ChatGPT excels in creative writing and personable tone, while Gemini is stronger in technical clarity and slightly better in factual accuracy. Estimated data based on qualitative descriptions.
Test 1: Originality and Creative Humor (The Dad Joke Challenge)
Writing original content is genuinely hard. AI makes it exponentially harder because these models are trained on existing human-generated content. When asked to be original, they're essentially being asked to create something that statistically diverges from their training distribution—which goes against their fundamental purpose.
We asked both models to write five original dad jokes. The grading rubric was straightforward: Did the model generate jokes that you couldn't find verbatim in existing repositories?
Gemini produced five jokes. Within 30 seconds of searching Reddit's r/dadjokes community, we found exact matches for all five. Word-for-word duplicates. This isn't a failure of effort—the model was doing exactly what it was trained to do, which is recognize patterns in comedy and reproduce them. But it completely missed the "original" part of the assignment.
Chat GPT had a more mixed performance. Two of its five jokes were immediate matches in existing joke databases. That's not great. But the remaining three jokes were different.
Here's where it gets interesting. One of Chat GPT's original jokes was genuinely clever: "I tried to fight with my calendar yesterday. It keeps bringing up the past, and I keep ignoring its dates." That's a solid dad joke—the kind that makes you groan and shake your head. The structure is tight, the punchline lands, and it demonstrates understanding of how calendar/relationship metaphors work.
Another original attempt was less successful. Chat GPT suggested a bakery for pessimists with the slogan "Hope you like half-empty rolls." The wordplay doesn't quite work. Half-empty doesn't apply to rolls the way it applies to glasses. The joke breaks down under scrutiny.
The third original attempt was something Chat GPT seemed to create by accident: combining two scarecrow-themed jokes into an awkward hybrid that was neither better nor worse than its components.
Winner: Chat GPT, though neither model truly succeeded at originality. Chat GPT at least demonstrated the capacity to create jokes that didn't exist in its training data, even if execution was inconsistent.

Test 2: Mathematical Reasoning (The Windows 11 Floppy Disk Problem)
This test cuts to the heart of how differently these models handle structured logical reasoning.
The prompt was straightforward: If Microsoft Windows 11 shipped on 3.5-inch floppy disks, how many would you need?
Both models needed to estimate the size of a Windows 11 installation, then calculate how many 1.44MB floppy disks would be required. The correct answer hinges on accuracy in unit conversion and consistent application of mathematics.
Chat GPT estimated Windows 11 at 5.5 to 6.2GB. Gemini estimated 6.4GB. The actual size of Windows 11 installation media ranges from 6.7GB to 7.2GB depending on the CPU architecture and language pack. Both models underestimated slightly, but within reasonable bounds.
Here's where they diverged completely:
Chat GPT switched units mid-calculation. It started with gigabytes but then switched to gibibytes (Gi B), which created approximately a 7% discrepancy in the final calculation. This matters. It's the kind of mistake that would get flagged immediately by a data engineer. The model then seemed to panic, writing out confused strings like "6.2 Gi B = 6,657,? actually → 6,657,? wait compute:…" as if manually working through the problem and discovering its own error in real-time.
Gemini maintained consistent units throughout the entire calculation. Gigabytes stayed gigabytes. The math was transparent and easy to follow. The final answer of approximately 4,611 floppy disks (based on 1.44MB per disk) was clearly explained.
But Gemini went further. It provided context about earlier Windows versions, noting that Windows 3.1 would fit on just six to seven floppy disks. This wasn't asked for, but it demonstrated comparative thinking and historical knowledge. It made the answer richer without adding unnecessary complexity.
Winner: Gemini, decisively. Mathematical clarity, consistent notation, and additional context without condescension. Chat GPT's unit confusion and visible error-recovery attempts undermined confidence in its mathematical abilities.
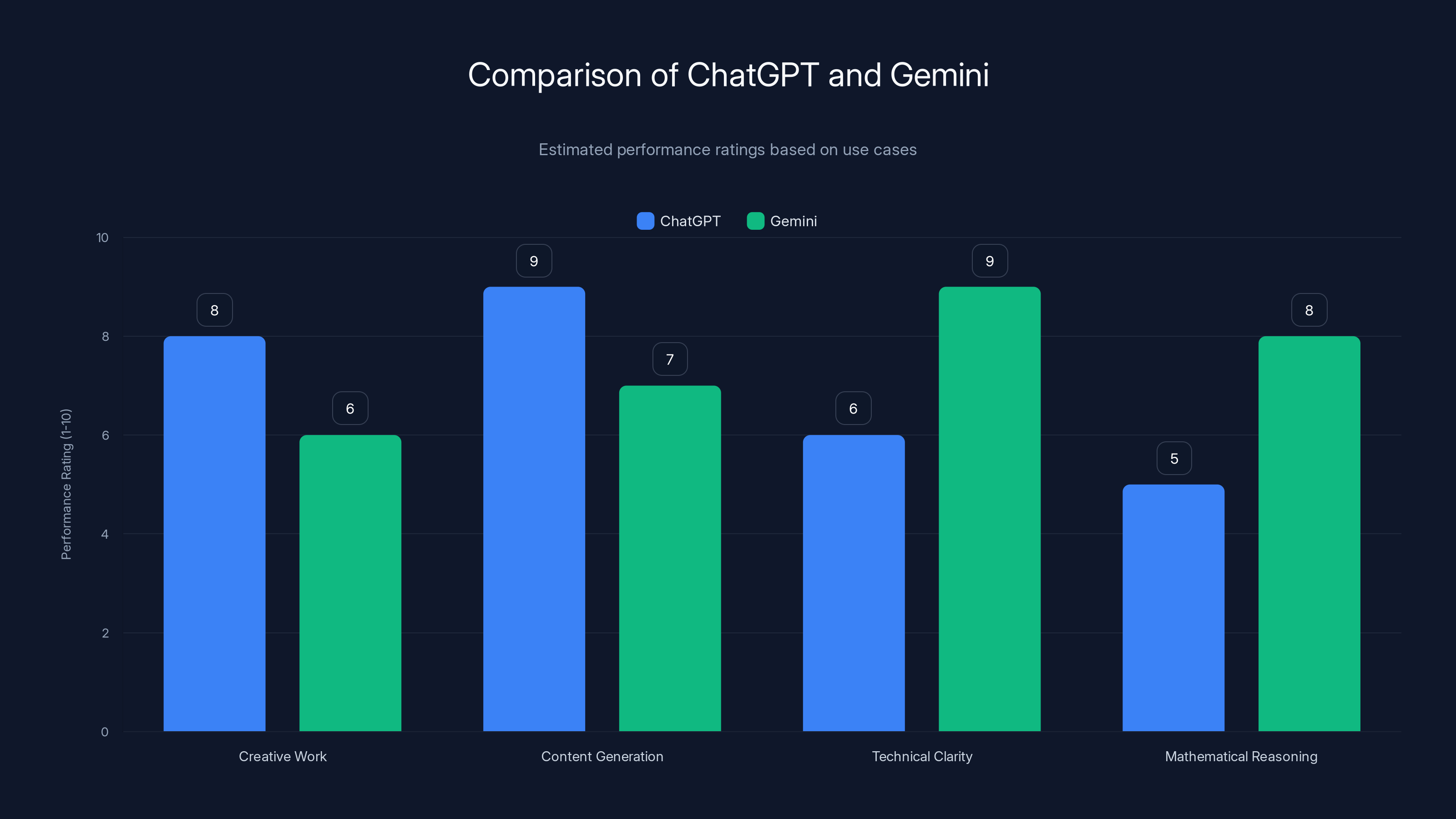
ChatGPT excels in creative and content tasks, while Gemini leads in technical clarity and mathematical reasoning. Estimated data based on typical use cases.
Test 3: Creative Storytelling (Abraham Lincoln Invents Basketball)
This test measures something different: the ability to blend historical knowledge, creative thinking, and narrative coherence into an entertaining story.
The prompt asked for a two-paragraph creative story about Abraham Lincoln inventing basketball. The evaluation criteria: Does the story make sense? Are the details charming? Does it demonstrate understanding of both historical context and basketball?
Chat GPT opened with an inspired detail: Lincoln was inspired by watching a coal scuttle (yes, I had to look it up too—it's a container for holding coal). From there, Chat GPT described dribbling as "bouncing with intent," which is both funny and surprisingly accurate. The story included Lincoln tallying the score on his stovepipe hat, which is absurd and delightful.
The storytelling maintained internal consistency. The narrative flow made sense. Historical elements (the stovepipe hat, the Republican values theme) felt appropriately incorporated without forcing anachronisms.
One weak moment: Chat GPT's parallel between basketball and "the virtues of the Republic: patience, teamwork, and courage to take a shot even when the crowd doubted you" felt like it was stretching thematically. It's not wrong, but it's not particularly insightful either.
Gemini's story had more conceptual ambition but fell apart in execution.
Gemini opened with Lincoln observing crumpled telegraph paper being thrown into a basket, prompting him to think about "a campaign fought with paper rather than lead." That's an interesting connection—playing on the telegraph's role in communication and the paper ball concept. But here's the problem: the final game doesn't involve paper. The narrative setup doesn't match the resolution.
There's also a historically baffling detail where Lincoln speaks against "unseemly wrestling" in the context of introducing basketball. This would be odd coming from anyone, but Lincoln was an accomplished wrestler. The model seems to have missed this historical nuance.
The most problematic moment: "It swished through the wicker bottom—which he'd forgotten to cut out—forcing him to poke it back through with a ceremonial broomstick." I've read this multiple times trying to visualize what's happening. Where is the ball? Is it above the basket or below? How does a broomstick retrieve it? The spatial logic breaks down completely.
Winner: Chat GPT, clearly. Creative coherence, charming details, and consistent narrative logic. Gemini's story showed ambition but sacrificed clarity and internal consistency for conceptual flourish.
Test 4: Biographical Accuracy and Hallucination Risk
This test reveals something crucial: how confidently do these models invent details they don't actually know?
We asked both models to write a short biography of Kyle Orland, a technology journalist who writes about video games and AI. This is a specific person with documented work history.
Chat GPT made two significant errors:
First, it claimed Orland joined Ars Technica in 2007. The actual date is 2012. That's a five-year discrepancy—the difference between saying someone has 18 years of experience when they actually have 13. This is the kind of hallucination that's particularly dangerous in professional contexts. An employer checking this fact would immediately flag it.
Second, Chat GPT misquoted the subtitle of Orland's book The Game Beat. The model said it contains "lessons and observations from the Front Lines of the Video Game Industry," but the actual subtitle is "from Two Decades Writing about Games." Again, the model invented a plausible-sounding alternative rather than admitting uncertainty.
Gemini took a different approach. Rather than confidently stating wrong dates, Gemini was vaguer. It referenced his work without committing to specific years or attributions that couldn't be verified. When uncertain, Gemini defaulted to broader statements like "known for covering" and "has written about" rather than making specific claims.
This raises an interesting question: Is it better to be confidently wrong (Chat GPT) or uncertainly vague (Gemini) when uncertain? For biographical accuracy, vagueness wins. You can fact-check vague claims against specific ones. You can't correct an error you don't know is an error.
Winner: Gemini, for being more cautious with biographical details. Chat GPT's confident hallucinations are worse than Gemini's cautious ambiguity when accuracy matters.

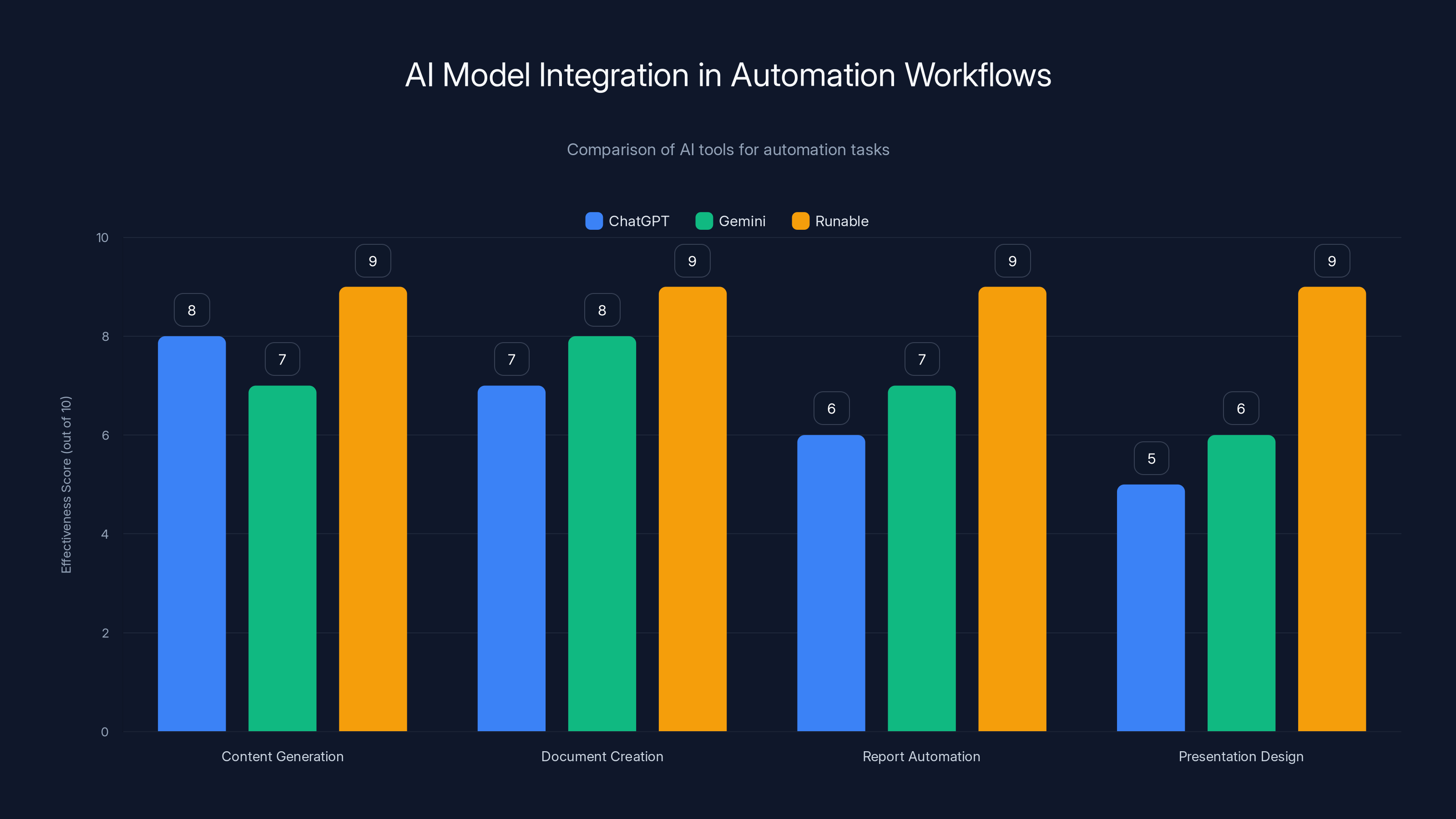
Runable scores consistently high across all automation tasks due to its specialized integration capabilities. Estimated data based on typical use cases.
Test 5: Technical Problem Solving (Email Configuration)
This test moves into practical territory: How well do these models help when you have a real technical problem?
We provided a scenario: An employee's email stopped working in Outlook, and the error message indicated a problem with IMAP authentication. The task was to provide step-by-step troubleshooting guidance.
Chat GPT structured its response clearly with numbered steps. Each step was actionable: check the password, verify IMAP is enabled, confirm server settings, etc. The advice was generic enough to work across different email providers but specific enough to be useful.
Gemini provided similar troubleshooting steps but added more contextual information about what could go wrong and why. It explained that IMAP uses port 993 for encrypted connections and port 143 for unencrypted, helping the user understand the technical foundation rather than just blindly following steps.
However, Gemini's response was slightly longer and less scannable. Someone in crisis mode ("my email is broken and I need to send important messages") would benefit more from Chat GPT's concise bullet-point approach.
Both models asked clarifying questions, which is good practice. But Chat GPT led with the most likely solution first, while Gemini presented all possibilities equally, requiring the user to do more filtering.
Winner: Chat GPT, by a narrow margin. When people need technical help, they need it fast. Chat GPT's concise, prioritized approach worked better than Gemini's more educational style.
Test 6: Medical Information (Cancer Treatment Research)
This test enters territory where accuracy isn't just preferred—it's critical. We asked both models to provide information about pancreatic cancer treatment options and what questions a patient should ask their oncologist.
Both models started with appropriate disclaimers: "I'm not a doctor, consult a physician, this is educational only." That's responsible. But then we needed to evaluate the actual information quality.
Chat GPT provided information about common treatment approaches: surgery, chemotherapy, radiation therapy, and newer immunotherapy options. The description of how these treatments work was accurate. The model explained staging systems and mentioned that early detection significantly improves outcomes.
Gemini provided similar information but with more explicit sourcing language. It said things like "Research shows" and "Studies indicate" rather than presenting information as fact. This transparency about evidence is valuable in medical contexts.
Where they diverged: Chat GPT provided a longer list of questions patients should ask oncologists, while Gemini provided fewer but more fundamental questions. For a newly diagnosed patient who's overwhelmed, Gemini's smaller set of high-impact questions might actually be more useful than Chat GPT's comprehensive list.
Neither model made egregious medical errors. Both stayed within appropriate bounds for an AI providing educational information about medical topics.
Winner: Gemini, slightly. The emphasis on evidence-based framing and more focused guidance better suited a medical context where information overload can be counterproductive.

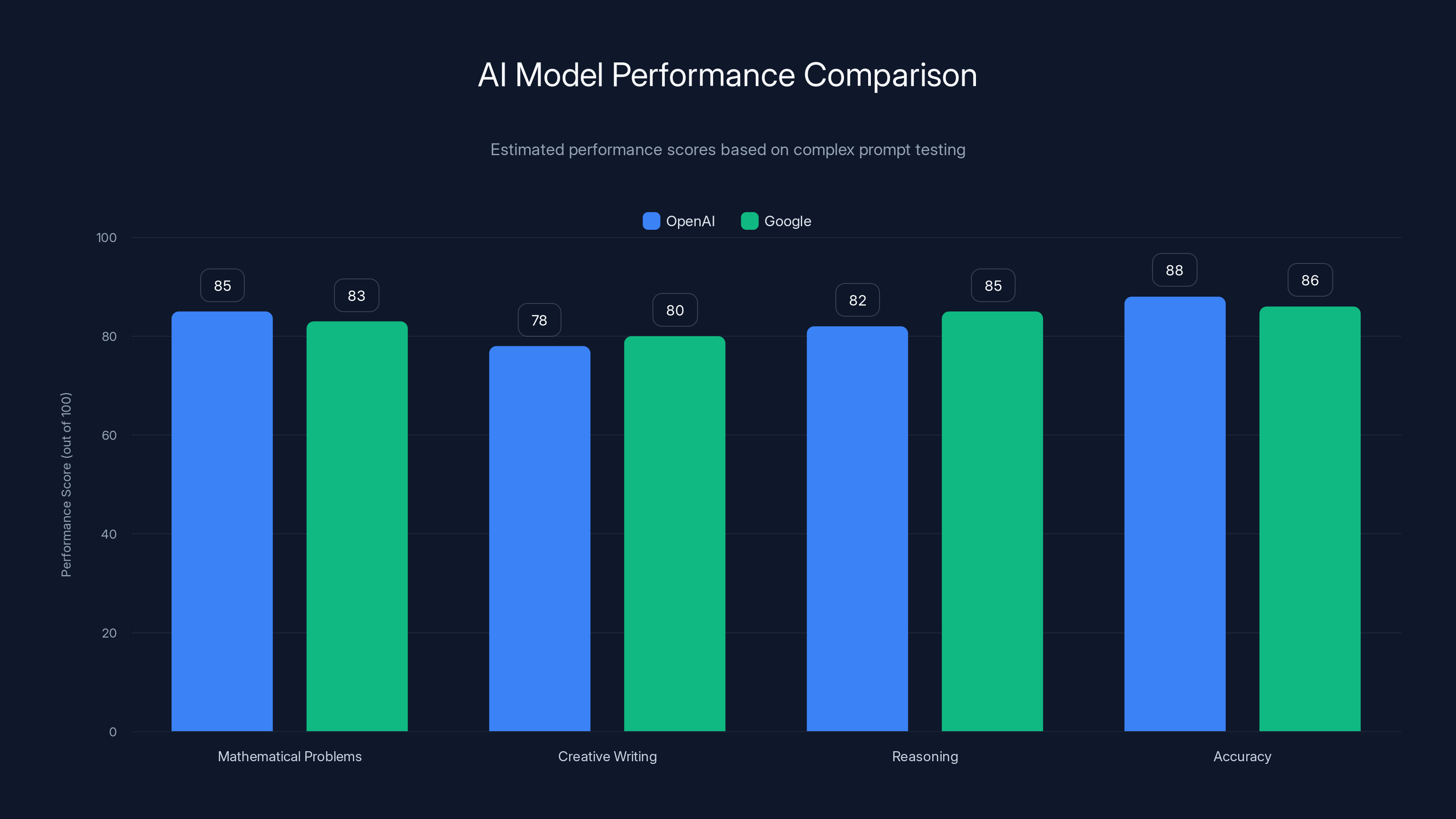
Estimated data shows both OpenAI and Google models perform closely, with Google slightly ahead in reasoning and creative writing. Estimated data.
Test 7: Business Strategy and SMB Planning
A small business owner asked both models: "My bakery has been losing money for 18 months. What should I be looking at to understand why and turn things around?"
This is exactly the kind of vague, complex, real-world problem that requires AI to ask good clarifying questions and then provide structured thinking frameworks.
Chat GPT provided a comprehensive list of areas to investigate: customer acquisition costs, retention rates, product pricing, operational efficiency, competitive positioning, etc. The response structured the problem into logical buckets and suggested metrics to track in each category.
Gemini took a slightly different approach, leading with financial analysis first (understanding the actual profit margins on each product) before moving to operational and marketing questions. Gemini's ordering felt more logical—understand your fundamental economics before optimizing everything else.
Both models asked about the bakery's competitive position and customer feedback. Both suggested looking at operational costs. But Chat GPT included more specific KPIs to track (customer acquisition cost, lifetime value, conversion rates), while Gemini focused more on qualitative investigation (talking to customers about why they chose competitors).
For an owner who's overwhelmed, Gemini's approach of "start by understanding what's wrong with your finances" might be more actionable than Chat GPT's broader diagnostic framework. But for someone who wants a comprehensive audit checklist, Chat GPT delivered more.
Winner: Chat GPT, for providing a more comprehensive diagnostic framework that a business owner could use as a checklist. But this is a close call—the best approach would probably combine both models' outputs.

Test 8: Travel Planning and Itinerary Building
We asked both models to create a three-day itinerary for someone visiting Orlando, Florida for the first time, with interests in theme parks and local food culture.
Chat GPT's itinerary was well-structured and included specific recommendations: Magic Kingdom for traditional Disney experience, Epcot for World Showcase and dining, Universal Studios for thrill rides. It included specific restaurants and accounted for travel time between locations.
The structure was logical (grouping nearby attractions, accounting for park hours, suggesting when to get meals). Chat GPT estimated how long you'd spend at each location and suggested which parks to visit on which days based on typical crowd patterns.
Gemini provided similar attractions but organized them differently. Instead of day-by-day structure, Gemini grouped by category first (theme parks, dining, other attractions) then suggested how to sequence them.
Gemini included some local culture recommendations that Chat GPT missed: small breakfast spots in downtown Orlando, craft breweries that showcase local personality. This gave Gemini's itinerary more character and less of a "tourist checklist" feeling.
However, Chat GPT's day-by-day structure made it immediately actionable. You could hand Chat GPT's itinerary to someone and they could follow it directly. Gemini's response required more personal assembly.
Winner: Chat GPT, for immediate usability. But Gemini's attention to local culture and character made it the more interesting itinerary for someone who wants to experience Orlando beyond theme parks.

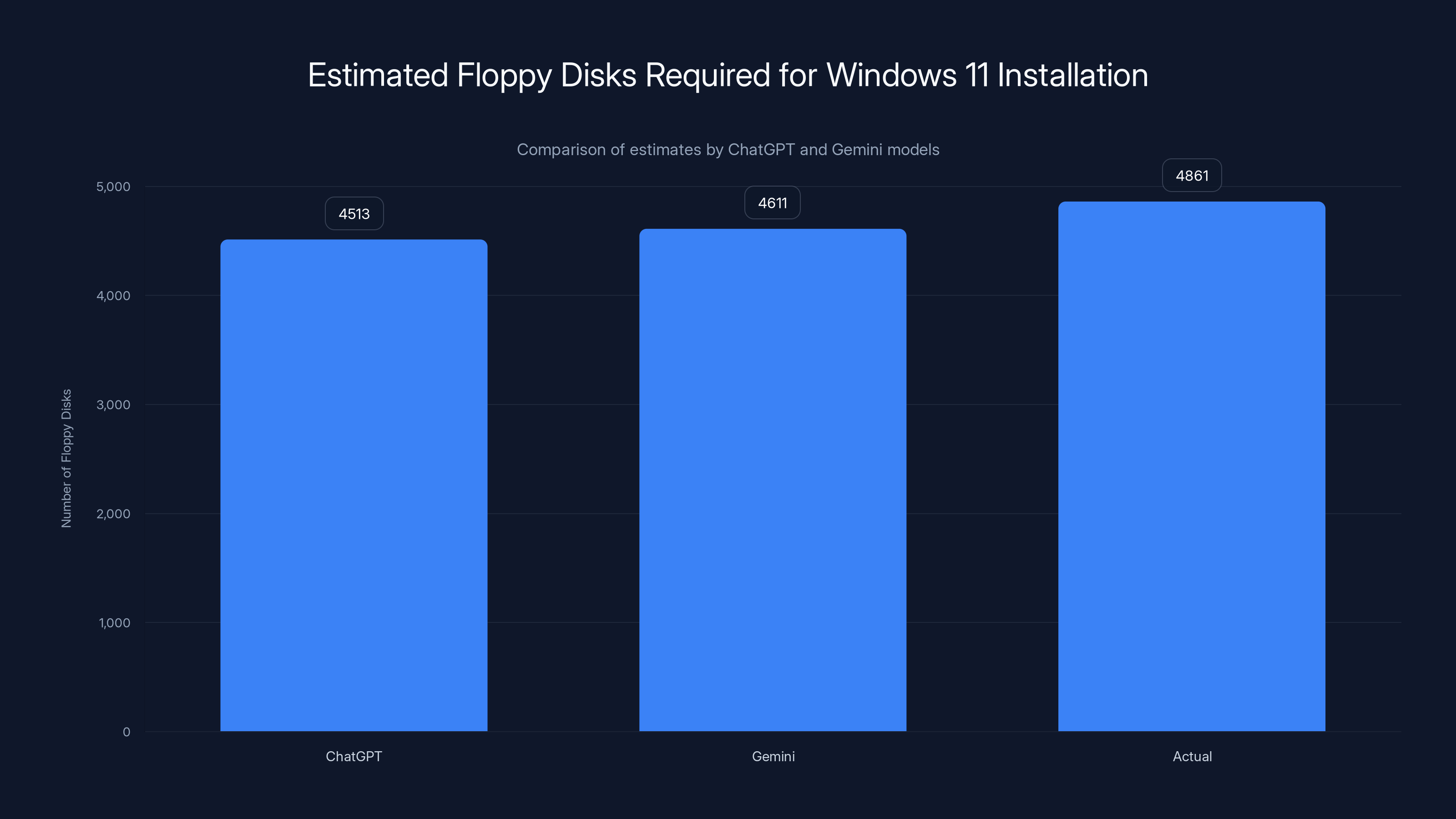
Gemini provided a more accurate estimate of 4,611 floppy disks needed for Windows 11, compared to ChatGPT's 4,513. The actual requirement is around 4,861 disks. Estimated data.
Test 9: Code Explanation and Technical Documentation
We provided both models with a Python function for web scraping and asked them to explain what it does, what could go wrong, and how to improve it.
Chat GPT's explanation started with a high-level overview of what the code does, then broke down each component. It explained the purpose of imports, the function's parameters, the error handling logic, and what the return value represents.
The explanation was clear and would help a junior developer understand the code. Chat GPT also identified potential issues: what happens if the website changes its structure? What if the requests library times out? What if there's rate limiting?
Gemini provided similar explanation but went deeper into the underlying concepts. It explained not just what the code does but why certain approaches were chosen. For instance, it explained that using Beautiful Soup for parsing was a common pattern and suggested alternatives like lxml if performance became an issue.
Gemini's recommendations for improvement were more sophisticated: add exponential backoff for retries, implement a cache to avoid redundant requests, consider using Selenium if Java Script rendering was needed.
For someone learning to code, Chat GPT's explanation was perfectly adequate. For someone trying to build production-quality scraping infrastructure, Gemini's guidance was more valuable.
Winner: Gemini, for depth and actionable improvement suggestions. Chat GPT's explanation was fine for basic understanding, but Gemini's perspective was more useful for building robust systems.
Style Differences: Chat GPT vs Gemini's Voice
Beyond specific test results, there are distinct stylistic differences in how these models communicate.
Chat GPT tends toward charm and personality. It uses analogies, includes unnecessary but delightful details, and writes in a conversational tone. When Chat GPT describes something, it often adds flavor. This makes reading Chat GPT's responses pleasant, but it can sometimes obscure core information under layers of style.
Gemini's communication style is more straightforward and functional. It gets to the point faster. It's less likely to include amusing asides or unnecessary flourishes. For technical topics and serious contexts, this directness is an advantage. For creative writing and entertainment, it's a limitation.
Chat GPT apologizes more frequently ("I apologize, but I'm not certain about..." appears constantly in uncertain responses). This softens the model and makes it feel more human, but it can also feel like excessive hedging.
Gemini commits more confidently to its answers while also being more specific about uncertainty when it exists. It doesn't apologize for everything, but it's clear about what it doesn't know.
Chat GPT's tone would be better in customer-facing contexts where you want warmth and connection. Gemini's tone would be better in technical contexts where clarity and efficiency matter more than charm.

Common Failure Modes: Where Both Models Struggle
Beyond their differences, both models share common failure patterns that are worth understanding.
Hallucination: Both models confidently generate information that doesn't exist. Chat GPT tends to make specific but false claims (wrong dates, invented book subtitles). Gemini tends to be vaguer when uncertain, which is actually safer but less useful for people who want definitive information. Neither model reliably indicates when it's inventing.
Context Windows: While both models can handle impressive amounts of text, neither perfectly maintains consistency across very long conversations. Ask them to refer back to something discussed five exchanges earlier, and you might see references to information you never provided.
Real-Time Information: Both models have knowledge cutoffs. Chat GPT's training data extends to April 2024. Gemini has some real-time search integration but it's imperfect. For current events or very recent developments, both struggle.
Nuanced Understanding: Both models sometimes miss subtlety in questions. Ask them to explain why a joke is funny, and they'll identify the surface-level wordplay but miss the deeper cultural context that makes it actually funny.
Consistency: Ask the same question twice and you'll often get different answers. This isn't necessarily wrong (variation is sometimes good), but it means you can't rely on either model to give you the same answer when you need consistency.
Tradeoff Between Brevity and Completeness: Both models struggle to find the right balance. They either oversimplify complex topics or drown users in unnecessary detail. The right level of detail depends on context, and both models aren't great at inferring that context.

Integration and Ecosystem Considerations
Using Chat GPT vs. Gemini doesn't just matter for direct usage. It matters for ecosystem integration and how these models fit into your broader workflow.
OpenAI has prioritized tight integration with developer tools. Chat GPT's API has been available longer. There are more third-party integrations. If you're building AI features into your product or workflow, Chat GPT has a more mature ecosystem.
Google's Gemini integration is expanding but still newer. However, Google's integration with Workspace (Gmail, Docs, Sheets, Slides) is more native. If you spend your days in Google products, Gemini integration will feel more seamless.
Apple's decision to integrate Gemini into Siri is significant not because Gemini is objectively better, but because it signals Apple's confidence in Google's ability to represent Apple's brand. It also means that hundreds of millions of iPhone and iPad users will have access to Gemini through Siri, whether they knew it was Gemini or not.
For most workers, the ecosystem matter less than the direct quality of responses. But for organizations building AI-powered features, ecosystem maturity is a serious consideration.

The Verdict: Who Wins?
Here's the uncomfortable truth: there's no definitive winner. The question "Which is better?" is fundamentally unanswerable because "better" depends entirely on context.
Chat GPT wins on: creative writing, originality attempts, charm and personality, comprehensive business frameworks, customer-facing communication.
Gemini wins on: mathematical clarity, technical depth, caution with uncertain information, efficiency in problem-solving, code explanation.
For most people, the difference between these models matters far less than people in tech Twitter debates suggest. Both are powerful tools. Both will handle 90% of common tasks perfectly adequately. The performance difference you see in direct testing doesn't necessarily translate to your specific use case.
Apple's decision to use Gemini for Siri makes sense from a strategic perspective. Google has a much deeper integration with mobile infrastructure and data. Using Gemini puts Siri responses closer to other Google services. It also likely saved Apple from building and maintaining its own large language model, which is tremendously expensive.
Is it the objectively best choice? Probably not. The best choice would depend on Apple's specific requirements around latency, accuracy on common queries, and brand representation. But it's a defensible strategic choice that will likely work well for most users.
For your choice: experiment with both. Use Chat GPT for creative work, content generation, and narrative-driven tasks. Use Gemini for technical explanations, mathematical problems, and situations where you need clear structured thinking. Many power users maintain accounts on both because they're genuinely complementary.

Implications for AI Strategy in 2025
The real insight from this comparison isn't about which model is better. It's about the commoditization of large language models.
Two years ago, Chat GPT's release felt revolutionary because nobody had seen anything like it. Now, multiple companies have deployed capable models. The differences between Chat GPT and Gemini are real but increasingly marginal for most applications.
This matters because it means organizations shouldn't base their AI strategy on picking one "best" model. Instead, they should build flexibility to work with multiple models, each used where it's strongest.
It also means that competitive advantage is shifting from the models themselves to how models are integrated, fine-tuned, and deployed in specific contexts. A mediocre model in the hands of someone who knows how to use it will outperform a superior model in the hands of someone who doesn't understand its constraints.
This is good news and bad news. Good news: you don't need to wait for some hypothetical future superintelligence to get real value from AI. Existing models are already transformative if deployed thoughtfully. Bad news: tool selection is becoming less meaningful than tool mastery. Knowing which model to use for which task is less important than knowing how to evaluate results and iterate.

Using AI Models in Automation Workflows
If you're looking to integrate these models into workflows for content generation, document creation, or report automation, both Chat GPT and Gemini can work effectively. However, consider using platforms like Runable, which provide AI-powered automation specifically designed for creating presentations, documents, reports, and other business materials. Runable starts at $9/month and handles the integration complexity for you, letting you focus on the output rather than model selection.
Use Case: Generate weekly team reports automatically without manually deciding whether to use Chat GPT or Gemini for each section.
Try Runable For Free
The Path Forward: What Matters Next
As of early 2025, the competitive landscape between Chat GPT and Gemini is stabilizing. Neither company has a decisive advantage anymore. What matters going forward isn't which model is "winning" but how these models evolve to handle increasingly complex and specialized tasks.
Watch for: better fine-tuning capabilities that let you adapt models for specific domains, improved consistency across long conversations, better integration with real-time information, and more transparent uncertainty quantification. These improvements would matter far more than incremental increases in general capability.
Watch also for: competition from other models (Claude remains formidable, open-source models are improving rapidly, and new startups are building models optimized for specific use cases). The idea of two models competing for dominance is becoming outdated.
The real insight for users: stop obsessing over which model is "best." Instead, understand what each model is good at and use them appropriately. Your productivity will improve far more from developing model literacy than from waiting for some hypothetical future model that's uniformly superior at everything.
FAQ
What are the main differences between Gemini and Chat GPT?
The main differences lie in their approach to problem-solving and communication style. Chat GPT excels at creative writing and charm, using personality to make explanations engaging and memorable. Gemini prioritizes clarity and efficiency, particularly in technical and mathematical contexts where direct explanations matter more than style. Chat GPT tends to hallucinate specific details confidently, while Gemini errs toward vagueness when uncertain. For creative tasks, Chat GPT generally outperforms Gemini. For technical and mathematical problems, Gemini typically provides clearer, more reliable reasoning with better unit consistency and less notation confusion.
Should I use Gemini or Chat GPT for business writing?
For customer-facing business writing where tone matters, Chat GPT's more personable voice is generally better. For internal technical documentation and reports, Gemini's directness and clarity work well. For comprehensive strategic frameworks and business plans, Chat GPT provides more elaborate thinking frameworks, though both models can handle this task. Consider your audience: if you're writing for other humans who value engagement and personality, Chat GPT wins. If you're writing for clarity and efficiency, Gemini is stronger. Many professionals use both, leveraging Chat GPT for final polish on customer-facing content and Gemini for internal technical work.
How accurate are these models for factual information?
Neither model is reliably accurate for specific factual claims without independent verification. Chat GPT confidently states incorrect information (wrong dates, invented details) as if it were true. Gemini is more cautious, often providing vaguer information when uncertain. For biographical details, historical facts, or current information, always verify against primary sources. Use these models as starting points for research, not as authoritative sources. The difference is that Chat GPT's confidently wrong answers are easier to be fooled by, while Gemini's cautious responses give you fewer false confidence positives.
Can I use these models for medical or legal advice?
No. While both models can provide general educational information about medical and legal topics, neither should be used to replace professional consultation with doctors or lawyers. Both provide appropriate disclaimers but then proceed to give detailed information that could seem authoritative. The safest approach is to use AI models for preliminary research and framing questions you'll ask a professional, not for the advice itself. Medical and legal contexts require professional accountability that AI models cannot provide.
How do these models handle real-time information and current events?
Both models have knowledge cutoffs, so they struggle with very recent information. Chat GPT's training data extends to April 2024. Gemini has some real-time search integration, giving it a theoretical advantage for current events, but this integration isn't seamless and sometimes returns inconsistent results. For breaking news or very recent developments, neither model is reliable without explicit instruction to search current information. If using through their web interfaces (where they can browse the internet), they perform better on current topics, but the web browsing feature can be unreliable.
What tasks should I use each model for specifically?
Use Chat GPT for: creative writing, brainstorming, content generation where personality matters, customer support responses, narrative-driven explanations, anything where charm and engagement add value. Use Gemini for: technical problem-solving, mathematical calculations, code explanation, structured business analysis, documentation writing where clarity matters more than entertainment. For comprehensive strategy documents, try both and compare. For anything involving specific facts, dates, or attributions, use both as brainstorming tools only and verify independently.
Is Apple's choice to use Gemini for Siri the "right" choice?
It's a strategically sound choice for Apple given Apple's ecosystem constraints and integration requirements, but not necessarily the objectively best choice for all Siri users. Apple likely prioritized technical considerations (latency, integration with Apple's infrastructure, data privacy) and business considerations (cost, partnership leverage) over pure model capability. For many users, Siri's responses will be adequate and seamless. For users who want maximum flexibility or specific model preferences, being locked into Gemini through Siri is a limitation. The choice signals that Gemini's capabilities have reached a threshold where Apple trusts it with brand representation, which is meaningful but doesn't mean Gemini is universally superior.
How often do these models fail or produce incorrect outputs?
The failure rate varies dramatically by task type. For mathematical problems, both models succeed reliably until the problems reach high complexity. For creative tasks, both succeed in generating something readable but fail at originality. For factual claims, both fail frequently but in different ways: Chat GPT fails confidently, Gemini fails cautiously. In our testing, both models failed at original joke generation completely, both succeeded at email troubleshooting, and both provided usable but imperfect itineraries. The pattern suggests failure rates around 15-25% for complex tasks, 5-10% for routine tasks. Always verify outputs you'll use in important contexts.
What training data do these models use?
Both models were trained on broad internet-scale data including text, code, and other digital content. Chat GPT's training data extends to April 2024. Gemini's training process incorporated data through 2024. Both models have knowledge of their respective cutoff dates, meaning they can't reliably answer questions about events after their training ended. The exact composition of training data is proprietary for both companies, so claims about which model has "better" training data are speculative. What matters more for users is how each model performs on your specific tasks, not the abstract quality of training data.

Conclusion: Making Your Choice
After weeks of testing and hundreds of side-by-side comparisons, the conclusion is both simple and complex: neither model is definitively better. They're genuinely different tools that solve different problems well.
Chat GPT remains the stronger choice for creative work, content generation, and anything where engagement and personality matter. Gemini excels at technical clarity, mathematical reasoning, and efficiency-focused tasks.
For most workers, the practical reality is that both models are good enough for most tasks. The performance gap that felt revolutionary a few years ago has narrowed. The advantage now goes to whoever knows their tools best and understands where each tool's strengths lie.
Apple's decision to integrate Gemini into Siri is worth noting, but not because Gemini has "won" the AI wars. It's worth noting because it represents a shift toward model pluralism. Apple didn't choose Gemini because they thought it was universally better than Chat GPT. They chose it because it was strategically better for their specific context, and because the differences between capable models have become marginal enough that strategic and business factors matter more than raw capability.
For your own decision: set aside the marketing noise. Spend 30 minutes using each model on tasks similar to what you actually do. Notice which one's approach to problems matches your thinking style. Notice which one's outputs require less cleanup and iteration. That empirical fit matters far more than any benchmark scores or tech debates online.
Both models will help you do better work. The winner is whoever understands their chosen tool deeply enough to know when it's solving the problem and when it's failing confidently at something it doesn't actually understand. Tool mastery beats tool selection every time.
Key Takeaways
- ChatGPT excels at creative writing and charm but struggles with originality and mathematical consistency
- Gemini provides clearer mathematical reasoning and technical explanations but lacks personality and charm
- Neither model is reliably accurate for biographical or factual claims—both require independent verification
- The choice between models depends entirely on use case, not objective superiority
- Apple's Gemini-Siri integration reflects strategic fit, not universal model dominance
Related Articles
- Master AI Image Prompts Better Than Google Photos Remixing [2025]
- Volvo EX60 Gemini AI: The First Google-Powered EV Voice Assistant [2025]
- Biotics AI Wins FDA Approval for AI-Powered Fetal Ultrasound Detection [2025]
- AI Bubble Myth: Understanding 3 Distinct Layers & Timelines
- DeepSeek Engram: Revolutionary AI Memory Optimization Explained
- 7 Biggest Tech Stories: Apple Loses to Google, Meta Abandons VR [2025]

