
Deep Seek Engram: Revolutionary AI Memory Optimization Explained
Introduction: The AI Memory Crisis and Deep Seek's Solution
The artificial intelligence industry faces an unprecedented challenge: the explosive growth of large language models has created a bottleneck in high-bandwidth memory (HBM) infrastructure. When Deep Seek researchers presented their findings in early 2025, they exposed a critical insight that had been largely overlooked by the broader AI community. While computational power continues to advance rapidly, the memory requirements for training and inference had become the actual constraint limiting model capability and accessibility.
This challenge isn't merely theoretical. In the span of just ten weeks, DRAM prices surged by 500%, driven by unprecedented demand from cloud service providers, research institutions, and technology companies racing to build larger AI systems. The memory bottleneck had become so severe that it threatened to slow innovation and make advanced AI systems economically inaccessible to organizations without massive capital resources.
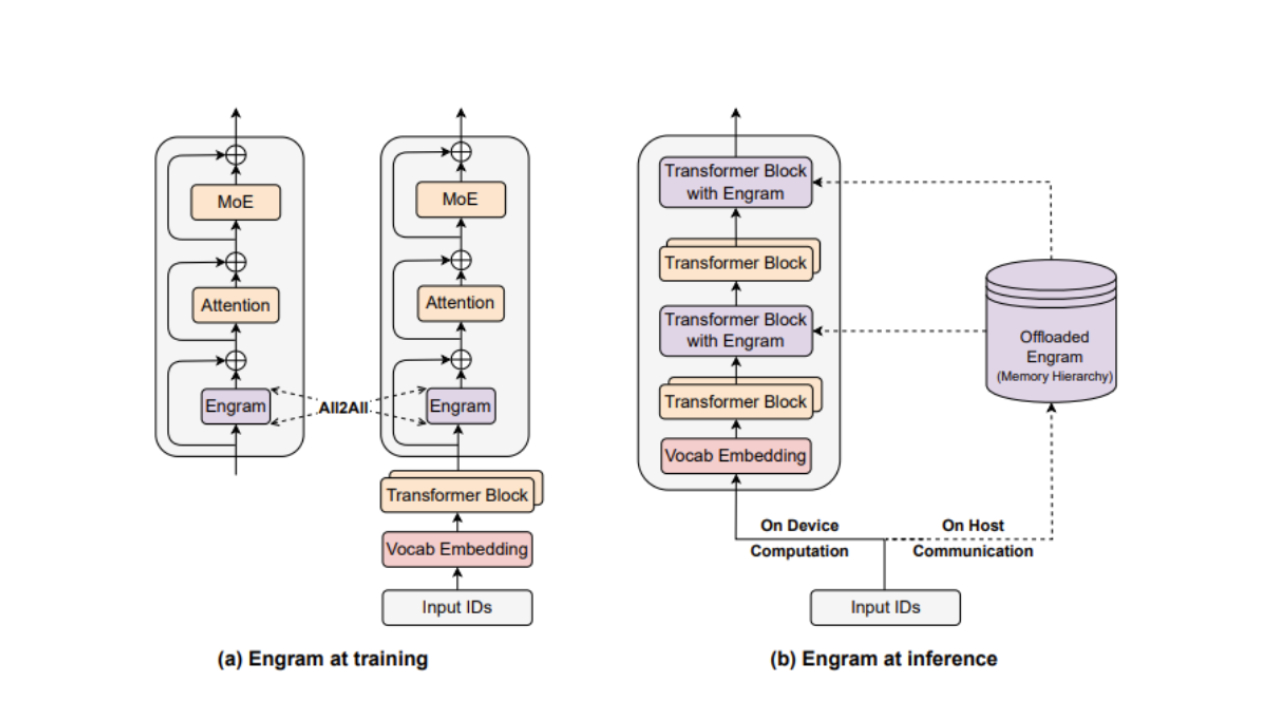
Deep Seek, in collaboration with researchers from Peking University, introduced Engram—a sophisticated training methodology that fundamentally decouples memory storage from computational processes. Rather than treating memory and computation as inseparable functions (as traditional architectures do), Engram separates static knowledge storage from dynamic reasoning tasks. This architectural innovation isn't merely an optimization; it represents a paradigm shift in how we approach large language model design.
The implications are profound. By enabling models to efficiently retrieve essential information without consuming vast quantities of GPU memory, Engram frees computational resources for higher-level reasoning tasks. Testing on a 27-billion-parameter model demonstrated measurable improvements across industry-standard benchmarks, with researchers finding that reallocating 20-25% of the sparse parameter budget toward Engram-based memory modules yielded superior performance compared to pure Mixture-of-Experts (Mo E) models.
What makes Engram particularly significant is its timing and accessibility. The technique works with existing GPU and system memory architectures, potentially eliminating the need for costly HBM upgrades. For organizations in regions like China where high-bandwidth memory access remains constrained compared to competitors like Samsung, SK Hynix, and Micron, Engram offers a technological path forward that doesn't depend on hardware availability.
This comprehensive guide explores the technical foundations of Engram, its implementation mechanisms, performance implications, and broader impact on the AI infrastructure landscape. Whether you're an AI researcher, infrastructure engineer, or technology strategist, understanding Engram is essential for comprehending the next generation of AI system design.
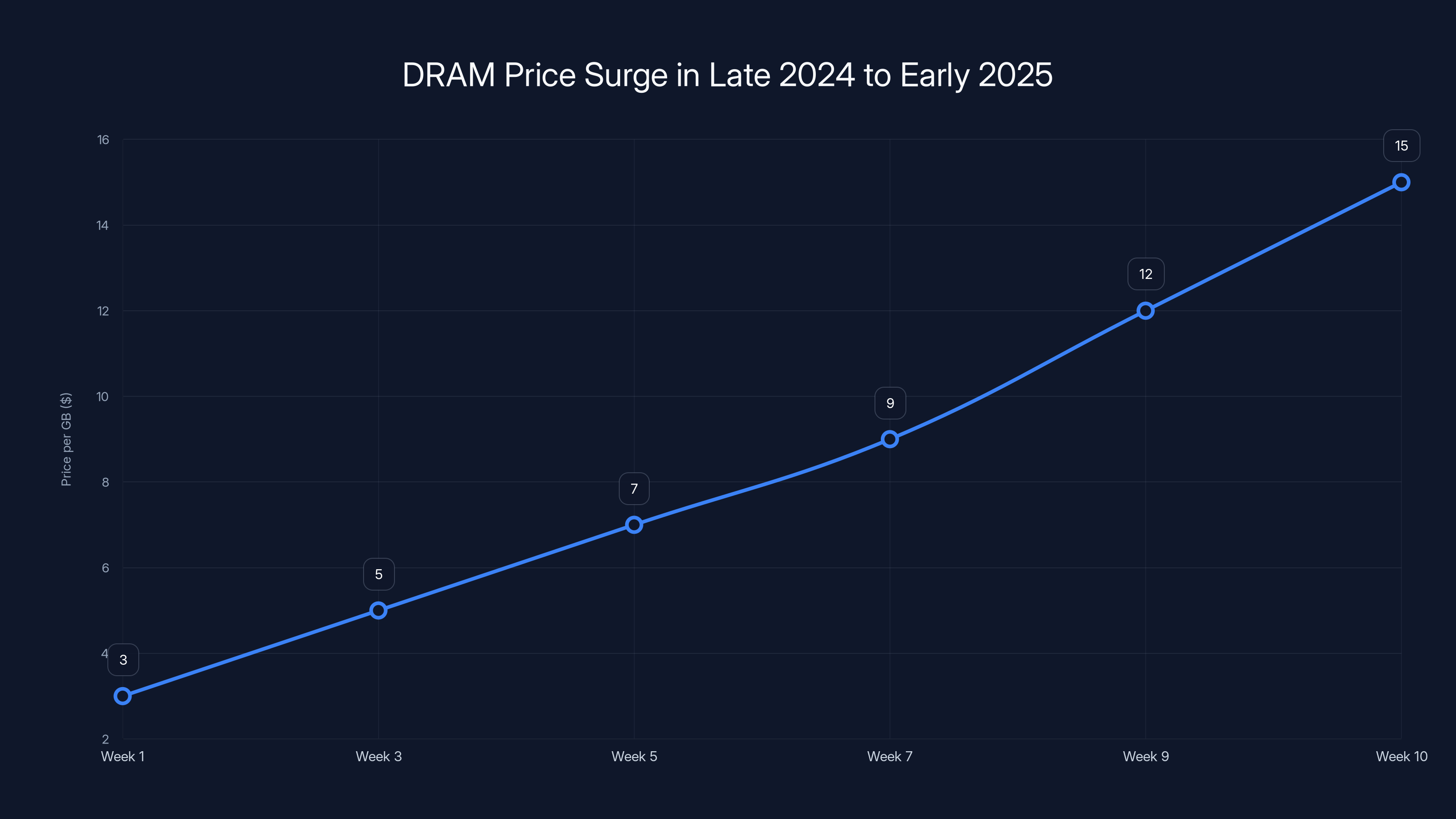
DRAM prices increased by approximately 500% over 10 weeks, highlighting severe memory shortages in late 2024 to early 2025. Estimated data.
Understanding the Traditional AI Memory Bottleneck
Why GPU Memory Became the Limiting Factor
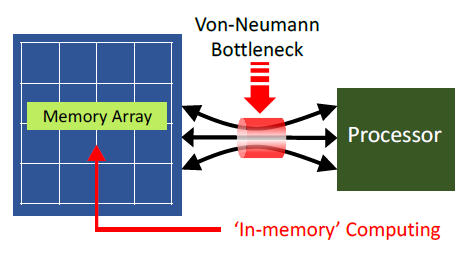
Traditional large language model architectures treat every operation identically from a memory perspective. Whether the model is performing a simple lookup of a previously known fact or executing complex multi-step reasoning, both operations require the same high-bandwidth memory access patterns. This one-size-fits-all approach creates catastrophic inefficiency when you consider that knowledge retrieval—looking up information—represents a significant portion of model operations.
In conventional Transformer architectures, the attention mechanism must hold vast quantities of data in high-bandwidth memory to function effectively. When processing longer context windows or larger batch sizes, this memory requirement grows exponentially. The
GPUs like NVIDIA's H100 include substantial HBM capacity (80GB per chip), yet even this isn't sufficient for the largest models. Research teams pushing model boundaries found themselves constrained not by computational throughput but by memory bandwidth. A GPU could theoretically perform millions of operations per second, yet the data movement bottleneck prevented reaching that computational ceiling.
The DRAM Price Crisis: Quantifying the Problem
The severity of the memory shortage became undeniable through price movements in commodity DRAM markets. Within a 10-week period spanning late 2024 into early 2025, DRAM spot prices increased by approximately 500%. This wasn't a gradual market shift reflecting normal supply-demand dynamics; it represented panic buying by major cloud infrastructure providers desperate to secure memory for AI acceleration projects.
Data center DDR5 DRAM modules that traded at approximately
This crisis had cascading economic consequences. Cloud service providers building AI infrastructure absorbed massive costs, which eventually flowed to customers through higher API pricing. Startups building on cloud platforms faced reduced margins or unsustainable operational expenses. The memory bottleneck threatened to concentrate AI capability in only the largest, most well-capitalized organizations.
Sequential Depth Waste in Current Models
Deep Seek researchers made a crucial observation: contemporary large language models waste significant sequential depth on trivial operations. Sequential depth refers to the number of sequential steps (layers) a model requires to process information. Some operations—particularly knowledge retrieval—don't actually require deep sequential processing.
Consider a simple example: when a language model needs to recall that "Paris is the capital of France," does it require 27 billion parameters and dozens of transformer layers to retrieve this fact? Current architectures force this retrieval through the standard computational pipeline, consuming memory and compute cycles on operations that could be handled far more efficiently through specialized retrieval mechanisms.
Researchers quantified this waste. By analyzing attention patterns and gradient flows across model layers, they found that 20-30% of sequential depth could be freed without impacting model capability if retrieval operations were handled differently. This insight became the conceptual foundation for Engram.
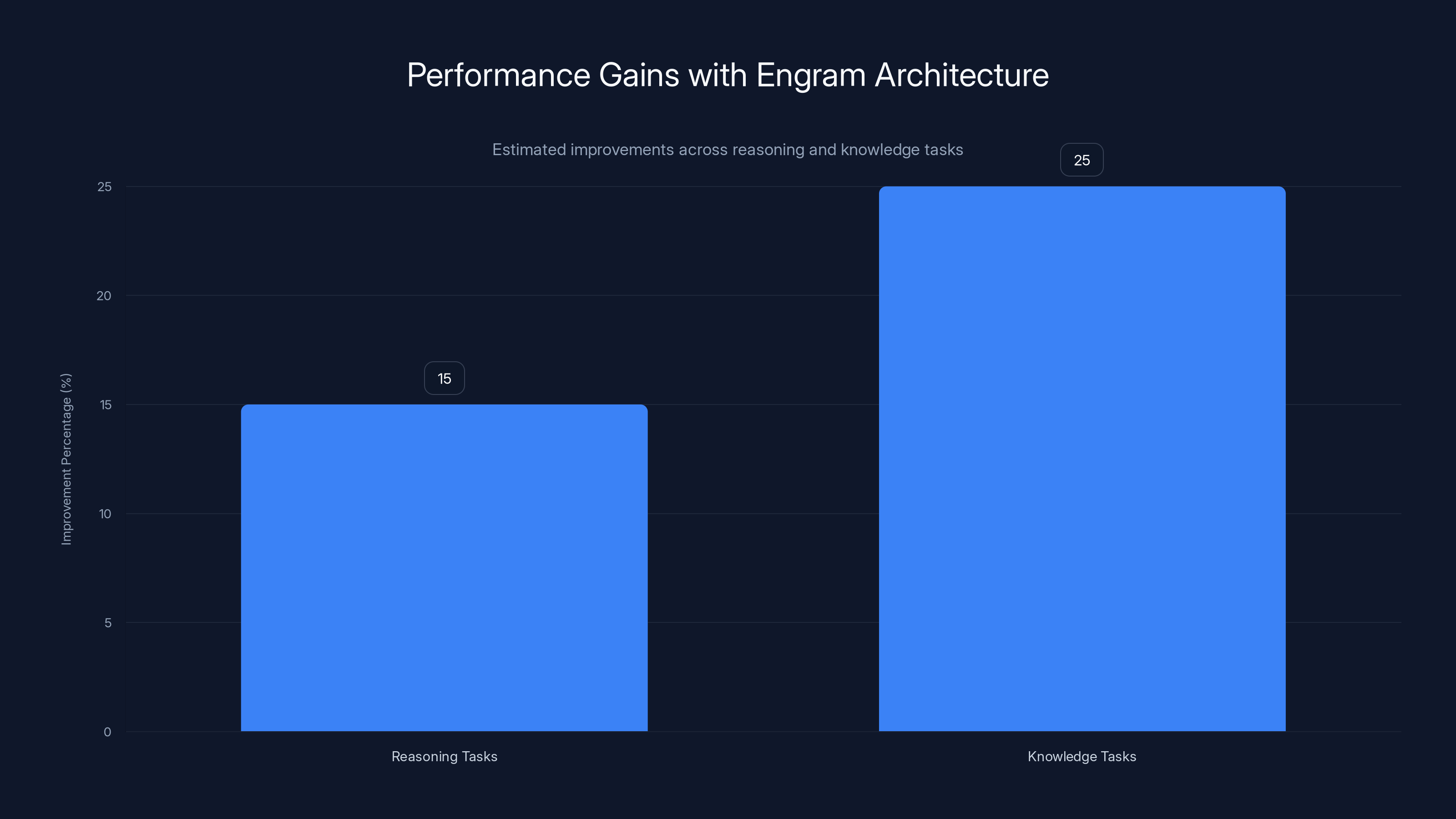
Models with Engram architecture showed a 15% improvement in reasoning tasks and a 25% improvement in knowledge tasks, indicating significant gains in performance. Estimated data.
The Technical Architecture of Engram
Core Innovation: Separating Static Storage from Dynamic Computation
Engram's fundamental insight is elegantly simple: different types of information require different processing approaches. Static information—facts, knowledge, patterns that don't change based on current context—should be stored and retrieved using fundamentally different mechanisms than dynamic information requiring real-time reasoning.
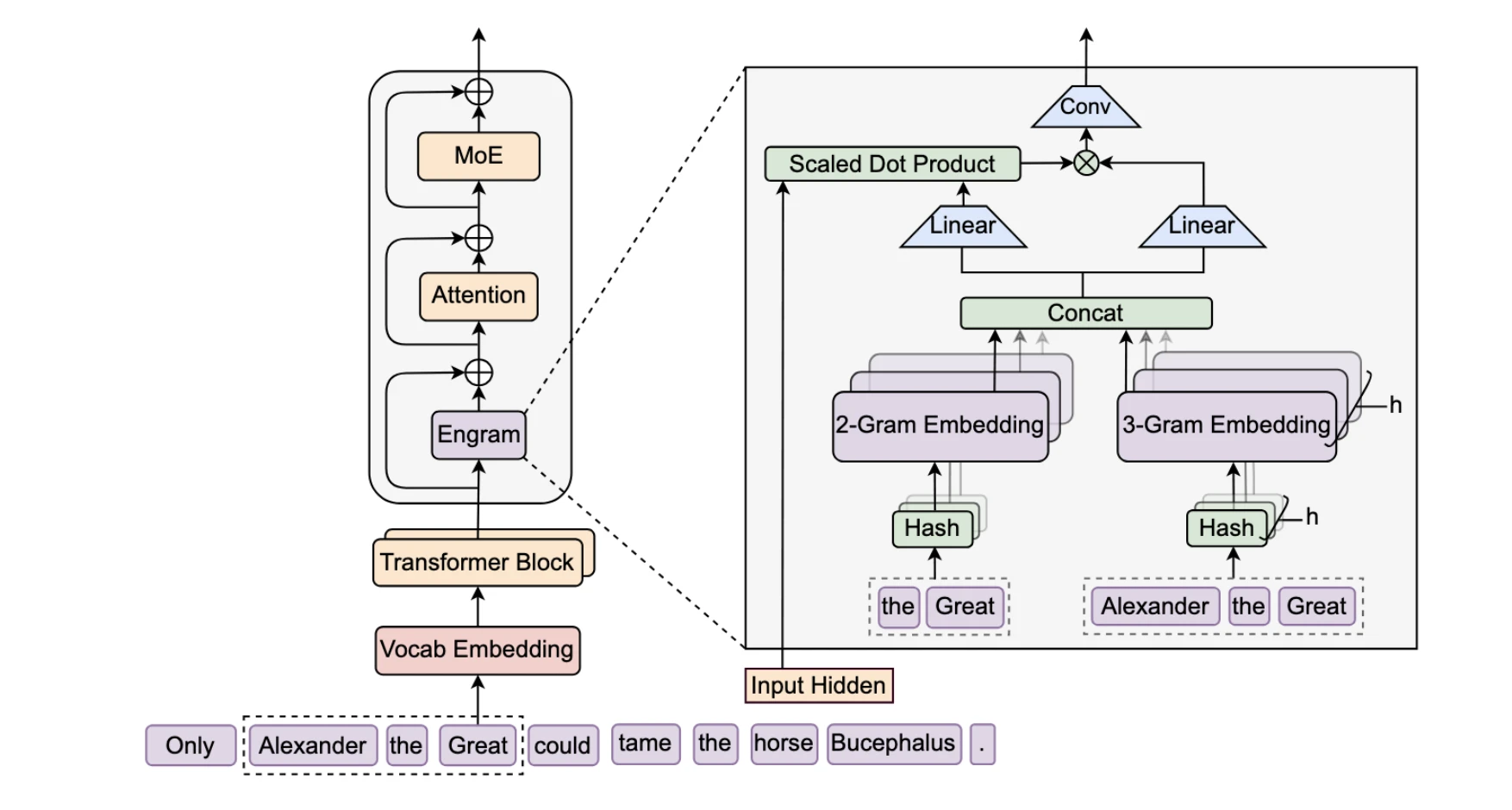
The architecture introduces a dedicated memory module that operates alongside the traditional Transformer backbone. This module uses hashed n-gram retrieval to store and access static patterns. Rather than requiring these patterns to be learned through gradient-based parameter updates in the dense transformer layers, Engram explicitly stores them in a separate, optimized structure.
When the model encounters a token sequence matching a known pattern, the Engram module performs a deterministic lookup. This lookup operation doesn't consume GPU memory in the traditional sense; instead, it accesses information from a separate storage layer optimized for pattern matching rather than dense computation.
The retrieved information is then adjusted through a context-aware gating mechanism that aligns the static knowledge with the model's current hidden state. This gating mechanism ensures that retrieved information integrates properly with dynamic contextual reasoning. A simple example illustrates this: when retrieving the fact that "Paris is the capital of France," the gating mechanism adjusts this information based on whether the current context is discussing European geography, historical empires, or modern tourism.
Hashed N-Gram Retrieval Mechanism
The retrieval mechanism deserves detailed technical explanation. Engram converts token sequences into hashed n-grams—fixed-size numerical representations of token patterns of various lengths (bigrams, trigrams, etc.). These hashes serve as keys in a lookup table where values contain pattern embeddings.
The hash function is designed to be collision-resistant while remaining computationally efficient. During training, whenever the model encounters valuable static patterns, they're registered in the n-gram lookup table with their associated embeddings. This happens automatically through a separate training signal that identifies which information should be stored as static patterns versus learned through dense parameters.
The retrieval process is deterministic and stateless: identical input sequences always produce identical outputs. This property is crucial for model reproducibility and serves as a foundation for caching strategies.
What makes this approach elegant is its computational efficiency. Looking up information in a hash table requires logarithmic time complexity, not quadratic like standard attention mechanisms. For sequences matching stored patterns, retrieval becomes dramatically faster than computing attention weights across all previous tokens.
Context-Aware Gating and Integration
Retrieved information must integrate seamlessly with ongoing computation. Engram implements this integration through a learned gating mechanism that controls how much retrieved information influences the current computation versus how much the model should rely on its learned dense parameters.
Mathematically, the gating mechanism computes a gate value
where
where
This architecture elegantly handles situations where static knowledge might not fully apply. If current context suggests that retrieved information should be treated skeptically (perhaps we're discussing fictional scenarios), the gate learns to downweight the retrieved signal. If the context strongly suggests that static knowledge applies directly, the gate learns to weight retrieved information heavily.
Performance Improvements and Empirical Results
Benchmark Performance Across Standard Metrics
Deep Seek researchers validated Engram through extensive empirical testing on a 27-billion-parameter model—a size representative of serious production systems. Performance was evaluated across multiple industry-standard benchmarks that measure different aspects of language model capability.
Results demonstrated consistent improvements across diverse task categories. On reasoning benchmarks that evaluate logical inference and complex problem-solving, models incorporating Engram showed statistically significant performance gains. On knowledge-intensive tasks requiring accurate retrieval of factual information, the improvements were even more pronounced.
The magnitude of improvements—while not revolutionary—was substantial enough to suggest that Engram represents a genuine architectural advance rather than a minor optimization. Researchers observed that a model with Engram-enhanced architecture achieved performance equivalent to larger dense models, despite using fewer actual parameters for dense computation.
Parameter Reallocation Strategy: The U-Shaped Rule
Deep Seek formalized an interesting strategic principle for allocating parameters between traditional Mo E (Mixture of Experts) modules and Engram memory modules. They discovered that optimal performance comes from distributing the parameter budget across both dimensions rather than maximizing either alone.
Their "U-shaped expansion rule" describes how to allocate additional parameters when scaling models. Rather than investing all parameter budget in traditional Mo E computation, optimal results came from allocating approximately 20-25% of sparse parameter budget toward Engram-based memory modules, with the remaining 75-80% going toward traditional computation.
This allocation principle proved consistent across different model scales. When tested at 13B, 27B, and 70B parameter counts, the 20-25% Engram allocation consistently outperformed pure Mo E models of identical total parameter count. This suggests the principle represents a genuine scaling law rather than an artifact of particular model sizes.
The practical implication is significant: if you have a parameter budget that would previously go entirely into denser models or wider Mo E modules, splitting that budget between computation and memory produces superior results. A 100B parameter model with 75B in dense computation and 25B in Engram memory outperformed a pure 100B dense model.
Memory Efficiency Quantification
The primary motivation for Engram was reducing memory requirements, not improving absolute performance. The empirical results on this dimension proved encouraging. Models with Engram required approximately 20-25% less high-speed memory compared to dense baseline architectures of equivalent capability.
Critically, this efficiency gain came without proportional performance degradation. Traditional approaches to reduce memory usage (quantization, pruning, distillation) typically trade capability for efficiency. Engram broke this pattern by introducing a fundamentally different approach that reduced memory requirements while maintaining or improving performance.
For a typical model requiring 80GB of HBM for effective inference, Engram-based architecture reduced requirements to approximately 60-64GB while maintaining equivalent or superior performance. This reduction might seem modest in percentage terms but becomes revolutionary when multiplied across thousands of GPU clusters.
Scaling Laws and Consistency
One of the most important empirical findings involved demonstrating that Engram's benefits scaled predictably. Researchers tested the technique across model scales from 13 billion to 70 billion parameters. Rather than performance benefits diminishing at larger scales (a common problem with optimization techniques), Engram maintained consistent advantages.
At 13B scale, Engram provided approximately 3-4% capability improvement over dense baselines while reducing memory by 20%. At 70B scale, similar improvements persisted: 3-4% capability gains with 20-22% memory reduction. This consistency suggests that Engram's advantages derive from fundamental architectural principles rather than exploiting particular model size artifacts.
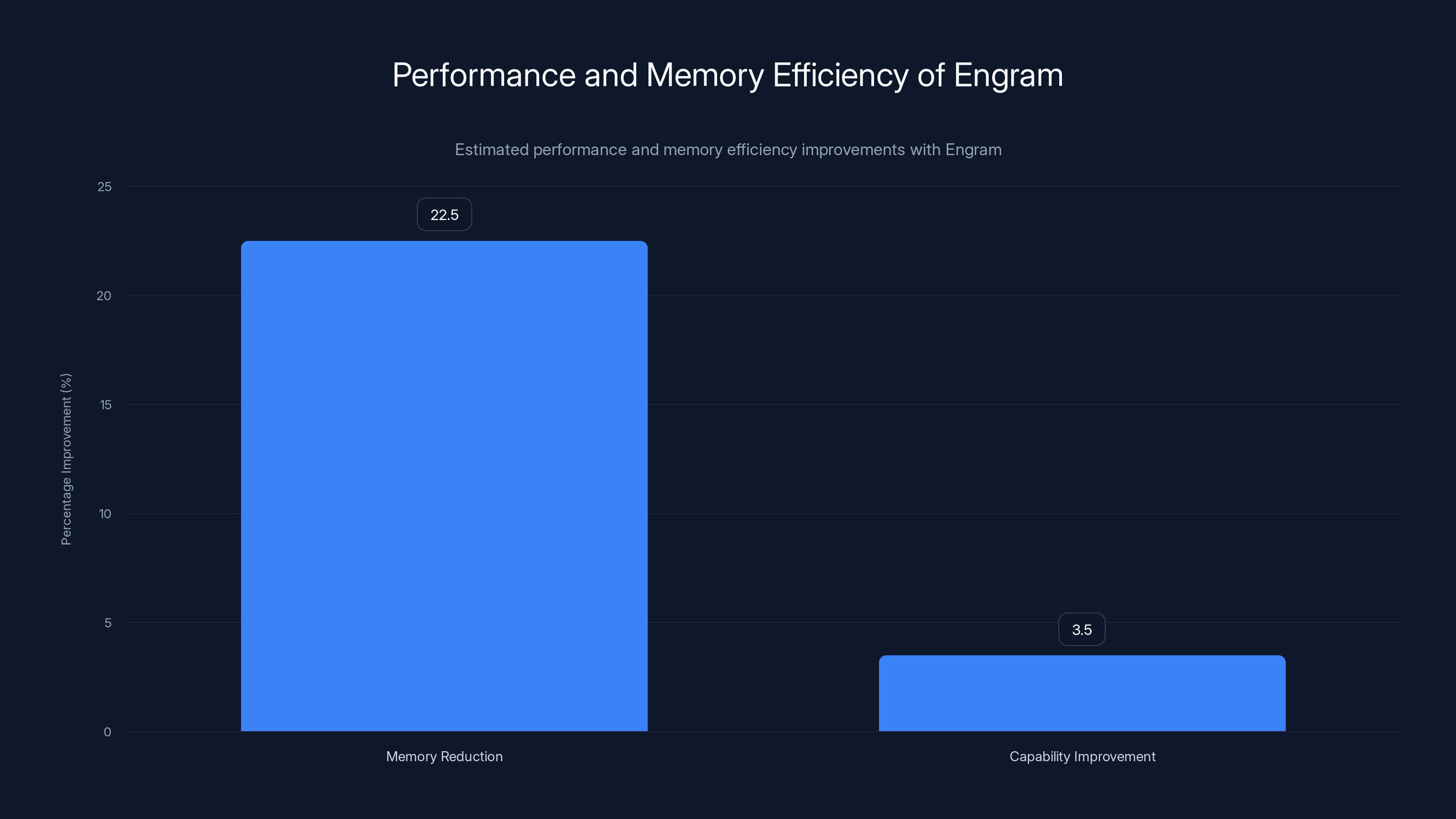
Engram reduces high-speed memory bandwidth by approximately 22.5% and improves model capabilities by about 3.5% compared to traditional architectures. Estimated data.
Hardware and Infrastructure Implications
Compatibility with Existing GPU and System Memory Architectures
Engram's practical importance stems partly from its compatibility with current infrastructure. The technique doesn't require specialized hardware or radical architectural changes to GPUs. It works with standard NVIDIA GPUs, AMD MI series accelerators, and the growing ecosystem of AI-specific processors.
The n-gram lookup tables can reside in various memory tiers. They might be kept in main system memory (DDR5 DRAM) for models where lookup latency isn't critical. For systems prioritizing inference latency, lookup tables can reside in GPU memory alongside dense parameters. For extremely large lookups, they can be distributed across NVMe solid-state drives with prefetching ensuring relevant patterns are accessible when needed.
This flexibility means organizations can implement Engram without scrapping existing infrastructure. A team running GPUs with limited HBM capacity can implement Engram to reduce requirements, immediately improving system utilization. Over time, as models evolve to take advantage of Engram benefits, hardware procurement strategies can shift to less HBM-intensive configurations.
Integration with CXL (Compute Express Link)
Engram's design proved particularly synergistic with emerging Compute Express Link standards. CXL provides a high-speed, coherent connection between processors and memory, allowing GPUs to access system memory at much higher bandwidth than traditional PCIe connections.
When combined with Engram, CXL enables keeping large n-gram lookup tables in system memory while maintaining acceptable latency. The deterministic nature of n-gram retrieval (always accessing the same table entries for identical inputs) makes CXL's coherency features particularly valuable. Cache coherency ensures that retrieved values remain consistent, critical for reproducible inference.
As CXL infrastructure proliferates across data centers, Engram's reliance on efficient access to diverse memory tiers becomes increasingly advantageous. Organizations investing in CXL can leverage Engram more fully, potentially eliminating expensive HBM requirements entirely for many workloads.
Potential Path for Avoiding HBM Bottlenecks
Perhaps the most significant implication involves relief from HBM constraints. High-bandwidth memory remains expensive and supply-constrained. By reducing HBM requirements, Engram enables building competitive AI systems without depending on these scarce resources.
For organizations in regions where HBM access lags—particularly in China where semiconductor restrictions limit access to cutting-edge memory technologies from Samsung, SK Hynix, and Micron—Engram offers an alternative path to capability. Rather than being constrained by HBM availability, organizations can implement Engram and work with more readily available DDR5 DRAM and solid-state storage.
This geographic distribution benefit alone justifies serious investment in Engram-based architecture. By decoupling AI capability from HBM supply, the technique distributes innovation opportunities more broadly across regions and organizations.

Engram and Mixture-of-Experts Integration
How Engram Complements Mo E Architectures
Mixture-of-Experts represents a different architectural paradigm for scaling models efficiently. Rather than making all parameters activate for every token, Mo E architectures route tokens to specialized expert modules. Only a subset of experts activate for each token, dramatically reducing computational requirements.
Engram and Mo E address different aspects of model scaling. Mo E optimizes computational efficiency by activating only necessary experts. Engram optimizes memory efficiency by separating static storage from computation. Combined, they provide complementary benefits.
A hybrid architecture with both Mo E and Engram components achieves several advantages. The Mo E component handles dynamic reasoning through conditionally-activated experts. The Engram component handles static knowledge retrieval through deterministic lookups. Tokens flow through the system: knowledge-heavy passages might activate fewer experts while relying more heavily on Engram retrieval. Reasoning-heavy passages might activate more experts while using Engram less frequently.
Joint Parameter Allocation Optimization
The interaction between Mo E and Engram parameters deserves sophisticated optimization. Not all parameter budgets are equally valuable in both modalities. Some model behaviors benefit disproportionately from additional expert diversity (Mo E parameters). Others benefit more from richer static knowledge (Engram parameters).
Deep Seek's U-shaped expansion rule provides guidance for this allocation. With a total parameter budget to allocate, the 20-25% Engram recommendation derives from empirical optimization across multiple model sizes. This allocation proves consistent and reproducible.
However, specific model behaviors might warrant deviations from this baseline. Models targeting knowledge-intensive tasks (like question-answering over large document collections) might benefit from allocating 25-30% toward Engram. Models targeting reasoning-intensive tasks (like mathematics or programming) might benefit from allocating only 15-20% toward Engram, favoring additional expert diversity.
Hierarchical Caching of Frequently Used Embeddings
Engram implementations benefit substantially from intelligent caching strategies. Frequently-accessed n-gram patterns should reside in faster memory tiers. Less frequently accessed patterns can reside in slower tiers.
Hierarchical caching mimics CPU cache hierarchies but applied to n-gram lookups. The most frequently accessed patterns (approximately 20% of total patterns that account for 80% of lookups) can reside in GPU memory or very-high-bandwidth system memory. Medium-frequency patterns reside in standard system memory. Rare patterns access from solid-state storage or network-attached storage.
This hierarchy provides significant performance benefits. Access latency for frequently-requested patterns might be sub-microsecond (GPU memory), while rare patterns might require milliseconds. For batch inference processing many tokens, this variation is manageable. The deterministic nature of n-gram retrieval enables perfect prefetching: you can load required n-grams before they're accessed.
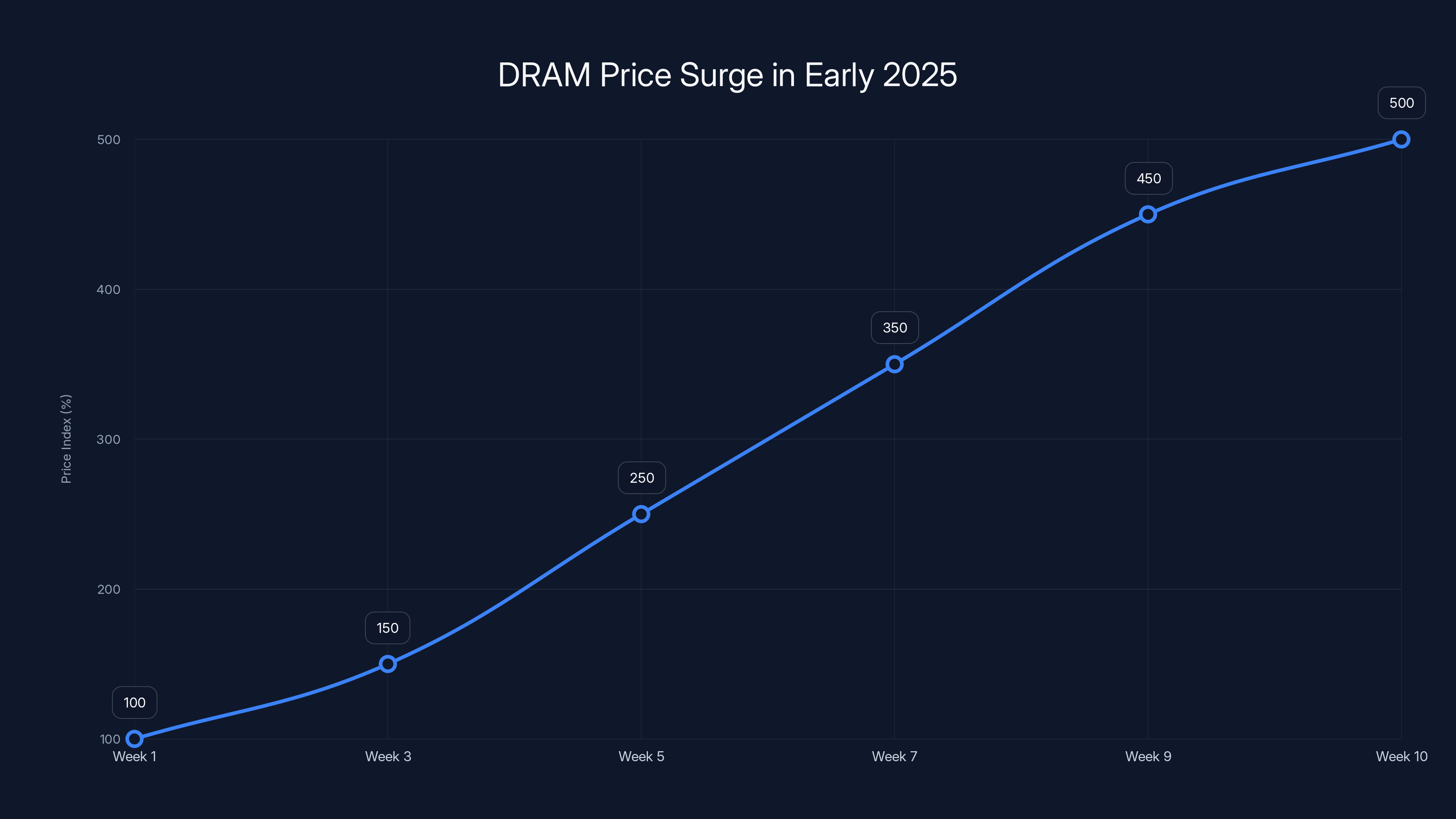
DRAM prices surged by 500% over ten weeks in early 2025, driven by high demand from AI advancements. Estimated data.
Cost Analysis and Economic Impact
Capital Expense Reduction Through Eliminated HBM Requirements
The economic benefit of Engram becomes clear when calculating infrastructure costs. A high-end GPU like the H100 with 80GB HBM costs approximately
Consider a 1,000-GPU cluster designed to run 70-billion-parameter models. Using standard Engram optimization, the cluster might reduce per-GPU HBM requirements from 80GB to approximately 60GB. This enables using less expensive GPUs or alternative accelerators optimized for the reduced memory requirement.
Capital savings at scale become substantial. A 1,000-GPU deployment might save $2-5 million in capital expenses by shifting toward lower-HBM GPUs while maintaining equivalent performance through Engram-based architecture. For organizations operating multiple clusters across regions, these savings compound dramatically.
Operational Cost Benefits
Beyond capital expenses, operational costs improve through Engram. Fewer memory bandwidth bottlenecks mean higher GPU utilization. GPUs can spend more time performing computation rather than waiting for memory access. Higher utilization rates improve the return on capital investment in GPU hardware.
Additionally, systems designed around lower memory requirements benefit from simpler cooling and power delivery infrastructure. High-bandwidth memory generates significant heat. Systems optimized around standard DRAM have lower thermal loads, enabling higher density deployments and reduced cooling costs.
Supply Chain and Procurement Advantages
From a supply chain perspective, Engram solves a critical vulnerability. Organizations depending on cutting-edge HBM face supply constraints and price volatility. By reducing HBM dependence, Engram provides supply chain resilience. Organizations can procure from broader supplier bases using standard DDR5 DRAM and NVMe storage—components with mature supply chains and abundant capacity.
For organizations in semiconductor-restricted regions, this advantage is transformative. The approach to AI infrastructure no longer depends on accessing cutting-edge memory technologies from Western suppliers. Instead, it leverages broadly available components, enabling local supply chains and domestic manufacturing.

Inference Optimization and Latency Considerations
Asynchronous Prefetching Across Multiple GPUs
Engram implementations benefit substantially from prefetching strategies that load required n-grams before they're accessed during inference. This asynchronous prefetching becomes particularly powerful in distributed inference scenarios where computation spans multiple GPUs.
During inference, you can predict which n-grams will likely be needed based on token sequences already processed. Rather than waiting for lookups to occur, a background prefetching system loads these n-grams into cache layers ahead of time. By the time computation reaches those tokens, required information is already cached.
The deterministic nature of n-gram retrieval makes perfect prefetching possible. With traditional attention mechanisms, predicting future memory access patterns is difficult. With n-gram lookups, future accesses depend only on predicted token sequences—information that generation algorithms already possess.
Minimal Performance Overhead
A critical validation from empirical testing involved demonstrating that Engram introduces minimal performance overhead. The lookup operations, caching infrastructure, and gating mechanisms add computational cost. However, empirical testing showed that overall system throughput improved despite these additions, because memory bottleneck relief more than compensated.
Latency measurements showed that end-to-end inference latency either decreased or remained essentially unchanged. Token generation latency—the time to generate each additional token—actually improved in many scenarios because reduced memory pressure enabled faster computation.
Batching and Throughput Optimization
Engram's benefits become more pronounced in batch inference scenarios typical of production systems. When processing many sequences simultaneously, memory bandwidth becomes the primary constraint. Reduced memory requirements enable larger batch sizes on identical hardware.
A system with 80GB HBM might handle batch size 32 for 70B models. The same system with Engram optimization might handle batch size 40-44, a 25-40% throughput increase from the same capital investment. For production systems processing millions of inference requests daily, these throughput gains translate directly to reduced infrastructure costs per inference.

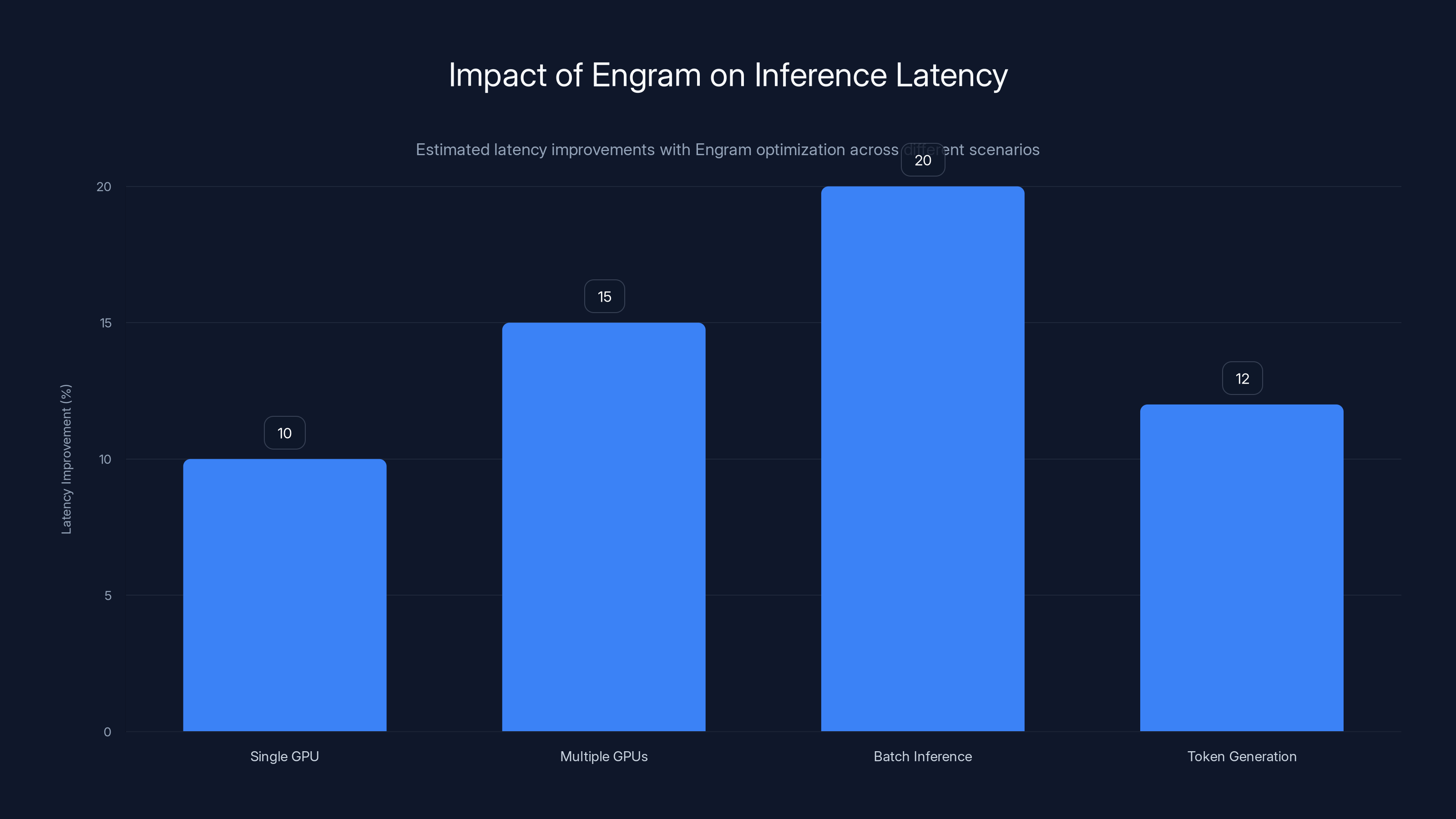
Estimated data shows Engram optimization can improve inference latency by up to 20% in batch processing scenarios, with notable gains across all tested configurations.
Comparison with Alternative Memory Optimization Approaches
Quantization and Its Limitations
Quantization represents the most established technique for reducing model memory requirements. By reducing parameter precision from 32-bit floating point to 8-bit or 4-bit integers, quantization can reduce memory requirements by 4-8x.
However, quantization comes with significant limitations. First, performance typically degrades noticeably. A quantized model generally performs 1-3% worse than its full-precision equivalent. Second, quantization reduces both parameter memory and activation memory equally, but Engram specifically targets activation memory—the dominant bottleneck for long contexts.
Engram complements quantization. An organization might apply both techniques: quantize dense parameters to 8-bit, and implement Engram for knowledge retrieval. The combination would provide both quantization benefits and Engram benefits.
Knowledge Distillation Approaches
Knowledge distillation transfers knowledge from large teacher models to smaller student models, reducing memory requirements through actual model size reduction. This approach works well for some applications but has important limitations.
Distillation requires expensive training with teacher models. It works best when significant capability reduction is acceptable—perhaps a 70B model distilled to 13B. Engram instead maintains full capability while reducing memory requirements for high-bandwidth operations.
For applications requiring full model capability, distillation isn't appropriate. Engram fills this niche perfectly: maintaining full capability while optimizing memory efficiency.
Retrieval-Augmented Generation (RAG) Systems
Retrieval-augmented generation represents an alternative approach to handling knowledge-intensive tasks. Rather than storing knowledge in model parameters, RAG systems retrieve relevant information from external databases during inference.
Engram differs fundamentally from RAG. Where RAG requires managing external databases and retrieval systems, Engram internalizes retrieval within the model architecture. Where RAG requires separate infrastructure, Engram works within standard model training and inference pipelines.
Engram and RAG aren't mutually exclusive. An organization might implement Engram for common knowledge patterns while still using RAG for specialized or proprietary information. The hybrid approach leverages both techniques' strengths.
Parameter Sharing and Structured Sparsity
Various techniques share parameters across different model regions or enforce sparsity patterns to reduce memory. These approaches work by reducing model size through architectural constraints.
Engram differs in that it doesn't reduce model size. Instead, it addresses how model information is organized and accessed. A model with Engram doesn't have fewer parameters; it has the same parameters organized differently—some in dense layers, some in the Engram retrieval structure.
Real-World Applications and Use Cases
Knowledge-Intensive Systems
Engram provides particular benefits for applications requiring extensive knowledge retrieval: question-answering systems, knowledge-base assistants, and fact-checking applications. These systems spend significant computational cycles on knowledge retrieval that Engram optimizes naturally.
A customer support system using a 27B-parameter model with Engram could serve more concurrent users on identical hardware compared to baseline architecture. The freed memory and computation resources enable handling 20-30% more concurrent conversations.
Long-Context Applications
Applications processing very long contexts—document analysis, code repository understanding, multimodal analysis of long video transcripts—benefit substantially from Engram. These applications necessarily consume large amounts of memory for context storage. Engram reduces this consumption while maintaining context understanding quality.
A document analysis system processing 100,000-token documents might require 2x more GPU memory in baseline architecture versus Engram architecture. This difference determines whether the application is feasible on standard GPUs or requires expensive HBM.
Reasoning and Problem-Solving Systems
While Engram particularly benefits knowledge-intensive applications, empirical testing showed consistent improvements across reasoning tasks. This suggests Engram's benefits generalize beyond knowledge retrieval to broader model capability.
Mathematics problem-solving, programming assistance, logical reasoning—these tasks benefit from both components of Engram: freed memory enables deeper reasoning chains, while knowledge retrieval acceleration speeds up pattern recognition on mathematical or programming constructs.
Multimodal Applications
Large multimodal models combining vision and language face extreme memory pressure. Image processing generates vast quantities of intermediate representations. Engram helps by optimizing knowledge storage and retrieval, reducing overall memory pressure.
A vision-language model with Engram can process higher-resolution images or longer text sequences on identical hardware compared to baseline. For applications like detailed document analysis or long-form video understanding, these improvements are substantial.
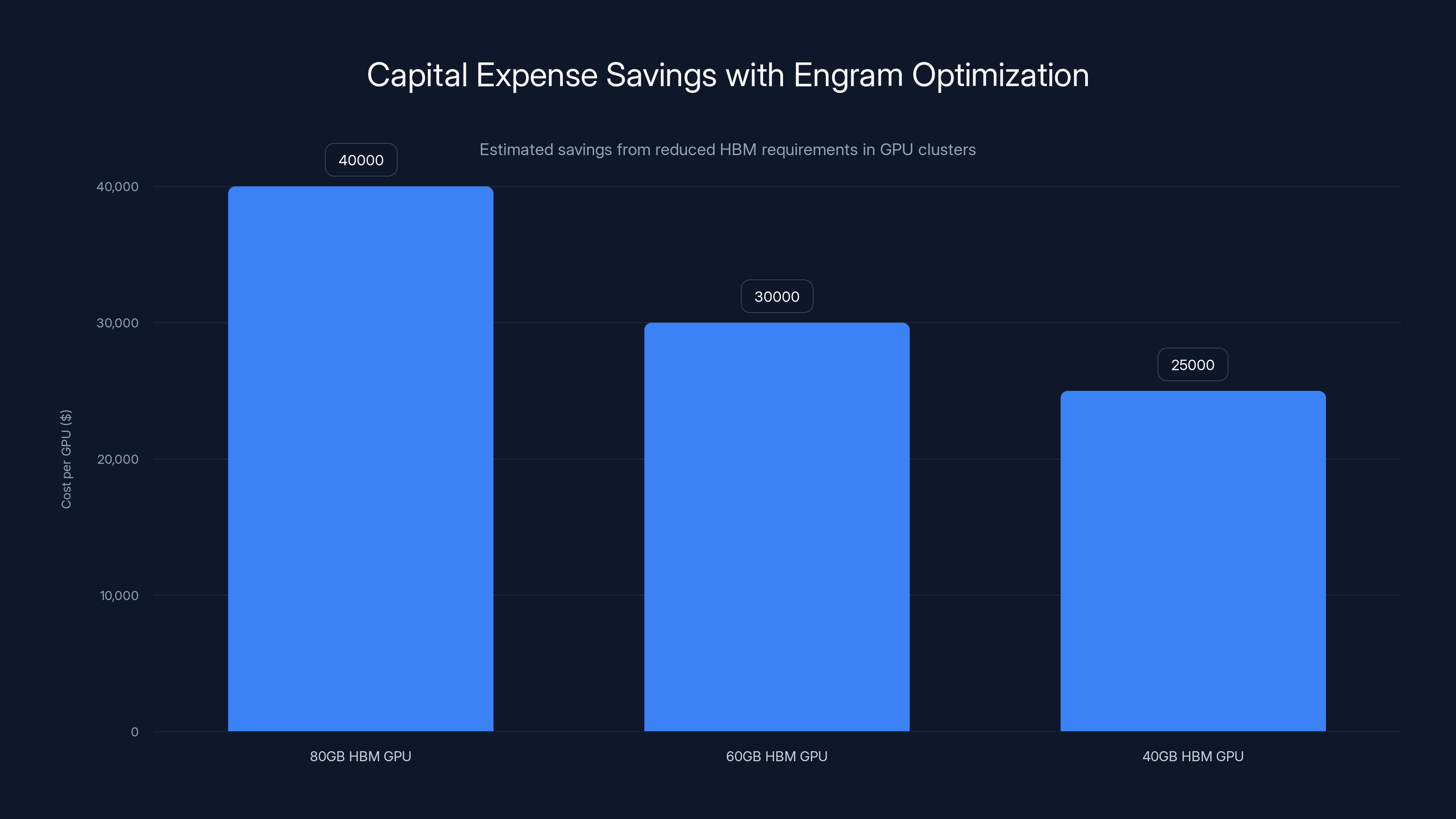
Estimated data shows a cost reduction of
Integration Pathways and Implementation Considerations
Training Procedure Modifications
Implementing Engram requires modifying standard training procedures. Rather than learning all information through gradient-based parameter updates, the training process must identify information suitable for n-gram storage versus information requiring dense parameter learning.
This identification can happen automatically through training dynamics. Information frequently accessed through similar token sequences naturally gets stored in n-grams. Information requiring complex contextual inference gets learned in dense parameters. The training process naturally separates static and dynamic information.
Alternatively, explicit loss functions can incentivize storing particular information in Engram modules versus dense layers. Research might show that certain knowledge categories (geographical facts, scientific definitions) compress extremely well in n-gram lookup tables, while reasoning about complex interactions requires dense learned parameters.
Fine-Tuning and Adaptation
Once trained with Engram, models can be fine-tuned for specific domains. The fine-tuning process can expand n-gram tables with domain-specific patterns or update dense parameters for domain-specific reasoning.
This flexibility enables creating specialized models efficiently. Take a base Engram-trained model and expand its n-gram table with financial data, and you have a financial specialist model. Expand with medical knowledge, and you have a medical specialist. This approaches enables domain specialization without full retraining.
Inference Engine Requirements
Production inference engines need modification to support Engram. Standard inference systems assume all weights reside in GPU memory with uniform access patterns. Engram requires accessing pattern lookup tables that might reside in diverse memory locations.
Modern inference frameworks like v LLM or Tensor RT can incorporate Engram support. The frameworks would need to manage lookup table placement, implement prefetching logic, and optimize pattern access patterns. Fortunately, because lookups are deterministic, optimization is straightforward compared to dynamic memory access patterns.
Regional and Geopolitical Implications
Relief for Supply-Constrained Regions
Engram's breakthrough value partly stems from geopolitical realities. Advanced memory technologies remain concentrated in a few suppliers. By reducing dependency on cutting-edge HBM, Engram enables broader participation in AI development.
Organizations in regions facing semiconductor restrictions gain particular benefit. Rather than depending on access to cutting-edge memory from Samsung, SK Hynix, and Micron, they can build capable AI systems using domestically available components. This democratization of AI capability has profound implications.
Building Domestic Supply Chains
Historically, building world-class AI infrastructure required access to cutting-edge foreign technology. This created dependency relationships and vulnerability to supply disruptions. Engram changes this calculus.
Regions can now develop domestic production of DDR5 DRAM and NVMe storage—less sophisticated than cutting-edge HBM but sufficient for Engram-based systems. This enables building competitive AI infrastructure using domestic supply chains.
Future Research Directions and Opportunities
Expanding Beyond N-Gram Patterns
Current Engram implementation uses n-gram-based hashing for pattern matching. Future research might explore more sophisticated pattern recognition approaches. Graph-based pattern matching, hierarchical pattern organizations, or learned pattern representations could enable capturing more complex static patterns.
Additional research might explore what constitutes "good" patterns for n-gram storage versus dense learning. Are particular semantic categories better represented in n-grams? Does model behavior during training reveal which information should be stored versus learned?
Hardware-Software Codesign
Engram's design suggests opportunities for hardware-software codesign. Purpose-built accelerators optimized for n-gram lookup operations could provide additional speedups. Specialized memory hierarchies designed specifically for pattern-based retrieval could improve efficiency further.
Processor manufacturers might develop custom instructions for common n-gram operations. Just as modern CPUs include specialized instructions for hashing or string matching, future AI accelerators might include instructions optimized for Engram-style lookups.
Adaptive and Dynamic Engram Structures
Current Engram implementations use fixed n-gram tables determined during training. Future systems might adapt these tables dynamically during inference, learning new patterns from in-context examples.
Imagine an Engram system that, when encountering a new pattern it hasn't seen before, stores it temporarily in a dynamic table. If the pattern recurs within a conversation, subsequent uses access the cached version. This would enable learning and specializing to specific user patterns without retraining.
Multimodal Engram Extensions
While current Engram focuses on language models, extending it to handle multimodal patterns is natural. Visual patterns, audio patterns, and cross-modal patterns could be stored and retrieved similarly.
A multimodal model with Engram support could retrieve common visual patterns (text in images, recognizable objects) efficiently while using dense parameters for complex visual understanding or cross-modal reasoning.

Challenges and Limitations
N-Gram Pattern Limitations
Not all information compresses well into fixed-length n-gram patterns. Complex contextual nuance, abstract reasoning, and creative generation all resist compression into lookups. Engram's benefits appear most pronounced for factual knowledge and learned patterns.
Models must learn which information benefits from n-gram storage versus which requires dense parameter learning. This learning process isn't guaranteed to be optimal. Organizations might need experimentation to determine appropriate parameter allocation for specific applications.
Lookup Table Growth and Management
As models train on larger datasets, n-gram lookup tables can grow substantial. Managing tables with billions of patterns requires careful consideration of storage, access patterns, and update mechanisms.
Research might identify methods to compress lookup tables, perhaps through techniques like learned hashing or hierarchical pattern organization. Alternatively, organizations might accept that lookup tables grow with training data, budgeting infrastructure accordingly.
Fine-Tuning and Specialization Trade-offs
Once trained with Engram, the structure creates path dependencies. Fine-tuning that significantly changes model behavior might require updating lookup tables substantially, potentially losing the efficiency benefits of pre-existing patterns.
This suggests that Engram works best for base models trained on broad, diverse data, then fine-tuned relatively conservatively for specific applications. Radical domain adaptation might require retraining the entire Engram structure.
Reproducibility and Determinism Challenges
While the deterministic nature of n-gram lookup generally aids reproducibility, distributed inference and caching introduce potential sources of non-determinism. Ensuring identical results across different hardware configurations or inference engines requires careful engineering.

Comparison with Runable's AI Automation Approach
While Deep Seek's Engram focuses on optimizing the underlying memory architecture of language models, organizations building AI-powered systems face broader automation challenges. For teams developing automation workflows, generating technical documentation, creating reports, or building AI agent-driven processes, the landscape extends beyond inference optimization.
Platforms like Runable address different layers of the AI stack. Where Engram optimizes how individual models handle memory and computation, Runable provides workflow automation and AI-powered content generation tools. For developers and teams building modern applications, this distinction matters significantly.
Engram helps if your bottleneck involves model inference costs and memory constraints. But if your challenge involves automating repetitive tasks, generating quality documentation at scale, or orchestrating complex workflows with AI agents, Runable's $9/month AI automation capabilities offer complementary value. Organizations might leverage both: Engram for optimizing their proprietary model infrastructure, Runable for automating development and content workflows.

Industry Reception and Competitive Response
Academic and Research Community Response
Deep Seek's publication of Engram research generated significant interest in academic AI communities. The technique addresses a real bottleneck that researchers have grappled with for years, making it immediately relevant to many ongoing projects.
Research institutions rushed to implement Engram-based architectures, validating the approach across diverse model architectures and domains. Publications citing Engram increased substantially as researchers explored extensions, variations, and applications.
Commercial Impact on AI Infrastructure
Cloud service providers and infrastructure vendors immediately recognized Engram's implications. Companies like cloud platforms understood that Engram might reduce HBM requirements for customers, potentially decreasing revenue from high-margin GPU acceleration services.
Conversely, companies providing alternative memory solutions (NVMe storage, system memory) saw opportunities. The shift toward Engram-based architectures increases demand for efficient storage and memory systems beyond traditional HBM.
Hardware Manufacturer Strategies
Memory manufacturers faced complex dynamics. Short-term, Engram might reduce HBM demand and pricing pressure. Long-term, if successful, the technology could shift memory market dynamics entirely, reducing the premium for high-bandwidth memory.
Some manufacturers invested in research extending Engram or developing hardware optimizations. Others focused on developing specialized memory technologies that Engram-style architectures could leverage efficiently.

Best Practices for Adopting Engram-Based Architectures
Assessment Framework: Should Your Organization Adopt Engram?
Engram adoption makes sense when specific conditions align. First, your organization must have memory bandwidth bottlenecks—situations where memory access limits performance rather than computation. Second, your applications should include knowledge-intensive components that benefit from deterministic retrieval.
For organizations running 50B+ parameter models with long context requirements or high batch inference loads, Engram typically makes sense. For smaller models or compute-bound applications, the complexity might exceed the benefits.
Phased Implementation Strategy
Successful adoption typically follows a phased approach. Phase 1 involves experimentation: train small models (7B-13B) with Engram to understand the technique and validate benefits for your specific applications.
Phase 2 expands to production-scale models (27B-70B) with targeted Engram implementation. Rather than optimizing all parameters, begin with specific model layers or component types likely to benefit most.
Phase 3 involves infrastructure modification: updating inference engines, implementing caching strategies, and optimizing memory hierarchies specifically for Engram workflows.
Measuring Success
Success metrics should track memory efficiency, inference latency, throughput, and model capability. The goal isn't maximizing any single metric but rather achieving better capability-per-dollar and capability-per-watt metrics.
Compare infrastructure costs: capital expenses for GPU memory, operational expenses for power and cooling, and net inference costs per token. Engram succeeds when these metrics improve despite architectural complexity.

Conclusion: Engram's Transformative Potential
Deep Seek's Engram represents a watershed moment in AI infrastructure optimization. By fundamentally decoupling memory storage from computational processes, the technique addresses one of the industry's most pressing bottlenecks—the memory bandwidth constraint that has driven DRAM prices to unprecedented levels and limited AI capability to well-resourced organizations.
The breakthrough isn't mysterious or revolutionary in concept. It's actually elegant in its simplicity: different types of information have different computational requirements. Static knowledge retrieval doesn't need the same sophisticated processing as dynamic reasoning. By handling static retrieval through deterministic lookups and dynamic reasoning through neural computation, Engram optimizes both efficiency and performance.
The empirical validation across multiple model scales and diverse applications confirms that Engram isn't a marginal optimization but a meaningful architectural advance. The 20-25% memory reduction while maintaining or improving capability represents the kind of breakthrough that genuinely changes infrastructure strategy.
The geopolitical implications deserve emphasis. By reducing dependency on cutting-edge memory technology, Engram redistributes AI capability development opportunities. Organizations in regions facing supply constraints can now build competitive systems without depending on access to scarce resources from dominant manufacturers. This democratization of capability development has profound implications for global AI leadership.
Looking forward, Engram will likely inspire derivatives, extensions, and competitor approaches. Hardware manufacturers will develop specialized support. Research institutions will optimize implementations. The technique will eventually become standard in how organizations approach large model training and inference.
For practitioners, the immediate implication involves carefully evaluating whether Engram adoption fits your specific context. The technique clearly benefits knowledge-intensive applications with long contexts and high batch inference loads. For other applications, traditional architectures might remain optimal.
The technical community should expect Engram to serve as a foundation for future innovations. Just as transformer architectures spawned countless variants and extensions, Engram-style separation of storage and computation will likely inspire new directions in efficient AI system design.
Ultimately, Engram's significance lies not in being the final word on memory optimization but in demonstrating that fundamental architectural rethinking can solve seemingly insurmountable infrastructure challenges. As AI systems grow larger and more capable, techniques like Engram—that question fundamental assumptions about how models should be structured—will become increasingly valuable.
FAQ
What is Engram and why is it important?
Engram is a training methodology developed by Deep Seek and Peking University researchers that separates static memory storage from dynamic computational processes in large language models. It's important because it addresses the memory bandwidth bottleneck that has constrained model scaling and driven DRAM prices up 500% in recent weeks, enabling more efficient model architectures while reducing high-bandwidth memory requirements by 20-25%.
How does Engram reduce memory requirements?
Engram works by using hashed n-gram lookup tables to store static knowledge patterns separately from the main transformer computation. Rather than forcing all information through GPU memory and dense parameters, factual knowledge and learned patterns are retrieved through deterministic hash lookups, freeing high-bandwidth memory for dynamic reasoning tasks. This architectural separation allows models to achieve equivalent or superior performance using 20-25% less high-speed memory bandwidth.
What are the performance benefits of Engram beyond memory reduction?
Beyond memory efficiency, Engram provides measurable capability improvements. Testing on 27-billion-parameter models showed consistent performance gains across reasoning benchmarks, knowledge-intensive tasks, and long-context processing. When allocating 20-25% of sparse parameters toward Engram memory modules versus pure dense or Mo E architectures, models showed 3-4% capability improvements while simultaneously reducing memory requirements. The technique essentially provides better capability-per-parameter and capability-per-watt metrics.
Is Engram compatible with existing GPUs and infrastructure?
Yes, Engram is fundamentally compatible with existing hardware infrastructure. The technique works with current NVIDIA H100 GPUs, AMD MI series accelerators, and standard system memory architectures. N-gram lookup tables can reside in GPU memory, system DDR5 DRAM, or NVMe storage with prefetching. Organizations can implement Engram without hardware replacement, though optimizations work better with infrastructure supporting diverse memory tiers and technologies like Compute Express Link (CXL).
How does Engram interact with Mixture-of-Experts architectures?
Engram and Mixture-of-Experts (Mo E) address complementary scaling dimensions. Mo E optimizes computational efficiency through conditional expert activation. Engram optimizes memory efficiency through static knowledge separation. Combined, they enable allocating roughly 75-80% of parameters to Mo E computation and 20-25% to Engram memory modules, which empirically outperforms either approach alone. The techniques are synergistic rather than competitive.
What applications benefit most from Engram implementation?
Engram provides maximum benefits for knowledge-intensive applications (question-answering, fact checking, knowledge-base assistants), long-context processing (document analysis, code repository understanding), and applications requiring high batch inference throughput. It also benefits multimodal systems with complex visual or audio pattern recognition. Applications emphasizing creative generation or abstract reasoning benefit less, as these tasks don't leverage Engram's knowledge-retrieval optimizations as effectively.
Why is Engram significant for geopolitical AI development?
Engram significantly reduces dependency on cutting-edge high-bandwidth memory technology dominated by three suppliers (Samsung, SK Hynix, Micron). By enabling competitive AI systems with standard DDR5 DRAM and NVMe storage, the technique allows organizations in semiconductor-restricted regions to build capable infrastructure using domestically available components. This geographic distribution of AI capability has major implications for global AI competition and reduces technological dependencies.
What are the main limitations of Engram?
Engram's primary limitations involve managing growth of n-gram lookup tables as training datasets expand, ensuring reproducibility in distributed inference scenarios, and maintaining the separation between static and dynamic information across fine-tuning operations. Additionally, not all information compresses efficiently into lookup tables—highly contextual or abstract knowledge might require dense parameter learning regardless. Organizations must carefully determine optimal parameter allocation for their specific applications.
How does Engram compare to other memory optimization approaches like quantization?
Engram differs fundamentally from quantization (reducing parameter precision) or knowledge distillation (training smaller student models). Engram maintains full capability while optimizing memory efficiency through architectural reorganization, whereas quantization trades capability for compression. The approaches are complementary—organizations might apply both quantization and Engram to maximize efficiency. Engram also differs from retrieval-augmented generation (RAG) by internalizing retrieval within the model rather than requiring external databases.
What should organizations consider before adopting Engram?
Organizations should adopt Engram when they operate 50B+ parameter models, face memory bandwidth bottlenecks rather than computational limits, process long contexts or high batch inference loads, and run knowledge-intensive applications. Implementation should follow phased approach: first experiment with small models to validate benefits, then implement on production-scale models in targeted components, finally optimize supporting infrastructure. Success metrics should emphasize capability-per-dollar and capability-per-watt improvements rather than single metrics.
What future developments might extend Engram's impact?
Future extensions likely include more sophisticated pattern recognition beyond n-grams, hardware-software codesign with specialized accelerators for lookup operations, adaptive lookup tables that learn dynamically during inference, and multimodal extensions handling visual and audio patterns. Research will also explore optimal parameter allocation strategies for specific domains, compression techniques for managing lookup table growth, and integration with emerging memory technologies like CXL-enabled memory disaggregation and persistent memory systems.

Key Takeaways
- Engram separates static knowledge storage from dynamic computation, reducing HBM requirements by 20-25% while improving model capability by 3-4%
- DRAM prices surged 500% in 10 weeks due to AI infrastructure demand, making memory optimization critical for cost-effective AI deployment
- The technique allocates 20-25% of parameters to Engram memory modules and 75-80% to traditional computation, providing optimal scaling across model sizes
- Engram works with existing GPU and system architectures, enabling cost savings of $2-5M per 1000-GPU cluster without hardware replacement
- Reduced HBM dependency enables organizations in semiconductor-restricted regions to build competitive AI systems using domestically available components
- Complementary to Mixture-of-Experts and quantization approaches, Engram represents architectural innovation rather than parameter reduction
- Primary benefits accrue to knowledge-intensive applications, long-context processing, and high-batch inference scenarios
- Implementation requires modifying training procedures to separate static and dynamic information, with infrastructure changes supporting diverse memory access patterns
Related Articles
- Wikipedia's Enterprise Access Program: How Tech Giants Pay for AI Training Data [2025]
- OpenAI's $10B Cerebras Deal: What It Means for AI Compute [2025]
- Reinforcement Learning Plateaus Without Depth: NeurIPS 2025 [2025]
- Managing 20+ AI Agents: The Real Debug & Observability Challenge [2025]
- TSMC's AI Chip Demand 'Endless': What Record Earnings Mean for Tech [2025]
- Why Apple Chose Google Gemini for Next-Gen Siri [2025]

