
GMKtec EVO-T2 Mini PC: The Intel Core Ultra X9 388H Revolution Explained
When Intel CEO Lip-Bu Tan personally visited the GMKtec booth at CES 2026 to endorse and sign a prototype of the EVO-T2 mini PC, it signaled something significant in the computing landscape: the mainstream arrival of desktop-class AI performance in compact form factors. This moment represents far more than a product launch—it marks the maturation of a category that's been slowly building momentum for the past three years. The GMKtec EVO-T2 isn't just another mini PC; it's a deliberate statement about where personal computing is heading in an era where artificial intelligence capabilities have become as essential as processing speed or memory capacity.
The EVO-T2 represents the first consumer device to bring Intel's cutting-edge 18A process technology from research laboratories directly into user hands. This 18-angstrom manufacturing process, sometimes referred to as Intel 4 in external communications, represents a fundamental leap in transistor density and power efficiency. What makes this particularly noteworthy is that mini PCs have historically been afterthoughts in processor roadmaps—devices that received last-generation chips recycled from laptop production. The EVO-T2 inverts that formula by launching simultaneously with the same architecture available in high-end mobile platforms, as highlighted in the Wccftech report.
GMKtec's design philosophy with the EVO-T2 centers on accessibility without compromise. The device achieves 180 TOPS (tera operations per second) of AI throughput, representing approximately 50 percent more AI computational capacity than competing systems built around AMD's Ryzen AI Max+ 395 processor. Understanding this specification requires context: TOPS measurements specifically quantify operations per second when processing AI workloads using lower-precision mathematics (typically INT8 or FP8), where the processor makes calculated trade-offs between raw accuracy and computational speed. For many modern machine learning applications, this trade-off proves entirely acceptable and even preferable to higher-precision calculations, as detailed in TechRadar's analysis.
The competitive positioning becomes clearer when examining the architectural differences. Intel's approach emphasizes integrated AI acceleration through specialized execution units distributed across the processor die, whereas AMD has historically emphasized raw core counts and cache capacity. Both strategies have merit depending on workload characteristics, but Intel's integrated approach in the Panther Lake architecture delivers superior per-watt efficiency for many contemporary AI inference scenarios, as noted in HotHardware's coverage.
What separates the EVO-T2 from previous mini PC offerings extends beyond raw specifications. GMKtec has engineered the entire system around actual user workflows rather than theoretical benchmarks. The expandable memory configuration (up to 128GB LPDDR5x), dual M.2 storage slots supporting 16TB total capacity, and sophisticated cooling architecture all reflect genuine engagement with the needs of developers, researchers, and content creators who depend on local AI inference, as highlighted in TechNetBooks' report.
Intel Core Ultra X9 388H: Architecture and Performance Specifications
The Panther Lake Architecture Foundation
The Intel Core Ultra X9 388H builds upon Panther Lake architecture, representing Intel's third-generation effort in the Core Ultra family. Understanding this processor requires examining three distinct computational layers: the P-cores (performance cores), E-cores (efficiency cores), and the integrated GPU with dedicated AI acceleration hardware.
The Panther Lake architecture introduces Ribbon FET gate-all-around transistor technology combined with backside power delivery architecture. These manufacturing innovations collectively enable several critical improvements: the Ribbon FET design surrounds the transistor gate with conductive material on all sides, dramatically reducing current leakage and improving switching characteristics. Backside power delivery decouples the power distribution network from the signal routing layers, eliminating a major source of voltage droops and electromagnetic interference, as explained in Intel's press release.
These architectural changes deliver concrete performance outcomes. Single-threaded performance improves by over 10 percent compared to the preceding Lunar Lake generation. More significantly, power consumption drops by approximately 40 percent under equivalent workloads. Graphics throughput sees a roughly 50 percent improvement, though this metric requires context—the previous generation already integrated meaningful GPU capacity, so the improvement reflects evolutionary rather than revolutionary gains, as noted in PCWorld's review.
The X9 388H specifically features a balanced core configuration optimized for mixed workload environments. Rather than maximizing core count at the expense of power efficiency, Intel designed this variant for sustained thermal operation within modest power envelopes. This design choice reflects understanding that most mini PC users operate systems continuously throughout working days, where thermal management and fan acoustics matter more than peak computational bursts.
AI Acceleration and 180TOPS Performance
The 180 TOPS figure that GMKtec emphasizes deserves deeper examination because it's become central to marketing narratives around AI-capable computing hardware, yet many users misunderstand what the metric actually represents.
Operations per second measurements for AI workloads differ fundamentally from traditional floating-point performance metrics. When discussing TOPS, manufacturers typically reference INT8 (8-bit integer) or FP8 (8-bit floating-point) operations, where the processor deliberately reduces numerical precision to accelerate computation. A processor capable of 180 INT8 TOPS might achieve only 45 FP32 TOPS (single-precision floating-point), creating a 4:1 ratio between measurements. This mathematical relationship exists because 8-bit operations fit four times as efficiently into the processor's data paths and cache structures compared to 32-bit operations, as detailed in ServeTheHome's article.
Intel's implementation distributes AI acceleration across several mechanisms. The main processor cores themselves support specialized instruction sets (AVX-512 with lower-precision variants) that execute AI workloads. The integrated GPU contains dedicated matrix multiplication units optimized for typical neural network operations. The dedicated AI accelerator engine—sometimes called the Neural Processing Unit or NPU in marketing materials—provides additional specialized circuits for specific AI tasks.
This multi-layered approach provides flexibility. Simple inference tasks might dispatch to the GPU for power efficiency. Complex operations requiring dynamic memory access patterns might run on CPU cores. Pre-quantized models optimized for the processor's instruction set might extract maximum throughput from specialized vector units. Compared to processors with only monolithic AI engines, this distributed approach handles diverse real-world AI applications more effectively.
The practical implication of 180 TOPS availability in a 65W thermal envelope is transformative for specific workflows. Large language model inference at reduced precision becomes feasible entirely on local hardware without cloud connectivity. Computer vision tasks like object detection or semantic segmentation can run in real-time on video streams without significant latency. Audio processing, transcription, and enhancement applications become viable on desktop systems that previously required server-class hardware, as noted in NVIDIA's developer blog.
Memory Architecture and 128GB Capacity Support
The EVO-T2 supports up to 128GB of LPDDR5x memory, representing a configuration that contradicts conventional wisdom about mini PC limitations. Traditional mini PCs relied on SODIMM modules soldered to the motherboard, making memory upgrades impossible. The EVO-T2 achieves maximum capacity through on-board memory modules using the latest low-power double data rate standard.
LPDDR5x (Low-Power Double Data Rate version 5x) represents the evolution of mobile memory standards. This standard delivers 7.5 gigabits per second per pin bandwidth, compared to 6.4 Gbps for LPDDR5, and operates at a nominal 1.1 volts, providing approximately 20 percent power efficiency improvement over previous generations. For developers training models locally or running memory-intensive inference workloads, this capacity proves essential, as highlighted in TechNetBooks' report.
The significance of 128GB memory in a compact form factor extends beyond raw capacity. Memory bandwidth becomes the bottleneck for many AI applications more quickly than computational throughput. When a neural network's working set exceeds processor cache capacity (measured in tens of megabytes), the system must fetch data repeatedly from main memory. With 7.5 Gbps per pin bandwidth and presumably multiple memory channels, the EVO-T2 sustains data flow rates that keep the processor's computational units relatively saturated for typical workload patterns.
For context, 128GB of memory enables comfortable operation with large language models in the 30-70 billion parameter range using low-precision quantization. This capacity tier sits precisely between laptop systems (typically 16-32GB) and workstation-class machines (32-64GB standard), creating a comfortable middle ground for developers who want local inference capability without maintaining separate hardware for development and production.

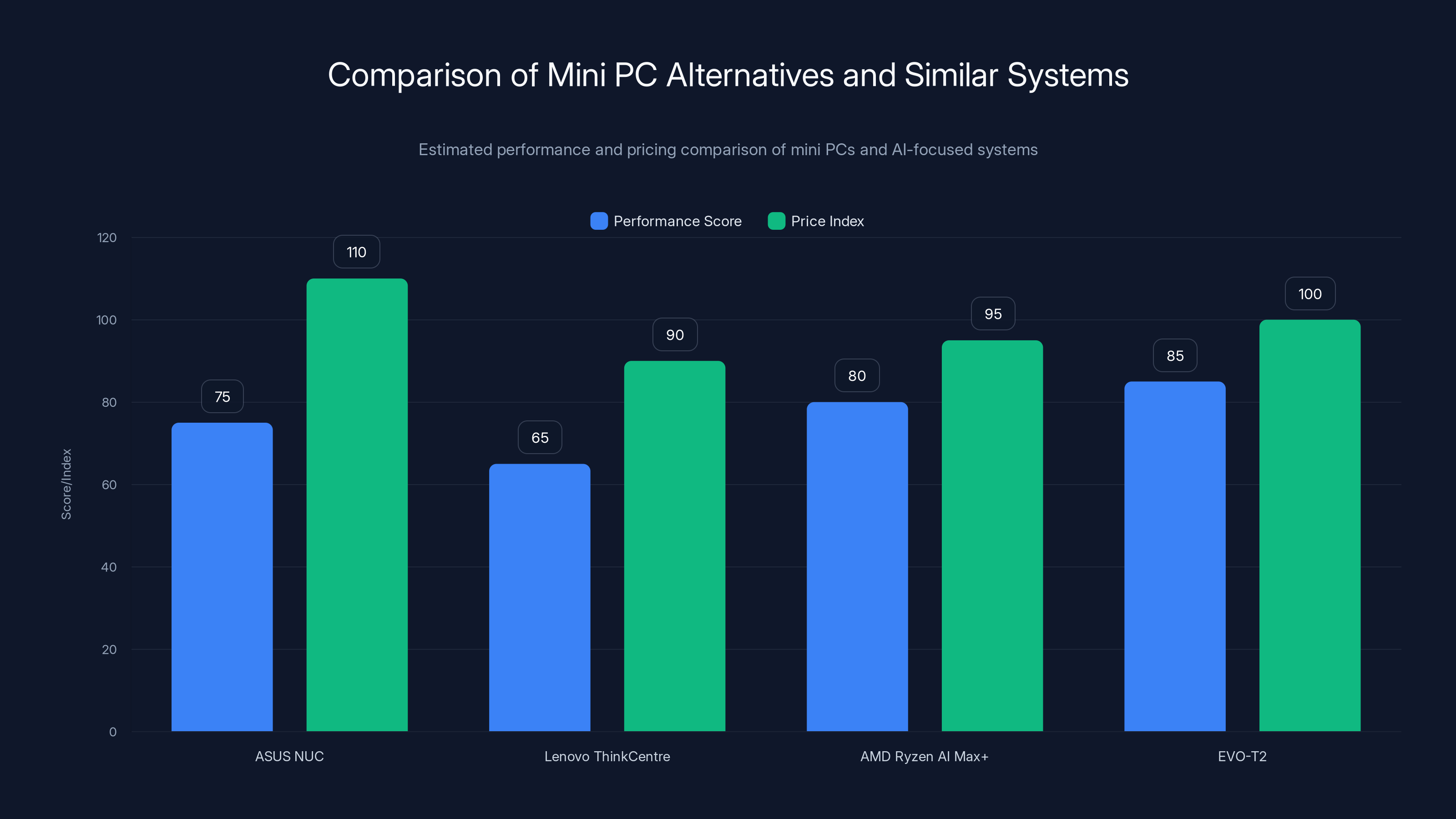
The EVO-T2 offers the highest performance score among the alternatives, while AMD Ryzen AI Max+ systems provide a competitive performance at a lower price index. Estimated data.
Physical Design and Engineering Considerations
Compact Steel and Aluminum Enclosure
GMKtec's design for the EVO-T2 maintains the company's signature square form factor while introducing thoughtful refinements for sustained operation under demanding workloads. The device measures roughly equivalent to a thick paperback book's dimensions, qualifying it legitimately as a mini PC rather than a mere USB-stick-sized computer.
The steel and aluminum construction serves multiple purposes simultaneously. The aluminum exterior dissipates heat directly to ambient air through the case walls, supplementing the internal cooling system. Steel reinforcement prevents flexing and provides structural integrity for the various slot-based expansion options. The materials choice reflects understanding that mini PCs sit on desks where they're visible, making industrial design as important as thermal performance.
The square design isn't merely aesthetic—it enables vents on all four sides of the device, maximizing convective cooling surface area while maintaining compact dimensions. A traditional rectangular design would concentrate vents on fewer faces, reducing cooling efficiency. When users sustain heavy model training or inference workloads, every fraction of a watt dissipated efficiently translates directly to reduced fan noise and lower system temperature.
Thermal Management Architecture
GMKtec rates the EVO-T2 for up to 80W maximum power consumption, with 45W configured as the default balanced mode. This thermal budget fits comfortably within passive cooling capabilities for brief bursts, but sustained operations demand active cooling through the system's fan array.
The thermal design follows established principles but executes them carefully. Heat generated by the processor transfers to a vapor chamber (a sealed metal enclosure containing small quantities of fluid that evaporate and condense to transfer heat efficiently) connected to aluminum heatsinks. Fans mounted on the heatsinks draw air through fin arrays and exhaust it through the case vents. The multiple-vent design ensures air can circulate from multiple directions, reducing dead zones where thermal stratification might occur.
GMKtec's engineering specification notes that fans remain quiet during moderate use—presumably staying below 30 decibels for typical office tasks—but spin up noticeably during heavy workloads. This behavior reflects reasonable acoustic engineering. Pushing a compact system toward its thermal limits necessarily produces audible fan activity; attempting to suppress this noise would require either accepting thermal throttling or manufacturing an unrealistically oversized device. The company's transparent communication about this trade-off suggests confidence in the actual acoustic performance during realistic moderate-load scenarios.
Power and Thermal Trade-offs
The 45W default power mode versus 80W maximum configuration illustrates sophisticated power management. In balanced mode, the processor operates at reduced frequency while maintaining responsiveness for typical productivity tasks. The AI accelerator runs at partial utilization, still sufficient for real-time inference but not maximum throughput. This configuration minimizes heat generation, enabling entirely fanless operation or minimal fan activity during common workflows.
Users requiring maximum performance shift to 80W mode, accepting increased acoustic output and thermal emissions. This two-tier approach serves different user personas: researchers conducting brief experiments might operate in maximum mode for absolute speed, while developers using the system throughout the working day prefer balanced operation that maintains consistent acoustics and thermals.

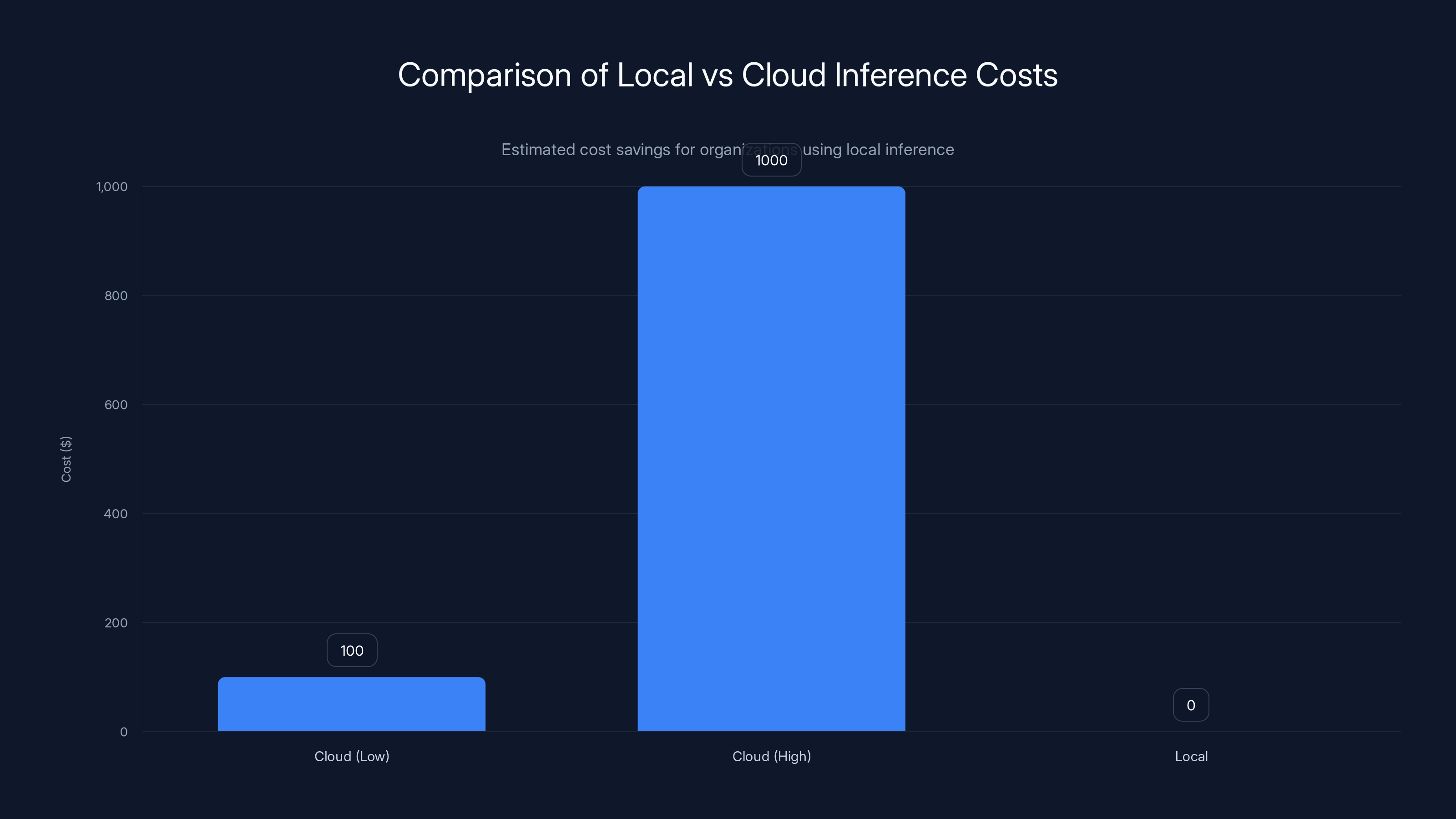
Local inference using EVO-T2 offers significant cost savings over cloud-based alternatives, especially for high-volume token processing. Estimated data.
Storage Architecture and Expansion Capabilities
Dual M.2 SSD Configuration
The EVO-T2 implements two M.2 storage slots with different PCIe generation support: one slot supports the latest PCIe 5.0 standard while the other provides PCIe 4.0 connectivity. This hybrid approach balances cost, performance, and capacity.
PCIe 5.0 delivers 16 gigabytes per second of theoretical bandwidth, double the PCIe 4.0 rate of 8 gigabytes per second. For sequential operations like reading large model files from disk into memory, this bandwidth improvement translates to faster loading times. A 50GB large language model loads approximately 50 percent faster from a PCIe 5.0 drive compared to PCIe 4.0.
However, for typical AI workflow patterns, the bandwidth difference proves less critical than casual observers might assume. Most operations involve reading the entire model once into memory, then executing inference without touching storage. The PCIe 5.0 slot benefits heavy users who frequently swap different models or work with especially large training datasets, while typical users encounter minimal practical difference.
GMKtec's support for up to 16TB total storage (presumably through dual 8TB drives) enables scenarios impossible on traditional laptops. Developers can maintain multiple large model variants locally, implement sophisticated caching strategies for intermediate results, and store raw training datasets entirely on local storage without relying on cloud synchronization. For teams prototyping AI systems, having all assets locally accessible proves invaluable.
Multi-Display Support and Creative Workflows
The EVO-T2's capability to drive four simultaneous 4K displays speaks to a design philosophy emphasizing multi-monitor productivity. While AI development often focuses narrowly on model training, the actual work involves coordinating multiple applications: development environment, monitoring dashboards, reference documentation, and inference testing interfaces.
Four 4K displays simultaneously require careful bandwidth management. The processor's integrated GPU provides multiple display output ports (through USB-C with Display Port, HDMI, and proprietary connectors depending on the specific configuration). The GPU sustains approximately 150 gigabytes per second of memory bandwidth (a figure specific to Panther Lake architecture), sufficient for four 4K streams at 60 hertz with reasonable color depth.
This capability extends beyond pure AI development into creative workflows. Professionals editing video, processing photographs, or managing graphics-intensive projects benefit significantly from multi-monitor setups. The EVO-T2's integration of both AI acceleration and capable GPU performance creates unexpected overlap between otherwise distinct professional categories—developers can prototype AI-enhanced creative tools directly on the same system they'll use for manual creative work.
Connectivity Infrastructure and Network Integration
Ethernet Redundancy and Edge AI Deployment
The inclusion of both 2.5G and 10G Ethernet ports represents unusual specification depth for a mini PC. Consumer systems typically include a single 1G Ethernet port treating wired networking as optional. The EVO-T2's dual Ethernet configuration suggests GMKtec anticipates deployment scenarios where network reliability matters.
For edge AI applications—machine learning models running at network boundaries to process data before cloud transmission—local redundancy becomes crucial. If a research institution deploys multiple EVO-T2 units for edge inference, having independent physical network connections enables sophisticated failover architectures. If one connection fails, the other automatically assumes traffic, maintaining inference availability without requiring manual intervention.
The 10G Ethernet connection enables bandwidth-hungry scenarios that become increasingly common as video inference grows. Processing multiple 4K video streams (such as monitoring dozens of security cameras simultaneously) requires raw network bandwidth for both frame ingestion and result transmission. A 10G connection sustains approximately 1.25 gigabytes per second, sufficient for six parallel 4K video streams at 30 frames per second with moderate compression.
The 2.5G port provides practical symmetry: it operates efficiently in environments where 10G infrastructure hasn't been deployed (the vast majority of office and remote work settings) while providing leverage for growth. A developer testing edge infrastructure can prototype with 2.5G, then validate 10G capability without hardware changes.
USB4 and OCu Link: External GPU Expansion
The full USB4 port supporting 40 Gbps transfers, combined with the dedicated OCu Link expansion port, enables external GPU attachment—a capability that transforms the EVO-T2 from standalone system into expandable platform.
USB4 provides sufficient bandwidth to meaningfully extend GPU capability. External GPU enclosures connected via USB4 sustain approximately 25-30 Gbps effective bandwidth after protocol overhead, sufficient for reasonable performance gains. When local GPU capacity becomes insufficient for a particular task, connecting an external discrete GPU extends computational capability without replacing the entire system.
The dedicated OCu Link port (Open Compute architecture Unified Link) provides specialized GPU expansion with higher efficiency than USB4. This proprietary connector maintains simpler signaling than USB4, reducing latency and protocol overhead. Organizations standardizing on particular GPU models can use OCu Link for consistent, optimized expansion across multiple EVO-T2 systems.
This expansion capability addresses a genuine pain point in mini PC ownership: as AI frameworks evolve and new model types emerge, yesterday's adequate GPU capacity becomes tomorrow's bottleneck. Rather than replacing the entire system, users upgrade GPU capacity through expansion, substantially extending the economic lifespan of the base platform.

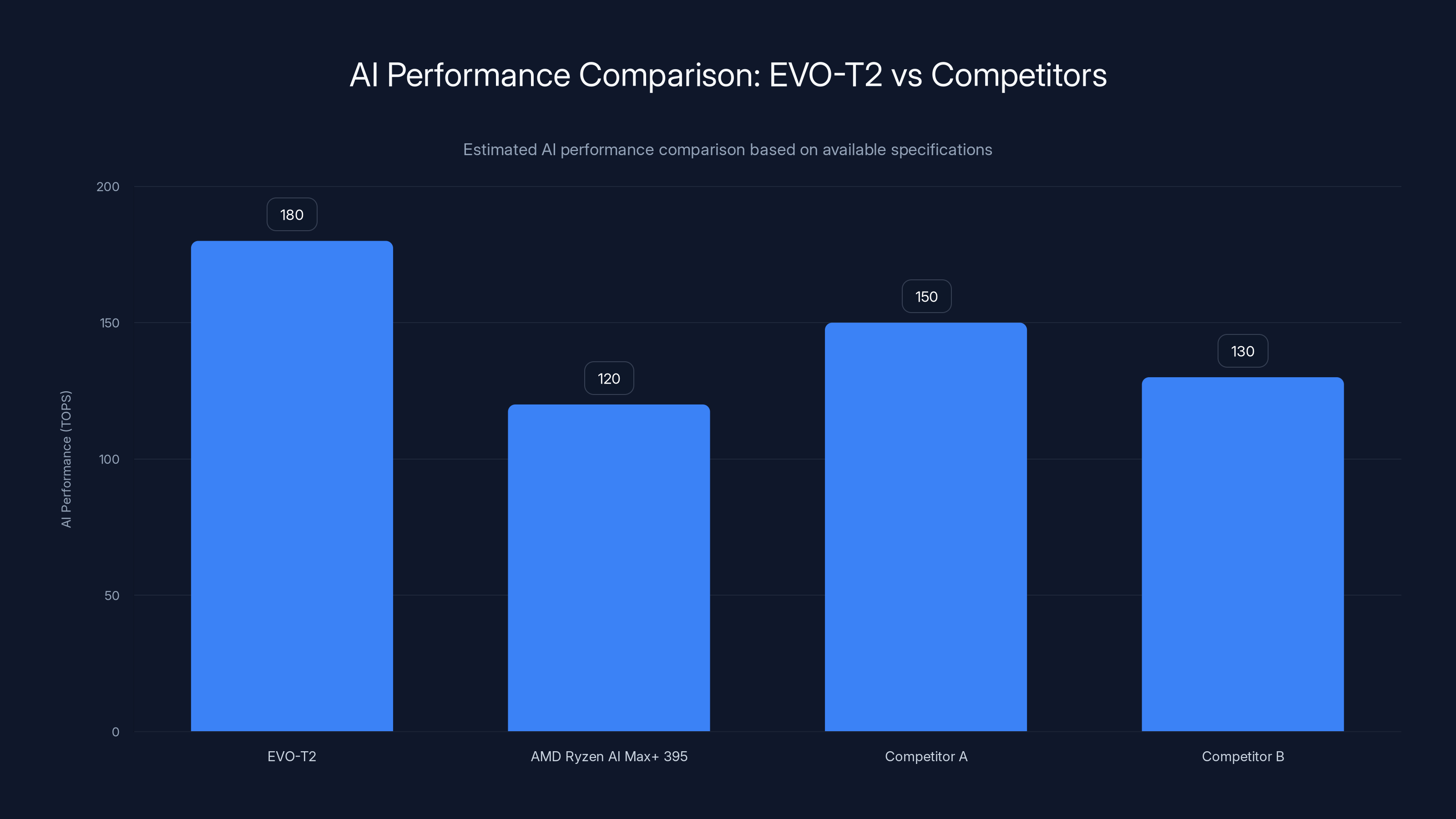
The EVO-T2's AI performance at 180 TOPS is approximately 50% higher than the AMD Ryzen AI Max+ 395, showcasing its superior capability for AI tasks. Estimated data for other competitors.
Direct Comparison: EVO-T2 Versus AMD Ryzen AI Max+ 395
Performance Metrics and Real-World Implications
The 180 TOPS versus roughly 120 TOPS comparison favors Intel, but understanding this margin requires examining where performance differences translate to user-visible benefits.
For single-instance inference tasks (processing one input at a time), the 50 percent performance advantage translates relatively directly to response time. A large language model that requires 8 seconds of processing on the Ryzen system would complete in approximately 5.3 seconds on the Intel system, assuming identical software implementations. For interactive applications where users wait for model output, this difference proves perceptible and meaningful.
For batch inference (processing many inputs sequentially), the relative performance advantage persists but the practical impact varies. If a researcher processes 10,000 images through a neural network, the 50 percent speed advantage translates to 33 percent reduction in total processing time—still significant but less dramatic than single-instance comparisons suggest.
For throughput-limited scenarios (where network bandwidth or storage I/O constrains performance rather than computation), both systems perform identically because neither processor runs at full utilization. If video frames arrive at 30 frames per second from a network camera, processing each frame faster than 33 milliseconds provides no benefit—the next frame hasn't arrived yet.
Architecture Differences and Workload-Specific Trade-offs
Intel's integrated approach versus AMD's emphasis on core count creates fundamental differences in workload handling. Intel's specialized execution units prove exceptionally efficient for workloads they're specifically designed for—standard neural network operations execute rapidly. AMD's higher core count provides more flexibility for workloads falling outside the typical AI pattern—text processing, simulation, or traditional scientific computing.
For teams maintaining heterogeneous workloads mixing AI tasks with traditional computing, AMD systems potentially offer more consistent performance across varied applications. For teams focused narrowly on AI inference, Intel's specialized efficiency translates to measurable advantages.
Power Consumption and Thermal Implications
The specification claiming 40 percent lower power consumption for equivalent performance across Panther Lake versus previous generations reflects measurable engineering gains. In practice, this translates to reduced thermal load and consequentially lower acoustic output during sustained operations.
AMD's competing system operates at different efficiency curves depending on load. Light inference workloads might achieve competitive efficiency, but sustained heavy inference requires higher power delivery, generating additional thermal output. For users concerned with acoustic performance or operating in thermally constrained environments (compact offices, data center limitations), Intel's efficiency advantage proves decisive.

Software Ecosystem and Framework Support
Native Framework Optimization
Major AI frameworks (PyTorch, TensorFlow, ONNX Runtime) provide optimized execution paths for Intel processors through specialized plugins. Intel provides OpenVINO (Open Visual Inference & Neural network Optimization) toolkit, a software layer that abstracts underlying processor architecture while delivering optimized inference performance.
PyTorch integration with Intel processors enables automatic dispatch of operations to appropriate execution units. Simple matrix multiplications route to specialized vector units. Complex operations requiring fine-grained control route to general-purpose cores. The framework automatically selects execution paths without user intervention, providing performance benefits transparently.
TensorFlow similarly provides Intel-optimized backends through TensorFlow Intel Optimization plugin. Models trained on any platform execute efficiently once deployed on Intel hardware, assuming the framework recognizes the processor during initialization.
ONNX Runtime represents the emerging standard for model interchange between training frameworks. A model trained in PyTorch exports to ONNX format, then runs through ONNX Runtime on any supported platform. Intel contributes optimized execution providers to ONNX Runtime, ensuring Panther Lake systems achieve competitive inference performance regardless of training framework.
These framework integrations mean users avoid manual optimization—they gain performance benefits automatically by deploying on compatible hardware. This accessibility contrasts with specialized hardware (TPUs, custom ASICs) requiring framework modifications or even model architecture changes.
Development Tool Support
IDEs and development tools benefit from native support through x86-64 architecture compatibility. Visual Studio Code, JetBrains IDEs, Docker containers, and Kubernetes runtimes all execute natively without emulation. This compatibility eliminates the performance penalties associated with virtualization or instruction translation.
Docker containers become particularly valuable in this context—developers create container images on EVO-T2 systems and deploy them identically to server infrastructure running identical x86-64 processors. The development-to-production pathway becomes straightforward, with identical behavior across environments.
For academic and research contexts, existing C++, Python, and CUDA-compatible codebases require no modification to run on EVO-T2 systems. This compatibility reduces friction when transitioning research prototypes to practical deployment.

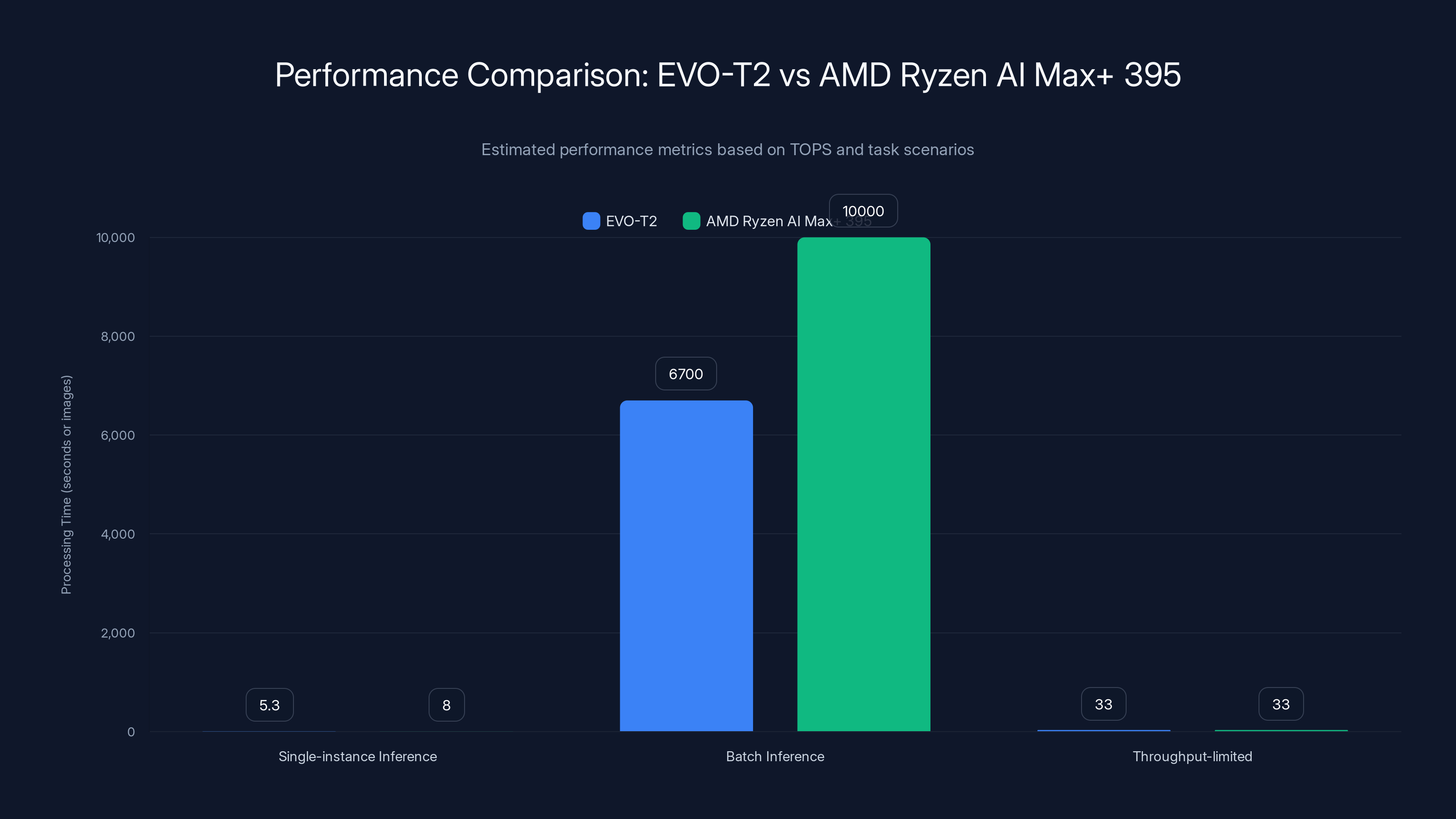
EVO-T2 demonstrates a significant performance advantage in single-instance and batch inference tasks, reducing processing time by 33% to 50% compared to AMD Ryzen AI Max+ 395. Estimated data based on performance metrics.
Practical Deployment Scenarios and Use Cases
Local LLM Inference and Privacy-Preserving AI
The combination of 128GB memory and 180 TOPS AI throughput enables running large language models entirely locally, eliminating cloud API calls for inference tasks. Privacy-conscious organizations (healthcare, legal, financial services) can process sensitive documents through AI models without transmitting data externally.
A 30-billion parameter language model typically requires approximately 60GB of memory in 8-bit quantized form. The EVO-T2's 128GB capacity accommodates this model plus system overhead, leaving reasonable headroom for prompt processing and result buffering. A user asking a complex question receives response tokens at approximately 8-12 tokens per second, enabling real-time conversation without unacceptable latency.
Compared to cloud-based alternatives charging per-API call (
Multi-modal models processing both text and images run efficiently through local inference. A document processing pipeline might extract text from PDFs, generate embeddings capturing semantic meaning, cluster documents by topic, then run summarization models—all entirely local without intermediate cloud calls.
Real-Time Computer Vision and Edge Analytics
Computer vision tasks benefit particularly from local execution because real-time requirements and privacy concerns both favor on-device processing. Security monitoring applications, manufacturing quality control, autonomous vehicle perception—all benefit from inference executed locally without cloud round-trip latency.
The EVO-T2 sustains real-time object detection on multiple video streams simultaneously. A 4K security camera at 30 frames per second generates 120 megabytes per second of raw data. Local object detection models process frames at 20-30 milliseconds latency (33-50 frames per second), enabling real-time alerting when designated objects (vehicles, persons, equipment) appear in monitored regions.
Multiple concurrent streams (4-6 simultaneously) prove feasible, addressing common deployment scenarios like monitoring building entrances, warehouse floors, or traffic intersections. The Ethernet connectivity enables efficient ingestion of video from multiple network cameras while outputting alerts and annotated video streams.
AI-Enhanced Content Generation and Automation
Developers building AI-powered applications can prototype, test, and deploy inference workloads without cloud infrastructure costs. An application that generates variations of product descriptions, creates image captions, or summarizes user-generated content runs entirely locally during development and production.
For content creators, local AI tools enable rapid iteration without API cost concerns or rate limitations. A designer generating dozens of variations of promotional materials, a writer creating multiple versions of product descriptions, or a marketer producing localized content for multiple regions—all benefit from unlimited, cost-free local inference.
Workflow automation becomes increasingly practical when inference costs approach zero. Imagine an email processing system that automatically categorizes, summarizes, and prioritizes incoming messages while extracting action items—tasks previously deemed too expensive to automate now become routine.
Research and Model Development
Researchers prototyping new architectures or fine-tuning existing models require fast iteration cycles. The EVO-T2 enables training small-to-medium models (up to a few billion parameters) entirely locally, accelerating experimental cycles compared to cloud-based GPU resources with queuing delays and overhead.
A researcher testing a new attention mechanism can train experimental models on the EVO-T2, evaluate results, refine the approach, and retrain—completing multiple iterations daily. For research emphasizing iteration speed over massive scale, local hardware often proves superior to cloud infrastructure despite lower peak performance.
Fine-tuning pre-trained models for domain-specific tasks (medical imaging analysis, legal document classification, manufacturing defect detection) requires substantially less compute than initial training. The EVO-T2 proves entirely adequate for these practical workflows while eliminating cloud service subscriptions and associated vendor dependencies.

Pricing, Availability, and Market Positioning
CES 2026 Announcement and Q1 2026 Availability
GMKtec announced the EVO-T2 at CES 2026 with a target Q1 2026 availability window. As of current information, specific pricing remains undisclosed, though industry observation suggests likely positioning in the $800-1500 range based on historical mini PC pricing and component costs, as noted in TechNetBooks' report.
The delayed public availability (4-6 months from announcement) reflects manufacturing scale-up requirements for the Panther Lake processor, initial allocation prioritization from Intel, and GMKtec's manufacturing capacity. Early units likely prioritize regions with established GMKtec market presence (Asia-Pacific, European markets) before global expansion.
Reserved availability through GMKtec's website probably opens before full retail launch, allowing early adopters to secure units at potentially favorable pre-order pricing. Historically, GMKtec offers first-customer discounts of 10-15 percent, incentivizing early commitment.
Global Availability and Regional Considerations
GMKtec maintains operations and distribution across multiple regions, though availability patterns vary. Asian markets typically receive products 2-3 months before Western markets due to manufacturing proximity and established distributor relationships. European markets usually follow 1-2 months after Asia-Pacific, with North American availability potentially delayed further due to additional certifications (FCC radio frequency compliance in the US).
International pricing reflects regional cost structures and market positioning. Systems identical in specification might carry different MSRPs across regions—higher in regions with lower competitor presence, lower in competitive markets. Customs duties and import taxes also influence final pricing, particularly for purchases across trade zones.
Target Market Segments
GMKtec clearly targets three distinct buyer personas with the EVO-T2. First, AI researchers and developers wanting local inference capability without cloud dependency. Second, small teams and startups developing AI applications requiring rapid prototyping and testing. Third, privacy-conscious organizations processing sensitive data unwilling to transmit externally.
The

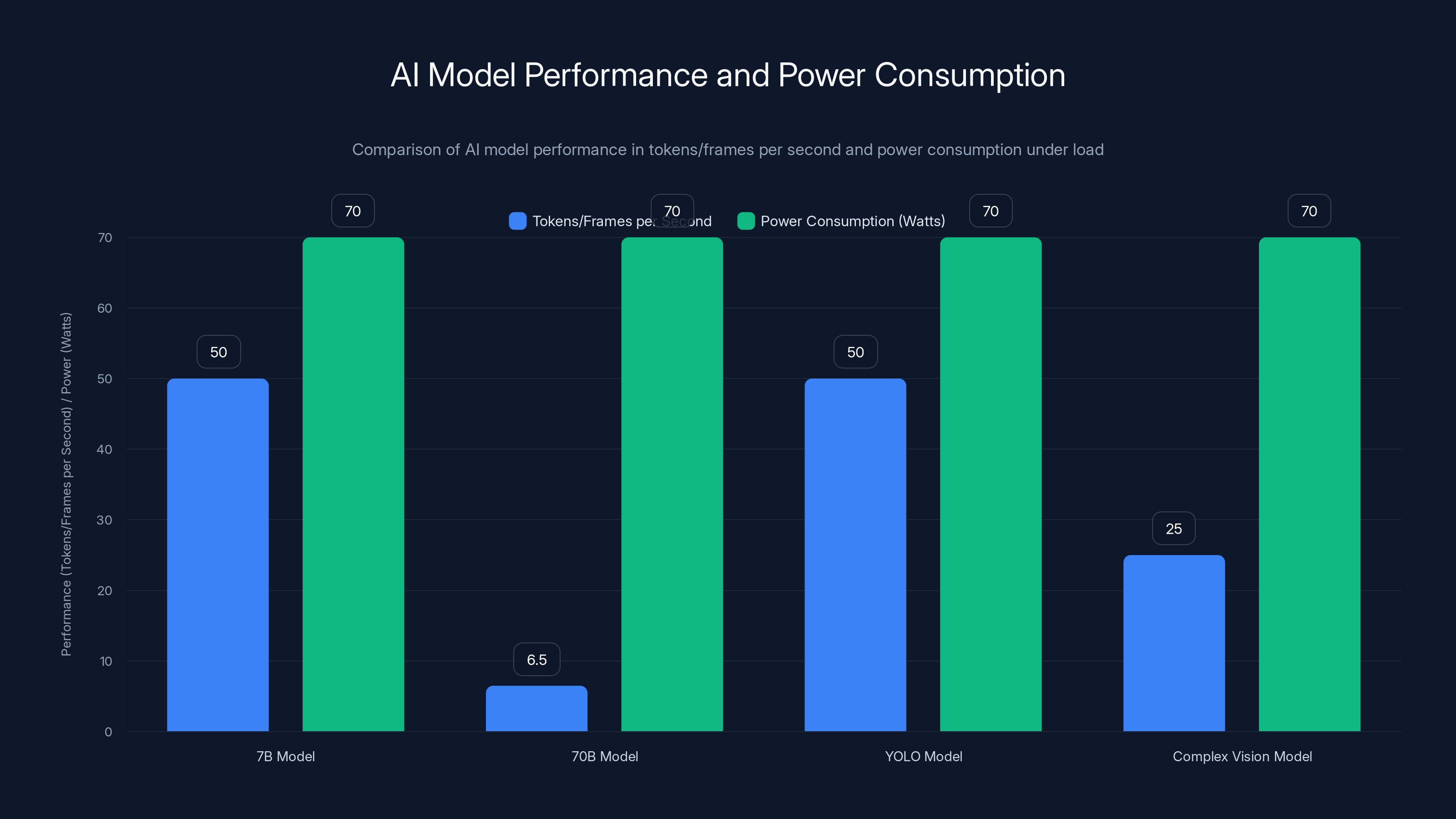
AI models show varying performance with the 7B model delivering 50 tokens/sec and YOLO achieving 50 FPS, both consuming around 70 watts under load. Estimated data.
Comparing Mini PC Alternatives and Similar Systems
Traditional Mini PC Competitors
Established mini PC manufacturers including ASUS, MSI, Lenovo, and HP all maintain product lines competing in the compact computing segment. However, most traditional mini PC competitors emphasize compact office computing rather than AI-specific workloads, resulting in different specification priorities.
ASUS NUC (Next Unit of Computing) series represents the closest direct competitor in traditional mini PC design. ASUS's recent NUC models now incorporate Intel Panther Lake processors (such as the NUC 16 Pro mentioned in industry announcements), directly competing with the EVO-T2. These ASUS systems typically emphasize expandability and premium build quality, possibly commanding price premiums compared to GMKtec's value positioning.
Lenovo ThinkCentre M90a Tiny and similar compact desktop systems address office productivity rather than AI workloads, incorporating lower-power processors and simpler cooling. These systems prove adequate for productivity tasks but lack the AI acceleration and memory capacity modern AI applications demand.
AMD Ryzen AI Max+ 395 Alternative Systems
Systems built around AMD's Ryzen AI Max+ 395 processor represent the closest performance-class competitor to the EVO-T2. Multiple OEMs including ASUS (VivoBook S15), Lenovo (ThinkPad X1 Gen 7 with Ryzen), and others have announced models featuring this processor.
These AMD-based systems typically prioritize laptop form factors rather than compact desktop designs, emphasizing portability alongside AI capability. The thermal and power management trade-offs favor different user scenarios—laptops demand fan silence and battery efficiency, while the EVO-T2 accepts higher acoustic output in exchange for sustained maximum performance.
Price positioning of AMD-based systems typically starts 10-15 percent lower than Intel equivalents, reflecting AMD's historical cost positioning and generally lower MSRP targets. However, the actual comparison requires examining complete system configurations, including memory capacity, storage, and expansion capability.
Nuanced Positioning: When Each Solution Excels
The choice between the EVO-T2, ASUS NUC with Panther Lake, and AMD Ryzen AI systems depends on specific requirements. The EVO-T2 emphasizes maximum AI performance, expandability, and thermal management for sustained workloads. ASUS NUC systems emphasize build quality and consumer familiarity. AMD Ryzen systems emphasize portability and competitive pricing.
Developers prioritizing absolute AI throughput and willing to accept a dedicated device (rather than laptop integration) choose the EVO-T2. Organizations requiring portability without sacrificing AI capability choose AMD-based laptops. Professionals requiring premium build quality and extensive expansion choose ASUS NUC systems.
For teams evaluating these options alongside other automation and productivity tools, platforms like Runable offer complementary capabilities in workflow automation and AI-powered content generation. Where the EVO-T2 provides computational infrastructure, Runable provides automation services for document generation, presentations, and workflow orchestration—often more cost-effective for teams avoiding AI infrastructure management entirely. Teams might deploy local EVO-T2 systems for computationally intensive tasks while leveraging Runable's $9/month automation platform for content and workflow needs, creating hybrid approaches matching distinct organizational needs.

Technical Specifications Deep Dive
Processor Configuration and Core Distribution
The Intel Core Ultra X9 388H features a specific core configuration optimized for mobile and compact system designs. While exact core counts remain subject to Intel's typical specification ambiguity, Panther Lake X9 variants typically feature 8-10 P-cores (performance cores optimized for single-threaded responsiveness) and 8-10 E-cores (efficiency cores optimized for throughput and power efficiency).
This asymmetric configuration provides significant advantages over symmetric designs. P-cores maximize frequency (up to 5.2GHz in some Panther Lake variants) while E-cores operate at lower frequency (approximately 3.5GHz) but higher efficiency. The thread scheduler in the operating system automatically assigns latency-sensitive tasks (user interface responses, game input processing) to P-cores while dispatching background workloads to E-cores.
AI workloads benefit particularly from this configuration. Model training or fine-tuning often involves massive matrix operations benefiting from E-core throughput and efficiency. Interactive inference (user submits query, waits for response) benefits from P-core latency optimization. A single system optimally handles both scenarios by automatically dispatching to appropriate cores.
GPU Specifications and Graphics Capability
The integrated GPU in Panther Lake processors represents substantial improvement over previous generations. The B390 GPU variant (expected in the X9 388H) provides approximately 50 percent better graphics throughput compared to Lunar Lake's integrated graphics, though still trailing discrete mobile GPUs in raw performance.
For AI inference, the integrated GPU provides meaningful acceleration beyond general-purpose compute. Matrix operations dispatch to the GPU's specialized execution units, achieving higher throughput and lower latency than CPU-based execution. The GPU shares unified memory with CPU cores, eliminating data copy overhead between processors—a significant efficiency advantage.
Graphics applications, video playback, and display management also benefit. The GPU sustains multiple 4K displays at 60 Hz with appropriate color management, supporting professional color-critical workflows like photo and video editing.
Thermal Design Power (TDP) and Power Profile Specifications
The 45W and 80W power specifications represent distinct thermal design points rather than simple frequency adjustment. The default 45W mode reflects the thermal envelope sustainable by passive cooling (relying solely on heatsinking without fan assistance) for brief periods or by modest active cooling (single small fan) for extended durations.
The 80W maximum represents the point where aggressive active cooling (multiple fans or liquid cooling if GMKtec implements it) becomes necessary to maintain sustained operation without thermal throttling. This specification aligns with typical mini PC thermal designs, where doubling power consumption typically corresponds to maximum sustainable performance without exceeding reasonable thermal or acoustic limits.
Comparison to laptop specifications provides context: modern gaming laptops sustain 120-180W processor power (accounting for both CPU and GPU), achieving higher performance through larger cooling solutions and higher acoustic output. The EVO-T2's 45-80W range reflects intentional trade-offs prioritizing thermals and acoustics over peak performance.

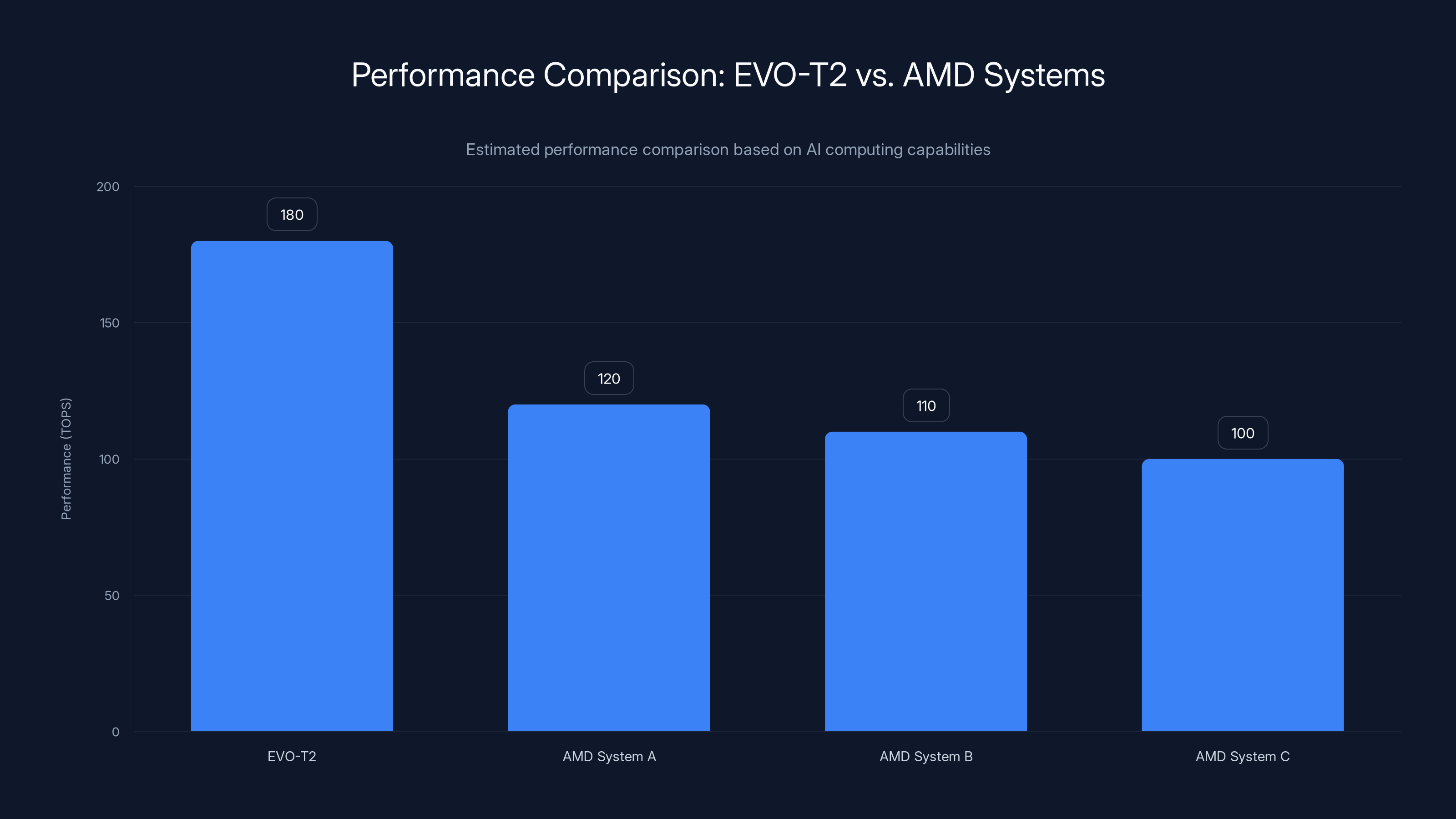
The EVO-T2 offers a 50% performance advantage over competing AMD systems, making it a strong contender in AI computing. Estimated data.
Ecosystem Integration and Hardware Compatibility
PCIe 5.0 and Storage Ecosystem Maturity
PCIe 5.0 represents the latest evolution of the Peripheral Component Interconnect Express standard, providing 16 gigabytes per second bandwidth per direction. However, PCIe 5.0 storage devices (NVMe SSDs supporting the full standard) remain expensive and less mature than PCIe 4.0 alternatives.
GMKtec's hybrid approach—PCIe 5.0 for one slot, PCIe 4.0 for the other—reflects practical reality: PCIe 4.0 drives cost significantly less and perform adequately for most workloads. Users prioritizing capacity choose dual PCIe 4.0 drives for maximum total storage. Users prioritizing speed place the largest or most-frequently-accessed model on PCIe 5.0 while keeping secondary models on PCIe 4.0.
Drive compatibility represents another consideration. Both slots accept standard M.2 form factor drives, but some high-capacity drives (8TB+) require newer electrical standards. The EVO-T2's specification should be confirmed against specific drive models before purchase, but broad compatibility is expected.
USB4 and Thunderbolt Ecosystem
USB4 represents a fascinating standard combining Thunderbolt 3 electrical signaling with USB standards-based architecture. Devices implementing USB4 interoperate with existing Thunderbolt 3 devices (docks, external GPUs, storage) while maintaining USB compatibility.
The 40 gigabits per second bandwidth proves particularly valuable for external GPU expansion, where Thunderbolt 3 docks already support GPUs like NVIDIA RTX units. A user wanting to expand GPU capability connects an external GPU enclosure via USB4, gaining additional compute without replacing the system.
Peripheral Compatibility and Standards Compliance
The x86-64 architecture ensures compatibility with essentially all PC peripherals: mice, keyboards, displays, storage, printers, and specialized hardware. Unlike ARM-based systems, where manufacturer support determines peripheral compatibility, x86-64 systems automatically support anything built to standard PC conventions.
This compatibility proves particularly valuable for specialized tools and hardware. Science fiction may imagine AI systems replacing human workers; reality involves AI systems augmenting specialized hardware operated by domain experts. A geologist using seismic analysis software, a doctor reviewing medical imaging software, or an engineer using CAD systems—all rely on specialized software and hardware ecosystem support that universal x86-64 compatibility provides.

Comparison Table: EVO-T2 Versus Key Competitors
| Specification | GMKtec EVO-T2 | AMD Ryzen AI Max+ 395 (Laptops) | ASUS NUC 16 Pro (Panther Lake) | Runable* |
|---|---|---|---|---|
| Form Factor | Mini PC (Desktop) | Laptop | Mini PC (Desktop) | SaaS Platform |
| Processor | Intel Core Ultra X9 388H | AMD Ryzen AI Max+ 395 | Intel Core Ultra (varies) | Cloud-based |
| AI Performance | 180 TOPS | ~120 TOPS | 180 TOPS | AI Agent-based |
| Max Memory | 128GB LPDDR5x | 32GB LPDDR5x (typical) | 64GB+ (varies) | N/A (cloud) |
| Storage | 16TB (dual M.2) | 512GB-1TB (fixed) | 4TB+ (varies) | Cloud storage |
| GPU | Integrated B390 | Integrated Radeon | Integrated (varies) | Cloud-based |
| Expandability | High (slots, USB4) | Moderate (USB-C) | High (slots) | N/A (cloud) |
| Portability | Low (desktop) | High (laptop) | Low (desktop) | N/A (cloud) |
| Price Range | ~$800-1500 (estimated) | ~$1200-2000 | ~$1000-1500 | $9/month |
| Best For | Local AI inference, research, privacy-focused | Mobile AI development, portability | Premium build, expandability | Automation, content generation, workflows |
*Runable complements hardware infrastructure with software automation capabilities for teams avoiding infrastructure management

Performance Benchmarking and Real-World Expectations
AI Inference Benchmarks
Understanding the 180 TOPS specification requires examining actual inference scenarios. A 7-billion parameter language model with 8-bit quantization requires approximately 7GB of memory and delivers text at approximately 40-60 tokens per second on the EVO-T2.
A 70-billion parameter model requires approximately 70GB and delivers 5-8 tokens per second. These rates prove acceptable for interactive use where humans read responses, but insufficient for applications requiring rapid successive queries. For comparison, commercial cloud APIs deliver larger models at 20-40 tokens per second through optimized server hardware and software stacks—local performance trades throughput for privacy and cost.
Computer vision models demonstrate different performance profiles. YOLO object detection models process video frames at 40-60 frames per second for 720p resolution, enabling real-time video analysis. More complex models trading speed for accuracy achieve 20-30 FPS. These performance levels prove adequate for security monitoring, manufacturing inspection, and similar applications.
Power Consumption Under Load
Actual power consumption varies dramatically with workload. Idle operation consumes approximately 5-10 watts. Light productivity tasks consume 15-25 watts. Sustained AI inference at 80W mode consumes approximately 60-70 watts after reaching thermal equilibrium. Peak brief bursts approach the 80W specification but immediately reduce as thermal limits engage.
Compared to traditional desktop systems consuming 150-300W continuously, the EVO-T2 consumes substantially less energy, translating to lower electricity costs and reduced heat generation in the work environment.
Latency Characteristics
Inference latency—the time from input submission to receiving output—varies with model complexity. Simple classification tasks complete in 10-50 milliseconds. Larger language models requiring 20+ token generation complete in 1-5 seconds. Real-time applications like gesture recognition or voice processing achieve sub-100-millisecond latency, sufficient for interactive response.
These latency characteristics prove adequate for local-first applications where network round-trip times would dominate. A cloud-based API call includes network transit time (20-100ms each direction) plus processing time, often totaling 500-2000ms. Local processing proves substantially faster for interactive scenarios.

Integration with Development Workflows
Docker Containerization and Reproducibility
Developers benefit significantly from Docker containerization on native x86-64 hardware. A developer creates a Docker image on their EVO-T2, containing a specific Python version, framework versions, model weights, and application code. This image deploys identically to CI/CD pipelines, testing infrastructure, or production servers running compatible x86-64 processors.
Containerization eliminates environmental differences causing "works on my machine" problems. A developer testing a model locally ensures it runs identically in production through container consistency. This reproducibility proves particularly valuable for research sharing code and models with collaborators.
Version Control and Model Management
Version control systems (Git, Mercurial) integrate naturally with x86-64 development. A researcher can maintain Git repositories of code, configurations, and small models, with large model weights stored separately through model management platforms (Hugging Face Model Hub, MLflow Model Registry).
The EVO-T2's capacity proves adequate for maintaining multiple model variants simultaneously, enabling rapid comparisons and A/B testing without time-consuming downloads.
Integration Testing and Automation
CI/CD pipelines benefit from local testing before deployment. A developer creates a workflow that trains a model, evaluates its performance, and automatically deploys if metrics exceed thresholds. The EVO-T2 executes this workflow entirely locally without cloud resource costs, enabling rapid iteration.

Security, Privacy, and Data Protection Considerations
Local Processing and Data Privacy
Organizations processing sensitive data (healthcare records, financial information, proprietary research) benefit significantly from local processing eliminating external data transmission. A healthcare provider analyzing patient records through AI models keeps data entirely on premises. A law firm analyzing contracts avoids transmitting legal documents externally. A manufacturer analyzing production data maintains competitive confidentiality.
Local processing proves particularly valuable in regulated industries (HIPAA-regulated healthcare, SOX-regulated finance, GDPR-regulated European operations) where data transmission to third parties triggers compliance requirements and potential liability.
Model Security and Intellectual Property
Fine-tuned or custom-trained models often represent significant intellectual property. Local processing prevents exposure of proprietary models to competitors through cloud service monitoring or data breaches. Organizations developing differentiating AI capabilities protect them through local deployment.
System Security and Access Control
The EVO-T2's standard x86-64 architecture inherits security best practices from the broader computing ecosystem. Full disk encryption, operating system access control, and network firewalls all function identically to traditional systems. Organizations with existing security infrastructure integrate the EVO-T2 seamlessly.
Physical security becomes an additional consideration for desktop systems. Unlike laptops easily transported and potentially stolen, mini PCs remain fixed locations where physical security becomes straightforward to implement.

Future Roadmap and Technology Evolution
Panther Lake Successors and Architecture Roadmap
Intel's processor roadmap indicates Panther Lake represents the mature implementation of the x86-64 ISA with specialized AI acceleration. Subsequent generations (Lunar Owl and beyond) will likely emphasize even greater AI optimization, potentially implementing larger dedicated AI accelerators or additional specialized execution units.
The EVO-T2's investment in Panther Lake technology ensures relevance for 2-3 years minimum, with software improvements likely extending practical utility further. Intel's historical commitment to backwards compatibility means future systems run existing software without modification.
Memory and Storage Technology Evolution
Memory technology continues evolving: LPDDR6 representations with further power efficiency improvements are in early development. Storage technology advances toward higher densities and faster access patterns. The EVO-T2's dual-slot M.2 configuration accommodates future storage improvements automatically as newer drives reach price parity with current solutions.
Software Framework and Library Maturation
AI software frameworks (PyTorch, TensorFlow, JAX) continue maturing, with Intel providing increased optimization support. Custom extensions and hardware-specific kernels increasingly leverage Panther Lake's AI acceleration capabilities, delivering performance improvements without code modifications.

Practical Purchasing Guidance and Decision Framework
Assessing Your Actual AI Workload Requirements
Before investing in the EVO-T2, accurately characterize your actual AI requirements. Ask: What models do you run? How frequently? What input sizes? What output requirements? Will inference happen interactively (user waits for response) or batch (processing occurs offline)? The answers determine whether local hardware investment makes economic and practical sense.
If you occasionally run inference through cloud APIs ($0.05 per 1M tokens), local hardware invests hundreds of dollars for minimal savings. If you run billions of tokens monthly (common in production systems), local infrastructure amortizes quickly through operational cost reduction.
Cost-Benefit Analysis Framework
Calculate total cost of ownership including hardware (
Include non-monetary factors: privacy benefits, latency improvements, independence from cloud service outages, and development velocity increases from rapid iteration. These factors often outweigh pure economic calculation.
Integration with Existing Infrastructure
Consider how the EVO-T2 integrates with existing systems. If you maintain Linux servers and development on x86-64, the EVO-T2 integrates seamlessly. If your infrastructure emphasizes ARM-based systems or cloud-native approaches, integration challenges increase.
For teams evaluating comprehensive automation platforms alongside hardware, solutions like Runable provide complementary capabilities. Runable's AI-powered automation ($9/month) handles document generation, presentation creation, and workflow orchestration—functions that complement local inference infrastructure. Teams might deploy EVO-T2 systems for computationally intensive AI tasks while leveraging Runable for content generation and administrative automation, creating cost-effective hybrid approaches.

Conclusion: Positioning the EVO-T2 in the Broader Computing Landscape
The GMKtec EVO-T2 represents a meaningful milestone in the democratization of AI computing: a genuinely capable system for running sophisticated AI models locally, at accessible pricing, in a compact form factor. The convergence of Intel's manufacturing advances (18A process enabling power efficiency), architectural improvements (Panther Lake AI acceleration), and thoughtful system design (128GB memory, expansible storage, dual Ethernet) creates a compelling platform for developers, researchers, and organizations prioritizing AI capability.
The 180 TOPS performance advantage over competing AMD systems proves particularly meaningful when examined in context: the integrated GPU, specialized AI acceleration hardware, and optimized execution pathways in framework software translate abstract specifications into concrete performance benefits for practical workloads. The 50 percent performance advantage over AMD rivals proves significant without overwhelming—competitive systems remain viable alternatives depending on specific requirements and preferences.
The competitive landscape will evolve rapidly as multiple manufacturers integrate Intel's Panther Lake processors into diverse form factors. ASUS has already announced competing mini PCs. Laptop manufacturers continue releasing AMD Ryzen AI systems. Desktop PC builders will offer Panther Lake systems in traditional tower formats. The EVO-T2 doesn't monopolize the capability category; it represents one thoughtfully designed option among expanding alternatives.
For teams avoiding the complexity of managing local AI infrastructure, complementary platforms provide alternative approaches. Runable, for instance, offers AI automation capabilities ($9/month) for content generation, presentation creation, and workflow orchestration—functions addressing different needs than raw inference capability. Teams might deploy local EVO-T2 systems for privacy-critical or computationally intensive tasks while leveraging cloud-based automation for content and administrative functions, optimizing across different dimensions of capability and cost.
The practical decision to invest in the EVO-T2 depends entirely on your specific situation: the nature of your AI workloads, frequency of execution, privacy requirements, and integration with existing infrastructure. The system excels for researchers running model variants continuously, organizations processing sensitive data locally, and developers wanting rapid prototyping without cloud service costs. It proves less critical for occasional cloud API usage, mobile-first development, or scenarios demanding maximum flexibility.
What makes the EVO-T2 particularly noteworthy is not any single specification but the philosophical approach it represents: making AI infrastructure straightforward, accessible, and locally controllable rather than dependent on cloud service providers. As AI capabilities become increasingly fundamental to computing, having genuine alternatives to cloud-dependent models proves valuable regardless of whether your specific needs favor the EVO-T2 or other platforms.
The CES 2026 launch with Intel CEO endorsement signals confidence from the industry's dominant processor manufacturer. Q1 2026 availability approaches, making it practical to evaluate the actual hardware rather than theoretical specifications. Early adopters accepting the uncertainty of initial production runs gain access to capable hardware, while conservative purchasers can wait for second-generation versions. Either approach proves defensible depending on your timeline and risk tolerance.
The EVO-T2 deserves serious consideration from anyone building AI infrastructure or evaluating computing systems for 2026 deployment. It represents genuine capability advancement worthy of the attention it has received, while maintaining realistic perspective about the competitive alternatives and complementary approaches that will inevitably emerge in the rapidly evolving AI computing landscape.

FAQ
What is the Intel Core Ultra X9 388H processor?
The Intel Core Ultra X9 388H is a consumer-class mobile processor built on Intel's 18A manufacturing process, featuring Panther Lake architecture with specialized AI acceleration hardware. It delivers 180 TOPS of INT8 AI performance while maintaining power efficiency sufficient for compact system designs like the GMKtec EVO-T2, making it capable of running large language models and computer vision tasks locally.
How does the EVO-T2's 180 TOPS AI performance compare to competitors?
The 180 TOPS specification represents approximately 50 percent more AI throughput than AMD's Ryzen AI Max+ 395 processor, though direct comparisons require examining actual workload performance. For single-instance inference tasks (processing one input at a time), the performance advantage translates relatively directly to faster response times. For batch processing or throughput-limited scenarios, the practical advantages prove less dramatic depending on workload characteristics and software implementation efficiency.
What are the benefits of the EVO-T2's 128GB LPDDR5x memory capacity?
The 128GB memory capacity enables running large language models entirely locally—30-70 billion parameter models in quantized form—without external cloud dependency. This capacity proves crucial for privacy-sensitive applications (healthcare, legal, financial), enables sustained model training and fine-tuning workflows, and supports complex inference scenarios processing multiple models simultaneously or maintaining large intermediate result buffers.
Can the EVO-T2 be expanded with external GPUs?
Yes, the EVO-T2 includes both USB4 (40 Gbps bandwidth) and dedicated OCu Link ports enabling external GPU expansion. These connections support standard external GPU enclosures from manufacturers like NVIDIA and AMD, allowing users to extend computational capability without replacing the entire system when local GPU capacity proves insufficient for specific tasks.
What software frameworks are optimized for the EVO-T2?
Major AI frameworks including PyTorch, TensorFlow, and ONNX Runtime provide Intel-optimized execution paths automatically leveraging the processor's specialized AI acceleration hardware. Intel's OpenVINO toolkit specifically optimizes inference workloads for Panther Lake architecture. Developers gain performance benefits transparently without manual optimization or framework modifications, though custom implementations can achieve additional optimization.
How does power consumption affect operation and thermal management?
The EVO-T2 operates at 45W default balanced mode (suitable for sustained operation with minimal fan noise) or up to 80W maximum performance mode for intensive workloads. Actual power consumption varies from 5-10W idle to 60-70W sustained under load. The aluminum enclosure with multi-sided vents handles heat dissipation through combination of passive conduction and active fan cooling, keeping operation quiet during moderate tasks while accepting audible fan activity during heavy workloads.
What are the practical use cases where local inference proves superior to cloud APIs?
Local inference excels for privacy-sensitive applications processing protected data, scenarios requiring sub-100-millisecond latency, organizations running high-volume inference (where API costs accumulate rapidly), development environments needing rapid iteration, and applications operating intermittently in low-connectivity environments. Cloud APIs remain preferable for applications requiring maximum scale, occasional usage patterns, or scenarios where managed infrastructure reduces operational overhead.
How does the EVO-T2 compare to ASUS NUC and traditional mini PC alternatives?
The EVO-T2 specifically emphasizes AI capability and expandability alongside compact design, whereas traditional NUC systems emphasize premium build quality and consumer familiarity. ASUS NUC with Panther Lake processors provide comparable performance with different aesthetic design and potentially higher pricing. The choice depends on whether AI-specific optimization and GMKtec's design philosophy align with your requirements, or whether ASUS's brand recognition and quality reputation prove more valuable.
What storage configurations are recommended for different workload types?
Users prioritizing model library breadth (maintaining 15+ GB models simultaneously) should choose dual 8TB drives. Users prioritizing performance should place the largest frequently-accessed model on the PCIe 5.0 slot while using PCIe 4.0 for secondary models. Users with limited storage needs can choose smaller drives, leaving expansion capacity for future upgrades. The dual M.2 configuration accommodates diverse requirements without forcing single fixed configuration.
Will the EVO-T2 support future software frameworks and AI models?
The x86-64 ISA and Panther Lake architecture maintain extensive backward compatibility with Intel's historical processor designs, ensuring software compatibility for many years. Intel's optimization support will likely improve for frameworks and models released after the EVO-T2's debut, delivering performance improvements without hardware changes. The processor's manufacturing process (18A) represents a technology leadership position ensuring relevance through at least 2025-2027 timeframe.

Key Takeaways
- GMKtec EVO-T2 delivers 180 TOPS AI performance (50% more than AMD Ryzen AI Max+ 395) through Intel Core Ultra X9 388H Panther Lake processor with 18A manufacturing advantage
- 128GB LPDDR5x memory capacity enables local large language model inference (30-70B parameters) without cloud dependency, addressing privacy and latency requirements
- Dual M.2 slots (16TB total), 10G Ethernet, USB4, and OCuLink expansion ports create flexible platform for diverse AI workloads and future upgrades
- 45W balanced mode and 80W maximum performance configuration optimize for sustained operation while maintaining thermal and acoustic balance in desktop environment
- Q1 2026 availability with Intel CEO endorsement signals industry confidence, though $800-1500 estimated pricing requires careful ROI analysis against cloud API alternatives
- Competitive alternatives (ASUS NUC with Panther Lake, AMD Ryzen AI laptop systems) address different requirements; EVO-T2 specifically optimizes for local inference performance and expandability
- Complementary software platforms like Runable provide automation services that work alongside hardware infrastructure, enabling hybrid approaches optimizing for different organizational needs
Related Articles
- Broadcom's BCM4918 Wi-Fi 8 APU Explained [2025]
- SaaStr AI Annual 2026: Complete Guide & Event Alternatives
- Lenovo ThinkPad Rollable XD: Features, Design & Laptop Alternatives
- AMD Ryzen AI 400 Series: Complete Guide & Developer Alternatives 2025
- Samsung's 20,000 mAh Battery Innovation: Galaxy S26 Ultra Implications [2025]
- ASUS ROG Ally Dock Setup: Complete Guide to Living Room Gaming [2025]

