![How PDF Metadata Exposes Hidden Government Documents [2025]](https://tryrunable.com/blog/how-pdf-metadata-exposes-hidden-government-documents-2025/image-1-1771614335002.jpg)
How PDF Metadata Exposes Hidden Government Documents: The ICE Detention Center Case [2025]
You've probably shared a PDF without thinking twice about it. Hit send, move on. Nobody's going to know who edited it or what got deleted before you hit the button, right?
Wrong.
A few years back, a Department of Homeland Security official sent what they thought was a clean PDF to a state governor's office. It contained plans for a massive expansion of immigration detention centers across the United States. What nobody caught before sending it: embedded inside that document were detailed comments, author metadata, and edit history that revealed exactly who created it, who reviewed it, and what they really thought about the project.
One comment stood out. A deputy chief of staff asked a detention facility contractor to confirm the average length of stay for detainees would be 60 days. The contractor's response, supposedly private: "Ideally, I'd like to see a 30-day average for the Mega Center but 60 is fine."
That single sentence, hidden in metadata, exposed the thinking behind a government initiative that affects thousands of people.
This isn't some rare security breach. It's how most organizations handle documents. Sensitive government plans, corporate strategy, legal negotiations, personnel records, financial data—all of it gets shared with hidden metadata still attached. Most people have no idea it's even there.
In this guide, we're diving deep into how document metadata works, why it matters for security and privacy, and what happens when it falls into the wrong hands. You'll learn exactly what information gets stored in PDFs, how adversaries extract it, and most importantly, how to actually prevent it.
TL; DR
- Metadata is everywhere: PDFs contain author names, creation dates, edit history, and comments that most users never see
- It reveals more than you think: Comments from decision-makers, internal discussions, and hidden information get embedded automatically
- One mistake can expose sensitive info: Accidental metadata exposure has revealed government operations, corporate strategy, and personal information
- Stripping metadata requires deliberate action: Standard tools like email or shared drives don't remove embedded data by default
- Privacy and security depend on awareness: Understanding what metadata is and how to remove it is now essential for anyone handling sensitive documents
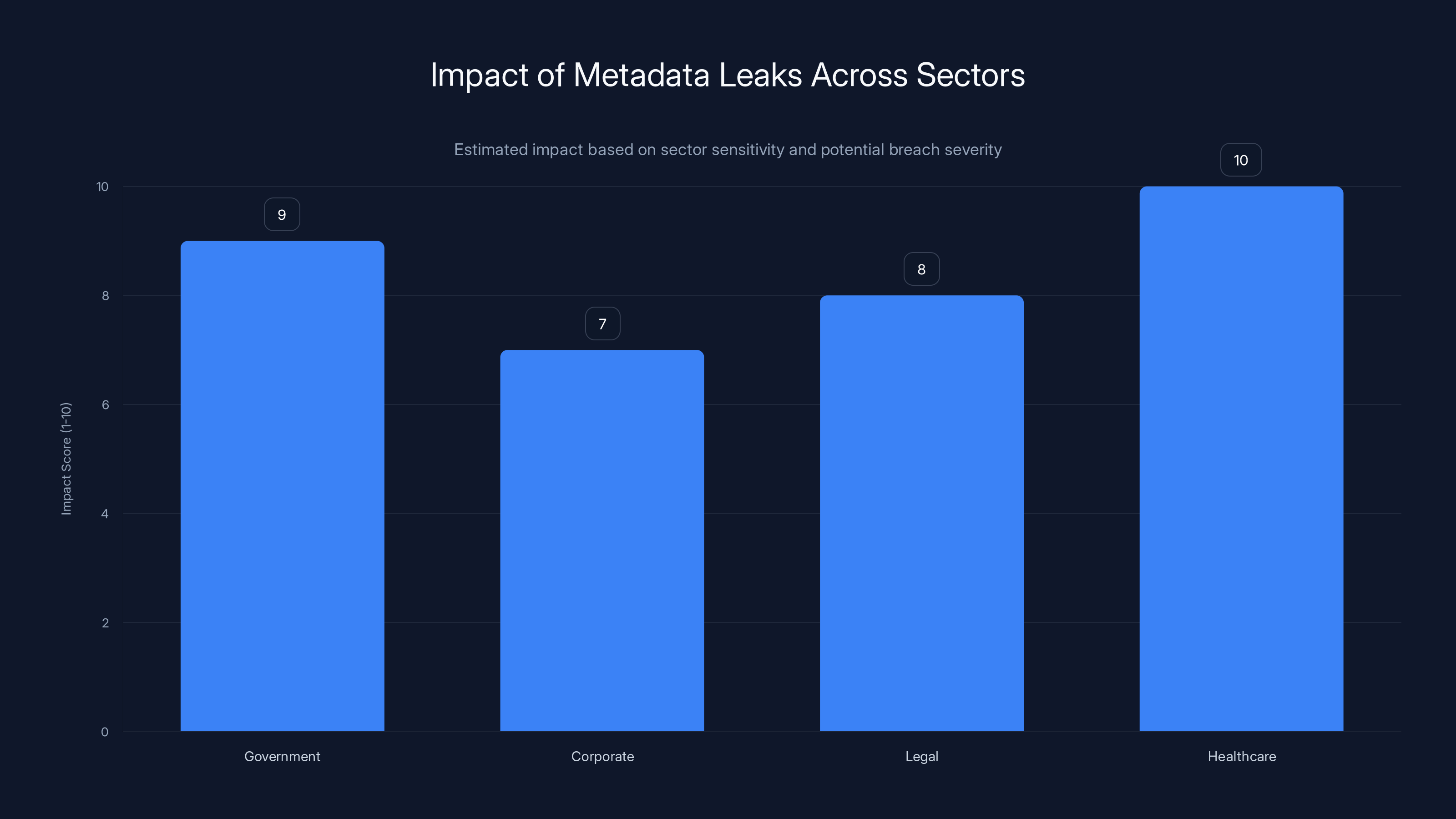
Estimated data: Government and healthcare sectors face the highest impact from metadata leaks due to sensitive information exposure.
What Is Document Metadata and Why Should You Care
Metadata is data about data. It's the invisible layer of information that exists alongside the actual content of a document. When you create a Word document, Google Slides presentation, or PDF, your computer automatically records a bunch of stuff: who created it, when it was created, what changes were made, who made those changes, software versions, computer names, user accounts.
The thing that catches most people off guard: metadata keeps accumulating. Every time someone opens a document, edits it, leaves a comment, or saves a version, more data gets added. If you pass that document to five people and they all make changes, now the document contains a complete trail of who touched it and when.
For PDFs specifically, metadata can include author information, creation date, modification date, application that created it, and most critically, any comments or notes embedded in the document. PDFs are basically containers. The visible content (the text and images you see) is just one layer. Everything else—the metadata, comments, form data, embedded objects—lives in there too.
Why does this matter? Because metadata tells stories. In the DHS case, it revealed the actual decision-making process. A comment asking someone to confirm a specific number isn't accidental data. It's evidence of how a policy was shaped. It shows who influenced whom, what options were considered, and what the real thinking was behind official positions.
For individuals, metadata can expose home addresses, computer names, office locations, employee IDs, and personal information that's supposed to be confidential. For organizations, it reveals internal communication, strategic thinking, decision-making authority, and sometimes direct evidence of knowledge about problematic activities.


Estimated data shows personal information and work patterns are the most common metadata types, each making up about 25% and 20% respectively. Location data is less frequent at 15%.
How the DHS PDF Leak Exposed a Detention Center Initiative
Let's walk through exactly what happened with the DHS document, because it's a perfect case study in how metadata exposure works in practice.
In early 2025, the Department of Homeland Security was developing what it called the "Detention Reengineering Initiative" (DRI). The plan involved building large-scale detention and processing centers across the United States, with the capacity to hold 7,000 to 10,000 people for extended periods. This was controversial. Local communities were pushing back. Environmental concerns were raised. Questions about human rights were inevitable.
DHS officials created a PDF to brief state governors on the initiative. They included FAQs, operational details, timelines, and facility specifications. The document was supposed to present the official position on detention policy. Factual. Professional. No personal opinions.
But before sending it, apparently nobody ran it through a metadata stripper.
The PDF had comments embedded throughout. One question in the FAQ asked about average length of stay for detainees. Tim Kaiser, the deputy chief of staff for US Citizenship and Immigration Services, left a note asking David Venturella (a former contractor executive now advising on detention contracts) to confirm that the average would be 60 days.
Venturella's response: "Ideally, I'd like to see a 30-day average for the Mega Center but 60 is fine."
That comment reveals several things that weren't in the official document. First, there was negotiation happening internally about what the actual average stay would be. Second, Venturella had a preference (30 days) that was different from the official figure (60 days). Third, "but 60 is fine" suggests he accepted a less-preferred outcome, which could imply pressure or compromise.
None of that nuance appears in the published document. All of it lives in metadata.
The document also listed Jonathan Florentino, the director of ICE's Newark Field Office, as the author. That's not just a name. It's a person who can be identified, contacted, and associated with the initiative. If someone wanted to protest the detention center plan, they now knew exactly who to contact.
What makes this case particularly significant is that it wasn't a one-time accident. A second version of an accompanying economic impact analysis also contained errors and metadata that shouldn't have been there. It suggests the organization didn't have standardized processes for cleaning documents before sharing sensitive information.
The Technical Side: What Information PDFs Actually Store
If you've never looked at PDF metadata yourself, here's what's typically stored inside:
Standard Metadata Fields:
- Creator (the person who made the original document)
- Producer (the software used to create it)
- Creation Date (when the file was first created)
- Mod Date (when it was last modified)
- Subject (if someone filled in the subject field)
- Keywords (if someone added them)
- Title (if someone named it in the document properties)
- Author (whoever the computer was registered to)
Comment Data:
- Author name of the person who left the comment
- Timestamp when the comment was created
- The actual text of the comment
- Whether the comment is resolved or still open
Revision History:
- Every edit that was made
- Who made it
- When it was made
- What was changed
Form Data:
- Any information submitted through fillable forms
- Digital signatures
- Checkbox states
- Text entries
Embedded Objects:
- Other files attached to the PDF
- OLE objects (like embedded Excel files)
- Any other binary data
Document Structure:
- Bookmarks and their names
- Hyperlinks and their destinations
- Layer information (which layers are hidden/visible)
- Annotation data
The key thing to understand: most of this gets stored automatically. You don't have to deliberately add metadata for it to exist. Just opening a document in different software creates new metadata entries. Saving it with a different version of the same application changes modification dates. Printing to PDF and re-saving it adds producer information.
For PDFs created from Word documents, the metadata problem gets worse. When you export a Word document to PDF, you're taking all that Word metadata (tracked changes, comments, author history) and embedding it in the PDF. Someone can then open that PDF, extract the embedded Word document, and see everything you thought you deleted.
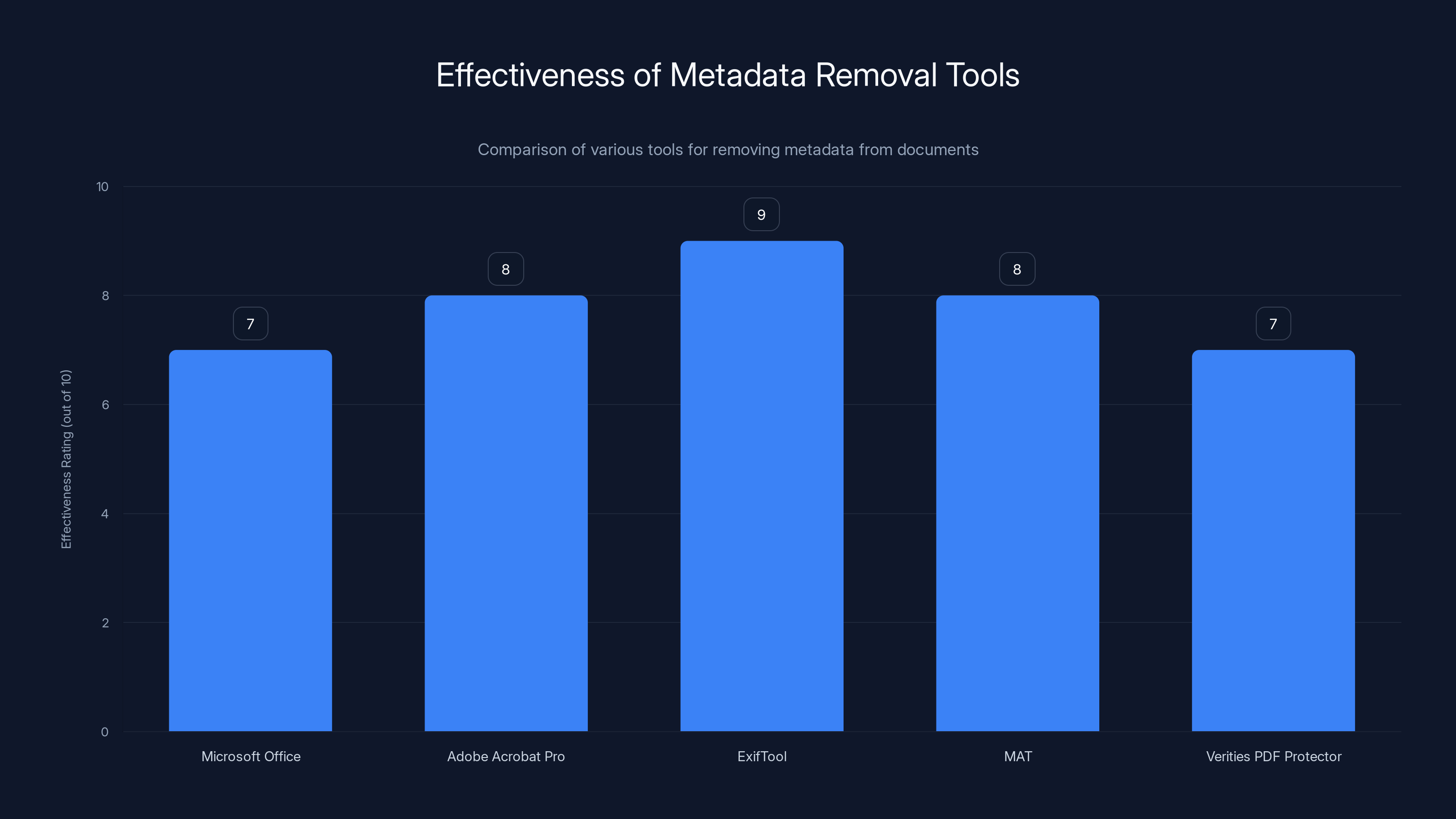
Comparison of metadata removal tools shows ExifTool as the most effective, followed closely by Adobe Acrobat Pro and MAT. Estimated data based on typical user feedback.
How Adversaries Extract and Use Metadata
Here's the uncomfortable truth: extracting metadata from PDFs is trivially easy. It doesn't require special skills or expensive tools.
Method 1: Using Free Online Tools
You can paste a PDF into any free online metadata extractor and it will pull out every field. These services work on any PDF. No login needed. No technical skill required. Within seconds, you have a complete list of who created the document, when it was created, what software was used, and every comment embedded in it.
Method 2: Using Command-Line Tools
For people comfortable with terminal commands, tools like exiftool or pdfinfo can extract metadata instantly. One command and you have the complete metadata dump. On Windows, Mac, or Linux, it works the same way.
Method 3: Using Adobe Reader
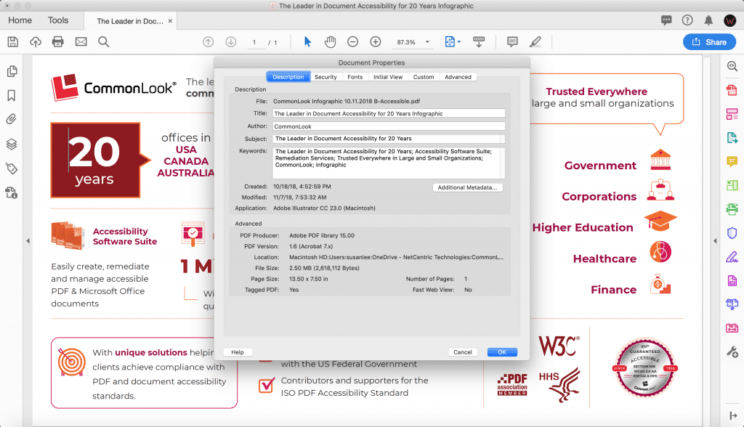
You don't even need external tools. Open the PDF in Adobe Reader, go to File > Properties > Document Properties, and click the Additional Metadata tab. Everything is visible. Comments show up in the Comments panel on the side.
Method 4: Using Python or Other Scripts
For large-scale extraction, a simple Python script using libraries like Py PDF2 or pdfminer can batch-extract metadata from hundreds or thousands of PDFs. Someone could scan an entire organization's publicly available documents and build a profile of who works there, what projects are being discussed, and when things are being worked on.
Once extracted, how is this metadata used?
Intelligence Gathering: Metadata builds pictures of organizational structure, decision-making processes, and project timelines. If you're investigating someone or something, metadata comments can reveal the thinking behind decisions.
Targeting: Author information and modification dates help identify which employees are involved in specific projects. Comments can reveal who has influence, who disagrees with decisions, and where organizational tension exists.
Evidence Collection: In legal or regulatory contexts, metadata can be more valuable than the actual document. Comments show the thinking that went into a decision, disagreements that were hidden from the final version, and information about who knew what and when.
Pattern Analysis: By analyzing metadata across multiple documents, someone can identify patterns in how organizations work, who communicates with whom, and how decisions are actually made (versus how they're officially documented).
Leak Identification: If a document gets leaked, metadata reveals who had access to it and when. It can narrow down which employee or contractor was responsible for sharing it.
In the DHS case, metadata extraction was straightforward. Someone downloaded the PDF, opened it, looked at the comments, and found evidence of the actual decision-making process. No hacking required. No security breach. Just someone examining publicly available information that shouldn't have been there.
Real-World Cases: When Metadata Exposure Went Wrong
The DHS case isn't unique. This has happened repeatedly across government, business, and legal contexts.
Case Study 1: The Sony Hack and Executive Communications
When hackers breached Sony Pictures in 2014, they didn't just steal encrypted files. They extracted metadata and used it to understand the organization's structure, identify key employees, and find the most valuable targets. Comments in documents revealed internal conflicts, salary information, and personal information about executives. The metadata made the breach significantly more damaging because it provided context and intelligence, not just raw data.
Case Study 2: Microsoft Office Documents and Author Information
For years, organizations shared Microsoft Office documents without removing author metadata. An employee would create a document, their username would be embedded, the document would be shared externally, and anyone opening it could see that it was created by "John Smith" or "Legal Department." This revealed organizational structure to competitors and exposed which employees worked on specific projects.
Case Study 3: Metadata in Medical Records
Healthcare providers have had to deal with metadata issues in patient documents. A PDF file containing medical information that was supposedly anonymized still had the treating physician's name in the metadata. Patient files that were de-identified still had creation dates revealing when specific treatments occurred. Supposedly deleted documents still had revision history showing what was removed.
Case Study 4: Legal Discovery and Hidden Edits
In litigation, metadata from documents can prove that something was deleted. A contract might show a final version in the visible text, but the metadata shows that crucial language was removed in the final revision. Comments can show that attorneys knew about problems but the final agreement doesn't mention them. These metadata revelations have changed the outcomes of multimillion-dollar lawsuits.
Case Study 5: Government Contracts and Negotiation Secrets
Beyond the DHS case, metadata in government contract documents has revealed the negotiation positions of contractors, the priorities of government officials, and the actual terms being considered before they were finalized. Comments showing disagreement about terms become evidence of awareness and consent.
Each of these cases shows the same pattern: sensitive information got shared without removing metadata, and that metadata told a story that the visible document was designed to hide.


Metadata exposure has varying impacts across sectors, with healthcare and legal sectors facing the highest risks due to sensitive information. Estimated data.
The Privacy Implications: What Metadata Reveals About You
If you're an individual sharing documents, metadata exposure might seem less critical than government secrets. But think through what's actually stored.
Your Name and Computer Information
Every document you create is tagged with your name, your username, your computer name, and sometimes your network location. If you work from home, that's not a big deal. But if you use corporate networks, your computer name might reveal your department or role. If someone correlates metadata across documents, they can figure out which computers you use, where you work, and sometimes even your physical location.
Your Work Patterns
Modification dates and creation times reveal when you work. Someone analyzing your documents could figure out your schedule, when you take vacation, and when you're most productive. For remote workers, this reveals your timezone and work hours.
Your Relationships and Communications
Comments and revision history show who you communicate with, who has influence over your work, and whose edits you accept or reject. If you work on a document with colleagues and then provide comments that change the direction, metadata shows your influence and your thinking.
Your Opinions and Disagreements
Comments in documents reveal what you actually think, separate from what the final document says. You might have suggested something different, left a note about a concern, or questioned a decision. That comment stays in the metadata even if it's not in the final version. For sensitive topics, metadata comments can reveal personal views about company policies, colleagues, or decisions.
Your Location Data
Some PDFs created from images include GPS coordinates embedded in the file. A photo of a document that was taken in your home now includes your home location in the metadata. Scan a document at an office location and that location data gets embedded. Share the PDF externally and your location is exposed.
Your Financial Information
Metadata in invoices, contracts, and financial documents can reveal pricing, payment terms, and negotiation positions. If you're doing freelance work and share contracts with clients, metadata might reveal what you charged other clients or what your negotiation position was.
For sensitive individuals—activists, journalists, security researchers, dissidents—metadata becomes a serious threat. A document shared anonymously might still have embedded information that reveals who created it or where they were when they created it.
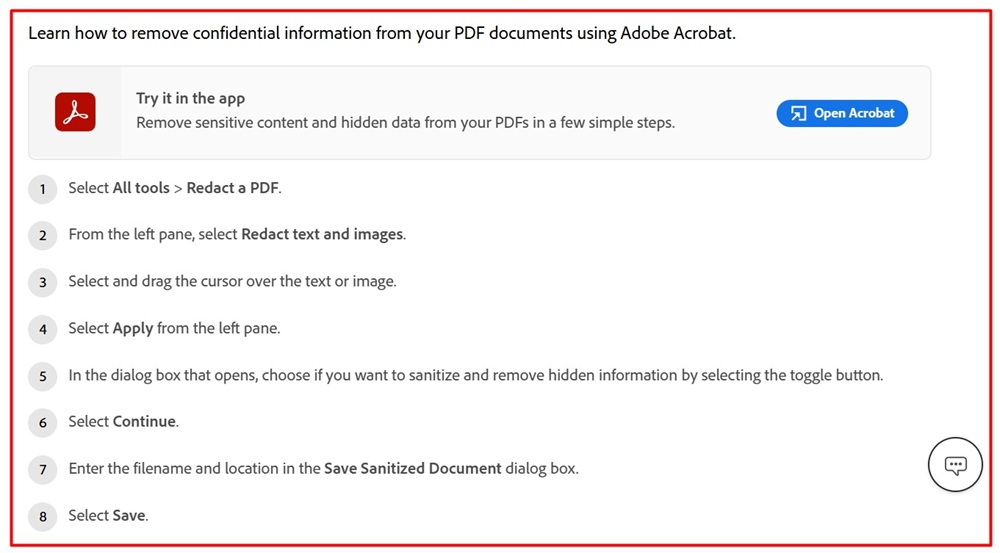
How to Strip Metadata from Documents: The Practical Steps
Now that you understand the risk, here's how to actually remove metadata before sharing documents.
Step 1: Identify What Needs Cleaning
Before you can strip metadata, you need to know which documents contain it. Ask yourself: Is this document being shared externally? Does it contain internal discussions, comments, or sensitive information? Has it been edited by multiple people? If you answered yes to any of these, it needs metadata removal.
Step 2: Use Built-In Tools First
Microsoft Office has a built-in metadata removal feature. Open any Word, Excel, or Power Point file, go to File > Info > Check for Issues > Inspect Document. This shows you what metadata is present. Then use File > Options > Trust Center > Trust Center Settings > Privacy Options and check "Remove personal information from this file properties on save."
For PDFs, Adobe Reader has similar functionality. In Adobe Acrobat Pro (paid version), you can use File > Properties > Security > Redact. But this only works if you have the Pro version.
Step 3: Recreate the Document
The most reliable way to remove metadata is to recreate the document from scratch. Copy the final text, paste it into a new document, and save with a new name. This removes all previous metadata. For formatted documents, copy from the source, paste as unformatted text, and then reformat.
This approach works but is time-consuming. For a single document, it's reasonable. For hundreds of documents, it's impractical.
Step 4: Use Third-Party Metadata Removal Tools
Several tools are designed specifically for metadata removal:
- Exif Tool (free, command-line): Works on PDFs, images, and other files. Remove all metadata with a single command.
- Metadata Anonymization Toolkit (MAT) (free, open-source): GUI tool that works on multiple file formats. Removes metadata from PDFs, documents, images, and more.
- Verities PDF Protector (free): Windows tool specifically for removing PDF metadata.
- Online metadata removers: Various free websites will strip metadata from uploaded files. The privacy risk here is that you're uploading your document to someone else's server.
Step 5: For PDFs, Export to PDF Format
If you have a document with embedded metadata and you want to clean it, open it in its native application (Word, Excel, etc.), remove comments and tracked changes, and then export or print to PDF. Don't just save as PDF. Export or print creates a new file without the history.
Step 6: Verify Removal
After removing metadata, verify it's actually gone. Use an online metadata viewer or command-line tool to check the document after cleaning. Some metadata removal processes fail silently. You think the data is removed, but it's still there.

PDFs often contain various metadata types, with document properties and author information being the most common. Estimated data.
Organizational Best Practices: Preventing Metadata Exposure at Scale
For organizations, individual document cleaning isn't scalable. You need systematic processes.
Establish Document Standards
Create organization-wide guidelines about document handling. Specify which documents need metadata removal before external sharing. Designate who is responsible for cleaning documents. Make it part of the approval process before anything leaves the organization.
Automate Metadata Removal
Use scripts or workflow automation to strip metadata from documents before they're shared. A simple Python script can batch-process documents and remove metadata automatically. This removes human error and ensures consistency.
Version Control Through Repositories
Instead of emailing documents around with tracked changes enabled, use version control systems like Git or document management platforms like Share Point. These systems maintain history and comments separately from the shared document, so you can share clean files without loss of information.
Train Employees
Most metadata exposure happens because people don't understand the risk. Training employees on what metadata is, why it matters, and how to remove it prevents the majority of accidental leaks. Make it part of onboarding and annual security training.
Use Professional Tools
For sensitive documents, use professional-grade document management systems designed specifically to handle metadata. These systems remove metadata as part of their workflow, verify removal, and create audit trails showing which documents were cleaned and when.
Review Before Publication
Establish a review process where documents are checked for metadata before external sharing. This is especially important for government, legal, and healthcare organizations where metadata can have serious consequences.
Monitor Your Documents
If you share documents publicly, monitor them for metadata leaks. Periodically download PDFs from your website and check their metadata. If you find leaked information, it reveals process failures that need fixing.
The Bigger Picture: Privacy, Security, and Transparency
The DHS detention center case raises bigger questions about privacy, government transparency, and how information gets used.
On one hand, metadata exposure can reveal important information about how government works. The comment about preferring 30 days versus 60 days shows that official positions aren't unanimous. It reveals the actual thinking behind policies. In a democracy, that transparency can be valuable. It shows how decisions are actually made, not just the official story.
On the other hand, people have a legitimate expectation of privacy in their internal communications. A comment asking someone to confirm a number isn't a public statement. It's an internal discussion. The fact that it became public because of a technical oversight isn't the same as deliberately publishing it.
This tension plays out across many contexts. Leaked metadata from Sony revealed internal drama and personal information that shouldn't have been public. Leaked metadata from legal cases revealed attorney strategy and client confidences. Leaked metadata from medical records revealed patient information and treatment details.
The pattern is consistent: metadata exposes what people were trying to keep private.
Moving forward, organizations need to take metadata seriously as a security and privacy issue. Individuals need to understand what information their documents contain. And tools and processes need to make metadata removal easy and automatic.
For government specifically, there's an argument for stronger metadata standards. If documents are being shared with the public or with other agencies, they should be metadata-free by default. That protects both privacy and security while still maintaining transparency about official positions.
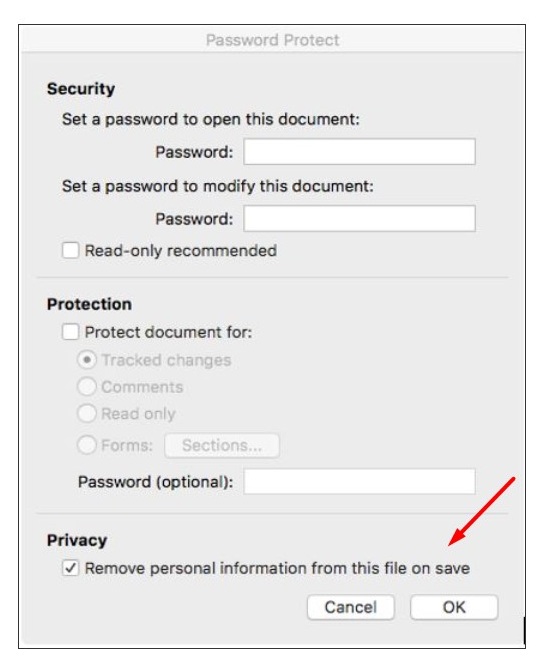

This pie chart illustrates the estimated distribution of common metadata types found in documents. Each type, such as author information and comments, plays a critical role in understanding the document's history and context. (Estimated data)
Future of Document Security: Where This Is Heading
Metadata exposure isn't going away. As documents become more collaborative and more integrated with cloud systems, metadata becomes more abundant.
Cloud Collaboration and Metadata Explosion
Google Docs, Microsoft 365, Notion, and similar tools track every edit, every comment, every person who touched the document. Collaboration metadata is actually useful within an organization. But if you share a link with external people, all that metadata goes with it. Someone can see the entire edit history, every comment ever made, and every person who contributed.
AI-Powered Metadata Analysis
As AI tools improve, they'll get better at extracting meaning from metadata. Instead of just finding author names and dates, AI will analyze patterns of collaboration, map organizational relationships, and identify decision-making processes. Metadata won't just reveal what's been said, but how organizations actually work.
Blockchain and Immutable Records
Some organizations are exploring blockchain-based document systems that create immutable records of every change. This is great for security and audit trails, but it means metadata becomes permanent. You can't remove it because the whole point is that you can't remove it.
Privacy-Preserving Technologies
On the flip side, new technologies are emerging to preserve privacy while maintaining functionality. Zero-knowledge proofs can verify document authenticity without revealing metadata. Secure enclaves can process documents without exposing metadata. Differential privacy techniques can add noise to metadata while preserving its utility for legitimate purposes.
Regulatory Requirements
As privacy regulations tighten (GDPR, CCPA, and others), organizations will face legal requirements to remove certain metadata. Personal data in metadata will need to be stripped before documents are shared. This could drive better tools and processes.
The future probably involves three parallel trends: better automation of metadata removal, stronger encryption around metadata, and smarter analysis of metadata patterns. Organizations will need to adapt to all three.

What Happened After the DHS Metadata Leak
Worth noting: the DHS document remained on the New Hampshire governor's website with the metadata still visible. The government didn't respond to requests for comment about what specifically the people mentioned in the metadata were working on, or whether they had access to tools that should have removed the metadata before sharing.
The document exposed a timeline: ICE planned to activate all detention facilities by November 30, 2026. It revealed the scale: regional processing centers holding 1,000 to 1,500 people, mega detention centers holding 7,000 to 10,000. It outlined the rationale: ICE was hiring 12,000 new law enforcement officers and needed detention capacity to match the anticipated increase in enforcement operations.
All of that was intended to be public. The comments about 30-day versus 60-day average stays, the negotiations about facility specifications, and the personal preferences of specific officials—that was the accidental part.
The larger story is that metadata exposure happens constantly. Documents leak with sensitive information all the time. Sometimes it's government secrets. Sometimes it's corporate strategy. Sometimes it's personal information. The difference between an inconvenient leak and a major security breach often depends on whether the metadata contained valuable information.
For the DHS, the leak revealed decision-making processes. For Sony, it revealed internal conflict. For legal cases, it reveals attorney strategy. For healthcare organizations, it reveals patient information. The technology is the same. The impact depends on what metadata you're exposing.

Practical Security Checklist: Protecting Your Documents
Here's what you should do right now to secure your documents:
For Everyone:
- Check a document you recently created or edited. Use exiftool or an online metadata viewer. See what's actually stored.
- For your next document that you plan to share externally, remove the metadata before sharing. Use one of the tools mentioned above.
- Create a personal policy: all external document sharing requires metadata removal.
- Check your cloud storage settings. If you use Google Drive or One Drive, understand what metadata they preserve and what's visible to recipients.
- For sensitive documents, consider whether you actually need to share them, or whether a summary document with metadata removed is sufficient.
For Organizations:
- Audit your currently shared documents. Download a sample of PDFs and Word documents from your public sites and external sharing platforms. Check for metadata.
- If you find metadata, remove it and publish updated versions.
- Create a document handling policy that specifies which documents need metadata removal before external sharing.
- Implement automated metadata removal in your workflow. Use a script or professional tool that strips metadata before documents are published.
- Train employees on metadata risks and removal procedures.
- Establish a review process where documents are checked before external sharing.
- Consider implementing a document management system that handles metadata removal automatically.
- Conduct regular audits to verify that your metadata removal process is working.
FAQ
What exactly is metadata in a PDF?
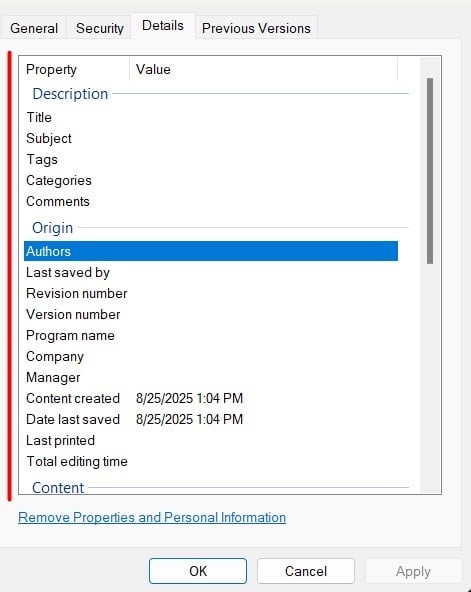
Metadata in PDFs includes the author name, creation and modification dates, comments, tracked changes, form data, revision history, and embedded information about the software used to create or edit the document. This data is stored alongside the visible content but isn't visible on the printed page unless you specifically look for it in document properties or use metadata extraction tools.
Can metadata be removed from any PDF?
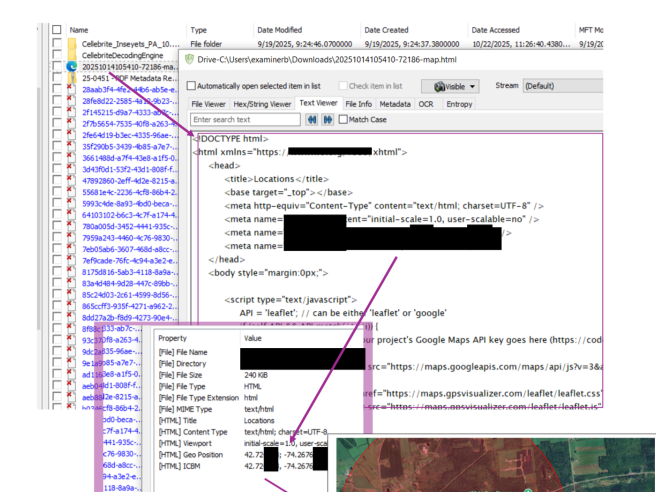
Most PDFs can have metadata removed using specialized tools, but the ease depends on how the PDF was created and what permissions are set. PDFs created from Word or Excel documents can be cleaned by exporting fresh PDFs. Password-protected PDFs might resist metadata removal. Using online tools like exiftool or dedicated software like MAT usually works for standard PDFs, though some may require manual recreation for complete removal.
Why do government organizations keep getting caught sharing documents with metadata?
Government organizations typically don't have standardized metadata removal processes built into their document workflows. Employees create documents using standard tools, add comments during review, and then share the final version without realizing metadata is attached. The lack of automated metadata stripping and inconsistent training means sensitive information gets exposed repeatedly despite the high stakes involved.
How can I tell if a document I received contains sensitive metadata?
Open the document in its native application and check the properties panel. In Word, go to File > Properties > Advanced Properties. In PDFs, open the document properties. Online tools like exiftool.org let you upload a file and instantly see all metadata. Comments are usually visible in a comments panel in the application. If you suspect sensitive information, extract the full metadata and review what's there.
Does simply deleting comments from a document remove the metadata about them?
No. Deleting visible comments might remove the visible text, but metadata about the comment (who wrote it, when it was written, what it said) often remains embedded in the file's revision history or internal structure. The only reliable way to remove comment metadata is to recreate the document from scratch or use a dedicated metadata removal tool that actually deletes the underlying data structures.
What's the difference between removing metadata and redacting information?
Redacting means visually blocking out text so it's not visible on the page, but the text still exists in the metadata. Removing metadata means the data structures themselves are deleted from the file. For sensitive documents, you need to do both: redact visible information AND remove any metadata that might contain the unredacted version.
Can cloud storage services like Google Drive or One Drive protect documents from metadata exposure?
Cloud services preserve detailed metadata about file access, editing, and sharing, but they usually don't automatically remove metadata from the files themselves. When you share a Google Docs or One Drive file with someone, they can see the full edit history and comments unless you specifically configure privacy settings. Sharing a downloaded PDF created from these files will include metadata unless you deliberately remove it before download.
Is metadata exposure a bigger security risk for individuals or organizations?
For organizations, metadata exposure reveals strategy, decision-making processes, and relationships. For individuals, it reveals location, work patterns, relationships, and personal opinions. Both are serious. Government employees and contractors face security clearance risks from metadata exposure. Dissidents and activists face safety risks. Most individuals underestimate the risk because the exposure usually happens silently, without their knowledge.
Conclusion: Why This Matters and What You Should Do
The DHS detention center document leak wasn't the result of sophisticated hacking. Nobody cracked encryption or bypassed security systems. A government official sent a PDF through normal channels, and the metadata that was supposed to be hidden became public. One sentence in metadata—a comment about preferring shorter detention stays but accepting longer ones—told a story that the official document didn't explicitly mention.
That single incident illustrates why metadata matters. It's not just technical information. It's the invisible record of how decisions get made, what people really think, and how information moves through organizations.
For individuals, metadata exposure reveals personal information and behavior patterns that you never intended to share. For organizations, it exposes decision-making processes and internal disagreements. For governments, it reveals how policy actually gets shaped, separate from official narratives.
The fix isn't complicated. It requires two things: awareness that metadata exists and contains sensitive information, and deliberate action to remove it before sharing documents. For individuals, this means using metadata removal tools before sharing important documents. For organizations, it means automating metadata removal as part of the document publishing workflow.
We live in a world where documents are constantly shared. Email, cloud storage, shared drives, and collaborative platforms mean documents move between people and organizations constantly. Most of that sharing happens without anyone thinking about metadata. Most recipients never check what metadata is attached. Most senders never remove it.
Until this becomes a standard practice—where metadata removal is automatic and where people understand what information their documents contain—privacy leaks will continue. The information is just sitting there in the metadata, waiting to be discovered by someone paying attention.
The good news: this is fixable. You don't need new technology or security breakthroughs. You just need to use existing tools and build awareness into your workflows. Start today. Check a document you created. See what metadata it contains. Remove it before you share. Then make it a habit.
Your documents contain more information than you realize. Make sure the information you share is actually the information you intend to share.
Key Takeaways
- PDF metadata contains author names, creation dates, comments, and edit history that most users never see—and can expose sensitive information when documents are shared
- The DHS detention center document leak revealed how a single embedded comment about detention facility policies exposed the internal decision-making process that official documents concealed
- Extracting metadata is trivially easy using free tools, allowing anyone to analyze publicly shared PDFs and discover organizational secrets, government operations, and personal information
- Metadata removal must be deliberate and automated—simply sharing final documents without tools or training leaves sensitive information exposed in the invisible metadata layers
- Organizations need systematic processes for metadata removal, employee training, and automated workflows to prevent repeated accidental exposure of confidential information
Related Articles
- Android AI Photo Editor Data Breach: 2M Users Exposed [2025]
- Chrome's New Split View and PDF Tools Transform Browser Productivity [2025]
- Epson WorkForce Pro All-In-One Printer Guide [2025]
- Google Play's AI Defenses Block 1.75M Bad Apps in 2025 [Analysis]
- Cellebrite's Double Standard: Phone Hacking Tools & Human Rights [2025]
- Adidas Data Breach: Was It Really Hacked or Third-Party? [2025]

