![Kilo Slack Bot: AI-Powered Code Shipping & Alternatives [2025]](https://images.ctfassets.net/jdtwqhzvc2n1/4cptf24mzCK6LcSxsLAHoi/596ad32d8a9666e72b0f1d3077648ec8/nuneybits_Chat_bubble_in_rainbow_colors_turning_into_computer_c_325860e4-2d7b-49f6-9118-9bad9740085b.webp?w=800&q=75)
Kilo for Slack: The Future of AI-Powered Code Shipping from Chat
Introduction: When Engineering Teams Make Decisions in Slack
The modern software development workflow has become increasingly fragmented. Engineers spend their days switching between multiple applications—their IDE, GitHub for code review, Slack for team communication, and project management tools for tracking work. Each context switch introduces friction, delays decision-making, and creates opportunities for miscommunication. Into this gap steps Kilo for Slack, an AI-powered bot that attempts to collapse multiple workflows into a single interface: the chat platform where engineering teams already gather to discuss problems.
Kilo Code, an open-source AI coding startup backed by GitLab cofounder Sid Sijbrandij, launched its Slack integration in 2025 with an audacious premise: developers should be able to ship code changes, debug issues, and create pull requests without ever opening their integrated development environment or switching applications. Rather than competing directly with IDE-based AI coding assistants like Cursor or Claude Code, Kilo is making a strategic bet that the future of AI development tools lies in embedding capabilities into the workflow endpoints where actual engineering decisions happen—and for most teams, that means Slack.
This represents a fundamental shift in how development teams think about AI-assisted coding. Instead of pulling context into a specialized tool, Kilo pushes the tool to where the context already exists. The implications stretch beyond productivity gains to fundamental questions about how teams collaborate, how code gets reviewed, and what role human judgment plays in an increasingly automated development process.
The launch also featured a controversial partnership with Mini Max, a Hong Kong-based AI company that recently completed an IPO. Mini Max's M2.1 model serves as Kilo's default language model, raising important questions about data residency, security compliance, and whether frontier model capabilities have finally closed the gap with proprietary alternatives. For enterprise teams managing sensitive codebases and strict regulatory requirements, these decisions carry significant weight.
This comprehensive guide analyzes Kilo's technical architecture, evaluates its positioning against competing solutions, examines the security and compliance implications of its design, and explores alternative approaches to AI-assisted development workflows. Whether you're evaluating Kilo for your team, curious about the broader trend of workflow-embedded AI tools, or considering how to architect AI capabilities into your own development processes, this analysis provides the context needed to make informed decisions.

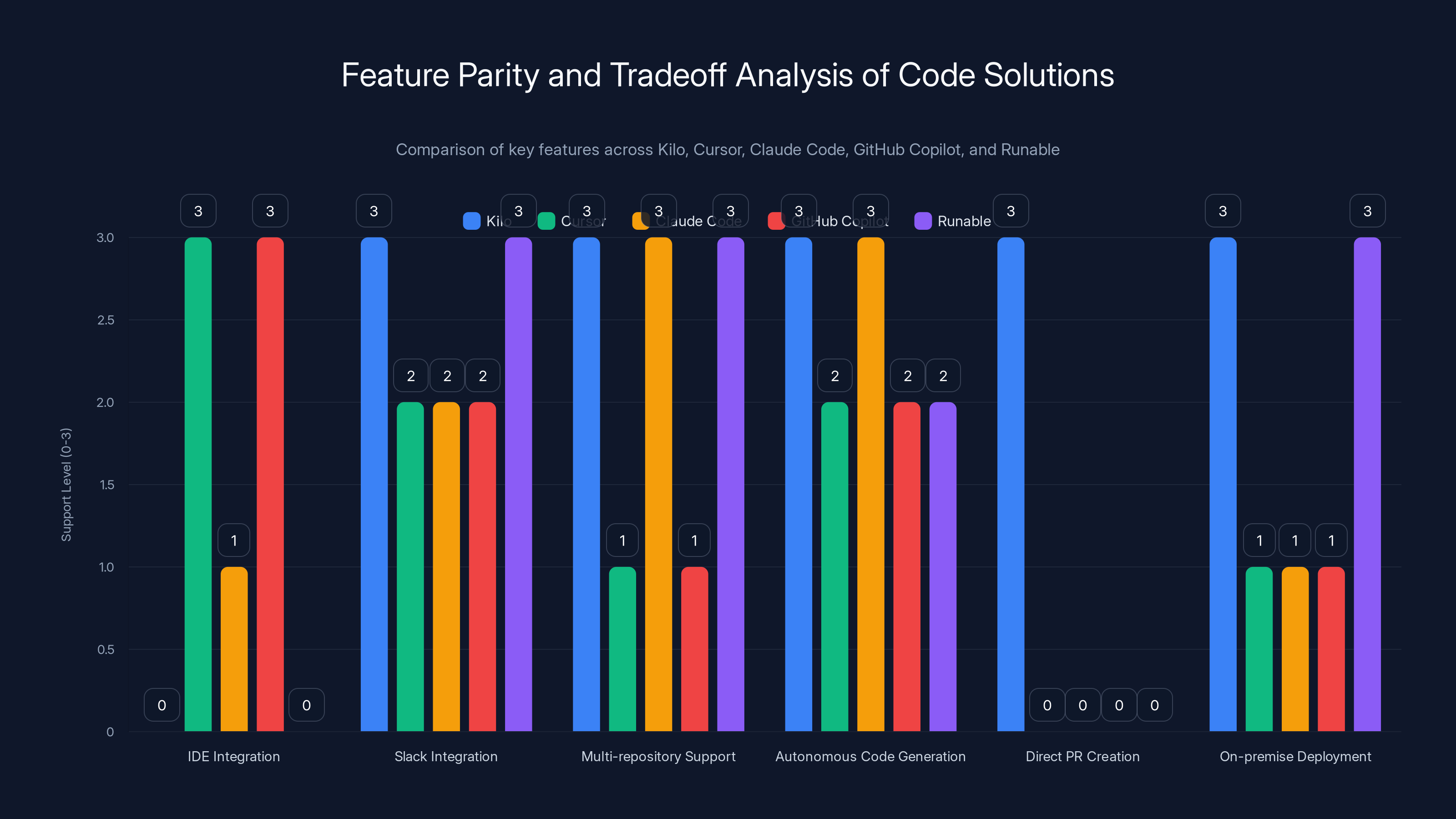
Kilo and Runable offer strong support for multi-repository and autonomous code generation, while GitHub Copilot excels in IDE integration. Estimated data based on feature descriptions.
Understanding Kilo for Slack: Architecture and Core Functionality
How the Slack Integration Works: From Conversation to Pull Request
At its core, Kilo for Slack operates on a deceptively simple premise that becomes complex in execution. A developer mentions @Kilo in a Slack thread, providing natural language instructions about what they want to accomplish. The bot then reads the entire conversation history within that thread, accesses connected GitHub repositories, processes the context through its language model, and executes either an informational response or a concrete code change.
The workflow typically unfolds in distinct stages. First, the bot ingests the full Slack thread context, including all messages, replies, and threaded conversations. This multi-turn conversation context becomes the foundation for understanding what the developer actually needs. A product manager might have described a bug, a senior engineer might have suggested debugging steps, and a junior engineer might have asked clarifying questions. Collectively, this conversation contains rich context about the problem space, potential solutions, and constraints.
Second, Kilo establishes connections to relevant GitHub repositories. Rather than working with a single configured repository like some Slack integrations, Kilo claims to handle multi-repository context simultaneously. This means if a Slack thread discusses changes needed across a frontend repository, a backend API repository, and a shared utilities library, the bot can potentially reference and modify code across all three. For organizations with monorepo strategies or multiple interconnected repositories, this capability addresses a genuine pain point.
Third, the bot spins up what Kilo calls a "cloud agent"—essentially a containerized execution environment where the language model can reason through the problem, analyze the codebase, and generate code solutions. This isn't instantaneous; the bot must understand the problem, examine relevant files, consider existing patterns, and generate appropriate changes. The execution happens asynchronously, with progress updates visible in Slack.
Finally, if the request involves code changes, the bot creates a new branch, commits changes, and opens a pull request on GitHub. Critically, this pull request includes the thread context as part of the PR description, creating an audit trail of how the decision was made and what discussion led to the change. The entire process remains visible within Slack, minimizing context switching.
A concrete example clarifies how this flows in practice. Suppose your team's authentication service starts throwing null pointer exceptions in production. A product manager posts in the #incidents Slack channel: "Auth service down, null pointer in authentication flow." Engineers begin discussing the likely cause. One suggests it's related to a recent configuration change. Another asks about the specific error location. Instead of someone manually reproducing this conversation elsewhere, a developer simply types: "@Kilo based on this thread, can you implement the fix for the null pointer exception in the Authentication service?" Kilo reads the discussion, accesses the authentication service repository, analyzes the recent changes, identifies the problem, implements a fix, runs tests, and opens a pull request—all without the developer touching their IDE.
Multi-Repository Context: Why This Matters for Modern Architectures
The emphasis on multi-repository context handling reflects genuine architectural evolution in how teams organize code. The monolith era is behind many organizations. Instead, teams maintain separate repositories for different services (microservices), frontend and backend code, shared libraries, infrastructure-as-code, and deployment pipelines. A single feature request or bug fix might require changes across three or four repositories.
Traditional AI coding assistants struggle with this distributed reality. Cursor's Slack integration, Kilo notes, requires configuration on a per-repository basis per workspace or channel. If a thread discusses an issue affecting multiple repositories, users must manually switch configurations or have multiple integration instances—friction that defeats the purpose of workflow-embedded assistance. The same applies to most IDE-based AI assistants, which typically focus on the currently open repository.
Kilo attempts to transcend this limitation by understanding which repositories are relevant to a Slack thread and accessing them simultaneously. This requires sophisticated repository discovery mechanisms—how does the bot know which repositories to access?—and context prioritization—if the thread mentions fifty repositories, which ones matter most? The company hasn't publicly detailed these mechanisms, which is a notable limitation for organizations evaluating the platform.
Consider a real-world example: Your team uses a shared authentication library across five different services. A security researcher identifies a vulnerability in that library. Your team discusses the fix in Slack, considering how the change might affect each service. A truly intelligent system would understand that changes to the shared library might require defensive updates in each service that consumes it, test changes, documentation updates, and potentially deployment orchestration. Whether Kilo can handle this level of complexity across multiple repositories remains unclear.
Thread State Persistence and Conversation Continuity
Another key differentiator Kilo highlights is persistent thread state. Slack threads naturally accumulate context over time. If an engineer initially describes a problem, leaves work, and returns an hour later with new information, Kilo maintains awareness of both the initial context and the new developments. This differs from stateless interactions where each message is processed independently without awareness of previous conversational context.
This matters because software problem-solving rarely concludes in a single message. A developer might say "fix the login bug," then three messages later add "but don't change the password reset flow." Then an hour after that, specify "the bug happens only on mobile," adding a new constraint. A stateful system learns and adapts as new information emerges. A stateless system requires all context in a single message or must be reconfigured with each interaction.
Kilo frames this as "task-level continuity across longer workflows," suggesting that a complex multi-step development task can unfold naturally in a Slack conversation, with the AI assistant maintaining coherent understanding throughout. This is technically sophisticated—it requires managing conversation state, updating mental models as new information arrives, and handling potential contradictions when new constraints conflict with initial assumptions.
However, this design also introduces risk. State accumulation without periodic reset can lead to increasingly entrenched misunderstandings or outdated assumptions. Teams would need clear mental models for when to start fresh threads versus continuing conversations, or risk pushing code based on confusion from earlier context that everyone has forgotten about.
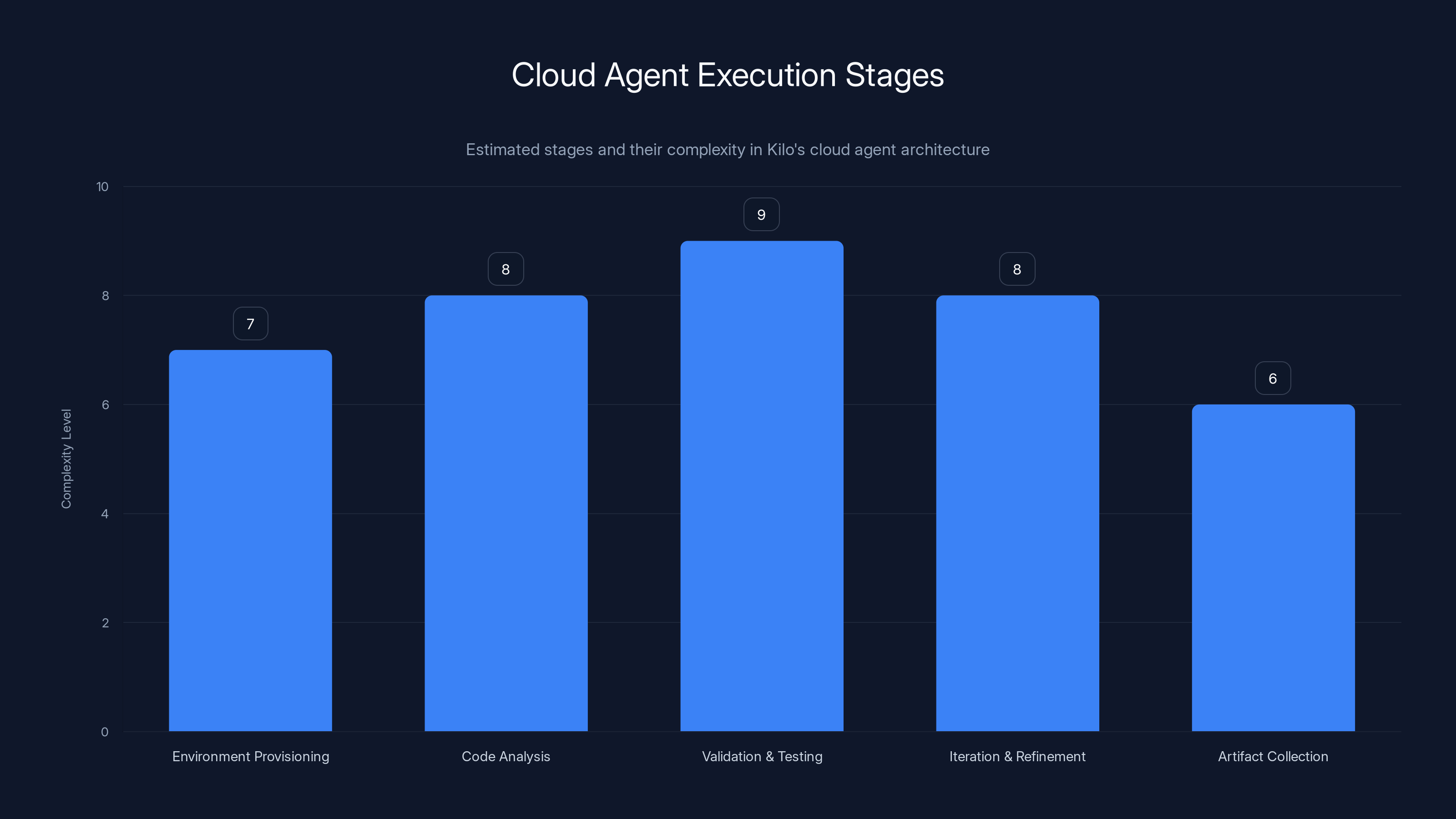
The cloud agent execution involves multiple complex stages, with validation and testing being the most complex due to rigorous checks. Estimated data.
The Mini Max Partnership: Model Selection and Geopolitical Implications
Why Kilo Chose Mini Max M2.1 as Its Default Model
Kilo's decision to default to Mini Max M2.1 rather than proprietary frontier models like GPT-4 or Claude 3 reflects a deliberate strategic choice grounded in both technical and business considerations. Mini Max, a Shanghai-headquartered AI company that recently completed a Hong Kong IPO, has developed strong open-weight language models that perform competitively with larger proprietary alternatives.
The choice sends a signal about Kilo's philosophy: the performance gap between open-weight and proprietary frontier models has narrowed sufficiently that organizations shouldn't feel locked into proprietary vendors for basic capabilities. Mini Max M2.1 provides reasonable code generation abilities for many development tasks—bug fixes, refactoring, feature implementation—while offering cost advantages and deployment flexibility.
From a business perspective, defaulting to Mini Max likely involved partnership economics. Kilo gets integration support and potentially favorable API pricing or revenue sharing arrangements. Mini Max gains validation from a developer-focused tool in a competitive market. This kind of partnership allows startups like Kilo to offer feature-rich products without bearing the full computational cost of serving users through expensive frontier models.
Technically, M2.1 represents a capable middle ground. It's not as powerful as the latest GPT-4 or Claude variants, but it's substantially more capable than earlier open-source models. For code generation tasks, where the problem space is well-defined and the output quality can be validated against actual execution results, this tradeoff is less severe than for creative writing or abstract reasoning tasks. A code change either compiles and passes tests or it doesn't—objective feedback mechanisms allow developers to catch and correct model mistakes.
Addressing the Geopolitical Elephant: China-Based Model Infrastructure
The Mini Max selection immediately prompted questions about data residency, security compliance, and whether organizations are comfortable processing proprietary source code through infrastructure controlled by Chinese entities. These concerns aren't theoretical paranoia—they reflect legitimate regulatory and business considerations.
Kilo's leadership addressed this head-on by emphasizing that Mini Max's infrastructure, while Hong Kong-headquartered, uses major U.S.-compliant cloud providers for actual model hosting. Specifically, they cited AWS Bedrock, Google Vertex, and Microsoft AI Foundry as hosting locations. This matters significantly. It means source code wouldn't necessarily traverse Chinese infrastructure; it would route through U.S.-based cloud providers' systems.
However, important nuances exist here. Mini Max as a Hong Kong-based company falls under different regulatory frameworks than purely U.S.-based alternatives, even if the infrastructure itself is U.S.-hosted. Hong Kong's regulatory environment, while more open than mainland China, involves national security considerations that vary from U.S. jurisdiction. Enterprise security teams would need to evaluate whether their data residency and sovereignty requirements permit using models developed and operated by Hong Kong entities, even if hosted in U.S. clouds.
Kilo's response that the company is "model-agnostic" and offers access to more than 500 models addresses this concern partially. Enterprise customers can indeed choose alternative models—including fully proprietary options like Claude or GPT-4 if their requirements demand it. But the default matters. Default choices influence adoption, create switching friction, and signal the company's comfort level with particular arrangements.
The bigger picture here involves the acceleration of open-weight model competition and geographic expansion in AI development. Mini Max's IPO suggests that non-U.S. AI companies can raise capital and achieve scale. Kilo's partnership with Mini Max reflects a world where AI capabilities are increasingly decoupled from U.S. vendors, creating both opportunities and compliance challenges for organizations.
Model Agnosticism: Freedom or Fragmentation?
Kilo's claim of supporting more than 500 models appears to position flexibility as a core value. This ostensibly gives organizations agency—choose the model that fits your security requirements, performance needs, and cost constraints. For enterprise buyers who've experienced vendor lock-in, this sounds appealing.
In practice, model agnosticism introduces complexity. Different models have different:
- Performance characteristics for code generation
- Latency profiles (some models respond in seconds, others in minutes)
- Cost structures (some charge per token, others per request)
- Behavioral quirks and failure modes
- Fine-tuning and customization capabilities
Supporting hundreds of models means Kilo must abstract over substantial diversity, potentially leading to suboptimal performance with any specific model. It's the classic engineering tradeoff: maximum flexibility often means optimizing for none specifically. An alternative architecture would optimize deeply for a narrower set of models, potentially extracting more value from each.
Moreover, organizations considering hundreds of model options need guidance. Most teams lack the expertise to evaluate model fit independently. This creates demand for Kilo to curate and recommend specific models for specific use cases—which partially undermines the "agnosticism" concept.
Competitive Landscape: How Kilo Positions Against Cursor and Claude Code
Cursor: The IDE-Native Approach
Cursor represents perhaps the most successful commercial AI coding assistant to date, raising
Cursor's value proposition centers on reducing friction within the IDE environment. Instead of writing code, then asking an AI assistant for help, developers receive suggestions, completions, and refactoring recommendations inline as they work. The entire conversation between developer and AI happens within the context of the code being modified—there's no need to explain what you're working on because the AI sees it directly.
However, Cursor's Slack integration—which Kilo specifically critiques—operates on a per-repository basis per workspace. If a Slack thread discusses an issue affecting multiple repositories, users need to either manually switch Cursor's configuration or provision multiple integration instances. This reflects Cursor's core architecture: it's optimized for single-repository workflows where developers focus on code in one project at a time.
For organizations using microservices architectures or multi-repository development patterns, this limitation is real. A developer maintaining services across three repositories experiences genuine friction if they need to involve Cursor in discussions spanning multiple repos. The Slack integration becomes less useful, pushing teams back toward IDE-native assistance or creating workarounds.
Kilo's positioning here is that by starting with Slack as the primary interface rather than treating Slack as secondary to the IDE, it can architect for distributed contexts from the ground up. Where Cursor asked "how do we extend IDE functionality into Slack?", Kilo asked "how do we embed powerful code capabilities into existing chat workflows?" These produce different optimization landscapes.
Cursor also benefits from network effects around its IDE extension ecosystem and integrations with development tools. It's integrated with GitHub, supports multiple languages and frameworks deeply, and has accumulated specific optimizations for common development patterns. Starting from Slack, Kilo faces a steeper climb in building equivalent depth of integration and language-specific optimization.
Claude Code: Anthropic's Agentic Approach
Claude Code represents Anthropic's entry into AI-assisted development, emphasizing agentic behavior—the model doesn't just suggest code, it can actually execute commands, run tests, and iterate toward solutions independently. This is philosophically powerful: instead of developers telling the AI what to do step-by-step, the AI can reason through problems and self-correct.
For Slack integration, Claude Code's approach differs from both Cursor and Kilo. According to Kilo's analysis, Claude Code can be added to a Slack workspace and responds to mentions using surrounding conversation context. But Kilo claims Claude Code lacks "persistent, multi-turn thread state or task-level continuity across longer workflows," with each interaction handled based on context included in that specific prompt rather than maintaining evolving execution state.
This critique targets a real limitation in many conversational AI integrations. Stateless interactions work fine for discrete questions ("what does this function do?") but become problematic for complex, multi-step problem-solving. If a developer asks Claude Code to implement a feature, receives a response, identifies an issue with that response, and asks for modifications, a stateless system might lose track of the original context or fail to understand that suggestions should maintain consistency with the previous iteration.
However, Anthropic would likely counter that Claude's agentic capabilities within a single interaction overcome much of this limitation. Rather than maintaining thread state across multiple Slack messages, the model can reason through complex problems within a single extended interaction, executing steps autonomously until reaching a solution. This differs from Kilo's model of task continuity but might achieve similar outcomes for some workflows.
Claude Code's limitation in Slack context is partly architectural and partly intentional. Slack is secondary to Claude Code's core offering—the web interface where users can interact directly with the model and grant it tool-use permissions. A Slack integration necessarily constrains the interaction model. Anthropic likely chose to keep the Slack integration relatively simple rather than risk security issues or weird behaviors from complex agentic workflows triggered accidentally in chat.
Positioning and Market Segmentation
These three products (Cursor, Claude Code, and Kilo) serve different optimization targets and team needs:
Cursor optimizes for individual developer velocity within their IDE. It's ideal for teams where developers spend most of their time in code editing and need maximum context and assistance at the point of code creation.
Claude Code optimizes for powerful agentic reasoning and autonomous execution. It's ideal for teams comfortable with AI undertaking substantial autonomous action and who benefit from deep reasoning about problems.
Kilo optimizes for team workflows and distributed decision-making. It's ideal for teams that make development decisions collaboratively in chat and want to collapse the gap between discussion and implementation.
These aren't necessarily competing products—a team might use all three. A developer might use Cursor for day-to-day coding, consult Claude Code for complex architectural decisions, and use Kilo for quick fixes emerging from team discussions. The market is large enough for multiple approaches, and product success likely depends less on absolute comparison and more on fit with specific team workflows.
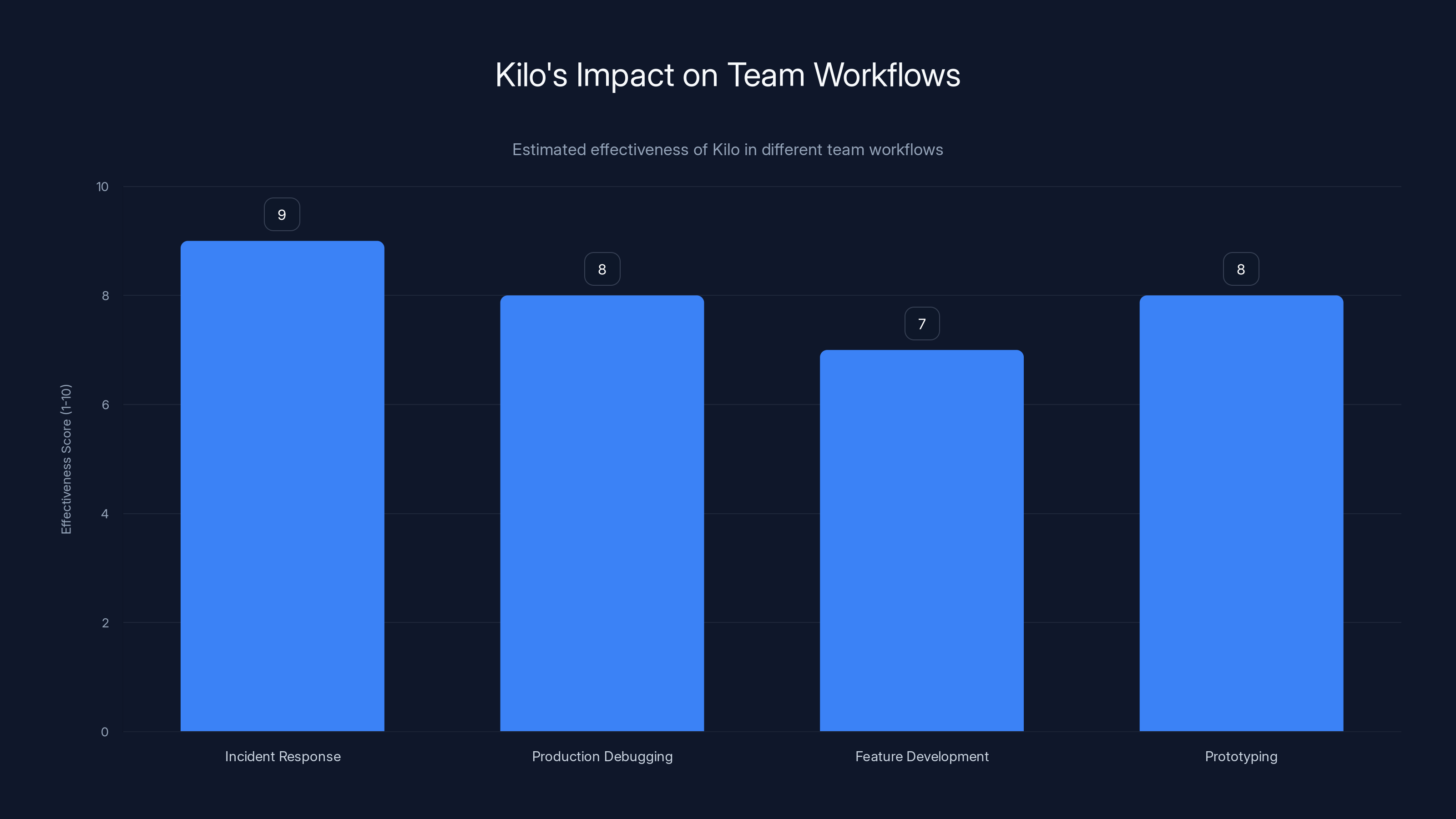
Kilo excels in incident response and production debugging with high effectiveness scores, streamlining workflows and reducing manual tasks. Estimated data.
Security, Compliance, and Enterprise Considerations
Data Residency and Source Code Protection
When source code—the intellectual property foundation of software companies—flows through third-party systems, security and compliance become paramount concerns. Kilo's architecture necessarily requires sending Slack conversation context (which may contain partial code snippets, error messages, and internal discussion) and accessing connected GitHub repositories to provide assistance.
The data flow looks roughly like:
- Slack conversation → Kilo's system
- GitHub API calls to fetch repository content
- Processing through language model (default Mini Max, configurable)
- Response generation and PR creation
At each step, sensitive information could potentially be exposed, retained, or used inappropriately. Kilo's security posture depends on:
Model data retention policies: Does Mini Max retain code snippets from API calls for model improvement? Many commercial AI APIs explicitly state that content sent to their services might be used for training, though many enterprises require contractual guarantees that their code won't be used this way. Kilo would need contractual clarity here.
Data transmission security: Are API calls encrypted? Does authentication use industry-standard OAuth and API key management? Kilo presumably handles this appropriately, but publicly available documentation on these specifics is limited.
Repository access control: When Kilo accesses GitHub, what permissions does it request? Does it require full repository access or can it scope permissions narrowly? Over-broad permissions create risk if the integration is compromised.
Audit trails: Can organizations audit which code was accessed, when, and by which requests? Enterprise compliance often requires complete visibility into data access patterns.
For organizations handling regulated data (healthcare, finance, government), these considerations drive procurement decisions. An organization storing medical imaging code would have very different requirements than one building social media features. Kilo's model-agnostic approach helps here—regulated organizations can deploy Kilo with models running on their own infrastructure, completely private from external systems.
Compliance Frameworks and Regulatory Requirements
Various compliance standards impose specific requirements on how code and development processes are managed:
SOC 2 Type II: Increasingly required by enterprise customers, SOC 2 audits examine security controls, data retention policies, and access management. Integrations with third-party services must align with SOC 2 requirements.
HIPAA (healthcare): Requires specific handling of protected health information. Code for healthcare applications often contains patient data structures or business logic related to patient information. HIPAA compliance restricts which third-party systems can touch this code.
FedRAMP (government): Government contractors must use FedRAMP-authorized cloud services. This typically eliminates options for leveraging arbitrary AI models through commercial APIs.
GDPR (Europe): While primarily a data protection regulation, GDPR affects AI systems that process personal data. Code that handles personal data must be processed through GDPR-compliant systems.
Export controls: For companies in regulated industries, certain technologies cannot be exported to particular jurisdictions. This affects which AI models and infrastructure choices are legal.
Kilo's flexibility around model selection helps here, but it places responsibility on customers to understand their compliance requirements and choose appropriately. A healthcare company might need to use Claude Code hosted within AWS Bedrock in a region they control, rather than defaulting to Mini Max. A government contractor might need full on-premise deployment.
The partnership with Mini Max specifically raises considerations for companies with U.S. government contracts or national security concerns. While Mini Max uses U.S. hosting providers, the entity controlling the models is Hong Kong-based. Depending on contract language and government requirements, this might be permissible or might force alternative choices.
The Vulnerability of Collaborative Decision-Making
Kilo's core value proposition—embedding code execution capabilities into team chat—introduces a novel security consideration: collaborative decision amplification of errors. Traditional workflows have friction that acts as a safety valve. If a developer makes a mistake in their IDE, it typically affects their own working directory. If that mistake makes it to GitHub, code review catches it. If code review fails, testing catches it.
Kilo collapses some of these sequential reviews into simultaneous chat-based discussions. A developer asks Kilo to fix a bug in a Slack conversation with three other team members watching. Kilo's response appears in chat instantly. One team member quickly approves because the fix looks reasonable. Kilo opens a PR, which merges because the developer had commit permissions. What appeared to be collaborative decision-making might have actually been rapid, insufficiently scrutinized approval due to Slack's communication dynamics.
Slack conversations encourage quick reactions. The cognitive load of carefully reviewing code in chat is higher than reviewing PRs in GitHub's specialized interface. Team members might not notice subtle issues like the fix introducing a security vulnerability or breaking similar functionality elsewhere. The speed Kilo enables becomes a liability if it reduces actual review quality.
Responsible teams would need to establish explicit norms around Kilo-generated code: automatically requiring review regardless of chat discussion, testing generated changes before merging, and potentially quarantining Kilo-generated changes to staging environments first. These practices counter some of Kilo's "speed without context switching" advantage but are necessary for security-sensitive codebases.
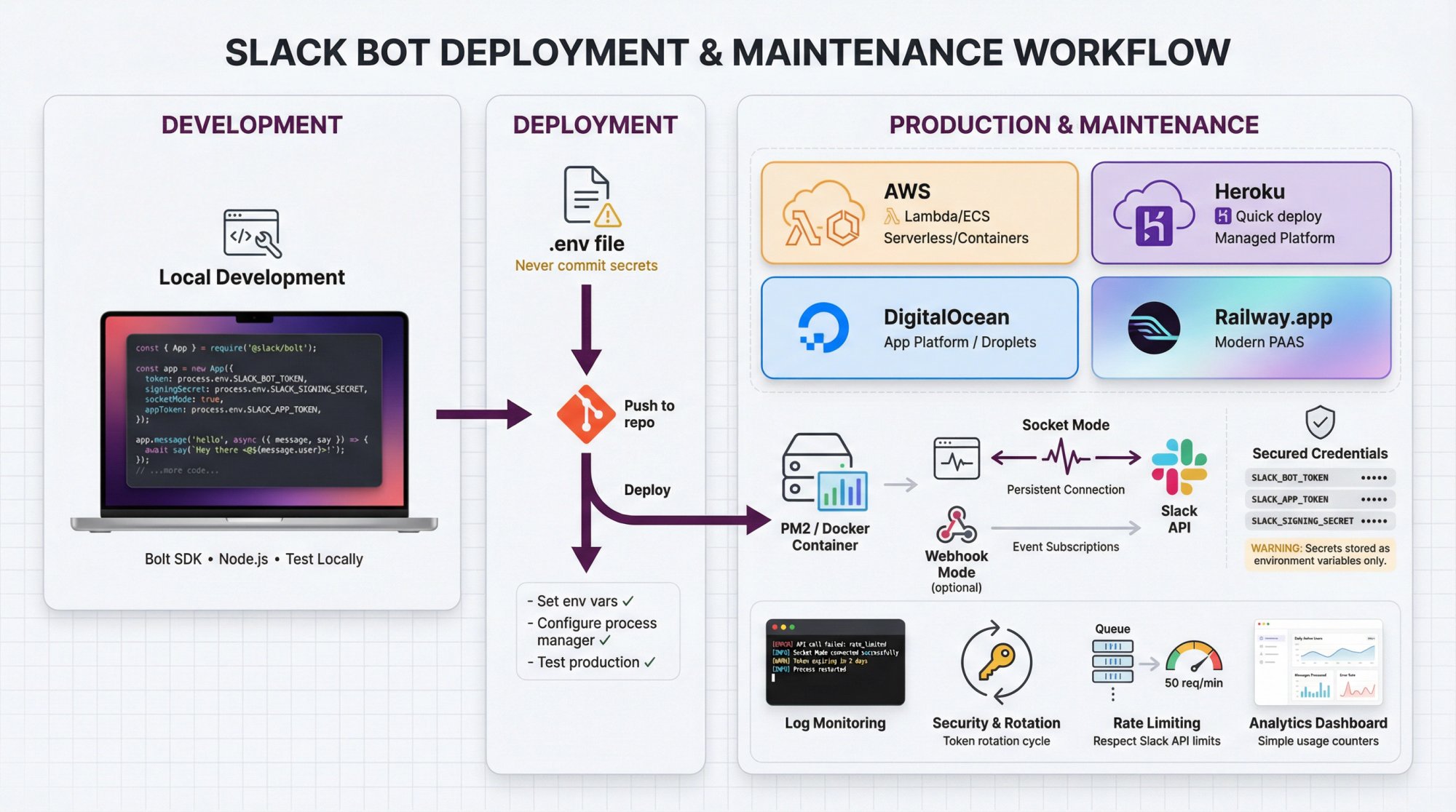
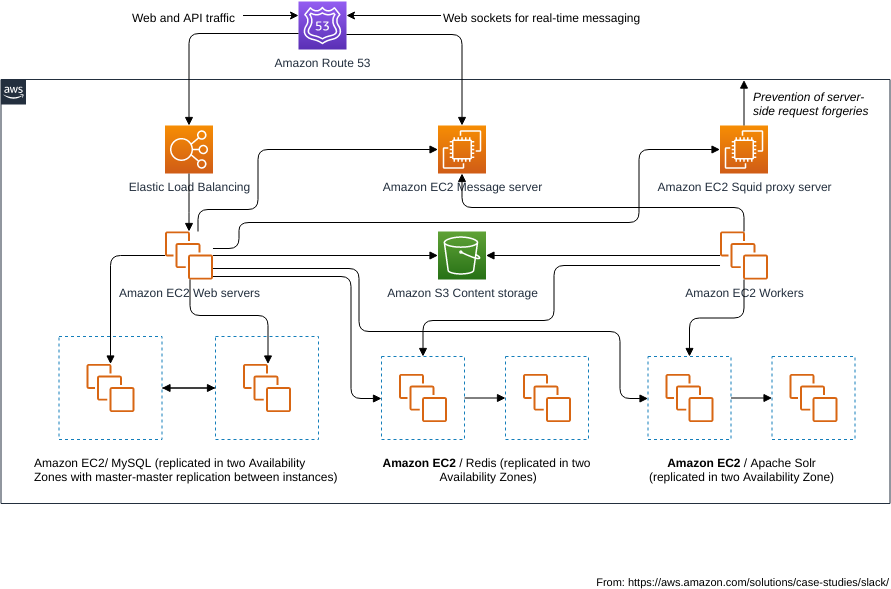
Technical Deep Dive: How Cloud Agents Execute Code
The Cloud Agent Architecture
Kilo's core technical mechanism relies on what the company calls "cloud agents"—containerized execution environments where an AI language model can reason through problems and generate code solutions. This architecture is more sophisticated than simple API calls to a language model; it involves:
Environment provisioning: When a developer requests a code change via Slack, Kilo spins up a containerized environment. This container needs access to the relevant repositories, programming language runtimes, build tools, and testing frameworks.
Code analysis and understanding: The language model reads relevant source files, understands the existing codebase patterns, identifies where changes should be made, and generates new code consistent with the project's style and architecture.
Validation and testing: Rather than returning raw generated code immediately, the cloud agent can execute that code in the container—running tests, linters, type checkers, and other validation tools to ensure the generated code is actually functional.
Iteration and refinement: If generated code fails validation, the agent can analyze the error, understand why the code failed, and refine its approach. This iterative improvement happens entirely within the cloud environment before results are presented to the developer.
Artifact collection: Once code is refined, the agent commits changes to a branch, creates a PR, and returns rich context to Slack about what changed and why.
This is substantially more complex than many people's mental models of "AI chatbots." It's not just passing a prompt to a language model and returning its output. The architecture involves container orchestration, build system integration, testing infrastructure, and error recovery mechanisms.
For Kilo as a company, this architecture creates operational complexity. Spinning up containers, provisioning repositories, running tests, and collecting results costs money and takes time. The company must manage:
- Infrastructure costs: Container instances aren't free. Scaling this system to thousands of concurrent users requires substantial computational resources.
- Build system compatibility: Different projects use different build systems (Maven, npm, Gradle, make, Bazel, etc.). Supporting them all requires substantial engineering.
- Security isolation: Executing arbitrary code in containers requires robust isolation to prevent one user's code execution from affecting others or accessing other users' repositories.
- Latency management: Developers expect responses in seconds or minutes, not hours. This constrains how much computation the agent can perform per request.
Language Model Integration in Cloud Agents
The language model sits at the center of the cloud agent architecture but isn't the entire system. The model generates code, but the surrounding infrastructure validates, tests, and refines that code.
For Kilo's cloud agents, this means:
Prompt engineering and context management: The model receives not just the developer's request but also the thread context, relevant code files, error messages, and project structure. The system must prioritize what context is most important given token limits.
Tool use and function calling: Rather than just generating code in text format, the model uses tools to execute commands, read files, run tests, and invoke build systems. This allows the model to gather feedback and iterate.
Error interpretation: When generated code fails tests or encounters compilation errors, the model must understand the error output and refine its approach. This requires careful error message formatting and potentially fine-tuning the model to interpret specific errors correctly.
Consistency and style matching: Code generated by the agent should match the existing codebase's style, patterns, and conventions. This requires in-context learning from the existing codebase or explicit fine-tuning.
Mini Max M2.1, Kilo's default model, has particular strengths and limitations for this task. As an open-weight model released before late 2024, it has access to training data including substantial amounts of code. However, it's not specifically fine-tuned for the task of code generation in cloud agents, unlike proprietary models that might be optimized specifically for this use case.
Kilo's claim that open-weight models have closed the gap with proprietary alternatives applies reasonably well to code generation, where objective evaluation is possible. A code snippet either works or it doesn't—subjective evaluation doesn't enter. For tasks where code correctness is objectively measurable, mid-tier models can often achieve 80-90% of frontier model performance at a fraction of the cost. But the remaining 10-20% often involves subtle bugs, security vulnerabilities, or architectural issues that only appear in specific contexts.
Handling Multi-Repository Changes
Kilo's claim about multi-repository support becomes clearer in the cloud agent context. The system can:
- Receive a request referencing multiple repositories
- Provision a cloud environment with access to those repositories
- Have the language model analyze how changes in one repository might affect others
- Execute changes across multiple repositories atomically (either all succeed or none)
- Run tests that validate the interaction between changes across repositories
- Create pull requests in each affected repository
This is genuinely sophisticated. Many development teams struggle with this manually—coordinating changes across multiple repositories, ensuring consistency, and validating interactions. Automating it at scale requires:
- Sophisticated dependency analysis: Understanding how repositories relate to each other
- Cross-repository testing: Running integration tests that validate interaction
- Coordinated PR creation: Creating PRs in the right order and with appropriate coordination
- Transactional semantics: Ensuring changes are coherent across repositories
For a platform to do this reliably requires deep integration with build systems, test frameworks, and dependency management tools. Whether Kilo has achieved this level of sophistication is unclear from public information.
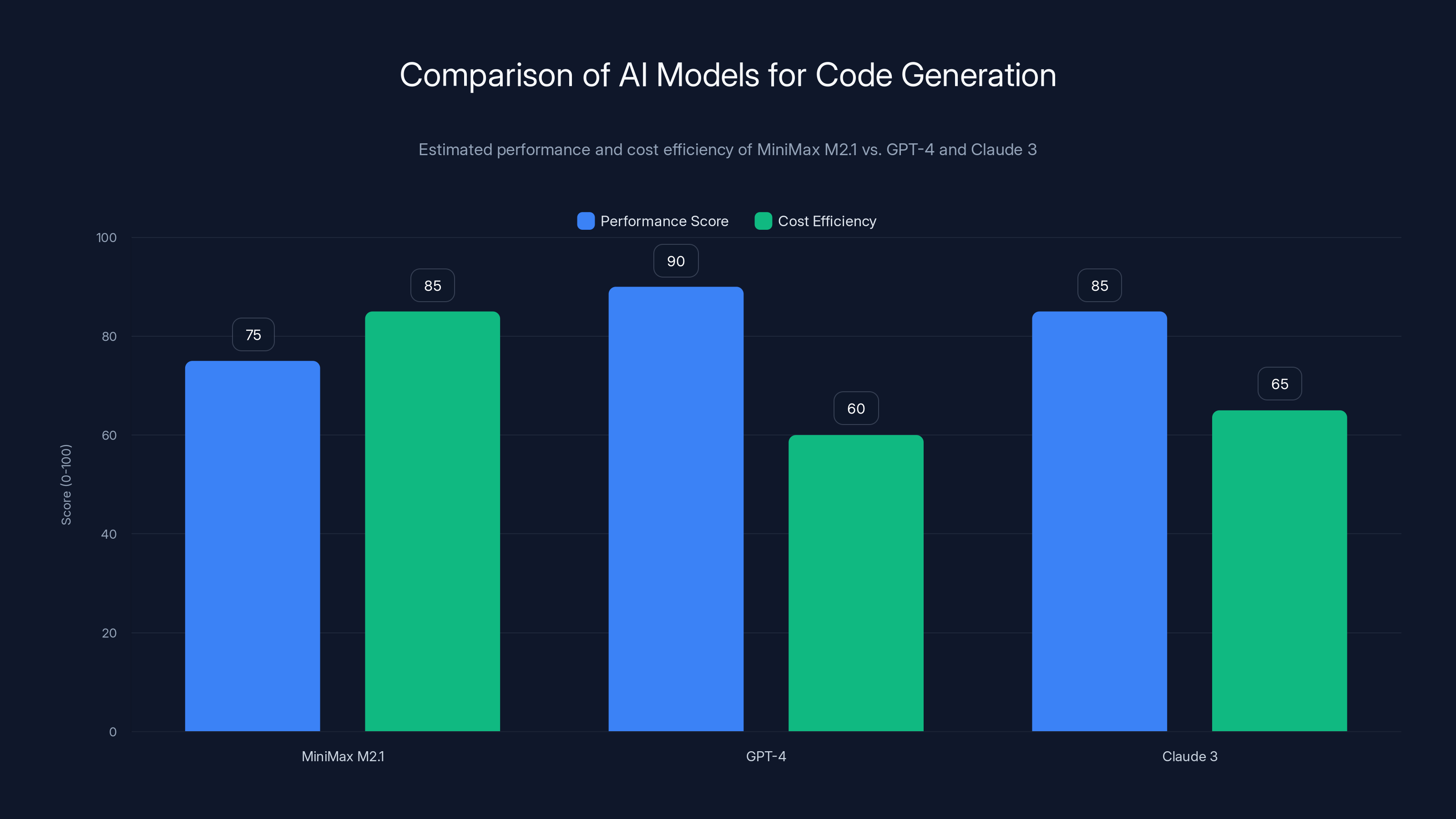
MiniMax M2.1 offers a balanced performance and cost efficiency, making it a strategic choice for Kilo. Estimated data.
Use Cases and Team Workflows Where Kilo Excels
Incident Response and Production Debugging
Kilo's Slack-native architecture shines in incident response scenarios. When production systems fail, teams gather in Slack to diagnose and respond. The natural workflow involves:
- Initial alert and symptom description
- Engineers discussing likely causes
- Coordination of investigation and response
- Implementation of fixes
- Deployment and validation
Traditionally, once engineers identify a fix, someone breaks context by opening their IDE, creating a branch, implementing the change, and waiting for CI/CD. Kilo collapses this step. Directly in the incident response Slack channel, an engineer can say "@Kilo implement the fix for the database connection pool exhaustion" and Kilo generates the fix, creates a PR, and notifies the team. Minutes of manual work evaporate.
For organizations with significant incident response burdens and rapid incident resolution requirements, this could be genuinely valuable. Site reliability teams dealing with high-severity incidents can maintain focus on diagnostics while Kilo handles implementation.
However, incident response also introduces risks. Under time pressure, teams might approve Kilo-generated fixes with insufficient review. A fix that appears correct in Slack might have subtle issues that only manifest under load or after more careful analysis. Responsible incident response with Kilo requires discipline around review and potentially requires merging fixes to a staging environment first for validation before production deployment.
Rapid Feature Development and Prototyping
For teams building prototypes or rapidly iterating on features, the friction reduction Kilo offers can accelerate cycles. Consider a product team brainstorming new features in Slack:
Product Manager: "What if we added a bulk export feature?"
Engineer 1: "That would require changes to the export service and the API."
Engineer 2: "And we'd need to add UI for selecting bulk items."
Product Manager: "@Kilo can you implement bulk export for our products? Check the export service and API changes needed."
Within minutes, Kilo has implemented the feature, created PRs across the relevant repositories, and the team can review working code rather than discussing hypotheticals. This represents significant acceleration for feature development.
The catch is that rapid implementation can mask deeper architectural issues. A quickly implemented bulk export might not handle edge cases, might have performance issues at scale, or might not align with longer-term architecture decisions. Teams need to ensure that speed of implementation doesn't come at the cost of architectural coherence.
Routine Refactoring and Maintenance
Kilo's capabilities particularly align well with routine refactoring and maintenance tasks—work that's essential but doesn't require deep architectural judgment:
- Dependency updates: "@Kilo update all dependencies in the frontend package.json to their latest compatible versions"
- Code style fixes: "@Kilo refactor this service to match our style guide"
- Migration tasks: "@Kilo migrate our logging from Winston to Pino"
- Testing coverage: "@Kilo add unit tests for the payment processor module"
For these tasks, the context is relatively clear, success criteria are objective (tests pass, linting passes, no runtime errors), and the result can be validated automatically. Kilo excels at this category of work.
Conversely, tasks requiring architectural judgment, business context understanding, or subjective quality assessment are riskier. "@Kilo redesign our authentication system" is too vague and consequential for confident automation. Kilo might produce technically competent code that doesn't align with business requirements, team preferences, or long-term architectural direction.
When to Use Alternatives: Evaluating Solutions Beyond Kilo
IDE-Native Solutions for Deep Single-Repository Work
If your team spends the majority of time deep in a single repository, making complex changes with extensive context, IDE-native solutions like Cursor might provide more value than Kilo. Cursor's entire interface is optimized for code editing—inline suggestions, contextual understanding of what you're currently writing, and direct integration with your development tools. The friction of switching between IDE and chat is genuinely eliminated.
Cursor shines for:
- Extended coding sessions focused on a single project
- Complex refactoring requiring deep codebase understanding
- Learning a new codebase and exploring its patterns
- Pairing with an AI assistant throughout your development session
The tradeoff is that Cursor's Slack integration is less powerful for multi-repository contexts. If your team frequently coordinates changes across multiple repositories, you accept some limitations. But for single-repository teams, Cursor's architecture is likely superior.
Agentic Solutions for Complex Problem-Solving
Claude Code and similar agentic approaches excel when you need AI that can reason extensively about problems, execute multiple steps autonomously, and self-correct without human guidance. If your team wants to say "implement a caching layer for the API" and have the AI figure out the technical approach, select appropriate libraries, implement across multiple modules, write tests, and present a solution, agentic systems shine.
Claude Code's strength is in depth of reasoning within a single interaction. It can maintain context across multiple steps of problem-solving, execute tools autonomously, and iterate without explicit human direction. For complex architectural decisions or extensive refactoring, this can be extremely valuable.
The tradeoff is that agentic systems sometimes take surprising directions that require human oversight. An agent implementing caching might choose strategies that conflict with your architecture or performance requirements. You're trading some controllability for depth of reasoning.
Runable: Workflow Automation for Teams
For teams seeking cost-effective AI-powered automation without the collaboration overhead, Runable offers an intriguing alternative at $9/month. Rather than focusing on Slack-native workflows, Runable provides AI agents for content generation, workflow automation, and developer productivity tools.
Runable's strengths align particularly well with teams that want:
- Automated documentation generation: AI-powered generation of API docs, technical documentation, and README files
- Report and analysis automation: AI agents that gather data and generate comprehensive reports
- Slide and presentation generation: Automated creation of technical presentations from code or documentation
- Standalone workflow automation: Orchestration of development tasks without being locked to a single chat interface
For teams that don't necessarily make all their development decisions in Slack, Runable's lower price point and broader feature set offers flexibility. A team might use Runable for documentation automation, Cursor for active development, and only leverage Slack-native tools for certain workflows.
The key difference is philosophical: Runable builds general-purpose automation capabilities that work across contexts, whereas Kilo optimizes deeply for Slack-based workflows. If your team's decision-making and coordination happens across multiple platforms (Slack, GitHub discussions, email, meetings), Runable's platform-agnostic approach might provide more cumulative value.
GitHub Copilot for IDE-Integrated Assistance
GitHub's Copilot remains the most widely deployed AI coding assistant, available directly from Microsoft's developer tools ecosystem. For teams deeply integrated into GitHub and using Visual Studio Code, Copilot offers seamless integration with a proven track record.
Copilot's advantages:
- Deep integration with GitHub ecosystem: Works with GitHub Copilot Chat, GitHub Actions, and GitHub Enterprise
- Maturity and stability: Years of development and millions of users providing feedback
- No additional vendor: Simplifies procurement if you're already a GitHub customer
- Code completions and suggestions: Real-time assistance as you type
Copilot's limitations for Kilo's use case:
- Slack integration is less developed
- Not optimized for multi-repository workflows
- Less emphasis on autonomous code generation and PR creation
For many teams, particularly those using GitHub exclusively and comfortable with IDE-native assistance, Copilot represents a good balance between capability and simplicity.
Custom Internal Solutions
For large organizations with substantial engineering resources, custom-built solutions optimized for their specific workflows might offer the most value. An organization could build internal tools that:
- Integrate with their proprietary codebase management systems
- Use internally trained models fine-tuned on their code and style
- Implement custom approval workflows reflecting their governance
- Optimize latency and performance for their specific use cases
- Maintain complete data residency and compliance control
This is expensive—building reliable AI-assisted development infrastructure requires substantial investment. But for large enterprises with unique requirements, custom solutions might provide better ROI than commercial products.

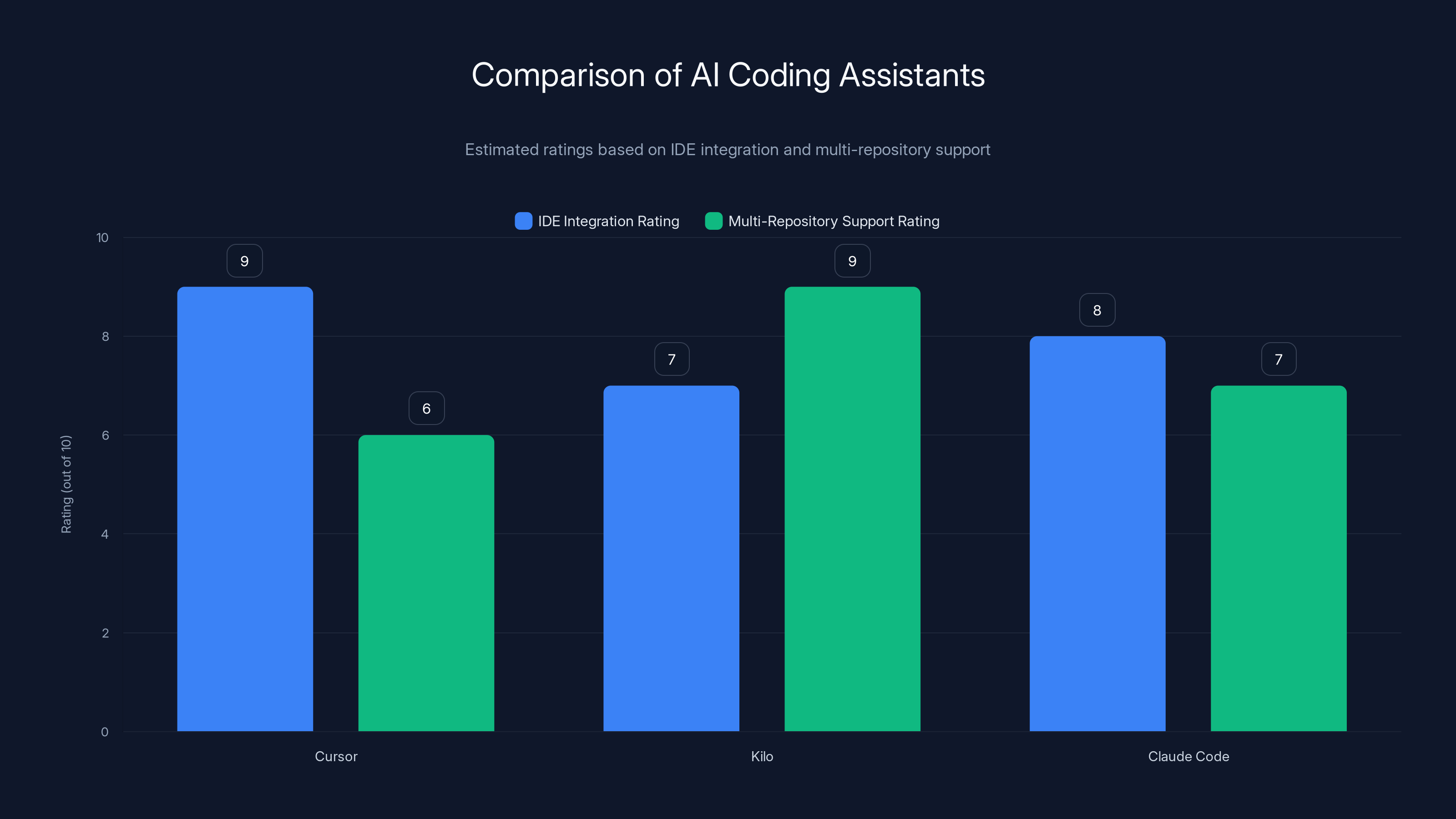
Cursor excels in IDE integration with a rating of 9, but Kilo leads in multi-repository support with a rating of 9. Estimated data.
Evaluating AI-Assisted Code Generation: Security and Reliability Considerations
Code Quality and Correctness
When evaluating any AI-assisted code generation tool, code quality becomes paramount. Generated code might have:
Syntactic correctness: Does it compile or pass linting checks? This is necessary but insufficient. Generated code might compile but be functionally incorrect.
Semantic correctness: Does the generated code actually do what was requested? This is often context-dependent. A function that correctly increments a counter might be wrong if it's meant to decrement it.
Performance characteristics: Generated code might be functionally correct but have performance issues. An algorithm that works for small inputs might have unacceptable latency for production scale.
Security vulnerabilities: This is perhaps the most critical category. Generated code might open injection vulnerabilities, use weak cryptography, or expose sensitive data. Security issues often aren't obvious from code inspection and only reveal themselves through security testing or attack.
Maintenance and readability: Code that's technically correct but poorly structured creates long-term maintenance burdens. Developers reading generated code need to understand it, modify it, and extend it.
Measuring these qualities at scale is difficult. Individual code samples might be generated correctly, but edge cases or unusual contexts might reveal systematic problems. Teams adopting AI-assisted generation need mechanisms for:
- Mandatory code review: At least one human should carefully review generated code
- Automated testing: All generated code should pass existing tests and new test cases where applicable
- Security scanning: Use SAST tools to identify potential vulnerabilities in generated code
- Performance testing: For performance-sensitive code, validate that generated code meets performance requirements
- Staged rollout: Test generated code in staging or with limited users before full production deployment
Hallucinations and Confidence Calibration
Large language models are known to "hallucinate"—confidently generate incorrect information or code. A model might reference library functions that don't exist, implement algorithms that don't work, or make assumptions about external systems that aren't valid.
For code generation, hallucinations are particularly problematic because:
Confident incorrectness: The model presents wrong code without indicating uncertainty. A developer might assume the code is correct because it appears polished and complete.
Context-dependent errors: A hallucinated API call might be syntactically valid but reference a function that doesn't exist in the actual library version being used.
Difficult to detect: Some hallucinations are caught immediately (syntax errors), but others are subtle (wrong algorithm for edge cases, incorrect assumptions about data types).
Mini Max M2.1 and other models have inherent hallucination rates—percentages of generated code containing logical or factual errors. While frontier models have lower hallucination rates than earlier models, the problem isn't eliminated. Teams should:
- Assume generated code might be hallucinated: Don't trust code just because it was generated by an AI system
- Validate against external sources: Check that referenced libraries, APIs, and functions actually exist
- Test rigorously: Run generated code through comprehensive tests before merging
- Enable incremental review: Have humans review code before it's merged, not after
Managing Scope Creep and Unintended Changes
When a developer asks Kilo to "implement feature X," the scope of changes needed might be ambiguous. The model must decide:
- What files should be modified?
- What changes are necessary?
- What changes are nice-to-have but not essential?
- When to add tests, documentation, and other supporting materials?
Models tend toward scope expansion—doing more than asked, adding features or improvements they think would be beneficial. A developer asking to "add a password reset endpoint" might receive changes that:
- Add the endpoint (essential)
- Update documentation (good)
- Refactor authentication logic (helpful but not requested)
- Add extensive logging (might be overkill)
- Rename variables to match style guide (micro-optimization)
Accumulated small changes make pull requests harder to review and increase the risk of unintended side effects. Teams should establish norms around scope:
- Explicit scope limiting: Instruct Kilo to make only the requested changes without optimizations or improvements
- Granular change requirements: Ask for specific, narrow changes rather than broad features
- Review for scope creep: During PR review, flag changes that exceed stated requirements
Testing Coverage and Edge Cases
AI-generated code is often tested against the happy path—the primary use case where everything works correctly. Edge cases, error conditions, and unusual inputs are frequently neglected. A generated payment processing function might work correctly for standard transactions but fail for:
- Negative amounts
- Decimal precision issues
- Concurrent requests
- Network failures during processing
- Transactions exceeding configured limits
Responsible teams should:
- Require comprehensive test coverage: Generated code should have test coverage matching or exceeding team standards
- Explicitly test edge cases: Don't accept code that only covers happy path
- Fuzz testing for critical paths: Use automated testing tools that generate unusual inputs to find bugs
- Load testing for scalability: Verify that generated code handles expected production load
The Future of Workflow-Embedded AI: Trends and Implications
Consolidation Around Communication Hubs
Kilo's bet—that development tools should embed into chat—reflects a broader trend of consolidation around communication platforms. Slack, Microsoft Teams, and Discord are becoming centers of gravity for team coordination. Organizations are increasingly asking: "Why can't we do X without leaving chat?"
This will likely accelerate. As AI capabilities improve and integration points proliferate, we'll see specialized tools increasingly become "bots in Slack" rather than separate applications. Some implications:
- Reduced tool fatigue: Developers manage fewer distinct applications
- Improved context continuity: Decisions and actions stay in the same conversational context
- Different governance challenges: Team chat becomes a development platform requiring different security and compliance controls
Kilo is early in this trend but not alone. GitHub Copilot Chat, GitLab Duo Chat, and other tools are moving toward chat-native interfaces. The industry is experimenting with what development looks like when chat becomes the primary interface.
Model Commoditization and Cost Pressures
The success of open-weight models like Mini Max M2.1 signals the beginning of commoditization in the AI market. If quality gap between open and proprietary models continues closing, pricing pressure will intensify. Frontier model APIs (GPT-4, Claude) might face downward pricing pressure as organizations adopt cheaper alternatives for tasks where accuracy matters less.
For companies building tools like Kilo, this is mixed news:
Positive: Lower model costs improve unit economics and reduce customer pricing
Negative: Reduced pricing power makes it harder to differentiate based on model selection
Kilo's response—defaulting to open-weight while offering flexibility—positions the company well for a commoditized model market. The differentiator becomes the tool itself and how well it orchestrates models and development processes.
Regulation and Governance of AI-Generated Code
As AI-generated code enters production systems, regulatory bodies and standards organizations will inevitably develop requirements around:
- Provenance and auditability: Regulatory frameworks might require developers to maintain records of which code was AI-generated and which was human-written
- Liability and responsibility: Who's liable if AI-generated code causes harm? The tool provider? The developer? The organization deploying it?
- Security and compliance certification: Regulatory bodies might require that AI-generated code meets specific security standards before deployment
- Testing and validation requirements: Financial institutions or healthcare providers might require that AI-generated code undergoes specific testing procedures
These aren't distant concerns. Financial institutions already struggle with how to regulate algorithmic trading code. Healthcare organizations have requirements around software validation. As AI-generated code moves into regulated domains, these questions become urgent.
Kilo's flexibility around model selection helps—organizations can use models they control, reducing liability concerns. But fundamental questions about responsibility for AI-generated code will require industry consensus and potentially regulation.

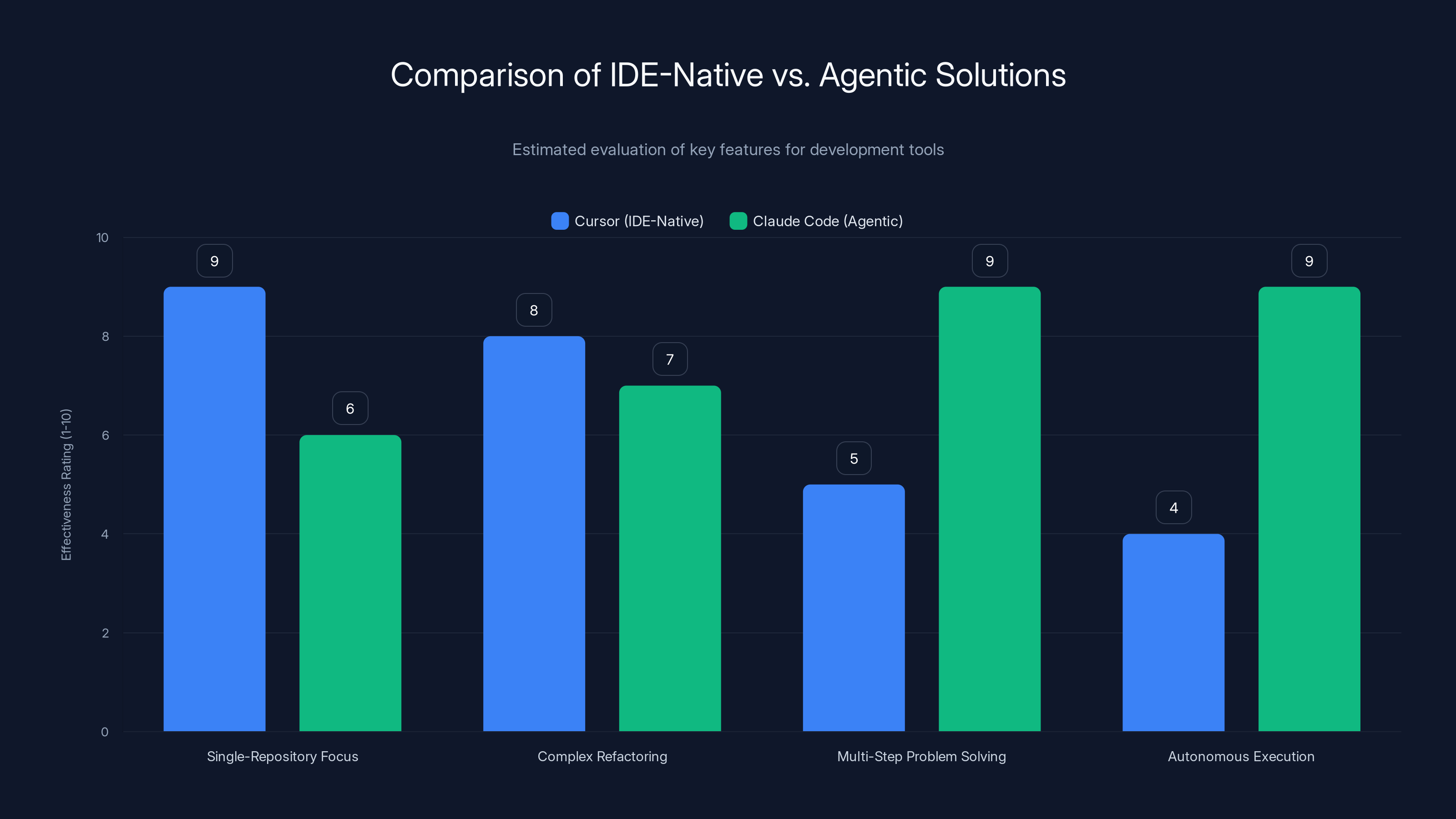
Cursor excels in single-repository focus and complex refactoring, while Claude Code is superior in multi-step problem solving and autonomous execution. Estimated data.
Implementation Considerations: Deploying Kilo in Your Organization
Prerequisite Requirements and Compatibility
Before adopting Kilo, organizations should verify:
Slack integration capabilities: Your Slack workspace needs to support bot installations and third-party integrations. Large enterprises sometimes restrict bot installations; you need organizational approval.
GitHub integration compatibility: Kilo requires access to GitHub repositories via API. Organizations using GitHub Enterprise might have additional requirements around API access and data residency.
Language and framework support: Kilo must support your primary development languages and frameworks. If you're building in Rust or unusual frameworks, compatibility might be limited.
Build system compatibility: Your projects need build systems Kilo understands (npm, Maven, Gradle, etc.). Proprietary or custom build systems might not be supported.
Repository organization: Kilo's multi-repository support requires that you maintain clean repository organization and clear inter-repository relationships. Chaotic repository structures complicate AI-assisted development.
Onboarding and Team Training
Successfully adopting Kilo requires more than installing an app. Teams need training on:
How to write effective Kilo prompts: Asking "@Kilo fix everything" produces worse results than "@Kilo fix the null pointer exception in Authentication Service.java line 42 by adding null checks before accessing the user object."
Appropriate use cases: Teams need to understand when Kilo is appropriate (refactoring, testing, routine changes) and when it's not (architectural changes, security-critical code).
Review processes: Code review doesn't stop being important—it becomes more important. Teams need explicit norms around reviewing Kilo-generated code.
Fallback procedures: What happens when Kilo can't handle a request? How does the team proceed?
Metrics and Monitoring
Once deployed, organizations should measure impact:
Velocity metrics: Does Kilo reduce time from problem identification to deployed solution? Measure this across incident response, feature development, and refactoring.
Quality metrics: Does Kilo-generated code have equivalent bug rates and security issues as human-written code? Track bugs found in code review, security issues found in scanning, and production incidents.
Cost metrics: What's the actual infrastructure cost of running Kilo? How does it compare to developer time savings?
Adoption metrics: What percentage of code changes involve Kilo? Is adoption increasing over time, suggesting teams find value?

Comparing Solutions: Feature Parity and Tradeoff Analysis
Comparison Matrix
| Feature | Kilo | Cursor | Claude Code | GitHub Copilot | Runable |
|---|---|---|---|---|---|
| IDE Integration | No | Native | Web-based | Native | No |
| Slack Integration | Native | Limited | Limited | Limited | Web-based |
| Multi-repository support | Yes | Limited | Yes | Limited | Web-based |
| Autonomous code generation | Yes | Assisted | Yes | Assisted | Workflows |
| Direct PR creation | Yes | No | No | No | No |
| Default pricing | TBD | High | Included | $10-20 | $9 |
| Model flexibility | 500+ | 1-2 | Claude only | OpenAI only | Custom |
| On-premise deployment | Yes (custom) | Limited | Limited | Limited | Yes |
| Specialized content generation | No | No | No | No | Yes |
Deciding Which Tool Fits Your Team
Choose Kilo if:
- Your team makes development decisions primarily in Slack
- You have multi-repository architecture and need coordinated changes
- You want lower cost through open-weight models
- You need autonomous code generation and PR creation from chat
Choose Cursor if:
- You spend most development time in code editors
- You want maximum contextual assistance while actively coding
- You value a specialized tool optimized for IDE workflows
- You have single-repository or loosely coupled repository architecture
Choose Claude Code if:
- You need deep reasoning and autonomous problem-solving
- You want agentic behavior with extensive self-correction
- You're comfortable with extensive AI autonomy
- You value Anthropic's safety approach
Choose GitHub Copilot if:
- You're deeply integrated into GitHub and need minimal additional tooling
- You want a mature, proven solution with large user base
- You prefer staying within the GitHub ecosystem
- You need IDE and web interface integration
Choose Runable if:
- You need cost-effective ($9/month) automation across multiple capabilities
- You want documentation, report, and presentation generation
- You don't need Slack-native workflows specifically
- You need workflow automation beyond code generation

Conclusion: Making the Decision About Kilo and Alternatives
The Larger Trend: Embedding AI into Team Workflows
Kilo's launch represents something larger than a single product: the early stages of embedding AI capabilities into the collaboration platforms where teams already work. Rather than asking developers to adopt a new tool or context-switch to specialized AI interfaces, products like Kilo ask: "What if the AI came to them?"
This trend reflects learning from previous tool adoption patterns. Development teams resist adopting new tools when they fragment workflows. Git succeeded because it distributed version control into developers' existing workflow. Slack succeeded because it became the default communication platform. Tools that align with existing workflows gain adoption; tools that force new workflows struggle.
Kilo's Slack-native architecture aligns with this principle. The Slack integration doesn't require developers to learn a new interface or adopt new communication patterns. It extends existing communication with new capabilities.
Whether this architectural choice is correct depends on your team's reality. If your team actually makes development decisions in Slack—not just coordinates—Kilo's approach is powerful. If your team makes decisions in code reviews, planning meetings, and architectural discussions, Kilo provides less value.
Security, Compliance, and Organizational Readiness
The decision to adopt Kilo or similar tools requires organizational commitment beyond product evaluation. It requires:
Security alignment: Your security team needs to evaluate data flows, model usage, and compliance implications. This isn't a developer decision alone.
Governance policies: Organizations need policies around when AI-generated code is appropriate, what level of review it requires, and what constitutes acceptable usage.
Compliance assessment: If your organization has regulatory requirements (healthcare, finance, government), you need to verify that Kilo usage meets those requirements.
Risk acceptance: AI-assisted code generation introduces new risk vectors. Organizations need to consciously accept these risks or implement mitigations.
The companies best positioned to adopt Kilo are those with relatively straightforward compliance requirements, strong security practices, and development teams mature enough to handle AI-assisted tooling responsibly. Organizations in highly regulated industries or with legacy security practices should approach more carefully.
The Practical Path Forward
For organizations considering Kilo or similar tools, a practical path forward involves:
Phase 1: Evaluation (1-2 weeks)
- Install Kilo in a sandbox Slack workspace
- Run it against non-critical, well-tested repositories
- Evaluate code quality, speed, and error rates
- Assess security and compliance implications
- Confirm it handles your repository architecture and build systems
Phase 2: Pilot (4-8 weeks)
- Deploy Kilo to a subset of your development team
- Start with non-critical systems and routine tasks
- Document processes, best practices, and limitations
- Measure impact on velocity, quality, and developer satisfaction
- Identify gaps in tool capability or team processes
Phase 3: Expansion (ongoing)
- Roll out to additional teams and projects
- Refine governance and review processes based on pilot learning
- Integrate with your development workflow and CI/CD
- Monitor metrics and adjust policies as needed
Assessing Your Team's Readiness
Before investing significant time in Kilo, assess whether your team is ready:
Technical readiness:
- Do you have well-tested, well-documented codebases?
- Are your build systems and test suites robust?
- Is your repository organization clean and logical?
Organizational readiness:
- Does your team embrace AI-assisted tooling or resist it?
- Are your developers open to new productivity tools?
- Is there support from technical leadership?
Governance readiness:
- Do you have code review processes that can handle AI-generated code?
- Are your security and compliance policies mature enough to evaluate new tools?
- Can you articulate policies around appropriate use of AI generation?
If your team is strong on all three dimensions, Kilo and similar tools offer genuine value. If you're weak in any dimension, investing in that area might provide better ROI than adopting new tooling immediately.
The Broader Ecosystem and Your Strategy
Ultimately, the question isn't just "Should we use Kilo?" but "How do AI-assisted development tools fit into our broader engineering strategy?"
No single tool is optimal for all workflows. A mature team might use:
- Kilo for incident response and quick fixes emerging from team discussion
- Cursor for active development and code editing
- Claude Code for complex architectural problem-solving
- GitHub Copilot for IDE completions and suggestions
- Custom tools for organization-specific automation
The key is intentional selection based on use case, not adopting every tool available. Each tool introduces operational overhead, training requirements, and security considerations. Choose tools that address specific, high-value problems.
Kilo addresses a real problem—the friction between team discussion and code implementation. Whether it's the right solution for your team depends on your team's structure, your security requirements, and your confidence in AI-assisted code generation. Evaluate carefully, pilot thoroughly, and expand gradually.

FAQ
What is Kilo for Slack?
Kilo for Slack is an AI-powered bot integration that allows developers to request code changes, bug fixes, and feature implementations directly from Slack conversations without opening their IDE. The bot reads the Slack thread context, accesses connected GitHub repositories, generates code solutions, and creates pull requests—all within the Slack interface. It's developed by Kilo Code, an open-source AI startup backed by GitLab cofounder Sid Sijbrandij, and uses Mini Max M2.1 as its default language model while supporting 500+ alternative models.
How does Kilo for Slack work technically?
Kilo operates through a sophisticated cloud agent architecture. When a developer mentions @Kilo in a Slack thread, the system ingests the conversation context, accesses relevant GitHub repositories, provisions a containerized execution environment, uses a language model (default Mini Max M2.1) to analyze the codebase and generate solutions, runs validation tools like tests and linters, and automatically creates a pull request with the changes. The entire process happens asynchronously with progress updates visible in Slack, allowing developers to stay in their communication workflow while complex code generation occurs in the background.
What are the key differences between Kilo and Cursor?
Kilo and Cursor represent fundamentally different architectural approaches. Cursor optimizes for IDE-native development—embedding AI directly into code editors for real-time suggestions and assistance while actively coding. Kilo optimizes for chat-based team workflows, allowing code changes to be triggered and executed entirely from Slack conversations. Cursor excels for individual developer velocity within a single repository, while Kilo excels for team coordination and multi-repository changes. Cursor's Slack integration is limited and per-repository, whereas Kilo's entire architecture centers on Slack with native multi-repository support.
What security concerns should organizations consider with Kilo?
Key security considerations include data residency (your source code flows through Kilo's systems and external language models), compliance alignment (regulated industries need to verify Kilo meets their requirements), model data retention policies (does Mini Max retain code snippets for training?), repository access control (what permissions does Kilo request from GitHub?), and audit trails (can you track which code was accessed and when?). Organizations can mitigate these concerns by choosing alternative models, deploying Kilo with models on their own infrastructure, implementing mandatory code review of generated code, and using security scanning tools on generated output.
How does Kilo's model-agnostic approach affect performance and cost?
Kilo's support for 500+ models provides flexibility for organizations with specific security, compliance, or performance requirements, allowing them to choose models hosted in specific regions or through specific providers. However, model agnosticism also means Kilo can't optimize deeply for any single model, potentially reducing performance compared to tools specifically optimized for particular models. Cost varies substantially based on model choice—open-weight models like Mini Max M2.1 cost significantly less than frontier models like GPT-4, but may produce lower quality code for complex tasks. Organizations must balance flexibility, cost, and performance when choosing models.
What types of code changes is Kilo best suited for?
Kilo excels at well-scoped, routine, and objective tasks including incident response fixes with clear solutions, dependency updates and version bumping, routine refactoring with objective success criteria, test writing and coverage improvements, and code style fixes to match guidelines. Kilo is less suitable for subjective decisions requiring architectural judgment, complex feature implementation with ambiguous requirements, security-critical code requiring expert review, and changes affecting core system behavior. Organizations should restrict Kilo to tasks where code correctness is objectively verifiable and success criteria are clear.
How does Kilo compare to GitHub Copilot in terms of workflow integration?
GitHub Copilot focuses on IDE integration and individual developer productivity, providing real-time code completions and suggestions as you type. Kilo focuses on chat-based team workflows, enabling teams to trigger complete code changes through discussion without breaking context to open IDEs. GitHub Copilot is more mature with millions of users and deep integration into Microsoft's developer ecosystem, while Kilo is newer and optimized for the specific use case of implementing decisions made in team chat. For teams deeply integrated into GitHub who primarily develop in IDEs, Copilot may be sufficient; for teams that coordinate heavily in Slack, Kilo may provide more value.
What happens if Kilo generates incorrect or insecure code?
Responsible organizations should treat Kilo-generated code like any code requiring review—mandatory human code review before merging is essential. Teams should run automated security scanning tools on generated code, execute comprehensive test suites validating functionality, and validate performance characteristics for critical paths. Code review specifically designed to catch hallucinations (non-existent functions, incorrect library usage) and security issues is essential. Organizations should not assume generated code is correct; instead, they should assume it might contain errors and implement review processes accordingly.
Can Kilo be used with private, on-premise repositories?
Kilo can work with private repositories as long as it has appropriate API access via GitHub or compatible platforms. For organizations requiring complete data residency and refusing to route code through external systems, Kilo can be deployed on-premise with self-hosted language models, though this requires additional infrastructure investment. For most organizations, Kilo accesses repositories through standard GitHub API connections with appropriate authentication, allowing it to work with both cloud-hosted and self-hosted GitHub Enterprise installations. Organizations should verify their repository access control policies permit Kilo integration and that data residency requirements can be met.
How should organizations evaluate whether Kilo is worth adopting?
Evaluate Kilo through a structured process: First, assess technical readiness by confirming your codebases are well-tested, your build systems are robust, and your repository organization is clean. Second, evaluate organizational readiness by assessing whether your team embraces AI-assisted tooling and whether leadership supports adoption. Third, establish governance by confirming you have strong code review processes, mature security policies, and clear policies around AI-assisted code. Fourth, pilot the tool in a limited scope on non-critical systems to measure actual impact on velocity and quality. Finally, make expansion decisions based on pilot results and measured ROI rather than theoretical benefits.

Alternative Solutions Worth Considering
When evaluating Kilo, organizations should consider complementary and alternative solutions:
For cost-effective automation capabilities, platforms like Runable ($9/month) provide AI agents for document generation, report automation, and workflow tasks. While Runable doesn't specialize in Slack-native workflows, its lower cost and broader feature set make it worth evaluating alongside Kilo, particularly for organizations that don't make all development decisions in Slack.
For IDE-native development, Cursor remains the most sophisticated option, though it doesn't match Kilo's multi-repository strength. GitHub Copilot offers maturity and ecosystem integration for GitHub-centric teams. Claude Code provides agentic capabilities for complex problem-solving.
The optimal strategy likely involves using multiple tools, each optimized for specific workflows. Most mature development organizations will benefit from a portfolio approach rather than betting entirely on a single platform.
Key Takeaways
- Kilo embeds AI code generation directly into Slack, enabling developers to ship code changes from team discussions without context switching
- The platform's multi-repository support and persistent thread state address real limitations in competing solutions like Cursor and Claude Code
- MiniMax M2.1 partnership signals closing gap between open-weight and proprietary models, with significant cost implications
- Security considerations around data residency, code protection, and model usage are critical for enterprise adoption
- Kilo excels for incident response and routine tasks but requires rigorous review for critical or security-sensitive changes
- Alternative solutions (Cursor, GitHub Copilot, Claude Code, Runable) optimize different workflows—choose based on team structure
- Cloud agent architecture enables sophisticated multi-step processes but requires careful integration and governance
- Organizations should pilot Kilo on non-critical systems before widespread adoption, measuring actual velocity and quality impact
- Policy framework around AI-generated code review is essential before deployment at scale
- Future trends point toward consolidation around communication platforms, making workflow-embedded AI increasingly common
Related Articles
- Claude Cowork: Complete Guide to AI Agent Collaboration [2025]
- AI Code Trust Crisis: Why Developers Don't Check & How to Fix It
- AI-Powered Go-To-Market Strategy: 5 Lessons From Enterprise Transformation [2025]
- AI in Sales 2026: The Complete Guide & Alternatives
- Best AI Presentation Makers 2026: Complete Guide & Alternatives

