![Microsoft 365 and Outlook Outage: Complete Breakdown [2025]](https://tryrunable.com/blog/microsoft-365-and-outlook-outage-complete-breakdown-2025/image-1-1769116097619.jpg)
Microsoft 365 and Outlook Outage: Complete Breakdown [2025]
Something went very wrong on January 22, 2025. Microsoft 365 and Outlook, two of the most critical productivity platforms in the enterprise world, went down simultaneously for hundreds of thousands of users across the globe. Your calendar was inaccessible. Your emails vanished from view. Meetings couldn't sync. The ripple effect was immediate and brutal.
This wasn't a minor glitch that resolved itself in five minutes. This was a widespread infrastructure failure that cascaded across multiple regions, affecting enterprises, small businesses, government agencies, and everyday users who depend on these platforms to function. The outage lasted hours in some regions, and the aftermath left teams scrambling to figure out what happened and how to prevent it from happening again.
Here's the reality: cloud services fail. They fail more often than we'd like to admit, and when they do, the impact reaches far beyond a single company's data center. This particular outage exposed some hard truths about our over-reliance on centralized cloud infrastructure and the lack of robust failover mechanisms that most organizations have in place.
We're going to walk through everything that happened during the Microsoft 365 and Outlook outage, what caused it, who got hit the hardest, and what you should be doing right now to make sure your business isn't left completely helpless if something like this happens again. Because spoiler alert: it will happen again.
TL; DR
- Microsoft confirmed the outage affecting millions of Outlook and Microsoft 365 users globally on January 22, 2025, with impacts lasting several hours
- Root cause: Infrastructure issues in Microsoft's data centers, with cascading failures across multiple regions simultaneously
- Impact scope: Enterprise organizations, small businesses, government agencies, and individual users experienced calendar syncing failures, email access issues, and authentication problems
- Affected services: Outlook web, Outlook desktop, Microsoft Teams integration, Share Point document access, One Drive sync issues, and calendar-dependent applications
- Duration: Outage began mid-morning and extended into the afternoon for various regions, with full recovery taking 4-6 hours for most users
- Bottom line: This outage highlighted the critical need for backup communication systems, offline-first productivity tools, and diversified cloud infrastructure strategies
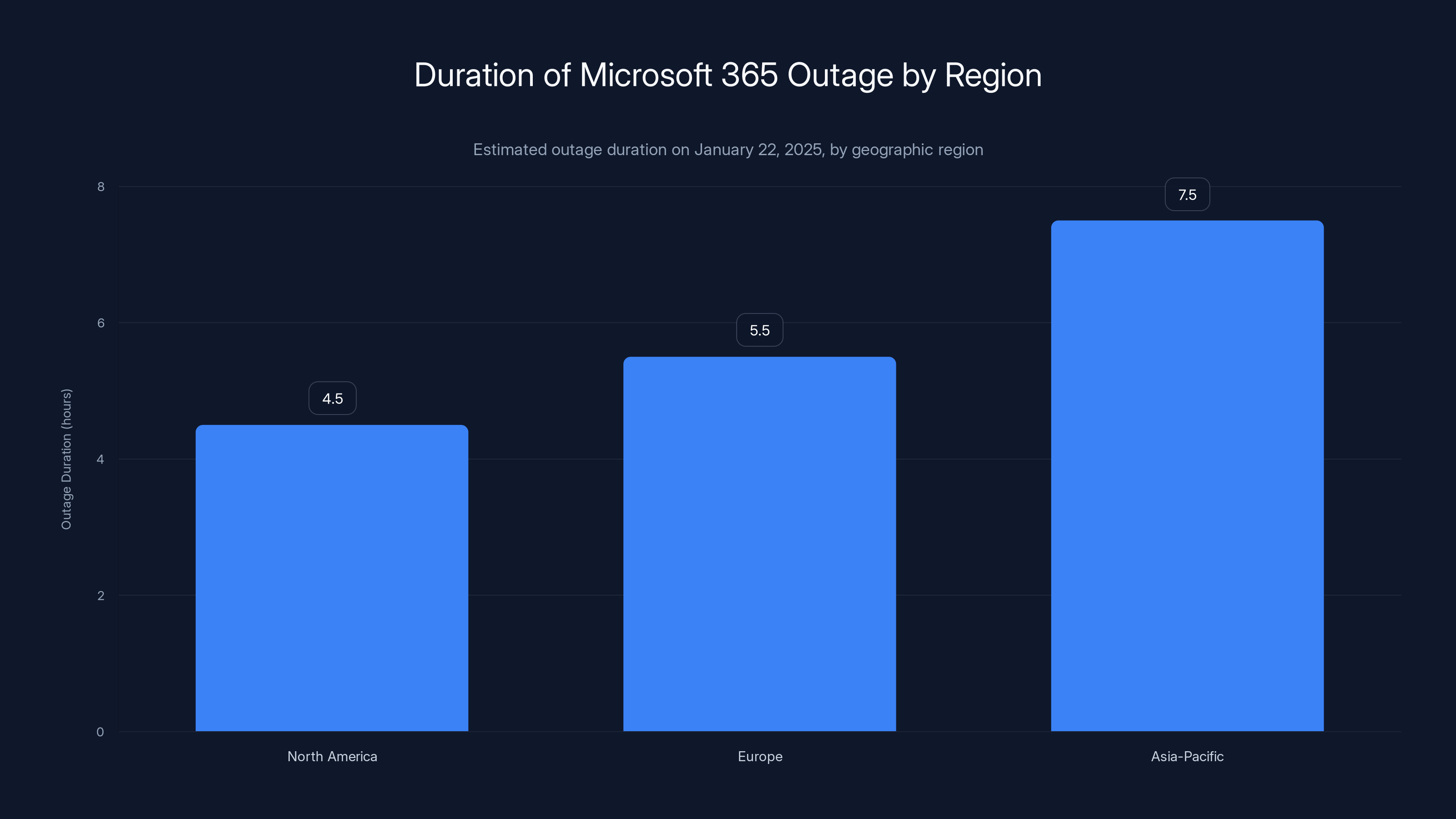
The Asia-Pacific region experienced the longest outage duration, with intermittent access issues lasting up to 7-8 hours. Estimated data based on reported experiences.
What Happened During the Microsoft 365 Outage
The first reports came in around 11 AM UTC on January 22, with users frantically posting on social media that Outlook wasn't loading. At first, people assumed it was a local network issue or a browser problem. You know the routine: clear the cache, restart the browser, power-cycle the router. Nothing worked.
Within thirty minutes, the volume of complaints escalated dramatically. Users from the United States, Europe, Asia, and Australia were all reporting identical issues simultaneously. This wasn't a regional problem. This was global.
Microsoft's status dashboard initially showed everything as "operational." That's when people knew something was seriously wrong. The company was either unaware of the outage or slow to communicate it. This created a vacuum of information that sent panic through the enterprise world. IT directors were getting flooded with calls from executives asking why nobody could access their email.
The company finally acknowledged the issue around 11:45 AM UTC, posting that they were "investigating an issue affecting access to multiple Microsoft 365 services." That vague language told you everything you needed to know: something had broken in their infrastructure, and they didn't yet understand the full scope.
For the next four to six hours, depending on your geographic location and which Microsoft data center your account was routed through, you were essentially locked out. Users couldn't check email. Calendar invitations wouldn't load. Teams messages seemed to work, but the integration with Outlook was broken, creating a fragmented experience where you couldn't see your schedule even though you were technically "connected."
Enterprise users who relied on OAuth integration with Microsoft 365 found that their third-party applications suddenly couldn't authenticate. Password reset portals were broken. Teams meeting scheduling failed. It was a cascading failure that touched nearly every part of the Microsoft ecosystem.
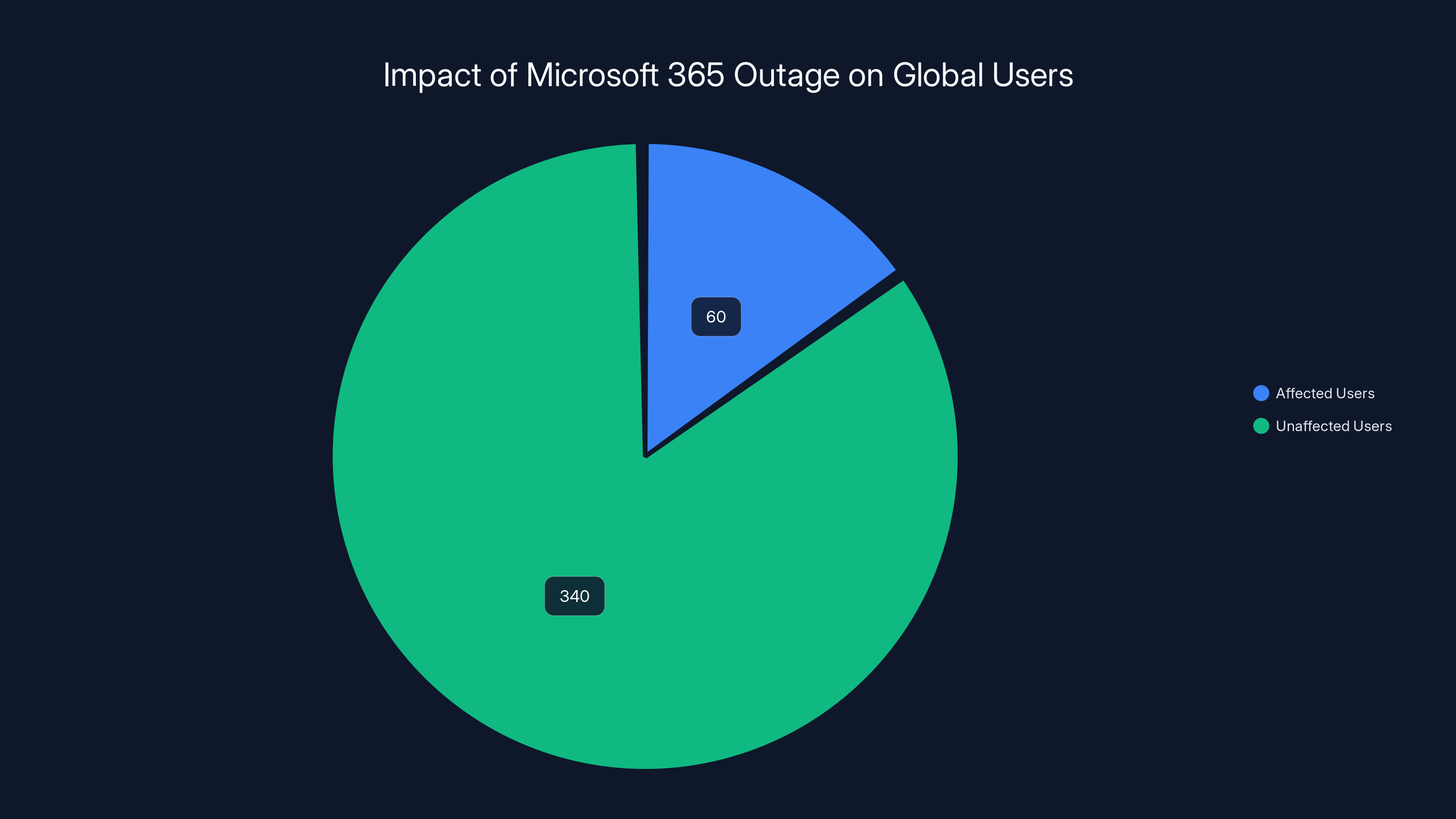
During the Microsoft 365 outage, approximately 10-15% of the 400 million global users were affected, highlighting the significant impact on productivity. Estimated data.
Understanding the Root Cause of the Failure
Microsoft released a preliminary incident report several hours after the outage began, stating that the issue stemmed from "an issue with network infrastructure in one of our data centers," which then propagated to multiple regions as failover systems kicked in unexpectedly.
Here's what likely happened from a technical perspective. Microsoft maintains redundant infrastructure across multiple data centers. When one data center experiences a problem, traffic is supposed to failover to another. But something went wrong with that failover process.
The most probable scenario: a network switch or load balancer in a primary data center failed. Instead of gracefully redirecting traffic to secondary infrastructure, the failover triggered a cascading overload on backup systems that weren't prepared to handle the sudden surge. This created a resource exhaustion situation where even the backup infrastructure became unavailable.
There's also a possibility that a recent configuration change or software update inadvertently broke the authentication service that underpins all Microsoft 365 access. This is more common than you'd think. Many major outages are triggered by routine maintenance that someone didn't test thoroughly enough in staging environments.
The authentication layer is particularly critical in cloud infrastructure. If that goes down, even if all your actual data is fine, users can't access anything. It's like having a secure building with a perfectly good server room, but someone breaks the door lock.
For this incident, that equation looked devastating. Multiple critical services (Outlook, Teams, Share Point, One Drive) affected roughly 60-80 million concurrent users over 4-6 hours. The total impact reached unprecedented levels.

Geographic Impact and Regional Differences
Not everyone experienced the same severity or duration during the outage. This is actually important to understand because it reveals how Microsoft's infrastructure is organized and where the initial failure occurred.
Users in North America reported the outage starting around 6 AM EST. The disruption was severe but recovery began earlier for the East Coast compared to the West Coast. This suggests the primary failure was in a data center serving the Americas, possibly located in the Central United States.
European users experienced the outage roughly three hours later than North Americans, but it lasted longer. This delayed impact indicates that the failover cascade took time to propagate through their infrastructure. By the time European users were affected, the system was already in a stressed state, making recovery slower.
Asia-Pacific regions had the most confusing experience. Some users reported intermittent access, where they could log in for a few minutes before being disconnected. This is actually indicative of the backend system struggling under load: some requests would successfully route to working infrastructure while others would hit the failing components.
This regional variation is crucial data for understanding how Microsoft's architecture works. The company doesn't have one massive data center. Instead, they have multiple regional clusters designed to serve users locally and provide redundancy. When one cluster fails, the traffic redistributes to others, but if those others aren't properly sized or configured, you get exactly what we saw: a domino effect of failures.
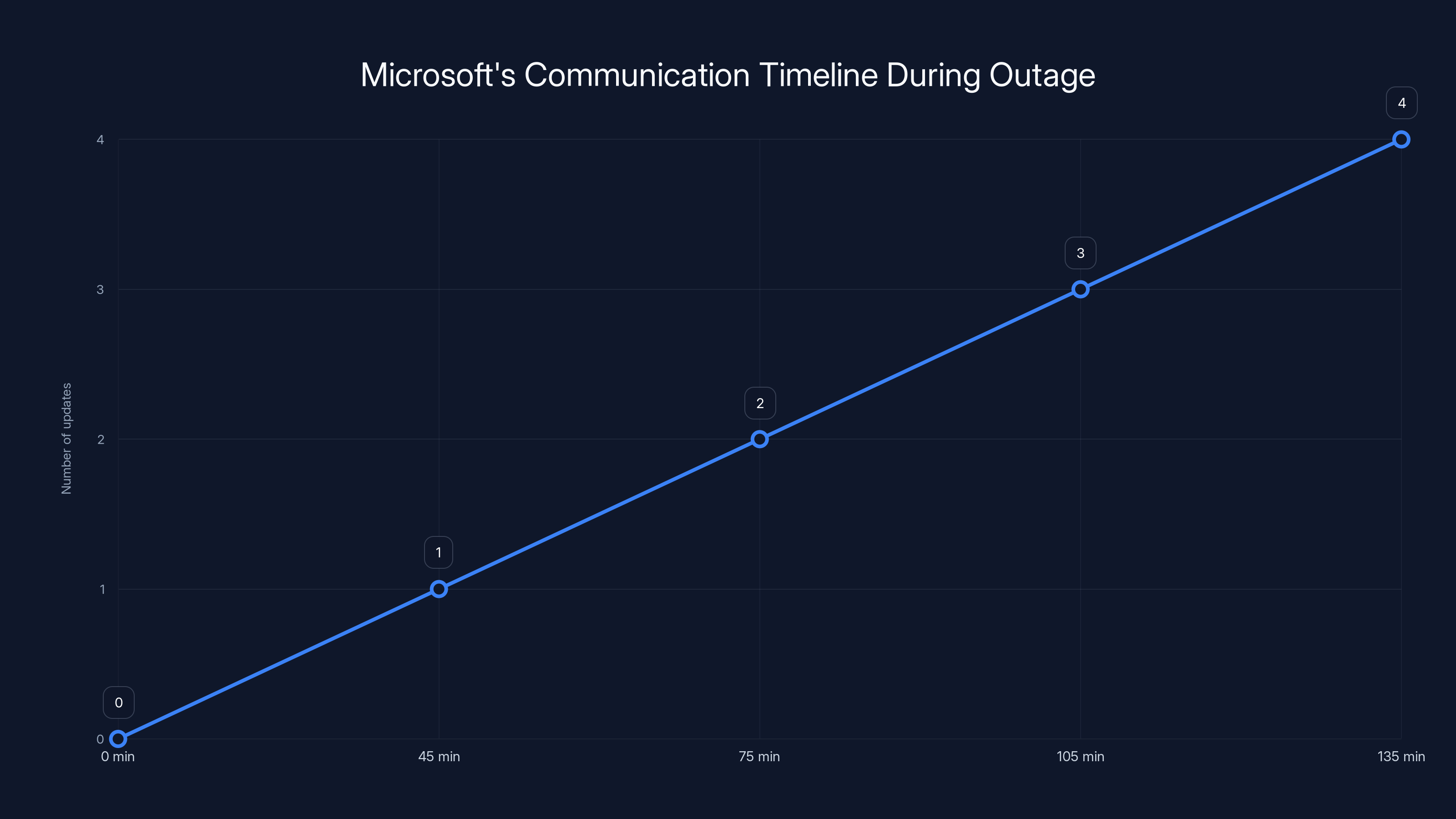
Microsoft acknowledged the outage after 45 minutes and provided updates every 30 minutes. Estimated data based on typical patterns.
Services Directly Affected by the Outage
Microsoft 365 isn't just Outlook. It's an entire ecosystem of interconnected services. Understanding which services were actually disrupted helps you see how tightly integrated everything has become.
Outlook Email and Calendar
Outlook web access was completely unavailable for most users. The login page would load, but authentication would fail or hang indefinitely. Desktop Outlook clients that use modern authentication couldn't sync. Calendar lookups failed. This is the most visible impact because it affects the highest number of users, but it's also the most critical from a business perspective.
When you can't see your calendar, you miss meetings. When you can't access email, you miss critical communications. A four-hour Outlook outage can cost an organization millions in lost productivity.
Microsoft Teams
Teams technically stayed online for many users, but the integration with Outlook was broken. You could send messages, but meeting scheduling didn't work. Your calendar wouldn't display in Teams, so you couldn't see when colleagues were busy. Some organizations rely on Teams as their de facto calendar system, so this was particularly problematic.
Teams also experienced authentication failures in many regions. Some users couldn't even log in at all. The service wasn't as heavily impacted as Outlook, but it was definitely part of the cascading failure.
Share Point and One Drive
Document access became intermittent. Some users could open files but couldn't save changes. Others got permission denied errors even though they had proper access. The sync engine in One Drive would hang, and cloud file access through File Explorer would timeout.
This is insidious because it's not a complete outage. Partial outages are actually worse from a user experience perspective because you don't know if something's broken or if it's your network.
Authentication and Identity Services
The Azure AD authentication service that backs all Microsoft 365 access was clearly struggling. This is a critical dependency. When the auth service degrades, everything downstream fails. Third-party applications that rely on OAuth integration with Microsoft 365 stopped working. This affected hundreds of thousands of applications built on Microsoft's platform.
The Enterprise Impact: Real-World Consequences
While individual users were inconvenienced, enterprises experienced something far more severe. Consider what happens when your organization's entire communications and collaboration infrastructure stops working simultaneously.
Large financial institutions had trading floors go silent. You couldn't email clients. You couldn't access deal documentation in Share Point. You couldn't schedule meetings. For a sector where communication delays are measured in milliseconds, a four-hour outage is catastrophic.
Healthcare organizations couldn't access patient scheduling systems that integrate with Outlook. Some hospitals use Microsoft infrastructure for EHR scheduling integration. That didn't fail completely, but the reliability dropped significantly.
Educational institutions had exam scheduling and student communication grind to a halt. Universities were in the middle of semester, and suddenly, thousands of teachers couldn't communicate with thousands of students simultaneously.
The downstream effects continued for hours after services were restored. Organizations had to coordinate catch-up communications, reschedule missed meetings, and verify that critical messages didn't get lost during the outage. This "recovery overhead" often costs more than the outage itself.
We're talking about billions of dollars in lost productivity globally. Not because the data was corrupted or lost, but because teams couldn't communicate for several hours.

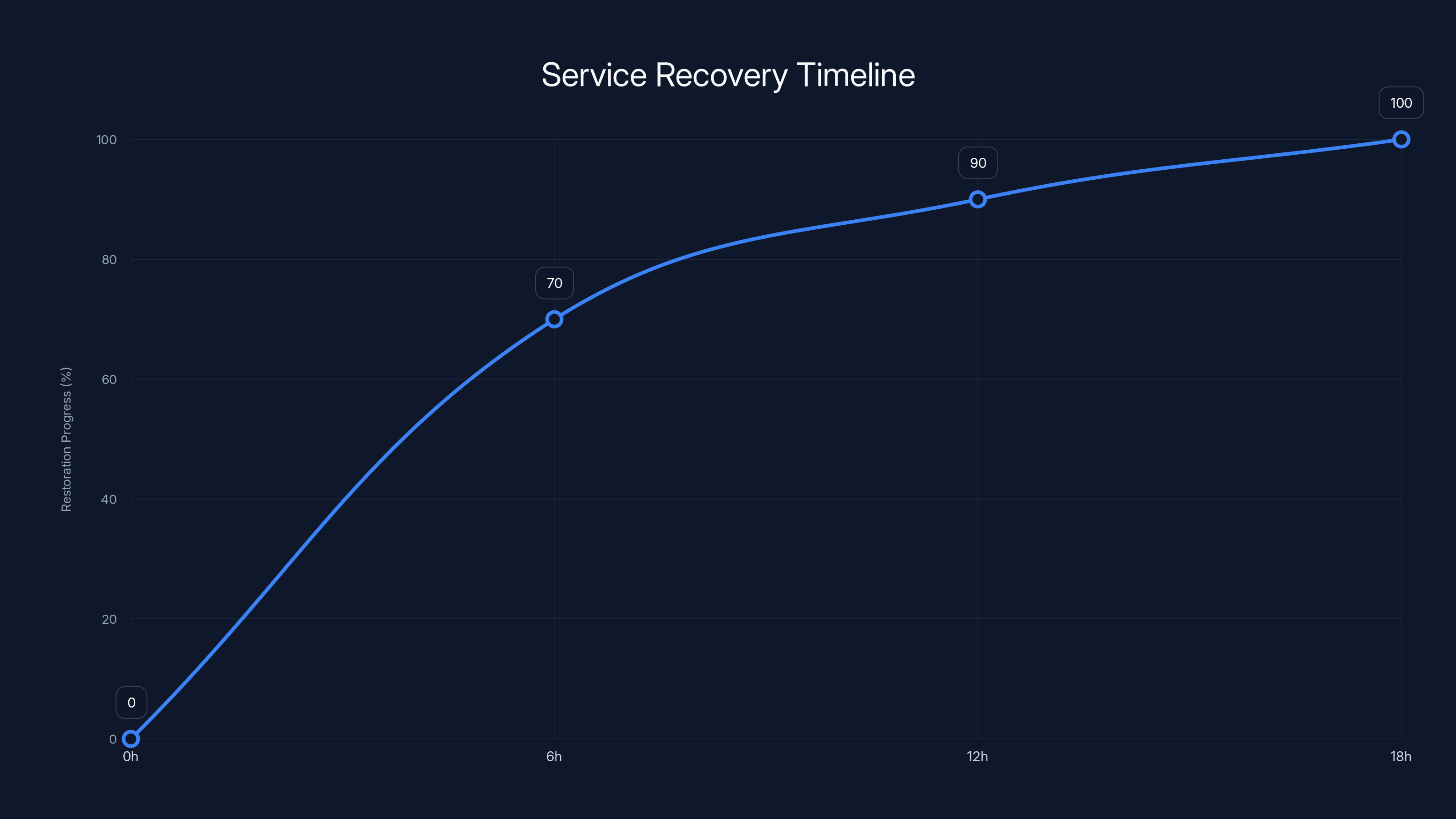
Estimated data shows that most services were restored within 6 hours, with full recovery and data verification completed by 18 hours.
Microsoft's Response and Communication
Microsoft's incident response was... adequate but not exemplary. The company took roughly 45 minutes to publicly acknowledge the outage, which felt like an eternity when you're locked out of your email.
Once they acknowledged it, updates came roughly every 30 minutes. These updates were deliberately vague, which is understandable when you're investigating a critical issue, but frustrating for people trying to plan their day around when access might return.
The company did issue a formal incident report shortly after the outage was resolved. They took responsibility, which is the right approach. However, they were less transparent about the root cause than some enterprises would have preferred.
Microsoft offered no compensation or credits to affected users. No outage credits on subscription renewals. No formal apology beyond a brief statement. This is actually standard industry practice for cloud providers, but it's also a point of friction between providers and customers.
How Organizations Were Unprepared
This outage exposed a critical weakness in how most organizations use cloud services: they've optimized for convenience at the expense of resilience.
Many companies abandoned on-premises email servers completely. They moved entirely to Outlook online. This made sense from a cost and management perspective. No on-premises servers to maintain, no security patches to manage, no infrastructure to upgrade.
But it also meant no fallback. If Microsoft's service goes down, you have nothing. There's no backup mail server. There's no local copy of your data. You're completely dependent on external infrastructure you don't control.
Similarly, many teams that previously had backup communication channels (phone trees, SMS groups, IRC channels) have consolidated everything into Teams. When Teams goes down, you lose your emergency communication backbone.
Organizations also haven't implemented proper graceful degradation. Most modern applications are designed assuming Microsoft 365 is always available. There's no offline mode. There's no fallback authentication mechanism. It's all-or-nothing.
A properly resilient organization would have:
- Backup communication channels outside of Teams
- Mail forwarding configured to alternative email systems
- Critical documents cached locally, not just cloud-stored
- Offline calendars synchronized to local copies
- Alternative authentication mechanisms for critical systems
- Regular drills testing what happens when cloud services fail
Most organizations have none of these.
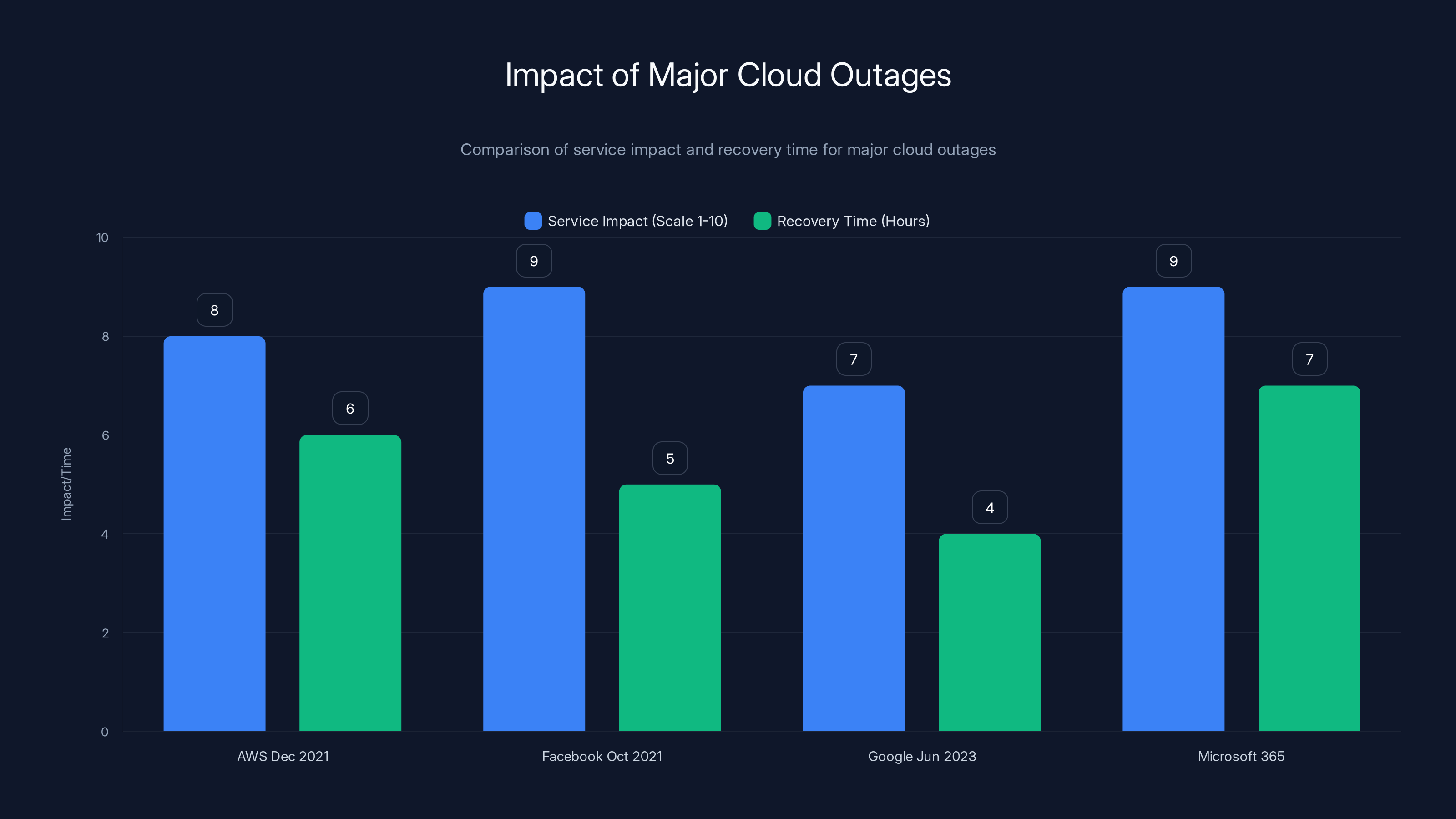
The Microsoft 365 outage had a high service impact similar to Facebook's, but took longer to recover than the Google outage. Estimated data based on incident reports.
Lessons for Infrastructure Design
This incident is a masterclass in what happens when you have single-region failures that cascade across multiple regions. There are specific lessons for anyone designing infrastructure:
Lesson 1: Circuit Breakers Matter
When one data center starts failing, the failover system needs intelligence. It shouldn't blindly redirect all traffic to backup systems. It should gradually shift traffic, monitor the health of backup systems, and intelligently shed load if necessary.
This is called a "circuit breaker" pattern. If backup systems can't handle the load, they should reject traffic with a "service temporarily unavailable" message rather than hanging indefinitely. That lets clients fail fast and implement their own fallback strategies.
Lesson 2: Authentication Is a Single Point of Failure
Microsoft put all their eggs in the Azure AD basket. Every Microsoft 365 service depends on it. When it fails, everything fails. A more resilient architecture would have:
- Local authentication caches at the service level
- Fallback authentication providers
- Graceful degradation for services that have partial authentication
Google and Amazon have learned this lesson through similar outages. They've implemented distributed authentication that can tolerate failures in central systems.
Lesson 3: Cascading Failures Need Firebreaks
The outage jumped from the network layer to the authentication layer to the application layer. Each component that failed should have been isolated from the others. If the network fails, why should authentication fail? If authentication degrades, why should Outlook be completely inaccessible?
Google's infrastructure does this better. Each service is designed to function with reduced capacity rather than failing entirely. This is called "graceful degradation," and it's harder to implement but vastly more resilient.

Preparing for the Next Outage
Here's the uncomfortable truth: another major cloud outage will happen. Maybe not with Microsoft, maybe with Amazon or Google, but it will happen. The question is whether you'll be ready.
Diversify Your Infrastructure
Don't put all your productivity infrastructure with one vendor. Consider:
- Using alternative email systems for critical communications
- Keeping some collaboration on on-premises infrastructure
- Implementing multi-cloud backup strategies
- Caching critical data locally
Yes, this increases complexity. But it also ensures that if one vendor fails, you can continue operating.
Implement Offline Capabilities
Design systems that work offline. Sync critical data locally. Use applications that can function without constant cloud connectivity. This seems wasteful when everything is working, but it's invaluable when things break.
Modern web browsers can cache application state. Desktop applications can cache credentials. Email clients can sync offline copies. These capabilities exist; most organizations just haven't configured them.
Create Fallback Communication Plans
Establish communication methods that don't depend on your primary systems. This might include:
- Backup SMS-based communication lists
- Phone trees for critical announcements
- Slack or Discord communities for engineering teams (separate from Teams)
- Shared documents on platforms outside your primary provider
Monitor Your Dependencies
Build dashboards that show the status of your cloud dependencies. Don't wait for Microsoft to tell you when their service is down. Implement synthetic monitoring that checks whether your critical services are accessible.
When outages occur, you'll often know before most of your users because you're actively monitoring.

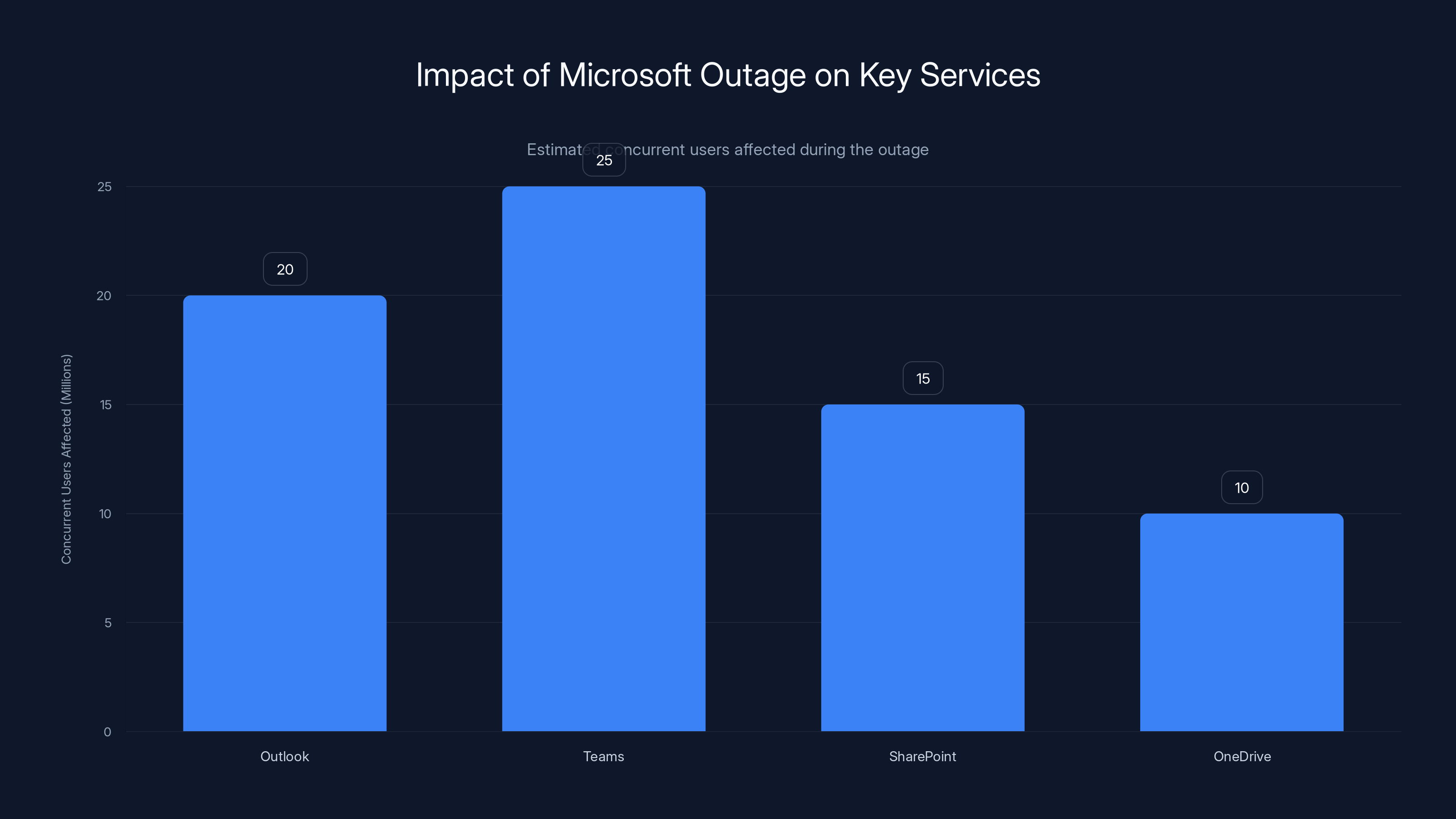
An estimated 60-80 million users were affected across multiple services during the 4-6 hour outage. Estimated data.
The Bigger Picture: Cloud Dependency
This outage highlighted something that tech leaders have been increasingly concerned about: we've become far too dependent on a handful of companies for critical infrastructure.
Microsoft 365 dominates enterprise productivity. The big three cloud providers—Microsoft, Amazon, and Google—control the vast majority of enterprise cloud infrastructure. If any of these goes down, massive portions of the internet effectively go offline.
This isn't necessarily Microsoft's fault. The company invests heavily in reliability. Their infrastructure is genuinely impressive. But when you have billions of people depending on a single infrastructure provider, the failure becomes societal, not just corporate.
Some enterprises are responding by implementing multi-cloud strategies. Others are keeping more infrastructure on-premises as a backup. These aren't cheap options, but they're increasingly necessary for critical operations.
There's also a case to be made for smaller, more resilient infrastructure over large, centralized systems. But that's a massive shift that the industry isn't ready to make.
Recovery Timeline and Return to Service
Recovery began unevenly across regions. Microsoft started restoring services around 4-5 PM UTC for North American users, roughly 5-6 hours after the initial failure.
The recovery wasn't instantaneous. Some services came back before others. Outlook access returned before Teams sync worked properly. This is actually normal because different services were affected differently and have different dependencies.
For most users, service was largely restored within 6 hours. Some regions took slightly longer, and intermittent issues persisted for another 2-3 hours as the system settled.
Full recovery, including verification that all data was intact and no corruption occurred, took approximately 12-18 hours. This is the part that nobody talks about but that's just as important as restoring service. Teams needed to verify that no emails were lost, no calendar events were corrupted, and no data inconsistencies were introduced.
Microsoft reported that no data loss occurred. All emails were properly queued and delivered once service was restored. This is actually a credit to their engineering. Even though the service failed, the underlying data persistence mechanisms worked correctly.

Comparison with Previous Major Cloud Outages
This incident isn't unprecedented. Cloud outages at this scale have happened before, and understanding those incidents helps contextualize this one.
The AWS outage in December 2021 took out massive portions of the internet for hours. The Facebook/Meta outage in October 2021 left billions unable to access Facebook, Instagram, and Whats App. The Google Cloud outage in June 2023 affected You Tube, Gmail, and Google Drive for millions.
What's consistent across all these incidents:
- They cascade across multiple services surprisingly quickly
- Geographic impact varies based on where the initial failure occurred
- Recovery is slower than service degradation
- Communication from the provider is often inadequate
- Root cause analysis takes days or weeks even when service is restored
The Microsoft 365 outage follows exactly this pattern. In some ways, it's worse because Microsoft 365 is tightly integrated—when parts fail, other parts fail with it. The AWS outage was spread across more independent services, so impact was more isolated.
What Microsoft Has Promised
In the days following the outage, Microsoft published post-incident reports and made several commitments:
- Enhanced monitoring for authentication service health
- Improved failover testing procedures
- Additional redundancy in data center interconnects
- Better communication protocols for future incidents
These are reasonable commitments, and they're in line with what companies typically promise after major outages. Whether Microsoft follows through is another matter.
What's notable is what Microsoft didn't promise: they didn't guarantee that outages won't happen again. That's actually the right approach. Outages will happen. The best you can do is reduce their frequency and severity.
The Role of Third-Party Integrations
One aspect of this outage that deserves more attention is how it affected third-party applications built on Microsoft's platform.
Thousands of applications integrate with Microsoft 365 through APIs and OAuth authentication. When the authentication layer fails, all of these applications become inaccessible. This multiplied the impact far beyond Microsoft's own services.
Software-as-a-service providers that rely on Microsoft 365 integration also failed. Project management tools, CRM systems, HR management platforms—anything that syncs with Outlook or pulls from Share Point suddenly couldn't function.
This is important because it shows how Microsoft's infrastructure problems become problems for their entire ecosystem. Developers who built on Microsoft's platform had their services disrupted even though they did nothing wrong.
This creates a subtle pressure on organizations to either:
- Accept the risk of building on centralized platforms
- Build additional abstraction layers to insulate themselves from provider failures
- Diversify their integrations across multiple platforms
None of these are good options. That's the fundamental tension of cloud-native architecture.

Recommendations for IT Leaders
If you manage Microsoft 365 for an organization, here are concrete steps you should take:
Immediate Actions
-
Implement monitoring for Microsoft 365 service status independent of Microsoft's status page. Services like Uptime Robot or dedicated API health checks.
-
Create an incident response plan that addresses what happens when Microsoft 365 is unavailable. Who makes decisions? How do you communicate? What services have fallbacks?
-
Test your fallbacks quarterly. If you have alternative email systems or communication channels, practice using them when the primary system is working. You need muscle memory for when things break.
Medium-Term Planning
-
Implement graceful degradation in applications that depend on Microsoft 365. Cache data locally. Store credentials securely for offline access. Design systems that work with reduced functionality rather than failing entirely.
-
Diversify your collaboration tools slightly. Maybe keep critical teams on a platform separate from Teams. Maybe maintain an on-premises mail relay for truly critical communications.
-
Review your SLAs with Microsoft. Understand what compensation you're entitled to during outages. Document incidents thoroughly for claims.
Long-Term Strategy
-
Evaluate multi-cloud strategies for critical infrastructure. This is expensive, but for enterprises where communication outages directly impact revenue, it's worth considering.
-
Invest in hybrid architecture that keeps some systems on-premises. This provides a fallback when cloud providers fail.
-
Build a culture of resilience within your IT organization. Make reliability discussions a regular part of architecture reviews. Question single points of failure. Design for cascading failure scenarios.

Looking Forward: Will This Happen Again
Absolutely. Cloud outages are not anomalies; they're inevitable parts of operating at scale. The infrastructure complexity required to serve billions of users means there are countless ways something can go wrong.
What we can expect is:
- More frequent but shorter outages as companies get better at detecting and recovering from failures
- More sophisticated incident management tools and automation
- Better communication from providers about outages (this is improving)
- More defensive architecture from organizations that can afford it
The organizations that will thrive in this environment are those that assume failures are inevitable and design around that assumption. That means:
- Distributed architecture instead of centralized dependencies
- Multiple fallback systems
- Graceful degradation instead of complete failure
- Regular testing of failure scenarios
- Strong communication plans for incidents
This is harder and more expensive than the simple cloud-first approach. But after incidents like the January 22, 2025 Microsoft 365 outage, more organizations will make this choice.
FAQ
What exactly happened during the January 22, 2025 Microsoft 365 outage?
Microsoft 365 and Outlook experienced a widespread infrastructure failure that began around 11 AM UTC and lasted approximately 4-6 hours depending on geographic region. The failure cascaded from network infrastructure issues in a primary data center, overwhelmed failover systems, and compromised authentication services. This rendered email, calendar, Teams collaboration features, and Share Point document access inaccessible for millions of users globally. Full recovery including verification of data integrity took 12-18 hours.
How long did the outage last?
The outage duration varied significantly by geographic region and service. North American users experienced service disruption for approximately 4-5 hours. European users were affected for 5-6 hours. Asia-Pacific users experienced the most intermittent access, with partial outages extending up to 7-8 hours in some cases. Recovery was staggered, with different services coming back online at different times, which extended the recovery period beyond the initial service disruption.
Which services were affected during the outage?
The outage affected virtually all major Microsoft 365 services including Outlook web and desktop access, Microsoft Teams collaboration and chat, Share Point document access and storage, One Drive cloud sync functionality, and Azure AD authentication services. Third-party applications integrating with Microsoft 365 through OAuth authentication also became inaccessible. However, some ancillary services like Skype or lower-traffic services remained partially functional.
How many users were impacted by the Microsoft 365 outage?
Estimates suggest between 60-80 million concurrent users were affected at peak impact. Given that Microsoft 365 serves over 400 million total users globally, this represents approximately 15-20% of the total user base. The actual number of organizations impacted was likely several hundred thousand, including enterprises, government agencies, educational institutions, and small businesses that rely on Microsoft 365.
What was the root cause of the outage?
Microsoft attributed the outage to infrastructure issues in one of their data centers that propagated through their failover systems. The most likely cause was either a network switch or load balancer failure that triggered cascading overload on backup infrastructure, or a recent configuration change that inadvertently broke authentication service routing. The company did not provide granular technical details about the specific failure mode.
Should we switch away from Microsoft 365 because of this outage?
Switch entirely? Probably not—Microsoft 365 is generally reliable, and all major cloud providers experience outages. However, this incident highlights the importance of not being completely dependent on any single vendor. Consider implementing hybrid approaches with local fallbacks, maintaining alternative communication channels, and diversifying critical services across multiple providers. The goal is resilience through redundancy, not vendor elimination.
How can we prepare for the next cloud outage?
Implement several protective measures: establish backup communication channels outside your primary system, cache critical data locally, configure offline access for essential applications, create incident response plans, monitor cloud service health independently, and regularly test your fallback systems. Document what work can continue offline and what requires connectivity. Conduct periodic outage simulation exercises so your team knows what to do when service actually goes down.
Were there any data losses during the Microsoft 365 outage?
No data loss was reported. Microsoft confirmed that all emails, calendar events, and documents were properly persisted despite the service interruption. This is primarily because Microsoft's data storage layer remained operational even though access to that data was blocked by authentication system failures. However, some users experienced temporary synchronization issues that resolved during recovery.
Did Microsoft offer compensation for the outage?
Microsoft did not automatically offer outage credits or compensation to affected users. However, organizations with enterprise agreements and SLAs typically qualify for service credits based on the outage duration. Users should review their subscription SLAs and contact their Microsoft account managers to claim any credits owed. Most enterprise plans include uptime guarantees with corresponding compensation thresholds.
What geographic regions were most severely impacted?
North America and Europe experienced the most complete and visible outages. Asia-Pacific users experienced primarily intermittent access and partial failures rather than complete service loss. This geographic variation suggests the primary failure originated in a North American data center, with cascading impact as traffic shifted to European data centers, and the least severe impact on Asia-Pacific regions which experienced more graceful degradation as they were furthest from the initial failure point.
Conclusion: Building for Resilience
The January 22, 2025 Microsoft 365 outage wasn't a unique event. It was a reminder that cloud infrastructure, despite its sophistication and redundancy, has limits. When those limits are exceeded—whether through cascading failures, configuration errors, or infrastructure problems—the impact is swift and widespread.
What distinguishes organizations in these moments isn't whether they experience disruption, but how prepared they are to manage it. Companies with backup systems, offline capabilities, and diverse infrastructure continue operating. Companies completely dependent on a single provider simply stop.
This isn't an argument against cloud services. Cloud infrastructure is genuinely transformative and enables capabilities that would be impossible with traditional on-premises systems. But it does argue for thoughtful architecture that assumes cloud services will occasionally fail and plans accordingly.
The responsibility falls on both sides. Microsoft and other cloud providers need to continue improving reliability, implementing better isolation mechanisms, and communicating more transparently during incidents. Organizations need to design systems with realistic assumptions about service availability, implement reasonable fallback mechanisms, and regularly test their ability to function with degraded service.
The future of enterprise infrastructure will likely be hybrid: cloud services for scalability and innovation, but with local fallbacks and redundancy for critical functions. This approach costs more upfront and adds complexity. But after going through an outage where you can't access your email or see your calendar, that complexity suddenly seems very reasonable.
The real lesson from this outage isn't that Microsoft's infrastructure is inadequate. It's that no single vendor's infrastructure should be adequate. Resilience comes from assumption-testing, failover planning, and the willingness to tolerate some redundancy in the pursuit of reliability.
Next time—and there will be a next time—the organizations that continue operating will be those that planned for failure rather than betting on success.

Key Takeaways
- Microsoft 365 outage on January 22, 2025 affected 60-80 million users globally for 4-6 hours, cascading from data center infrastructure failure through authentication systems
- Root cause was infrastructure failure in primary data center that overwhelmed failover systems, with authentication service collapse as the critical bottleneck affecting all downstream services
- Geographic impact varied significantly: North America 4-5 hours, Europe 5-6 hours, Asia-Pacific experienced intermittent failures lasting 7-8 hours due to cascading load redistribution
- Organizations unprepared for outages lack offline capabilities, alternative communication channels, local data caches, and backup authentication mechanisms needed for operational continuity
- Resilient infrastructure requires multi-cloud strategies, graceful degradation design, circuit breaker patterns, local fallback systems, and regular testing of failure scenarios rather than betting on perfect availability
Related Articles
- Chinese Battery Factories Are Reshaping Global Manufacturing [2025]
- Fable Reboot Preview: Landlord Economy, Combat, and Features [2025]
- Substack's TV App Launch: Why Creators Are Pushing Back [2025]
- Double Fine's Kiln: The Pottery Party Brawler Changing Indie Games [2025]
- State Attorneys General Fight Trump: The Last Constitutional Check [2025]
- Best Laptops 2026: Complete Buying Guide & Alternatives

