![Music Publishers Sue Anthropic for $3B Over AI Training Data Piracy [2025]](https://tryrunable.com/blog/music-publishers-sue-anthropic-for-3b-over-ai-training-data-/image-1-1769713658694.png)
Music Publishers Sue Anthropic for $3B Over AI Training Data Piracy: What You Need to Know
When you build an AI company worth $350 billion, someone's going to notice if you're cutting corners. Anthropic is learning that lesson the hard way.
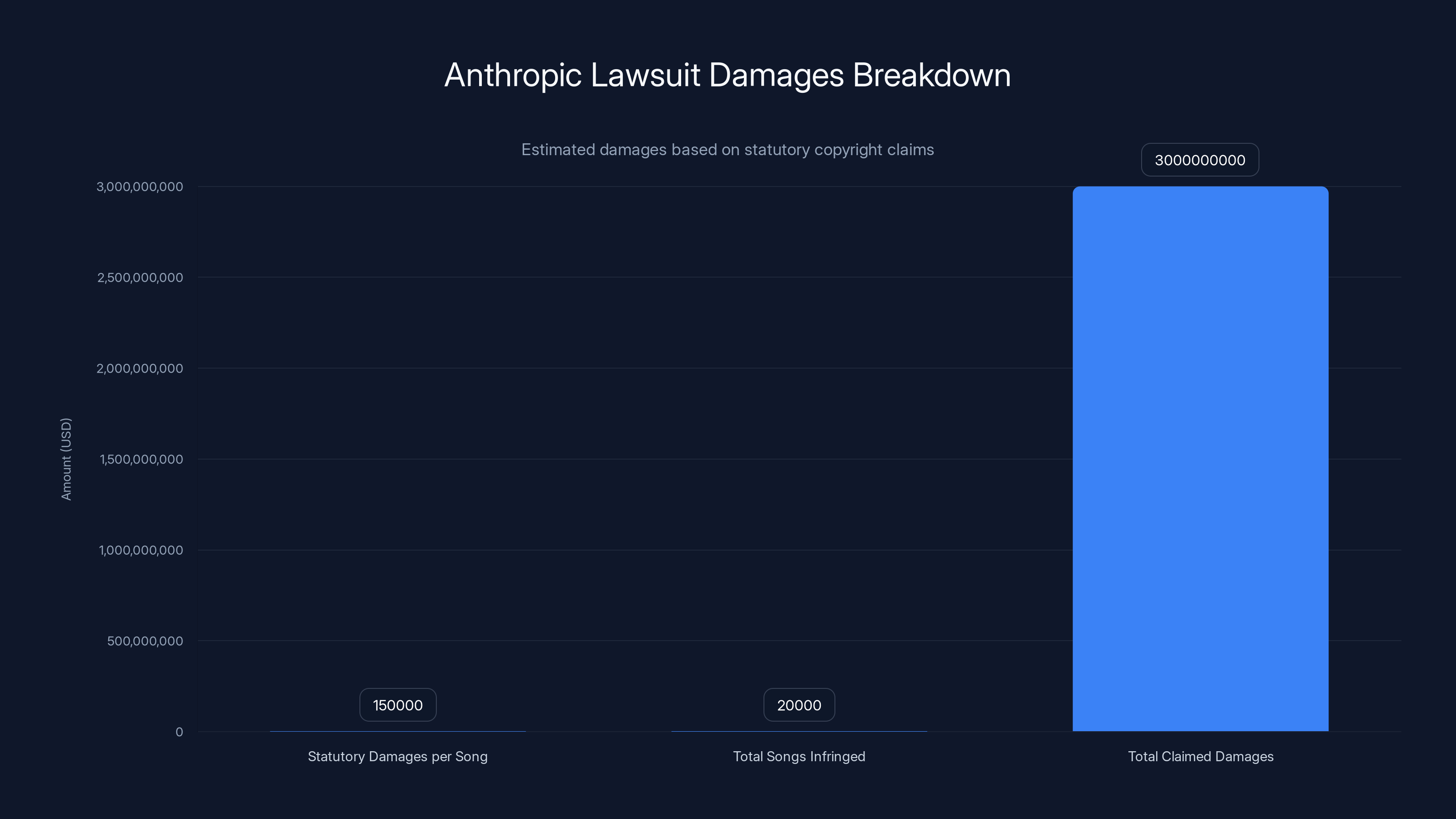
A major legal battle is unfolding that could reshape how AI companies train their models. Universal Music Group and Concord Music Group are suing the AI company for allegedly downloading more than 20,000 copyrighted songs without permission to train Claude, Anthropic's flagship AI chatbot. The lawsuit seeks damages exceeding $3 billion, making it one of the largest non-class action copyright cases in U.S. history, as reported by Music Business Worldwide.
But here's what makes this case so interesting: it's not the first time Anthropic has faced this exact accusation. The same legal team that handled a previous copyright suit against the company has returned with even bigger ammunition. And this time, the discovery process revealed something damning about how Anthropic sources its training data, according to Complete Music Update.
This lawsuit represents a critical inflection point for the entire AI industry. For years, tech companies have justified using copyrighted material for AI training as "fair use." Now, the courts are drawing a line between what's legal to do with data you own and what's legal to obtain that data in the first place. That distinction might seem subtle, but it could cost Anthropic billions, as noted by IPWatchdog.
Let's break down what happened, why it matters, and what it means for the future of AI development.
TL; DR
- The Lawsuit: Music publishers are suing Anthropic for $3+ billion over allegations of illegally downloading 20,000+ copyrighted songs without permission, as detailed by Reuters.
- The Scale: This ranks among the largest non-class action copyright cases in U.S. history, with iconic artists including The Rolling Stones, Neil Diamond, and Elton John named in the suit.
- The Legal Precedent: A prior judge ruled that training on copyrighted content itself might be legal, but acquiring it through piracy is not—a crucial distinction Anthropic may have overlooked.
- The Pattern: This is the second major copyright lawsuit against Anthropic from the same legal team, suggesting systemic issues with data acquisition practices.
- The Industry Impact: The ruling will likely force all AI companies to restructure how they source training data, potentially requiring licensing agreements or stricter content vetting.

The lawsuit against Anthropic claims over
Understanding the Core Allegations
Let's start with what we know. The lawsuit claims that Anthropic used torrenting mechanisms to download music files—not just the audio, but sheet music, lyrics, and compositions. These files then became training material for Claude, as explained by TechBuzz.
This isn't some gray area interpretive question. Torrenting copyrighted content without a license is textbook copyright infringement. It's the same mechanism people use to download movies illegally. The publishers have evidence of this happening. They discovered it during the discovery process of a previous lawsuit.
The specific songs named in the suit read like a greatest hits compilation. The Rolling Stones' catalog, Neil Diamond's work, Elton John's compositions—these aren't obscure b-sides. These are iconic pieces of music that generate millions in licensing revenue every year.
What makes this different from fair use arguments is the method of acquisition. Fair use doctrine typically allows transformative use of copyrighted material—think parody, criticism, commentary, or education. But fair use doesn't extend to the unlicensed acquisition of that material in the first place.
Imagine a filmmaker who makes a transformative critique of a movie. Fair use might protect their commentary. But if they stole the film instead of licensing it to make their critique, the legal protections disappear. That's essentially what happened here.
The lawsuit explicitly states: "While Anthropic misleadingly claims to be an AI 'safety and research' company, its record of illegal torrenting of copyrighted works makes clear that its multibillion-dollar business empire has in fact been built on piracy."
That's not subtle. The publishers are saying Anthropic's entire value proposition is built on theft.
The Companies Behind the Lawsuit
Understanding who's suing helps explain the severity. These aren't small independent labels. We're talking about major players in the music industry.
Universal Music Group is the world's largest music conglomerate. They own and distribute music for countless artists across every genre imaginable. Taylor Swift, The Weeknd, Ariana Grande, Billie Eilish—if a song is massive, there's a good chance UMG has a stake in it.
Concord Music Group operates differently. As an independent publisher, Concord represents artists like Common, Killer Mike, and Korn. They're smaller than Universal, but they're scrappy and they're aggressive about protecting their artists' rights.
Together, these two publishers control rights to an enormous catalog of music. When they say 20,000 songs were downloaded, that represents billions of dollars in potential lost licensing revenue.
The fact that multiple publishers banded together on this case sends a message: this isn't just one company's problem. The entire music industry has noticed what's happening. If Anthropic gets away with this, every AI company will follow the same playbook.
That's why the $3 billion damages figure matters. It's not just compensation. It's a deterrent.

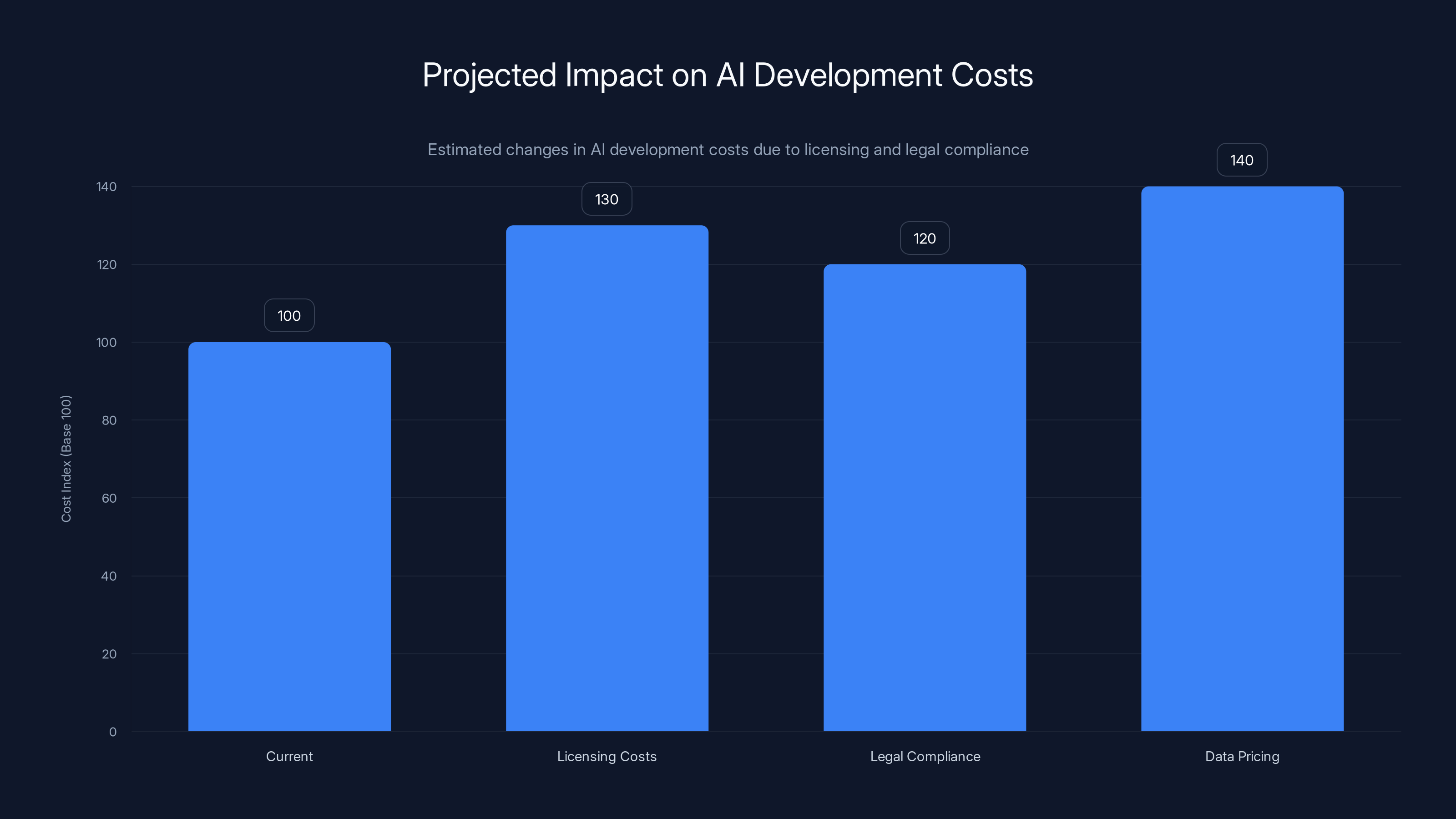
Estimated data suggests that AI development costs could increase by 30-40% due to licensing, legal compliance, and data pricing changes.
The Prior Lawsuit That Set the Stage
Here's where things get really interesting. This isn't Anthropic's first rodeo with copyright lawsuits. In fact, the same legal team is back for another round.
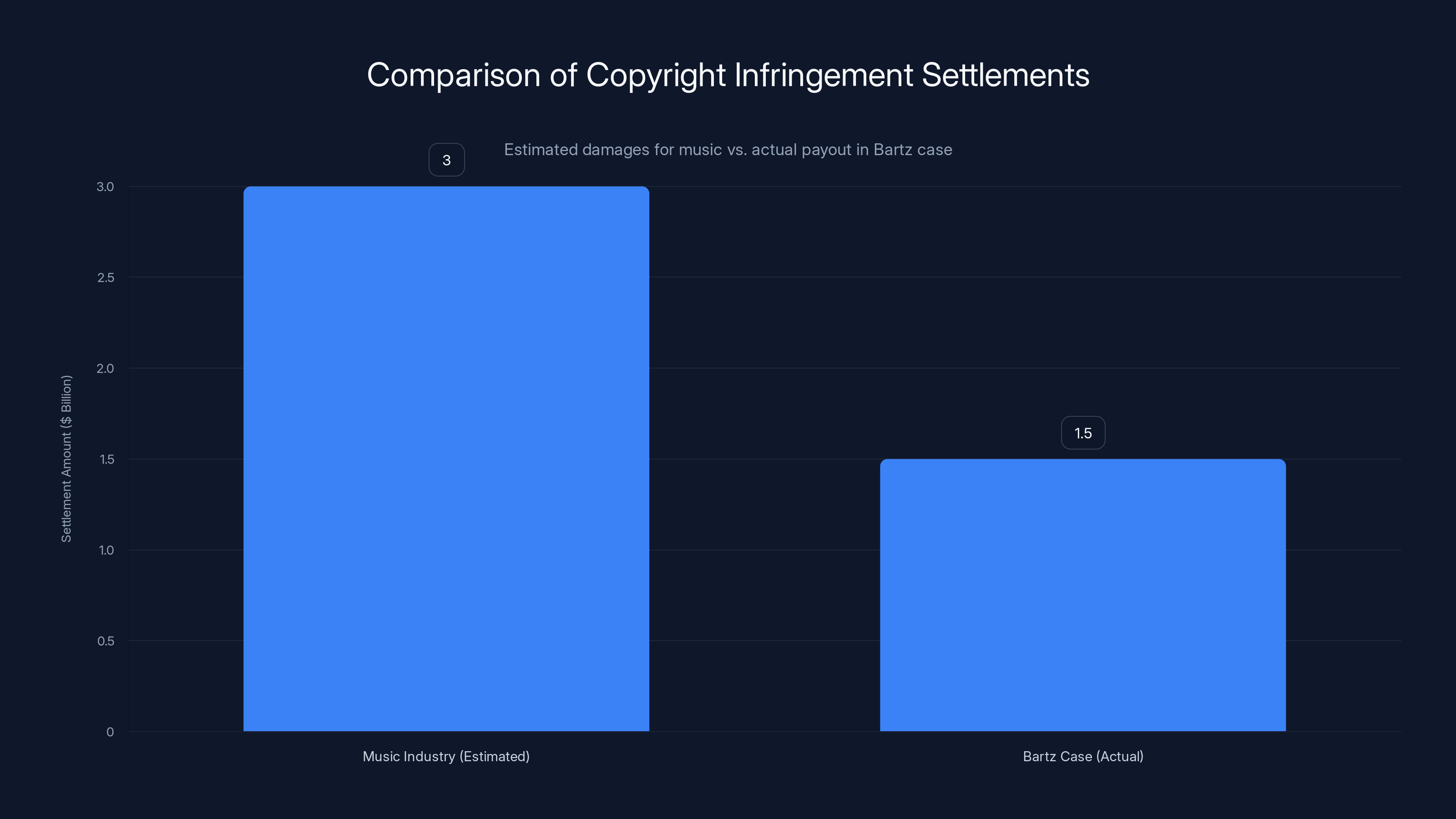
In the previous case, known as Bartz v. Anthropic, the company faced allegations that it had downloaded published works from 500,000 authors without permission to train Claude. That case resulted in a $1.5 billion settlement.
But here's the key part: the judge, William Alsup, issued a ruling that seemed to give Anthropic some cover. He determined that while it was illegal to acquire the copyrighted content through piracy, training an AI model on copyrighted content—once you have it—might actually be protected under fair use doctrine.
That's a crucial distinction. It's like saying the burglary is illegal, but keeping the stolen goods once you have them might be legal. The ruling essentially put the burden on how the content was acquired, not what you do with it once you have it.
For Anthropic, this probably felt like a win. Sure, they had to pay $1.5 billion, but the legal framework seemed to say: "Next time, just license the content instead of stealing it, and you'll be fine."
Except Anthropic didn't seem to learn that lesson. Which brings us to the music lawsuit.
The Math Behind the $3 Billion Number
Let's talk about why the publishers are asking for $3 billion specifically. This isn't random.
Under U.S. copyright law, a copyright holder can claim either actual damages or statutory damages. Statutory damages for willful infringement can reach
With 20,000 songs allegedly stolen, here's the math:
That calculation assumes willful infringement. And the lawsuit description—"flagrant piracy"—strongly suggests the publishers will argue willfulness.
Now, compare this to what happened in the Bartz case. That settlement gave 500,000 authors $3,000 each. It sounds generous until you do the math:
But here's the thing: that settlement was for training on published works. If you assume each author had multiple published works (books, articles, essays), the actual per-work compensation was probably much lower—maybe just a few hundred dollars per work.
The music industry is driving a harder bargain. They're saying: "If you're going to put works through industrial-scale copyright infringement, the price is going to be substantially higher than what writers got."

How Anthropic Actually Got the Music
This is the damning part. The lawsuit isn't speculating. The publishers have actual evidence of how Anthropic acquired the content.
They found that Anthropic used torrenting technology. That means peer-to-peer file sharing, the same infrastructure that powers piracy operations worldwide. This wasn't a gray area situation where maybe they licensed something and misunderstood the terms. This was deliberate use of piracy infrastructure, as detailed by Cloudwards.
Why would Anthropic do this instead of licensing music properly? The obvious answer: cost. Licensing 20,000 songs from major publishers would have required negotiation, documentation, payment agreements, and transparency. That's expensive and time-consuming.
Downloading the same content via torrent? Cheap. Fast. Invisible (until someone does a forensic audit during discovery).
The use of torrenting also raises questions about whether Anthropic even knew which songs were being downloaded. Torrent downloads often include thousands of files. Did Anthropic employees manually verify that they were only getting music? Or did they just grab whatever the torrent contained?
If it's the latter, that's even worse. It suggests reckless disregard for copyright law, not just deliberate infringement.
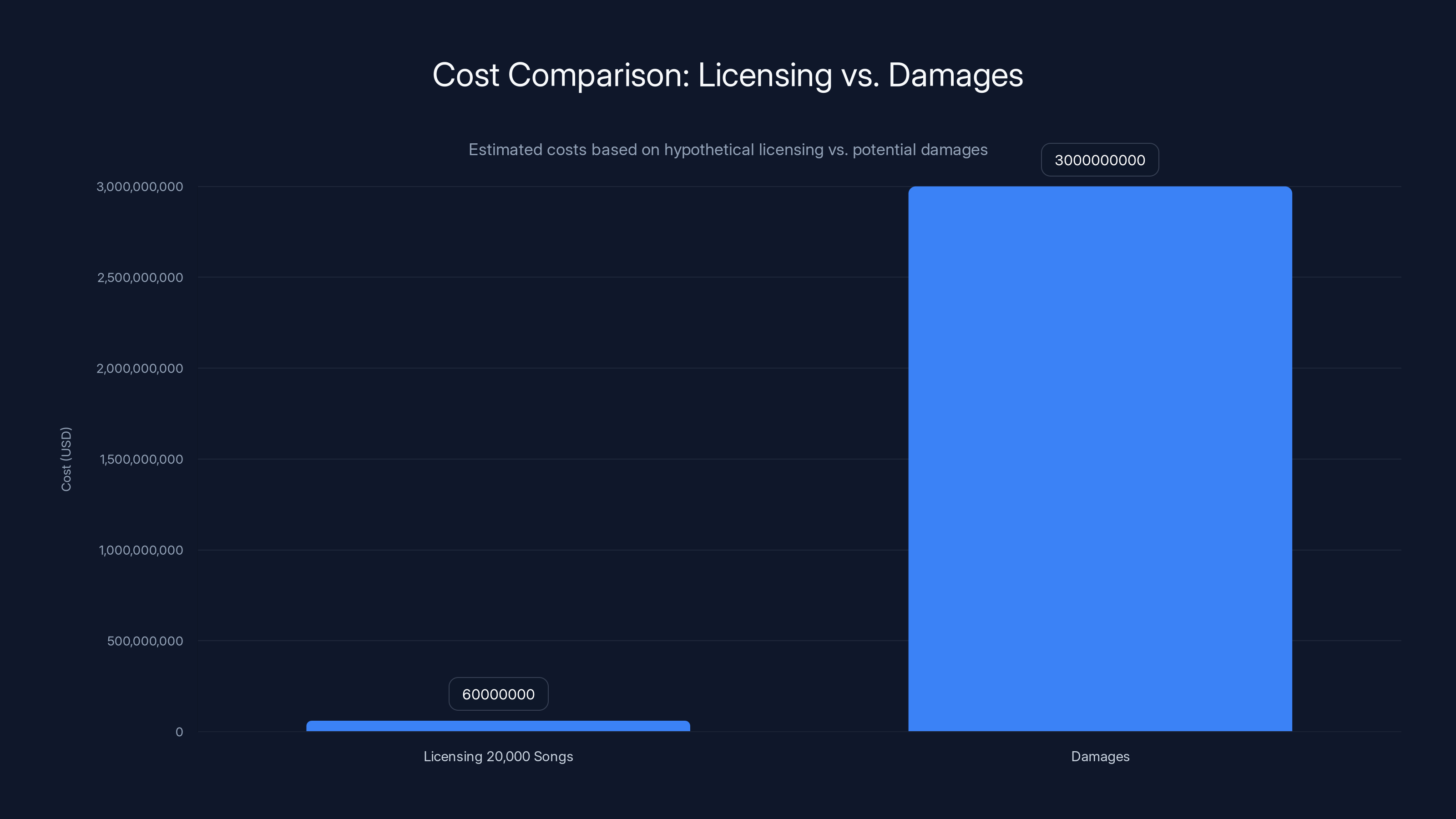
Estimated data shows that licensing 20,000 songs could have cost
The "Flagrant Piracy" Language
The lawsuit uses the word "flagrant." That's not accidental wording.
Flagrant means obvious, intentional, blatant. It's a legal term that carries weight. By using "flagrant piracy," the publishers are arguing that Anthropic couldn't have possibly misunderstood what it was doing. This wasn't some gray area technical mistake. This was deliberate copyright violation.
Flagrant violations get higher damages. They open the door to willful infringement findings. They can also potentially trigger criminal referrals, though that's less common in copyright cases.
The language the publishers chose tells us how they're planning to argue the case. They're not saying "Anthropic maybe infringed copyright." They're saying "Anthropic deliberately and obviously violated copyright law."
The evidence backs them up. You can't accidentally download content via torrent. It's not like clicking "next" on an installer where you don't read the terms. You're specifically choosing to download files from a distributed network.
What Anthropic's Defense Might Look Like
Now let's think about how Anthropic might defend itself. They'll probably try several angles.
First, they might argue fair use. Even if they acquired the content through torrents, maybe training AI models on music is transformative enough to qualify as fair use. The previous judge's ruling gives them some hope here.
But the acquisition method undermines that argument. You can't rely on fair use as a defense against a willful infringement charge when you deliberately obtained the content illegally.
Second, they might argue that they didn't know the content was protected. But that's almost impossible to maintain. Every song by The Rolling Stones or Neil Diamond is obviously copyrighted. Concord and Universal actively manage and protect these works.
Third, they might try to settle. Anthropic has deep pockets. A settlement might be cheaper than going to trial and losing badly. But the settlement number would probably be substantial.
Anthropic could also try to argue that some of the 20,000 songs were actually in the public domain or licensed more liberally than the publishers claim. But the publishers presumably did their homework before filing. They're not naming iconic artists casually.
The Broader Impact on AI Development
This lawsuit doesn't just affect Anthropic. It affects every AI company.
Right now, there's an implicit assumption in AI development: grab data, build models, worry about legal consequences later. The industry has operated under the belief that volume and speed matter more than permission.
That calculation is changing. If Anthropic loses (or settles for $3 billion), other AI companies will reassess. They'll realize that cutting corners on data licensing isn't a savings—it's a massive liability, as discussed by JD Supra.
Open AI is currently dealing with similar lawsuits. Microsoft has been sued for training on copyrighted content. Meta has faced similar allegations. This isn't unique to Anthropic—it's industry-wide behavior that's finally facing legal consequences.
The music industry is being particularly aggressive, probably because they've seen how much money AI companies are making off copyrighted content. If Anthropic's Claude is trained partially on The Rolling Stones' songs, and that helps Anthropic build a $350 billion company, shouldn't The Rolling Stones get a cut?
That's a compelling moral and legal argument. And the courts might agree.

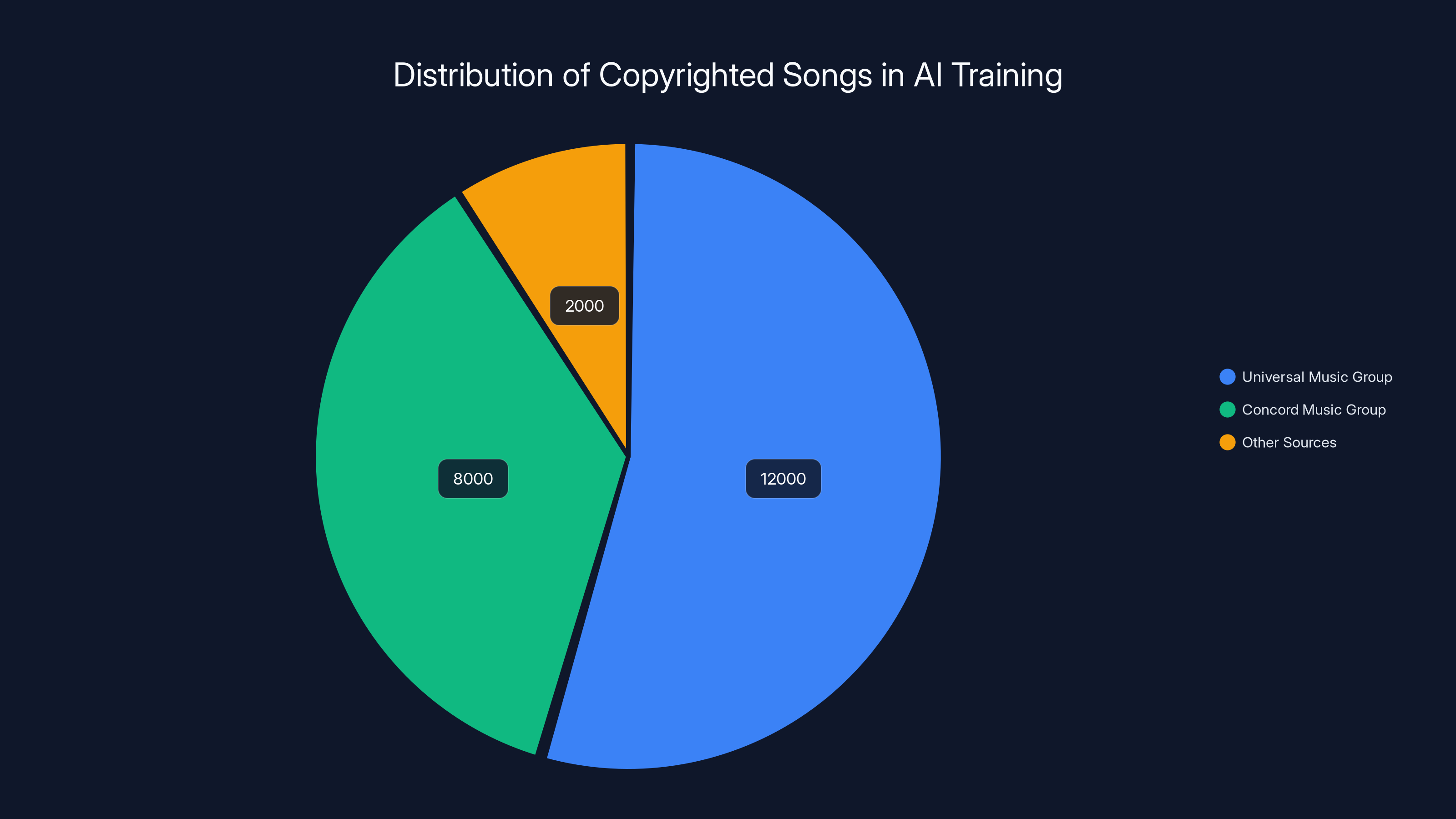
Estimated data shows the majority of copyrighted songs used by Anthropic for AI training come from Universal Music Group and Concord Music Group, highlighting the scale of alleged infringement.
The Prior Judge's Ruling Creates Ambiguity
Judge William Alsup's ruling in the Bartz case actually created an interesting gray zone.
The ruling suggested that training on copyrighted content might be fair use, but acquiring it through piracy is not. That creates three separate questions:
- Acquisition: Was the content obtained legally? (Apparently not, based on the evidence)
- Transformation: Is the use transformative enough to qualify as fair use? (Probably yes, teaching an AI is transformative)
- Market Impact: Does the use harm the original market for the content? (Debatable)
Anthropic's vulnerability is specifically on question one. They can't defend the acquisition method. Everything else flows from that failure.
But for other AI companies watching this case, there's a clear path forward: license your training data properly, and you're mostly protected. Use pirated content, and you'll face massive damages.
That's actually good news for the AI industry long-term. It creates certainty. Companies will license content, pay for it, and move on. Prices for training data licenses will increase, which means content creators get compensated, which reduces incentives to steal.
It's not ideal for AI companies hoping to build models cheaply. But it's fair and sustainable.
The Difference: Bartz Writers vs. Music Publishers
Why did writers get a
For writers, a typical settlement might be: the author wrote something, Anthropic used it to train Claude. The author lost one potential licensing deal (selling their work to a book club, for example).
For musicians and music publishers, the loss is different. A song has perpetual licensing value. It generates money every single year. If you license a song to Spotify, YouTube, or a movie studio, you get paid. If that song is also being used to train an AI model, that's a separate licensing deal that should generate separate revenue.
Music publishers are essentially saying: "You've built a multi-billion dollar company partially on our assets. We want real compensation, not a token settlement."
The $3 billion number reflects that reality. It's not just compensation for past use—it's a signal about future value.

How This Compares to Other Tech Lawsuits
To put $3 billion in perspective, it's worth looking at other major copyright cases.
The Department of Justice settled with Microsoft over browser monopoly abuses for less than $1 billion. Google has paid out billions across multiple antitrust and privacy settlements, but usually spread across multiple cases.
A single $3 billion judgment against an AI company for copyright infringement would be unusual. Most companies settle for less. But Anthropic is also unusual: it's well-funded, it's growing fast, and the evidence of infringement is solid.
Plus, the music industry doesn't negotiate like tech companies. They're not interested in settling for a token amount. They want to send a message to the entire industry.
The music industry's estimated
What Success Would Look Like for Each Side
For the publishers, success is straightforward: winning the case (or settling for a large amount) and establishing precedent that AI companies can't use pirated content for training.
For Anthropic, "success" at this point probably means limiting damages. They're unlikely to get the case dismissed. They might get the per-work damages reduced. They might negotiate a settlement that's meaningful but not catastrophic.
The real winner in all of this is the legal profession. Copyright litigation is expensive. This case will probably cost both sides tens of millions in legal fees before it's resolved.
But there's also a winner in terms of policy clarity. After this case, AI companies will know exactly where the line is: you can train on copyrighted content (arguably), but you have to license it first. Don't use piracy to acquire it.
That's actually reasonable. It creates a market for training data licensing.

The Timing and Discovery Process
One detail worth examining: how did the publishers find out about the torrenting? They discovered it during the discovery process of the prior Bartz v. Anthropic case.
During litigation, both sides exchange documents. Presumably, Anthropic was ordered to produce documents showing how it created training datasets. Somewhere in those documents, evidence emerged that torrenting was used to acquire music files.
This raises a question: did Anthropic executives know this was happening at the time? Or was it buried in technical decisions made by engineers who didn't think to check the legality?
That distinction matters for willfulness. If the CEO knew they were downloading music via torrent, that's clearly willful infringement. If some engineer did it without explicit authorization, Anthropic might argue lack of knowledge.
But either way, it's bad. If executives knew, they deliberately broke the law. If they didn't know, they have a massive internal control problem.
Other AI companies are probably having uncomfortable conversations with their legal teams right now about how their own training data was acquired.
Future Implications for AI Development
Assuming Anthropic loses or settles for a substantial amount, what changes?
First, AI companies will need licensing agreements for training data. That's already starting to happen. Open AI now has partnerships with news organizations. Google has licensing deals with publishers. The market is shifting toward legitimate data acquisition.
Second, legal compliance teams will become more important in AI development. Right now, development teams focus on accuracy and speed. Soon, they'll need to focus equally on provenance and licensing.
Third, data pricing will increase. Creators will demand fair compensation for their work. That will increase the cost of building AI models, which will increase the cost of AI services. It's not ideal for consumers, but it's fair.
Fourth, smaller AI companies might struggle. If licensing is expensive, only well-funded companies can afford to build models at scale. That's arguably good for safety (fewer competitors, more scrutiny), but bad for innovation (fewer new entrants).
Fifth, there will be ongoing litigation. Open AI, Meta, Google, and others are all facing similar lawsuits. The next few years will be messy legally.

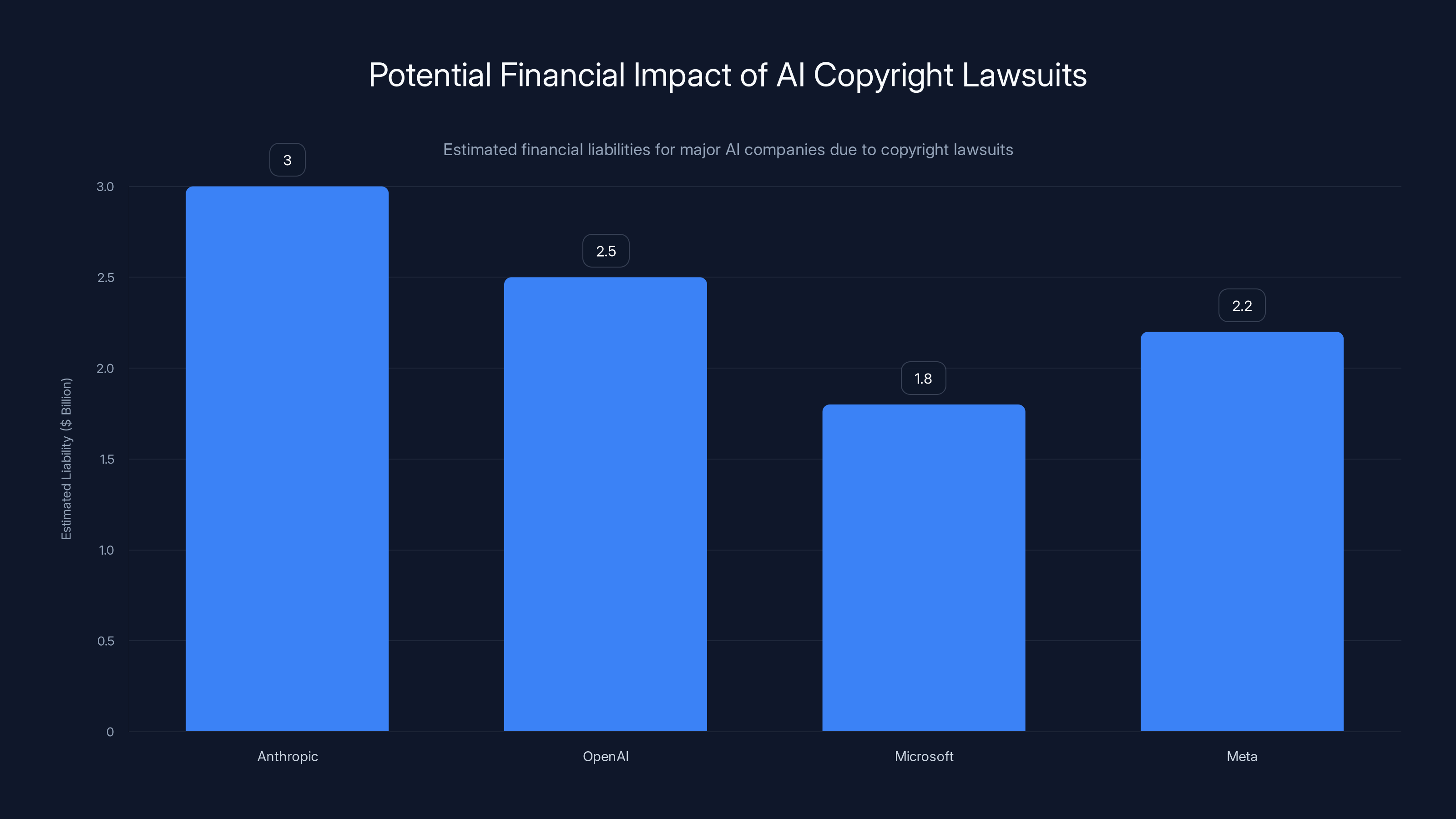
Estimated data shows potential financial liabilities from copyright lawsuits, highlighting the significant risks AI companies face if they lose or settle these cases.
The Role of Industry Standards
One thing that might emerge from this case is industry standards for data sourcing.
Right now, there's no common framework. Each AI company sources data differently. Some use licenses, some rely on fair use arguments, some apparently just steal it.
The industry might benefit from establishing standards: "We will only use data that is licensed, in the public domain, or clearly falls under fair use." That would provide legal protection and competitive fairness.
Trade associations like the AI Alliance or the AI Coalition could drive this. They could establish certification for companies that follow proper data licensing practices.
That's actually in the AI industry's long-term interest. A race to the bottom on copyright compliance damages everyone. Standards create stability.
The Counterfactual: What If Anthropic Had Licensed?
Let's think about what would have happened if Anthropic had done this the right way from the start.
Say they licensed 20,000 songs at an average of
Instead, they might pay $3 billion in damages.
The economics of choosing to steal rather than license are bizarre. The only explanation is that Anthropic believed they wouldn't get caught, or they didn't care about the legal risk.
The Bartz case should have been the wake-up call. Instead, they apparently doubled down with music.
This suggests either a company culture that doesn't respect intellectual property rights, or an executive team that's wildly overconfident in their ability to dodge legal consequences.
Either way, it's a red flag for the company's values and judgment.

Where Things Stand Now
As of now, the lawsuit is filed and the legal process is underway. Discovery will happen. Depositions will be taken. Anthropic will either defend the case or try to negotiate a settlement.
This probably takes 2-4 years to resolve, unless Anthropic settles quickly to avoid the public trial.
Meanwhile, every AI company is watching. The precedent being set here will influence how they source data, how they structure their legal defenses, and how much they budget for potential settlements.
For music rights holders and content creators generally, this case is a win even before the verdict. It establishes that their work has value, that companies can't just take it, and that there are real consequences for infringement.
For consumers, the impact is less clear. Higher licensing costs for AI companies might translate to higher prices for AI services. Or companies might absorb the costs. That'll depend on competition and market dynamics.
Lessons for Every AI Company
If you're building or investing in an AI company, here are the clear lessons from this case:
-
Document your data sources meticulously. Assume everything will be examined in court.
-
Don't use piracy infrastructure for any purpose. Ever. The legal risk is enormous compared to the savings.
-
License properly. It's more expensive upfront but catastrophically cheaper than litigation.
-
Have your legal team review training data practices. If they've approved it, at least you've done diligence (even if the court disagrees).
-
If you're sued, settle quickly if the evidence is bad. Fighting at trial is expensive and you'll probably lose anyway.
-
Remember that copyright holders are increasingly organized and litigious. The days of companies using copyrighted content without consequence are ending.

The Bigger Picture: Fair Compensation for Creators
Underlying all of this is a fairness question: should creators be compensated when their work is used to train AI?
Most people would say yes. If a song or a book or an article is valuable enough to use for training, it's valuable enough to pay for.
The legal system is starting to agree. Copyright law already protects creators' rights to control how their work is used. The courts are saying: yes, that protection extends to AI training.
The remaining question is price. How much should creators get paid? The market will determine that through licensing negotiations. Some creators will get premium rates. Others will get smaller amounts. That's how markets work.
But at least there will be a market. That's progress.
FAQ
What exactly is Anthropic alleged to have done?
Anthropic is accused of using torrenting technology to illegally download more than 20,000 copyrighted songs, including sheet music, lyrics, and compositions owned by Universal Music Group and Concord Music Group. These files were then allegedly used as training data for Claude, the company's AI chatbot. The lawsuit argues this constitutes flagrant copyright infringement.
Why is this different from the previous Anthropic copyright lawsuit?
The previous lawsuit, Bartz v. Anthropic, involved authors whose published works were allegedly used to train Claude. That case settled for $1.5 billion. The music lawsuit targets a similar pattern of behavior but involves different rights holders (music publishers) and different copyrighted works (songs instead of books). The same legal team is pursuing both cases, suggesting a pattern of systematic copyright infringement by Anthropic. The key legal distinction is that Judge Alsup ruled training on copyrighted content might be fair use, but acquiring it through piracy is not—establishing that the method of data acquisition, not just the use, matters legally.
How much does the lawsuit claim in damages and why that number?
The lawsuit claims damages exceeding
What does "flagrant piracy" legally mean in a copyright context?
"Flagrant" means obvious, intentional, and blatant. In copyright law, calling something flagrant piracy suggests deliberate knowledge of wrongdoing, which supports a finding of willful infringement. This matters because willful infringement penalties are significantly higher (up to
Could Anthropic argue this falls under fair use?
Anthropic will likely attempt a fair use defense, arguing that training AI models is transformative and qualifies as fair use. However, the previous judge's ruling in the Bartz case created a critical distinction: while training on copyrighted content might be fair use, acquiring that content through piracy is not. The acquisition method undermines fair use protections, especially if the infringement can be characterized as willful. Using torrenting technology to obtain copyrighted files is harder to defend than arguing the subsequent use is transformative.
Why didn't Anthropic just license the music instead of allegedly downloading it illegally?
The most straightforward answer is cost and speed. Licensing 20,000 songs from major publishers would have required time-consuming negotiations, formal agreements, documentation, and transparency about usage. Downloading via torrent was faster and appeared (to Anthropic) to have lower risk. However, the cost calculation was wildly wrong: licensing might have cost a few million dollars total, whereas legal damages could reach $3 billion. This suggests either reckless decision-making or a corporate culture that didn't take copyright seriously.
How does this affect other AI companies like Open AI or Google?
This lawsuit is likely to have ripple effects across the entire AI industry. Companies like Open AI, Google, and Meta are all facing similar copyright lawsuits from authors, publishers, and content creators. The Anthropic case establishes a legal precedent that could force all AI companies to restructure how they source training data. Companies that relied on similar torrenting or other unauthorized acquisition methods face similar exposure. The likely outcome is that AI companies will need to implement proper licensing agreements and data vetting processes, increasing the cost of developing AI models.
What's the timeline for this case to resolve?
Copyright litigation is typically slow-moving. Most experts expect this case to take 2-4 years to resolve, assuming it doesn't settle earlier. Discovery (where both sides exchange documents and evidence) is already underway. Depositions will follow. Unless Anthropic opts to settle quickly—which is possible given the strong evidence against them—the case will likely proceed through preliminary motions and toward trial. A full trial could take 6+ months alone.
Could Anthropic settle instead of going to trial?
A settlement is quite possible. Given that Anthropic has deep pockets (the company is worth
What does this mean for smaller content creators who want protection?
This case establishes legal leverage for creators. It demonstrates that copyright law protects your work, that companies must license content before using it for AI training, and that there are real financial consequences for infringement. Creators can point to this case as evidence of their rights and the need for proper licensing agreements. For creators concerned about AI training on their work, now is a good time to consult a lawyer about how to protect your intellectual property and potentially negotiate licensing deals with AI companies before they take your work without permission.
The Anthropic music publishers lawsuit represents a critical moment in AI development. It answers a fundamental question: Can AI companies train models on copyrighted content without permission? The courts are increasingly saying no—at least not without proper licensing.
For Anthropic, the judgment will be substantial. For the industry, the lesson is clear. The era of treating copyright as an inconvenient obstacle rather than a serious legal obligation is ending.
Content creators should expect a future where their work has clear licensing value. AI companies should expect to pay for access. And the broader tech industry should understand that intellectual property rights aren't negotiable—they're foundational to how a fair economy functions.
The $3 billion number might get negotiated down, or Anthropic might surprise everyone and win (unlikely), but the direction is unmistakable. AI companies will need to respect copyright law, pay for content they use, and operate with legal compliance as a core part of their development process.
That's not a bad thing. It's just the cost of doing business responsibly.

Key Takeaways
- Music publishers led by Universal and Concord are suing Anthropic for $3 billion over illegally downloading 20,000+ copyrighted songs to train Claude AI
- The lawsuit claims 'flagrant piracy' using torrenting technology, with potential statutory damages of $150,000 per work for willful infringement
- A prior judge ruled that acquiring copyrighted content through piracy is illegal even if training on the content could be fair use—establishing a critical legal distinction
- This is the second major copyright lawsuit against Anthropic from the same legal team, following a $1.5 billion settlement in the Bartz writers case
- The ruling will likely force all AI companies to implement proper licensing agreements for training data, fundamentally changing how models are developed

