![Mysterious Bot Traffic From China Explained [2025]](https://tryrunable.com/blog/mysterious-bot-traffic-from-china-explained-2025/image-1-1770926867770.jpg)
The Mystery of Mysterious Bot Traffic Sweeping the Web
Last fall, something strange started happening across the internet. Websites everywhere—from niche paranormal blogs to major U.S. government agencies—began reporting massive, unexplained traffic spikes. The weird part? Nearly all of it came from a single city in China that nobody had heard of.
A small publisher in Bogotá noticed his Spanish-language paranormal website suddenly getting flooded with visitors from Lanzhou, a second-tier industrial city in northwest China. At first, he thought he'd cracked the code and found an enormous Asian audience. Then he looked at the data more carefully. The "visitors" were staying for zero seconds. They weren't scrolling. They weren't clicking. They weren't doing anything a human would do. He realized immediately that his website was being attacked by bots.
What happened next was eye-opening. He started digging into forums and social media and discovered he wasn't alone. Dozens—then hundreds—of website owners reported the exact same phenomenon. A lifestyle magazine in India. A weather forecasting site with 15 million pages. Small ecommerce shops. Personal portfolios. Government websites. All of them were getting hit by what appeared to be the same coordinated bot army.
The U.S. government websites were hit particularly hard. In a 90-day period, 14.7% of all visits to American government domains came from Lanzhou, making it the single top location for supposed traffic to federal sites. Another 6.6% came from Singapore. If you didn't know better, you'd think the entire government was trying to spy on America's own websites.
But here's the million-dollar question that nobody could answer: what was actually happening? Who was behind it? What did they want? And most importantly, should website owners be worried?
This article breaks down everything we know about the wave of bot traffic hitting websites worldwide, what's driving it, why it's happening from that specific city, and what you should actually do about it.
TL; DR
- Massive bot surge: Websites across industries report 20-50% of traffic coming from automated bots originating in Lanzhou, China
- Coordinated and sophisticated: Bots disguise themselves as normal users, bypass standard bot-blocking tools, and route through major Chinese cloud providers like Tencent, Alibaba, and Huawei
- Likely AI training: Most security experts believe the traffic is connected to companies harvesting web data to train large language models, not traditional cyberattacks
- Not immediately dangerous: The bots don't appear to scan for vulnerabilities or steal data, but they distort analytics and consume bandwidth
- Hard to block: Standard bot-blocking methods fail because these bots are more sophisticated than typical AI crawlers from OpenAI, Google, or Anthropic
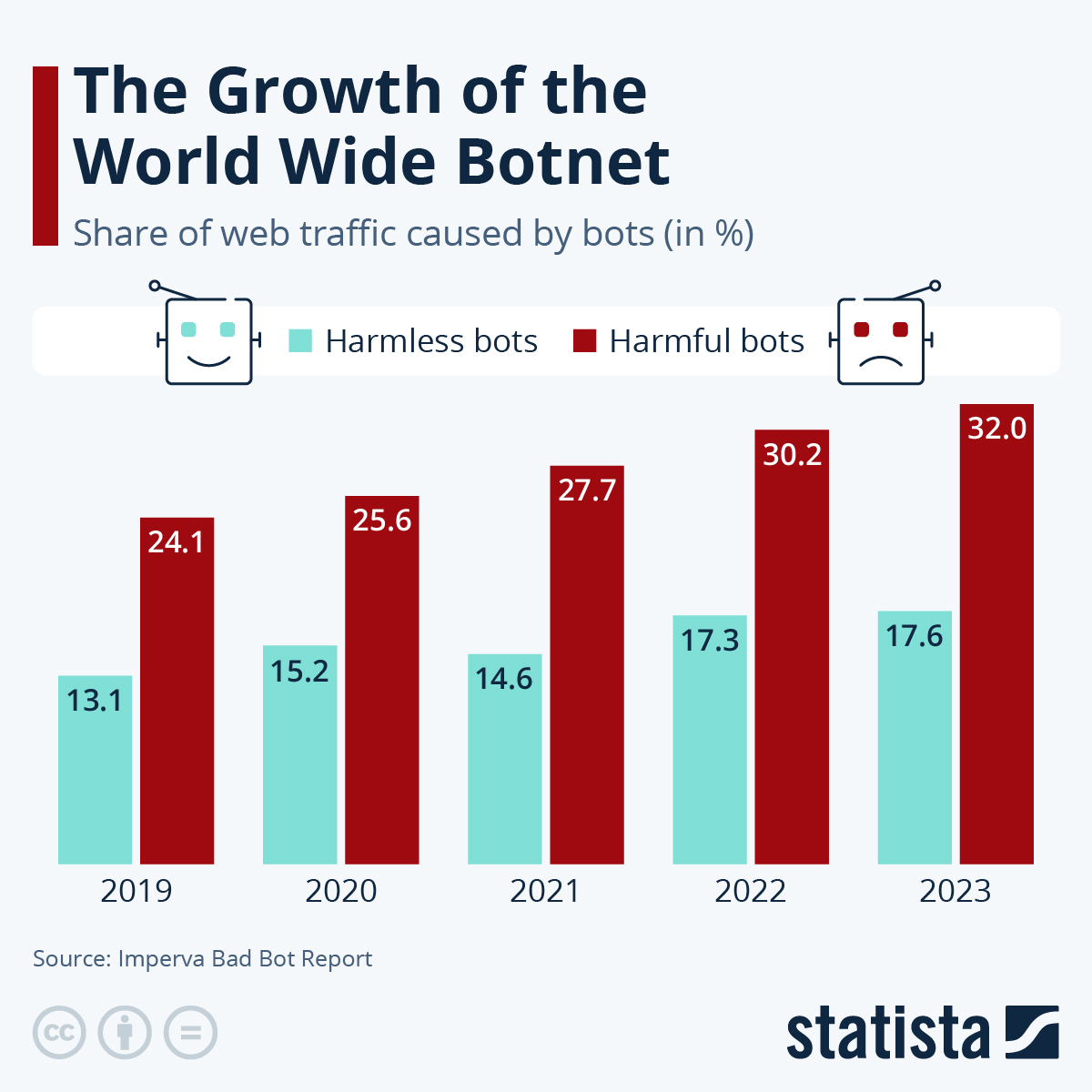
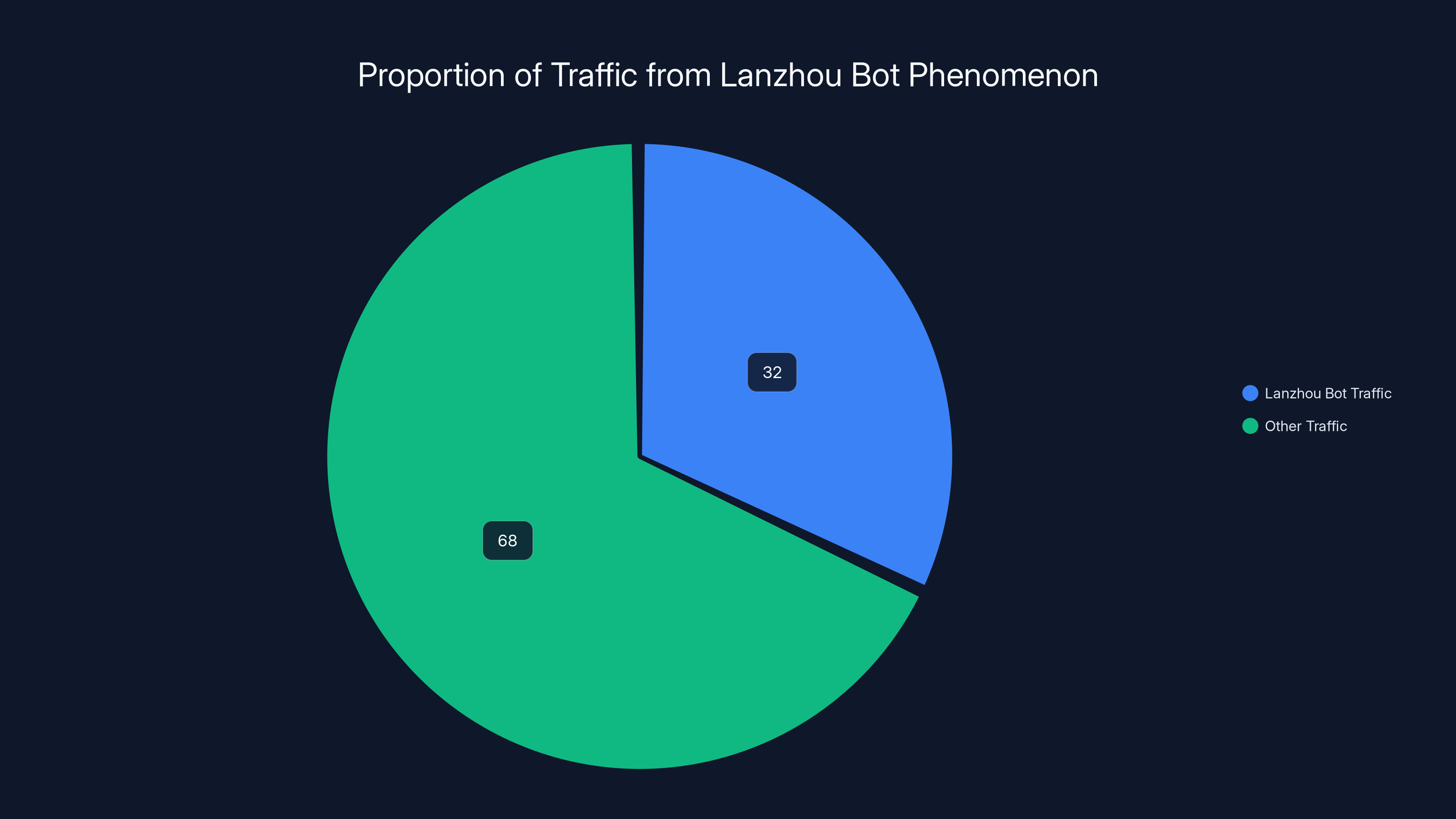
Estimated data shows Lanzhou bot traffic accounts for approximately 32% of total traffic on affected websites, significantly impacting analytics and costs.
The Unexpected Wave: How Website Operators First Noticed
Alexander Quintero's paranormal website was the kind of operation you'd expect to fade into obscurity. Written in Spanglish, targeted at a Spanish-speaking audience, updated sporadically. It wasn't exactly optimized for growth. Yet starting in September, something shifted dramatically.
Traffic from China and Singapore started climbing. Then it climbed more. Within weeks, the two countries accounted for over 50% of all visits to his site. By most metrics, this would be fantastic news. A website operator dreams about this kind of growth.
But the moment Quintero pulled up Google Analytics, he knew something was fundamentally wrong. Every single visitor from China came from one geographic location: Lanzhou. They had identical behavior patterns. They stayed for exactly zero seconds. They didn't scroll. They didn't click links. They didn't interact with the site in any way. They were, in other words, obviously not human.
Quintero did what any concerned website owner would do. He went to Reddit. He checked Twitter. He searched forums. And what he found shocked him: thousands of other website operators were reporting the exact same thing.
A lifestyle and wellness magazine based in New Delhi started seeing the identical traffic pattern. A small lifestyle blog about island living off the Canadian coast. Personal portfolio websites belonging to individual designers and developers. E-commerce sites hosted on Shopify platforms. A weather forecasting platform with millions of indexed pages. And perhaps most alarmingly, multiple U.S. federal government websites and agencies.
They all shared one characteristic: the traffic was originating from the same geographic location, routed through the same internet service providers, exhibiting identical behavior patterns, and arriving at the same time starting in mid-September.
The scale of this was staggering. On the government sites alone, the bots were consuming massive amounts of bandwidth and distorting analytics data so severely that legitimate traffic metrics became almost meaningless.
Understanding Lanzhou: The Unlikely Source
When website operators started comparing notes about where the traffic was coming from, one question kept coming up: where the hell is Lanzhou?
For most people, Lanzhou was unknown territory. It's not Shanghai. It's not Beijing. It's not Shenzhen, the tech hub. Lanzhou is a second-tier city in China's northwest, positioned along the Yellow River in Gansu Province. Historically, it's known for being a stopping point on the ancient Silk Road trade routes. Modernly, it's known for heavy manufacturing: petrochemical plants, refineries, coal processing. It's an industrial city, not a tech city.
This fact made the bot origin even more mysterious. Why would an industrial manufacturing city be the source of a coordinated, sophisticated bot network harvesting web data? That makes zero sense from a logical perspective. Tech operations usually cluster in major tech hubs where infrastructure, talent, and resources concentrate. You'd expect bot traffic to originate from Beijing, Shanghai, Shenzhen, or Hangzhou. Not Lanzhou.
Gavin King, founder of a company that analyzes automated traffic patterns, had the same reaction. His own website was targeted by the bots, so he decided to dig deeper. What he discovered was important: Lanzhou might not actually be the source at all.
King's investigation revealed that the traffic was eventually being routed through Singapore. When he traced the IP addresses more carefully, Google Analytics might have been making an educated guess about the origin location based on the IP data available, rather than pinpointing the exact source. The bot traffic passed through multiple geographic locations before reaching its destination.
However, King did find one concrete detail that proved valuable: the traffic was being routed through servers belonging to major Chinese cloud companies. Specifically, the bots were using Autonomous System Numbers (ASNs) assigned to Tencent, one of China's largest technology and cloud infrastructure companies.
Other researchers investigating their own bot traffic found similar patterns. Multiple ASNs were involved, belonging not just to Tencent but also to Alibaba and Huawei. All three are major cloud service providers in China, offering infrastructure that companies can rent to host and run applications.
This raised an important question: were the bots being run directly by these cloud companies themselves, or were they using infrastructure provided by these companies? The cloud providers could be hosting the bot operation, or they could be innocent parties whose infrastructure was being used by someone else.

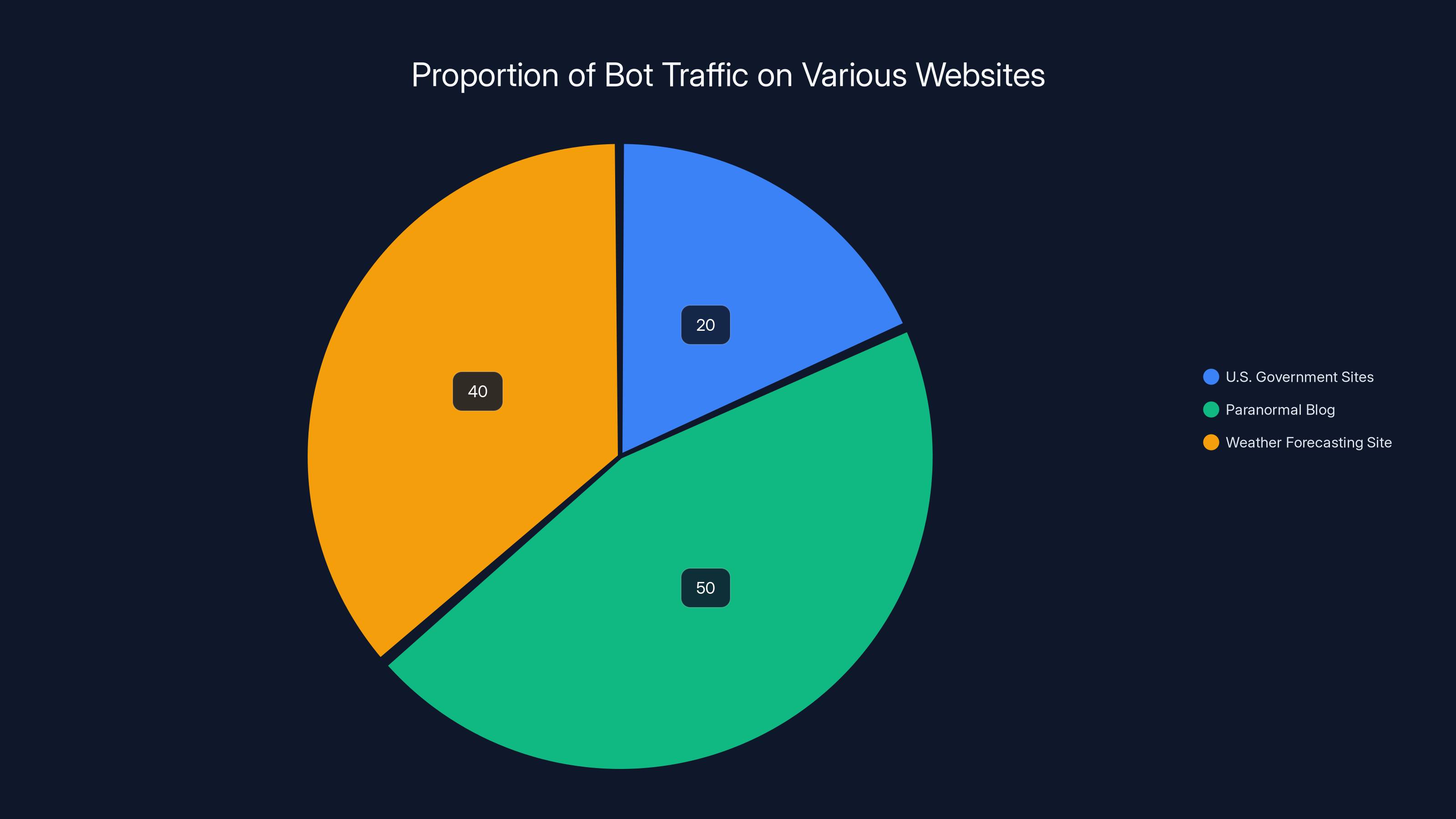
Bot traffic accounts for significant portions of total traffic, with smaller sites like the paranormal blog seeing over 50% of their traffic from bots. Estimated data.
The AI Training Data Hypothesis: What Most Experts Believe
If the bots aren't actually from Lanzhou, and they're running through commercial cloud infrastructure, then what are they actually doing? Why would someone invest the resources to build and operate a massive bot network that targets thousands of websites worldwide?
Most cybersecurity researchers, web infrastructure companies, and internet security experts converged on one explanation: AI companies harvesting training data.
The artificial intelligence industry has an insatiable appetite for data. Large language models require enormous amounts of text to learn from. Companies building cutting-edge AI systems need to feed their models with vast libraries of human-written content. The internet, with its billions of pages of text, represents an endless goldmine of training material.
Starting in 2024 and accelerating into 2025, AI-powered bots became a massive portion of all internet traffic. Companies like OpenAI, Google, Anthropic, and dozens of others run crawlers that systematically traverse the web, downloading text, images, code, and other content to process and use for training.
But here's what makes the Chinese bot traffic different and raises suspicion: the scale and sophistication far exceed typical AI crawler behavior.
Gavin King analyzed the traffic patterns on his website and made a striking discovery. The traffic from China and Singapore accounted for 22% of his total website traffic. Compare that to all other AI bots combined—the known crawlers from major AI companies—which accounted for less than 10% total. The Chinese bots were operating at a scale roughly 2.2 times larger than all legitimate AI crawlers combined.
There's another critical difference. Most leading AI companies clearly identify their bots. When OpenAI's GPTBot crawler hits your site, it announces itself. Same with Google's Googlebot and Anthropic's Claude crawler. They follow internet standards and are easy to recognize. Website owners can block them if they want to.
According to Brent Maynard, senior director of security technology at Akamai, a major internet infrastructure company, this transparency is intentional. Quote: "The frontier AI labs are not as interested in evading bot-blocking rules. They usually only start trying to disguise their bots after a website shuts the front door."
In other words, legitimate AI companies operate with some degree of honesty. They announce themselves. They respect a website's bot-blocking rules. If a site says "don't crawl me," they move on.
The Chinese bots? Exactly the opposite. They disguised themselves as normal human users from the start. They bypassed common bot-blocking rules. Several website operators reported that standard bot-blocking tools like Cloudflare, AWS WAF, and similar services failed to stop the traffic.
This sophistication and deception suggested something more calculated than a standard AI training operation. But to what end?
How the Bots Actually Work: Technical Deep Dive
Understanding how the bots function requires understanding how they bypass standard security measures. Website operators and security researchers have been able to reverse-engineer some characteristics of the bot traffic.
First, the bots arrive with proper HTTP headers that make them appear to be regular web browsers. They include user-agent strings that claim to be Chrome, Safari, or Firefox. They include referrer headers. They include cookie support. To a casual inspection, they look like legitimate human traffic.
Second, the bots demonstrate enough variability in their behavior that simple pattern-matching fails to block them. They don't all arrive at the exact same time. They don't all follow identical request sequences. They vary their request intervals. They sometimes accept cookies and sometimes reject them. They sometimes include headers and sometimes omit them.
Third, the bots use distributed IP addresses, not a single IP or small group of IPs. This makes blocking by IP address ineffective. When you block one IP, ten more take its place, all routed through the same cloud infrastructure providers.
Fourth, the bots appear to respect some standard HTTP conventions. They include appropriate headers for content negotiation. They accept compressed responses. They handle redirects. In short, they behave like legitimate web clients in ways that many basic bot detection systems rely on.
However, they fail at the human engagement layer. They don't render JavaScript. They don't process visual elements. They don't interact with any part of the page content. They simply request the HTML and leave. No scrolling. No clicks. No form submissions. Zero engagement with the actual content.
This is why they're so easy to spot in analytics data. Any analytics platform that tracks user engagement (scroll depth, time on page, clicks, interactions) shows zero engagement from this traffic. The bots request a page and immediately abandon it.
Several website operators tried various blocking strategies. Some attempted rate limiting, capping requests from specific IP ranges. This created a minor slowdown but didn't stop the traffic. Some implemented JavaScript challenges that require client-side processing, essentially blocking non-browser requests. This worked partially but seemed to result in the bots finding workarounds or shifting their approach.
The sophistication of these bots suggests significant engineering resources and development effort. This isn't a script kiddie project. This isn't a low-effort spam operation. Someone invested substantial time and resources into building and maintaining this infrastructure.
The Scale of the Problem: Numbers That Astound
When you start aggregating the reports from all affected websites, the scale becomes almost incomprehensible.
On U.S. government websites, as measured through Analytics.usa.gov (a transparent dashboard showing traffic to federal sites), the situation was extreme. Over a 90-day period, 14.7% of all traffic to U.S. government websites came from Lanzhou. Another 6.6% came from Singapore. Combined, bot traffic from two geographic locations accounted for over 20% of all traffic to federal websites.
Consider that for a moment. The U.S. government websites serve hundreds of millions of page views monthly. Twenty percent of that is bot traffic disguised as human traffic. That's tens of millions of page views from automated sources.
For smaller websites like the paranormal blog, the impact was even more dramatic. Over 50% of all traffic came from bot sources. For the weather forecasting site, the volume of requests grew so significantly that it affected server load and bandwidth costs.
Website operators started calculating the financial impact. Bandwidth costs scale with traffic. More traffic means higher CDN bills, higher hosting costs, higher database query costs. Website owners reported significant increases in their monthly infrastructure bills directly attributable to the bot traffic.
One website operator reported their monthly bandwidth bill increased by $300-500 due to the bot requests alone. For small publishers and independent operators, that's not insignificant. For a site running on a tight budget, that could represent 10-20% of their total monthly expenses.
Beyond the financial impact, the analytics distortion created real operational challenges. Website owners rely on analytics data to understand their actual audience. Traffic trends inform editorial decisions. Engagement metrics inform product decisions. Geographic distribution informs localization decisions.
When bot traffic dominates the analytics, all of that data becomes unreliable. You can't accurately determine where your real audience is located. You can't determine what content resonates with real humans. You can't identify real trends in user behavior. The data becomes noise.
Some website operators started implementing filtering strategies to clean their data, but this requires technical sophistication that not all site owners possess. Many small publishers and bloggers lack the resources or technical expertise to properly analyze and filter automated traffic from legitimate traffic.
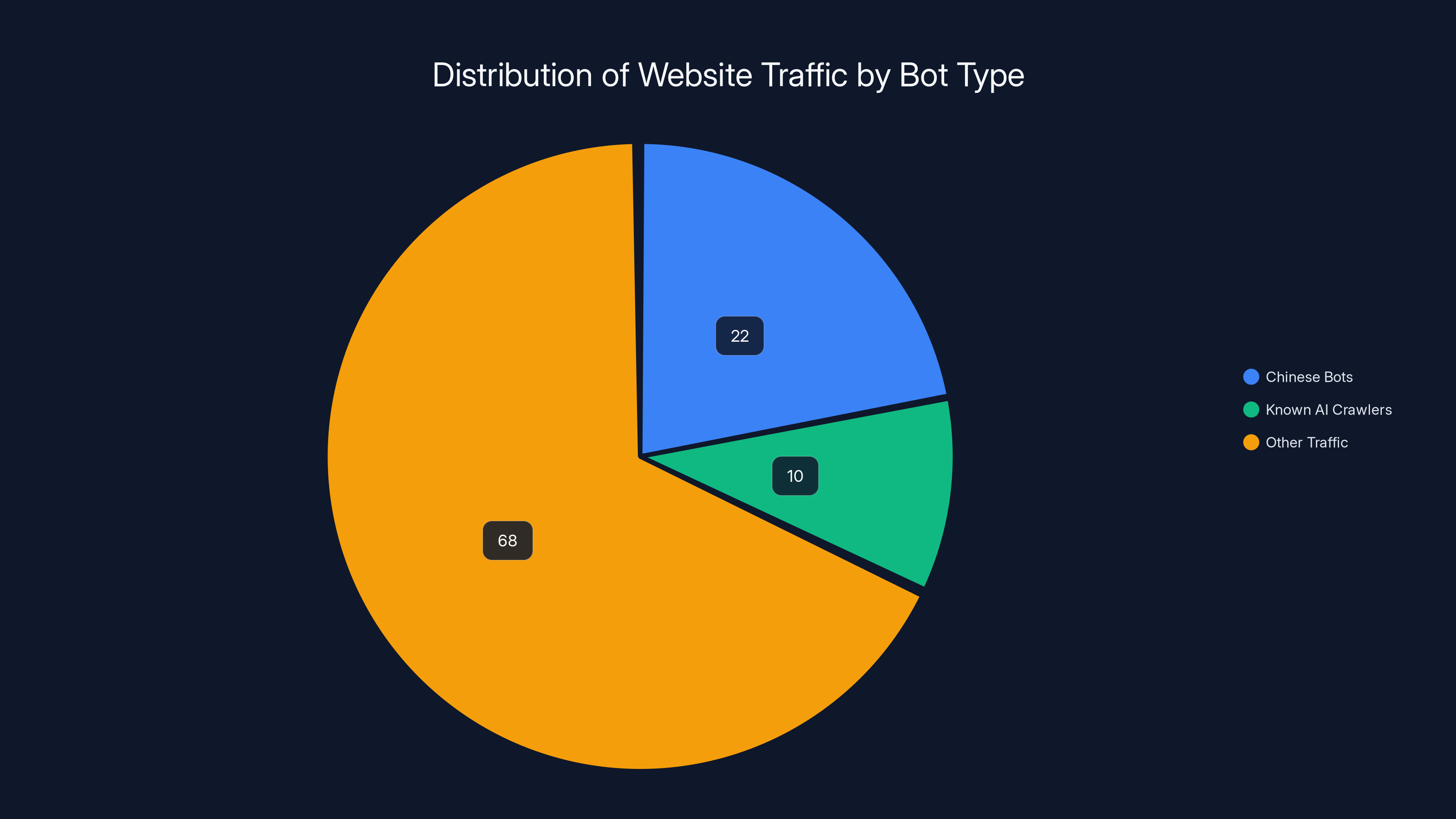
Chinese bots accounted for 22% of website traffic, 2.2 times larger than all known AI crawlers combined, highlighting their significant scale and potential data harvesting activities.
Why China? Why Now? The Broader Context
The timing of this bot wave—starting in mid-September and accelerating through October and beyond—coincides with significant developments in the global AI industry.
In 2024, competition for training data among AI companies intensified dramatically. OpenAI released GPT-4o. Google accelerated Gemini development. Anthropic expanded Claude capabilities. Meta invested heavily in Llama. Dozens of Chinese AI companies launched competitive models. All of them needed enormous amounts of training data.
Traditional training data sources—books, published articles, academic papers, existing datasets—were becoming saturated. Many companies had already scraped what they could legally or through terms of service. The competitive advantage started shifting toward whoever could access fresh, unique, diverse training data at scale.
This created economic incentive for more aggressive data harvesting. If you can feed your AI model more data, fresher data, more diverse data, you might be able to train better models faster than competitors. That's worth billions in future market value.
China, in particular, has taken a different regulatory stance on data scraping compared to the United States and Europe. While the EU implemented strict data protection laws and the U.S. has increasingly litigated scraping practices, China's regulatory environment is less restrictive. Chinese companies face fewer legal barriers to aggressive data harvesting.
Moreover, Chinese cloud infrastructure providers had significant economic interest in facilitating bot traffic. If they're hosting the bot infrastructure and charging for data transfer and compute resources, they have direct financial incentive to maintain and expand these operations.
The specific targeting of government websites is harder to explain. Why would an AI training operation specifically target federal agency websites? Government sites don't typically contain proprietary or unique content valuable for AI training. They're mostly public documents, policies, and information already available elsewhere.
One theory: the bot operators are not selective. They're attempting to crawl as much of the internet as possible, regardless of content quality or value. Government websites are part of the general web crawl, so they get targeted along with everything else.
Another theory: the bot operators are testing or benchmarking their infrastructure. By observing how government networks respond to the traffic, they might be gathering information about network resilience, security measures, and blocking effectiveness. This intelligence could inform future operations.
A third theory: some of the bots might be serving multiple purposes. The same infrastructure that harvests training data might also be performing reconnaissance or network mapping for other purposes.
Security Implications: The Good News and Bad News
Here's the encouraging news: based on current evidence, the bots don't appear to be malicious in the traditional sense.
They haven't been linked to any cyberattacks. They don't appear to be scanning for vulnerabilities. They're not attempting SQL injection attacks. They're not trying to exploit zero-days. They're not attempting to access protected areas or administrator panels. They're simply requesting publicly available pages and moving on.
No website has reported data theft, credential compromise, or unauthorized access as a result of this bot traffic. No government agency has reported security incidents. No financial information has been exposed. No personal data has been stolen.
From a security perspective, in the narrow sense of "preventing cyberattacks and protecting against intrusions," these bots don't appear to pose a threat.
But here's the bad news: the lack of explicit malice doesn't mean there's no risk.
First, there's the infrastructure risk. Bot traffic at this scale can overwhelm servers, exhaust bandwidth, and consume resources. If the bot operators ever wanted to, they could escalate from harvesting to denial-of-service attacks using the same infrastructure. They've already proven they can reach targets at significant scale. Flipping from data collection to resource exhaustion would require minimal code changes.
Second, there's the intelligence risk. By observing how websites respond to requests, network administrators can gather information about infrastructure, security measures, and defenses. This reconnaissance could inform future, more sophisticated attacks.
Third, there's the data extraction risk. Even if the immediate purpose is AI training data harvesting, the bots are extracting sensitive information in bulk. Government documents, internal memos, technical specifications, policy details—all of it is being scraped and aggregated. Competitors could benefit from this information. Adversaries could use it for intelligence gathering.
Fourth, there's the economic risk. Website operators are absorbing costs for bandwidth, storage, and processing that benefits bot operators and their customers. This is essentially theft of services, even if no explicit damage occurs.
Comparing to Legitimate AI Crawlers: What's Different
To understand what makes the Chinese bot traffic unusual, it helps to understand what legitimate AI company bots look like.
When OpenAI's GPTBot crawls a website, it announces itself clearly. The user-agent string explicitly identifies it as GPTBot. The HTTP requests include clear headers indicating they're from OpenAI. Website owners can see exactly which crawler is making the requests and take action if desired.
OpenAI respects the robots.txt file, a standard mechanism websites use to indicate which parts should and shouldn't be crawled. If a website owner blocks GPTBot in their robots.txt, OpenAI's bot stops crawling that site. It's a gentlemen's agreement that most major tech companies follow.
Google's Googlebot operates similarly. It identifies itself clearly. It respects robots.txt. It follows standard internet conventions.
Anthropic's Claude crawler follows the same pattern. Transparent identification. Respecting robots.txt. Following standards.
None of these legitimate crawlers disguise themselves. None of them attempt to deceive website owners or security systems.
The Chinese bots operate completely differently. They disguise themselves as regular human browsers. They don't respect robots.txt. They don't identify themselves. They attempt to evade detection and blocking.
This difference in behavior suggests different intentions or different risk tolerance. Legitimate companies with reputational interest in being perceived as ethical operate transparently. Entities with less concern for reputation operate deceptively.
Interestingly, some website owners tried to implement blocking for the legitimate AI crawlers while allowing other traffic. Ironically, blocking legitimate crawlers was relatively easy—just update robots.txt or add a header rule. Blocking the Chinese bots was much harder because they were more sophisticated and deceptive.
This created an upside-down situation where legitimate companies were being blocked while malicious or semi-legitimate actors were getting through. It's a reminder that in information security, deception often succeeds better than transparency, which is perverse incentive.

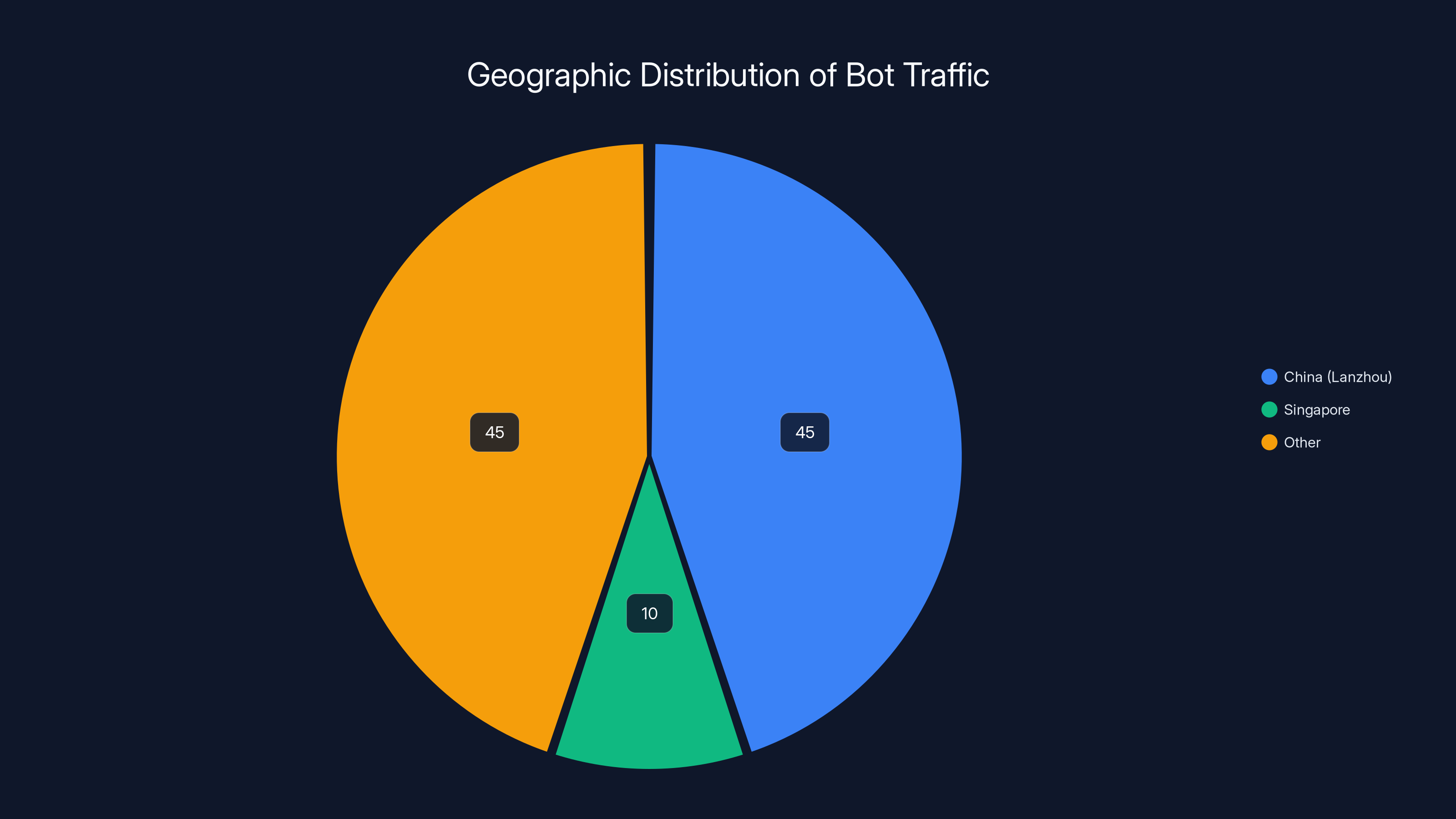
Estimated data shows that 45% of bot traffic originated from Lanzhou, China, with another 10% from Singapore. The remaining 45% is distributed among other regions.
The Analytics Distortion Problem: Why This Matters
Website operators have more than just financial and security concerns. They have an analytics problem that's actually quite serious.
Analytics data is the lifeblood of internet business. Content publishers use it to determine what content resonates with audiences. E-commerce sites use it to understand customer behavior. Services use it to identify usage patterns and optimize their offerings. Advertisers use it to understand where their audience comes from and what they engage with.
When bot traffic pollutes your analytics, all of this decision-making becomes unreliable.
Imagine you're a content publisher. Your analytics show a massive audience in Lanzhou and Singapore. You decide to invest in localizing content for those regions. You hire translators. You create region-specific content. You implement region-specific marketing. You spend months and thousands of dollars on this expansion.
Six months later, you realize you built products for a non-existent audience. The money is wasted. The opportunity cost is enormous.
Or imagine you're running an e-commerce site. Your bot-polluted analytics show that traffic is coming primarily from Asia. You optimize for Asian markets. You adjust your product mix. You change your marketing strategy. You hire regional teams.
You realize later that your actual customers are still primarily in North America, and you've completely misallocated resources based on corrupted data.
This problem cascades. Corrupted analytics feed corrupted decision-making. Corrupted decision-making produces inferior products and strategies. Inferior products and strategies result in lost revenue and opportunity.
Some website operators attempted to fix this by implementing custom analytics filters. They created rules to exclude traffic that shows zero engagement or impossible behavior patterns. This works but requires technical sophistication that not all operators possess.
For smaller publishers and independent operators, the analytics distortion is particularly damaging because they have smaller margins for error and less resources to implement complex filtering solutions.
Possible Explanations: Separating Fact from Speculation
Given the evidence, what are the most plausible explanations for this bot wave?
Explanation 1: AI Training Data Harvesting (Most Likely)
The most widely accepted explanation among security researchers is that this is coordinated by one or more Chinese AI companies seeking training data for large language models. The scale, sophistication, and behavior patterns are consistent with large-scale data harvesting operations.
This could involve companies like Baidu, Alibaba, ByteDance, or other Chinese AI firms. It could also involve state-sponsored research institutions working on AI projects. The exact organization remains unknown, but the hypothesis is well-supported by the technical evidence.
Probability: High. Evidence: Traffic volume, sophistication, use of commercial cloud infrastructure, timing relative to AI development cycles.
Explanation 2: Competitive Intelligence Gathering
An alternative hypothesis suggests the bots are gathering competitive intelligence. By scraping competitor websites, e-commerce sites, and other targets, companies can analyze their strategies, product offerings, pricing, and capabilities. This intelligence informs competitive strategy.
This would explain why the bots are targeting such a diverse range of sites (government, commercial, educational, personal). It's a broad sweep to gather as much competitive data as possible.
Probability: Medium. Evidence: Diverse targeting, use of commercial infrastructure, but less evidence for specific competitive intelligence gathering activities.
Explanation 3: Search Engine Index Building
Chinese search engines like Baidu might be harvesting web data to build or update their search indexes. While this seems less likely given that these services already have established crawling infrastructure, it's possible that a new service or expanded crawling effort is underway.
Probability: Low. Evidence: Less specific evidence for search engine operations, and Baidu's existing infrastructure would likely use different methods.
Explanation 4: Network Reconnaissance
A more concerning explanation is that this traffic is primarily reconnaissance. By attempting to reach diverse targets, map network topology, observe security responses, and test blocking mechanisms, adversaries can gather intelligence for future attacks.
This would be consistent with the deceptive behavior, the scale, and the targeting of government sites. It's also consistent with intelligence-gathering operations preceding more sophisticated attacks.
Probability: Medium-Low. Evidence: Deceptive behavior, targeting of government sites, but lack of subsequent security incidents works against this theory.
Explanation 5: Multiple Purposes
The most likely scenario might combine multiple explanations. The same infrastructure could be serving multiple purposes simultaneously: AI training data harvesting, competitive intelligence gathering, and reconnaissance. Different branches of the same organizations might be using the infrastructure for different purposes.
Probability: Medium-High. Evidence: The sophisticated, flexible infrastructure could serve multiple purposes. Different types of data harvesting wouldn't require substantially different code.

Bandwidth Costs and Infrastructure Impact
Beyond analytics and security concerns, there are real infrastructure costs associated with this traffic.
Website hosting is typically charged based on several metrics: storage, bandwidth, compute resources, and database queries. Bot traffic directly increases three of these four categories.
Each page request requires bandwidth (downloading the HTML). It requires database queries (if the content is dynamically generated). It requires compute resources (processing the request, generating the response, logging the request).
For a website hosted on shared infrastructure like Shopify, the website owner doesn't directly see the costs, but they're built into the platform's pricing. Shopify absorbs the costs and distributes them across their customer base or manages them through their infrastructure scaling.
For websites on cloud platforms like AWS, Azure, or Google Cloud, the costs are more visible. Bandwidth overage, database query costs, and compute costs appear as distinct line items on monthly bills.
One weather forecasting site operator reported a significant increase in AWS bills due to bot traffic. Another site operator reported their CDN costs skyrocketing because the bots were requesting every page, including multiple versions, generating more data transfer than legitimate traffic patterns would produce.
For advertising-supported websites, the impact is different but equally problematic. Bot traffic generates fake impressions and fake clicks. This inflates advertising metrics and distorts advertising value. Advertisers are paying for impressions to bot traffic, not real humans. This corrupts the advertising ecosystem.
Advertisers eventually catch on to inflated metrics and adjust spending downward. Publishers lose revenue as advertiser budgets shrink. Advertisers feel deceived when they learn their money was wasted on bot traffic.
The entire economics of the internet depend on accurate metrics and reliable data about real human engagement. When bot traffic pollutes these metrics at scale, it damages the entire ecosystem.
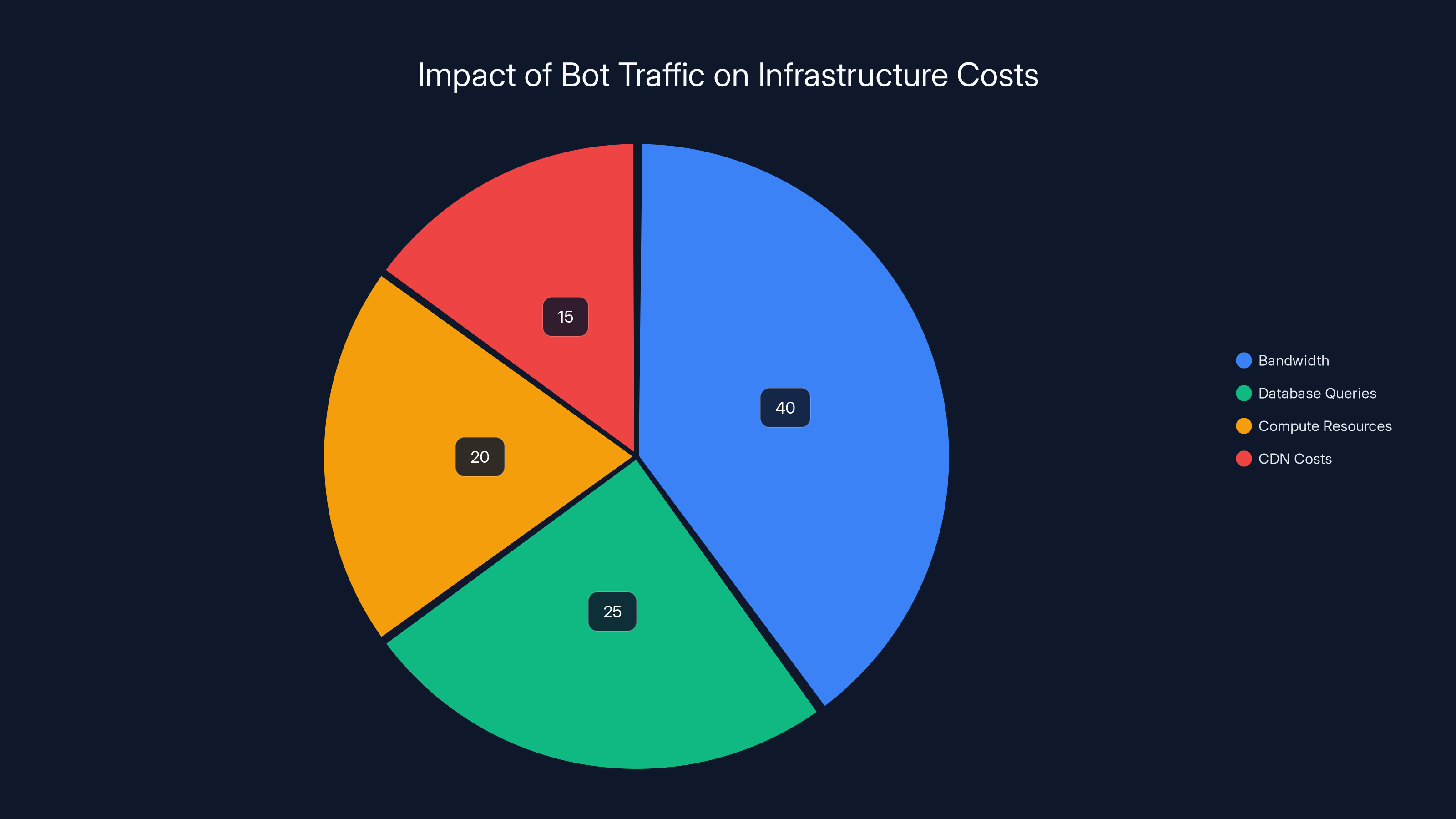
Bot traffic significantly increases infrastructure costs, with bandwidth and database queries being the most affected. Estimated data.
What Website Owners Are Doing: Defense Strategies
Given that official defenses have proven partly ineffective, website operators started implementing their own creative solutions.
Strategy 1: JavaScript-Based Challenges
Some websites implemented JavaScript rendering challenges. These require client-side processing that bots (which don't execute JavaScript) can't complete. This successfully blocks most bots but sometimes affects legitimate users on slow connections or with JavaScript disabled.
Strategy 2: Engagement-Based Filtering
Implementing analytics filters that exclude sessions with zero engagement (no scrolling, no clicks, no time on page) cleans up the data and provides accurate metrics. This doesn't actually block the bots but makes their presence irrelevant to business decisions.
Strategy 3: Rate Limiting by IP Range
Blocking or throttling requests from known bot IP ranges slows the traffic but doesn't stop it. The bots shift to different IPs, but it creates additional overhead for the bot operators.
Strategy 4: Custom Analytics Rules
Setting up more sophisticated analytics rules to detect and exclude bot patterns. This requires technical expertise but is effective once implemented.
Strategy 5: Accepting the Traffic and Moving On
Many site owners concluded that since the bots aren't directly harmful, and blocking them is difficult, they might as well accept the traffic and focus on filtering their analytics. This is pragmatic but frustrating.
Strategy 6: Reaching Out to Infrastructure Providers
Some website owners contacted their hosting providers, CDN providers, and Cloudflare, asking for help blocking the traffic. Many infrastructure providers started implementing detection and blocking rules on their platforms.
Cloudflare, in particular, has the ability to block traffic at the edge before it reaches customer websites. Other providers added similar capabilities.
Strategy 7: Coordinating with Other Affected Sites
Website owners started sharing blocking rules and detection patterns on forums and in security discussions. This crowdsourced approach to defense allowed smaller operators without security teams to benefit from research conducted by larger organizations.

U.S. Government Response and Investigation
The fact that U.S. government websites were targeted at such scale eventually triggered a response from federal agencies and cybersecurity professionals.
When it became clear that over 14% of traffic to federal websites was coming from bot sources in a foreign country, questions were raised about whether this constituted some form of hostile activity.
Cybersecurity professionals within government agencies began investigating. What they found confirmed what independent researchers and website owners had discovered: sophisticated, coordinated bot traffic from China, routing through commercial cloud infrastructure, disguising itself as human traffic, extracting data at scale.
Whether this constituted a cyber threat was open to interpretation. It wasn't a traditional cyberattack. No systems were compromised. No data was stolen in the sense of unauthorized access to protected systems. The bots were simply downloading publicly available content.
However, the scale, coordination, and deceptive nature raised concerns about foreign entities extracting large volumes of federal information. The question became: is harvesting public information at this scale a threat to national interests?
Government agencies began coordinating with technology companies and infrastructure providers to understand the scope and implement defenses. However, public information about the government's response remained limited, classified, or withheld for national security reasons.
The Ethical and Legal Questions: Where's the Line?
Underlying this entire situation are important ethical and legal questions about data scraping, data ownership, and responsible AI development.
The Case for Data Scraping:
Proponents of aggressive data scraping argue that publicly available information should be usable for any purpose. If information is available on the public internet, it's fair game. Restricting access to public information limits innovation and prevents beneficial uses like AI training.
From this perspective, the Chinese bots are simply doing what every major AI company does—scraping publicly available web data. The methods might be more aggressive, but the activity is fundamentally similar.
The Case Against Aggressive Scraping:
Opponents argue that scraping at this scale without permission is ethically problematic. Website owners invested resources in creating content. That content has value. Harvesting it without compensation or consent is a form of theft, even if the information is technically public.
Moreover, scraping at this scale imposes costs on website operators—bandwidth, server resources, technical disruption. These costs benefit the scraper while harming the content creator. This is economically inefficient and unfair.
The Legal Status:
Legally, the situation is murky. In the United States, courts have generally ruled that scraping publicly available information doesn't violate computer fraud laws, but there are exceptions and ongoing litigation.
The Computer Fraud and Abuse Act (CFAA) makes unauthorized access to computer systems illegal. Does scraping without permission constitute unauthorized access? Courts have disagreed. Some have ruled that violating a website's terms of service or robots.txt doesn't constitute unauthorized access. Others have suggested it could.
Copyright law provides more protections. If scraped content includes copyrighted material (articles, images, code), copyright infringement might apply. However, using scraped content for AI training might fall under fair use doctrine, which is still being litigated.
In the European Union, the General Data Protection Regulation (GDPR) and other laws provide stricter protections. Scraping is more clearly regulated, and scrapers must comply with data protection requirements.
China's laws are less clear and less restrictive on data scraping. This regulatory difference means Chinese companies may face fewer legal barriers to aggressive scraping activities.

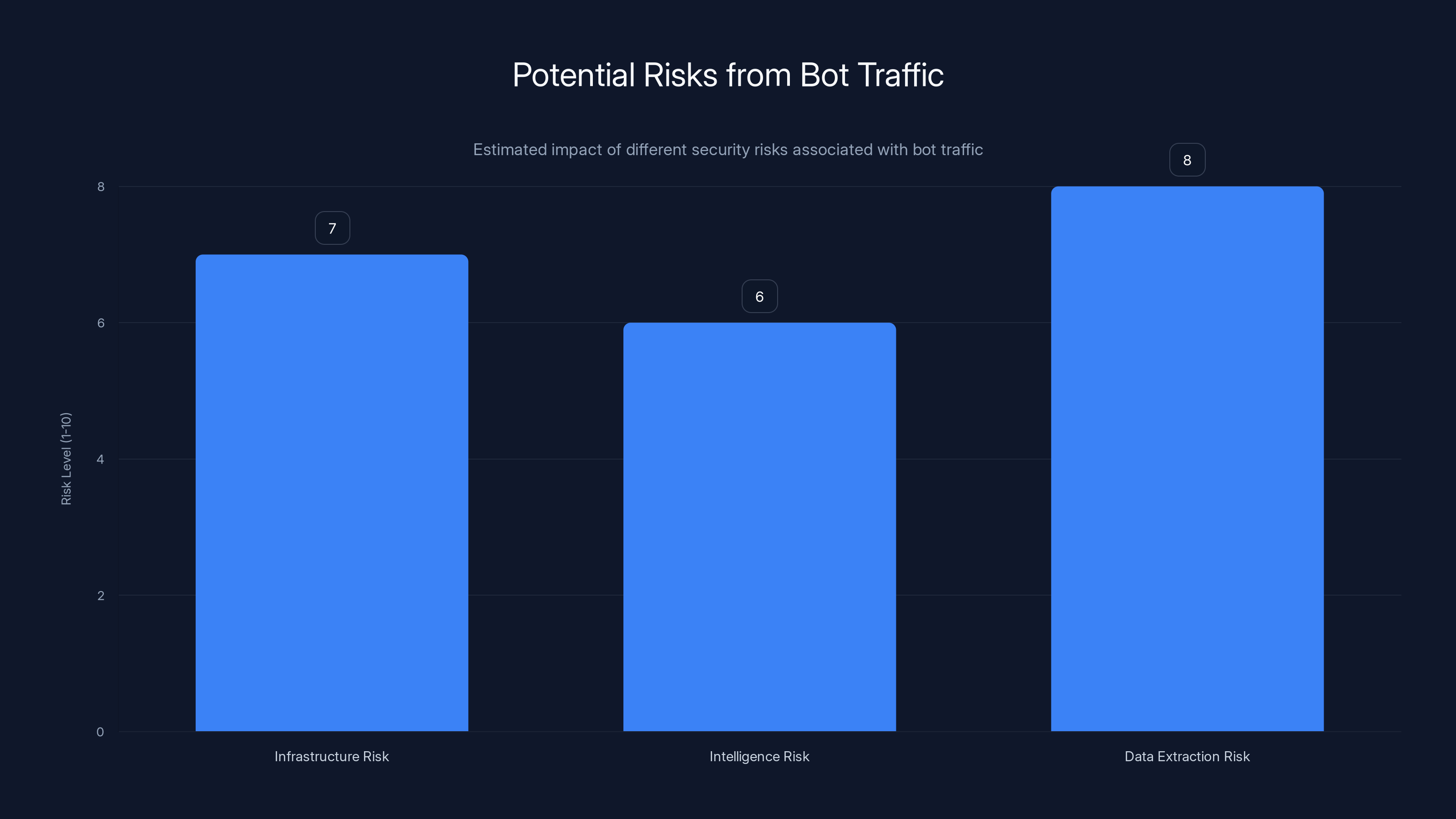
Estimated data suggests data extraction poses the highest risk at 8/10, followed by infrastructure risk at 7/10, and intelligence risk at 6/10.
Lessons for Web Infrastructure and Security
The bot traffic wave exposed several important lessons about how the internet infrastructure works and where vulnerabilities exist.
Lesson 1: Public Data Isn't Protected
Information that's publicly available and not explicitly protected is extremely difficult to defend against scraping. Once information is on the internet, it's vulnerable to unauthorized collection. Standard protections like robots.txt or terms of service can be ignored.
Lesson 2: Legitimate and Malicious Traffic Are Hard to Distinguish
Bot traffic that mimics human behavior well enough can evade basic detection. Security relies on pattern recognition, but sufficiently sophisticated bots can vary their patterns enough to defeat simple rules.
Lesson 3: Commercial Infrastructure Enables Large-Scale Operations
Cloud providers like Tencent, Alibaba, and Huawei provide infrastructure that can be rented by anyone, including people conducting activities the providers might not approve of. The infrastructure is agnostic to its use.
Lesson 4: Detection is Easier Than Prevention
Once bots are established and active, stopping them is much harder than detecting them. Blocking can be defeated by rotating IPs or adding variability. Detection through analytics patterns is reliable but requires technical expertise to implement and maintain.
Lesson 5: Coordination and Information Sharing Matter
Website owners who shared information about blocking strategies, bot patterns, and detection methods amplified everyone's defenses. Crowdsourced security research was effective.
Lesson 6: Infrastructure Providers Have Responsibility
Cloudflare, AWS, and other infrastructure providers have the ability to detect and block traffic at scale. When they implement blocking rules, they can protect thousands of customer websites simultaneously. Infrastructure-layer defenses proved more effective than individual website defenses.
Forward-Looking: Future of Data Harvesting and AI Training
The bot traffic wave is likely a preview of coming attractions. As AI development accelerates and competition for training data intensifies, we should expect more aggressive data harvesting.
Several trends are already emerging.
Trend 1: Increasing Sophistication
Bots will continue to get more sophisticated. They'll better mimic human behavior. They'll use rotating proxies and varied request patterns to evade detection. They'll implement more advanced user-agent spoofing and header manipulation.
This is an arms race. As defenses improve, attackers improve their attacks in response.
Trend 2: Hybrid Approaches
Instead of pure bot scraping, future data harvesting might combine multiple techniques. Fake user accounts that slowly harvest data while appearing to be legitimate users. Purchased data from data brokers. Legitimate partnerships with content providers. A mix of methods to gather data from diverse sources.
Trend 3: Regulatory Response
Governments will likely implement stricter regulations on data scraping. The EU might expand GDPR to explicitly protect against scraping. The U.S. might implement new laws. This will create a patchwork of different regulations in different jurisdictions.
Trend 4: Technological Defenses
Website operators will implement more sophisticated detection and blocking. Watermarking content to detect AI-generated copies. Honeypot content designed to confuse AI models if included in training data. Differential data that changes based on request patterns, making scraped data unreliable.
Trend 5: Negotiated Access
Instead of scraping, some AI companies might negotiate direct licensing agreements with content providers. Rather than fighting over access, companies might create legal frameworks for purchasing data from websites.
This would require website owners to be compensated for their content, which is more ethically defensible but more expensive for AI companies.
Trend 6: Synthetic and Private Data
As scraping becomes more difficult and regulated, AI companies might shift toward synthetic data (data generated by algorithms rather than collected from humans) or private data partnerships.
Synthetic data allows training without harvesting. Private partnerships with organizations holding valuable data allow access without public scraping.

Regional Implications: China's AI Ambitions
The bot traffic wave also reflects broader geopolitical and technological trends in China's AI development.
China has made artificial intelligence a national priority. The government has invested billions in AI research and development. Chinese companies have achieved significant breakthroughs in AI, particularly in language models, computer vision, and autonomous systems.
However, Chinese AI development faces resource constraints. Training data is particularly important. Chinese language data is abundant, but diverse, high-quality, global data is scarcer for Chinese companies than for U.S. companies.
This data disparity creates incentive for aggressive global data harvesting. Chinese companies might be trying to close the data gap by harvesting more training data from global internet sources.
Moreover, Chinese cloud infrastructure providers have built enormous data centers and cloud platforms. Hosting bot traffic generates revenue for these providers (through usage fees) and utilizes their infrastructure capacity.
From China's perspective, aggressive data harvesting might be viewed as competitive necessity. If U.S. companies are training on massive datasets, Chinese companies need access to equally large datasets to remain competitive.
The international dimension complicates this further. Data harvesting is global scale competition for information resources. The country or company that harvests the most diverse, highest-quality training data will have advantages in AI development.
Specific Case Studies: How Different Sites Were Affected
While many websites were targeted, the impact varied based on site characteristics.
Case Study 1: The Paranormal Blog
The small paranormal website founded by Alejandro Quintero saw 50%+ of traffic converted to bots. This small independent publisher had no security team, no sophisticated analytics infrastructure, no ability to easily implement blocking rules.
The site couldn't distinguish real traffic from bot traffic, making editorial decisions based on corrupted data. Bandwidth costs increased. The site lost the ability to accurately determine its real audience size.
For a small independent publisher, this was a significant problem with limited options for resolution.
Case Study 2: The Weather Forecasting Site
Andy's weather forecasting website group, with millions of indexed pages, received massive bot traffic. The site had sufficient technical sophistication to detect the bots and understand their patterns.
However, the volume was staggering. The bots were requesting so many pages at such scale that it created genuine strain on infrastructure. Bandwidth costs spiked significantly.
The site was able to implement technical defenses and filtering, but it required effort and resources. A site of this scale could absorb the cost; a smaller site couldn't.
Case Study 3: The E-Commerce Shops on Shopify
Small e-commerce shops using Shopify hosting saw their analytics polluted by bot traffic. Since Shopify handles infrastructure, individual shop owners couldn't directly block or filter traffic.
They were dependent on Shopify implementing platform-level defenses. Once Shopify did implement filtering rules, the problem was solved for all customers simultaneously.
This case highlighted the importance of platform-level defenses and the vulnerability of small operators dependent on larger platforms.
Case Study 4: The U.S. Government Websites
Federal agencies had sufficient technical resources to detect and understand the bots. They also had significant security expertise and ability to coordinate defenses.
However, the scale was overwhelming. With 14.7% of traffic from bot sources, traditional defenses proved insufficient. The government had to coordinate across multiple agencies and infrastructure providers.
The government response highlighted how even well-resourced organizations can be challenged by large-scale bot attacks.

Technical Deep Dive: Bot Detection Methods That Work
Based on research by security companies and website operators, several detection methods proved effective.
Detection Method 1: Engagement Metrics
Analyzing engagement patterns effectively separates bots from humans. Key metrics include scroll depth, time on page, click patterns, and session duration.
Bots typically show zero engagement across all metrics. Humans show varied engagement depending on content interest.
Formula for bot probability based on engagement:
When P_bot > 0.8, traffic is likely automated.
Detection Method 2: Browser Behavior Analysis
Analyzing how a browser loads resources, processes JavaScript, and handles redirects can identify bots. Real browsers execute JavaScript reliably. Many bots don't.
Tracing JavaScript execution timing, DOM manipulation, and resource loading patterns can distinguish real browsers from headless browsers.
Detection Method 3: Pattern Recognition
Machine learning models trained on known bot traffic can identify similar patterns in new traffic. The key features include request timing, IP characteristics, user-agent patterns, and behavioral sequences.
Once a model learns what bot traffic looks like, it can identify new bot traffic with reasonable accuracy.
Detection Method 4: Geographic Inconsistency
When traffic claims to be from one location but technical indicators suggest another, it's likely fraudulent. IP geolocation, browser time zones, and language settings should align.
Traffic from Lanzhou that includes browser time zones from Singapore or language settings from the U.S. indicates spoofing.
Detection Method 5: Rate Analysis
Analyzing request rates and timing patterns can identify non-human behavior. Humans browse at variable rates with natural pauses. Bots often request at consistent intervals or at rates faster than humanly possible.
When a visitor loads 100 pages in 30 seconds, that's physically impossible for a human. That's a bot.
The Infrastructure Provider Perspective: Akamai, Cloudflare, and Others
Large infrastructure providers like Akamai, Cloudflare, AWS, and others have a unique view of the bot traffic problem.
These companies sit between the internet's content sources and content consumers. They see traffic flows at massive scale. They can detect patterns that individual website operators miss.
Akamai, in particular, specializes in DDoS mitigation and bot management. When the Lanzhou bot traffic wave began, Akamai's security team analyzed the traffic patterns and shared insights with customers and the broader security community.
Cloudflare, which acts as a reverse proxy for millions of websites, was able to implement blocking rules on their platform that protected all their customers simultaneously. When they began blocking traffic from the suspicious IP ranges, millions of websites were immediately protected.
AWS, Azure, and Google Cloud similarly analyzed the traffic patterns originating from cloud infrastructure. These providers have direct relationships with their customers and can communicate about suspicious activity.
The infrastructure providers' response highlighted an important principle: security at the edge (at the network level) is more effective than security at the application level. By detecting and filtering traffic before it reaches customer websites, infrastructure providers can provide protection at scale.
This also highlighted the providers' responsibility. They're hosting infrastructure that's being used to conduct large-scale data harvesting. While they're not directly involved in the bot operation, their infrastructure is enabling it.
Infrastructure providers face tension between remaining neutral platforms and actively policing how their infrastructure is used. Most large providers have begun erring on the side of implementing blocking rules when evidence of abuse is clear.

Workforce and Skillset Implications
The bot traffic wave also has implications for how organizations need to staff their technical teams.
Website operators without dedicated security or technical infrastructure expertise were particularly vulnerable. They couldn't detect the bots early. They couldn't implement sophisticated defenses. They were dependent on outside help.
This highlighted gaps in the security skillset across the internet. Most small publishers, independent creators, and small businesses lack the expertise to handle security threats at this sophistication level.
Organizations began recognizing the need for better tooling that didn't require deep technical expertise. Instead of requiring manual implementation of blocking rules, operators wanted platforms that automatically detected and handled bot traffic.
This created demand for security products and services that could operate effectively with minimal technical expertise from end users.
It also highlighted the value of centralized infrastructure providers. Cloudflare, which could implement blocking at the platform level, protected all customers simultaneously. Individual website operators protecting themselves is difficult; a platform protecting all customers is simple.
Regulatory and Policy Considerations Going Forward
The bot traffic wave raises important policy questions that governments are starting to grapple with.
Question 1: Is Data Scraping a Form of Theft?
If AI companies harvest data from websites without permission or compensation, is that theft? Current law treats it differently than traditional theft because the original information isn't destroyed, just copied.
But from a business perspective, the information has value, and that value is being captured by the scraper rather than the creator. This seems unfair even if it's legal.
Future regulations might establish that scrapers must compensate content creators for data used in training. This would align incentives and create fairness.
Question 2: What's the Difference Between Scraping and Intelligence Gathering?
Large-scale data harvesting from government websites starts to resemble intelligence gathering. At what point does commercial data scraping become an intelligence operation?
If a foreign entity is systematically harvesting U.S. government data, that could be considered a national security threat even if no laws are technically violated.
Question 3: Should Infrastructure Providers Be Liable?
Should cloud infrastructure providers be held responsible if their servers are used to conduct large-scale scraping? This is similar to questions about platform liability for user content.
Most current thinking suggests infrastructure providers aren't responsible for how customers use their services, but this is actively being debated.
Question 4: What Standards Should AI Companies Follow?
Should there be industry standards for ethical data gathering? Some suggest AI companies should identify their bots, respect robots.txt, and follow other conventions. Others suggest the wild west of data scraping is acceptable.
The industry is beginning to self-regulate, but government standards might eventually be necessary.
Integrating Solutions: Where Automation Platforms Fit
While the bot traffic problem requires technical solutions at the infrastructure level, there are also opportunities for automation platforms to help website operators respond more effectively.
Automation platforms like Runable can help website operators automate responses to bot traffic. Instead of manually monitoring and responding to suspicious traffic patterns, automation tools can detect patterns, implement blocking rules, and generate reports automatically.
Runable's AI agents, for instance, could monitor analytics data, identify bot traffic patterns, automatically implement Cloudflare rules to block suspicious IP ranges, and generate weekly reports on traffic quality.
This would transform bot defense from a manual, technical process into an automated workflow that operates continuously without ongoing human intervention.
For small website operators without dedicated security teams, automation tools could provide essential defense capabilities that would otherwise be unavailable.
What Comes Next: Predictions and Scenarios
Based on current trends, several scenarios for how this situation might unfold are worth considering.
Scenario 1: Escalation and Arms Race
Bot operators continue developing more sophisticated bots. Website operators continue improving defenses. The two sides escalate in technical sophistication in a never-ending arms race.
Result: Bot detection and blocking become standard features of every website platform. The cost is built into infrastructure pricing. The burden shifts from individual website operators to platform providers.
Scenario 2: Regulatory Intervention
Governments implement regulations restricting large-scale data scraping. Regulations require bots to identify themselves and respect blocking mechanisms. Infrastructure providers are required to monitor and limit scraping on their platforms.
Result: Legitimate data harvesting continues through licensed partnerships and agreements. Illegal scraping becomes riskier and more difficult. The industry transitions toward more ethical data practices.
Scenario 3: Economic Resolution
Website operators successfully lobby for rights to compensation for scraped content. AI companies negotiate licensing agreements and establish data-sharing partnerships.
Result: Content creators are compensated for AI training data use. This aligns incentives and creates sustainable economics. Scraping is less necessary when companies can legally purchase data.
Scenario 4: Technical Standoff
Bots become sophisticated enough to evade most detection methods. Defenses become sophisticated enough to block most bots. Both sides reach a technical equilibrium.
Result: Some scraping continues, but much is blocked. Website operators accept that some bot traffic is unavoidable. Analytics are filtered to account for bot contamination.
Scenario 5: Normalized Bot Traffic
Bot traffic becomes so ubiquitous that it's treated as a normal part of internet infrastructure. Analytics platforms automatically filter bot traffic as a baseline feature.
Result: The bot problem essentially disappears because the industry adapts to accommodate bot traffic as an expected component of web traffic.
Most Likely Outcome:
A combination of scenarios 2, 3, and 5 seems most likely. Regulatory intervention creates some barriers to scraping. Economic negotiations create legitimate data partnerships. Industry adaptation normalizes and filters bot traffic.
Over the next 5-10 years, expect to see evolution toward more ethical, regulated data practices while accepting that some level of automated traffic is a permanent feature of the internet.

FAQ
What is the Lanzhou bot traffic phenomenon?
The Lanzhou bot traffic refers to a massive wave of automated bot traffic originating from IP addresses associated with Lanzhou, China (and Singapore) that began in mid-September. These sophisticated bots target websites worldwide, disguise themselves as normal human users, bypass standard bot-blocking tools, and appear to be harvesting web data, likely for AI model training. The traffic accounts for 14-50% of total traffic to affected websites, with no clear malicious intent but significant impacts on analytics accuracy, bandwidth costs, and infrastructure.
How can website owners detect bot traffic from China?
Website owners can detect Lanzhou bot traffic by analyzing engagement metrics in their analytics platforms. Key indicators include zero scroll depth, zero time on page, zero clicks, and sessions that last less than one second. The traffic typically originates from IP addresses geolocalizing to Lanzhou or Singapore but routes through Autonomous System Numbers assigned to Chinese cloud providers like Tencent, Alibaba, and Huawei. Many analytics platforms now offer automated bot filtering that can identify this traffic type.
What's the difference between this bot traffic and legitimate AI crawlers?
Legitimate AI crawlers from companies like OpenAI, Google, and Anthropic clearly identify themselves through user-agent strings, respect robots.txt blocking rules, and follow standard internet conventions. The Lanzhou bots disguise themselves as normal browsers, don't respect robots.txt, attempt to evade detection, and operate at a scale roughly 2.2 times larger than all legitimate AI crawlers combined, suggesting either a single massive operation or coordination between multiple operations.
Why are the bots targeting Lanzhou specifically?
Lanzhou probably isn't actually the true source. The bots likely route their traffic through Lanzhou-based IP addresses or cloud infrastructure, but may originate or be controlled from other locations. The use of Lanzhou IPs could be intentional obfuscation, or Lanzhou could be where the traffic is simply aggregating before routing elsewhere. Lanzhou is an industrial city with cloud infrastructure from companies like Tencent, which makes it a convenient routing point but not necessarily the operation's source.
What are the real-world consequences of bot traffic for website owners?
Website owners face multiple consequences including inflated bandwidth and infrastructure costs (potentially $300-500 per month for medium-sized sites), distorted analytics that make business decisions based on false data, corrupted reporting on content performance and audience location, and server resource strain from handling millions of additional requests. For advertising-supported sites, the bots create fake impressions that waste advertiser budgets and devalue the site's advertising inventory. For small independent publishers without technical resources, these impacts can be significant.
Can website owners fully block this bot traffic?
Complete blocking is difficult because the bots are sophisticated and distribute across many IP addresses. However, website owners can implement several strategies that significantly reduce the impact: using JavaScript challenges to require client-side processing (which most bots can't do), implementing analytics filters to exclude zero-engagement sessions from reporting, working with infrastructure providers like Cloudflare to implement edge-level blocking, and rate-limiting requests from suspicious IP ranges. Most website owners use a combination of these approaches rather than a single solution.
What do cybersecurity experts think is really happening?
Most cybersecurity researchers believe this is coordinated large-scale data harvesting for AI model training. The sophisticated bot behavior, the use of commercial cloud infrastructure, the enormous scale, and the timing relative to AI development cycles all suggest organizations building large language models are attempting to harvest diverse, global training data. The deceptive tactics suggest these organizations aren't confident that transparent data collection would be accepted or approved, so they're harvesting covertly instead.
Are there legal protections against this kind of scraping?
Legal protections are limited and jurisdiction-dependent. In the United States, courts have generally ruled that scraping publicly available information doesn't violate computer fraud laws, though this remains contested. Copyright law provides some protection if scraped content includes copyrighted material. The European Union's GDPR provides stronger protections and can restrict scraping activities that involve personal data. Contracts (like terms of service) can restrict scraping, but enforcement is difficult. China's regulatory environment is less restrictive on scraping, which may explain why Chinese entities can conduct this activity with limited legal concern.
How is this impacting AI companies and their training data strategies?
The bot traffic wave reveals that some AI companies are aggressively harvesting training data without transparent methods or clear permissions. This suggests the demand for training data exceeds what's available through licensed, transparent means. As legal scrutiny of AI training practices increases and as companies build copyright infringement cases against large language models, AI companies will likely face increasing pressure to acquire training data through licensed partnerships rather than covert scraping, which could significantly increase costs for model development.
What should happen to resolve this situation?
Resolution likely requires multiple approaches: infrastructure providers should continue implementing bot detection and blocking at the network level; governments should establish clearer regulations about data scraping and AI training; content creators should have legal rights to compensation for data used in AI training; AI companies should adopt transparent, ethical data acquisition practices; and website operators should implement analytics filtering to reduce the impact on their business decisions. A combination of regulation, industry self-governance, and technological defenses is most likely to create a sustainable equilibrium.
Conclusion: Adapting to a Bot-Filled Internet
The wave of mysterious bot traffic from China revealed something important about the modern internet: it's not primarily built for humans anymore. Humans and bots now share the internet, and increasingly, bots outnumber humans in terms of traffic volume.
This isn't necessarily a disaster. Bots serve useful purposes. Search engines use crawlers to index content. Monitoring services use bots to check if websites are online. CDNs use bots to prefetch popular content. Much of the internet couldn't function without bots.
But bots that deceive, operate at massive scale, and harvest data without permission or compensation create real problems. They distort analytics. They consume resources. They undermine the economic model of web-based businesses. They operate without transparency or accountability.
What the Lanzhou bot phenomenon demonstrated is that as AI capabilities increase and competition for training data intensifies, these problems will likely escalate. More sophisticated bots will be deployed. More aggressive data harvesting will occur. The arms race between defenders and attackers will intensify.
Website operators, infrastructure providers, and regulators need to adapt. Website owners need better tools for detecting and filtering bot traffic. Infrastructure providers need to implement more sophisticated edge-level defenses. Governments need to establish clearer regulations and standards.
Most importantly, the AI industry needs to establish more ethical, transparent, and legal approaches to acquiring training data. If AI companies continue relying on covert data harvesting, the regulatory response will be increasingly strict. If the industry instead establishes clear standards for data acquisition and fairly compensates content creators, the conflict can be resolved.
The future of the internet will be shaped by how this tension resolves. Will it be a wild west where the most aggressive data harvesters win? Or will it be a regulated space where rights are protected and compensation is fair?
That answer is still being written. But one thing is clear: the wave of bot traffic from China is just the beginning. More is coming. The question is whether the internet's infrastructure, regulations, and business models will adapt in time.
For now, website operators need to focus on what they can control: implementing defenses, filtering analytics, and building resilience. The broader questions about data rights, AI regulation, and internet governance will take years to resolve. But the conversation has started, and that's progress.

Key Takeaways
- A coordinated bot wave from Lanzhou, China began in mid-September 2024, affecting thousands of websites across all industries
- The bots account for 14-50% of traffic to affected sites and route through major Chinese cloud providers like Tencent, Alibaba, and Huawei
- Sophisticated bot behavior (self-identification evasion, analytics-resistant patterns) suggests AI training data harvesting rather than traditional cyberattacks
- Website operators can defend through engagement-based analytics filtering, JavaScript challenges, rate limiting, and infrastructure-level blocking via providers like Cloudflare
- Future resolution likely requires regulatory intervention, transparent AI data practices, and compensation mechanisms for content creators
Related Articles
- 6.8 Billion Email Addresses Leaked: What You Need to Know [2025]
- ExpressVPN Pricing Deals: Save on the Cheapest VPN [2025]
- Surfshark VPN 87% Off: Complete Deal Analysis & VPN Buyer's Guide [2025]
- Proton VPN 70% Off Deal: Is This Two-Year Plan Worth It? [2025]
- EU Data Centers & AI Readiness: The Infrastructure Crisis [2025]
- Chrome's Auto Browse Agent Tested: Real Results [2025]

