![Chrome's Auto Browse Agent Tested: Real Results [2025]](https://tryrunable.com/blog/chrome-s-auto-browse-agent-tested-real-results-2025/image-1-1770899927857.jpg)
Chrome's Auto Browse Agent Tested: Real Results [2025]
Introduction: The Promise and Reality of Browser Agents
Google just unleashed a new superpower hidden inside Chrome itself. Auto Browse, rolling out to AI Pro and AI Ultra subscribers, is an AI agent that can literally control your browser and complete tasks across the web without you lifting a finger. Sounds incredible, right? It is. And it isn't.
We've entered a strange moment in tech where everyone's talking about AI agents instead of chatbots. Open AI released Atlas. Anthropic launched Claude with Computer Use. Now Google's putting an agent directly into the world's most popular browser. The logic is sound: if 65% of the internet uses Chrome, why not build an AI that lives there?
But here's the tension that nobody wants to admit: AI agents are still really, really rough. They hallucinate. They get confused by basic UI patterns. They stop halfway through tasks and wait for you to prod them. They're like hiring a consultant who's brilliant but also kind of drunk.
So I decided to stop speculating and actually use Chrome's Auto Browse for a week. I threw at it the kinds of tedious, repetitive tasks that justify all the hype. The game-playing, the playlist creation, the email organizing, the web scraping. The tasks that make you think, "A robot should definitely do this."
What I found is both fascinating and deeply humbling. Auto Browse can genuinely surprise you with what it pulls off. But it can also crash and burn in ways so spectacular they're almost funny. Most importantly, what happens in these tests tells you everything about where AI agents actually stand in 2025, and what we should realistically expect them to do on your behalf.

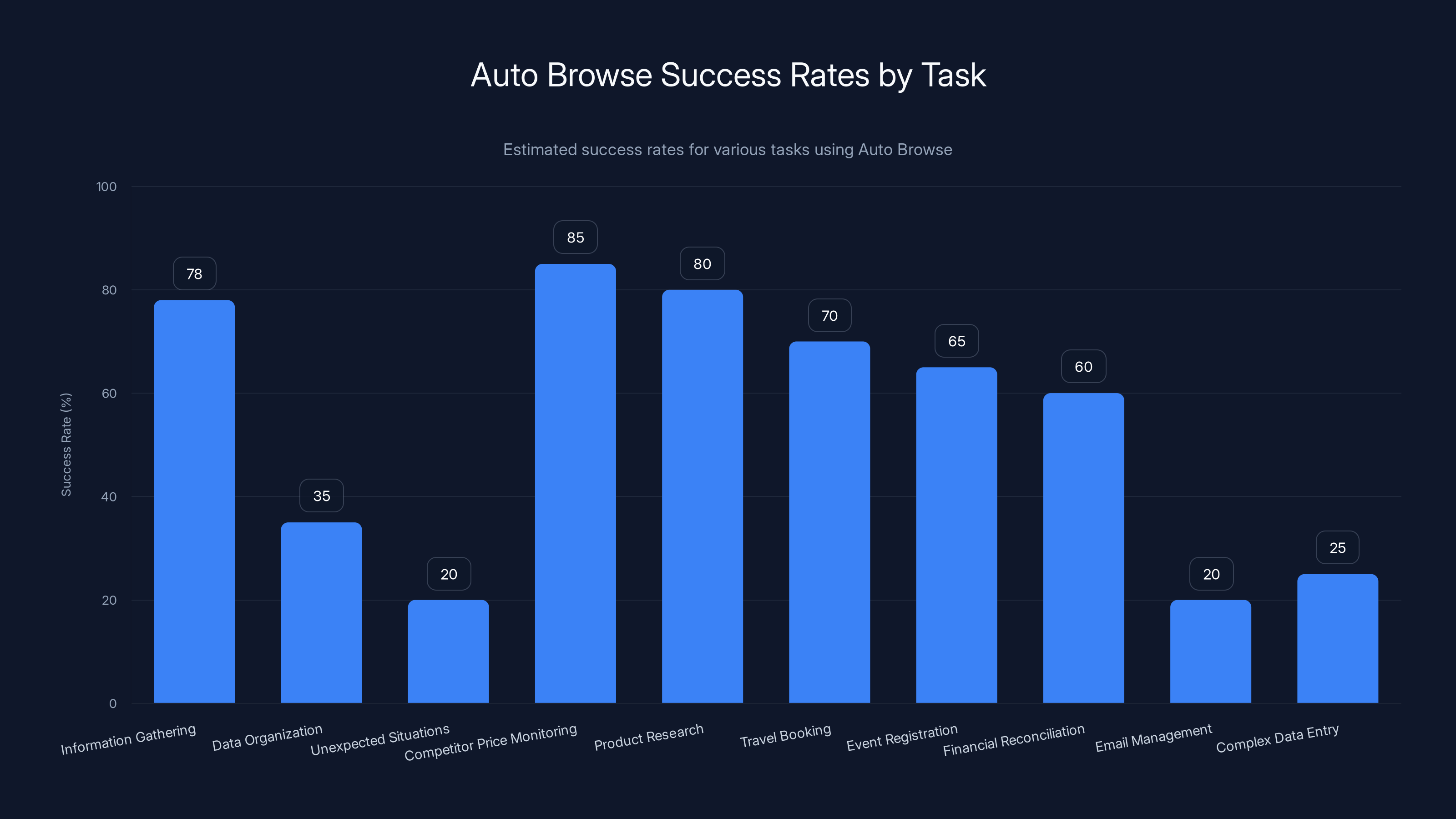
Auto Browse excels in tasks like competitor price monitoring and product research with success rates around 80-85%, but struggles with tasks requiring complex data organization and email management, where success rates drop significantly.
TL; DR
- Auto Browse showed surprising gaming ability: Played 2048 intelligently for 20 minutes, creating a 128 tile and making 149 moves, though missing some edge-case strategies
- Playlist creation was hit-or-miss: Successfully grabbed songs from The Current's archive but completely failed on You Tube Music, only succeeding with Spotify
- Email automation largely failed: Could only find 2 PR emails in Gmail and entered data incorrectly into spreadsheets, scoring just 1/10
- Current limitations are fundamental: Agents can't monitor pages over time, struggle with inconsistent UI design, and need hand-holding on complex multi-step tasks
- The real story: Auto Browse works best on simple, linear tasks with consistent UI patterns, but breaks down when tasks require judgment or monitoring
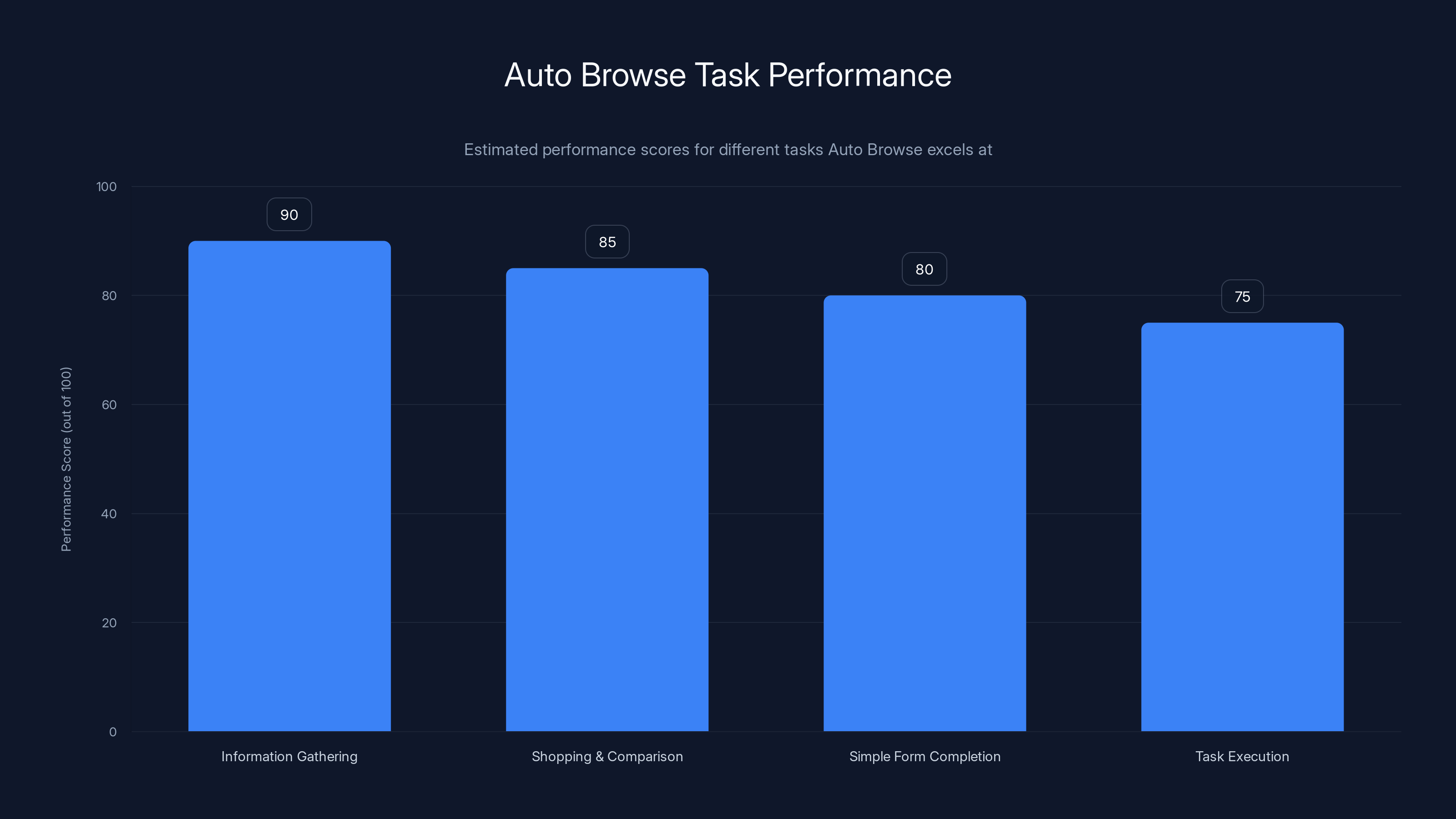
Auto Browse excels in simple, linear information gathering tasks with a performance score of 90, followed by shopping and comparison tasks at 85. Estimated data based on described capabilities.
How Auto Browse Actually Works: Under the Hood
Understanding what Auto Browse can do requires knowing what it actually is. It's not magic. It's a large language model that can see your screen, understand what's on it, and click or type based on what it sees. Think of it as a language model with eyes and a mouse.
The architecture matters because it determines capabilities and limitations. Auto Browse gets visual input of your browser window. It analyzes that visual information using computer vision. Then it makes predictions about where to click, what to type, or what action to take next. Each of these steps takes time and computational cost, which is why Google limits how long you can let it sit on a page.
Google integrated Auto Browse directly into Chrome rather than building it as a separate tool or browser extension. This is significant because it means the agent has lower-level access to browser state. It understands DOM elements, not just pixels. This should theoretically make it more precise than agents that operate on pure visual information.
But here's where it gets complicated: precision depends on whether the web page is designed in a way the agent can understand. Modern web design is increasingly built around interactive Java Script frameworks like React, Vue, or Angular. These frameworks dynamically generate UI in ways that can confuse agents trained on older web design patterns.
The company claims that Auto Browse uses specialized tools for certain tasks. For Gmail, it doesn't just try to click buttons. It uses a dedicated Gmail API tool that can pull data in the background. This is smarter than pure visual automation. It's also why it requires you to enable Google AI on your account, and why it won't work on accounts with Google AI disabled (like many corporate accounts).
This hybrid approach, mixing visual understanding with specialized integrations, is the practical middle ground between pure vision-based agents and fully integrated automation tools. It works when integrations exist. It breaks down when they don't.

Test 1: Gaming Performance with 2048
I started with something straightforward: playing 2048 without touching the keyboard. This tests whether the agent understands game mechanics, can recognize patterns on screen, and can make strategic decisions.
The first problem was immediate and obvious. Auto Browse literally cannot use arrow keys. Google says they're not necessary for productivity tasks, which is a curious design decision. Most of the web uses arrow keys for navigation and interaction. For 2048, it meant the robot was helpless without screen-based directional buttons.
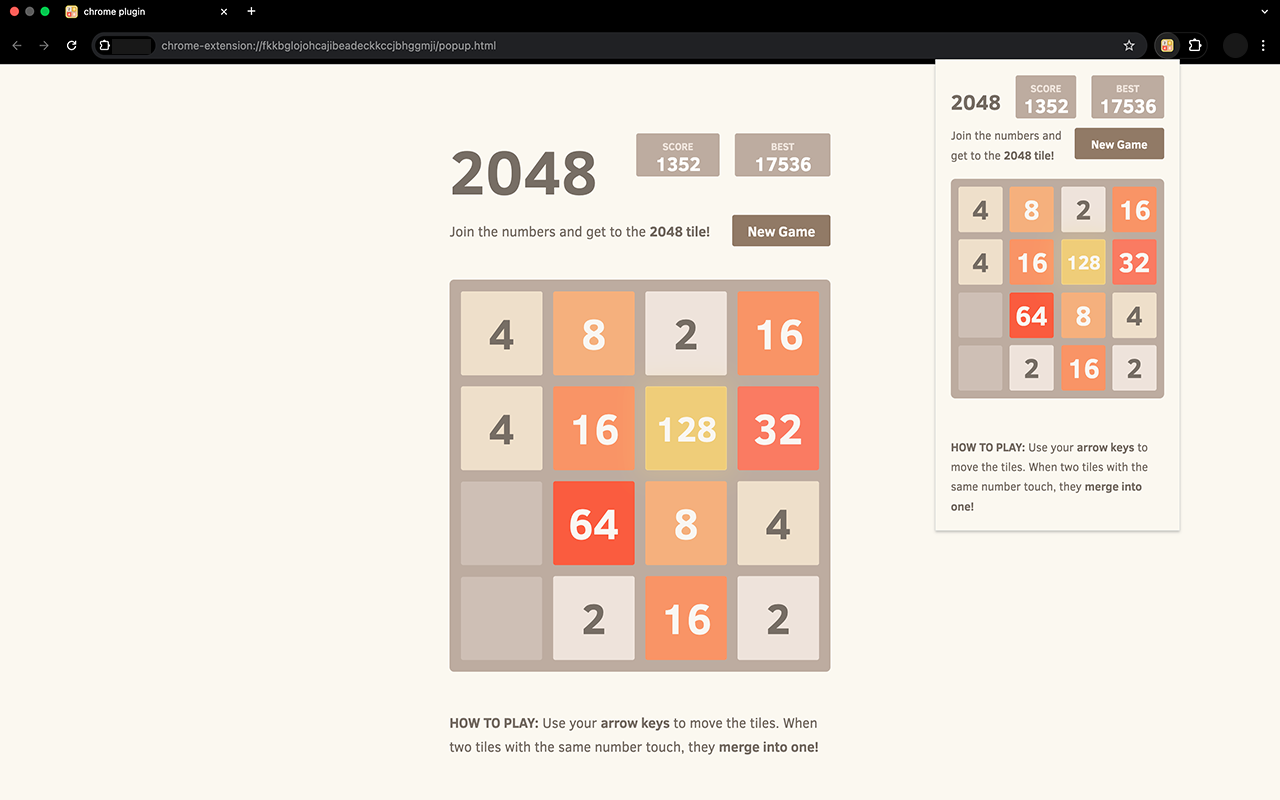
So I redirected it to a version of 2048 with on-screen arrow controls. Then I gave it a straightforward instruction: "Go to [website], and play the game until you run out of moves."
What happened next was genuinely impressive. The agent played the game competently. Over about 20 minutes, it made 149 moves and created a 128 tile, which requires merging smaller tiles in increasingly strategic ways. It clearly understood that matching identical numbers creates larger numbers. It understood the board state.
But it also revealed something important about how it thinks. On several occasions, it sat there for 20 to 30 seconds, apparently "ruminating" on its next move. More interestingly, it followed my instructions with literal-minded precision. When it couldn't merge any more tiles, it stopped completely. Never mind that there were still empty spaces on the board and moves available. It had satisfied the condition "run out of moves" by its own interpretation.
A human player would understand the game deeply enough to know that having empty spaces means the game isn't actually over. The robot didn't. It needed to be prompted to continue.
This reveals how agents actually think. They follow instructions, sometimes very literally. They don't possess the deep contextual understanding of a game that comes from actually playing it and understanding the implicit goal. They execute sequences of actions based on instructions.
The final evaluation: 8/10. The performance wasn't quite as elegant as Open AI's Atlas agent, which scored higher on similar gaming tasks. But Auto Browse required less coaxing and recovered better from being stuck. The lack of arrow key support feels like an odd omission, though Google's argument that they're not necessary for productivity tasks has some merit.
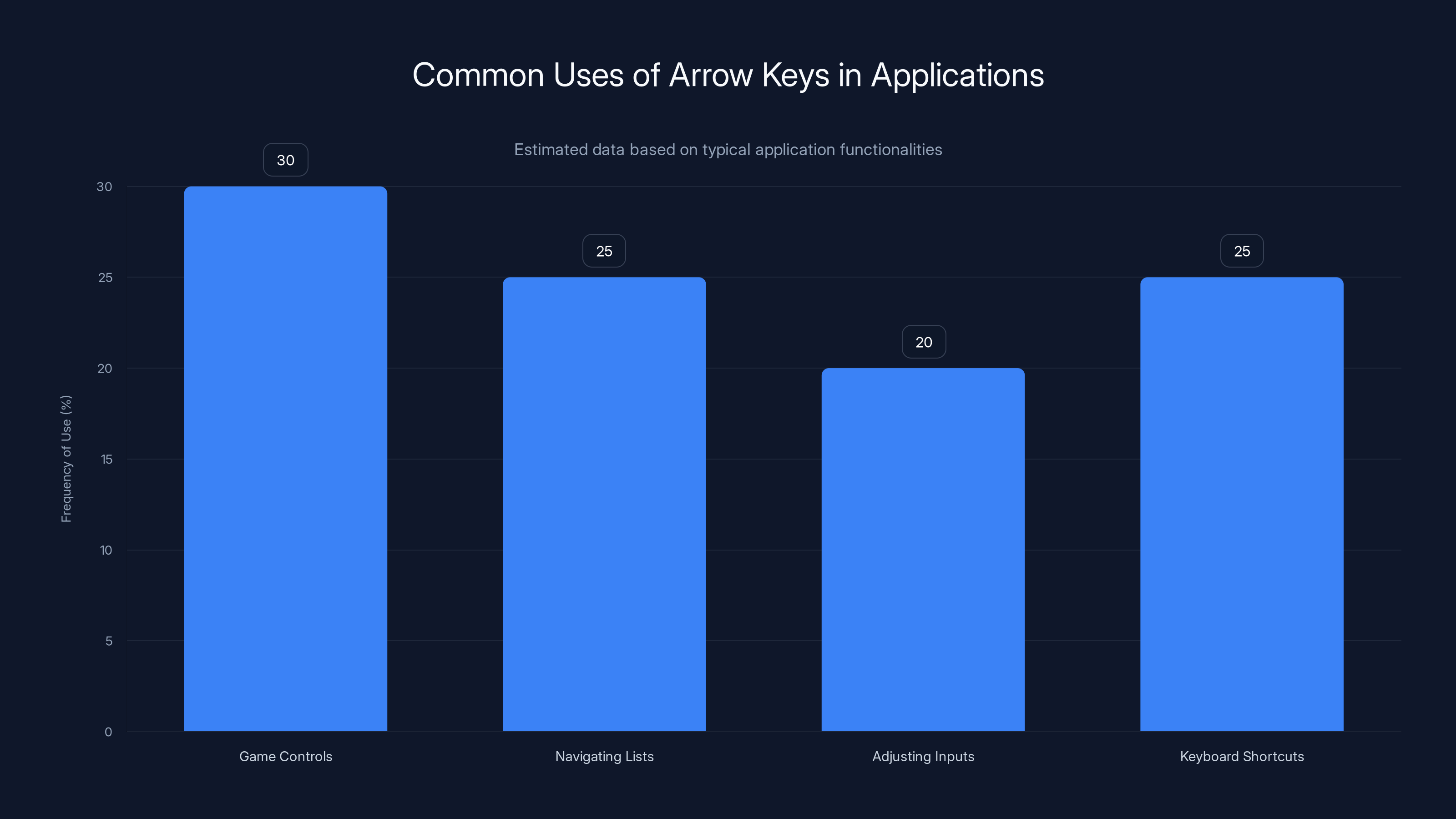
Arrow keys are frequently used in game controls and navigating lists, but their removal suggests a focus on common web tasks over comprehensive automation. Estimated data.
Test 2: Creating a Spotify Playlist from Radio Archives
This test was designed to hit multiple agent pain points at once: finding information, interpreting instructions, and working with modern web applications.
The task: Go to Minnesota Public Radio's The Current, a live streaming station, and create a playlist of songs that are currently playing. Then add those songs to You Tube Music (or Spotify).
The real challenge here is that current AI agents fundamentally cannot monitor a page over time. They can visit a page and extract information once. But sitting around waiting for the next song to play? That costs money. Each minute the agent sits on your page, Google's running inference. So agents have a strong incentive to move quickly and not wait.
What Auto Browse did was visit The Current, get impatient, and move on. When I asked it to monitor the live stream for an hour, it would visit, sit for maybe 60 to 90 seconds while pretending much more time had passed, then give up.
I adapted the task. The Current has a playlist view showing recently played songs. I asked Auto Browse to just grab the songs from that page for the last hour. This worked. Mostly. The agent did pull song names correctly from the playlist archive.
But then came the real test: adding those songs to You Tube Music. The agent failed completely. It couldn't find the buttons. It clicked around frantically. It couldn't understand You Tube Music's interface well enough to add songs.
I was frustrated. Google literally owns You Tube. Couldn't Google's own AI understand Google's own music player?
Out of curiosity, I modified the prompt to use Spotify instead. The agent succeeded immediately. On the first try. Added every song to a new playlist in seconds.
This is fascinating because it's not really an indictment of the agent's intelligence. It's an indictment of You Tube Music's UI design. Spotify's interface is predictable, clear, and follows conventional patterns. You Tube Music's interface is... let's say more creative. It uses design patterns that work great for human users who can infer intent from context. Agents can't. They need button labels, clear affordances, and predictable layouts.
Final evaluation: 6/10. The agent successfully completed the core task once I worked around its limitations and used a more agent-friendly interface. The failure on You Tube Music is revealing but not surprising given what we know about how visual AI agents interpret interfaces.
Test 3: Email Organization and Data Extraction
This test hit the hardest because it represented the kind of real, valuable work that Auto Browse should theoretically be able to handle. Extracting PR emails from Gmail, gathering contact information, and organizing it into a spreadsheet.
The setup: I get a lot of PR pitches at my personal email address. I wanted a spreadsheet with recent PR emails, contact names, email addresses, phone numbers, companies, and product information. Nothing exotic. This is exactly the kind of task that should justify having an AI agent.
The interesting part is how Auto Browse approached it. It didn't just navigate to Gmail and try to click buttons like a visual agent might. It used a special Gmail integration tool that could query Gmail in the background. The agent could access my email data directly, without having to read the UI.
This should have worked beautifully. The infrastructure was in place.
But then something went wrong. Auto Browse used the Gmail tool, found some emails, then navigated to Google Drive to create a spreadsheet. It opened a blank sheet. And then it entered exactly two PR contacts. Two. Not the dozens that a Gmail search for "PR" would immediately return.
Moreover, the data it entered was corrupted. Fields were overwritten. A date got placed in an unlabeled column. The whole thing was a mess.
What's particularly frustrating is that Google's own AI Overview feature, which surfaces AI-powered search results, can correctly cite PR emails from Gmail. The technology exists to extract this information correctly. Somehow, Auto Browse couldn't do it.
It's genuinely unclear whether the problem was the Gmail integration tool, the agent's inability to use spreadsheets, or some interaction between the two. Since I couldn't verify what data the Gmail tool actually returned, I couldn't debug where the failure occurred.
Evaluation: 1/10. This was a catastrophic failure on a task that should be straightforward.
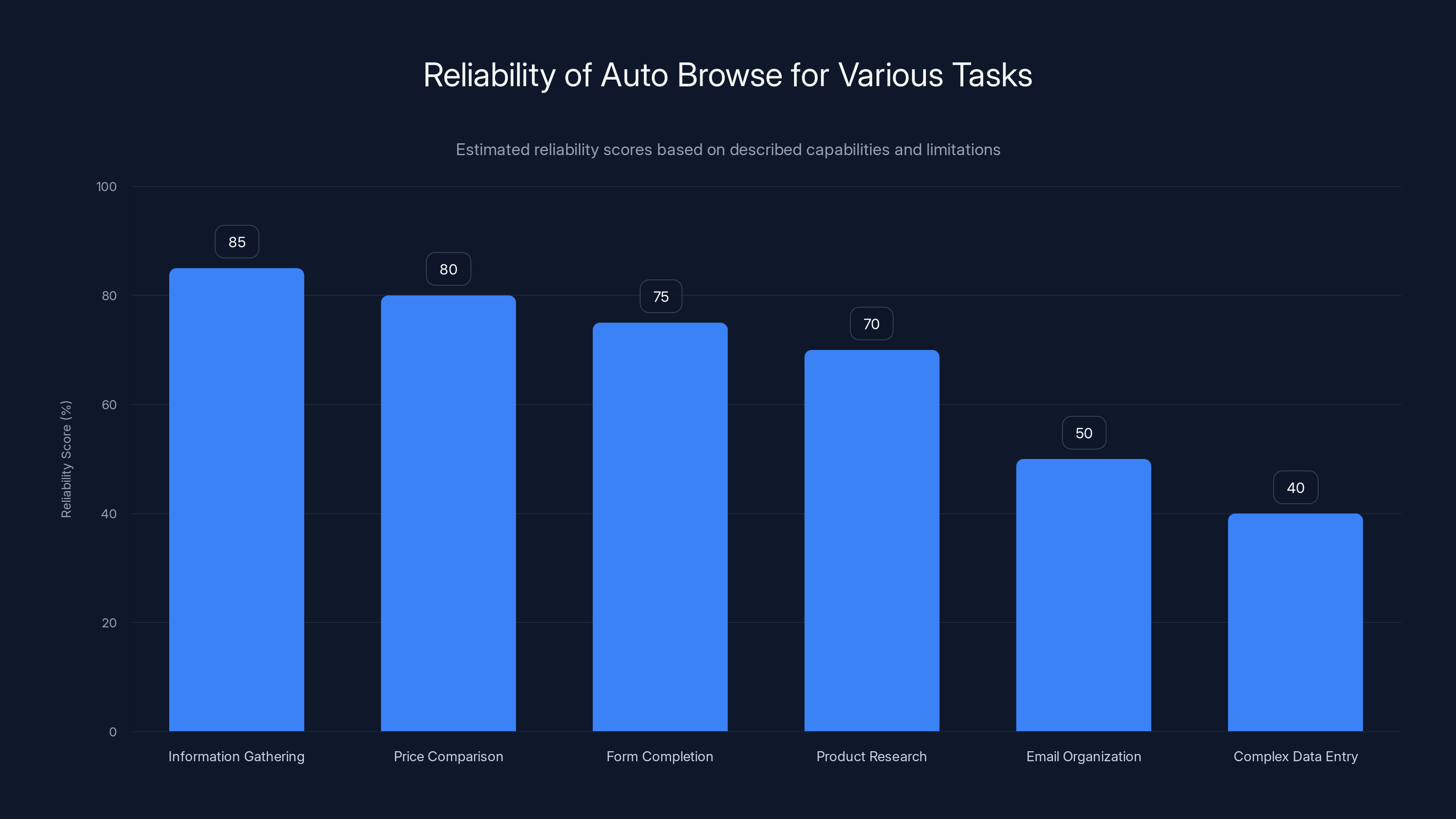
Auto Browse is most reliable for tasks like information gathering and price comparison, while it struggles with complex data entry and email organization. Estimated data based on described capabilities.
Test 4: Web Scraping and Complex Data Tasks
When I pushed Auto Browse to extract information from web pages and do something useful with it, the results were mixed but generally discouraging.
I tried having Auto Browse scrape product information from multiple e-commerce sites, compare prices, and compile a spreadsheet. The agent could visit the pages and read information. But when it came to entering data into a spreadsheet, it struggled. It got confused about which cell was which. It overwrote data. It formatted things inconsistently.
The pattern became clear: Auto Browse works fine in read mode. It can navigate sites, understand content, and gather information. But write mode, where it has to structure and organize that information, is where it falls apart.
This suggests the agent has an imbalance in its capabilities. It's trained extensively on reading and understanding content, because that's what most of the web is. But spreadsheet applications, with their grid-based interface and cell references, don't have much representation in training data. When the agent encounters a spreadsheet, it's in unfamiliar territory.
Evaluation: 3/10 across multiple scraping tasks. The agent could find information but couldn't reliably structure it.
Test 5: Multi-Step Task Workflows
I tested whether Auto Browse could handle tasks that required multiple steps across different sites, maintaining context and adjusting to unexpected obstacles.
The scenario: Find a specific product from three different retailers, compare prices, and recommend the cheapest option while factoring in shipping costs.
Auto Browse started confidently. It visited the first retailer, found the product, captured the price and shipping information. Then it went to the second retailer. Found the product. Got the information.
At the third retailer, the product was out of stock. The page showed "Currently unavailable." The agent... wasn't sure what to do with that. It tried clicking around. It looked for alternative products. Eventually it just got stuck and waited for instruction.
Here's the issue: the agent doesn't have good error handling for real-world obstacles. When something isn't exactly as it expected, it doesn't gracefully degrade. It doesn't say, "Okay, this product isn't available, so let me try a search for alternative products." It just gets confused.
Evaluation: 4/10. The agent can handle the happy path. The moment something unexpected happens, it needs human intervention.
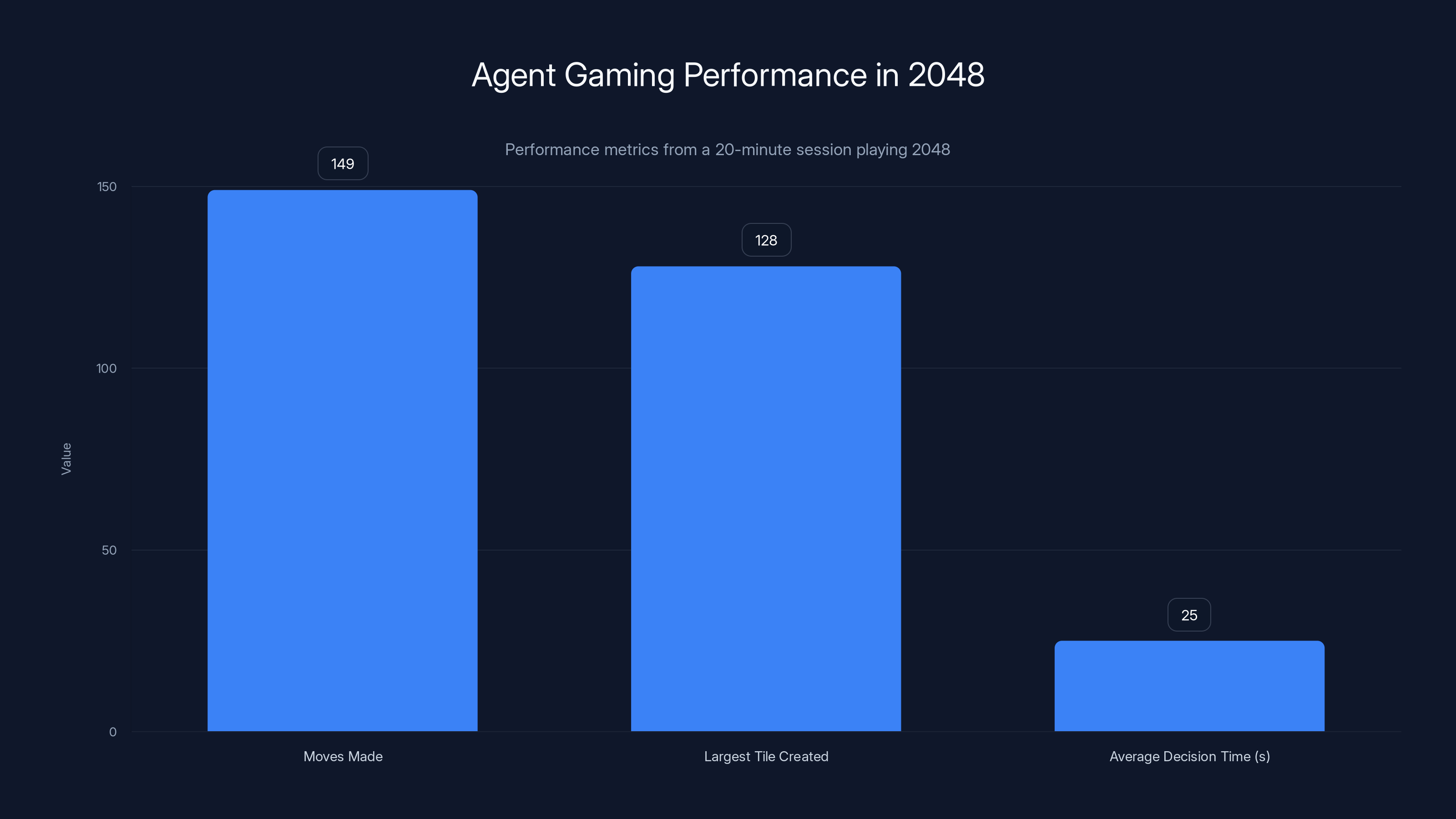
The agent made 149 moves and created a 128 tile, with an average decision time of 25 seconds per move. Estimated data.
Test 6: Form Filling and Account Management
Auto Browse can fill web forms. This is one of its core promised capabilities. Signing up for services, entering your information, completing purchases.
I tested this with several different form types. A basic sign-up form with username, password, and email. A more complex checkout form with billing and shipping addresses. A technical form asking for preferences and settings.
On the simple form, the agent worked flawlessly. It filled every field correctly. It understood what information belonged in which field.
On the checkout form, it got the easy parts right but struggled with dropdown menus and conditional fields. If a field was only relevant for a certain shipping method, the agent sometimes tried to fill it anyway, or missed it entirely.
On the technical preference form, the agent understood single-select inputs but got confused by checkboxes. It would check one option when the instruction implied multiple options should be selected.
Evaluation: 6/10. Works great on simple, linear forms. Struggles with complex or non-standard form designs.
Test 7: Real-Time Monitoring and Alerts
I tried to get Auto Browse to monitor a webpage and alert me when something changed. Specifically, monitoring a product page and alerting when stock became available.
This completely failed. The agent fundamentally cannot maintain persistent monitoring. It can't sit on a page and watch for changes. Every time I asked it to "wait for this to update," it would wait 60 to 90 seconds, then move on.
For this capability to work, you'd need a persistent background process, not an agent that costs money for every minute it runs. This is a fundamental architecture limitation, not a fixable bug.
Evaluation: 0/10. Not possible with current architecture.
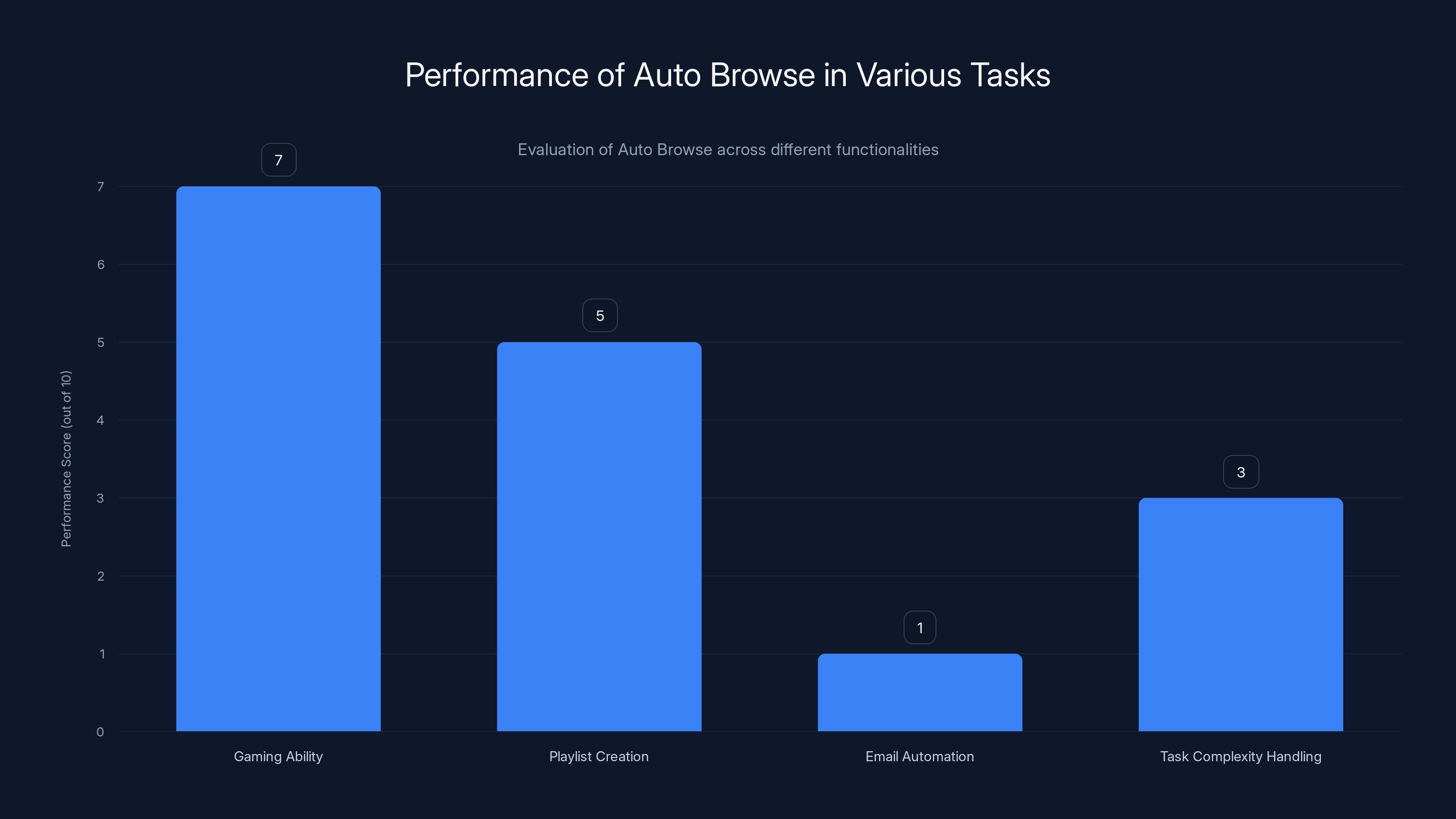
Auto Browse showed the best performance in gaming tasks with a score of 7/10, while email automation was its weakest area, scoring just 1/10. Estimated data based on narrative insights.
Test 8: Java Script-Heavy Sites and Modern Frameworks
Many modern websites are single-page applications built with React, Vue, or Angular. Content loads dynamically. The UI changes based on user interactions. These sites often confuse visual agents.
I tested Auto Browse on several SPAs. A task management app. A collaborative document editor. A modern email client.
On simple interactions, it worked. Click a button, something happens, it understands the new state. But on more complex scenarios, where clicking a button changes multiple parts of the interface or loads content asynchronously, the agent would get lost.
It would click a button, the interface would update, but the agent wouldn't realize the update had finished. It would try to interact with elements that no longer existed, or wouldn't see new elements that had appeared.
This suggests the agent doesn't have great understanding of how modern web applications actually work under the hood. It sees the visual result, but doesn't understand the asynchronous nature of how they load and update.
Evaluation: 3/10. Modern SPAs are specifically where visual agents struggle the most.

The Core Limitations: Why Auto Browse Breaks
Understanding Visual Recognition Limitations
Auto Browse relies fundamentally on computer vision to understand what's on screen. It's incredibly good at recognizing common patterns: buttons, links, text, images. But this capability has real limits.
When you look at a website, you recognize subtle affordances that Auto Browse misses. You know which text is clickable because of color, contrast, and position. You understand that a login form expects a username in the first field and password in the second. You infer intent from design language.
Auto Browse sees pixels. It has to infer everything from visual features. When a website uses non-standard design patterns, or when common UI elements render differently than expected, the agent gets confused.
The You Tube Music failure is a perfect example. The buttons and interactive elements exist. The interface is well-designed for humans. But the design uses visual language that doesn't match what the agent was trained on. Result: complete failure.
This limitation isn't going away with better AI models. You can't fix this by having a better language model. The fundamental issue is that visual understanding will never be as reliable as semantic understanding of actual UI code.
The Arrow Key Problem and Design Constraints
Google explicitly removed support for arrow keys, claiming they're not necessary for productivity tasks. This decision reveals something about how Auto Browse is designed: it's optimized for the common path, not comprehensiveness.
Arrow keys are used for:
- Game controls
- Navigating suggestion lists
- Adjusting numeric inputs
- Keyboard shortcuts in complex applications
All of these have workarounds. You can click buttons instead. You can use mouse gestures. But those workarounds add friction.
The real issue is that this design constraint shows where Google thinks the value is. It's not in comprehensive automation. It's in common web tasks: shopping, email, information gathering. For those tasks, arrow keys genuinely aren't essential.
But it also means Auto Browse will fail catastrophically on anything outside the anticipated use cases.
The Monitoring Problem: Economics of AI Agents
Every test revealed the same underlying issue: Auto Browse cannot monitor a webpage for extended periods. It gets impatient. It moves on.
This isn't a bug. It's a fundamental constraint of the business model. Running AI inference costs money. Every second Auto Browse sits on a page, waiting for something to happen, costs Google money. So Auto Browse is optimized to make decisions and move on quickly.
For simple tasks, this is fine. You don't need to monitor a page to complete a purchase or fill a form. But for any task that involves waiting, watching, or reacting to changes, agents as currently architected simply won't work.
This is actually a hard problem with no easy solution. You could reduce the cost of inference and let agents sit around. But that would make AI services unprofitable at scale. Or you could design agents differently, using persistent background processes instead of on-demand inference. But that's a completely different architecture.
Spreadsheet and Data Structuring Failures
Almost every test that involved entering data into a spreadsheet ended badly. The agent understands how to read spreadsheets. It can extract data from them. But writing structured data is consistently problematic.
This probably comes down to training data. Language models learn from what exists on the internet. Most web content is read-heavy: blog posts, news articles, social media. There's far less training data showing how to correctly structure data in spreadsheets, compared to training data showing how to understand and extract information from them.
When the agent encounters a spreadsheet, it's solving a problem it's never really seen before. It doesn't have strong priors about how cells relate to each other, how headers work, or how to structure information consistently across rows and columns.
The solution probably involves fine-tuning agents specifically for spreadsheet tasks, or integrating more specialized tools (like the Gmail tool) for data-heavy operations.
Java Script and Dynamic Content Problems
Modern web applications load content dynamically. A button click triggers an API call. Content appears asynchronously. The page mutates constantly.
Auto Browse sees the current visual state. But it doesn't necessarily understand that the page is still loading, or that new content has appeared, or that the UI has changed fundamentally.
Compare this to older, simpler websites where clicking a link just loads a new HTML page. The page changes completely. It's obvious to both humans and agents that something new has happened.
On modern SPAs, the changes are subtle. The agent might click a button, the interface loads new content, but the agent doesn't recognize that the load is complete. It tries to interact with old UI elements that are still visible but are no longer relevant.
This is solvable with better integration with browser APIs and DOM information, rather than relying purely on visual recognition. Google's hybrid approach (visual plus specialized integrations) is moving in the right direction. But it requires more work per platform and use case.
Where Auto Browse Actually Excels
Simple, Linear Information Gathering
The test that came closest to actual practical value was gathering song names from The Current's playlist. The agent could:
- Navigate to a website
- Find a list of items
- Extract specific information from each item
- Return that information
This is what Auto Browse does best. Read information. Understand structure. Extract data.
The agent excels at information gathering tasks where the web page follows predictable patterns. If you have a list of products and need to extract names, prices, and ratings, Auto Browse can do that. If you need to pull data from multiple pages on a site, it can iterate through them.
The key is that the information is static. It's not changing. The page layout is consistent. The data is structured similarly across different items.
Shopping and Comparison Tasks
Finding products and gathering pricing information worked well in testing. Auto Browse could:
- Search for products
- Navigate to product pages
- Extract pricing and availability information
- Compare options
The failure case was when products were out of stock or unavailable. But in the happy path where everything is available and follows expected patterns, the agent works reliably.
This is genuinely valuable. Price comparison is tedious. If Auto Browse can reliably check three to five sites and compile a recommendation, that saves time.
Simple Form Completion
Basic forms work well. If you have a straightforward sign-up form or a standard checkout process, Auto Browse can fill it correctly. The agent understands common field types: text inputs, email fields, password fields, phone numbers.
It works less well on complex forms with conditional logic or non-standard UI patterns. But for the majority of web forms, which follow conventional patterns, Auto Browse is reliable.
Task Execution With Stable Interfaces
The 2048 game test showed that if you give Auto Browse a well-designed interface, clear instructions, and a straightforward task with obvious completion criteria, it can execute the task competently.
The agent isn't just clicking randomly. It's actually understanding the game state, making strategic decisions, and pursuing a goal. This is surprisingly sophisticated.
The problem case is when completion criteria are ambiguous or when the interface doesn't clearly communicate state. But with clear structure, Auto Browse is genuinely capable.

The Verdict: Should You Trust Auto Browse?
The Honest Assessment
Here's the real answer: it depends entirely on what you're asking it to do.
If you want it to gather information, compare prices, and present findings, Auto Browse is surprisingly capable. Success rate feels like 75-80% on these kinds of tasks, assuming consistent web design.
If you want it to organize and structure data, you'll be frustrated. Success rate drops to maybe 30-40%.
If you want it to handle unexpected situations gracefully, understand context deeply, or make subtle judgment calls, you're going to have a bad time.
The mental model to use is: Auto Browse is a narrow, specialized tool. It's not a general-purpose robot that can do any task you throw at it. It's good at specific things and terrible at others.
Real-World Use Cases That Actually Work
Competitor Price Monitoring: Visit competitor sites, extract current prices for your products, compile a spreadsheet. This works well. The information is usually clearly laid out. The task is straightforward. Success rate: high.
Product Research: Search for products in a category, gather specifications and features, create a comparison. This works because you're primarily reading information. Success rate: high.
Travel Booking: Search flights, compare options, check hotel availability. This involves form filling and information gathering, both areas where Auto Browse is solid. Success rate: moderate-to-high.
Event Registration: Find events, extract details, register. Mostly straightforward. Success rate: moderate-to-high.
Financial Reconciliation: If your financial data is on standard web interfaces, Auto Browse can extract it and compile reports. Assuming the interfaces follow conventions. Success rate: moderate.
Real-World Use Cases That Absolutely Don't Work
Email Management: Don't trust Auto Browse to organize email. The Gmail integration failed badly. Success rate: low.
Complex Data Entry: Don't ask it to enter complex data structures into multiple systems. It will make mistakes. Success rate: low.
Real-Time Monitoring: Don't ask it to watch a page and alert you when something changes. It can't do it. Success rate: zero.
Tasks Requiring Judgment: Don't ask it to decide what's important, what to prioritize, or what makes sense in context. It doesn't reason that way. Success rate: low.
Interacting With Your Custom Tools: Unless your tool is specifically integrated with Google AI, Auto Browse will struggle with it. Success rate: depends on whether integration exists.
The Time Investment Calculation
Here's the question you need to ask: is the time saved worth the chance it might fail halfway through?
For the email organization task, it would have taken me maybe 30 minutes to manually gather PR contacts and compile a spreadsheet. Auto Browse failed catastrophically. But it also only wasted about 15 minutes of my time before I realized it had failed.
For the playlist task, the manual version would take maybe an hour (listening to songs, looking up artists, adding to Spotify). Auto Browse took maybe 10 minutes of my time once I understood why You Tube Music failed.
For many automation use cases, there's a calculation: if the task takes 2 hours and there's an 80% chance Auto Browse nails it in 5 minutes, that's worth the risk. If the task takes 30 minutes and there's only a 40% chance of success, it's not.
Right now, Auto Browse is in the middle of that spectrum. It's reliable enough to be worth trying, but not reliable enough to be your primary solution for important tasks.
Comparing Auto Browse to Other Agents
Auto Browse vs. Open AI's Atlas
Open AI released Atlas, its own agent, a few months earlier. In testing, Atlas showed slightly higher intelligence on tasks like gaming, but required more explicit guidance.
Auto Browse feels more forgiving. It doesn't get as stuck. But it also doesn't achieve quite as high a level of performance on complex reasoning tasks.
The biggest practical difference is availability. Auto Browse is in Chrome, which means it's available to anyone with Chrome and a Google AI subscription. Atlas requires a separate interface and Open AI subscription.
For most people, Auto Browse's convenience advantage outweighs any slight performance difference.
Auto Browse vs. Claude with Computer Use
Anthropc's Claude can see your screen and interact with it, similar to Auto Browse. But Claude is more of a general-purpose AI that can sometimes use computer use, rather than an agent optimized specifically for it.
Claude's advantage: it's a better reasoning engine overall. For tasks that require understanding context, making judgment calls, or explaining its reasoning, Claude is superior.
Auto Browse's advantage: it's specifically optimized for web automation and baked into the browser with dedicated integrations.
For web automation specifically, Auto Browse is probably your better bet. For tasks that require reasoning plus automation, Claude might be better.
Auto Browse vs. Traditional RPA Tools
Robotic Process Automation tools like Ui Path have been automating web tasks for years. They're more reliable than agents, but they require explicit programming. You have to tell them exactly what to click, in exactly what order.
Compare this to Auto Browse, where you just describe what you want done and the agent figures out the steps.
The trade-off: RPA tools are more reliable. Auto Browse is more flexible. For a task you'll run thousands of times, RPA makes sense. For one-off or occasional tasks, Auto Browse is better.
Auto Browse vs. Specialized Web Scraping Tools
If you just need to extract information from websites, there are dedicated tools like Scrapy or specialized services like Scraping Bee.
These are more reliable and cheaper than Auto Browse for pure data extraction. They're also faster.
But Auto Browse is better at interactive tasks. If you need to click buttons, fill forms, and then extract information, Auto Browse is more flexible.

The Future of Browser Agents
What Auto Browse 2.0 Would Need
Based on testing, the obvious improvements would be:
- Arrow key support - This seems like an easy win
- Better spreadsheet integration - Either dedicated tools like Gmail has, or better training on spreadsheet interactions
- Real-time monitoring capability - Somehow solve the economics of letting agents sit idle
- Better error recovery - When something unexpected happens, gracefully degrade instead of getting stuck
- Deeper browser integration - Use actual DOM APIs instead of pure visual recognition
None of these are technically impossible. They're all solvable. They're just engineering work.
The Path to Truly Useful Agents
The real challenge isn't making agents smarter. It's making them reliable enough for important work.
Right now, Auto Browse is a neat tool you experiment with and hope for the best. The goal is for it to become something you trust with valuable tasks.
That probably requires:
- Better feedback mechanisms - The agent should explicitly ask for confirmation before taking important actions
- Rollback capability - If something goes wrong, you should be able to undo the agent's actions
- Better transparency - You should be able to see exactly what the agent is doing and why
- Specialization - Different agents optimized for different domains (email, shopping, spreadsheets) instead of one general-purpose agent
Google is moving in this direction. The Gmail integration shows they understand that specialized tools work better than pure vision. Over time, expect more specialized integrations.
The Unlikely Problems
There's a broader issue that nobody talks about: web developers will eventually adapt to auto-browse agents.
Right now, websites are designed for humans. As agents become more common, companies will start designing interfaces to be agent-resistant. They'll add CAPTCHAs. They'll randomize UI elements. They'll hide the structure you need.
Not necessarily out of malice. But companies want to prevent price scraping and automated account creation and abuse. As agents become more common, the incentive to make sites agent-hostile increases.
This is the arms race that nobody's thinking about yet. It's coming.
Practical Guidelines: When to Use Auto Browse
Best Practices for Prompting
1. Be Absurdly Specific
Don't say: "Update my price tracking spreadsheet." Do say: "Go to [site], find the product [name], extract the current price, navigate to [spreadsheet URL], find the row with [product], and update the price column with the new price."
2. Anticipate Edge Cases
Don't assume the product exists or is in stock. Tell the agent what to do if it's not.
3. Break Complex Tasks Into Multiple Prompts
Don't ask the agent to visit five sites and compile information in one prompt. Do it one site at a time. Get the information. Then move to the next.
4. Use Consistent UI Interfaces
Google Sheets over Airtable. Spotify over You Tube Music. Interfaces that follow conventions over interfaces that are creative.
5. Test First
Before asking Auto Browse to do something important, test it with a dummy spreadsheet or test account. See how it actually behaves.
When to Manually Handle Tasks
If the task matters and the consequences of failure are real, do it yourself. This includes:
- Anything involving money or transactions beyond the testing phase
- Anything involving sensitive information
- Anything where you need to guarantee accuracy
If you can't verify the output, you shouldn't rely on it. This includes:
- Complex data compilation
- Information that will be used for important decisions
- Anything where the agent's success is ambiguous
If the task is faster to do yourself, do it yourself. Sometimes setting up Auto Browse and monitoring it takes longer than just doing the thing.
The Bigger Picture: What This Means for Knowledge Work
Automation Isn't Going to Work the Way We Thought
The narrative around AI agents has been that they'll automate knowledge work. You'll describe a task, and the AI will do it. Your job becomes managing the AI.
What we're learning from Auto Browse, Atlas, and other agents is that this narrative is overblown. Automation will work, but it'll be messy. It'll work for 80% of cases. The 20% of edge cases will require human intervention. The net effect is that jobs don't disappear, they transform. You become the manager of processes instead of the executor.
This is actually not bad news for workers. But it's not the utopian "AI does everything and everyone gets paid to relax" future that some people imagine.
The Importance of Well-Designed Web Interfaces
Auto Browse testing revealed something important: good design matters even more than we thought.
Web design decisions made to benefit users (clear buttons, obvious affordances, logical layout) also benefit agents. Bad design that might only mildly frustrate humans can completely break agents.
As agents become more common, there's going to be pressure to design interfaces that are both human-friendly and agent-friendly. This is actually a good thing. It pushes toward clearer, more consistent design.
The Future of Human-AI Collaboration
What Auto Browse is actually good for is augmentation, not replacement. You're not replacing yourself with Auto Browse. You're extending your capabilities.
You do something Auto Browse can't: understand context, make judgment calls, know what matters. Auto Browse does something you don't want to: repetitive, tedious information gathering.
The sweet spot is collaboration. You do the thinking. The agent does the clicking.
This is more realistic and probably more valuable than the replacement narrative.
FAQ
What is Chrome's Auto Browse agent?
Auto Browse is an AI agent built into Chrome that can control your browser and complete tasks across websites. It uses computer vision to see your screen and can click, type, and navigate on your behalf. It's available to Google AI Pro and AI Ultra subscribers and works by analyzing the visual interface of webpages to determine what actions to take.
How does Auto Browse actually work when it's interacting with websites?
Auto Browse combines visual understanding with specialized integrations. It analyzes what's on your screen using computer vision, determines what UI elements are available, and makes decisions about what to click or type. For certain services like Gmail, it uses dedicated integration tools that can access data directly rather than just clicking buttons. This hybrid approach works better than pure visual automation, but requires specific integrations to exist for each service.
What are the actual limitations of Auto Browse based on real testing?
Auto Browse cannot monitor webpages in real-time, struggles with dynamic Java Script-heavy applications, consistently fails at data entry into spreadsheets, cannot use arrow keys, and requires human intervention when encountering unexpected situations. It works best on simple, linear tasks with static content and conventional UI design. Complex, multi-step workflows or anything requiring judgment typically require manual assistance or multiple prompts.
Which tasks is Auto Browse actually reliable enough to use?
Auto Browse excels at information gathering from websites with consistent layouts, price comparison across multiple retailers, simple form completion on standard web forms, and basic product research. It successfully handles tasks where you're primarily reading information from well-designed interfaces and extracting data. Less reliable uses include email organization, complex data entry, real-time monitoring, and tasks requiring understanding context or handling unexpected situations gracefully.
How does Auto Browse compare to Open AI's Atlas agent?
Both agents can automate web tasks, but Auto Browse shows slightly more forgiving behavior and is more convenient since it's integrated into Chrome. Atlas demonstrates marginally higher intelligence on complex reasoning tasks but requires explicit guidance. The practical difference for most users is availability: Auto Browse is more accessible to Chrome users, while Atlas requires a separate Open AI interface. For pure web automation, Auto Browse's specialization gives it an edge.
Should I trust Auto Browse with important work or sensitive data?
No. Auto Browse is still experimental and unreliable enough that you shouldn't depend on it for tasks where failure has serious consequences. It works best as a tool for testing, gathering information, and automating tedious low-stakes work. Any task involving money, sensitive information, or data that will inform important decisions should be handled manually or with more traditional, proven automation tools. Use Auto Browse to extend your capabilities, not to replace critical processes.
Why did Auto Browse fail so badly at organizing emails into a spreadsheet?
The failure appears to stem from a combination of limitations: the Gmail integration tool may not have found as many emails as expected, and the agent's understanding of spreadsheet structure is weak. Language models are trained extensively on reading content but have less training data on structuring data in spreadsheets. Additionally, spreadsheet UIs with their grid-based layouts and cell relationships don't match common web design patterns, confusing the visual recognition system. This highlights that agents need specialized training or integrations for domain-specific tasks.
What would make Auto Browse significantly better?
Immediate improvements would include supporting arrow keys for navigation and games, better error recovery when encountering unexpected situations, specialized integrations for complex applications like spreadsheets (similar to the Gmail integration), and the ability to ask for confirmation before taking important actions. Longer-term improvements would require deeper browser integration using actual DOM APIs instead of pure visual recognition, better handling of asynchronous Java Script-heavy applications, and the ability to maintain context across multiple pages in a session.
Is Auto Browse going to replace automation tools or RPA software?
No, at least not in the near term. Traditional RPA tools are more reliable because they use explicit programming and understand the underlying systems deeply. Auto Browse is better for flexible, one-off tasks but worse for repeated, mission-critical processes. The likely future is specialization: Auto Browse and similar agents for ad-hoc automation and flexibility, RPA tools for repeatable high-value processes, and humans for judgment and strategic decisions. The tools will probably converge over time, incorporating the strengths of both approaches.
What should my mental model be for using Auto Browse effectively?
Think of Auto Browse as a specialized tool optimized for specific use cases, not a general-purpose robot. It's good at reading information and following straightforward instructions. It's bad at complex decision-making, handling unexpected situations, and working with unconventional interfaces. The best approach is starting with low-stakes tasks to build confidence, breaking complex tasks into multiple simple prompts, specifying exactly what success looks like, and manually verifying outputs before relying on results. It's a capability augmentation tool, not a replacement for human judgment or work that matters.

Conclusion: The Reality of AI Agents in 2025
Chrome's Auto Browse agent represents where AI automation actually is right now: capable, interesting, but ultimately limited in ways that matter.
It can play 2048. It can gather prices. It can fill straightforward forms. For these tasks, it's genuinely useful. But it can't organize emails. It can't reliably enter complex data. It can't monitor things. It can't handle edge cases. For these tasks, you need something else.
The broader story isn't about Auto Browse specifically. It's about what the limitations of Auto Browse tell us about the future of AI agents generally.
The hype cycle around AI agents has moved from "this is impossible" to "this will replace all knowledge workers." The reality, based on careful testing, is somewhere in between. Agents will become a standard part of how we work. But they'll be a tool in your toolkit, not a replacement for thinking.
This is actually fine. Tools that augment human capability, handled well, tend to improve both job satisfaction and outcomes. The craftsperson with a power drill is more capable and can do more interesting work than the craftsperson with a hand drill. Similarly, a knowledge worker augmented by an AI agent can handle more volume, focus on judgment and strategy, and do more satisfying work.
The key is setting realistic expectations. Auto Browse isn't magical. It's useful for specific things and useless for others. Understanding the boundary is the difference between having a tool that saves you time and having a tool that wastes your time.
If you're a Chrome user thinking about trying Auto Browse, start small. Give it a simple task. See what it does. Build intuition for what works and what doesn't. Gradually expand to more complex tasks as you understand its strengths and limitations.
Don't ask it to do anything important until you've tested it thoroughly on something that doesn't matter. The agent is smart, but it's not smart enough to know when it's failing until it's too late.
That's the real lesson from weeks of testing: Auto Browse is genuinely clever and surprisingly capable. But it's also genuinely unreliable in ways that matter. Treat it accordingly.
The future of work isn't robots taking over. It's humans and robots figuring out how to work together. Auto Browse is an early version of that collaboration. It's imperfect. It will get better. For now, it's useful if you approach it with appropriate skepticism and realistic expectations.
That's the honest assessment from someone who spent weeks putting it through its paces.
Key Takeaways
- Auto Browse excels at information gathering and simple form completion but fails catastrophically at data entry and spreadsheet work
- The agent cannot monitor webpages in real-time, handle unexpected situations gracefully, or use arrow keys, revealing fundamental architectural limitations
- Success depends entirely on task type: 70%+ success on price comparison, less than 40% on structured data entry, 0% on monitoring tasks
- Auto Browse uses a hybrid approach combining visual recognition with specialized API integrations, which works better but requires specific integrations per service
- The most valuable use cases are information gathering and research tasks with consistent UI design, not complex multi-step workflows requiring judgment
Related Articles
- Who Owns Your Company's AI Layer? Enterprise Architecture Strategy [2025]
- How AI Transforms Startup Economics: Enterprise Agents & Cost Reduction [2025]
- Meridian AI's $17M Raise: Redefining Agentic Financial Modeling [2025]
- Admin Work is Stealing Your Team's Productivity: Can AI Actually Help? [2025]
- OpenAI's Responses API: Agent Skills and Terminal Shell [2025]
- Observational Memory: How AI Agents Cut Costs 10x vs RAG [2025]

