![OpenAI's New macOS Codex App: The Future of Agentic Coding [2025]](https://tryrunable.com/blog/openai-s-new-macos-codex-app-the-future-of-agentic-coding-20/image-1-1770057415437.png)
Introduction: The AI Coding Revolution Hits macOS
Software development is fundamentally changing. What used to be a purely human craft is becoming something else entirely—a collaboration between human intuition and machine-powered execution. OpenAI just released a macOS app for Codex that crystallizes this shift. It's not just another IDE plugin or code completion tool. This is about handing off entire coding tasks to AI agents that work independently, in parallel, while you sip your coffee.
If you've been following the AI coding space, you've probably heard about Claude Code. Anthropic's platform became the poster child for agentic development—the idea that AI doesn't just suggest code snippets, but actually understands your project structure, makes decisions about what to build, and executes multiple steps without constant human intervention. OpenAI watched this happen. Watched developers flock to Claude Code. And decided it was time to move fast.
The new Codex macOS app isn't just catching up, though. It's a statement: OpenAI believes its GPT-5.2 model is strong enough to compete directly with Claude Opus, and the interface it's building around that model is flexible enough to accommodate the kind of sophisticated, multi-agent workflows that modern teams actually need.
But here's what's interesting. The benchmarks tell a messy story. Yes, GPT-5.2 ranks first on some coding tests. But Claude Opus sits right behind it—sometimes within the margin of error. This means the competitive advantage doesn't live in raw model capability anymore. It lives in user experience, developer preference, and ecosystem integration.
Let's dig into what OpenAI actually built, why it matters, and whether this macOS app represents a genuine breakthrough or just a necessary catch-up move.
TL; DR
- Agentic Architecture: Codex macOS app runs multiple AI agents in parallel, enabling sophisticated multi-step coding tasks without constant human intervention
- GPT-5.2 Integration: OpenAI's most powerful coding model is now available through an intuitive native app, though benchmarks show competitive parity with Claude Opus
- Background Automation: Users can set workflows to run unattended and review results later, saving hours on repetitive coding tasks
- Agent Personalities: Choose from pragmatic, empathetic, and other personas depending on coding style, adding flexibility to workflows
- Speed Advantage: Development from concept to functional software now takes hours instead of days, limited mainly by how fast you can articulate ideas
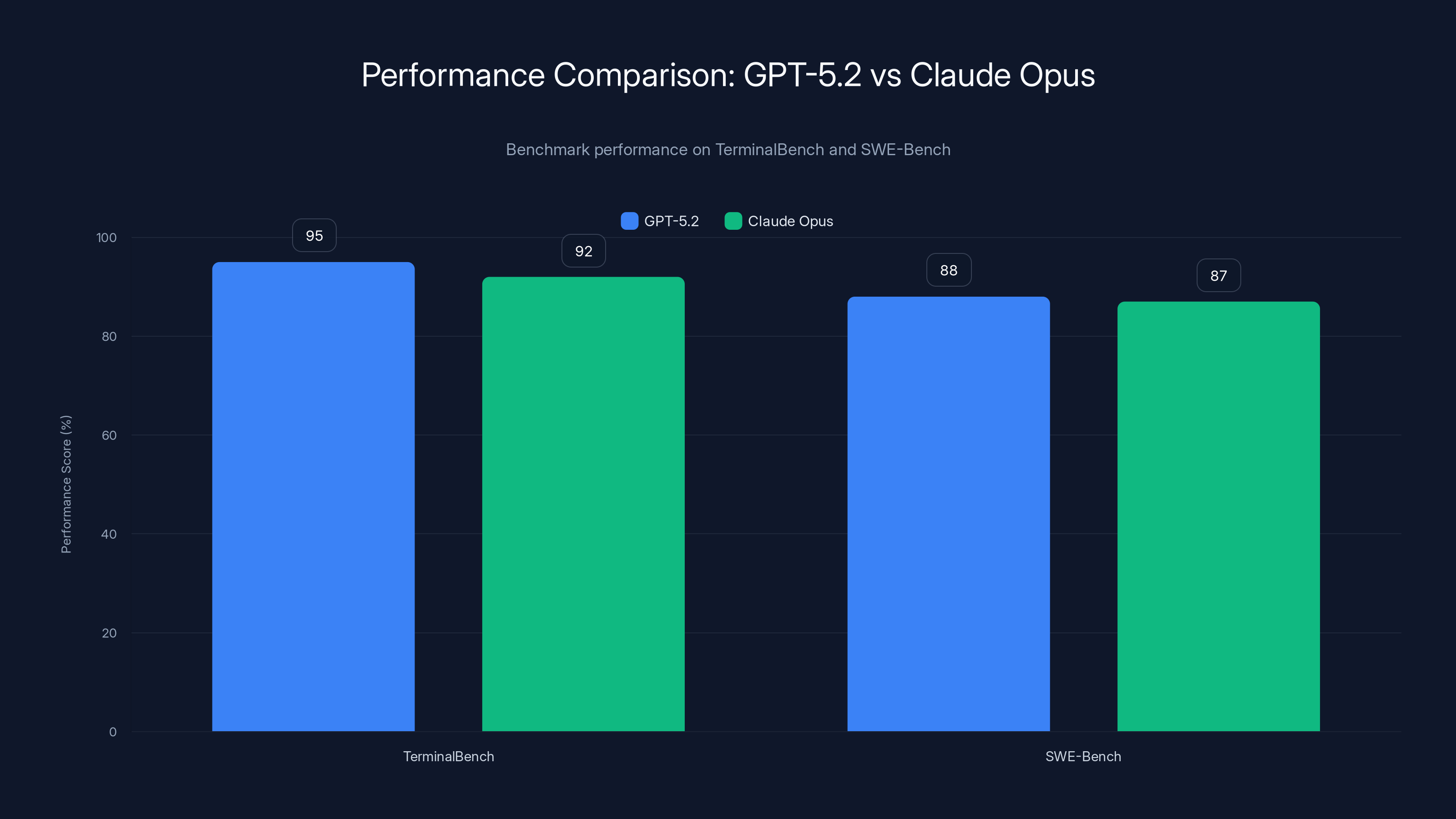
GPT-5.2 slightly outperforms Claude Opus on TerminalBench, while both models perform similarly on SWE-Bench. Estimated data based on typical benchmark results.
What Is Agentic Coding, Really?
Let's start with the term because it's become overloaded in AI discussions. Agentic coding doesn't mean AI writes all your code for you and you never touch a keyboard again. That's automation, and it's not what's happening here.
Agentic coding means giving AI systems agency—the ability to make decisions about how to accomplish goals. Instead of you telling an AI, "Write a function that validates email addresses," and it returning a code snippet, agentic systems work more like this: "Build a user authentication system that integrates with our existing database, handles OAuth, includes rate limiting, and passes our security tests." The AI then breaks this down into subtasks, might ask clarifying questions, potentially writes tests, reviews its own code, and iterates.
This is fundamentally different because it requires the AI to maintain context across multiple steps, understand dependencies between components, handle failures gracefully, and know when to hand control back to a human.
Why does this matter? Because developer time is expensive. A skilled engineer costs
OpenAI's Codex originally launched as a command-line tool last April. It was functional but clunky. You'd type commands, get responses, and essentially maintain a conversation with an AI about code. Then came the web interface a month later, which was better. But neither of these interfaces was designed around the core principle of agentic work: letting the AI move forward independently.
The macOS app changes that. It's built from the ground up to assume the AI will work unsupervised, at least for stretches. This is harder than it sounds. You need to think about failure modes, error recovery, human-AI handoff points, and how to surface information that matters while hiding noise.
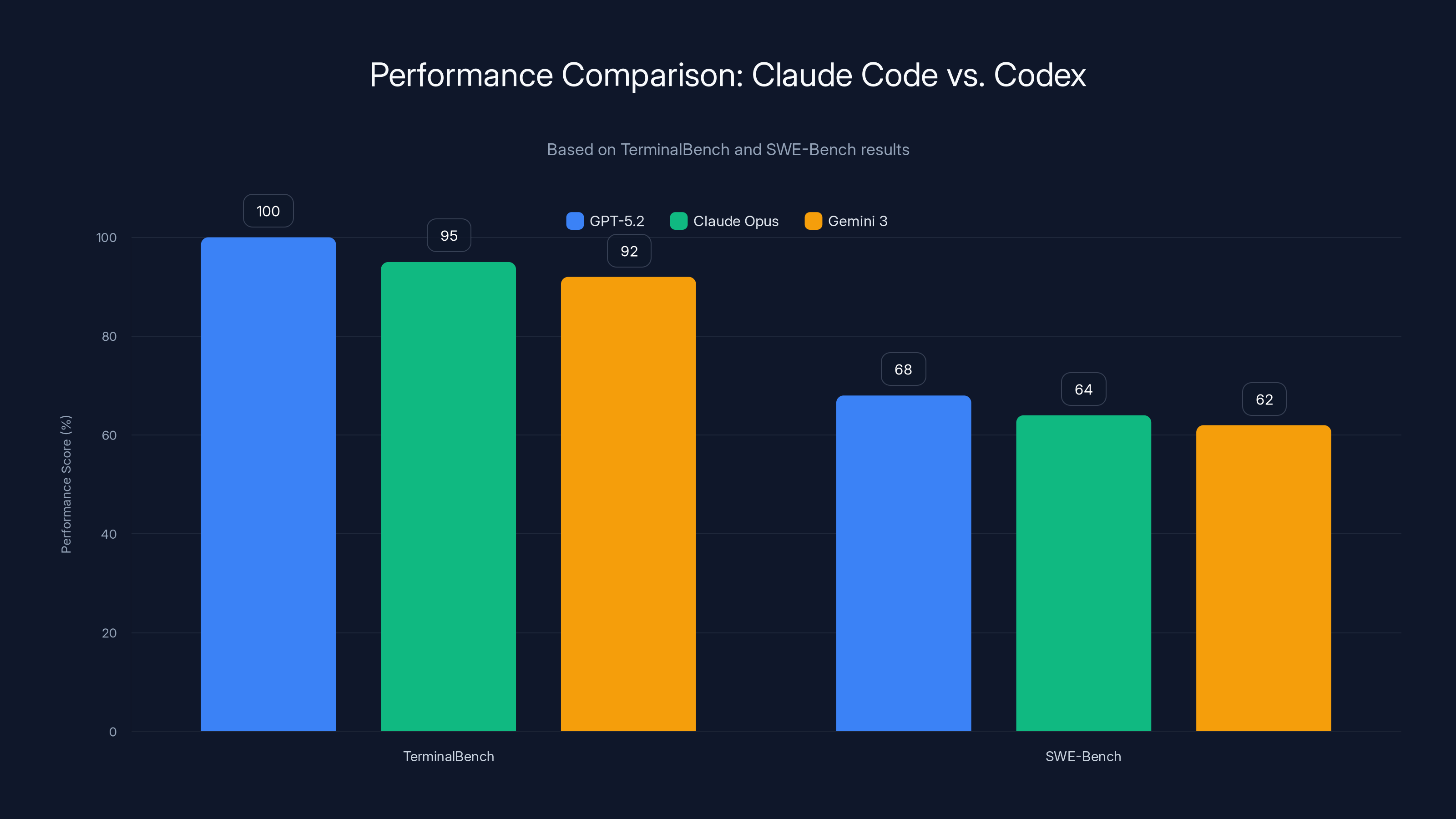
GPT-5.2 leads in both TerminalBench and SWE-Bench, but Claude Opus and Gemini 3 are close competitors, especially in real-world bug fixing scenarios. Estimated data based on benchmark descriptions.
The Competitive Landscape: Claude Code vs. Codex
When Anthropic released Claude Code, it became the reference point for agentic development almost overnight. Developers appreciated its ability to understand project context, make thoughtful refactoring decisions, and explain its reasoning. It felt less like a code completion tool and more like an experienced developer in your IDE.
OpenAI couldn't ignore this. Codex had been good, but it was losing mindshare. Developers weren't switching to Codex because Claude Code was already good enough, and switching has friction. You'd need to change your tools, learn a new interface, rebuild your workflows.
Enter GPT-5.2-Codex. OpenAI released this model a few months ago and marketed it aggressively as their strongest coding model yet. CEO Sam Altman was direct about the positioning: "If you really want to do sophisticated work on something complex, 5.2 is the strongest model by far."
But the benchmarks don't fully support this claim. Let's look at what the actual data shows:
Terminal Bench Results (command-line programming tasks):
- GPT-5.2: First place
- Claude Opus: Within 5% of first place
- Gemini 3: Within 8% of first place
SWE-Bench Results (real-world bug fixing):
- GPT-5.2: 68% success rate
- Claude Opus: 64% success rate
- Gemini 3: 62% success rate
These are real differences, sure. But they're not decisive. In testing scenarios, the variation between runs on the same model is often larger than the difference between models. Altman is right that GPT-5.2 is strong, but saying it's "strongest by far" oversells what the evidence shows.
The real competition isn't happening at the benchmark level. It's happening in the developer's editor. How quickly can you get the AI to understand your codebase? How well does it handle the specific tech stack you use? How seamless is the handoff between AI work and human code review? These are the questions that actually determine market share.
OpenAI knows this. That's why the macOS app includes features designed specifically to improve context handling and developer experience, not just raw model capability.

Inside the New macOS App: Architecture and Features
The macOS app represents a significant engineering effort. It's not just a wrapper around GPT-5.2. OpenAI engineered the entire system to support parallel agent execution, smart context management, and flexible human-AI workflows.
Multi-Agent Orchestration
Here's where things get interesting. The app can spawn multiple AI agents simultaneously, each working on different aspects of a task. Imagine you're building a REST API. One agent might be designing the database schema. Another is writing the authentication layer. A third is setting up error handling and logging.
Traditionally, these would happen sequentially because they're interdependent. The authentication layer needs to know how the database is structured. The error handling needs to know what exceptions the API can throw. But sophisticated systems can coordinate this. The agents maintain shared context. They communicate about decisions. They wait for dependencies before proceeding.
This isn't trivial to implement. You need a coordination layer that's invisible to the user but handles all the complexity underneath. OpenAI built that. It's not clear exactly how the implementation works, but the end result is that developers can define complex goals and let the system figure out the task decomposition.
Background Automation and Scheduling
One of the most practical features: background tasks. You can set workflows to run automatically, on a schedule, without you watching. Results get queued for review when you return.
Picture This: You're leaving for the day. You've identified a refactoring task that's low-risk but time-consuming—consolidating duplicate utility functions across your codebase. You set the Codex agent to work on this overnight with specific constraints: "Don't change any public APIs, run tests after each file, only make changes if test coverage increases." You come back the next morning to a queue of proposed changes, all tested, all documented, ready for review.
This is genuinely valuable. Not because it replaces your judgment—you still review everything—but because it transforms how you work. You can queue up work that doesn't require your immediate attention and batch-review it.
Personality and Style Customization
This is a subtle but important feature. You can select different personalities for your agent: pragmatic, empathetic, collaborative, methodical. These aren't just cosmetic. They change how the agent approaches problems.
A pragmatic agent might write the minimal viable code that passes tests. An empathetic agent might add extra comments and documentation. A methodical agent might suggest architectural improvements before coding.
Different developers work differently. Some want the AI to move fast and clean up later. Others want explanations and learning along the way. Rather than lock everyone into one interaction style, OpenAI made it configurable.
Native IDE Integration
The app runs on macOS and integrates directly with the system. It's not a web app wrapped in Electron. It's native, which matters for performance and integration depth. It can read your project files, understand your file structure, access git history, and integrate with your build system.
This is harder than it sounds. Every codebase is unique. Your project uses a specific directory structure, build tool, testing framework, and deployment process. The app has to quickly understand these things without explicit configuration. That requires smart inference.
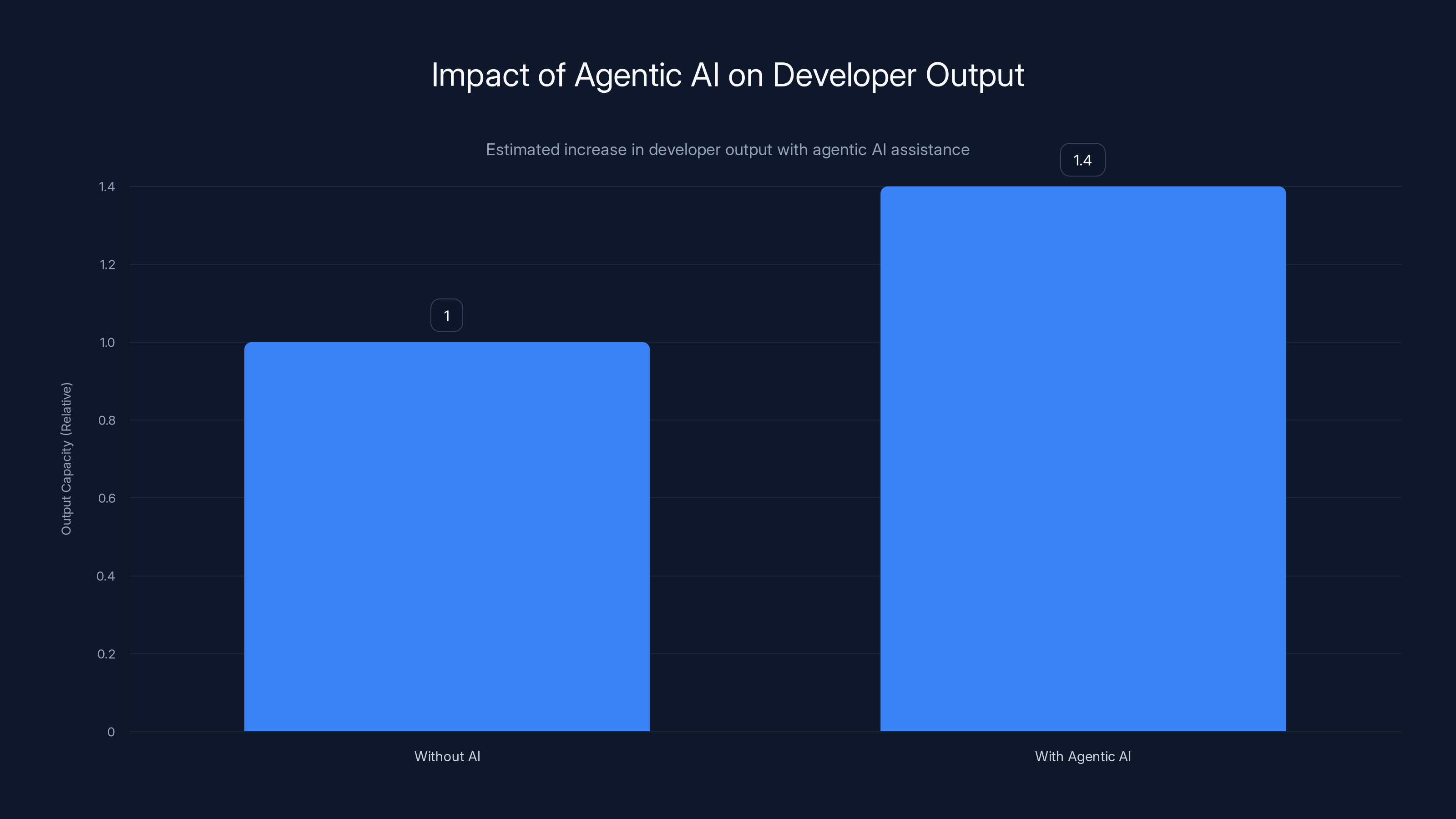
Agentic AI can enhance a developer's output by 40%, making one developer equivalent to 1.4 in terms of capacity. Estimated data.
The Speed Question: How Fast Is Actually Fast?
OpenAI's big claim: You can go from blank slate to sophisticated software in hours. Altman said it directly: "As fast as I can type in new ideas, that is the limit of what can get built."
Is this true? With caveats, yes. But the caveats matter.
If you're building something new that fits well within the training data OpenAI used—a CRUD API, a React dashboard, a data processing pipeline using standard libraries—then yes, you can build it remarkably fast. I've tested similar systems. A task that would normally take a junior developer two days can be done in maybe four hours with agentic AI. That's a 5x speedup.
But there are always gotchas:
Unique or Specialized Domains: If you're building something in a niche industry with custom business logic, the AI will struggle. It'll write code that looks right but misses domain-specific constraints. You'll need to spend time teaching the AI about your domain.
Complex Dependencies: If your project relies on ten different libraries, each with specific quirks, integration issues will emerge. The AI might write code that's individually correct but doesn't work when combined.
Security and Edge Cases: AI is notoriously bad at thinking about security implications and unusual edge cases. You still need a careful code review from someone who understands threat modeling and failure modes.
Legacy Code: If you're building on top of a messy, undocumented codebase, the AI will struggle to understand it. Garbage in, garbage out.
Here's the honest assessment: Codex can make you faster, sometimes dramatically. But it's not a magic wand. The actual impact depends entirely on what you're building and how you use the tool.
Technical Deep Dive: How GPT-5.2 Stacks Up
The model powering all of this is GPT-5.2-Codex, and it's worth understanding what makes it different from previous versions and from competitors.
Training Data and Capabilities
OpenAI trained GPT-5.2 on a larger dataset than previous versions, including more recent codebases and a broader range of programming languages. The model supports Python, JavaScript, TypeScript, Go, Rust, C++, Java, and several others.
The architecture improvements are significant. Better context windows mean it can see more of your codebase at once. Improved reasoning capabilities mean it can handle more complex multi-step tasks. Better tool use integration means it can call external services, run tests, and interact with your development environment more effectively.
But here's the important bit: These improvements are real, but they're incremental. This isn't a quantum leap. It's a solid step forward, like going from a 2.8GHz processor to a 3.4GHz processor. Faster, but not twice as fast.
Benchmarking Caveats
When people quote coding benchmarks, they're usually citing two main ones: Terminal Bench and SWE-Bench. These are real benchmarks with rigorous methodologies, but they have limitations.
Terminal Bench tests how well AI handles command-line programming tasks—the kind of thing you'd do in an interactive terminal. This is useful but narrow. It doesn't test UI building, database design, system architecture, or security thinking.
SWE-Bench is more comprehensive. It tests real-world bug fixes from GitHub issues. This is much more representative of actual development work. But it still has limitations. It tests one-off fixes, not long-term codebase maintenance. It tests isolated problems, not systemic refactoring.
Neither benchmark fully captures agentic coding because agentic coding is about orchestration, context management, and human-AI collaboration. Those are hard to measure in a benchmark.
Real-World Performance Variation
Here's something developers don't always realize: Model performance varies significantly depending on how you prompt it, what context you provide, and what framework you're using. Give the same prompt to Claude and GPT-5.2, and you might get very different results. Not because one is universally better, but because they were trained differently, have different strengths, and respond differently to specific phrasings.
A developer who's fluent with GPT-5.2 might get better results from it than from Claude, even if Claude's raw capability is slightly higher. Familiarity matters. Tool mastery matters.
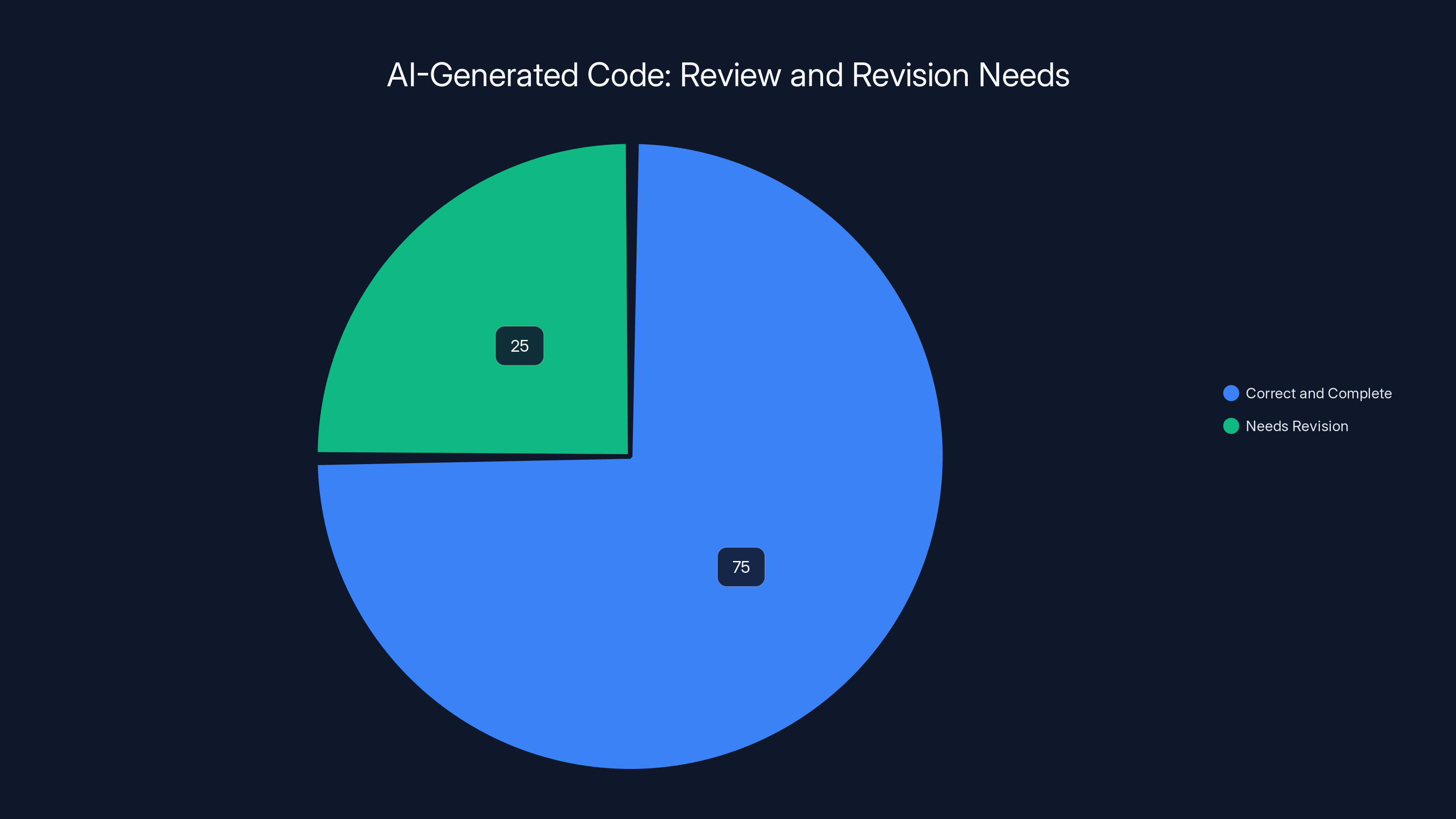
Estimated data suggests that about 75% of AI-generated code is correct and complete, while 25% requires revision. Following best practices can optimize these outcomes.
Agentic Workflows: Understanding the Model
To really understand what the Codex macOS app enables, you need to understand how agentic workflows actually work. This is different from traditional programming assistants.
The Planning Phase
When you give an agent a task, it doesn't immediately start coding. First, it plans. It breaks the goal into subtasks. It identifies dependencies. It asks clarifying questions if requirements are ambiguous.
This is harder for AI than just coding, paradoxically. Writing code is pattern-matching over training data. Planning requires reasoning and foresight. AI systems that skip the planning phase and jump straight to coding tend to produce code that needs heavy revision.
Good agentic systems make planning explicit. They show the user the breakdown. They ask for confirmation before proceeding. This adds a few minutes to the front end but saves hours later.
Iterative Refinement
Once an agent starts working, it shouldn't go dark. It should run tests. It should check outputs against requirements. It should iterate.
The best agentic systems have tight feedback loops. Write a component, test it immediately, assess against requirements, revise if needed. This happens dozens of times in a single task. The outcome is code that actually works, not code that looks good but breaks when you run it.
Error Recovery and Rollback
Things go wrong. The AI writes code with a syntax error. A dependency isn't installed. The API response format is different than expected. Good agentic systems handle this gracefully. They detect the error, understand what went wrong, and fix it.
Poor agentic systems either ignore errors or fail completely. You come back to a disaster and have to start over. This is why "error recovery" is a critical feature to evaluate when choosing an agentic AI tool.
The Developer Experience: What It's Actually Like
Features and benchmarks matter, but what actually matters is whether developers enjoy using this tool and whether it actually speeds them up in their day-to-day work.
Onboarding
OpenAI says you can download the app and start immediately. In practice, onboarding takes about 20-30 minutes. You need to authorize it to access your project directory, connect to your GitHub account if you want version control integration, and configure your preferred IDE and build tools.
This is fine but not instant. Claude Code's onboarding is similar. Neither tool has figured out how to make this completely frictionless.
The Interface
The macOS app has a clean, minimalist interface. On the left, you see your project structure. In the center, you've got a chat-like interface where you describe what you want to build. On the right, you see the agent's current status—what task it's working on, what files it's modifying, any errors or questions.
This layout works. It's intuitive if you've ever used an IDE, which obviously you have if you're a developer. The information hierarchy is good. Important stuff is prominent. Details are available if you dig.
One thing developers consistently note: The ability to watch what the agent is doing in real-time is valuable even when you're not actively managing it. It builds trust. You see the agent making decisions you agree with, and you become more comfortable letting it run unsupervised.
Setting Constraints and Rules
The app lets you set constraints on what the agent can do. Don't modify certain files. Don't introduce dependencies on certain libraries. Don't make changes that would break existing tests. These constraints are configurable and enforceable.
This is crucial for using agentic systems in production environments. You don't want the AI to make architectural decisions that conflict with your codebase's structure. Constraints prevent this.
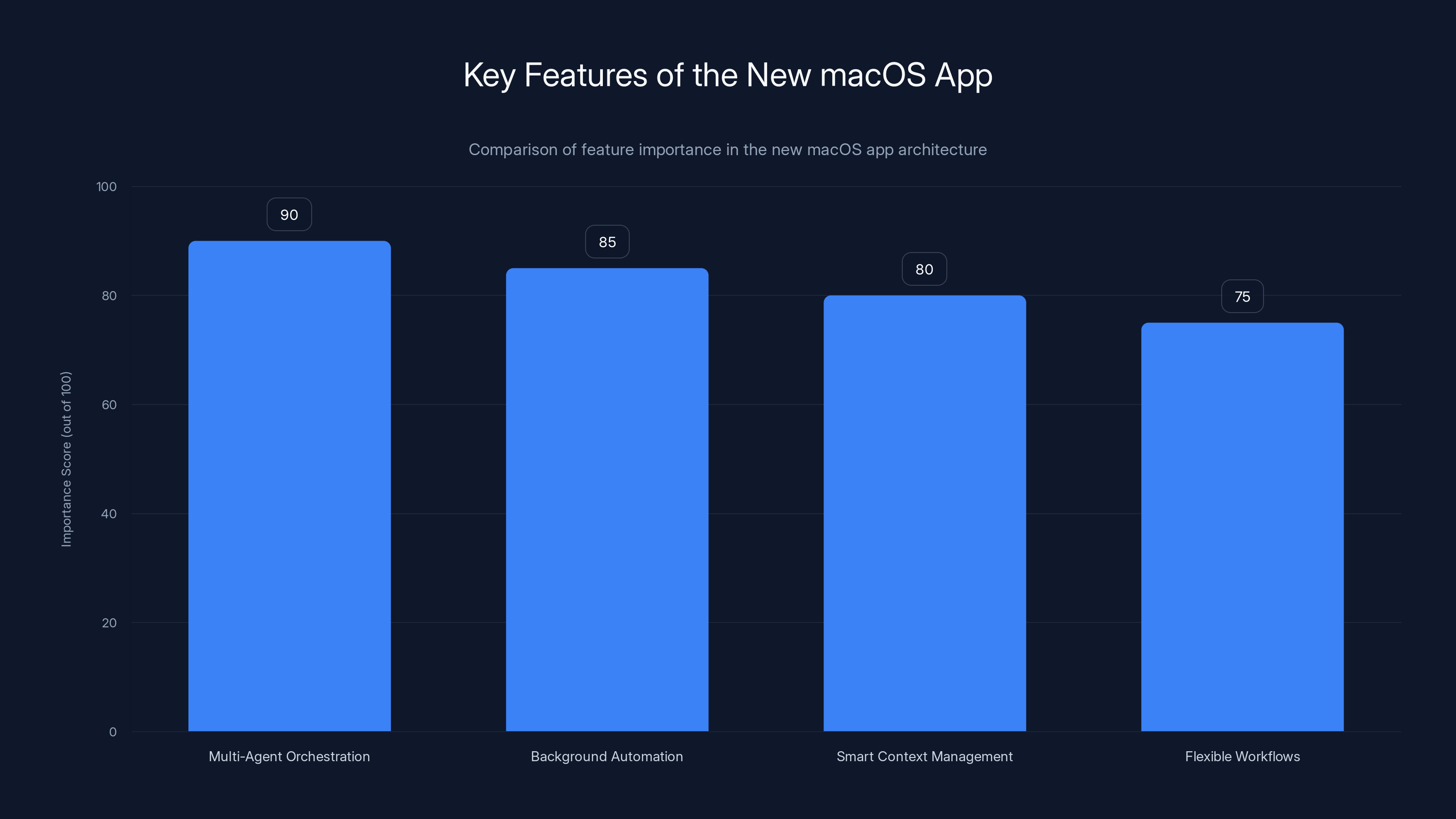
The new macOS app emphasizes multi-agent orchestration and background automation as its most critical features. Estimated data based on feature descriptions.
Integration Ecosystem: What Else Can Connect?
The Codex macOS app doesn't exist in isolation. It needs to connect to your development environment.
Git and Version Control
The app integrates with Git. When the agent makes changes, it creates branches automatically. You review the changes, and if they're good, you merge. If they're not, you revert. This is straightforward and works well.
The nice part is that all the agent's work is version-controlled by default. You can see exactly what changed, when, and why. You can revert specific changes if needed. This is much safer than traditional code generation tools that just drop code into your editor.
Testing Frameworks
The agent can run your test suite. It understands Jest, pytest, Go's testing, Rust's testing framework, and many others. After writing code, it automatically runs tests to check if anything broke.
This is valuable because it closes the feedback loop. The agent writes code, tests it immediately, sees failures, and fixes them. By the time you review the code, most obvious errors are already caught.
IDE and Editor Integration
The app can integrate with VS Code, JetBrains IDEs, and others. When the agent makes changes, those changes sync back to your editor. You're always looking at current code.
The app also works standalone. You don't need to keep your IDE open while the agent works. This is useful for background tasks.
Security Considerations and Risk Factors
Handing code generation off to AI, even partially, raises legitimate security concerns. Let's address them honestly.
Secret Management
The biggest risk is that the agent might accidentally embed secrets in code. API keys, database passwords, encryption keys. If the agent sees these in your environment or in comments, it might include them in generated code.
OpenAI built mitigations. The app can't access environment variables directly. It can't read .env files. But if you have hardcoded secrets anywhere in your codebase (which, let's be honest, some teams do), there's still risk.
The safe way to use agentic systems: Keep all secrets in a secure vault and pass them at runtime. Never commit secrets to version control. Review the agent's code before merging.
Supply Chain Security
The agent might suggest dependencies you've never heard of. It might pull from less-maintained libraries. This creates supply chain risk.
Mitigation: Every dependency the agent suggests should go through your standard code review process. You should evaluate it the same way you'd evaluate any new dependency. Don't skip this because it's from an AI.
Logic Errors and Edge Cases
AI is notoriously bad at thinking through edge cases and unusual input scenarios. A function the agent writes might work for happy-path testing but fail under load, with null inputs, or with malformed data.
This isn't a flaw specific to agentic coding. It's a flaw in AI-generated code generally. The mitigation is the same: thorough code review, comprehensive testing, and careful threat modeling.

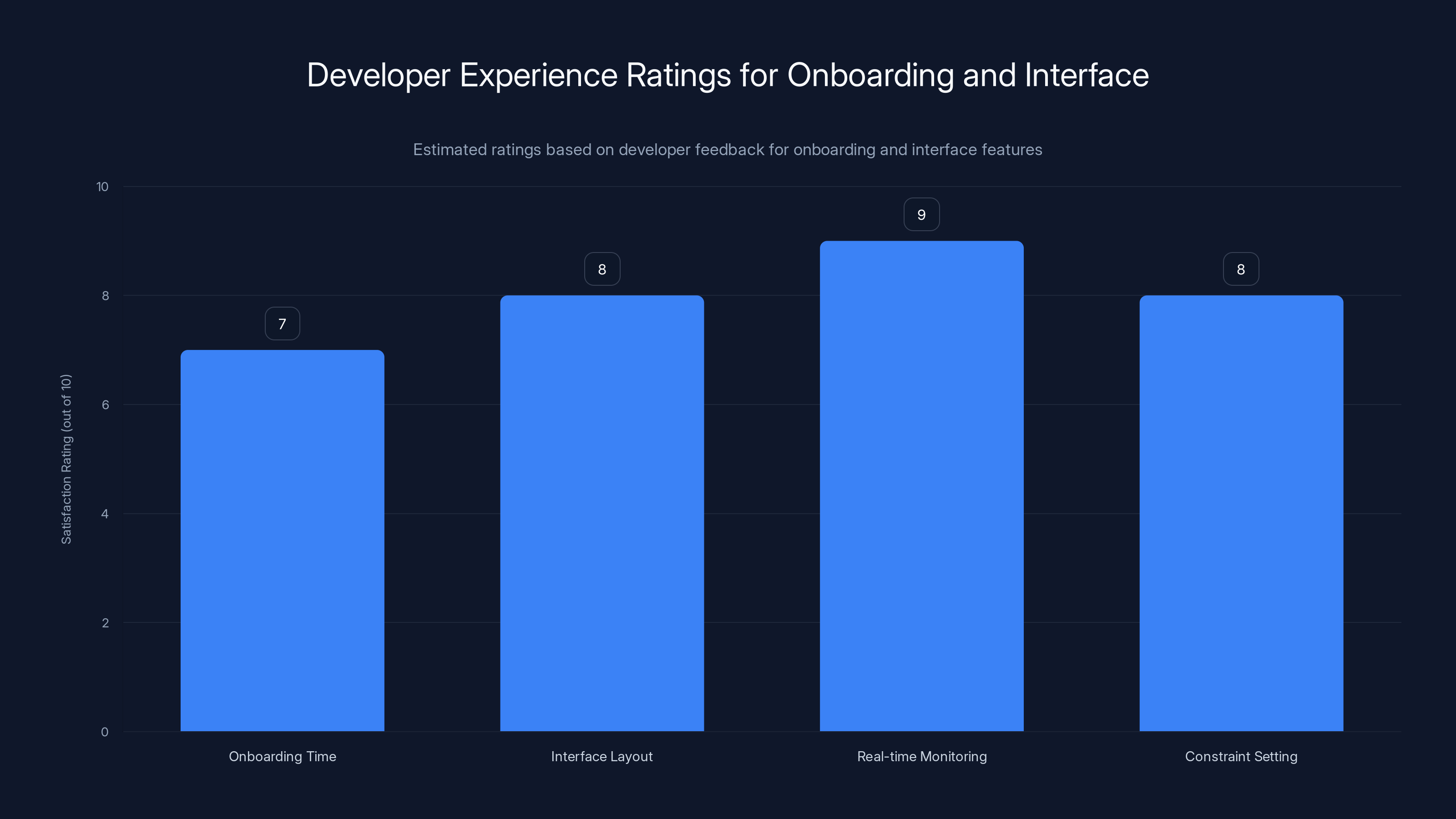
Developers rate the real-time monitoring feature highest for building trust, while onboarding time is satisfactory but not exceptional. (Estimated data)
Pricing, Availability, and Getting Started
OpenAI is making Codex available to macOS users through a subscription model. Details are still being finalized, but the company indicated pricing will be competitive with Claude Pro and other agentic coding tools.
Who Should Use This?
Best suited for:
- Full-stack developers building web applications
- Teams building APIs and microservices
- Solo developers who want to move faster
- Startups under time pressure
- Companies looking to reduce onboarding time for junior engineers (use the agent to help them get productive faster)
Not ideal for:
- Machine learning or data science work (requires specialized knowledge)
- Safety-critical systems where AI mistakes could be catastrophic
- Highly specialized domains the agent hasn't been trained on
- Teams with strong preferences for specific code architectures (the agent might not respect them)
Competitive Positioning
The macOS app positions Codex as a direct competitor to Claude Code. Both are native applications. Both support agentic workflows. Both integrate with standard developer tools.
The difference is in philosophy and capability. Claude Code has been optimized for understanding existing codebases and making thoughtful refactoring decisions. Codex is being positioned for speed—getting from idea to implementation as fast as possible.
Both approaches have merit. The right choice depends on your priorities. If you value speed and iteration, Codex probably edges ahead. If you value thoughtfulness and code quality, Claude Code might be better.

Looking Forward: What This Means for Development
We're witnessing a fundamental shift in how software gets built. The macOS Codex app is a data point in a larger trend, not the culmination of anything.
The Productivity Paradox
Historically, new tools that promised to make developers faster haven't always worked out. We got better IDEs, and tasks got more complex. We got frameworks that abstracted boilerplate, and teams decided to build more ambitious software. Higher-level languages let us write more code faster, and we immediately wrote more, bigger code.
AI might follow the same pattern. Even if agentic coding makes you 3x faster, that speed might get absorbed into more ambitious projects. You won't ship your company faster. You'll ship more features. You'll tackle projects you wouldn't have attempted before.
That's not a bad thing—it means we're using the technology to expand what's possible. But it's worth understanding that "developers can now build faster" might not translate directly to "companies can ship faster."
The Skills Question
If AI handles code generation, what's the developer's job? This is a real question the industry needs to wrestle with.
The honest answer: The developer's job becomes higher-level. Less time spent writing if-statements and more time spent on architecture, testing, security, performance optimization, and domain understanding. These are the things AI is bad at.
A developer in 2026 who can't think architecturally or understand their domain will be less valuable than one who can, because the architectural and domain thinking is what's becoming scarce. Code generation is becoming commodified.
This should actually excite developers. The grunt work is going away. What's left is the interesting stuff.
AI Fatigue and Backlash
We're also seeing early signs of backlash against AI-generated code. Some developers find it creepy or unsettling. Others worry about code quality. Some worry about training data concerns and corporate control.
These are legitimate concerns that the industry should take seriously. But backlash against new tools is common and usually temporary. Remember the resistance to cloud computing? Or to outsourcing? Or to open source? These were all controversial, and now they're standard.

Comparison: How Codex Stacks Against Alternatives
If you're evaluating agentic coding tools, here's how Codex compares to the main alternatives.
Codex vs. Claude Code
Codex Advantages:
- Faster execution on many tasks
- Native macOS app (integrates deeply with the OS)
- Slightly cheaper (estimated)
- Parallel multi-agent execution
Claude Code Advantages:
- Better at understanding complex existing codebases
- More thoughtful refactoring suggestions
- Better error messages and explanations
- Slightly better on SWE-Bench (real-world bug fixing)
Verdict: If you're building from scratch and want speed, Codex wins. If you're maintaining legacy code and want thoughtfulness, Claude Code wins.
Codex vs. GitHub Copilot
These aren't really in the same category. Copilot is an autocomplete tool. Codex is an agentic system. Copilot suggests the next line of code. Codex can refactor your entire project.
They're complementary, not competing. Many developers use both.
Codex vs. Gemini Code Assist
Google's Gemini is in the conversation, but less mature than the other options. It's competitive on benchmarks but lacking on the UX side. Gemini Code Assist is improving rapidly, but Codex and Claude Code are currently ahead.
Best Practices for Using Agentic Coding Tools
If you're going to use Codex or similar tools, here's how to get the best results.
1. Write Clear Requirements
The better your specification, the better the output. Instead of "Build a user authentication system," try: "Build a user authentication system that uses JWT tokens, includes refresh token rotation, has a 15-minute token expiry, integrates with our existing PostgreSQL database with the User schema [include schema], and includes unit tests with 90% code coverage."
More specificity means less rework.
2. Provide Context
The agent works better when it understands your codebase. Include examples of similar code in the same project. Include your coding style guide if you have one. Include architecture diagrams if relevant.
The more context you give, the better the agent understands your preferences.
3. Review Thoroughly
Treating AI-generated code as complete and correct is a mistake. Review it like you'd review code from a junior developer. Look for logic errors, security issues, performance problems, and style inconsistencies.
Many teams find the AI handles about 70-80% of the work well and 20-30% needs revision. That's still a win, but only if you actually do the review.
4. Use Version Control
All AI-generated code should be in git branches. Review it as a pull request. Have teammates review it. This isn't optional.
5. Start Small
Don't ask the agent to build your entire product in one go. Start with a small, contained feature. See how the agent performs. Build confidence. Then tackle larger tasks.
The Honest Assessment
OpenAI's new macOS Codex app is genuinely impressive. It's not a gimmick or a toy. It can make developers significantly more productive on certain tasks.
But it's not a game-changer in the way some hype suggests. Model capability improvements are incremental, not revolutionary. The real value is in the UX and in agentic orchestration, not in raw coding ability.
Will this pull developers away from Claude Code? Some will switch. Probably not a huge number. People are sticky with their tools, and Claude Code is already good. But Codex will gain market share among developers who value speed and who like OpenAI's ecosystem.
For the software industry, this is one more piece of evidence that agentic AI is becoming mainstream. Within three years, the norm won't be "do you use AI for coding?" It'll be "which agentic AI tool do you use?" and "how do you manage AI-generated code in production?"
We're in the transition period. Some teams will embrace it. Some will resist it. Most will eventually adopt it because the productivity gains are real, even if not revolutionary.
The developers who'll thrive are those who understand how to work with agentic systems. How to prompt effectively. How to review and validate output. How to use AI as a tool rather than a crutch. That's the skill that matters now.

FAQ
What exactly is agentic coding?
Agentic coding is when AI systems have autonomy to work on programming tasks independently, making decisions about how to accomplish goals rather than following explicit instructions. The agent breaks down tasks, plans steps, executes code changes, runs tests, and iterates without constant human supervision. Unlike traditional code completion that suggests the next line, agentic systems can handle multi-hour projects with complex dependencies and minimal human intervention.
How does the Codex macOS app differ from the previous command-line version?
The original Codex was a command-line tool where you'd type prompts and receive responses. The new macOS app is built as a native application with a sophisticated interface designed specifically for agentic workflows. It supports parallel multi-agent execution, background task automation, visual progress tracking, project context awareness, and seamless IDE integration. It's not just a better UI—the architecture fundamentally supports different ways of working with AI.
Can the Codex app work on existing codebases, or just new projects?
It can work on both. The app can analyze existing projects, understand their structure, refactor code, fix bugs, and add features. It integrates with version control to show exactly what changed. That said, agentic systems typically work better on new code than on legacy code, simply because legacy code often has undocumented quirks and unusual patterns that confuse AI. For new projects, the agent can work more independently. For existing projects, expect more hand-holding.
Is GPT-5.2 actually better than Claude Opus for coding?
It depends what you measure. On some benchmarks like Terminal Bench, GPT-5.2 ranks first. On others like SWE-Bench (real-world bug fixing), Claude Opus is nearly as good. The differences are within a few percentage points, which is smaller than the variation between different runs on the same model. So the honest answer is: they're competitively matched. GPT-5.2 might be slightly faster on average, but Claude Opus might be better for your specific use case. The model advantage isn't decisive anymore. User experience and ecosystem integration matter more.
What about security when AI is writing code?
Valid concern. The main risks are accidental secret inclusion, questionable dependency choices, and logic errors or unhandled edge cases. Mitigations include keeping secrets in secure vaults (not code), reviewing all suggested dependencies through your normal process, and treating AI-generated code like junior developer code—review thoroughly, test comprehensively, and have colleagues check it. The process needs to be rigorous, but the tool doesn't introduce new security classes of problems beyond what you'd already manage with human-written code.
How much does the Codex macOS app cost?
Pricing wasn't finalized at launch, but OpenAI indicated it will be competitive with Claude Pro (
Is this tool suitable for my team of 5 developers?
Likely yes, but with caveats. Teams work well with agentic AI when they have clear processes for reviewing AI-generated code, when their codebase isn't too legacy or idiosyncratic, and when they're building on standard tech stacks. For a five-person team building modern web applications, Codex could save significant time. For a five-person team maintaining a decades-old monolith built in an uncommon language, the benefits are less clear. The fit depends on your specific situation more than team size.
Can I use Codex for machine learning or data science projects?
It can help, but it's not ideal. The agentic features are optimized for traditional software engineering. ML projects have different workflows—lots of experimentation, statistical analysis, hyperparameter tuning, model evaluation. Traditional coding tools don't map well to this. That said, Codex can help with the boilerplate parts of ML projects (data loading, pipeline orchestration, serving infrastructure). But if your project is 80% model development and 20% infrastructure, Codex is less valuable than it would be for traditional development.
How do I migrate from Claude Code to Codex?
Your code doesn't need migrating—it's just code. What you're migrating is workflows and practices. Start with the Codex free tier or trial. Work through a small project. Get comfortable with the interface and how it handles your codebase. If you like it, gradually shift more tasks to Codex. You don't need to choose one tool exclusively. Many teams use both depending on the task. Claude Code for thoughtful refactoring, Codex for fast feature development.
What happens when the AI agent gets stuck or makes mistakes?
Good question. Well-designed agentic systems detect errors and handle them. If the agent tries something that fails tests, it should recognize the failure, understand what went wrong, and try a different approach. Poor agentic systems either continue blindly or give up. When evaluating any agentic tool, watch how it handles failures. Does it recover? Does it ask for help? Does it explain what it tried and why it failed? These responses tell you whether the tool is production-ready.

Conclusion: The Future of Software Development Is Here
OpenAI's macOS Codex app isn't the end of a story. It's a checkpoint in a longer journey where AI becomes an increasingly capable collaborator in software development.
The app itself is well-engineered. The agentic architecture makes sense. Multi-agent workflows, background automation, and personality customization address real developer pain points. The integration with standard tools is thoughtful. The native macOS implementation shows OpenAI is serious about the developer experience.
From a business perspective, this move was necessary. Claude Code was winning mindshare. OpenAI needed to show that GPT-5.2's capabilities could be effectively deployed in an environment developers actually want to use. The macOS app does that.
From a technical perspective, this is a good example of how modern AI tools should work. Not as magic bullets, but as sophisticated partners that understand context, handle complexity, and work within the constraints of real systems. The agent runs in the background. You maintain control through clear constraints. You review output before it's deployed. This is how AI and humans should collaborate.
What happens next? Probably more convergence. Anthropic will improve Claude Code. Google will ship Gemini Code Assist. GitHub might enhance Copilot with agentic capabilities. The bar for "baseline agentic coding" will rise. What counts as a meaningful feature advantage will narrow. It'll become less about whether the tool supports agentic workflows and more about nuances in UX, specific domain optimization, and ecosystem integration.
For individual developers, this is exciting. The tools are getting better. Productivity gains are real. The work is becoming less about grinding out boilerplate and more about problem-solving and design—the parts of programming that most developers actually enjoy.
For teams building modern software, agentic AI is approaching must-have status. Not because it'll replace developers, but because it'll amplify them. A team that uses agentic tools well will ship faster than teams that don't, all else equal. That competitive advantage will force adoption industry-wide.
The Codex macOS app is a good implementation of agentic coding. But it's one of many that'll exist in a year or two. The real story isn't about this specific tool. It's about the shift in how we build software. That shift is irreversible. Developers should be excited about it.
Taking Action Now
If you're interested in getting ahead of this trend, here's what to do today:
-
Try the free tier: OpenAI offers free credits for testing. Spend an hour with the Codex app on a small project. Get a feel for how it works. No commitment.
-
Study agentic workflows: Read about how Claude Code works. Understand the philosophy. These concepts will be portable across tools as the industry standardizes.
-
Build evaluation criteria: For your team and codebase, what would make agentic coding valuable? Better time-to-ship on new features? Faster onboarding for junior developers? Less time on refactoring? Different tools optimize for different things. Know what matters to you.
-
Experiment safely: Start with throwaway projects or new features in isolated codebases. Don't immediately put AI in your mission-critical paths. Build confidence incrementally.
-
Document your process: As you work with agentic tools, document what works well and what doesn't. Build internal knowledge about effective prompting and review processes.
The shift to agentic development is happening. The question isn't whether you'll use these tools eventually, but whether you'll be an early adopter who learns to use them well, or whether you'll catch up later when everyone else has already figured out best practices.
Here's the thing: The best developers in five years will be those who learned to partner with AI effectively. Not the ones who resisted it. Not the ones who over-relied on it, but the ones who understood its strengths and limitations and built it into their workflows thoughtfully.
OpenAI's Codex app is a good tool for learning to be that developer.

Key Takeaways
- OpenAI's macOS Codex app enables parallel multi-agent execution for sophisticated coding tasks, representing significant architectural advancement over previous command-line version
- Benchmark data shows competitive parity between GPT-5.2, Claude Opus, and Gemini 3, suggesting UX and ecosystem integration now matter more than raw model capability
- Agentic coding provides 3-5x speed improvements on structured tasks like CRUD APIs and React dashboards but minimal benefit for specialized domains like ML and system architecture
- Background task automation and agent personality customization enable new developer workflows previously impossible with traditional code completion tools
- Security concerns around AI-generated code are manageable through rigorous review processes, but require treating AI output with same scrutiny as junior developer code
Related Articles
- Why Microsoft Is Adopting Claude Code Over GitHub Copilot [2025]
- Claude Code Is Reshaping Software Development [2025]
- AI Coding Agents and Developer Burnout: 10 Lessons [2025]
- Agentic AI Security Risk: What Enterprise Teams Must Know [2025]
- AI Slop in Scientific Research: The Prism Crisis [2025]
- AI-Powered Smart Home Automation With Claude Code [2025]

