![TikTok's First Weekend Meltdown: What Actually Happened [2025]](https://tryrunable.com/blog/tiktok-s-first-weekend-meltdown-what-actually-happened-2025/image-1-1769424134597.jpg)
Introduction: When a Platform Collapses on Day One
Imagine launching the biggest software migration of your career and watching everything catch fire before Sunday breakfast. That's essentially what happened to TikTok the weekend it transferred to new US ownership. The app didn't just have hiccups—it had a full system meltdown.
Videos weren't uploading. The algorithm that's made TikTok famous got completely reset, serving users generic content instead of personalized feeds. Comments wouldn't load. The For You Page—the beating heart of TikTok's engagement—turned into a ghost town of placeholder videos. For a platform with over 170 million US users, this wasn't a minor bug. This was a catastrophic failure at exactly the wrong moment.
What makes this story wild is the timing and the speculation that followed. The outages happened right as Minneapolis faced major ICE activity over the weekend. Error messages that felt deliberately vague. Accounts suddenly unable to post political content. Of course, people wondered if censorship had arrived. But here's what's actually interesting: the technical reality is probably messier, dumber, and more instructive than any conspiracy.
This article breaks down what went wrong, why it likely happened, what it tells us about massive platform migrations, and what the future might hold for TikTok under new management. If you work with large systems, content distribution, or real-time platforms, this story has lessons embedded in every failure point.
TL; DR
- TikTok suffered widespread outages the weekend after US ownership transfer, affecting video uploads, algorithm feeds, and comment loading globally. According to The Verge, these issues were widespread and significant.
- The timing sparked conspiracy theories about censorship given concurrent political events, but technical evidence points to migration-related backend failures instead. As noted in The Verge's review, the timing coincided with political events, fueling speculation.
- Video processing pipelines failed completely, with uploads stuck in "under review" limbo for 6+ hours without progression.
- The For You Page algorithm reset itself, serving generic content instead of personalized recommendations that drive engagement.
- Some regions were affected more than others, suggesting infrastructure inconsistencies or incomplete migration across data centers.
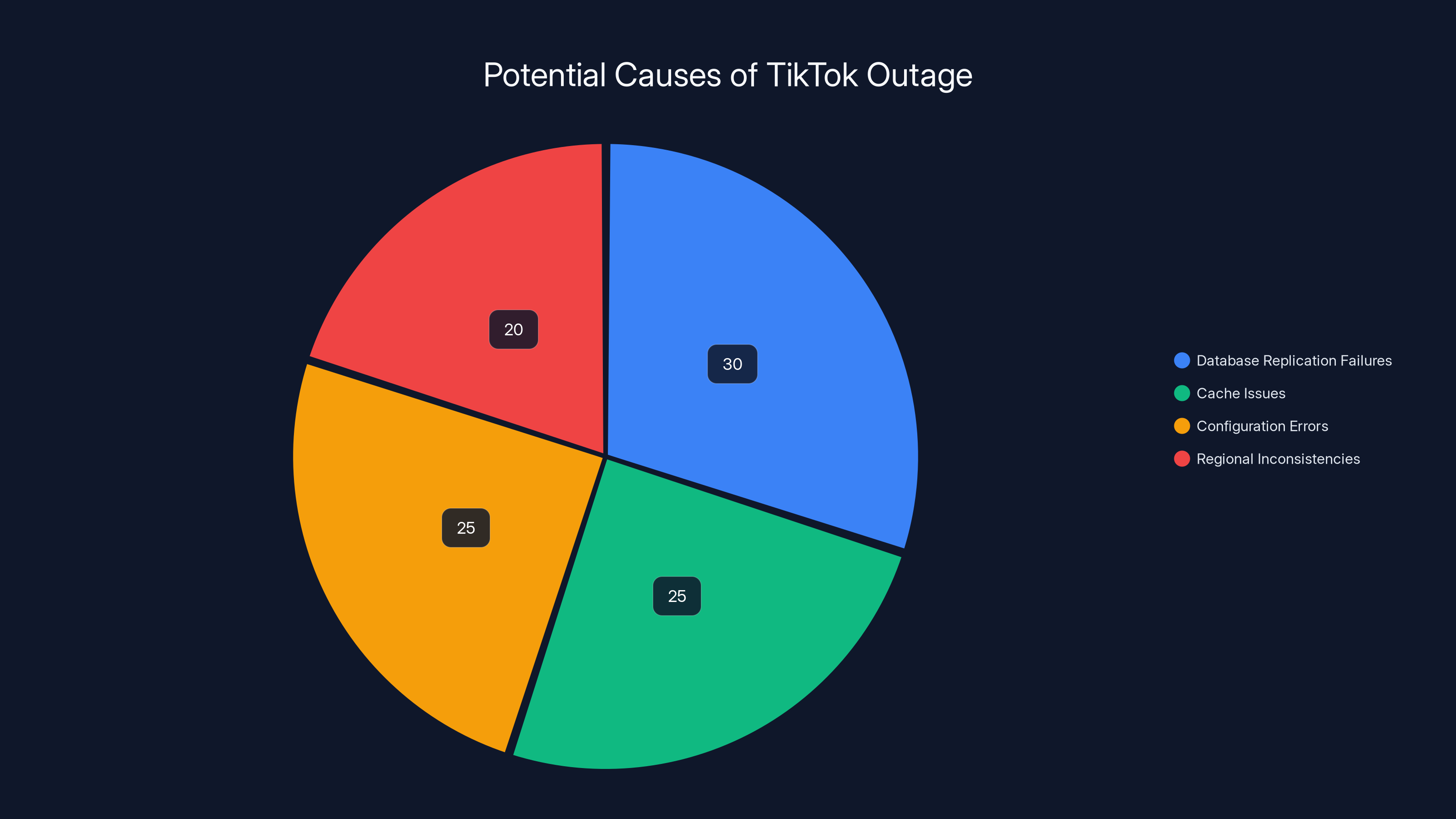
Estimated data suggests database replication failures were the largest contributor to TikTok's outage, followed by cache and configuration issues. Regional inconsistencies also played a role.
What Actually Broke: A System-by-System Breakdown
Let's get specific about what stopped working. This isn't vague "the app was slow" territory. This is core functionality grinding to a halt.
The Video Upload Crisis
TikTok's video upload system involves several critical steps: client-side encoding, transmission to regional servers, transcoding into multiple formats, AI-powered content review, and then distribution to the For You Page algorithm. When users reported videos stuck "under review," that's usually step four.
But here's the problem: videos weren't just delayed in review. They were completely stalled. One Verge writer had a video that wouldn't publish for six hours straight. No error message telling them to try again. No progress indicator. Just... nothing. This suggests the review pipeline—likely an automated system checking for policy violations using machine learning models—either crashed or got disconnected from the upload queues.
When one component in this chain breaks, everything backs up. Think of it like a traffic jam where the exit ramp is closed. Cars keep arriving, but they can't go anywhere. At scale, you get thousands of videos piling up in a queue with nowhere to go.
The Algorithm Blackout
TikTok's For You Page is a machine learning algorithm that's constantly learning from billions of user interactions. It's absurdly complex. But when it works, it's why people scroll for hours instead of minutes.
Then it broke. Completely.
Users reported getting completely depersonalized feeds filled with generic, low-engagement content. Your normal algorithmic recommendations—the videos specifically designed for your viewing patterns—disappeared. Instead: random stuff that probably isn't relevant to you at all.
This isn't just a bad user experience. This is a revenue problem. TikTok's ad targeting uses the same recommendation system. Generic feeds mean generic ad placement, which means worse CPM rates for advertisers. Every hour of broken recommendations is money walking out the door.
The algorithm likely reset because of one of three reasons: a database corruption during the migration, a configuration file error during deployment, or a complete cache miss where the model weights didn't load. Any of these would cause the fallback behavior we saw: serve whatever's newest instead of whatever's most relevant.
Comments Failing to Load
Comments seem simple compared to video uploads and the recommendation algorithm. They're just text. But they're not simple at all.
When users couldn't load comments, that suggests a few possibilities: the comment database was unreachable, the caching layer (likely Redis or Memcached) was empty or failing, or the API endpoints serving comments were down. Since some users could load comments while others couldn't, this points to regional or zone-specific failures.
Comments are crucial for engagement metrics. TikTok uses comment velocity (how many comments per minute) to help decide which videos trend. No comments loading means no trending algorithm working either. The platform was becoming increasingly broken in cascading ways.
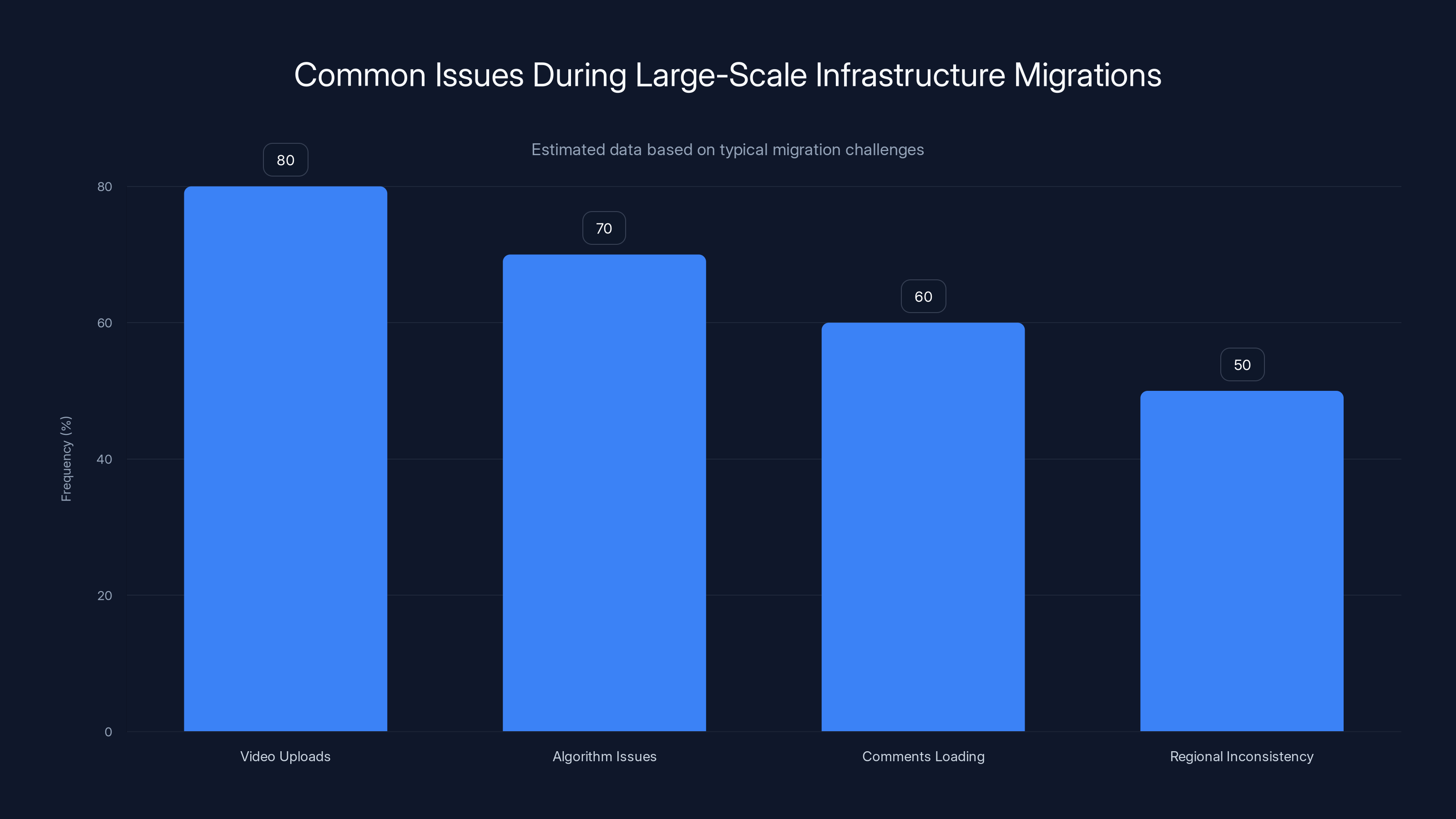
Estimated data shows video uploads and algorithm issues are the most frequent problems during large-scale migrations, affecting up to 80% and 70% of operations respectively.
The Timing Problem: Why Everyone Suspected Censorship
Here's why people freaked out. It wasn't paranoia—it was reasonable inference based on incomplete information.
The Political Context
The outages happened during a significant moment in Minneapolis: federal ICE agents killed a second person in local protests, Alex Pretti. Politically active accounts on TikTok were trying to document and share what was happening. Then their videos wouldn't upload. The algorithm that usually amplifies politically relevant content suddenly vanished. Error messages were vague.
Connect those dots and you get: censorship. That's not crazy. That's how you'd interpret the situation if you didn't know about backend migrations.
The Error Message Ambiguity
TikTok's error messages when uploads failed weren't helpful. They didn't say "Our servers are experiencing issues, please try again in 5 minutes." They didn't offer any explanation. The vagueness made people assume the worst. In a platform constantly dealing with moderation drama, vague errors feel like intentional obstruction.
Geographic Inconsistency
Here's the weird part: not everyone was affected equally. Some British Verge writers had no issues at all. Some US users couldn't upload anything. Some users experienced partial failures. This geographic patchiness actually argues against intentional censorship (which would usually be comprehensive) and toward technical failure (which is often messy and regional).
If someone wanted to censor TikTok in the US, they'd probably block the US cleanly. They wouldn't half-work it and leave some users unaffected while others got completely locked out. The messiness here is very consistent with a migration gone wrong.

What Likely Actually Happened: The Technical Explanation
Let's talk about what probably actually broke things. A US ownership transfer of TikTok is one of the most complex software migrations ever attempted. It's not just moving a company—it's potentially moving infrastructure while keeping billions of active users connected.
The Infrastructure Migration Nightmare
When a platform transfers ownership, especially with government/regulatory pressure, the physical infrastructure sometimes needs to move too. TikTok probably needed to migrate data from ByteDance-controlled servers to new US-controlled infrastructure. That's not a weekend task. That's a months-long operation with hundreds of engineers involved.
But if they tried to do it while keeping the platform live, you get a classic situation: old systems and new systems trying to talk to each other, database replication getting out of sync, caches not warming up properly on new hardware, and load balancers sending traffic to servers that don't have the right data.
This exact scenario explains everything we saw:
- Video uploads stalling: Upload handlers connected to old database, transcoding farm connected to new one, handoff failed
- Algorithm breaking: ML model cache didn't warm up on new infrastructure, system fell back to default behavior
- Comments not loading: Database connection pools exhausted due to migration traffic overhead
- Regional inconsistency: Some data centers completed migration, others didn't
Configuration Errors During Deployment
Or maybe simpler: someone deployed wrong configuration values during the migration. A single typo in an environment variable can take down entire systems. Set your database connection pool to 0 by accident and suddenly nothing can talk to the database. Mess up a feature flag and your video processing turns off for 30% of traffic.
Large-scale migrations involve thousands of configuration changes. Even with automated testing, something always slips through. Usually, it's caught in staging. Sometimes it slips to production.
Load Balancer Misconfiguration
Load balancers are the traffic cops of large platforms. They decide which server gets which request. Misconfigure a load balancer and you get exactly what we saw: some users completely blocked, others fine, some partially working.
If a load balancer pointed traffic to servers that hadn't finished migrating yet, those requests would fail. Meanwhile, requests going to already-migrated servers would work fine. This creates the exact patchwork of failures reported.

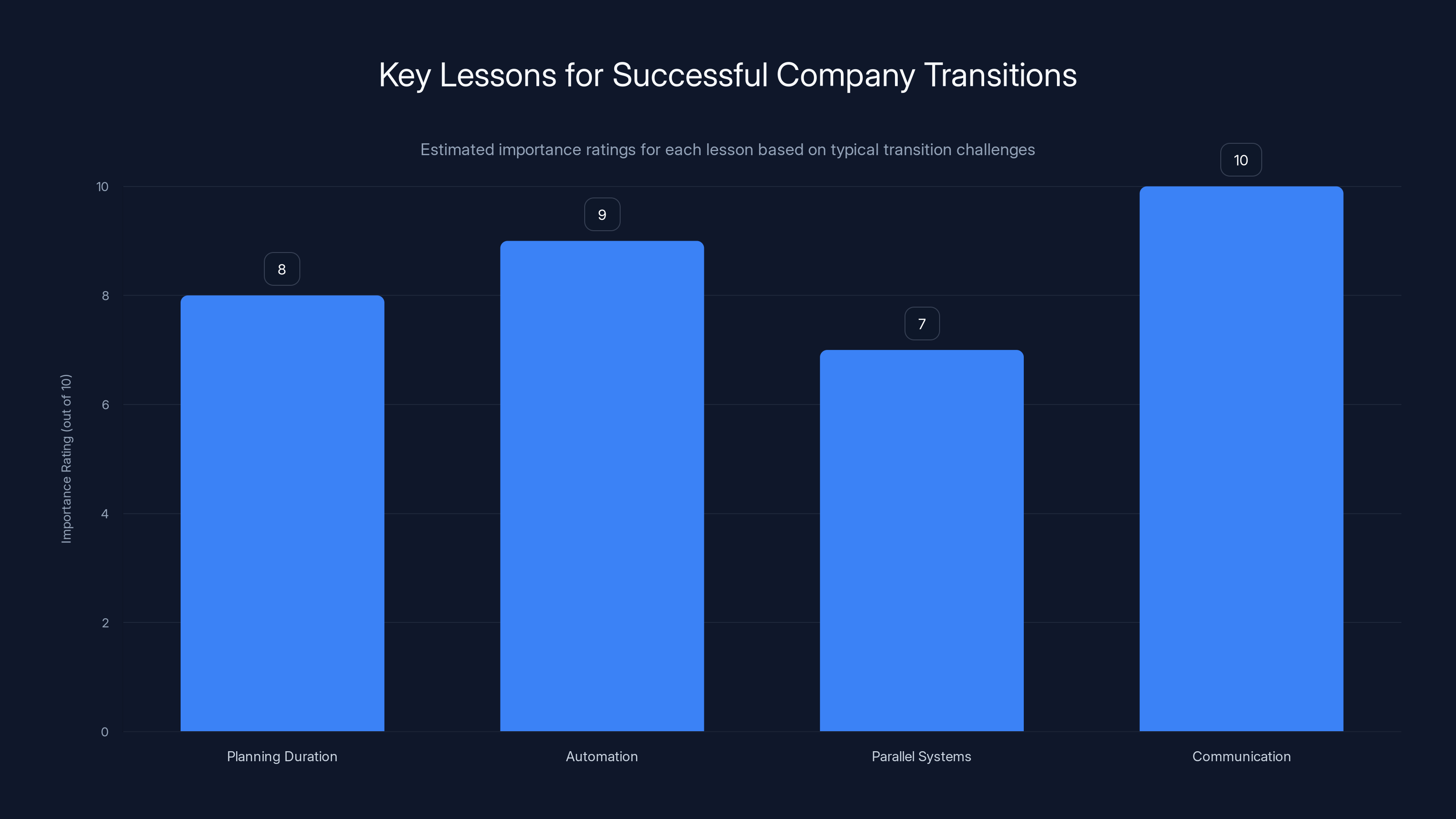
Communication is rated as the most crucial lesson for companies undergoing transitions, followed closely by automation and planning duration. Estimated data.
Why Platform Migrations Are Ridiculously Dangerous
If you've never been part of a major system migration, let me explain why TikTok's meltdown isn't surprising—it's almost inevitable.
The Scale Problem
TikTok isn't a normal app. The numbers are absurd. Imagine every single second, millions of users are doing something on TikTok simultaneously:
- 170+ million daily active users in the US alone
- Roughly 50 million videos uploaded per day globally
- Each video needs multiple format versions: low quality for slow connections, high quality for Wi-Fi, vertical for phones, 16:9 for websites
- Comments, likes, and shares happening constantly across all this content
- The algorithm running continuously, analyzing engagement patterns in real-time
Migrating this while keeping it running is like replacing an airplane's engines mid-flight. There's nowhere safe to land. The system can't go down.
Here's what makes it even worse: TikTok's backend probably consists of thousands of services. The video upload service, the transcoding service, the moderation service, the recommendation service, the social graph service, the notification service, the monetization service. Each one has databases, caches, load balancers, and monitoring systems.
Migrating all of this together while keeping them perfectly synchronized is... well, it's basically impossible. Something will get out of sync. Something will drop. And when it does, the failures cascade.
The Stateful System Problem
Simple services are easy to migrate. Take your "hello world" REST API, move it to a new server, done. But TikTok's services are deeply stateful. They maintain in-memory caches, persistent connections, distributed locks, and transactional state across multiple databases.
When you migrate stateful systems, you don't just copy data. You need to:
- Quiesce (stop accepting new requests)
- Drain in-flight requests
- Copy the full state
- Warm up caches
- Verify consistency
- Redirect traffic
- Monitor for issues
If you skip any of these steps, you get inconsistencies. Users might see old data on one request and new data on the next. Videos might exist in some databases but not others. The cache on the new servers might be empty, causing database overload as it re-learns what's popular.
The Testing Impossibility Problem
Here's the philosophical problem with migrations: you can't actually test them fully. You can test on staging servers with synthetic load, but real traffic is different. Real traffic is chaotic. Real users will try to do things in exactly the combination that breaks your assumptions.
So even with the best testing, migrations to production are always kind of a roll of the dice. This is why companies do them at off-peak times and keep massive rollback plans ready. But TikTok couldn't choose an off-peak time where millions of users wouldn't be affected. The app never truly sleeps.

The Regulatory Pressure Factor
TikTok's situation is unique because of regulatory pressure. This wasn't a normal company choosing when to migrate. There were deadlines, legal requirements, and political pressure involved.
Why This Matters for Migration Quality
When you're under regulatory pressure to move fast, you sometimes have to choose between perfect and done. TikTok probably had a hard deadline. If they missed it, there were legal and political consequences. This might have meant:
- Skipping some validation steps
- Migrating faster than prudent
- Running old and new systems in parallel with less verification time
- Not having time for proper load testing at scale
This doesn't mean TikTok's engineers are incompetent. Even the best teams make mistakes when under external pressure. A team with unlimited time might have caught these issues in staging. Under a deadline, things slip.
The Political Dimension
Here's something people don't talk about: political and regulatory pressure actually makes systems less secure and less reliable. When regulators demand "move to US infrastructure" quickly, you can't do it perfectly. You just do it fast.
This is why the conspiracy theories about intentional censorship probably miss the mark. The actual problem is worse in a way: an important service broke because of regulatory pressure forcing faster-than-safe migration. That's not conspiracy. That's bureaucratic dysfunction creating real problems for real users.

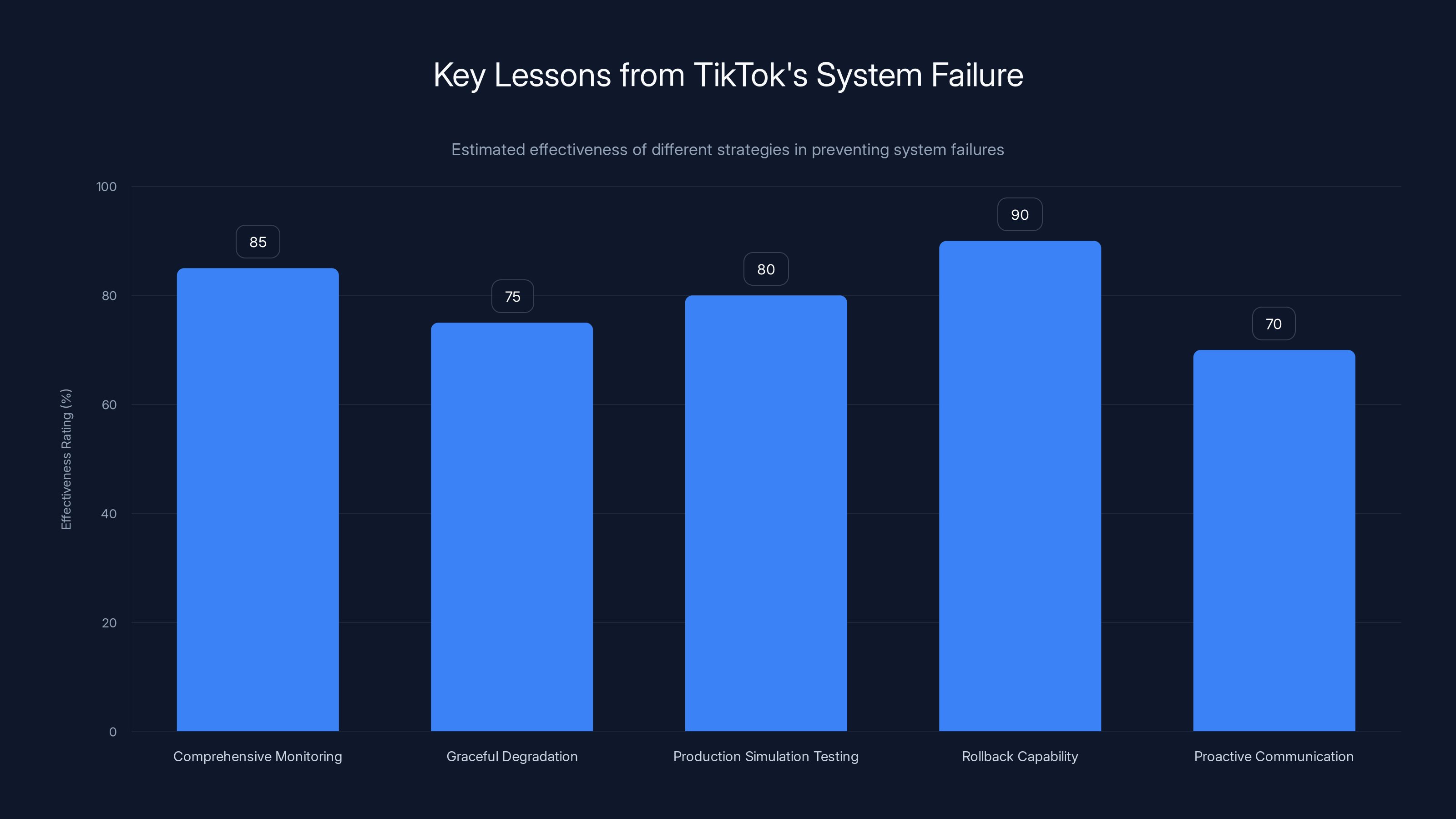
Estimated data shows that maintaining rollback capability is the most effective strategy, while proactive communication is crucial but slightly less effective. Estimated data.
How TikTok Responded (Or Didn't)
One of the strangest things about the outage was TikTok's silence.
The Non-Response
TikTok didn't immediately acknowledge the problems. Users were posting about issues on Reddit, Twitter, TikTok itself. The press was reporting it. But TikTok's official status page? Silent. The company's official account? No explanation. Nothing.
This matters more than you might think. When a platform is broken, users need to know:
- Is this on my end or TikTok's? (Reassurance: it's not them)
- When will it be fixed? (Time estimate)
- What should I do? (Advice to wait vs. try specific steps)
- Why did it happen? (Trust restoration)
TikTok provided none of this. The absence of communication probably amplified the censorship theories. If TikTok had said "We're migrating infrastructure and experienced database synchronization issues," people would have understood. Instead, silence felt like confirmation of something fishy.
The Investigation Opacity
A day after the problems began, TikTok still hadn't publicly stated what happened or how extensive the issues were. For a platform with tens of millions of US users trying to make money creating content, this lack of transparency is frustrating.
Normally, platforms publish postmortems after major outages. They explain what went wrong, what it affected, and what they're doing to prevent it. TikTok didn't do that (at least not immediately). Whether that's because they were still investigating, because the answers were politically sensitive, or because of new management's approach to communications, it contributed to the information vacuum that conspiracy theories filled.

What This Tells Us About System Architecture at Scale
If you're building large platforms, TikTok's failure is a masterclass in what not to do (or what's nearly impossible to avoid).
The Fallback Strategy Problem
TikTok had no real fallback for when core services failed. The recommendation algorithm is built into the platform so deeply that when it breaks, there's no "serve generic content but keep things running." Well, there is now—we all saw it. Generic content everywhere.
Modern platforms should have graceful degradation: when the fancy recommendation algorithm fails, fall back to recency-based sorting. When video transcoding fails, serve the original quality. When comments fail to load, at least show a "comments unavailable" message instead of crashing.
The Infrastructure Redundancy Problem
The fact that some regions experienced more problems than others suggests TikTok's infrastructure isn't evenly redundant. Maybe they have better redundancy in some data centers than others. Maybe traffic routing during migrations didn't account for unequal capacity across regions.
At TikTok's scale, you need every region to be independently capable of handling full traffic if other regions fail. If that's not true, you're always one failure away from cascading problems.
The Monitoring Blindness Problem
The fact that TikTok didn't immediately know how extensive the problem was (or at least didn't say) suggests their monitoring systems might not be comprehensive enough. Modern platforms should have dashboards showing:
- Video upload success rate (minute-by-minute)
- Algorithm response times and accuracy
- Comment load latency
- Error rates by region
If TikTok had visible monitoring, they would have known immediately that uploads were failing across the US. Instead, they seemed to learn about it from users on social media.

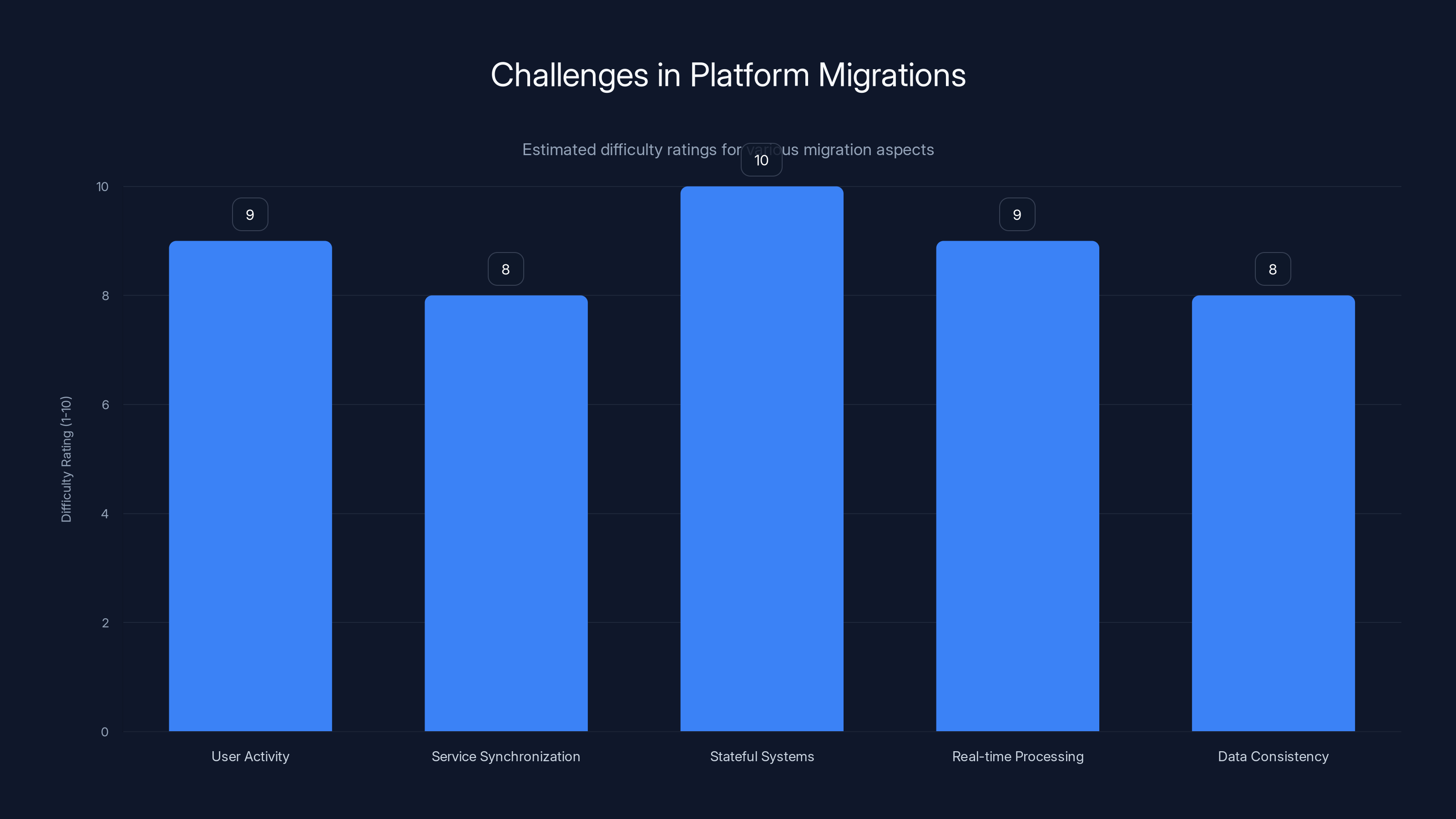
Platform migrations, especially for complex systems like TikTok, face high difficulty levels across multiple aspects, with stateful systems being the most challenging. Estimated data.
The Political Fallout and Trust Implications
Whatever actually caused TikTok's outage, the damage to user trust is real.
The Credibility Problem
TikTok has a credibility deficit with a significant portion of its US user base. There are real concerns about data privacy, algorithmic bias, and the company's relationship with the Chinese government. When the platform breaks right after US ownership transfer, and the company refuses to explain why, it feeds every existing concern.
For creators who depend on TikTok for income, the outage was genuinely scary. What if this happens again? What if their account gets trapped in some inconsistent state? These aren't paranoid questions. They're rational concerns given:
- Major outage on day one under new management
- No clear explanation provided
- Previous patterns of the company being opaque
The Creator Economy Impact
TikTok has become a genuine economic platform for millions of creators. These aren't hobbyists. These are people making
Think about what a platform outage means for someone making $5,000 per week on TikTok:
- No new videos being published = no new views
- No new views = no new engagement
- No engagement = algorithm penalizes them for days
- Algorithm penalty = reduced reach = reduced income
One day of broken platform might cost a creator $1,000+ in lost earnings. TikTok broke for roughly 24 hours across the US. That's real money lost from real people.
The Competition Opportunity
This outage is a gift for other platforms. Instagram Reels, YouTube Shorts, and even BeReal or other emerging platforms can say "We were here when TikTok wasn't." Creators will hedge their bets by diversifying. Viewers will explore alternatives.
TikTok's network effect—the massive value of having everyone in one place—is its only real competitive advantage. When network effects break, even temporarily, it reminds users that alternatives exist.

Lessons for Companies Undergoing Massive Transitions
If you're in a position where your company is going through major infrastructure changes, TikTok's experience offers several lessons.
Plan for Longer Than You Think
Any executive saying "We'll migrate in a weekend" is either lying or going to learn a hard lesson. Major migrations take months. If you only have a weekend, you're not really migrating—you're creating a new disaster.
TikTok probably started planning this migration months ago. They probably underestimated the complexity. This is universal. Every migration takes 30-50% longer than estimated. Plan accordingly.
Automate Everything, Then Automate More
Manual steps in migrations are where humans make mistakes. Every step should be automated, tested, and monitored. If someone has to manually run commands to complete a migration, that's a failure waiting to happen.
The more you automate, the more consistent and repeatable the process becomes. The fewer edge cases slip through.
Run Parallel Systems Until You're Sure
Old and new systems should run in parallel for longer than seems necessary. Yes, it costs more. Yes, it's inefficient. But it's infinitely cheaper than an outage affecting 170 million users.
TikTok probably ran parallel systems for a while, but maybe not long enough. If they'd kept the old system fully operational alongside the new system for an extra month, they could have caught these issues before users experienced them.
Communicate Constantly
When you're going through changes, users need to know what to expect. TikTok should have published a timeline: "We're migrating US infrastructure this weekend. You might experience reduced performance." Followed by: "Here's the status." Followed by: "Here's what happened." Followed by: "Here's how we're preventing it next time."
Instead, silence. That silence was the real failure. Outages happen to every platform. How you communicate about them defines trust.

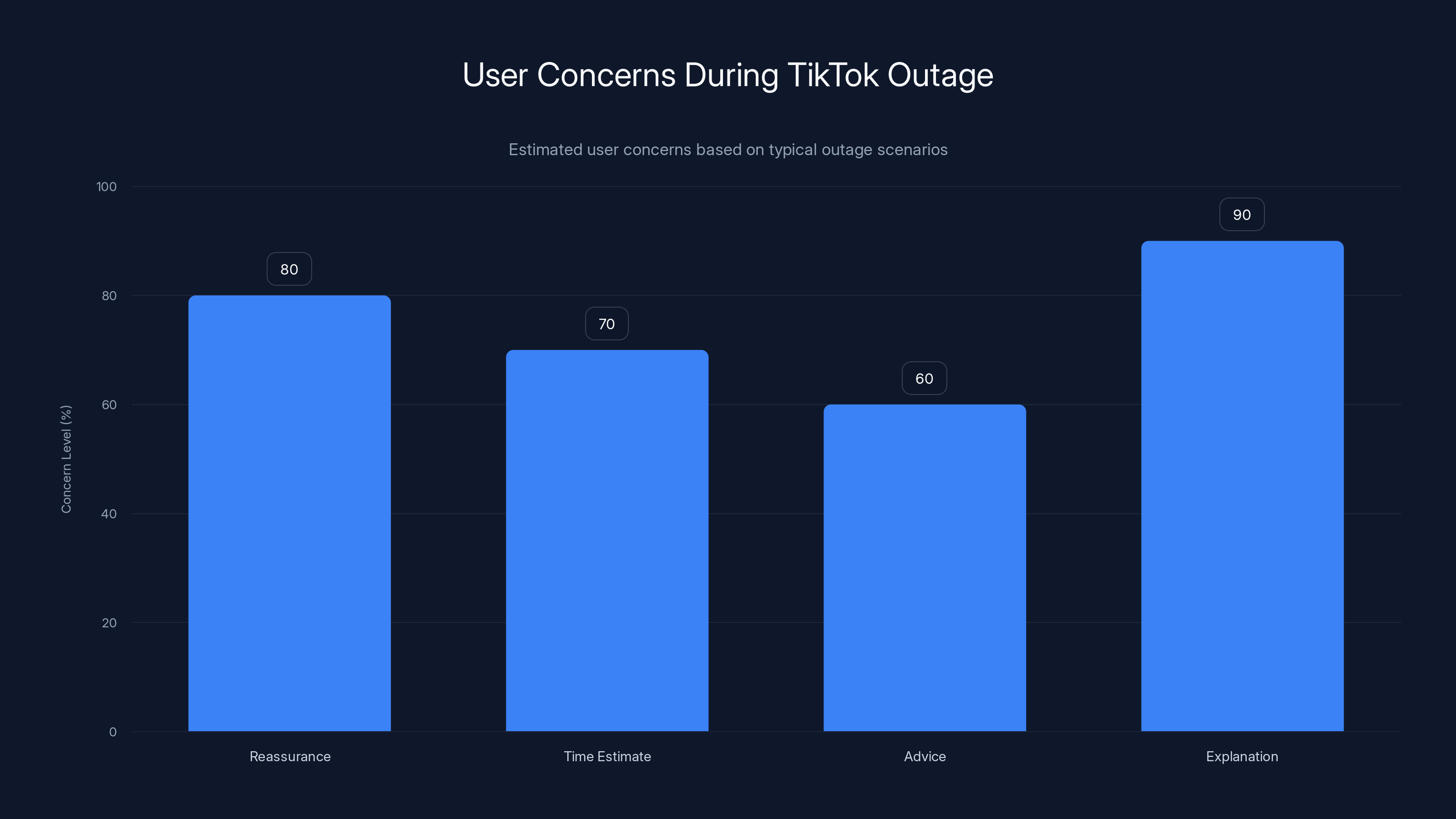
During the TikTok outage, users were most concerned about the lack of explanation (90%) and reassurance (80%). Estimated data based on typical user expectations during platform outages.
What Happens Next: The Real Questions
The immediate technical issues will get fixed. Videos will start uploading. The algorithm will get reset and repopulated. Comments will load again. But several bigger questions remain.
Will This Happen Again?
Probably, yes. Migration to new ownership and infrastructure is ongoing. There will be more changes, more potential for failures. TikTok probably has weeks or months of migration work still to do. Each migration point is another chance for failures.
The question is whether TikTok's new management will invest in the infrastructure, testing, and monitoring needed to make these transitions as smooth as possible. Or whether they'll prioritize speed over safety, which could lead to more outages.
Will Creators Leave?
Some will diversify. Smart creators already are. But the death of TikTok isn't coming from a weekend outage. Platforms die from chronic problems, not acute ones. One bad weekend might cause some creators to put more effort into Instagram Reels or YouTube Shorts, but they won't abandon TikTok overnight.
What would cause a mass exodus: repeated outages. If TikTok breaks again in a month, and then in three months, and then in six months, creators will start treating it as unreliable. That's when they truly leave.
What About Data Privacy and Trust?
This outage will fuel existing concerns about TikTok under new US ownership. Some of that's fair—migrations can go wrong. Some of it's unfair—attributing technical failures to intentional censorship without evidence.
But the core issue remains: who controls TikTok's data? Who has access? What are the rules about how it's used? These questions existed before this outage. The outage doesn't answer them, but it does make users more paranoid about the answers.
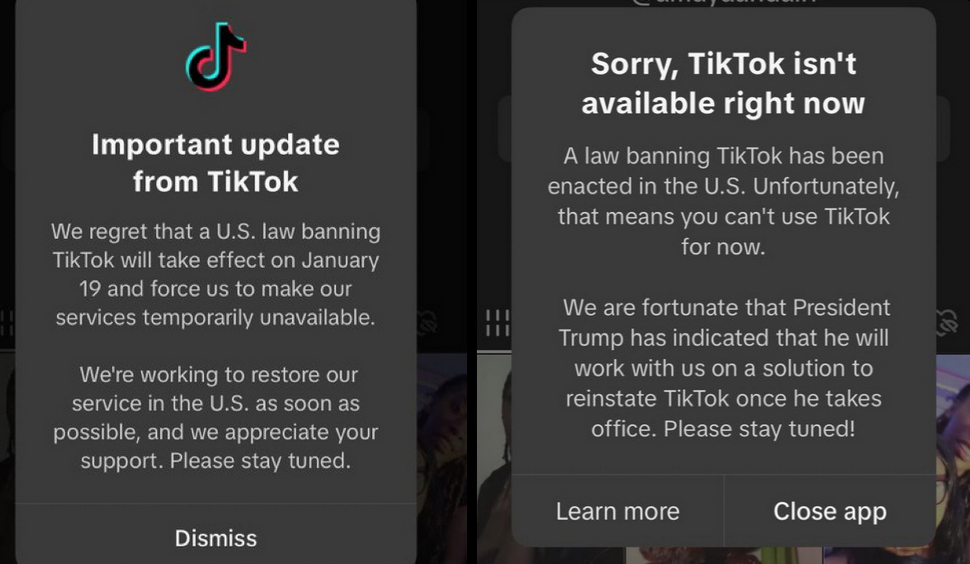
The Bigger Picture: Platform Fragility at Massive Scale
TikTok's outage isn't unique. It's just more visible because TikTok is huge. But every platform at scale is one bad migration away from catastrophic failure.
The Brittleness of Digital Infrastructure
We've built systems so complex that no single person understands all of them. That's powerful—it enables amazing capabilities. But it's also fragile. One misconfiguration, one database replication lag, one cache miss can cascade into hours of downtime affecting hundreds of millions of people.
And the worrying part: as systems get bigger and more complex, they don't get more robust. They get more fragile. There are more places for things to break.
The Dependency Problem
Creators depend on TikTok for income. Advertisers depend on TikTok for reach. Users depend on TikTok for entertainment and connection. This concentration of dependency creates real fragility. If TikTok breaks, hundreds of millions of people are immediately affected.
This is why distributed, federated alternatives are interesting. They're slower and less polished. But they fail gracefully. When one server goes down, others keep working.
The Future of Migrations
As systems get bigger, migrations get harder. The only real solutions are:
- Build for changeability: Design systems that can migrate components independently, not all at once
- Invest in redundancy: If it's important, it needs to work even when parts fail
- Automate ruthlessly: Remove human decision-making from critical paths
- Communicate transparently: When things break, tell users what happened
TikTok's outage suggests they need work on all four fronts.

Learning from Failure: What We Can Actually Use
If you're building systems, here are the actual, actionable lessons from TikTok's meltdown:
Set Up Comprehensive Monitoring
Before you migrate anything, you need monitoring that answers these questions in real-time:
- What percentage of video uploads are succeeding?
- What's the latency from upload to processing completion?
- Are all regions operating normally?
- Are databases replicating correctly?
- Is the cache hit rate healthy?
If you can't answer these questions instantly, you won't know you have a problem until users tell you.
Build Graceful Degradation Into Everything
When your recommendation algorithm is down, don't show nothing. Show recency-based content. When your comment system is down, show a message explaining it. When your transcoding farm is slow, serve what you have instead of failing completely.
This makes the platform worse, but it keeps it running. A slow platform is always better than no platform.
Test Migrations in Production Simulation
You can't test a migration at TikTok's scale in a staging environment. Staging is always too small. But you can test it on a slice of production:
- Pick 1% of users
- Route them through the new system
- Monitor everything
- Expand gradually if working
This takes time, but it catches problems before they affect everyone.
Maintain Rollback Capability
Every migration should have a clear rollback plan. If something goes wrong, you should be able to flip a switch and revert to the previous system. This takes engineering effort, but it's the difference between a 2-hour outage and a 2-minute one.
Communicate Proactively
Before, during, and after migrations, users need information. Here's what we're doing. Here's how long it will take. Here's what you should expect. Here's what actually happened. Here's how we're preventing it next time.
TikTok's silence was the worst part of the entire incident.

The Regulatory Angle: Policy Meets Infrastructure
There's a broader policy question hiding inside this technical story.
When Regulations Break Technology
Governments regulating technology companies to move infrastructure creates genuine technical problems. It's not just bureaucratic friction—it's actual software engineering challenges.
When the US government demanded TikTok move to US servers and US ownership, they created a deadline. Deadlines and migrations don't mix well. Every day the migration takes is a day the company must operate two parallel systems, incurring massive costs.
The pressure to move fast probably contributed directly to the outage. Engineers probably said "We need three months." Management said "You have three weeks." This is how things break.
The Broader Platform Risk
As governments increasingly regulate platforms, these forced migrations will become more common. China will demand data moved to Chinese servers. The EU will demand certain data stored in Europe. India, Russia, others will follow.
Every forced migration is an outage risk. Every outage is a trust risk. So the regulatory push for localized data, while well-intentioned, actually creates instability.
There's no easy solution. You can't ignore security concerns about foreign data storage. But you also can't force companies to move servers without expecting disruptions.

What Users Should Know Going Forward
If you use TikTok, here's what this outage actually means for you.
It Probably Won't Happen Again Soon
TikTok has now learned exactly what breaks during migrations. The next time they move servers or transfer ownership, they'll do it more carefully. They'll have monitoring, rollback plans, and probably more time.
The first migration after a catastrophic failure is usually pretty smooth because everyone's learned. It's the second migration where people get overconfident and rush.
But Outages Will Happen
No platform is immune. TikTok, Instagram, YouTube, all of them will have outages. It's not a question of if, but when. The fact that it happened once means TikTok's infrastructure isn't magical or invulnerable. It's just software, and software has bugs.
Prepare for this by:
- Diversifying your audience: Don't depend entirely on TikTok
- Backing up your content: Save your videos elsewhere
- Building on multiple platforms: YouTube, Instagram, etc.
Your Data Is Probably Fine
While the platform was broken, your data wasn't lost. TikTok's backend issues didn't cause data deletion. Your videos are still there. Your likes and comments are still there. The outage was about access, not data integrity.

How Other Platforms Have Handled Similar Transitions
TikTok isn't the first platform to go through massive transitions. Here's how others have fared.
Twitter/X's Migration Under New Management
Twitter's transition to X under new ownership involved significant infrastructure changes. There were definitely outages and problems, but Twitter had some advantages: smaller infrastructure, years of migration experience, and a smaller creator dependency base. Creators on Twitter don't make as much money proportionally, so the economic impact of outages is lower.
Facebook's Data Center Transitions
Facebook has moved between data centers multiple times. They've generally handled it better than most platforms because they invest heavily in infrastructure automation and have redundancy across multiple regions. When one data center fails or migrates, traffic routes to others.
Instagram's Independence From Facebook
Instagram has gradually moved toward infrastructure independence from Facebook. This is still ongoing and has caused occasional hiccups, but the gradual approach means no catastrophic failures.
The lesson from other platforms: gradual, well-planned transitions with lots of redundancy work better than fast, deadline-driven ones.

The Creator Economy at Risk
This is worth its own section because TikTok's outage exposed something important about how we've built the creator economy.
The Centralization Problem
We've allowed the creator economy to become dangerously centralized. TikTok hosts roughly 40% of short-form video creators. When TikTok goes down, 40% of creators lose their primary income source for that day.
Compare this to traditional media: TV networks, radio stations, publications. They have competing platforms. If one fails, creators can work elsewhere. But TikTok's algorithm and audience are so powerful that creators who leave TikTok lose 80%+ of their income.
What Creators Should Actually Do
If you're a creator on TikTok (or any platform), you need to:
- Cross-post content: Post to TikTok, Instagram, YouTube, Snapchat, etc.
- Own the relationship: Build an email list, Discord community, or Patreon
- Diversify revenue: Don't depend entirely on platform sponsorships
- Assume platforms will break: Maintain content backups
The platforms aren't going anywhere, but they're not trustworthy as sole income sources.
The Funding Implication
If you're funding creators or building a creator platform, TikTok's outage should make you rethink dependency. Maybe your creators need to spread their presence across multiple platforms. Maybe you should facilitate that instead of fighting it.
Predictions: What Comes Next
Based on what we know about TikTok's situation and similar platform transitions, here's what I expect:
Near-term (Next 2-4 weeks)
TikTok will publish a technical postmortem. It will probably blame the migration and take responsibility without being entirely specific. They'll announce infrastructure improvements and monitoring enhancements. Things will work better for a while as everyone's hyper-vigilant.
Mid-term (Next 3-6 months)
More migrations will happen. There will be smaller outages—a few minutes here, brief degradation there. These will be less visible because they'll affect fewer regions or users. Some creators will start diversifying more aggressively.
Long-term (Next 1-2 years)
TikTok will either become more stable and reliable, proving this was just teething pains, or it will have repeated problems. If it's the former, growth continues. If it's the latter, creators will fully diversify and TikTok's leverage will decrease.
The politics around TikTok ownership will continue. There will be more regulatory pressure, possibly more forced migrations. Each one is an outage risk.

Conclusion: Technical Failure, Political Implications
TikTok's first weekend meltdown under US ownership was probably caused by routine technical failures during a massive infrastructure migration, not by intentional censorship. But the platform's complete silence about what happened allowed conspiracy theories to fill the information vacuum.
Here's what actually matters:
The technical lesson: Migrating platforms at scale is absurdly hard. When you do it under time pressure and political scrutiny, mistakes are almost guaranteed.
The platform lesson: Platforms need graceful degradation, better monitoring, and more transparent communication. When things break, users need to know what's happening.
The creator economy lesson: Building your entire income on one platform is dangerous. The outage highlighted this in the clearest possible way.
The regulatory lesson: Forcing platforms to move infrastructure creates real technical risks. Regulators who want localized data should understand the costs and risks involved.
TikTok's situation isn't unique. It's a preview of what happens when platforms grow too large to fail, but still fail anyway. It's a reminder that digital infrastructure is more fragile than we pretend. And it's proof that when systems break, how you communicate about it matters as much as fixing it.
The story of TikTok's first weekend isn't really about politics or censorship. It's about the gap between our ambitions for massive, always-on systems and the reality of building them. We want platforms that work perfectly, migrate instantly, and serve billions of people simultaneously. We can't have all three. The outage is what that tradeoff looks like in practice.

FAQ
What actually caused TikTok's outage?
TikTok hasn't officially explained the root cause, but evidence points to infrastructure migration problems. The company was transferring US operations to new servers and systems as part of the US ownership transition. Database replication failures, cache issues, or configuration errors during deployment likely caused the cascading failures across video uploads, the recommendation algorithm, and comment loading. Some regions were affected more than others, suggesting zone-specific migration inconsistencies rather than a single point of failure.
Was TikTok really censoring political content during the outage?
There's no evidence that the outages were intentionally linked to the political events happening that weekend in Minneapolis. While the timing was suspicious and error messages were vague, the technical evidence points to migration-related failures: regional inconsistency (some areas fine, others broken), partial functionality (comments sometimes loading, sometimes not), and the algorithm being completely depersonalized rather than selectively blocking certain content. Intentional censorship would probably be more uniform and comprehensive. This was more likely incompetence than conspiracy.
Why didn't TikTok explain what happened?
TikTok's silence was puzzling and probably a mistake. The company didn't immediately acknowledge the outage, didn't provide updates about scope or cause, and didn't publish a technical explanation. This could be because new management was still assessing the situation, because they were uncertain about what actually happened, or because there were legal/regulatory complications. Regardless, the silence made users assume the worst. Transparent communication would have significantly reduced the conspiracy theories.
Will this happen again?
Likely, yes, but probably not immediately. TikTok has now identified what breaks during migrations and will invest in better monitoring and gradual rollout strategies. But the company still has more infrastructure work to do related to the US ownership transition. Each migration point is another risk. The question is whether TikTok's new management will prioritize stability or speed.
Should creators leave TikTok because of the outage?
Not because of this one outage, but yes, creators should diversify. No single platform is reliable enough to be a sole income source. Smart creators post to TikTok, Instagram Reels, YouTube Shorts, Snapchat, and build their own communities via email or Discord. One outage isn't a reason to abandon TikTok, but it's a reminder that all platforms are vulnerable.
How long should I expect to experience issues if TikTok has another migration problem?
It depends on what breaks. Small issues (some comment features slow, some regions lagging) might last minutes to hours. Major issues (like this one with uploads and algorithm) could last 4-24 hours. The platform probably won't go completely offline—that's actually harder to do than most people think. But users might experience degraded functionality (slower uploads, generic recommendations, missing features) for extended periods if another serious migration problem occurs.
What can platforms do to prevent outages like this?
They should: (1) Invest in comprehensive monitoring that catches issues before users do, (2) Build graceful degradation so partial failures don't cascade, (3) Test migrations at production scale using a slice of real traffic, (4) Maintain parallel systems until they're absolutely sure the migration is successful, (5) Communicate transparently about planned changes and actual problems, and (6) Make sure rollback is always possible if something goes wrong. TikTok probably needs work on all fronts.
How does this affect TikTok's ability to compete with Instagram and YouTube?
Short-term: Not much. Users and creators will still be on TikTok because the network effects are strong. The algorithm still works better than competitors when it's working. But long-term: If TikTok becomes known for outages while Instagram and YouTube are stable, creators will diversify more aggressively. The outage also gave competitors a good weekend while TikTok was down—Instagram Reels and YouTube Shorts probably saw increased usage.
Does this prove that TikTok is run incompetently?
Not necessarily. TikTok's infrastructure is incredibly complex. Running a platform for 170+ million daily active users while simultaneously migrating ownership and infrastructure is arguably impossible to do perfectly. Some outages are nearly inevitable in this situation. What's telling is not that the outage happened, but how TikTok responded: with silence. That's a management and communication failure, not necessarily a technical incompetence failure.
This article provides technical analysis based on publicly reported symptoms and standard platform infrastructure knowledge. TikTok has not officially confirmed the cause of the outages, so some analysis involves educated inference from how similar systems typically fail.

Key Takeaways
- TikTok experienced widespread outages affecting video uploads, recommendations, and comments during its first weekend under US ownership, likely due to complex infrastructure migration rather than intentional censorship
- The platform's complete silence about the outage created an information vacuum that allowed conspiracy theories to spread, highlighting the importance of transparent communication during technical failures
- Massive platform migrations are inherently risky: even the best engineering teams struggle when moving systems serving 170+ million daily users under tight deadlines
- The outage exposed the fragility of the creator economy, where creators depending on TikTok for income lost money during the 6-24 hour failures
- Graceful degradation, comprehensive monitoring, parallel systems running during migration, and automated rollback capabilities are essential for preventing future outages at this scale
Related Articles
- TikTok's Trump Deal: What ByteDance Control Means for Users [2025]
- TikTok US Deal Finalized: 5 Critical Things You Need to Know [2025]
- TikTok's US Deal Finalized: What the ByteDance Divestment Means [2025]
- TikTok's US Future Settled: What the $5B Joint Venture Deal Really Means [2025]
- How Cloud Storage Transforms Sports Content Strategy: Wasabi & Liverpool FC [2025]
- Age Verification & Social Media: TikTok's Privacy Trade-Off [2025]

