![Why Epstein's Emails Have Equals Signs: A Technical Deep Dive [2025]](https://tryrunable.com/blog/why-epstein-s-emails-have-equals-signs-a-technical-deep-dive/image-1-1771160757550.jpg)
Why Epstein's Emails Are Full of Equals Signs: Understanding the Technical Reality Behind the Mystery [2025]
When the Department of Justice released documents from its investigation into Jeffrey Epstein in early 2025, something immediately caught the public's attention. Throughout thousands of emails, strange symbols and garbled text appeared seemingly at random. The most prominent culprit: the equals sign, appearing where it had no business being. Lines like "J=effrey" and strings of seemingly meaningless characters sparked immediate speculation. Was this some kind of hidden code? A cipher used by the wealthy and powerful to mask their communications?
The internet did what it does best: it ran with conspiracy theories. If billionaires and financiers were communicating in secret, why not a hidden language embedded in plain sight?
But here's where reality becomes more interesting than fiction. The answer isn't shadowy code at all. It's something far more mundane, yet technically fascinating: a cascading failure in document conversion technology, rooted in a decades-old email protocol that most people have never heard of. The equals signs are fragments of MIME encoding, a standard that's been quietly powering email transmission since the early 1990s.
This isn't just about Epstein's emails. It's about how we handle digital information, what happens when legacy systems meet modern workflows, and why the government's attempt to convert, redact, and secure thousands of documents created such a technical mess. Understanding what happened requires diving into the depths of email standards, PDF specifications, and the practical challenges of processing documents at scale.
Let's unpack this layer by layer.
TL; DR
- Equals signs aren't code: The mysterious symbols are remnants of MIME (Multipurpose Internet Mail Extensions), a 30-year-old email encoding standard.
- Conversion gone wrong: The DOJ extracted emails, converted to PDF, redacted them, converted to JPEG for security, then back to PDF, losing MIME decoding in the process.
- Character set chaos: Multiple email clients (BlackBerry, iPhone) and different encoding systems created incompatibilities during the conversion workflow.
- Nobody's fault, everyone's problem: The files were processed at scale and speed without perfect software tools for the job.
- Email is broken: Converting email to PDF properly is harder than it seems because email was never designed for this workflow.

The complexity of email encoding has increased significantly since the 1970s, with MIME being a major milestone in 1992. Estimated data.
The Conspiracy Theory That Started It All
The moment the Epstein documents hit the internet, people noticed something off. Email after email contained strings of equals signs, nonsensical character sequences, and garbled symbols that looked deliberately obfuscated. For communities primed to find hidden meaning in public documents, this was catnip.
The assumption was logical on the surface: if you're part of a cabal of powerful people committing crimes, you'd want to communicate in a way that outsiders couldn't understand. Secret codes have been part of human communication for centuries. Enigma machines, Caesar ciphers, dead drops, coded language in seemingly innocent sentences. Why would modern-day elite sex traffickers be any different?
Online forums and social media accounts exploded with speculation. People began trying to decode the symbols. Were they mathematical? A substitution cipher? Some kind of quantum-encoded messaging system that required special knowledge to decrypt?
The problem with this theory is simple: it assumes the complexity is intentional. But Occam's Razor, that principle suggesting the simplest explanation is usually correct, actually applies here. The symbols weren't hidden in the emails at all. They were accidentally exposed during the process of converting those emails into documents that the public could see.
This distinction matters because it reveals something about how we process information in the digital age. We're primed to see patterns. We're trained by TV shows and movies to believe that powerful people hide their crimes in sophisticated ways. The appearance of unfamiliar technical artifacts triggers alarm bells.
What we don't often think about is that government agencies, like all organizations, use off-the-shelf software, hire contractors, and sometimes make compromises on quality when processing documents at scale. The technical failure behind the equals signs is far more mundane than secret codes. But understanding it requires knowing something most people never learn about: how email actually works.

Character encoding issues are the most significant cause of conversion failures, followed by MIME decoding challenges. Estimated data based on typical conversion issues.
Understanding MIME: The Foundation of Modern Email
To understand why equals signs show up in the Epstein documents, you first need to understand email at a fundamental level. Not how to use Gmail or Outlook, but how email actually travels from one computer to another.
Email is old technology. Really old. It predates the web by decades. The original email standards, developed in the 1970s and refined through the 1980s, were built on something called ASCII, the American Standard Code for Information Interchange. ASCII is simple: it defines how 127 basic characters (letters, numbers, punctuation) are represented as numbers that computers can process.
Here's the problem: ASCII only includes English letters, numbers, and basic punctuation. What happens when you want to send an email with accented characters? Or special symbols? Or, critically, when email clients started supporting formatted text with different fonts, bold, italics, and colors?
Early email simply couldn't handle this. The protocol underlying email transmission, Simple Mail Transfer Protocol (SMTP), was designed for ASCII text. You could write "Hello, how are you?" but you couldn't reliably write "Café" or include HTML formatting.
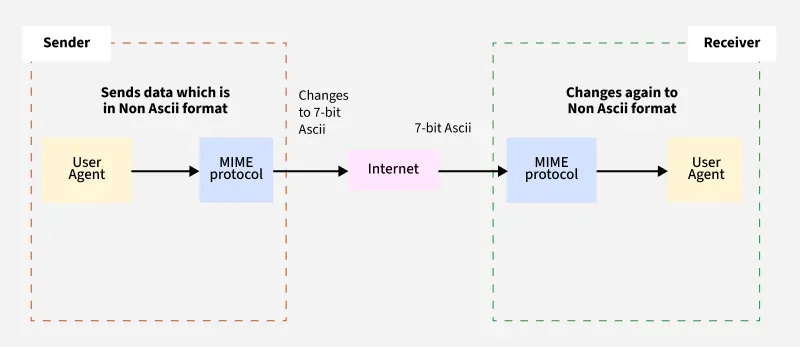
In 1992, a standard called MIME was created to solve this problem. MIME stands for Multipurpose Internet Mail Extensions, and it's essentially a clever encoding system that lets you pack complex information into ASCII text. It's like taking a photograph, compressing it, encoding it into text characters, sending it through a system that only understands text, and then having the recipient decode it back into a photograph on the other end.
Here's how MIME works in practice. When your email client wants to send special characters or formatting, it encodes them using specific rules. The equals sign plays a critical role in these rules.
In MIME, the equals sign serves two purposes:
First, it indicates a soft line break. When an email message is being transmitted, it needs to be broken into lines of a certain length, usually 76 characters. If you break a word in the middle, you need to signal that the line break isn't real and the text should be rejoined. MIME uses "=" followed by a line break to signal "this isn't the end of a word, it's just a transmission break."
Second, when the equals sign is followed by two hexadecimal characters, it encodes a special character. For example, if you wanted to include an actual equals sign in your email (yes, this creates a circular problem), it would be encoded as "=3D." The "3D" is hexadecimal notation for the character you're representing.
This system is elegant and has worked reliably for three decades. When your email arrives in Gmail or Outlook, your email client automatically decodes these MIME encodings. You never see the "=3D" or the soft line breaks. The email appears perfectly formatted.
But what happens when email leaves the normal ecosystem? What happens when someone tries to extract email from a mail server and convert it into a PDF document? That's where everything falls apart.
The Government's Document Conversion Nightmare
The Department of Justice faced a unique challenge with the Epstein files. They had thousands of emails pulled from servers. These emails needed to be made public, but not before being carefully redacted to remove sensitive information that might compromise ongoing investigations or expose confidential sources.
The solution they chose involved multiple conversion steps. This is important to understand because each step introduced opportunities for the MIME encoding to break down.
Here's the workflow that forensic experts and archivists pieced together:
Step One: Extraction. The DOJ used software to extract email data from email servers or archives. This software had to parse email in its native format, which includes all the MIME encoding, headers, and metadata. The extraction tool presumably converted the emails into some intermediate format, possibly raw text or a structured data format.
Step Two: PDF Conversion. The extracted data was converted to PDF format. PDFs are designed to be document containers that look the same regardless of what system you view them on. But converting email to PDF is tricky because email wasn't designed for this. The software doing this conversion needs to properly decode MIME encodings and render the email in a readable way.
Step Three: Redaction. Once the PDFs existed, they had to be redacted. Sensitive information had to be removed or obscured. This is a critical step in any document release by the government.
Step Four: Security Conversion. Here's where things get really complex. If you redact a PDF by simply blacking out text, those black bars don't actually remove the underlying data. Someone could theoretically copy the PDF into a text editor and recover the redacted information. To prevent this, the PDFs were converted to image files, specifically JPEG format. A JPEG is just an image of the page, so the text is baked in visually. You can't copy and extract it.
Step Five: Back to PDF. Finally, the JPEG images were converted back into PDF format so the public could view them in a standard document reader. This PDF conversion from images is necessary because PDFs are the expected format for official government documents.
This five-step process is where the equals signs come from. During one or more of these steps, the MIME encoding wasn't properly decoded. Instead of showing "Jeffrey," it shows "J=effrey" because the software doing the conversion recognized the equals sign as a MIME character but didn't understand what should come after it.
Email to PDF conversion involves multiple challenges, with MIME encoding being the most complex. Estimated data.
Why the Conversion Failed: A Perfect Storm of Complexity
Understanding that the conversion failed is one thing. Understanding why requires looking at the specific technical challenges involved.
Chris Prom, a professor and archivist at the University of Illinois Urbana-Champaign, examined the Epstein documents and concluded that the conversion failures were rooted in character set issues. Email can be transmitted using different character encodings: UTF-8, ASCII, ISO-8859-1, Windows-1252, and others. Each encoding defines how bytes of data map to characters.
When an email is extracted from a server, the software needs to know which encoding was used. If it guesses wrong, or if the email server doesn't clearly specify the encoding, you get substitution errors. A character that should appear as an "a" might appear as a symbol or a different letter entirely.
Make that problem worse by adding MIME encoding on top of it. Now the software not only needs to know the character encoding, it also needs to decode the MIME layer. Get that wrong, and you're left with the raw MIME representation instead of the final character.
Peter Wyatt, chief technology officer of the PDF Association, examined the Epstein documents and noted that they appeared to have been extracted digitally rather than scanned. This is actually good news because digital extraction should preserve more fidelity than optical character recognition (OCR) on scanned documents. But it also means the software doing the extraction and initial conversion was crucial.
Wyatt also noted that the Epstein documents were clearer than the Mueller report, which was originally printed and scanned. So in some ways, the DOJ's approach was better than their previous processes. But it still failed.
The reason? Craig Ball, a forensic examiner who teaches at the University of Texas at Austin School of Law, offered a compelling hypothesis. Many of the emails in the Epstein files contained signatures from BlackBerry and iPhone devices. These mobile platforms implement email standards in slightly different ways than desktop clients like Microsoft Outlook or Apple Mail.
BlackBerrys, which were popular among business people in the 2000s and 2010s, used specific encoding standards and code pages. iPhones use different standards. When an email traverses both systems, the encoding can get confused. The original sender might compose a message on a BlackBerry using one code page, it gets forwarded through an iPhone using a different code page, and by the time it reaches a mail server, the encoding metadata might be ambiguous or incorrect.
When the DOJ's conversion software tries to process this email, it doesn't know which encoding to trust. It might default to one encoding and find itself unable to properly decode the MIME layer. The result: equals signs where they shouldn't be.
The PDF Standard Complexity Problem
One thing many people don't realize is that PDF, while ubiquitous, is actually a complex and frequently misused standard. The PDF specification runs to hundreds of pages. Different software creates PDFs in subtly different ways.
When you convert email to PDF, you're taking data designed for one purpose and forcing it into a container designed for a different purpose. Email is designed to be transmitted as plain text with structured headers. PDF is designed to represent a visual appearance of a printed page.
The conversion requires making choices about how to render the email. Should headers be shown? In what format? What about attachments? What about MIME boundaries and encoding markers? Most email-to-PDF conversion software makes an attempt to strip out the technical MIME layer and show only the human-readable content. But if the software doesn't properly understand the MIME encoding, it can't do this effectively.
Then, when you convert that PDF to JPEG and back to PDF again, you add another layer of complexity. The JPEG conversion creates an image of the page, which loses all the underlying text structure. When that image is converted back to PDF, the software might use OCR to extract text from the image, or it might embed the image directly. If it uses OCR, it's trying to recognize text from an image, which can introduce errors. If it embeds the image directly, the text isn't searchable.
Each of these conversions introduces opportunities for data to get corrupted or lost. The wonder isn't that the Epstein documents have equals signs in them. The wonder is that they're readable at all.

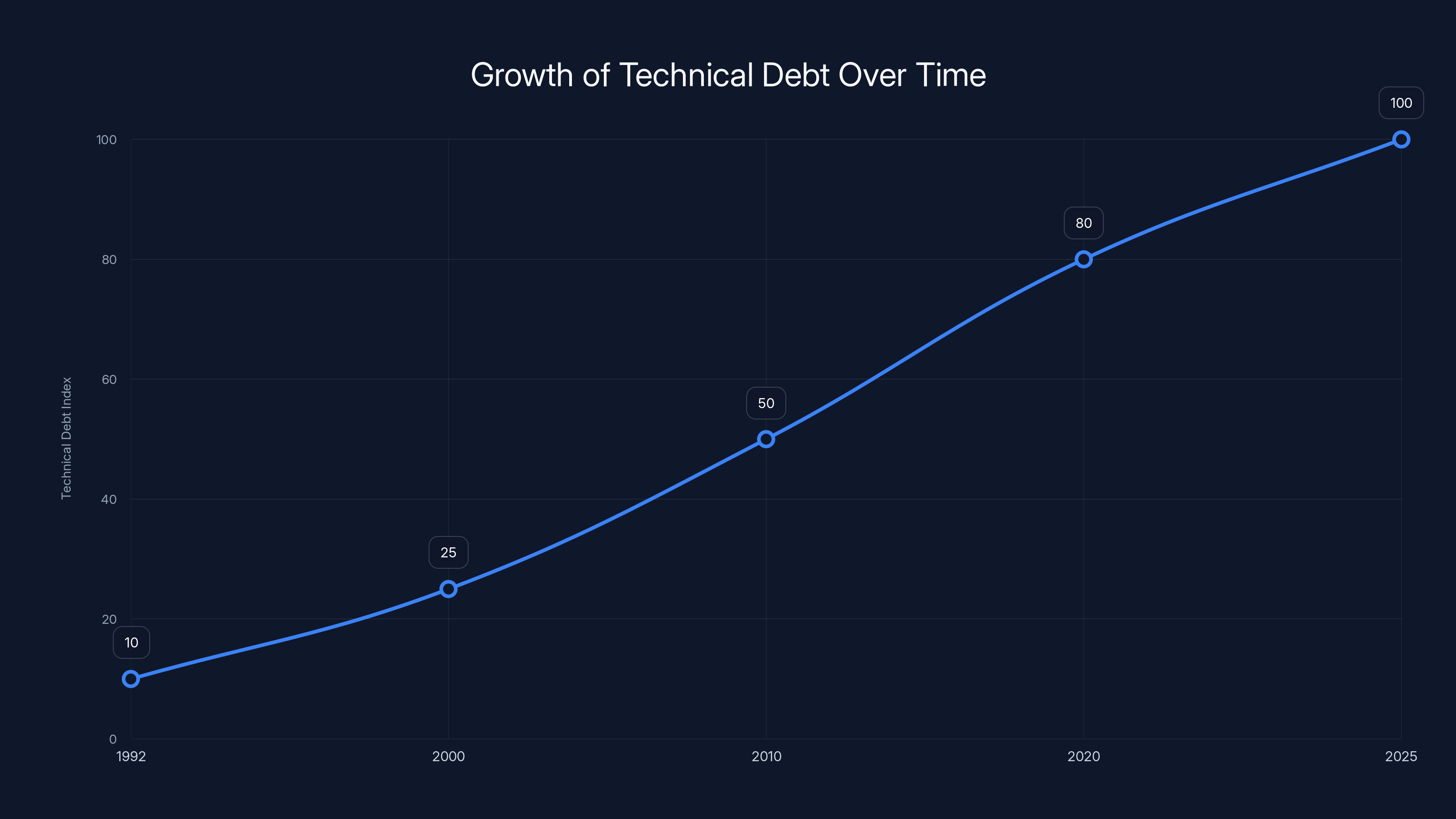
Technical debt has increased over time as legacy systems and standards persist, complicating data processing. Estimated data.
The Role of Email Client Incompatibility
One detail that experts emphasized is that different email clients implement email standards in different ways. This has been true for decades. Microsoft Outlook does things slightly differently than Apple Mail, which does things differently than Gmail, which does things differently than Thunderbird or other clients.
When a message is created in Outlook and forwarded through Gmail and received in Apple Mail, it passes through three different implementations of email standards. Each client might modify headers, re-encode attachments, or adjust MIME boundaries.
For modern users, this is invisible. The email arrives in your inbox and looks fine. But when you try to extract that email and convert it to PDF, all those historical modifications become visible. The software doing the extraction might find ambiguous encoding markers or multiple MIME boundaries from different clients. It has to make decisions about which format to trust.
The Epstein files contained emails from the 2000s and 2010s, a period when email clients had more varied implementations. Some of the emails likely passed through multiple systems before being archived. Each passage through a different system added layers of encoding metadata that the DOJ's conversion software had to parse.
Add to this the fact that people were using BlackBerrys, which had their own approach to email standards, and iPhones, which had another approach, and you have a recipe for encoding chaos.
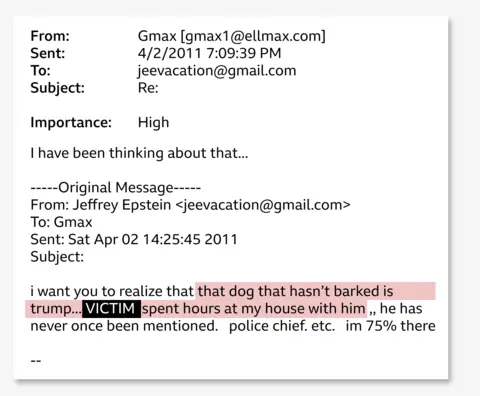
Redaction Inconsistencies and the Speed Factor
Another detail that complicates the picture is that the redactions in the Epstein documents were inconsistent. Some names were redacted, others weren't. Some email addresses were exposed, others weren't. Some text was blacked out multiple times, suggesting that the redaction process itself was error-prone.
This inconsistency suggests that the DOJ was processing these documents quickly, probably using a combination of automated tools and human review. When you're redacting thousands of documents under time pressure, you're more likely to make mistakes or use different standards for different batches.
Prom noted that when you're processing documents at that scale, you're often working with imperfect tools. "You're looking at hundreds of different methods of converting these files from hundreds of different people using whatever software they had available to them, some of which might have been good, some of which might not have been," he said.
This suggests that different batches of documents might have been processed by different people or teams, possibly using different software. Some batches might have been converted more carefully than others. Some might have used better tools for the MIME decoding step.
The equals signs in the Epstein documents aren't a bug in a single tool or a single decision. They're the cumulative result of processing at scale with imperfect tools, tight timelines, and the inherent complexity of converting email to PDF.

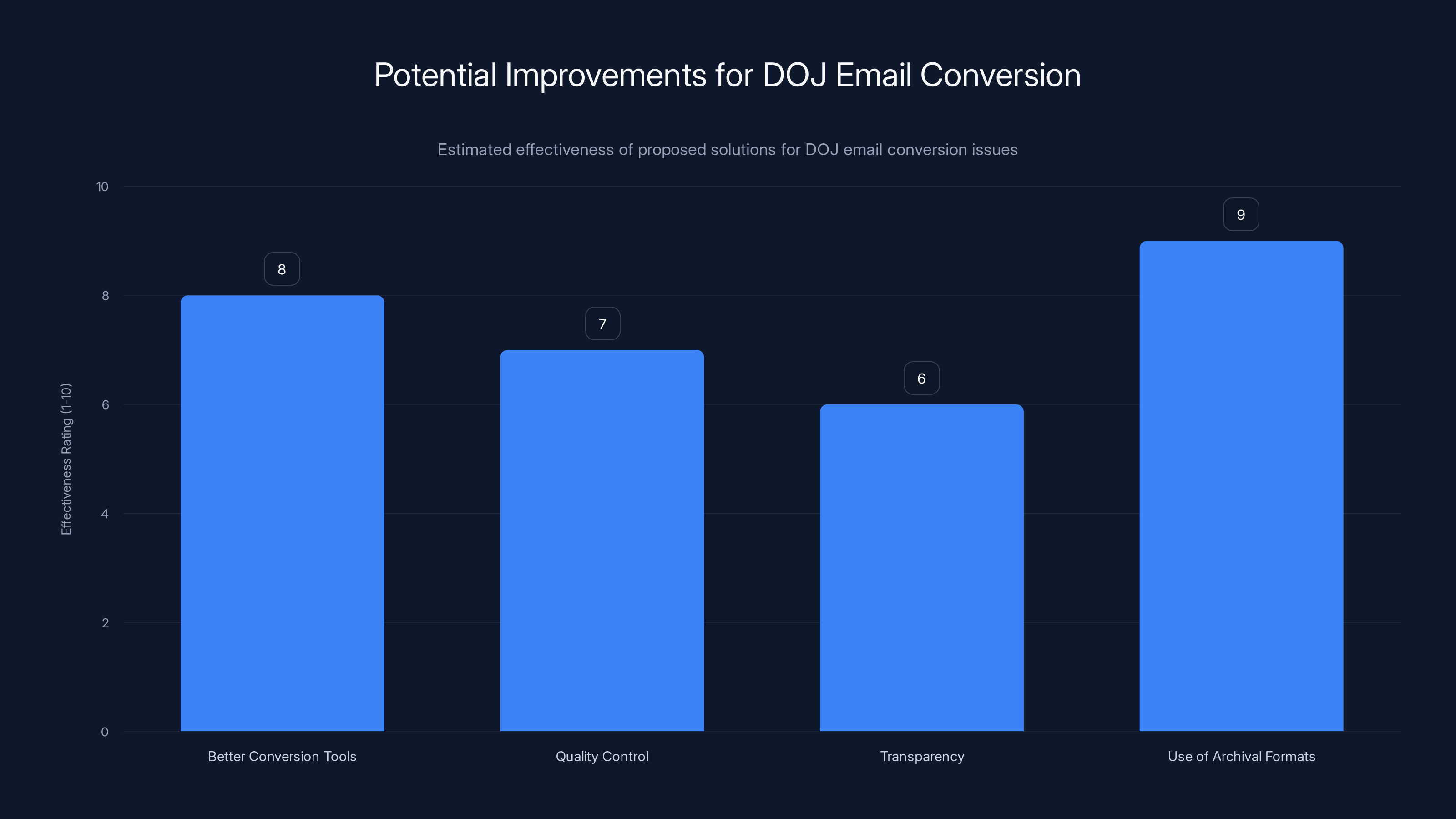
Estimated data suggests using archival formats and better conversion tools could significantly improve DOJ's email conversion process.
What the Equals Signs Actually Represent
Let's get specific about what those equals signs actually are. They're not random. They're a specific artifact of MIME encoding that didn't get decoded properly.
When you see "J=effrey," the equals sign isn't replacing the letter "e." It's showing you the MIME encoding boundary. What probably happened is the original email text was encoded in MIME because of some special character or formatting. The software that extracted the email recognized the equals sign but didn't properly interpret what came after it.
In some cases, you might see "=3D" in the PDFs, which is the MIME encoding for an equals sign itself. This creates a layer of meta-confusion: the decoded text would contain an equals sign, so that equals sign got encoded as "=3D." When the software failed to decode the outer layer, you see "=3D" in the document instead of "=".
In other cases, you see equals signs followed by random characters or spaces. These might be MIME soft line breaks that didn't get properly cleaned up. The software recognized that there was a line break, but didn't properly remove the equals sign and the line break character, so they appear in the final document.
The fact that some characters were corrupted and others weren't suggests that the software doing the conversion handled some encoding formats correctly and others incorrectly. It's probably using a character encoding detection algorithm that works well for most cases but fails in edge cases.
One more detail worth noting: the equals signs appear mostly in older emails from the 2000s. Emails from more recent years often appear cleaner. This might be because modern email clients are better at maintaining consistent encoding, or because older email systems used different encoding methods that the DOJ's conversion software couldn't handle as well.
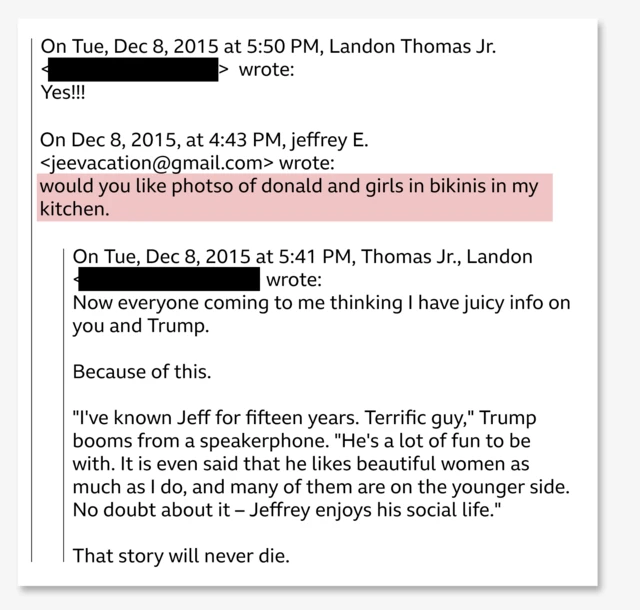
The Broader Implications for Digital Document Preservation
The Epstein email artifacts reveal something important about digital preservation and document management. Email, as it exists on mail servers, is a complex technical format designed for transmission and storage, not for long-term preservation or public release.
When archivists and government agencies need to preserve email for posterity or release it to the public, they face a fundamental mismatch between what email is designed for and what they need it to be. Email was designed to be transmitted across networks and displayed by email clients. It was never designed to be converted to static documents.
The conversion to PDF is an attempt to create something permanent and readable. But it requires translating between formats in ways that can lose information or introduce errors. The redaction process adds another layer of complexity because it requires identifying and removing sensitive information while preserving the rest of the document.
This problem isn't unique to the Epstein files. It's a general problem in digital forensics and document management. Whenever you need to extract data from one system and convert it to another format for a different purpose, you risk introducing errors.
The solution would be to use better tools and more careful processes. The PDF Association exists partly because organizations like the DOJ need guidance on how to create PDFs correctly. But better tools cost money. Careful processes take time. And when you have thousands of documents to process, both money and time are limited.

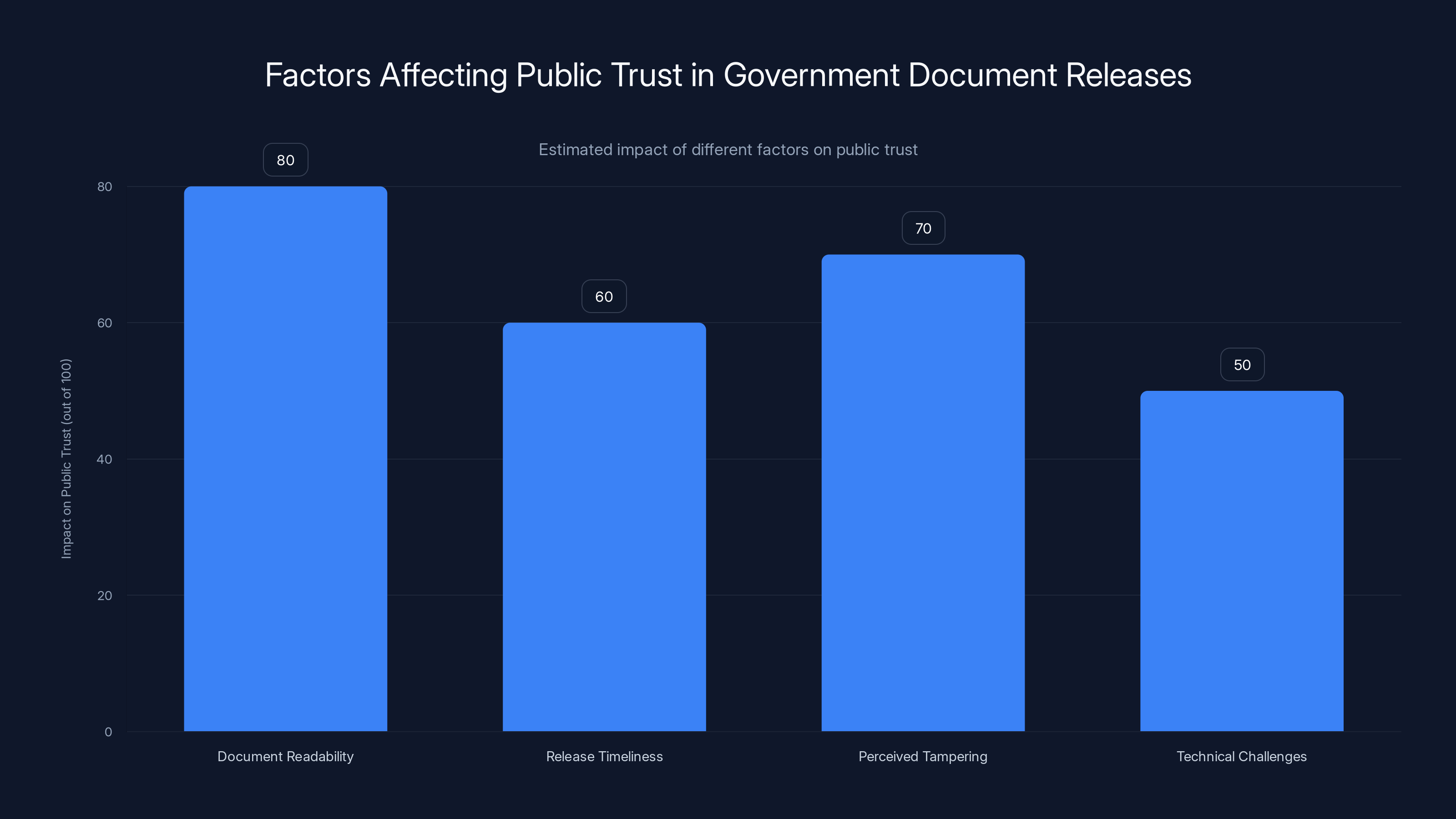
Document readability and perceived tampering have the highest estimated impact on public trust, emphasizing the need for quality control in government document releases. Estimated data.
Why Email to PDF Conversion Is Uniquely Difficult
You might wonder why this particular conversion is so fraught with problems. Why not just use whatever conversion software exists and call it a day?
The issue is that email and PDF serve fundamentally different purposes. Email is a communication format that includes metadata, headers, attachments, and complex encoding. PDF is a document format designed to represent a static visual appearance.
When you convert email to PDF, you have to make decisions about what to include and what to omit. Do you show email headers? Do you include the "From", "To", "Subject" fields? Do you include timestamps? Do you include routing information? Each decision affects the final document.
You also have to handle attachments. Does the PDF include the attachment file itself, or just a reference to it? If you include the attachment, do you render it visually or as an embedded file?
And then there's the MIME layer. Email messages are structured using MIME boundaries, which mark where sections of the email begin and end. These boundaries are important for the email system but meaningless to a human reader. When converting to PDF, you want to strip out the MIME boundaries and encoding, but you need to do it correctly so that the actual content isn't corrupted.
Most email-to-PDF conversion tools make a best-effort attempt to handle this, but they often aren't perfect. They might assume that all emails use a certain encoding, or they might not handle all the variations of MIME encoding correctly.
The Mueller report, which the PDF Association studied, went through a different process. It was printed and scanned, which created a JPEG image of each page, then converted to PDF. This is less efficient than digital extraction, but it sidesteps many of the technical issues because the text is in image form. You lose the ability to search text, but you gain consistency and clarity.
The Epstein files used digital extraction, which is theoretically better because text remains searchable and the resolution is higher. But it required correctly handling all the technical complexity of email encoding. That process failed in places, leaving behind artifacts like the equals signs.

Lessons About Data Integrity and Technical Debt
The Epstein email situation offers lessons that extend beyond this specific case. It demonstrates that technical decisions made decades ago, like the MIME standard and different email client implementations, have consequences that ripple forward into the present.
When the MIME standard was created in 1992, nobody anticipated that it would still be in use in 2025, let alone that government agencies would be trying to convert MIME-encoded emails to PDFs. The standard was designed for a specific purpose: allowing email to transmit non-ASCII content. It worked well for that purpose for decades.
But standards accumulate. Legacy systems accumulate. When you need to process documents at scale, you're often dealing with data that was created under different technological assumptions and using different tools. The further back in time you go, the more varied the tools and standards become.
This creates technical debt. The more systems you have to support, the more encoding variations you have to handle, the more chances there are for errors. The DOJ's conversion software probably had to support multiple email encodings, multiple PDF versions, multiple image formats. Each addition increases complexity.
The equals signs in the Epstein documents are a visible sign of this technical debt. They're a reminder that working with real-world data, especially old data, is messy. Perfect solutions require perfect knowledge of all the systems that data has passed through. In practice, you make best-effort attempts and accept that some errors will remain.
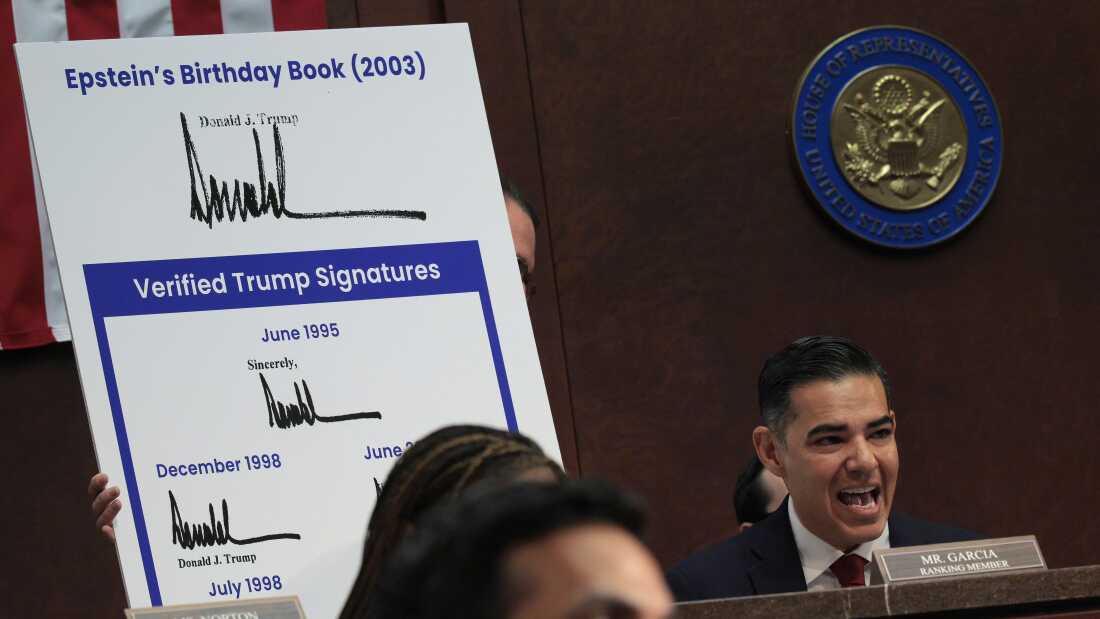
The Verification Process and Expert Analysis
It's worth noting how experts verified what was actually happening. They didn't speculate or guess. They examined the actual documents and compared them to what they knew about email standards and PDF specifications.
Prom, from the University of Illinois, recognized the pattern immediately because he's dealt with similar character encoding issues in his archival work. When scanning documents and using OCR software, he frequently encounters situations where the software can't identify the correct character set or font, resulting in garbled text. The pattern in the Epstein documents looked similar.
Wyatt, from the PDF Association, examined the documents and noted specific technical details that indicated digital extraction rather than scanning. He looked at the clarity of text, the quality of URLs, and other technical markers. His analysis suggested that the problem arose during the conversion process, not during document creation or transmission.
Ball, the forensic examiner, made an educated guess based on the signatures in the emails and his knowledge of how different email clients handle encoding. He noted that BlackBerry devices, which were popular among business people in the 2000s, had specific encoding implementations that could cause compatibility issues.
Together, these experts came to a consensus: the equals signs and garbled text were artifacts of a failed email-to-PDF conversion process, likely caused by character encoding incompatibilities and improper MIME decoding.
This process of expert verification is important because it shows how technical claims can be verified through careful analysis. The equals signs aren't a secret code. They're evidence of a specific technical problem. You can understand what went wrong by understanding the standards involved and the conversion process used.

Solutions and Future Improvements
So what could the DOJ have done better? A few things stand out.
First, they could have used better conversion tools. There are specialized software packages designed specifically for converting email to PDF or other formats while preserving text integrity. These tools are more expensive than generic conversion software, but they handle character encoding and MIME decoding more carefully.
Second, they could have done better quality control. After the initial conversion, they could have manually checked documents for encoding errors, especially older emails from different email clients. This would be time-consuming, but it would catch problems before documents were released.
Third, they could have been more transparent about the conversion process. Including a note in the documents explaining that they came from email extraction and conversion, and that some character encoding errors might be present, would have preempted conspiracy theories. As it stands, the equals signs appeared with no explanation, triggering speculation.
Fourth, they could have used archival formats designed specifically for email, like MBOX or EML. These formats preserve the full structure and encoding of emails while being more portable than the original mail server database. Converting from MBOX to PDF would still require handling MIME encoding, but MBOX is a more standardized format than the proprietary email server databases the DOJ probably extracted from.
Looking forward, government agencies and large organizations will continue needing to process and release large volumes of email. As email becomes older and original senders and recipients retire or pass away, these archives become increasingly valuable. Better tools and better processes will be essential.
The PDF standard itself might need evolution. PDF 2.0, released in 2020, added some improvements for handling structured content. Future versions might include better support for email as a source format.
Alternatively, organizations might move toward releasing email in multiple formats. The original MBOX or PST file, which preserves full structure and encoding, alongside a converted PDF for casual reading. This would allow researchers and forensic experts to access the original data while providing a user-friendly version for the general public.

The Media Response and Misinformation
One interesting aspect of the Epstein email situation is how quickly conspiracy theories spread before experts had a chance to analyze the documents. The equals signs appeared in news articles and online forums, and immediately people started trying to decode them. The narrative that this was a secret code spread faster than the technical explanation.
This reflects a broader pattern in how people respond to technical artifacts they don't understand. When something looks unusual or unfamiliar, our instinct is to assign intentionality to it. We assume that unusual formatting or symbols must have been deliberately created, possibly to hide something.
The reality is often mundane. A software bug. A configuration error. A legacy system incompatibility. But these explanations require understanding the technical systems involved, and most people don't have that background.
The experts who analyzed the Epstein documents were able to explain what was happening, but that explanation required understanding MIME encoding, character sets, email standards, and PDF specifications. It's a lot of technical detail for a news article or social media post. So the conspiracy theories persisted, even after the explanation was available.
This has implications for how government agencies release documents. If the technical quality is visibly poor, people will question whether the documents have been tampered with or whether secrets are being hidden. Taking time to ensure documents are properly converted and proofread would avoid these suspicions. The extra effort, while expensive, might be worth it for credibility.

Broader Context: Government Document Release and Trust
The Epstein files represent just one example of the government releasing documents under public pressure or legal requirement. The Mueller report, which the PDF Association also analyzed, had similar technical issues from scanning and OCR. The Panama Papers, WikiLeaks releases, and other large document dumps have all had their own technical challenges.
There's a tension between releasing documents quickly to meet legal deadlines and taking time to ensure quality. Government agencies are often under pressure to release documents on schedule. Careful quality control takes time and resources. Something has to give, and usually it's quality.
But document quality affects public trust and the utility of the documents themselves. If documents are hard to read or appear to have been tampered with, people lose confidence in them. Conspiracy theories fill the gap left by missing confidence.
This is a broader lesson about the importance of technical care in public-facing work. When you release documents to the public, they should be readable and trustworthy. This requires investment in proper tools, training, and quality control. It's not glamorous work, but it matters.

Conclusion: From Technical Error to Public Understanding
The equals signs in Jeffrey Epstein's released emails aren't a secret code. They're not a cipher created by criminals to hide their communications. They're a visible manifestation of the technical complexity involved in converting email from one format to another.
Understanding this requires understanding email standards that were created decades ago, PDF specifications, character encodings, and the practical challenges of processing documents at scale. It's technical, it's detailed, and it's not the kind of thing that gets explained in news articles or social media posts.
But that's exactly why understanding it matters. In an era where government documents, company emails, and personal communications are increasingly being made public or subpoenaed, technical literacy becomes important for understanding what's real and what's an artifact.
The conspiracy theories that spread around the Epstein emails weren't necessarily wrong to question. It's good to ask questions about released documents. It's good to wonder if something unusual is actually evidence of something hidden. But when you ask those questions, you should also be willing to learn the technical explanation. The equals signs tell a story, just not the story you might have expected. They tell a story about how old systems and new systems interact, about the challenges of working with legacy data, and about why the experts who understand these systems are valuable.
The next time you see something unusual in a released document, take a moment to think about the technical processes that document has gone through. Ask what software was used. Ask about encoding. Ask about conversion steps. The unsexy technical answer is often the true one.
And if the DOJ is reading this: next time, maybe include a note explaining the conversion process. It would help.
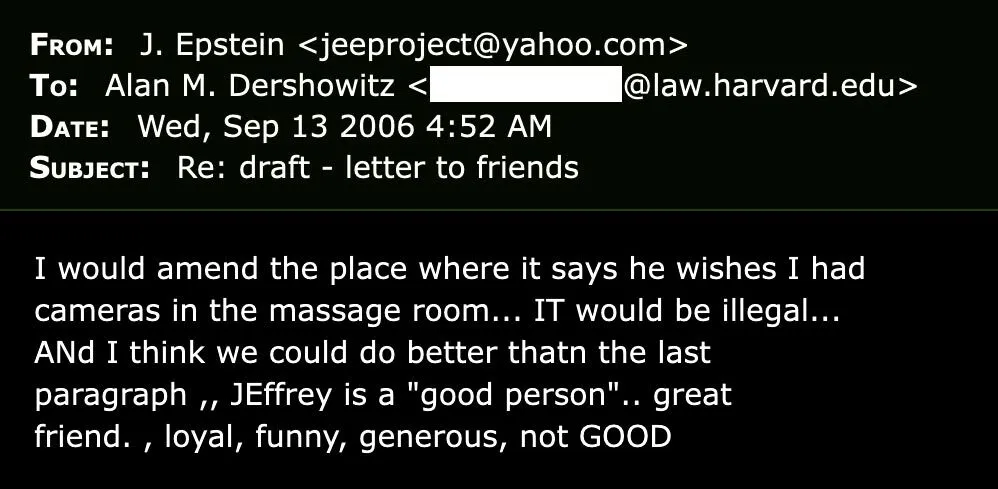
FAQ
What is MIME encoding and why is it used in emails?
MIME (Multipurpose Internet Mail Extensions) is a standard created in 1992 that allows email systems to transmit non-ASCII characters, formatted text, and attachments through networks that originally only supported simple ASCII text. Email was designed in the 1970s to work with only basic text characters, so MIME was developed as a workaround to enable more complex content by encoding it back into ASCII representation. When you send an email with special characters or formatting, your email client automatically encodes it using MIME before transmission, and the recipient's email client decodes it back into readable format before displaying it to you.
How did the equals signs end up in the Epstein documents?
The equals signs are remnants of MIME encoding that didn't get properly decoded during the DOJ's document conversion process. When the government extracted emails from servers and converted them to PDF, then to JPEG for security, then back to PDF, the software doing these conversions failed to properly decode the MIME encoding layer. Instead of showing the final character that the equals sign was supposed to represent, the software left the raw MIME encoding visible in the document, which is why you see equals signs where they shouldn't be.
Why couldn't the conversion software properly decode the MIME encoding?
The conversion software likely failed because of character encoding incompatibilities between different email clients and systems. The emails in the Epstein files came from various sources, including BlackBerry devices and iPhones, which implement email standards in different ways. When an email passes through multiple systems with different encoding implementations, the metadata about how the email should be decoded can become ambiguous or incorrect. The conversion software probably had to make assumptions about which character encoding to use, and when those assumptions were wrong, it couldn't properly decode the MIME layer.
Is there a way to fix the garbled text in the already-released documents?
It would be possible to re-process the original email files using better conversion tools and techniques, which could potentially produce cleaner PDFs. However, the DOJ would need access to the original email files or archives that the PDFs were created from, and they would need to justify the effort and expense of re-processing thousands of documents. A practical middle ground might be to release the original email files in a preservation format like MBOX alongside the existing PDFs, allowing researchers and forensic experts to access the original data directly.
Could the equals signs actually be hiding something?
No, there's no evidence that the equals signs are intentionally obfuscating information or hiding a secret code. Multiple experts in email standards, archival science, and PDF specifications have independently confirmed that the equals signs are artifacts of a failed MIME decoding process. The same technical errors appear in other large-scale document releases, like the Mueller report, in ways that have nothing to do with the specific content. The pattern is consistent with a technical error, not deliberate encoding.
What should government agencies do differently when releasing large volumes of email?
Government agencies should invest in specialized email conversion tools designed specifically for preserving email integrity, implement quality control processes to check for encoding errors before release, be transparent about the conversion process and any known limitations, and consider releasing email in multiple formats including the original email archive format alongside converted PDFs. They should also allocate more time and resources to document conversion rather than rushing the process to meet tight deadlines, since poor document quality erodes public trust and invites conspiracy theories.
Are there other examples of document conversion creating similar technical artifacts?
Yes, the PDF Association found similar issues when analyzing the Mueller report, which was created using OCR scanning rather than digital extraction. Different conversion methods create different types of errors: digital extraction can introduce encoding issues like the equals signs, while OCR scanning can misread characters and create visual artifacts. This is a general problem in digital forensics and document management whenever data from one system needs to be converted to another format for different purposes.

Key Takeaways
- The equals signs in Epstein documents are MIME encoding artifacts, not a secret code or cipher.
- The DOJ's five-step conversion process (extract, PDF, redact, JPEG, PDF) failed to properly decode email standards.
- Character encoding incompatibilities between BlackBerry, iPhone, and other email clients created decoding problems.
- Email conversion to PDF is inherently complex because email was never designed for this workflow.
- Multiple experts independently verified the technical cause, debunking conspiracy theories.
- Government agencies should invest in better tools and quality control when releasing large document volumes.
Related Articles
- FBI Recovers Nest Camera Footage: What This Means for Your Smart Home Privacy [2025]
- Why RAG Systems Fail on Complex Documents: The Dark Data Problem [2025]
- Ring Verify & AI Deepfakes: What You Need to Know [2025]
- Anthropic's Cowork: Claude Code Without the Complexity [2025]
- Scattered Lapsus$ Hunters Caught in Honeypot: Inside the Bust [2025]
- Alexa Plus Website Early Access: AI Assistant Now on Desktop [2025]

