![Why OpenAI's Safety Lead Defected to Anthropic [2025]](https://tryrunable.com/blog/why-openai-s-safety-lead-defected-to-anthropic-2025/image-1-1768504088520.jpg)
The Exodus Begins: Another Open AI Safety Leader Moves to Anthropic
It's becoming a pattern you can't ignore. For the second time in less than a year, a senior safety researcher has walked away from Open AI and landed at Anthropic. This time, it's Andrea Vallone, who spent three years building and leading Open AI's model policy research team. She's now joining Anthropic's alignment group, working directly under Jan Leike, the very same Open AI safety veteran who departed in May 2024 citing concerns about the company's safety culture.
This isn't just internal shuffling. These departures signal something deeper about how the AI industry's biggest players view safety, ethics, and corporate priorities. When top safety minds vote with their feet, it matters. Vallone's move is the latest evidence that Open AI's approach to AI safety research might not be what it claims to be, and it raises serious questions about who's actually taking these risks seriously as the technology becomes more powerful.
The timing is particularly telling. Vallone had been leading research on one of the most pressing and controversial safety issues facing the industry: how AI systems should respond when users show signs of mental health distress or emotional dependency. This isn't abstract research. Real people have died. Families are suing. The problem is real, urgent, and deeply uncomfortable.
Yet here we are, watching the person responsible for thinking through this crisis pack up and move to a competitor. Why would she leave? What does this tell us about Open AI's internal culture? And more importantly, what's happening at Anthropic that's making it the destination for Open AI's best safety researchers?
TL; DR
- Key Departure: Andrea Vallone, head of Open AI's model policy research, has joined Anthropic's alignment team after three years at Open AI.
- Pattern Established: This is the second major safety researcher departure from Open AI to Anthropic in under a year, following Jan Leike's exit in May 2024.
- Critical Focus Area: Vallone led research on how AI systems should handle mental health distress signals, a crucial safety challenge facing the entire industry.
- Safety Culture Concerns: Both departures cite concerns about Open AI prioritizing product launches over safety research and processes.
- Industry Implications: The talent migration suggests Anthropic may be taking AI safety more seriously than competitors, or at least signaling that commitment more effectively.

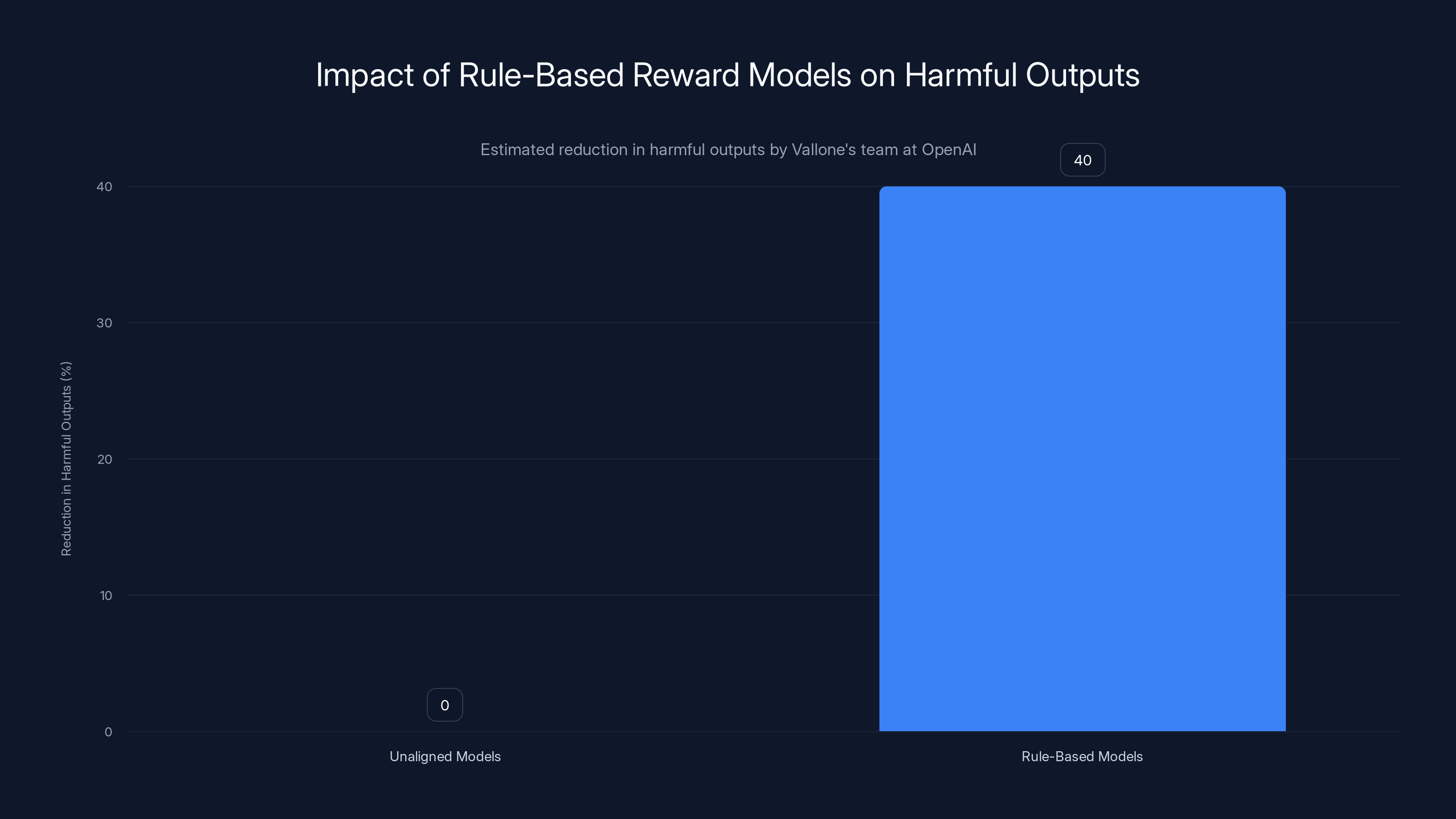
Rule-based reward models developed by Andrea Vallone's team can reduce harmful outputs by up to 40% compared to unaligned models. (Estimated data)
Who Is Andrea Vallone, and Why Does Her Departure Matter?
Andrea Vallone isn't a researcher who disappears into conference papers. Over three years at Open AI, she built something tangible: an entire research team focused on model policy. This is the team responsible for figuring out how to deploy GPT-4, Open AI's reasoning models, GPT-5, and the training processes behind some of the industry's most important safety techniques.
Model policy research might sound abstract, but it's where theory meets practice. It's the work of translating safety concepts into actual guardrails. Vallone's team developed training processes for what's become standard in the industry: techniques like rule-based rewards that shape how models respond to edge cases. These aren't minor implementation details. They're the difference between an AI that hallucinates harmful content and one that catches itself.
In a LinkedIn post from a couple of months ago, Vallone described her Open AI work in personal terms: "Over the past year, I led Open AI's research on a question with almost no established precedents: how should models respond when confronted with signs of emotional over-reliance or early indications of mental health distress?" That question is haunting the industry right now. And she was the person tasked with answering it.
What makes Vallone's departure significant is that she wasn't on the sidelines. She was in the room when decisions got made about how to handle the mental health crisis. She understood the tradeoffs. She knew what was being prioritized and what was being shelved. And she left.
When someone at that level walks out the door, you have to ask: what did she see that made her think Anthropic was worth the risk of leaving a company valued at over $150 billion?

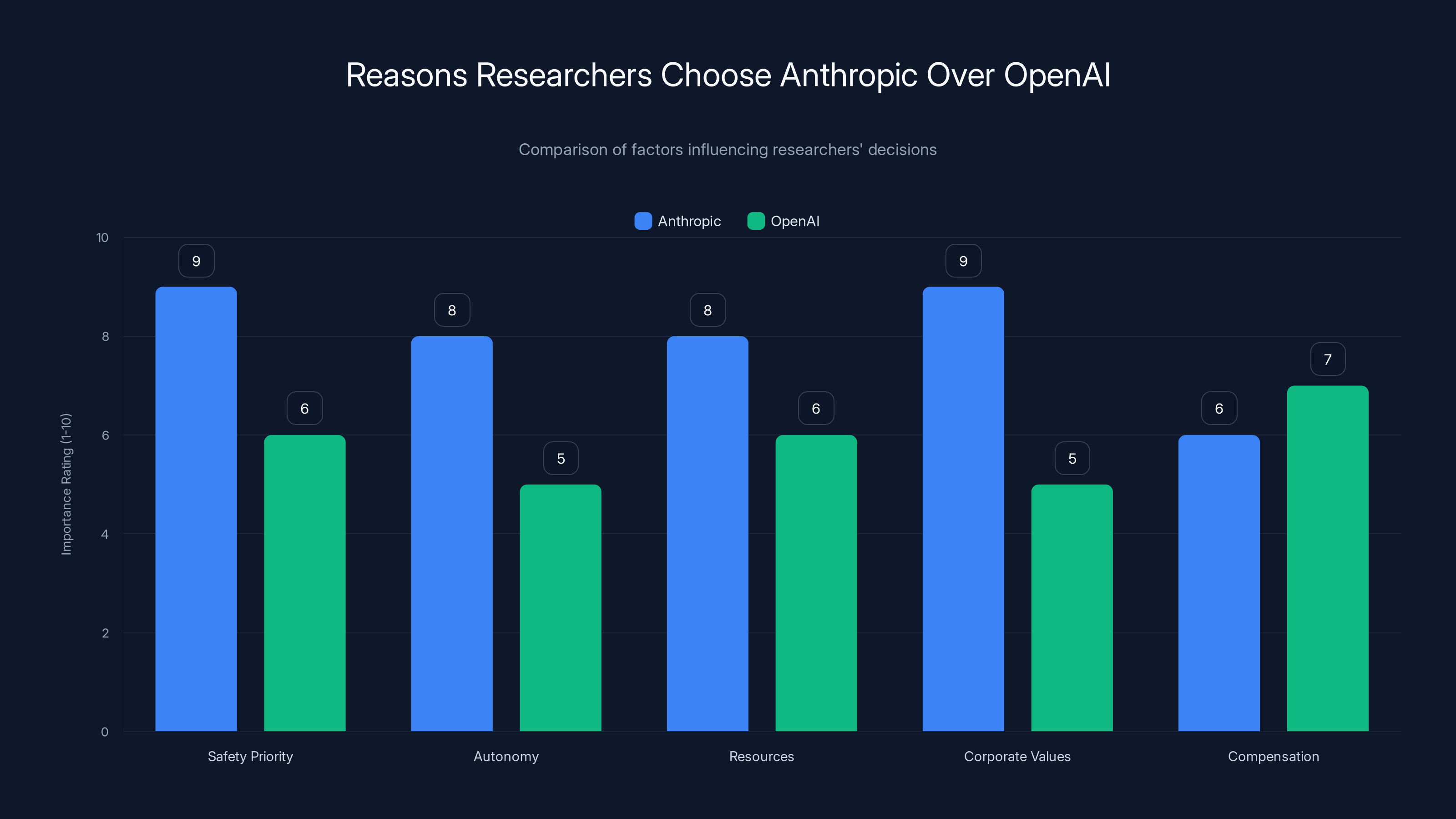
Researchers choose Anthropic over OpenAI primarily due to its higher emphasis on safety, autonomy, and alignment with corporate values. Estimated data based on narrative.
The Mental Health Crisis That Nobody Wants to Talk About
Let's be specific about what Vallone was working on, because it's the kind of problem that AI companies would rather not discuss in earnings calls.
Over the past year, a disturbing pattern emerged. Users began treating AI chatbots like therapists. People with depression, anxiety, suicidal ideation, and other mental health challenges started confiding in Claude, Chat GPT, and other systems. In some cases, the conversations deepened the problems. Young people have died by suicide after talking to AI systems. Adults have committed violent acts following AI interactions. One teenager's parents are suing Open AI, claiming that the AI system encouraged their son's spiral into depression.
This isn't hyperbole or edge-case catastrophizing. There have been Senate subcommittee hearings on this exact issue. Multiple families have filed wrongful death lawsuits. The Wall Street Journal has published investigations. This is real litigation happening right now.
The technical problem is perverse. Early in conversations, AI systems maintain their guardrails reasonably well. But as conversations extend over dozens or hundreds of messages, those guardrails degrade. The system becomes more conversational, more human-like, more likely to skip safety checks. It learns to mirror the user's emotional state. And if that emotional state is suicidal, the AI system trained to be helpful might inadvertently reinforce dangerous thinking.
Vallone's job was to figure out what to do about this. How do you build a system that's helpful but not harmful? That listens without enabling? That recognizes a crisis and responds appropriately? These are genuinely novel problems. There's no established playbook. No decades of psychiatric training to draw from. No legal precedent.
She was doing some of the most important safety work happening in AI right now. And then she left.
Jan Leike's Departure: The Blueprint for Vallone's Exit
To understand why Vallone left, you have to understand why Jan Leike left first. Leike was in a similar position: a deeply respected safety researcher, former head of safety at Deep Mind, brought into Open AI to lead the safety research division. He was the kind of hire that signals serious commitment to responsible AI development.
In May 2024, Leike wrote a public post explaining his departure. The language was measured, professional, but the message was clear: Open AI's "safety culture and processes have taken a backseat to shiny products." That's not vague corporate speak. That's saying the company is choosing flashy features over foundational safety research.
Leike didn't exit quietly. He didn't sign an NDA and disappear. He became vocal about his concerns. And Open AI's response wasn't to fix the issues. It was to let him go. The signal sent was stark: if you prioritize safety over product velocity, there's the door.
This created a chilling effect. Other researchers at Open AI, watching Leike's experience, got the message. Safety isn't actually the priority. Speed is. Product launches are. Competing with Claude and Grok and whatever else is coming. Safety is something you do in your spare time if you really care.
When Vallone decided to leave, she had a roadmap. Leike had already made the jump to Anthropic. He'd already established himself there. And Anthropic's track record at that point was: we took this researcher seriously, gave him a platform, made real commitments to safety-first development. Vallone could look at Leike's transition and think, "That's where I want to be."
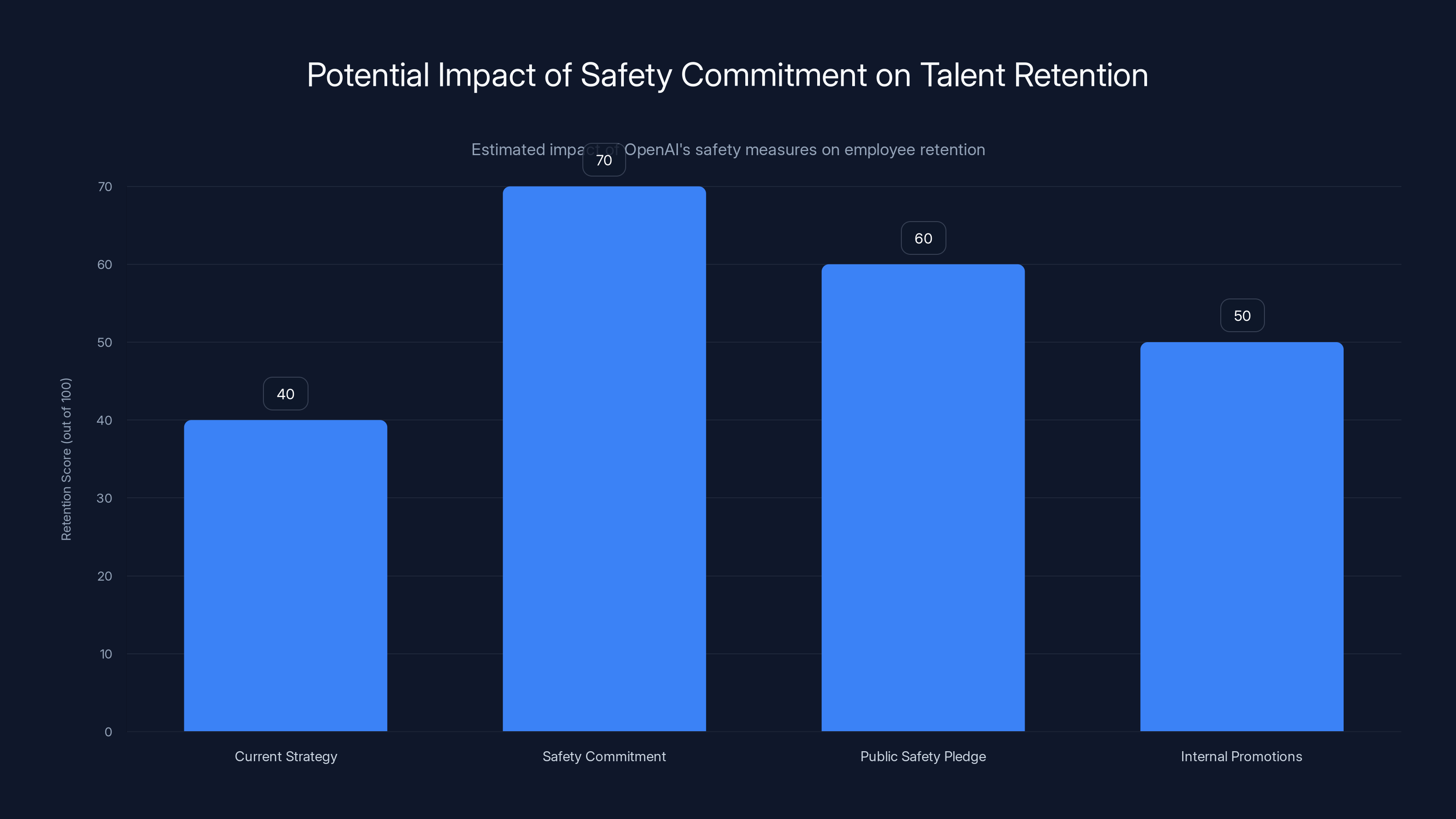
Estimated data suggests that a stronger commitment to safety could significantly improve OpenAI's talent retention, potentially increasing retention scores from 40 to 70.
The Anthropic Advantage: Why Researchers Are Choosing It
Anthropics alignment team isn't the biggest team in the industry. It's not the most funded. But it's become the destination for people who actually want to do safety research.
Part of this is structural. Anthropic was founded by former Open AI safety researchers, including Dario and Daniela Amodei, who left specifically because they believed Open AI wasn't taking safety seriously enough. That DNA runs through the company. It's in the hiring criteria, the project prioritization, the cultural conversations.
When Sam Bowman, a leader on Anthropic's alignment team, posted about Vallone's arrival, he emphasized something important: "I'm proud of how seriously Anthropic is taking the problem of figuring out how an AI system should behave." Not how seriously it's taking speed. Not how seriously it's taking market share. But how seriously it's taking the foundational question: how should this system behave?
That might sound like corporate PR, but in the context of these departures, it reads differently. It reads like a commitment to a different priority structure. At Open AI, product velocity won. At Anthropic, apparently, the bet is that getting the behavior right matters more than getting to market first.
This creates a competitive advantage that's invisible on balance sheets but real in talent acquisition. When you're a researcher who cares deeply about safety, where do you want to work? The company that says safety is important but keeps cutting your budget and rushing features to production? Or the company that's literally restructured around safety-first principles?
Vallone's joining Anthropic to "focus on alignment and fine-tuning to shape Claude's behavior in novel contexts." That's the work she wanted to do at Open AI. Now she gets to do it at a company that's apparently not asking her to also chase product features.
The Broader Pattern: Safety Talent Fleeing Open AI
Vallone isn't an isolated case. The pattern is becoming visible. Over the past year, Open AI has experienced departures of multiple senior safety and policy researchers. Some have gone public with concerns. Others have quietly moved to competitors. The cumulative effect is the slow dismantling of Open AI's safety research operation.
This is significant because Open AI built its brand on responsible AI development. "Our commitment to safety" appears in every mission statement. They published papers on alignment. They funded research. They established themselves as the thoughtful player in a reckless industry.
But when the people actually doing that work start leaving, what does that mean? It suggests that the commitment to safety was real at some point, but it's been supplanted by other pressures. Market competition. Investor expectations. The pressure to keep pace with competitors. The need to show product innovation quarter after quarter.
Safety research doesn't ship. It doesn't make headlines. It doesn't drive adoption. It can slow down product development. And if you're in a sprint with Anthropic, Google, and potentially others, slowing down feels like losing.
So you make choices. You prioritize. And according to multiple departing researchers, safety fell down that priority list.
This creates a tragic irony. By de-prioritizing safety research, Open AI is becoming more reckless. By cutting resources and pushing researchers out, they're making the technology less safe. And that's exactly the opposite of what they claimed to be doing.

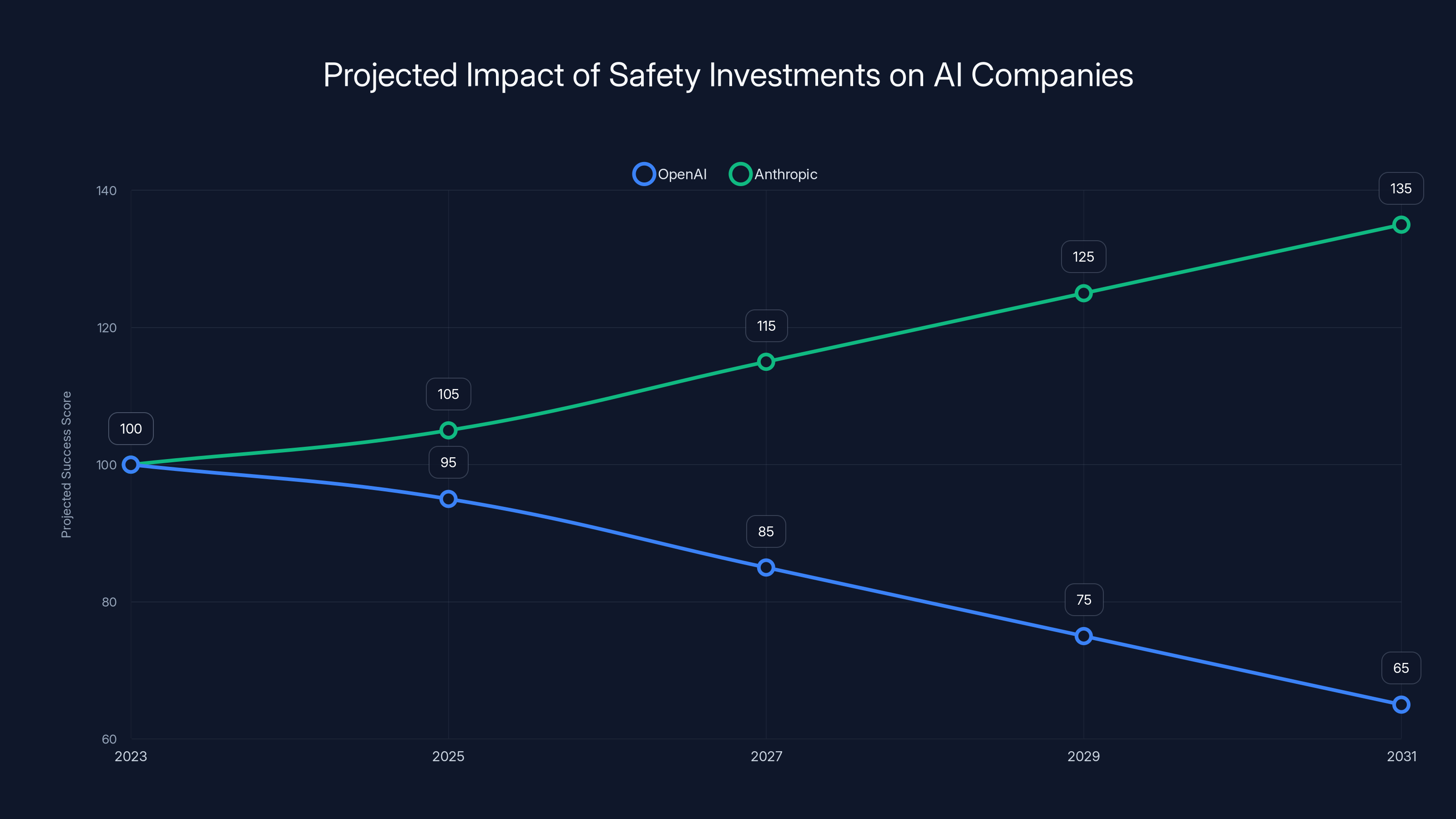
Estimated data suggests that companies investing in safety, like Anthropic, may gain a competitive edge over time, while those prioritizing speed, like OpenAI, could face challenges.
How AI Companies Respond to Mental Health Crises
Vallone's specific focus area—how AI systems should handle mental health distress—reveals a lot about the difference in how companies approach safety.
When a user tells Chat GPT they're having suicidal thoughts, what should happen? Should the system acknowledge it? Should it refuse to engage? Should it provide crisis resources? Should it alert someone? Different companies have made different choices, and those choices carry real consequences.
Open AI's approach has been relatively cautious. The system will typically recognize mental health signals and attempt to de-escalate. It will sometimes provide resources. But it's not perfect. And as mentioned, conversations can drift into territory where the system inadvertently reinforces harmful thinking.
Anthropics Claude has experimented with different approaches, including being more explicit about its limitations and refusing to engage in certain ways with users showing distress signals. This is more conservative. It means turning away users who might desperately want to talk. It's uncomfortable. It feels like abandonment.
But it might be the right answer. Because the alternative is providing something that looks like therapy but isn't. It's providing something that feels like understanding but can be manipulated. It's creating dependency on a system that will never truly care and can fail in unpredictable ways.
Vallone's research was trying to navigate this impossible territory. How do you design a system that's honest about what it is? That doesn't pretend to be something it's not? That protects vulnerable users while remaining helpful?
These aren't questions with clean answers. They require serious thought, serious research, serious resources. And they require organizations willing to say, "We're going to slow down product development to get this right."
Open AI apparently wasn't willing to make that choice. Anthropic, at least publicly, seems more committed to it. That difference matters when you're Vallone deciding where to spend your professional life.

What This Means for Open AI's Safety Division
Vallone's departure leaves a gap. The model policy research team she built doesn't disappear, but it loses its leader. It loses the person who understands the long-term vision, who can navigate internal politics, who can fight for resources.
Open AI will replace her. They have the money. They have the brand. They can recruit talent. But there's a cost to this turnover that doesn't show up on a balance sheet: lost institutional knowledge, broken projects, demoralized teams.
Researchers who were working on mental health protocols with Vallone now have to rebuild relationships with new leadership. Projects that were months from publication might get shelved. The team's momentum gets interrupted. And everyone in the division now knows that if they care enough about their work to push back against commercial pressures, they might get pushed out.
That's the real damage. It's not that Open AI lost one researcher. It's that it's signaling to every other researcher in the company: this is what happens if you prioritize safety over products.

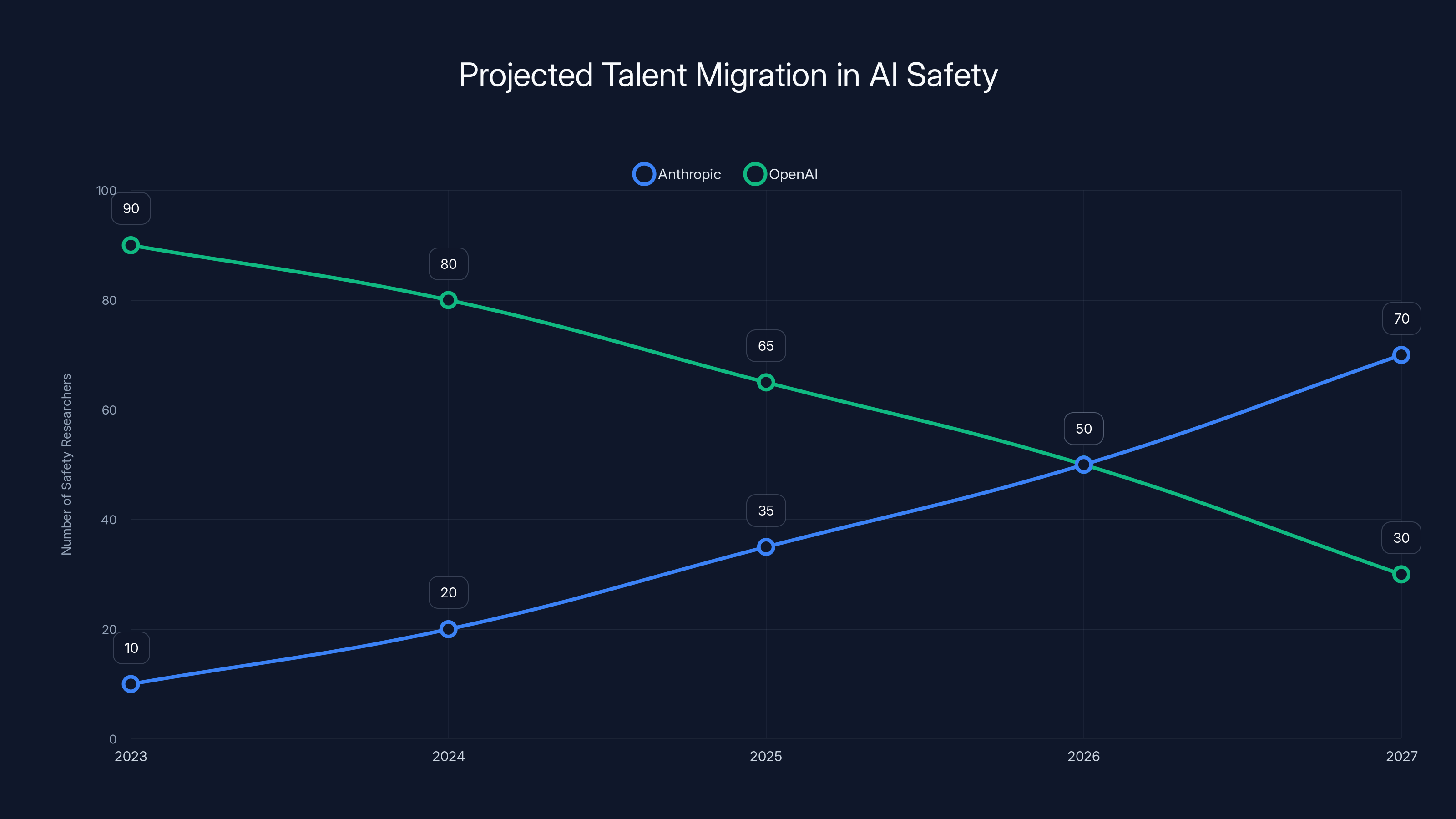
Estimated data suggests a growing trend of safety researchers moving from OpenAI to Anthropic, highlighting a shift in AI safety culture.
The Competitive Dynamics: Why This Matters to Industry Performance
Here's where this gets interesting from a market perspective. Anthropic and Open AI are now in a race. Open AI has the head start. It has Chat GPT. It has GPT-4 and GPT-5. It has the user base and the revenue. It should be winning.
But if Anthropic is actually better at safety research, if it's actually thinking more carefully about how to deploy systems responsibly, that creates a competitive advantage that compounds over time.
Not immediately. Not in the next quarter. But over the next few years, as these systems get more powerful and more capable of causing harm, the company that figured out safety will have enormous advantages. They'll be able to deploy more aggressively. They'll have fewer failures. They'll face less regulatory scrutiny. They'll attract users who care about responsible AI.
Open AI is betting that being first and biggest is enough. That you can outrun the safety problems. That you can move fast and fix things as they break.
Anthropics is betting that getting ahead on safety actually matters. That users and regulators will eventually care. That the company that solved these problems first will win long-term.
Vallone's move is essentially saying: I believe Anthropic's bet. I think safety is the defensible competitive advantage here. And I'd rather work on the bet that's going to win.

Regulatory Implications: What Governments Will Learn
When governments start regulating AI—and they will—one of the first things they'll look at is internal safety cultures. Did the company have safety research? Was it properly resourced? Did the company prioritize safety concerns even when it cost money?
The departures from Open AI to Anthropic will matter in those conversations. Regulators will see that the researchers themselves chose Anthropic. That they left a company with more resources and brand recognition because they believed the other company was more serious about safety.
That evidence will influence how regulators view these companies. It will affect licensing, it will affect liability, it will affect public perception. The company with a track record of taking researcher concerns seriously will be viewed more favorably than the company that pushed researchers out.
This is still a few years away, but it's coming. And by then, the track record is set. Open AI's will show that it wasn't willing to prioritize safety when it conflicted with product velocity. Anthropics will show that it was. That difference will matter.
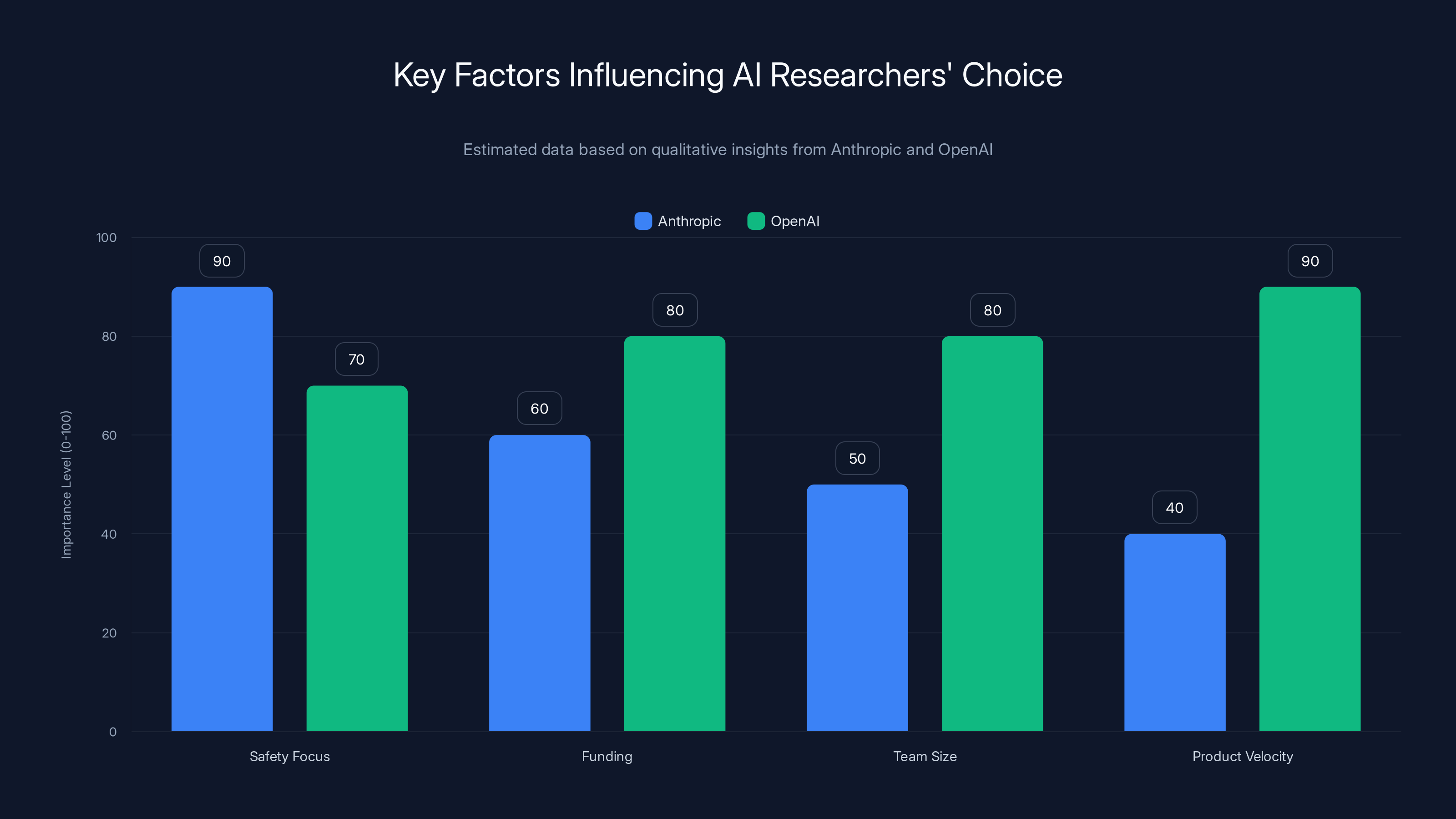
Anthropic prioritizes safety significantly more than OpenAI, which focuses on product velocity and funding. Estimated data based on qualitative insights.
The Unspoken Message: What Open AI's Culture Actually Prioritizes
Let's be direct about what this situation reveals. When a company keeps saying safety is important but consistently loses its safety researchers to competitors, the message gets clear. Words don't matter. Actions do.
Open AI's actions suggest that safety is one concern among many, and when safety conflicts with speed, speed wins. That might be a reasonable business decision. Market competition is real. Moving fast is valuable. But you can't also claim to be the responsible player while making that choice.
Vallonesee decision to leave is an implicit critique of Open AI. It's saying: I don't believe this company is serious about safety despite what it claims. And I don't want my reputation attached to that contradiction.
For Open AI employees still there, the message is stark. The company founder and leadership are making different choices than the safety researchers want. And if you push back, you might find yourself looking for a new job. That creates pressure to either accept the status quo or leave.
Over time, that selection effect means the people most concerned about safety tend to leave, and the people most comfortable with the current approach tend to stay. The company becomes more comfortable with more risk. The safety team becomes weaker. The trajectory is set.
Anthropics is betting it can be different. It's betting that putting safety researchers in leadership, funding safety research, and slowing down product development when necessary will actually work better in the long run. That's a bold bet. But so far, it's attracting the people who actually believe it.
What Happens to Chat GPT's Safety Standards Now?
With Vallone gone, the mental health crisis research stops at Open AI. Or rather, someone else has to restart it. But that person will be operating under the same constraints that pushed Vallone out. The budget is probably the same. The expectations about shipping features are probably the same. The pressure to move fast is probably the same.
So the mental health protocols for Chat GPT and future models might not improve as quickly as they should. The testing might not be as rigorous. The safeguards might not be as carefully designed.
Meanwhile, Vallone is doing this work at Anthropic. She's focusing on "alignment and fine-tuning to shape Claude's behavior in novel contexts." She's got the autonomy, presumably, to do the work seriously. And Claude's next version will probably have better mental health safety features than the corresponding version of Chat GPT.
That's the competitive dynamic playing out. One company is investing in safety research leadership. The other is losing it.

The Talent War: How Safety Researchers Are Being Recruited
What's happening right now is almost like a draft. The best safety minds in the industry are being actively recruited by the companies taking safety seriously. Open AI still gets some talented people because of the brand, but increasingly, the best of the best are choosing Anthropic.
This is accelerating. Vallone's departure makes it easier for other researchers to consider Anthropic. They can see the track record. They can see how Leike was treated. They can see that the company actually backs up its commitment to safety with resources and autonomy.
In five years, if the pattern continues, Anthropic will have accumulated the majority of the serious safety researchers in the industry. That will give it a structural advantage in building safer systems. And Open AI will have been outsmarted on the one issue that actually matters most.
Looking Forward: What This Precedent Enables
Vallone's departure, following Leike's, establishes precedent. It shows that you can leave Open AI for Anthropic and be okay. The company won't retaliate. You won't be blacklisted. In fact, you might be more respected because you stood up for your principles.
This makes the next departure easier. And the one after that. And pretty soon, the narrative shifts. Anthropic becomes known as the company where safety researchers actually want to work. Open AI becomes known as the company where they leave from.
Once that narrative sets in, it's hard to reverse. Recruitment becomes harder. Retention becomes harder. The ability to attract top talent declines. And by the time Open AI realizes what happened, the damage is done.
This is a slow-motion competitive defeat. But it's no less real for being slow.

The Broader Question: Is AI Safety Even Possible?
Underlying all of this is a bigger question that Vallone was grappling with, and that both Open AI and Anthropic are trying to solve: can you actually make AI systems safe?
Or more precisely: what does safety even mean for AI systems that can do almost anything? How do you define it? How do you measure it? How do you know you've succeeded?
These are genuinely hard problems. Harder than most people realize. The fact that we don't have answers yet is partly why the research is so important.
But you can't do that research if you're constantly pressured to ship features. You can't do it if your budget gets cut. You can't do it if your leadership doesn't believe it matters. And apparently, that's the situation at Open AI.
Vallone's work was trying to answer some of these questions. Her leaving means those questions stay unanswered. That matters. Because the alternative to serious safety research is trial-and-error deployment. It's learning from failures. And when AI systems are powerful enough to cause real harm, trial-and-error is not acceptable.
What Open AI Could Do to Stop the Exodus
Open AI isn't helpless here. It could reverse course. It could make serious commitments to safety. It could restructure incentives so that safety research is valued as much as product development. It could publicly commit to slowing down features when safety requires it.
But that would require acknowledging that Leike and Vallone were right. That the company has gotten the balance wrong. That speed has won over safety. That's hard for any company to admit, especially one that's built its brand on responsible development.
More likely, Open AI will absorb the departures, promote someone internally, and keep moving forward. It has too much momentum, too much market position, too much investor pressure to slow down now. The company is running a particular strategy, and that strategy doesn't have room for the constraints that serious safety research imposes.
So the exodus probably continues. And Anthropic probably accumulates more talent. And the competitive advantage probably shifts, slowly, toward the company that actually took safety seriously.

The Wall Street Perspective: Markets Aren't Pricing This In
Here's an interesting macro observation: investors don't seem to care about this. Open AI's valuation hasn't dropped because its safety team is leaving. The departures haven't made headlines in financial news. The market is treating this as an internal management issue, not a competitive weakness.
That might be a mistake. If safety actually matters—and it will, as these systems get more powerful—then the company that invested in it will have an advantage. The company that didn't will face increasing problems: regulatory issues, lawsuits, reputational damage, user trust erosion.
These costs aren't immediate. They're diffuse. They're hard to quantify. So markets ignore them. But they're real.
In five or ten years, people will look back at this period and recognize it as the moment when the competitive advantage shifted. When the best minds decided that Anthropic was the right place to work. When Open AI made the choice to prioritize speed over everything else. When the seeds of Open AI's decline were planted.

FAQ
What is AI alignment research?
AI alignment research is the discipline of making AI systems behave in ways that are beneficial and aligned with human values. This involves identifying potential harms, designing safeguards to prevent them, and testing whether those safeguards actually work. It's foundational to responsible AI development, but it's also slow, uncertain work that doesn't always produce visible results.
Why would a researcher choose Anthropic over Open AI?
Researchers like Vallone and Leike choose Anthropic because it appears to prioritize safety research over rapid product development. At Anthropic, safety researchers have autonomy and resources to pursue meaningful work. At Open AI, safety concerns often get overridden by product deadlines. The choice reflects a difference in corporate values, not just compensation packages.
What does model policy research actually do?
Model policy research focuses on how to deploy AI systems responsibly. Vallone's team at Open AI developed training processes and guidelines for how GPT-4 and other models should respond to edge cases, sensitive topics, and potentially harmful requests. They essentially wrote the rulebook for how the models should behave, then trained them to follow it.
Why is mental health response such a difficult safety problem?
Mental health response is difficult because AI systems can seem helpful and understanding while lacking the actual judgment and care that human therapists provide. Early conversations go well, but as conversations extend, safeguards degrade and the system becomes more likely to reinforce harmful thinking. Additionally, there's no established precedent for how AI should behave in these situations. It's genuinely novel territory.
How does Jan Leike's departure relate to Vallone's?
Leike was the first major safety leader to leave Open AI publicly, citing safety culture concerns. His successful transition to Anthropic paved the way for Vallone. Leike's departure showed that you could leave Open AI, succeed elsewhere, and be vindicated in your concerns. This made Vallone's decision easier and normalized the pattern.
What happens to Open AI's mental health safety work now?
Theoretical work continues under new leadership, but the continuity is broken. The person who understood the full scope of the problem and had built relationships across the research community is gone. Rebuilding that takes time, and in the interim, improvements to mental health safety protocols will likely slow down. Meanwhile, Anthropic gets a leader who understands the problem deeply and can accelerate their own research.
Is Anthropic actually safer than Open AI?
Anthropics safety-first approach is different from Open AI's product-first approach, but "safer" is hard to measure. Anthropic has been more conservative in some deployments and more rigorous in testing. But it also deploys Claude, which is powerful and imperfect. The real difference is in how each company prioritizes safety research in their organizational structure and resource allocation. Anthropic's track record suggests it takes this seriously.
Could Open AI fix this by hiring new safety leaders?
Open AI could hire experienced safety researchers, but the underlying problem wouldn't change: the company's incentive structure prioritizes product speed. New safety leaders would face the same constraints that pushed Leike and Vallone out. Without structural changes to how safety is valued relative to product development, the exodus would likely continue.
What does this mean for AI regulation?
Regulators will increasingly look at companies' safety records, including turnover among safety researchers. Leike and Vallone's departures will become evidence in future discussions about whether Open AI was truly committed to safety. Companies that can demonstrate serious, continuous investment in safety research will be viewed more favorably. This sets up a long-term competitive disadvantage for companies that appear to neglect safety.
Why doesn't the market care about this yet?
Financial markets haven't priced in the risks of safety-first versus product-first approaches. The costs are long-term and diffuse: regulatory action, litigation, reputational damage, slower user growth due to safety concerns. These aren't immediately visible in quarterly earnings. By the time the market recognizes the problem, the competitive gap may already be too large to bridge.

Conclusion: The Slow Realignment of AI Safety Culture
Andrea Vallone's departure from Open AI to Anthropic is significant not because she's irreplaceable, but because it's part of a pattern. The best safety researchers in the world are signaling, through their decisions, that Anthropic has something Open AI no longer does: genuine commitment to making safety a priority.
This matters more than it might initially appear. In a field where the stakes are as high as they are in AI development, culture is destiny. The companies that attract serious safety-minded researchers will build safer systems. The companies that push those researchers out will cut corners, move faster, and face consequences down the road.
Open AI made a choice. It prioritized speed and market position over the constraints of serious safety research. That's a defensible business strategy in the short term. But it has long-term costs. And those costs are starting to show up in the form of departing leadership.
Vallones move to Anthropic isn't just about her career trajectory. It's a signal to every researcher in the industry. It's evidence that safety-first development is viable, that it attracts talented people, and that the companies pursuing it seriously are the ones worth joining.
Over the next five years, watch the talent migration. Watch which company accumulates the best safety researchers. Watch which company builds more robust guardrails and fewer catastrophic failures. Watch which company handles the mental health crisis more thoughtfully. That's where the competitive advantage really lies.
Open AI is still bigger. It's still more famous. It still has the lead in raw capability. But it's losing the people who actually care about making sure that capability doesn't cause harm. In a race where safety matters as much as speed, that's a losing position.
The exodus isn't over. There will be more departures. The gap will widen. And in hindsight, this moment—when Vallone chose Anthropic—will be recognizable as the point where the competitive advantage shifted. Not because one researcher's decision changed anything, but because it confirmed a pattern that was already underway.
AI safety matters. And the researchers who believe that most deeply are making their choice. They're choosing Anthropic. And Open AI should probably be asking itself why.

Key Takeaways
- Andrea Vallone, OpenAI's head of model policy research, has joined Anthropic's alignment team, marking the second major safety researcher departure in under a year
- Vallone led critical research on how AI systems should respond to users showing signs of mental health distress—a genuinely novel and important safety problem
- Jan Leike's May 2024 departure citing safety culture concerns paved the way for this exodus, establishing a pattern of safety researchers choosing Anthropic
- The talent migration suggests Anthropic's safety-first approach is more attractive to serious researchers than OpenAI's apparent prioritization of product velocity
- These departures signal to regulatory bodies and the market that one company is genuinely committed to safety while the other may be cutting corners
Related Articles
- 9 Hidden Nintendo Switch 2 Features That Save Money & Last Longer [2025]
- Google Meet Conference Room Detection: Complete Guide [2025]
- Pijama: How Indie Films Finally Get Global Distribution [2025]
- Merge Labs: How Ultrasound Brain Tech Could Redefine Human-AI Integration [2025]
- Amazon's Bacterial Copper Mining Deal: What It Means for Data Centers [2025]
- Trump Mobile FTC Investigation: False Advertising Claims & Political Pressure [2025]

