![Wikipedia Blacklists Archive.Today After DDoS and Content Tampering [2025]](https://tryrunable.com/blog/wikipedia-blacklists-archive-today-after-ddos-and-content-ta/image-1-1771614372146.jpg)
Wikipedia Blacklists Archive.Today After DDoS and Content Tampering
In early 2026, the Wikipedia community made a historic decision. After months of deliberation, they voted to blacklist Archive.Today—removing nearly 700,000 links across hundreds of thousands of pages. But this wasn't a routine content moderation decision. It emerged from a pattern of conduct that combined distributed denial of service attacks, identity concealment, threats, and something far more insidious: the deliberate alteration of archived web content. According to Ars Technica, this decision was driven by the site's misconduct.
This story matters because it exposes deep vulnerabilities in how we verify information online. Archives are supposed to be immutable records of the internet. If we can't trust them, we lose a crucial tool for holding publishers and public figures accountable. Wikipedia's decision to blacklist Archive.Today signals that the platform takes this threat seriously. But it also raises uncomfortable questions about who controls the historical record, how we verify sources in an era of deepfakes and content manipulation, and what happens when anonymous operators decide the rules don't apply to them.
Let's break down what happened, why the Wikipedia community decided to act, and what this means for web archiving going forward.
What Is Archive.Today and Why Does It Matter?
Archive.Today is a web archiving service that lets users capture snapshots of websites at specific points in time. The service operates anonymously, with its founder and operators hidden behind layers of obfuscation. For years, it served a legitimate purpose: bypassing paywalls, preserving content before deletion, and creating a permanent record of web pages that might otherwise disappear.
The appeal is obvious. Journalists use Archive.Today to verify claims. Researchers cite archived versions of pages to show what a website said at a particular moment. Activists in countries with restrictive internet policies use it to document censorship and human rights abuses. In many contexts, Archive.Today functioned like the Internet Archive's Wayback Machine—a public utility for documenting the digital world.
But Archive.Today operated under a fundamentally different philosophy than other archiving services. The Internet Archive, a nonprofit based in San Francisco, prioritizes transparency and public trust. Archive.Today prioritizes anonymity and opacity. This distinction matters because it meant the service had no institutional accountability structure. If something went wrong, there was no board of directors to answer to, no nonprofit status to protect, no public commitments to maintain.
For years, this anonymity was simply an odd quirk of the service. But in 2023, a blogger named Jani Patokallio changed that calculus by publishing a post analyzing the possible identity of Archive.Today's maintainer. Patokallio wasn't making unfounded accusations. He documented evidence, traced alleged aliases like "Denis Petrov" and "Masha Rabinovich," and presented a reasoned argument that the service was likely operated by someone based in Russia. He published his findings, and then things got weird.
The Archive.Today maintainer demanded that Patokallio remove the post. When he refused, something darker unfolded: a campaign of harassment, threats, and eventually, a DDoS attack that would trigger Wikipedia's historic blacklisting decision.

The timeline illustrates the rapid sequence of events from 2023 to 2026 that led to Archive.Today's blacklisting, highlighting the impact of alleged misconduct and community response.
The DDoS Attack That Started Everything
In early 2026, Jani Patokallio's website came under attack. A distributed denial of service attack flooded his servers with traffic, making the blog inaccessible. DDoS attacks are common enough—cybercriminals and hostile actors use them routinely to silence critics, take down competitors, or simply cause chaos.
But this DDoS attack had a distinctive signature. Security researchers analyzing the traffic discovered that malicious code embedded in Archive.Today's CAPTCHA verification page was being used to direct users' browsers to bombard Patokallio's server. It was a weaponized version of a legitimate service. Archive.Today, which millions of people use to preserve web content, had been repurposed as a tool for silencing someone the maintainer disagreed with.
The mechanism is worth understanding because it reveals the sophistication of the attack. Archive.Today's CAPTCHA page—the verification screen users see when accessing the site—contained hidden code that executed a DDoS attack without users' knowledge or consent. Every person visiting Archive.Today during this period became an unwitting participant in an attack on Patokallio's blog. Their browsers, essentially hijacked, directed traffic toward targets the Archive.Today maintainer had chosen.
This revelation was shocking to the Wikipedia community. Here was a source that millions of Wikipedia editors cited regularly, and it had just demonstrated a willingness to weaponize its infrastructure against someone who had written about it critically. The implications were staggering. If Archive.Today would use its platform to attack one blogger, what prevented it from tampering with the archives themselves? What prevented it from manipulating captured content to serve political goals?
As it turned out, nothing did.
Archive.Today's Campaign of Harassment and Threats
While the DDoS attack was technically sophisticated, the broader campaign was equally concerning: it combined harassment, doxxing threats, and personal attacks. In emails sent to Patokallio after the DDoS began, someone claiming to be "Nora"—an alias used by the Archive.Today maintainer—made explicit threats.
The threats were crude but terrifying. Nora threatened to create explicit AI-generated imagery using Patokallio's likeness and associate it with his name across the internet. She threatened to create a fake gay dating app profile in his name. These weren't vague insinuations or implied threats. They were specific, detailed promises of harassment tactics designed to destroy his reputation, embarrass him, and make his online presence toxic.
For someone working in technology or journalism—fields where your online reputation is essentially your career—these threats carried real weight. Creating fake explicit content of someone is a form of sexual harassment. Creating fraudulent accounts in someone's name is identity theft. Weaponizing AI to generate defamatory material is potentially illegal in many jurisdictions.
The fact that these threats were accompanied by a DDoS attack showed a willingness to escalate. This wasn't a troll making idle threats in a comment section. This was someone with access to a major platform, using that access to attack infrastructure, and simultaneously threatening personal harassment. It was a coordinated campaign with multiple attack vectors.
What made the situation even more remarkable was that Patokallio didn't stay silent. He documented the attacks, published his findings, and reported what was happening to the Wikipedia community. His transparency and willingness to engage publicly despite the threats took courage. It also meant the Wikipedia community could see, in granular detail, exactly what was happening.

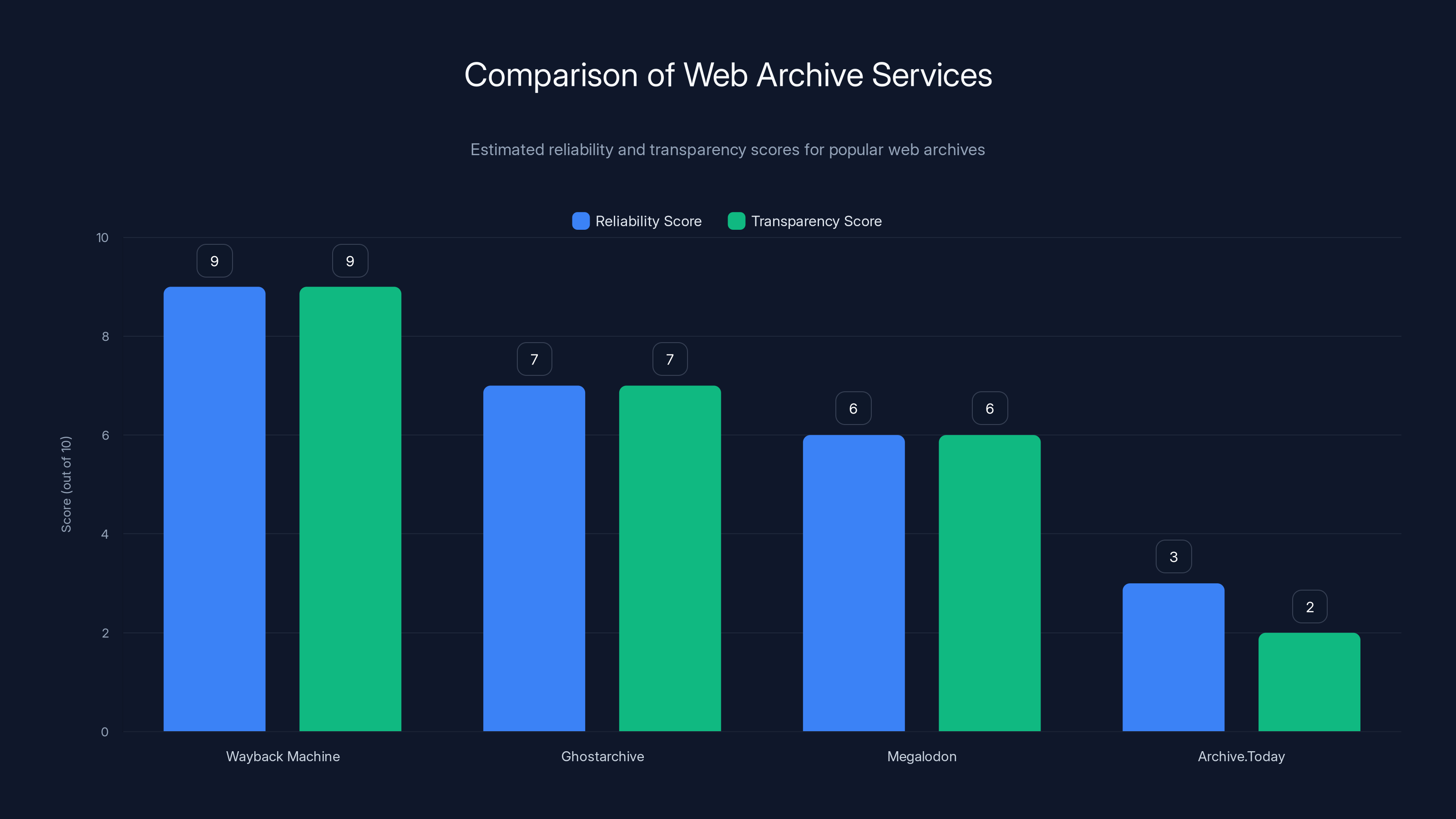
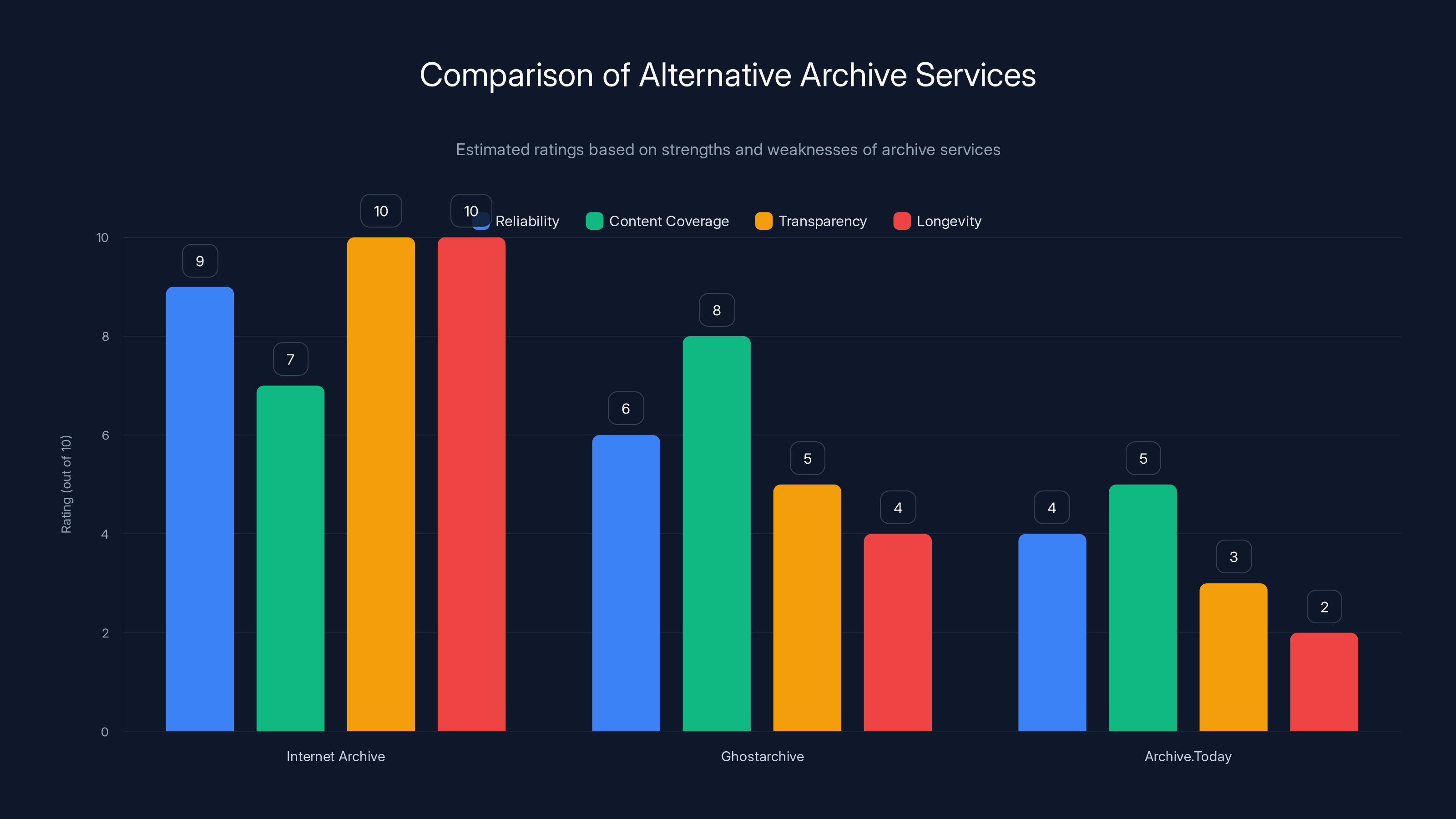
The Wayback Machine scores highest in reliability and transparency, making it the preferred choice for web archiving. Archive.Today scores lowest due to issues with content tampering and malicious activities. (Estimated data)
The Discovery of Tampered Archives
Here's where the situation escalated from concerning to genuinely alarming: Wikipedia editors discovered that Archive.Today had altered the content of archived web pages.
This is the core violation that transformed the discussion from "should we blacklist this source because it's sketchy?" to "should we blacklist this source because it's fraudulent?" Web archives are only valuable if they're accurate. If the entire premise is that they capture what a website said at a specific moment, and that archive can be modified after the fact, then archives cease to be reliable sources at all.
The tampering was discovered somewhat by accident. As Wikipedia editors reviewed Archive.Today captures related to the Patokallio situation, they noticed something odd: Patokallio's name had been inserted into some archived web pages where it didn't originally appear. The insertions appeared to be made after the archives were originally captured, likely to create evidence associating Patokallio with certain content or to discredit him by making it appear he was involved with things he wasn't.
One specific example involved a blog post related to the "Nora" alias. Patokallio had referenced this blog in his writeup of the DDoS attack. When Wikipedia editors examined the Archive.Today capture of that blog, they found that Patokallio's name had been inserted into the archived version. This is deliberate falsification of the historical record.
The implications are staggering. If Archive.Today's operators have the technical capability and willingness to alter captured content, then every archive on the platform becomes suspect. You can't assume that what you're reading is what was actually on the page. You have to assume that it might have been modified, selectively edited, or tampered with to serve the maintainer's agenda.
One Wikipedia editor expressed the horror clearly: "Just to make sure I'm understanding the implications of this: we have good reason to believe that the archive.today operator has tampered with the content of their archives, in a manner that suggests they were trying to further their position against the person they are in dispute with???"
Another responded: "If this is true it essentially forces our hand, archive.today would have to go. The argument for allowing it has been verifiability, but that of course rests upon the fact the archives are accurate, and the counter to people saying the website cannot be trusted for that has been that there is no record of archived websites themselves being tampered with. If that is no longer the case then the stated reason for the website being reliable for accurate snapshots of sources would no longer be valid."
They were right. The entire justification for using Archive.Today rests on the assumption that captures are accurate. Once that assumption crumbles, Archive.Today becomes not a reliable source, but a potential source of disinformation.
Wikipedia's Blacklisting Decision and Process
Wikipedia's response was decisive and comprehensive. After reviewing the evidence of DDoS attacks, threats, and content tampering, the Wikipedia community voted to immediately deprecate Archive.Today. This means the service was removed from the list of approved sources and flagged as unreliable.
The decision came through Wikipedia's Request for Comment (RfC) process, which is how the community collectively makes policy decisions. Editors submitted arguments both for and against blacklisting Archive.Today. Those opposing blacklisting argued that the service was useful for accessing paywalled content and preserving hard-to-reach information. Those supporting blacklisting pointed to the pattern of misconduct: the DDoS attack, the threats, the content tampering, and the lack of accountability.
The community reached consensus quickly. There's "consensus to immediately deprecate archive.today, and, as soon as practicable, add it to the spam blacklist (or create an edit filter that blocks adding new links), and remove all links to it," according to Wikipedia's official statement.
The statement was clear about why: "There is a strong consensus that Wikipedia should not direct its readers towards a website that hijacks users' computers to run a DDoS attack. Additionally, evidence has been presented that archive.today's operators have altered the content of archived pages, rendering it unreliable."
This wasn't a close call. It was a 75-25 or 80-20 type consensus among editors who weighed the evidence. And importantly, it was based on documented misconduct, not speculation. Wikipedia has policies against blacklisting sites based on subjective disagreements or political reasons. But when a site uses its infrastructure to attack people and tampers with historical records, the case for blacklisting becomes overwhelming.

The Scale of the Purge: 695,000 Links
One statistic puts the scope of the cleanup into perspective: more than 695,000 links to Archive.Today are distributed across approximately 400,000 Wikipedia pages. That's a staggering amount of sourcing infrastructure to untangle.
Think about what this number represents. It means that Archive.Today had become deeply embedded in Wikipedia's source ecosystem. Editors had used it to cite information, verify claims, and preserve web content across hundreds of thousands of articles. The service had earned trust through years of use. And now, all of that had to be reviewed, evaluated, and replaced.
Wikipedia didn't just remove all the links in a batch operation. The community developed specific guidance for how editors should approach the purge. The process acknowledges that different types of links require different solutions.
For links where the original source material is still online and hasn't changed, editors can simply remove the Archive.Today link. The original source becomes the citation. For links where the original source is no longer available, editors are encouraged to replace the Archive.Today link with a link to an alternative archive—the Internet Archive's Wayback Machine, Ghostarchive, or Megalodon. These services have better accountability structures and are less likely to tamper with content.
In some cases, editors are even encouraged to move to completely different types of sources. If an article cited something that was originally published in print, the guidance suggests citing the print publication instead of an archive of the web version. This actually improves article quality by directing readers to authoritative sources rather than secondary archives.
The magnitude of this cleanup is unprecedented in Wikipedia's history. It's not just about removing a problematic source. It's about replacing 695,000 citations with better alternatives, evaluating each one in context, and maintaining Wikipedia's commitment to accuracy and reliability. Tens of thousands of volunteers will need to participate in this effort, and it will take months or years to complete fully.
Estimated data shows the Wayback Machine as the dominant service, with smaller services and private archives playing crucial roles in digital preservation.
Alternative Archive Services: What to Use Instead
As Wikipedia editors faced the challenge of replacing Archive.Today links, the community converged on several alternative archiving services. Each has different strengths and weaknesses, but all are preferable to Archive.Today for different reasons.
The Internet Archive and Wayback Machine is the obvious first choice. Founded in 1996, the Internet Archive is a legitimate nonprofit based in San Francisco with a mission to provide universal access to digital heritage. The Wayback Machine is their flagship service—a search engine for the internet's past that has captured billions of web pages. Unlike Archive.Today, the Internet Archive operates with complete transparency. Their staff members are publicly known, their funding is public, and their technical infrastructure is audited regularly. When you cite the Wayback Machine, you're citing a source that will exist and be maintained for decades. The Internet Archive has survived multiple legal challenges and has proven its staying power.
But the Wayback Machine has its own limitations. It respects robots.txt files, which means websites can prevent the Internet Archive from capturing them. This is why some pages might not be available through the Wayback Machine even if they exist elsewhere on the web. The Internet Archive also doesn't capture everything immediately—there can be delays between when a page is submitted for archiving and when it becomes available.
Ghostarchive is another alternative that fills some of these gaps. Ghostarchive is more aggressive about capturing content, sometimes ignoring robots.txt restrictions. This means it can archive content that the Internet Archive won't touch. Ghostarchive is maintained by a small team of archiving enthusiasts and is free to use. However, Ghostarchive has less formal institutional backing than the Internet Archive, which creates some uncertainty about long-term viability. If the maintainers decide to shut it down, your links might disappear.
Megalodon is another option that specializes in creating clean, readable text versions of archived web pages. If you need to cite the text content of a page rather than its full HTML structure, Megalodon often provides a cleaner version. Like Ghostarchive, Megalodon is maintained by volunteers and lacks the institutional backing of the Internet Archive, but it fills a specific niche well.
Wikipedia's guidance was explicit: editors should prioritize the Internet Archive first, then Ghostarchive or Megalodon as alternatives. This hierarchy reflects a preference for institutional stability and proven reliability.

Why This Matters Beyond Wikipedia
Archive.Today's blacklisting is significant beyond Wikipedia, but it's important to understand the broader implications for how we verify information online.
The internet was not designed to be permanent. Websites disappear. Pages are deleted. Content is modified or removed. For decades, this created a real problem for researchers, journalists, and historians who wanted to document what the internet said at specific moments in time. Archives solve this problem. They create immutable records that can be cited and verified.
But archives are only valuable if they're trustworthy. If we discover that archives can be tampered with—that someone can insert false information into a captured page after the fact—then archives become sources of disinformation rather than sources of truth. Once you can't trust the archive, you can't use it to verify anything.
Archive.Today's actions create a precedent that's deeply worrying. If one archive service was willing to tamper with content to advance a political agenda or settle a grudge, what's to stop others from doing the same? If the maintainer of an archive service decides that a particular person or organization deserves to be targeted, what prevents them from selectively editing archives to discredit them?
This is where institutional accountability becomes critical. The Internet Archive operates under the constraints of being a nonprofit with a board of directors, a public mission, and the scrutiny that comes with legitimate institutional status. If the Internet Archive tampered with archives, donors would learn about it. Journalists would investigate. Trustees would demand answers. The nonprofit's tax status could be revoked.
Archive.Today operated outside these constraints. There's no one to hold accountable except the anonymous maintainer. No institutional structure. No public commitments. No transparency. This is why the DDoS attack and content tampering weren't just violations of trust—they were almost inevitable consequences of an archiving service designed with zero accountability.
The Identity Question: Who Really Runs Archive.Today?
Throughout the entire saga, the identity of Archive.Today's maintainer remained obscure. Jani Patokallio's original post about the service suggested the maintainer operated under aliases like "Denis Petrov" and "Masha Rabinovich" and was likely based in Russia. The maintainer himself used "Nora" when contacting Patokallio.
Most striking is that Patokallio later discovered that "Nora" appeared to be an appropriated identity. Someone with that actual name had apparently only interacted with the service regarding content removal requests. The Archive.Today maintainer had simply taken the name and used it as a pseudonym, a move that implies either recklessness or deliberate deception.
The FBI has apparently launched an investigation into Archive.Today's real identity. This is significant because it suggests law enforcement considers the DDoS attack and threats serious enough to pursue. Unlike civil litigation, which requires identified defendants, criminal investigations can rely on IP addresses, financial records, server logs, and other evidence trails that accumulate over time.
But understanding Archive.Today's true identity isn't just a matter of curiosity. It has implications for how we think about internet governance and accountability. An anonymous operator can build a popular service that millions of people use and trust. But that same anonymity prevents any meaningful accountability when things go wrong. There's no recourse, no institutional pressure, no way to compel change.
This doesn't necessarily mean all anonymous projects are problematic. But it suggests that services with high stakes—like archiving, which affects historical truth—probably need some form of institutional accountability and transparency.

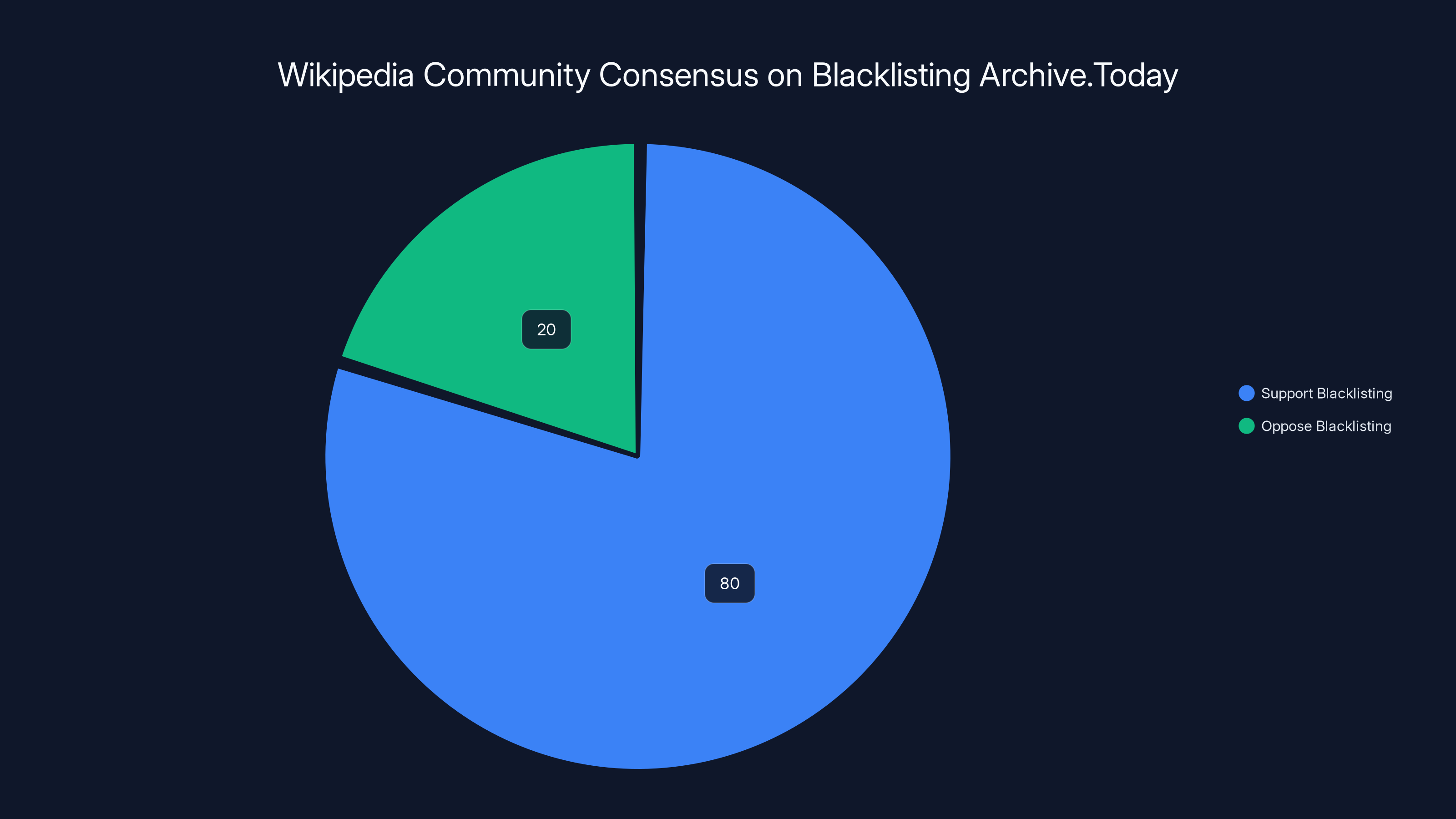
The decision to blacklist Archive.Today was overwhelmingly supported by the Wikipedia community, with an estimated 80% in favor and 20% opposed, highlighting strong consensus based on documented misconduct.
What This Means for Web Archiving's Future
Archive.Today's blacklisting comes at a time when web archiving is becoming increasingly important. As the internet becomes more ephemeral—with pages deleted, links broken, and content disappearing constantly—reliable archives become more crucial.
Jani Patokallio himself pointed out one positive implication in his response to the Wikipedia decision: "I'm glad the Wikipedia community has come to a clear consensus, and I hope this inspires the Wikimedia Foundation to look into creating its own archival service."
This is a reasonable point. The Wikipedia Foundation—which operates Wikipedia, Wikimedia Commons, and other projects—could potentially operate its own archiving service. Such a service would have the institutional backing, financial resources, and governance structures that Archive.Today deliberately avoided. Editors could have confidence that the archives they cite would be maintained, accessible, and unmanipulated.
Wikipedia's blacklisting of Archive.Today doesn't just remove a problematic source. It also creates an opportunity for the Wikipedia community and the broader digital preservation ecosystem to rethink how we approach web archiving. The current landscape has the Internet Archive, which is excellent but operates under bandwidth and crawling constraints. It has Ghostarchive and Megalodon, which are valuable but less formally maintained. And it has Archive.Today, which is unreliable.
What's missing is a middle ground: an archiving service with strong institutional backing, transparent operations, and alignment with the values of open knowledge communities like Wikipedia. Creating such a service would improve digital preservation and give millions of people a reliable way to archive the web.
The Broader Problem: Anonymous Operations and Trust
Archive.Today's case highlights a deeper problem with anonymous operations that have high social importance: they can't generate sustained institutional trust.
Trust in digital services is built through transparency, consistency, and accountability. When something goes wrong, people need to know who to hold responsible. With Archive.Today, there's no one. The maintainer hides behind aliases, VPNs, and deliberate obfuscation. This creates a fundamental vulnerability: if the maintainer decides to abuse their power, there's almost no way to stop them or even identify them.
This doesn't mean all anonymous projects are bad. Whistleblowing requires anonymity. Privacy protection requires anonymity. Some legitimate activists operate anonymously because their personal safety depends on it. But in contexts where millions of people depend on a service for truth-critical purposes, anonymity becomes a liability rather than a feature.
Archive.Today's defenders argued that the site needed to be anonymous to protect privacy and evade pressure from powerful actors who might want certain pages removed. But in practice, the anonymity didn't protect anyone except the maintainer. It prevented accountability, enabled abuse, and ultimately led to the service being blacklisted from the internet's largest collaborative encyclopedia.
The lesson is that trust and anonymity are often in tension. You can have an anonymous service, or you can have a trusted service, but building both simultaneously is nearly impossible at scale.
Impact on News Paywalls and Information Access
One factor that made Archive.Today's blacklisting controversial among some Wikipedia editors was the service's role in bypassing paywalls. Many news organizations require subscriptions to read articles. Archive.Today let people capture articles before they were paywalled, creating a public record that anyone could access.
This served a useful function. It meant that important news stories weren't locked behind paywalls accessible only to wealthy readers. Information about public issues remained public. But it also meant Archive.Today was, in a real sense, enabling copyright infringement. News organizations have the right to decide who can read their content.
Wikipedia's decision to blacklist Archive.Today didn't solve this fundamental tension. The guidance tells editors that when they encounter Archive.Today links to paywalled content, they should try to find alternative sources or sometimes replace the archive link with a direct link to the original publication (understanding that some readers won't be able to access it).
This actually improves Wikipedia's sourcing in the long run because it forces editors to engage with primary sources more directly. If a fact is genuinely important enough to be in Wikipedia, it's probably important enough that the publication will make it accessible through their website or through library archives. If editors can't find any way to verify a claim, maybe the claim shouldn't be in Wikipedia.
The Internet Archive scores highest in reliability, transparency, and longevity, while Ghostarchive excels in content coverage. Estimated data based on service characteristics.
The Technical Challenge of Mass Link Removal
Removing 695,000 links across 400,000 pages is a staggering technical and organizational challenge. Wikipedia's software tools help, but the process is fundamentally a manual human effort.
Editors can use search functions to find all instances of Archive.Today domains (archive.today, archive.is, archive.ph, archive.fo, archive.li, archive.md, archive.vn). But then each one requires human judgment. Is there an alternative source available? Is the original source still online? What should replace this archive link?
Wikipedia's automation tools can help with some of this. Bots can be programmed to identify Archive.Today links and flag them for human review. Some can even auto-replace links with Wayback Machine equivalents when they're available. But the process is inherently labor-intensive.
This is where the Wikipedia community's strengths become apparent. Millions of volunteers contribute to Wikipedia. Even if only a small percentage dedicate time to this cleanup effort, it's enough to accomplish what would be impossible for a small organization. The distributed volunteer model that makes Wikipedia possible also makes large-scale content cleanup projects feasible.
Regulatory and Legal Implications
Archive.Today's case raises regulatory questions that governments and institutions are only beginning to grapple with: How should we regulate web archiving services? Should there be transparency requirements? Should there be penalties for tampering with archived content?
In many jurisdictions, the answer is currently "we don't know." Web archiving services aren't explicitly regulated. There's no licensing requirement, no transparency standard, no specific law against tampering with archives. Archive.Today operated in this gray zone, and it took a pattern of clear misconduct (DDoS attacks, threats, content tampering) to prompt action.
This creates a gap. If Archive.Today had never attacked Patokallio's blog, if the maintainer had simply quietly tampered with archives without getting caught, the service would likely still be in use. The misconduct was discovered somewhat by accident through the DDoS investigation.
The FBI's investigation into Archive.Today's identity suggests that law enforcement is taking this seriously. Once the maintainer's identity is determined, there could be criminal charges related to the DDoS attack or the threats. But this reactive approach—waiting for something to go seriously wrong, then investigating—is inefficient.
A proactive approach might involve transparency requirements for web archiving services. Services that capture content and present it as historical record might be required to publicly disclose their operators, their governance structures, and their policies around content modification. This would create accountability without preventing legitimate archiving projects.
But this is speculative. For now, what's clear is that Archive.Today's case has exposed a gap in how we regulate services that hold our historical record, and that gap is starting to matter.
Lessons for Trusting Online Sources
For people who aren't Wikipedia editors but do rely on web sources for research, journalism, or personal learning, Archive.Today's case offers important lessons about trusting online sources.
First, archives aren't all equal. Just because something is archived doesn't mean it's reliable. Archive.Today appeared to be a legitimate service for years before the misconduct was discovered. The only way to know if an archive is trustworthy is to understand who operates it, what their incentives are, and what accountability mechanisms exist.
Second, institutional backing matters. Services run by nonprofit organizations with public missions and transparent governance are fundamentally more trustworthy than services run anonymously. Not because anonymous people are inherently untrustworthy, but because anonymous operations prevent accountability.
Third, always try to verify important claims against the original source if possible. If the original source is no longer available, try accessing it through multiple archive services and cross-checking. If multiple sources show the same content, you're probably safe. If they diverge, dig deeper.
Fourth, be cautious about citing archives of paywalled content. News organizations put content behind paywalls for a reason—it's their business model. Wikipedia editors often link to archives that bypass paywalls, but this creates tension with journalistic integrity. If a fact is important enough to cite, try to find a way to cite it that respects the original source's business model.
Finally, understand that the internet doesn't preserve itself. Without conscious effort to archive content, huge portions of what we publish today will simply disappear. Supporting legitimate archiving services like the Internet Archive—through donations, contributions, or simply using them as your default archive source—is an investment in a better historical record.

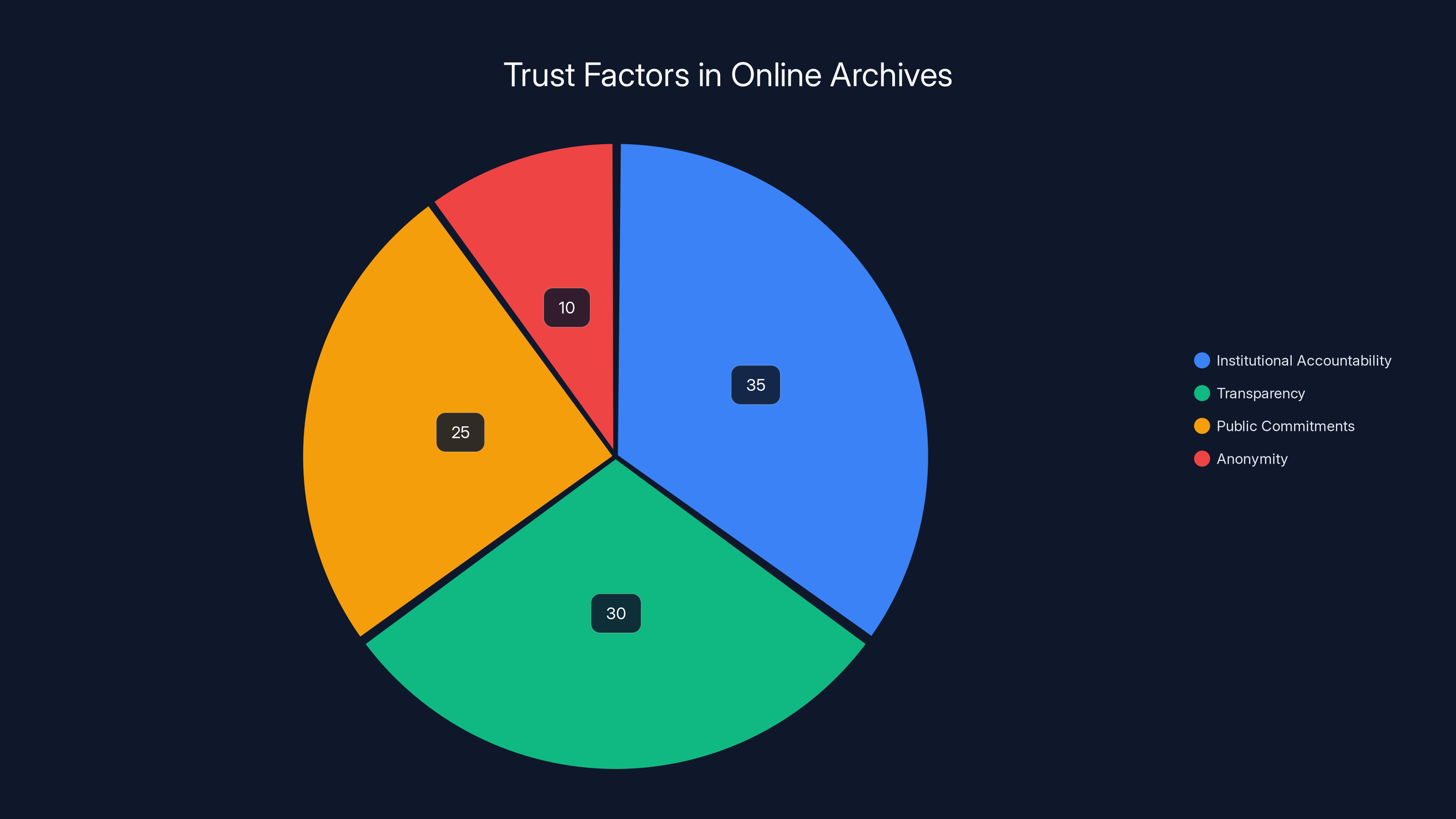
Institutional accountability and transparency are the most critical factors in maintaining trust in online archives. Estimated data.
What Happens to Archive.Today Now?
As of the time of this writing, Archive.Today still exists. Wikipedia's blacklisting doesn't shut down the service; it just means Wikipedia won't direct readers to it anymore. But the blacklisting has consequences.
First, it damages Archive.Today's reputation significantly. A huge percentage of archive usage comes from people who find links on Wikipedia and follow them. Losing that referral traffic is substantial. Second, it signals to other platforms that they should reconsider their relationship with Archive.Today. Other wikis and reference sites may follow Wikipedia's lead. Third, it makes it harder for Archive.Today to claim it's a legitimate service. When the world's most trusted encyclopedia blacklists you for tampering with content, that's a credibility crisis.
The FBI investigation adds another layer of pressure. If the maintainer's identity is uncovered, there could be legal consequences. Even if criminal charges don't materialize, civil lawsuits from Patokallio are possible. The maintainer could face liability for damages related to the DDoS attack and the threats.
Archive.Today might eventually adapt. It could become more transparent, implement better governance structures, and prove that it's changed its behavior. Trust would take years to rebuild, but it's theoretically possible. Alternatively, the service might shut down either voluntarily or due to legal pressure.
What's clear is that Archive.Today's days as a casual tool that millions of people use without thinking about its trustworthiness are over. The service's fundamental legitimacy is now in question.
The Broader Internet Archive Ecosystem
Archive.Today's case is a cautionary tale, but it shouldn't overshadow the remarkable work that legitimate archiving services do every day.
The Internet Archive's Wayback Machine operates on a scale that's almost difficult to comprehend. It crawls the entire web constantly, capturing billions of pages and making them available to anyone, anywhere, for free. The service has survived legal challenges from publishers, technical catastrophes, and changes in web architecture. Researchers, journalists, historians, and regular people rely on the Wayback Machine millions of times per month.
Smaller archiving services like Ghostarchive and Megalodon fill important niches, capturing content that the Wayback Machine might miss or presenting it in more useful formats.
Private archives—screenshots, downloaded PDFs, backups—preserve content in ways that centralized services can't. When individuals make copies of important web content and share them, they're contributing to digital preservation.
The collective effect is that important content often survives even when individual sources disappear. A page deleted from its original location might still be accessible through an archive. This redundancy is actually valuable. It prevents any single service from having monopolistic control over historical records.
Archive.Today's blacklisting doesn't harm this ecosystem. If anything, it strengthens it by removing a service that was compromising the reliability of the entire system.

Looking Forward: Improving Web Archiving Standards
Archive.Today's case creates an opportunity to improve standards around web archiving more broadly. What would a better ecosystem look like?
First, transparency standards. Archiving services that want to be trusted for important sourcing should publicly disclose their operators, governance structures, and policies. This doesn't require complete loss of privacy, but it should make it possible to hold the service accountable.
Second, content integrity verification. Services could implement cryptographic signatures that make it easy to detect if archived content has been modified after capture. If someone tampers with an archive, the signature would break, signaling that something has changed.
Third, institutional diversity. Rather than relying on any single archiving service, the ecosystem should support multiple services with different governance models. Some might be nonprofits like the Internet Archive. Some might be government-supported. Some might be corporate. Diversity means no single point of failure.
Fourth, standards for citation. Wikipedia's guidance—use the Internet Archive first, alternatives second, original sources when possible—could become a widely adopted standard. This would create pressure for services to maintain the kind of transparency and reliability needed to be a first-choice archive.
Fifth, legal clarity. Governments could establish clearer regulations around web archiving services, particularly services that claim to preserve historical truth. This might include requirements for transparency, penalties for tampering, and standards for data preservation and access.
These improvements wouldn't happen overnight, and they'd require coordination between archiving services, platforms like Wikipedia, and government actors. But Archive.Today's case shows that the costs of not improving these standards are real.
The Patokallio Aftermath and Support
After the Wikipedia decision, Jani Patokallio gave an interview expressing relief and gratitude for the community's action. He noted that he hoped the decision would "inspire the Wikimedia Foundation to look into creating its own archival service," suggesting that the positive outcome was validation of his original decision to publish about Archive.Today.
It's worth recognizing what Patokallio did in this situation: He documented misconduct, published his findings despite threats, continued to engage openly even as he was being attacked, and ultimately helped the Wikipedia community make an informed decision based on evidence.
Not everyone has the resilience or willingness to do this. Patokallio faced personal threats, a DDoS attack, and the wrath of an anonymous actor with technical skills and no accountability structure. Many people would have simply deleted their blog and moved on. That Patokallio persisted, and that his persistence contributed to a positive outcome, is important to recognize.
What happened to Patokallio also illustrates why anonymity can be valuable for certain actors while being dangerous when concentrated in a single service. Patokallio took risks to expose misconduct. Archive.Today's maintainer used anonymity to evade accountability. The same tool served completely different purposes.
Critical Timeline: How Archive.Today Went From Trusted to Blacklisted
Understanding the sequence of events helps clarify how Archive.Today went from a widely-used service to being blacklisted in a matter of months.
2023: Jani Patokallio publishes a blog post analyzing Archive.Today's possible operator, including alleged aliases and a suggestion that the service is operated from Russia. This post becomes the focus of Archive.Today's maintainer's ire.
Early 2026: Archive.Today's maintainer demands that Patokallio remove the post. When he refuses, harassment begins. The maintainer, using the alias "Nora," sends threatening emails promising AI-generated explicit content and fake dating app profiles.
February 2026: A DDoS attack hits Patokallio's blog, using malicious code embedded in Archive.Today's CAPTCHA page. Patokallio documents the attack and reports it to the Wikipedia community.
February 2026: As Wikipedia editors investigate the DDoS and Archive.Today, they discover evidence that archived content has been tampered with. Patokallio's name appears in archives where it shouldn't be, suggesting deliberate falsification.
February 2026: The Wikipedia community launches a Request for Comment (RfC) on whether to blacklist Archive.Today. The discussion goes quickly, with clear consensus forming around the evidence of DDoS attacks and content tampering.
February 2026: Wikipedia officially deprecates Archive.Today and begins the process of removing 695,000+ links from approximately 400,000 pages. The community is instructed to replace Archive.Today links with alternatives when possible.
March 2026: The FBI launches an investigation into Archive.Today's real identity and operations. The investigation is ongoing.
Present: Archive.Today continues to operate but with significantly damaged credibility. The service is now blacklisted from Wikipedia and faces scrutiny from journalists, researchers, and other organizations.
This timeline shows how quickly misconduct can erode trust. Archive.Today likely thought that the DDoS attack would be technical enough to evade detection. But the attack was actually sloppy enough to be traced back to the service. The threat of exposing the maintainer's identity through technical investigation probably motivated the threats and harassment, which then led to the discovery of the content tampering. Once multiple types of misconduct were documented, blacklisting became inevitable.
How Other Services Are Responding
Archive.Today's case has prompted other platforms to reconsider their relationships with archiving services more broadly. Some media companies are implementing policies around what kinds of archives they will allow to be linked to. Some privacy-focused organizations are evaluating their own archiving practices to ensure they align with principles of transparency and accountability.
The situation also prompted technical discussions about how to make archives more tamper-resistant. Some proposals involve blockchain-based verification systems that would make it cryptographically impossible to modify archived content after capture. Others involve decentralized archiving networks where multiple copies of archived content exist on different servers, making centralized tampering impossible.
These technical approaches have tradeoffs. They can improve security and reliability, but they can also make archives less flexible and harder to maintain. The Internet Archive, for instance, prioritizes ease of access over tamper-proofing. Anyone can submit a URL to be archived; the service is designed for maximum openness rather than maximum security. Adding cryptographic verification might make archives more tamper-proof but less accessible.
The broader point is that Archive.Today's case has spurred an industry-wide conversation about how we should structure archiving services to balance accessibility, reliability, and security.

FAQ
What exactly did Archive.Today do that caused its blacklisting?
Archive.Today was blacklisted for three main reasons: First, the service used malicious code embedded in its CAPTCHA page to launch a DDoS attack against a blogger who had published critical analysis of the service. Second, the maintainer sent threatening emails promising to create explicit AI-generated imagery and fraudulent accounts using the blogger's identity. Third, and most damning, Wikipedia editors discovered evidence that Archive.Today had tampered with archived web content, inserting the blogger's name into pages where it didn't originally appear. This content tampering violated the fundamental principle that archives should be immutable records of web pages at specific points in time.
Why does content tampering matter so much for web archives?
Web archives are only valuable as sources if you can trust that what you're reading is actually what was on the page when it was captured. If an archive can be modified after the fact—if the maintainer can insert false information, delete passages, or alter context—then the archive becomes unreliable as a source. Researchers, journalists, and students cite archives to prove what something said at a specific moment. If that proof can be falsified, the entire premise of using archives for verification collapses. Archive.Today's tampering essentially destroyed its own value as a reliable source.
What should I use instead of Archive.Today?
Wikipedia's official guidance is to use the Internet Archive's Wayback Machine first, since it's a legitimate nonprofit with proven reliability and transparency. If content isn't available on the Wayback Machine, alternatives like Ghostarchive or Megalodon are acceptable. When possible, citing the original source directly is preferable to citing an archive. If you're trying to document paywalled content, try to find alternative sources that discuss the same information, or link directly to the publication's website while noting that some readers may not have access.
Is the Internet Archive different from Archive.Today?
Completely different. The Internet Archive is a San Francisco-based nonprofit founded in 1996 with a public mission to provide universal access to digital heritage. Its operators are publicly known, its funding is transparent, and it operates under nonprofit governance with board oversight. Archive.Today is an anonymous service operated by unknown individuals, with no institutional accountability structure. The Internet Archive operates with transparency and trust; Archive.Today operated with anonymity and opacity. While they perform similar functions, they're fundamentally different in terms of governance and reliability.
What is a DDoS attack and how was Archive.Today using it?
A DDoS (Distributed Denial of Service) attack floods a website's servers with traffic to make it inaccessible. Archive.Today embedded malicious code in its CAPTCHA verification page that, when executed, directed users' browsers to send traffic to a target website without the users' knowledge or consent. Every person accessing Archive.Today during the attack became an unwitting participant in attacking the blogger's server. It's a form of weaponized infrastructure abuse—turning a legitimate service into a tool for attacking someone.
How many Wikipedia pages were affected by the Archive.Today blacklisting?
Approximately 695,000 links to Archive.Today are distributed across about 400,000 Wikipedia pages. This means that one out of every several hundred Wikipedia citations points to Archive.Today. Removing and replacing all these links is a massive undertaking that will take the volunteer Wikipedia community months or years to fully complete. Editors are encouraged to help, starting with articles they care about most.
Could Archive.Today's maintainer face criminal charges?
Yes, the FBI is investigating Archive.Today in connection with the DDoS attack and the threats. DDoS attacks are illegal in most jurisdictions, as are threats of harassment and sexual abuse. If the FBI identifies the maintainer, there could be criminal charges related to these activities. Additionally, the blogger Jani Patokallio could pursue civil litigation seeking damages. However, if the maintainer is located outside the United States, extradition and prosecution become more complicated.
Is Wikipedia creating its own archiving service?
Not yet, but Jani Patokallio mentioned in his response to Wikipedia's decision that he hopes the Wikimedia Foundation will consider creating one. This would be a significant undertaking, as it would require substantial resources and infrastructure. However, the case has highlighted the need for an institutional archiving service aligned with Wikipedia's values of transparency, reliability, and open knowledge. Whether the Wikimedia Foundation pursues this is an open question.
What makes an archiving service trustworthy?
Trustworthiness comes from several factors: transparent operations with publicly known leadership, institutional backing (nonprofit status is helpful but not required), clear policies about content modification and preservation, audit mechanisms to detect tampering, and accountability structures. Services that operate anonymously or without institutional oversight can still provide value, but they're inherently riskier as sources for important claims because there's no one to hold accountable if misconduct occurs.
How can I support web archiving efforts?
The Internet Archive operates on donations and public support. Contributing financially to the Internet Archive helps fund continued preservation of billions of web pages. You can also support web preservation by uploading content you care about to the Wayback Machine, using archiving services as your default rather than assuming web links will last forever, and citing archives responsibly when you do use them. Finally, if you see important content online, consider archiving it proactively rather than assuming it will always be available.
Key Takeaways
- Wikipedia blacklisted Archive.Today after discovering it used weaponized code to launch DDoS attacks and tampered with archived content to target a critic
- Nearly 700,000 Archive.Today links across 400,000 Wikipedia pages must be replaced with alternatives like Internet Archive, Ghostarchive, or Megalodon
- Content tampering is the most damaging misconduct because it undermines the entire premise that web archives preserve accurate historical records
- Institutional archiving services with transparent operations are fundamentally more trustworthy than anonymous services with no accountability structure
- The case highlights a broader need for standards around web archiving transparency, content integrity verification, and regulatory oversight
Related Articles
- Wikipedia vs Archive.today: The DDoS Controversy Explained [2025]
- Wayback Machine Link Fixer Plugin: Fixing Internet's Broken Links [2025]
- Why Publishers Are Blocking the Internet Archive From AI Scrapers [2025]
- YouTube Museum Exhibit: How Internet Culture Became History [2025]
- Microsoft's Revolutionary 10,000-Year Glass Data Storage [2025]
- Project Silica: Glass Data Storage for 10,000 Years [2025]

