![X's Open Source Algorithm: Transparency, Implications & Reality Check [2025]](https://tryrunable.com/blog/x-s-open-source-algorithm-transparency-implications-reality-/image-1-1768086508243.jpg)
Introduction: The Algorithm Promise That Changed Everything
When Elon Musk announced that X would open-source its recommendation algorithm, the internet had one collective reaction: wait, really? For years, social media platforms have been black boxes. The algorithm decides what you see, what you don't see, and ultimately, what shapes your reality on these platforms. Nobody really knows how it works. Regulators don't. Researchers don't. Users definitely don't.
Then Musk made a promise that sounded radical. The algorithm—including all the code that determines which posts you see, which ads get shown to you, which content gets suppressed—would be public. Not just open to researchers under strict NDAs. Not sanitized or redacted. Actually, genuinely open source.
But here's the thing: open-sourcing an algorithm is way more complicated than just uploading code to Git Hub. There's a massive difference between making code available and making it actually useful. There's an even bigger gap between transparency and accountability. And there's the question of whether a massive tech platform can genuinely operate in the open while competing with rivals who operate entirely in private.
This article digs into what X's algorithm transparency actually means. We'll break down what was promised, what actually happened, what it really shows us about how social media works, and whether this changes anything about platform accountability. Because spoiler alert: the story is way more nuanced than "Musk said it would be open source, so now it is."
TL; DR
- The Promise: Elon Musk announced X would make its recommendation algorithm entirely open source, including all code determining organic and ad recommendations.
- The Reality: The code was released on Git Hub, but key details were missing, documentation was sparse, and maintaining it proved difficult.
- The Impact: While well-intentioned, the release hasn't fundamentally changed how the algorithm works or how much users can actually control what they see.
- The Regulation: European regulators demanded transparency as part of investigations into X's practices; open sourcing was partly a response to that pressure.
- The Future: Quarterly updates were promised, but inconsistent execution raises questions about whether X will maintain genuine transparency going forward.


X open-sourced its algorithm due to regulatory pressure, commitments by Musk, public criticism, and accountability concerns, each contributing equally to the decision. Estimated data.
What Exactly Did Musk Promise?
Let's start with the actual announcement. On a Saturday in early 2025, Elon Musk posted that X "will make the new X algorithm, including all code used to determine what organic and advertising posts are recommended to users, open source in 7 days." He added that this would happen "every 4 weeks, with comprehensive developer notes, to help you understand what changed."
That's a pretty sweeping statement. Not just the recommendation algorithm—literally all code. Not just theoretical docs—comprehensive notes. And not a one-time thing—recurring releases every month.
Why'd he make this promise? Several reasons converged at once. First, there was mounting regulatory pressure. The European Commission had been investigating X's practices and extended their retention order through 2026, specifically demanding information about how the platform's algorithms work. France's regulators were also investigating. In the modern regulatory landscape, transparency has become a compliance requirement, not just a nice-to-have.
Second, Musk had already made similar promises. Back in 2023, when he took over Twitter, he published the "For You" feed code on Git Hub. That release got attention, but it also got criticism. Researchers who examined it found that key details were missing. The code was real, but it didn't tell the whole story about how the algorithm actually prioritizes content.
Third, there's genuine criticism around algorithmic opacity. For years, platforms like Facebook, Twitter (as it was), and Tik Tok have faced accusations that their algorithms promote engagement over accuracy, amplify outrage over nuance, and create filter bubbles. Users have no way to know why they're seeing what they're seeing. Opening up the algorithm seemed like a way to address that fundamental criticism.
The promise was bold. The execution, as we'll see, was more complicated.
The History of Algorithm Transparency (Before X)
X didn't invent algorithmic transparency. The movement toward open-sourcing algorithms actually has roots going back further than you might think.
In 2019, Facebook released some research on how its News Feed algorithm worked. Not the actual code, but academic papers explaining the methodology. That became a model: researchers could see how platforms thought about recommendation, even if they couldn't see the code itself.
In 2020, Twitter (before the Musk takeover) started publishing research on its algorithm and even opened some of its code to academic researchers through structured partnerships. These partnerships came with strict conditions: researchers had to sign NDAs, couldn't commercialize findings, and had limited access to the actual systems.
Tik Tok did something similar, releasing limited algorithmic details in response to regulatory pressure and user concerns about the company's Chinese ownership. But again, this was carefully controlled transparency, not open-source release.
The difference between controlled transparency and genuine open sourcing is huge. Controlled transparency means the company decides what you can see and study. Open sourcing means anyone can download it, examine it, modify it, and run it locally.
Musk's promise represented a shift to the genuinely open side of that spectrum. At least in theory.
Why hadn't other platforms done this earlier? Several practical reasons:
- Competitive advantage - The algorithm is how platforms compete. Revealing how it works gives competitors a blueprint.
- Liability concerns - If people can see the code and find bias or discrimination baked in, that's legally risky.
- Complexity - Modern recommendation systems involve machine learning models trained on massive datasets. The code alone doesn't show how models were trained or what data they used.
- Security - Knowing exactly how an algorithm works makes it easier for bad actors to game it. Researchers who study platform manipulation have shown that adversarial attacks become more effective when you understand the system.
X's open-sourcing approach, if done right, could address some of these concerns while still leaving others unresolved.
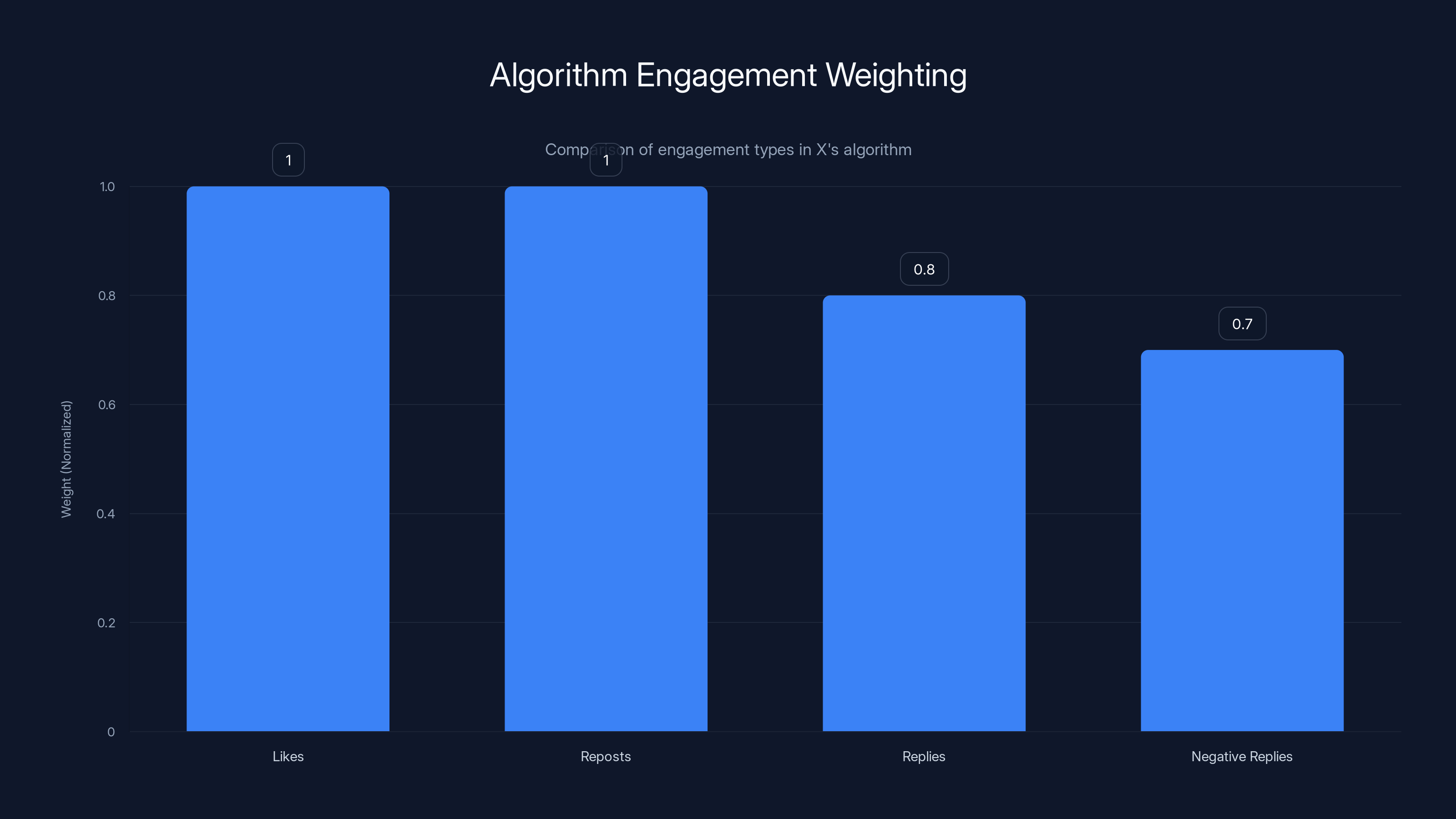
The algorithm gives equal weight to likes and reposts, slightly less to replies, and almost as much to negative replies, indicating a potential bias towards controversial content. Estimated data.
Understanding X's Recommendation Algorithm Architecture
Before you can understand what open-sourcing the algorithm means, you need to know what X's algorithm actually does. And that's more complex than just "it shows you posts."
X's recommendation system has several components working together:
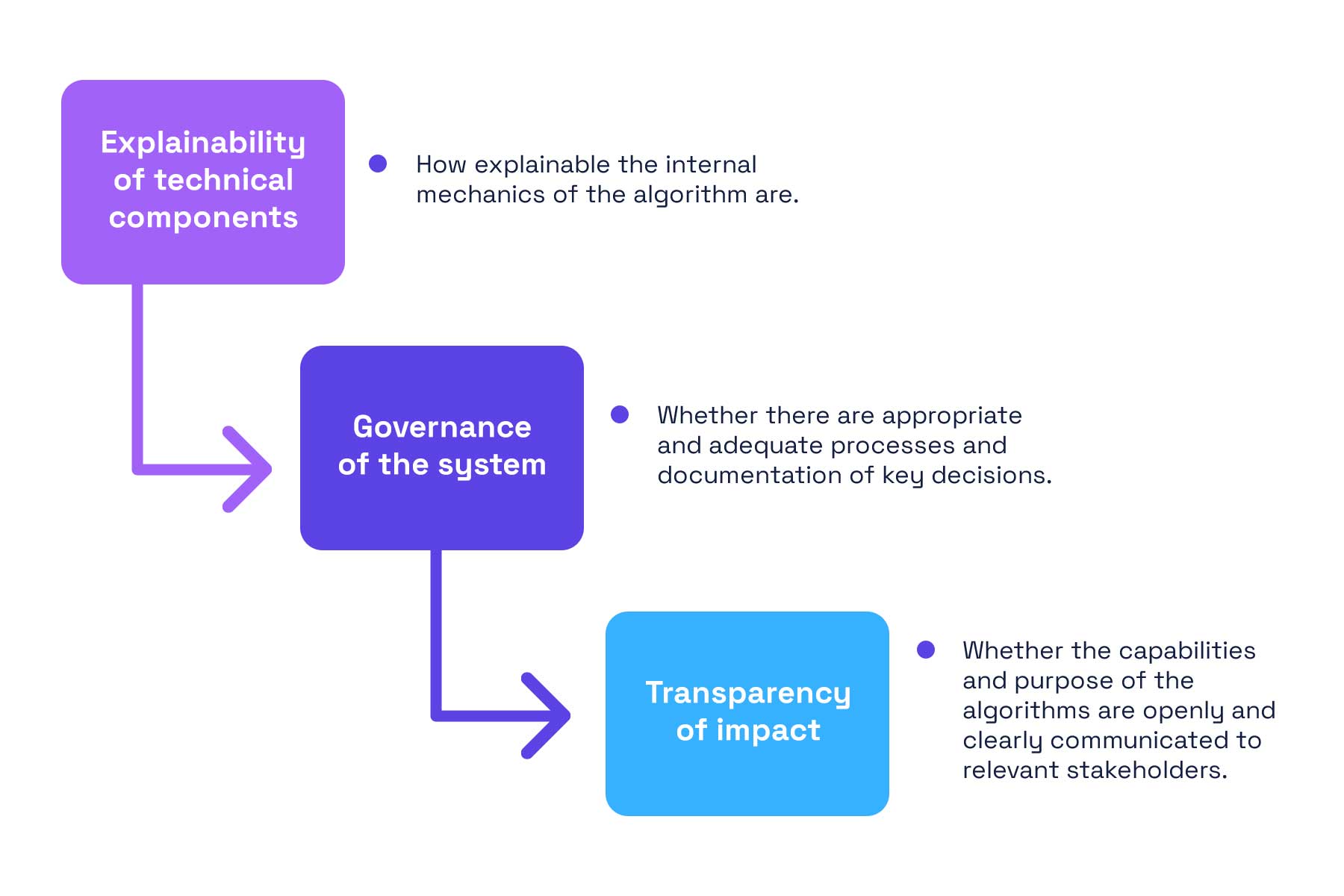
The Ranking Component - This is the core. You see thousands of potential posts at any given moment. The algorithm has to decide which ones appear in your feed, in what order, and for how long. This uses a combination of signals: who you follow, who else engages with posts, what hashtags you search, how long you look at certain content, and more.
The Filtering Component - Not everything gets shown. Some posts are suppressed based on content policies, user reports, quality scores, and yes, algorithmic decisions about what's "spam" or low-quality. This is where it gets controversial, because decisions here happen invisibly.
The Ad Ranking Component - X makes most of its money from advertising. The algorithm doesn't just rank organic posts—it also decides which ads you see, in what order, and how frequently. This involves different signals than organic ranking (advertiser bids, conversion data, audience targeting) but uses similar infrastructure.
The Diversity Component - If the algorithm just ranked by "most engaging," you'd see the same creators over and over. Modern algorithms try to balance engagement with diversity, showing you content from different accounts, different topics, and different media types.
The Freshness Component - You want new content, not yesterday's posts. The algorithm weights recently posted content higher, though this varies. Sometimes you want to see older, highly-voted posts (this is the "Best" tab). Sometimes you want pure chronology (which X killed as a default).
All of these components involve machine learning models, ranking functions, and real-time decisions. The open-sourced code released by X includes implementations of these, but understanding how they work in practice requires understanding more than just the code.
For example, if you look at the ranking function, you might see something conceptually simple: calculate a score for each post based on engagement signals, then sort by score. But what are those signals? How are they weighted? What does "engagement" mean—replies, likes, reposts, or something else? That changes everything.
This is where open-sourcing gets tricky. The code can show you the implementation logic, but it can't show you the trained machine learning models (those are separate and often proprietary), the exact weighting of signals (those often change), or the real-time decisions made by the live system.
What Code Actually Got Released?
When X released its code on Git Hub, what exactly did users and developers find?
The released code includes:
- Ranking utilities - Functions for calculating scores based on various signals
- Feature extraction - Code for pulling signals from user interactions and content metadata
- Filtering logic - Rules for what content gets shown or suppressed
- Time-decay functions - How the algorithm discounts older content
- Diversity functions - How the algorithm balances between showing popular content and content diversity
But critically, what wasn't released:
- Trained models - The machine learning models themselves aren't released. These are separate from the code and have millions or billions of parameters tuned on X's data.
- Real-time weights - The actual numerical weights used by the live system. The code shows the structure, but not the current values.
- Training data - How were these models trained? What data was used? This info wasn't released.
- Decision thresholds - The exact values that trigger suppression, promotion, or other algorithmic actions
- Rate limiting logic - How the algorithm decides when to show ads versus organic content, or whether to suppress certain creators
Researchers who examined the initial release in 2023 and subsequent updates found it useful but incomplete. One researcher noted that "the code explains the methodology, but the parameters are the real magic." You can understand what the algorithm is trying to do without understanding what it actually prioritizes.
There's also the question of versioning and updates. Musk promised updates every 4 weeks with "comprehensive developer notes." Did that actually happen? Inconsistently. Some updates came regularly. Others had gaps. And "comprehensive developer notes" often meant a few bullet points rather than detailed explanations.
The Regulatory Pressure Behind the Promise
Musk didn't make this promise in a vacuum. There was serious regulatory pressure driving it.
The European Union's Digital Services Act (DSA) requires platforms to explain how their algorithms work, especially concerning content moderation and recommendation. The European Commission began investigating X specifically regarding content moderation practices and algorithmic transparency. That investigation was extended through 2026, with regulators demanding detailed information about how X's algorithms function.
France's regulators were investigating separately, with particular focus on whether X's algorithms were promoting illegal content or creating harmful filter bubbles.
In this context, saying "we'll open-source our algorithm" became a strategic move. It addressed regulator concerns about opacity while (from X's perspective) offering proof of transparency without necessarily giving up competitive advantages. After all, releasing code is different from explaining how the code is actually configured and deployed.
But the regulatory pressure wasn't just about transparency. There were also concerns about content moderation. X had been criticized for inadequate moderation, including allowing CSAM (child sexual abuse material) to remain on the platform and being used to create synthetic sexual imagery of women without consent. When those issues emerged, they added urgency to the transparency promises. Showing the algorithm could theoretically help explain what went wrong, though critics argued it was mostly PR recovery.
Regulators weren't entirely satisfied with the code release. Several European regulatory bodies noted that while the release was a step forward, it didn't fully address their concerns about how the algorithm makes real-world decisions. The code shows the structure, but not the configuration, tuning, or deployed behavior.
This created an interesting situation: X could point to open-sourcing as proof of transparency for regulatory purposes, while regulators could note that true understanding of X's algorithms still required information X hadn't shared. Both statements could be simultaneously true.
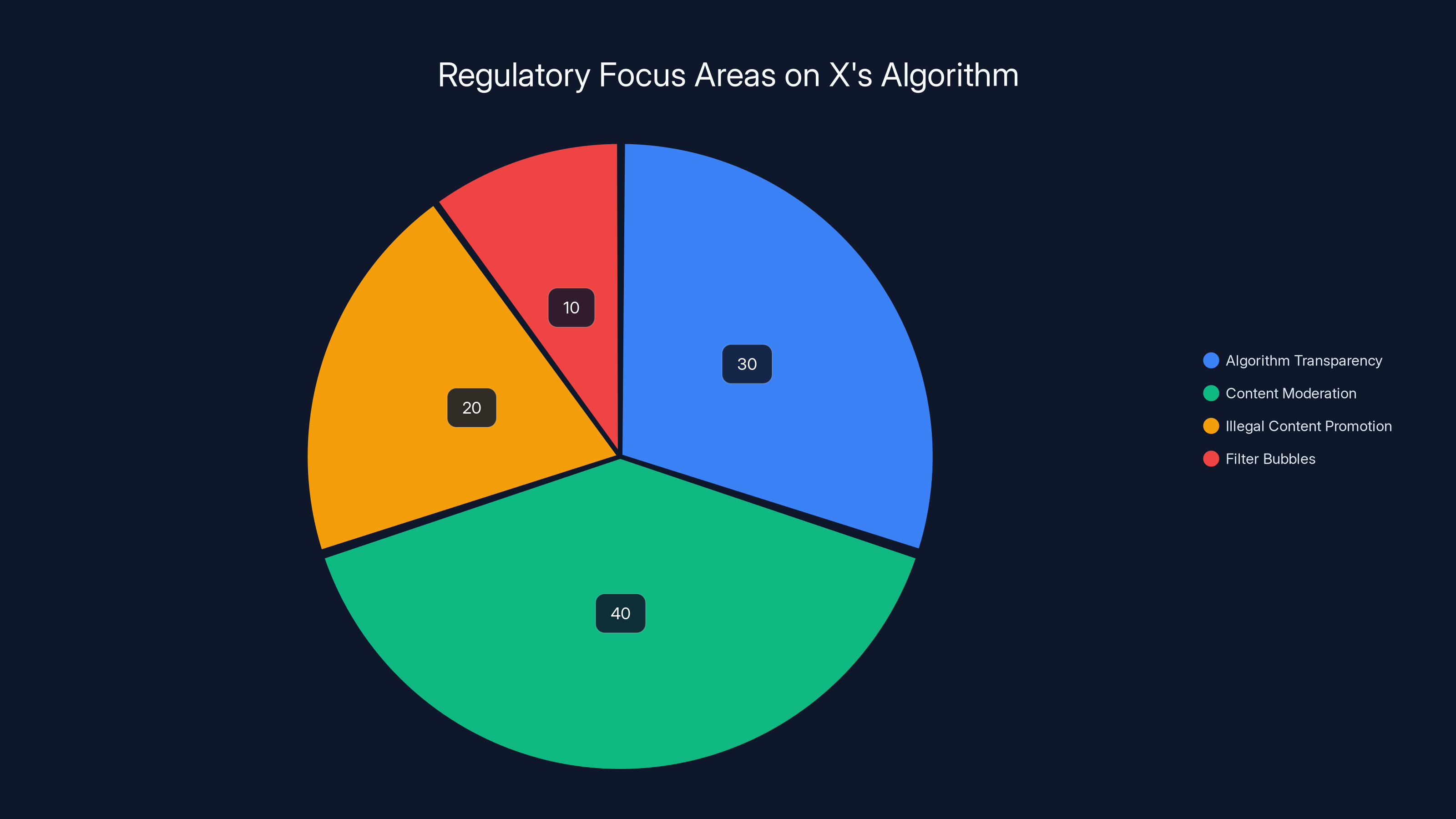
Estimated data shows content moderation (40%) and algorithm transparency (30%) as primary regulatory focus areas, highlighting the pressure on X to address these issues.
The Difference Between Code, Models, and Real Behavior
Here's where things get really important. A lot of people think "open-sourcing the algorithm" means you can now fully understand how X works. That's not quite right, and the gap between code and real behavior is where a lot of algorithmic opacity still hides.
Let's say you download X's algorithm code from Git Hub. You can run it locally. You can see exactly what it's doing. Does that mean you understand how your X feed works in real life?
Not necessarily. Here's why:
Code vs. Deployment - The code shows you the logic, but the actual ranking might depend on dozens of parameters that change frequently. A researcher might find that the code weights "replies" heavily, but the live system might have that weight set to 0.0 this week because X's data scientists noticed it was creating too much spam. The code is truth, but only part of it.
Model Training - Modern ranking algorithms involve machine learning models. These aren't just hand-coded rules. They're neural networks or other ML systems trained on data. The code that invokes these models might be open source, but the trained models themselves (often gigabytes of parameters) usually aren't. You see the structure of the model but not the actual weights.
Real-time Behavior - X's algorithm isn't static. It makes decisions based on current signals: what's trending now, what's being reported now, what competitors are doing now. The code shows the methodology, but real-time behavior requires real-time data and real-time model inference that you can't perfectly replicate locally.
Feedback Loops - Algorithms often have feedback loops. If the algorithm shows you a post and you engage with it, that engagement signal goes back into the system and influences future decisions. You can't replicate these feedback loops just by running the code locally with fake data.
A concrete example: Let's say you want to understand why a particular post doesn't appear in your feed. You look at the open-sourced code. You can see the ranking function. You can calculate what the score should be. But then you realize: the score is high enough to be shown, but it's not showing. Why?
Possible reasons:
- The trained model weights have changed since the last code update
- Real-time rate limiting is capping how many posts from this creator X shows
- The content was flagged for review and is temporarily suppressed
- A/B testing is running, and your account is in a variant that doesn't show this content
- The model detected something that makes this post lower priority in your personal ranking
None of these would be obvious from just reading the code. You'd need access to more configuration, more data, and more explanation.
This doesn't mean open-sourcing was a bad idea. It's genuinely useful. Researchers have used it to understand algorithmic principles. Developers have used it to audit for bias. The broader point: open-sourcing code is one form of transparency, but it's not the same as full transparency.
What Researchers Actually Found When They Examined the Code
When X's algorithm code was first released, academic researchers jumped on it. What did they discover?
The Good Findings:
Researchers confirmed that X's algorithm does indeed use engagement as a primary signal. Posts with more replies, likes, and reposts rank higher. This confirmed what users had suspected.
The diversity component is real. The code includes logic specifically designed to prevent you from seeing the same creator over and over, even if their posts are highly engaging. This was actually a positive finding—it showed X's algorithm tries to avoid filter bubbles.
Recency matters, but older posts can still get high placement if they're highly engaged. The time-decay function decreases scores based on age, but it's not a hard cutoff.
The filtering logic includes clear rules about removing content violating X's policies. Researchers could see that there are actual policies encoded in the algorithm, not just arbitrary suppression.
The Concerning Findings:
The algorithm heavily favors certain creators and certain types of content. Researchers found that tweets with URLs, videos, or images rank higher than plain text. This biases the platform toward certain types of creators (those with production capabilities) over others (text-based commentators).
Engagement weighting is asymmetrical. Negative engagement (replies that often indicate conflict) sometimes counts almost as much as positive engagement. This can mean controversial posts rank high, which many critics argued promoted polarization.
There's limited transparency about the trained models. The code alone didn't explain how certain decisions get made in edge cases. Researchers found that their attempts to replicate the live system behavior using just the released code were only about 70-80% accurate.
The algorithm appears to have hardcoded biases. Certain accounts or content types get different treatment without clear explanation. Whether this is intentional or emergent from the model training wasn't clear.
The Honest Assessment:
Researchers concluded that X's open-sourcing was a meaningful step, but incomplete. One major finding: the code explains the general logic of the algorithm, but to actually understand X's personalized feed ranking for any given user would require knowing that user's specific data, the trained model weights, real-time configuration, and other details that weren't and couldn't be shared.
In other words: open-sourcing helped explain X's general approach, but didn't actually make X's algorithm fully transparent in the way a user might hope.
Impact on Moderation and Suppression Decisions
One key question: does open-sourcing the algorithm explain how X makes moderation decisions and content suppression choices?
Partially, yes. The code released does include some filtering logic. You can see rules like "if content violates policy X, suppress it" or "if reported by N users, flag for review."
But here's what's tricky: content moderation decisions aren't purely algorithmic. They're also made by humans. X has teams of content moderators. Some decisions are made by algorithm, some by humans, and some by both working together. The open-sourced code shows algorithmic decisions but not human decisions or the human-in-the-loop process.
There's also the question of bias. If X's algorithm promotes content from certain types of creators and suppresses others, is that moderation? Or just how the algorithm was designed? The line gets blurry.
When the Grok chatbot issue emerged (where X's AI was generating CSAM at users' requests), it raised questions that open-sourcing the recommendation algorithm doesn't really address. Grok is a separate system. The recommendation algorithm doesn't control what Grok generates. But the incident highlighted that open-sourcing one part of X's systems doesn't necessarily illuminate how the whole platform works or what safeguards exist.
Some researchers noted that understanding how X suppresses bad content requires understanding not just the code, but:
- What gets reported and why
- Which reports trigger algorithmic action
- What human moderators do with flagged content
- How appeals work
- What meta-moderation systems exist (moderation of moderators)
The open-sourced code addresses some of these, but not all.

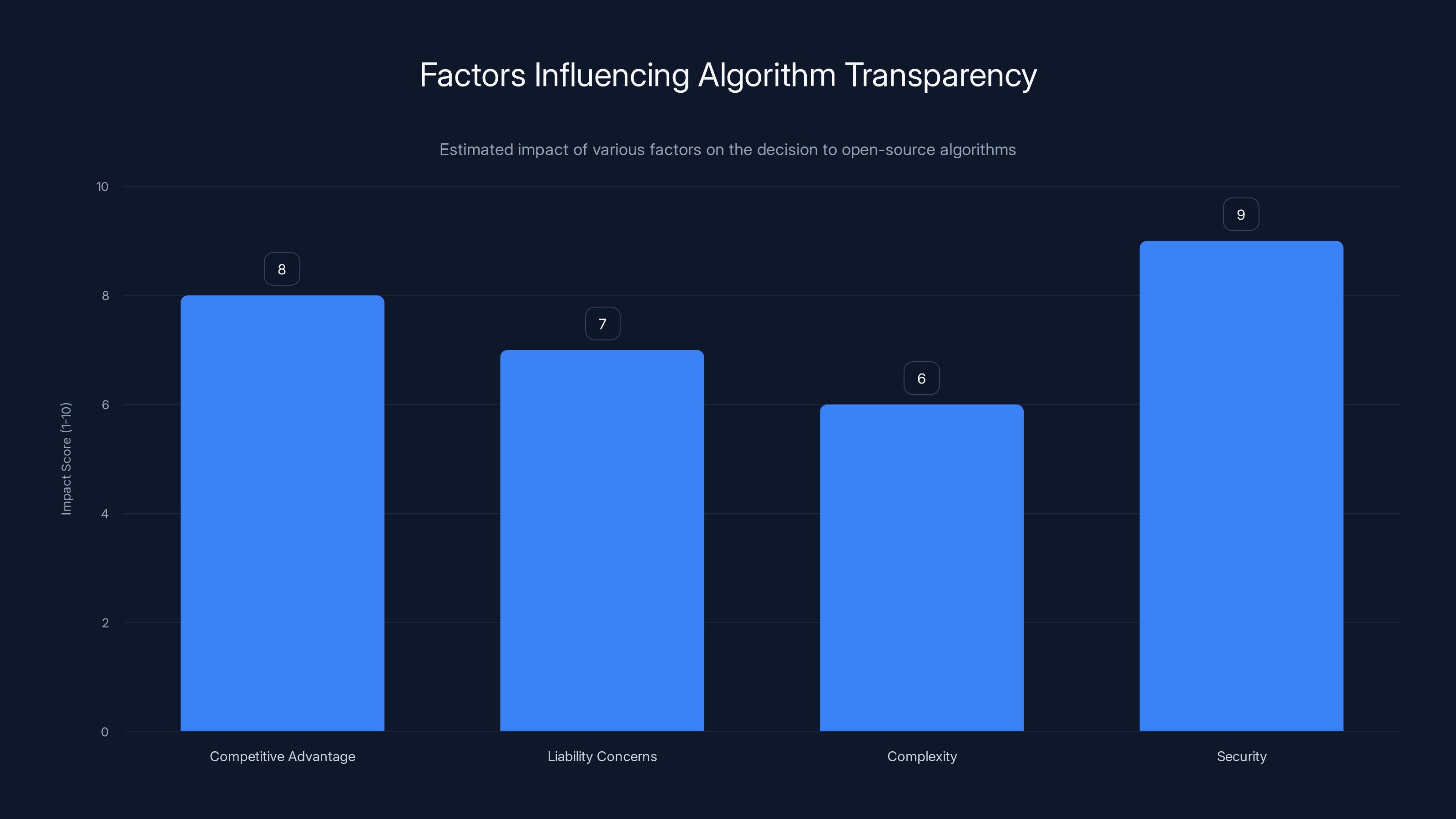
Security concerns are the most significant barrier to open-sourcing algorithms, followed by competitive advantage. Estimated data.
How Users Actually Benefit (or Don't) From Algorithm Transparency
Let's be practical: if you're a regular X user, what do you gain from the algorithm being open source?
Real benefits:
Understanding why posts you like get suppressed. If you can access the code and your engagement data, you could theoretically debug why certain content isn't appearing. Some power users have actually done this.
Knowing the algorithm's general behavior helps you work with it. If you know that X's algorithm favors engagement signals, you can craft posts more likely to generate engagement. Some creators have explicitly used understanding of the released code to optimize their strategies.
Trust, potentially. If you can audit the code yourself or read researchers' audits, you might trust that X's algorithm isn't doing something as sinister as you feared. Or you might discover it is, which at least gives you information.
Incentive for X to not do bad things. If researchers can see the code and identify bias, suppression, or other problems, X has an incentive to fix them (or at least to be caught and have to explain). This theoretical accountability is valuable.
Limitations on benefits:
Most users won't actually read the code or understand machine learning enough to audit it. The benefits mostly accrue to researchers, engineers, and power users.
The code doesn't actually change how the algorithm behaves. Understanding why you see what you see is interesting, but if the algorithm still makes decisions you don't like, understanding those decisions doesn't help.
You still can't control the algorithm. X doesn't give users knobs to adjust algorithm parameters. You can't say "I want this weight higher, that weight lower." The transparency is read-only.
The real behavior of X's algorithm in production is still opaque. The code is one thing. The actual deployed system, with its specific configuration, trained models, and real-time decisions, is another. The code helps but doesn't fully close that gap.
There's also a question of trust. If X open-sourced the algorithm partly to address regulatory pressure and reputation concerns, does that make it trustworthy? Or does it make transparency a marketing tool? Those are separate questions from whether the transparency itself is real.
The Quarterly Update Promise: Has It Been Kept?
Musk promised that X would release updated algorithm code "every 4 weeks, with comprehensive developer notes."
How's that going?
Inconsistently is the honest answer.
For the first few months after the announcement, X did release updates with relatively regularity. Developer notes accompanied some releases, explaining what changed.
But over time, the consistency deteriorated. Some updates came later than promised. Some had minimal notes. A few cycles were skipped entirely with explanation.
Why? Several possible reasons:
-
It's actually hard - Keeping open-source code up-to-date while running a live platform is genuinely difficult. You have to package the current state, document changes, and release it without disrupting the live system. It's not a trivial engineering task.
-
Competitive concerns - X's engineers might have felt that releasing updates too frequently revealed too much about how the algorithm was changing. Competitors could use that information to understand X's strategy.
-
Legal concerns - Some updates might involve changes to moderation logic or filtering rules. Releasing those details might create legal or regulatory complications.
-
Resource constraints - X went through significant layoffs and restructuring. Resources for maintaining the open-source release might have been reallocated.
-
Lost enthusiasm - Initial commitment to transparency might have waned once the immediate regulatory and PR pressure decreased.
The quarterly update issue highlights a real problem with transparency commitments: they're easy to make, harder to maintain. A one-time release of code is relatively simple. Consistent, ongoing releases with good documentation require sustained commitment.
Some observers noted that the update inconsistency actually created a different transparency problem. If you can't rely on the code being current, how useful is it? Researchers had to track which version of the code corresponded to which time period and which version of the live algorithm. That's an unnecessary layer of complexity.

Comparison: How X's Approach Differs From Other Platforms
X isn't the only platform experimenting with algorithmic transparency. How does it compare?
Reddit's Approach:
Reddit released its recommendation algorithm code in 2024. Like X, the release included the ranking logic but not all trained models. Reddit went further in documenting the system and providing clearer developer resources. However, Reddit's release came later than X's, and by then, Reddit had higher public trust around the issue (partly because it had been consistent about transparency through the API controversy and other challenges).
Tik Tok's Approach:
Tik Tok released research papers and some technical documentation about its algorithm, but not full code. Tik Tok's situation is different because of geopolitical concerns (the platform's Chinese ownership) and regulatory pressure in Western countries. Full code release would be more politically sensitive. Instead, Tik Tok opted for detailed academic documentation.
Meta's Approach:
Meta (Facebook, Instagram) has been more cautious. Instead of open-sourcing algorithm code, Meta has released research, published academic papers, and provided API access to researchers. There's no open-source algorithm code. Meta argues that its approach is safer and still provides meaningful research access.
Open AI and Anthropic's Approach:
For AI systems like Chat GPT and Claude, there's no code release of the trained model. The weights aren't open source. However, both companies released detailed technical documentation (Open AI more reluctantly, Anthropic more thoroughly). The reasoning: releasing model weights could enable misuse.
Key Differences:
X's approach is the most aggressive in terms of actual code release. The trade-off is that it still leaves out the trained models, but it goes further than most competitors in terms of sharing implementation details.
X also committed to ongoing updates. Most other platforms did one-time releases or released static documentation. X's promise of quarterly updates (even if inconsistent) was more ambitious.
However, X's transparency around why decisions are made is arguably weaker than Meta's. Meta publishes more research explaining the reasoning. X published the code but less explanation.
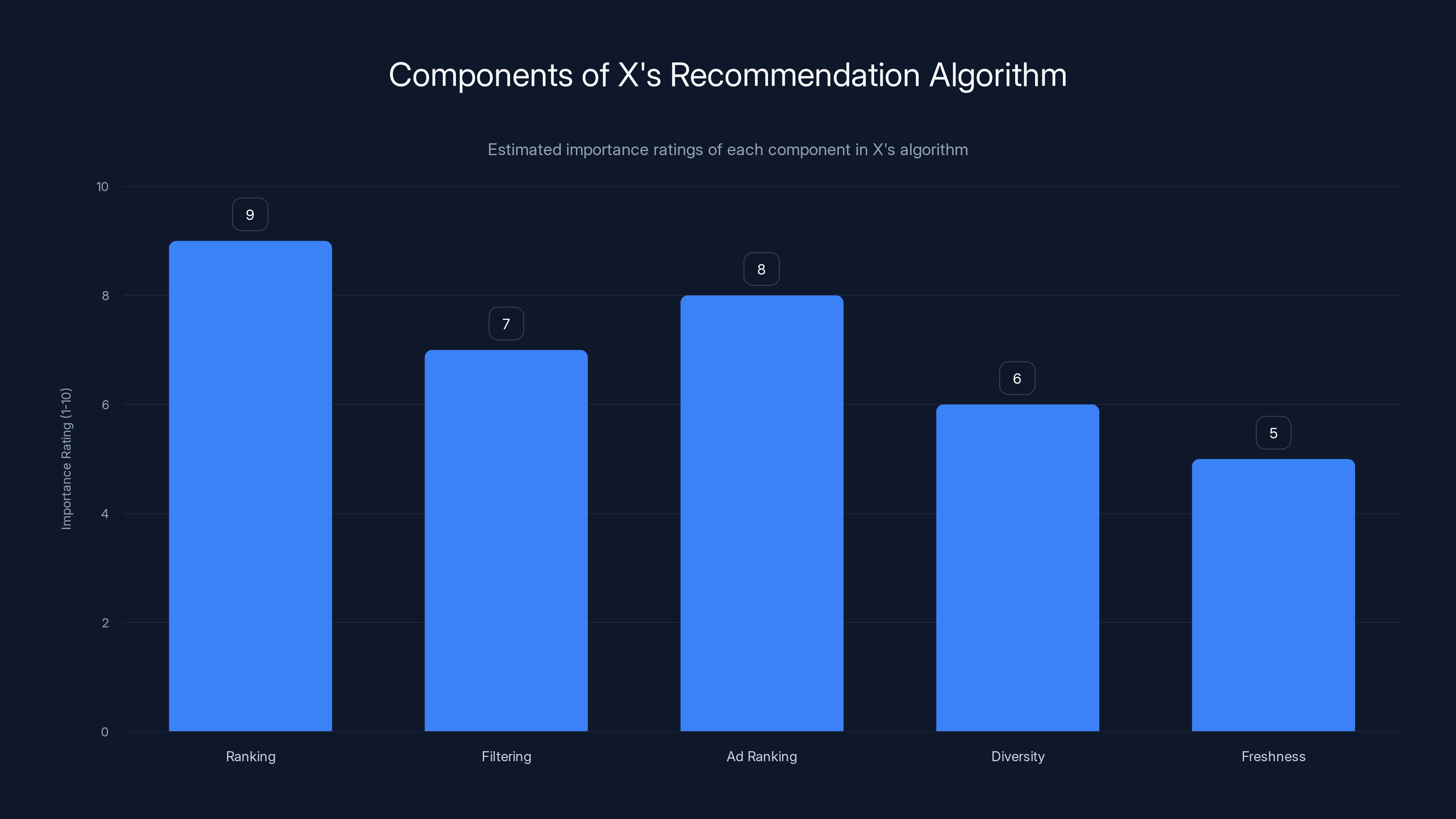
The Ranking Component is estimated to be the most crucial part of X's recommendation system, followed by Ad Ranking and Filtering. Estimated data.
The Limits of Open Source as a Solution to Algorithmic Harm
Open-sourcing the algorithm sounds like a solution to algorithmic bias, filter bubbles, and other algorithmic harms. But does it actually address the core problems?
Not entirely. Here's why:
Algorithmic Bias:
If the algorithm was trained on biased data, publishing the code doesn't fix the bias. Researchers might be able to identify where bias comes in, but they can't fix it without retraining. And retraining requires data and resources that researchers don't have. So the visibility doesn't necessarily lead to accountability.
Filter Bubbles:
The algorithm's code might show you that it's designed to reduce filter bubbles. But if the live system's configuration or trained models have different priorities, the design intention doesn't match lived reality. Publishing the ideal code doesn't fix mismatches between intention and implementation.
Opacity of Decision-Making:
Some harms come from the way algorithmic decisions are made, not the algorithm itself. If X suppresses a particular creator's posts, that creator might want to know why. The published code might explain the general methodology but not the specific decision for that creator. Real transparency would require case-by-case explanations that scale to millions of users.
Structural Incentives:
Even with fully transparent code, the fundamental incentive structure remains: X makes money from engagement. The algorithm is optimized for engagement because that drives ad revenue. You can see how it optimizes for engagement, but you can't change that underlying incentive. If the problem is engagement-driven algorithms, transparency doesn't solve it.
Power Asymmetries:
A large tech company has far more resources to use algorithm knowledge than a researcher or individual user. X can use knowledge of how the algorithm works to optimize it further. Users and researchers use that knowledge to understand and audit. The asymmetry remains even with transparency.
The Arms Race:
Once an algorithm is public, adversaries—spammers, manipulators, malicious actors—can also read the code and figure out how to game it. This can actually make the system less stable, not more. X has to keep changing the algorithm to stay ahead of people trying to exploit it. But if changes are public, the arms race just continues.
The broader point: open-sourcing is not a complete solution to algorithmic opacity or algorithmic harm. It's a useful tool for transparency and auditing. But it doesn't solve the fundamental problems of algorithmic decision-making at scale.

What Changed After Open-Sourcing?
One important question: did anything actually change on X after the algorithm was open-sourced?
In terms of the user experience, mostly not. The algorithm didn't fundamentally change. You still see roughly the same mix of content. The ranking logic is the same. The behavior is the same.
But there were some changes:
For Researchers:
Researchers could now study X's algorithm directly without waiting for the company to respond to requests or going through lengthy approval processes. This led to more academic work on X's algorithm.
Some studies published after open-sourcing revealed issues with the algorithm that X then worked to address. Not all (some issues remain), but some responsiveness to research findings.
For Auditing:
Advocacy groups and civil society organizations could now audit X's algorithm for bias and potential harms. Some did, publishing reports on what they found. This created pressure for X to address issues.
For Regulatory Compliance:
X could point to open-sourcing as evidence of compliance with algorithmic transparency requirements in regulations like the DSA. Whether regulators were satisfied varied, but X had a stronger position to negotiate from.
For Trust:
Publishing the code created a modest improvement in how some audiences perceived X's transparency. Not everyone, and the effect was limited. But some users and observers noted it as a positive step.
For Developers:
Some developers have used the open-source code to build research tools, auditing tools, and educational materials. This ecosystem building is valuable even if it hasn't changed X's actual algorithm.
But honest assessment: the open-sourcing didn't lead to massive changes in how X works or in how X is perceived. It was a meaningful transparency step, but not a revolution.
The Regulatory Interpretation of Algorithm Transparency
Regulators didn't necessarily see open-sourcing as fully satisfying their transparency demands. Here's how regulators actually interpreted it:
European Commission:
The Commission noted that while code transparency is valuable, it must be paired with explanation of real-world deployment and impact. They continued their investigation even after open-sourcing, looking for answers about how the algorithm actually behaves in production.
France's CNIL:
France's data protection authority emphasized that transparency requires not just code, but documentation, user-facing explanations, and ongoing monitoring of algorithmic impact. Code alone wasn't deemed sufficient.
UK's Ofcom (Communications Regulator):
When Ofcom examined X's algorithm transparency as part of Online Safety Bill enforcement, they noted that open-source code was one data point, but they also needed to understand model behavior, decision-making in edge cases, and real-world impact on different user groups.
The Regulatory Consensus:
Across jurisdictions, regulators seemed to view open-sourcing as "good, but not enough." They wanted:
- Code transparency (check, X did this)
- Documentation of how code is deployed (partial)
- Explanation of real-world impact (limited)
- User-facing information about algorithmic decisions (very limited)
- Ongoing auditing and adaptation (inconsistent)
In some ways, X's open-sourcing satisfied the letter of transparency requirements but not the spirit. Regulators wanted to understand how X's algorithms affect users, societies, and discourse. Code helps with that, but it's not the complete picture.
This created an interesting dynamic: X could say it was complying with transparency requirements, and regulators could say those requirements weren't fully met. Both statements could be true simultaneously.

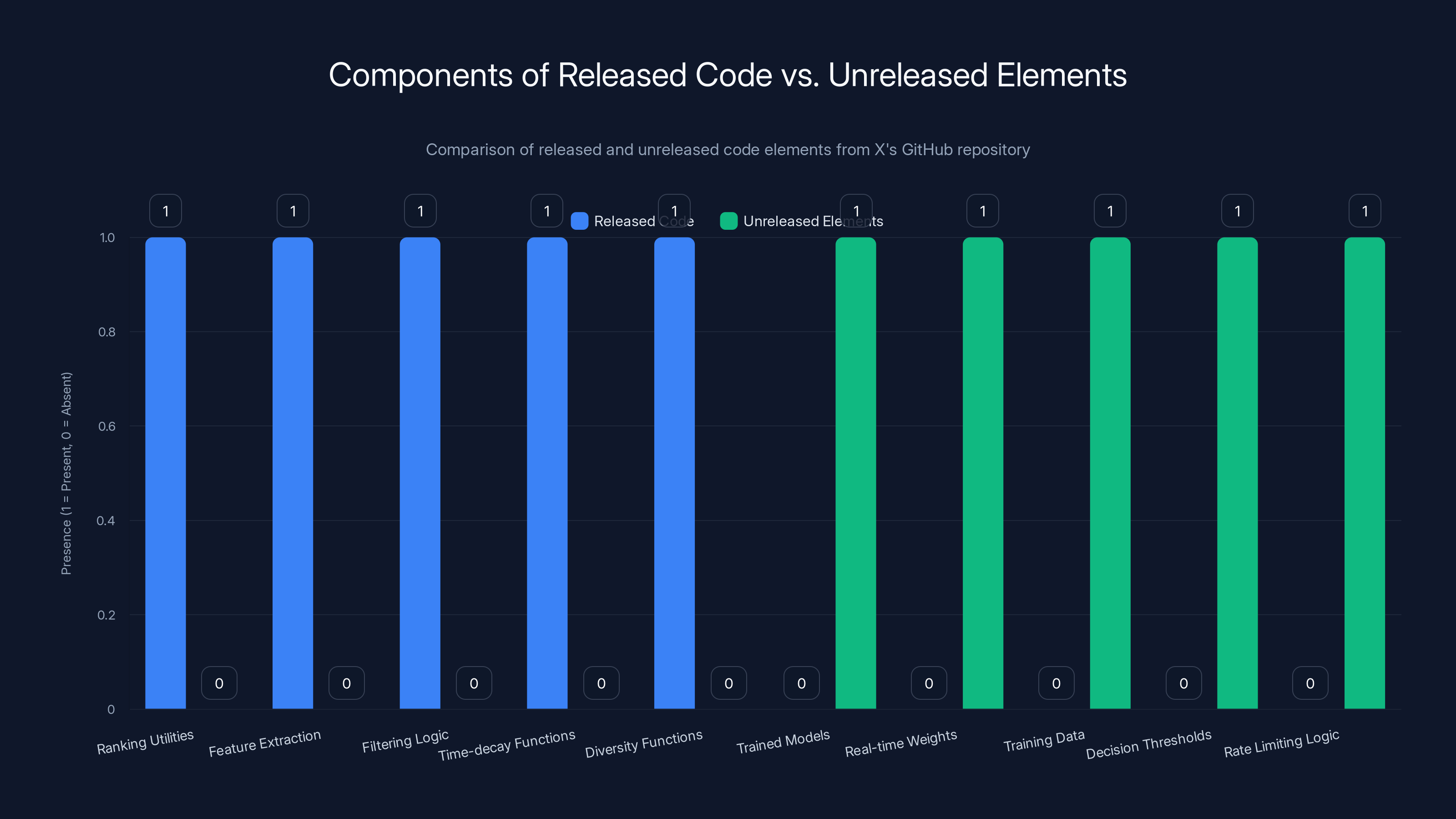
The chart highlights that while X released several algorithmic components, critical elements like trained models and real-time weights remain unreleased.
Technical Challenges of Maintaining Open-Source Transparency
One thing worth understanding: maintaining an open-source version of a complex, constantly-evolving production algorithm is genuinely difficult.
Versioning Problems:
X's algorithm in production changes frequently. Features are added, models are retrained, parameters are tuned. Keeping the open-source version in sync is complex. At any given time, the open-source code might be slightly out of date.
Sometimes code changes are security-related and can't be published immediately. Other times, changes are experimental and might not make it to production. So which version do you publish?
Model Versioning:
Machine learning models are trained regularly as new data comes in. Publishing the trained models would be enormous in file size (possibly hundreds of gigabytes). So X publishes the code and methodology but not the actual trained models.
This creates a reproducibility problem. Even if you have the code and all the documentation, you can't actually replicate the live system without the trained models. Researchers have noted this as a significant gap.
Configuration Drift:
The same code, with different configurations or parameters, behaves very differently. Over time, the gap between the published code and the configured production system widens. Updating the publication requires documenting all these configurations, which is time-consuming and complex.
Feedback Loop Complexity:
X's algorithm has feedback loops: user behavior influences the algorithm, which influences what users see, which influences user behavior differently. Simulating these loops requires access to live data and live models. Researchers can't fully recreate this locally.
Competitive Concerns:
Even though the code is published, there's competitive advantage in how it's configured and deployed. X might be hesitant to publish detailed configuration information because competitors could use it to understand X's strategy and build better systems.
Resource Constraints:
Maintaining open-source code requires engineering effort. Someone has to update documentation, respond to issues, maintain versions. At X, which has been through multiple restructurings, resources for this work might not have been prioritized.
These aren't excuses—they're real constraints of the task. They help explain why open-sourcing an algorithm is easy in principle but challenging in practice.
Future of Algorithmic Transparency in Social Media
Where does this all go from here?
Regulatory Trajectory:
It seems likely that more jurisdictions will require algorithmic transparency similar to the DSA. If that happens, other platforms might follow X's approach. But regulators will probably refine requirements to specify what transparency actually means: code? Model cards? Impact reports? User-facing explanations?
We might see standards emerge around what "transparent algorithm" means. The Open AI Card framework (documenting model details) and model cards from AI ethics research provide possible templates.
Platform Evolution:
Platforms might move toward building explainability directly into systems. Instead of publishing code after the fact, they might build systems that inherently explain their decisions to users. This is harder but more useful than open-sourcing code.
We might also see platforms moving away from pure algorithmic ranking toward more transparent, user-controllable systems. Giving users knobs to adjust their own feeds might become more common.
Competitive Dynamics:
As transparency becomes a differentiator, some platforms might compete on transparency. Others might differentiate on other features or experiences. There will probably be a mix.
Researcher Engagement:
More academic research on published algorithms will likely continue. This builds an external auditing function that improves over time. But researchers need to stay current as algorithms evolve.
Technical Standards:
The community might develop technical standards for algorithm publishing: what should be included, how should it be documented, what tools should be available for analysis. This would make transparency more meaningful and comparable across platforms.
User Control:
There's also a possibility of moving toward more user control. Instead of just understanding the algorithm, users might get options to customize it. "Show me more from creators I follow, less from trending." "Prioritize recent posts over engagement." This is more useful than transparency alone, though also more complex to implement.

Comparison Table: Algorithm Transparency Across Major Platforms
| Platform | Approach | Code Released | Models Released | Ongoing Updates | Regulatory Compliance |
|---|---|---|---|---|---|
| X | Open-source code | Full (incomplete) | No | Inconsistent | Partial |
| Open-source code | Full | No | Yes | Partial | |
| Meta | Research & API | No | No | Research papers | Partial |
| Tik Tok | Documentation | No | No | Academic papers | Partial |
| You Tube | Research & limited access | No | No | Research papers | Partial |
| Bluesky | Open-source (whole platform) | Full | No | Yes | N/A (emerging) |
Key Takeaways and Implications
Let's step back and summarize what X's open-source algorithm actually means:
What Was Promised:
Full algorithmic transparency through open-sourced code, updated regularly, with comprehensive documentation.
What Actually Happened:
X released significant algorithm code on Git Hub with documentation. Code included ranking logic, filtering logic, and helper functions. Updates came inconsistently. Trained models, real-time configuration, and production behavior remained partially opaque.
What Changed:
Researchers could audit the algorithm directly. Some advocacy groups did. Regulators had more evidence to evaluate. Users could theoretically understand the general algorithm, though most didn't. Actual behavior for users remained the same.
What Didn't Change:
The fundamental incentive structure (algorithm optimized for engagement). User control over algorithmic ranking. Access to trained model details. Real-time decision-making transparency. Overall platform trust significantly.
What We Learned:
Open-sourcing is valuable but insufficient for full algorithmic accountability. Transparency about code is different from transparency about behavior. Publishing code helps researchers and regulators but has limited impact on regular users. Maintaining transparent algorithms is harder than a one-time release.
Where It Matters:
For academic research, open sourcing genuinely helped. For regulatory compliance, it was a meaningful step but not complete satisfaction. For user trust and understanding, impact was limited. For auditing and civil society oversight, valuable. For actually controlling what you see on X, minimal impact.
The Broader Implication:
Algorithmic transparency is necessary for accountability, but transparency alone is insufficient. You also need auditing capacity (researchers), enforcement power (regulators), user control mechanisms, and clear incentive alignment. X's open-sourcing addressed one component of a larger system.

FAQ
What exactly did Elon Musk promise about X's algorithm?
Elon Musk announced that X would open-source its recommendation algorithm, including all code determining what organic and advertising posts users see. He stated this would happen within 7 days and be repeated every 4 weeks with comprehensive developer notes to help people understand algorithmic changes.
Why did X open-source its algorithm?
X open-sourced its algorithm for several reasons: regulatory pressure from European authorities investigating algorithmic transparency, previous commitments Musk had made, public criticism of algorithmic opacity, and efforts to address accountability concerns following content moderation scandals. Open-sourcing became both a compliance strategy and a trust-building move.
What exactly was included in the code release?
The released code included ranking utilities, feature extraction functions, filtering logic, time-decay functions for content freshness, and diversity mechanisms. However, trained machine learning models, real-time parameter weights, training data specifications, and exact decision thresholds were not released.
Does open-sourcing the algorithm actually make it transparent?
Partially. Open-sourcing provides code transparency, allowing researchers and technically sophisticated people to understand the general methodology. However, true transparency would also require access to trained models, real-time configuration, deployment details, and real-world impact documentation. Code alone doesn't show actual algorithmic behavior in production systems.
What have researchers discovered by examining the released code?
Researchers found that X's algorithm heavily weights engagement signals, includes diversity mechanisms to prevent filter bubbles, and uses time-decay to prioritize recent content. However, they also discovered the algorithm favors certain content types (multimedia over text), has asymmetrical treatment of positive and negative engagement, and remains approximately 20-30% opaque even with published code.
Did open-sourcing change how X's algorithm actually works?
Not significantly. The algorithm's core logic and behavior remained largely the same after open-sourcing. Users experienced similar feeds. The main changes were in visibility to researchers and regulatory bodies, not in how the algorithm functions for regular users.
Are the quarterly updates still happening?
Updates have been inconsistent. The first several cycles occurred relatively regularly, but subsequent updates showed gaps, reduced frequency, and minimal accompanying documentation. The quarterly cadence Musk promised has not been consistently maintained.
How do regulators view X's algorithm transparency?
European regulators view open-sourcing as a positive step but insufficient for meeting algorithmic transparency requirements in regulations like the Digital Services Act. They continue to demand documentation of real-world impact, user-facing explanations, and ongoing monitoring of algorithmic effects on discourse and user well-being.
Can regular users actually understand X's algorithm from the published code?
Not practically. While technically available, the code requires advanced programming and machine learning knowledge to understand. Regular users would need significant technical expertise and time investment to extract useful insights about how their personal feeds are ranked.
What's missing from the open-source release that would make it truly transparent?
Key missing elements include trained model weights, real-time configuration parameters, explicit decision thresholds for moderation and suppression, case-by-case explanation of individual ranking decisions, impact studies showing how the algorithm affects different user populations, and complete documentation of human-in-the-loop moderation processes.
How does X's approach compare to other platforms' transparency efforts?
X has been relatively aggressive with code release compared to Meta (which hasn't released algorithm code) and Tik Tok (which released documentation but not full code). However, X's approach is less well-maintained than Reddit's open-source release and provides less documentation than Meta's research publishing. No major platform has achieved complete algorithmic transparency.
What's the future of algorithmic transparency in social media?
Future developments likely include more specific regulatory requirements around what transparency means, potential standardization of algorithmic documentation, more platforms publishing some level of algorithm details, and possibly more user-facing controls and explanations. The consensus is moving toward transparency being essential but insufficient without accountability mechanisms and user control.
Conclusion: The Reality Behind the Promise
When Elon Musk announced that X would open-source its algorithm, it sounded revolutionary. A major social media platform, finally, lifting the veil on one of its most important systems.
The reality is more nuanced and more interesting than the headline.
X did open-source meaningful algorithm code. Researchers can examine it, audit it, and learn from it. That's genuinely valuable. It's more transparency than most platforms offer. It matters for academic understanding, for regulatory compliance, and for civil society oversight.
But the open-source code isn't the full algorithm. It's one component of a complex system that includes trained models, real-time configuration, production deployment, feedback loops, and human decision-making. Understanding the code helps you understand the principles, but not the practice.
Users didn't get radically more control over what they see. They just got visibility into why they see it. That's better than before, but it's not the same as having agency.
Regulators got more evidence for their investigations but not complete answers to their questions. X could point to open-sourcing as evidence of transparency while still keeping significant operational details private.
The promise of quarterly updates wasn't consistently maintained. Transparency, it turns out, requires sustained commitment, not just a one-time gesture.
And here's the deeper insight: even with perfect transparency about how the algorithm works, you still face the fundamental problem. X's algorithm is optimized for engagement because engagement drives ad revenue. Seeing the code doesn't change that incentive structure. Understanding why the algorithm does something doesn't give you control over it.
So what's the broader takeaway? Algorithmic transparency is necessary for accountability and understanding. It's a meaningful step forward. But it's not sufficient on its own. Real accountability requires transparency, yes, but also auditing capacity, regulatory power, user control mechanisms, and incentive alignment.
X's open-source algorithm is a good example of what transparency can do and what it can't. It's progress, but incomplete. And in a world where algorithms shape billions of people's information access and political discourse, incomplete transparency is an important and challenging problem.
The question going forward isn't just whether platforms will publish their algorithms. It's what happens next: how regulators, civil society, and users use that transparency to demand not just visibility, but actual accountability and control.
That's the conversation that matters. And X's open-source release is just the beginning of it.

Related Articles
- Elon Musk's Open-Source X Algorithm Promise: History, Reality, and What It Means [2025]
- WhatsApp Under EU Scrutiny: What the Digital Services Act Means [2025]
- Grok's AI Deepfake Crisis: What You Need to Know [2025]
- Grok's Deepfake Problem: Why the Paywall Isn't Working [2025]
- Grok's Deepfake Crisis: UK Regulation and AI Abuse [2025]
- Indonesia Blocks Grok Over Deepfakes: What Happened [2025]

