![Xikipedia: Wikipedia as a Social Media Feed [2025]](https://tryrunable.com/blog/xikipedia-wikipedia-as-a-social-media-feed-2025/image-1-1770055616324.jpg)
The Problem With Doomscrolling: Why Your Mental Health Needs a Digital Detox
Let's be honest. Your phone probably lit up about forty-seven times while you were reading this sentence. And that's not a judgment—it's just the reality of living in 2025. Social media feeds are engineered to be addictive. They're designed by teams of behavioral psychologists and machine learning engineers whose entire job is keeping you scrolling past your bedtime, doom-consuming content that makes you feel like the world is burning down.
The irony? Most of that content is negative. A study from multiple tech companies' own internal research shows that algorithmic feeds emphasize engagement above all else, and negative emotions generate more engagement than positive ones. Anxiety, outrage, and fear are the currencies of modern social media. Your Twitter feed isn't trying to make you smarter or happier. It's trying to make you addicted.
But what if there was another way? What if you could experience that satisfying infinite scroll, that dopamine hit of discovering something new, but instead of rage-inducing political arguments or carefully filtered life updates, you got genuine knowledge? What if your feed was filled with articles about obscure inventor biographies, the history of refrigeration, or the science behind why cats purr?
That's the premise behind Xikipedia. And honestly, it might be the healthiest thing to happen to the internet in years.
TL; DR
- What it is: Xikipedia is a free web app that transforms Simple Wikipedia into an infinite, algorithmic social media-style feed using local machine learning
- The creator: Developer Lyra Rebane built it as a proof of concept showing how non-ML algorithms can create engaging feeds without tracking user data
- Why it matters: It offers a genuinely addictive content discovery experience without the mental health toll of traditional social media
- How it works: The algorithm learns from your "likes" and serves more content from similar categories, with all processing happening locally on your device
- The catch: It pulls from Simple Wikipedia, which updates less frequently than the main site, and occasionally surfaces NSFW content

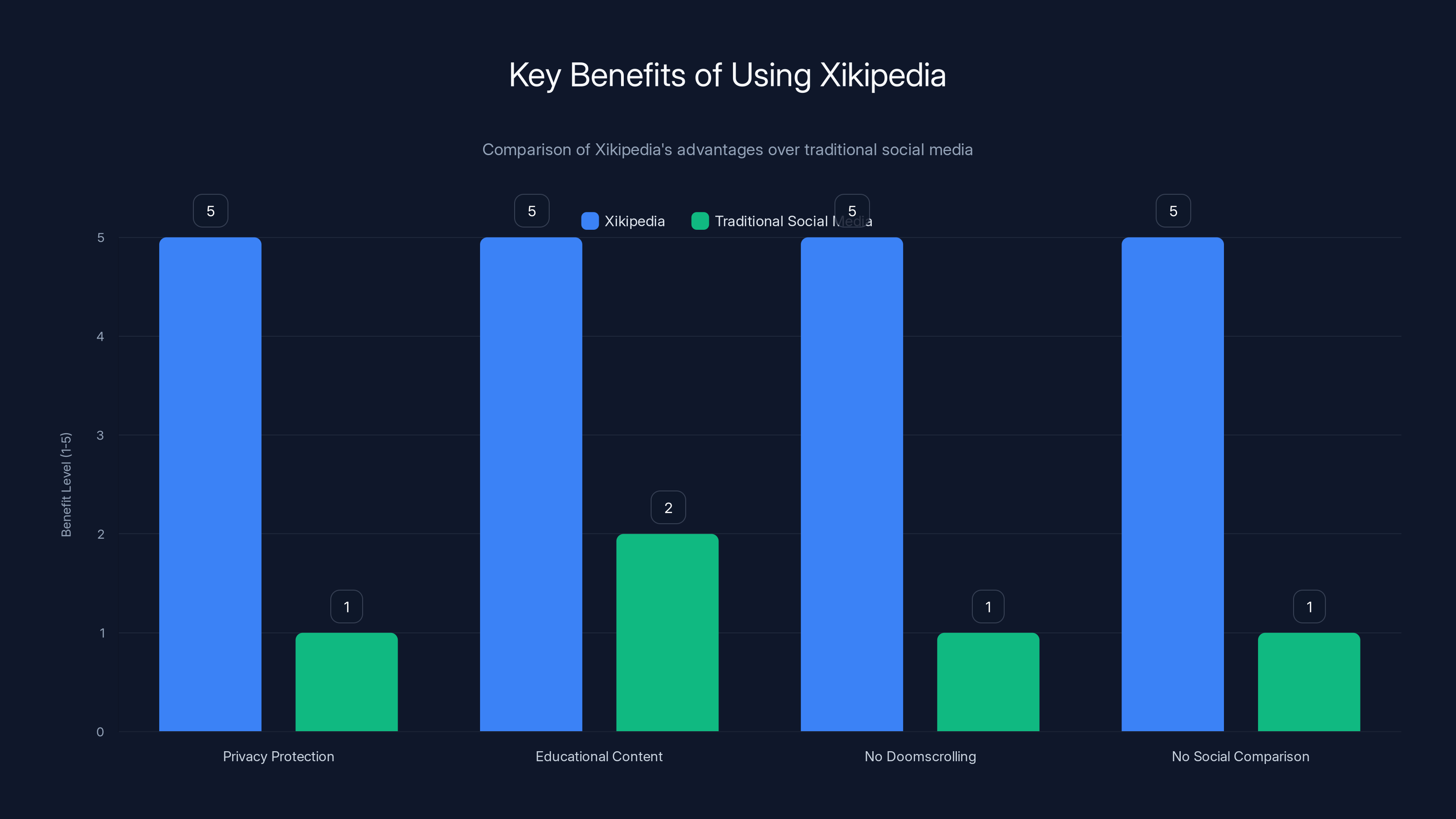
Xikipedia excels in privacy protection, educational content, and eliminating doomscrolling and social comparison, unlike traditional social media platforms. (Estimated data)
Who Is Lyra Rebane and Why Did They Build This?
Lyra Rebane isn't a household name. They're not a celebrity entrepreneur with a TED talk or a Forbes cover. But they represent something increasingly rare in tech: a developer who saw a problem and built a solution for the right reasons, not for venture capital or user acquisition metrics.
Rebane's background is in full-stack web development with a focus on algorithms and user experience design. Over the years, they'd watched the same pattern repeat across every major platform: engagement algorithms optimized for watch time and clicks rather than user wellbeing. They'd read the research papers. They'd seen the internal documents leaked from major tech companies. They understood the mechanism of the trap.
But instead of becoming another voice complaining about algorithmic harm on Twitter, Rebane did something radical: they built an alternative.
The initial concept was deceptively simple. What if you took the world's largest free knowledge base—Wikipedia—and fed it through an algorithm that worked exactly like social media feeds, but instead of serving you outrage, it served you curiosity? What if that algorithm ran entirely on your device, collecting zero data, respecting your privacy completely?
The project started as a weekend experiment. Rebane wanted to demonstrate a specific technical principle: you don't need massive datasets, sophisticated machine learning models, or invasive tracking to create a genuinely engaging feed. A basic algorithm that understands local preferences can work surprisingly well.
The response surprised everyone. When Xikipedia launched, it went viral in tech circles. People on Reddit, Twitter, and tech forums lit up with excitement. Here was something fundamentally different. Not another app trying to extract data or engagement. Just a tool that seemed to understand what people actually wanted: a way to learn about the world without feeling emotionally manipulated.

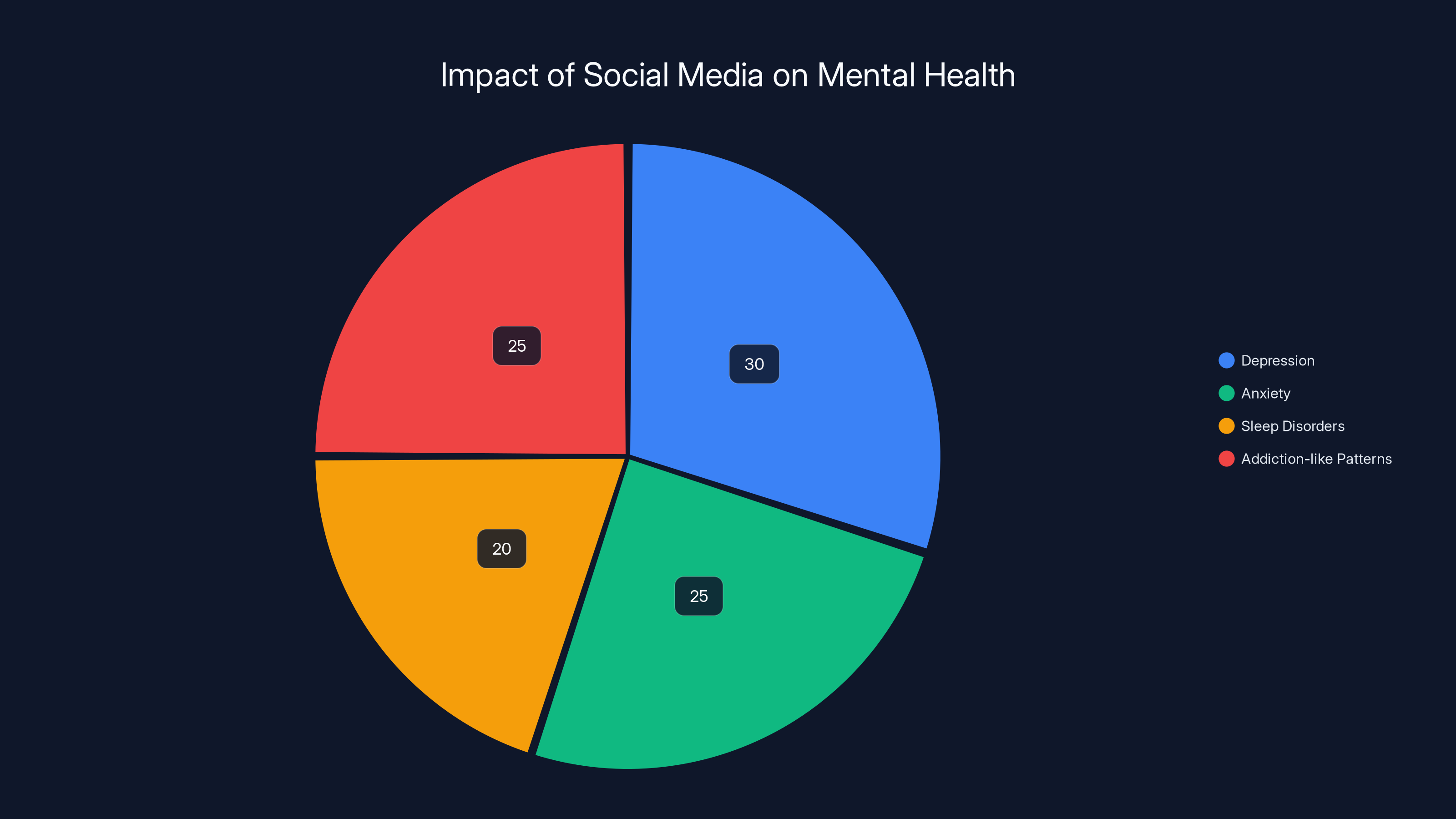
Estimated data suggests that heavy social media use contributes to depression (30%), anxiety (25%), sleep disorders (20%), and addiction-like patterns (25%).
How Xikipedia Works: The Technical Architecture
Understanding how Xikipedia actually works requires understanding why most social media feeds feel so addictive and why they're so harmful. Let's break down the technical architecture.
The Simple Wikipedia Advantage
Xikipedia doesn't pull from the main Wikipedia. Instead, it uses Simple English Wikipedia. This is a crucial distinction. Simple Wikipedia has been designed from the ground up to explain complex topics using basic vocabulary and shorter articles. It's intended for people learning English, young readers, or anyone who wants straightforward explanations without academic jargon.
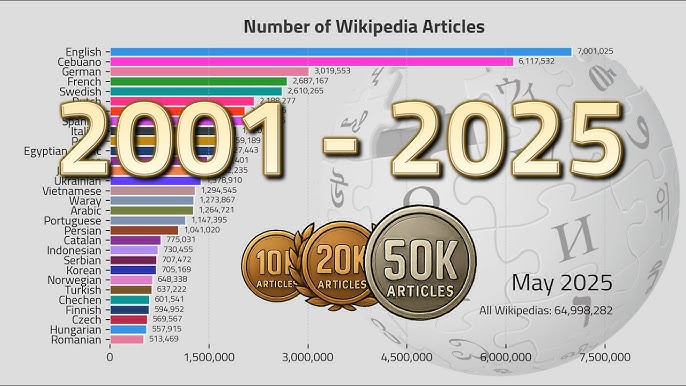
This actually makes it perfect for what Rebane wanted to build. The articles are self-contained, easier to parse algorithmically, and less likely to contain overly technical information that breaks engagement. Simple Wikipedia has over 278,000 articles, which provides an enormous pool of content to draw from.
When you boot up Xikipedia, the application downloads this entire dataset to your device. Yes, that's 40MB of data. Yes, it takes a moment to load. This is intentional. That loading time, that moment of friction, is part of the design philosophy. It creates a natural pause. You're not reflexively opening the app in line at the grocery store. You're making a conscious choice to engage with learning.
The Local-First Algorithm
Here's where Xikipedia gets genuinely clever. The algorithm that powers the feed isn't running on Rebane's servers. It's running on your device, in your browser. This is a crucial privacy distinction. Every other major social media platform collects data about what you click, how long you spend on each post, when you open the app, what device you're using. That data gets stored in massive databases, sold to advertisers, and used to build ever-more-sophisticated engagement models.
Xikipedia does none of that.
Instead, the algorithm works with information that only exists on your device. When you like a post about ancient Rome, the algorithm notes that you liked an article from the "History" category. It increases the probability of serving more articles from History, from articles linked to Rome, from parent categories of both. The algorithm learns contextually, building a personal profile of your interests that exists nowhere but in your browser cache.
This is actually elegant. Because the algorithm doesn't need to transmit data back to servers, it doesn't need to store anything permanently. Close your browser or refresh the page, and all records of your browsing history disappear. The app has no incentive to track you because there's nowhere to send the data.
The Engagement Loop, Done Right
Social media feeds work through a positive feedback loop. You engage with content. The algorithm notes this engagement. It serves more similar content. You engage more. The loop repeats, and you suddenly look up to realize three hours have passed and you've gone down a rabbit hole of videos about celebrity drama.
Xikipedia uses the same loop structure, but the output is fundamentally different. You like an article about marine biology. The algorithm serves more articles about ocean life, environmental science, related species. You click through and realize you're now deeply interested in bioluminescence, a subject you'd never considered before. You've spent two hours learning instead of feeling anxious.
The psychological difference is subtle but profound. In traditional social media, engagement is the goal. In Xikipedia, discovery is the goal. The algorithm is optimized for keeping you interested in following your curiosity, not for maximizing watch time or ad views.
Category and Custom Filtering
You're not forced into a completely algorithmic experience either. Xikipedia lets you manually select which categories you want to see. Want to focus exclusively on science and technology? Done. Want to add art history and music? You can. Want to create custom categories by entering specific keywords? The system supports that too.
This level of control is radical compared to Twitter, Instagram, or Tik Tok, where the algorithm's decision-making is opaque and you have limited ability to directly influence what you see. With Xikipedia, you're a collaborator in shaping your feed, not a passive recipient of algorithmic choices.
The Mental Health Case for Better Content Discovery
Let's dig into why this matters beyond just being a cool technical project. This is about your actual mental health.
The Research Behind Algorithmic Harm
Over the past decade, research into social media's psychological impact has become increasingly dire. A meta-analysis published by the American Psychological Association found correlations between heavy social media use and increased rates of depression, anxiety, and sleep disorders. The mechanisms are clear: social media algorithms optimize for engagement, engagement is maximized by triggering emotional reactions, and negative emotions are more engaging than positive ones.
Facebook's internal research, leaked through the platform's former product manager, showed that the company's own algorithms were making users miserable, yet they continued to deploy increasingly aggressive engagement strategies because engagement drove ad revenue. Tik Tok's algorithm has been documented by researchers as one of the most effective engagement machines ever built, capable of creating addiction-like patterns of use in teenagers within days.
The mechanism is almost mechanical. Your brain's dopamine system is triggered by variable rewards. You open social media not knowing what you'll see. Sometimes it's interesting, sometimes it's boring. Sometimes it's engaging, sometimes it's enraging. That unpredictability creates a compulsive checking behavior remarkably similar to gambling addiction.
Xikipedia doesn't eliminate this response. Curiosity is powerful. But it reframes what's rewarding. Instead of random outrage, you get random knowledge. Instead of comparing your life to carefully curated versions of others' lives, you get to follow your genuine intellectual interests.
The Doomscroll Problem Is Real
Doomscrolling is when you compulsively consume negative news even though it makes you feel worse. You know the sensation. Something terrible happened in the world, and instead of looking away, you keep scrolling, reading more horrible details, watching videos, reading reactions. You feel progressively more anxious and helpless, yet you can't stop.
This is a feature, not a bug, of algorithmic feeds. News algorithms are optimized for engagement, and crisis content is maximally engaging. During the 2020 pandemic, studies showed that people spending more than 30 minutes per day on social media news feeds reported significantly higher rates of anxiety. During the 2024 election cycle, similar patterns emerged. Your feed isn't trying to inform you calmly. It's trying to upset you enough that you keep scrolling.
With Xikipedia, doomscrolling becomes physically impossible. There is no crisis content. There's no breaking news designed to trigger panic. There's just an infinite stream of factual, educational content. You can scroll for hours and feel progressively more knowledgeable instead of progressively more anxious.
The psychological literature on this is consistent: consuming educational content, even through infinite scrolling, has dramatically different effects on mental health than consuming algorithmically curated news and social content. Your brain experiences similar dopamine responses to discovery, but without the anxiety cascade.
Comparison and FOMO Don't Exist Here
Another significant source of social media harm is social comparison. Instagram is sometimes called "Instagram vs. Reality" because the platform exclusively shows people's best moments. Your feed is filled with vacation photos from people you went to high school with, promotional content from influencers, carefully composed images designed to make people jealous.
Research shows that exposure to these carefully curated presentations of others' lives correlates strongly with body image issues, financial anxiety, and depression. People feel like they're failing because everyone else's life looks perfect. Of course everyone else's life looks perfect—they only post the best parts.
Xikipedia has zero social comparison mechanics. You're not comparing yourself to anyone. There's no following, no follower counts, no retweets, no likes visible to anyone else. You're just exploring knowledge. There's no way to fail at learning about the history of typewriters or the biology of tardigrades.
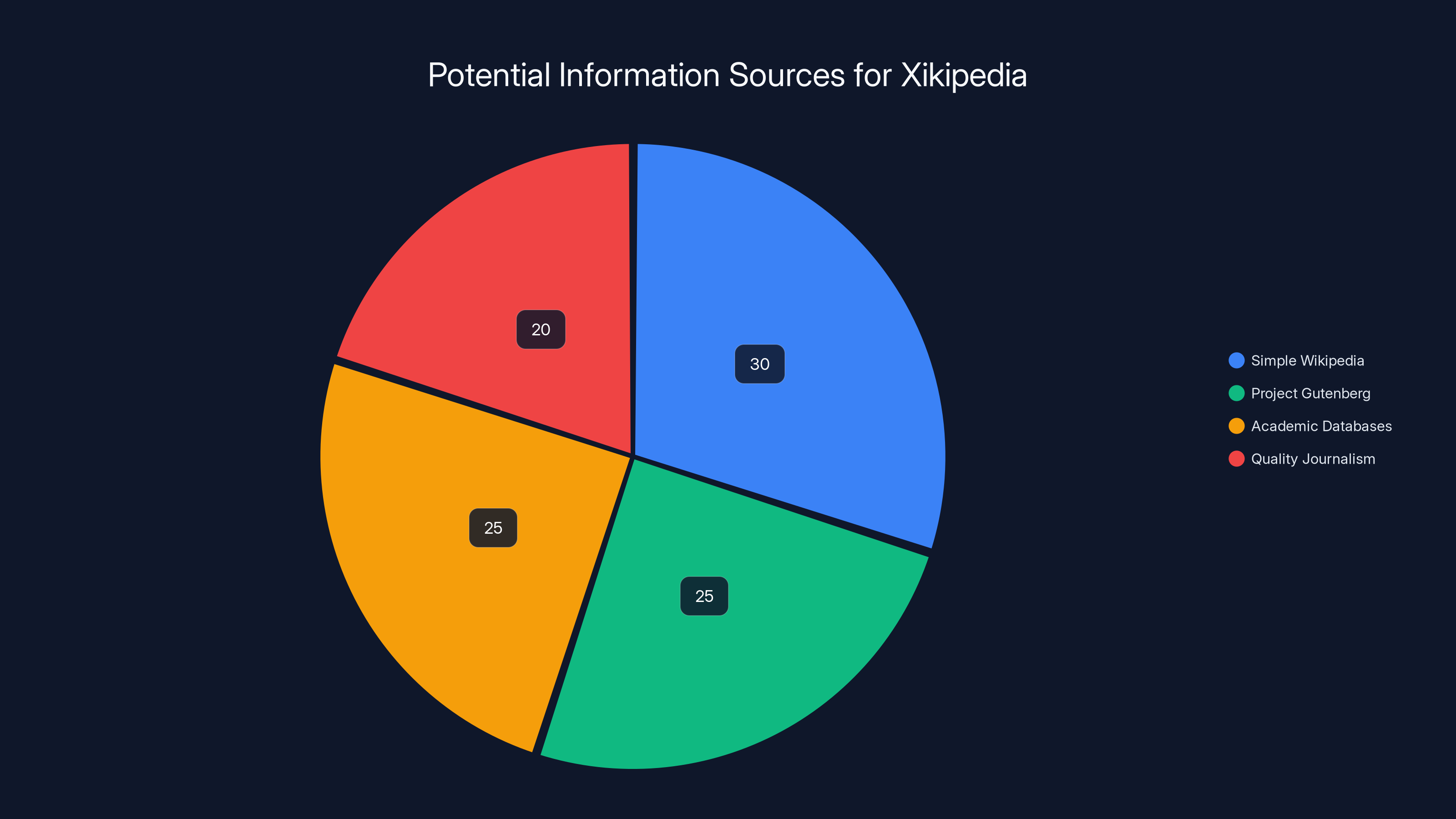
Estimated data shows a balanced distribution of content sources for Xikipedia, with Simple Wikipedia and Project Gutenberg as major contributors.
Comparing Xikipedia to Other Solutions
Xikipedia isn't the first attempt to create a better, healthier feed. Let's look at how it compares to other solutions that people have tried.
Versus Stumble Upon (R. I. P.)
Stumble Upon, which shut down in 2018, was probably the closest ancestor to Xikipedia. Users would click a button to jump to a random website based on their interests. It was delightful in a way that feels almost impossible to imagine now. You'd set your interests—science, art, music, humor—and then the algorithm would take you to random, often beautiful corners of the internet.
The difference with Xikipedia is that it's focused exclusively on Wikipedia's structured content, which tends toward more reliable, fact-checked information than the entire open web. Stumble Upon could take you to Geocities pages with MIDI files. Xikipedia takes you to articles that have been through Wikipedia's editorial process.
Also, Xikipedia is open source and decentralized. Stumble Upon was owned by e Bay, which shut it down when it wasn't profitable enough. Xikipedia could theoretically exist forever because it's just a web app that works with freely available data.
Versus Bored Button and Similar Tools
There are various "random Wikipedia article" tools online. The simplest is just a button that loads a random Wikipedia page. Xikipedia improves on this in crucial ways. First, it's algorithmic. The random selection isn't truly random—it's influenced by what you've already engaged with, creating thematic coherence. Second, it's more like a feed. You're not waiting for page loads and clicking back and forth. You're scrolling through summaries and deciding what interests you.
These tools also lack any filtering. You might click a random article and get something completely off-topic, which breaks the flow. Xikipedia's category system and algorithmic selection create a more coherent experience.
Versus Traditional News Feeds and Newsletters
Some people have tried to solve the doomscroll problem by switching to email newsletters. Substack newsletters from quality writers are genuinely good, but they're fundamentally passive. Someone else has decided what's important for you to learn about. You're a consumer of their curation.
With Xikipedia, you're an active participant. You're deciding what's interesting. The algorithm is learning your taste, not trying to shape your opinions. There's no author trying to drive a particular narrative. You're just reading factual information about whatever topics fascinate you.
Versus Reddit Communities and Forums
Online communities can be wonderful sources of knowledge and connection. But they come with built-in problems. They're social, which means they're prone to the same social comparison and status-seeking behavior as other social platforms. They have moderation, which can be good or can be terrible depending on the moderators. They're often dominated by strong personalities and group consensus.
Xikipedia is antisocial by design. There's no community. There's no moderation battles. There's no status hierarchy. It's just you, knowledge, and an algorithm trying to understand your interests.

The Limitations: What Xikipedia Doesn't Do Well
Let's be honest about the weaknesses. Xikipedia is brilliant at what it does, but it's not a silver bullet for all your information needs.
Simple Wikipedia Lags Behind Main Wikipedia
Simple Wikipedia is maintained by volunteers, just like main Wikipedia. But it has a much smaller editor base. This means that recent events, newly discovered information, and contemporary developments sometimes don't make it into Simple Wikipedia as quickly as they do into main Wikipedia.
If you're trying to learn about a musician's recent album, a scientific discovery from last month, or a historical event from the past year, Simple Wikipedia might not have the information yet. Main Wikipedia probably does. The lag isn't extreme—usually weeks or months at most—but it's noticeable if you're trying to stay on top of current events.
This is actually by design. Xikipedia's value proposition isn't being current. It's being timeless. The articles it serves you are stable, well-researched, and not going to change dramatically. There's something genuinely relaxing about that. You're not trying to keep up with the news cycle. You're just learning.
NSFW Content Occasionally Appears
Wikipedia covers all topics, including adult and medical content. Because Xikipedia pulls from the full Simple Wikipedia dataset without aggressive filtering, you'll occasionally encounter articles about human anatomy, adult diseases, historical violence, or other mature content.
Rebane is transparent about this on the landing page. If you're browsing in public or around children, this is worth knowing. The content isn't gratuitously explicit—Wikipedia maintains editorial standards—but it's also not being hidden. You might scroll through articles about ancient Rome and then see an article about contraception methods. It's all factual and educational, but it might not be what you expected.
Users can mitigate this by using category filtering. If you stick to science, history, and nature categories, you'll minimize encounters with this content. But there's no perfect filter without rebuilding the entire dataset.
It's Not a Replacement for Specialized Learning
If you want to deeply learn something specific, Xikipedia is a discovery tool, not a learning platform. You might stumble across an article about photosynthesis, read the summary, and decide to click through to the full article. Now you're on Wikipedia proper, and you can follow links and explore more deeply.
But if you're trying to learn Python programming, study for an exam, or develop expertise in a specific field, you need more structured resources. Xikipedia is for casual learning and discovery, not directed education.
This is actually a feature rather than a bug. It keeps the tool focused on what it does well: introducing you to topics you didn't know you were interested in.
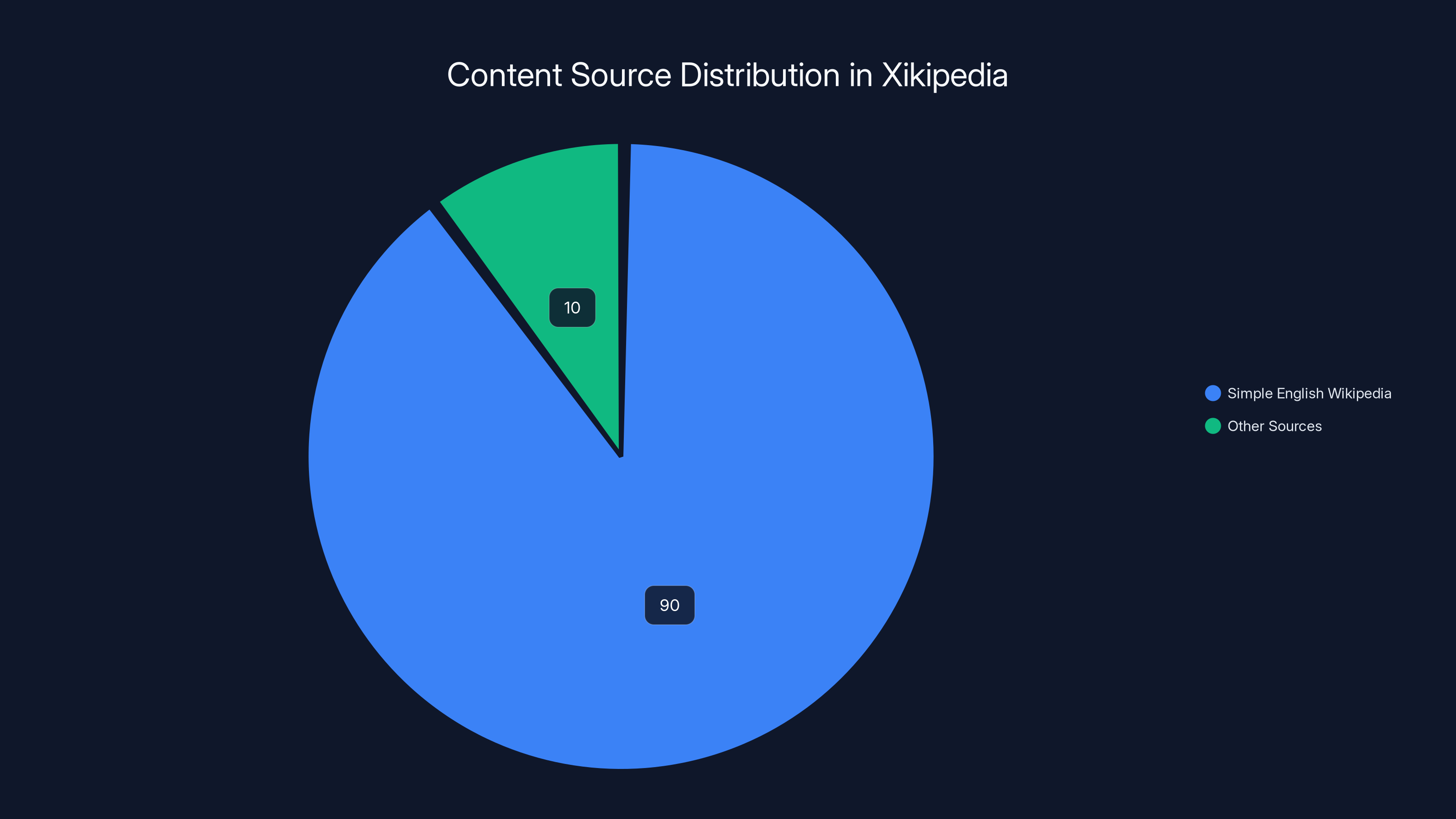
Xikipedia primarily utilizes Simple English Wikipedia, which constitutes 90% of its content source, ensuring simplicity and accessibility. Estimated data.
Building a Healthier Relationship With Information
What Xikipedia really represents is a proof of concept for something bigger: the possibility of algorithms designed for wellbeing rather than engagement.
The Philosophy Behind Healthy Algorithms
Most platforms treat algorithms as black boxes, optimization functions that maximize engagement without considering the user's actual wellbeing. The most successful platforms of the past fifteen years have essentially said: "We don't care if you're happy. We care if you're using our product."
Rebane's approach is different. The algorithm is optimized for discovery and learning. Yes, people get engaged. Yes, they spend time on it. But the time spent correlates with education rather than anxiety. The engagement is built on genuine curiosity rather than exploiting psychological vulnerabilities.
This is what a healthy algorithm looks like. It respects user autonomy. It collects no data. It doesn't try to manipulate behavior. It's transparent about how it works. It optimizes for long-term wellbeing rather than short-term engagement.
The Open Source Advantage
Xikipedia is open source. You can see exactly how the algorithm works. You can fork it and modify it. You can build versions that work the way you want them to. This transparency is crucial. With closed-source social media platforms, you never really know what's happening behind the scenes. Twitter's algorithm is a black box. So is Instagram's. Tik Tok's is the most effective black box ever built.
With Xikipedia, there are no secrets. Anyone technically inclined enough can understand exactly why they're seeing what they're seeing. This creates accountability and prevents the platform from slowly degrading in response to the pressure to increase engagement.
Building a Culture of Intentional Use
Xikipedia's friction—the loading time, the need to consciously choose what you want to learn about, the lack of notifications pushing you back—actually creates better behavior. You're not reflexively opening it while waiting for the microwave. You're making a deliberate decision to spend time learning.
Research in behavioral psychology shows that this intentionality is crucial. When you consciously choose an activity, you get more satisfaction from it. When you're lured by notifications and pushed by algorithms, you get compulsive use that feels empty.
Xikipedia encourages the first pattern. You decide you want to learn something new. You open the app. You set your categories. You start scrolling. An hour later, you've learned things you didn't know existed. You feel good about how you spent your time, not guilty.

The Broader Movement Toward Ethical Tech
Xikipedia isn't alone. There's a growing recognition in tech circles that the engagement-at-all-costs model is unsustainable and harmful.
Other Ethical Alternatives Emerging
People are building alternatives to algorithmically driven social media. There are federated social networks like Mastodon that prioritize user control over engagement. There are newsletter platforms that emphasize quality writing over virality. There are forums and communities that value meaningful discussion over engagement metrics.
None of these have achieved the scale of traditional social media. But they're growing. They're proving that people will use platforms that respect their time and wellbeing if given the choice.
Xikipedia fits into this broader movement. It's saying: "You don't have to choose between having your feed curated for you and having your data harvested and your behavior manipulated. There's a third way."
The Sustainability Question
One challenge that Xikipedia shares with other ethical tech projects is sustainability. How do you keep a project running without venture capital or advertising revenue?
In Xikipedia's case, the answer is elegant. The project has minimal infrastructure costs. It's a static web app that can be hosted on cheap servers or CDNs. There's no data storage to maintain. There's no customer support infrastructure needed. Rebane built it in their spare time and can maintain it indefinitely with minimal ongoing work.
This is different from platforms that need to scale servers, moderate content, and handle customer support. Those platforms almost inevitably end up needing advertising or venture capital. But Xikipedia's architecture allows it to remain sustainable and independent.

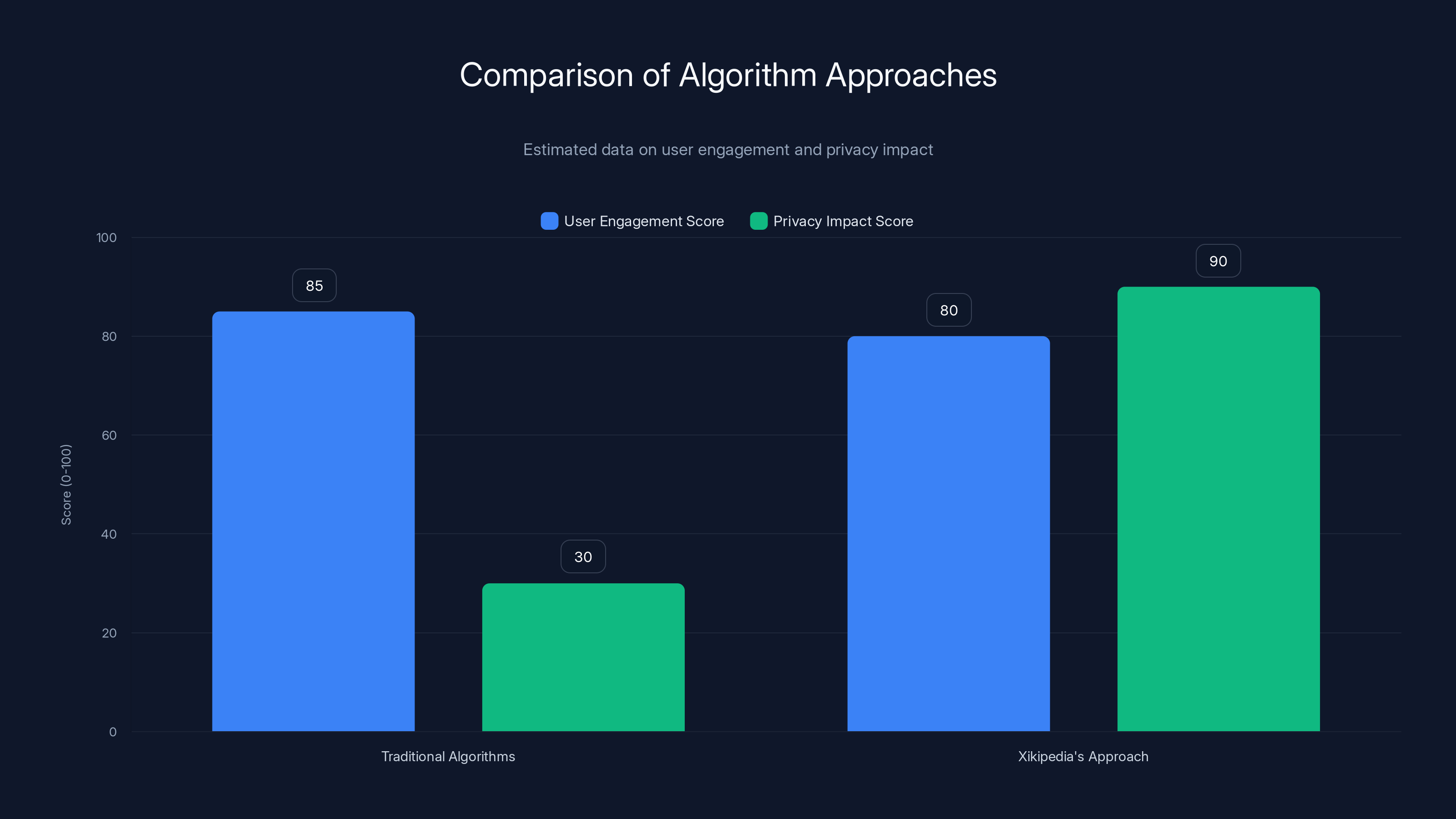
Estimated data suggests that while traditional algorithms may slightly lead in user engagement, Xikipedia's approach significantly enhances privacy without sacrificing personalization.
How to Use Xikipedia Effectively
If you want to try Xikipedia, here's how to get the most out of it.
Setting Up Your Initial Preferences
When you first load Xikipedia, you'll see options to select categories. The default categories include history, science, technology, art, and more. You should think about what genuinely interests you. Don't just select everything. The algorithm works better with some initial guidance.
If you're interested in specific things—maybe you love food history, ancient civilizations, and marine biology—select those categories. You can always add more later. The algorithm will learn as you like and dislike posts.
You can also create custom categories by entering keywords. Want an "architecture" category that doesn't exist? Just add it. The system will interpret it and start including relevant articles.
Engaging With the Algorithm
Like posts you find interesting. Don't overthink it. If an article summary makes you curious, click the like button. The algorithm is tracking this and will start surfacing more similar content.
You'll probably notice that your feed becomes increasingly coherent. After liking several articles about ancient Rome, you'll start seeing more articles about Mediterranean history, Italian culture, and classical civilization. This is the algorithm learning your interests and running with them.
Don't be afraid to unlike things either. If the algorithm starts surfacing too much of a particular type of content, unlike a few posts in that category. The algorithm will adjust.
Clicking Through to Deep Dives
When something catches your attention enough to want more information, click on the post. This takes you to the full Wikipedia article. From there, you can follow Wikipedia's internal links and do a deep dive into related topics.
This hybrid approach—Xikipedia for discovery, Wikipedia for learning—is probably the most effective way to use both tools together. Xikipedia introduces you to topics you didn't know existed. Wikipedia lets you explore deeply once you're interested.
Using It as a Break From Your Phone
Xikipedia works great on mobile, but it also works great on desktop. Consider using it as a deliberate break from your regular social media. When you feel the compulsion to open Instagram or Tik Tok, open Xikipedia instead.
You'll get the same satisfaction of infinite scrolling, the same dopamine response to discovery, but without the anxiety and social comparison that come with other platforms. After a few weeks of using Xikipedia regularly, you might find that you're less compelled by traditional social media because you've realized how much better it feels to scroll through knowledge.

The Future of Information Discovery
What happens next? Where does this all go?
Could This Scale to Compete With Social Media?
Probably not in the traditional sense. Xikipedia will never have a billion users because it's not trying to maximize engagement at any cost. It's deliberately designed to be less addictive than traditional social media, not more.
But that's okay. Xikipedia isn't trying to replace Tik Tok or Instagram. It's trying to be better than those platforms at one specific thing: helping you discover knowledge while respecting your wellbeing.
That's a smaller market, but it's a real market. There are millions of people who are consciously trying to reduce their social media use and replace it with something healthier. Xikipedia is perfect for that use case.
Other Knowledge Sources Could Be Added
Right now, Xikipedia only uses Simple Wikipedia. But the architecture could theoretically support other sources. Project Gutenberg has over 70,000 free books. Academic databases could potentially be included. Quality journalism could be added.
Imagine a version of Xikipedia that pulls from all of these sources, with your algorithm learning not just which categories you're interested in, but which types of sources—books, articles, essays, videos—you prefer. That would be genuinely powerful.
Rebane hasn't committed to adding these sources, but the technical foundation is there. It's an open source project, so community members could build these extensions.
The Mainstream Adoption Challenge
Right now, Xikipedia is used by people who are already conscious about their social media use and actively looking for alternatives. Getting mainstream adoption—getting the average person to use this instead of Tik Tok—would be incredibly difficult.
Social media platforms have spent billions on engagement optimization. They have network effects (your friends are on them). They have celebrities and creators. They have notifications pushing you back. Xikipedia has none of that.
But mainstream adoption might not be the goal. Creating a genuinely better tool for people who want to use it might be enough. And it might inspire other people to build ethical alternatives to other problematic platforms.
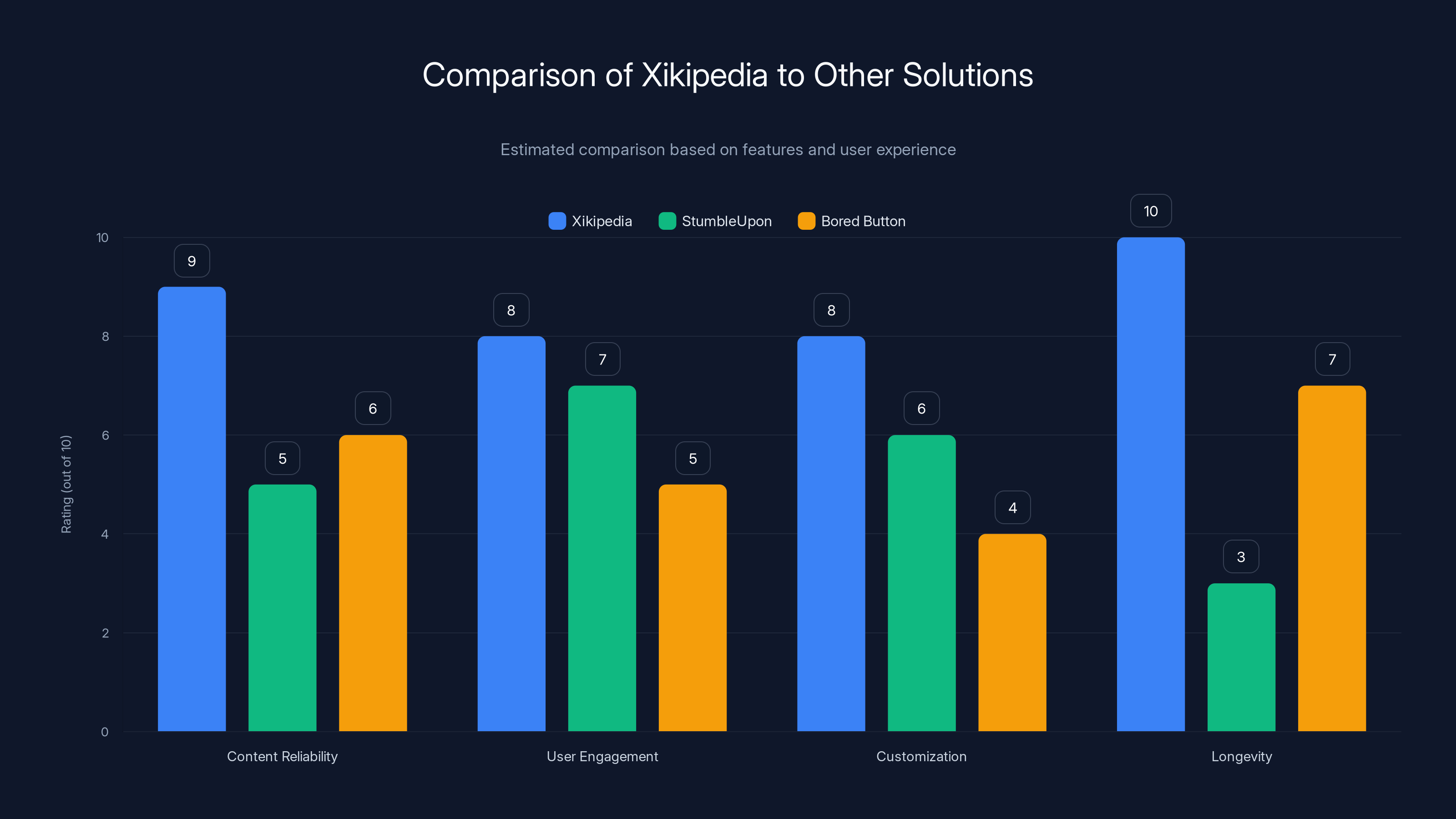
Xikipedia excels in content reliability and longevity due to its focus on Wikipedia and open-source nature. Estimated data based on qualitative analysis.
The Bigger Conversation: Algorithms and Ethics
Xikipedia is technically impressive and practically useful. But it's also philosophically important because it challenges a core assumption in tech.
The Assumption That Algorithms Must Exploit
For years, the tech industry has operated on an unstated assumption: to build something that scales, to build something that makes money, you have to exploit human psychology. You have to find the addictive points. You have to make people feel compelled to use your product.
Xikipedia challenges this assumption. It proves that you can build something genuinely engaging and useful without any of that exploitation. You can build an algorithm that serves user wellbeing rather than opposing it.
This is a threat to billion-dollar companies. If people realized that you could have an engaging feed without anxiety, without social comparison, without doomscrolling, they might start demanding that from platforms they actually use. They might demand their algorithms be better.
The Privacy Architecture Is the Model
Another assumption Xikipedia challenges is the necessity of data collection. Most platforms say they need to collect data about users to personalize experience and improve their products. That's sometimes true, but it's also sometimes just convenient justification for surveillance capitalism.
Xikipedia proves that personalization and improvement can happen without collecting any data. All the algorithm logic is local. Your data never leaves your device. And yet the product is just as personalized as any of the major platforms.
If other platforms adopted this architecture, they couldn't sell your data. They couldn't target you with hyper-specific ads. They couldn't build profiles of your behavior. But they could still personalize your experience and keep you engaged.
The fact that no major platform does this proves that data collection isn't necessary for the user experience. It's profitable for the platforms. That's why it happens.
What Users Actually Want
Xikipedia demonstrates something important about human preferences. When given the choice between an engaging, addictive platform and a healthier alternative, users choose the healthier one, at least as a supplement to their main social media use.
That doesn't mean people are going to abandon Instagram tomorrow. But it suggests that if platforms offered ethical algorithms as an option—"turn off the engagement optimization, show me a healthier feed"—people would use that option at least sometimes.
This matters because it means that the optimization-at-all-costs approach of major platforms isn't inevitable. It's a choice. It's a choice that's made for profit reasons, not because there's no alternative.

Real-World Impact: Stories From Xikipedia Users
When Xikipedia launched, the response from users was enthusiastic. People shared their experiences on social media and forums. Patterns emerged.
The Teacher Who Rediscovered Learning
One user, a middle school teacher, described using Xikipedia as a break during the work day. She'd spend 10-15 minutes scrolling through articles about topics she'd never studied in depth. She discovered an interest in Arctic history, then in climate science, then in indigenous peoples' survival techniques. She started weaving these topics into her teaching.
What struck her was how different this felt from her normal social media use. With Instagram, 10 minutes would leave her feeling inadequate about her appearance and her life. With Xikipedia, 10 minutes would leave her excited about something new and eager to learn more.
The Former Doomscroller
Another user described themselves as a chronic news consumer who'd developed significant anxiety from constantly checking updates on global crises. They were aware of the problem but couldn't stop. Switching to Xikipedia broke the habit.
Without the constant influx of crisis content, without the algorithmic push toward the most alarming news, they felt noticeably less anxious. They could still access news if they wanted to. But they weren't being constantly bombarded by it. After a few weeks, their compulsion to check news diminished significantly.
The Insomnia Sufferer
One user who struggled with insomnia found that using Xikipedia before bed, instead of their usual Instagram and Twitter use, helped them sleep better. The knowledge-focused content didn't trigger the same anxiety response as social media. They could scroll for a bit, calm their mind with interesting information, and then sleep without lying awake worrying about the world.
These stories aren't scientific evidence. They're anecdotes. But they're consistent with psychological research about how algorithm choice affects wellbeing.
Building Your Own Ethical Feed: The Technical Side
If you're technically inclined, Xikipedia's open source nature means you can modify it or build on it.
Understanding the Code
Xikipedia is built with standard web technologies: HTML, CSS, and Java Script. It's a progressive web app, which means it works offline once loaded. The algorithm is implemented in vanilla Java Script—no complex machine learning frameworks needed.
The code is clean and well-commented. Rebane clearly cares about maintainability. If you want to understand how algorithmic feeds work, reading Xikipedia's source code is incredibly educational.
Forking and Modifying
You could fork the project and modify it to your specifications. Want to use main Wikipedia instead of Simple Wikipedia? That's a modification you could make. Want to add filtering to remove NSFW content? You could implement that. Want to change the aesthetic? That's doable.
The beauty of open source is that innovation doesn't stop with the original creator. It becomes a collaborative process. Community members can contribute improvements, and everyone benefits.
Using the Architecture for Other Data Sources
The algorithm and UI architecture could theoretically be applied to other knowledge sources. You could build a version that pulls from a different wiki, from academic papers, from curated essay collections, from historical archives.
Each would have different properties. An academic paper version might surface more complex content. A historical archive version might surface primary sources and documents. An essay collection might surface well-written analysis and opinion pieces.
The technical architecture doesn't care what the data source is. It just needs structured content with categories and links. That opens up possibilities.
The Competitive Landscape: Why Hasn't Tech Done This Before?
Xikipedia is impressive partly because nothing like it exists in the mainstream tech landscape. Why hasn't Meta, Google, or Apple built something similar?
The Business Model Problem
The short answer is money. Major platforms make money through advertising. Advertising is more effective when it's targeted based on detailed user data. Detailed user data requires tracking and collection. Ethical platforms don't collect data.
Xikipedia can be funded through volunteer effort and minimal infrastructure costs. A competitor would need to pay employees, maintain servers, provide customer support. That requires revenue. That requires monetization. That requires either ads (which require tracking) or subscriptions (which require enough unique value to justify paying).
For a platform built on public knowledge like Wikipedia, a subscription is tough to justify. You're not creating unique content. Why would someone pay when they could just use Wikipedia directly?
So any major player that built something like this would end up falling back on ads and tracking, losing the ethical advantage.
Network Effects and Path Dependency
Even if a major platform wanted to build an ethical alternative, they couldn't kill their existing platform to switch to it. They have billions of users, billions of dollars of advertiser relationships, and billions of dollars of value based on the current model.
Switching to an ethical algorithm would be equivalent to burning money. The CEO would be fired. The shareholders would sue. The company would collapse.
Path dependency is real in tech. Companies can't change course dramatically without destroying themselves. So you get incremental improvements to unethical systems rather than wholesale replacement.
The Innovation Ceiling in Big Tech
There's another factor: organizations have incentives. Once a company is built around engagement metrics and advertising revenue, everyone working at that company is trained to optimize for those metrics. Product managers are evaluated on engagement. Engineers are evaluated on engagement. Designers are evaluated on engagement.
Innovation away from engagement isn't rewarded. It's punished. This creates an organizational culture where better ideas can't emerge. Even if someone at Meta had the idea for an ethical feed, the incentive structure wouldn't support building it.
Smaller projects like Xikipedia have advantages because the incentives are different. Rebane isn't trying to maximize engagement or revenue. They're trying to build something better. That freedom of purpose enables innovation that big tech can't match.
FAQ
What is Xikipedia and who created it?
Xikipedia is a free web application that transforms Simple English Wikipedia into an infinite, social media-style feed curated by a local machine learning algorithm. Developer Lyra Rebane created it as a proof of concept demonstrating that engaging feeds can be built without tracking user data or deploying sophisticated engagement optimization techniques that harm mental wellbeing.
How does Xikipedia's algorithm work?
Xikipedia uses a local-first algorithm that runs entirely in your browser rather than on company servers. When you like a post, the algorithm increases the probability of showing you more articles from similar categories and linked topics. All processing happens locally on your device, and all data disappears when you refresh or close the browser. No information about your behavior is stored or transmitted anywhere.
What are the main benefits of using Xikipedia instead of traditional social media?
Xikipedia addresses multiple problems with conventional social media platforms. It eliminates doomscrolling by serving educational content rather than crisis-focused news. It removes social comparison mechanics like followers and likes visible to others. It protects your privacy by collecting zero data about your behavior. It replaces the anxiety-generating engagement optimization of traditional platforms with an algorithm optimized for discovery and learning.
What is Simple Wikipedia and why does Xikipedia use it instead of main Wikipedia?
Simple English Wikipedia is a version of Wikipedia designed to explain topics using basic vocabulary and simpler sentence structures, originally created for English language learners and young readers. Xikipedia uses Simple Wikipedia because articles are self-contained, easier for algorithms to parse, and contain fewer overly technical details that could disrupt engagement. Simple Wikipedia has over 278,000 articles, providing an enormous pool of diverse content.
Can I control what content appears in my Xikipedia feed?
Yes, Xikipedia gives you significant control over your feed. You can select specific categories of articles you want to see (history, science, art, etc.), add custom categories by entering keywords, and actively like or dislike posts to influence what the algorithm shows you. If the feed starts trending toward topics you're less interested in, unliking several posts in those categories signals the algorithm to adjust.
What are the limitations and downsides of Xikipedia?
Xikipedia has several limitations worth knowing about. Simple Wikipedia updates less frequently than main Wikipedia, so recent discoveries or current events may not be covered quickly. The initial load is slow because it downloads 40MB of data to your device. Since Wikipedia covers all topics comprehensively, NSFW and mature content occasionally appears in feeds. Xikipedia is best used as a discovery tool for casual learning rather than as a platform for in-depth study or staying current on breaking news.
Is Xikipedia free and is my data private?
Xikipedia is completely free to use and has no paid tier. Your data is entirely private. No information about what you view, like, or click is collected, stored, or transmitted to any server. All algorithm personalization happens locally on your device using only information stored in your browser. When you close or refresh Xikipedia, all records of your activity disappear permanently. This local-first architecture means Xikipedia has no ability to harvest user data even if the creator wanted to.
How does Xikipedia compare to random Wikipedia article tools?
Xikipedia improves on simple random article tools in multiple ways. It's algorithmic rather than purely random, meaning articles are influenced by your engagement and interests, creating thematic coherence. It features a feed-based interface allowing you to scroll through multiple summaries before clicking to learn more, rather than clicking a button and waiting for full page loads. It includes filtering options to exclude irrelevant categories. It provides a more engaging, social media-like experience while serving educational rather than engagement-optimized content.
Can Xikipedia be used on mobile devices?
Yes, Xikipedia works on both mobile and desktop browsers. It's built as a progressive web app, meaning it can be used online with a mobile browser and provides a responsive interface optimized for phone screens. The initial 40MB data download works the same way on mobile as desktop. After loading, it functions smoothly even on slower mobile connections.
Is Xikipedia open source and can I build modified versions?
Yes, Xikipedia is open source, meaning anyone can examine the code, fork the project, and create modified versions for their own needs. The code is written in standard web technologies (HTML, CSS, Java Script) and is well-commented for educational purposes. Potential modifications include using main Wikipedia instead of Simple Wikipedia, adding NSFW content filtering, changing the visual aesthetic, or applying the algorithm architecture to other knowledge sources.
Why is Xikipedia better for mental health than traditional social media?
Xikipedia addresses multiple psychological harms of traditional social media. It eliminates doomscrolling by serving factual educational content instead of algorithmically amplified crisis content. It removes social comparison mechanisms like visible follower counts and likes that trigger inadequacy feelings. It prevents anxiety-inducing engagement optimization that traditional platforms use to maximize watch time. It supports intentional use through interface friction (loading time, category selection) rather than addiction through notifications and variable rewards. Research in psychology supports that these design choices create healthier usage patterns with better mental health outcomes compared to traditional platforms.
Conclusion: The Future of Ethical Tech
Xikipedia might seem like a small project. It's a free web app that repurposes public data with a relatively simple algorithm. Lyra Rebane built it largely alone, in their spare time, without venture capital or corporate backing.
But small projects often have outsized importance. They prove what's possible. They change conversations. They inspire others to build better things.
In this case, Xikipedia proves that you don't need to choose between an engaging platform and a healthy one. You don't need to sacrifice user wellbeing for engagement metrics. You don't need invasive tracking to personalize experience. You don't need exploitative algorithms to create something people actually want to use.
These lessons matter because the current state of technology is not inevitable. The engagement-at-all-costs approach of major social media platforms isn't the only possible way to build platforms. It's just the most profitable way, at least in the short term.
Longer term, that model is obviously unsustainable. You can't have a healthy society if everyone's spending hours a day in anxiety-optimized feeds. You can't maintain cultural coherence if algorithms are deliberately fragmenting people into warring factions. You can't support human flourishing if technology is optimized for addiction rather than wellbeing.
So eventually, things have to change. It might not be through the major platforms reforming themselves—that seems unlikely given their incentive structures. But it might be through people like Rebane building better alternatives. It might be through users trying those alternatives and deciding they prefer them. It might be through younger generations growing up with healthier technology and demanding that existing platforms improve.
Xikipedia is a small contribution to that change. But it's a real one. It's proof that the future of technology doesn't have to look like the present. It can be healthier. More respectful. More honest about what algorithms actually do. More focused on human flourishing rather than human exploitation.
That's worth something. That's worth knowing about. That's worth trying.
When you're tired of doomscrolling, when you want to feel like your time online is actually making you smarter and calmer instead of angrier and more anxious, Xikipedia is waiting. It's free. It's private. It's ethical. And it actually works.
Maybe that's the future of technology after all. Not bigger, not faster, not more engaging at any cost. Just better.
Key Takeaways
- Xikipedia proves that engaging platforms can be built without data collection or engagement exploitation
- Local-first algorithms work effectively while maintaining complete user privacy and agency
- Knowledge-discovery feeds produce different psychological effects than engagement-optimized social media
- Open source ethical alternatives can compete on user experience while refusing profit-driven surveillance
- The future of technology isn't predetermined by corporate incentives but can be shaped by better design choices
Related Articles
- UpScrolled Hits 2.5M Users: How This TikTok Alternative Exploded [2025]
- 7 Apple Watch Settings to Change for Better Experience [2025]
- Social Companion Robots and Loneliness: The Promise vs Reality [2025]
- Why Gen Z Is Rejecting AI Friends: The Digital Detox Movement [2025]
- The Offline Club: How People Are Fighting Phone Addiction in 2025
- TikTok Censorship Fears & Algorithm Bias: What Experts Say [2025]

