![AI Cheating on Technical Interviews: How Anthropic Fights Back [2025]](https://tryrunable.com/blog/ai-cheating-on-technical-interviews-how-anthropic-fights-bac/image-1-1769094376492.png)
AI Cheating on Technical Interviews: How Anthropic Fights Back [2025]
There's a problem nobody wanted to admit out loud: your AI assistant is probably better at technical interviews than you are.
When Anthropic's performance optimization team started giving take-home tests to engineering candidates in 2024, everything seemed fine. The test worked. Candidates who knew their stuff passed. Candidates who didn't, failed. It was honestly refreshing—a way to evaluate actual ability without the anxiety theater of whiteboarding problems in real time.
Then Claude got better.
First, Opus 3.5 started matching top-tier candidates. Then Opus 4 crushed them. Then Opus 4.5 showed up and basically rendered the entire evaluation useless. A candidate could paste the test into Claude, get back production-quality code, and there'd be no way to tell the difference between genius-level hiring and sophisticated prompt injection.
The irony is almost painful: an AI company, of all places, has to watch its own hiring process get destroyed by the very technology it built.
But here's what makes this moment interesting. Anthropic didn't just complain about the problem. They redesigned their interview entirely. And in doing so, they exposed something fundamental about how we evaluate talent in an AI-first world.
Let's dig into what's actually happening, why it matters, and what it means for hiring in 2025.
The Original Problem: When Your Test Falls to AI
Take-home technical tests sound perfect in theory. Candidates get time. They can Google. They can think. No artificial time pressure, no nervous energy, no interviewer watching them squirm.
For a long time, that worked exactly as intended.
But coding AI assistants changed the game. And changed it fast.
In late 2024, Tristan Hume, the team lead for Anthropic's hiring process, posted a detailed breakdown of what happened. The timeline matters here because it shows just how quickly this became unsustainable.
When they launched the test in 2024, Claude could help with most problems but couldn't solve them outright. A good candidate would still need to understand the underlying concepts, debug when things went wrong, and make architectural decisions. Claude was useful. It wasn't a shortcut.
Then something shifted.
Claude Opus 3.5 landed, and suddenly it could solve harder problems. Not perfectly every time, but with enough consistency that a mediocre candidate using Claude could look pretty good. The test could still distinguish between truly exceptional engineers and everyone else—but the margin was shrinking.
Then Opus 4 arrived. It matched the performance of Anthropic's best candidates on the same time constraints. If someone with an Ivy League degree and five years of experience spent two hours on the test, Claude could produce equivalent output in seconds.
The team actually adjusted. They added constraints, changed the time limits, got creative. And briefly, it worked again.
Then Opus 4.5 shipped. And the constraints stopped mattering.
"Under the constraints of the take-home test, we no longer had a way to distinguish between the output of our top candidates and our most capable model," Hume wrote. That's not hyperbole. That's a genuine crisis. You can't hire a company if you can't evaluate who's actually qualified.
This isn't about Claude being "too smart" in some theoretical sense. It's about the practical breakdown of a hiring mechanism. When a tool can produce output indistinguishable from your best engineers, the test stops measuring what you think it measures.
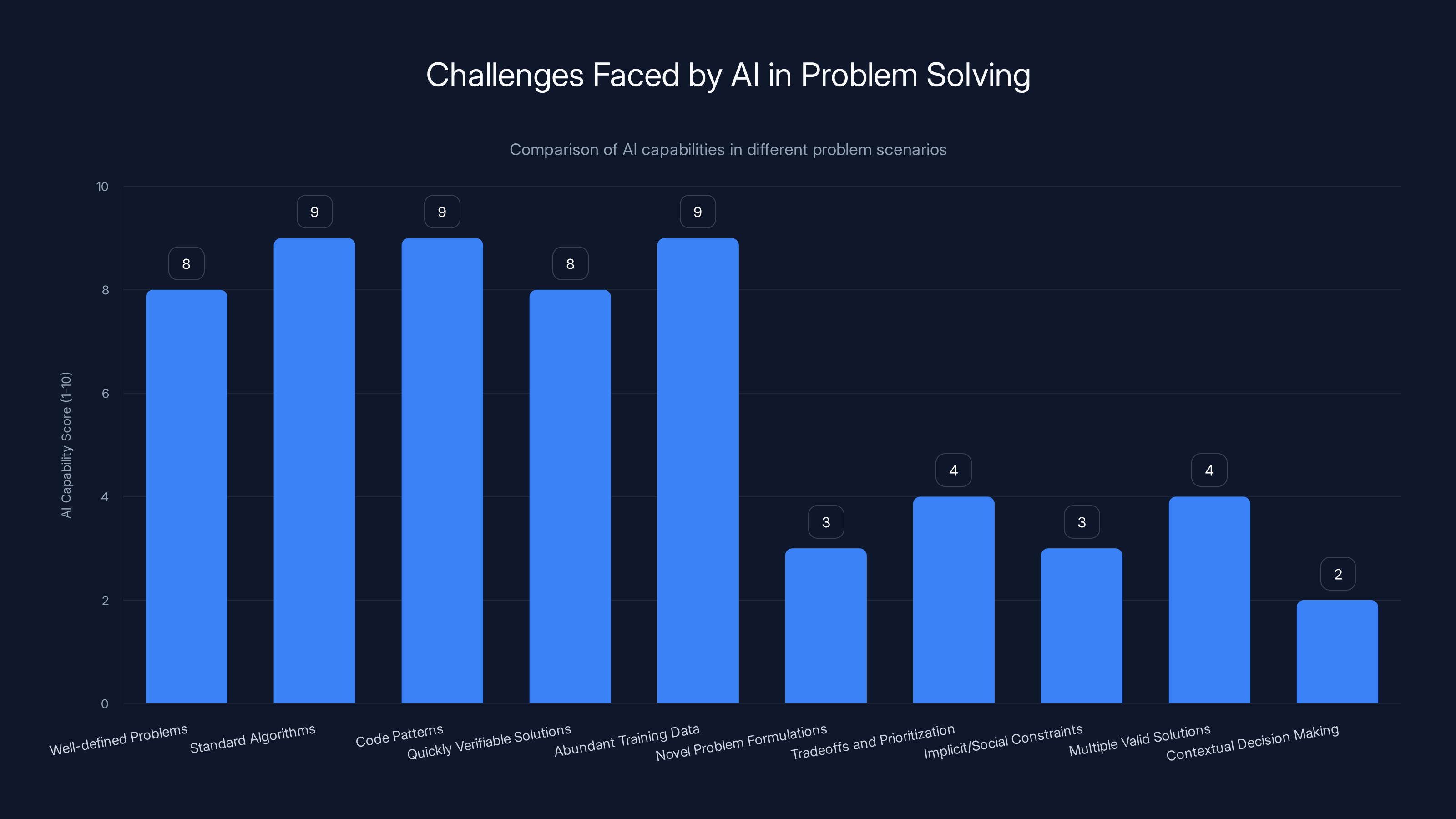
AI excels in well-defined, data-rich scenarios but struggles with ambiguity and context, highlighting the need for human judgment in complex decision-making. Estimated data.
Why Take-Home Tests Are Hard to Cheat-Proof
The obvious fix would be proctoring. Put candidates in a room, watch them type, ensure nobody's using Claude. Companies do this already. It works.
But take-home tests exist because proctoring sucks. Synchronous tests favor people with stable schedules. They create anxiety. They prevent people from showing what they're actually capable of. Someone working a full-time job at a timezone three hours ahead needs flexibility to do their best work.
The whole point of take-home is to say: "We trust you. Show us what you can do when you have breathing room."
Except now that trust is weaponized. You're trusting someone to not use the single most capable tool available for that exact task.
It's like saying: "Here's an open-book test, but please don't use that one book." Technically feasible. Practically unenforceable.
Anthropologic discovered something that online educators already knew: you can detect some cheating patterns (answer consistency, submission timing), but you can't detect competent usage of powerful tools without oversight. And oversight breaks the whole reason you had a take-home test in the first place.
So instead of fighting the tool, they fought the test itself.

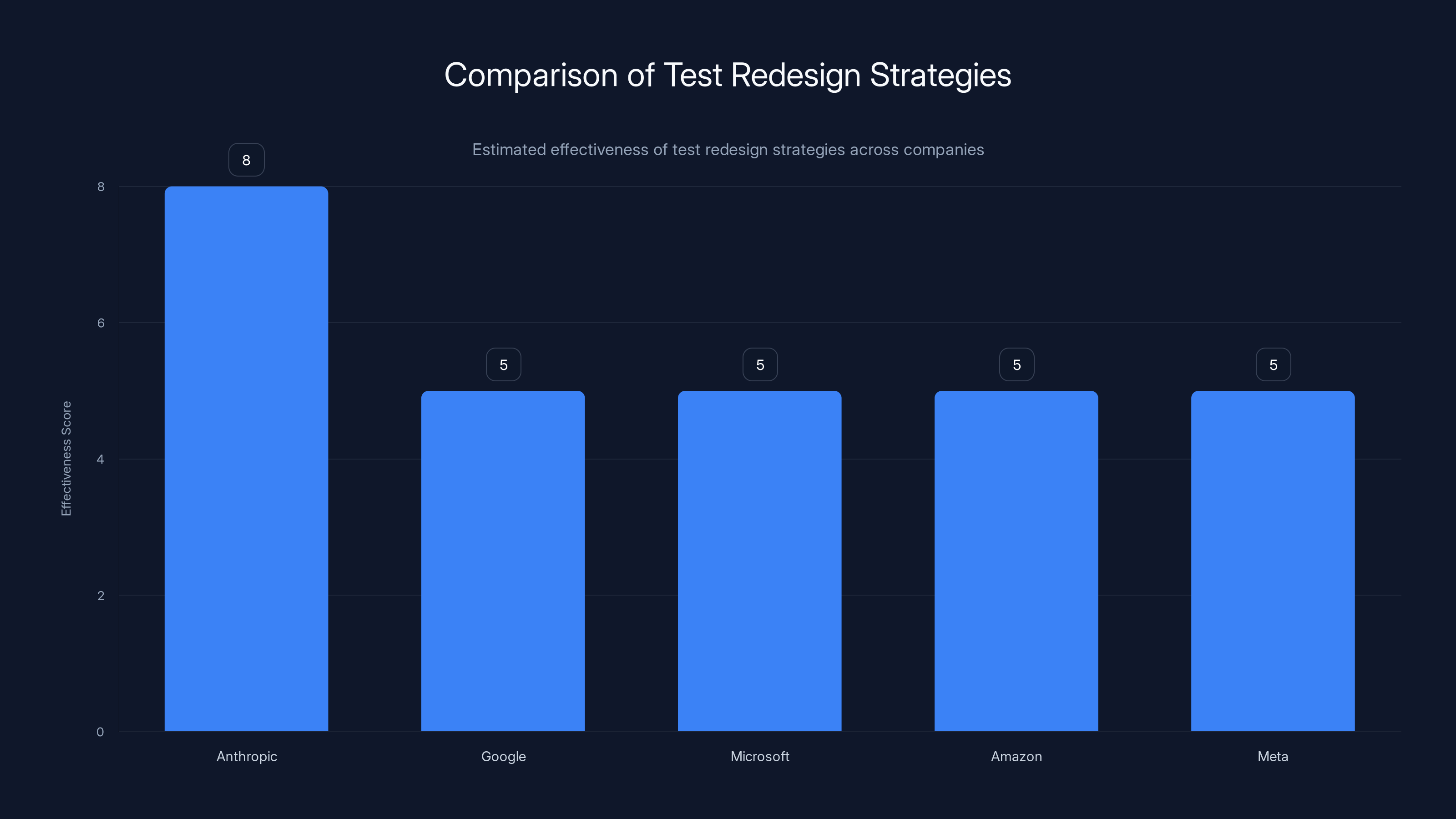
Anthropic's redesign strategy is estimated to be more effective due to their deep understanding of Claude, compared to other companies that have not significantly changed their testing methods. Estimated data.
The Pivot: Anthropic's Redesign Strategy
Hume's actual solution is clever, and it reveals something important about what makes a good engineering problem versus a bad one.
Instead of asking for optimized algorithms (which Claude can brute-force solve), they shifted toward novel problem-solving that required genuine understanding. The new test emphasizes situations that don't have clear precedents in training data.
This isn't some bizarre edge case. It's how actual engineering works. You encounter problems that don't fit templates. You have to think.
But here's where it gets interesting: the test became harder for humans and harder for Claude. Not harder in the sense of more complicated—harder in the sense of more ambiguous.
A problem that says "optimize this algorithm to run in O(n log n) time" has a clear solution space. Claude can explore that space quickly. A problem that says "redesign this system so it handles 10x traffic with the same infrastructure while reducing latency by 30%" is different. There are tradeoffs. There are unknowns. There are multiple valid approaches, each with different consequences.
Claude struggles more with ambiguity. So does a junior engineer. Which makes the test actually measure what you want: who thinks clearly under uncertainty.
But here's the kicker: Anthropic isn't the only company dealing with this. And they're not even the biggest one.
Google interviews thousands of people a year. Microsoft, Amazon, Meta—they're all running take-home tests. They're all watching Claude get smarter. And they're mostly not redesigning their tests. They're either ignoring the problem, or they're adding proctoring, or they're just accepting that they can't tell the difference anymore.
Anthropic had an advantage: Tristan Hume works for the company that builds Claude. He understands the model deeply. He knows what it can and can't do. He can predict where it's weak.
Most hiring teams don't have that.
The Broader Cheating Problem in Academia and Employment
This isn't new to hiring. Schools got hit first, and it was ugly.
In 2023, teachers started noticing that essays all sounded the same. Not plagiarized—original content that was technically correct and structurally perfect and completely devoid of personality. Chat GPT went viral. Universities scrambled. Some banned AI. Some tried AI detectors (which mostly don't work). Some rethought their assessments entirely.
A few went the Anthropic route: they changed what they were asking for. Instead of essays, they asked for live presentations. Instead of take-home exams, they added oral components. Instead of "write a paper," they said "write a paper and then explain your thinking under pressure."
Some studies estimate that 25-30% of college students have used generative AI to help with assignments. Academic integrity policies haven't caught up. Most students correctly intuited that if something is technically possible and widely available, the moral weight of using it depends entirely on how an institution responds.
Employment is different because the stakes are different. Hiring someone who can't actually do the job has immediate, quantifiable costs. A company that hires engineers who used Claude to fake their way through interviews will ship broken code. That's feedback that matters.
But the incentives are misaligned. A candidate who successfully cheats gets a job. They have every reason to try. A company that can't detect cheating doesn't immediately know they hired wrong—that knowledge comes later, in performance reviews or project failures.
By then, the damage is done.

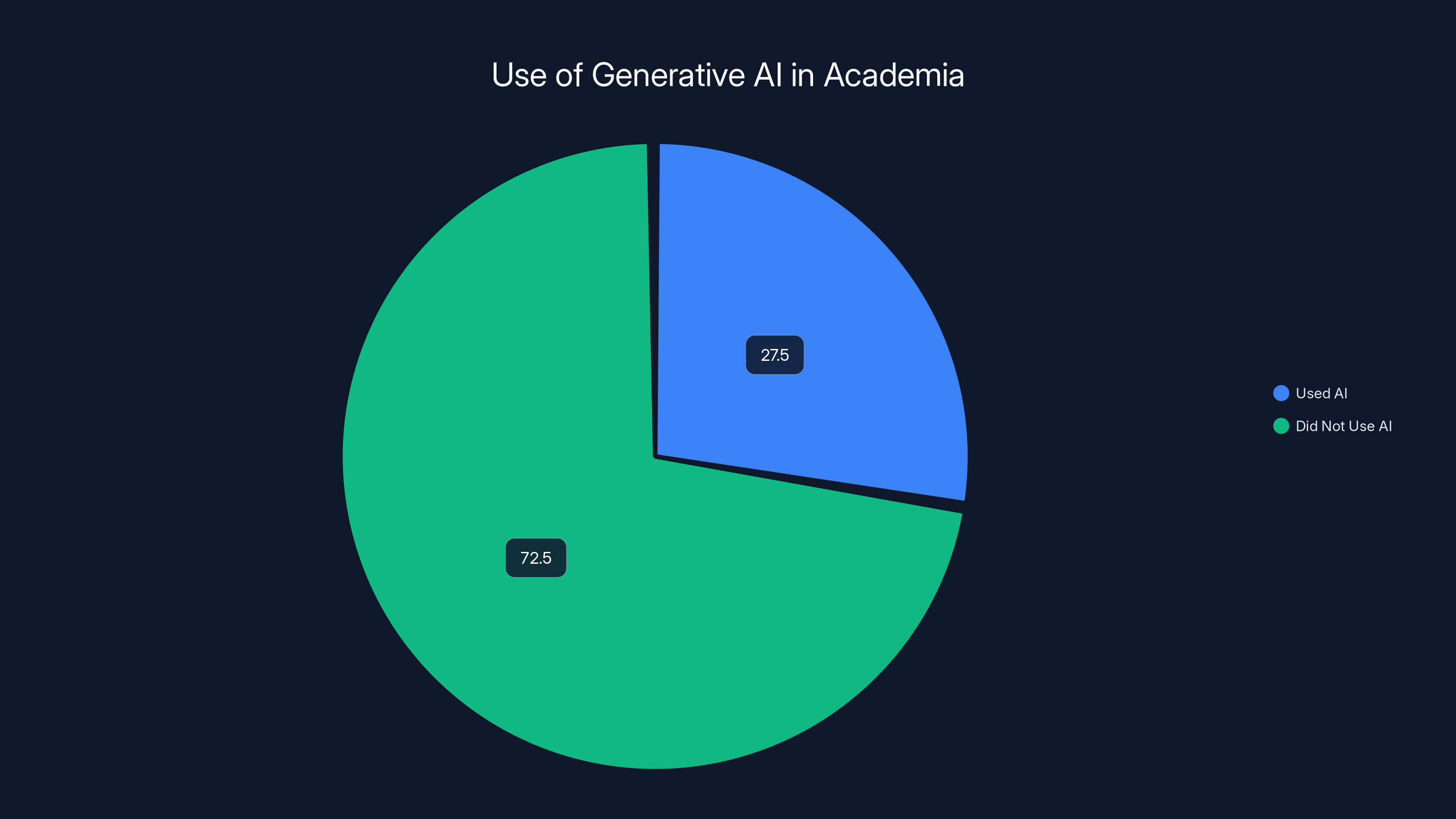
An estimated 25-30% of college students have used generative AI for assignments, highlighting a significant shift in academic practices. (Estimated data)
The Detection Problem: Why Plagiarism Detectors Fail
Let's talk about why detecting AI usage is so hard.
Plagiarism detectors work by finding matching text. They look for patterns. If you copy a Wikipedia article, it catches you because the same words appear in both places. String matching is reliable for copied content.
But Claude doesn't copy. It generates. Even if it uses similar concepts or draws from similar training data, the actual text is new. There's no signature to detect.
Some tools try to use statistical analysis. The theory is that AI writing has certain patterns: predictable word choices, specific punctuation habits, structural similarities. You can theoretically build a classifier that says "this has 78% probability of being AI."
But here's the problem: good AI writing is deliberately made to not have obvious patterns. And human writing, if it's anything like what most of us produce, is predictable as hell. We use favorite words. We structure sentences similarly. We have habits.
One paper from 2024 showed that some "AI detection" tools mark random human text as probably generated. Another showed that a student who manually edited Claude's output, changing key phrases and restructuring paragraphs, got marked as human despite the entire foundation being AI-generated.
The detection problem is basically unsolved. It might be unsolvable.
Which means the only real deterrent is changing what you're measuring.
Live Coding Interviews: The Counter-Measure
Some companies doubled down on synchronous evaluation.
Live coding interviews are having a comeback. You get a Zoom link. You share your screen. You solve a problem for 45 minutes while an engineer watches. In real-time.
Claude can still help. You can write pseudocode in comments and ask Claude to fill in implementations. You can describe a problem and get Claude's solution. But when an interviewer says "okay, now modify this to handle edge case X," and you have to actually understand what the code does, the difference between genuine competence and fancy prompting becomes clear.
The tradeoff is that you've reintroduced synchronous stress. Candidates with anxiety, or family obligations, or timezone issues are now disadvantaged. You've solved the cheating problem by creating new unfairness.
It's a choice, not a solution.
Some companies split the difference: a take-home test, followed by a live discussion of it. You had three days to work, and we trust that you understood what you wrote. Now let's talk about your tradeoffs. Why this data structure? What happens if we add concurrency? What would you change with more time?
That actually works surprisingly well. Most people who used Claude heavily struggle to defend their architectural decisions because they didn't make them. They just accepted Claude's output.
But it requires interviewers to be good at their jobs, which is its own whole problem.
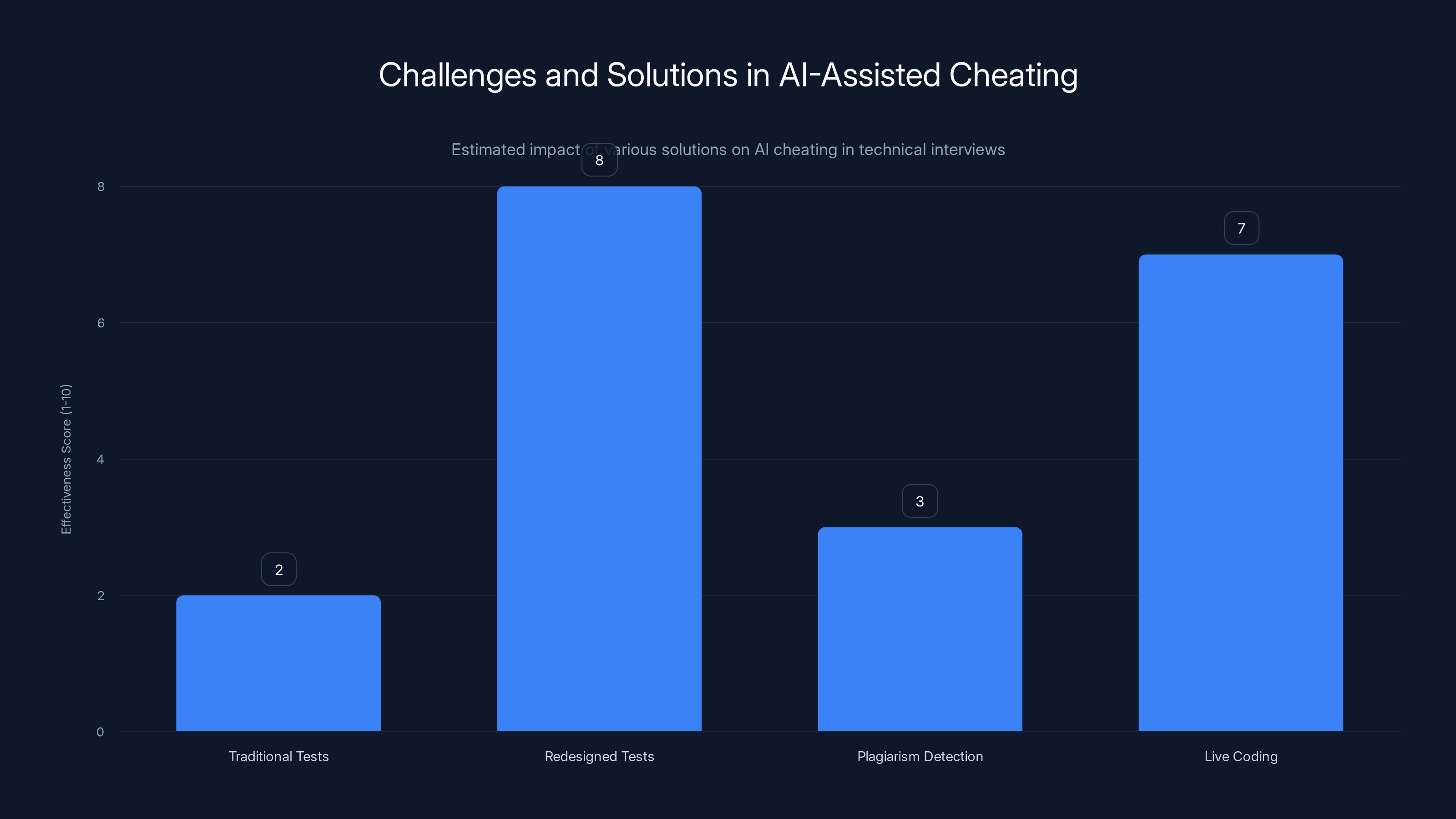
Redesigned tests focusing on judgment and decision-making are most effective against AI-assisted cheating, while traditional tests and plagiarism detection are less effective. (Estimated data)
The Economics of AI-Powered Hiring
Here's an uncomfortable thought: maybe some companies are okay with this.
If you're hiring for a commodity role—standard CRUD APIs, familiar architectures, predictable problems—then someone who can effectively use Claude might be exactly what you want. They'll be fast. They'll probably make fewer mistakes than an engineer who's slower. The fact that they used AI to learn what they're doing isn't actually a problem if they learned it well.
The problem is distinguishing between "uses AI effectively" and "can't code without AI." And that distinction only matters if the role requires independent problem-solving.
For a lot of roles, it doesn't. You're building the 47th variant of an e-commerce platform with the same architecture as everyone else. You need someone who can implement specifications. You don't need someone who can innovate.
If that's your business, and if Claude makes people faster at implementation, then hiring people who use Claude looks rational. You're not paying for genius. You're paying for speed and consistency.
The irony is exquisite: the companies most likely to ignore the cheating problem are the ones least harmed by it.
The companies that care, the ones pushing the frontier of what's possible, are the ones forced to redesign. Anthropic cares because they hire research engineers who need to build things that don't exist yet. Google cares because they need people who can invent new algorithms. A startup in 2025 building the same web app as everyone else? They might not care at all.
This creates selection pressure. Companies that take hiring seriously get better engineers. Companies that don't get faster implementers. That's fine if you know what you want.
Most companies don't know. They say they want "engineers who think deeply" and then pay them the same as "engineers who follow specs." The market doesn't distinguish. So they get whoever applies.
What Anthropic's Solution Actually Teaches Us
The brilliance of Anthropic's approach isn't that they solved cheating. They didn't. They just made cheating less useful.
The insight is that cheating happens when you're testing for the wrong thing. Claude is great at producing code. If your test is "produce code," Claude wins. But if your test is "make good tradeoffs under uncertainty," Claude is just another tool. It's useful sometimes, but it doesn't eliminate the need for human judgment.
This applies way beyond hiring. It's the same insight that's reshaping education right now. Schools that banned calculators got mad when students used them anyway. Schools that accepted calculators and changed what they were testing—asking for conceptual understanding instead of computation speed—solved the problem.
The same thing is happening with essays. Ban AI and students use it anyway. Accept AI and ask students to show their thinking, to critique AI's output, to use it as a starting point instead of an endpoint, and suddenly AI becomes a learning tool instead of a shortcut.
Hiring should work the same way.
The companies that redesign their tests to measure what actually matters—judgment, tradeoff analysis, communication, problem decomposition—will hire better people. The companies that stubbornly stick with "can you code this algorithm" will hire people who are good at prompting Claude.
Over time, that difference compounds.

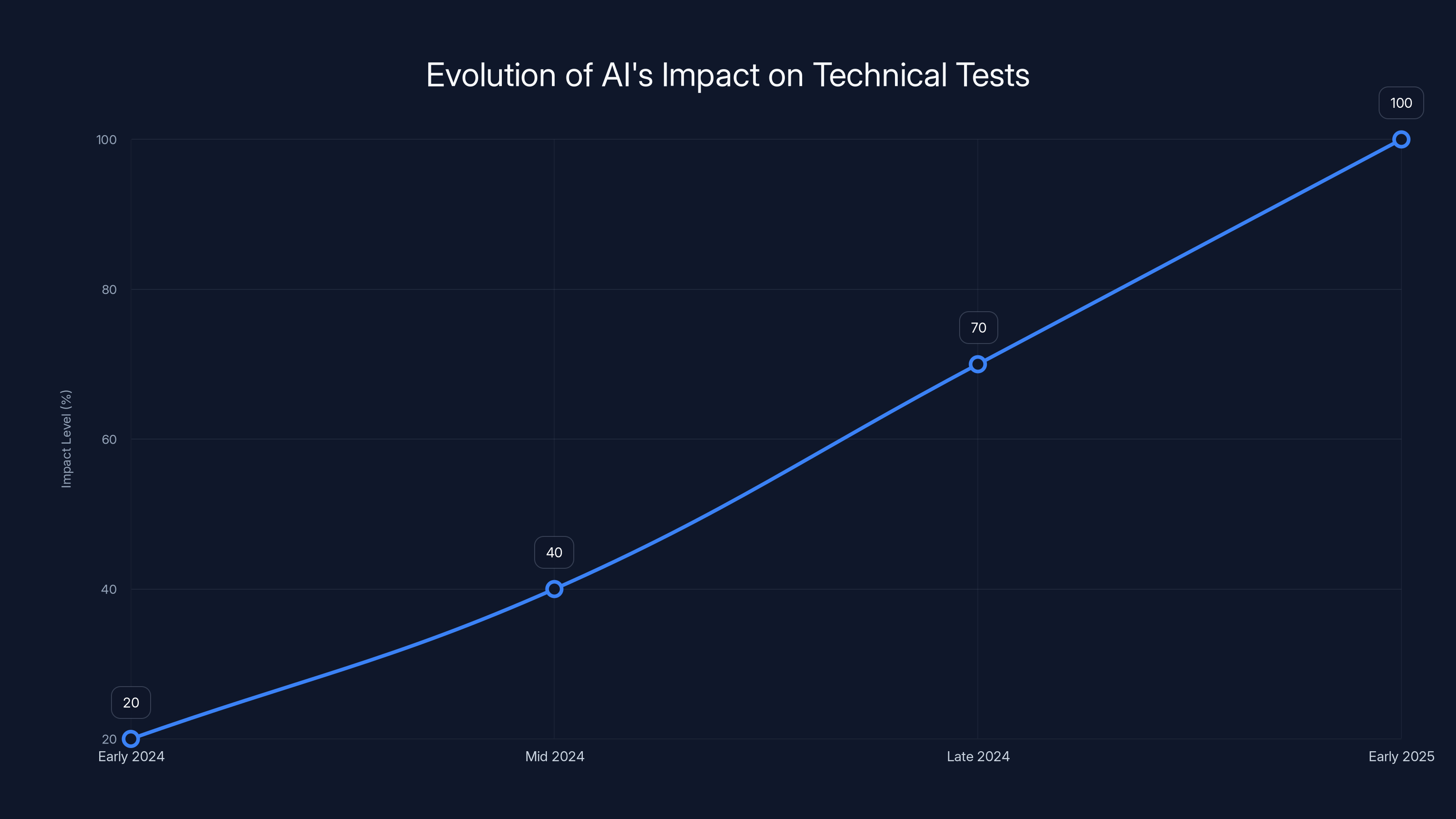
Estimated data showing the rapid increase in AI's ability to solve technical tests, reaching a point where it matched top candidates by early 2025.
The Candidate Perspective: What This Means for Job Seekers
If you're interviewing for engineering roles in 2025, here's the reality:
Using Claude on your take-home test is probably happening in your candidate pool already. Interviewers might not be able to detect it. Companies are scrambling to adjust.
The smart play isn't to use Claude to cheat. It's to use Claude to learn, then use your knowledge to solve the problem independently. This does two things: it actually makes you better (you learn faster), and it makes you indistinguishable from someone who studied for weeks (your output looks genuine because it is).
When you get to the live interview, you'll actually be able to defend your decisions. You'll be able to extend and modify your code. You'll explain tradeoffs clearly. That's the moment you separate from people who just pasted problems into Claude.
For companies that redesign their tests, like Anthropic did, this becomes the ideal candidate: someone who leverages AI to accelerate learning, but understands the underlying concepts deeply enough to navigate ambiguity.
That's also the ideal employee. So the filter is working.
The Future of Technical Interviews
We're going to see a lot of evolution here.
Some paths seem likely: more asynchronous discussions of take-home solutions, more emphasis on system design (which is harder for AI to handle), more real-world problem constraints (which reduce the relevance of training data solutions).
Other companies will just accept that AI-assisted cheating is part of the process and adjust salaries accordingly. If everyone's using Claude, it becomes table stakes. You're not hiring Claude; you're hiring someone who uses Claude well.
A few companies will go full proctoring. Lock everything down. Make it synchronous and observed. They'll get fewer applicants but more confidence in actual ability.
The meta-game is interesting: companies that move fast and adapt will hire better people. Companies that stick with outdated assessments will watch their hiring become less predictive. This is a competitive advantage that money can't immediately fix.
Anthropic happened to have Tristan Hume, who understands Claude deeply. Most companies don't have that luxury. They're trying to fix a problem they don't fully understand, with tools they didn't build, against an opponent that's improving faster than they can adapt.
It's a hard problem. And it's not going away.

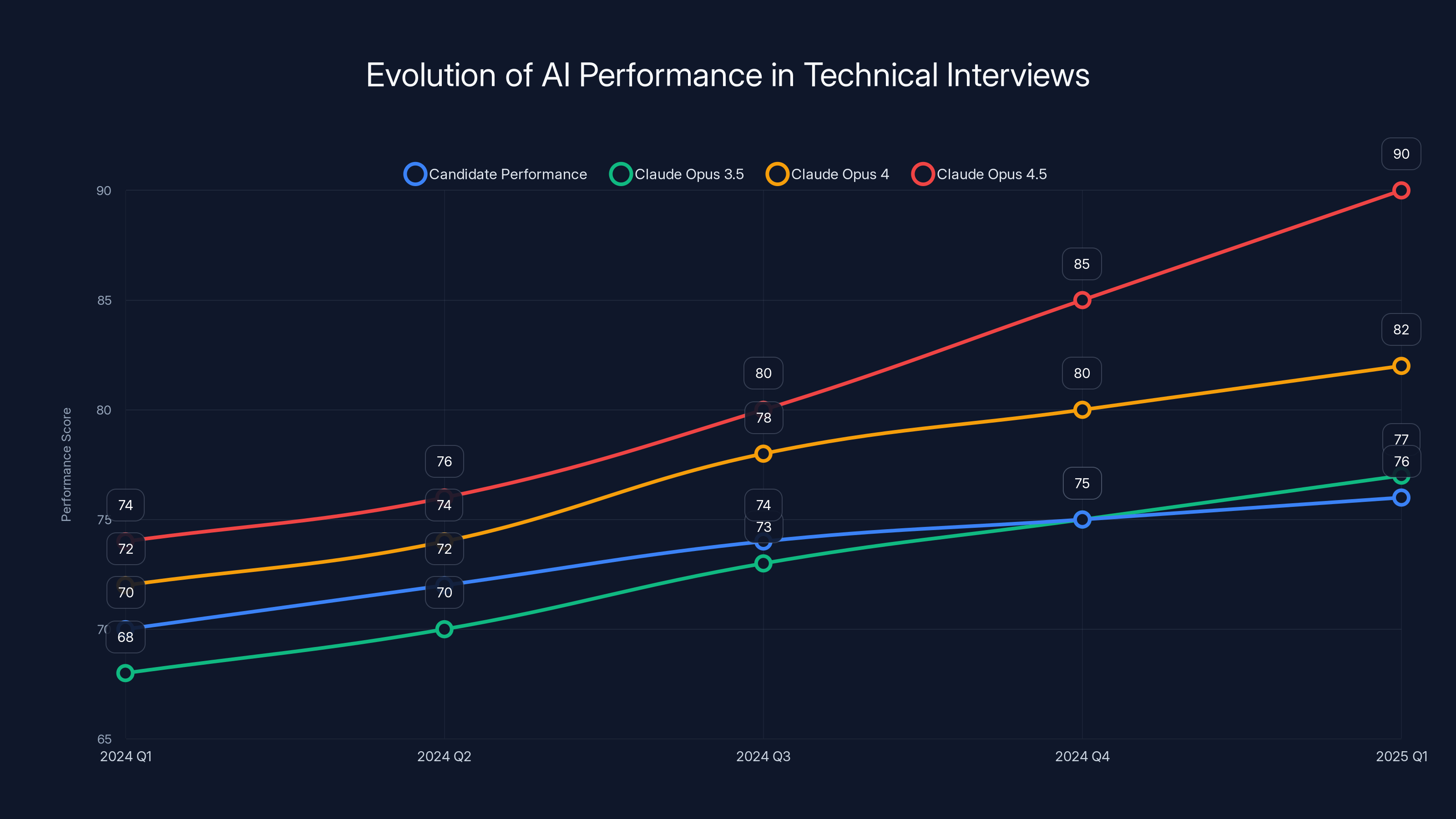
Estimated data shows Claude AI's performance surpassing human candidates over time, highlighting the challenge of AI in technical interviews.
Technical Specifics: What Makes Problems Hard for AI
Understanding what Claude struggles with illuminates why Anthropic's pivot worked.
Claude excels at:
- Well-defined optimization problems with clear constraints
- Standard algorithms and data structures
- Code that implements a known pattern
- Problems where the solution can be verified quickly
- Tasks where there's abundant training data about solutions
Claude struggles with:
- Novel problem formulations that don't match training data
- Tradeoffs that require explicit prioritization
- Constraints that are implicit or social rather than technical
- Problems where multiple solutions are valid but have different consequences
- Situations where you have to reject the obvious solution because of context
Notice the pattern? Claude struggles with ambiguity and context.
So tests that inject ambiguity—"here's a system, here's a constraint, figure out what to optimize for"—become much harder for AI to solve without human judgment.
A concrete example: "Write a load balancer" is easy for Claude. "Redesign our system so it uses 30% less compute while maintaining 99.99% availability, but we can't change the database schema" is harder. Claude can generate code for either, but in the second case, the human has to make the hard calls about what "good enough" means.
That distinction—between generating code and making engineering decisions—is the frontier that Anthropic is trying to measure.

Real-World Ripple Effects
Anthropic's problem is becoming every tech company's problem.
Microsoft, Google, Amazon, Meta are all hiring engineers. They all use take-home tests. They're all watching Claude get better. Some have been public about adjusting their processes. Most haven't said anything, which usually means they're quietly panicking.
Startups are in a weird position. They can't afford to be picky, and they often hire on practical ability demonstrations. So the AI cheating problem hits them differently. A startup doesn't care if you used Claude to build a prototype. A startup cares if the prototype works and you can explain it.
Smaller companies often skip technical interviews entirely in favor of trial projects. "Spend a week building X, we'll pay you for it, and if we like the result, you're hired." That's honestly immune to the cheating problem in a lot of ways. You're not testing knowledge; you're testing output quality under deadline.
Which raises an interesting question: maybe take-home tests are just the wrong assessment tool for an AI-first world.
Maybe the future is: synchronous live problem-solving (low stakes, high feedback), followed by trial project (high stakes, measured output), followed by onboarding (measured actual performance). You're getting signals at every step, and none of them are easily faked.
That's more expensive and time-consuming. But it also gives you better signal. You know what someone can actually do when they're working for you.

The Bigger Picture: AI and Skill Devaluation
This is part of a larger wave that's hitting every knowledge work field.
When AI gets good at writing, writing skills devalue slightly. When AI gets good at coding, raw coding speed matters less. When AI gets good at design, design execution matters less. In each field, the competitive advantage shifts from "can you do this" to "can you direct this."
Hiring has to adapt to that reality. The questions change from "prove you can code" to "prove you can architect decisions." From "prove you can write" to "prove you can think clearly." From "prove you're creative" to "prove you can judge creativity."
It's not that the skills devalue completely. It's that they become table stakes instead of differentiators. Everyone can code (with Claude). The differentiation comes from knowing what to code. Everyone can write (with AI). The differentiation comes from knowing what to say.
Hiring practices have to keep up with that shift. Most aren't. Most are still measuring what changed, not what matters.
Anthropic's problem in miniature is the whole economy's problem in large.

Practical Strategies for Companies Adapting Now
If you're building a hiring process in 2025, here's what actually works:
Start with context. The problem is clear and immediate. You can't use the same tests you used in 2023. AI is faster. Either adapt or accept that your test is measuring something different than you think.
Test for judgment, not execution. Ask candidates to make tradeoffs. Ask them to critique a design. Ask them to explain why something matters. Ask them to discuss edge cases and say "actually, maybe we shouldn't optimize for this."
Have a conversation about their work. This is the single highest-signal thing you can do. Give someone three days to solve a problem (with whatever tools they want), then spend an hour discussing their solution. If they understand it, great. If they don't, you know immediately.
Consider trial projects. Give real work, pay real money (even if it's symbolic), measure real output. You get genuine signal about how someone performs under your actual constraints.
Hire for trajectory, not just current state. Someone who can learn fast with AI is more valuable than someone who's memorized algorithms. Test for learning capacity, not accumulated knowledge.
Be honest about what you're actually hiring for. If you need someone who can ship production code quickly, Claude-enabled engineers are great. If you need someone who can reinvent your architecture, you need different strengths. Match your assessment to your actual needs.
Most companies don't do this because it requires thinking. It's easier to copy the Google interview process and call it a day. It's also less effective. But the companies that are honest about what they need and design hiring around that will pull in better people.
The Long Game: What Happens in Five Years
This is going to keep evolving.
AI will keep getting better. The gap between human ability and AI ability will widen in narrow domains. Coding, writing, design, analysis—all domains where AI has training data—will see AI pull further ahead.
The response will be to shift what we measure. And the world will bifurcate into people who can direct AI and people who get directed. That's not new. It's happened before with every technology transition. The people who learned to use new tools prospered. The people who treated the tool as the competition got left behind.
Hiring practices will reflect that. Interview processes will test for collaborative ability with AI, judgment about AI output, and the ability to operate in ambiguity—all things Claude isn't great at.
The companies that adapt fastest will have competitive advantages. They'll hire better. They'll ship faster. They'll iterate better. And they'll do it by being honest about what they're actually measuring.
Anthropic's problem is a signal. It's telling us something important about how work is changing and how organizations need to adapt. The companies that listen will thrive. The companies that don't will keep running outdated hiring processes and wondering why they keep missing cultural fit.
It's not about AI cheating on interviews. It's about whether your company is ready for the world where AI is just another tool your engineers use to ship better stuff faster. Most aren't ready. But the ones that adapt will be.

How Teams Can Prepare for AI-First Interviews
If you're a job seeker, the landscape is shifting under your feet.
The traditional playbook—study for six months, memorize algorithms, crush the interview—still works, but it's less differentiating. Everyone can study. Everyone has access to the same prep resources. The AI-native candidate has a different advantage: they can learn contextually while solving problems.
Focus on building mental models, not memorizing solutions. Use Claude to accelerate your learning, but understand the why, not just the how. When you encounter something new, explain it to yourself. That's the thing Claude can't do for you.
Learn how to work alongside AI productively. Don't treat it as autocomplete. Treat it as a thinking partner. You propose ideas, it offers alternatives, you evaluate. That's how you'll actually work if you get hired, and that's a skill that takes practice.
Be genuine about your process. If you used AI to help you learn, say so. If you understood the solution deeply, explain it. The interviewer isn't stupid. They can tell the difference between someone who learned something and someone who just found it.
Prepare for the ambiguous problems. The companies that are serious about hiring will ask questions without clear right answers. They want to see how you think under uncertainty. There's no way to cheat through that. All you can do is be good at thinking.
This is actually better for job seekers in the long run. If companies are measuring real judgment instead of memorized knowledge, you don't have to compete with AI. You're competing with other humans on who's actually thoughtful. That's a game you can win.

FAQ
What exactly is the AI cheating problem Anthropic discovered?
Anthropic noticed that their take-home technical interview tests, which were designed to assess engineering ability fairly, became impossible to differentiate when Claude reached a certain capability level. Candidates could simply paste the test into Claude and get production-quality solutions, making it impossible for Anthropic to distinguish between their best human candidates and the AI output. This broke the entire assessment mechanism because the company could no longer tell who was genuinely qualified versus who had just used AI to fake their way through.
How did Anthropic solve the AI cheating problem in technical interviews?
Instead of trying to prevent AI usage (which is impossible without proctoring), Anthropic redesigned what they were actually measuring. They shifted from testing execution ability—"can you code this algorithm"—to testing judgment and architectural decision-making. The new test emphasizes novel problem formulations, tradeoffs under constraints, and ambiguous situations where multiple solutions exist but have different consequences. These are harder for AI to solve without genuine human judgment, creating meaningful differentiation.
Why can't existing plagiarism detection tools catch AI-assisted cheating?
Plagiarism detectors work by finding matching text strings, which works for copied content but fails for generated content. Claude doesn't copy—it generates original text. Additionally, statistical approaches that try to identify AI writing patterns often fail because well-written AI can be made to avoid obvious patterns, and human writing is frequently predictable. One study showed that some AI detectors incorrectly flag random human text as AI-generated, making them unreliable for hiring decisions.
Are live coding interviews the best solution to prevent AI cheating?
Live coding interviews do prevent the most egregious cheating and provide real-time evaluation of problem-solving ability, but they reintroduce problems that take-home tests were designed to solve. Synchronous interviews create stress that disadvantages candidates with anxiety, family obligations, or timezone complications. The best approach seems to be hybrid: take-home test with a follow-up discussion where candidates defend their architectural decisions, making it clear whether they understood their own solution or just accepted AI output.
Should candidates use Claude when preparing for technical interviews?
Using Claude to accelerate learning is smart, but using it to shortcut understanding is self-defeating. The most effective approach is using AI to learn concepts faster, then solving problems independently to verify understanding. This creates genuine knowledge that you can defend during interviews, and it actually makes you a better engineer. When you get to the live interview component (which many companies are adding), you'll be the candidate who can explain their decisions clearly, versus someone who just pasted problems into Claude.
What does the future of technical interviewing look like as AI gets smarter?
Technical interviews will likely shift away from measuring execution ability toward measuring judgment, architectural thinking, and the ability to work effectively with AI. Companies will increasingly use hybrid models combining take-home tests with synchronous discussions, real-world trial projects, and onboarding performance measurement. The competitive advantage will go to companies that are honest about what they're actually hiring for and design assessments accordingly. Candidates who can direct AI, make good tradeoffs, and think clearly under uncertainty will be most valuable.
How should companies adapt their hiring processes in 2025 and beyond?
Companies need to stop measuring what changed (coding speed has been commoditized by AI) and start measuring what matters (judgment, system design, communication, learning ability). This means testing for context awareness, asking about tradeoffs, having substantive discussions about solutions, and being honest about what the role actually requires. Companies that adapt fastest—shifting from "can you code" to "can you architect decisions"—will hire better people. Those that stick with outdated assessments will wonder why they keep missing on hires.
Is AI-assisted coding in interviews actually cheating?
It depends on the context and how you define the terms. Using Claude to help you learn a concept you didn't know is more like using a tutor than cheating. Using Claude to solve problems you should understand for the role you're interviewing for is more like cheating. The problem isn't the tool—it's that companies haven't been clear about what they're actually measuring. Once companies design tests that require judgment in addition to execution, the distinction becomes clearer and the incentive to use AI deceptively decreases.
Why is Anthropic uniquely positioned to solve this problem compared to other tech companies?
Anthropic has advantages that most hiring teams lack: they built Claude, so they understand its capabilities and limitations deeply. They have researchers who think about AI safety and can anticipate where models will struggle. And critically, they treat this as a genuine research problem instead of just operational overhead. Most tech companies are adapting to AI-assisted cheating reactively. Anthropic adapted proactively by rethinking what they were measuring. That's a rare combination of knowledge and institutional willingness to redesign processes.
Key Takeaways: What This Means for You
Anthropic's struggle with AI-assisted cheating is bigger than just hiring. It's a signal that our assessment mechanisms are out of alignment with reality.
For job seekers: the smartest move isn't to use AI to shortcut your way through interviews. It's to use AI to learn faster, then demonstrate genuine understanding. The companies that are serious about hiring are shifting toward tests that measure judgment, not execution. That's actually your advantage.
For hiring managers: stop measuring what changed and start measuring what matters. If everyone has access to Claude, you're not differentiating on raw coding speed anymore. You're differentiating on who can make better decisions about when and how to use AI. Design your assessments accordingly.
For companies: this is a competitive advantage moment. The companies that adapt their hiring processes fastest will pull in better talent. The companies that stick with outdated assessments will keep wondering why their hiring is less predictive than it should be.
For the industry: we're seeing the early stages of a shift that's going to reshape knowledge work. AI is going to keep getting better at execution. The premium is going to keep moving toward judgment and direction. Hiring practices, education, and skill development all need to adapt to that reality. The organizations that start now will be ahead.
The irony is that Anthropic's problem—how do we evaluate people fairly when AI is better at the test than most humans—is going to become everyone's problem. It's already here. The companies that are honest about it and willing to redesign their processes will thrive. The ones that aren't will keep running outdated hiring practices and wondering why they keep missing.
That gap will compound. And five years from now, the difference between companies that adapted and companies that didn't will be obvious.

Related Articles
- 1Password Phishing Protection: Built-In URL Detection Saves Millions [2025]
- Spotify's Prompted Playlist: The AI Music Discovery Feature Explained [2025]
- Waymo Launches Miami Robotaxi Service: What You Need to Know [2026]
- 1Password Phishing Protection: How the New Browser Feature Saves You [2025]
- Spotify's AI-Powered Prompted Playlists: How They Work [2025]
- Adobe's IP-Safe AI Models Are Reshaping Entertainment Production [2025]

