![Nvidia's Vera Rubin Chips Enter Full Production [2025]](https://tryrunable.com/blog/nvidia-s-vera-rubin-chips-enter-full-production-2025/image-1-1767656250438.jpg)
Nvidia's Vera Rubin Chips Enter Full Production: What You Need to Know
Last month at CES in Las Vegas, Jensen Huang dropped a line that made the AI industry sit up straight. Vera Rubin is in full production. Not coming soon. Not on track for mid-2026. Right now. Full production.
If you're not neck-deep in semiconductor news, here's why this matters: Vera Rubin is Nvidia's next-generation AI superchip platform, and it's designed to do something the industry has been chasing for years. It cuts the cost of running AI models to roughly one-tenth the price of Blackwell, Nvidia's current flagship chip. At the same time, it requires about one-fourth as many processors to train certain large language models.
Let that sink in. One-tenth the cost. One-fourth the chips. Those aren't marginal improvements. They're the kind of numbers that reshape how companies think about deploying artificial intelligence at scale.
The announcement matters for a few specific reasons. First, Microsoft and CoreWeave are already lined up to start offering Vera Rubin-powered services later this year. Microsoft is building two massive data centers in Georgia and Wisconsin specifically to house thousands of these chips. That's not theoretical capacity. That's real infrastructure being built right now.
Second, this signals something larger about Nvidia's strategy. The company isn't just selling faster chips anymore. It's building an entire integrated system: compute, memory, networking, storage, and software orchestration all working together. That's a harder target to displace than a single component, no matter how good your custom silicon is.
But there's complexity here too. When Nvidia says full production, what does that actually mean? The chip industry uses specific terms, and full production doesn't mean the same thing at different stages. We'll get into that.
The bigger picture is this: AI infrastructure costs have been climbing faster than anyone predicted. Cloud providers, hyperscalers, and enterprises are all getting squeezed by the bill. Vera Rubin is designed to be the answer. And if Nvidia delivers on those cost reductions, it changes the economics of AI deployment for virtually everyone building anything substantial with large language models.
Understanding the Vera Rubin Platform Architecture
Vera Rubin isn't a single chip. That's important. It's a system made up of six different components working together, and each one was engineered specifically to reduce bottlenecks that plague current AI infrastructure.
The system includes the Rubin GPU, which handles the actual AI computations, and a Vera CPU that manages memory and data orchestration. Both are built using Taiwan Semiconductor Manufacturing Company's (TSMC) most advanced 3-nanometer process. That's not a marketing detail. That level of fabrication density means more transistors packed into the same physical space, which translates directly to better power efficiency and more compute power per watt.
But here's where it gets interesting. Nvidia also integrated what they call the "most advanced bandwidth memory technology available." This is crucial because one of the biggest limiting factors in AI training isn't actually the processor speed. It's moving data between the GPU and memory. If you optimize compute but leave memory bandwidth constrained, you're solving the wrong problem.
The system also includes Nvidia's sixth-generation interconnect and switching technologies. This is the networking fabric that links all these components together. In a large AI cluster, you might have thousands of chips working in parallel. The way they talk to each other matters enormously. A slow interconnect will bottleneck even the fastest processors.
Jensen Huang called each component "completely revolutionary and the best of its kind" during the CES presentation. That's standard CEO hyperbole, but the engineering reality is that designing six different components to work as a unified system is extraordinarily complex. Each piece has to be optimized not just for its own performance, but for how it interacts with every other piece.
The design work started years ago. Huang first publicly announced Vera Rubin during a keynote speech in 2024, and at that point Nvidia already had working prototypes. The company then said systems would begin shipping in the second half of 2026. Now they're saying full production has begun. That's about six months earlier than the original timeline, which could mean several things: the design is more mature than originally announced, demand is forcing acceleration, or Nvidia is being optimistic about what "full production" means. Probably some combination of all three.

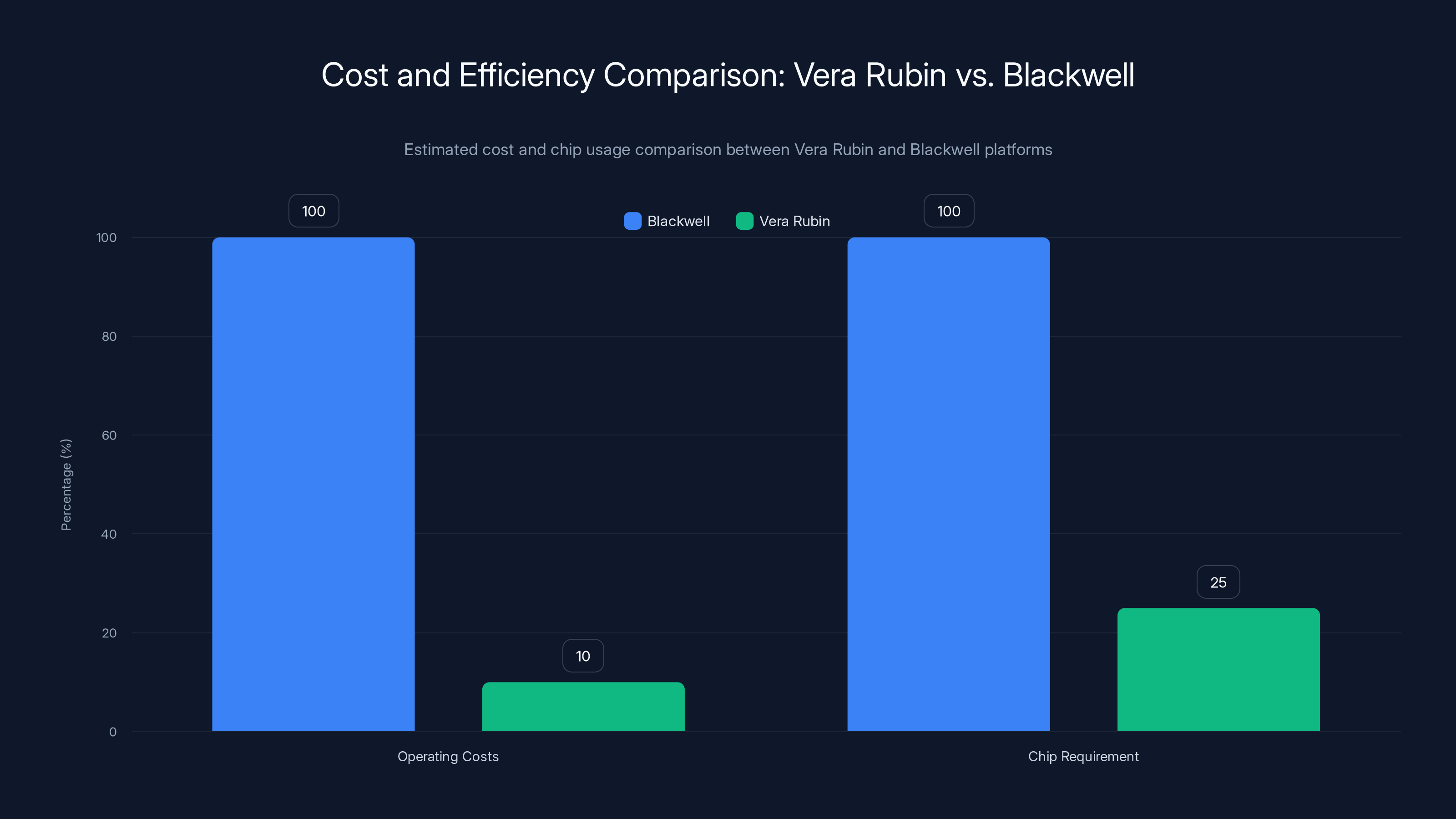
Vera Rubin reduces operating costs to 10% and chip requirements to 25% compared to Blackwell, highlighting significant efficiency improvements (Estimated data).
Cost Reduction: The Math Behind One-Tenth Price
When Nvidia claims that Vera Rubin cuts operating costs to one-tenth of Blackwell, they're not talking about the price of the chip itself. They're talking about the total cost of ownership across the entire AI infrastructure lifecycle. That includes power consumption, cooling, data center real estate, and operational overhead.
Let's break down where the savings come from. First, there's compute efficiency. Vera Rubin performs the same AI operations with less wasted energy. That's not magic. It's a combination of better chip design, improved memory hierarchy, and more efficient data flows. But in a data center running 24/7, a 10% improvement in power efficiency compounds quickly.
Second, there's the memory angle. Current AI systems often run into memory constraints before they hit compute constraints. A model might have enough processing power to finish a training run, but not enough memory bandwidth to feed data to the processors fast enough. Vera Rubin's enhanced bandwidth memory means less idle time, more productive computation cycles.
Third, there's the network overhead. In large clusters, processors spend time waiting for data to arrive from other processors. Nvidia's improved interconnect fabric reduces that wait time. That doesn't sound like much, but when you're running a model that takes months to train, shaving off inefficiency at the network level matters.
There's also a fourth factor that matters but gets less attention: software optimization. Nvidia is shipping Vera Rubin with updated software stacks specifically optimized for this hardware. That means fewer algorithmic workarounds, less software overhead, more direct path from algorithm to silicon.
Let's put some numbers on this. If a company is currently training an AI model on Blackwell and the monthly electricity bill for that training run is
Now, there's a catch. Nvidia is talking about what they call "certain large models." That's intentionally vague. The efficiency gains apply most dramatically to specific workloads: large language model training, inference at scale, certain types of deep learning. They'll be less dramatic for other types of compute. You won't see one-tenth cost reduction across every possible AI application.
But for the primary use cases driving current data center expansion, that's where most of the demand is. Large language model training. Large language model inference. So the claim, while technically hedged, applies to the applications that matter most to Nvidia's customers.
Training Efficiency: Using One-Fourth the Hardware
The ability to train certain large models using one-fourth as many chips as Blackwell is the other half of the cost equation. This is about both capital expenditure and operational simplification.
Capital expenditure first. If you're building a data center to train large language models, you're buying thousands of chips. Literally thousands. At current prices, a single Nvidia H100 GPU costs around $40,000. A complete system for training large models might include dozens or hundreds of these. If Vera Rubin can do the work of four Blackwell chips, then you're buying one-fourth as many processors, which means one-fourth the capital investment.
For a company like Microsoft, that's a meaningful reduction in upfront spending. The Georgia and Wisconsin data centers under construction are already committed to heavy Vera Rubin deployment. That suggests Microsoft calculated the return on investment and decided the cost savings justify building the infrastructure now, before competitors do.
But there's another efficiency hidden in that one-fourth figure: operational simplification. Running 4,000 chips in a cluster requires sophisticated orchestration software, fault tolerance, careful monitoring, and experienced operations teams. Running 1,000 chips to do the same work is dramatically simpler. Fewer points of failure, easier to troubleshoot, faster to scale up or down.
There's also a thermal aspect. More processors means more heat. More heat means more cooling infrastructure, which drives up operational costs and physical space requirements. Vera Rubin uses less hardware to achieve the same results, which means less overall power draw, less heat generation, lower cooling costs.
Some of Nvidia's partners are already testing this on early systems. Red Hat, the enterprise open-source software company, is working with Nvidia to certify their software stack on Vera Rubin. That kind of early validation is important because it surfaces edge cases and optimization opportunities before full market launch.
The key insight here is that this isn't just about making chips faster. It's about making AI infrastructure more efficient across every dimension: energy, capital, operations, maintenance. That's harder to do than just increasing clock speed, but it's also more valuable to customers.

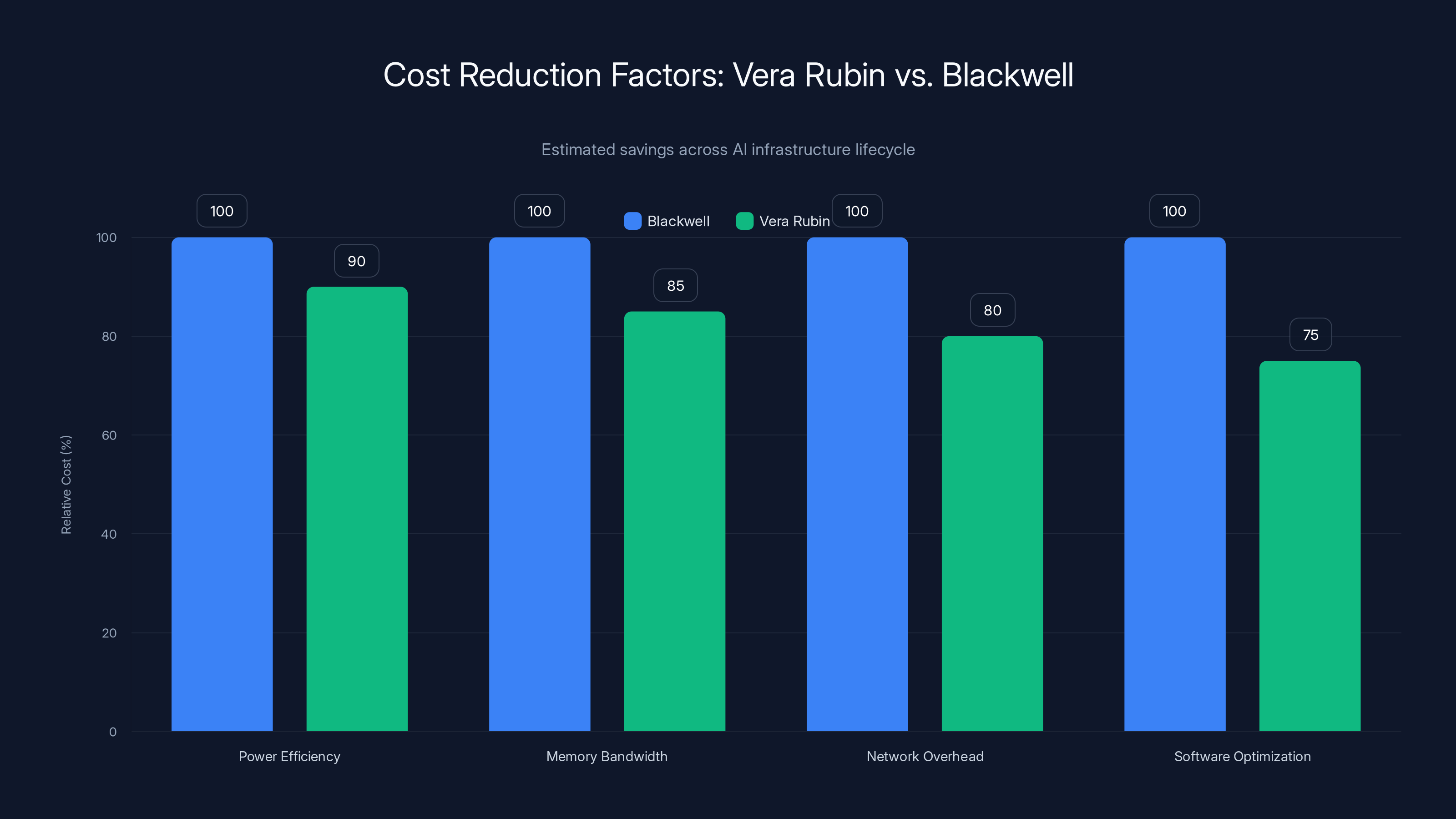
Vera Rubin offers significant cost reductions across multiple factors, reducing total costs to one-tenth of Blackwell's. Estimated data based on typical AI infrastructure savings.
Why This Announcement Matters for AI Economics
Step back for a moment and think about what's been driving AI spending. Companies and governments have been allocating enormous capital to build AI infrastructure because they believe AI will deliver transformative value. But they're also getting hammered by the operating costs.
OpenAI, Google, Meta, Microsoft, and other heavy investors in large language models have been transparent about one thing: the cost of training and running these models is massive. We're talking about multi-billion dollar operations. As these models get larger and more capable, costs climb faster than performance improvements sometimes justify.
Vera Rubin is designed to break that pattern. By reducing per-unit costs while maintaining or improving performance, it makes those billion-dollar budgets go further. A company could either train larger models with the same budget, or train the same models at lower cost. Either way, that's a dramatic shift in the economics.
There's also a competitive angle. AI capability is increasingly constrained by compute budget. The teams that can afford to run the biggest models with the most data tend to build the best models. Vera Rubin's efficiency improvements level the playing field slightly. Smaller companies or less-well-funded teams might now be able to afford training runs that would have been impossible with Blackwell. That changes the competitive dynamics.
For cloud providers like Microsoft, Amazon, and Google, efficiency improvements translate directly to margin improvements. They can either offer Vera Rubin-powered AI services at lower prices to gain market share, or keep prices the same and expand profit margins. Most likely they'll do some combination: offer lower prices to win customers, keep some of the savings as margin.
For enterprises buying AI services from these cloud providers, Vera Rubin matters because it eventually flows through to lower service costs. That's usually a 6 to 12 month lag, but it matters.
The announcement also sends a signal about Nvidia's product roadmap. They're not slowing down. Vera Rubin in full production now means the timeline for the next generation (presumably named Blackwell's successor) is also accelerating. That cadence of improvement is unprecedented in the semiconductor industry and puts pressure on competitors to match it.
The Full Production Question: What Does That Actually Mean?
There's some ambiguity in what Nvidia means by saying Vera Rubin is in "full production." In the semiconductor industry, production ramps happen in stages.
Typically, when a new chip design first goes into manufacturing, it's produced in very small volumes while the manufacturer (in this case, TSMC) validates the design, tests different manufacturing conditions, and works out any bugs. This phase is called "early production" or "low volume production."
As the design gets validated and yields improve (yield is the percentage of wafers that produce working chips), production volume increases. Eventually you reach "full production," which means manufacturing is running at target volume with validated processes.
But there's a spectrum here. Nvidia's announcement doesn't specify whether Vera Rubin is at 50% of target volume, 100% of target volume, or somewhere in between. The term "full production" is marketing language more than technical specification.
There's historical precedent worth considering. In 2024, Nvidia hit a major problem with Blackwell. The chips were overheating when connected together in server racks. This was a design flaw that caused delays. Shipments eventually got back on schedule, but not before customers had to wait. That experience probably makes Nvidia more careful about the language they use around production status. When they say Vera Rubin is in full production, they're probably not going to repeat Blackwell's experience.
Still, the cautious interpretation is that full production means the chips are being manufactured in meaningful volume, early customers are receiving them, and manufacturing processes have been validated. It doesn't mean every customer who wants Vera Rubin will get it immediately. Demand will likely exceed supply for months or quarters.
That's actually important context for understanding Nvidia's market position. Even announcing production doesn't immediately solve scarcity. Customer allocation and supply constraints are likely to remain a factor well into 2026.
Strategic Importance: Computing Platform, Not Just Chips
The broader strategic shift at Nvidia is worth understanding because it affects everything else. The company isn't positioning itself as a chip company anymore. It's positioning itself as a complete computing platform architect.
Historically, Nvidia made GPUs. They were powerful at graphics processing and matrix operations, which made them great for AI. But the full stack around those GPUs was someone else's problem. Customers had to integrate Nvidia chips with processors from other companies, memory systems, networking equipment, storage solutions, and software frameworks.
Vera Rubin changes that calculus. The system integrates compute, memory, networking, and software orchestration. A customer isn't buying an Nvidia GPU anymore. They're buying into an Nvidia ecosystem.
That's strategically important because it makes Nvidia harder to displace. If a customer is unhappy with just the GPU, they might switch to a competitor's processor. But if the entire system is optimized as a unit, switching requires rethinking every other component. The switching costs go up dramatically.
That's also why Nvidia is investing in ecosystem partnerships. Red Hat isn't a data center hardware company. They're a software company. But Nvidia is working with them to ensure Red Hat's enterprise software stack runs optimally on Vera Rubin. That's expanding the moat around Nvidia's platform.
There's a risk to this strategy too. The more integrated and proprietary the system becomes, the more it looks like something customers might want to replace with alternatives they control themselves. Some of Nvidia's largest customers, like OpenAI, are already investing in custom silicon designed specifically for their own workloads.
OpenAI has been working with Broadcom to develop custom chips for their next-generation AI models. These chips won't be general-purpose AI accelerators. They'll be designed specifically for OpenAI's architecture and training pipeline. That's a long-term play, but it suggests even Nvidia's biggest customers are hedging their bets.
The question is whether Nvidia's integrated platform is so good that the efficiency gains outweigh the loss of flexibility from custom silicon. Right now, that seems to be the case. But as custom silicon designs mature, that calculation might change.
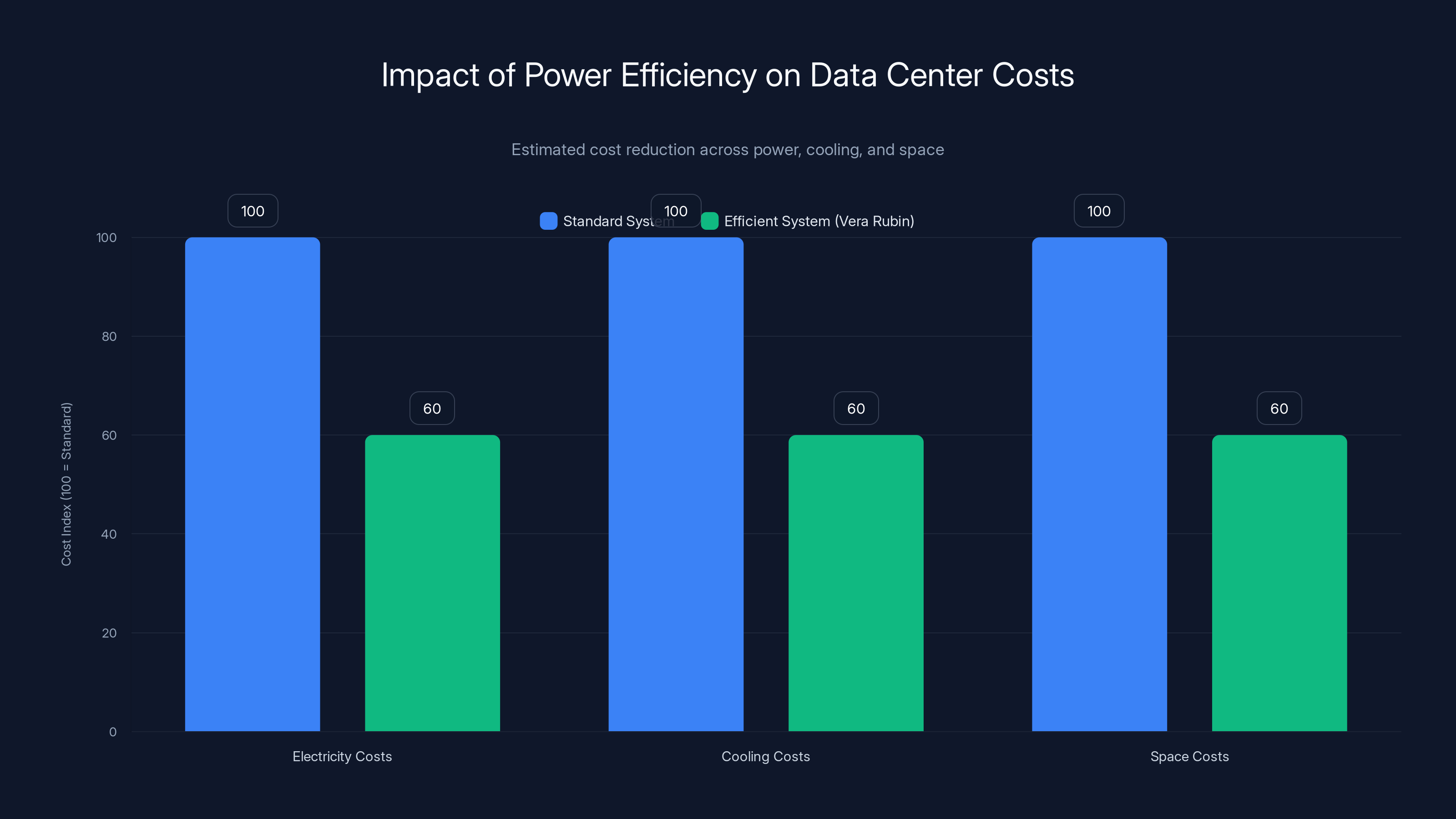
Vera Rubin's efficiency improvements can reduce data center costs by 40% across electricity, cooling, and space. Estimated data based on Nvidia's claims.
Microsoft's Vera Rubin Investment and Infrastructure Plans
Microsoft's involvement in the Vera Rubin launch is significant because it signals serious commitment. The company is building two massive new data centers specifically designed to house thousands of Vera Rubin chips. One is in Georgia, one is in Wisconsin. Both are described as "eventually" including thousands of Rubin chips.
That's a measured way of saying the infrastructure is under construction and will phase in Vera Rubin deployment over time. These aren't small facilities. Data centers that house thousands of high-end AI accelerators are massive capital projects. We're talking about investments in the hundreds of millions of dollars.
Why is Microsoft making this bet? Because they've calculated that the efficiency improvements and cost reductions from Vera Rubin justify the infrastructure investment. They're essentially putting capital at risk based on Nvidia's timeline and promises.
Microsoft has been aggressively expanding its AI capabilities specifically to compete with Google and Amazon in the cloud market. OpenAI partnership, Copilot integration, GitHub Copilot, and a whole suite of AI services are all competing against Google Cloud and AWS. Access to cutting-edge, cost-efficient AI infrastructure is crucial to that strategy.
Vera Rubin deployment in these data centers will likely start with high-value AI workloads: large language model training, inference at scale, custom model development for enterprise customers. As supply increases and costs stabilize, it will roll out to a wider range of services.
For enterprise customers buying AI services from Microsoft Azure, this eventually means lower costs. But there's probably a 6-12 month lag before those cost reductions flow through to customer pricing. That's normal. Cloud providers absorb initial cost advantages, then gradually pass some of them along as competitive pressure forces it.
CoreWeave's involvement is also worth noting. CoreWeave is a specialized cloud infrastructure company focused specifically on AI and GPU workloads. They're not a hyperscaler like Microsoft or Amazon. They're more specialized. But they're also usually earlier adopters of new GPU technology because their entire business model is built around offering customers access to the latest compute infrastructure.
CoreWeave offering Vera Rubin services likely means enterprises and AI startups will have another option for accessing the new chips besides the big hyperscalers. That's important for market competition and for customers who want to avoid being locked into a single provider.

Market Implications: Who Benefits and How Much
The market implications of Vera Rubin are genuinely substantial. Let's think through the winners and losers.
Clear winners: AI infrastructure companies, cloud providers, and enterprises building large AI systems. For them, the cost reductions are immediate and direct. Lower per-unit training and inference costs flow straight to their bottom line or allow them to offer more competitive pricing to their customers.
Among those winners, the biggest winners are companies doing inference at scale. Inference is the process of running a trained model to generate predictions or outputs. It's ongoing, never-ending compute. If you're running a large language model API that processes millions of requests per day, inference costs dominate your operating budget. A 10x improvement in inference efficiency changes the entire business model. You can either cut prices dramatically and gain market share, or keep prices the same and suddenly have massive margins.
Another big winner: Nvidia. If Vera Rubin achieves the promised efficiency gains and becomes the standard for AI infrastructure, demand is likely to be enormous. The company might not sell as many individual chips (because customers need fewer of them), but the dollar value per customer might actually go up because entire systems get purchased together.
Losers? Companies that spent billions building infrastructure around Blackwell are now stuck with partially depreciated assets. They'll eventually transition to Vera Rubin, but there's a window where they're managing mixed-generation infrastructure. That's operationally complex and economically painful.
Competitors to Nvidia lose again. AMD, Intel, and other companies building AI accelerators are watching Nvidia release systems that are dramatically more efficient than what they can offer. The gap is widening, not narrowing. That's a long-term threat to competitive position.
Also worth considering: the timeline compression. Vera Rubin was supposed to arrive in mid-2026. Now it's in full production with customers already lined up for delivery this year. That means the next generation of Nvidia chips is probably moving up in the timeline too. Competitors can't keep pace with that cadence of innovation.
The Semiconductor Supply Chain and TSMC's Role
None of this happens without TSMC. The Taiwan Semiconductor Manufacturing Company is the only company in the world currently capable of manufacturing 3-nanometer chips at the scale Nvidia needs. That's not hyperbole. It's fact. Samsung has 3-nanometer capability, but at significantly lower yield rates and capacity. Intel is still working toward competitive 3-nanometer manufacturing.
TSMC is effectively Nvidia's only option for leading-edge manufacturing. That creates both leverage and risk.
From Nvidia's perspective, the leverage is important. A company this size doesn't want to depend entirely on a single manufacturing partner. But realistically, for 3-nanometer production at the volume and cost Nvidia needs, TSMC is the only viable option. That gives TSMC significant negotiating power.
From a geopolitical perspective, there's risk. TSMC is in Taiwan. The relationship between Taiwan and China is complicated and potentially volatile. Any disruption to Taiwan's stability would disrupt global semiconductor supply. For that reason, there's increasing interest in manufacturing advanced chips outside of Taiwan. But we're still years away from that being realistic at scale.
For now, Vera Rubin's full production depends on TSMC's ongoing ability to manufacture 3-nanometer chips. Nvidia has likely negotiated long-term supply agreements with TSMC to secure capacity. But constraints are still possible if demand across the entire semiconductor industry exceeds TSMC's total capacity.
One thing worth noting: TSMC's 3-nanometer process is expensive. The company has to amortize massive capital investments in manufacturing equipment across millions of wafers. That makes advanced chip manufacturing inherently expensive. Vera Rubin chips, while more efficient in operation, are probably more expensive to manufacture than previous generations. That's a normal trade-off: you spend more on the chip, but save more on operations. Over the lifetime of a data center, the math works out.

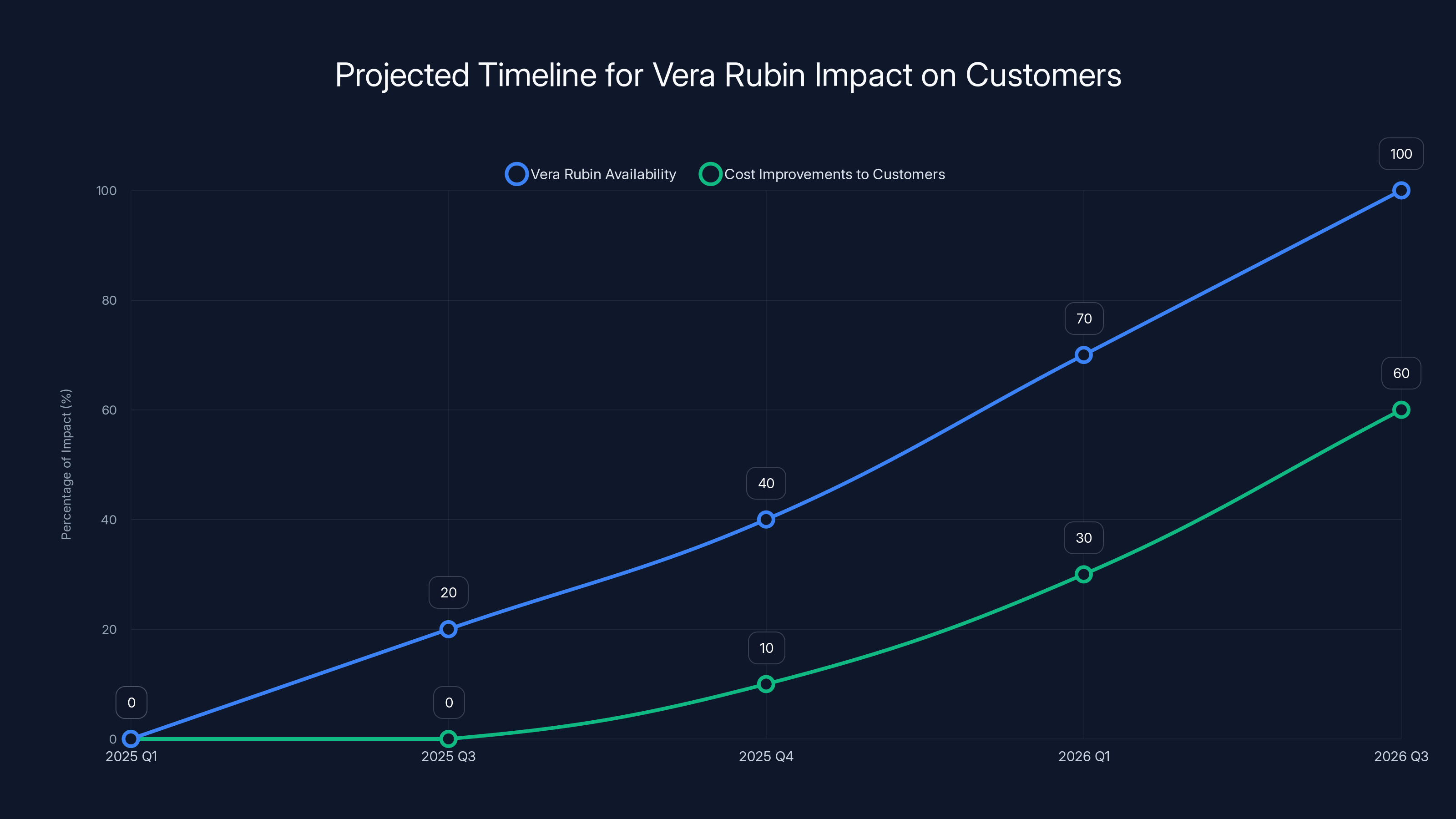
The rollout of Vera Rubin systems and associated cost improvements for customers is expected to gradually increase from 2025 into 2026, with significant availability and benefits likely by late 2026. Estimated data.
Custom Silicon: The Long-Term Competitive Challenge
While Nvidia is announcing Vera Rubin, some of the company's largest customers are simultaneously developing custom silicon designed specifically for their own use cases. That's not because they think Nvidia's chips are bad. It's because, at massive scale, custom silicon optimized for your specific workload outperforms general-purpose hardware.
OpenAI is the most public example. The company has been working with Broadcom to design custom chips for their next-generation AI models. These won't be called OpenAI chips or sold to customers. They're internal infrastructure. But they represent a strategic shift: move from buying off-the-shelf GPUs to building hardware specifically designed for OpenAI's architecture.
The timeline for this is important. Custom silicon takes years to design, test, and bring to production. If OpenAI started this project a few years ago, they're probably still years away from full deployment. Meanwhile, Vera Rubin is arriving now. So custom silicon is a hedge, not a replacement.
But the trend matters. As companies get larger and more mature in their AI capabilities, they're likely to move toward more custom silicon. Google has done this with TPUs (Tensor Processing Units). Amazon is developing custom AI chips through its AWS division. Microsoft is likely exploring similar options.
This represents a genuine long-term risk to Nvidia's market position. It's not a risk that manifests next quarter or next year. But over a 5-10 year horizon, significant portions of AI compute might migrate from Nvidia's general-purpose GPUs to custom silicon optimized for specific companies' workloads.
Nvidia's response is what we're seeing with Vera Rubin: build an increasingly comprehensive platform that's so tightly integrated and so efficient that the effort and time required to replicate it with custom silicon isn't worth the benefit. It's a race to see whether Nvidia's vertical integration is good enough to outweigh the benefits of custom optimization.
Right now, Nvidia is winning that race. But it's a race that will continue. The outcome isn't predetermined.
Vera Rubin Software and Development Stack
The chips themselves are only part of the story. Vera Rubin comes with software optimizations, development frameworks, and operational tools specifically designed for this hardware.
CUDA, Nvidia's proprietary parallel computing platform, is what made GPUs useful for AI in the first place. Before CUDA, GPUs were primarily graphics processing tools. CUDA made them accessible to AI researchers and engineers. Now, two decades later, CUDA is so entrenched that building neural networks without CUDA is difficult and inefficient.
Vera Rubin expands on CUDA with new libraries, frameworks, and optimization routines. Some of this is general-purpose tooling for any AI workload. Some is specific to common patterns: large language model training, transformer networks, diffusion models. The more specific the optimization, the better the performance improvement.
Nvidia has also been working with major software companies and research institutions to optimize popular frameworks. TensorFlow, PyTorch, JAX, and other frameworks are getting Vera Rubin-specific optimizations. That matters because it means when you run your standard PyTorch training code on Vera Rubin, it automatically gets better performance without requiring code changes.
There's also the integration with Red Hat's enterprise software. Red Hat provides open-source software for enterprise customers: operating systems, containerization, orchestration, monitoring. Getting Red Hat's stack certified and optimized for Vera Rubin means enterprises can deploy AI infrastructure using familiar, well-supported tooling.
That's not sexy. It doesn't make headlines. But it's critical for market adoption. Enterprise customers don't want to deal with custom integrations or unsupported software configurations. They want to deploy infrastructure using standard tools and frameworks. Vera Rubin's ecosystem approach makes that easier.
The software stack also includes monitoring, profiling, and debugging tools. Running large-scale AI infrastructure requires visibility into what's actually happening. Where is compute time being spent? What operations are bottlenecked? Where is power consumption coming from? Nvidia's tools answer these questions and suggest optimizations.

Competitive Responses and the Arms Race in AI Chips
Vera Rubin's announcement triggers responses from competitors. AMD, Intel, Google, and others are all working on next-generation AI accelerators. But they're starting from behind.
AMD's INSTINCT MI300 series is competitive with Nvidia's current generation, but not with Vera Rubin. Bringing a new generation to market takes years. AMD is probably 18-24 months away from releasing something that would compete with Vera Rubin, and even then they'd be starting from a less mature software ecosystem.
Intel is further behind. The company has been struggling to catch up in GPU manufacturing and has a less developed AI software stack. Their next-generation accelerators are still in development.
Google has TPUs, which are phenomenal for certain Google-specific workloads. But TPUs are designed and used internally. Google isn't packaging them as a general-purpose offering for external customers the way Nvidia does. That limits their competitive impact.
The arms race is real, but Nvidia has a substantial lead. Lead times for chip design and fabrication are measured in years. By the time competitors catch up to Vera Rubin's capabilities, Nvidia will have announced the next generation.
That cadence advantage is something competitors can't easily overcome. It requires capital, talent, and execution excellence at scale. Nvidia has all three. Most potential competitors lack at least one of those elements.
This suggests the competitive dynamics in AI chips will remain dominated by Nvidia for at least the next 3-5 years. After that, it depends on whether custom silicon becomes the dominant paradigm or whether Nvidia's integrated platform approach remains more cost-effective.
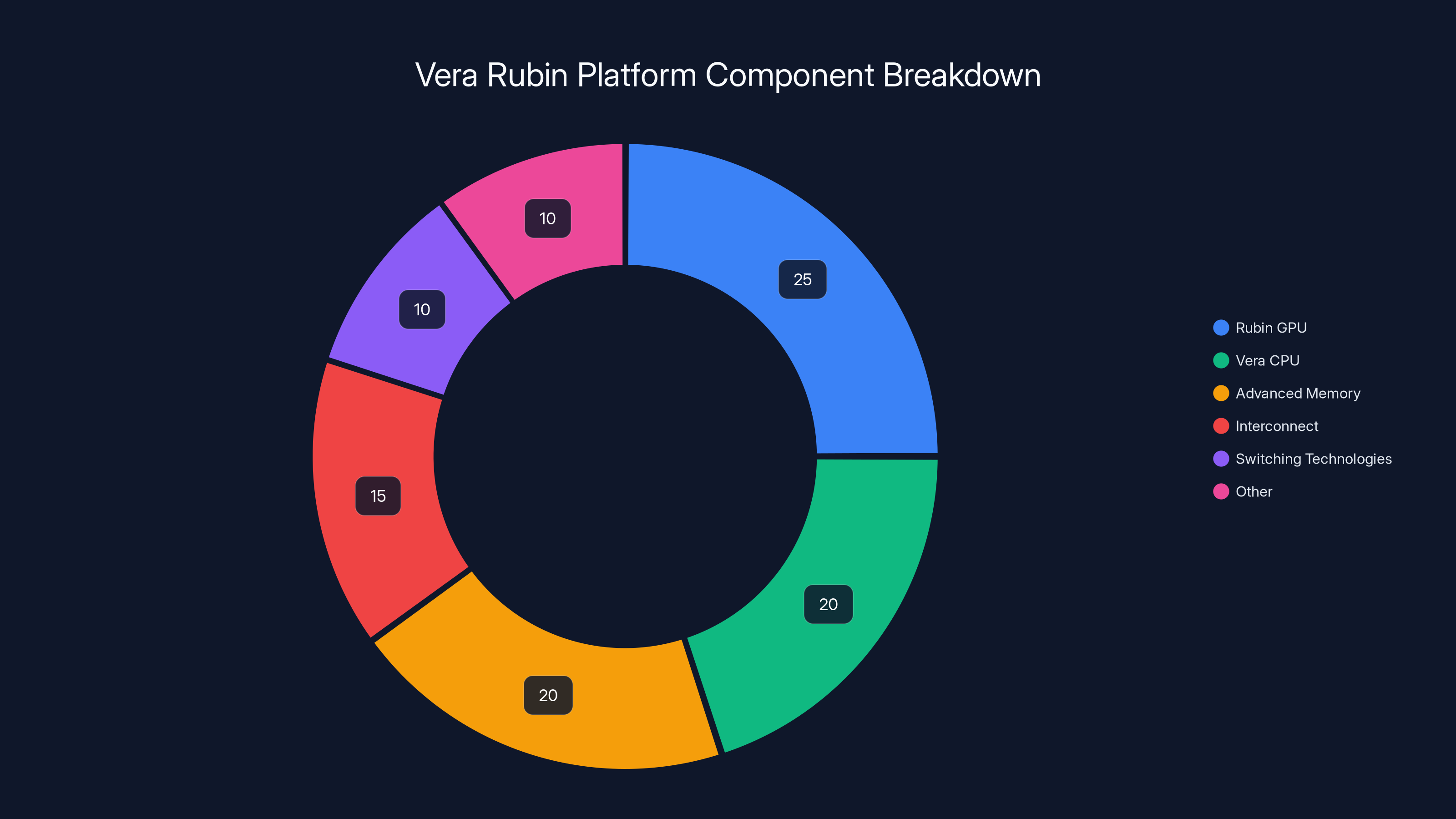
The Vera Rubin platform consists of six key components, with the Rubin GPU and Vera CPU forming the core, supported by advanced memory and interconnect technologies. (Estimated data)
Cost Implications for Training Large Language Models
Let's get specific about what Vera Rubin means for the economics of training large language models.
Training a state-of-the-art large language model on current hardware (Blackwell) might cost $20-50 million depending on model size and training duration. That's not a guess. Companies have been publishing approximate costs. OpenAI spent hundreds of millions on GPT-4. Google spent similar amounts on Gemini.
With Vera Rubin, that same training run would cost $2-5 million. That's a dramatic reduction.
But it's important to understand what's driving the cost reduction. It's not that the chips are cheaper to buy. It's that you need fewer chips, they use less power, and they finish the job faster. The total capital required is lower, the operational costs are lower, and the timeline is shorter. All three factors compound.
Shorter training timelines matter more than people realize. If a training run takes six months instead of a year, you get two model iterations per calendar year instead of one. That doubles your experimentation velocity. Faster iteration leads to better models because you can try more variations.
For companies doing this kind of work, that's an enormous competitive advantage. More experiments, better models, better products. All flowing from improved hardware efficiency.
Smaller companies and startups benefit disproportionately. A startup that couldn't afford
Of course, Vera Rubin chips will probably cost more per unit than Blackwell chips because they're more advanced and more complex. But you need one-fourth as many, so the math still works out strongly in favor of lower total cost.

Inference at Scale: The Bigger Long-Term Opportunity
While training gets headlines, inference is the bigger economic opportunity long-term. Inference is the process of running a trained model to generate output. For large language models, that's processing user queries and generating responses.
Once a model is trained, it's trained. You do it once (or occasionally update it). But inference happens continuously. An API serving millions of user requests per day generates massive inference compute loads. That's recurring, ongoing, never-ending compute.
The economics are stark. If a company is running a large language model API that processes 10 million queries per day, the inference costs per year are enormous. Hundreds of millions of dollars. That's where the real money is, and that's where efficiency improvements create enormous value.
Vera Rubin's one-tenth cost improvement on inference would reduce that from hundreds of millions to tens of millions per year. That's a transformative change in the business model. It makes more types of AI applications economically viable. It makes existing applications much more profitable.
Claude (Anthropic), ChatGPT (OpenAI), and Google's Gemini are all constantly optimizing their inference infrastructure to reduce costs. Every 10% improvement in efficiency flows directly to bottom-line profitability or allows them to cut prices to gain market share.
Vera Rubin puts all these companies in a better position. It also creates opportunity for new entrants. If inference costs drop enough, you could build viable AI services that would have been uneconomical before. That increases competition, which is good for customers and bad for incumbents.
Energy Efficiency and Data Center Operations
Power consumption is underestimated as a factor in data center economics. People focus on chip speed and capacity. But power has three costs: electricity itself, cooling equipment to manage the heat, and physical space in the data center to house everything.
A high-power system in a dense configuration generates enormous amounts of heat. Cooling that heat requires significant infrastructure. In locations where electricity is expensive (California, Northern Europe), cooling costs dominate. In locations where electricity is cheap (Iceland, Norway), power draw is still a major cost.
Vera Rubin's improved efficiency reduces power draw, which cascades into savings across all three dimensions. Lower electricity costs, less cooling infrastructure required, more compute density per square foot.
For a company building or operating a data center, this matters enormously. It affects the feasibility of certain locations. It affects how many servers you can pack per rack. It affects the size and cost of the HVAC systems required.
Over the lifetime of a data center, which might be 5-10 years of operation, the cumulative impact is substantial. A system that uses one-tenth the power operates 40% less expensively when you factor in cooling, space, and overhead. That combines with the direct electricity cost savings to create the one-tenth total cost figure Nvidia is quoting.
This is also relevant to discussions about AI's environmental impact. Skeptics worry that training ever-larger language models will consume ever more electricity. If that's true, AI infrastructure could become a significant fraction of global electricity consumption. But Vera Rubin and similar efficiency improvements suggest the trend might bend. Yes, models are getting larger. But the hardware running them is getting more efficient. The net effect might be much smaller than feared.

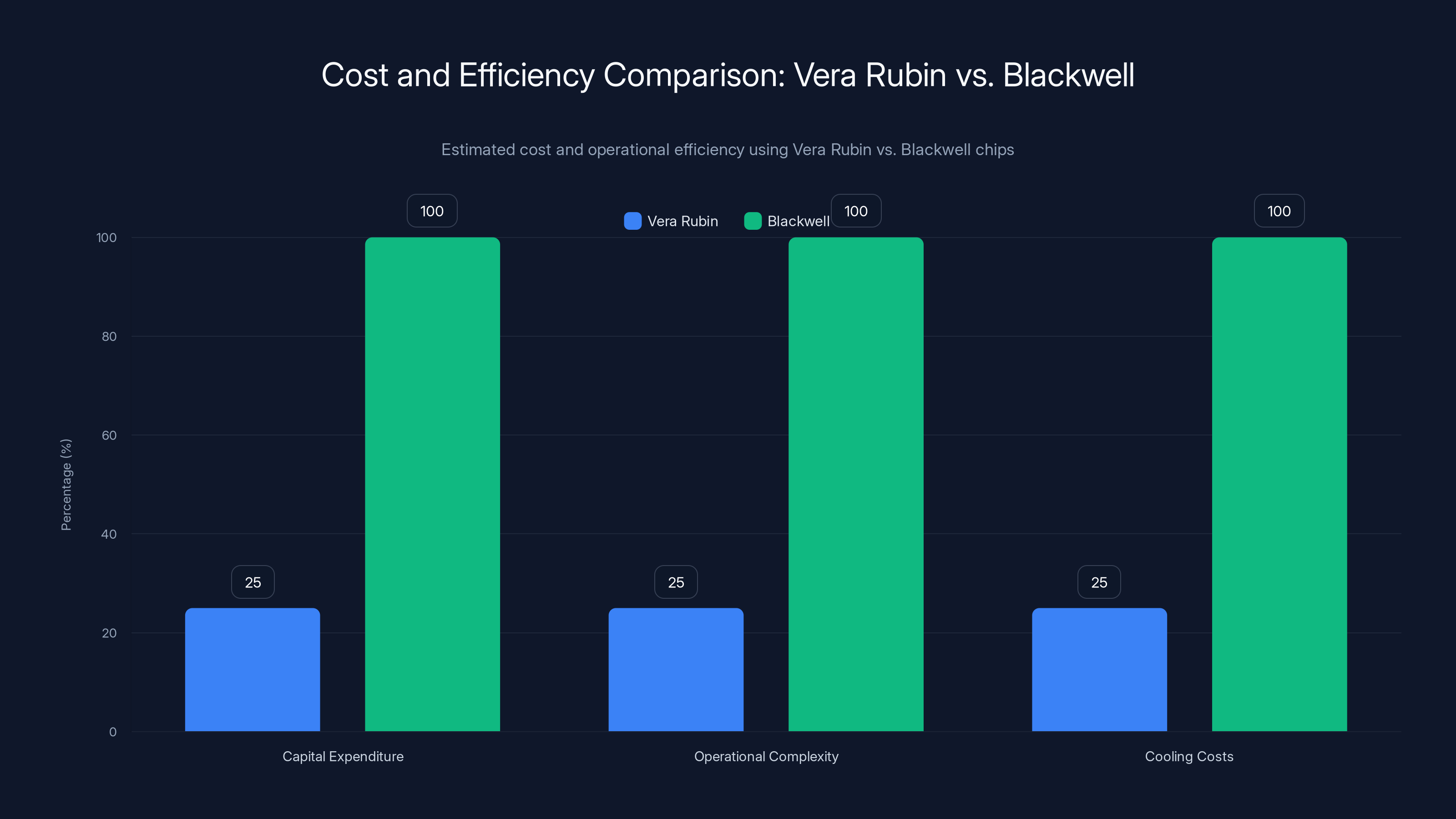
Using Vera Rubin chips can reduce capital expenditure, operational complexity, and cooling costs by 75% compared to Blackwell chips. Estimated data based on hardware usage reduction.
Timeline and When Customers Will See Real Impact
Understanding the timeline is important because it affects when cost improvements actually flow to customers.
Vera Rubin is in full production now (early 2025). Microsoft and CoreWeave will have systems online later this year (probably Q3-Q4 2025). But that doesn't mean every customer gets access immediately.
Initially, these systems will likely be reserved for the most important customers or applications. As supply increases and supply constraints ease, access expands. By 2026, Vera Rubin systems should be more broadly available in cloud offerings.
For customers buying AI services from cloud providers, expect 6-12 months of lag between Vera Rubin becoming available in cloud data centers and those cost improvements flowing to your service pricing. Cloud providers need time to shift workloads, validate performance, and update pricing. They also want to capture some of the efficiency gains as margin improvement.
For companies building their own infrastructure, the timeline depends on when they order, how long lead times are, and when their data centers come online. Companies that ordered early (like Microsoft) will have advantage. Companies ordering now might not get systems until late 2025 or early 2026.
For startups and smaller companies without their own infrastructure, the timeline is about when cloud providers offer Vera Rubin-powered services. If you're using OpenAI's API, you're benefiting from their infrastructure upgrades, but you don't directly control timing. If you're using Azure, you'll see Vera Rubin services become available as Microsoft rolls them out. That's probably starting to accelerate through 2025.
The key insight: don't expect immediate price drops or universally available Vera Rubin-powered services. This is a gradual rollout that will unfold over 12-18 months. But the trajectory is clear.
Broader Implications for AI Accessibility and Concentration
At a macro level, Vera Rubin's efficiency improvements affect the landscape of who can build and deploy AI systems.
Currently, advanced AI capabilities are concentrated among companies with massive resources: Google, Microsoft, OpenAI, Anthropic, Meta, and a handful of others. That concentration exists partly because training large models is phenomenally expensive. Accessing data and compute at scale requires capital.
Vera Rubin's cost reductions level the playing field slightly. A well-funded startup might now be able to train competitive models that would have been impossible before. A research institution or company with access to significant cloud credits becomes capable of serious research.
But concentration still matters. Even with Vera Rubin, training a state-of-the-art large language model costs millions. That's still prohibitive for most organizations. Concentration won't disappear. It might just include more players.
The bigger accessibility question is about inference and deployment. If inference costs drop enough, small companies, research groups, and individuals might be able to deploy language models. That's where Vera Rubin creates real democratization. Not everyone can train GPT-4. But with cheap inference, everyone could potentially run open-source models like Llama or Mistral.
That's genuinely transformative. It means more people building applications on top of AI. More diverse use cases. More innovation at the edges. Even if core research remains concentrated, the applications layer could become much more distributed.

Open Questions and Uncertainties
There's genuine uncertainty around several aspects of the Vera Rubin story.
First, can Nvidia actually achieve the cost claims at scale? The one-tenth cost and one-fourth hardware figures are impressive. But they're also cherry-picked for best-case scenarios. Some workloads might not see that level of improvement. Others might exceed it. The real-world average will probably fall somewhere in the middle.
Second, how quickly will supply meet demand? Nvidia is saying full production, but demand for cutting-edge AI accelerators exceeds supply. That gap might persist for months or quarters. That affects how quickly these efficiency gains flow to customers.
Third, what will custom silicon look like by the time it matures? OpenAI and other large companies are betting on custom silicon. If those bets pay off, it could significantly reduce Nvidia's addressable market. If they don't pan out, Nvidia's position strengthens.
Fourth, what about geopolitical constraints? TSMC is in Taiwan. Any disruption to Taiwan affects global semiconductor supply. That's not Nvidia's fault, but it's a real risk to the supply chain.
Fifth, how will competitors respond? AMD and Intel aren't sitting still. They're developing next-generation accelerators. Google is improving TPUs. By the time competitors launch, will they be close enough to Vera Rubin to offer meaningful alternatives? Or will the gap continue to widen?
These are open questions. The trajectory is clear, but the details are uncertain.
The Vera Rubin Ecosystem and Strategic Partnerships
Nvidia's strategy with Vera Rubin involves building an ecosystem of partners that make deployment easier. This is deliberate. A chip is only useful if people can actually use it effectively.
Red Hat is one example. Red Hat provides enterprise operating systems, containerization platforms, and management tools. Enterprises use Red Hat because it's well-supported and maintains compatibility with their existing systems. By certifying Red Hat on Vera Rubin, Nvidia makes it much easier for enterprises to adopt the new hardware. They don't have to learn new software. They can use familiar tools.
Similar partnerships are happening across the stack. Software vendors are optimizing for Vera Rubin. System integrators are designing reference architectures. Cloud providers are building Vera Rubin-native services.
This ecosystem approach is valuable because it reduces friction. Each partnership removes one obstacle to adoption. When everything is optimized together, adoption accelerates.
But it also creates lock-in. The more of your infrastructure is built on Nvidia hardware and software, the more expensive it becomes to switch to something else. That's good for Nvidia's long-term moat, but it's something customers should be aware of.

Looking Ahead: What Comes After Vera Rubin?
If Vera Rubin ships with full production starting now, what's the next generation? Nvidia doesn't announce far ahead, but we can infer from patterns.
The company typically refreshes major product lines every 2-3 years. Vera Rubin was announced in 2024 for delivery in the second half of 2026 (though it's arriving earlier). That suggests the next generation might be announced in late 2025 or early 2026, with delivery in 2027-2028.
Will the next generation follow the same pattern? Probably. Dramatic efficiency improvements, lower cost, new system components. At some point you hit physical limits (3-nanometer is already incredibly advanced), but there's runway for several more generations.
The competitive pressure is visible. AMD needs to accelerate their roadmap. Intel needs to actually achieve competitive 3-nanometer manufacturing. Startups are exploring novel architectures. But catching up to Nvidia's current pace seems difficult.
The most likely scenario is that Nvidia remains the dominant force in AI accelerators for at least the next 5 years. After that, custom silicon and alternative architectures might start carving out niches. But the incumbents face an uphill battle.
Practical Takeaways for Different Audiences
This announcement means different things for different people.
If you work for a cloud provider, Vera Rubin is a critical infrastructure decision. You need to decide how much of your AI capacity to allocate to Vera Rubin versus other options. Early adopters (Microsoft, CoreWeave) will have first-mover advantage. Waiting too long risks competitive disadvantage.
If you run an enterprise developing AI applications, Vera Rubin matters because it affects your hosting costs over the next 2-3 years. Track when your cloud provider of choice brings Vera Rubin online. When it does, migrate appropriate workloads. The cost savings will be meaningful.
If you're a startup building AI products, Vera Rubin's efficiency improvements improve your unit economics. This might be the difference between a viable product and an impossible one. Track availability and cost as key factors in your infrastructure planning.
If you're investing in the semiconductor industry, Nvidia's ability to maintain this pace of improvement is impressive and concerning for competitors. The company is extending its lead. Long-term betting against Nvidia in this space is difficult.
If you work in policy or environmental areas, Vera Rubin's efficiency improvements are relevant to discussions about AI's environmental impact. Efficiency improvements can offset the environmental cost of larger models and more widespread deployment.

FAQ
What exactly is Vera Rubin and how does it differ from Blackwell?
Vera Rubin is Nvidia's next-generation AI superchip platform consisting of six integrated components including the Rubin GPU, Vera CPU, advanced bandwidth memory, and sixth-generation interconnect technologies, all designed to work as a unified system. Unlike Blackwell, which is a single GPU, Vera Rubin is a complete integrated platform that reduces the cost of running AI models to approximately one-tenth of Blackwell's operating costs while requiring roughly one-fourth as many chips to train certain large language models.
When will Vera Rubin actually be available for customers to purchase?
Vera Rubin is entering full production now in early 2025, with Microsoft and CoreWeave expected to have systems online later in 2025. However, availability will be limited initially, with broader market availability expected throughout 2026. Lead times and supply constraints are likely to persist for several quarters, so immediate universal access shouldn't be expected.
How do the cost savings from Vera Rubin actually work in practice?
The cost reductions come from multiple sources: requiring fewer total chips to accomplish the same work (one-fourth the hardware), reduced power consumption (lowering electricity costs and cooling requirements), faster training times (enabling more iterations per calendar year), improved memory efficiency (reducing idle compute), and optimized software specifically designed for the Vera Rubin architecture. For a company currently spending
Why is Nvidia building an integrated platform instead of just making faster chips?
An integrated platform creates a strategic moat that's harder for competitors to displace. When compute, memory, networking, storage, and software are all optimized together, switching to alternative hardware requires rethinking every component. Additionally, integration allows Nvidia to optimize across the entire stack simultaneously, achieving efficiency improvements that would be impossible with individual components from different vendors. This platform approach also enables deeper partnerships with software companies and systems integrators.
What does this mean for custom silicon strategies like OpenAI's approach with Broadcom?
Custom silicon designed for specific companies' workloads offers tailored optimization unavailable with general-purpose hardware. However, developing custom silicon takes years and requires significant expertise and investment. Vera Rubin's dramatic efficiency improvements and integrated design narrow the economic advantage of custom silicon while being immediately available. Most large companies are hedging by pursuing both strategies: using Vera Rubin while developing long-term custom alternatives as a contingency.
How does Vera Rubin affect the concentration of AI capabilities among large companies?
While Vera Rubin's cost reductions make advanced AI more accessible, significant barriers remain. Training state-of-the-art models still requires millions of dollars in infrastructure and expertise. However, inference costs drop dramatically, which means smaller organizations might deploy existing models economically. This creates opportunity for more diverse applications and innovation at the deployment layer, even if model training remains concentrated among well-funded organizations.
What about supply constraints and manufacturing capacity?
Vera Rubin is manufactured exclusively by TSMC using their advanced 3-nanometer process. TSMC is the only manufacturer currently capable of producing 3-nanometer chips at the required scale and cost. This creates both advantages (proven manufacturing excellence) and risks (geopolitical exposure, capacity constraints). Nvidia has likely negotiated long-term supply agreements, but demand across the entire semiconductor industry may still create temporary supply constraints through 2025-2026.
How will cloud providers use Vera Rubin to offer services?
Cloud providers like Microsoft Azure will deploy Vera Rubin systems in data centers and offer Vera Rubin-powered AI services through their platforms. This might include specialized services for large language model training, inference APIs, or managed machine learning environments. Expect 6-12 months of lag between Vera Rubin arriving in data centers and those cost advantages flowing through to customer pricing, as providers validate performance, update infrastructure, and potentially capture some efficiency gains as margin improvements.
Key Takeaways
- Vera Rubin achieves dramatic cost reduction: One-tenth the operational cost and one-fourth the required hardware compared to Blackwell, fundamentally changing the economics of AI deployment
- Full production started in early 2025: Microsoft and CoreWeave already deploying, with broader availability expected throughout 2026
- Integrated platform strategy strengthens Nvidia's moat: By combining compute, memory, networking, and software, Nvidia creates a system harder to displace than individual components
- Timeline compression matters: Next-generation release cycles are accelerating, making it difficult for competitors to catch up
- Accessibility improves at the edges: While core model training remains concentrated, inference cost reductions democratize deployment of existing models
- Supply constraints likely to persist: TSMC's exclusive manufacturing role and high demand suggest limited availability through 2025-2026
- Custom silicon remains a long-term hedge: Large companies like OpenAI continue developing alternatives, but Vera Rubin's immediate advantages are substantial
- Environmental implications positive: Efficiency improvements help offset the environmental cost of increasingly large AI models
- Enterprise adoption will be gradual: Cloud provider rollout, ecosystem partnership maturation, and supply constraints mean real-world cost benefits phase in over 12-18 months

Related Articles
- Nvidia Rubin Chip Architecture: The Next AI Computing Frontier [2025]
- AI's Hype Problem and What CES 2026 Must Deliver [2025]
- AI Chatbots and Breaking News: Why Some Excel While Others Fail [2025]
- Nvidia in 2025: GPU Innovation, AI Dominance & RTX 5000 Debates [2025]
- The Highs and Lows of AI in 2025: What Actually Mattered [2025]
- SCX-LAVD: How Steam Deck's Linux Scheduler is Reshaping Data Centers [2025]

