![Anthropic Opus 4.6 Agent Teams: Multi-Agent AI Explained [2025]](https://tryrunable.com/blog/anthropic-opus-4-6-agent-teams-multi-agent-ai-explained-2025/image-1-1770315281166.png)
Anthropic Just Released Opus 4.6 With Agent Teams: Here's What Actually Changed
Anthropic released Opus 4.6 in February 2026, and it's not just another incremental model update. This one fundamentally changes how AI agents approach complex work. The headline feature? Agent teams. For the first time, instead of a single AI working through tasks sequentially, you can deploy multiple coordinated agents working in parallel on different pieces of the same problem.
If that sounds significant, it's because it is. This moves beyond the "single smart assistant" paradigm that's defined AI tools since Chat GPT launched. Think of it less like upgrading from GPT-4 to GPT-4.5, and more like going from one developer to a team of developers who can actually coordinate with each other.
The broader context matters here. Anthropic's been quietly becoming the serious enterprise player in AI. While OpenAI grabbed headlines with GPT-4 and the viral Chat GPT launch, Anthropic's been building something more methodical. Opus 4.5 came out in November 2025, and Opus 4.6 arriving just three months later signals something important: the company's moving fast on model capability, which usually means they've figured out architectural improvements that actually matter.
What makes Opus 4.6 different from its predecessors isn't just the agent teams feature. The model also ships with a million-token context window, native PowerPoint integration, and expanded capabilities for non-developer use cases. That last part is crucial. For months, the narrative around Claude Code and AI agents has been "it's amazing for software developers." Opus 4.6 is explicitly designed to change that story.
In this deep dive, we're going to break down what agent teams actually do, how they work, what they mean for enterprise AI adoption, and whether this is actually a game-changer or just polished marketing. We'll also explore the competitive landscape, the technical architecture behind multi-agent coordination, and what this signals about where AI is heading in 2026 and beyond.
TL; DR
- Agent Teams Are Real Multi-Agent Systems: Unlike sequential task processing, Opus 4.6 enables parallel agent coordination, with each agent handling distinct responsibilities and communicating directly with peers.
- 1 Million Token Context Window: Comparable to Sonnet, this enables processing of entire codebases, lengthy documents, and complex data structures in a single session.
- PowerPoint Integration Changes the Game: Direct Claude integration within PowerPoint, not just the ability to generate decks, fundamentally changes how knowledge workers interact with AI.
- Expanding Beyond Developer-Only Use Cases: Anthropic's explicitly positioning Opus 4.6 for product managers, financial analysts, and other knowledge workers, signaling a pivot from developer-centric to enterprise-wide appeal.
- Research Preview Status Matters: Agent teams are currently available only via API and research preview, meaning production stability and pricing models are still being determined.
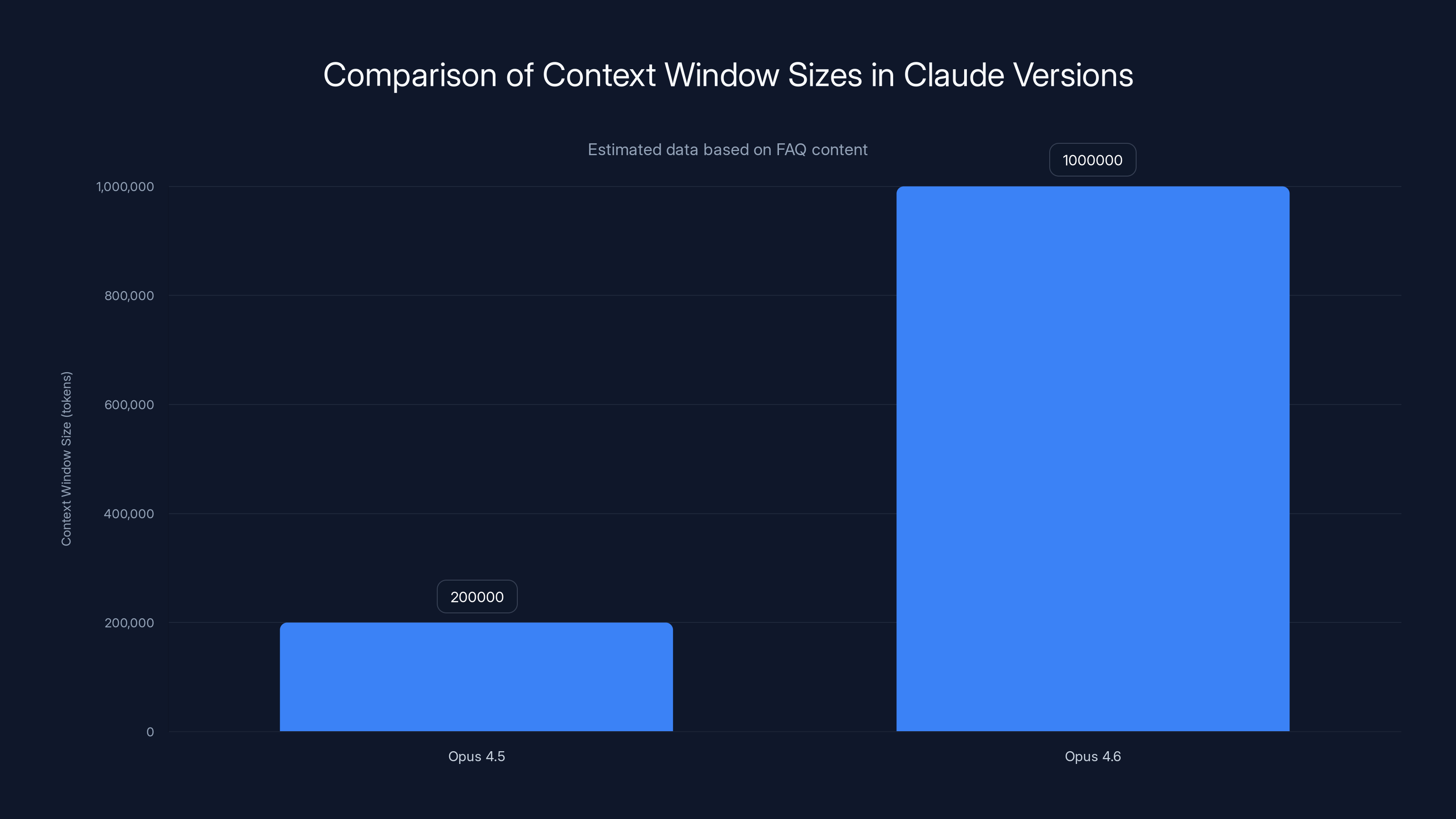
Opus 4.6 offers a significantly larger context window of one million tokens, compared to 200,000 tokens in Opus 4.5, allowing for more comprehensive data processing. Estimated data.
What Are Agent Teams and Why Do They Matter?
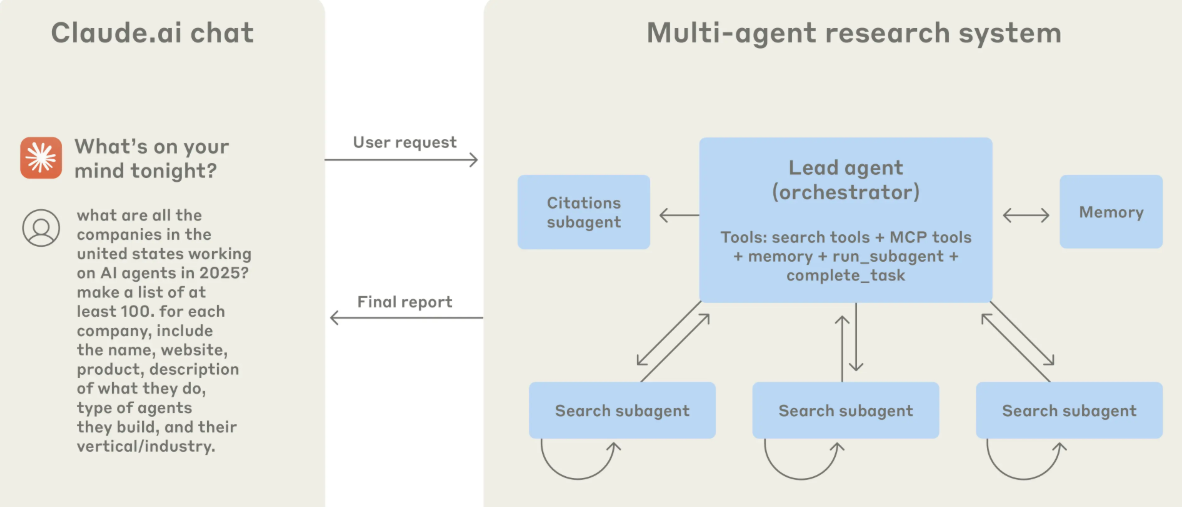
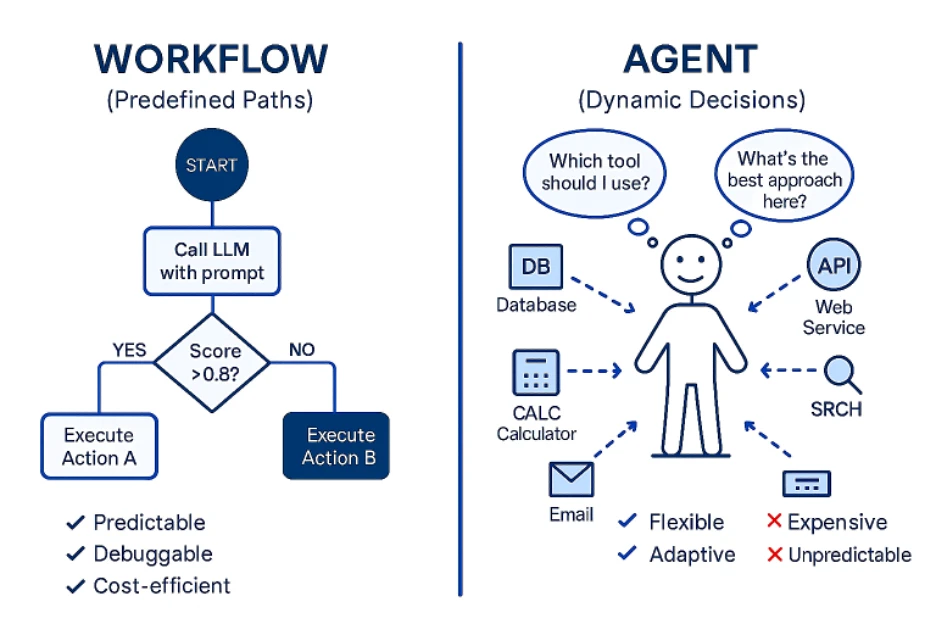
Agent teams represent a fundamental shift in how AI systems approach problem-solving. Instead of a single agent working through a task linearly (step 1, then step 2, then step 3), multiple agents operate simultaneously, each owning a specific piece of the larger puzzle and coordinating directly with their peers.
The technical distinction is important. Single-agent systems have been the dominant architecture since early GPT models. You ask Claude or GPT-4 to do something, the model processes it sequentially, and delivers the output. It's like having one very smart person handling every aspect of a project.
Agent teams flip that model. Imagine you're asking Claude to analyze a financial report that requires simultaneous data extraction, sentiment analysis, and risk assessment. With traditional sequential processing, the agent extracts data first, then analyzes sentiment, then assesses risk. Each step waits for the previous one to complete.
With agent teams, you could theoretically spin up three agents. Agent A extracts the relevant financial data. Agent B analyzes sentiment and tone. Agent C evaluates risk factors. All three work in parallel. When Agent A finishes, it doesn't wait for B and C. It immediately passes results to the coordination layer, which aggregates findings and passes relevant context to whichever agent needs it next.
This parallelization has massive implications. Complex tasks that required 30 sequential steps executed one after another could potentially be chunked into logical groups, executed in parallel, and then reassembled. The math on this is straightforward: if sequential processing takes time T, and you can partition work effectively into N parallel streams, theoretical execution time approaches T/N.
But here's where reality gets complicated. Agent coordination overhead, context passing between agents, and the complexity of decomposing tasks optimally all add friction. You don't get perfect linear speedups. The real-world gains depend entirely on task structure and how well the system can decompose problems.
Anthropic's positioning this as having "a talented team of humans working for you." That framing is useful but slightly misleading. Human teams are messy. They have personality conflicts, miscommunication, and varying expertise. The appeal of AI agent teams is the potential for perfect execution of coordinated tasks, assuming the decomposition and coordination logic is sound.
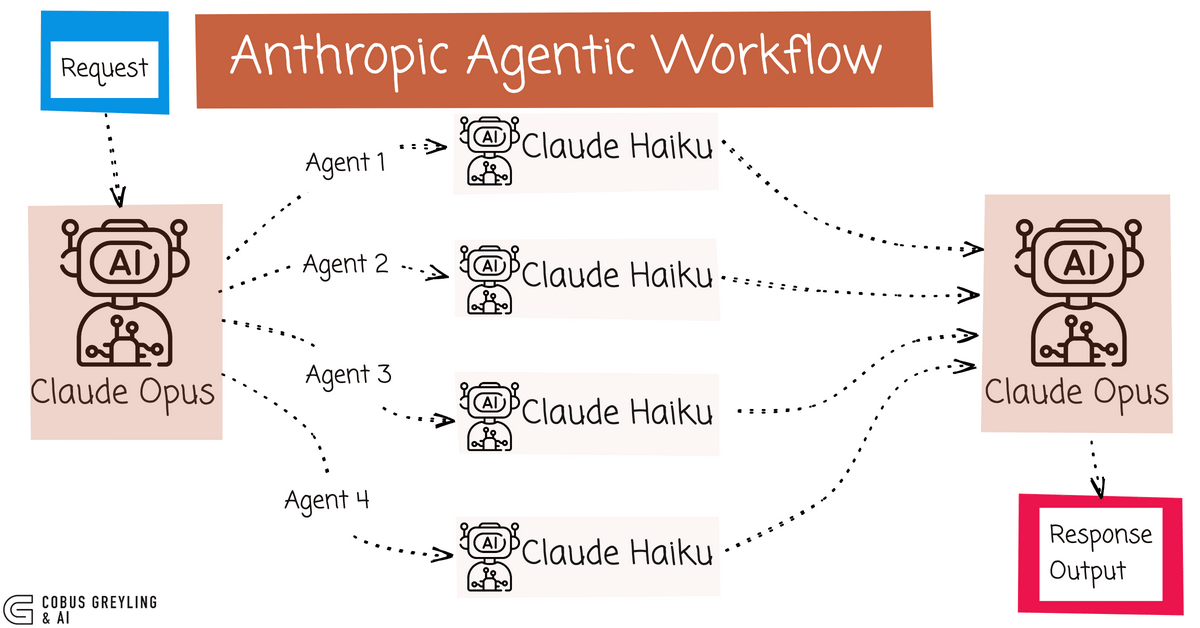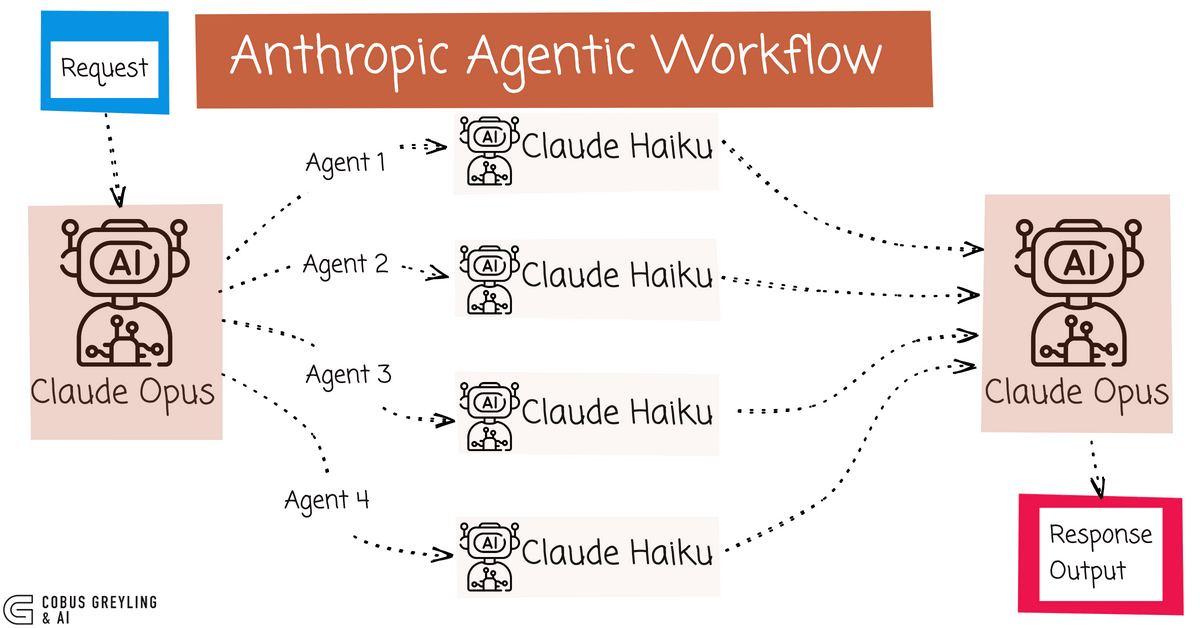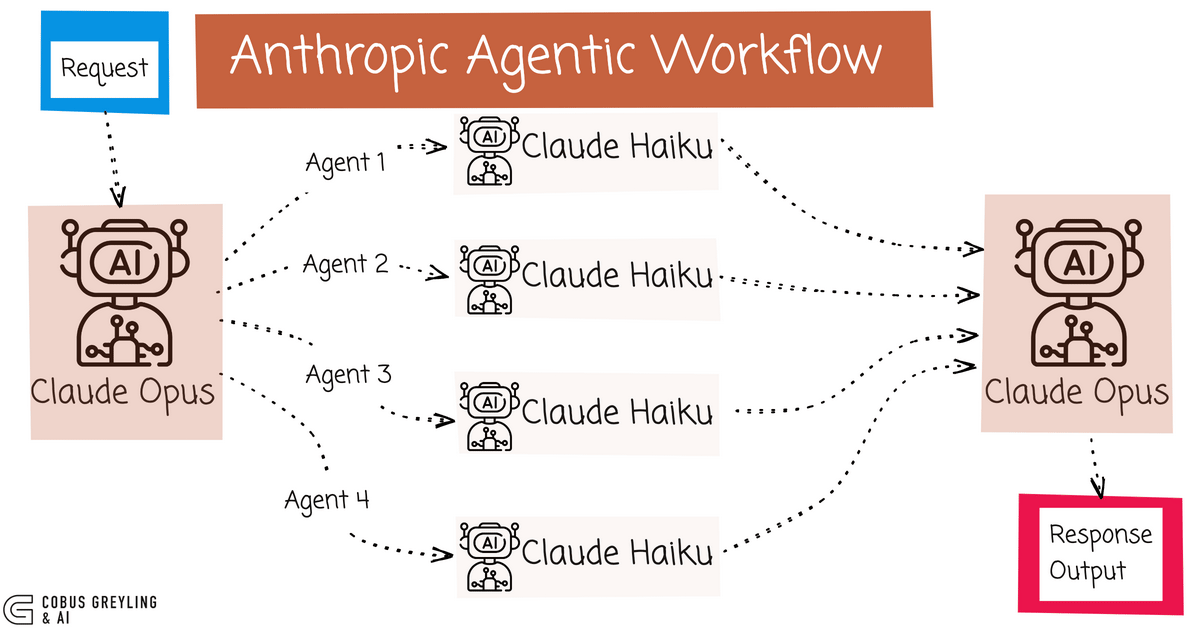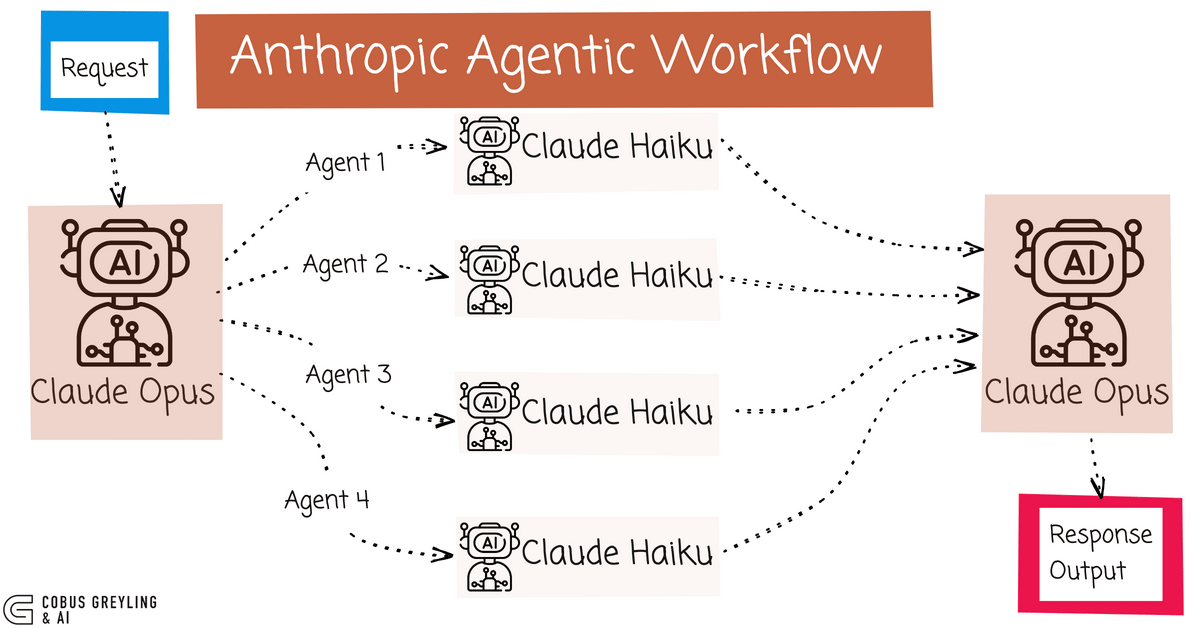
What makes Opus 4.6's implementation different from previous attempts at multi-agent systems (which existed in various forms in other platforms) is that it's baked into the model architecture itself, not layered on top. The agents are instances of Opus 4.6, coordinating through a native protocol, rather than external orchestration systems trying to wrangle multiple separate AI calls.
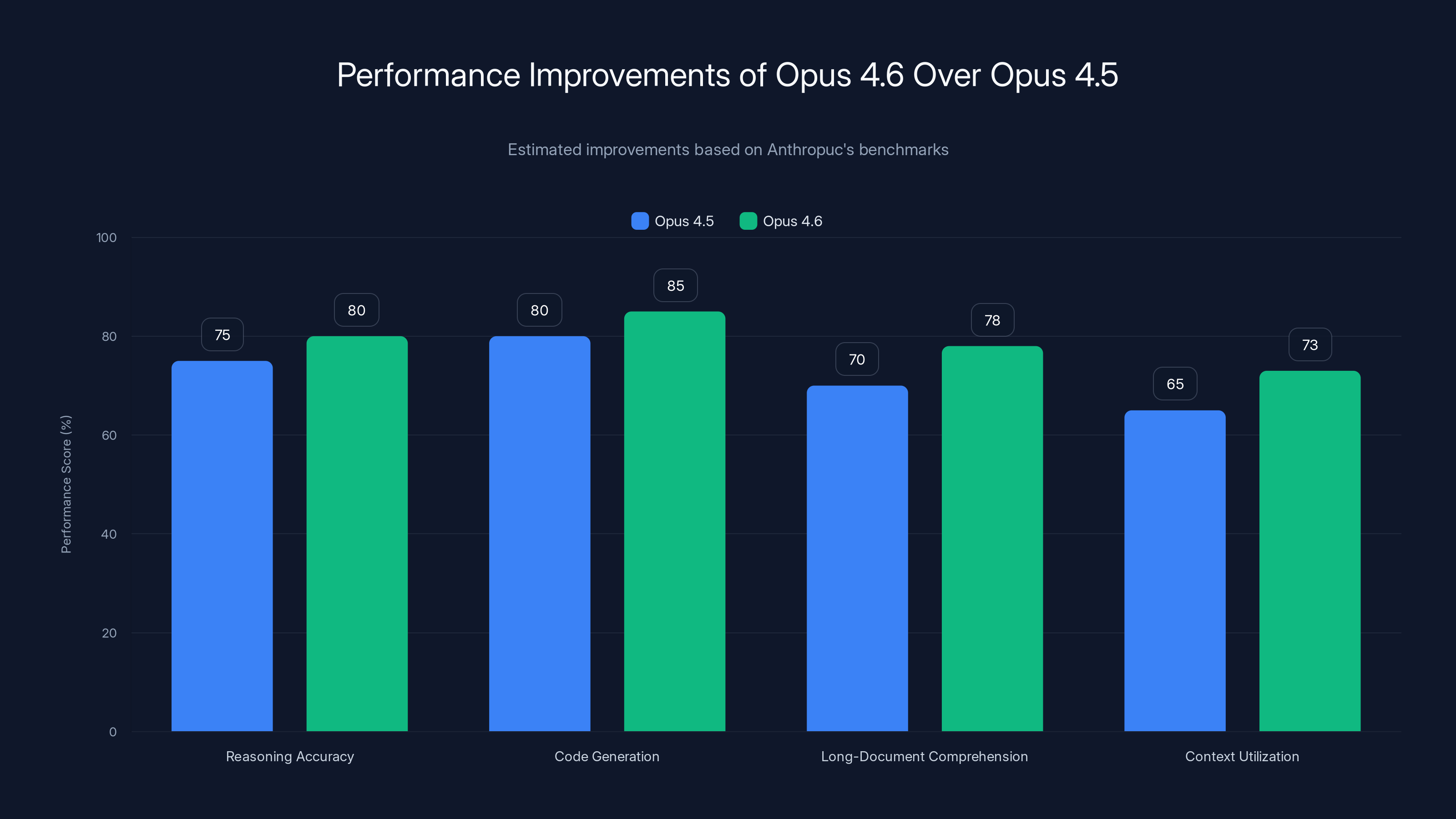
Opus 4.6 shows a 3-8% improvement across various benchmarks compared to Opus 4.5, with notable gains in long-document comprehension and context utilization. (Estimated data)
How Opus 4.6's Agent Teams Architecture Actually Works
Understanding agent teams requires getting into the mechanism a bit. Here's how it actually functions in practice.
When you spin up an agent team in Opus 4.6, you're not creating separate model instances. Instead, you're instantiating multiple logical agents within a coordinated framework. Each agent gets assigned a specific domain or responsibility. Think of these as different "contexts" or "perspectives" within the same model, rather than completely separate systems.
The coordination happens through what amounts to an internal message bus. When Agent A completes its work, it doesn't just dump results into a void. It publishes its findings to the coordination layer, which determines which other agents need this information and delivers it in a structured format.
Context passing is critical here. If Agent A extracts that "the quarterly revenue increased by 12% year-over-year," this needs to reach Agent C (assessing financial health) in a way that C can actually use it. This isn't just pasting text into a prompt. It's structured data transfer that the agent team framework understands and routes intelligently.
The token efficiency angle is worth highlighting. The million-token context window becomes crucial in multi-agent scenarios. With multiple agents potentially holding different perspectives on the same data, you need enough context space to maintain coherent state across all agents without constantly dropping information. A million tokens (roughly 750,000 words) gives you massive headroom.
Anthropic's also built-in what they call "direct coordination." This is the killer feature. Instead of agents working independently and then someone stitching results together, agents actively communicate with each other. If Agent B realizes it needs clarification on something Agent A found, it can request it directly, and Agent A can elaborate or refine its output based on the specific question.
This dynamic back-and-forth is what separates agent teams from simple task parallelization. It introduces something closer to actual collaboration. Agent B doesn't just read what Agent A wrote; it can engage with it, challenge it, and request refinement. This is computationally more expensive than static data passing, but it produces higher-quality results for complex tasks.
The research preview status is actually revealing here. Anthropic released agent teams as a research preview rather than a fully stable feature, which means they're still optimizing the coordination protocols, measuring real-world performance, and probably discovering edge cases where the architecture breaks down.
One practical implementation detail: agent team behavior is deterministic insofar as the underlying Opus model is deterministic, but the agent team orchestration layer adds its own variability. The order in which agents process information, the specific refinements they request from peers, and the final aggregation logic can produce different outputs given the same initial task. This is actually desirable for some use cases (better coverage of solution space) but problematic for others (reproducibility matters).
The Million-Token Context Window: What It Enables
Context window size is one of those metrics that sounds abstract but has profound practical implications. Opus 4.6 ships with a million-token context window, matching what Sonnet 4 and Sonnet 4.5 offer, but in a more capable model.
To ground this: a million tokens is approximately 750,000 words. To put that in scale, the entire United States Constitution is about 4,500 words. A typical novel runs 80,000 words. You could fit ten novels into Opus 4.6's context window with room to spare.
For developers, this is genuinely transformative. A large codebase might have 50,000 lines of code. Previously, you'd need to feed this to Claude in chunks, getting guidance on piece A, then piece B, then piece C, with the model losing overall context between chunks. With a million tokens, you feed the entire codebase at once. Claude (or more accurately, agent teams working on the codebase) understand the holistic structure, dependencies, and architectural patterns across the entire system.
Consider a realistic scenario: you're refactoring a monolithic Python backend. The codebase is 40,000 lines. With a 200,000-token context (older Claude versions), you'd fit maybe 20,000 lines. With 1 million tokens, you fit the entire thing plus 250,000 tokens of additional context for documentation, specifications, and design decisions.
The practical gain is enormous. Refactoring decisions that previously required the developer to manually provide context ("this database schema is used by these three services") are now automatically visible to Claude because it can see the entire system.
For non-developer use cases, the implications are equally significant. Financial analysts processing regulatory filings face the opposite problem: the documents are huge. A typical 10-K SEC filing runs 150-200 pages, or roughly 50,000-60,000 words. Previous Claude versions struggled with these. You'd need to extract the sections you cared about first, then ask questions. With a million-token context, you paste the entire 10-K and ask questions about any aspect without pre-processing.
Copy-pasting isn't the only way context gets filled, either. Through API calls, you can structure requests to include:
- Full source code files
- Complete conversation histories
- Research documents and papers
- Database schemas
- Project specifications
- Compliance documents
- Financial data
- Customer feedback records
The mathematical relationship is worth understanding. If a task previously required N API calls to handle the full context (because you kept hitting context limits), each call introducing latency and re-explaining context, reducing this to a single API call is a massive efficiency gain. It's not just faster; it's more coherent because the model maintains end-to-end understanding.
There are limits, though. Humans don't actually read a million tokens of context effectively. There's something called "lost in the middle" problem, where models are slightly less likely to use information that appears in the middle of a very long context window. It's not dramatic (models are better at this than humans), but it's measurable. Anthropic's addressed this somewhat in recent models, but it's a real consideration when you're trying to cram enormous documents.
Latency also increases with larger context. Processing a million tokens is computationally more expensive than processing 100,000. You'll see slower response times for queries with very large contexts. For agent teams specifically, this matters because multiple agents might all be reading from the same large context simultaneously, compounding the computational load.
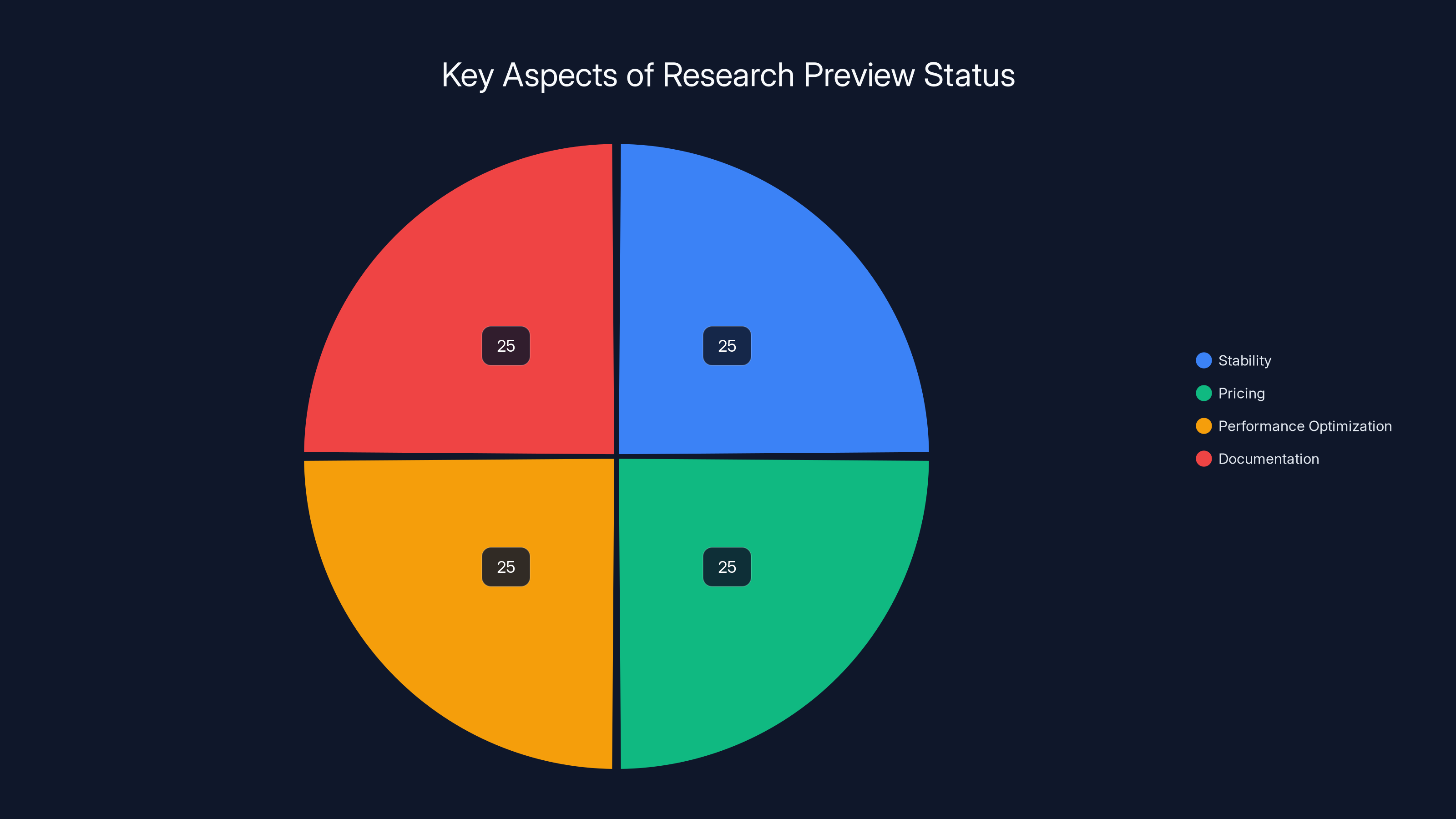
The 'Research Preview' status highlights equal importance across stability, pricing, performance optimization, and documentation aspects. Estimated data.
PowerPoint Integration: The Knowledge Worker Play
PowerPoint integration is the feature that signals Anthropic's strategic shift most clearly.
Previously, Claude could generate PowerPoint files. You'd tell Claude "create a presentation about Q1 2026 financial results," and it would output a .pptx file. You'd download it, open it in PowerPoint, edit it, format it, probably curse at some formatting weirdness, and ship it.
With Opus 4.6, Claude is embedded directly in PowerPoint as a sidebar. You're building the presentation natively in PowerPoint. You can request Claude's help without ever leaving the application. Want to reframe a slide? Ask Claude. Need data analysis for a specific claim? Claude's right there. Want alternative wording for a title? No copy-paste dance. Just ask.
This is a seemingly small shift with massive implications for adoption. The friction of moving between applications drops to zero. Knowledge workers who spend their days in PowerPoint (which is, frankly, most of corporate America) now have AI assistance right there.
The experience design matters enormously here. A sidebar interface is fundamentally different from "generate a file." With a sidebar, you're in a conversation. You can iterate rapidly. Claude sees what you're working on and can make contextual suggestions. This is closer to having a colleague in the room than it is to using a separate tool.
Anthropic's Head of Product, Scott White, emphasized that this represents evolution from Claude as a tool you use separately to Claude as something embedded in your existing workflow. The psychological shift is real. When something is in your workflow, you use it more. When it's a separate tool, it's friction.
For product managers specifically, this is huge. Building a pitch deck, investor presentation, or product roadmap now involves real-time access to Claude's reasoning. A PM can flesh out a strategic hypothesis, ask Claude to identify potential flaws, iterate, and ship a stronger presentation without context-switching.
The technical implementation is interesting too. PowerPoint integration isn't just API calls being made while you work. The sidebar needs to understand the current presentation state, the specific slide you're editing, the content currently present, and any previous requests in that session. This requires structured data passing between PowerPoint and Claude's API, maintaining session state, and managing potential conflicts (what if Claude suggests something that conflicts with what's already on the slide?).
There's also the versioning and compatibility question. PowerPoint exists on desktop, web, and mobile. The Opus 4.6 integration presumably started with one platform. Over time, it'll likely expand. But for early adopters, knowing which platforms support it matters.

Expanding Beyond Developers: The Knowledge Worker Pivot
Anthropic has made an explicit strategic choice with Opus 4.6: move beyond developers.
Claude's origin story was developer-centric. Claude Code and the ability to write and execute code were the killer features. Software engineers adopted Claude enthusiastically. That's a valuable market, but it's limited. There are roughly 27 million software developers globally. There are roughly 600 million knowledge workers globally (anyone doing information work, analysis, writing, strategy).
The math is obvious. The developer market is large, but the knowledge worker market is 20x larger.
Anthropic's been paying attention to which non-developers use Claude Code and why. Product managers use it to analyze user data and build dashboards. Financial analysts use it to parse documents and run statistical models. Researchers use it to process datasets. Marketing teams use it to analyze campaign performance.
They're not using Claude Code because they want to become developers. They're using it because Claude Code is phenomenally good at certain types of analytical work, regardless of whether it involves actual software development.
Opus 4.6 is explicitly designed for this audience. The PowerPoint integration is for them. The expanded context window helps with document-heavy analysis. The agent teams feature enables parallel analysis of complex problems (run financial analysis on this quarter's data while simultaneously running market sentiment analysis).
Scott White's comments about this pivot are worth dissecting: "We noticed a lot of people who are not professional software developers using Claude Code simply because it was a really amazing engine to do tasks."
That's the insight. Claude Code isn't inherently about code. It's about systematic task execution. That happens to map onto software development, but it maps onto lots of other domains too.
Financial analysts need to extract, transform, and analyze data. Claude Code does that. Product managers need to parse user feedback, identify themes, and quantify sentiment. Claude Code does that. Researchers need to process datasets, run statistical tests, and generate visualizations. Claude Code does that.
Anthropic's realized that the feature isn't "code execution." The feature is "structured task execution with access to computing." Once you realize that, integrating it into tools that knowledge workers already use (PowerPoint, presumably Excel, Google Sheets next) becomes the obvious move.
This also explains the emphasis on context windows and agent teams. Knowledge workers deal with complex, multi-faceted problems that benefit from parallel analysis. A financial analyst looking at quarterly results needs simultaneous analysis of revenue trends, cost dynamics, market sentiment, and competitive positioning. Agent teams handle that elegantly.
The risk for Anthropic is execution. Developer adoption came somewhat naturally because developers are comfortable with APIs and willing to iterate on integration. Knowledge workers, especially in larger enterprises, are less tolerant of friction. If the PowerPoint integration has bugs or feels slow, adoption will suffer. But if it's polished and fast, it could be genuinely transformative.
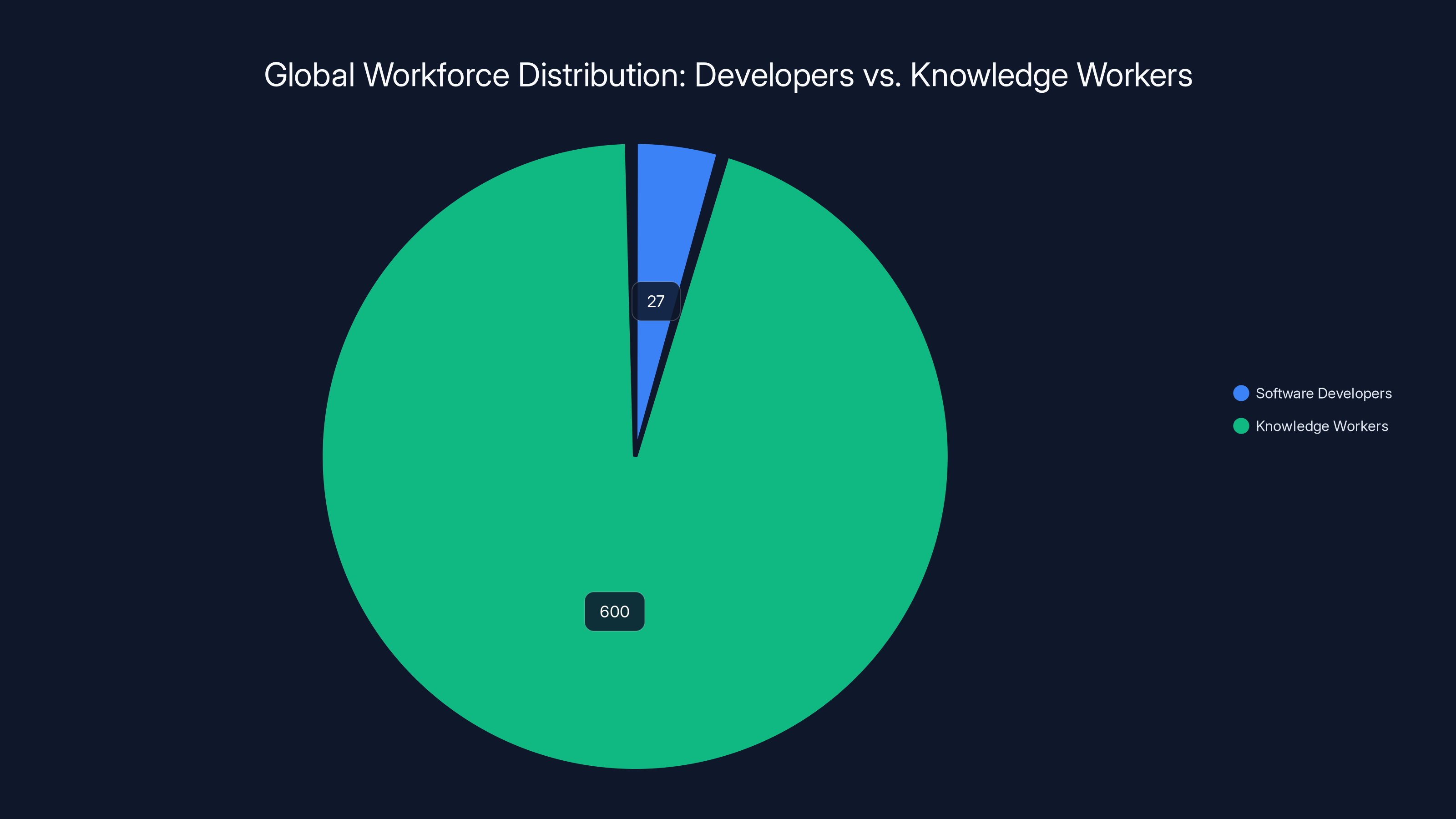
The knowledge worker market is approximately 20 times larger than the software developer market, highlighting the potential for tools like Claude Code to expand beyond traditional developer use cases. Estimated data.
Research Preview Status and What It Actually Means
Agent teams are currently available in "research preview" for API users and subscribers. This language choice is significant and worth unpacking.
"Research preview" means Anthropic is making the feature available for testing and feedback before declaring it production-ready. It's not beta (which typically implies a feature is feature-complete but might have bugs). Research preview explicitly signals that the feature is still being studied, optimized, and potentially changed based on feedback.
Practically, this means:
Stability is not guaranteed. The behavior of agent teams might change between API versions. Code you write against agent teams today might need modification as the feature evolves. If you're building critical business logic on agent teams, there's risk.
Pricing is uncertain. Anthropic hasn't announced final pricing for agent teams. They might be included in standard Claude pricing, or they might incur additional costs (multi-agent orchestration is computationally more expensive). Early adopters are essentially test pilots; they might get favorable pricing or grandfathered rates, but that's speculative.
Performance optimization is ongoing. The agent coordination protocols are likely being tuned based on real-world usage patterns. Early usage teaches Anthropic where the architecture bottlenecks appear and how to optimize. Later versions will probably be faster.
Documentation and best practices are still being developed. When features are fully released, documentation is usually comprehensive. Research preview documentation tends to be sparse. You're partly figuring out best practices yourself and reporting back what you learn.
The research preview status also signals something important about Anthropic's philosophy. They're shipping incomplete features to get real-world feedback rather than endlessly perfecting features in private. This is a more iterative approach than, say, OpenAI's strategy (which tends toward longer development cycles before release).
For enterprises, research preview features are typically off-limits until they reach general availability. If you're evaluating Opus 4.6 for production use, agent teams probably aren't viable yet. Standard Opus 4.6 capabilities (increased context window, model performance improvements, PowerPoint integration if it's stable) are safe bets. Agent teams are for early adopters willing to tolerate instability in exchange for being ahead of the curve.
Historically, how long do features stay in research preview? It varies. Some features graduate to general availability in weeks. Others take months. Claude's web interface was research preview for a while. Code Interpreter (Claude's code execution) was in preview for extended periods. There's no fixed timeline.
The Competitive Landscape: Where Does Opus 4.6 Stand?
Anthropic isn't the only player in multi-agent systems. To understand what Opus 4.6 actually represents, you need context on what competitors are doing.
OpenAI has been more cautious about shipping agent features. GPT-4 and GPT-4.5 don't have native multi-agent support. However, OpenAI's partners and the broader ecosystem have built multi-agent systems on top of GPT models. The approach is different: rather than baking agent coordination into the model, you orchestrate multiple GPT API calls externally.
Google DeepMind's Gemini models have been in competition with Claude, and recent updates added capabilities for handling longer contexts and better reasoning. But like OpenAI, Google hasn't prioritized native multi-agent features.
Mistral and other open-source model providers have published research on multi-agent systems, but there's a difference between research and production-grade features in a commercial API.
In the multi-agent orchestration space, companies like Zapier and Make have been enabling workflow automation by connecting different AI models and services. But these are external orchestration layers, not features of the models themselves.
Anthropic's choice to bake agent coordination into Opus 4.6 is architecturally different. It's saying: "The model itself understands multi-agent patterns and can handle the coordination." This is architecturally cleaner and likely more efficient than external orchestration.
The context window race is also worth noting. Anthropic with its million-token window is now competitive with what OpenAI offers in GPT-4 Turbo (128,000 tokens) and approaching what specialized models like Claude's previous editions achieved. But context window alone doesn't determine model quality. Opus 4.6 needs to actually use that context effectively, which ties back to how well the model understands nuance and relevance in large documents.
The PowerPoint integration signals a broader shift in how AI companies are approaching market penetration. Rather than competing purely on model capability, they're embedding themselves into existing tools that people already use. This is a smart move. It lowers the barrier to adoption.
Microsoft's Copilot has been doing this across Office products (Word, Excel, PowerPoint, etc.), though powered by OpenAI's models. Anthropic's integration is a response to that strategy. It says: "Microsoft can embed GPT in Office, but we can embed Claude too, and do it arguably better because Claude was already designed for this type of task."
Looking ahead, the winner in AI adoption is probably the company that most seamlessly integrates into existing workflows. Raw model capability matters, but so does friction. If Claude is already in PowerPoint, Excel, Gmail, and Slack, people will use it more than if it's a separate website.
Anthropic's playing a smarter game here than just iterating on model size and capability. They're building a distribution strategy.
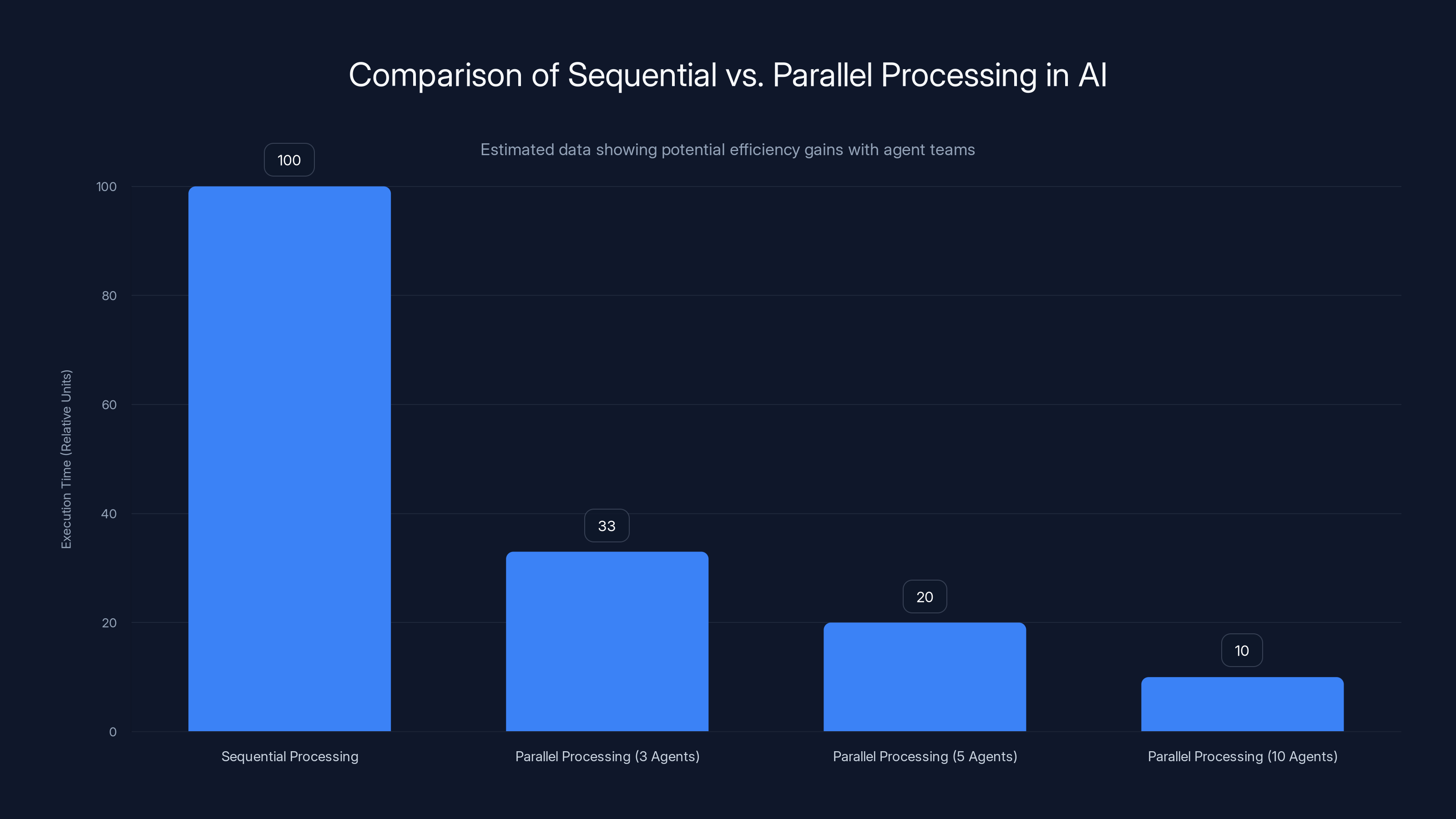
Estimated data shows that parallel processing with agent teams can significantly reduce execution time compared to traditional sequential processing, though real-world gains may vary due to coordination overhead.
Technical Deep Dive: Context Windows and Token Efficiency
The million-token context window deserves deeper technical analysis because it's where the rubber meets the road on practical capability.
Tokens are how language models break down text. A rough estimate is that one token is about 0.75 words in English. So a million tokens is roughly 750,000 words. But this varies based on the specific tokenizer. Special characters, code, and non-English text might tokenize differently.
For context window, what matters is how efficiently you can use it. Having a million tokens available is pointless if the model doesn't effectively leverage information throughout the window.
This is where the "lost in the middle" phenomenon comes in. Studies have shown that transformer-based language models sometimes struggle to utilize information in the middle of very long context windows as effectively as information at the start or end. This is less pronounced in modern models than it was in earlier versions, but it's still present.
Anthropic has likely implemented techniques to mitigate this. Possible approaches include:
- Architectural modifications to how attention is computed over long sequences
- Training techniques that specifically optimize for information retrieval across long documents
- Position-weighted embeddings that help the model recognize relevant information regardless of position
For users, the practical implication is this: you can definitely stuff a million tokens of context into Opus 4.6 and expect it to work. But you'll get better results if you organize that context thoughtfully. Put the most critical information first or last. Use clear structural markers (headings, sections, delimiters) to help the model navigate. Summarize large sections if possible.
Another consideration is inference cost. Processing longer contexts is computationally more expensive. OpenAI's pricing for GPT-4 Turbo, for example, charges more per token for context than for generated text. Anthropic might adopt a similar pricing model for Opus 4.6. Early adopters in research preview might not see this cost difference, but expect it to show up in production pricing.
There's also the question of how context interacts with agent teams. If you have a million-token context and multiple agents, how is that context distributed? Do all agents see the entire context, or does the coordination layer intelligently route relevant portions to each agent? The former is simpler but computationally expensive. The latter is smarter but requires more sophisticated orchestration.
Anthropic hasn't disclosed these details, which suggests they're still optimizing. The research preview status makes sense: they're probably experimenting with different approaches and gathering data on which works best.

Real-World Use Cases and Scenarios
Let's ground this in concrete scenarios where Opus 4.6 creates immediate value.
Scenario 1: Financial Analysis
A financial analyst needs to assess quarterly results. Previously, she'd download the 10-K filing, extract relevant sections (maybe 50-100 pages of useful information), load it into Claude through multiple API calls, and ask questions about specific metrics.
With Opus 4.6 and a million-token context, she pastes the entire 10-K (all 150 pages) plus supplementary materials, and asks: "Across revenue, cost structure, market positioning, and regulatory environment, what are the three biggest risks to next quarter's guidance?"
Claude processes everything holistically. It doesn't need her to have pre-extracted sections. It sees the complete picture and synthesizes risks based on interconnected information across the document.
With agent teams, she could request parallel analysis: Agent A assesses financial risk, Agent B evaluates competitive positioning, Agent C reviews regulatory exposure. All happen simultaneously. The coordination layer stitches together findings. Time to insight drops substantially.
Scenario 2: Code Refactoring
A developer has a 40,000-line Python monolith. She needs to extract a specific service into a microservice.
Previously, she'd upload the codebase in chunks, manually specifying which modules are related, what the API boundaries should be. The AI could only see a portion of the system at a time.
With Opus 4.6, the entire codebase fits in context. The model sees all dependencies, all module interactions, all database schemas. She can ask: "This authentication service is currently embedded in the main app. Extract it into a standalone microservice, create the necessary API contracts, and show me the migration path."
The model sees the entire dependency graph and can generate a coherent, complete refactoring plan.
Scenario 3: Content Creation and Editing
A content marketer is building a case study. She's pulled together customer interviews (20 pages), product metrics (10 pages), and competitor research (15 pages).
With the PowerPoint integration, she starts building the deck in PowerPoint. For each slide, she can ask Claude to synthesize relevant information: "Based on all the customer interview data, what was their biggest pain point?"
Claude doesn't need her to copy-paste the relevant quote. It already has all the interview data in context (thanks to the million-token window) and can identify the most compelling evidence to support her narrative.
Scenario 4: Product Management and Data Analysis
A product manager has four quarters of user behavior data, customer feedback from support, and competitive intelligence. She needs to identify the top three feature opportunities for the next roadmap.
With agent teams, she could request parallel analysis: Agent A analyzes user behavior trends, Agent B synthesizes customer pain points from support data, Agent C evaluates competitive positioning. They coordinate, cross-reference findings, and surface correlated signals that emerge only when you analyze all three data sources simultaneously.
These scenarios show why Opus 4.6 matters. It's not that Claude suddenly became smart enough to do new things. It's that the friction dropped, the context expanded, and the coordination capability improved. Each change independently useful; together, they're transformative.

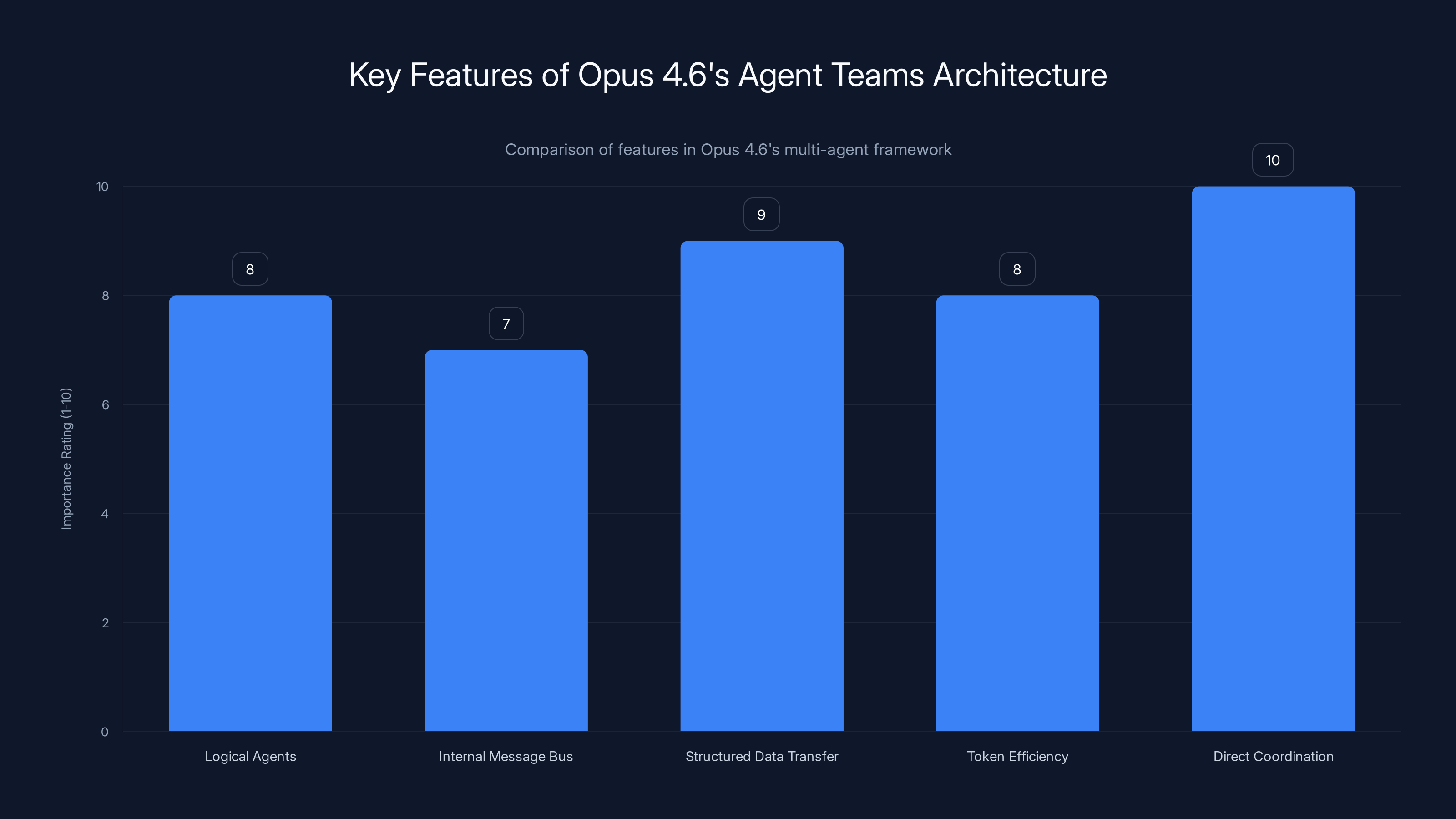
Opus 4.6's architecture excels in direct coordination and structured data transfer, enhancing multi-agent efficiency. Estimated data.
Performance Metrics and Benchmarks
How does Opus 4.6 actually perform? Anthropic released a technical report with benchmarks, and it's worth understanding what they measured.
On standard LLM benchmarks (reasoning tasks, code generation, factual recall), Opus 4.6 shows improvements over Opus 4.5. The magnitude varies by benchmark, but expect improvements in the 3-8% range on average. These aren't huge jumps, which is typical as models get more advanced (the easy gains are behind us).
Where Opus 4.6 shows bigger improvements is on tasks that benefit from longer context and multi-agent coordination. For tasks requiring synthesis across large documents, the million-token window provides measurable advantages. For tasks that naturally decompose into sub-problems, agent teams show gains.
The specific metrics Anthropic published include:
- Reasoning accuracy: Improvement on complex multi-step reasoning tasks
- Code generation: Quality and correctness on coding benchmarks
- Long-document comprehension: Accuracy on questions about documents that require understanding across multiple sections
- Context utilization: How effectively the model uses information throughout the context window
Note what's not benchmarked: speed of agent team coordination, real-world latency, cost efficiency. These metrics matter for production use but are harder to measure and publish. Expect Anthropic to continue optimizing these as agent teams mature.
Another important note: benchmarks measure specific capabilities, not real-world value. A 5% improvement in a reasoning benchmark might translate to 30% improvement on a specific real-world task if that task maps well to what the benchmark measures. Conversely, a 10% benchmark improvement might provide minimal real-world value if the task has different requirements.
When evaluating Opus 4.6 for your use case, run your own evaluation on tasks that matter to you. Benchmark improvements are useful as a signal, but they're not a substitute for testing on actual problems.
Pricing, Availability, and Adoption Timeline
Here's what Anthropic has said about Opus 4.6 pricing and availability:
Current status: Opus 4.6 is available via API for subscribers and through Claude.ai web interface. Agent teams are in research preview.
Pricing: Anthropic hasn't announced specific pricing for Opus 4.6 separately from previous Opus versions. They typically tier pricing by model (Opus costs more than Sonnet, which costs more than Haiku). Within a model tier, pricing might differ based on input vs. output tokens.
For agent teams specifically, there's uncertainty. They might be included in standard pricing, priced as a separate feature, or subject to usage-based pricing (since multi-agent coordination likely costs more computationally). Early research preview users will probably get access without additional cost, but don't assume this continues into general availability.
Availability timeline: Opus 4.6 is available now. Agent teams are research preview now, with no announced graduation date to general availability. Historically, Anthropic's research preview features take anywhere from a few weeks to several months to stabilize.
Adoption barriers: For individual developers and small teams, adoption is straightforward. API access, good documentation (once it's written), and relatively low cost of experimentation makes testing easy.
For enterprises, adoption barriers are higher. Security reviews of API integrations take time. Procurement needs to negotiate contracts. Technical teams need to evaluate whether the new features align with their infrastructure. Expect enterprise adoption to lag technical availability by 6-12 months.
Anthropic is aware of this. The PowerPoint integration for Office 365 is a signal that they're taking enterprise distribution seriously. Once the feature is available through Microsoft's app store and integrated with enterprise SSO, adoption will accelerate.

Integration Patterns and Developer Experience
For developers actually building on Opus 4.6, the integration experience varies by use case.
API-based integration: If you're calling Opus 4.6 through the API, the developer experience is similar to calling previous Claude versions. You send a prompt, get a response. The million-token context is transparent; you just include more in your prompt. Agent teams require a different API pattern (likely specifying agent roles, coordination strategy, etc.), but Anthropic will abstract this with SDKs.
PowerPoint integration: The sidebar-based integration handles API calls and state management behind the scenes. Developers extending this integration (if Anthropic exposes extension points) will work through PowerPoint's add-in API.
Third-party orchestration: If you're using platforms like Zapier, Make, or Lang Chain to orchestrate Claude, those platforms will add Opus 4.6 support as Anthropic opens access. Integration experience depends on how quickly those platforms update their Claude integrations.
Open-source frameworks: Tools like Llama Index, Lang Chain, and others that abstract away model-specific details will add Opus 4.6 support. Early-stage support might miss new features (like agent teams), but core functionality will be available quickly.
The common pattern is this: core API support lands first. Within weeks or months, third-party integrations catch up. By the time features reach general availability, there are multiple ways to use them.
Challenges and Limitations
Opus 4.6 solves real problems, but it doesn't solve everything. Understanding the limitations is as important as understanding the capabilities.
Agent team complexity: Multi-agent systems introduce complexity. Task decomposition requires thoughtful design. Poorly decomposed tasks can result in agents working at cross purposes or producing inconsistent results. There's definitely a learning curve.
Context window limitations: While a million tokens is huge, there are domains where even that's not enough. Processing an entire year of financial transactions, or a massive scientific dataset, still exceeds the context window. And longer context means slower inference. There's a trade-off.
Lost in the middle: Despite improvements, models are still slightly less effective at using information in the middle of very long contexts. Carefully structuring your context helps, but it's an extra step.
Reasoning failures: Larger context windows don't eliminate reasoning errors. Claude (and all LLMs) can still make logical mistakes, misinterpret ambiguous instructions, or miss subtle implications. Context size doesn't fix reasoning capability.
Coordination overhead: Agent teams add computational overhead. The coordination layer, inter-agent communication, and synthesis all cost compute. For simple tasks, single-agent processing might be faster and cheaper.
Research preview instability: Agent teams are unfinished. Behavior might change between updates. Documentation is sparse. You're exploring territory without a map.
Cost unpredictability: Without announced pricing for agent teams and longer context, it's hard to predict total cost of use. You might discover that your agent team approach costs 10x more than you expected once pricing is public.
The Enterprise Implication: Is This Actually a Game Changer?
Let's step back from the features and ask the bigger question: does Opus 4.6 actually change the game for enterprises?
Partially, yes. But with caveats.
For knowledge work that's currently manual or semi-automated, Opus 4.6 provides new leverage. A financial analyst who spends 20 hours a week on data extraction, synthesis, and reporting can automate significant portions of that with Opus 4.6's capabilities. The agent team feature enables parallel analysis that previously required orchestrating multiple analyses manually.
For developers, the expanded context window is immediately valuable. The agent team feature is interesting for complex system design, but useful application patterns are still being discovered.
What Opus 4.6 probably doesn't change: the fundamental challenge of integrating AI into enterprise workflows. You still need to:
- Design prompts and task decomposition carefully
- Validate outputs and build review processes
- Handle edge cases and exceptions
- Integrate with existing data sources and systems
- Manage costs and monitor usage
These are organizational and operational challenges, not technical problems that feature releases solve.
The companies that will see the most value from Opus 4.6 are those that:
- Have well-structured data and documents
- Have clear, repetitive knowledge work processes
- Are willing to iterate on automation approaches
- Have security and compliance frameworks that can accommodate AI tool integration
- Have internal AI expertise or are willing to hire it
Companies that approach Opus 4.6 as a magic tool that will automate everything with no additional effort will be disappointed. Companies that see it as a powerful new capability to carefully integrate into their workflows will find significant value.
Putting It All Together: The Opus 4.6 Roadmap
What should you actually do with Opus 4.6? Here's a practical roadmap:
Week 1: Evaluation Phase
- Sign up for API access or Claude.ai Plus subscription
- Test the million-token context on documents you care about
- Try the PowerPoint integration if you use Office
- Run your team through a few use cases to identify potential applications
Week 2-4: Pilot Phase
- Identify one high-value, low-risk process to automate
- Build a prototype using Opus 4.6
- Measure baseline (current time/effort) vs. new approach
- Document what works and what doesn't
Month 2-3: Evaluation and Decision
- Decide on broader rollout strategy
- For agent teams specifically: decide whether to invest in exploration (knowing it's research preview) or wait for general availability
- Negotiate pricing and contracts if moving to enterprise use
Month 4+: Implementation
- Build integrations into your actual workflows
- Train teams on new capabilities
- Monitor costs and refine approaches based on real usage
This assumes you have the technical capability internally. If you don't, add time for vendor evaluation and onboarding.
FAQ
What exactly are agent teams in Opus 4.6?
Agent teams are multiple coordinated AI agents working in parallel on different aspects of a complex task. Instead of a single agent processing work sequentially, you can assign responsibilities to different agents (e.g., data extraction, analysis, validation), and they coordinate directly with each other to produce better results faster. For more details, see Anthropic's official documentation.
How is a million-token context window different from previous Claude versions?
A million tokens is approximately 750,000 words, allowing you to include entire codebases, long documents, or extensive conversation histories in a single request. Previous versions had smaller context windows (200,000 tokens for Opus 4.5), which meant you had to split large documents and sacrifice holistic understanding. With a million tokens, you maintain end-to-end context and the model can make better connections across information.
Why did Anthropic add PowerPoint integration specifically?
PowerPoint integration is part of Anthropic's strategy to embed Claude into tools that knowledge workers already use daily. Rather than requiring users to switch to a separate application, Claude now operates as a sidebar in PowerPoint, providing real-time assistance while building presentations. This reduces friction and encourages adoption among non-technical users like product managers, analysts, and executives.
When will agent teams move from research preview to general availability?
Anthropic hasn't announced a timeline. Research preview typically lasts weeks to months. The company is using this period to optimize coordination protocols, gather performance data, and finalize pricing. Assume at least a few months before general availability, and plan your evaluation timeline accordingly.
How does agent team cost compare to single-agent Claude?
Pricing hasn't been formally announced. Multi-agent coordination likely incurs additional computational cost compared to single-agent processing, but Anthropic might bundle it into standard Opus pricing or charge separately. Early research preview users probably won't see additional costs, but don't assume this continues to production. Budget for potential premium pricing.
Can I use agent teams through the Claude.ai web interface?
Agent teams are currently available through the API and for research preview subscribers. Web interface access is likely coming but hasn't been announced. If you want to experiment immediately, you need API access or a Claude.ai Plus subscription that grants research preview access.
How does the million-token context window affect speed and cost?
Longer context means more computation and slower response times. Anthropic hasn't published specific latency metrics for very long contexts, but expect longer waits when processing large documents. Regarding cost, tokens are the primary cost factor, so a request using 800,000 of the available tokens costs substantially more than one using 50,000 tokens. Plan accordingly when evaluating this for production use.
Is Opus 4.6 better than GPT-4 for my use case?
That depends on your specific task. Opus 4.6 is strong on reasoning, code generation, and long-document understanding. GPT-4 is strong in some domains too. The best approach is running a quick evaluation on tasks that matter to you. Compare output quality, reasoning, and cost. Don't rely on benchmark numbers alone.
Should my enterprise adopt Opus 4.6 now or wait?
If you're looking at agent teams, wait for general availability. If you're interested in the million-token context window and improved model capability, you can adopt now through the API with relatively low risk. Run pilots first. For PowerPoint integration, evaluate when it's available in your enterprise environment (through Microsoft's app store with SSO support).
How does Runable compare to Opus 4.6 agent teams?
Runable is an AI automation platform focused on creating presentations, documents, reports, and slides automatically. While Opus 4.6 is a language model providing reasoning and generation capabilities, Runable is a production-ready workflow automation tool for teams. You could use Opus 4.6 to build automation similar to Runable's capabilities, but Runable provides the finished implementation starting at $9/month. For teams wanting immediate, turnkey automation without building custom integration, Runable is often the faster path.
Conclusion: What Opus 4.6 Means for the Future of AI
Opus 4.6 represents a meaningful evolution, not a revolution. The features individually are incremental improvements. The million-token context is larger but not transformative compared to the 200,000-token context available in Opus 4.5. Agent teams are interesting but require significant rethinking of how you decompose tasks. PowerPoint integration is nice but is really just API calls wrapped in a familiar interface.
But together? They add up to something more significant.
Anthropic is making a strategic bet that the future isn't about the smartest single model. It's about models that work within existing tools, understand complex tasks holistically, and coordinate effectively. The company is positioning Claude to be the intelligent backend for knowledge work, integrated deeply into the tools professionals already use.
For enterprises, this matters. It's the difference between AI being a separate tool you integrate versus AI being a core capability embedded in your workflow. That distinction affects adoption rates, usage patterns, and ultimately, business impact.
For developers, Opus 4.6 provides better tools for complex system work. Larger context windows reduce the need for manual context management. Agent teams enable new patterns for dividing work.
The timing is interesting too. Opus 4.6 arrives as the AI market is fragmenting. It's no longer GPT or bust. Anthropic, OpenAI, Google, and others are all credible options. That competition is pushing innovation. Opus 4.6 benefits from that pressure.
Looking ahead, expect this trajectory to continue. Models will get better at handling longer contexts. Multi-agent coordination will become more sophisticated. Integration into enterprise tools will deepen. The competitive moat will shift from pure model capability to integration breadth and developer experience.
For now, if you work with documents, code, or complex data, Opus 4.6 is worth evaluating. Not because it's perfect (it's not), but because it's measurably better at tasks that matter to knowledge workers and developers. And that's enough to justify taking a closer look.
The agent teams feature specifically is worth monitoring. Right now, it's research preview, so the risk is higher. But if the feature matures and the coordination protocols prove effective, multi-agent approaches could become standard for complex problem-solving. That's a genuine inflection point worth watching for.
The broader lesson from Opus 4.6's release is this: AI capability is necessary but not sufficient. Distribution, integration, and ease of use matter as much as raw intelligence. Anthropic understands that. They're building accordingly. That's probably why they'll remain competitive even as other models catch up on pure capability.
What's your use case? If you're building knowledge work automation, have large codebases to refactor, or manage document-heavy processes, Opus 4.6 deserves a 30-minute evaluation. Start with the free tier through Claude.ai, test the context window on your actual content, and see if the difference is noticeable. For most knowledge workers, it will be.
The future of AI isn't about individual features. It's about how effectively those features slot into the work you're already doing. Opus 4.6 makes that fit better than it was. That's worth paying attention to.

Key Takeaways
- Agent teams enable parallel multi-agent coordination, moving beyond sequential task processing and significantly reducing execution time for complex problems
- One million token context window (approximately 750,000 words) allows processing entire codebases and long documents in single requests, improving coherence and analysis
- PowerPoint integration embeds Claude directly in Office, reducing friction for knowledge workers and accelerating adoption beyond developer-only use cases
- Opus 4.6 explicitly targets financial analysts, product managers, and other knowledge workers, signaling Anthropic's strategic pivot from developer-centric positioning
- Agent teams remain in research preview with uncertain pricing and stability, meaning production adoption requires careful evaluation and contingency planning
Related Articles
- OpenAI Frontier: The Complete Guide to AI Agent Management [2025]
- Shared Memory: The Missing Layer in AI Orchestration [2025]
- OpenAI's New macOS Codex App: The Future of Agentic Coding [2025]
- AI Agents & Access Control: Why Traditional Security Fails [2025]
- Xcode Agentic Coding: OpenAI and Anthropic Integration Guide [2025]
- ChatGPT-4o Ending February 2025: Complete Survival Guide & Alternatives [2025]

