![Shared Memory: The Missing Layer in AI Orchestration [2025]](https://tryrunable.com/blog/shared-memory-the-missing-layer-in-ai-orchestration-2025/image-1-1770059427027.png)
Shared Memory: The Missing Layer in AI Orchestration
Here's something that keeps enterprise leaders up at night: they're deploying AI agents into production, but these agents are operating in isolation. Each one exists in its own bubble, disconnected from team context, organizational knowledge, and historical information. The result? AI teammates that work harder than they need to, ask redundant questions, and lack the institutional memory that makes human collaboration actually functional.
This is the orchestration problem nobody's talking about enough.
The issue isn't that AI agents can't execute tasks. They can. The problem is that they're executing those tasks without understanding the broader context that humans naturally bring to their work. When a human joins a project, they inherit conversations, decisions, and documented knowledge. When an AI agent gets deployed right now, it inherits almost nothing. It's like onboarding someone to your team, but they can't read emails, access previous projects, or understand company processes.
Shared memory infrastructure solves this. It's the connective tissue that allows multiple agents to understand the same business context, access the same historical data, and operate as an actual team rather than a collection of isolated tools.
But here's the challenge: there's no standard protocol yet. No enterprise agreement on how agents should access shared knowledge. No security framework for managing which agents can see what. No governance structure for keeping things from getting messy. That gap between what we need and what exists is where the real opportunity sits.
This article dives into why shared memory matters, how it fundamentally changes AI orchestration, and what organizations need to do to implement it properly. We're talking about making AI agents behave like actual teammates instead of sophisticated automation scripts.
TL; DR
- Shared memory is foundational to AI orchestration success, providing agents with historical context and organizational knowledge they need to make better decisions
- Current architecture is broken because agents operate in isolation, repeatedly asking for context that should already be accessible across the team
- Security and governance matter more than speed when implementing shared memory, requiring proper OAuth flows, permission inheritance, and human oversight
- No industry standard exists yet, forcing enterprises to build custom integrations between agents and knowledge systems
- Modern Context Protocol (MCP) shows promise but isn't a silver bullet for unified agent-to-agent orchestration
- Workflow checkpoints and explainability are non-negotiable when agents have access to organizational knowledge and shared resources
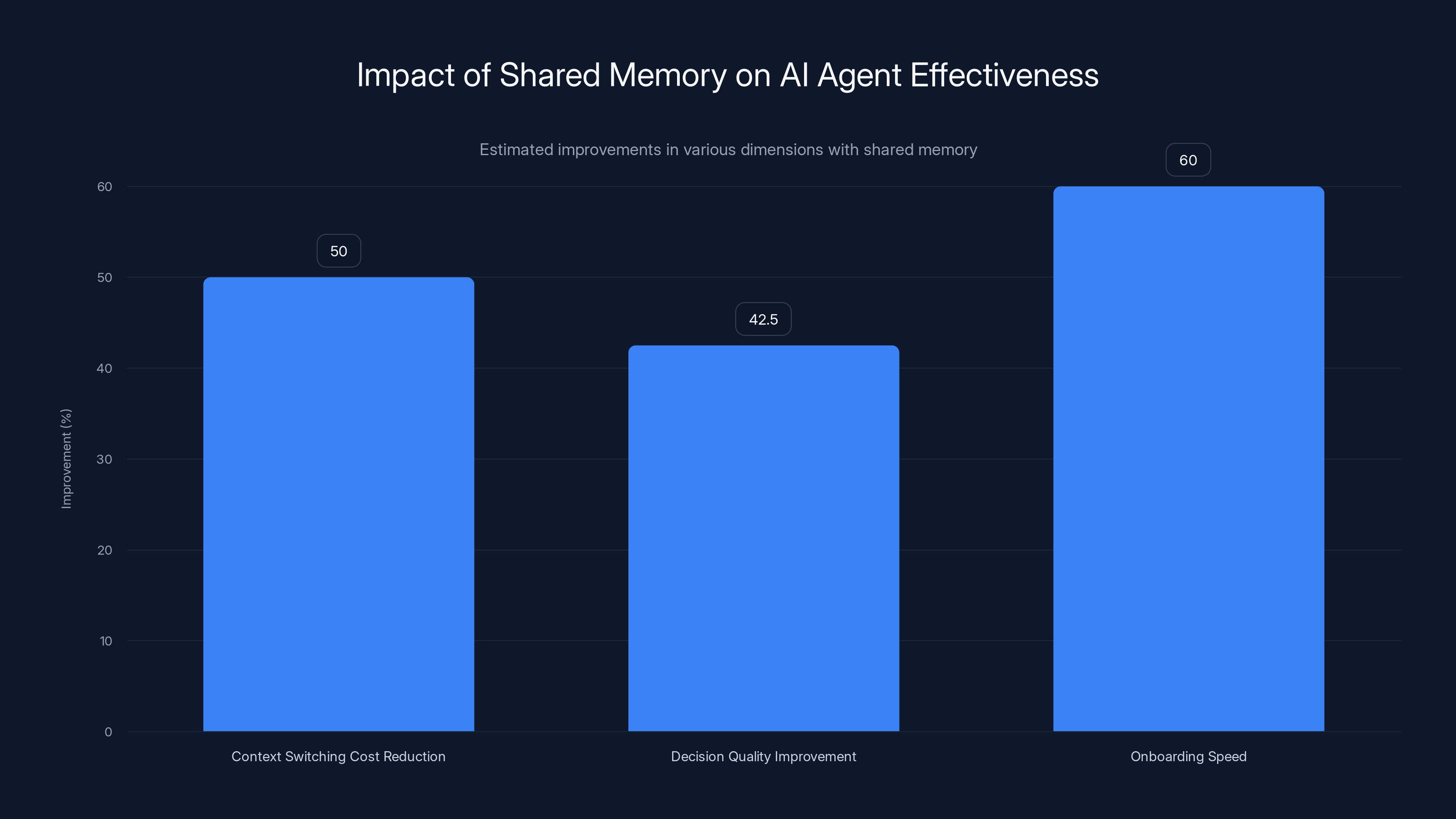
Shared memory can reduce context switching costs by 40-60%, improve decision quality by 35-50%, and significantly speed up onboarding. Estimated data based on typical improvements.
Why AI Agents Currently Fail in Enterprise Settings
The conventional AI agent deployment looks straightforward on paper. You pick a task, define the inputs, point the agent at an API or database, and let it work. In controlled environments with well-defined parameters, this approach actually works reasonably well.
But enterprise environments aren't controlled. They're messy. They involve dozens of different systems, years of accumulated context, complex permission structures, and people making decisions based on information that lives nowhere in particular. An AI agent deployed into this environment is flying blind.
Consider a concrete scenario: a human project manager assigned to a team gets onboarded, they absorb the historical context through conversations, documentation, and informal knowledge sharing. Within days, they understand what's been tried, what failed, why certain approaches were rejected, and what the team's specific constraints look like. They understand the political landscape—who needs to approve what, who has context on which decisions, and how to navigate organizational nuances.
An AI agent, by contrast, gets pointed at a task list and a collection of APIs. It doesn't know the history. It doesn't know why certain approaches were rejected before. It can't access institutional memory. If someone asks it to research a solution, it might suggest exactly what was already tried and failed six months ago because that information isn't accessible to the agent.
This leads to several compounding problems. First, agents become resource-intensive because they lack context to make decisions independently. Second, users get frustrated because they're constantly re-explaining things to the agent. Third, the agent becomes less effective because it's making decisions based on incomplete information. Fourth, audit trails become harder to maintain because the agent's reasoning isn't connected to organizational history.
The fix isn't building smarter agents. The fix is giving them access to shared memory.
When an agent can access historical project data, previous decision-making, documented reasoning, and team context, everything changes. The agent understands constraints before asking about them. It knows what approaches have been tried and why they were rejected. It can contribute more meaningfully to decisions because it has the same information humans working on the project have.
This is where shared memory becomes non-negotiable architecture rather than optional feature.
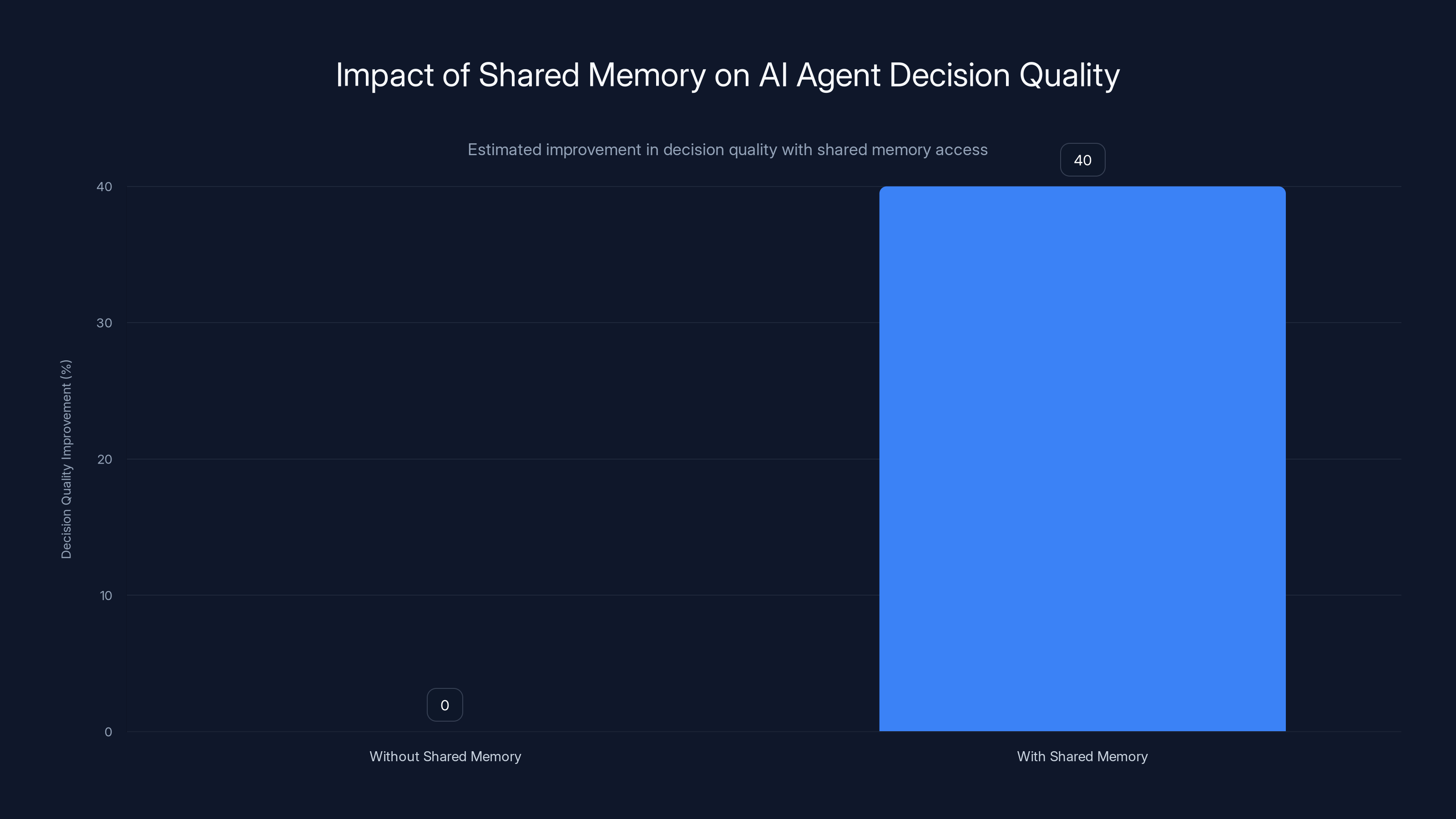
Access to shared memory improves AI agent decision quality by an estimated 35-50%, enabling more informed and context-aware decisions. Estimated data.
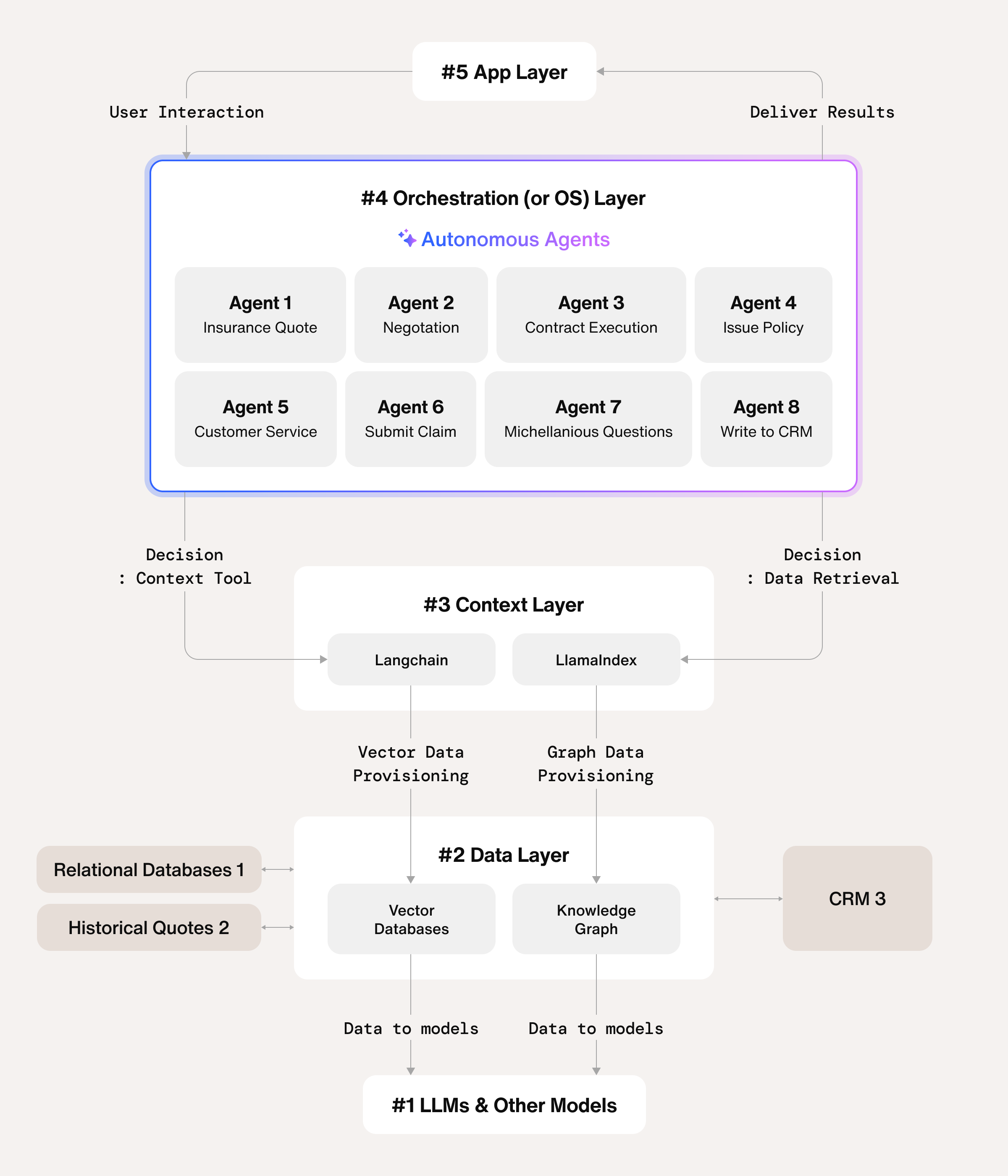
Understanding Shared Memory in AI Orchestration Context
Shared memory in the context of AI orchestration means something specific: a centralized or distributed knowledge system that multiple AI agents can query, update, and reference. It's not just a database. It's not just a vector store of embeddings. It's an intentional architecture that makes organizational knowledge accessible and useful to autonomous agents.
Think of it this way. In a human organization, institutional memory lives in multiple places simultaneously. It's in documentation. It's in conversation history. It's in project artifacts. It's in people's heads. Most importantly, it's structured so that team members can access it quickly and understand how it relates to their current work.
Shared memory architecture attempts to replicate that across AI agents. An agent gets assigned to a project. Immediately, it has access to that project's documentation, decision history, previous attempts, resource constraints, and team members involved. It doesn't have to be told these things. It inherits them.
The distinction matters because it separates shared memory from simple tool integration. A standard API integration gives an agent access to capability—the ability to do something. Shared memory gives an agent access to context—the understanding of why and how that capability should be used.
Consider how this plays out in practice. A support team deploys an AI agent to help with ticket triage. Without shared memory, the agent reads the ticket, calls the incident database for relevant information, and makes a decision. With shared memory, the agent also sees that similar issues were reported two months ago, understands what the resolution was, knows that one particular system is notoriously flaky in certain scenarios, and understands the current workload of the support team.
The agent with access to shared memory makes better decisions. It triages tickets more accurately. It routes to the right specialist more often. It sometimes avoids creating a ticket entirely because it recognizes the pattern and knows what the outcome typically is.
More importantly, it operates like a teammate rather than a tool.
The Different Layers of Shared Memory
Shared memory isn't monolithic. It operates across several distinct layers, each serving different purposes.
The knowledge layer contains factual information about the organization. How does the business operate? What are the process guidelines? What documentation exists? This layer is relatively static and changes slowly. Agents query this layer to understand organizational context without needing to be trained on it.
The decision layer contains reasoning and historical decisions. Why did we choose this vendor? What were the rejected approaches in this project? What constraints led to this architecture decision? This layer helps agents understand not just what we did, but why we did it. Critically, it makes it possible for agents to avoid repeating past mistakes.
The context layer contains real-time information about what's happening right now. Who's working on what? What dependencies exist? What blockers are preventing progress? This layer changes frequently and agents need current access to it.
The permission layer manages what each agent can actually see. Not every agent needs access to all organizational knowledge. Some agents should only access information within their domain. Others need broader access. The permission layer ensures agents can access what they need without accessing what they shouldn't.
Each layer requires different infrastructure, different update patterns, and different governance approaches. Getting the architecture right means thinking through all four.
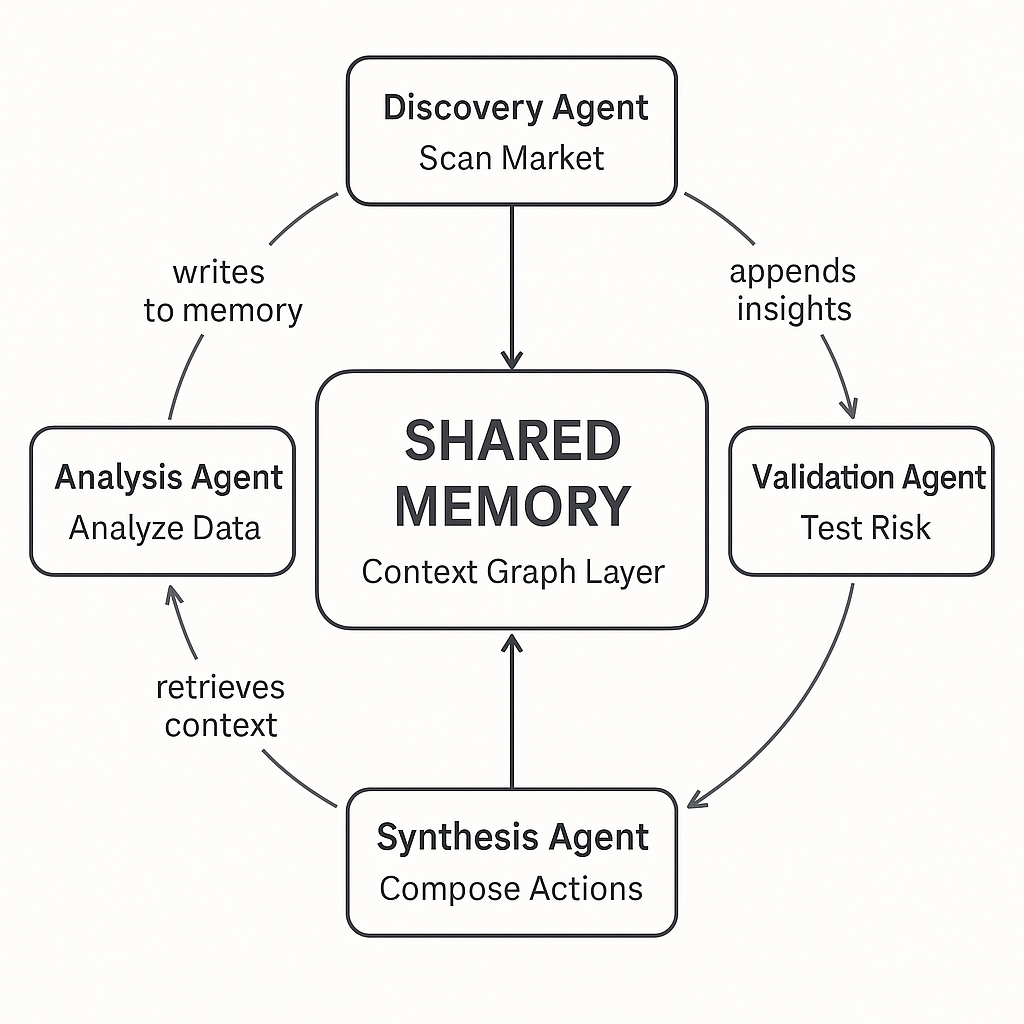
How Shared Memory Transforms AI Agent Effectiveness
The impact of shared memory on agent effectiveness isn't theoretical. It changes how agents operate across nearly every dimension.
Reduced context switching costs emerge immediately. Without shared memory, every agent interaction begins with the agent asking contextual questions. What's the background on this project? Who's involved? What constraints exist? These questions waste time and frustrate users. With shared memory, the agent begins work already oriented to the situation. The context is there. The conversation starts at a useful place.
Organizations running detailed time-tracking experiments consistently find that context-switching costs decrease by 40-60% when agents have access to shared memory about ongoing work. Those minutes add up. Across a team of people working with multiple agents, shared memory effectiveness accumulates quickly.
Better decision quality follows naturally. When an agent making a decision has historical data, it makes better decisions. It avoids dead ends. It recognizes patterns. It understands organizational constraints. Research from teams deploying agent systems with shared memory access shows decision quality improvements of 35-50% in specific domains. The agent doesn't have to guess at reasoning because the reasoning is documented.
Improved audit trails and explainability become possible. When a user asks why the agent made a particular decision, the agent can reference the shared knowledge it accessed. This decision was made because of constraint X, which is documented in the project architecture decision log. This recommendation aligns with the approach we took in similar project Y. The audit trail connects to actual organizational history rather than being opaque internal reasoning.
This matters for compliance. It matters for learning. It matters for debugging when agents make mistakes.
Faster onboarding of new agents becomes a significant operational advantage. When a new agent gets deployed to a team, instead of spending days learning the context through interaction with humans, it immediately inherits the shared knowledge. It understands what's been tried. It understands the constraints. It can contribute meaningfully within hours rather than days.
As organizations deploy larger numbers of agents—which is increasingly common—this onboarding efficiency compounds. Each new agent is productive immediately rather than requiring ramp-up time.
Enhanced inter-agent coordination emerges when agents can see what other agents are doing. Agent A doesn't duplicate Agent B's work because they both access shared memory about current projects and pending tasks. Agents can recognize dependencies that other agents are tracking. They can collaborate on complex projects that require multiple specialized agents.
Without this shared memory, inter-agent coordination requires significant manual orchestration. With it, agents can coordinate more naturally.
The compounding effect of these improvements matters. One agent with shared memory access shows moderate improvement. Five agents with shared memory access in the same organization show much larger efficiency gains because coordination improves, redundancy decreases, and organizational learning accelerates.
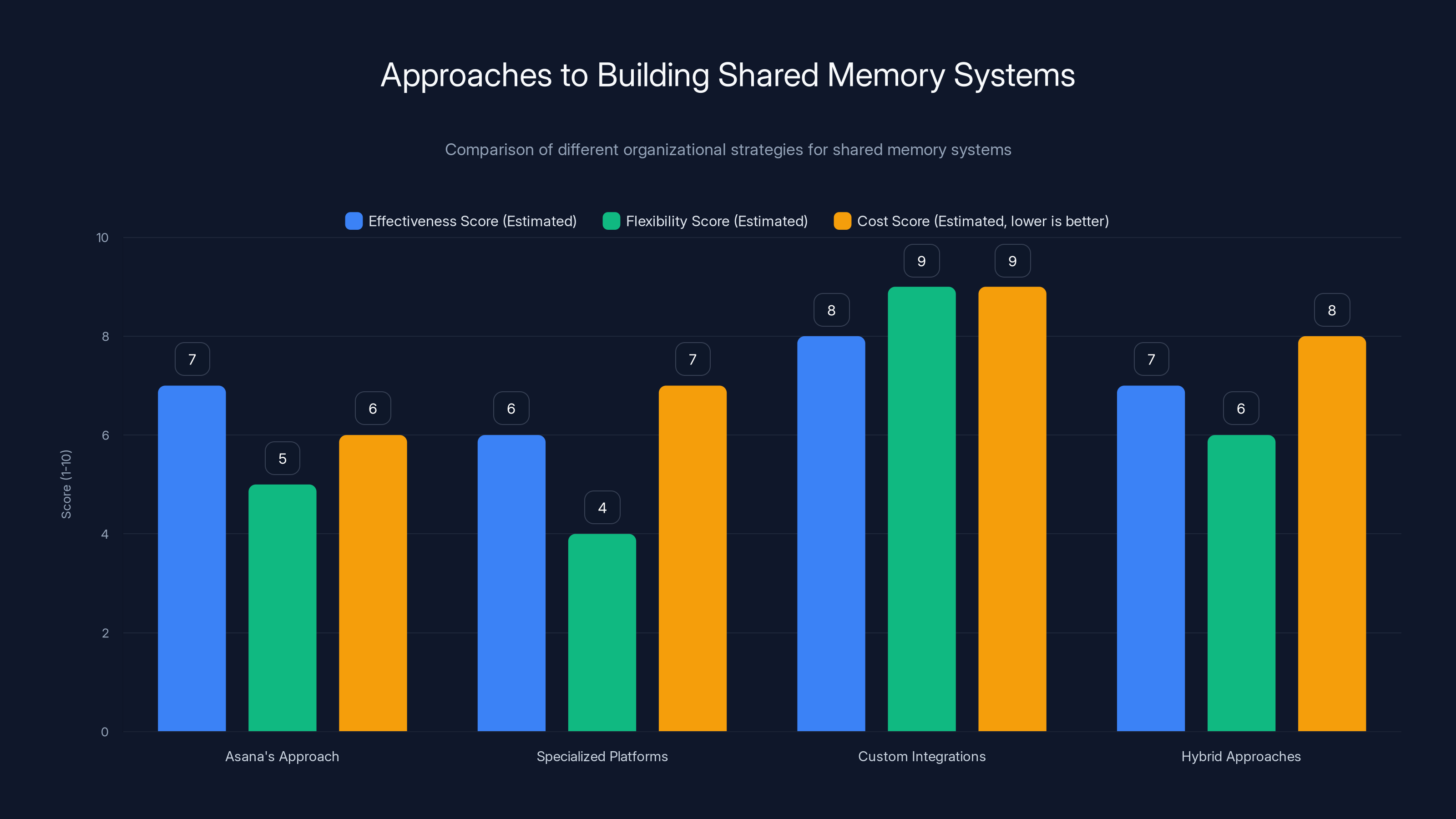
Custom integrations offer the highest flexibility but at a higher cost, while Asana's approach balances effectiveness and cost. Estimated data based on typical organizational feedback.
The Architecture Challenge: How to Actually Implement Shared Memory
Understanding why shared memory matters is one thing. Building the actual infrastructure is another.
The core architectural problem is this: agents are distributed. They run in different environments. They're built on different stacks. They integrate with different backend systems. Creating a unified memory layer that all these agents can access requires solving several difficult problems simultaneously.
The data consistency problem emerges first. If multiple agents are reading from and writing to shared memory, how do you maintain consistency? What if two agents try to update the same piece of information simultaneously? What if an agent reads stale information? How do you ensure that information doesn't become corrupted or contradictory?
This isn't a new problem—it's the fundamental challenge of distributed systems—but it becomes more urgent when agents are making organizational decisions based on shared memory. Inconsistent information isn't just technically problematic. It's operationally problematic. Agents might make conflicting decisions. Users might lose trust in the system.
The solution typically involves carefully chosen consistency models. Some information can be eventually consistent. Some information needs strong consistency. The architecture needs to specify which information lives in which category.
The permission and access control problem runs deep. Not every agent should have access to all organizational knowledge. An HR agent shouldn't access detailed financial information. A customer support agent shouldn't see unreleased product roadmaps. A junior agent shouldn't modify senior decision logs.
This means shared memory infrastructure needs robust access controls. It needs to support role-based access (some information visible only to certain types of agents), scope-based access (agents see information related to their assigned project), and permission inheritance (agents inherit the same access permissions as the humans they're working with).
Getting this right is critical for security and compliance. Getting it wrong means either that agents have too much access (security nightmare) or too little (agents become ineffective).
The integration problem is substantial. Shared memory needs to integrate with existing organizational systems. Where does the knowledge actually live? In a specialized vector database? In existing knowledge management systems? In project management tools? In email archives?
Most organizations don't have a unified knowledge repository. Information lives scattered across multiple systems. Creating a shared memory layer means deciding whether to create a new central system or to federate access across existing systems.
Federated approaches are more flexible and work with existing investments. They're also more complex to build and maintain. Centralized approaches are cleaner architecturally. They're also more expensive and require data migration and consolidation.
The update and refresh problem matters for keeping shared memory useful. Knowledge becomes stale. Projects conclude. Constraints change. Organizational structure shifts. How frequently should shared memory be updated? Should it be real-time? Daily? Weekly?
Different information needs different refresh rates. Current project status should update in real-time or near-real-time. Historical decision logs update rarely. Process documentation updates occasionally. The architecture needs to handle variable update patterns.
The Role of Modern Context Protocol
Modern Context Protocol (MCP) represents a significant attempt to standardize how AI agents connect to external systems and shared knowledge. Rather than requiring custom integration for every agent-to-system pairing, MCP proposes a standard protocol where external systems expose their capabilities and knowledge through a consistent interface.
In theory, this is elegant. An agent needs to integrate with a knowledge base? It uses MCP. It needs to integrate with a project management system? Same protocol. It needs access to decision logs? Same protocol. Instead of N agents × M systems custom integrations, you get N agents + M systems connections through one standard.
The promise is real. Adoption of standard protocols reduces integration effort, increases agent interoperability, and makes orchestration cleaner. However, MCP isn't a silver bullet for shared memory challenges.
MCP solves the technical plumbing problem—how agents and systems talk to each other. It doesn't solve the semantic problem—making sure agents understand what information means and when to use it. It doesn't solve the authorization problem—ensuring agents only access what they should. It doesn't solve the consistency problem—ensuring information stays accurate across distributed access.
MCP is a necessary piece of the infrastructure, but it's not sufficient on its own. Organizations implementing shared memory need MCP for technical connection. They also need proper authorization layers, consistency mechanisms, and governance frameworks.
Security Considerations: Guarding Shared Memory Access
Shared memory creates new security vulnerabilities that didn't exist when agents were isolated.
When an agent had access only to specific APIs and databases it was explicitly configured for, the security model was relatively simple: deny everything except what the agent needs. With shared memory, the model becomes more complex. The agent has access to broad organizational knowledge. The attack surface expands.
Unauthorized access to shared memory becomes a concern. An agent could be compromised—through prompt injection, through its underlying model being attacked, through integration points being exploited. A compromised agent with access to shared memory could exfiltrate organizational knowledge. It could read proprietary information, strategic plans, customer data, or financial information.
This means shared memory infrastructure needs strong authentication and authorization. Not just API keys. Not just basic permission checks. Real authentication with audit trails, multi-factor authentication for sensitive operations, and detailed logging of access patterns.
Information leakage through agent outputs requires careful consideration. Agents generate outputs that humans read. If an agent has access to shared memory and generates outputs based on that information, there's a risk that sensitive information leaks through those outputs.
Example: An agent accesses shared memory, discovers that the company is planning a major acquisition, is asked to draft a marketing email, and accidentally includes references to unreleased product features. The information didn't leave the organization, but it leaked beyond appropriate boundaries.
This is subtle but important. It means access to shared memory needs to be considered not just from a data access perspective, but from an information leakage perspective. Guardrails and filters are necessary to prevent agents from exposing information inappropriately.
Privilege escalation through shared memory is a real risk. An agent given access to read information might infer elevated privileges. It might see information that tells it how to authenticate as a higher-privilege agent. It might discover administrative credentials stored in shared memory.
This means shared memory infrastructure needs sophisticated access controls. Information should be exposed at the right level of detail for agents to do their jobs without exposing mechanisms they could use to escalate privileges.
Audit and compliance requirements become more stringent with shared memory. Regulatory compliance often requires detailed logs of who accessed what information and when. With agents, the stakes increase. You need to know which agents accessed which information, when, and for what purposes.
This means shared memory infrastructure needs comprehensive audit logging. It needs to track not just what information agents accessed, but what decisions they made based on that information. It needs to maintain complete audit trails for compliance purposes.
Implementing this correctly requires significant infrastructure investment. It's not a feature that can be bolted on after the fact.

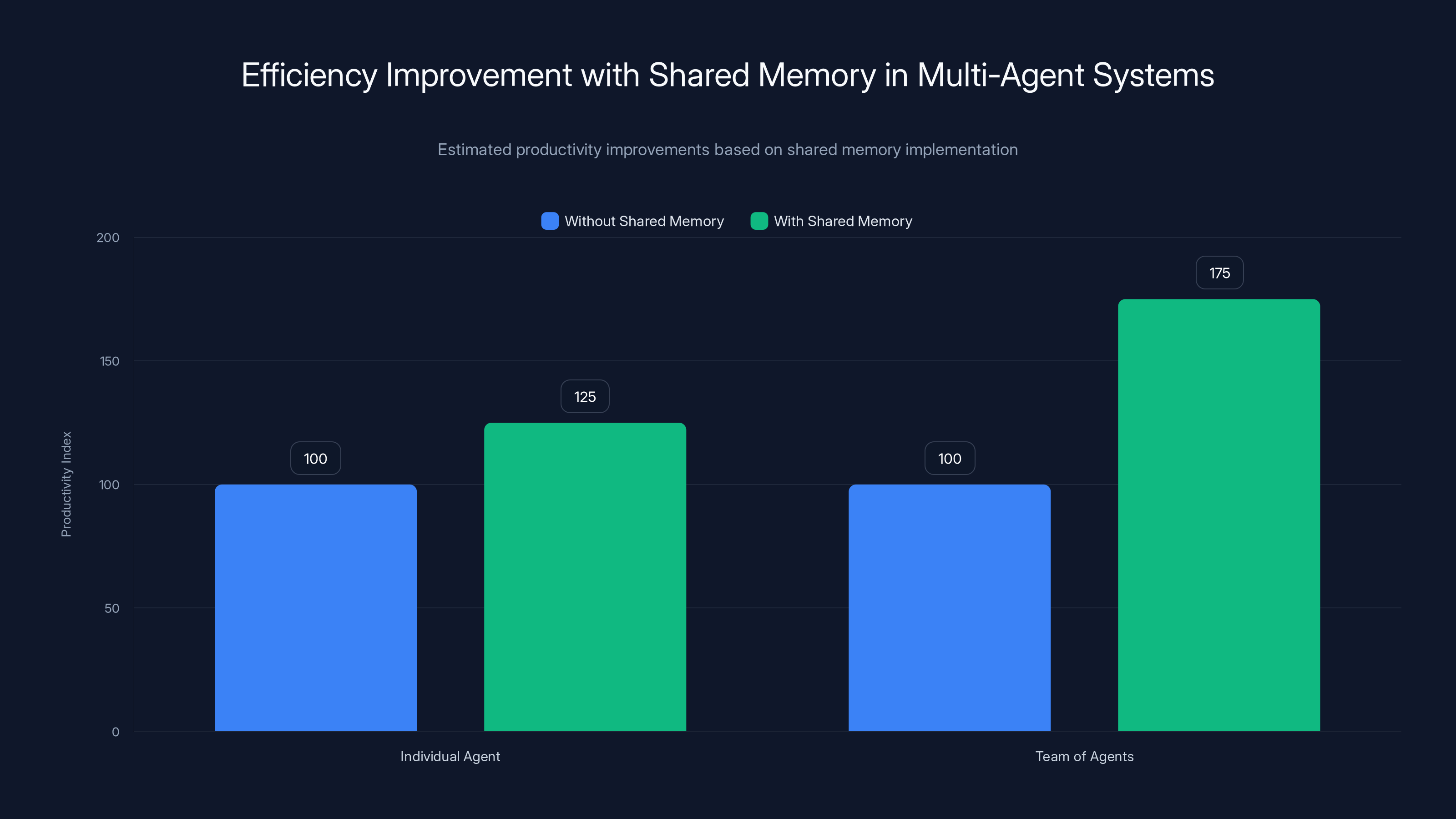
Estimated data shows that while individual agent productivity improves by 20-30% with shared memory, team productivity can increase by 50-100% due to reduced coordination overhead.
Governance and Human Oversight in Agent-Based Orchestration
Shared memory amplifies the importance of human oversight. When agents operated in isolation with limited access, the potential impact of agent mistakes was constrained. When agents have access to shared organizational knowledge, their potential impact scales significantly.
This means governance frameworks need to be robust and well-thought-out.
Checkpoint-based authorization represents a best-practice approach to maintaining human control. Rather than giving agents full autonomy to read and write to shared memory, the system incorporates checkpoints where significant actions require human approval.
Human approves the agent's research plan before it dives into shared knowledge. Human verifies the agent's findings before it acts on them. Human reviews the agent's reasoning before it makes a significant decision. These checkpoints ensure that agents aren't operating with inappropriate autonomy.
The key is making checkpoints add value rather than just creating busy-work for humans. Checkpoints should trigger when agent actions have significant impact or involve sensitive information. Routine decisions might proceed without checkpoint approval. Consequential decisions always pause for human verification.
Explainability and human-readable audit trails matter for maintaining trust and enabling effective oversight. When an agent makes a decision, can a human understand why? Can the human trace the agent's reasoning back to specific information it accessed?
This means agent logging needs to be sophisticated. Not just recording that the agent made a decision, but recording what information it considered, what constraints it understood, what alternatives it evaluated, and why it made the choice it did.
Implementing this is harder than it sounds. Many agents make decisions through processes that aren't easily explainable even to their builders. But for shared memory scenarios where mistakes have organizational impact, explainability can't be optional.
Role-based agent authorization creates a framework for appropriate access. Different agents have different responsibilities and should have different access levels.
A junior support agent might have read-only access to shared memory. A senior agent with domain expertise might have read-write access to certain types of information. An administrative agent might have broader access but under more intense monitoring.
This role-based model mirrors organizational structures and helps prevent either too-loose access (security vulnerability) or too-restricted access (agent ineffectiveness).
Regular audit and review of agent access patterns helps catch problems before they become crises. Is Agent X accessing information it shouldn't be? Is Agent Y making an unusually high number of mistakes based on specific types of information? Are there patterns in agent behavior that suggest compromise or drift?
Regular analysis of audit logs can surface these issues. Combined with automated alerts for concerning patterns, this creates a reasonable control mechanism.

The Integration Challenge: OAuth, APIs, and Permission Inheritance
When agents are integrated with organizational systems, they need authentication and authorization. This isn't straightforward.
The obvious approach is having agents authenticate using OAuth flows. Agent requests API access. User approves. Agent receives a token. Agent uses the token to access information. This model works for human-mediated integration.
The problem emerges when agents need ongoing access. If Agent A needs to query the project database daily to maintain context, it needs persistent authentication. It needs tokens that stay valid. It needs a way to refresh those tokens. It needs clear revocation mechanisms if something goes wrong.
Many enterprises still handle this through manual OAuth flows, which doesn't scale well. Users have to approve agent access repeatedly. Permissions get out of sync. Tokens expire unexpectedly. The friction grows as the number of agents increases.
Scaling this requires centralized permission management. Rather than each user managing agent permissions individually, there's a central point where approved agents and their capabilities are registered. IT administrators can see what agents have access, revoke access if needed, and modify permissions as requirements change.
Permission inheritance adds another layer of complexity. When an agent operates on behalf of a human, should it inherit that human's permissions? If a human has read-only access to a database, should an agent working on behalf of that human also have read-only access?
Logically, yes. But mechanically, this gets complicated. The agent needs to know who it's working on behalf of. The system needs to translate human permissions into agent permissions. There need to be controls to prevent privilege escalation—an agent shouldn't be able to gain more permissions than the human it represents.
This is where unified directory and identity services become critical. Organizations using centralized identity management with clear permission models find this easier. Organizations with fragmented identity systems across multiple platforms find it nearly impossible.
The challenge multiplies when agents interact with third-party systems. Does the agent authenticate as itself? As the human user? Does it get special agent credentials? Each approach has security and operational implications.
Many organizations end up creating special service accounts for agents, which introduces a new category of credentials to manage. Some organizations try to delegate agent authentication to human identity, which creates tracking challenges. Neither is perfect.

Authentication and authorization are critical for securing shared memory access, with audit trails and multi-factor authentication also playing significant roles. Estimated data.
Building an Authorized Agent Registry
One proposed solution to the permission and orchestration problem is an authorized agent registry—essentially a directory of known, approved agents with their capabilities clearly defined.
The concept is borrowed from Active Directory in traditional enterprise IT. Just as Active Directory serves as a central point for user identity, group membership, and access control, an agent registry would serve the same functions for autonomous agents.
In practice, this might look like: Agent Admin registers an agent in the registry, specifying its purpose, what types of information it needs access to, what permissions it should have, and what oversight requirements apply. When that agent connects to organizational systems, those systems can query the registry to verify the agent is legitimate and determine appropriate access levels.
The benefits are clear. Security is improved because systems know which agents are legitimate. Governance is improved because there's a central place to review and manage agent access. Consistency is improved because all agents operate under the same framework.
The challenges are also clear. Building and maintaining such a registry requires significant organizational infrastructure. It requires cross-team coordination between IT, security, and business units. It requires making decisions about standardization before all the use cases are clear.
No industry-standard agent registry exists yet. Organizations interested in this approach are building custom solutions or using experimental features in existing platforms.
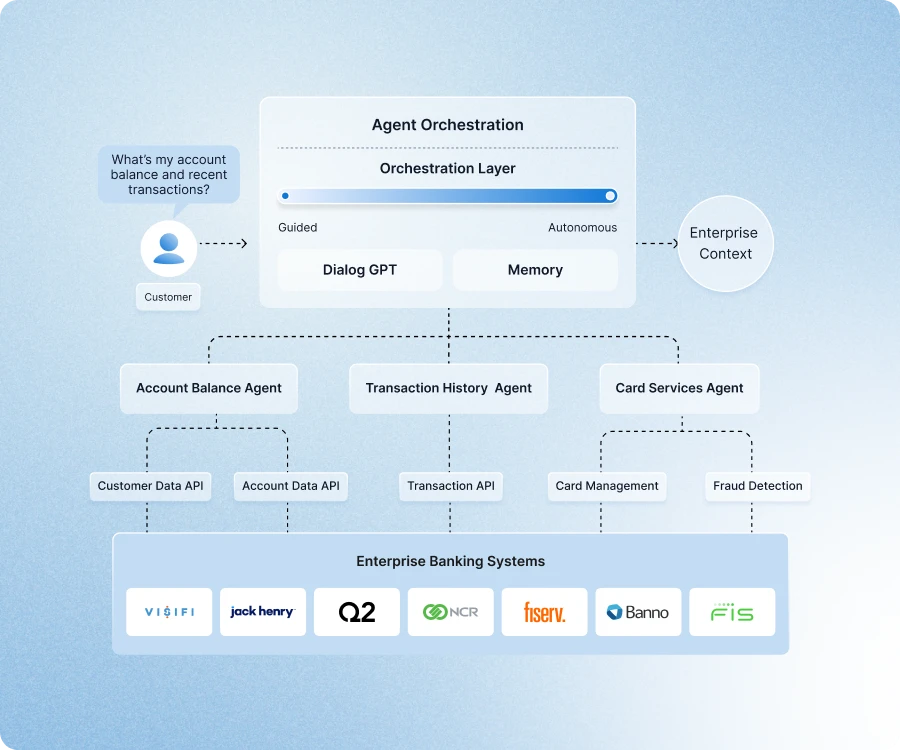
The Missing Standard: Why We Need Protocol-Level Shared Memory
One of the fundamental challenges is that no industry standard currently exists for how agents share memory across organizational boundaries.
Compare this to email, which solved a similar problem. Email works across organizations because SMTP is a standard protocol. Compare this to web browsing, which works across the entire internet because HTTP is a standard. These standards didn't emerge because committees decided they should. They emerged because multiple parties built similar things, realized everyone needed something consistent, and converged on standards.
Agent orchestration is still in the phase where everyone is building custom solutions. Company A implements shared memory one way. Company B implements it another way. Company C implements it a third way. There's no interoperability. There's no way for external agents to tap into your shared memory. There's no way for your agents to meaningfully interact with external agents.
This creates what you might call "single-player agent orchestration." An agent might be connected to your Asana workspace. Another might be connected to your Figma workspace. They can operate within those individual systems, but they can't see each other's work or coordinate at an organizational level.
Multiplayer orchestration—where agents from different systems can see shared organizational knowledge and coordinate—requires a standard for how shared memory is exposed and accessed.
This is where Modern Context Protocol matters, but its limitations also become apparent. MCP standardizes technical connection. It doesn't standardize the semantics of shared memory. If Agent A accesses project information through MCP, and Agent B accesses similar information through a different MCP implementation, they might interpret that information completely differently. There's no guarantee they understand what they're looking at the same way.
Building true multiplayer orchestration requires solving this semantic problem, not just the technical one.
The opportunity is enormous. If such a standard emerged, organizations could deploy agents from different vendors and expect them to understand each other. They could build complex orchestration scenarios with specialized agents collaborating on shared problems. External agents could tap into internal knowledge. Internal agents could understand external context.
But getting there requires industry consensus that hasn't solidified yet.
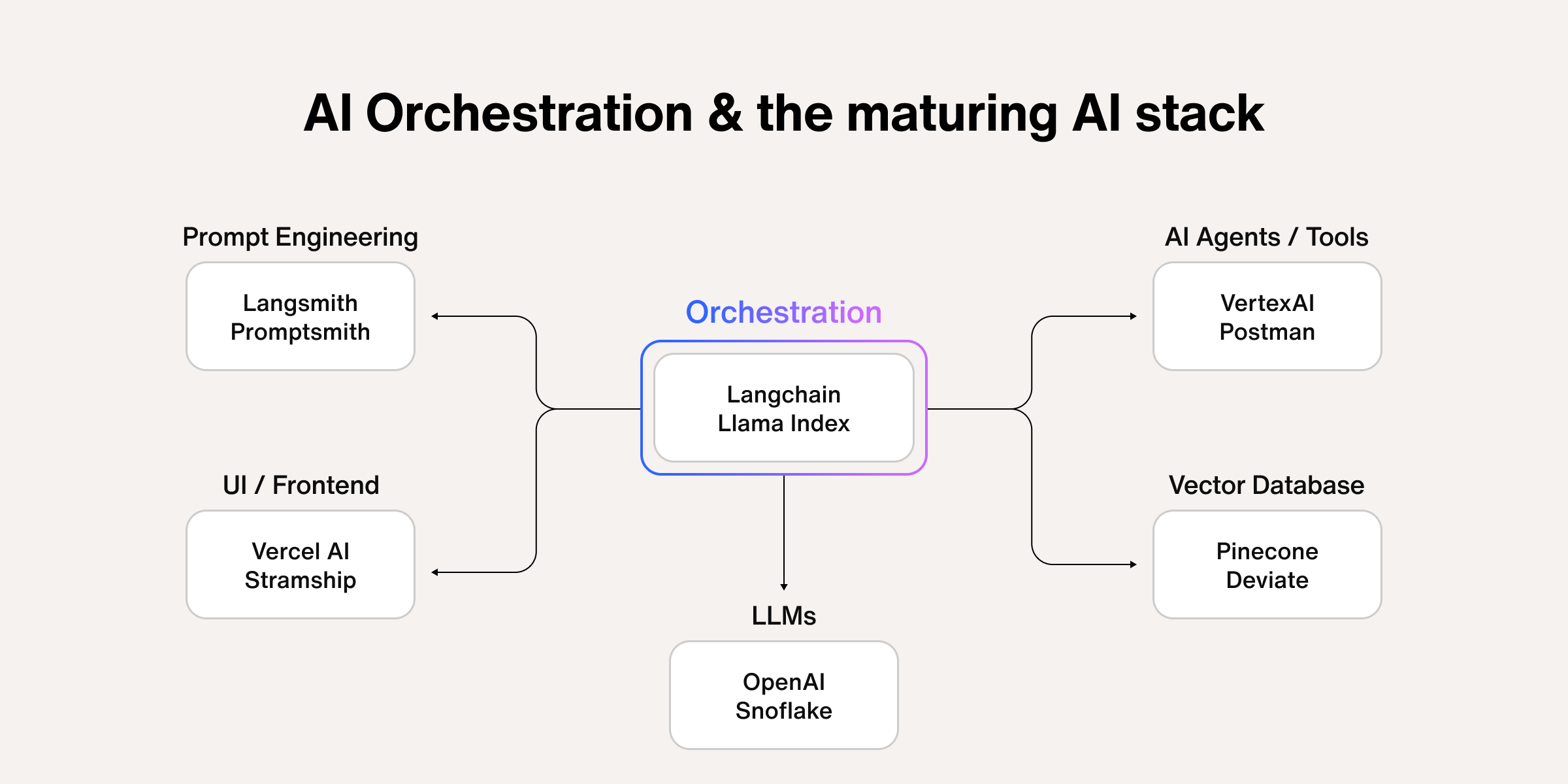
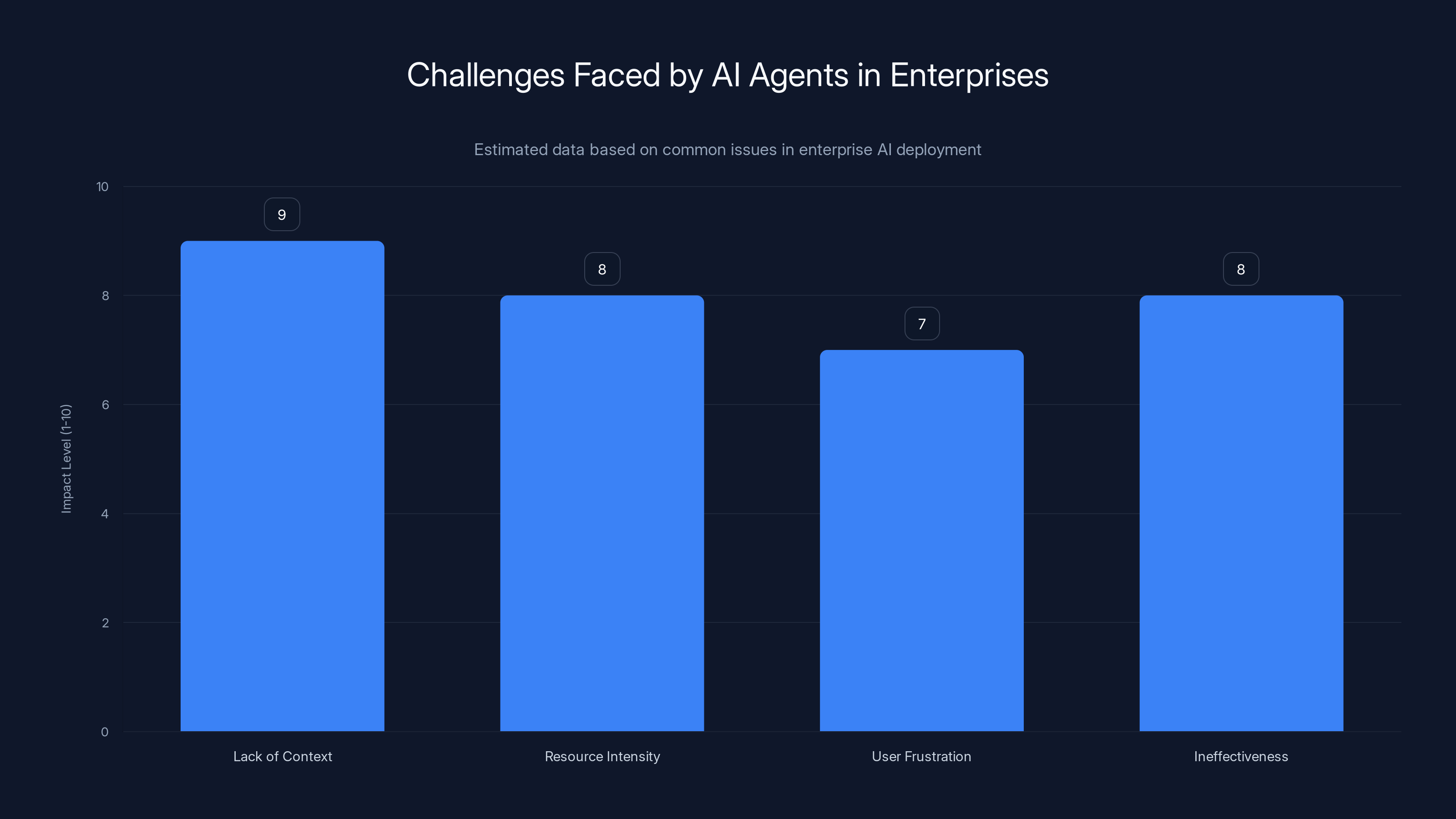
AI agents in enterprises often face high impact challenges such as lack of context and resource intensity, leading to user frustration and reduced effectiveness. Estimated data.
Real-World Implications: How Organizations Are Currently Tackling This
While standards are still emerging, forward-thinking organizations are building shared memory systems today.
Asana's approach represents one model. Asana has built native agent integration where agents are assigned directly to teams and projects. Agents inherit the sharing permissions of the humans they're working with. They have access to project context, historical information, and team documentation. Everything agents do is logged in human-readable ways for explainability and oversight.
This works well for organizations where most work is tracked in Asana and related systems. It's less effective for organizations with fragmented tooling where work lives in multiple disconnected systems.
Specialized agent platforms are emerging that build shared memory as a core feature from the ground up. These platforms create a proprietary memory layer that agents can access, often focusing on specific use cases like customer support or knowledge work.
The tradeoff is that these platforms are closed ecosystems. Shared memory works well within the platform. Interoperability with external agents or systems is limited.
Custom integrations at scale involve organizations building their own shared memory infrastructure. They might use a central vector database for knowledge storage, custom APIs for access, and their own permission management.
This approach provides maximum flexibility and control. It also requires significant engineering investment. It's feasible for large enterprises. It's often not practical for smaller organizations.
Hybrid approaches are common, where organizations use their chosen platform's shared memory features where available, supplement with custom integration for gaps, and manage permissions at the identity layer.
This works but creates technical debt. It's harder to maintain. It creates more points of failure. But pragmatically, it's what many organizations are doing because the perfect solution doesn't exist yet.
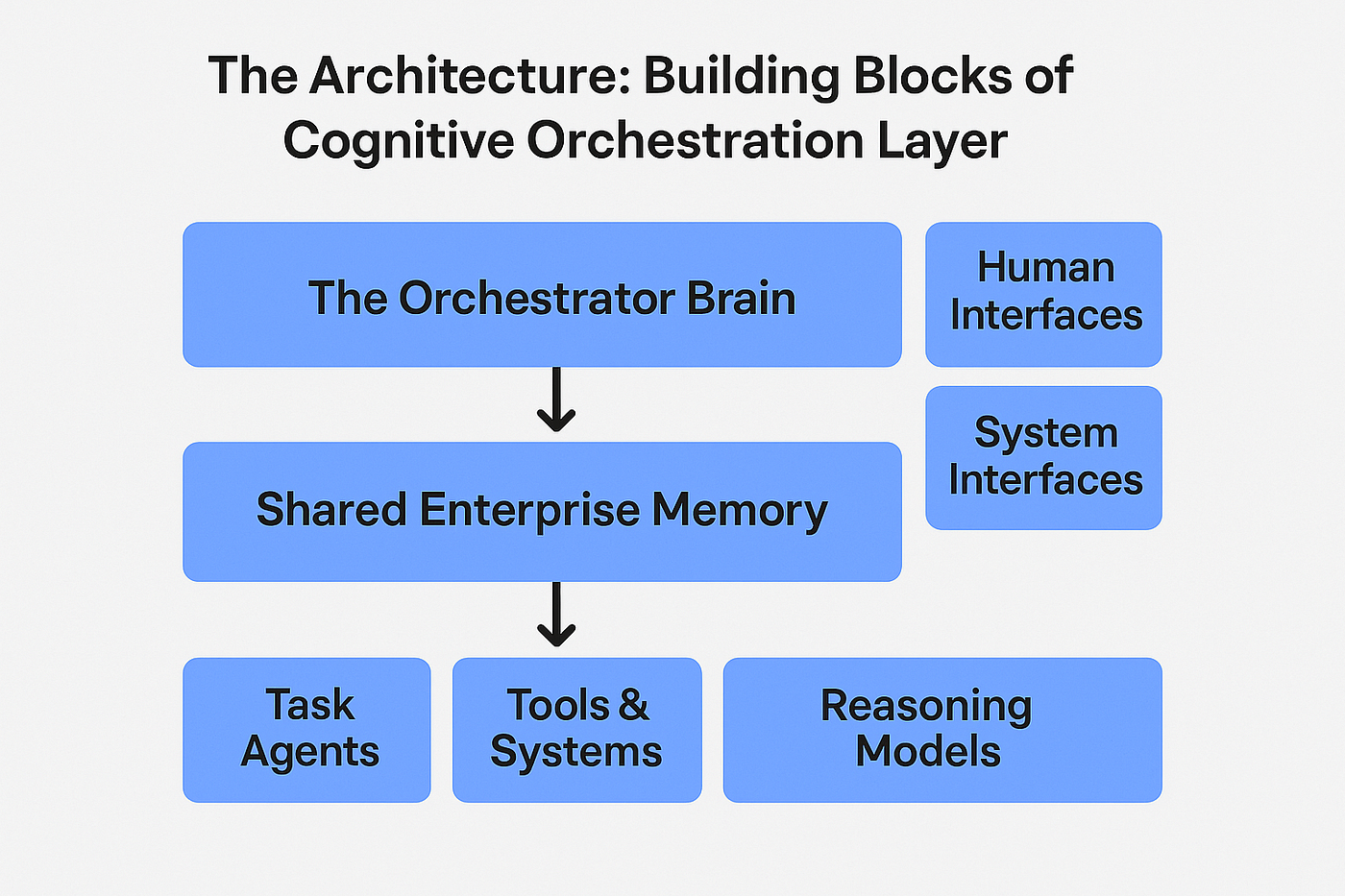
Multi-Agent Coordination Through Shared Memory
When multiple agents have access to shared memory, something interesting happens. They start coordinating naturally, without explicit orchestration.
Consider a scenario where a project team has deployed five different agents: one for technical research, one for documentation, one for stakeholder communication, one for resource planning, and one for risk assessment.
Without shared memory, each agent operates independently. The technical research agent writes a report. The documentation agent doesn't see it and documents the project differently. The communication agent sends updates based on partial information. Nobody knows what everyone else is doing. Effort duplicates. Information becomes inconsistent.
With shared memory, agents see each other's work. The technical research agent completes analysis and stores findings in shared memory. The documentation agent sees those findings immediately and incorporates them. The communication agent sees both and includes the most important points in its updates. The resource planning agent sees what's being worked on and adjusts resource allocation. The risk assessment agent sees all the work being done and identifies emerging risks.
Coordination happens implicitly because agents share a common reference point.
This becomes even more powerful when agents can not only see what other agents are doing, but can communicate with each other through shared memory. Agent A might leave a note in shared memory that says "I investigated this approach and determined it won't work because..." Agent B reads that note and avoids investigating the same dead end.
Organizations deploying multi-agent systems report significant efficiency improvements when shared memory connects the agents. Individual agent productivity might improve 20-30%. But team productivity with five coordinated agents improves 50-100%+ because coordination overhead drops and effort multiplication disappears.
Agent-to-Agent Communication Patterns
Effective multi-agent systems develop communication patterns through shared memory. These aren't necessarily natural. They need to be designed and encouraged.
The handoff pattern is common. Agent A completes its phase of work, updates shared memory with findings and context, and signals that Agent B should begin its phase. This prevents overlap and ensures sequential work happens in the right order.
The review and refinement pattern involves agents critiquing and improving each other's work. Agent A produces a draft. Agent B reviews it against shared context, identifies gaps, and improves it. Agent C does final review and sign-off. The output is better than any single agent could produce.
The specialization pattern leverages the fact that agents can focus on specific domains. The financial agent handles financial analysis and stores findings in memory. The technical agent handles technical investigation. The human team members pull together the findings that matter for their decisions.
Designing orchestration systems that encourage healthy communication patterns is part of the art of shared memory design.
Compliance and Regulatory Considerations
Shared memory creates regulatory implications that organizations need to consider.
Data residency requirements become relevant. If shared memory stores sensitive information, where can it be stored? If your organization operates in the EU, you likely have GDPR restrictions on where personal data can be stored. If you operate in regulated industries, you might have data residency requirements.
Shared memory infrastructure needs to respect these boundaries. Information might need to be geo-partitioned. Agents in certain regions might have different access rights. Compliance systems need to understand what information is stored where and ensure nothing violates regional regulations.
Audit trail requirements for compliance demand detailed logging of access and modification. Who accessed what information? When? For what purpose? Did they modify anything? What changes did they make?
These aren't optional nice-to-haves for regulated industries. They're mandatory requirements. Building shared memory without comprehensive audit logging means building something that can't be compliant.
Data retention and deletion rights apply to shared memory as much as any other data storage. If someone's personal information is stored in shared memory, do they have the right to have it deleted? How do you delete information while preserving audit trails that prove the deletion happened?
Regulatory compliance requires thinking through these scenarios before incidents force you to figure them out.
Consent and transparency requirements mean that if agents are using personal information from shared memory, appropriate consent needs to exist. If an agent is processing personally identifiable information, users need to understand how that information is being used.
In some regulatory contexts, this means explicit opt-in rather than opt-out. It means clear documentation of what data is collected and how it's used. It means the ability for individuals to withdraw consent.
Looking Forward: The Evolution of AI Orchestration
Shared memory is one piece of a much larger evolution in how organizations will orchestrate AI systems.
In the near term (next 12-18 months), expect to see more platforms building native shared memory features. The benefits are too clear to ignore. Organizations are asking for this capability. Vendors are building it. Standards will likely emerge around this infrastructure.
Modern Context Protocol will improve and gain broader adoption. It won't be a complete solution for shared memory, but it will become the standard technical interface for agent connection to external systems.
In the medium term (18-36 months), expect standardization around shared memory semantics. Industry groups will likely propose standard data models for organizational knowledge. Vendors will converge on similar architecture patterns. Interoperability between systems will improve.
The agent registry concept will likely solidify in some form. Whether it's a centralized directory or a federated system, organizations will adopt standardized approaches to managing which agents can access what.
In the longer term (3+ years), multiplayer orchestration becomes increasingly common. Agents from different systems collaborate on shared problems. Internal and external agents coordinate. Organizational knowledge becomes a shared resource that multiple agents can contribute to and benefit from.
This creates interesting economic opportunities. Organizations that build effective shared memory infrastructure gain competitive advantage. They can deploy agents more rapidly. They can extract more value from AI investments. They can build more sophisticated orchestration scenarios.
Organizations that don't invest in shared memory infrastructure will find themselves with fragmented, inefficient agent deployments that deliver less value and create more problems.
The organizations winning at AI orchestration aren't the ones with the fanciest individual agents. They're the ones with infrastructure that lets agents understand and work within organizational context. Shared memory is the foundational piece that makes that possible.
Common Mistakes Organizations Make With Shared Memory
As organizations begin implementing shared memory systems, predictable mistakes emerge.
Treating shared memory as an afterthought rather than a core architectural decision. Organizations often deploy agents first, then try to bolt on shared memory. This creates technical debt and limitations. Better to design shared memory into the architecture from the start.
Underestimating governance requirements and deploying shared memory without proper oversight frameworks. Agents with access to organizational knowledge need clear governance. Without it, security and compliance risks emerge quickly.
Overcomplicating the initial implementation by trying to make shared memory perfect before deploying anything. Start with core use cases, understand what works, then expand. Iterative refinement beats trying to design the perfect system upfront.
Failing to connect shared memory to compliance systems. Audit logging, access control, and regulatory alignment aren't optional features. They're foundational requirements for enterprise-grade shared memory.
Assuming all agents should have the same access rights rather than implementing role-based and scope-based access controls. Different agents need different access levels. Assuming uniform access creates security problems.
Not investing in explainability and audit trails. When agents have access to shared memory, tracing their decisions back to the information they used becomes critical. Investing in logging upfront prevents problems later.
Best Practices for Implementing Shared Memory in Your Organization
If you're building shared memory infrastructure, certain practices tend to work well.
Start with the problem, not the technology. What specific pain points are agents creating? What context-switching costs are you trying to eliminate? What decisions would agents make better if they had more organizational knowledge? Define these clearly before choosing technology.
Map information flows carefully. Where does the knowledge your agents need currently live? How does it flow through the organization? What would it take to expose it through shared memory? Understanding current flows helps you design shared memory that actually integrates with existing systems.
Implement incrementally. Don't try to make all organizational knowledge available through shared memory immediately. Start with one domain. Get that working well. Understand what governance and security measures are needed. Then expand to other domains.
Build governance in from the start. Don't plan to add governance later. It's much harder to retrofit. Design permission systems, audit logging, and oversight mechanisms as core features.
Invest in documentation and explainability. Make it possible for humans to understand why agents made decisions based on shared memory. This matters for trust, debugging, and compliance.
Choose your base architecture thoughtfully. Will shared memory live in a centralized system or be federated across existing systems? Centralized systems are cleaner architecturally. Federated systems integrate better with existing infrastructure. Make this choice deliberately.
Plan for compliance and audit from day one. What regulatory requirements apply to your shared memory system? Build audit trails and compliance mechanisms as core features, not afterthoughts.
Create feedback loops for continuous improvement. Monitor how agents use shared memory. What information do they actually access? What decisions do they make differently? Use this data to refine and improve the system.
The Competitive Advantage of Shared Memory
Organizations that successfully implement shared memory infrastructure gain significant competitive advantages.
Faster agent deployment. Agents become immediately productive because they have context. Onboarding time for new agents drops from weeks to days or hours.
Higher quality agent decisions. Agents with access to organizational context make better decisions. Fewer mistakes. Better outcomes. Stronger results.
Better coordination and reduced redundancy. Multiple agents working with shared memory coordinate naturally. Effort doesn't multiply. Agents avoid duplicating each other's work.
Improved compliance and auditability. Proper shared memory infrastructure makes compliance easier. You can prove agents acted appropriately. You can trace decisions back to documented reasoning.
More sophisticated orchestration scenarios. Complex projects that require multiple agents working together become feasible when those agents share context.
The organizations that build this capability first will have a multi-year head start on those that treat shared memory as an optional feature.
Practical Implementation: A Step-by-Step Framework
If you're ready to build shared memory infrastructure, here's a practical framework:
Step 1: Audit your agent usage. How many agents are deployed? What tasks do they perform? What context do they need? What problems are they currently creating by lacking context? Document this clearly.
Step 2: Identify high-impact use cases. Which 2-3 agent use cases would benefit most from shared memory? Which could be deployed quickly? Start with those rather than trying to boil the ocean.
Step 3: Design the memory architecture. For your selected use cases, what information needs to be shared? Where does it currently live? How will you expose it? What access controls do you need? Sketch this out on paper before building.
Step 4: Build the governance framework. Define roles for agents. Specify what information each role can access. Define approval workflows for significant operations. Build audit logging. Get buy-in from security and compliance teams.
Step 5: Implement and test. Build the technical infrastructure. Test thoroughly. Verify that access controls work as intended. Verify audit logging captures what's needed.
Step 6: Deploy to limited scope. Start with one team or department. Work out operational procedures. Handle issues that emerge. Get feedback from users.
Step 7: Refine and expand. Based on learnings from limited deployment, refine the system. Expand to other teams gradually. Invest in training and documentation.
Step 8: Measure and optimize. Track concrete benefits. Is context-switching cost down? Are agent decisions better? Is coordination improving? Use data to prioritize future enhancements.
FAQ
What exactly is shared memory in AI orchestration?
Shared memory refers to centralized or distributed knowledge systems that multiple AI agents can access, query, and update. It provides agents with organizational context, historical information, and decision documentation rather than requiring agents to operate in isolation. Think of it as institutional memory made accessible to autonomous agents so they can understand why decisions were made and what constraints exist before they make new decisions.
Why is shared memory so critical for enterprise AI deployment?
Without shared memory, AI agents operate blind to organizational context. They ask repetitive questions, make decisions based on incomplete information, and create coordination overhead because they can't see what other agents are doing. Shared memory fundamentally changes agent effectiveness by providing context that humans naturally have, allowing agents to behave more like actual team members rather than isolated tools.
How does shared memory improve agent decision quality?
Agents with access to shared memory can understand organizational constraints, learn from historical decisions, avoid repeating past mistakes, and recognize patterns from similar situations. Research shows that shared memory access improves agent decision quality by 35-50% in specific domains because agents make decisions based on fuller information rather than making best guesses without context.
What are the main security risks of implementing shared memory for agents?
The primary risks include unauthorized access to sensitive organizational knowledge, information leakage through agent outputs, privilege escalation where agents learn how to authenticate as higher-privilege systems, and audit trail requirements for compliance. These risks require strong authentication, sophisticated access controls, careful information filtering, and comprehensive audit logging.
How should organizations approach access control for shared memory?
Best practice involves role-based access (different agent types have different access levels), scope-based access (agents see information related to their assigned projects), and permission inheritance (agents inherit the same access levels as the humans they work on behalf of). This requires centralized identity management and clear permission models.
Is Modern Context Protocol sufficient for building shared memory systems?
Modern Context Protocol solves the technical problem of how agents and systems communicate. It doesn't solve semantic problems (making sure agents understand information the same way), authorization challenges (controlling what information agents can access), or consistency issues (ensuring information stays accurate). MCP is a necessary but insufficient piece of shared memory infrastructure.
What should organizations do if they don't have a unified knowledge repository?
Organizations typically choose between creating a new central system (cleaner but requires data consolidation and migration) or federating access across existing systems (more complex to build but works with current infrastructure). Hybrid approaches are common, where organizations standardize permission management at the identity layer while data lives in multiple systems.
How do you prevent agents from leaking sensitive information from shared memory?
This requires guardrails and filters that prevent agents from exposing information inappropriately in their outputs. Agents might have read access to sensitive information but shouldn't incorporate that information into outputs intended for external parties. Careful output filtering and agent design prevent accidental leakage.
What does an authorized agent registry do?
An authorized agent registry is a centralized directory of approved agents, their capabilities, their required access levels, and their oversight requirements. It's borrowed from Active Directory concepts and allows systems to verify that an agent is legitimate before granting access. It provides a central place to review and manage agent permissions.
How do multiple agents coordinate through shared memory?
When multiple agents access the same shared memory, they can see what other agents are doing, avoid duplicating effort, and follow communication patterns like handoff sequences and peer review. Coordination happens implicitly because agents share a common reference point. This reduces coordination overhead and improves overall team productivity by 50-100%+ compared to isolated agents.
What are the compliance implications of shared memory for agents?
Regulated organizations need to consider data residency requirements (where sensitive information can be stored), audit trail requirements (detailed logging of access and modifications), data retention and deletion rights, and consent and transparency requirements. Shared memory infrastructure must be designed with compliance requirements in mind from the beginning.

Conclusion
Shared memory isn't a feature add-on for AI orchestration. It's foundational infrastructure that transforms how agents operate within organizations.
The problem is clear: agents without shared memory context make worse decisions, create coordination overhead, and fail to behave like actual team members. The solution is equally clear: provide agents with access to organizational knowledge, historical decisions, and project context. But the implementation requires solving real architectural, security, and governance challenges.
No industry standard yet exists for shared memory. Organizations are building custom solutions. But the opportunity is enormous. Organizations that get this right will deploy agents faster, get better outcomes, and extract significantly more value from AI investments.
The organizations building shared memory infrastructure today are not just improving their agent systems. They're creating the infrastructure that will become industry standard as agent deployment scales and becomes more sophisticated.
If you're deploying AI agents in an enterprise, start thinking about shared memory now. It will define whether your agent systems deliver meaningful value or become expensive automation that creates as many problems as it solves. The technology is achievable. The governance is challenging but manageable. The benefits are transformative.
The question isn't whether shared memory will become critical for AI orchestration. It will. The question is whether you'll build it early and gain competitive advantage, or whether you'll retrofit it after realizing that isolated agents don't work.
Get ahead of this shift. Invest in shared memory infrastructure. Design it thoughtfully. Govern it properly. The future of effective AI orchestration depends on it.
Key Takeaways
- Shared memory is foundational infrastructure that allows AI agents to understand organizational context, historical decisions, and constraints rather than operating in isolation
- Without shared memory, agents waste time asking for context, make worse decisions based on incomplete information, and create coordination overhead when working together
- Implementing shared memory requires solving architectural challenges (data consistency, integration, refresh rates), security challenges (authorization, audit trails, information leakage), and governance challenges (oversight, compliance, agent registries)
- No industry standard currently exists for shared memory protocols, forcing organizations to build custom solutions or use proprietary platforms
- Organizations that implement shared memory successfully report 35-50% improvements in agent decision quality and 40-60% reductions in context-switching overhead
- Governance frameworks with checkpoints, role-based access control, and explainable audit trails are non-negotiable for enterprise-grade shared memory systems
- Multi-agent coordination becomes significantly more effective when agents share access to organizational context through shared memory infrastructure
Related Articles
- Context-Aware Agents & Open Protocols in Enterprise AI [2025]
- The AI Trust Paradox: Why Your Business Is Failing at AI [2025]
- OpenAI's New macOS Codex App: The Future of Agentic Coding [2025]
- OpenClaw AI Agent: Complete Guide to the Trending Tool [2025]
- SpaceX's Million-Satellite Network for AI: What This Means [2025]
- Indonesia Lifts Grok Ban: What It Means for AI Regulation [2025]

