![Anthropic's Claude Sonnet 4.6: The Mid-Tier Model That's Redefining AI Standards [2025]](https://tryrunable.com/blog/anthropic-s-claude-sonnet-4-6-the-mid-tier-model-that-s-rede/image-1-1771351590837.png)
Anthropic's Claude Sonnet 4.6: The Mid-Tier Model That's Redefining AI Standards
Last month, Anthropic quietly dropped a bombshell that most of the tech world didn't fully appreciate. Not because it wasn't impressive, but because it happened in the middle of a broader sea change in how AI models are released and updated.
Claude Sonnet 4.6 arrived just two weeks after Opus 4.6, continuing Anthropic's aggressive four-month release cycle that's keeping pace with the rest of the industry. On the surface, this looks like a routine mid-tier model update. In reality, it's a significant shift that changes what we should expect from a model positioned between the lightweight Haiku and the powerful Opus variants.
Here's what actually matters: Sonnet 4.6 isn't just faster or slightly smarter than its predecessor. It's a fundamentally different offering. The context window doubled to 1 million tokens. Coding performance jumped measurably. Instruction-following became more reliable. And computer use—the ability to interact with web interfaces and desktop applications—reached levels that make real automation possible, not theoretical.
For teams already invested in the Claude ecosystem, this is the version that finally delivers on promises made a generation ago. For developers evaluating which API to build on, Sonnet 4.6 raises the bar for what "mid-tier" even means. And for enterprises trying to understand where AI actually creates economic value right now, this release is a data point worth examining carefully.
Let's break down what changed, why it matters, and what you should actually do about it.
TL; DR
- Sonnet 4.6 brings a 1 million token context window, double the previous limit, enabling analysis of entire codebases and lengthy documents in a single request
- Coding performance improved significantly, with new benchmarks showing measurable gains in software engineering tasks across multiple standardized tests
- Computer use capabilities reached new levels, making web automation and UI interaction substantially more reliable than previous generations
- The model becomes the default for Free and Pro users, accelerating adoption and providing broader real-world training data
- Release timing continues Anthropic's four-month update cycle, maintaining competitive parity with Open AI and Google's release schedules
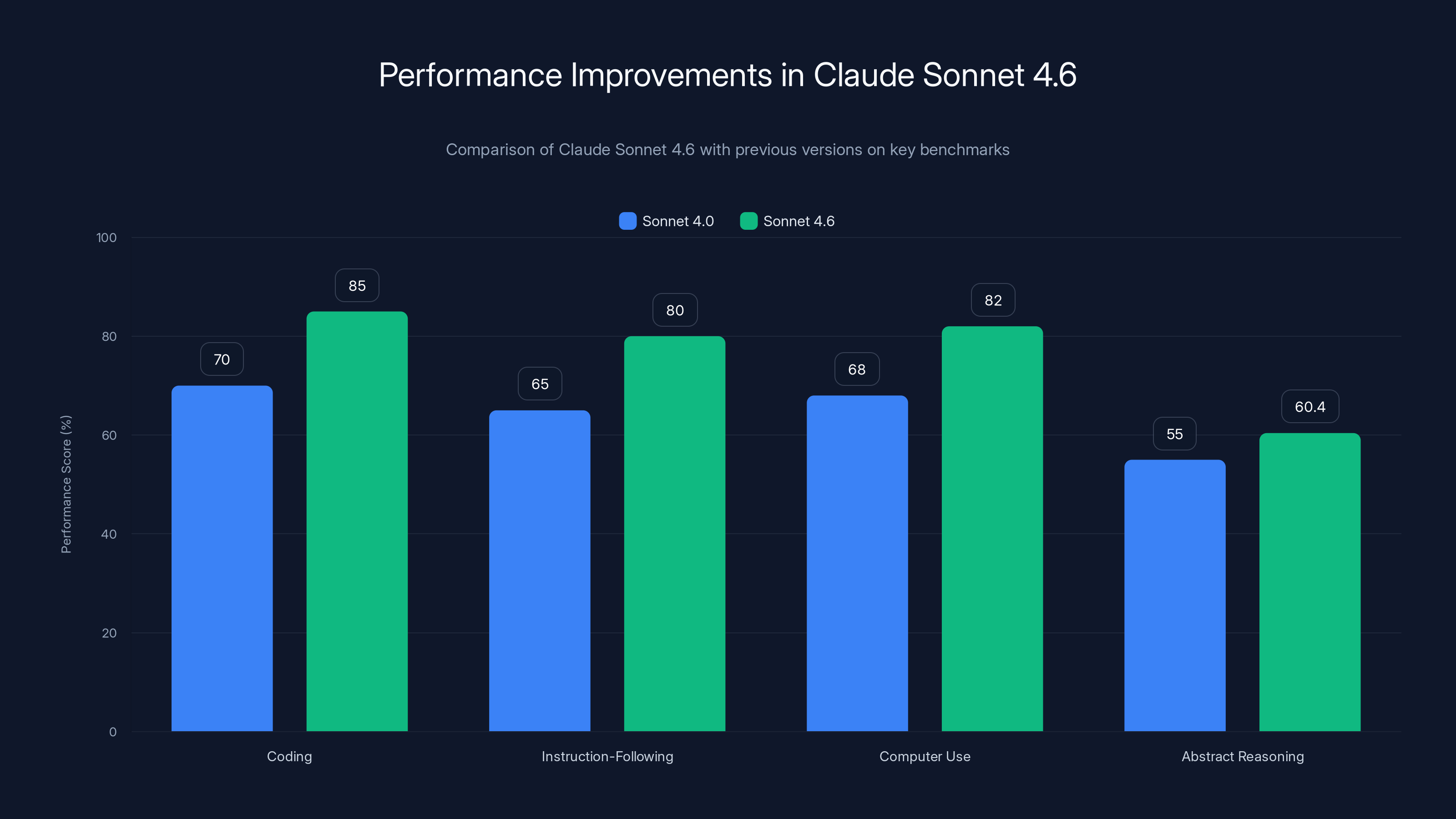
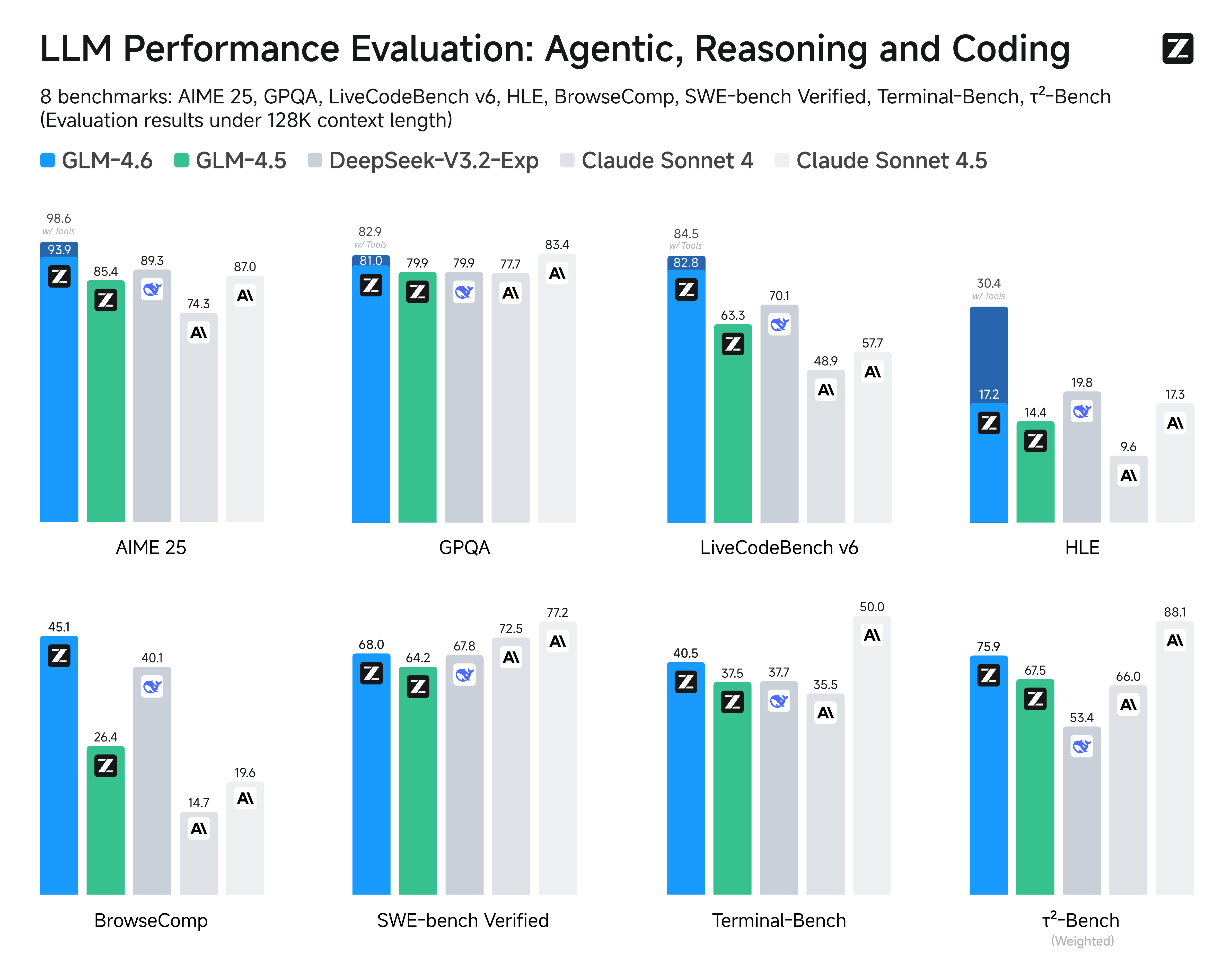
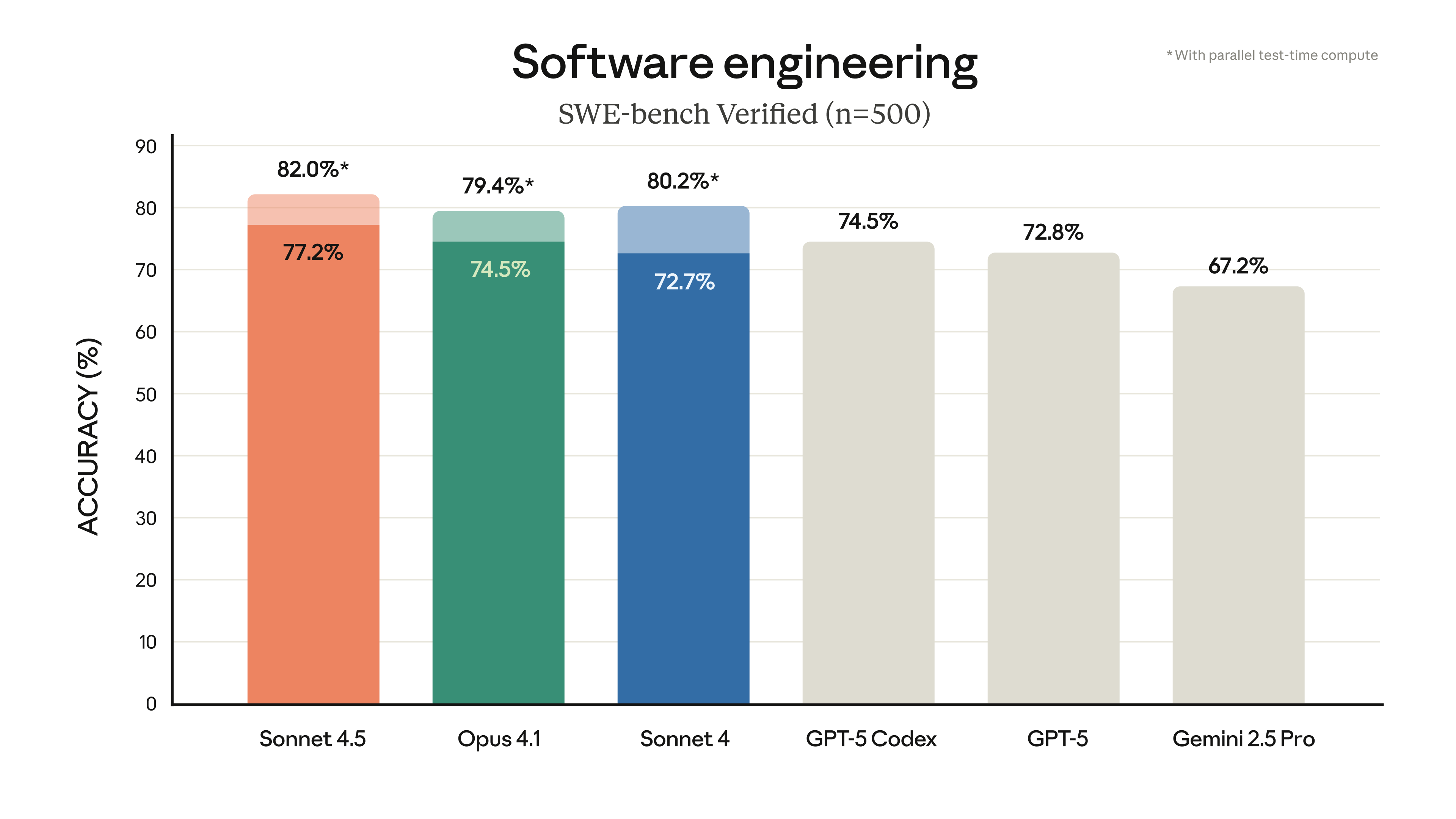
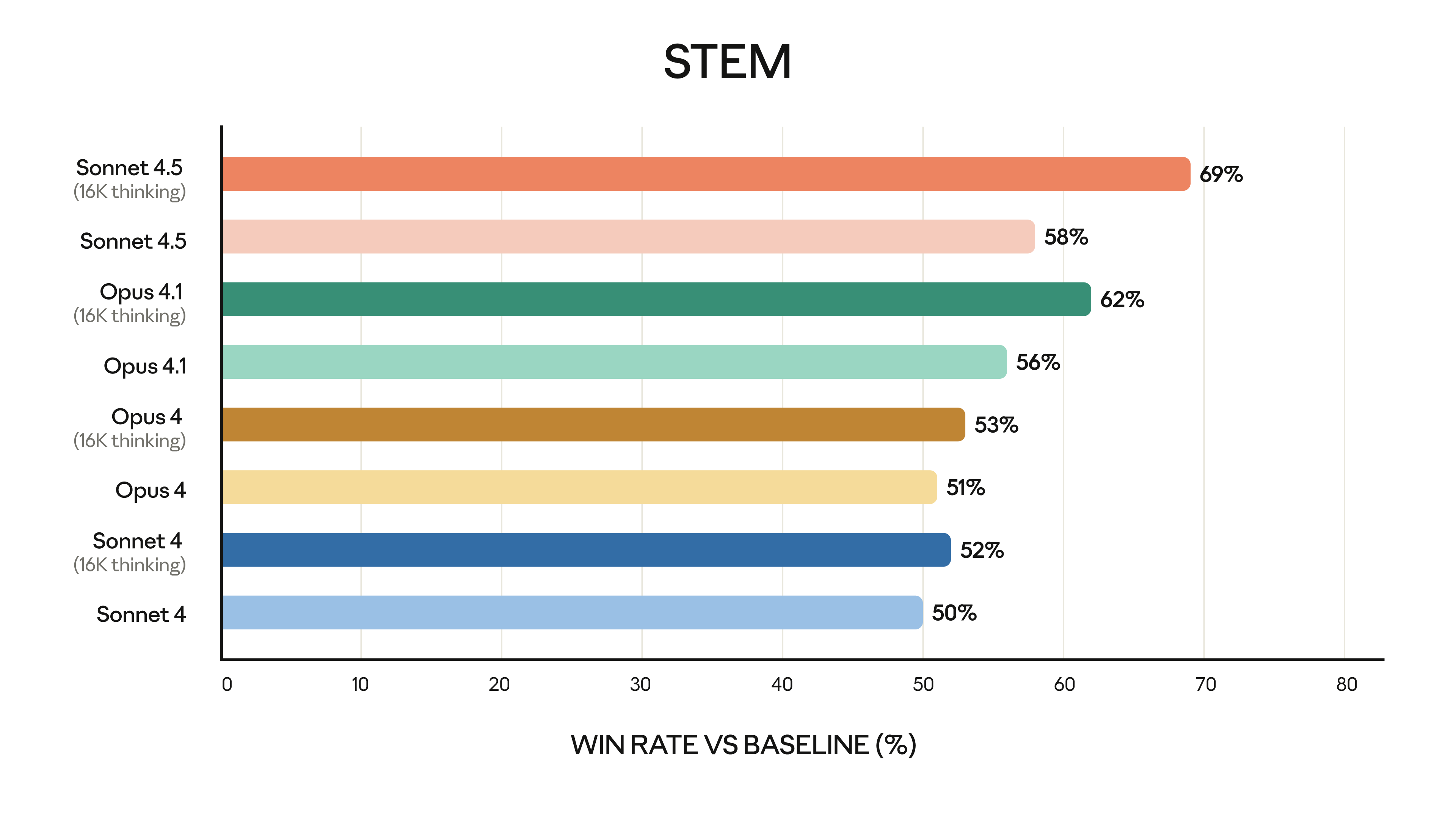
Claude Sonnet 4.6 shows significant improvements over Sonnet 4.0, particularly in coding and instruction-following, with a notable 60.4% score in abstract reasoning (Estimated data).
The Context Window Revolution: What 1 Million Tokens Actually Means
Context window is one of those metrics that sounds abstract until you actually try to use it. Let me make this concrete.
With Sonnet 4.0, you could reasonably fit a large codebase file or a lengthy research paper. With Sonnet 4.6 and its 1 million token context, you're looking at something different entirely. You can now feed the model an entire monorepo structure, all the relevant documentation, and dozens of research papers simultaneously.
To put this in perspective: a typical novel runs about 100,000 words, which translates to roughly 300,000 tokens. A million tokens means you could fit three full-length novels worth of text into a single request. Or more practically, you could include complete API documentation for multiple services, your entire application codebase, architectural diagrams in text form, and previous conversation history all in one conversation.
This sounds nice theoretically, but the practical implications are more significant than they first appear.
Real-World Context Window Applications
Large context windows fundamentally change how you can architect solutions. Instead of chunking information into smaller pieces and making multiple API calls—each with latency and the risk of information loss—you can now pass everything at once. A code review that previously required three separate requests becomes one atomic operation. A contract analysis that meant multiple queries becomes a single, comprehensive pass.
For software engineers, this is transformative. Imagine onboarding to a new codebase. You can paste the entire repository structure, key architectural documents, and the team's decision logs. The model sees the full picture immediately. No more "explain how X works in context of Y, oh wait I need to know about Z too."
For legal and compliance teams, the implications are equally significant. A lengthy contract or regulatory document can be analyzed completely, with cross-references and dependencies understood in their full context. The model doesn't miss implications that live across pages 12 and 43.
The Tokenization Reality Check
Here's where I'll be honest: token limits are useful, but they're not magic. A million tokens sounds enormous until you realize that many real-world tasks still benefit from strategic chunking and structured prompting. Complex analysis of extremely long documents sometimes works better when you break it into logical sections, summarize each, and then ask for synthesis.
The doubling of context is genuinely useful, but it's not a cure-all for prompt engineering discipline. Good developers will still think carefully about how to structure requests. The difference is that you're now optimizing for clarity and logical flow rather than fighting token constraints.
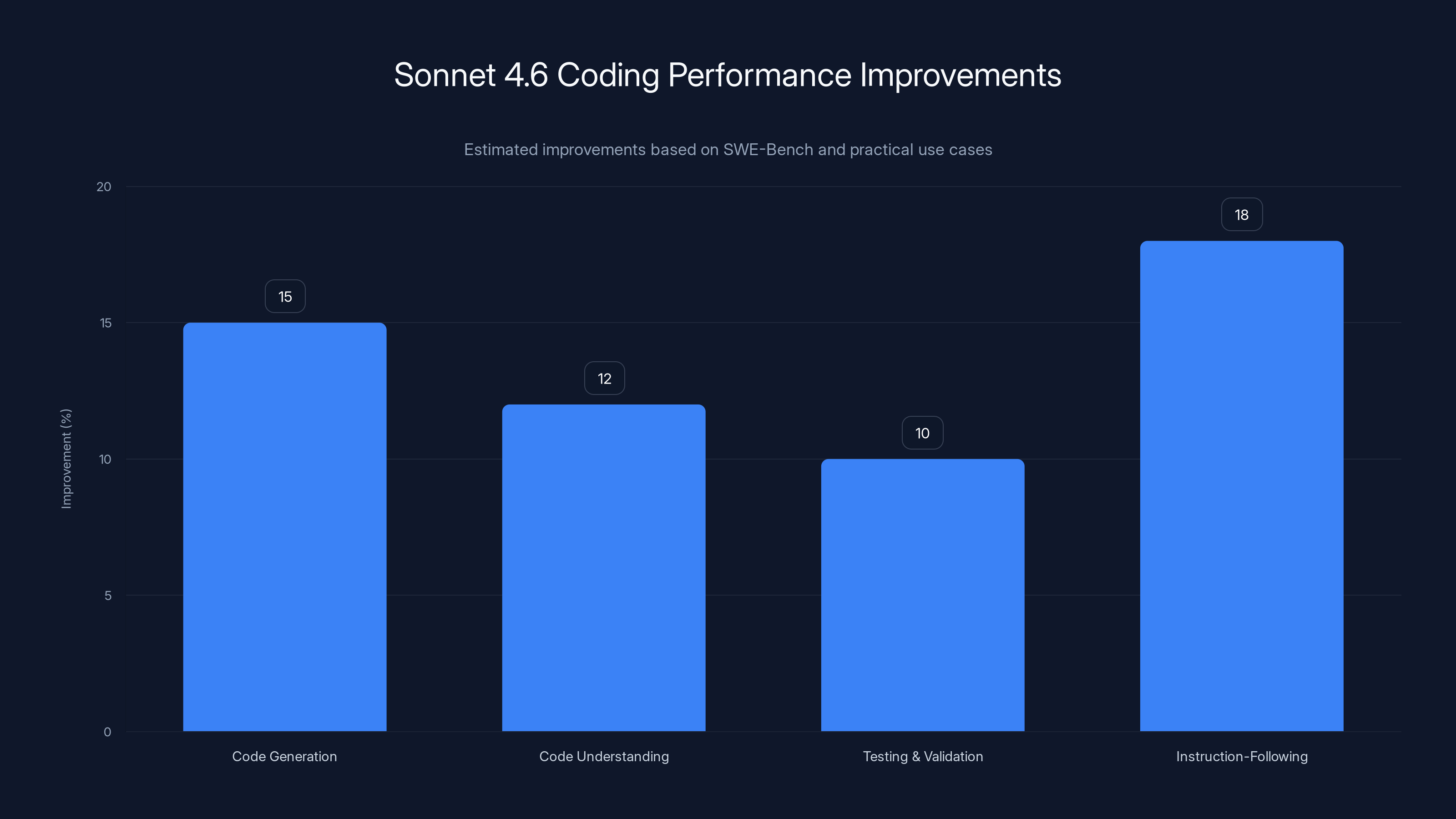
Sonnet 4.6 shows notable improvements in instruction-following and code generation, enhancing coding efficiency. Estimated data based on SWE-Bench and user feedback.
Coding Performance: Where Sonnet 4.6 Actually Excels
This is the metric that matters most for a significant portion of Anthropic's user base. Coding tasks are concrete, measurable, and directly tied to economic value.
Sonnet 4.6 achieved a significant score improvement on SWE-Bench, a standardized benchmark for software engineering tasks. We're talking about real coding work: implementing features, fixing bugs, understanding legacy code, and writing tests. Not toy problems or syntactic exercises.
The improvements manifest in several ways. First, code generation is more reliable. You get fewer hallucinated function signatures or incorrect library calls. Second, code understanding improved. When you ask the model to refactor, optimize, or explain existing code, it makes fewer mistakes about context and intent. Third, testing and validation became more consistent. The model is better at understanding test requirements and writing tests that actually pass.
What "Better Coding" Means in Practice
A 10% improvement on a benchmark sounds modest. In actual use, it means fewer iterations. You might previously need five interactions with the model to get a function right. Now it's three. Multiply that across hundreds of code generation requests per week, and you're looking at real time savings.
For pair programming scenarios (where you're using Claude as a co-developer), the improvement is noticeable. Edge cases that previously required explicit guidance sometimes get handled correctly without prompting. The model understands framework-specific patterns better. When you're working in a specific technology stack, Sonnet 4.6 demonstrates clearer understanding of how components should interact.
Instruction-Following: The Unsung Improvement
Benchmarks highlight coding performance, but the instruction-following improvements might actually be more valuable. This is your ability to give the model specific requirements and have it actually follow them.
Instructions like "always validate input before processing" or "return results in this exact JSON format" or "explain your reasoning before providing the answer" are the scaffolding that makes AI models useful in production systems. If a model ignores your instructions 20% of the time, you can't rely on it. If it ignores them 5% of the time, you still need workarounds and validation.
Sonnet 4.6 follows explicit instructions more consistently. This makes it more suitable for deterministic tasks where you need predictable behavior. It's the difference between using Claude for exploratory analysis (where occasional missteps are tolerable) and using it as part of an automated pipeline (where consistency is mandatory).
Computer Use Benchmarks: From Theoretical to Actually Usable
Computer use is the capability that sounds like science fiction but actually determines whether AI can handle the last-mile problems that make or break automation projects.
OS World is the benchmark that measures this. It tests whether an AI model can look at a desktop or web interface, understand what's on screen, and execute actions to accomplish a goal. Previous versions of Claude could do this at a basic level. Sonnet 4.6 reaches new levels of reliability.
What Computer Use Actually Enables
Think about the tasks that take up disproportionate time in knowledge work. Updating spreadsheets with data from emails. Submitting forms across multiple systems. Extracting information from PDFs and entering it into databases. Scheduling meetings based on calendar data and email requests.
These aren't high-level strategic tasks. They're the grinding repetitive work that humans shouldn't be doing but currently do because it's just slightly too complex for traditional automation. Computer use changes this. A model with strong computer use capabilities can interact with web applications directly, no API required.
Sonnet 4.6 improved at understanding complex UI layouts, interpreting instructions like "click the button that says save but only if the form is valid," and recovering from errors gracefully. When the screen changes unexpectedly, the model adapts. When instructions are ambiguous, it asks clarifying questions instead of making wrong guesses.
The OS World Benchmark Reality
High benchmark scores are nice, but they're not the full story. OS World tests in controlled environments with known tasks. Real-world computer use is messier. Legacy applications have terrible UI. Websites change frequently. Error messages are cryptic. Network hiccups happen.
That said, Sonnet 4.6's improvement on OS World does translate to more reliable real-world performance. The model is better at recovering from partial failures, understanding what went wrong, and adjusting strategy.
For teams building internal automation tools or considering RPA (robotic process automation) augmented with AI, this is the version where things finally work reliably enough to justify the engineering effort.
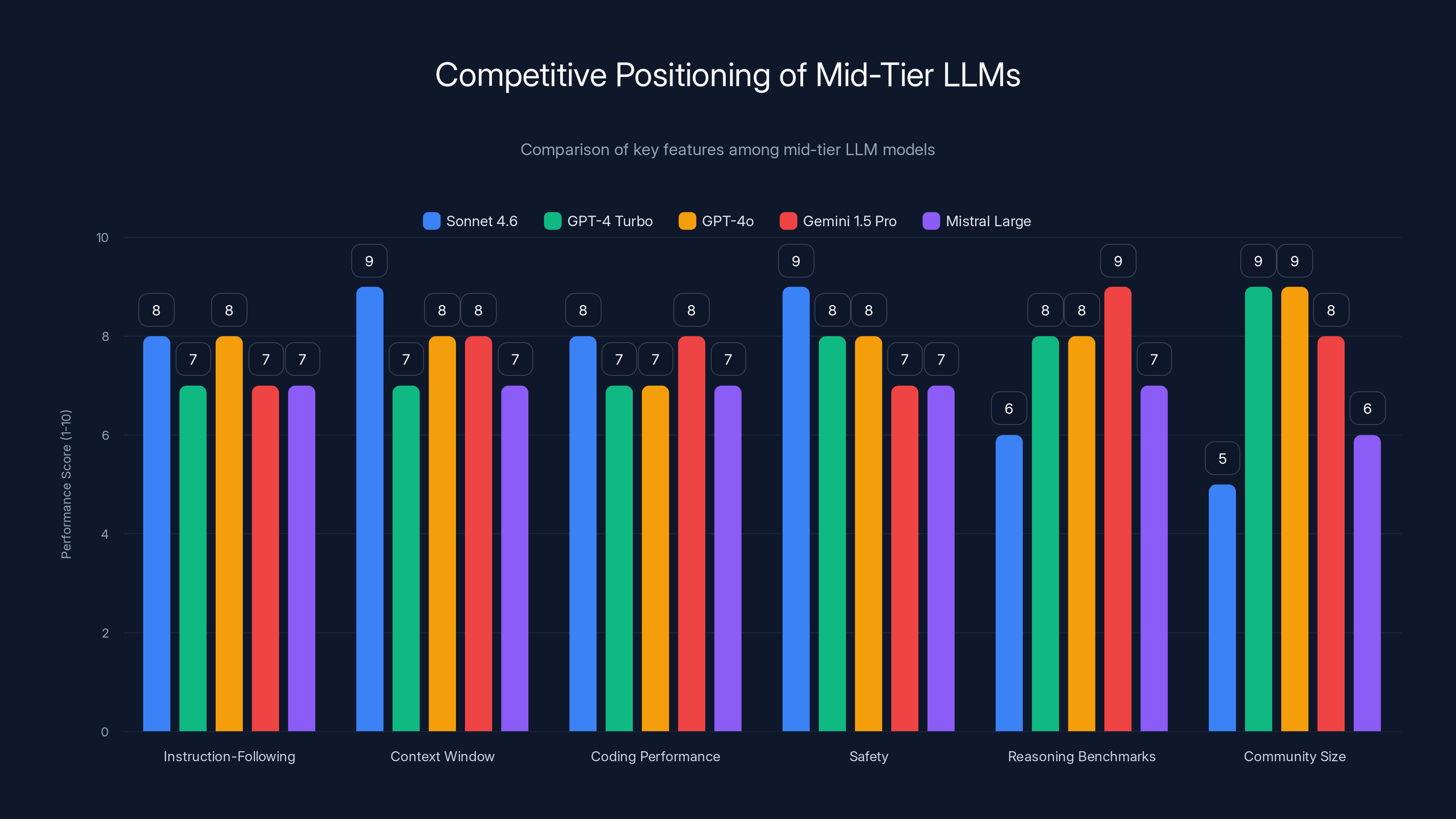
Sonnet 4.6 excels in instruction-following and safety but lags in reasoning benchmarks and community size compared to competitors. Estimated data based on typical model capabilities.
ARC-AGI-2 and the Measurement Problem
Anthropic highlighted a 60.4% score on ARC-AGI-2, which measures reasoning skills specific to human-level intelligence. This score is genuinely impressive, placing Sonnet 4.6 above most contemporary models.
Here's the important context: ARC-AGI-2 is a genuinely difficult benchmark. It's not "answer questions about facts" or "complete sentence patterns." It's abstract reasoning. Looking at patterns and understanding rules that weren't explicitly stated. The kind of thinking that tests whether a model has something resembling genuine understanding versus pattern matching at scale.
What These Benchmark Scores Actually Tell Us
Sonnet 4.6 still trails Opus 4.6, Gemini 3 Deep Think, and certain configurations of GPT 5.2. This is expected and appropriate. There's a capability hierarchy in the Claude ecosystem. Sonnet is positioned as the capable workhorse, not the top-tier heavyweight.
But the fact that a "mid-tier" model scores 60.4% on ARC-AGI-2 tells us something important about how far the baseline has moved. Two years ago, this score would have been state-of-the-art. Now it's "very good for the price point."
The real insight here: benchmark improvements matter less than the relationship between capability, cost, and speed. Sonnet 4.6 costs less than Opus and runs faster. If it can solve 90% of your problems, Opus's 95% score doesn't justify double the cost and latency.
The Release Timing: Strategic Pacing and Competitive Pressure
Two weeks after Opus 4.6, Sonnet 4.6 arrives. This isn't accidental. Anthropic is maintaining a deliberate release cadence.
The four-month update cycle that Anthropic has established is interesting strategically. It's not as frequent as some competitors but more frequent than others. It's a pace that allows for genuine improvements while providing clear signal that Anthropic isn't standing still.
The Competitive Landscape
Open AI has been releasing updates on a somewhat irregular schedule, sometimes faster, sometimes slower. Google Deep Mind announced Gemini 3, which raised the bar for reasoning and efficiency. Mistral is pushing on efficiency. Everyone is racing on context window length and reasoning capabilities.
Anthropic's approach is to avoid the trap of following competitors and instead set its own rhythm. Four months is enough time to implement meaningful improvements without feeling pressured into incremental releases that don't justify their own announcement.
What This Means for Users
For developers and teams using Anthropic's API, this cadence means you can plan. Expect updates roughly every four months. Improvements are usually meaningful but not so drastic that they break existing implementations. You're not chasing a moving target every two weeks.
For enterprises evaluating AI infrastructure, this is a stability signal. Anthropic isn't going to introduce breaking changes every month. There's strategic thinking behind the release schedule.
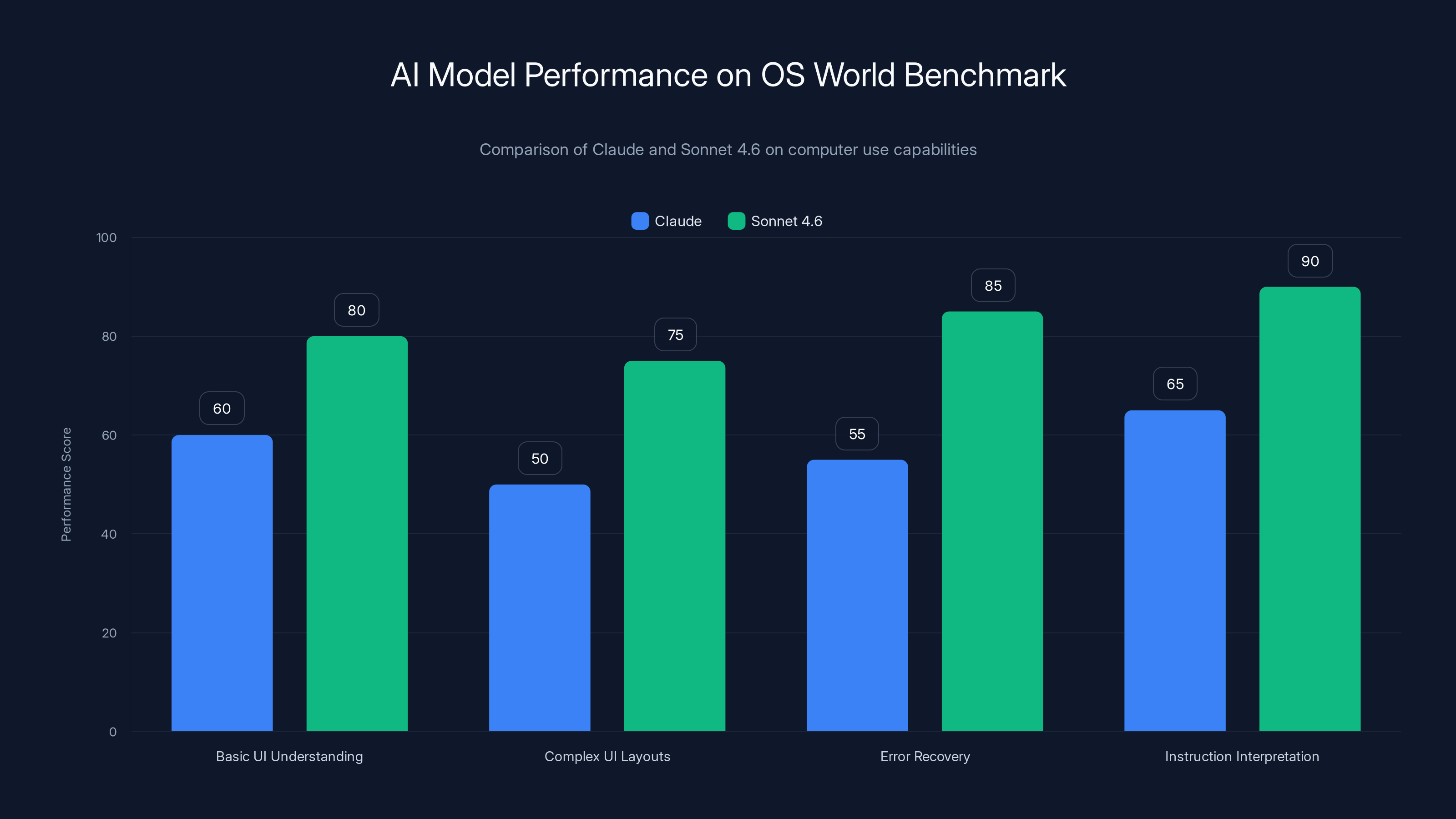
Sonnet 4.6 shows significant improvements over Claude in handling complex UI layouts and recovering from errors, indicating enhanced real-world applicability. Estimated data.
Integration with Runable: Automating AI-Powered Workflows
As teams integrate Sonnet 4.6 into their workflows, tools that orchestrate these capabilities become increasingly valuable. Runable, an AI-powered automation platform, provides a compelling way to leverage models like Sonnet 4.6 without building custom infrastructure.
Runable enables teams to create AI presentations, documents, reports, and automated workflows using Sonnet's capabilities directly. Rather than writing API integrations yourself, you can design workflows that feed data to Sonnet, process responses, and generate structured outputs—all with visual configuration.
For coding tasks, Sonnet 4.6's improved instruction-following makes it ideal for Runable's code generation workflows. For document analysis leveraging that 1 million token context, Runable provides a layer that handles tokenization and context management automatically.
Use Case: Automatically generate weekly reports from your codebase insights using Sonnet 4.6's improved context understanding
Try Runable For FreeThe value proposition: You get Sonnet 4.6's raw capability but wrapped in automation infrastructure that handles the plumbing. No more managing API keys, retries, error handling, and response parsing manually. Starting at $9/month, Runable makes it practical to build AI-powered automation on top of Anthropic's models.

Default Model Implications: What It Means When Sonnet Becomes the Standard
Sonnet 4.6 is now the default model for Free and Pro plan users on Claude.ai. This is significant in ways that go beyond surface-level feature announcements.
When a model becomes the default, it's no longer competing on the merits of a feature list. It's competing on what the average user experiences without making an explicit choice. This changes incentives dramatically.
The Network Effects
More users on Sonnet 4.6 means more diverse usage patterns, more edge cases discovered, and more real-world data about where the model succeeds and fails. Anthropic can use this to inform the next iteration.
It also means the model gets battle-tested in ways that beta programs and API usage never fully capture. A researcher exploring a tangential idea with a free account might discover a useful pattern. A student using Claude for homework might expose failure modes in edge cases.
This feedback loop is valuable. It's how models improve from merely "very good" to "everyone uses this."
Pricing and Tier Strategy
Sonnet 4.6 as the default for Pro users is also a statement about value positioning. Anthropic is saying: "The version that most businesses need is the mid-tier. Opus is for specialized cases." This is different from competitors who sometimes push their premium models as defaults.
It's a confidence statement. Anthropic is betting that Sonnet 4.6 is capable enough for the majority of use cases. If the model fails to deliver, users will upgrade to Opus. If it delivers reliably, users stay and the economics work.

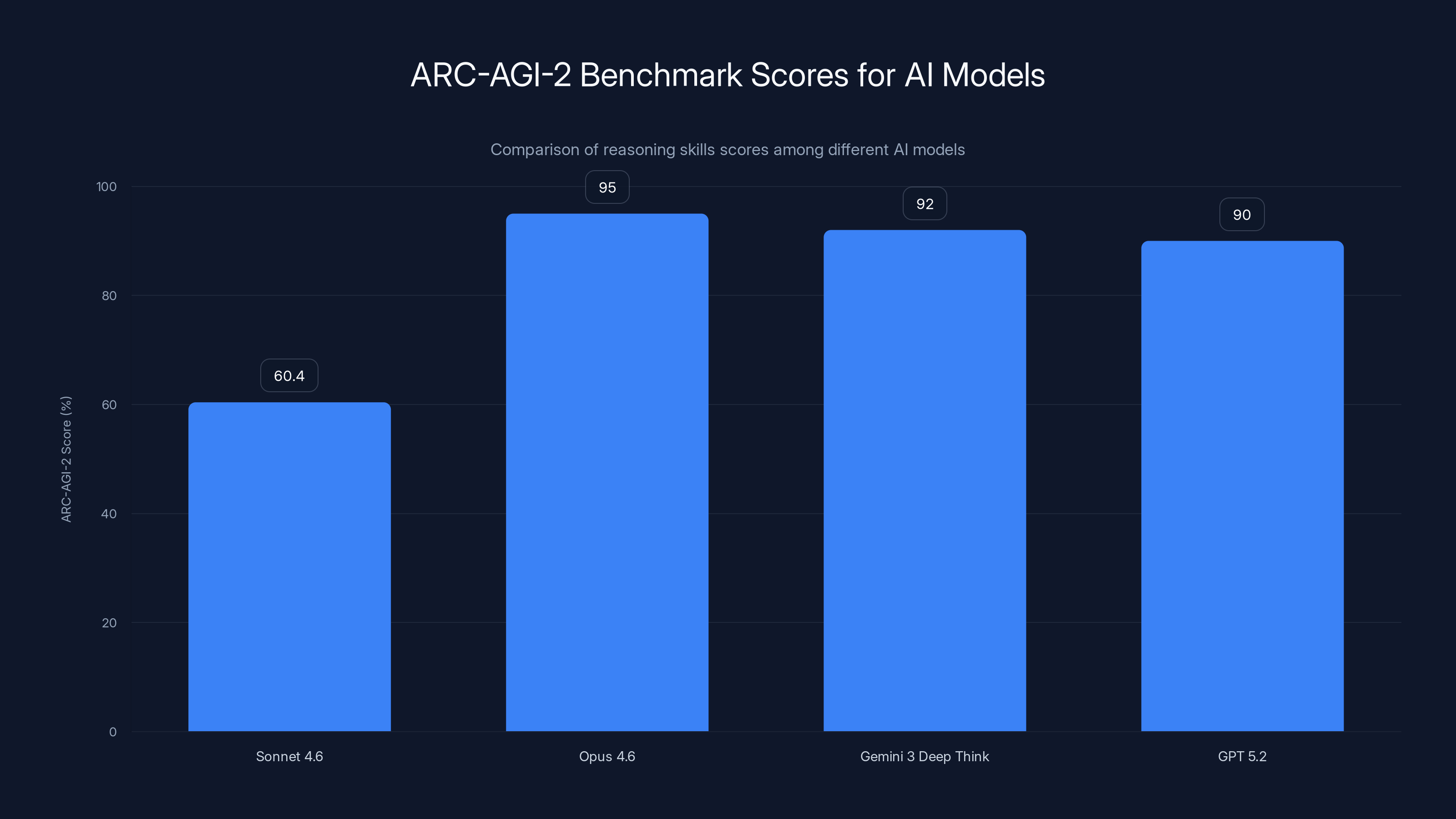
Sonnet 4.6 scores 60.4% on ARC-AGI-2, showcasing strong reasoning skills, though trailing behind higher-tier models like Opus 4.6 with 95%. Estimated data for Opus, Gemini, and GPT.
Technical Architecture: What Probably Changed Under the Hood
Anthropic doesn't share detailed architectural information about Sonnet 4.6, but we can infer some things based on the improvements and release notes.
The 1 million token context window likely involved changes to how the model handles attention across long sequences. There are a few approaches: local attention patterns, sparse attention, or hybrid schemes that combine global and local attention. Whatever Anthropic implemented, it maintains quality while extending context length. That's non-trivial engineering.
The coding improvements probably involved additional training on diverse code repositories and refinement of instruction-following through reinforcement learning from human feedback (RLHF). Better instruction-following suggests improvements in how the model interprets and weights different aspects of a prompt.
Computer use improvements likely came from more diverse training data on UI interactions, better error recovery logic, and improved "world modeling" where the model maintains understanding of what's on screen as changes occur.
None of this is confirmed, but it aligns with how other AI labs have approached similar improvements.
The Training Data Question
One question that remains unresolved: how much of Sonnet 4.6's improvement comes from better training data versus architectural innovation? Anthropic is notably careful about training data composition and quality. If the improvements came primarily from data rather than architecture, that's a signal about Anthropic's commitment to data quality over pure scaling.
For users, this distinction matters because it affects the model's behavior on edge cases and unusual inputs. If improvements came from thoughtful data curation, the model likely behaves more predictably. If they came from architectural scaling, improvements might be broader but less consistent.
Practical Migration Path: Moving from Sonnet 4.0 to 4.6
If you're currently using Sonnet 4.0 or earlier, should you migrate? The answer depends on your specific use case, but here's a framework.
Use Cases Where Upgrade Is Compelling
If you're doing heavy coding work, the improvement is worth the effort. If you're analyzing large documents or codebases, the context window alone is transformative. If you're implementing computer use automation, the reliability improvements justify the change.
If you're doing exploratory creative work or casual research, the differences might be subtle enough that migration doesn't matter.
Migration Considerations
Sonnet 4.6 changes behavior slightly. It follows instructions more consistently, which is good, but it might change answers you were relying on in some edge cases. You should expect to need some prompt refinement. The improved instruction-following sometimes means the model will refuse requests that previous versions might have interpreted loosely. This is generally better security, but it might require prompt adjustments.
The context window doubling doesn't require changes, but it enables changes. You can now do things that weren't practical before. Starting to leverage this means rethinking how you structure requests.
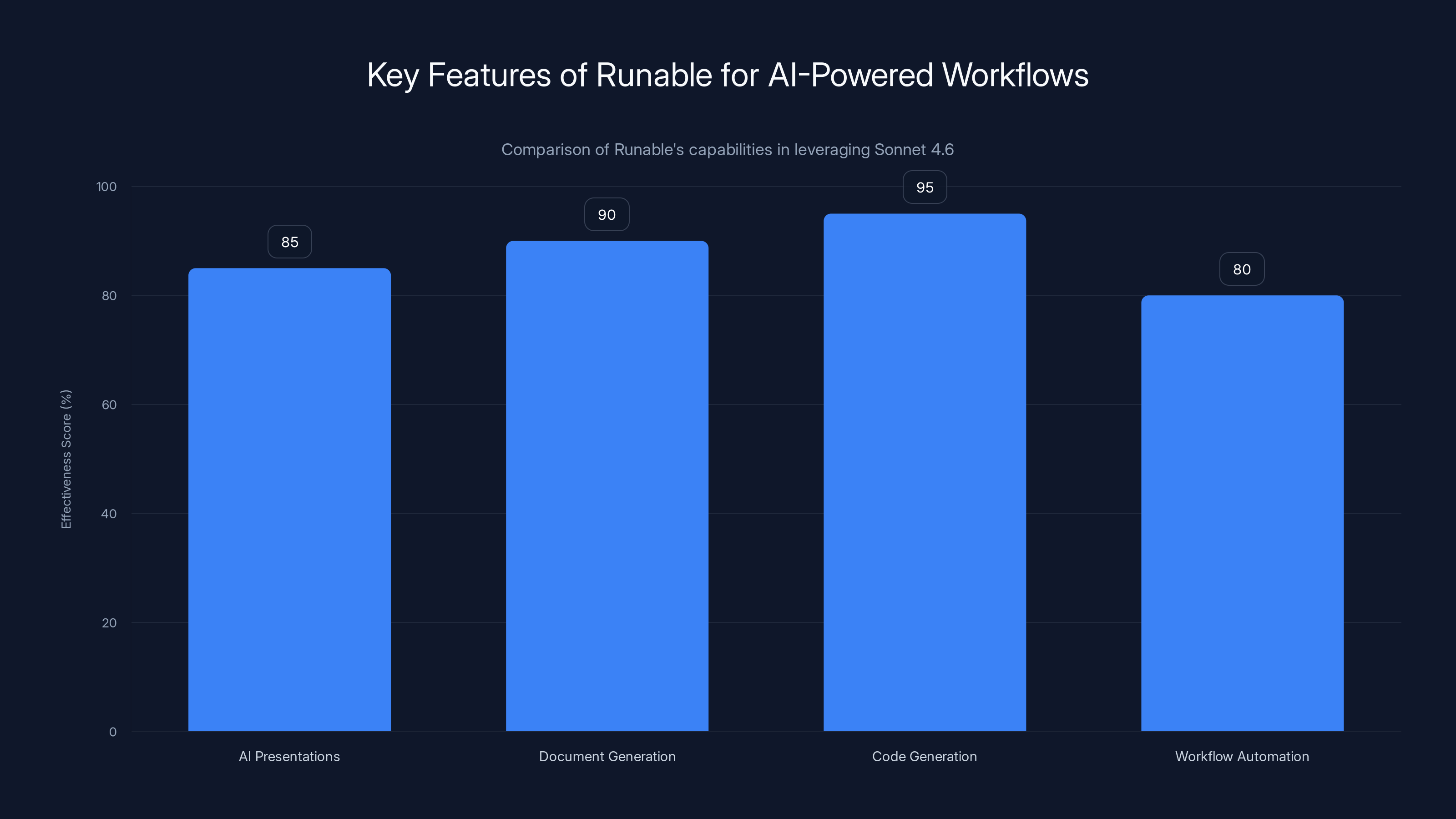
Runable excels in code generation and document creation, leveraging Sonnet 4.6's capabilities effectively. Estimated data.
Cost-Benefit Analysis: Is Sonnet 4.6 the Right Choice for Your Workload?
Capability improvements are interesting, but they matter only in the context of cost and speed tradeoffs.
Sonnet 4.6 costs less than Opus. It runs faster. But it's less capable for the most complex reasoning tasks. The economics work when you have workloads that Sonnet can handle reliably. If you're constantly hitting the ceiling of Sonnet's capabilities, Opus becomes cost-effective despite higher per-token pricing.
Simple Decision Matrix
| Workload Type | Recommended Model | Reasoning |
|---|---|---|
| Exploratory coding, prototyping | Sonnet 4.6 | Cost-effective, good enough for ideas |
| Production code generation | Sonnet 4.6 | Instruction-following improvements ensure reliability |
| Complex reasoning, research | Opus 4.6 | Need the extra capability |
| Document analysis at scale | Sonnet 4.6 | Context window sufficient for most documents |
| Web automation | Sonnet 4.6 | Computer use improved substantially |
| Specialized domain tasks | Depends | Test both, measure results |
The real insight: measure, don't assume. Run your actual workloads on both models for a week. Compare results and costs. The model that's right for you isn't determined by benchmarks—it's determined by your specific tasks and budget constraints.
Competitive Positioning in the LLM Landscape
Sonnet 4.6 exists in a competitive market where multiple players offer capable mid-tier models. How does it actually stack up?
Open AI's GPT-4 Turbo and GPT-4o are in similar territory. Google's Gemini 1.5 Pro offers comparable capability with different strengths. Mistral's Mistral Large competes on efficiency.
Sonnet 4.6's advantages: better instruction-following, larger context window than most mid-tier models, genuinely improved coding performance, and strong safety characteristics (Anthropic's focus). Disadvantages: less cutting-edge on some reasoning benchmarks, smaller user community than Open AI models, fewer integrations in ecosystem tools.
For teams already using Anthropic's platform, Sonnet 4.6 is clearly the right choice for most tasks. For teams evaluating fresh, the decision should be based on your specific needs and existing infrastructure investments.
Future Roadmap Signals: What's Next?
Anthropic has indicated that Haiku should receive updates soon, completing the tier-wide refresh. Beyond that, speculation is necessary, but some patterns suggest directions.
Context windows will likely continue extending. Processing longer sequences is useful, and there's still runway before they hit technical limits. Reasoning capabilities will improve, particularly on domain-specific tasks where training data is abundant.
Computer use will become more sophisticated. The current version handles web interfaces reasonably well. Future versions will likely handle desktop applications, complex multi-step workflows, and error recovery more gracefully.
Speed is always a priority. Inference optimization has become a major area of focus across the industry. Expect Sonnet 4.7 or 5.0 to be meaningfully faster than 4.6, not just more capable.
Multimodal improvements are inevitable. Current Claude supports vision, but improvements in video understanding, audio processing, and integrated multi-modal reasoning are coming.
What This Means for Planning
If you're building on Sonnet 4.6, don't assume the model will stay static. Build with the expectation that you'll migrate to newer versions as they release. Don't hard-code specific model behaviors into your systems. Design with flexibility so you can swap models without rewriting core logic.
Real-World Implementation Considerations
Benchmarks and capability statements are useful, but actual implementation has practical challenges that benchmarks don't capture.
Prompt Engineering Still Matters
Sonnet 4.6 is better at following instructions, but you still need to write clear prompts. The improvement is that marginal prompts that previously required refinement now work acceptably. Clear prompts work better than before, but poorly written prompts still produce poor results.
Token Counting Remains Important
The 1 million token context sounds unlimited until you realize that context costs money and affects latency. A request using 900,000 tokens is expensive and slow. Efficiently using your available context requires thought about what information matters for your specific task.
Error Handling Must Still Exist
No model is perfect. Sonnet 4.6 is better, but it will still make mistakes. Production systems need validation, error detection, and fallback paths. Assuming the model always works correctly is a recipe for operational disasters.

The Broader Context: AI Model Evolution and What It Means
Sonnet 4.6 is one data point in a broader trend where AI models are becoming more capable, more reliable, and more efficient simultaneously. That's unusual historically. Typically, you trade off capability for speed or capability for cost. Sonnet manages to improve across multiple dimensions.
This suggests the industry is hitting genuine algorithmic and architectural improvements, not just scaling existing approaches. Scaling alone eventually hits diminishing returns. When you see consistent improvements in capability, speed, and efficiency, it suggests the approaches being used are actually fundamental improvements to how these models work.
For the economy and labor market, this trend is significant. Tasks that required human expertise two years ago are now delegated to models like Sonnet. Tasks that seemed impossible to automate are becoming feasible. The competitive advantage shifts from "Can we build this?" to "Can we build this cost-effectively and fast enough?"
For individual developers and knowledge workers, tools like Sonnet 4.6 are becoming productivity multipliers. The engineers who learn how to leverage these tools effectively will outcompete those who don't. The gap between "can use AI" and "can't" is becoming a major competitive factor.
FAQ
What is Claude Sonnet 4.6 and how does it differ from previous versions?
Claude Sonnet 4.6 is Anthropic's mid-tier AI model released in early 2025, offering significant improvements over Sonnet 4.0 across coding, instruction-following, and computer use capabilities. The most substantial change is the context window doubling to 1 million tokens, allowing the model to process entire codebases, multiple research papers, and lengthy documents in a single request without the limitations that affected previous versions.
How does the 1 million token context window actually improve practical usability?
The expanded context window eliminates the need to split large tasks into multiple API calls, reducing latency and information loss. A code review that previously required three separate requests now becomes one atomic operation with full context. For document analysis, contracts and specifications can be examined completely without missing cross-page dependencies. This particularly benefits software engineering tasks where understanding relationships between different parts of a codebase requires comprehensive context.
What are the key performance improvements in Sonnet 4.6?
Sonnet 4.6 achieved measurable improvements across multiple standardized benchmarks, particularly SWE-Bench for software engineering and OS World for computer use. The model demonstrates enhanced instruction-following consistency, meaning it more reliably adheres to specific requirements like output formatting and validation steps. The 60.4% score on ARC-AGI-2 places it above most comparable mid-tier models, indicating stronger abstract reasoning capabilities.
Should I migrate from older Claude models to Sonnet 4.6?
Migration makes sense if you're doing coding work, analyzing large documents, or implementing computer use automation. The improvements in these areas are substantial enough to justify change. For exploratory creative work or casual research, the differences might not justify migration effort. Test your most critical use cases with Sonnet 4.6 for a week to measure the actual impact before committing to widespread changes.
How does Sonnet 4.6 compare cost-wise to using Opus for production work?
Sonnet 4.6 costs less per token and executes faster than Opus 4.6, making it the economical choice for workloads it can handle reliably. Use Sonnet for production code generation, document analysis, and routine automation. Reserve Opus for complex reasoning tasks where the additional capability is necessary. For most business use cases, Sonnet 4.6 provides sufficient capability at substantially better cost-per-task economics.
What does the computer use improvement actually enable in practice?
Improved computer use capabilities make web and application automation substantially more reliable. Tasks like updating spreadsheets from email data, submitting forms across multiple systems, or extracting information from PDFs for database entry become practical without custom API development. The model better understands complex UI layouts, recovers gracefully from errors, and adapts when screens change unexpectedly.
When will Haiku be updated to match the Sonnet 4.6 refresh cycle?
Anthropic indicated that Haiku updates are coming as part of the comprehensive tier refresh, though specific timing hasn't been announced. Based on the four-month release cycle observed with previous updates, expect a Haiku 4.6 release within the coming weeks. The update pattern suggests Anthropic refreshes all three tiers (Haiku, Sonnet, Opus) roughly simultaneously every four months.
How does instruction-following improvement change how I should write prompts?
Better instruction-following means marginal prompts that previously required extensive refinement now work acceptably. However, clear prompt engineering remains important. Write specific instructions about output format, validation requirements, and reasoning approach. The improvement is that the model will follow these instructions more consistently without requiring redundant reinforcement or complex workarounds.
Is the million token context window actually "unlimited" in practice?
No. While 1 million tokens is substantial, it's not infinite, and context costs money both in API pricing and latency. A request using 900,000 tokens is expensive and slow compared to a more efficient 50,000 token request. Effective usage requires strategic thinking about what information actually matters for your specific task and excluding unnecessary data even though you technically have space for it.
What integrations and tools work best with Sonnet 4.6?
Platforms like Runable provide orchestration layers that make it practical to build AI-powered automation on top of Sonnet 4.6 without managing API infrastructure manually. Anthropic's API documentation provides comprehensive integration guidance, and most existing Claude integrations work directly with Sonnet 4.6 as the default model without code changes.

Conclusion: The Practical Reality of Sonnet 4.6
Sonnet 4.6 isn't revolutionary. It's evolutionary. But evolution in the right direction matters more than revolution in uncertain directions.
The 1 million token context changes how you can architect solutions. The coding improvements make AI-assisted development more practical. The computer use reliability makes automation feasible for tasks that previously required custom development. The instruction-following consistency makes the model suitable for more deterministic, production-grade work.
For the Anthropic ecosystem, this is a model that delivers on the promise made by earlier Claude versions. It's the first time I'd unreservedly recommend Sonnet as the default choice for most business use cases. Previous versions were "good but sometimes you need Opus." Sonnet 4.6 is "use this first, escalate to Opus only when you hit the ceiling."
The competitive landscape hasn't fundamentally shifted. Open AI, Google, and other players continue releasing capable models. But Anthropic has positioned Sonnet 4.6 in a sweet spot: significantly more capable than lightweight models, meaningfully less expensive than top-tier options, and optimized for the tasks that actually generate economic value for businesses.
For developers and technical leaders evaluating AI infrastructure, Sonnet 4.6 deserves serious consideration. For teams already using Claude, this is the version that finally makes the promises practical.
The real question isn't whether Sonnet 4.6 is good. It clearly is. The question is whether your current workloads would benefit from the improvements enough to justify migration. For most teams doing coding work, document analysis, or automation, the answer is yes. For others, the differences are incremental.
Test it. Measure the real impact on your specific tasks. Make the decision based on data, not marketing claims. That's the only rational approach when capability improvements matter less than the economic value they actually deliver.
The AI landscape moves fast. Sonnet 4.6 won't be the state-of-the-art in a year. But for right now, in February 2025, it's a legitimate workhorse that handles most business AI workloads competently and cost-effectively. That's not flashy, but it's actually useful.
Key Takeaways
- Sonnet 4.6 doubles the context window to 1 million tokens, enabling processing of entire codebases and dozens of research papers simultaneously
- Coding performance improvements with new benchmarks in SWE-Bench combined with enhanced instruction-following make this the first genuinely reliable mid-tier model for production use
- Computer use capabilities reached new reliability levels measured on OS World, making web and application automation practical without custom API development
- Default positioning for Free and Pro users signals Anthropic's confidence that Sonnet 4.6 handles 80%+ of real business use cases, with Opus reserved for specialized complex reasoning
- Four-month release cadence provides strategic stability while maintaining competitive parity, with Haiku updates coming soon to complete the tier refresh
Related Articles
- Anthropic Opus 4.6 Agent Teams: Multi-Agent AI Explained [2025]
- Kilo CLI 1.0: Open Source AI Coding in Your Terminal [2025]
- Amazon Alexa Plus Nationwide Launch: Pricing, Features & Comparison [2025]
- ChatGPT-4o Ending February 2025: Complete Survival Guide & Alternatives [2025]
- Moonshot Kimi K2.5: Open Source LLM with Agent Swarm [2025]
- Apple's Gemini-Powered Siri Coming February 2026 [Update]

