![Kilo CLI 1.0: Open Source AI Coding in Your Terminal [2025]](https://tryrunable.com/blog/kilo-cli-1-0-open-source-ai-coding-in-your-terminal-2025/image-1-1770237609927.jpg)
Introduction: The Terminal is Back, and It's Agentic
You're 2 a.m. on a Tuesday. Your production database is throwing errors you've never seen before. You SSH into the server, fingers moving across your keyboard, and suddenly you realize: you're about to debug this alone, in a terminal window, without any fancy IDE sidebar suggesting fixes.
This is where most AI coding tools fail you.
For the past two years, the AI coding narrative has been dominated by sidebar plugins. GitHub Copilot lives in VS Code. Cursor built an entire IDE around AI suggestions. OpenAI launched a dedicated Codex app. They all optimize for one thing: developers working in a graphical interface, in their local IDE, during business hours.
But real engineering—production firefighting, infrastructure work, remote server configuration, late-night debugging—doesn't always happen in an IDE. Sometimes it happens in SSH sessions. Sometimes it happens across five different tools at once. Sometimes it happens in Slack, where your entire team is coordinating the response.
This is the gap Kilo is attacking with its new CLI 1.0 release. And they're doing it with radical openness: support for over 500 AI models, an MIT-licensed open source foundation, model-agnostic architecture, and a pricing model that strips away the black-box mystery of most AI tool subscriptions.
The strategic bet is clear: the future of AI development isn't about one interface, one model, or one vendor lock-in scenario. It's about tools that follow engineers wherever they go—IDE, terminal, Slack thread, remote server—without forcing context switching or starting from scratch each time.
Let's break down what Kilo CLI 1.0 actually does, how it works, why the architectural choices matter, and whether this kind of "anywhere AI" approach represents the future of developer tooling or just another niche player in an increasingly crowded space.
TL; DR
- Model Agnosticism: Kilo CLI 1.0 supports 500+ AI models including Anthropic, OpenAI, Google Gemini, and open source options, avoiding vendor lock-in.
- Terminal-First Design: Built specifically for remote SSH sessions, production debugging, and infrastructure work where GUI IDEs aren't practical.
- Agentic Architecture: Multiple operational modes—Code Mode, Architect Mode, Debug Mode—enable autonomous task management beyond autocompletion.
- Persistent Memory: "Memory Bank" feature maintains context across sessions using structured Markdown files, solving AI amnesia problems.
- Transparent Pricing: Kilo Pass charges exact provider API rates with zero commission, starting at $19/month for Starter tier with momentum rewards.
- Ecosystem Integration: Model Context Protocol (MCP) support enables integration with custom tools, documentation servers, and monitoring systems.
- Bottom Line: Kilo positions AI coding as infrastructure that travels with engineers rather than being confined to a single IDE or interface.
Kilo CLI 1.0 excels in model support and pricing transparency compared to GitHub Copilot and Cursor. It also offers strong team collaboration features. (Estimated data)
Why the Terminal Matters: The Real Engineering Narrative
Here's the thing about modern software development narratives: they're often told by people who work during normal business hours in comfortable development environments.
The reality is messier. A 2024 Stack Overflow survey found that 62% of developers spend at least 4 hours per week working in terminal environments, and 38% spend more than 8 hours. For DevOps engineers, site reliability engineers, and backend infrastructure teams, that number is closer to 80%.
Terminal work includes:
- Production incident response: SSH into a server at midnight, diagnosis is happening in a shell session.
- Infrastructure configuration: Terraform applies, Kubernetes manifests, Docker debugging—rarely done through a GUI.
- Remote development: Working on a server that hosts the only instance of your development database.
- Legacy system maintenance: Sometimes you're accessing a 15-year-old system through SSH because that's how it was built.
- DevOps automation: Writing and debugging automation scripts, often in a headless environment.
When you're in these contexts, an IDE sidebar doesn't help. You don't have VS Code open. You have a terminal, maybe vim or nano if you're editing files, and you need AI assistance that works in that environment.
Kilo CEO Scott Breitenother articulated this clearly: "The developer who moves between their local IDE, a remote server via SSH, and a terminal session at 2 a.m. to fix a production bug—they shouldn't have to abandon their workflow just because they're not in VS Code."
This observation is the entire premise of Kilo CLI 1.0. The company isn't trying to replace Cursor or GitHub Copilot. They're trying to fill the gap where those tools fundamentally don't operate.
Architecture Deep Dive: Rebuilding for "Kilo Speed" and Agentic Behavior
Kilo CLI 1.0 represents a complete architectural rebuild from the previous version. The company ditched incremental improvements and instead rewrote the foundation to enable what they call "agentic" behavior—AI agents that can manage end-to-end tasks independently rather than just suggesting the next line of code.
The core architectural decisions reveal a thoughtful approach to solving real engineering problems:
Operating Modes: Beyond Autocompletion
Traditional AI coding assistants operate in essentially one mode: given your cursor position and surrounding context, suggest what comes next. This works fine for filling in function implementations or generating boilerplate.
Kilo CLI 1.0 moves beyond this with three distinct operational modes:
Code Mode is optimized for high-speed code generation and multi-file refactors. When you're restructuring a large module or performing a sweeping change across multiple files, Code Mode can understand the scope of the refactor and make consistent changes across the codebase. It's not suggesting one line at a time—it's orchestrating multi-file changes.
For example, if you're renaming a core class that's referenced in 47 different files, Code Mode can understand the full scope of that change and execute it consistently, updating not just the class definition but all imports, interface implementations, and references.
Architect Mode shifts from implementation to strategic thinking. This mode is designed for high-level planning, technical decision-making, and architectural discussions. You might ask it to evaluate whether your current microservice split makes sense, or to design a migration path from monolithic to modular architecture.
Architect Mode works differently because it doesn't need to touch code—it needs to reason about code organization, dependencies, and system design. The AI operates with fuller context of the entire codebase structure and can reason about architectural implications.
Debug Mode is specialized for systematic problem diagnosis and resolution. When something is broken and you don't know why, Debug Mode operates more deliberately than Code Mode. It's designed to:
- Gather comprehensive diagnostic information.
- Form hypotheses about root cause.
- Test those hypotheses systematically.
- Narrow down to the actual problem.
- Generate targeted fixes.
Debug Mode doesn't just look at your code—it understands the broader system context: logs, error messages, dependency versions, environment variables. This is why Kilo built MCP integration (more on that later), which allows Debug Mode to hook into monitoring systems, log aggregation services, and external diagnostic tools.
The Memory Bank: Solving AI Amnesia
One of the most frustrating aspects of current AI coding tools is context loss between sessions. You ask Claude in one chat what the architecture of your microservice is. You close the chat. You open a new chat tomorrow and ask the same question—and it has no memory of your previous conversation.
In collaborative development, this becomes worse. A teammate uses the Slack integration to fix a bug. An hour later, you start using the terminal CLI on the same codebase. There's no shared context. The AI starts from scratch.
Kilo solves this with the "Memory Bank"—a persistent context system that stores information in structured Markdown files within your repository. Think of it as a second brain, written into version control.
The Memory Bank captures:
- Codebase architecture: High-level system design, module relationships, data flow.
- Decisions rationale: Why specific architectural choices were made.
- Known issues: Problems that are being tracked or that have unusual workarounds.
- Deployment topology: How services are deployed, dependencies between environments.
- Team conventions: Code style decisions, naming patterns, testing requirements.
- Context from previous sessions: Earlier fixes, learnings from previous debugging sessions.
Because this information is stored in Markdown files within the repository (not in some external AI service database), it benefits from all the properties of version control:
- Searchable history: You can see how your understanding of the codebase evolved.
- Distributed: It moves with your repository, not locked into a vendor platform.
- Reviewable: Team members can review and improve the architectural documentation.
- Auditable: You have a record of what the AI was told about the system.
This is conceptually powerful because it solves a fundamental problem with multi-tool AI development: consistency. If Kilo is operating in three different places—terminal, Slack, IDE sidebar (through future integration)—they all read from the same Memory Bank. The same context applies everywhere.
Kilo Pass offers a transparent pricing model with credits exceeding subscription costs, providing a 40% bonus for the Starter Tier. This model allows users to clearly see the value of their subscription.
Model Agnosticism: 500+ Models, One Interface
One of the most distinctive aspects of Kilo CLI 1.0 is its radical model agnosticism. The CLI supports over 500 different AI models. This isn't marketing hyperbole—it means Kilo built an abstraction layer that can work with:
- Proprietary models: OpenAI's GPT-4 and GPT-4o, Anthropic's Claude 3 family, Google's Gemini.
- Open source models: Meta's Llama 3, Alibaba's Qwen, Mistral, Deep Seek.
- Specialized models: Task-specific models optimized for coding, reasoning, multimodal tasks.
- Custom models: If your organization fine-tuned a model on your internal codebase, Kilo can integrate with it.
- Local models: Running models on your machine via Ollama or similar.
This is genuinely different from most AI coding tools, which are designed around one model (GitHub Copilot uses OpenAI's models, Cursor uses Claude or GPT-4, etc.).
Why does this matter? Several reasons:
Cost optimization: Different models have different pricing. For routine code generation, an open source model like Qwen might be 90% as good as GPT-4 but 10% of the cost. For complex architectural reasoning, Claude might be worth the premium. Kilo lets you pick based on task requirements.
Latency requirements: Some models have API latency measured in seconds. If you're using Kilo interactively in the terminal, you want faster response times. Local models via Ollama might be slower than API calls, but they have zero network latency and your code never leaves your server.
Data privacy: For work on sensitive systems (healthcare data, financial systems, government contracting), many organizations need models running in their own infrastructure or with specific data handling agreements. Kilo's model agnosticism enables this.
Resilience: If one model provider has an outage, you can switch to another without changing tools. This matters for production use cases.
Model quality evolution: As new models arrive (and they do, constantly in 2025), you can test and switch to them without waiting for your tool vendor to integrate them.
From a technical standpoint, Kilo likely uses a standardized API abstraction that maps to different model providers' actual APIs. This is non-trivial engineering—different models have different prompt formats, different context windows, different response structures, and different capabilities.
The practical implication is that organizations can adopt Kilo once and then experiment with model choices over time. This gives them optionality in a rapidly evolving AI landscape.
Integration Ecosystem: Model Context Protocol and External Tools
Having model agnosticism is powerful, but it only makes sense if those models can actually interact with relevant context. This is where Model Context Protocol (MCP) becomes critical.
MCP is an open standard (originally developed by Anthropic, now gaining broader adoption) that allows AI models to communicate with external services and data sources. Through MCP, a Kilo agent can:
- Access internal documentation: Query your team's knowledge base or internal wikis.
- Read monitoring and metrics: Check Prometheus, Datadog, or other monitoring systems to understand system health.
- Query databases: Read information from your database about data schemas, recent changes.
- Interact with version control: Access git history, pull request information, code review comments.
- Call custom tools: Any endpoint or tool your team has built can be exposed via MCP.
- Check infrastructure state: Query Kubernetes clusters, AWS state, or other infrastructure details.
The significance of this becomes clear in a debugging scenario:
You're in the terminal at 2 a.m. and your API is returning 500 errors. You ask Kilo to debug it. Without MCP integration, it can only see the code in your repository. With MCP integration, it can also:
- Check recent logs from Datadog and see that error rate spiked 5 minutes ago.
- Query the database to see if a recent schema migration failed.
- Check git history to see which code was deployed in the last 30 minutes.
- Access your internal runbook for this service.
- Check monitoring dashboards to see system load and error patterns.
Now the AI has the actual context needed for debugging, not just code context.
The extensibility through MCP is Kilo's way of making the terminal-based AI agent practical for real work. The agent isn't trying to reason about your entire system from code alone—it can query external sources for the information it needs.

Slack Integration: "Engineering Teams Make Decisions in Slack"
While Kilo CLI 1.0 is the flagship release, the company has been building out what they call "Agentic Anywhere" strategy. A key part of this is the Slack integration launched in January.
Slack integration for development tools isn't new. GitHub has a Slack bot. Vercel has Slack notifications. But most are notification-focused—they tell you something happened.
Kilo's Slack integration is execution-focused. From Slack, developers can:
- Describe a bug to the bot.
- Watch the bot analyze your codebase.
- Review proposed fixes.
- Approve and merge the fix directly from Slack.
This sounds simple, but it's architecturally complex because:
Multi-repo context: Most Slack integrations for code work are limited to single repositories. Kilo's Slack bot can ingest context from multiple repositories simultaneously, understanding dependencies and cross-repo implications.
Persistent thread state: Unlike a terminal session that starts fresh, the Slack bot maintains conversation context throughout the thread. If you discuss a bug across 20 messages in Slack, the bot understands the evolution of the discussion.
Team collaboration: The Slack bot naturally fits into team workflows. Product manager describes the issue, engineer provides context, bot proposes fix, team reviews—all in one thread.
Breitenother's observation—"Engineering teams don't make decisions in IDE sidebars. They make them in Slack"—reflects something that enterprise development has learned the hard way. Critical decisions about production incidents, architectural choices, and bug prioritization happen in chat where the full team can participate.
Breitenother emphasized that competing tools like Cursor's Slack integration or Claude Code's integrations are limited by single-repo configurations or lack persistent thread state. Kilo's approach of maintaining Memory Bank context means discussions in Slack thread connect to the persistent context system.
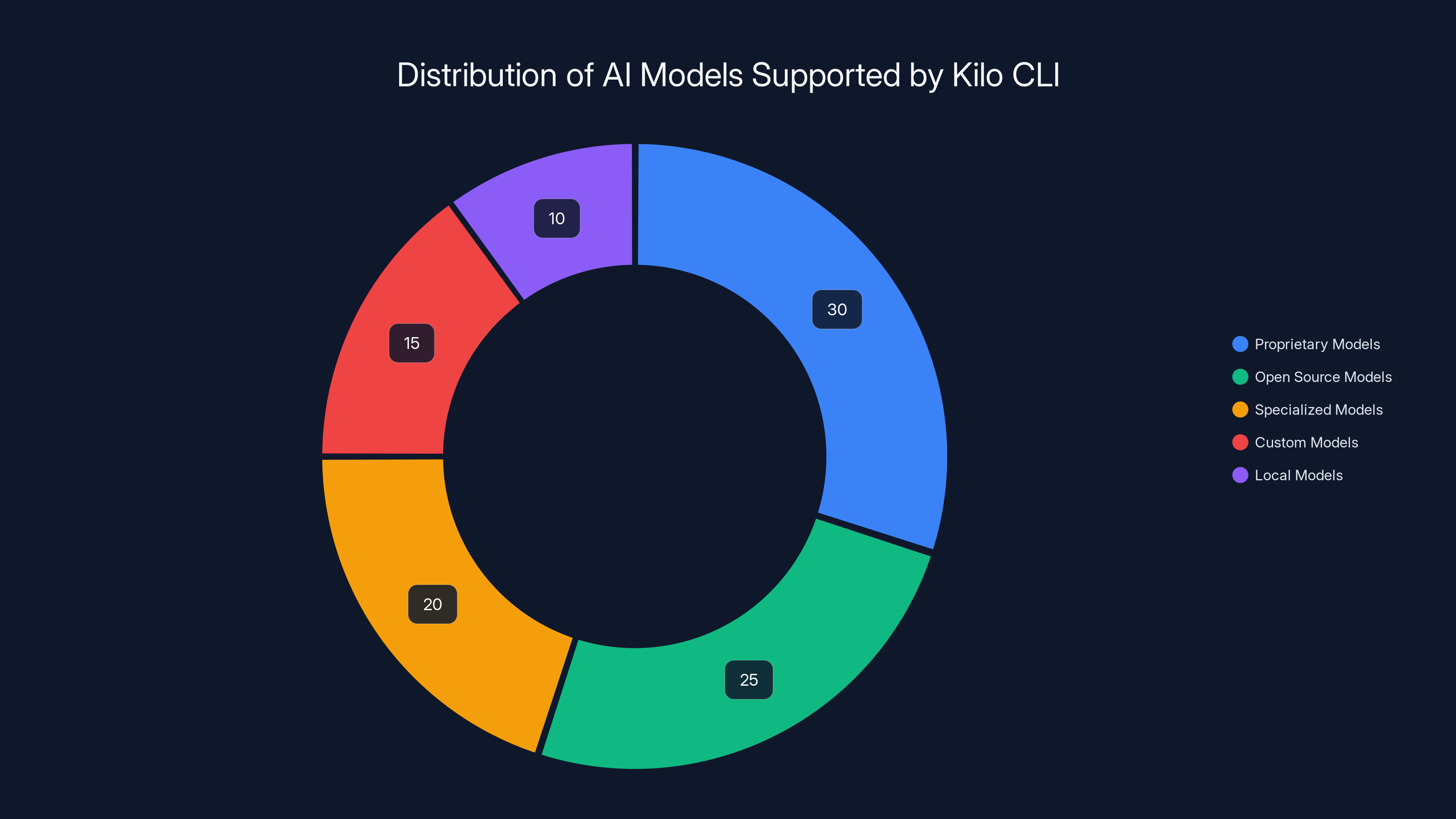
Kilo CLI 1.0 supports a diverse range of AI models, with a significant portion being proprietary and open source models. This distribution allows for flexibility in cost, latency, and privacy needs. (Estimated data)
Operational Modes in Practice: Real-World Scenarios
Understanding how Code, Architect, and Debug modes actually work in practice makes Kilo's design philosophy clearer.
Code Mode: The 3 a.m. Refactor
Imagine you're refactoring your authentication system. Your current implementation has a monolithic Auth Service class with 2,000 lines handling sessions, tokens, permissions, and credential validation. You've designed a new architecture splitting this into separate services:
Session Managerfor session lifecycle.Token Servicefor token generation and validation.Permission Resolverfor permission checks.Credential Validatorfor credential handling.
In an IDE sidebar, an AI might suggest the individual class implementations one by one. You'd implement each one, then manually hunt through 50 files to update imports and references.
In Kilo's Code Mode, you describe the refactor, and the agent:
- Scans your codebase to identify all 47 files that import from
Auth Service. - Understands the actual usage patterns in each file.
- Creates the new service classes with appropriate delegation.
- Updates imports consistently across all 47 files.
- Creates migration helpers for any gradual rollout needed.
- Updates tests to work with new architecture.
The entire multi-file refactor happens as a coherent unit, not 50 individual suggestions.
Architect Mode: Evaluating Microservice Boundaries
You're considering splitting your monolith into microservices. You have 400 database tables, 500+ API endpoints, and a team of 15 engineers. Where are the natural seams?
Architect Mode can:
- Analyze database schema to identify logical data domains.
- Trace API call patterns to understand request flow.
- Identify high-frequency cross-service calls (these suggest bad boundaries).
- Consider team ownership: if two services are always modified together, maybe they shouldn't be separate.
- Evaluate operational concerns: does the microservice boundary align with your deployment and scaling model?
The output isn't just a suggestion—it's a detailed analysis with trade-offs, implementation costs, and rollout strategy.
Debug Mode: The Production Fire
Your payment processing service returns 500 errors. Support has already received 40 complaints in the past 2 hours. You have:
- Error logs showing an exception in the charge processing pipeline.
- But the logs are truncated and don't show the root cause.
- A database slow-query log showing an unusual query.
- Monitoring showing CPU is high.
- No recent code deployments.
In Debug Mode, Kilo can:
- Cross-reference error timestamps with code deployments (recent data migration?).
- Check infrastructure metrics for resource constraints.
- Query your database schema to understand the slow query.
- Review recent configuration changes.
- Check vendor APIs (Stripe, payment processor) for outages.
- Form hypothesis: the slow database query is blocking the process queue, causing timeout errors.
- Generate targeted fixes: add index, optimize query, add timeout handling.
Because Debug Mode can access multiple data sources through MCP, it operates with full context rather than just reading code.
Pricing Model: Breaking the Black Box
Kilo's pricing strategy is deliberately different from most AI tools, and understanding why reveals something important about how they want to position the product.
Most subscription AI tools (Chat GPT Plus, GitHub Copilot Pro, Cursor Pro) use fixed monthly pricing with unclear economics. You pay
Breitenother's critique of this model is worth quoting directly: "We're selling infrastructure here... you hit some sort of arbitrary, unclear line, and then you start to get throttled. That's not how the world's going to work."
Kilo Pass instead charges based on actual provider costs:
**Starter Tier (
**Pro Tier (
**Expert Tier (
The math here is revealing. A
The pricing transparency means:
- You know exactly what your AI usage costs.
- If you don't use all credits, it's clear you're paying for capacity you don't need.
- You can calculate ROI: "This fix saved us 4 hours. Developer time is 8 in credits. ROI is 75:1."
For organizations trying to justify AI tool spending to finance or procurement teams, this transparency is valuable. You're not negotiating about "value" in the abstract—you're comparing clear numbers.
Kilo is also running a "Double Welcome Bonus" through February 6th, giving new users 50% bonus credits for their first two months. This effectively means a new Starter subscriber gets
The pricing strategy signals what Kilo is optimizing for: transparency, actual usage-based value, and low friction for adoption. They're betting that developers will try it out (with the welcome bonus), like it, and then subscribe to one of the tiers based on actual usage.
Comparison to competitors:
- GitHub Copilot: 100/year for individuals, fixed pricing regardless of usage.
- Cursor Pro: $20/month, fixed pricing regardless of usage.
- Codeium: Freemium model, paid tiers at $15-20/month.
- Kilo Pass: Usage-based with fixed monthly tiers, transparent cost structure.
Open Source Foundation: MIT License and Community Extensibility
The fact that Kilo CLI 1.0 is built on an MIT-licensed open source foundation is strategically important, even if it's buried in the technical specifications.
MIT license means:
- Anyone can download the code.
- Anyone can modify it for their own use.
- Anyone can incorporate it into commercial products.
- No viral copyleft requirements.
This is different from tools built on closed-source proprietary code. If you're deploying Kilo in an organization where security review is mandatory, you can actually audit the code. If you need to customize behavior for your specific workflow, you can fork it.
For terminal-based tooling specifically, open source is important because many organizations have complex terminal environments, custom shells, specific security requirements, or internal tools that need to integrate. Being able to modify and extend the source code matters.
The open source approach also helps Kilo differentiate against Cursor (which is closed source and IDE-specific) and GitHub Copilot (which is part of a massive closed-source ecosystem). Kilo is positioning itself as the "open source vibe coding" tool—transparent, auditable, extensible.
MIT licensing also has recruitment and community-building benefits. Open source attracts developers who want to contribute to tooling. Some of those contributors might become customers. Some might identify bugs or suggest features that improve the product for everyone.
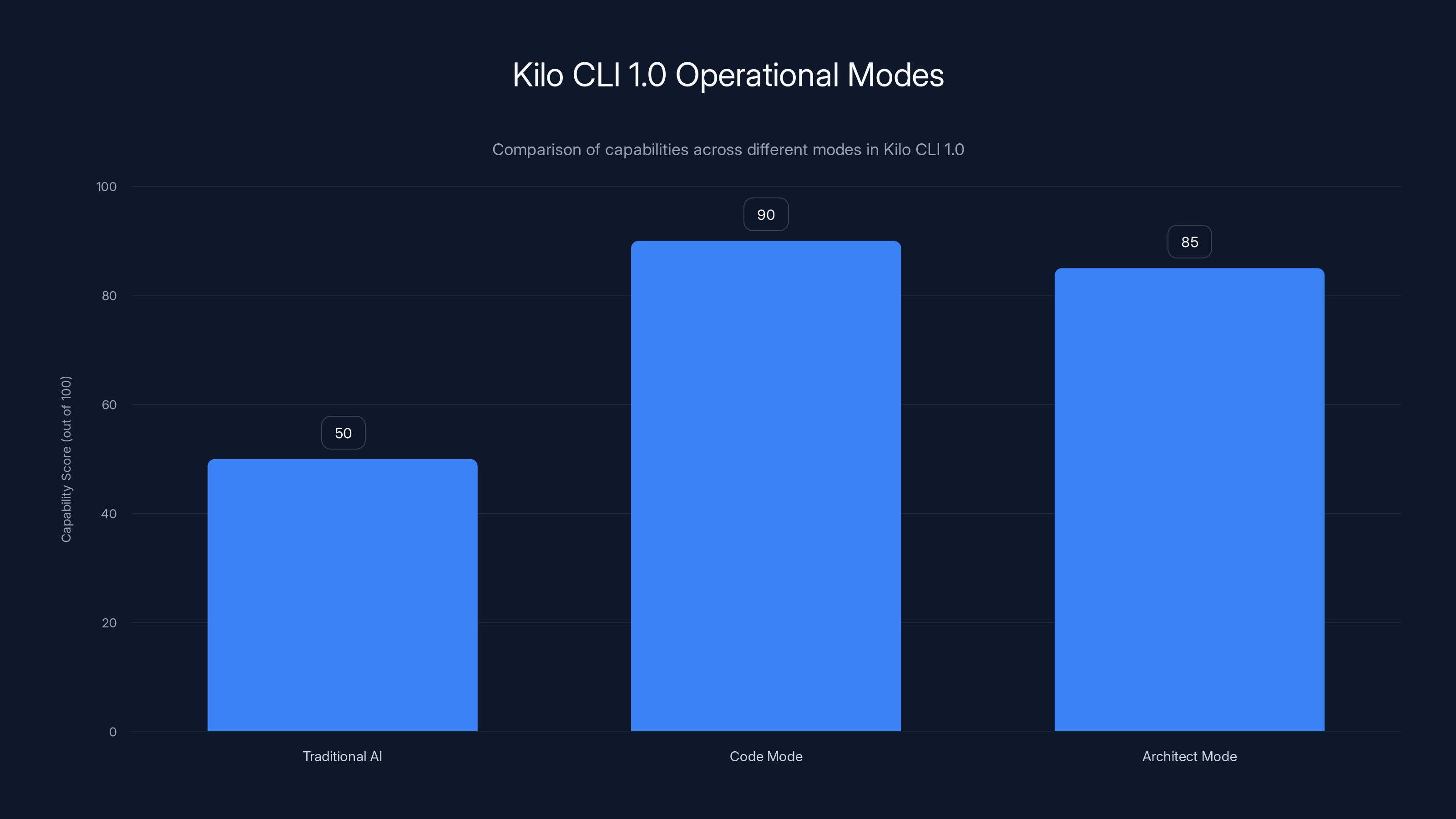
Kilo CLI 1.0 introduces advanced modes like Code Mode and Architect Mode, significantly enhancing capabilities beyond traditional AI coding assistants. Estimated data.
The Competitive Landscape: How Kilo Positions Against Cursor, Copilot, and Claude Code
To understand Kilo's strategy, it helps to see where competitors are and where Kilo is positioning itself.
GitHub Copilot owns the IDE sidebar space. It's built into VS Code, works with most major IDEs, and has massive distribution through GitHub. But it's fundamentally UI-constrained—it's designed for IDE environments.
Cursor took the sidebar approach further and built an entire IDE optimized around AI suggestions. It's become popular with developers who want a full IDE experience tuned for AI-assisted coding. But again, it's an IDE, which means production debugging doesn't happen there.
Claude Code (Anthropic's offering) is newer and positioned as a direct Cursor competitor. It offers code generation and file manipulation but is still oriented toward IDE-like interaction.
Codex CLI is a terminal-based competitor to Kilo, built for command-line coding. But it's single-model focused and less feature-rich than Kilo.
Kilo's positioning is distinct:
- Not replacing your IDE: Kilo isn't trying to be VS Code. It assumes you'll still use your IDE for normal development.
- Filling the gaps: Kilo operates in places IDEs can't—SSH sessions, remote servers, Slack threads, terminal environments.
- Model agnostic: You're not locked into one vendor's models or capabilities.
- Team-first: From day one, Kilo included Slack integration and shared Memory Bank context.
- Transparent infrastructure: You see exactly what your AI usage costs.
This is a classic "blue ocean" strategy—instead of competing directly with Cursor on IDE experience, Kilo is competing in underserved use cases: production debugging, remote work, terminal environments, team collaboration in chat.
Security and Production Readiness: Running AI in Critical Paths
One consideration often overlooked in AI coding tool discussions: security and production readiness.
If you're using Kilo CLI in a production SSH session, you're letting an AI agent modify code or infrastructure on a live system. This raises several concerns:
Code execution safety: What if the AI generates code with a security vulnerability? Debug Mode has direct access to your systems through MCP. What prevents it from making catastrophic changes?
Model inference safety: Different models have different hallucination rates and failure modes. Open source models like Qwen might hallucinate more than Claude. How does Kilo handle this?
Audit trail: When an AI makes a change in production, you need clear records for compliance and incident response.
Rollback capability: If the AI's change breaks something, how quickly can you revert?
Kilo addresses this through:
Multi-stage execution: Rather than directly executing code, Kilo typically proposes changes that humans approve first.
Memory Bank documentation: Changes are logged with context about why they were made.
Git integration: Terminal changes typically happen in git-controlled repositories, so rollback is version control rollback.
Model diversity: You can choose more conservative models for critical paths (use a slower but more careful model for production) and faster models for non-critical work.
That said, these are design features that require discipline. An engineer could potentially configure Kilo to auto-execute without review, which would be dangerous. The tool provides guardrails, but human judgment is still required.
The Memory Bank Deep Dive: How Persistent Context Actually Works
We touched on the Memory Bank concept earlier, but it's worth exploring in detail because it's genuinely innovative.
Traditional AI systems have no persistent memory between conversations. Every new conversation is a fresh start. In code-related work, this is incredibly limiting because the AI loses context about:
- Why architectural decisions were made.
- What experiments failed and why.
- Known limitations or edge cases.
- Future planned work that affects current decisions.
Kilo's Memory Bank solves this by storing context in Markdown files within your repository. The structure typically looks like:
kilo/
memory/
architecture.md # System design decisions
decisions.md # ADRs (Architecture Decision Records)
issues.md # Known issues and workarounds
context.md # Current state of development
These files are:
- Version controlled: You see history of how understanding evolved.
- Reviewable: Team members can comment on architectural understanding.
- Executable context: Every Kilo session reads these files and integrates them into the prompt context.
When you start a new Kilo session (whether CLI, Slack, or future IDE integration), the agent reads the Memory Bank and understands the current context.
A practical example: You documented that the reason you haven't migrated to the new authentication library is because it doesn't support your custom token format yet. Later, a new developer on the team asks Kilo to migrate to that library. Without Memory Bank, Kilo would suggest the migration without understanding the blocker. With Memory Bank, Kilo understands the constraint and doesn't suggest the migration.
The Memory Bank also enables something called "context decay awareness." If the Memory Bank says "X is a known issue," but that issue was resolved three months ago and never updated in Memory Bank, Kilo can learn from git history that X was actually fixed and update its understanding accordingly.
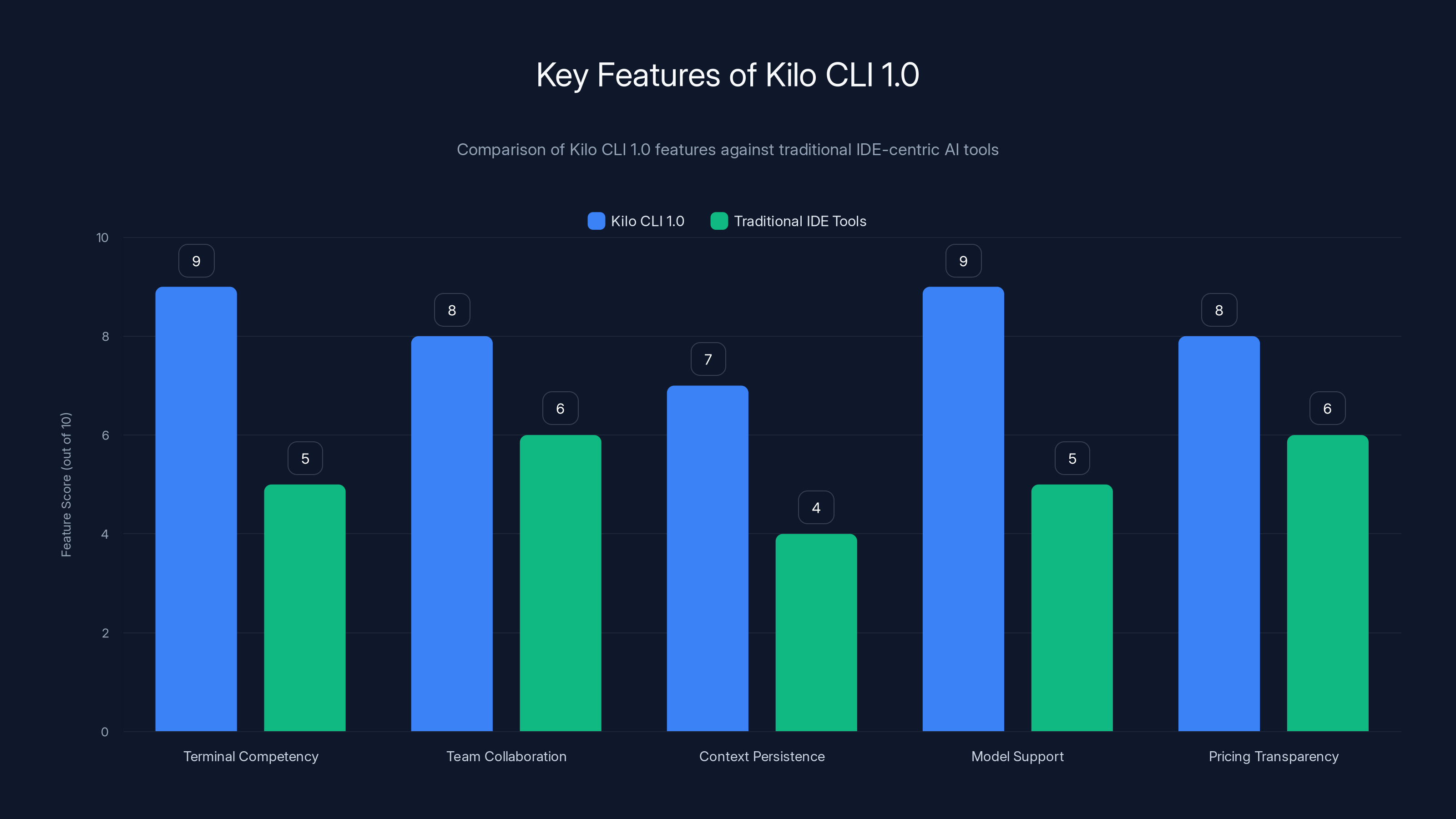
Kilo CLI 1.0 excels in terminal competency, model support, and pricing transparency compared to traditional IDE-centric AI tools. Estimated data.
Multi-Model Orchestration: How Kilo Routes Tasks
With 500+ models available, Kilo needs intelligent routing to decide which model to use for which task. This is non-trivial engineering.
Simple approaches would fail:
- Always use GPT-4: Expensive, sometimes overkill.
- Always use local model: Fast but lower quality.
- User manually selects: Requires expertise many developers don't have.
Kilo likely uses a routing layer that considers:
Task complexity: Architectural reasoning might get GPT-4. Boilerplate code generation might get Qwen.
Latency requirements: Interactive terminal use needs fast response times. Background analysis can wait longer for better results.
Cost sensitivity: If the user is on Starter tier with limited credits, prefer cheaper models. If they're on Expert tier, use premium models.
Model capabilities: Some models are better at reasoning, others at code generation, others at multimodal understanding.
Organization policy: Enterprise customers might restrict models that are trained on public data. Route to approved models only.
From a machine learning standpoint, this is a classic multi-armed bandit problem—how do you optimize model selection over time based on outcomes?

Integration Patterns: How Kilo Connects to Your Existing Tools
Kilo isn't trying to replace your entire toolchain. It's trying to integrate into it. This means compatibility with:
Version control: Git primarily, but understanding of GitHub, GitLab, Bitbucket APIs.
CI/CD systems: Jenkins, GitHub Actions, GitLab CI, CircleCI—Kilo agents need to understand your deployment pipeline.
Monitoring and observability: Datadog, New Relic, Prometheus, ELK stack—Debug Mode needs these.
Communication: Slack integration is first, but Discord, Teams, and internal communication tools would follow.
Package managers: npm, pip, go, Cargo—understanding dependencies and versions.
Container systems: Docker, Kubernetes, container registries.
The MCP framework is how Kilo makes these integrations pluggable. Rather than Kilo building one-off integrations with every tool, MCP defines a standard interface. Organizations can implement MCP adapters for their internal tools.
The Learning Curve: From Terminal to AI-Assisted Debugging
One real consideration: Kilo CLI requires learning a new tool with new commands, new concepts (Code Mode vs. Architect Mode), and new workflows.
For developers already comfortable with terminal tools, this isn't a huge barrier. For developers who primarily use IDEs, it's a bigger lift.
Kilo is banking on the value proposition being worth the learning curve: "2 a.m. production debugging is easier with Kilo than without." For that use case, it probably is worth it.
But for everyday coding, if you spend 90% of your time in VS Code, switching to Kilo CLI for the last 10% when you're debugging in production might not feel worth the context switching.
This is why Kilo's strategy of "Agentic Anywhere" makes sense. The more places Kilo shows up (IDE integration, Slack, CLI), the less context switching is required. The tool travels with the engineer rather than forcing the engineer to travel to the tool.
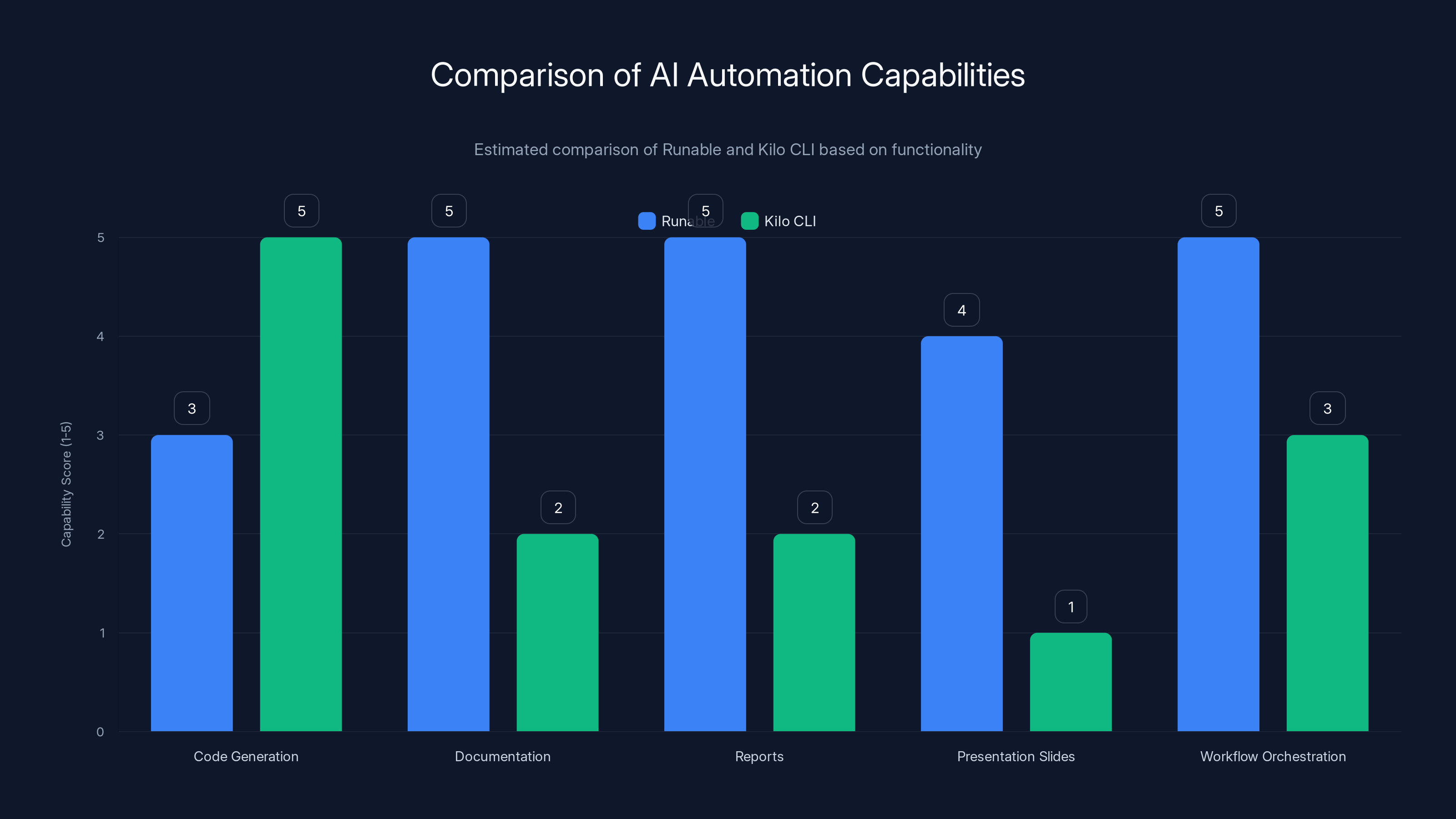
Runable excels in documentation, report generation, and workflow orchestration, complementing Kilo CLI's strengths in code generation. Estimated data based on typical feature sets.
Enterprise Deployment Considerations
For enterprises considering Kilo CLI 1.0, several deployment factors matter:
Data residency: Can Kilo run locally without sending code to external APIs? Yes, with local models via Ollama integration, but this requires infrastructure setup.
Audit and compliance: Can you audit what the AI does and generate compliance reports? Yes, through Memory Bank and version control history.
Model approval workflows: Can you restrict to approved models only? Yes, through configuration.
Team permissions: Can you restrict who can use Kilo on what systems? This depends on terminal-level access controls, not Kilo itself.
Integration with existing systems: Does it work with your monitoring, logging, and deployment tools? Through MCP, probably yes, but requires some engineering.
The transparency in pricing and open source foundation actually helps here. Enterprises evaluating Kilo can:
- Audit the code to understand security implications.
- Calculate costs precisely.
- Integrate with their security and compliance infrastructure.
- Customize for internal requirements.
These are advantages over closed-source, black-box pricing alternatives.
The Future: Agent Autonomy and Terminal Mastery
Kilo's view is that 2026 will be defined by agents that can manage end-to-end tasks independently. Not just generating code, but orchestrating fixes, understanding system state, and executing strategies.
In this vision, the terminal becomes a place where agents operate autonomously on behalf of engineers. The Memory Bank maintains context across these operations. Models are optimized for the specific task rather than one-size-fits-all.
But this raises questions:
- How autonomous is too autonomous? At what point does the engineer lose too much control?
- How do you handle agent mistakes in production?
- How do you maintain security and auditability at scale?
Kilo's design choices (multi-stage execution, Memory Bank logging, model diversity) suggest they're thinking about these questions.
But this is still early. The first product is Kilo CLI 1.0. The second is Slack integration. The vision of truly autonomous agents managing production incidents is still aspirational.

Comparing to Alternatives: When to Choose Kilo
Kilo CLI 1.0 isn't the right choice for everyone. Consider context:
Choose Kilo if you:
- Spend significant time in SSH sessions or remote servers.
- Want model flexibility and cost optimization through multiple model support.
- Like transparent pricing and understand your actual AI costs.
- Work in teams and use Slack for coordination.
- Value open source and want to audit/customize code.
- Do production debugging and want AI assistance in critical paths.
Choose GitHub Copilot if you:
- Work primarily in VS Code and want tight IDE integration.
- Value the simplicity of one subscription for all your tools.
- Want enterprise support from a massive company (Microsoft).
- Are already deep in the GitHub ecosystem.
Choose Cursor if you:
- Want a complete IDE experience optimized for AI.
- Prefer a cohesive product over a collection of integrations.
- Don't mind proprietary, closed-source tools.
- Want the absolute smoothest IDE + AI experience.
Choose Claude Code if you:
- Strongly prefer Claude's model for reasoning and code generation.
- Want web-based access without IDE lock-in.
- Like Anthropic's approach to AI safety.
Choose local models if you:
- Have strict data privacy requirements.
- Want zero vendor dependence.
- Are willing to manage and optimize your own models.
- Have sufficient compute infrastructure.
Kilo's unique position is as a terminal-centric, model-agnostic, team-first option. It's not trying to be all things to all developers. It's specifically serving the use case of production engineering in terminal environments with team collaboration.
Getting Started: First Steps with Kilo CLI
If you're interested in trying Kilo CLI 1.0:
- Start with the welcome bonus: Take advantage of the Double Welcome Bonus through February 6th for 50% bonus credits on your first two months.
- Test on non-critical code: Use Kilo first on side projects or non-critical services to understand the workflow.
- Understand the operating modes: Try Code Mode for refactoring, Architect Mode for design questions, Debug Mode for troubleshooting.
- Build your Memory Bank: Start documenting your codebase's architecture and decisions in the Memory Bank files.
- Integrate with your tools: Through MCP, connect your monitoring, logging, and internal systems so Debug Mode can access needed context.
- Involve your team: Use Slack integration so team members can participate in and learn from Kilo's suggestions.
The learning curve is real but manageable. Most developers are comfortable with terminal tools and will adapt quickly.

Broader Implications: AI Development Workflows Evolution
Kilo's approach reveals something important about how AI development tooling will evolve.
The early wave (2023-2024) was sidebar tools: GitHub Copilot, Cursor, Claude, etc. These optimized for the IDE environment and turned the development tool landscape into a battle for IDE market share.
The second wave (2024-2025) is location-aware tools: Claude Web, Chat GPT, Perplexity for broad research; Kilo for terminal; future IDE integrations. These tools follow developers across environments.
The third wave (2025-2026) will likely be fully integrated agents: AI systems that understand your entire development lifecycle and can operate across IDE, terminal, version control, CI/CD, monitoring, and team communication without requiring the engineer to manually copy-paste context between tools.
Kilo's Memory Bank and multi-location strategy (CLI, Slack, future integrations) is early positioning for that third wave.
Practical Implementation Considerations
If you're rolling out Kilo CLI 1.0 in your organization, think about:
Training: Team members need to understand when to use Kilo vs. other tools and how to get good results from each operating mode.
Guardrails: Set configuration policies around model selection, which systems can use Kilo, and what kinds of operations require review.
Integration effort: Connecting Kilo to your monitoring, logging, and deployment systems through MCP requires engineering time.
Cost allocation: Decide how to handle AI tooling costs—team budgets, central IT, or usage-based chargeback.
Documentation: Maintain the Memory Bank discipline so institutional knowledge persists.
These are organizational challenges, not technical ones. The technology works. The adoption challenge is human.
The Backing and Market Signals
Kilo is backed by Sid Sijbrandij, GitLab's co-founder. This signals a few things:
- Credibility: Sijbrandij isn't a first-time founder. GitLab is a multi-billion dollar company.
- Perspective: He understands enterprise development workflows, DevOps, and remote work at scale.
- Runway: GitLab's success means funding isn't an immediate constraint.
- Exit potential: VCs are more likely to fund companies with experienced founders with successful exits in the space.
This doesn't mean Kilo will succeed—many well-backed companies fail. But it means Kilo has resources to execute and a founder with credibility in the space.
The fact that they launched a complete rebuild (1.0) with 500+ model support, launched Slack integration, and are now building toward broader agent capabilities suggests a well-resourced team moving quickly.
FAQ
What is Kilo CLI 1.0?
Kilo CLI 1.0 is a command-line interface for AI-assisted coding that runs in terminal environments. It supports over 500 AI models from providers like OpenAI, Anthropic, Google, and open source sources like Qwen. Unlike IDE-based tools that work primarily in graphical code editors, Kilo CLI is designed specifically for terminal work, SSH sessions, and remote server access. It's built on an MIT-licensed open source foundation and emphasizes model agnosticism, transparency in pricing, and persistent context through a Memory Bank feature.
How does Kilo CLI 1.0 differ from GitHub Copilot and Cursor?
GitHub Copilot and Cursor are IDE-first tools—they're optimized for VS Code and other graphical editors. Kilo CLI is terminal-first and is designed for SSH sessions, production debugging, and command-line work where IDE tools don't operate. Copilot is model-locked to OpenAI's models, Cursor primarily uses Claude, while Kilo supports 500+ models giving users flexibility. Kilo also emphasizes transparent pricing (pay actual provider costs with zero markup) rather than fixed monthly subscriptions. Additionally, Kilo's strategy includes team-first features like Slack integration and persistent context through Memory Bank, making it suited for production incidents and team collaboration.
What are the three main operating modes of Kilo CLI 1.0?
Kilo CLI 1.0 operates in three distinct modes: Code Mode for high-speed code generation and multi-file refactors where the agent orchestrates changes across multiple files; Architect Mode for high-level strategic thinking about system design, technical decisions, and architectural trade-offs without touching code; and Debug Mode for systematic problem diagnosis in production environments where the agent accesses logs, monitoring data, and external systems through MCP to understand and fix issues. Each mode is optimized for different types of tasks developers encounter.
What is the Memory Bank and why does it matter?
The Memory Bank is Kilo's solution to "AI amnesia"—the problem of AI systems losing context between sessions. It stores persistent context in structured Markdown files within your repository, maintaining information about codebase architecture, architectural decisions, known issues, and team conventions. Because it's version controlled (not in an external database), the Memory Bank provides searchable history, team visibility, and auditability. When any Kilo agent starts a session (CLI, Slack, or future integrations), it reads the Memory Bank and understands the current system context, enabling consistent behavior across tools and time.
How does model agnosticism benefit developers?
Kilo's support for 500+ models provides several benefits: cost optimization by choosing appropriate models for each task instead of always using expensive models; latency control by selecting fast models for interactive work and thorough models for non-interactive analysis; data privacy by running models on internal infrastructure or with specific data agreements for sensitive work; resilience against provider outages by switching between providers; and flexibility to test and adopt new models as they become available without tool switching. You're not locked into one vendor's vision or capabilities.
What is Model Context Protocol and how does Kilo use it?
Model Context Protocol (MCP) is an open standard that allows AI models to securely query external services and access data sources beyond their training data. Kilo uses MCP to let agents access internal documentation, monitoring systems like Datadog, databases, version control history, and custom tools your organization has built. Through MCP, Debug Mode can check recent logs, query database schemas, understand infrastructure state, and read internal runbooks—all the contextual information needed for actual production debugging. MCP makes the agent's intelligence practical by connecting it to your real systems.
How does Kilo's pricing model work differently from competitors?
Kilo charges transparent pricing based on actual provider API costs with zero commission—
Can Kilo be used in production environments safely?
Kilo is designed for production use but requires discipline. Key safety features include: multi-stage execution where AI proposes changes that require human approval before execution; Memory Bank documentation of all changes with rationale; version control integration so any changes can be rolled back quickly; model selection flexibility to use conservative models for critical paths; and MCP integration that allows connecting to observability systems for context. However, an engineer could potentially configure Kilo to auto-execute without review, which would be risky. The tool provides guardrails, but human judgment about what level of autonomy to grant the agent is essential.
What's the difference between Kilo CLI and Kilo for Slack?
Kilo CLI 1.0 is for terminal-based work—SSH sessions, production debugging, remote servers. Kilo for Slack (launched January 2025) is for team collaboration—developers describe bugs in Slack, the bot analyzes the codebase, and fixes can be reviewed and merged from the Slack thread. The key difference is that CLI is synchronous and individual, while Slack is asynchronous and team-based. Both share context through Memory Bank and support multiple models. The strategy is "Agentic Anywhere"—making AI-assisted development work seamlessly whether the engineer is in the terminal, IDE, or Slack.
Is Kilo open source and can I customize it?
Yes, Kilo CLI 1.0 is built on an MIT-licensed open source foundation, which means the code is publicly available, auditable, and modifiable. Unlike closed-source competitors, you can customize Kilo for your specific workflow, integrate it with internal tools, and audit it for security. This matters for organizations with strict security requirements or complex internal tooling that needs integration. MIT licensing also means you can use Kilo in commercial products if needed, though the primary use case is for your own development workflows.
How much does Kilo cost and what's included?
Kilo offers three subscription tiers under Kilo Pass: Starter at
What systems and tools can Kilo integrate with?
Through Model Context Protocol (MCP), Kilo can integrate with monitoring systems (Datadog, New Relic, Prometheus), logging platforms (ELK stack, Splunk), version control (GitHub, GitLab, Bitbucket), CI/CD systems (Jenkins, GitHub Actions, CircleCI), container systems (Docker, Kubernetes), package managers (npm, pip, Cargo), and communication platforms (Slack, and future integrations). Organizations can also build custom MCP adapters for internal tools. The level of integration depth depends on engineering effort to expose your systems through MCP, but the framework is extensible to most development tools.

Runable Integration
For teams looking to automate broader aspects of AI-powered development workflows beyond code generation, Runable offers complementary AI automation capabilities. While Kilo CLI 1.0 specializes in terminal-based coding and production debugging, platforms like Runable can automate documentation generation, create automated reports from code quality data, generate presentation slides from deployment analytics, and orchestrate complex development workflows. Starting at $9/month, Runable complements terminal-centric tools like Kilo by handling the broader automation and reporting needs of development teams.
Conclusion: Terminal Coding Comes of Age
Kilo CLI 1.0 represents something important: the recognition that not all development work happens in graphical IDEs, and building great AI tools requires meeting developers where they actually work.
The terminal is where production incidents happen. It's where infrastructure gets built. It's where DevOps engineers operate. It's where remote work actually lives. For too long, AI coding tools have been optimized for the IDE experience, leaving these crucial workflows underserved.
Kilo's approach—terminal-first, model-agnostic, team-aware, transparent, open source—fills a gap. The tool isn't trying to replace Cursor or GitHub Copilot. It's trying to serve developers in contexts those tools don't address.
The strategic moves are well-calibrated: launching CLI 1.0 to prove terminal competency, integrating Slack to enable team collaboration, building Memory Bank to solve context persistence, supporting 500+ models to avoid vendor lock-in, and using transparent pricing to build trust.
From a pure product perspective, Kilo CLI 1.0 is competently built and thoughtfully designed. The team clearly understands the problem space. The backing from GitLab's co-founder suggests resources and credibility.
The open question is adoption. Terminal-based tools require learning new workflows. Organizations need to integrate Kilo with their systems. Teams need to understand when to use CLI vs. other tools. This is organizational friction, not technical friction.
But for organizations that take production engineering seriously, that have strong terminal-literacy culture, and that want transparent, flexible AI tooling without vendor lock-in, Kilo CLI 1.0 is worth evaluating. The value proposition—better production debugging, multi-file refactors, team collaboration in chat—is real for these use cases.
The broader trend is clear: AI development tooling is evolving from IDE-centric to everywhere. Tools that travel with engineers across contexts (IDE, terminal, Slack, future locations) will win market share. Kilo is early in building that everywhere strategy.
For developers who spend significant time in terminal environments and want AI that follows them there, 2025 is the year Kilo CLI 1.0 makes that possible.
Use Case: Generate automated incident reports from production debugging sessions and share them with your team in structured formats.
Try Runable For Free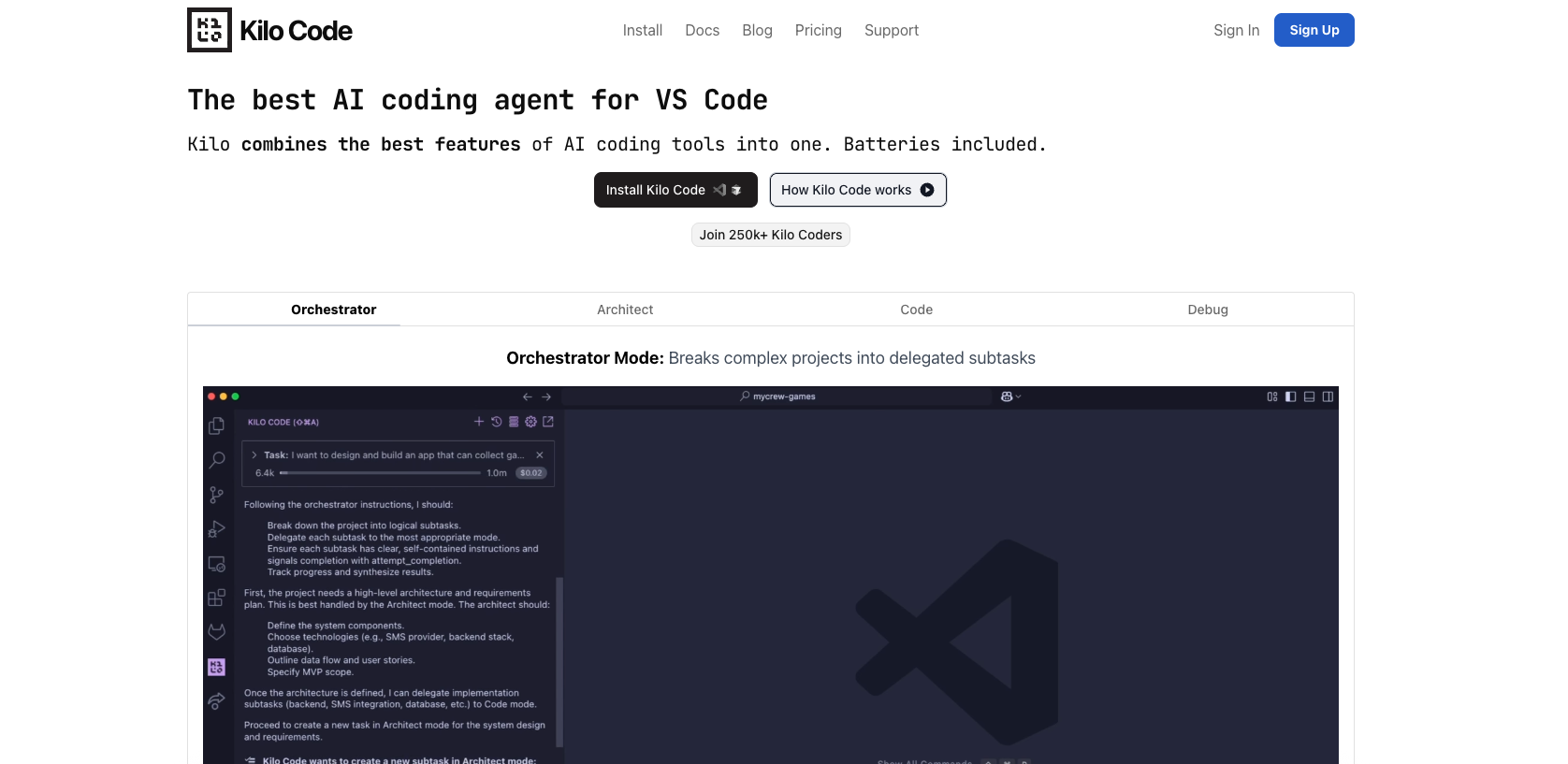
Key Takeaways
- Kilo CLI 1.0 is terminal-first, not IDE-first, serving production debugging, SSH sessions, and infrastructure work where sidebar tools don't operate.
- Support for 500+ models with transparent pay-for-what-you-use pricing eliminates vendor lock-in and enables cost optimization.
- Persistent Memory Bank context shared across CLI, Slack, and future integrations solves AI amnesia and enables consistent multi-tool workflows.
- Three operating modes (Code, Architect, Debug) optimize for different development tasks beyond simple autocompletion.
- Model Context Protocol integration enables agents to access monitoring, logging, databases, and custom tools for production-grade debugging.
- MIT-licensed open source foundation allows auditing, customization, and integration with internal organizational tools.
Related Articles
- Xcode Agentic Coding: OpenAI and Anthropic Integration Guide [2025]
- Apple Xcode Agentic Coding: OpenAI & Anthropic Integration [2025]
- Why Microsoft Is Adopting Claude Code Over GitHub Copilot [2025]
- GitHub's Claude & Codex AI Agents: A Complete Developer Guide [2025]
- Xcode 26.3: Apple's Major Leap Into Agentic Coding [2025]
- OpenAI's New macOS Codex App: The Future of Agentic Coding [2025]

