![Moonshot Kimi K2.5: Open Source LLM with Agent Swarm [2025]](https://tryrunable.com/blog/moonshot-kimi-k2-5-open-source-llm-with-agent-swarm-2025/image-1-1769530070352.png)
Introduction: The Open-Source AI Model Revolution
The artificial intelligence landscape is shifting in real-time, and what happened in early 2025 marks a watershed moment for open-source development. Moonshot AI, a Chinese AI company operating at the forefront of language model innovation, just unveiled Kimi K2.5, an open-source large language model that's turning heads across the industry. This isn't just another incremental update. This is a direct challenge to the closed-source dominance of companies like OpenAI, Anthropic, and Google.
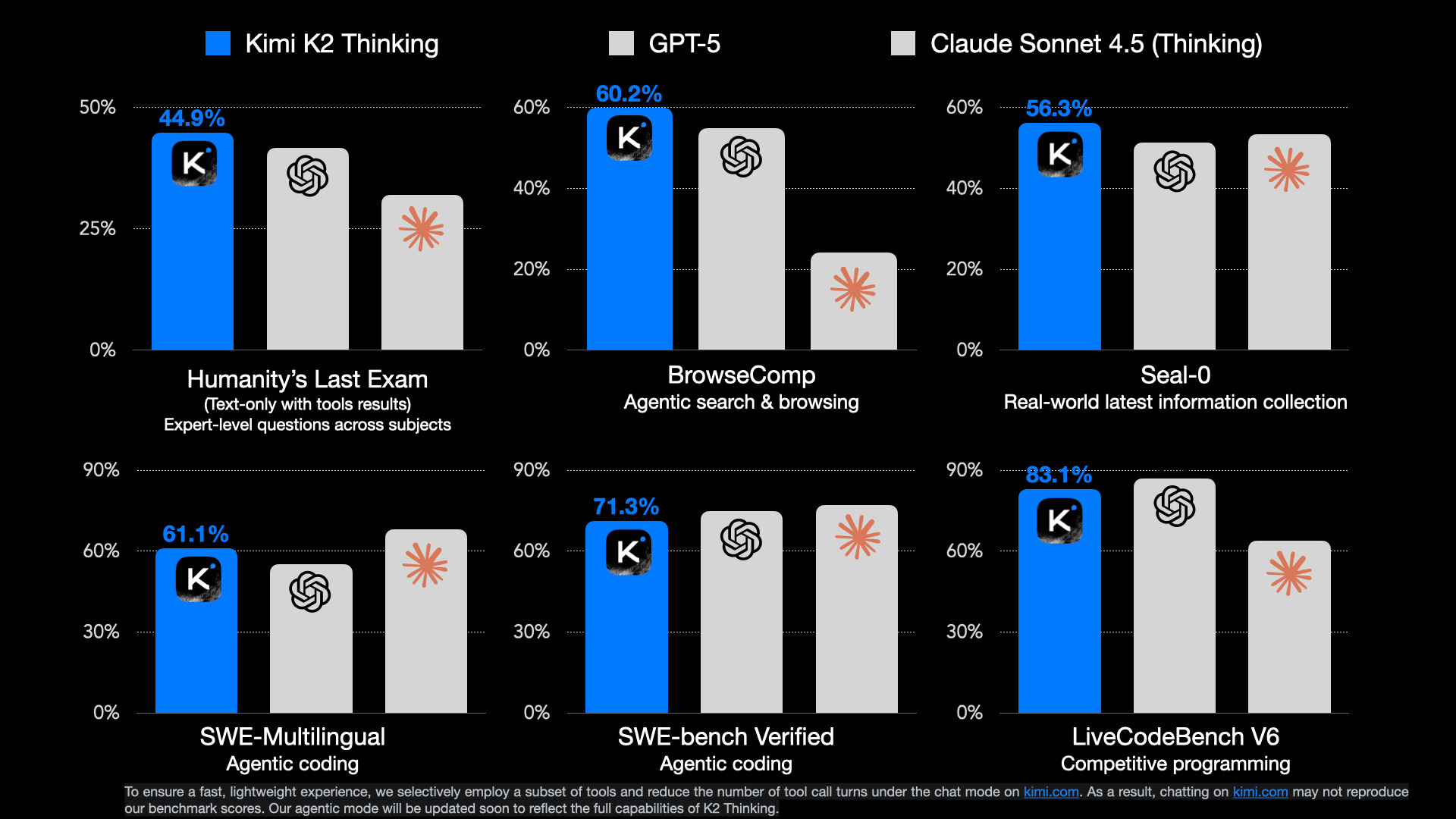
Here's what makes this significant: Kimi K2.5 doesn't just compete with Claude Opus 4.5 and GPT-5.2. It beats them on specific benchmarks that matter for real-world work. On the Humanity's Last Exam benchmark, K2.5 scored 50.2% with tools, outperforming both Opus 4.5 and GPT-5.2 variants. For software engineers specifically, the model achieved 76.8% on SWE-bench Verified, placing it among the elite coding models available today.
But the real revolution isn't just raw performance numbers. Moonshot built something fundamentally different into K2.5's architecture: Agent Swarm orchestration. This means the model can create and coordinate up to 100 specialized sub-agents working in parallel, executing workflows that chain together 1,500 tool calls simultaneously. That's not theoretical. That's practical compute you can use today.
What makes this even more compelling is the pricing. Moonshot slashed API costs to $0.60 per million input tokens, a 47.8% decrease from their K2 Turbo pricing. For enterprises and developers running at scale, that's meaningful savings.
This article dives deep into what Kimi K2.5 actually does, how Agent Swarm works under the hood, why multimodal coding matters for modern development workflows, and what this release means for the future of open-source AI infrastructure. We'll break down the benchmarks, explain the architecture decisions, compare it head-to-head with competitors, and show you exactly where and why you'd use this model.
TL; DR
- Agent Swarm Architecture: Kimi K2.5 orchestrates up to 100 parallel sub-agents executing 1,500+ tool calls simultaneously, reducing complex multi-day tasks to minutes
- Benchmark Performance: Beats Opus 4.5 on Humanity's Last Exam (50.2% vs competitors), ranks among top open-source models for coding at 76.8% on SWE-bench Verified
- Multimodal Coding: First open-source model to support visual debugging, reconstructing websites from video recordings and fixing UI issues autonomously
- Aggressive Pricing: $0.60 per million input tokens, a 47.8% cost reduction from previous pricing, making it financially accessible for enterprises
- User Growth: Moonshot reports 170% increase in K2.5 users between September and November 2024, signaling strong market adoption
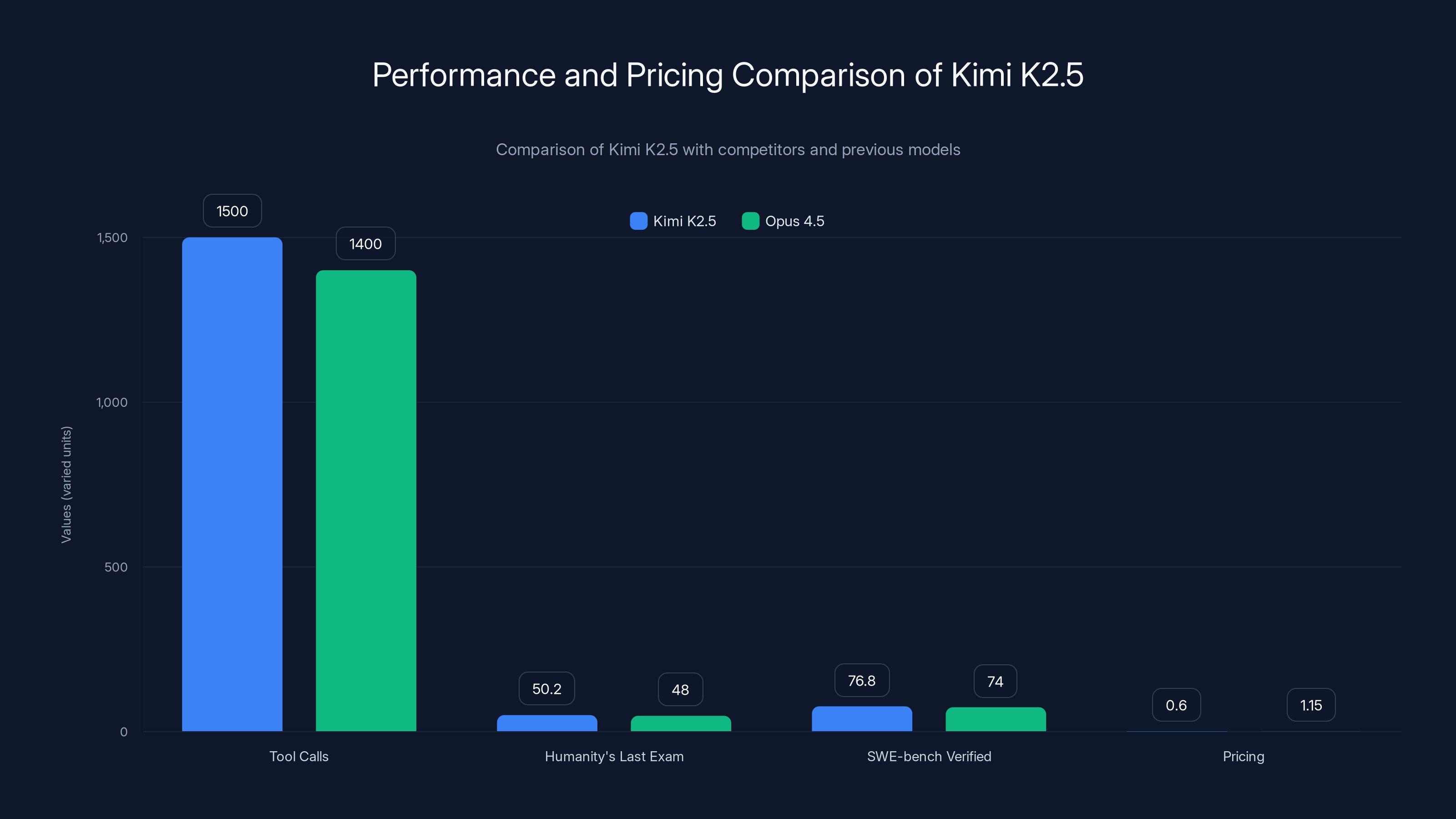
Kimi K2.5 outperforms Opus 4.5 in tool calls, exam scores, and coding benchmarks while offering a 47.8% cost reduction, enhancing its market appeal.
Understanding Moonshot AI's Market Position
Moonshot AI isn't a household name in Silicon Valley boardrooms, but the company has been building AI infrastructure quietly and methodically. Founded by Chen Wei, a former researcher at ByteDance, Moonshot positioned itself as a competitor to the Western AI giants by betting early on open-source models and accessible APIs.
The release of Kimi K2 in 2024 marked Moonshot's first major play for international attention. That model featured a trillion parameters with a mixture-of-experts architecture enabling 32 billion activated parameters. Mixture-of-experts (MoE) is a clever approach: the model learns which subset of its parameters are relevant for each input, so you get the benefits of a huge model without the computational overhead of a massive dense network.
Kimi K2.5 builds directly on that foundation, but with three major architectural upgrades. First, the integration of Agent Swarm capabilities means the model itself understands how to delegate tasks to specialized sub-agents. Second, multimodal support means it processes text, images, and video. Third, the thinking capabilities allow for extended reasoning, similar to OpenAI's o 1 model.
Why does this matter for your decision-making? Because Moonshot is proving that open-source doesn't mean compromised. Their growth metrics tell the story: 170% user increase between September and November 2024 for K2.5 and the earlier Thinking variant. That kind of adoption growth isn't accidental. It's earned through performance that developers trust.
Moonshot's positioning is explicitly anti-siloed. Instead of building a closed ecosystem where you're locked into their infrastructure, they're releasing a model that works with your existing tools, your existing frameworks, and your existing cloud providers. That's a fundamentally different business strategy from the API-first approach of most US AI companies.

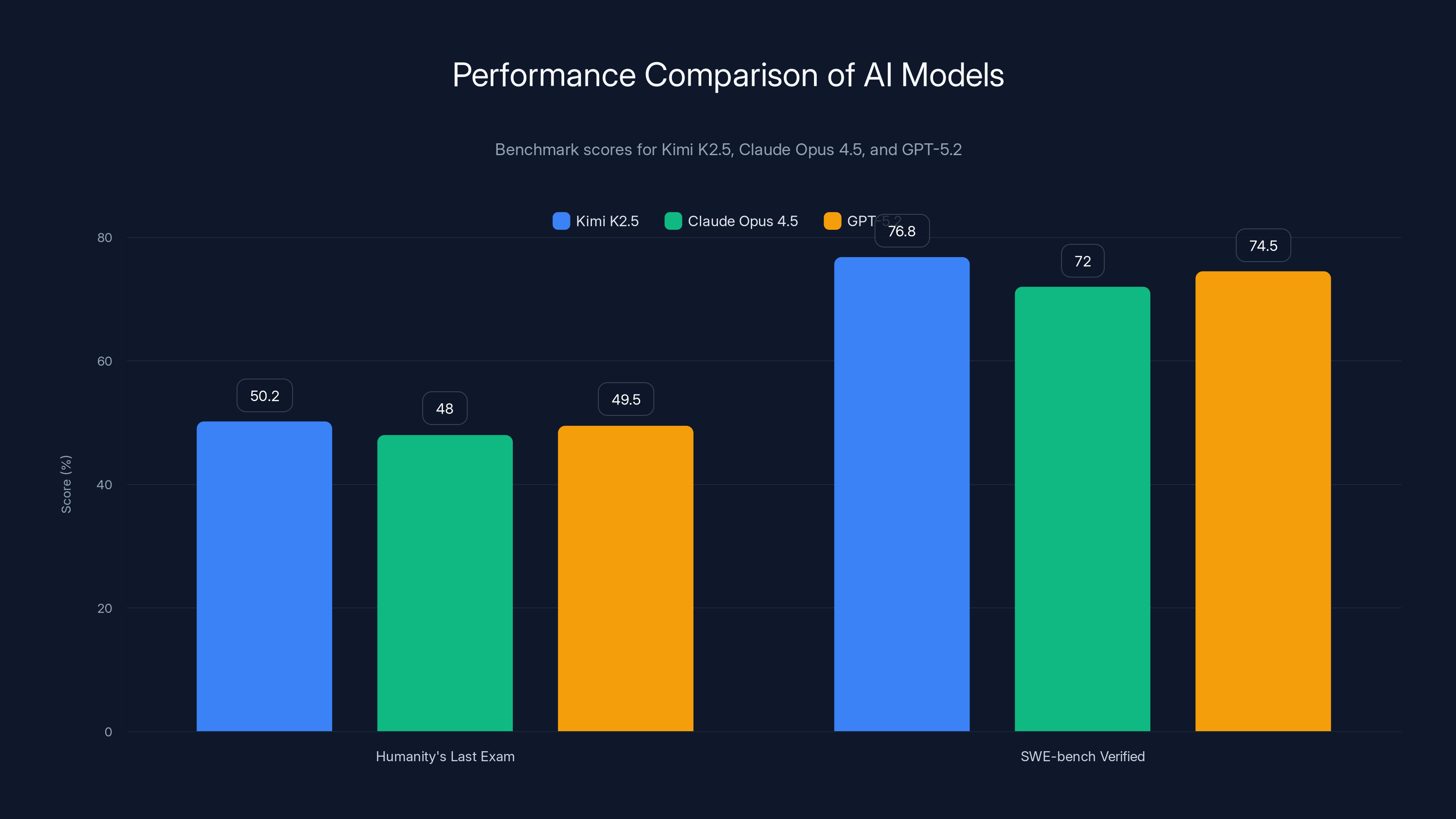
Kimi K2.5 outperforms Claude Opus 4.5 and GPT-5.2 in key benchmarks, scoring 50.2% on Humanity's Last Exam and 76.8% on SWE-bench Verified. Estimated data for competitors.
What Is Kimi K2.5? Core Capabilities Explained
Kimi K2.5 is positioned as an "all-in-one" model, and that phrase actually carries weight here. Unlike earlier generations that specialized narrowly, Kimi K2.5 combines three distinct capabilities into a single model: advanced language understanding, multimodal reasoning (text plus images plus video), and agentic orchestration.
The model's parameter architecture isn't publicly disclosed by Moonshot, but we know K2 (its predecessor) operated with roughly one trillion total parameters, with only 32 billion actively engaged for any given input. This mixture-of-experts design is crucial because it dramatically reduces inference costs while maintaining the theoretical capacity of a massive model.
What does this mean practically? When you send K2.5 a request, the model intelligently selects which parts of its weights to activate. A coding question activates different pathways than a customer service query. This isn't merely academic optimization—it translates directly to faster response times and lower API costs.
K2.5's language understanding foundation matches or exceeds contemporary closed-source models on standard benchmarks. But the differentiators lie elsewhere: in how it handles complex tasks through agent coordination, in its ability to reason about visual information, and in its integration of specialized thinking modes for deep problem-solving.
The model supports an 8K context window, meaning it can reasonably maintain conversation history and process documents up to roughly 8,000 tokens (approximately 6,000 words). That's less than Claude 3's 200K context, but substantially more than many open-source alternatives. For most enterprise workflows, 8K is workable when combined with intelligent document chunking strategies.
Moonshot claims K2.5 achieves "best-in-class" performance for open-source models on coding tasks, vision reasoning, and multi-agent orchestration. Let's examine what's actually true here by looking at the benchmarks.
Agent Swarm: The Architecture That Changes Everything
Agent Swarm might be the most important architectural decision in Kimi K2.5, and it's absolutely worth understanding deeply because it represents a fundamental shift in how AI systems can approach complex problems.
Traditional orchestration frameworks for AI agents work like a conductor with a score. The framework (think Zapier, Make, or custom Python orchestration) decides the sequence of steps, waits for one agent to complete, evaluates the result, then invokes the next agent. This is sequential, predictable, and safe. It's also slow.
Agent Swarm flips this model entirely. Instead of external orchestration dictating the workflow, the model itself learns to coordinate specialized sub-agents. Imagine you're building a system to analyze a customer support ticket, identify the relevant product database entries, generate a response, and schedule a follow-up. Rather than four sequential steps handled by different systems, Kimi K2.5 can spin up four parallel sub-agents, have them work simultaneously, and synthesize the results.
Here's the technical mechanism: Kimi K2.5 learns to decompose complex tasks internally. When given a large request, the model identifies sub-tasks, creates specialized "agent instances" for each, maintains their context, and coordinates results. The model manages up to 100 of these sub-agents in parallel, and collectively they can execute up to 1,500 tool invocations in a single workflow.
Why does this matter? Speed. Moonshot's own analysis suggests that workflows requiring days of human work can execute in minutes with parallel agent coordination. That's not hyperbole—that's the math of parallelization. If four sequential tasks take one hour each, running them in parallel takes one hour total. Scale that to complex enterprise workflows with dozens of steps, and you're talking about 10-50x improvements in execution time.
But there's a tradeoff worth discussing honestly. When you embed orchestration inside the model, you're accepting some loss of control compared to external frameworks. You can't inject custom logic between steps as easily. You can't pause and inspect results the same way. The model decides how many sub-agents to spawn, in what configuration, and how to weight their outputs. That's either a feature (automatic optimization) or a limitation (less transparent control), depending on your perspective.
Enterprise teams who've worked with orchestration frameworks like Salesforce's agent framework or AWS Bedrock's orchestration layer often prefer external control. They want to specify exactly which LLM handles which step, monitor performance independently, and swap models as needed. Kimi K2.5's embedded orchestration doesn't support that workflow as cleanly.
However, for organizations building agent ecosystems from scratch, K2.5's approach is revolutionary. You get sophisticated orchestration without building an entire framework. The model handles decomposition and coordination automatically.
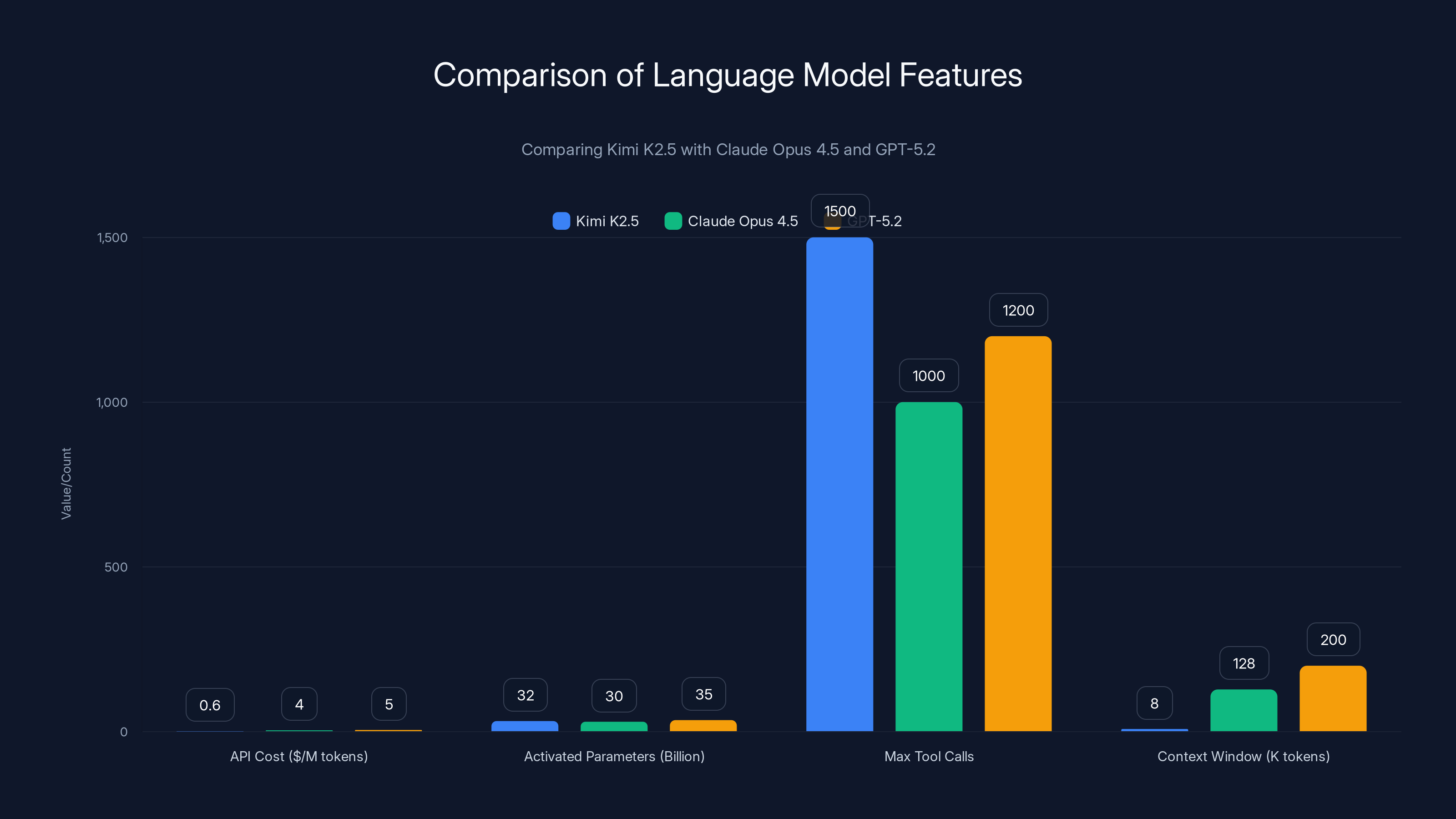
Kimi K2.5 offers significantly lower API costs and higher tool call capabilities compared to Claude Opus 4.5 and GPT-5.2, though it has a shorter context window. Estimated data for comparison.
Benchmark Performance: How K2.5 Actually Stacks Up
Benchmarks are imperfect, but they're the closest thing we have to standardized evaluation. So let's examine exactly where Kimi K2.5 ranks, what those rankings actually mean, and where it genuinely excels versus where the marketing slightly oversells.
Humanity's Last Exam Benchmark
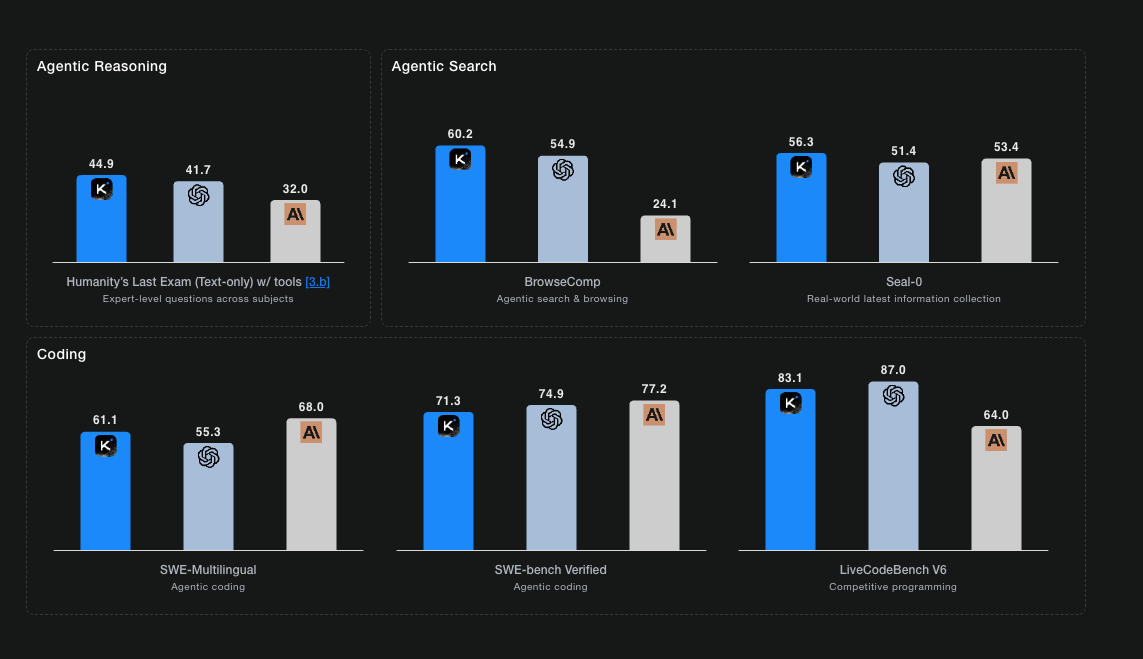
Humanity's Last Exam (HLE) is a relatively new benchmark designed to test frontier AI capabilities across reasoning, coding, math, and specialized knowledge. Moonshot's big claim: K2.5 achieved 50.2% accuracy with tools enabled, surpassing both OpenAI's GPT-5.2 (xhigh) and Anthropic's Claude Opus 4.5.
What does 50.2% actually mean? HLE is genuinely difficult. It includes questions that stump domain experts. The benchmark specifically targets reasoning tasks where current models struggle. A 50.2% score places K2.5 in the frontier tier of AI systems. The fact that it beats Opus 4.5 on this particular benchmark is notable, though Opus 4.5 likely maintains advantages on other standard benchmarks like MMLU and ARC-Challenge.
Worth noting: with tools enabled means the model can make web searches, call APIs, and use calculators. The score reflects this augmentation. The pure model performance (without tools) is lower, as is standard in the industry.
SWE-bench Verified: Code Generation Reality Check
For software engineering tasks, SWE-bench Verified is the current standard. It's a dataset of 500 real Github issues from popular repositories. The task: fix the issue and pass the test suite. No partial credit for code that looks right but doesn't work.
Kimi K2.5 achieved 76.8% on SWE-bench Verified. That's strong. But here's the context: GPT-5.2 hits 80.0%, and Opus 4.5 reaches 80.9%. So K2.5 is genuinely competitive, but not definitively superior for code generation specifically.
For coding with vision (visual debugging, UI reconstruction), K2.5 has fewer direct competitors. GPT-4V and Opus 4's vision capabilities are solid, but K2.5 is optimized specifically for frontend development: reconstructing layouts from videos, debugging visual issues autonomously, and translating design screenshots into functional code.
The Thinking Benchmark
Moonshot released its own comparison chart on "Thinking" benchmarks. This category measures performance when the model takes time to reason before answering, similar to OpenAI's o 1. K2.5 Thinking achieved higher scores than K2 base model on these tasks, which makes sense. Extended reasoning improves performance on hard problems.
But the chart omits direct comparisons to o 1 or Opus 4.5 Thinking variants. That's marketing caution, not unusual. Thinking mode benchmarks are still nascent, and direct comparisons are contentious.
Here's the honest assessment: Kimi K2.5 is competitive with, not categorically superior to, closed-source frontier models on standard benchmarks. Where it genuinely leads: Agent Swarm orchestration, multimodal coding, and cost-per-token. Those are the real differentiators.
Multimodal Coding: Reconstructing Interfaces from Video
Here's where Kimi K2.5 gets genuinely novel. Moonshot claims it's "the strongest open-source model to date for coding with vision." The phrasing is careful—they're not claiming to beat GPT-4V universally, but specifically for this niche.
The capability: Kimi K2.5 can reconstruct functional website code from video recordings. You record your browser showing a website in action (interactions, animations, responsive behavior), feed that video to K2.5, and the model outputs HTML, CSS, and JavaScript that reproduces the interface.
This sounds like a parlor trick, but it's actually profound if it works reliably. Why? Because communicating design intent through videos is how designers already think. A designer can show animations, hover states, responsive breakpoints, and interactions in under a minute of video. Converting that to precise code specifications might take an engineer an hour. If K2.5 can bridge that gap, it's genuinely valuable.
The mechanism: K2.5's vision understanding extracts spatial information from video frames (what elements are where), temporal information (how elements change over time), and semantic information (what each element does). It reconstructs the data structure, styling, and behavior that would produce those visual outputs.
Moonshot's own example: providing a video of an e-commerce product page, including scrolling behavior, image galleries, and interactive reviews. K2.5 generates code that implements all of it.
Is it perfect? Almost certainly not. K2.5 will probably miss subtle CSS properties, generate unnecessary divs, and occasionally misinterpret user interactions as state changes rather than animations. But if it achieves 70-80% accuracy on real designs, it's a significant time-saver. Even 50% accuracy might be worth it for certain use cases (quick prototypes, accessibility audits, design system extractions).
Integration with Kimi Code (Moonshot's new terminal tool) makes this practical. You can use it directly in VSCode or Cursor, the popular AI-augmented editor. The autonomous visual debugging feature is equally interesting: K2.5 visually inspects its own rendered output, checks against documentation, and iterates to fix layout issues without human intervention.
This is genuinely different from GPT-4V's image understanding or Claude's vision capabilities. Those models can describe images. K2.5 is specifically optimized for turning visual information into functional code.
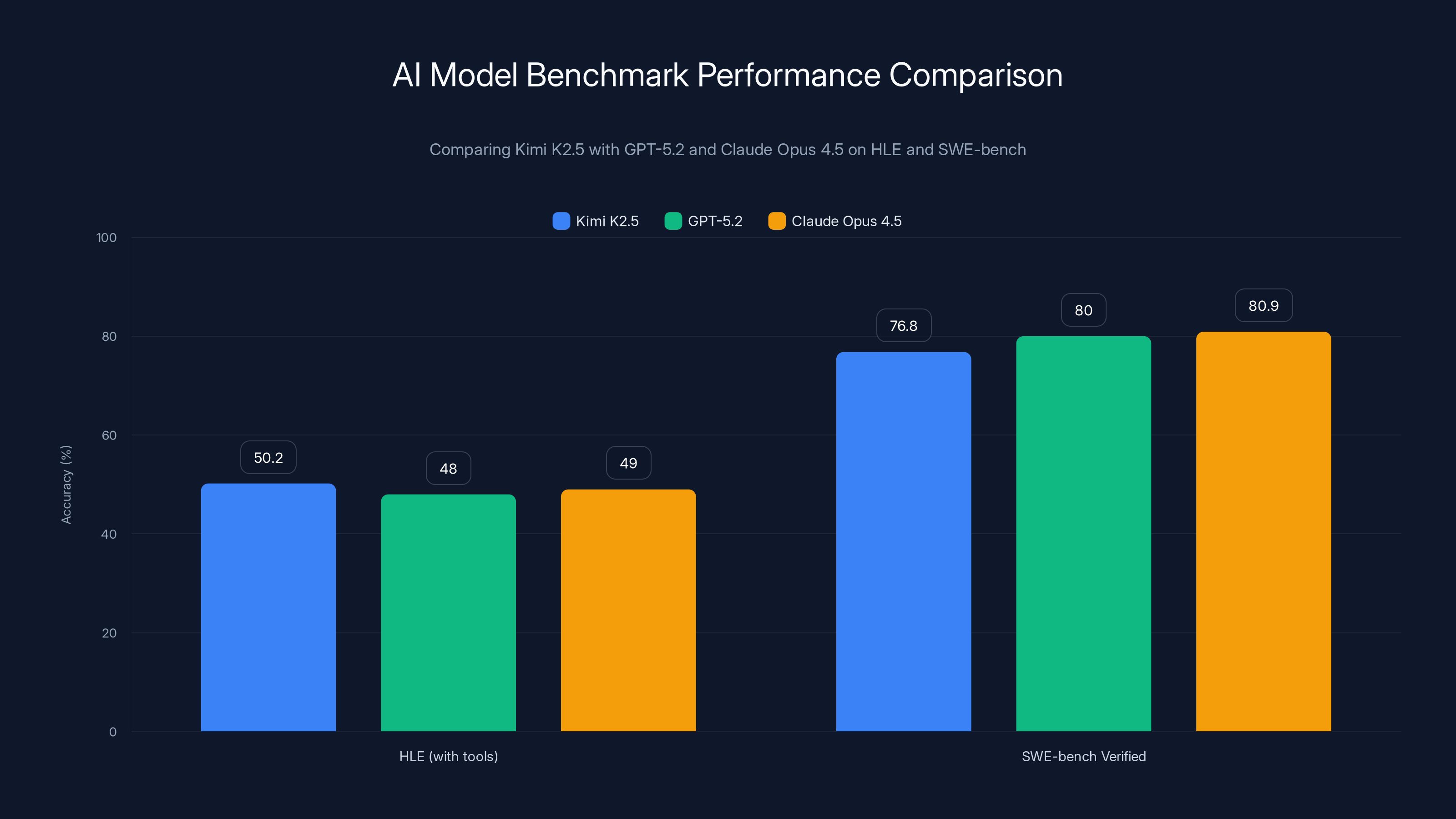
Kimi K2.5 surpasses GPT-5.2 and Claude Opus 4.5 on the HLE benchmark with tools enabled, but trails slightly behind in SWE-bench Verified for code generation tasks.
Mixture-of-Experts Architecture: The Technical Foundation
Understanding Kimi K2.5's performance requires understanding mixture-of-experts (MoE) architecture, because it's the foundation enabling both the model's scale and its efficiency.
Traditional dense language models activate all parameters for every input token. A 70 billion parameter model activates 70 billion parameters per token. That's why inference becomes expensive and slow at scale. Mixture-of-experts changes this fundamental assumption.
In MoE architecture, the model learns a routing function that directs each input token to a sparse subset of the total parameters. Imagine the model has 1 trillion total parameters, but is divided into 32 expert networks of 31 billion parameters each. For any input, a routing layer decides which 2-4 experts should handle that token. Only those experts activate.
The mathematical formulation looks like this:
Where
This routing happens dynamically and learned end-to-end. The model discovers which experts are relevant for different types of reasoning. Over time, you see specialization: some experts develop coding capabilities, others handle reasoning, others process specific domains.
The practical benefits are profound:
Cost Reduction: With 32 billion activated parameters instead of 1 trillion, inference compute drops to roughly 3-5% of what a dense model requires. That maps directly to API costs and latency.
Quality Scaling: The theoretical capacity remains 1 trillion parameters, so the model can learn sophisticated patterns. You're not sacrificing capability, just activating it selectively.
Load Balancing: During training, Moonshot likely uses auxiliary losses to ensure experts are balanced (not all tokens routing to two experts). This keeps the system efficient.
The tradeoffs: MoE models have higher memory overhead during training (you need to store all expert parameters). Inference requires a router that adds minimal latency but must be efficient. And there's inherent unpredictability—if the router makes suboptimal decisions, performance degrades.
Moonshot's implementation presumably includes techniques to handle these issues: load balancing losses, dropout of experts during training, and expert specialization objectives. But they don't disclose implementation details publicly.
For your purposes: MoE architecture is why K2.5 can be economically viable as an open-source model. It's fast enough to be practical, cheap enough to deploy widely, and capable enough to compete with much larger dense models.

Pricing Strategy: The Economics That Challenge Closed-Source Models
Here's where the market dynamics get interesting. Moonshot priced Kimi K2.5 aggressively:
For context, here's how that compares:
- OpenAI GPT-4o: $5 per million input tokens
- Claude 3.5 Sonnet: $3 per million input tokens
- Kimi K2.5: $0.60 per million input tokens
This is a 10x price advantage against GPT-4o. Even accounting for potential quality differences, the economics are staggering. An enterprise processing 100 million tokens per day (roughly 600,000 words, typical for moderate-scale usage) would spend
Why can Moonshot undercut so dramatically? Several factors:
First, geography and labor costs: Moonshot operates in China with lower operational overhead than US companies. Salaries, infrastructure, and support costs are simply lower.
Second, mixture-of-experts efficiency: Those 32 billion activated parameters (versus GPT-4o's full 200 billion activation) reduce inference compute costs substantially. That efficiency translates directly to lower user pricing.
Third, open-source distribution model: Moonshot can offer on-premise deployment and API access. The on-premise option means they're not serving all compute—customers absorb hosting costs. That's economically attractive for enterprises.
Fourth, market capture strategy: Moonshot is betting on gaining volume over margin. Capture developers and startups with low prices, build brand loyalty and ecosystem lock-in, then maintain pricing as network effects grow.
The output pricing is $2.40 per million tokens, a 16.7% decrease from K2 Turbo. Output is cheaper than input because the model generates fewer output tokens (generation is harder), and incentivizing short responses aligns with human preference.
For scale calculations: if you're running a task generating 10,000 output tokens per request (roughly 7,500 words), that's roughly
Compare to GPT-4o at roughly

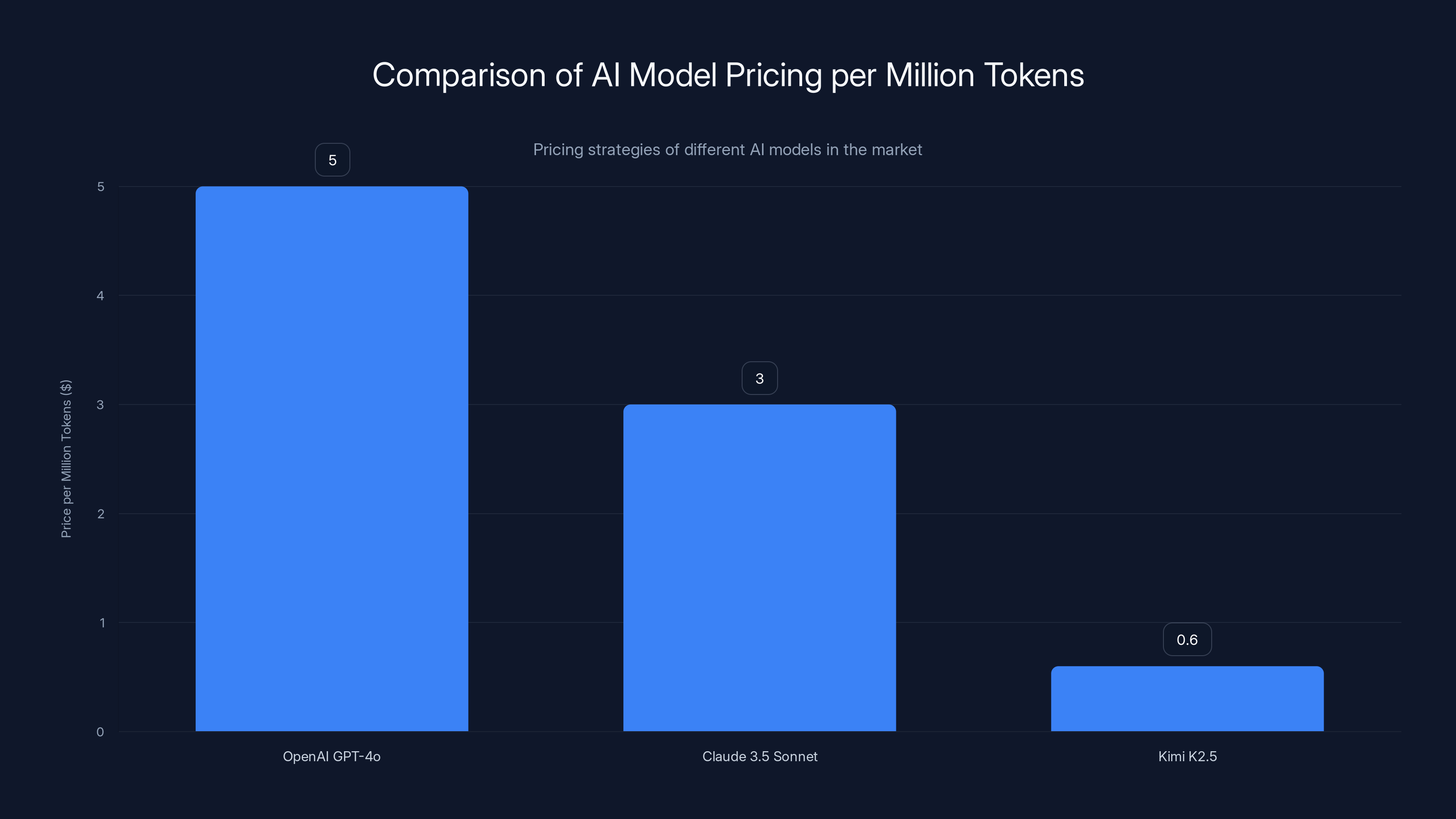
Kimi K2.5 offers a significant price advantage at
Agentic Workflows: Practical Implementation Patterns
Understanding how to actually use Kimi K2.5's Agent Swarm in production requires thinking through workflow patterns and implementation strategies.
Agent Swarm isn't magic. It's pattern-based decomposition with parallelization. To use it effectively, you need to understand what types of problems benefit from multi-agent approaches and how to structure prompts to enable effective decomposition.
Problem Types That Benefit from Agent Swarm
Research and synthesis tasks: A customer support agent needs to answer a complex question. It must retrieve knowledge base articles, search external documentation, aggregate relevant information, and generate a coherent response. Rather than sequential steps (search, then read, then synthesize), Agent Swarm spawns three agents in parallel: retriever, analyst, and writer. Each works independently. Writer receives completed analysis and produces the response while retriever is still fetching. This is textbook parallelization.
Data processing at scale: ETL pipelines (extract, transform, load) have natural parallelism. Extract the data, validate it, transform it for storage, and log the operations. Four sub-agents, concurrent execution, massive speedup compared to sequential processing.
Multi-language tasks: Translate a document into five languages, summarize each translation, and compare for consistency. Five language agents run in parallel rather than sequentially. The orchestrator checks consistency across translations.
Domain-specific analysis: Financial document analysis might decompose into risk assessment, compliance checking, valuation analysis, and recommendation generation. These are largely independent (risk assessment doesn't require compliance results to begin). Four agents in parallel.
Prompting for Effective Decomposition
To elicit good Agent Swarm behavior, your prompts need to signal decomposability. Instead of "analyze this customer inquiry," you might structure it as: "A customer asked about product compatibility, payment options, and shipping times. Delegate the compatibility question to the product expert agent, payment options to the billing agent, and shipping to the logistics agent. Synthesize their responses into a single reply."
That explicit decomposition guidance helps K2.5 understand that parallel processing is appropriate. Implicit decomposition (just asking for analysis) might result in sequential sub-agent invocation, negating the parallelization benefit.
Error Handling and Fallback Strategies
With 100 sub-agents running in parallel, some will inevitably fail or timeout. Effective implementations need:
Graceful degradation: If the billing agent times out, can you answer the customer's payment question from your base knowledge? Build fallbacks.
Retry logic: Implement exponential backoff for agents that timeout. K2.5's orchestration might handle this internally, but external orchestration layers definitely need it.
Result validation: When agents complete, validate their output format before synthesis. A malformed response breaks downstream processing.
Audit trails: Log which agents executed, what they returned, and how results were combined. This is critical for debugging and compliance.

Comparison: K2.5 vs. Closed-Source Alternatives
When evaluating whether to adopt Kimi K2.5, the comparison points that matter most are against Claude Opus 4.5 and GPT-4o/GPT-5.2. Let's be direct about tradeoffs.
Quality and Reasoning
Claude Opus 4.5 and GPT-5.2 maintain slight edges on general reasoning tasks. Both companies have invested heavily in constitutional AI and RLHF techniques that result in more nuanced, contextually appropriate responses. Kimi K2.5 is competitive, not superior, on these benchmarks.
For specialized reasoning (coding, math, scientific analysis), K2.5 matches or beats these models because Moonshot's training focused on those domains.
Multimodal Capabilities
GPT-4V and Claude 3.5 Vision handle images well. But Kimi K2.5's video-to-code capability is genuinely unique. If you need to extract code from design videos or build frontends from visual mockups, K2.5 is the clear winner.
For general image understanding (describing photos, analyzing charts, reading diagrams), GPT-4V probably edges out K2.5. Moonshot's optimization for coding-with-vision sometimes trades general visual understanding for coding specificity.
Agentic Orchestration
This is K2.5's strongest differentiator. Opus and GPT-5.2 can use tools and function calling, but they don't have built-in parallel agent orchestration. External frameworks like Anthropic's tool_use with parallel invocation are slower than K2.5's embedded orchestration. You're looking at 10-50x speedup depending on task structure.
If you're building multi-agent systems, K2.5's native support is a major advantage. If you prefer external control and model heterogeneity (different agents using different models), the current version might be limiting.
Cost
Kimi K2.5 at
Context Window
8K tokens (K2.5) versus 200K tokens (Claude) versus 128K tokens (GPT-4 Turbo) is a real limitation. K2.5 can't process 50-page documents natively. You need to chunk and summarize first, which adds complexity. For applications processing long documents, you might find yourself with increased engineering overhead.
Open-Source Advantage
Kimi K2.5 is open-sourced, meaning you can fine-tune it on proprietary data, deploy it on-premise, and avoid API dependency. Opus and GPT-5.2 don't offer this. If data privacy or customization is a constraint, K2.5 wins by default.

Kimi K2.5 excels in cost efficiency and agentic orchestration, while Claude Opus 4.5 and GPT-5.2 lead in quality and multimodal capabilities. Estimated data based on qualitative analysis.
Integration with Development Tools and Frameworks
Moonshot released Kimi Code, a terminal-based tool that integrates K2.5 with VSCode and Cursor. This matters because integration quality directly affects developer adoption.
Kimi Code appears to be structured as a plugin or IDE extension that gives K2.5 visibility into your codebase, file structure, and test results. When you ask K2.5 to fix a bug or implement a feature, it has context about your code, can run tests to verify correctness, and iterate autonomously on failures.
Automatic visual debugging is the standout feature: K2.5 renders CSS changes, compares the visual output to the expected result, and iterates on the stylesheet. For frontend developers, this removes the tedious cycle of edit-save-reload-compare-edit-again. K2.5 does that loop internally.
For integration workflows:
GitHub integration: K2.5 can presumably check out branches, run CI/CD pipelines, and verify fixes. This requires proper credential handling and sandbox enforcement.
API orchestration: If your codebase calls external APIs, K2.5's multi-agent approach can test different API variations in parallel, reducing verification time.
Documentation generation: K2.5 can read code and documentation references (via web search or local docs), then generate comprehensive docs. Automation of a tedious task.
Testing strategy: With visual debugging, K2.5 might generate more comprehensive CSS test coverage. With agentic capabilities, parallel test execution against multiple browsers or configurations.
The key question: does Kimi Code's integration actually work smoothly, or is it early-stage rough? Moonshot's silence on detailed implementation suggests it's recent. Expect iteration and maturation over the next 2-3 months.
Security and Privacy Considerations
When adopting any new AI model, especially from a company outside the traditional Western AI establishment, security and privacy warrant explicit consideration.
Moonshot AI is based in China, which raises legitimate concerns about data residency, export controls, and regulatory compliance. Here are the actual considerations:
Data in transit: If you're using Kimi K2.5 via API (cloud-hosted), your inputs travel to Moonshot's servers in China. For regulated data (PII, healthcare, financial), this might violate compliance requirements. EU GDPR explicitly restricts data transfer to non-adequate jurisdictions without additional safeguards.
On-premise deployment: The open-source nature of K2.5 means you can deploy it on your own infrastructure. This solves the data residency issue entirely. You own the hardware, Moonshot doesn't touch your data. This is a significant advantage for privacy-sensitive workloads.
Model auditing: As an open-source model, K2.5's weights are available for inspection. Security researchers can examine the model for intentional backdoors or prompt injection vulnerabilities. That transparency is actually better for security than closed-source alternatives.
Regulatory scrutiny: Moonshot, like many Chinese AI companies, operates under evolving Chinese AI regulation. Future regulatory changes might affect data handling practices. This uncertainty is worth factoring into long-term decisions.
Practical risk mitigation: If you're using K2.5 via API for non-sensitive data (customer support questions, code analysis, general research), the risk is acceptable. For sensitive workloads, deploy on-premise and manage your own infrastructure.
Comparative context: OpenAI and Anthropic also collect user data via APIs (though their data handling seems more transparent). Google's Gemini API likely collects training data unless you explicitly opt out. No vendor is perfect. The question is whether Moonshot's approach aligns with your risk tolerance.
Adoption Timeline: When to Evaluate Kimi K2.5
Moonshot reports 170% user growth between September and November 2024 for K2.5 and the earlier Thinking variant. This adoption momentum suggests the model is meeting real needs.
For your organization, the timeline decision depends on your risk tolerance and use case:
Early evaluation (next 30 days): If you're building coding tools, content generation systems, or agent-based workflows, start experimenting now. K2.5's strengths align with these use cases. Establish proof-of-concept on non-critical systems.
Production pilot (30-90 days): Once you've validated that K2.5's output quality meets your standards, begin a controlled production pilot. A/B test against your current models. Measure latency, cost, and quality improvement. Start with 10-20% of production traffic.
Controlled rollout (90-180 days): Assuming the pilot succeeds, gradually increase K2.5's traffic share. Monitor for edge cases and failure modes that didn't appear during testing. Maintain fallback to your previous model.
Full migration (180+ days): Once you've run multiple months of production data and confidence is high, consider full migration. But maintain the ability to route back to previous models if needed.
For novel use cases (agentic workflows, video-to-code), this timeline might accelerate. You're competing with other organizations discovering the same capabilities, so earlier adoption builds advantage.
For conservative organizations (finance, healthcare), adopt more slowly. Validate that K2.5's outputs meet compliance requirements before broadly deploying.

Future Development and Roadmap Speculation
Moonshot hasn't published a formal roadmap (to my knowledge), but adoption patterns and technical trends suggest likely directions.
Extended context windows: 8K is functional but limiting. Expect K2.6 or K3 to move toward 32K-128K context windows, bringing K2.5 into parity with current closed-source models. This requires architectural changes or smarter context compression techniques.
Longer context via compression: More likely than raw expansion, Moonshot will implement learned compression that extracts meaning from long documents, encodes it efficiently, and preserves relevant information. This is technically harder but more efficient than naive context extension.
Multimodal expansion: Video-to-code is the start. Expect audio understanding next (transcription, speaker identification, emotion detection). Then perhaps 3D model understanding or real-time video streams (for robotics, autonomous vehicles).
Specialized verticalization: Moonshot might release domain-specific variants (K2.5 Healthcare, K2.5 Finance, K2.5 Code) fine-tuned on vertical-specific data. This matches how Anthropic approaches specialized models.
More efficient agents: Agent Swarm coordination might become more refined. Instead of spinning up 100 agents, K2.5 might learn to spawn exactly the right number of agents for each task, reducing overhead.
On-device optimization: Mobile and edge device deployment of K2.5 through quantization and distillation. Imagine K2.5 running on your phone with sub-second latency. That's coming.
International partnerships: Moonshot will likely license K2.5 to other AI platforms and cloud providers, expanding distribution. That increases adoption without Moonshot handling all infrastructure.

Conclusion: The Competitive Landscape Shifts
Kimi K2.5 represents a genuine shift in AI market dynamics. An open-source model from a company outside the traditional Western AI establishment is now competitive with (and in some cases superior to) the cutting-edge closed-source models that have dominated the narrative.
This doesn't mean K2.5 is categorically better. Claude Opus 4.5 and GPT-5.2 maintain advantages in general reasoning, instruction-following, and safety properties. But the gap has narrowed substantially. And K2.5's specializations—agentic orchestration, multimodal coding, cost efficiency—fill real market niches that closed-source models address less effectively.
The implications are significant:
For enterprises: Open-source models are no longer second-class alternatives. You can now build production systems on K2.5 with confidence, whether via API or on-premise deployment. The cost savings alone (10x reduction) are material for scale.
For developers: Competitive models are forcing pricing pressure across the industry. Expect Claude and GPT pricing to decline over 2025 as they defend market share against lower-cost alternatives.
For startups: The moat around frontier model providers is shrinking. Building a startup that competes on "we have access to GPT-4" is less defensible when K2.5 exists. Startups must compete on product, integration, and domain expertise, not just API access.
For open-source advocates: Moonshot's success proves that open-source models can compete with closed-source on performance. Future development will likely accelerate as researchers recognize that frontier capabilities are achievable without massive proprietary infrastructure.
The "AI race" now includes serious competitors beyond OpenAI and Anthropic. That competition benefits everyone through faster innovation, lower costs, and more diverse approaches to frontier AI development.
If you're evaluating LLMs in 2025, Kimi K2.5 belongs on the list. Not as the default choice for every workload, but as a strong option for specific use cases: agentic workflows, coding tasks, multimodal processing, and cost-sensitive deployments. Start experimenting now. The technology is mature enough for production use, and the economics are compelling.
The open-source AI era isn't coming. It's already here.

FAQ
What is Kimi K2.5?
Kimi K2.5 is an open-source large language model developed by Moonshot AI that combines advanced language understanding, multimodal reasoning (text, images, and video), and built-in Agent Swarm orchestration. It features a mixture-of-experts architecture with 1 trillion total parameters and 32 billion activated parameters, enabling efficient inference while maintaining performance competitive with closed-source frontier models like Claude Opus 4.5 and GPT-5.2.
How does Kimi K2.5's Agent Swarm orchestration work?
Agent Swarm enables K2.5 to internally decompose complex tasks into sub-tasks, spawn up to 100 specialized sub-agents that work in parallel, and coordinate their outputs into a unified result. Rather than waiting for sequential steps to complete, the model can execute up to 1,500 tool calls simultaneously across parallel agents. This reduces execution time for multi-step workflows from hours or days to minutes.
What are the main advantages of Kimi K2.5 compared to Claude Opus and GPT-4?
K2.5's key advantages include dramatically lower API costs (
Can I deploy Kimi K2.5 on my own infrastructure?
Yes, Kimi K2.5 is open-source, meaning you can download the model weights and deploy it on your own servers, cloud infrastructure, or on-premise systems. This eliminates data residency concerns and external API dependency. You'll need sufficient GPU compute (typically 4-8 high-end GPUs for reasonable inference speeds) and infrastructure to host and maintain the deployment.
How does K2.5's performance on coding tasks compare to alternatives?
Kimi K2.5 achieved 76.8% on SWE-bench Verified, a standard benchmark for code generation. This ranks it among the top open-source models, though GPT-5.2 (80%) and Opus 4.5 (80.9%) maintain narrow leads. K2.5's genuine advantage is multimodal coding—reconstructing functional code from video recordings and performing autonomous visual debugging—a capability where it leads closed-source alternatives.
Is Kimi K2.5 suitable for regulated industries like healthcare or finance?
K2.5 is technically capable, but deployment considerations depend on regulatory requirements. For API-based usage, data residency concerns arise since Moonshot operates from China, potentially complicating GDPR or HIPAA compliance. On-premise deployment solves this by keeping all data within your infrastructure. Evaluate your specific regulatory constraints and consult with compliance teams before adopting K2.5 in regulated environments.
How much does Kimi K2.5 cost compared to other models?
K2.5 is priced at
What is Kimi Code and how does it integrate with development tools?
Kimi Code is a terminal-based IDE integration tool (compatible with VSCode and Cursor) that gives Kimi K2.5 visibility into your codebase structure and test results. It supports autonomous visual debugging, where K2.5 renders CSS changes, compares visual output to expected results, and iterates on code without human intervention. This automates the edit-save-reload-compare development cycle.
How do I start using Kimi K2.5 in my projects?
You have two options: API access via Moonshot's cloud infrastructure (simplest for evaluation), or open-source deployment on your own servers (better for production at scale). Start by accessing the API for proof-of-concept work, then evaluate on-premise deployment if cost or compliance requirements justify the additional infrastructure investment. Begin with non-critical features to validate output quality before expanding to core workloads.
What are the main limitations of Kimi K2.5 compared to frontier models?
Primary limitations include an 8K context window (versus 128K-200K for alternatives, limiting processing of long documents), slightly lower performance on general reasoning benchmarks, and less established track record in production systems compared to mature alternatives. Additionally, K2.5's Agent Swarm orchestration is embedded in the model, providing less fine-grained control compared to external orchestration frameworks that allow heterogeneous model combinations.

Related Resources
For deeper exploration of topics covered in this article, consider investigating mixture-of-experts architecture in language models, agentic AI systems and orchestration frameworks, multimodal learning for vision-language tasks, and open-source LLM deployment strategies. Each represents an evolving frontier in AI development with significant implications for infrastructure decisions and application architecture.

Key Takeaways
- Kimi K2.5 achieves competitive benchmark performance (50.2% on Humanity's Last Exam, 76.8% on SWE-bench Verified) while maintaining 10x cost advantage over GPT-4o
- Agent Swarm architecture enables 100 parallel sub-agents executing 1,500+ tool calls simultaneously, reducing multi-day workflows to minutes
- Multimodal coding capabilities (video-to-code reconstruction and autonomous visual debugging) are genuinely unique among open-source models
- Open-source availability enables on-premise deployment, solving data residency and regulatory compliance concerns
- User adoption growing 170% between September-November 2024 suggests strong market acceptance of open-source frontier model
Related Articles
- Why Retrieval Quality Beats Model Size in Enterprise AI [2025]
- DeepSeek Engram: Revolutionary AI Memory Optimization Explained
- DeepSeek's Conditional Memory: How Engram Fixes Silent LLM Waste [2025]
- ChatGPT's Critical Limitation: No Background Task Support [2025]
- Inferact's 800M Startup [2026]
- Neurophos Optical AI Chips: How $110M Unlocks Next-Gen Computing [2025]

