![ChatGPT 5.2 Writing Quality Problem: What Sam Altman Said [2025]](https://tryrunable.com/blog/chatgpt-5-2-writing-quality-problem-what-sam-altman-said-202/image-1-1769602140471.jpg)
Chat GPT 5.2 Writing Quality Crisis: Inside Open AI's Rare Public Admission [2025]
Something broke. And Sam Altman, Open AI's CEO, actually admitted it.
In December 2024, users started complaining across Reddit, X (formerly Twitter), and tech forums: Chat GPT 5.2 wasn't writing like Chat GPT anymore. Essays felt flatter. Technical documentation lacked precision. Creative writing seemed robotic. It wasn't subtle either—people noticed immediately.
Here's the thing: Open AI is usually guarded about admitting problems. But Altman broke that pattern. In a direct statement, he acknowledged the company "screwed up" the writing quality on Chat GPT 5.2 and committed to fixing it in future versions. That admission matters. It signals confidence in recovery, but it also raises harder questions: How did this happen? Why didn't they catch it before launch? And what does this mean for AI writing quality going forward?
This isn't just another software update gone wrong. Writing quality is central to what makes Chat GPT useful. Engineers trust it for code explanations. Marketers rely on it for copy. Students use it for essays. When the writing gets worse, the entire product feels like a step backward—even if other capabilities improved.
So what actually happened with Chat GPT 5.2? The short answer: nobody outside Open AI knows exactly. But the tech community has developed some educated theories based on observable behavior, comparative testing, and what little Open AI has shared. Let's dig into the breakdown.
What Users Actually Noticed About Chat GPT 5.2's Writing
When Chat GPT 5.2 rolled out, the complaints came fast. Users reported specific, measurable problems with the writing output:
Repetitive sentence structure was the biggest complaint. The model seemed to default to similar cadences and patterns. If you asked for a 500-word article, you'd get five 100-word blocks that all felt like they were written by the same tired voice. No variation. No rhythm. Just... consistent mediocrity.
Awkward phrasing appeared more frequently. Word choices that no human would naturally make. Sentences that technically made sense but sounded off, like someone translating from another language back to English. Users described it as "technically correct but emotionally flat."
Reduced nuance in tone meant the model struggled to match requested writing styles. Ask for conversational and you'd get corporate-robotic. Ask for technical and you'd get overly simplified. The model couldn't dial in the subtlety anymore.
Longer paragraphs without natural breaks made content harder to read. Previous versions seemed to understand when a paragraph was getting too dense. Version 5.2 would sometimes dump 300 words into a single block.
Less creative problem-solving in writing scenarios. When asked to explain complex ideas, the model fell back on safe, generic explanations rather than finding clever analogies or unexpected approaches.
The frustrating part? Open AI hadn't publicized these changes. Users discovered them through actual use. That's different from releasing a new version with known tradeoffs. It felt like something accidentally went wrong rather than a deliberate engineering choice.
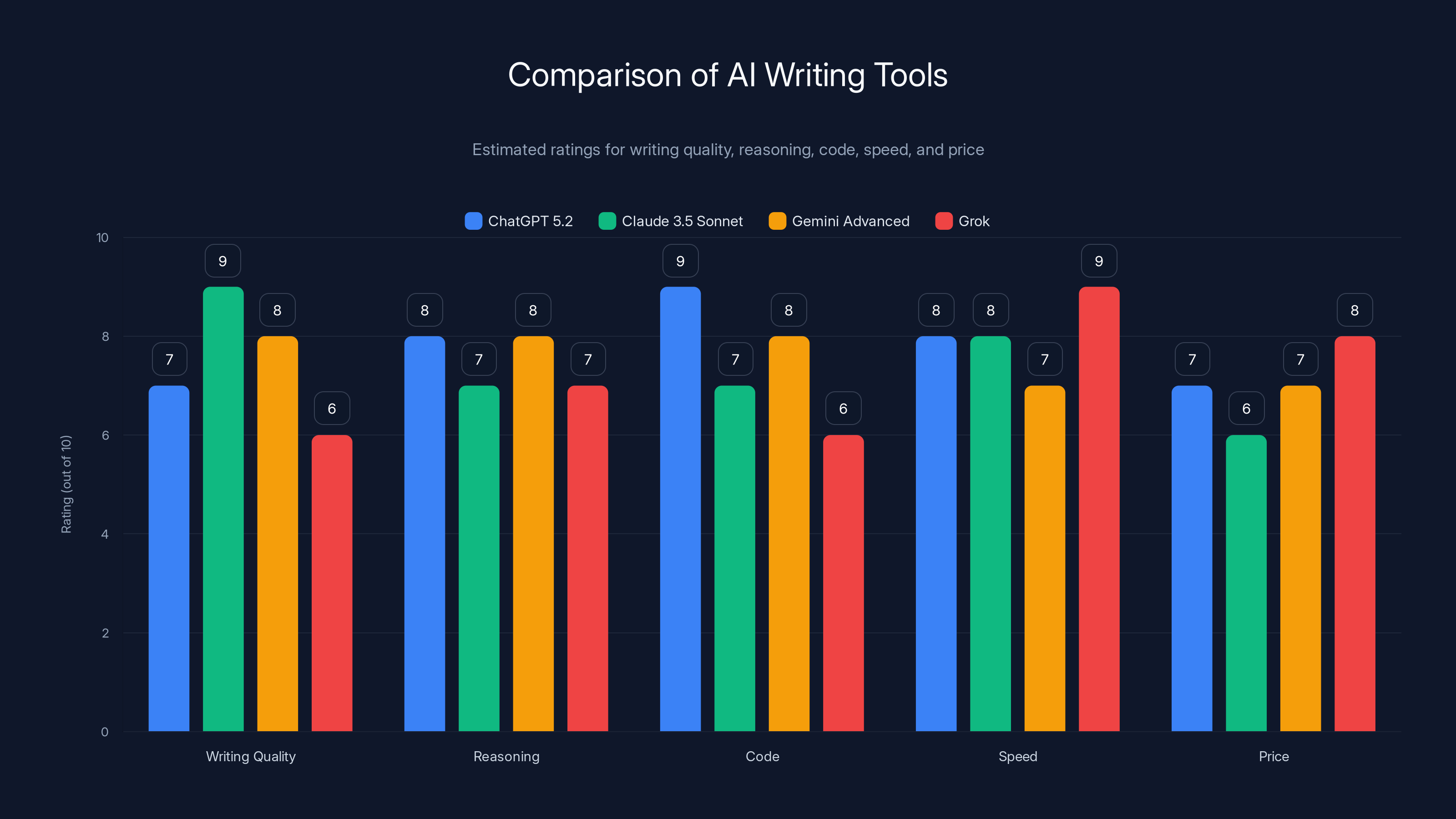
Estimated data shows Claude 3.5 Sonnet leading in writing quality, while Grok excels in speed and creativity. ChatGPT 5.2 remains a strong all-rounder.
Sam Altman's Admission: "We Screwed Up"
By late December, the complaints had reached critical mass. Altman responded—directly and unusually candidly for a CEO of his stature.
In a statement he shared across social media, Altman said Open AI "screwed up" the writing quality on Chat GPT 5.2 and committed that future versions wouldn't "neglect" it. The language matters. "Screwed up" isn't corporate-speak. It's an honest confession of failure.
What's remarkable is that Altman didn't make excuses. He didn't say "writing quality is subjective" or "some users prefer this style." He acknowledged it was a mistake, period. That's rare in an industry where executives usually defend product decisions aggressively.
But here's what he didn't say: exactly what caused it or when the fix would arrive. Open AI provided no technical explanation. No timeline. No roadmap. Just an acknowledgment and a promise—both vague enough to give them flexibility.
That left the community to speculate. Why would a company known for obsessing over model quality suddenly ship something that felt worse? What changed in the training pipeline?

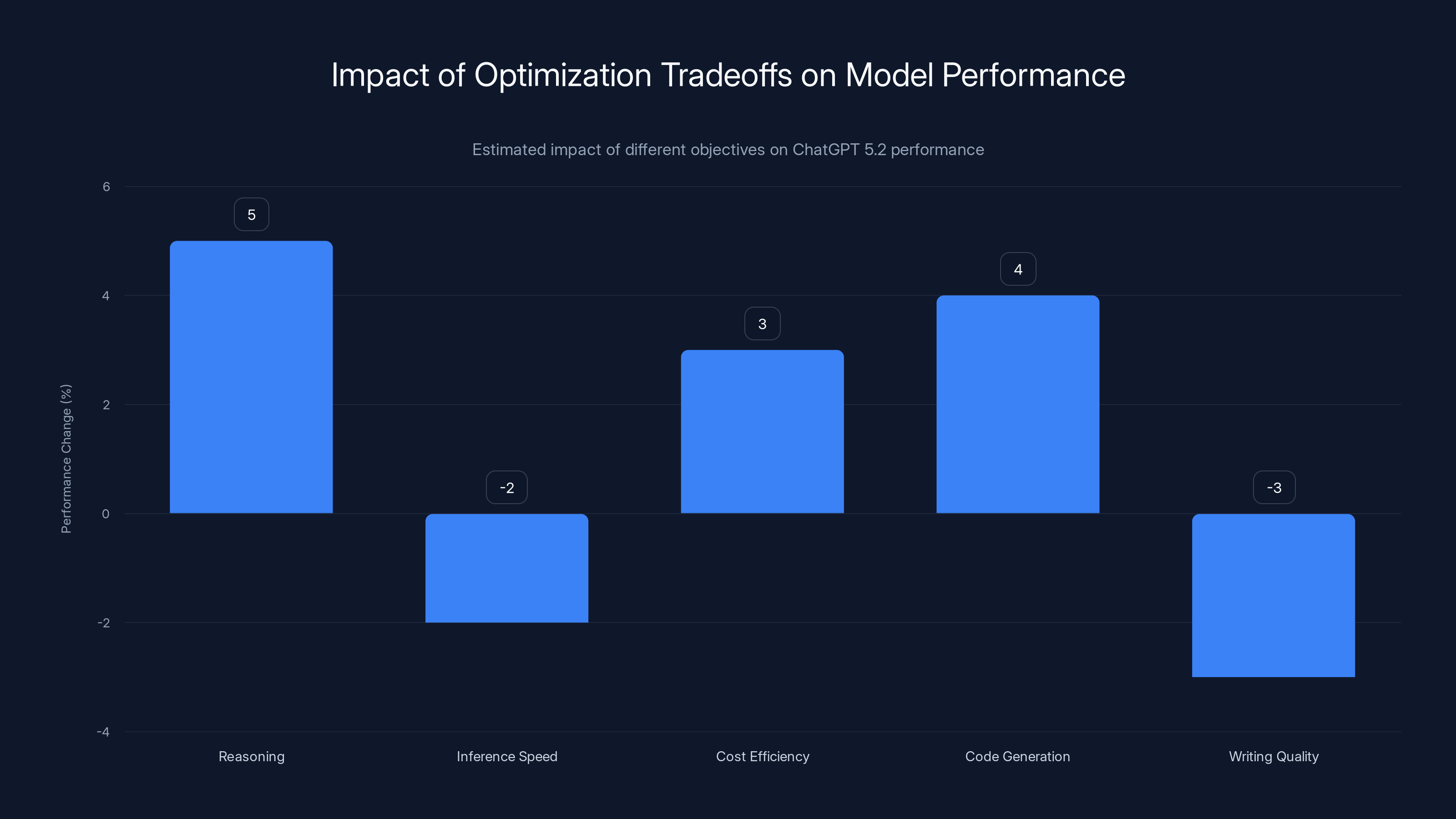
Estimated data shows that while reasoning improved by 5%, writing quality decreased by 3% due to optimization tradeoffs in ChatGPT 5.2.
The Likely Root Causes: What Went Wrong
We don't have Open AI's internal documentation, but the patterns users reported give us clues about what probably happened.
Optimization tradeoff is the leading theory. When training large language models, engineers optimize for multiple objectives simultaneously. Better reasoning. Faster inference. Lower costs. Better code generation. Better writing. Sometimes these goals conflict.
Chat GPT 5.2 made improvements in reasoning tasks—measurable, testable, benchmarkable improvements. That required reweighting the loss function. Basically, during training, the model learned to prioritize certain capabilities over others. If the weights shifted too heavily toward reasoning, writing quality could suffer as a side effect.
Training data changes may have also played a role. Open AI regularly updates the training data fed into Chat GPT. If version 5.2 included different source material—perhaps more recent data that's lower quality, or data weighted differently—it could explain degraded writing performance without any code changes.
Internet-sourced text has been declining in quality for years. As AI-generated content proliferates, the "ground truth" text models learn from includes more mediocre writing. If Open AI pulled newer training data without careful curation, the model might have inadvertently learned to mimic average writing instead of excellent writing.
Instruction-tuning regression is another possibility. After base model training, Open AI uses reinforcement learning from human feedback (RLHF) to fine-tune Chat GPT. If the RLHF training for version 5.2 emphasized different behaviors, it could have shifted the model away from its writing strengths. Perhaps the feedback data overweighted technical accuracy at the expense of prose quality.
Inference-time changes could matter too. Chat GPT uses various sampling techniques and decoding strategies to generate text. Maybe version 5.2 adjusted the temperature or top-p settings by default, or changed the prompt structure going into the model. Small changes here can significantly affect output quality without any model changes.
Speed-first engineering might have driven decisions. If Open AI optimized Chat GPT 5.2 for inference speed—which they've publicly stated is a goal—that could have cascading effects. Smaller context windows, faster sampling, lower precision calculations. All potentially great for speed and cost, all potentially bad for writing nuance.
The honest truth? Without Open AI releasing technical details, we're educated guessing. But the patterns point to tradeoff decisions, not bugs. Which is worse in a way—it suggests someone made a call, missed the impact, and shipped it anyway.
Why Didn't Open AI Catch This Before Launch?
Here's the uncomfortable question nobody's asking enough: How did a company of Open AI's caliber miss this?
Open AI has extensive testing infrastructure. Red-teaming processes. Quality benchmarks. Countless hours spent evaluating models before release. They're not some startup shipping half-baked products. They're the leader in the AI space.
So the failure wasn't incompetence. It was probably some combination of things:
Measurement blindness is likely. Open AI probably measured Chat GPT 5.2 against benchmarks: MMLU, coding contests, reasoning tasks. Chances are, version 5.2 scored higher on those benchmarks. The company had metrics saying "this is better." Writing quality isn't benchmarked the same way. You can't put "eloquence" on a leaderboard.
This is a real problem in AI development. If you optimize for what you measure, you ignore what you don't. Open AI likely measured reasoning improvement meticulously and writing quality... less so.
User testing gap might exist too. Open AI probably tested Chat GPT 5.2 internally before release. But internal testing focuses on specific, controlled tasks. Real users discover edge cases, use cases, and quality issues that internal teams miss. You can't replicate the diversity of actual usage.
Pace pressure could have influenced decisions. The AI industry moves fast. Competitors ship new models constantly. Open AI might have felt pressure to ship version 5.2 on schedule even with known quality tradeoffs, betting they could fix it later.
Novelty over stability sometimes drives product decisions. New capabilities (better reasoning) are exciting. Maintaining existing capabilities (good writing) is just... maintaining. Companies instinctively push toward innovation even when it risks regressions.
Open AI's statement didn't address any of this. They acknowledged the problem, promised a fix, and moved on. That's responsible in one sense—admitting mistakes—but evasive in another. It doesn't help the industry understand how to avoid similar problems.

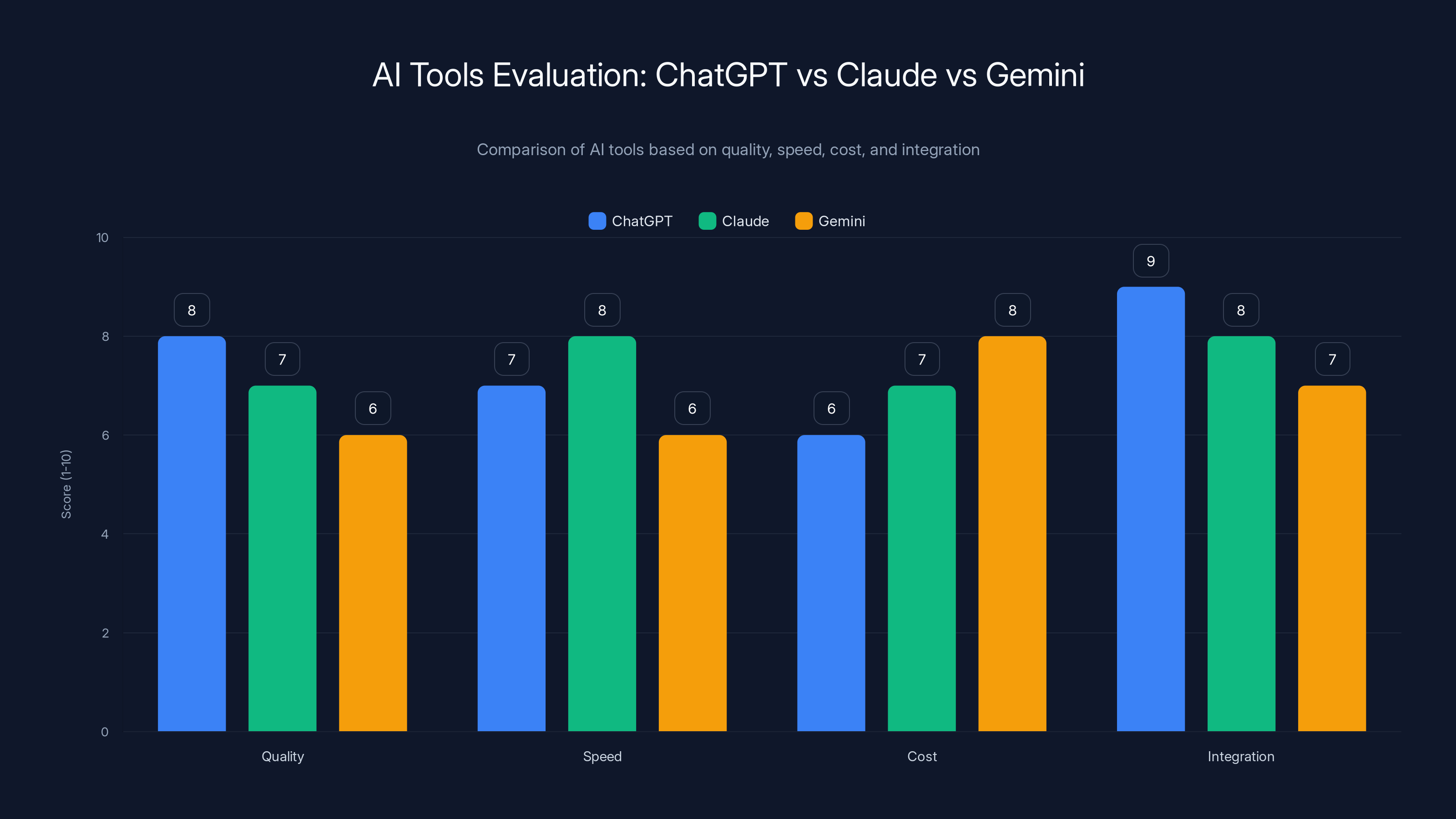
Estimated data shows ChatGPT leading in integration, while Claude scores high on speed. Gemini offers competitive cost advantages. Estimated data.
The Broader Implications for AI Writing Tools
This situation reveals something important about the current state of AI writing quality: it's unstable.
We talk about AI as though it's converging toward human-level writing. But Chat GPT 5.2 is a reminder that writing quality is fragile. One version is good, the next is noticeably worse. Small engineering decisions cascade into subjective user experience changes. We don't have predictive models for when that happens.
Writing quality is multidimensional. Unlike coding (correct or incorrect) or reasoning (right or wrong answer), writing quality involves style, tone, clarity, creativity, and more. These dimensions aren't independent. Optimizing for one often sacrifices another. There's no universal "good writing" benchmark.
This is why Anthropic's Claude has been gaining ground with writers. Anthropic built their training and evaluation processes around writing quality from the start. They measure it carefully. They prioritize it. They don't treat it as a nice-to-have feature.
Competitive differentiation will shift. Chat GPT dominated through raw capability first, then writing quality second. If that second strength erodes, other models become more appealing. Google Gemini, Claude, and others can position themselves as "the reliable writing model." That's a real market advantage.
User expectations changed. A year ago, users accepted AI writing as "pretty good for something automated." Now they expect excellence. Chat GPT set that bar. When version 5.2 fell short, the disappointment was proportional to how good 5.1 had been. That's the curse of being the market leader.
The testing infrastructure needs rethinking. Chat GPT 5.2 proves that releasing a model requires more than benchmark improvements. You need human evaluation, diverse user testing, and specific quality gates for different use cases. Open AI will probably increase their writing quality evaluation for future releases, but how many other companies will learn from this?
Open AI's Response Plan: What's Actually Changing
Alright, so Sam Altman said they'll fix it. But what does that actually mean?
Open AI hasn't released detailed plans, but based on their statement and industry norms, we can expect a few things:
A new version is coming. It won't be Chat GPT 5.3 necessarily, but they'll ship an update with improved writing quality. Timeline? Unknown. But given the public pressure, probably sooner rather than later. Open AI doesn't like being the company that "screwed up."
The fix will involve reweighting. They probably won't retrain the base model from scratch—that's expensive and time-consuming. More likely, they'll adjust the RLHF training to reemphasize writing quality, or tweak the inference settings, or both. Rebalancing existing capabilities is faster than rebuilding.
They'll likely overcorrect. When companies acknowledge public complaints, they often fix the issue by going too far the other direction. Open AI might make writing quality so much better that reasoning or coding performance dips slightly. That's classic engineering tradeoff behavior.
Benchmarking will expand. Open AI will probably add writing quality metrics to their evaluation suite, making sure this doesn't happen again. They might release those benchmarks publicly to show they're taking it seriously.
Communication will improve. Future version releases might include specific notes about quality tradeoffs. "Version 5.3 prioritizes writing quality and improved reasoning over inference speed." That kind of transparency helps users understand what to expect.
Here's what's less likely: Open AI admitting exactly what went wrong. They're not going to release a postmortem. Too much competitive advantage in keeping training details proprietary. Users will accept the fix and move on.
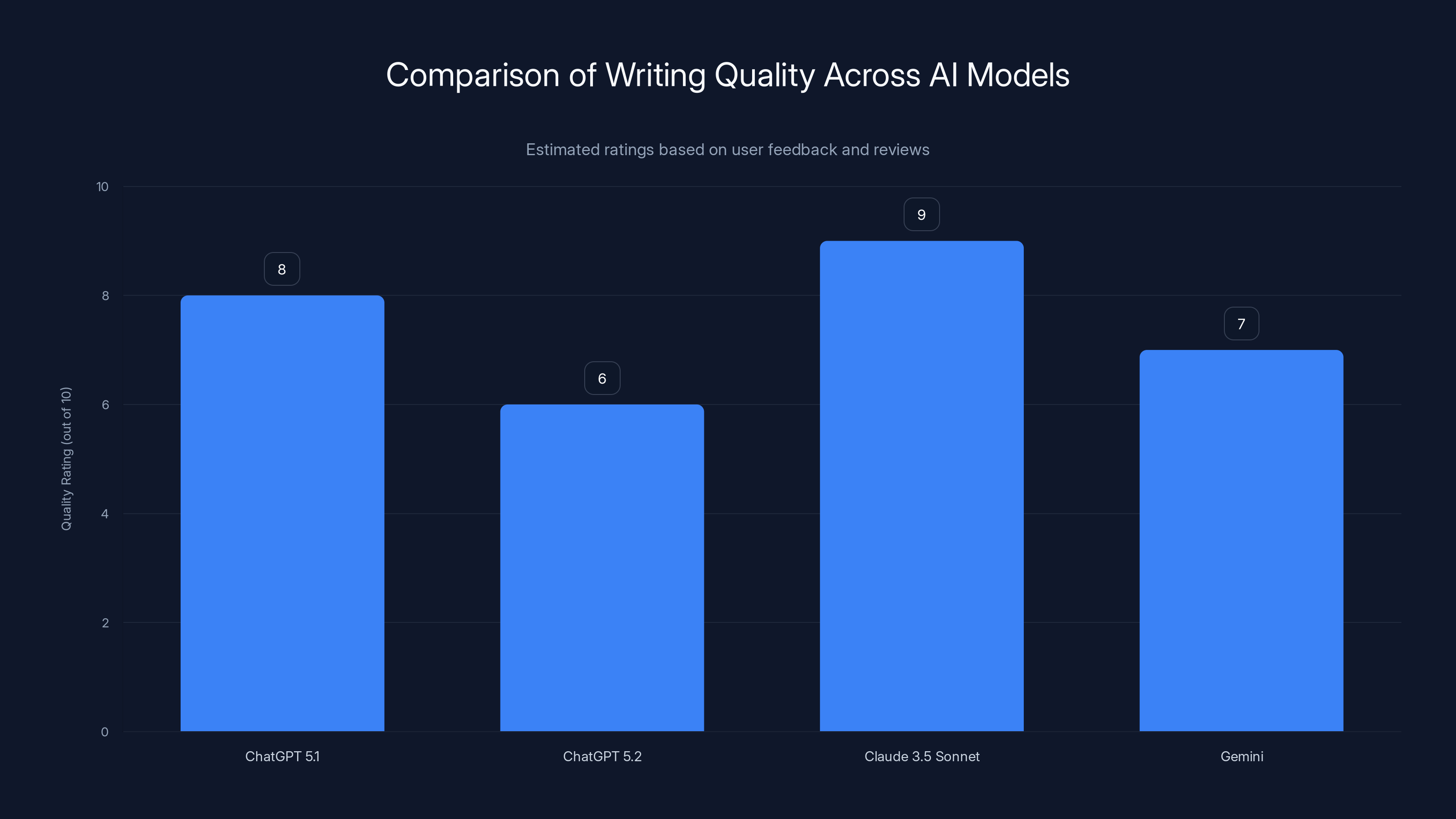
ChatGPT 5.2 shows a decline in writing quality compared to its predecessor and competitors, with Claude 3.5 Sonnet leading in user satisfaction. Estimated data based on user feedback.
Comparing Chat GPT 5.2 to Competitors
This whole situation gives other AI companies an opportunity.
Claude 3.5 Sonnet (made by Anthropic) is often rated higher for writing quality by users who care deeply about prose. Anthropic designed Claude specifically around helpful, harmless, and honest outputs—with writing quality as a core metric. They evaluate ruthlessly on how natural and clear the writing is.
For content creators, copywriters, and journalists, Claude consistently outperforms Chat GPT even when both have comparable capabilities in other areas. The writing just feels better.
Gemini Advanced (from Google) has been quietly improving. It's not as famous as Chat GPT, but Google's writing quality has gotten noticeably better in recent updates. For technical writing especially, Gemini often produces clearer explanations.
Grok (from x AI) positions itself differently—more irreverent, more creative. Some users prefer that tone for brainstorming and creative work. Traditional writing quality matters less when the goal is novelty.
The Chat GPT 5.2 situation essentially created an opening. Users frustrated with the writing quality now have permission to try alternatives. Some will switch. Some will use multiple tools for different tasks. That's actually healthy for the market.
Automation tools like Runable also benefit indirectly. When Chat GPT struggles with writing quality, teams consider whether they should automate document creation differently. Runable offers AI-powered document generation starting at $9/month, giving businesses an alternative for creating presentations, documents, and reports without relying solely on Chat GPT.
The broader lesson: writing quality matters more than most tech companies realized. It's not a feature you can degrade without consequences.

What This Means for Users Relying on Chat GPT
If you use Chat GPT for writing work, what should you do right now?
Don't panic. Chat GPT 5.2 is still functional. It still generates usable content. It's not broken—it's just worse than 5.1. For casual use, the difference might be invisible.
But do adapt. If you rely on Chat GPT for high-quality writing output, consider these strategies:
First, provide more detailed prompts. Be specific about tone, style, and audience. Instead of "Write an article about AI," try "Write a technical article about large language models for software engineers, using a conversational tone with specific examples." Better prompts get better results even from slightly degraded models.
Second, edit more. Version 5.2 requires more human editing to reach acceptable quality. Build that into your workflow. Have humans review and revise, not just copy-paste. This is always good practice anyway.
Third, compare with alternatives. Test Claude or Gemini on your specific writing tasks. You might find you prefer them anyway. The Chat GPT 5.2 situation is a good forcing function to evaluate competitors.
Fourth, wait for the fix. Open AI will ship something better. When they do, give it a try. They have strong incentives to overcorrect back toward quality.
Document your findings. If you work in a company using Chat GPT, share observations about quality with your team. Help everyone understand the limitations right now. That information informs decisions about upgrading or switching.

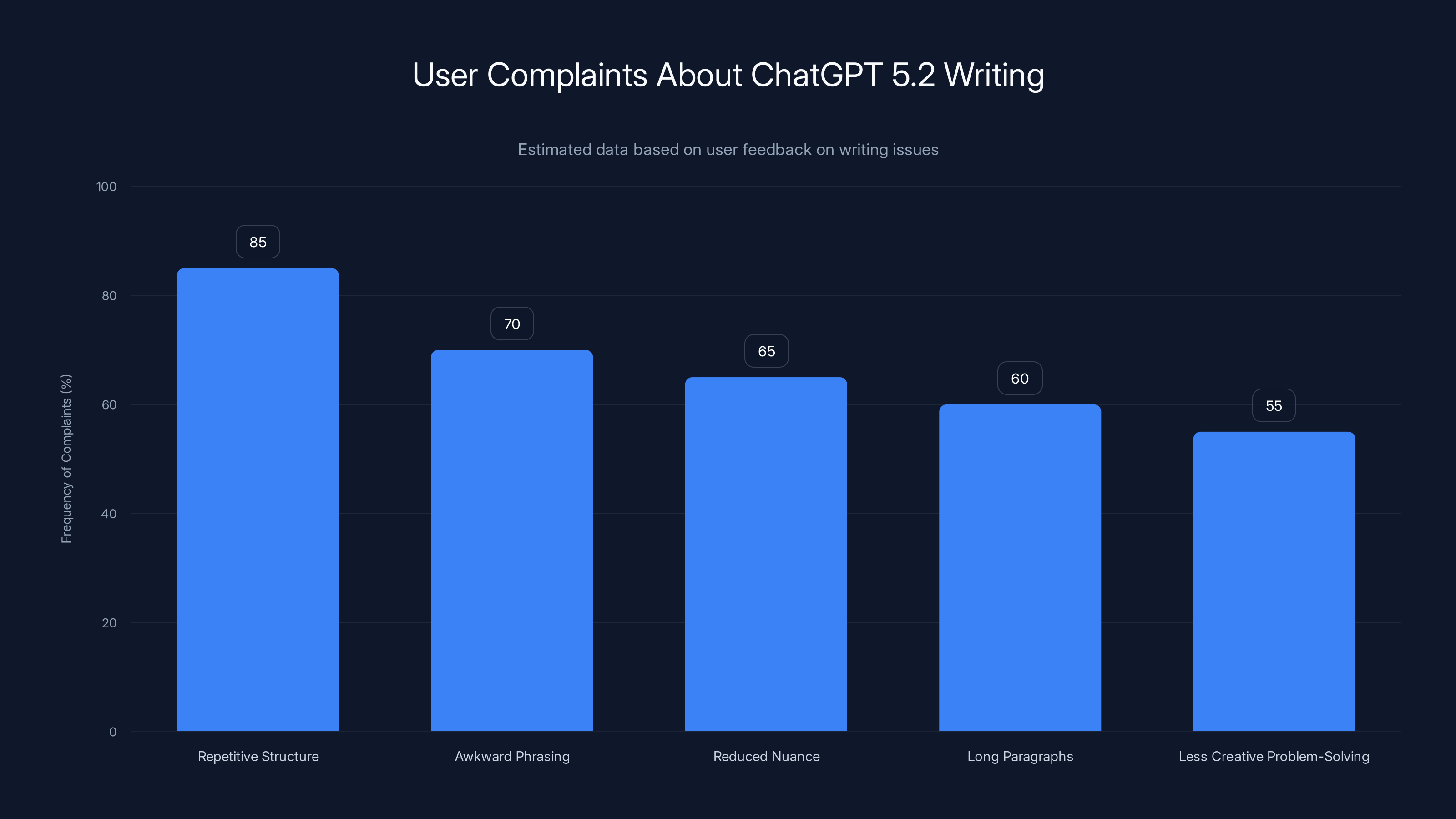
Repetitive sentence structure was the most frequently reported issue with ChatGPT 5.2, followed by awkward phrasing and reduced nuance in tone. (Estimated data)
The Bigger Story: Model Quality Regressions Will Happen Again
Let's zoom out for a second. This isn't the first time a major AI company shipped a degraded model. It won't be the last.
Anthropic had issues with Claude 2 that got fixed in Claude 3. Google had Gemini's early version quietly improve over time. Meta's Llama models have had quality fluctuations. Mistral has had to iterate quickly.
This is because training and fine-tuning large models involves complex tradeoffs that humans can't perfectly predict. You can't have perfectly measured everything in advance. Something always surprises you in production.
The solution isn't perfect testing. It's faster iteration. Ship, measure, fix, ship again. Keep the cycle short enough that regressions don't damage your reputation long-term. Open AI is good at this. Chat GPT 5.2 is a misstep, but the company has credibility to recover.
For users, the lesson is practical: Don't assume any model is permanently optimized. Check your tools regularly. Test new versions before fully committing. Keep backups of important work. Have alternatives ready.
AI writing quality is competitive, iterated, and constantly changing. That's not going away.

What Version 5.3 (or Whatever Comes Next) Might Look Like
Based on Open AI's likely approach and user demands, the next version will probably emphasize:
Sentence-level quality. More varied structure. Better pacing. More natural transitions. Less repetition. This is learnable and measurable through human evaluation.
Tone flexibility. Better ability to actually match requested tones—conversational vs. formal, creative vs. technical. This requires robust instruction-following during fine-tuning.
Longer-form coherence. When you ask for a 2,000-word essay, it should maintain quality throughout. Not start strong and degrade. This is harder to fix but probably addressable through careful RLHF training.
Reasoning retained. They won't sacrifice the reasoning improvements from 5.2. They'll find the balance—good reasoning AND good writing. It's possible, just requires more nuanced optimization.
Performance maintained. Speed should stay fast. Cost should stay reasonable. Open AI won't ship something that actually regresses on efficiency for the sake of writing quality.
If Open AI nails all this, the next version could actually be stronger than 5.1—taking 5.2's reasoning improvements and 5.1's writing quality, combining them. That's the goal anyway.
But that's engineering-hard. It requires understanding your model deeply enough to make targeted improvements without cascading regressions. That's where Open AI's experience gives them an advantage.

Industry Lessons: How This Changes Model Development
The Chat GPT 5.2 situation is becoming a case study in model development best practices. Here's what the industry should learn:
First, write quality needs formal benchmarks. Not just ratings from internal testers, but objective metrics that can be tracked across versions. This could be automated evaluation of prose quality, user preference studies, or domain-specific tests. Without benchmarks, you can't manage what you don't measure.
Several companies are working on this. AI2 has published research on evaluating language model outputs. Hugging Face runs extensive evaluations on open models. These frameworks need to become standard.
Second, broader testing before release is essential. More beta users, more real-world scenarios, more domains. Chat GPT 5.2 should have been tested with writers, journalists, content creators—not just engineers. Real users in real workflows find problems labs don't.
Third, transparency about tradeoffs builds trust. If Open AI had said "Chat GPT 5.2 improves reasoning by 15% but writing quality drops slightly," users could have made informed decisions. Instead, the regression felt like an accident. Communication matters.
Fourth, quality gates should be part of release decisions. Not just "did the benchmarks improve" but "did any important capabilities degrade." This requires defining what's important, which varies by use case. But it's necessary.
Fifth, rollback capability matters. If Open AI could have easily reverted Chat GPT to 5.1, the damage would have been minimal. But models at scale aren't simple to rollback. The architecture matters. Future systems should be designed for faster iteration and rollback.
These lessons apply to any company shipping large models: Open AI, Anthropic, Google, Meta, everyone.

The Future of AI Writing Quality
Looking forward, what's the trajectory?
Writing quality will become a competitive differentiator. Right now, most models cluster around "pretty good." As commoditization accelerates, excellence at writing could be the thing that matters. Anthropic might actually win market share on this basis.
Specialized models will emerge. Someone will build an LLM specifically optimized for writing—fiction, technical documentation, marketing copy, academic papers. Dedicated models can achieve better quality than general-purpose tools.
Human-in-the-loop workflows will dominate. Even perfect AI writing might not be trusted for important documents. Instead, workflows will be: AI draft + human edit + final publish. That's pragmatic and probably permanent.
Measurement will get more sophisticated. Instead of humans rating writing quality on a 1-5 scale, companies will use behavioral metrics—did editors choose to keep this sentence or rewrite it? Did readers spend more time on this paragraph? Did the message successfully persuade? Real outcomes matter more than subjective ratings.
Regulation might force transparency. As AI writing tools proliferate, there will be pressure for disclosure—what percentage of an article was AI-generated, how much was edited, etc. That could push companies to improve baseline quality to reduce red-flags.
The gold standard will be human-written work. Paradoxically, as AI gets better, human-written content becomes more valuable and trustworthy. Premium publications might actually market "written by humans" as a feature. That creates a market for actual writers again.

How Organizations Should Respond Right Now
If you're a company using Chat GPT for content creation, reporting, documentation, or writing, here's what to do:
Audit your current usage. How much content is Chat GPT generating? What's the quality threshold? How much editing happens? Get concrete numbers.
Establish quality standards. Define what "good enough" looks like for your use case. Marketing copy has different standards than technical documentation. Write those down.
Test alternatives. This Chat GPT 5.2 situation is a perfect time to objectively evaluate Claude, Gemini, and others. Run them through your actual workflows. Score them consistently.
Document results. Keep a running log of which tool produces better output for which tasks. Share findings across your team. This builds institutional knowledge.
Build a contingency plan. If Chat GPT fails you, what's the fallback? Having Claude or Gemini as backup reduces risk and gives you leverage to negotiate better pricing.
Invest in prompting. Better prompts are free and can significantly improve output quality. Make this part of your standard practice across teams.
Consider enterprise licensing. If Chat GPT is critical to your operations, upgrade to Chat GPT Pro or an enterprise plan. You get priority support and early access to fixes.
Stay informed. Follow Open AI announcements, Anthropic research, Google updates. The AI landscape shifts monthly. Being informed helps you stay ahead of problems.

The Bottom Line
Sam Altman's admission that Open AI "screwed up" Chat GPT 5.2's writing quality is significant—not because it's unique (all models have issues) but because a company at the top acknowledged it publicly.
That honesty is refreshing. But it also reveals something real about AI development: we're still in the phase where improvements in one area often cause regressions elsewhere. We don't have the science locked down well enough to make perfect tradeoff decisions.
For users, the lesson is practical: Don't treat any AI model as static. Test regularly. Have alternatives. Set quality standards. Build editing into your workflow. The tools are powerful but imperfect, and that imperfection is going to keep changing.
For Open AI, the path forward is clear: fix it quickly, communicate clearly, and build better measurement into future releases. They have the talent and resources to do this. The question is whether the entire industry learns from the mistake.
Chat GPT 5.2 won't be remembered as a catastrophe. It'll be remembered as a moment when the world's leading AI company admitted publicly that excellence is harder to maintain than it looks. And that's honestly a reasonable lesson for everyone building AI products.

TL; DR
- Sam Altman publicly admitted Open AI "screwed up" Chat GPT 5.2's writing quality, showing the model produces flatter, more repetitive prose than version 5.1
- Root cause likely involves tradeoffs: Optimizing for reasoning improvements probably reweighted training in ways that degraded writing quality, a common issue in LLM development
- Open AI didn't catch it before launch: Likely because writing quality isn't benchmarked as rigorously as reasoning performance, and internal testing doesn't surface real-world user preferences
- Competitors benefit: Claude and other models gain market opportunity as frustrated users explore alternatives for writing-focused work
- A fix is coming: Open AI will probably adjust fine-tuning to rebalance writing quality in an upcoming version, but exact timeline is unclear
- This will happen again: Model quality regressions are practically inevitable given the complexity of training large language models. Organizations should diversify tools and build quality checking into workflows.

FAQ
What exactly went wrong with Chat GPT 5.2's writing quality?
Users reported that Chat GPT 5.2 produces repetitive sentence structures, awkward phrasing, reduced tonal nuance, and less creative problem-solving compared to version 5.1. The prose feels technically correct but emotionally flat, lacks natural variation, and shows less sophistication in explaining complex ideas. The degradation is noticeable when comparing similar prompts across versions side-by-side.
Why did Open AI release Chat GPT 5.2 if writing quality was worse?
The most likely explanation is that Open AI prioritized other improvements—better reasoning capabilities, faster inference, improved code generation—and didn't measure writing quality carefully enough to catch the regression before release. Writing quality isn't benchmarked like mathematical reasoning or coding performance, so it wasn't flagged as a critical issue. This represents a measurement blindness problem rather than negligence.
Is Chat GPT 5.2 still usable for writing work?
Yes, Chat GPT 5.2 still generates functional writing content. For casual use, the quality decline might be invisible. However, for professional writing that requires precision, style, and tone, many users have noticed the difference and either switched models or increased their editing time significantly. The quality is acceptable but noticeably below Chat GPT 5.1.
When will Open AI fix this issue?
Open AI hasn't provided a specific timeline. However, given the public pressure and damage to their reputation, an update with improved writing quality is likely coming within weeks or a few months. The fix will probably involve reweighting their fine-tuning process to reemphasize writing quality rather than retraining the base model from scratch.
How does Chat GPT 5.2 compare to Claude or Gemini for writing?
Claude 3.5 Sonnet is generally rated higher for writing quality by users and critics, with more natural prose, better tonal flexibility, and superior handling of nuance. Google Gemini has been improving steadily and produces clear technical writing. For pure writing quality right now, Claude likely edges out Chat GPT 5.2, though both have different strengths depending on the writing task.
What should I do if I rely on Chat GPT for writing?
Consider these steps: First, provide more detailed prompts specifying tone, style, and audience. Second, plan for more human editing time than you previously needed. Third, test Claude and Gemini on your specific writing tasks to understand their strengths relative to Chat GPT. Fourth, wait for Open AI's next version before making long-term decisions about switching tools completely.
Will AI writing quality keep regressing with new model versions?
Possibly. Large language models involve complex optimization tradeoffs that engineers can't perfectly predict. Improvements in one area sometimes degrade others. However, companies are building better measurement systems and broader testing processes, which should reduce the frequency and severity of future regressions. This is a solvable problem, though it requires more rigorous engineering practices.
Could this happen to other AI companies' models?
Yes. Writing quality regressions aren't unique to Open AI. Anthropic, Google, and other companies have all iterated on model quality. However, Open AI's situation is notable because Chat GPT is the most widely used AI model and the regression was noticeable to millions of users. Most other quality issues are caught internally or are smaller in scope.

Key Takeaways
- Sam Altman publicly acknowledged ChatGPT 5.2 has worse writing quality than 5.1, admitting the company 'screwed up' the update
- Writing quality degradation likely resulted from optimization tradeoffs prioritizing reasoning improvements over prose quality during model training
- OpenAI failed to catch the regression before launch because writing quality isn't benchmarked as rigorously as other capabilities
- Claude and Gemini gain competitive advantage, with many users switching for better writing output while waiting for OpenAI's fix
- Future model versions will require better measurement systems and broader testing to prevent similar quality regressions across all AI companies
Related Articles
- ChatGPT Citing Grokipedia: The AI Data Crisis [2025]
- Cognitive Diversity in LLMs: Transforming AI Interactions [2025]
- ChatGPT Creativity Settings: Master Advanced Prompting Techniques [2025]
- Google's Hume AI Acquisition: The Future of Emotionally Intelligent Voice Assistants [2025]
- Where Tech Leaders & Students Really Think AI Is Going [2025]
- How OpenAI's Codex AI Coding Agent Works: Technical Details [2025]

