![Claude Code Outage: What Happened and Why AI Tool Reliability Matters [2025]](https://tryrunable.com/blog/claude-code-outage-what-happened-and-why-ai-tool-reliability/image-1-1770136895194.jpg)
Introduction: When Your AI Development Assistant Goes Silent
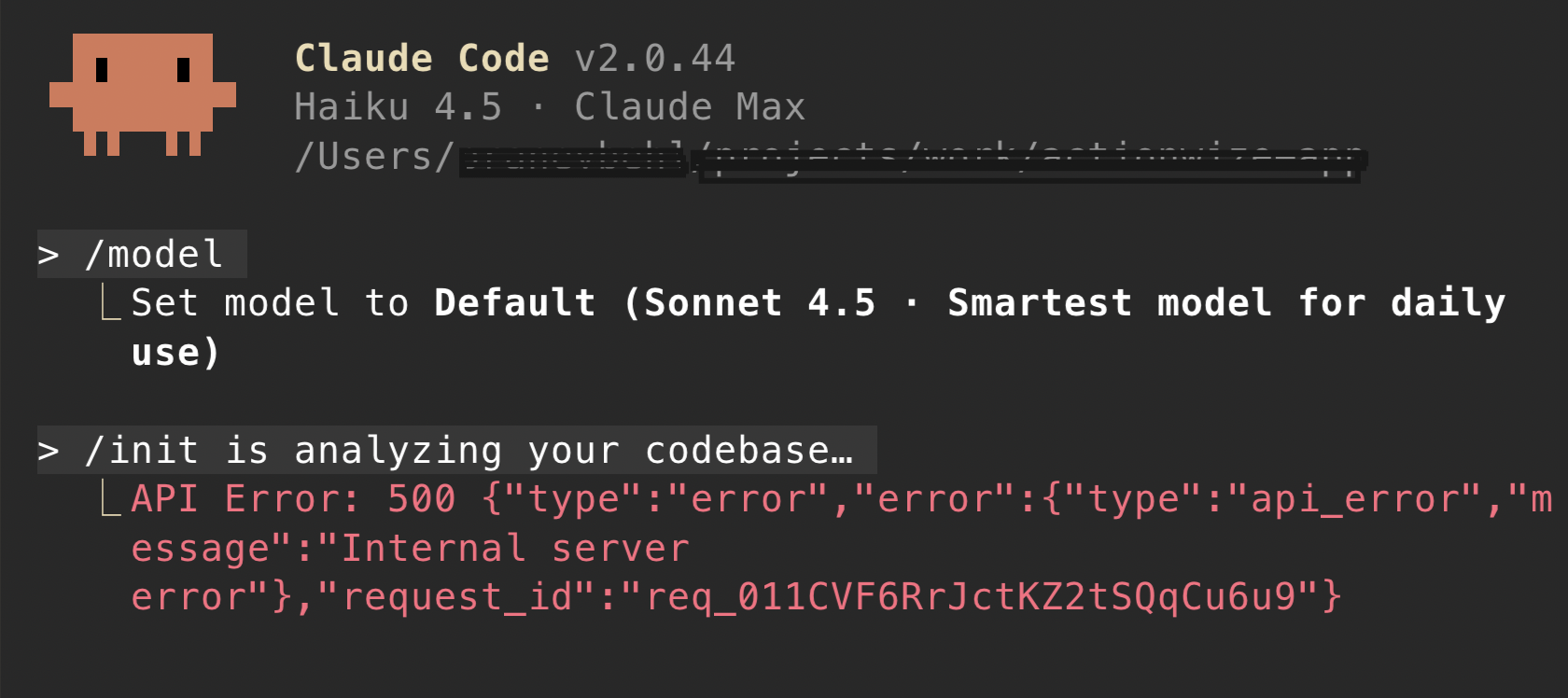
It was supposed to be a normal Tuesday. Developers worldwide opened their laptops, grabbed coffee, and loaded Claude Code, expecting to tackle their latest sprint tasks with AI-powered assistance. Instead, they were greeted with an unwelcome sight: a brutal 500 error message.
Anthropic's Claude Code experienced a significant outage that sent shockwaves through the developer community. The service, which has become integral to modern development workflows at companies ranging from Microsoft to independent startups, simply stopped working. While the outage lasted approximately 20 minutes from initial detection to resolution, those minutes felt like hours for developers whose entire workflow depends on AI-assisted coding.
This incident wasn't just about a single service going down. It exposed something deeper about the infrastructure we're building on and the hidden dependencies that now power development teams globally. When Claude Code goes offline, it's not just Anthropic losing uptime metrics. It's developers losing momentum, teams missing deadlines, and organizations discovering just how reliant they've become on AI tools for productivity.
The outage revealed elevated error rates "across all Claude models," meaning the issue affected not just Claude Code but the broader Claude API ecosystem. Developers using Claude through various integrations, third-party tools, and direct API calls all felt the impact. Some couldn't generate code. Others couldn't review pull requests. Still others couldn't access the AI features they'd built into their internal tools.
What makes this incident particularly important is what it tells us about the fragility of our AI infrastructure and the speed at which we've become dependent on these tools. Just weeks earlier, Claude Opus 4.5 had experienced separate errors, and earlier that same week, Anthropic had to patch purchasing issues with its AI credits system. These incidents suggest that reliability remains a persistent challenge in the AI tooling space, even for well-funded companies with strong engineering teams.
But there's more to this story than just "the service went down." This outage demonstrates a critical juncture in how we approach AI tool adoption, infrastructure resilience, and the responsibilities of companies serving as foundational layers for developer productivity.
TL; DR
- Claude Code experienced a major 500 error outage affecting developers globally, with elevated error rates across all Claude models
- Resolution took approximately 20 minutes from when the issue was identified to when the fix was implemented and service was restored
- The incident revealed widespread dependency on Claude for development workflows, with impacts across Microsoft AI teams and countless independent developers
- Reliability issues persist with Claude experiencing multiple service disruptions within weeks, including separate API errors and billing system problems
- Organizations need redundancy strategies for AI-dependent workflows, including fallback tools and architectural patterns that don't create single points of failure
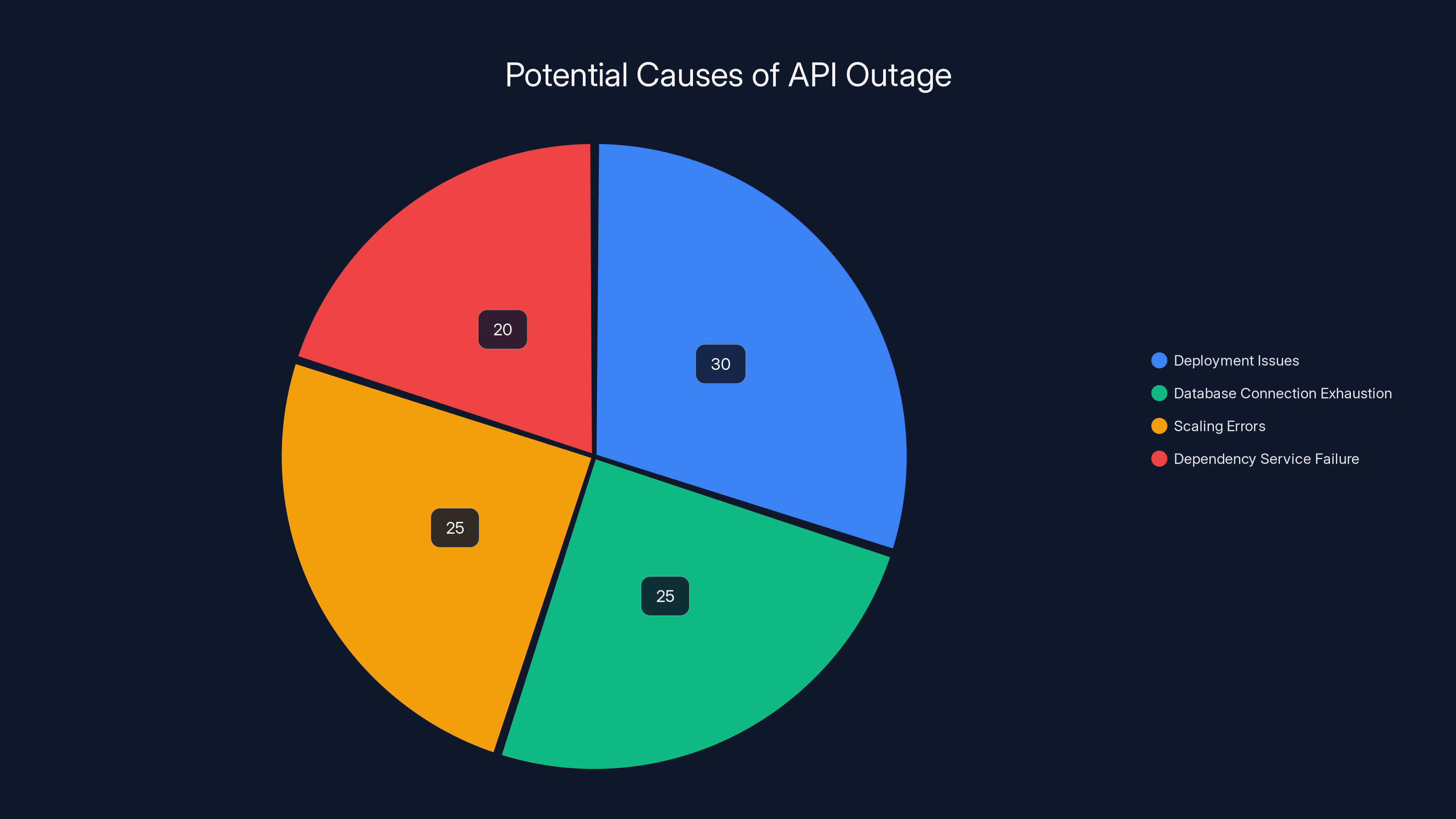
Estimated data suggests deployment issues are the most common cause of API outages, followed by database and scaling errors. Estimated data.
Understanding the Outage: Technical Breakdown
When Anthropic announced the outage, they provided minimal technical detail. The company stated they were "seeing elevated error rates on our APIs across all Claude models," which is developer-speak for "something fundamental broke." But what actually happened?
Based on the timeline and symptoms, the outage likely stemmed from one of several common scenarios in large-scale API infrastructure. Either a deployment went wrong (a common cause of widespread outages), a database connection pool was exhausted, infrastructure scaled incorrectly under load, or a dependency service failed. The 20-minute resolution time suggests it was something identifiable quickly and fixable without major rollback operations.
The 500 error specifically indicates a server-side problem, not a client issue. Users weren't misconfiguring something or hitting rate limits. Anthropic's infrastructure was returning errors for valid requests. This is critical context because it means there was nothing developers could do to work around the issue. No configuration change, no retry logic, no fallback strategy would help. The service was simply unavailable.
What's particularly concerning is that this affected "all Claude models." Claude Opus, Claude Sonnet, Claude Haiku—every variant of the service experienced problems. This breadth of impact suggests the issue wasn't localized to a specific model or feature set, but rather something at the infrastructure layer that affects the entire Claude ecosystem.
Developers quickly discovered that the outage wasn't limited to Claude Code either. Any integration using the Claude API was affected. Teams using Claude through Zapier, custom applications, IDE extensions, and other third-party integrations all experienced failures. This cascading effect demonstrates the interconnected nature of modern development infrastructure.
The irony wasn't lost on the developer community. Here's a tool designed to make developers more productive, but when it goes down, it doesn't just reduce productivity by 10% or 20%. It creates a hard stop for anyone whose workflow depends on Claude integration.

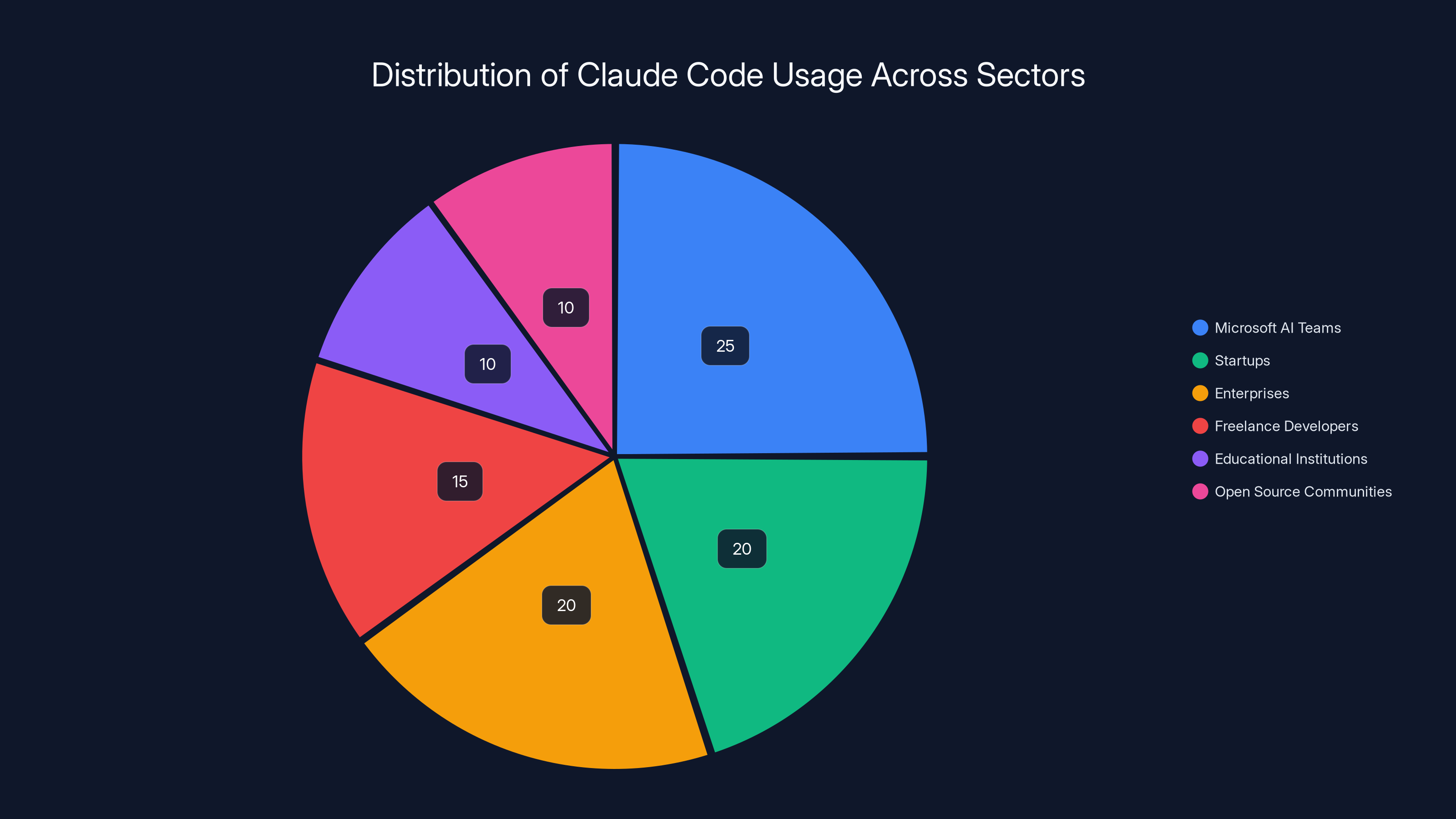
Claude Code is widely used across various sectors, with significant integration in Microsoft's AI teams and startups. Estimated data based on typical industry applications.
The Timeline: From Error to Resolution
Understanding when things happened helps illustrate just how quickly Anthropic responded, and how impactful even a short outage can be.
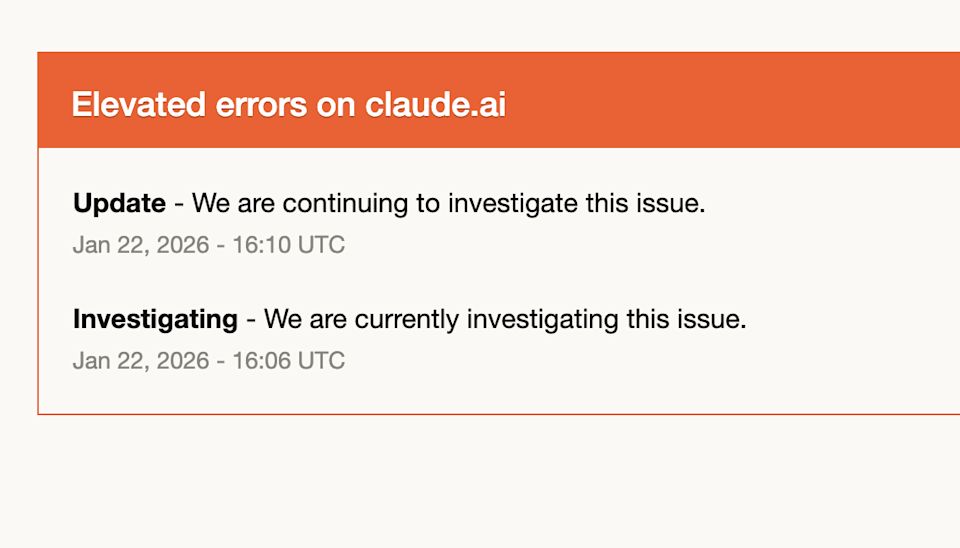
The outage wasn't announced with a precise start time, but based on social media and developer reports, the issues began in the early afternoon (US time) on February 3rd. The first 500 errors appeared when developers tried to use Claude Code or make direct API calls. Within minutes, reports flooded Discord servers, Twitter, and Slack communities dedicated to Claude and AI tooling.
Anthropic's team detected the problem and immediately began investigation. By their own account, they identified the root cause within a few minutes. This is actually impressive—in large distributed systems, identifying the problem can sometimes take longer than fixing it.
The fix was implemented relatively quickly, taking around 20 minutes total from when the issue was publicly reported to when service was restored. For context, this is faster than many cloud outages. Cloudflare once had a major incident that persisted for roughly an hour. Stripe has weathered outages lasting 30+ minutes. So 20 minutes is on the better end of the outage spectrum.
But here's the thing: when your development workflow is optimized around instant AI assistance, 20 minutes feels like an eternity. Developers can't just wait it out. Their deploys are timed, their sprints are scheduled, their deadlines are fixed. A 20-minute outage in the middle of a workday can ripple through the entire day's productivity.
The update came on February 3rd when Anthropic confirmed the outage had been resolved. No major incident postmortem was published immediately, which is somewhat typical for companies trying to move past incidents quickly, though transparency advocates would argue that public postmortems help the entire industry learn from failures.
Context: A Pattern of Recent Issues
This outage didn't happen in isolation. It was part of a concerning pattern of reliability issues for Anthropic's services in recent weeks.
Just the day before the major Claude Code outage, Claude Opus 4.5 experienced separate errors. Nothing confirmed publicly about the scope or duration, but the fact that it happened suggests systematic challenges rather than one-off bad luck.
Earlier that same week, Anthropic discovered and fixed purchasing issues with its AI credits system. This is the billing infrastructure that customers use to buy API usage credits. When billing breaks, it can create cascading problems. Customers can't purchase access. Existing credit-based plans might not execute properly. It's not just a revenue problem; it's a service access problem.
When you see multiple service disruptions within a 7-day window, it raises questions. Are there recent code deployments that introduced instability? Did Anthropic scale infrastructure too aggressively? Are there dependencies being relied upon that aren't reliable? Are test suites insufficient? Is on-call rotation and incident response stretched too thin?
These are the kinds of questions engineers ask when they see patterns like this. And they matter because they inform whether these are one-off issues or symptoms of deeper problems with infrastructure maturity.
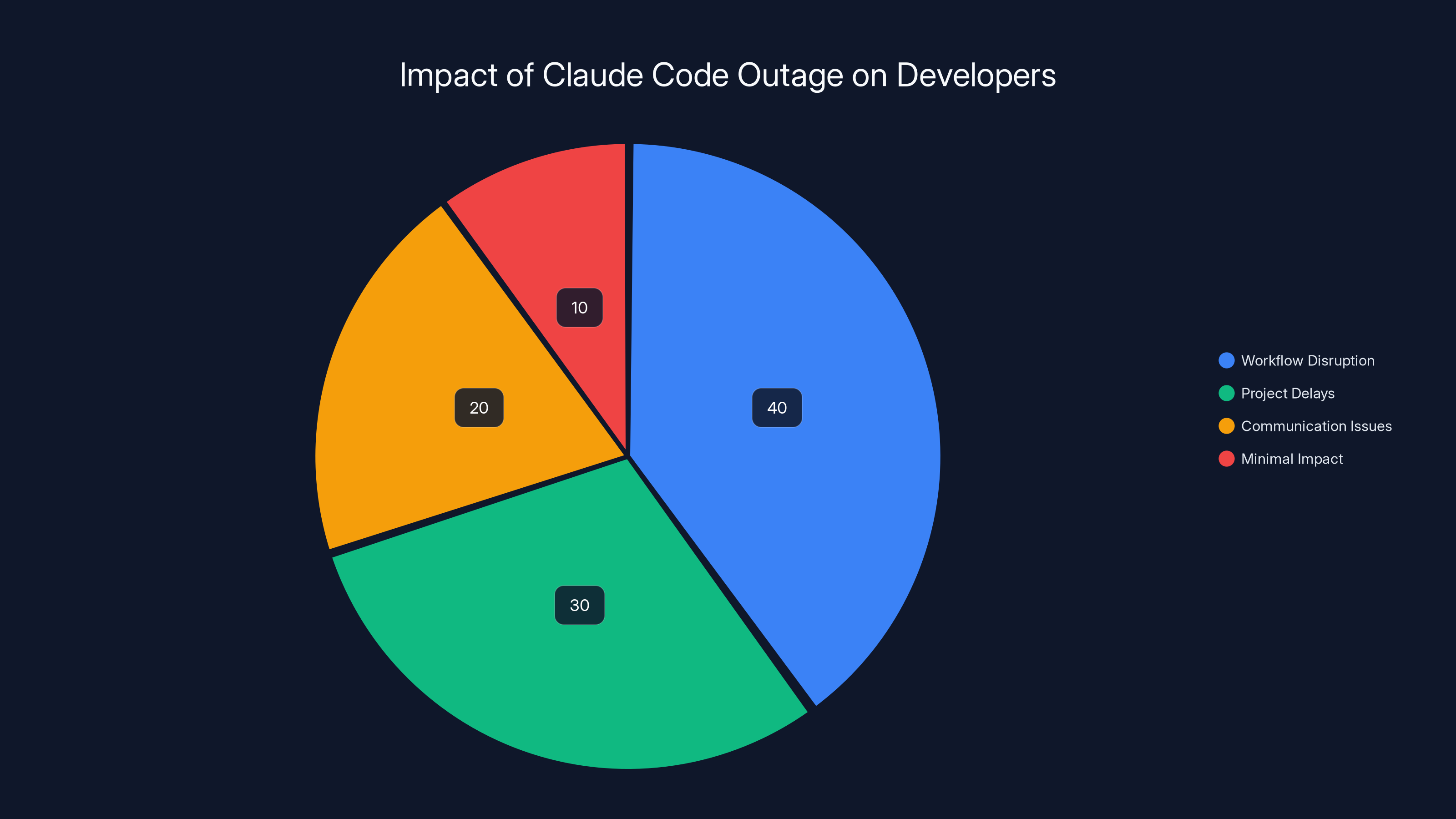
Estimated data suggests that the majority of developers experienced workflow disruption due to the Claude Code outage, with significant project delays also reported.
Who Was Affected: Beyond Individual Developers
Claude Code isn't just used by independent developers building side projects. It's embedded in enterprise development workflows, integrated into Microsoft's AI platforms, and relied upon by teams across the industry.
Microsoft's AI teams represent a particularly important constituency. Microsoft has been integrating Claude capabilities into its suite of developer tools and services. When Claude goes down, it's not just disrupting individual Microsoft developers; it potentially affects any of Microsoft's customers using these integrated services. That's thousands of organizations that might be indirectly impacted by Anthropic outages.
Beyond Microsoft, Claude Code is used by:
- Startups optimizing development velocity with fewer engineers
- Enterprises implementing Claude for internal developer productivity platforms
- Freelance developers relying on Claude for rapid prototyping and code generation
- Educational institutions using Claude for computer science teaching and learning
- Open source communities where contributors use Claude for cross-project code review and understanding
For startups particularly, the impact is acute. A startup with 10 engineers where 8 use Claude Code every day just lost 8 person-days of productivity in a 20-minute window. That's not hypothetical lost productivity. That's real developers waiting for a service to come back, watching the clock, unable to context-switch effectively because they might need Claude at any moment.
For larger enterprises, the impact is more subtle but still significant. If you've built internal tools that depend on Claude APIs, those tools are now broken. If you've architected workflows around Claude's availability (perhaps assuming 99.9% uptime), you're now seeing that assumption violated.
The developers building with Claude as a dependency bear some responsibility here. When you build on top of a service you don't control, you accept certain risks. But companies providing that service also bear responsibility for being clear about what availability guarantees they're making.
The Broader AI Infrastructure Question
This incident raises a critical question that the industry needs to confront: How reliable does an AI service need to be before enterprises can safely depend on it as critical infrastructure?
Traditional enterprise services like databases, message queues, and cloud compute providers are expected to maintain 99.9% to 99.99% uptime. That's 8.76 hours to 52 minutes of downtime per year. These aren't arbitrary numbers; they're calculated based on the cost of downtime and the expectations of the customers building on top.
Large language model APIs are relatively new in this context. They're powerful, they're useful, but they're also complex systems with novel failure modes. When you're running transformers at scale, dealing with distributed inference, managing model serving infrastructure—these are hard problems. Harder than serving a static API endpoint.
But the question isn't whether Claude's infrastructure is impressive (it likely is). The question is whether it's reliable enough for the use cases developers are building on top of it.
If you're using Claude Code as a nice-to-have tool that speeds up work, an outage is annoying but tolerable. If you've architected your business around Claude API calls as a core feature, an outage is potentially catastrophic.
Anthropic likely has service level agreements (SLAs) with enterprise customers specifying uptime guarantees and penalties for violations. The incident demonstrates why these agreements matter. For the enterprise customers who have SLAs, they can claim credits or compensation. For the rest of the developer community, there's no recourse. They just have to accept downtime and move on.
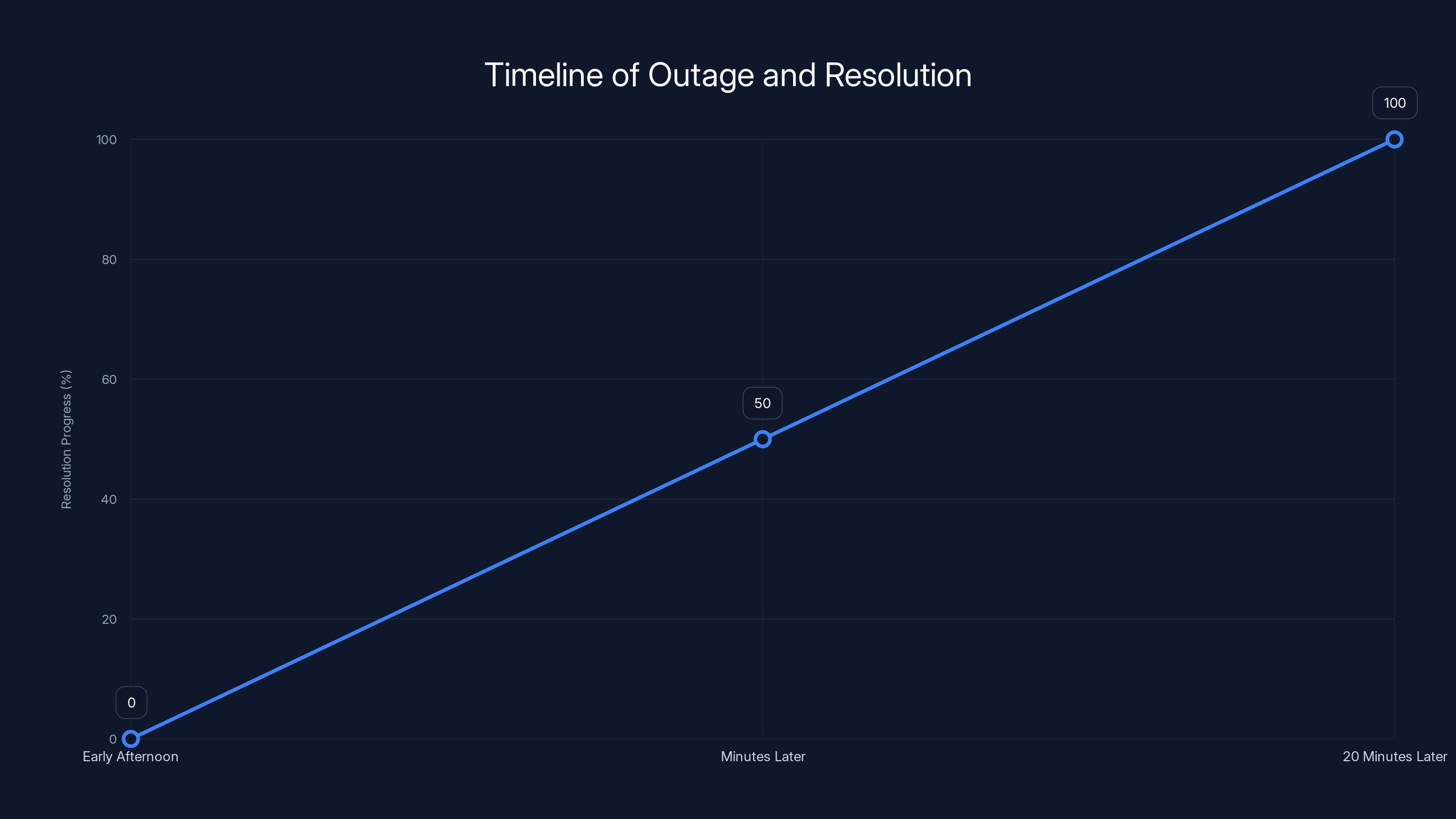
Estimated data shows Anthropic's rapid response, resolving the outage within 20 minutes from initial error detection.
Dependency Chains: How Outages Cascade
One often-overlooked aspect of major outages is how they cascade through dependency chains. Claude Code didn't just stop working in isolation. It stopped working, which affected people using Claude Code directly, which affected teams whose workflows depend on developers using Claude Code, which affected sprint schedules and deadlines.
Consider a concrete example: a team uses Claude Code for code review suggestions. Their developers push code, and an internal tool (powered by Claude API) comments on pull requests with improvement suggestions before human review. When Claude goes down, this tool breaks. PRs still get pushed, but the automated review suggestions don't appear. Developers wonder if the system is working. Some might push code assuming it's been reviewed when it hasn't.
Or another scenario: an engineering team uses a custom dashboard (powered by Claude API) to explain legacy codebases to new engineers. The API goes down. New engineers are now unable to access context they need to be productive. Training gets delayed.
These aren't hypothetical. They're the reality of how dependencies work in modern software infrastructure.
The interesting challenge is that many of these dependency chains exist without explicit documentation. A developer integrated Claude into a tool. That tool became integral to the team's workflow. Now the team is implicitly dependent on Anthropic's uptime. There was no formal dependency declaration, no architectural review, no risk assessment. It just happened.

Lessons in AI Tool Adoption: Building Resilience
What should developers and organizations take away from this incident? Several important lessons emerge.
First, understand what uptime guarantees you actually need. Not everything needs 99.99% uptime. Some tools can tolerate 20-minute outages once a month. Other tools cannot. Be honest about which is yours.
Second, implement fallback strategies from day one. If you're using Claude for critical functionality, design your system so that if Claude goes down, something still works (even if it's degraded). This might mean caching Claude responses, having a cheaper fallback model ready, or implementing a system that works without AI.
Third, monitor your dependencies explicitly. Know what happens when Claude goes down. Have alerts. Have runbooks. Have a plan for the 2 AM wake-up call when the service is offline.
Fourth, diversify your AI dependencies. Don't put all your AI eggs in one basket. Use multiple models. Use multiple providers. This costs more, but it also means your business continues operating when one provider has an outage.
Fifth, pressure providers for transparency. When outages happen, demand postmortems. Demand details about what went wrong and what's being fixed to prevent recurrence. The developer community is powerful. Use that leverage to demand better.
Anthropic has strong incentives to improve reliability. They want enterprise customers who demand SLAs. They want developers who trust their service. They want to be seen as a foundational infrastructure provider, not a best-effort tool. The series of incidents in late February probably prompted internal discussions about how to prevent recurrence.
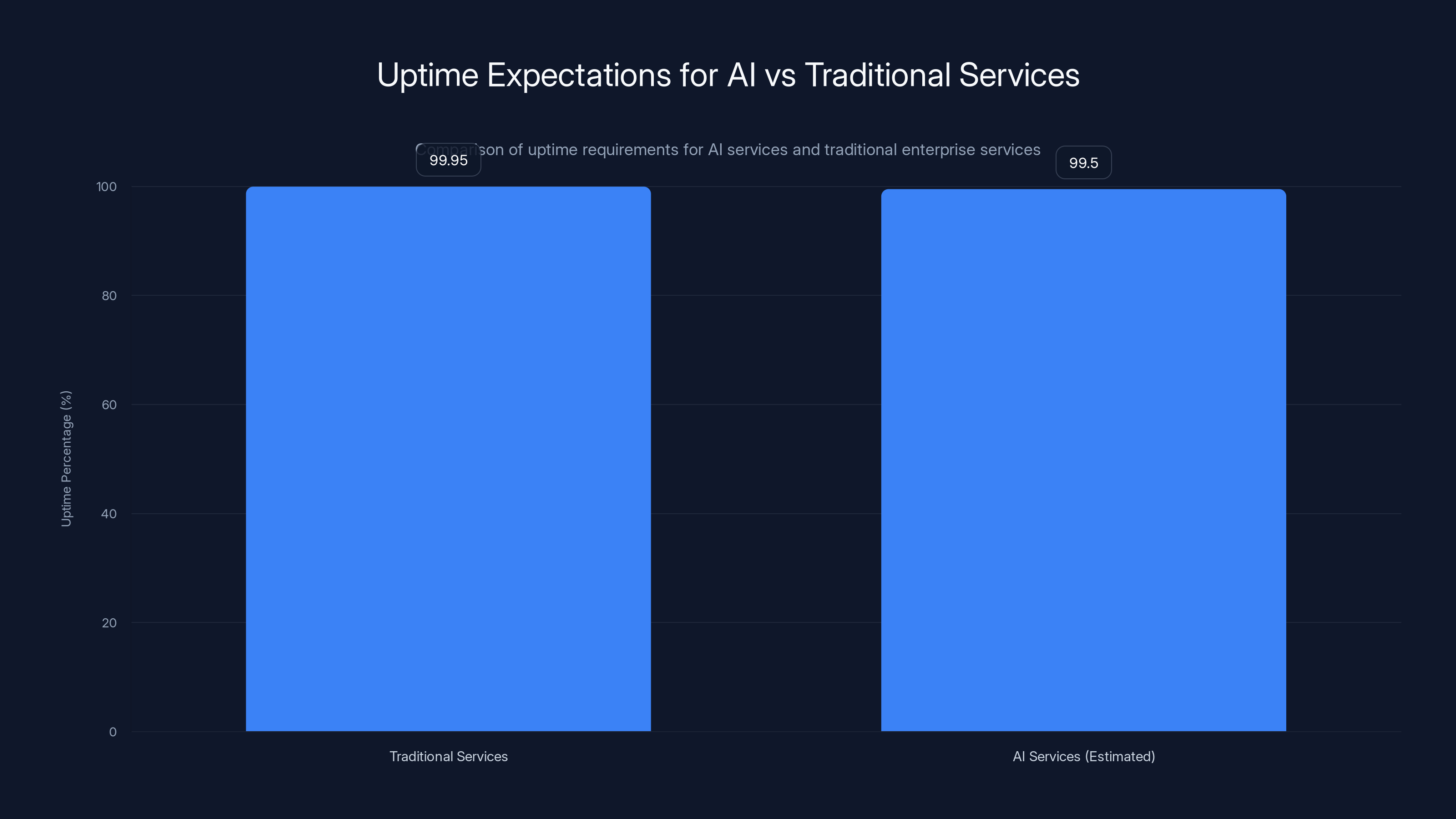
Traditional enterprise services aim for 99.9% to 99.99% uptime, while AI services might currently offer around 99.5% uptime. Estimated data highlights the reliability gap.
The Role of AI Tools in Modern Development
This outage happens against the backdrop of a fundamental shift in how developers work. AI coding assistants aren't new anymore. They're not experimental. They're production tools that millions of developers use daily.
Claude Code specifically is one of the most capable AI code generation tools available. It understands codebases. It generates working code. It explains legacy systems. It's genuinely useful, not just a novelty. This is why the outage mattered so much. It affected a tool that had become embedded in developer workflows.
The competition in this space is intense. Open AI's GitHub Copilot is ubiquitous. Google's tools are improving rapidly. Startups are building specialized AI coding tools. In this competitive landscape, reliability becomes a competitive advantage.
When Claude Code goes down and GitHub Copilot stays up, developers notice. They remember. Some might start hedging their bets, using multiple tools instead of relying on one. This is actually healthy for the market, even if it's inconvenient for Anthropic.
Infrastructure Maturity and Scaling Challenges
Anthropic is growing rapidly. Claude's capabilities are expanding. API usage is exploding. This kind of growth creates challenges. When your infrastructure is under stress, the risk of failures increases.
This is a common pattern in technology. Stripe had growing pains. GitHub had outages. Heroku had incidents. These are all companies that built strong services, but growth creates challenges.
The question isn't whether Anthropic will face scaling challenges (they will). The question is how they handle them. Will they invest heavily in reliability? Will they implement better testing? Will they slow feature velocity to prioritize stability? Will they hire reliability engineers and build SRE programs?
These are investments that impact company finances and growth velocity. There's always tension between moving fast and building reliable systems. Outages like this one shift that balance toward reliability.

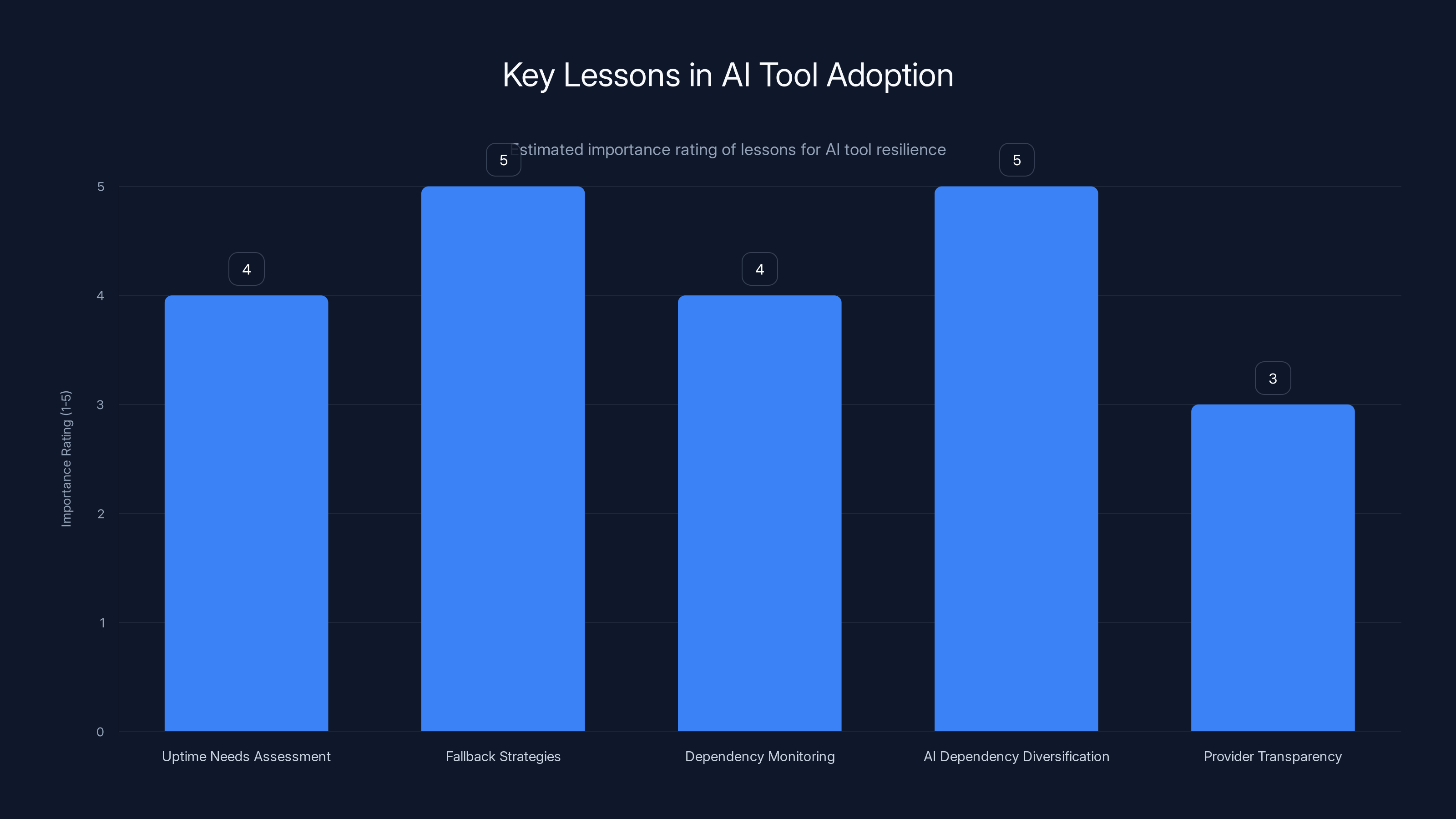
Fallback strategies and AI dependency diversification are rated highest in importance for building resilience in AI tool adoption. Estimated data based on typical industry priorities.
Comparing AI Service Reliability Across Providers
How does Anthropic's reliability compare to other AI providers? It's hard to say precisely, since most companies don't publish detailed incident data. But we can make some observations.
Open AI's APIs generally have strong uptime. Major outages are rare. This is partly because Open AI has been managing APIs for longer and has more operational maturity.
Google's cloud services have strong SLAs, though their newer AI services are sometimes excluded from SLA guarantees (a way of saying "this is still production, but we're not ready to guarantee 99.9% uptime").
Startup AI providers vary widely. Some are building impressive technology but struggling with operational maturity. Others are learning from others' mistakes and implementing strong reliability practices from the start.
For developers choosing which AI provider to depend on, reliability history matters, but shouldn't be the only factor. You also care about capability, cost, ease of use, and alignment with your use case. The ideal approach is to use multiple providers and design your system so no single provider failure is catastrophic.

Building AI-Resilient Applications
For developers and organizations building applications that depend on AI APIs, there are specific architectural patterns worth implementing.
Pattern 1: The Fallback Chain. When Claude isn't available, fall back to Claude 3 Haiku (cheaper, faster, sometimes sufficient), then to Open AI's GPT-4o, then to open source models. Each step down the chain might be cheaper, slower, or less capable, but the system keeps working.
Pattern 2: Caching Layer. Cache Claude responses aggressively. If a user asks the same question, serve the cached response instead of hitting the API. This reduces costs and improves reliability (if the cache hits and the API is down, you still serve a response).
Pattern 3: Graceful Degradation. Build features so they work without AI. If Claude is down, show the user a previous result, a pre-written template, or a human-crafted alternative. Don't just show an error message.
Pattern 4: Queue and Retry. Don't call AI APIs synchronously in the critical path. Queue requests. Process them asynchronously. Retry failed requests with exponential backoff. This decouples your product availability from API availability.
Pattern 5: Monitoring and Alerting. Set up alerts for API errors. Know when things start failing before users do. Have a runbook for incident response.
Implementing these patterns takes more engineering effort than just calling the API directly. But it's the difference between building a product that's resilient and building a product that's brittle.
The Cost of Downtime: More Than You Might Think
Twenty minutes might not sound like much, but the economic impact of downtime extends far beyond the immediate moment.
There's the direct cost: developers who can't work because their tools are down. If you have 100 developers at
There's the indirect cost: sprints that slip, deadlines that are pushed, features that are delayed. If the outage happens mid-sprint, it cascades into missed milestones and delayed releases.
There's the switching cost: developers who get frustrated and decide to switch to a different tool. Once they've switched, there's switching cost to switch back.
There's the reputational cost: developers talk. They post about outages. They warn their colleagues. Trust erodes.
For a company like Anthropic trying to position itself as enterprise-grade infrastructure, these costs are real.
What Anthropic Could Do Better
Learning from this incident, there are clear improvements Anthropic could make.
Transparency. Publish a detailed postmortem. Explain what went wrong, why it went wrong, how it was fixed, and what's being changed to prevent recurrence. The developer community respects honesty.
Communication. During an outage, communicate more frequently. Don't just post at the end. Post updates every 5 minutes. Let developers know you're aware and working on it.
SLA clarity. Be explicit about uptime guarantees. Different products can have different SLAs. Claude Code might be 99.5%, Claude API might be 99.9%, enterprise plans might include SLA credits. Clarity builds trust.
Redundancy investment. Make it clear that reliability is a priority. Share engineering blog posts about the systems you're building. Show the work you're doing to prevent failures.
Incident response. Establish clear processes. Dedicated on-call teams. Clear escalation paths. Incident postmortems. These are table stakes for infrastructure providers.
Anthropic has access to capital and talent. They have the resources to build world-class infrastructure. The question is priority and execution.

The Bigger Picture: AI Infrastructure Maturity
This incident is a small part of a larger narrative about AI infrastructure maturity. As AI becomes more central to software development, the infrastructure needs to become more robust.
We're still in the early innings of this transition. Most AI services are optimizing for capability and cost, with reliability as a secondary concern. Over time, reliability will become the differentiator.
The companies that win the AI developer tools space will be the ones that achieve both high capability and high reliability. It's not enough to have a great model. You need infrastructure that developers can depend on. You need SLAs. You need transparent incident response. You need to demonstrate that you can scale without breaking.
Anthropic clearly has the talent and resources to get there. The question is urgency. How quickly will they prioritize reliability alongside capability?

Practical Steps for Developers: Post-Incident Checklist
If the Claude Code outage affected you or your team, here's a practical checklist for what to do next.
Immediate (today):
- Document what broke during the outage
- Identify all services that depend on Claude APIs
- Estimate the cost of downtime for your specific use cases
- Create a brief runbook for the next outage
Short-term (this week):
- Implement a fallback provider for critical use cases
- Add monitoring and alerting for Claude API errors
- Cache Claude responses where feasible
- Test your fallback strategies
Medium-term (this month):
- Redesign workflows to be more resilient to API outages
- Evaluate whether you should use multiple AI providers
- Document AI dependencies in your architecture
- Brief your team on what happened and lessons learned
Long-term (ongoing):
- Review incident postmortems from Anthropic and other providers
- Stay informed about reliability improvements
- Periodically test failover and fallback strategies
- Adjust your architecture as AI tools and services evolve
These steps transform an outage from a one-time frustration into an opportunity to build more resilient systems.

Looking Forward: What's Next for Claude and AI Tools
Anthropic isn't going away. Claude isn't losing its position as one of the most capable AI models available. The company has strong funding, impressive technology, and a growing user base.
But this outage is a signal. It's a reminder that even strong companies can have reliability challenges. It's a nudge to developers to build more resilient systems. It's a warning to Anthropic that infrastructure quality matters.
The road ahead likely includes:
- Significant reliability investments to prevent future outages
- More transparent communication about uptime and incidents
- Potential SLA offerings for enterprise customers
- Better tooling and documentation for developers building resilient applications
- Competition intensifying around both capability and reliability
For the developer community, this is actually good news. It means reliability is becoming a competitive factor. Companies will compete on it. Infrastructure will get better. Systems will become more robust.
The short-term inconvenience of a 20-minute outage is worth it if the long-term trajectory is toward more reliable AI infrastructure.
FAQ
What exactly caused the Claude Code outage?
Anthropic didn't provide detailed technical specifics, but the outage involved elevated error rates across the Claude API infrastructure, likely stemming from a deployment issue, resource exhaustion, or critical dependency failure. The 20-minute resolution time suggests the issue was quickly identifiable and fixable, probably through a rollback or targeted fix rather than extensive debugging. The fact that it affected all Claude models simultaneously indicates the problem was at the infrastructure layer rather than isolated to a specific model or feature.
How long was the Claude Code outage?
The outage lasted approximately 20 minutes from when it was identified to when the fix was implemented and service was restored. While 20 minutes might not sound like much, for developers with optimized workflows around Claude, it represented complete inability to use the service. The impact was felt globally, affecting anyone using Claude Code directly, Claude APIs, or third-party tools built on top of Claude infrastructure.
Did Anthropic provide compensation for the outage?
Anthropic's public statement didn't mention compensation for individual developers, though enterprise customers with service level agreements would likely have grounds to claim SLA credits. The developer community expressed frustration that the company didn't proactively offer credits or compensation, viewing this as an opportunity to demonstrate commitment to reliability. How companies handle post-incident communication and compensation is often as important as fixing the technical issue itself.
Why did this outage matter so much to developers?
Claude Code had become integral to millions of developers' workflows. It's not a nice-to-have tool; it's a core part of how developers work. When you've optimized your workflow around AI assistance, losing that tool means complete workflow disruption. Teams couldn't make progress on sprints. Deadlines were affected. For organizations that had integrated Claude into multiple tools and services, the impact cascaded beyond just Claude Code itself.
What should developers do to prevent outages from affecting them?
Implement resilience patterns including fallback providers (use multiple AI services), caching layers (cache responses to reduce API calls), graceful degradation (functionality that works without the AI service), asynchronous processing (queue requests instead of calling APIs synchronously), and comprehensive monitoring and alerting. Test these strategies regularly. Many developers implement fallbacks but never test them, so when the real outage happens, their fallback is broken too. The pattern to follow is: design systems that tolerate provider outages, then regularly test that design.
How does Claude's reliability compare to other AI providers?
Direct comparison is difficult because most AI providers don't publish detailed uptime metrics. However, Open AI's APIs generally have strong operational maturity and rare major outages, while newer providers and startups have more variable reliability. Google's established cloud services have strong SLAs, though newer AI services sometimes exclude SLA guarantees. The safest approach is to design your architecture to work with multiple providers, so no single outage is catastrophic. This costs more initially but buys reliability.
Will this outage affect Claude's market position?
Short-term, it might cause some developers to hedge their bets and use multiple AI providers. Long-term, if Anthropic responds well (transparent postmortem, reliability investments, better communication), the incident becomes a learning moment rather than a loss of confidence. Companies like Stripe and GitHub had outages early in their history but became trusted infrastructure providers through strong incident response and reliability focus. Anthropic has the same opportunity if they make reliability a priority.
What's the pattern with Anthropic's recent reliability issues?
Within a single week, Anthropic experienced the Claude Code outage, separate Claude Opus 4.5 errors, and billing system purchasing issues. This pattern suggests either rapid growth creating scaling challenges, recent deployments introducing instability, or insufficient testing before production release. The pattern is concerning but not uncommon for fast-growing infrastructure companies. The important question is how Anthropic responds and whether reliability improvements are made.
Should enterprises trust Claude for critical infrastructure?
Enterprise customers should require SLA guarantees before depending on Claude for critical operations. The outage demonstrates that Anthropic is still in the phase where reliability can be variable. However, with proper architectural resilience (redundancy, fallbacks, graceful degradation), enterprises can safely use Claude while accepting provider-level risks. The key is not putting all critical functionality directly on Claude without redundancy. Use it in ways where temporary unavailability is tolerable or recoverable.
What should Anthropic do to prevent future outages?
Anthropic should invest in: (1) redundancy and failover systems, (2) more comprehensive testing before production deployments, (3) rate limiting and circuit breaker patterns to gracefully degrade under load, (4) improved monitoring and alerting, (5) dedicated on-call incident response teams, (6) regular chaos engineering and failure injection testing, and (7) transparent incident postmortems. These are standard practices for infrastructure providers and directly address the root causes of the outages experienced.

Conclusion: Learning From Failure
The Claude Code outage was a 20-minute incident that revealed important truths about modern software development and AI tool reliability. It showed us how dependent we've become on these services, how quickly outages cascade through dependency chains, and why building resilient systems matters.
For Anthropic, the incident is an opportunity. How they respond will shape their trajectory. Do they invest heavily in reliability and transparency? Or do they move on and assume it was a one-off issue? The pattern of multiple incidents in one week suggests there's work to do.
For developers and organizations, the incident is a wake-up call. You need to design systems that tolerate provider outages. You need to test your fallbacks. You need to diversify your dependencies. You need to communicate with your teams about what happens when tools fail.
The broader AI infrastructure space is still maturing. We're moving from experimental tools to production infrastructure, which means reliability is moving from nice-to-have to essential. The companies that recognize this transition and invest appropriately will become trusted providers. The others will struggle.
Claude is capable, impressive technology. But capability without reliability is just an expensive frustration. As Anthropic scales and developers increasingly depend on Claude for critical work, reliability becomes the most important feature.
The outage happened. It was fixed. Now the question is what comes next. Will Anthropic demonstrate the kind of operational maturity that enterprises need? Will they build the kind of reliability that makes Claude truly critical infrastructure? Will they earn the trust they need to compete at the highest level?
The answer will determine whether Claude becomes foundational infrastructure or remains a powerful tool that smart teams use carefully.
If you're using Claude, use it well. Build systems that tolerate failures. Test your assumptions. Communicate with your team. Learn from this incident even if it didn't directly affect you, because outages like this happen, and you want to be ready when they do.
The future of AI development depends on reliable infrastructure. Incidents like this one are the price of building that future. The question is whether we learn from them.
Use Case: Build resilient workflows with Runable's AI automation platform—create presentations, documents, and reports that don't depend on single-provider outages through backup automation patterns.
Try Runable For Free
Key Takeaways
- Claude Code experienced a 20-minute outage affecting developers globally due to elevated error rates across the Claude API infrastructure
- Pattern of multiple incidents within one week (Opus 4.5 errors, billing issues, major outage) suggests systemic reliability challenges despite Anthropic's strong engineering
- Organizations depending on Claude for critical workflows discovered they lack resilience strategies and fallback options
- Developers should implement multi-provider strategies, caching layers, graceful degradation, and comprehensive monitoring to tolerate AI provider outages
- How Anthropic responds with transparency, reliability investments, and detailed postmortems will determine whether Claude maintains enterprise trust
Related Articles
- Notepad++ Supply Chain Attack: Chinese State Hackers Explained [2025]
- Notepad++ Supply Chain Attack: What You Need to Know [2025]
- ShinyHunters SSO Scams: How Vishing & Phishing Attacks Work [2025]
- Notepad++ Supply Chain Attack: Chinese Hackers Hijack Updates [2025]
- TikTok Service Restoration After Major Outage: What Happened [2026]
- Agentic AI Security Risk: What Enterprise Teams Must Know [2025]

