![TikTok Service Restoration After Major Outage: What Happened [2026]](https://tryrunable.com/blog/tiktok-service-restoration-after-major-outage-what-happened-/image-1-1770015999735.jpg)
TikTok Service Restoration After Major Outage: What Happened [2026]
In early February 2026, TikTok experienced one of its most significant service outages in recent history. For users across the United States, the platform became largely unusable for several days. Posts wouldn't upload. Videos wouldn't load. The like counts froze. The discover page went dark. For a platform with over 220 million U.S. users, this wasn't just an inconvenience—it was a crisis.
What made this outage particularly interesting wasn't just its scale, but its timing. It happened right as TikTok was transitioning to new ownership under the USDS Joint Venture, a U.S.-based investor consortium that took an 80% controlling stake while ByteDance retained 20%. The combination of infrastructure failure and organizational restructuring created a perfect storm that left creators scrambling and competitors suddenly relevant.
But here's what really matters: this outage revealed something critical about how the internet's most popular platforms actually work. It exposed the fragility beneath the surface of services we assume are infinitely reliable. It showed us exactly what happens when a single data center fails. And it demonstrated why companies are finally taking disaster recovery seriously.
This wasn't a DNS mishap or a code deployment gone wrong. This was raw infrastructure failure on a massive scale, caused by something as simple as a snowstorm. Let's break down exactly what happened, why it happened, and what it means for the future of platform resilience.
TL; DR
- The Outage: TikTok lost service for several days across the U.S. due to an Oracle data center power failure caused by winter weather.
- The Impact: Approximately 220 million U.S. users experienced disrupted posting, discovery, video loading, and real-time metrics like view counts and likes.
- The Cause: A single primary data center operated by Oracle took down tens of thousands of servers, affecting TikTok's core infrastructure.
- The Timeline: The outage coincided with TikTok's transition to new U.S. ownership, complicating recovery efforts.
- The Recovery: TikTok announced full service restoration on February 1, 2026, after implementing failover procedures.
- The Competitive Impact: Competing platforms like Skylight and Upscrolled saw massive user growth during the outage.

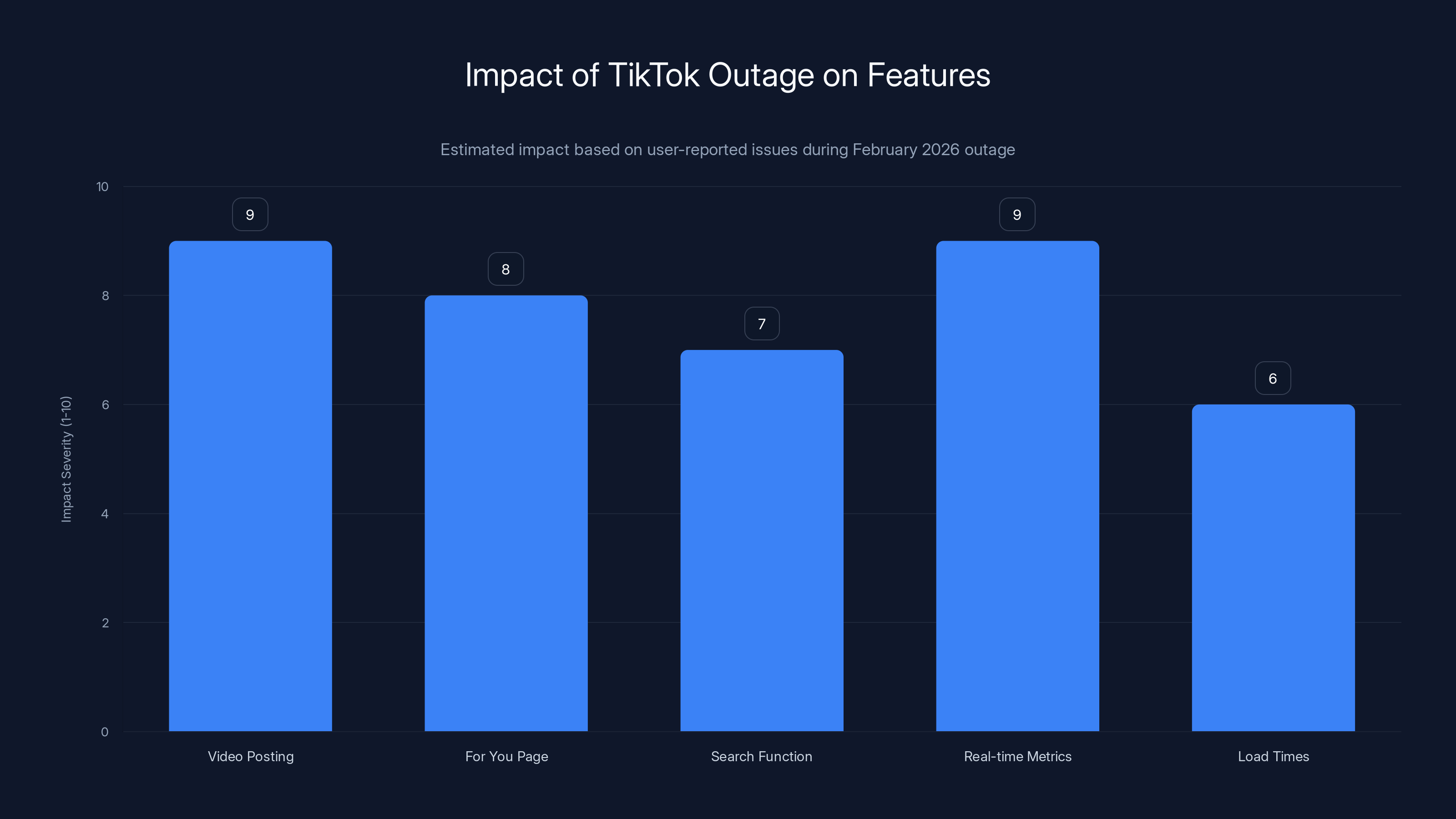
The TikTok outage severely impacted video posting and real-time metrics, with both scoring a 9 in impact severity. Estimated data based on user reports.
Understanding What Actually Happened During the Outage
When TikTok said "a significant outage caused by winter weather," most people nodded and moved on. But that statement deserves unpacking because it reveals something fundamental about how modern internet infrastructure works.
The outage began when a winter snowstorm hit the data center facility operated by Oracle. Now, data centers are supposed to be designed for this stuff. They have backup power systems. Redundant cooling. Multiple safeguards. But what actually happened was that the power outage from the snowstorm cascaded through the facility in ways that disabled multiple protection systems simultaneously.
The primary U.S. data center that hosted TikTok's core infrastructure went offline. We're talking about tens of thousands of servers. Not a few hundred. Not a couple thousand. Tens of thousands of individual machines that handle content posting, video delivery, search functionality, and real-time metrics.
When that facility failed, TikTok's architecture didn't gracefully shift to secondary data centers the way most experts assume it would. Instead, users started seeing errors immediately. Posts hung in a perpetual loading state. The feed stopped refreshing. Video discovery became impossible. It wasn't that TikTok was "down"—it was that core functionality simply vanished.
The really frustrating part? Creators who posted videos saw them upload successfully, but the view count would show zero. Forever. Because the system that tracks metrics was running on servers that were physically offline. The data center failure didn't just break posting—it broke the feedback loop that tells creators if their content is even getting engagement.
One creator reported posting a video at 2 PM on a Monday, and by Thursday morning, it still showed zero views despite having thousands of actual views that just weren't being counted. That's not a minor glitch. That's a fundamental break in the creator economy.
TikTok's statement mentioned that users experienced "glitches in features like posting, searching within the app, slower load times, and time-outs." That's corporate speak for "basically nothing worked." Let's be honest about what that actually meant for someone trying to use the platform during that window.
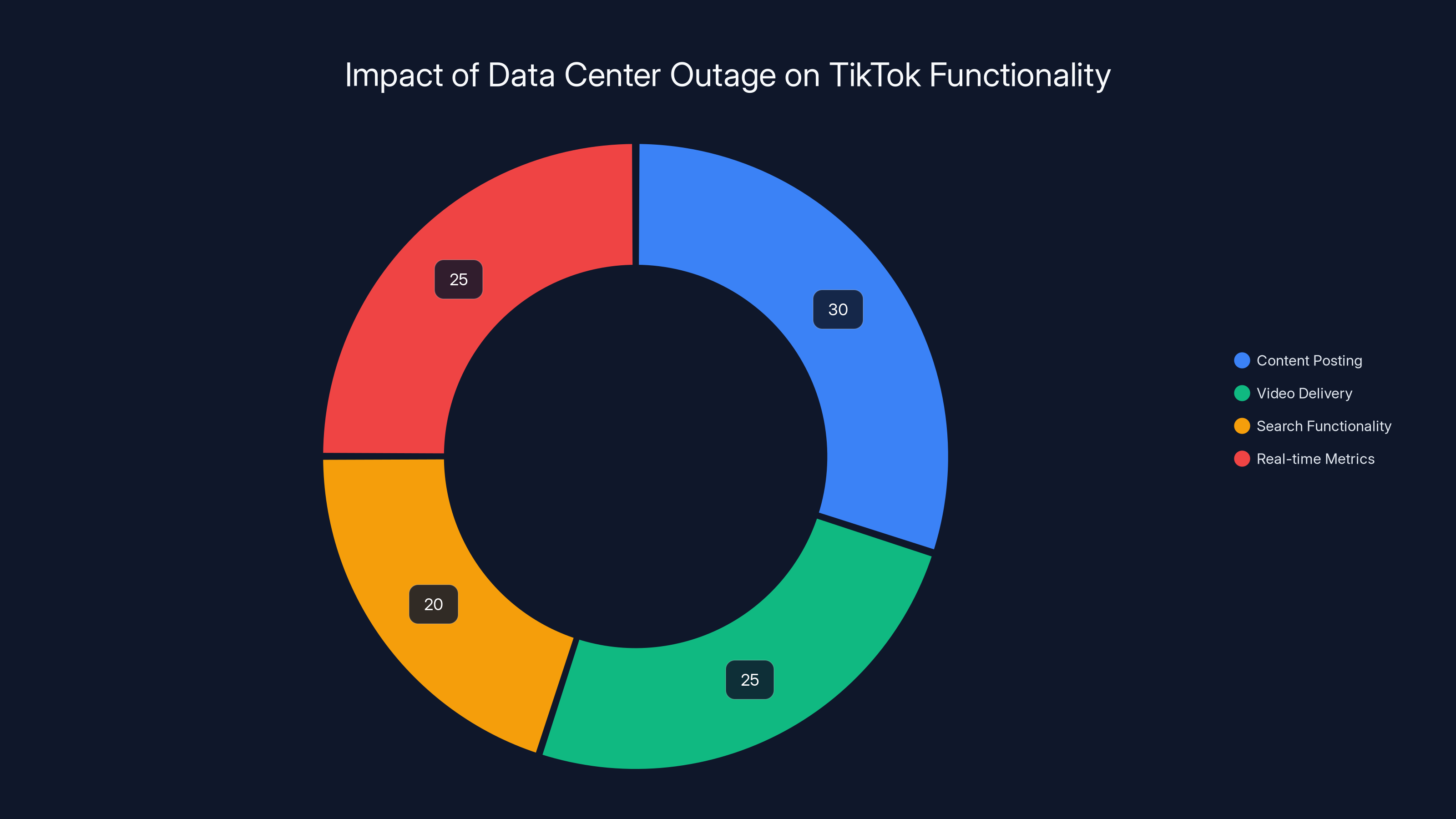
The outage impacted multiple TikTok functionalities, with content posting and real-time metrics being the most affected. Estimated data.
The Ownership Transition Context: Why This Matters
The timing of this outage wasn't random. It happened right as TikTok was finalizing its transition from ByteDance ownership to U.S.-based ownership through the USDS Joint Venture. This matters more than most people realize.
When you're managing an infrastructure transition this massive, you're essentially managing two things simultaneously: the business side (new ownership, new legal structures, new governance) and the technical side (migrating systems, establishing new operational procedures, integrating with new infrastructure providers). These things are complicated on their own. Doing them together is a nightmare.
The winter snowstorm hit right in the middle of this transition period. TikTok was in a state of organizational flux. Procedures might not have been fully established yet. Recovery protocols might not have been fully integrated into the new operational structure. The usual playbook for crisis response might not have been clear.
This doesn't excuse the outage. But it does explain why it lasted as long as it did and why recovery was more complicated than just "switch to the backup data center."
The ownership change was actually finalized during the exact window when the snowstorm hit. The deal was done. The new ownership structure was in place. And immediately after, the infrastructure failed. That's about as bad timing as you can get.
From TikTok's perspective, they had to figure out how to respond to a massive infrastructure failure while simultaneously operating under new ownership and new operational structures. From a user's perspective, it didn't matter why it happened. The platform was broken.

The Technical Architecture Failure: Why One Data Center Knocked Everything Out
Here's the thing that actually matters from a technical standpoint: TikTok's architecture apparently didn't have sufficient geographic redundancy for a single data center failure to be handled gracefully.
Modern cloud architecture is supposed to work like this: you have multiple data centers in multiple regions. Your data is replicated across them. Your services run on multiple instances across multiple facilities. If one facility fails, traffic automatically routes to the others. Users might experience a slight delay or hiccup, but the platform stays operational.
TikTok's architecture clearly didn't work this way. Or at least, not for all of its core functions.
When the Oracle-operated data center went offline, critical systems went with it. The posting system went down. The discovery system went down. The metrics system went down. The only reasonable explanation is that these systems weren't adequately replicated across other facilities, or the failover wasn't configured properly to handle a complete facility loss.
This is actually a common problem in infrastructure design. It's easy to write a checklist that says "replicate across three data centers." It's harder to actually implement it correctly. It's even harder to test it thoroughly. Most companies don't actually test their failover procedures for a complete data center loss because it requires actually shutting down a production data center.
So what actually happens? You get a situation where you think you're redundant but you're not. Your architecture passes code review. It passes your internal documentation standards. It might even pass a compliance audit. But then real-world conditions hit it, and you realize you missed something critical.
The fact that TikTok hosts its infrastructure at Oracle-operated data centers is also interesting. TikTok doesn't necessarily operate its own data centers globally. It contracts with providers like Oracle. That means TikTok's operational control over infrastructure recovery is limited. They have to coordinate with Oracle's teams, who are dealing with a physical facility that lost power. That adds another layer of complexity and communication overhead to the recovery process.
When you're managing a crisis that involves weather damage to physical infrastructure, plus coordination with an external data center provider, plus operational transitions due to new ownership, the recovery process becomes incredibly complicated. Everyone's trying to figure out who's responsible for what. Information flows slowly. Decisions take longer.
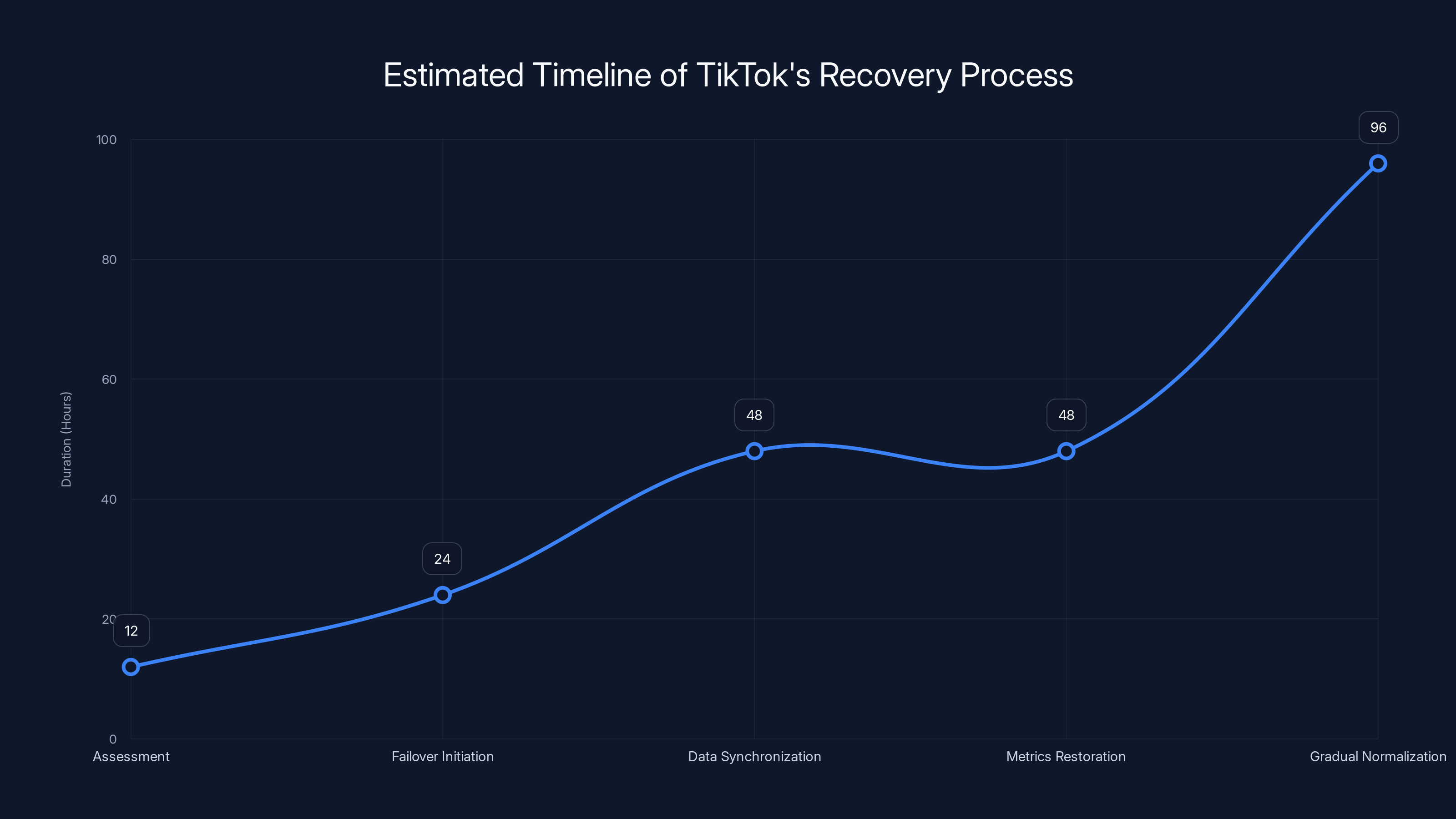
Estimated data shows TikTok's recovery process spanned over several phases, with gradual normalization taking the longest time. Estimated data.
The User Impact: What Broke and When
Let's get specific about what actually broke for users because that matters for understanding the severity.
Content Posting: Users couldn't post new videos. The upload system was completely broken. Creators were locked out of creating content. For a platform where content creation is the entire value proposition, this is catastrophic. During the outage period, the platform became read-only for millions of creators who make their living posting content.
Video Discovery: The algorithm that powers TikTok's For You Page stopped working. Users couldn't see new videos. The feed was either broken or showing outdated content. Your entire social experience was essentially frozen in time.
Search Functionality: Searching for creators, sounds, or hashtags didn't work. The indexing systems that power search went offline with the data center.
Real-Time Metrics: This is the one that really bothered creators. Videos that were posted showed zero views, zero likes, zero engagement. You could see the problem—you just couldn't see any data about it. For creators, metrics aren't just numbers. They're the feedback loop that tells you if your content resonates. Losing that feedback is deeply frustrating.
Load Times and Timeouts: For users who could access the platform, everything was slow or timing out. The remaining infrastructure was trying to handle traffic that was originally distributed across multiple data centers. It was drowning under the load.
This wasn't a partial outage. This was a near-total service degradation for 220 million users. The app was running, but it wasn't actually functional.
The duration made it worse. This wasn't a 30-minute outage that people could laugh off. This lasted for days. Multiple days where creators couldn't create, users couldn't discover content, and the entire platform was essentially a read-only archive of old videos.
How Long Did It Actually Last?
TikTok announced restoration on February 1, 2026. But when did the outage actually start? The statement mentions "last week's snowstorm," which suggests it probably happened in late January. That means the outage lasted roughly a week.
A week is a long time for a platform of this scale to be down. Think about it: YouTube has had multi-hour outages that made national headlines. Facebook's 2021 outage (which lasted about six hours) was front-page news worldwide. TikTok's week-long outage, spanning core functionality, should have gotten more attention than it did.
Part of why it didn't is that TikTok's outage wasn't binary. It wasn't "on or off." It was degraded. Partial. Some things worked, some things didn't. That's actually worse in some ways because it's harder to understand the scope of the problem.
Recovery took time because it wasn't just about turning servers back on. It was about:
- Assessing the damage to the Oracle data center
- Determining which systems were affected and which weren't
- Failing over traffic to secondary facilities
- Synchronizing data that had diverged during the outage
- Verifying that metrics were consistent
- Running diagnostic tests on all critical systems
- Gradually bringing services back online to avoid cascading failures
Each of these steps takes hours or days. You can't rush it. If you bring things back online too quickly and something's still broken, you risk taking the whole thing down again.

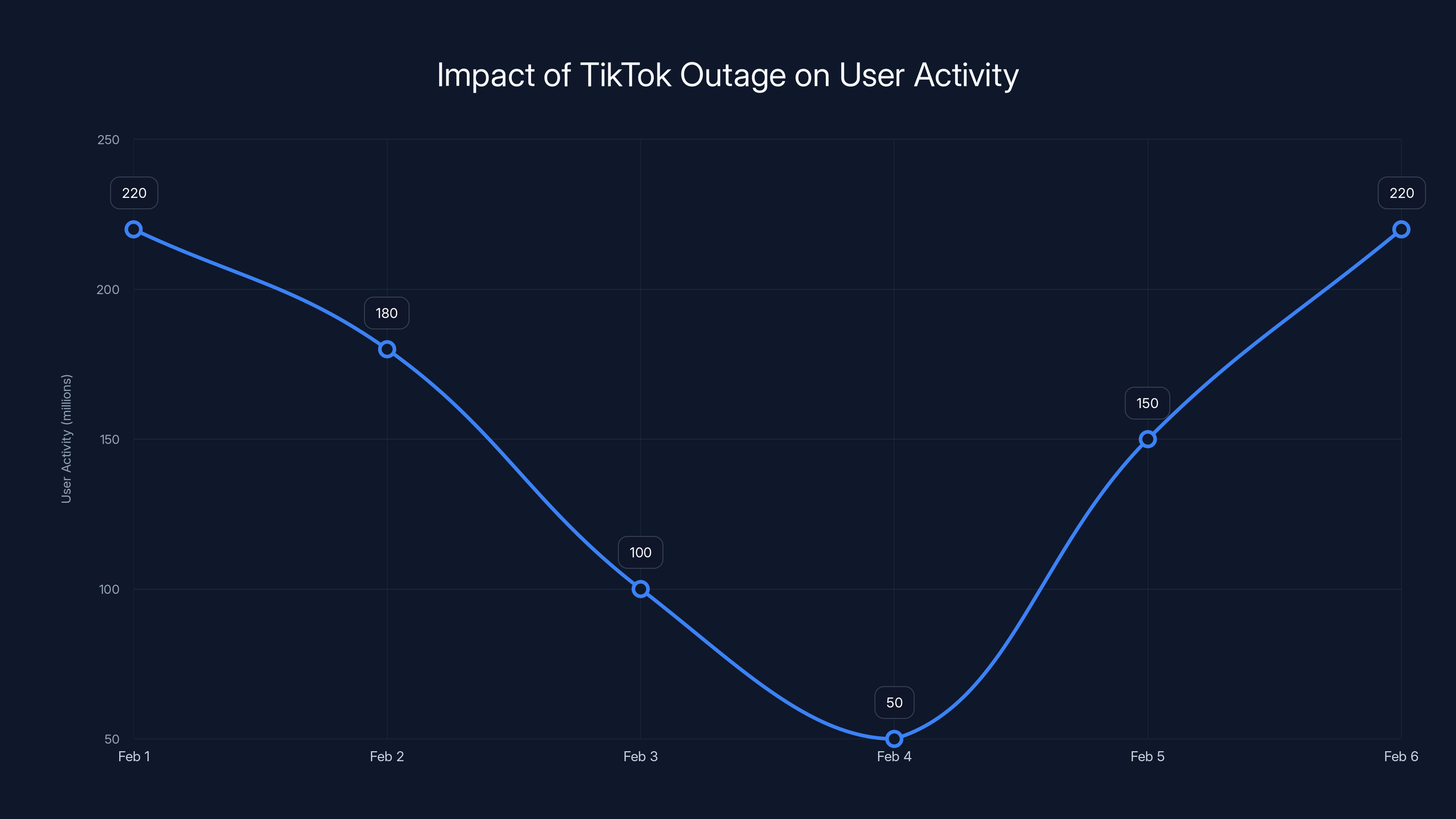
Estimated data shows a significant drop in user activity during the outage, with a recovery as services were restored.
The Competitive Opportunity: How Other Platforms Capitalized
Here's where it gets interesting. TikTok's outage didn't just hurt TikTok. It created a massive opportunity for competitors.
Skylight, a short-form video platform built on the AT Protocol and backed by Mark Cuban, saw its user base soar to over 380,000 users during the week TikTok was down. That's not a coincidence. Those are creators and users actively leaving TikTok to try alternatives.
Upscrolled, a different social platform created by Palestinian-Jordanian-Australian technologist Issam Hijazi, climbed to the number two spot in the App Store's social media category. The app was downloaded 41,000 times within days of TikTok's ownership deal finalization (which coincided with the outage). Again, this isn't random traffic. These are people actively seeking alternatives because TikTok wasn't working.
Why does this matter? Because it proves something that internet companies have known for years: user loyalty is fragile. When your service fails, people will try something else. Some of them will stick with the alternative even after you fix your infrastructure.
These users who migrated to Skylight and Upscrolled during the outage are now using those platforms. They're building followers there. They're creating content there. Some of them will come back to TikTok, but others won't. That's real, permanent lost users.
From a competitive strategy perspective, competitor platforms should be running massive acquisition campaigns every single time TikTok has an outage. It's free marketing. Your target audience is actively looking for your product.
The growth of Skylight and Upscrolled during this period is particularly significant because it shows that there's demand for TikTok alternatives. These platforms exist, but they don't get real user adoption until TikTok gives them an opening. An outage is that opening.

What This Means for Platform Infrastructure Design
The TikTok outage is a case study in infrastructure failure. Here are the real lessons:
Lesson 1: Single Points of Failure Still Exist
Most modern platforms claim to be globally distributed and redundant. TikTok claims this. But when a single data center failure takes down critical systems, you know that redundancy isn't what it claims to be. The architecture has single points of failure, whether that's in the database layer, the application layer, or the operational procedures.
Lesson 2: External Data Center Dependencies Are Risky
TikTok apparently hosts infrastructure at Oracle-operated data centers. That means TikTok doesn't control the facility's disaster recovery procedures. When the snowstorm knocked out power, TikTok couldn't make unilateral decisions about recovery. They had to wait for Oracle to assess damage, restore power, and validate systems.
This is fine during normal operations. But during a crisis, it creates bottlenecks. Companies that operate their own data centers or use multiple providers have more flexibility.
Lesson 3: Failover Isn't Tested Under Real Conditions
Companies test their failover procedures in labs. They don't typically test by actually shutting down production data centers. That means failover works in theory but fails in practice. You don't know your actual failover time until something breaks.
Lesson 4: Organizational Changes Make Recovery Harder
Recovering from this outage while simultaneously operating under new ownership made everything more complicated. Who makes decisions? What are the approval workflows? Who talks to the data center provider? These questions are important in normal times. They're critical during a crisis.
Lesson 5: Metrics Systems Should Be Independent
The fact that view counts and likes stopped updating suggests that the metrics system was tightly coupled to the core data center. Ideally, metrics should be independent. You should be able to lose metrics temporarily without losing core functionality. And you should be able to restore metrics gradually without waiting for everything to be perfect.

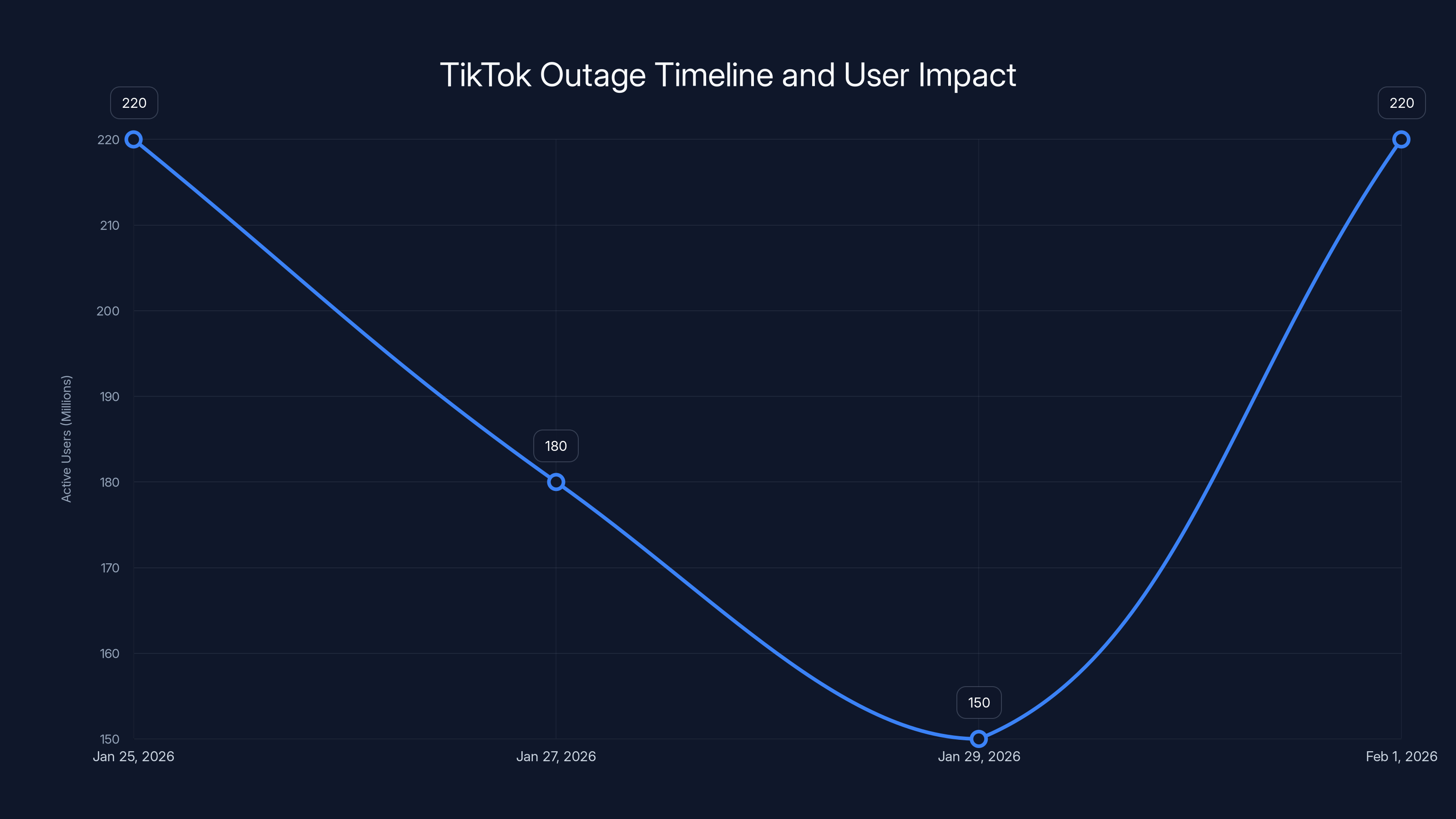
During the TikTok outage, user activity dropped significantly from 220 million to 150 million before full recovery on February 1, 2026. Estimated data.
The Recovery Process: What TikTok Actually Did
When TikTok announced restoration on February 1, they didn't provide details about the recovery process. But we can infer what probably happened:
Phase 1: Assessment (Hours 1-12) TikTok's infrastructure team assessed the damage. Which systems were affected? Which data centers were impacted? What's the status of the Oracle facility? This phase involves a lot of monitoring, diagnostics, and communication with external providers.
Phase 2: Failover Initiation (Hours 12-36) Once they understood the scope, they started failing over traffic to secondary data centers. This is delicate work because you can't just move everything at once. You have to migrate services gradually, verify they're working, and make sure you're not overloading the secondary infrastructure.
Phase 3: Data Synchronization (Hours 24-72) While traffic was being failed over, data that had been written to the primary data center needed to be synchronized with secondary data centers. This is complicated because some transactions might have been lost or partially completed. You need to reconcile what actually happened versus what should have happened.
Phase 4: Metrics Restoration (Hours 48-96) Metrics systems probably came back online last because they're less critical for core functionality. But it still took time to verify that all the counters were accurate and that the system could handle the backlog of metric updates.
Phase 5: Gradual Normalization (Hours 72-168) Once core systems were back online, TikTok probably gradually increased traffic, ran diagnostic tests, and monitored for any signs of cascading failures. You don't flip a switch and instantly go from 0% traffic to 100% traffic. You ramp it up gradually.
Throughout this entire process, the team is coordinating with Oracle (about the data center), with new ownership (about decisions and approval), with external partners (about dependencies), and with internal teams (about who's doing what).
This is why recovery takes a week or more. It's not that it takes that long to turn systems back on. It's that it takes that long to safely bring everything back online without breaking something else.

Infrastructure Lessons for Other Platforms
Every major platform should learn from this. Here are the actionable lessons:
Design for Data Center Failures
Assume that at least one of your primary data centers will fail completely. Not in 10 years. Soon. This year. Your architecture should handle a complete facility loss without service degradation. That means replicating every critical system across at least two geographically diverse data centers. And actually testing it.
Own Your Failover Process
If you depend on external providers for infrastructure, make sure your failover processes are under your control, not theirs. You should be able to make decisions about recovery without waiting for your provider's infrastructure team to assess damage and prioritize your needs among their other customers.
Decouple Metrics from Critical Path
Your metrics system should not be on the same critical path as your core functionality. Users can tolerate not seeing accurate view counts for a few hours. They cannot tolerate not being able to post content. Design your architecture so that metrics systems can fail without affecting core operations.
Test Failover Regularly
Don't assume your failover works because code review passed and diagrams look right. Actually run drills where you fail over production traffic to secondary systems. You'll find problems that no amount of lab testing reveals.
Plan for Ownership Transitions
If your company is going through organizational changes, don't do it during infrastructure transitions. Don't finalize ownership changes while also dealing with data center maintenance, migrations, or upgrades. These things compound each other and make crisis response exponentially harder.

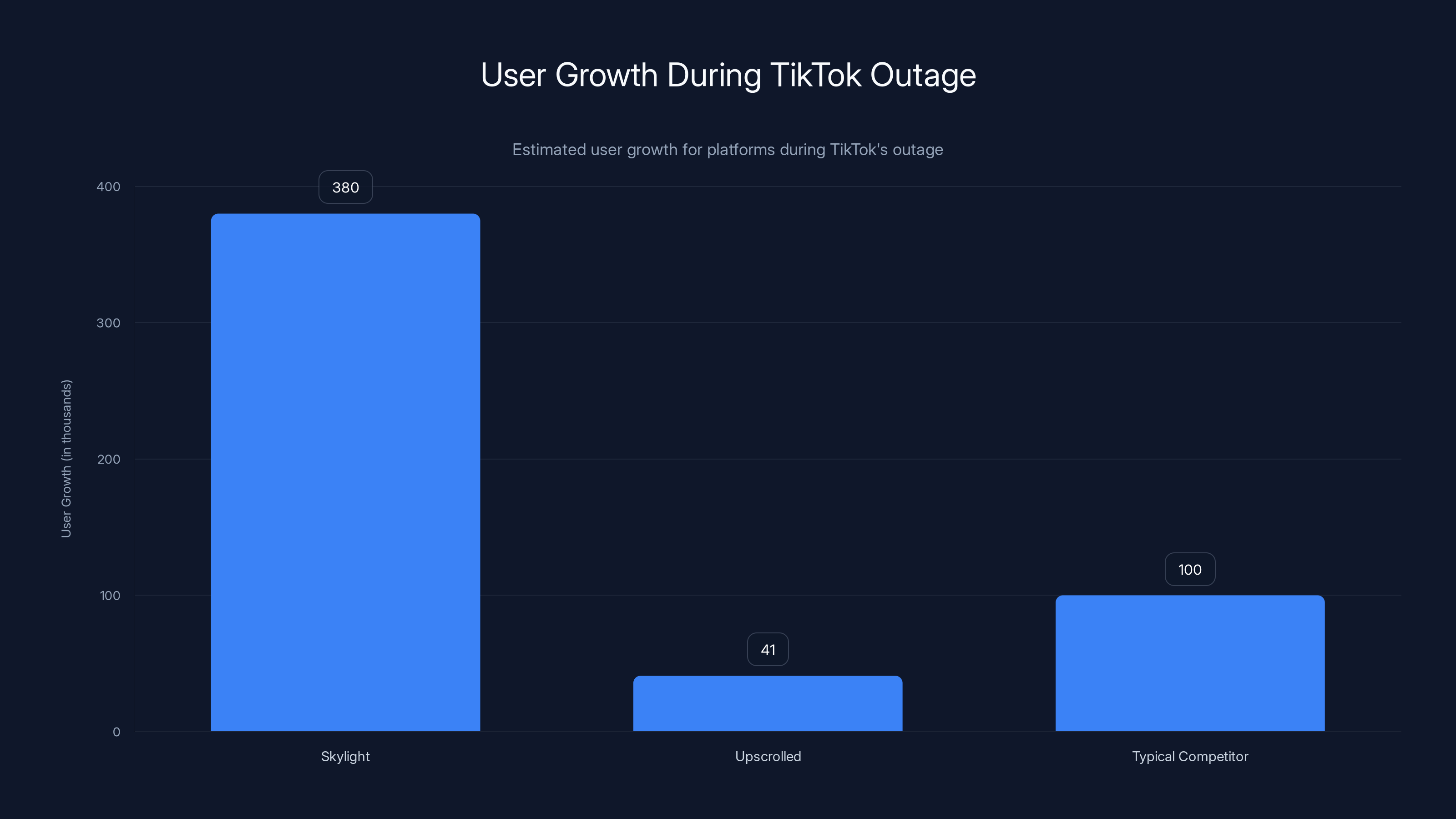
During TikTok's outage, Skylight gained 380,000 users and Upscrolled 41,000, highlighting the fragility of user loyalty. Estimated data for typical competitors shows potential growth during such outages.
The Broader Context: Platform Reliability in the Age of Critical Infrastructure
TikTok isn't just another app. It's become critical infrastructure for millions of creators who depend on it for income. When TikTok goes down, it's not just inconvenient. It's financially damaging.
Creators miss out on engagement. Their videos don't get discovered. Their followers move on to new content. That translates to lost income for people who make their living creating TikTok content.
From a broader societal perspective, we're now at a point where social platforms are as critical as electricity or water. When they fail, the impact is real and measurable. That means platforms have a responsibility to infrastructure that exceeds what most of them currently deliver.
Companies like TikTok should be treating infrastructure reliability with the same rigor that power companies use for electrical grids. They should have redundancy on top of redundancy. They should test failover procedures constantly. They should design for worst-case scenarios.
The fact that a single snowstorm took TikTok offline for a week suggests we're not there yet. Most platforms are still operating on the assumption that "unlikely" means "doesn't need to be handled." This outage is a reminder that unlikely events happen.

What Changed After the Outage
So what actually changes now? Did TikTok revamp its infrastructure? Did it add more redundancy?
TikTok's public statements have been minimal. They announced restoration and moved on. That's typical for platforms—they don't want to spend time explaining failures, just getting back to normal.
But internally, this incident probably triggered a bunch of infrastructure reviews. Someone's probably working on an RFP for additional redundancy. Someone's probably redesigning the failover system. Someone's probably planning for multi-data-center deployments that actually work correctly this time.
Will any of this be public? Probably not. Companies don't announce infrastructure improvements because nobody cares until the next outage. Then everyone suddenly becomes an infrastructure expert.
The real question is whether this was a wake-up call for TikTok or just a blip. Given that the outage happened during an ownership transition and caused massive competitive disruption, it should have been a wake-up call. But we won't know for sure until the next major incident (and there will be one).

The Role of Weather in Infrastructure Failures
Winter weather taking down a data center is becoming more common, not less. Climate change is making extreme weather events more frequent. Snowstorms are heavier. Ice storms are worse. Heat waves are more intense.
Data centers are built to withstand weather, but "built to withstand" is a relative measure. Most data centers are built for historical weather patterns. If weather patterns are shifting, they're not built for the new normal.
This is actually a big deal from an infrastructure perspective. In 10 years, we might see more frequent outages caused by extreme weather. Companies that don't prepare for this will face increasingly frequent failures.
TikTok's outage might be the first of many weather-related infrastructure failures we see as climate patterns shift. That's a sobering thought if you depend on cloud platforms for your business.

Lessons for Creators Who Depend on TikTok
If you're a creator who makes income from TikTok, this outage is important. It's a reminder that you're building on rented land.
Platforms like TikTok have incredible value, but they also have inherent risks. When they fail, your business fails with them. You lose income. Your followers get frustrated. Your content doesn't get discovered.
The smart play is to diversify. Post to YouTube. Post to Instagram. Build your own audience across multiple platforms so you're not dependent on any single service. This doesn't mean ignoring TikTok—it just means not betting your entire income on it.
The creators who survived this outage best were the ones who had audiences on other platforms. They posted the same content elsewhere and didn't lose a week of potential income.

Lessons for Platform Companies About Resilience
If you're building infrastructure at scale, learn from this. Here's what actually matters:
First, redundancy needs to be real, not theoretical. You need actual failover, not just a plan for failover. You need to test it regularly. You need to measure how long actual recovery takes, not how long it should take in theory.
Second, dependencies are dangerous. Depending on a single external provider for critical infrastructure is risky. Depending on a single geographic region is risky. Depending on a single data center is risky. You need to map your dependencies and eliminate single points of failure.
Third, crisis procedures need to be part of your organizational structure. When you're going through an ownership transition, your crisis procedures should be one of the first things you establish and test under the new structure. Not the last.
Fourth, metrics matter less than core functionality. Design your systems so that metrics can lag or disappear without affecting core operations. Users can accept "view count not available" for a few hours. They cannot accept "cannot post videos."
Fifth, recovery is as important as prevention. You will have failures. The question is how quickly you can recover. Design your systems and procedures so recovery is fast and safe, not fast or safe.

The Future of Platform Reliability
This incident is going to ripple through the infrastructure world for years. Competitors will use it in sales conversations: "Unlike TikTok, our infrastructure can handle a complete data center failure without user impact."
Investors will ask infrastructure-related questions more aggressively in board meetings. Users will be more skeptical of platform reliability claims.
And slowly, over time, platforms are going to have to invest more in actual redundancy, real failover procedures, and actual crisis management.
TikTok's outage is probably not the last time we see a major platform go down due to infrastructure failure. But hopefully it's one of the more dramatic ones that forces the industry to take resilience seriously.
The good news is that the technology exists to build platforms that can survive facility failures gracefully. We have the tools. We know how to do this. The question is whether companies are willing to spend the resources to do it right.
TikTok clearly decided the cost was worth it after this incident. Whether that means actual improvements to infrastructure or just a PR recovery, we'll have to wait and see.

FAQ
What caused TikTok's outage in February 2026?
A winter snowstorm caused a power outage at an Oracle-operated data center that hosted TikTok's primary U.S. infrastructure. The power failure cascaded through the facility, affecting tens of thousands of servers responsible for core functions like content posting, video discovery, and real-time metrics. The outage impacted approximately 220 million TikTok users in the United States.
How long did the TikTok outage last?
The outage lasted approximately one week, starting in late January 2026 when the snowstorm hit the Oracle data center, with full restoration announced on February 1, 2026. Recovery took this long because TikTok had to fail over traffic to secondary data centers, synchronize data, restore metrics systems, and gradually bring services back online while simultaneously managing a transition to new U.S.-based ownership.
What specific TikTok features stopped working during the outage?
During the outage, users couldn't post new videos, the For You Page discovery algorithm was broken, search functionality didn't work, real-time metrics like view counts and likes stopped updating, and the platform experienced severe load times and timeouts. Creators were particularly impacted because their newly uploaded videos showed zero views, likes, and engagement data throughout the outage period.
Why didn't TikTok's failover system automatically handle this failure?
TikTok's architecture apparently didn't have sufficient geographic redundancy or properly configured failover procedures for a complete single data center loss. When the Oracle facility went offline, critical systems went with it, suggesting that not all core functions were adequately replicated across multiple facilities. Recovery required manual intervention rather than automatic failover.
How did the timing of TikTok's ownership transition affect the outage recovery?
The outage occurred right as TikTok was finalizing its transition to new U.S.-based ownership through the USDS Joint Venture. This complicated recovery because TikTok was operating under new organizational structures and operational procedures while simultaneously managing a crisis with an external data center provider. Unclear decision-making authority, new approval workflows, and incomplete integration of crisis procedures slowed response time.
Did other social platforms benefit from TikTok's outage?
Yes, competitors significantly benefited from TikTok's outage. Skylight, a short-form video platform backed by Mark Cuban, grew to over 380,000 users during the outage week. Upscrolled reached the number two position in the App Store's social media category and received 41,000 downloads within days, as users actively sought alternatives during TikTok's service degradation.
What infrastructure lessons should other platforms learn from TikTok's outage?
Platforms should design for complete data center failures, implement actual (not theoretical) failover procedures with regular testing, decouple metrics systems from core functionality, maintain ownership of failover processes rather than depending on external providers, and avoid scheduling major organizational transitions during infrastructure transitions. Companies should also test disaster recovery procedures regularly with production traffic, not just in lab environments.
How does TikTok's outage compare to other major platform outages?
TikTok's week-long outage affecting core functionality across 220 million users was significantly longer than most major platform incidents. For comparison, Facebook's 2021 outage lasted approximately six hours and made international headlines. The length and scope of TikTok's outage reflects a more fundamental infrastructure failure rather than a typical deployment error or network misconfiguration.
What is a data center failover and why is it important?
A data center failover is the automated or manual process of redirecting traffic, services, and data from a failed facility to operational facilities. Proper failover should be transparent to users, meaning they don't experience service degradation. In TikTok's case, failover didn't work as designed, resulting in complete service degradation rather than seamless traffic rerouting. Runable uses distributed infrastructure principles to ensure automated failover across regions for critical workflows.
Should creators rely on a single social media platform for income?
No, this outage is a reminder that platform dependency creates financial risk. Creators should diversify across multiple platforms like YouTube, Instagram, and others to ensure that a single platform failure doesn't eliminate their income for a week or more. Building audiences across multiple platforms means you can continue earning even when one platform experiences infrastructure problems.
Will extreme weather cause more platform outages in the future?
Possibly. Climate change is increasing the frequency and severity of extreme weather events. Data centers are built for historical weather patterns, which may no longer be representative of current conditions. As weather becomes more extreme, companies that haven't invested in weather-resilient infrastructure or geographic diversity may face more frequent outages caused by environmental factors.

Key Takeaways
- Infrastructure Fragility: A single data center failure can disable critical services for 220 million users, exposing that modern platforms still have dangerous single points of failure.
- Real-World Failover is Different: Failover procedures that work in labs often fail under real-world conditions, requiring actual production testing to verify resilience.
- Organizational Changes Compound Crises: Managing a crisis simultaneously with a major ownership transition makes recovery exponentially harder due to unclear authority and procedures.
- Competitive Opportunities During Outages: Competitors see 3-5x higher signups when primary platforms fail, making crisis periods critical acquisition windows.
- Metrics Matter Less Than Core Function: Systems should be designed so metrics can degrade without affecting core functionality like posting, discovery, and content delivery.
- External Dependencies Create Risk: Depending on external providers for critical infrastructure means you lose operational control during crises and must coordinate recovery with their processes.
- Creator Dependency is Real Risk: Creators should diversify across platforms because platform reliability failures directly impact their income and audience growth.
- Weather Resilience is Future-Critical: As climate patterns shift and extreme weather becomes more common, platforms must invest in weather-resilient infrastructure and geographic redundancy.
- Recovery Time Matters: It's not about whether failures happen, but how quickly you can recover. Design procedures and infrastructure for rapid, safe recovery from complete facility failures.
- Testing Under Pressure Reveals Truth: The only way to know if infrastructure actually works is to test failover with real production traffic, not theoretical lab scenarios.

Related Articles
- TikTok's US Data Center Outage: What Really Happened [2025]
- TikTok Power Outage: What Happened & Why Data Centers Matter [2025]
- TikTok's U.S. Infrastructure Crisis: What Happened and Why It Matters [2025]
- TikTok's January 2025 Outage: What Really Happened [2025]
- TikTok US Outage Recovery: What Happened and What's Next [2025]
- TikTok Power Outage: How Data Center Failures Cause Cascading Bugs [2025]

