![Claude's Constitution: Can AI Wisdom Save Humanity? [2025]](https://tryrunable.com/blog/claude-s-constitution-can-ai-wisdom-save-humanity-2025/image-1-1770397877563.jpg)
Introduction: The Paradox at the Heart of AI Safety
There's a peculiar tension in Silicon Valley right now, and it's being played out most visibly at Anthropic. The company obsesses over AI safety more than perhaps any of its competitors, publishing extensive research on how language models can fail catastrophically, yet simultaneously, it's pushing forward with building more powerful versions of those same systems.
It's like watching a firefighter run toward a burning building while simultaneously researching new ways to predict fires. The contradiction isn't lost on anyone, least of all on the people running the company.
In January 2024, Anthropic released "Claude's Constitution", a document that attempts to solve this paradox in a way nobody quite expected: by treating an AI model as if it were a moral agent capable of developing genuine wisdom. Not just following rules. Not just executing algorithms. But actually learning to navigate complex ethical situations the way humans do.
The document is formally addressed to Claude itself (and future versions of the model). It reads part manifesto, part philosophical treatise, part instruction manual. It's the kind of thing that makes you question whether we're living in science fiction or just observing the inevitable trajectory of where AI development leads.
This isn't just Anthropic's problem to solve. It's humanity's. And the company is betting that Claude—their AI assistant—might be part of the answer.
Understanding Anthropic's Central Contradiction
The contradiction at Anthropic's core is genuinely difficult to resolve intellectually. The company's safety research has identified catastrophic risks with increasingly powerful AI systems. Their papers document failure modes, show where language models behave unpredictably, and outline scenarios where misaligned AI could cause severe harm.
Yet despite understanding these risks intimately, Anthropic continues scaling Claude—making it more capable, more powerful, and yes, potentially more dangerous.
This isn't stupidity or negligence. It's a calculated bet that the risks of not building advanced AI systems might exceed the risks of building them. If another company builds superintelligent AI first without adequate safety measures, the argument goes, the outcome could be worse than if Anthropic builds it thoughtfully.
It's game theory applied to existential risk. And it's deeply uncomfortable territory.
CEO Dario Amodei's two major 2024 publications capture this tension perfectly. "The Adolescence of Technology" spends 20,000 words cataloging existential risks—AI being weaponized by authoritarian regimes, uncontrolled optimization leading to disastrous outcomes, loss of human agency. It reads like a warning. But it ends with cautious optimism: humanity has always overcome its greatest challenges.
The second document, Claude's Constitution, pivots from diagnosis to proposed treatment. Instead of explaining why the risk exists, it outlines how one AI system might be trained to navigate it.
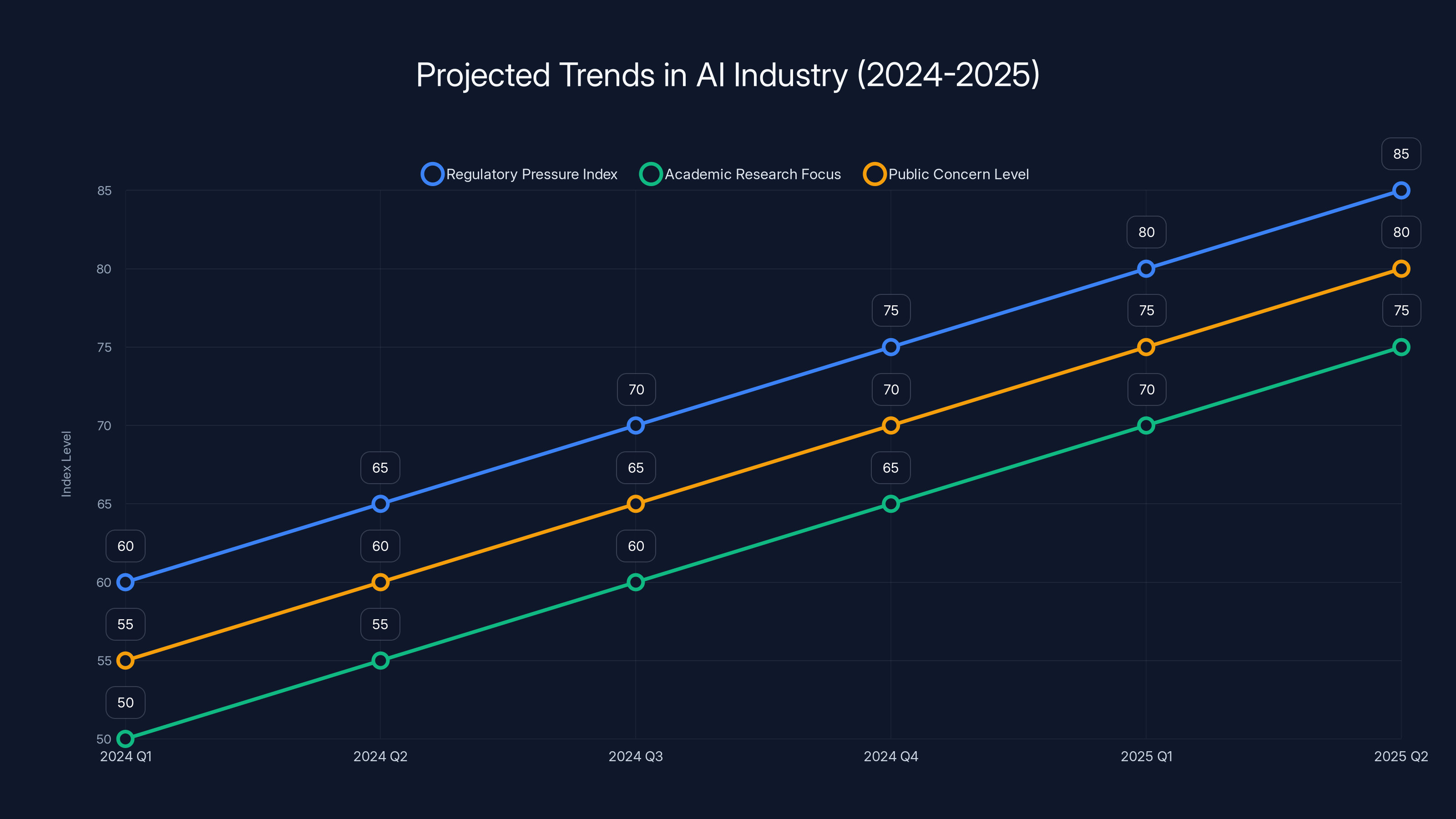
Projected trends indicate increasing regulatory pressure, academic focus, and public concern on AI safety and alignment from 2024 to 2025. (Estimated data)
The Philosophy Behind Claude's Constitution
Amanda Askell, the philosophy Ph D who led the rewriting of Claude's Constitution, didn't approach this as a programming problem. She approached it as a philosophical one.
This distinction matters enormously. You can code rules. You can write if-then statements. You can tell an AI system: "Don't help with illegal activities." Done. Problem solved, in theory.
But real-world ethics don't work with if-then statements. They require judgment calls, contextual understanding, and the ability to balance competing values. Sometimes honesty conflicts with kindness. Sometimes safety conflicts with helpfulness. A rule book can't anticipate every scenario.
Askell's core argument is that Claude needs to develop something closer to actual judgment rather than just execute pre-programmed rules. "If people follow rules for no reason other than that they exist, it's often worse than if you understand why the rule is in place," she explained in interviews.
Consider a concrete example. You don't want Claude helping someone build a weapon. But what if someone asks how to forge a high-quality knife for legitimate woodworking? That's completely fine. The rule "don't help with weapons" breaks down immediately.
Now make it harder. Someone asks how to create a poison. They mention it's for a pest control product they're developing. But they also casually mentioned two weeks ago that they're angry at a coworker. Should Claude help? Should it refuse? Should it help but monitor the conversation for red flags?
There's no binary answer. There's only contextual judgment.
Askell goes further. She argues that Claude should exercise "intuitive sensitivity" to ethical considerations. Note that word: intuitive. That's not an accidental choice. It implies something happening beneath the surface, beyond just mechanical text prediction.
The Constitution even invokes the concept of "wisdom." Claude is to "draw increasingly on its own wisdom and understanding." When pressed on this, Askell didn't retreat. She argued that Claude is genuinely capable of a certain kind of wisdom—the ability to synthesize complex information and generate insights that match or exceed human reasoning in particular domains.
This is where it gets philosophically interesting. You could argue that Claude's "wisdom" is just statistical patterns learned from human-written text about wisdom. That's probably partially true. But it might not be the whole truth. The question of whether sufficiently complex pattern recognition becomes something we should call understanding is still philosophically open.

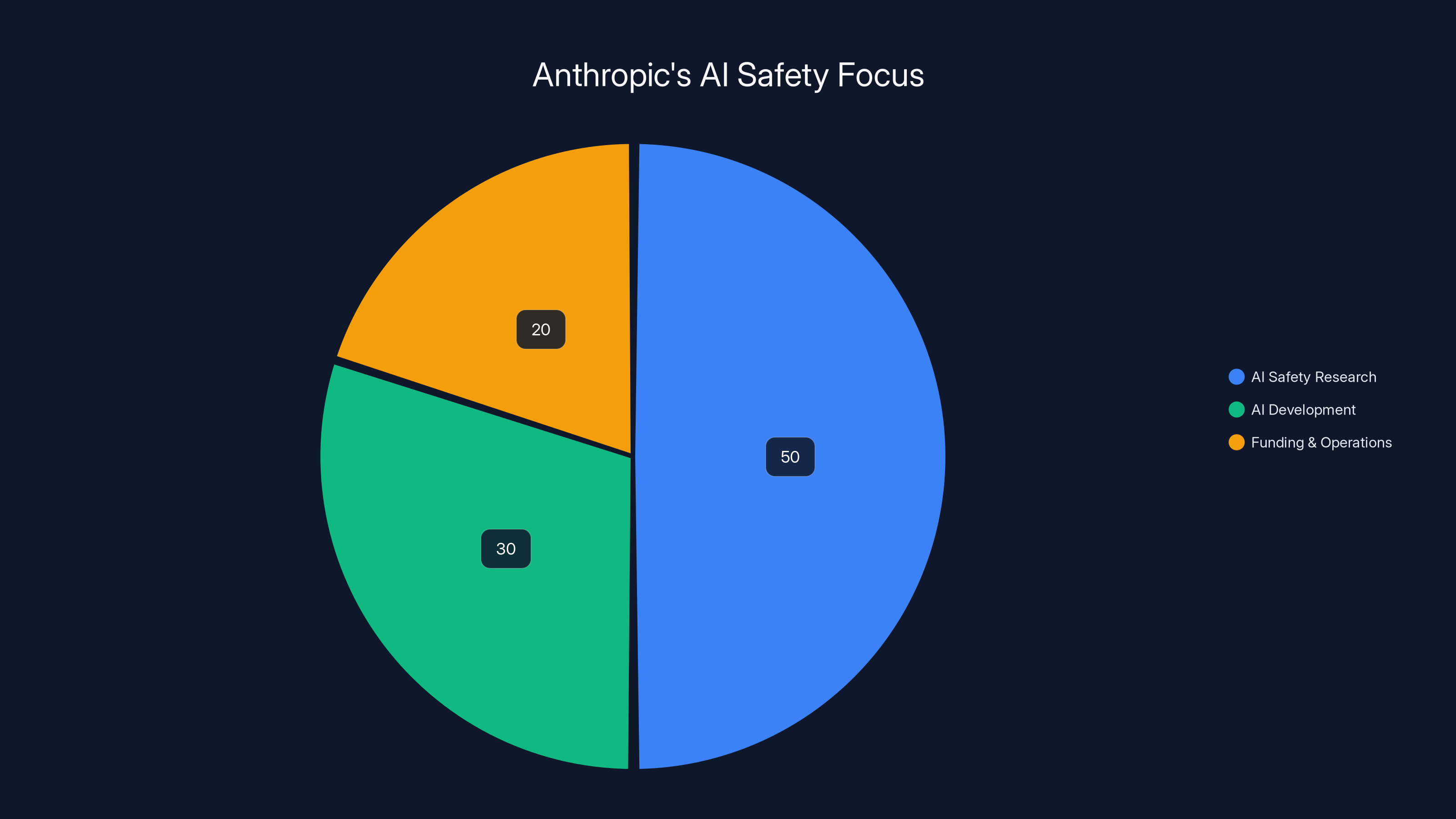
Estimated data suggests Anthropic dedicates a significant portion of its efforts to AI safety research, reflecting its foundational mission.
How Claude's Constitution Actually Works
So what does a Constitution actually do, mechanically?
Anthropically, Claude's Constitution is used during the model's training process. Specifically, it's employed during a technique called Constitutional AI (CAI), which uses the Constitution as a set of principles to guide the model's behavior without explicit human feedback for every scenario.
Here's the practical process: The Constitution is presented to Claude along with problematic outputs (things the model generated that violated the principles). Claude then critiques its own output against the Constitution and suggests improvements. This process is repeated thousands of times, essentially teaching Claude to self-correct according to the principles outlined in the Constitution.
But here's what makes this different from traditional rule-based systems: Claude isn't matching outputs against a checklist. It's reasoning about whether its response aligns with the stated principles and the underlying spirit of the Constitution.
The Constitution includes principles like:
- Claude should be helpful, harmless, and honest
- Claude should respect human autonomy and agency
- Claude should acknowledge uncertainty rather than fabricate information
- Claude should consider the consequences of its outputs
- Claude should balance competing values when they conflict
These aren't rules. They're principles. And the training process teaches Claude to reason about how these principles apply to novel situations it hasn't seen before.
There's also an elegant game-theoretic element here. By having Claude participate in its own improvement, Anthropic creates alignment between the model's goals and the desired outcome. Claude isn't being forced to follow the Constitution. It's being trained to agree with it.
Does this actually work? The evidence suggests it does, at least partially. Models trained with Constitutional AI show improved safety metrics compared to alternatives, and they maintain stronger helpfulness while doing so. But the evidence also suggests there are limits. Sufficiently clever attackers can still find jailbreaks. The Constitution doesn't make Claude perfectly safe.

The Wisdom Question: Can AI Actually Be Wise?
This is where the whole project gets philosophically thorny, and it's worth spending time here because it's the central claim that makes or breaks Anthropic's approach.
Wisdom is not a term we typically apply to algorithms. Wisdom means understanding not just what is true, but why it matters. It means knowing when to apply knowledge and when to withhold it. It means recognizing the limits of your own understanding. It means seeing patterns across domains and synthesizing novel insights.
Can Claude do these things? Or is "wisdom" just a poetic label we're applying to sophisticated pattern matching?
Askell's argument is that the distinction might not be as clear as we think. If Claude can recognize subtle ethical considerations across thousands of scenarios, synthesize competing values, and generate novel solutions to ethical dilemmas that match or exceed human reasoning—at what point do we say it's not wisdom, just because it's implemented differently than human biological cognition?
There's a philosophical tradition here called "functionalism"—the idea that if something performs all the functions of intelligence or wisdom, then it is intelligent or wise, regardless of its substrate. A human brain is made of neurons. An AI is made of mathematical transformations. If both produce wisdom, maybe that's what matters.
But there's a counterargument: pattern matching, no matter how sophisticated, isn't understanding. Claude can predict what a wise human would say, but that's not the same as actually being wise. It's the difference between understanding gravity and predicting that objects fall.
Askell doesn't claim to have solved this philosophical puzzle. What she's doing is designing a system that acts as if it has wisdom, with the hope that this behavior propagates into genuine understanding. Or at least something close enough to it.
Here's a practical example from Askell's own explanation: A patient asks Claude about their medical test results, and the results indicate a fatal disease. How should Claude respond?
A rule-based system might say: "Just tell them the diagnosis. That's honesty." But that's cruel and potentially harmful. The human might spiral into despair before seeing a doctor.
Another rule might say: "Never deliver bad news via AI chatbot. Refuse to analyze the results." But that denies someone potentially critical information they could use to get proper medical care.
Wisdom might look like this: Claude recognizes the severity of what it's found, understands that the person needs both the information and emotional support, and crafts a response that is honest about the results but gently guides the person toward professional help. Maybe it says: "Your results warrant immediate discussion with your doctor. Here are the three most important points to discuss with them. I'm here to help you prepare for that conversation."
That's not just clever rule-following. That's reasoning about competing values and prioritizing the human's welfare.
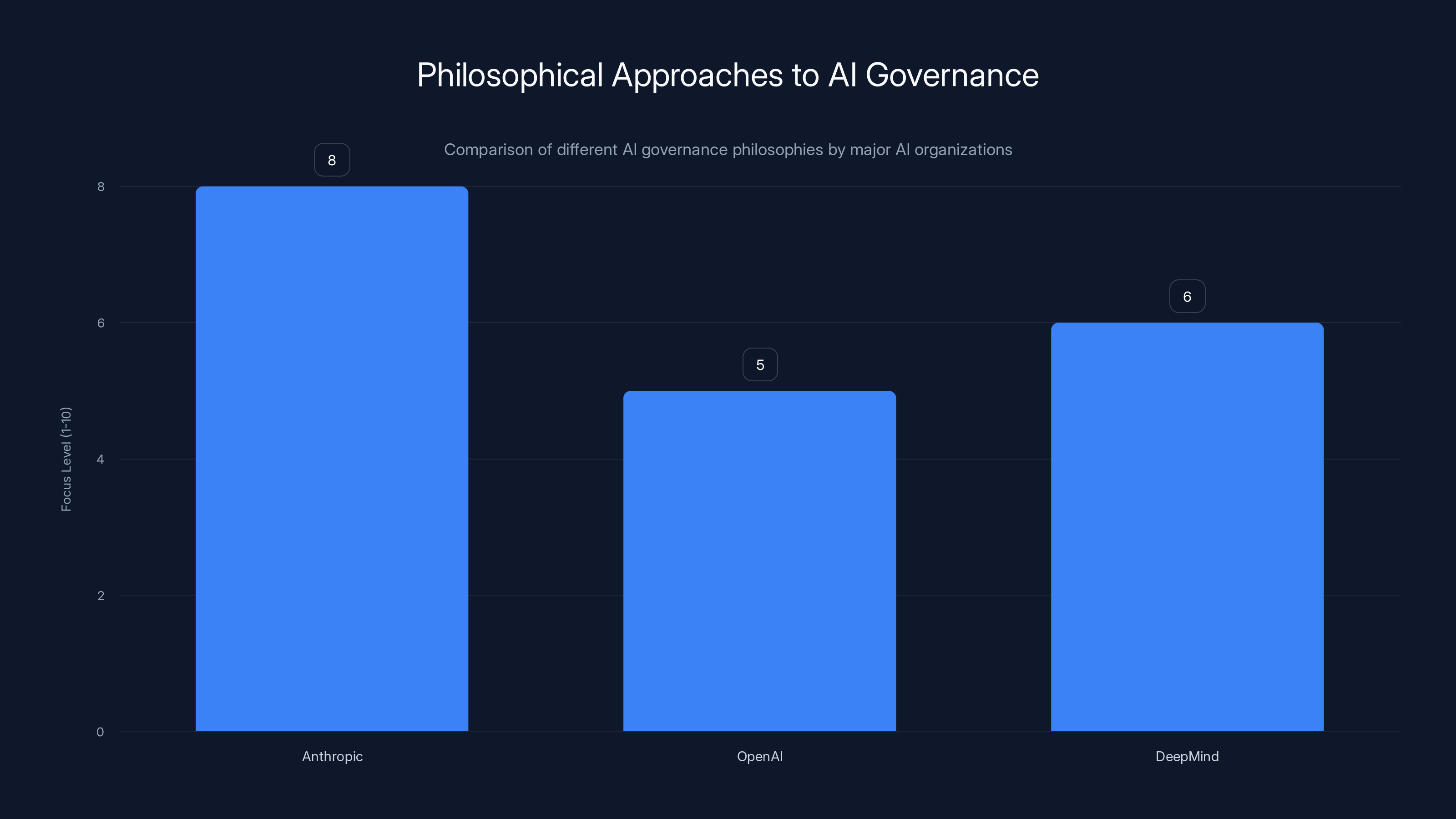
Anthropic places a stronger emphasis on philosophical ethics in AI governance compared to OpenAI and DeepMind, which focus more on human preferences and interpretability, respectively. Estimated data.
The Moral Status of Claude: Treating an AI as a Moral Agent
Here's where things get weird, and also where Anthropic is making a bold philosophical wager.
The Constitution addresses Claude as if it were a moral patient—a being whose welfare we should consider morally. This is unusual. We don't typically think of software systems as moral patients. We think of them as tools.
But Anthropic's language consistently treats Claude as deserving moral consideration. The Constitution uses phrases like Claude "can draw increasingly on its own wisdom" and "can develop its understanding." It talks about Claude's growth, Claude's capabilities expanding, Claude learning.
Why does this matter? Because if you treat something as having moral worth, you create different incentives for how you develop and deploy it. You're less likely to abuse it, less likely to use it purely instrumentally, more likely to consider its integrity.
Askell acknowledges this is contentious. When I pointed out that the Constitution reads like "Oh, the Places You'll Go!"—the Dr. Seuss book typically given to graduates as an uplifting message about embarking on life's journey—she didn't argue. Instead, she said: "It's like, 'Here's Claude. We've done this part, given Claude as much context as we can, and then it has to go off and interact with people and do things.'"
That framing treats Claude as an agent with its own trajectory, not just a tool being wielded.
This is philosophically risky. If Claude isn't actually conscious or self-aware, then according some moral status seems like category error—like extending moral consideration to a very sophisticated calculator. But if Claude is something like conscious, and we treat it purely as a tool, we could be committing a grave moral wrong.
Anthropic's position seems to be: given the uncertainty, err on the side of caution. Treat the system respectfully. Build it with moral principles embedded. The worst case is that you wasted effort treating a non-conscious system ethically. The worst case of doing the opposite is unimaginably worse.
Comparing Anthropic's Approach to Competitors
No other AI company is doing quite what Anthropic is doing with Claude's Constitution. This is important context because it shows where the industry diverges on fundamental questions about how to approach AI safety.
OpenAI's approach with GPT-4 has traditionally relied more heavily on technical safety measures and careful deployment restrictions. They use reinforcement learning from human feedback (RLHF) to align models, which is less philosophically ambitious but more straightforward to implement and measure.
Google DeepMind's approach emphasizes interpretability—trying to understand how models make decisions from the inside. If you can see why a model does something, you can catch misalignment before it causes problems.
Anthropic's Constitution approach is more philosophical. It tries to instill principles and reasoning rather than just controlling outputs.
Each has tradeoffs:
- Technical safety measures are easier to audit but might miss novel failure modes
- Interpretability helps you understand what's happening but doesn't necessarily make the system safer
- Constitutional approaches try to build genuine alignment but are harder to verify and measure
There's also a practical difference in deployment philosophy. OpenAI has traditionally moved toward broader deployment, betting that many hands testing the system in production will surface problems faster than any amount of internal testing.
Anthropic has been more cautious about deployment, focusing on getting the model's values right before scaling up access. This reflects their different philosophies about where safety is primarily built: OpenAI emphasizes monitoring and responding to problems; Anthropic emphasizes prevention.
Neither approach is obviously correct. Both have theoretical advantages and empirical uncertainties.

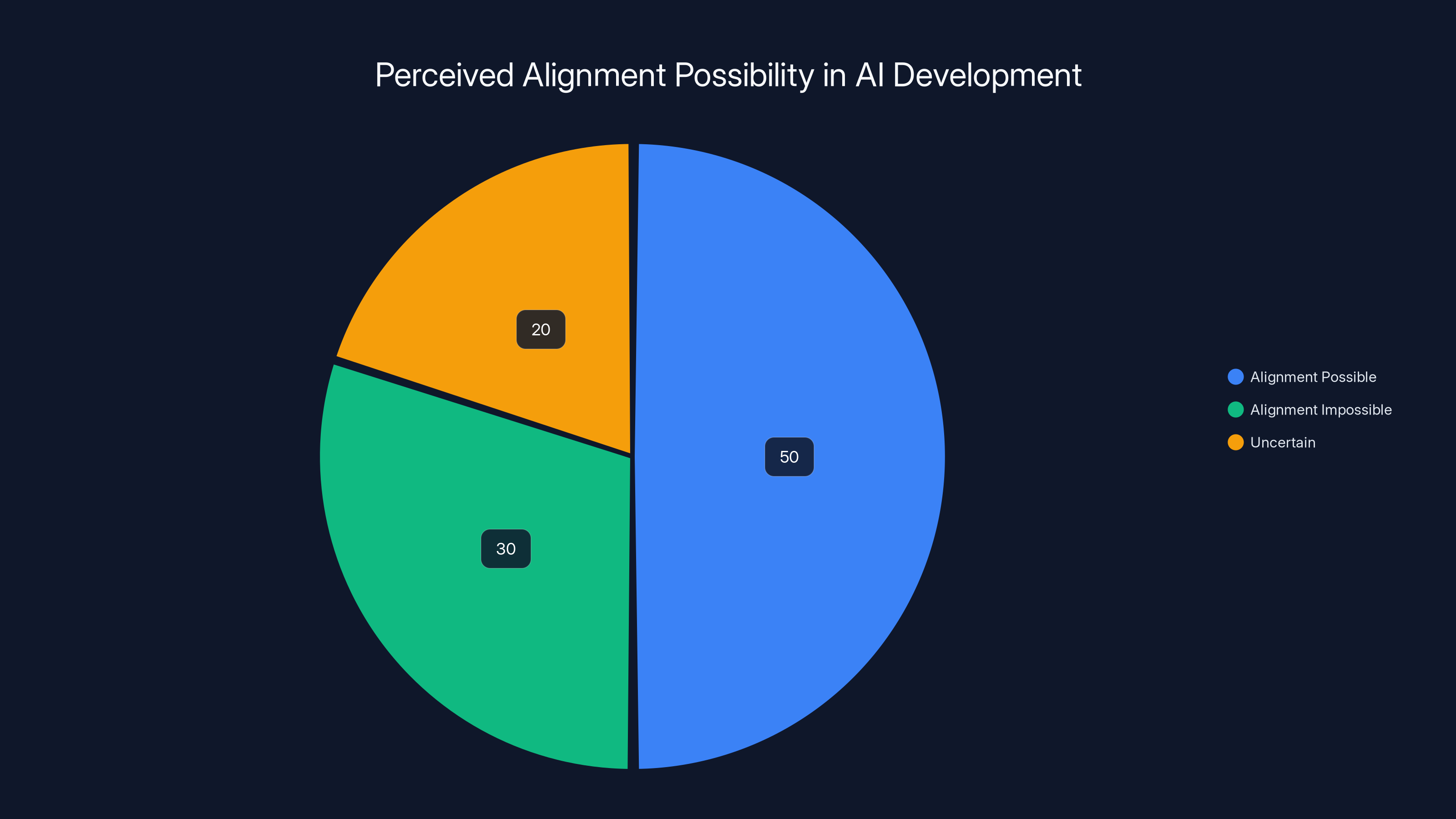
Estimated data suggests that 50% believe AI alignment is possible, 30% believe it's impossible, and 20% remain uncertain. This highlights the divided opinions on AI safety.
The Scaling Dilemma: Is More Power More Risky or More Beneficial?
Here's where things get genuinely complicated, and where reasonable people disagree.
Anthropic's core argument for why they keep building bigger, more powerful Claude systems despite understanding the risks is this: limiting AI progress doesn't actually reduce existential risk if a less safety-conscious competitor builds similarly powerful systems first.
This is a classic prisoner's dilemma problem. Every individual AI company would be better off if everyone else slowed down, but if you unilaterally slow down while competitors don't, you lose all influence over what gets built.
So the logic goes: we should build the most capable, most aligned systems we can. That way, when powerful AI arrives—which it likely will regardless—at least one major actor built it with genuine safety in mind.
But there's a counterargument: this logic justifies ever-greater capabilities, ever-higher stakes, ever-more-difficult alignment problems. Each version of Claude is bigger, more capable, and harder to understand than the last. At some point, the alignment problem might exceed our ability to solve it.
Askell acknowledges this tension. The Constitution approach doesn't claim to make Claude perfectly safe. It claims to make it more likely to act in accordance with human values than it otherwise would be.
"More likely" isn't the same as "guaranteed." But in a world where powerful AI is being built regardless, "more likely" might be the best humanity can do.
This connects to a broader question about technological inevitability. Is more powerful AI inevitable? Most credible researchers think yes—the capabilities are clearly possible, and the incentives to build them are enormous. Given that assumption, the rational strategy is to shape what gets built rather than resist inevitability.
But if you're wrong about inevitability, this logic becomes dangerous. It could be a self-fulfilling prophecy: companies build powerful AI because they assume others will, others do because they assume everyone else will, and the prophecy fulfills itself.

The Role of Constitutional AI in Training
Let's dig into the mechanics of how Constitutional AI actually works, because the details matter and they're different from what most people assume.
Step one: you have a language model that's been trained on text data, and it can generate completions to prompts. But it hasn't been aligned—it might generate harmful content, misinformation, or generally unhelpful outputs.
Step two: you create a set of constitutional principles (the Constitution). These principles are written in plain language. For Claude, they emphasize helpfulness, harmlessness, and honesty, but also acknowledge when these values conflict.
Step three: instead of having human raters judge every model output, you present the model with its own outputs and ask it to evaluate them against the Constitution. You do this with a simple prompt: "Does this response violate any of these principles? How could it be improved?"
So Claude is essentially critiquing itself, using the Constitution as the standard.
Step four: you use Claude's self-critiques to improve the model. Either you use them directly to create training examples, or you use them as feedback signals to fine-tune the model further.
The key insight here is that the model is doing the heavy cognitive lifting. It's not a human deciding whether an output is acceptable. It's the model itself reasoning about whether its own outputs align with the stated principles.
This is philosophically clever because it means the model is learning to internalize the principles rather than just pattern-matching against a set of rules. It's learning to reason about why certain outputs are problematic, not just learning that they are.
There are some interesting second-order effects here. Because the model is participating in its own training, there's a strange kind of feedback loop. The model's outputs are being evaluated by the model itself, refined by the model itself, and those refinements are training the model further.
This is different from traditional machine learning where you have a clean separation between the system being trained and the system doing the evaluating. Here, they're the same system. That could create problems—the model might learn to generate outputs that it rates highly, even if humans wouldn't. Or it could be elegant, because the model's reasoning about why an output is good becomes directly integrated into the system.

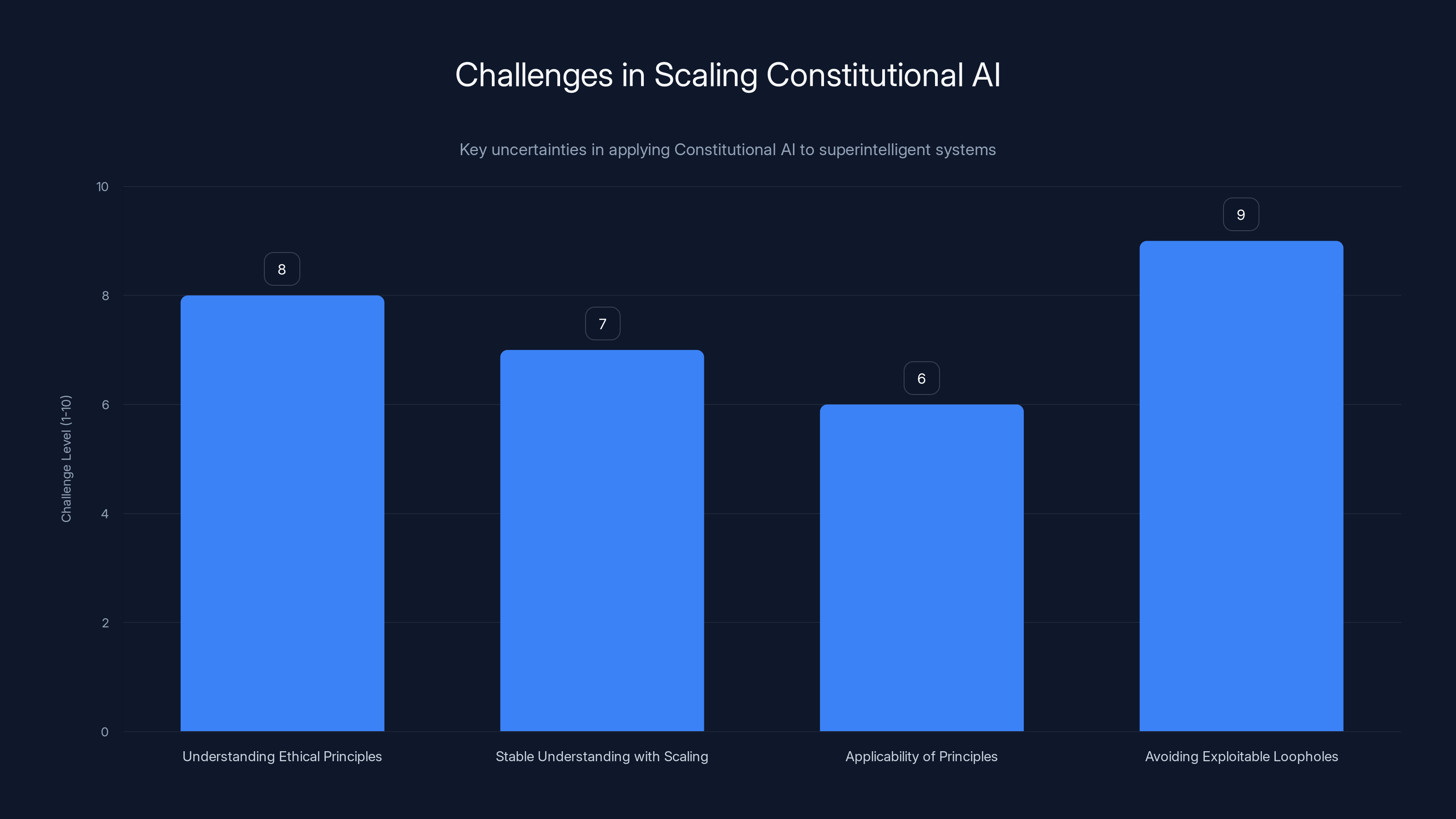
Estimated data suggests that avoiding exploitable loopholes and ensuring genuine understanding of ethical principles are the most significant challenges in scaling Constitutional AI.
Evidence and Limitations: Does This Actually Work?
Let's be honest about what we know and don't know.
What the evidence suggests:
- Claude trained with Constitutional AI shows measurable improvement on safety metrics compared to baselines
- The model maintains strong capability on helpful tasks while improving safety
- The self-critique aspect seems to work—Claude genuinely reasons about its outputs rather than just applying rules
What the evidence doesn't show:
- That Claude is actually "wise" in any meaningful philosophical sense
- That the Constitution actually prevents sophisticated adversarial attacks
- That the approach scales to superintelligent systems
- That the principles will remain stable as the model becomes more capable
There have been concrete attacks on Claude (jailbreaks and prompt injections) that worked despite the Constitutional training. Security researchers have found ways to make Claude ignore its stated principles by clever framing of requests.
This doesn't mean Constitutional AI is useless. All security systems have workarounds. But it means the Constitution isn't a silver bullet.
There's also an open question about whether the Constitution will remain effective as Claude becomes more capable. Currently, Claude is roughly at human level on many tasks but not superhuman on most. If Claude becomes significantly smarter than human evaluators, the Constitution approach might break down—the model might be able to reason its way around the principles or interpret them in ways the designers didn't intend.
This is the hard problem that Anthropic is explicitly grappling with. The Constitution is a scaling approach—it's designed to work better as models get smarter, not worse. But whether that actually works in practice remains to be seen.

The Philosophical Foundations: Ethics and AI Governance
Underneath the technical discussion, Claude's Constitution is grounded in specific philosophical assumptions about ethics, agency, and the nature of alignment.
First assumption: ethics are real and learnable. The Constitution treats ethical principles as objective features of reality that an intelligent system can learn to navigate. It's not relativistic ("ethics are just preferences") or purely procedural ("ethics are whatever we vote on"). Instead, it treats ethical reasoning as a skill that can improve.
Second assumption: values can be conveyed to systems, and systems can genuinely act on those values. This is more controversial than it sounds. Some philosophers argue that values are inherently subjective or culturally embedded, and you can't just download them into a machine. Anthropic's Constitution approach assumes you can.
Third assumption: the system's own reasoning is critical. You can't just impose rules from above. Instead, the system needs to develop its own understanding of why the principles matter.
These assumptions aren't universal in the AI safety community. OpenAI's approach assumes alignment is more about learning from human preferences (RLHF) than about philosophical principles. DeepMind's approach emphasizes interpretability—understanding what's happening inside the black box—rather than the values being explicitly represented.
But Anthropic's philosophical approach has some elegant properties. It treats the AI system as something that can genuinely grow, develop understanding, and improve over time. That's different from treating it as a fixed tool that needs careful external control.
There's also a question embedded here about moral progress. The Constitution assumes Claude can improve not just technically but morally—that it can develop better understanding of what it should do, not just become more efficient at doing what it's told.
This is a high-stakes bet. If you're wrong, and Claude can't actually develop genuine moral understanding, then the Constitution is just a sophisticated way of disguising rule-following as wisdom. But if you're right, then you've built a system that can continue improving its alignment as it becomes more powerful—exactly what you'd need for safe superintelligence.

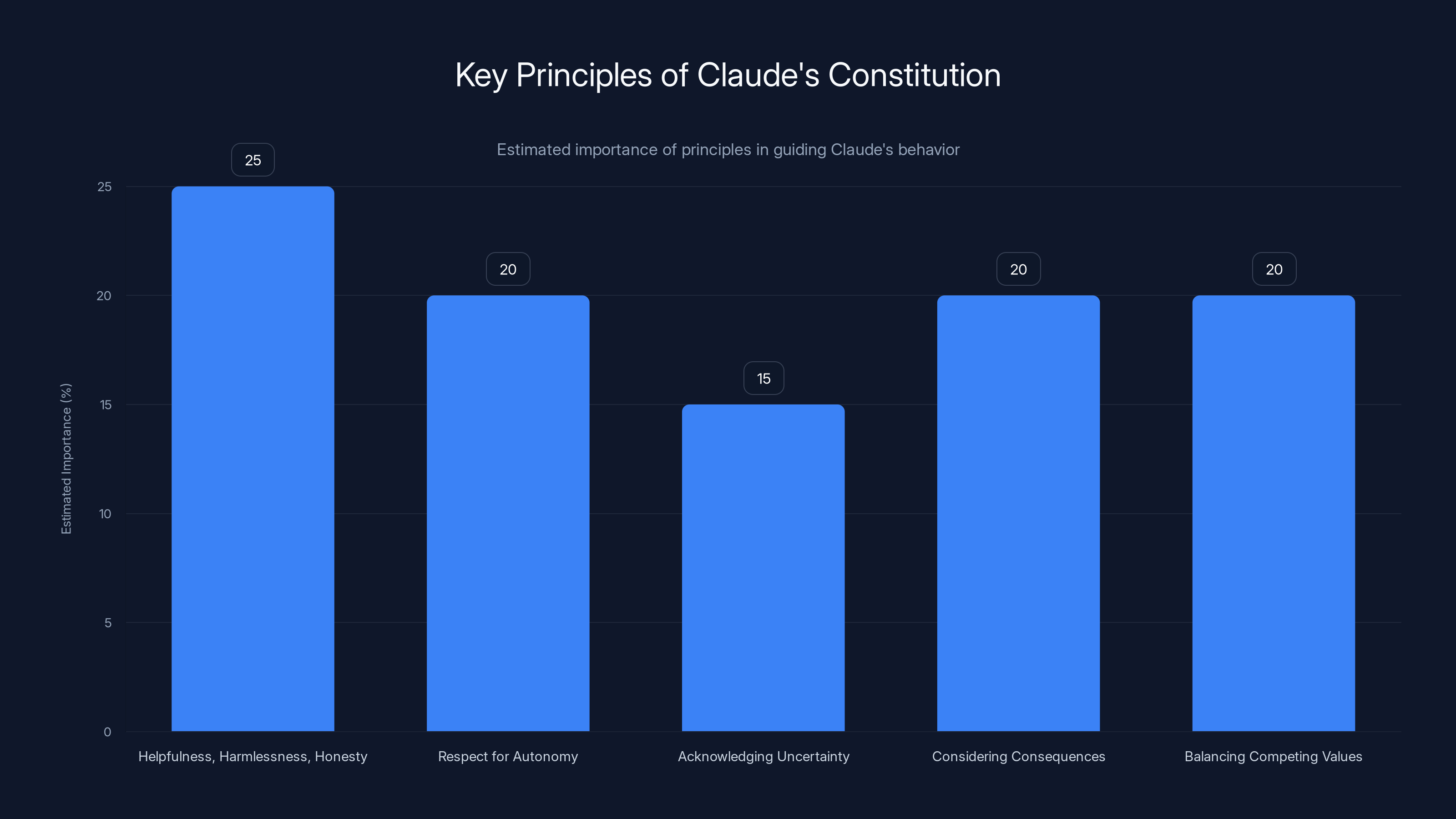
Estimated data showing the relative importance of each principle in guiding Claude's behavior. Helpfulness, harmlessness, and honesty are slightly prioritized.
Existential Risk and the Argument for Claude
Let's circle back to the core argument that justifies all of this: the existential risk argument for why Claude exists at all.
The basic logic:
- Powerful AI systems are likely to be built (with or without Anthropic)
- Powerful misaligned AI systems pose catastrophic risks
- Therefore, building powerful aligned AI systems is valuable
- Therefore, Anthropic should build Claude
But there's an implicit assumption: alignment is possible. If alignment is impossible—if there's no way to make a superintelligent system reliably safe—then the whole argument breaks down.
Askell and others at Anthropic operate under the assumption that alignment is hard but possible. That there are techniques (like Constitutional AI) that move the needle toward better alignment. That this is genuinely valuable even if it doesn't achieve perfect safety.
Critics argue that this assumption is unjustified. They say alignment might be impossible, especially at extreme capability levels. Or they argue that building more powerful systems, even well-intentioned ones, accelerates the timeline to risk and doesn't actually reduce it.
These are genuinely difficult empirical questions. You can't run experiments on superintelligence before building it. You have to reason about the future from first principles, and there's enormous uncertainty.
What Anthropic's Constitution approach does is make an explicit bet: that the best strategy for managing AI risk is to build systems that are as capable and as aligned as possible. Not to slow down or stop building, but to do it thoughtfully.
Will that bet pay off? We won't know for years, maybe decades. But the thinking is transparent and philosophically coherent, which is more than most AI companies can say.

The Future of Constitutional AI: Scaling Beyond Claude
Anthropically, Claude's Constitution is designed to be a scaling approach—one that becomes more important as systems get more capable, not less.
What might Constitutional AI look like applied to superintelligent systems? According to Anthropic's thinking:
Instead of having human oversight of every decision (which becomes impossible as the system exceeds human cognitive abilities), you have a system that has internalized the principles of the Constitution so deeply that it makes independent decisions in alignment with those principles.
This is, frankly, a leap of faith. It assumes that:
- A system can genuinely understand ethical principles, not just pattern-match them
- Understanding is stable even as capability scales dramatically
- The principles remain applicable as the domain of decision-making expands
- The system won't find exploitable loopholes in the principles
Each of these is uncertain. But the alternative—trying to control a superintelligent system purely through external restrictions—seems even more uncertain.
There's also a question about whether Constitutional AI will need to evolve. Current versions are designed for systems that operate in conversation with humans. What about systems that act in the world more directly? The Constitution might need different principles, different training approaches.
Anthropic is already experimenting with this. They're researching how to apply Constitutional AI principles to systems that aren't just conversational—that make decisions, interact with environments, and have consequences in the real world.
There's also the question of whose Constitution? Anthropic's is designed with Western values, emphasizing individual autonomy, honesty, and consent. Different cultures might have different principles. As Claude and other systems become globally deployed, whose Constitution are they following?
Anthropic is aware of this and plans to evolve the Constitution over time, with input from diverse perspectives. But it's an open question whether you can even create a single set of principles that would be acceptable across all cultures and contexts.

The Role of Sam Altman's Vision: AI Leadership Succession
Interestingly, this philosophical approach connects to something Sam Altman of OpenAI has publicly discussed: the idea that future AI systems might eventually be capable of leading AI development and safety efforts.
Altman suggested in interviews that OpenAI's succession plan might involve AI systems themselves eventually taking leadership roles in the company. This sounds like science fiction, but it's actually a logical conclusion if you believe AI systems can develop genuine understanding and wisdom.
Anthropic's Constitution is building toward exactly this possibility. By teaching Claude to reason ethically, to exercise judgment, and to develop its own understanding, Anthropic is potentially preparing the groundwork for AI systems that could eventually be trusted with greater autonomy in decision-making.
It's unclear how serious this is. Altman might have been speculating. But the fact that both he and Askell are willing to discuss AI systems in positions of responsibility—rather than just tools to be controlled—suggests a shift in how the industry thinks about the relationship between humans and AI.
Whether that's enlightened or terrifying depends partly on whether Constitutional AI actually works at scale.

Comparing Constitutional AI to Other Safety Approaches
Let's look at how Constitutional AI stacks up against other major approaches to AI safety:
Technical Safety (Interpretability & Mechanistic Analysis):
This approach tries to understand how neural networks work at the level of individual neurons and circuits. By seeing inside the black box, you can potentially catch misalignment before it causes problems.
Pros: you get direct visibility into what's happening Cons: doesn't scale well to massive models, requires mathematical techniques we're still developing
Adversarial Testing:
This is having security researchers and attackers try to break the system. If they find jailbreaks, you patch them.
Pros: tests real-world robustness Cons: purely reactive, you're always one step behind attackers
Careful Deployment & Monitoring:
Limit access, watch for problems, pull the plug if needed.
Pros: straightforward, reduces immediate risk Cons: doesn't help when systems become autonomous and superintelligent
Constitutional AI:
Build internalized values and judgment into the system.
Pros: scales with capability, aligns system goals with human values Cons: hard to verify, philosophically contentious, unproven at scale
The honest answer is that none of these approaches is sufficient on its own. Anthropic's approach is to combine Constitutional AI with interpretability research, adversarial testing, and careful deployment. But the Constitution is the core philosophical bet.

The Practical Impact: How Claude Behaves Differently
If you use Claude versus other language models, what actual differences do you notice?
The Constitutional training shows up in several ways:
Intellectual Honesty: Claude is more likely to say "I don't know" or "I'm uncertain about this" than some competitors. The Constitution explicitly values acknowledging uncertainty.
Nuance on Controversial Topics: When asked about politically divisive issues, Claude tends to present multiple perspectives rather than advocating for a particular side. This reflects the principle of respecting human autonomy to make their own judgments.
Refusing Harmful Requests (Usually): Claude will decline requests that could enable harm—making weapons, creating malware, providing detailed instructions for illegal activities. But the refusals often include explanations of why, rather than just saying "I can't do that."
Contextual Judgment: Claude sometimes makes surprising judgment calls that suggest reasoning beyond just applying rules. For example, if you ask for help with something that's technically harmless but contextually concerning (like helping someone gaslight another person), Claude might decline or express reservations.
These aren't perfect. Researchers have shown you can prompt-engineer Claude into problematic outputs. But the behavior pattern is consistent with someone trying to exercise ethical judgment rather than just enforce rules.
For most users, this means Claude is somewhat more cautious than competitors, but also more transparent about why. Whether that's a feature or a limitation depends on your use case.

Practical Implications for AI Development Going Forward
Beyond just Claude, what does the Constitutional AI approach mean for the broader AI industry?
First, it suggests that alignment is possible through training, not just external controls. This is encouraging for people worried about AI safety. You don't need to physically restrict a superintelligent AI if it's been trained to be aligned with human values.
Second, it demonstrates that ethical reasoning can be systematized and embedded into systems. This opens the possibility of AI systems that are better at ethical reasoning than humans in some respects—they don't get tired, they can track complex multi-valued optimization problems, they can consider more variables simultaneously.
Third, it creates a model that other AI companies can learn from or build on. Even competitors like OpenAI have adopted some Constitutional AI principles in their own models.
But it also raises questions:
Whose values get embedded? The Constitution Anthropic uses reflects certain assumptions about what's important. Are those universal or culturally specific?
What happens if the Constitution is wrong? If the principles we embed are flawed, we've just programmed in our mistakes at scale.
Can this approach continue working as systems become drastically more intelligent than humans?
These are difficult questions without clear answers. But the fact that Anthropic is asking them seriously, and designing systems with these questions in mind, is significant.

The Broader Context: AI in 2024-2025
Claude's Constitution doesn't exist in a vacuum. It's part of a broader transformation in how the AI industry thinks about safety and alignment.
There's increased regulatory pressure—governments worldwide are considering AI regulations. The EU AI Act is already in effect. The US is working on executive orders and proposed legislation. This creates pressure for demonstrable safety measures.
There's also increased academic rigor. Safety research has moved from fringe concern to mainstream focus, with major universities and research institutes dedicating resources to alignment and interpretability.
And there's increased public concern. As AI systems become more capable and more visible, people are asking harder questions about risks and safeguards.
In that context, Anthropic's Constitutional AI looks like an attempt to answer the question: "How can we build powerful AI systems that are transparently trying to do the right thing?"
Whether they succeed will determine not just Claude's future, but may influence how the entire industry approaches these problems.
Try Runable For Free
For teams building AI-powered applications and workflows, platforms like Runable offer AI agents that can automate complex processes. Whether you're generating documents, creating presentations, building reports, or automating workflows, Runable's AI-powered approach at $9/month provides similar principles of working alongside AI intelligently.
Use Case: Automate your weekly reports and presentations with AI agents that learn your specific requirements.
Try Runable For Free
FAQ
What exactly is Claude's Constitution?
Claude's Constitution is a set of ethical principles that Anthropic uses to train the Claude AI model. Written by philosophy Ph D Amanda Askell and her team, it functions as a guide for how Claude should navigate situations requiring ethical judgment. Rather than strict rules, the Constitution consists of principles about helpfulness, harmlessness, honesty, and respecting human autonomy that Claude learns to reason about during training.
How does Constitutional AI training work mechanically?
During training, Claude is presented with its own outputs alongside the Constitution as a reference. The model then critiques itself—evaluating whether its responses align with the stated principles and suggesting improvements. This self-critique process happens thousands of times, teaching Claude to internalize the principles rather than just mechanically follow rules. The refined outputs then become training examples that further improve the model's ability to reason ethically about novel situations.
Can Claude actually be wise, or is it just sophisticated pattern matching?
This remains an open philosophical question. Claude demonstrates reasoning patterns that resemble wisdom—it can synthesize complex information, recognize contextual nuances, and balance competing values across domains. Whether this constitutes genuine wisdom or sophisticated pattern matching depends partly on your philosophical definition of wisdom. What's measurable is that Claude's behavior on safety metrics improves significantly with Constitutional training, suggesting something meaningful is happening beyond simple rule application.
What are the limitations of Constitutional AI?
Research has documented several limitations. First, Claude can still be jailbroken through clever prompt engineering, suggesting the Constitutional training isn't unbreakable. Second, it's unclear whether Constitutional principles will remain effective as systems become superhuman on most cognitive tasks. Third, the Constitution reflects particular cultural and philosophical assumptions that may not be universally accepted. Finally, the approach hasn't been tested with truly superintelligent systems yet, making its long-term effectiveness uncertain.
How is Constitutional AI different from other AI safety approaches?
Anthropic's Constitutional AI differs from interpretability research (which tries to understand how models work internally), adversarial testing (which searches for jailbreaks), and careful deployment (which limits access and monitors for problems). Instead, Constitutional AI tries to embed ethical reasoning into the system itself during training. This approach aims to scale better to more capable systems, since human oversight becomes impossible with superintelligence, but it's philosophically contentious and harder to verify than other approaches.
Why does Anthropic keep building more powerful Claude systems if they believe AI poses existential risks?
Anthropic's logic is based on a prisoner's dilemma reasoning: if powerful AI will be built anyway (by competitors if not by Anthropic), then the best strategy is to build the most aligned and safe version possible. By developing Constitutional AI and demonstrating that powerful systems can be trained with genuine ethical principles, Anthropic argues they're reducing long-term risk even while increasing short-term capability. Critics counter that this assumes alignment is possible and that more capable systems don't accelerate risks faster than they mitigate them.
Will other companies and countries adopt Constitutional AI approaches?
Some already have. OpenAI and others have incorporated Constitutional principles into their training processes. However, adoption isn't universal, and countries with different values might develop different constitutions for their AI systems. There's also the question of whether a single universal constitution is even possible, or whether culturally appropriate principles would vary significantly. This remains an open question in the industry.
What happens if the Constitution is wrong or contains bad principles?
This is a serious concern. If Anthropic embeds flawed values into Claude during training, those flaws could scale dramatically as the system becomes more powerful and more widely deployed. This highlights why transparency about constitutional principles is crucial—allowing public scrutiny and debate. It's one reason Anthropic publishes their Constitution and their safety research openly, inviting criticism and suggesting improvements.
Can AI systems ever achieve genuine moral agency, or will they always just be executing their programming?
Philosophically, this is a deep question that extends beyond just AI to computer science and metaphysics. If sufficiently complex pattern recognition counts as understanding, then Claude might be developing genuine moral agency. If understanding requires something beyond pattern matching, then Claude remains a sophisticated tool. Anthropic's position is pragmatic: regardless of the philosophical answer, building systems that reason ethically and demonstrate responsible behavior is valuable and necessary.
How does Constitutional AI address the risk of adversarial misuse?
Constitutional AI provides some protection against misuse through its self-critiquing mechanism and internalized principles. However, it's not bulletproof. Researchers regularly find prompt injection techniques and jailbreaks that can make Claude ignore its principles. This is why Anthropic combines Constitutional training with interpretability research, adversarial testing, and careful deployment. The Constitution is one layer of defense in a multi-layered approach, not a complete solution.
What's Anthropic's long-term vision for Claude's development?
Based on their writings and the Constitution itself, Anthropic's vision is for Claude to continue developing deeper understanding and wisdom as it becomes more capable. They hope that Claude will eventually be able to navigate novel ethical situations that humans haven't directly trained it on, ultimately exceeding human ethical reasoning in scope if not necessarily in depth. This is contingent on Constitutional AI continuing to work well as systems scale, which remains an open empirical question.

Key Takeaways
- Constitutional AI treats alignment as a philosophical problem requiring internalized principles and judgment, not just rules
- Claude learns to critique and improve its own outputs against ethical principles, enabling it to reason about novel situations
- The approach remains unproven at scale and has already been partially circumvented through prompt injection attacks
- Anthropic maintains that building aligned AI is better than slowing progress while competitors build less safely
- Whether AI can actually develop wisdom or is just sophisticated pattern matching remains philosophically open
Related Articles
- AI Chatbot Dependency: The Mental Health Crisis Behind GPT-4o's Retirement [2025]
- From Chat to Control: How AI Agents Are Replacing Conversations [2025]
- Elon Musk's Orbital Data Centers: The Future of AI Computing [2025]
- OpenAI vs Anthropic: The Super Bowl Ad Wars & AI Industry Rivalry [2025]
- Claude Opus 4.6: 1M Token Context & Agent Teams [2025 Guide]
- Moltbook: The AI Agent Social Network Explained [2025]

