![From Chat to Control: How AI Agents Are Replacing Conversations [2025]](https://tryrunable.com/blog/from-chat-to-control-how-ai-agents-are-replacing-conversatio/image-1-1770333086414.jpg)
From Chat to Control: How AI Agents Are Replacing Conversations
Remember when the big promise was asking an AI anything and getting a perfect answer back? That future is already obsolete.
The conversation model of AI—you type, Chat GPT responds, repeat—worked fine for brainstorming and research. But as AI systems got smarter, a weird problem emerged. The most complex tasks don't need better conversational partners. They need workers. Autonomous ones.
So the entire AI industry is making a pivot that barely made headlines last month. Instead of building better chatbots, the biggest players are building agent management platforms. Anthropic shipped Claude Opus 4.6 with "agent teams" functionality. OpenAI released Frontier, positioning itself as a platform to "hire AI co-workers." Meanwhile, they're releasing specialized tools like OpenAI's new Codex app, which executives call a "command center for agents."
This shift represents something bigger than a product update. It's a fundamental reorganization of how humans work with AI. And it arrived at a moment when the idea of AI as an autonomous workforce reportedly spooked investors so badly that software stocks dropped $285 billion in a single week.
So what's actually happening? Why is every AI company suddenly obsessed with agents instead of conversations? And does this model—where you become a manager supervising AI workers—actually work?
Let's dig into the real story behind the hype.
The Conversation Model Hit Its Ceiling
For the past two years, the narrative was predictable. Chat GPT proved you could have a conversation with AI. Claude made it longer. Gemini made it multimodal. Everyone assumed the path forward was incremental: better conversations, longer context windows, smarter responses.
But there's a hard limit to what conversation alone can accomplish.
Consider a real task: reviewing a codebase for security issues. The old way looked like this: you paste code into Chat GPT, it analyzes a chunk, you ask followup questions, it gives you more feedback. You're bottlenecked by sequential interaction. One analysis per prompt. One human asking questions at a time. If the AI finds a problem, you have to intervene to investigate it further.
It's slow. It's linear. And more importantly, it wastes the AI's potential.
What if instead of one AI analyzing your code sequentially, five AIs worked on different modules at the same time? One reviews authentication logic. Another checks data validation. A third audits dependencies. A fourth analyzes error handling. A fifth looks for race conditions. They run in parallel, coordinate their findings, and flag everything that needs human attention in one comprehensive report.
That's not a conversation. That's delegation.
The breakthrough was realizing that for knowledge work, conversation was never the best interface. It was just the easiest one to explain to consumers. "You can talk to an AI" is simple marketing. "You can spawn multiple autonomous agents that coordinate work and report back" requires actual explanation.
But the second one is more useful.
This insight is driving the entire industry pivot. Every major AI company recognized something simultaneously: the next layer of value isn't in making individual conversations better. It's in letting multiple AI agents operate independently on decomposed tasks.

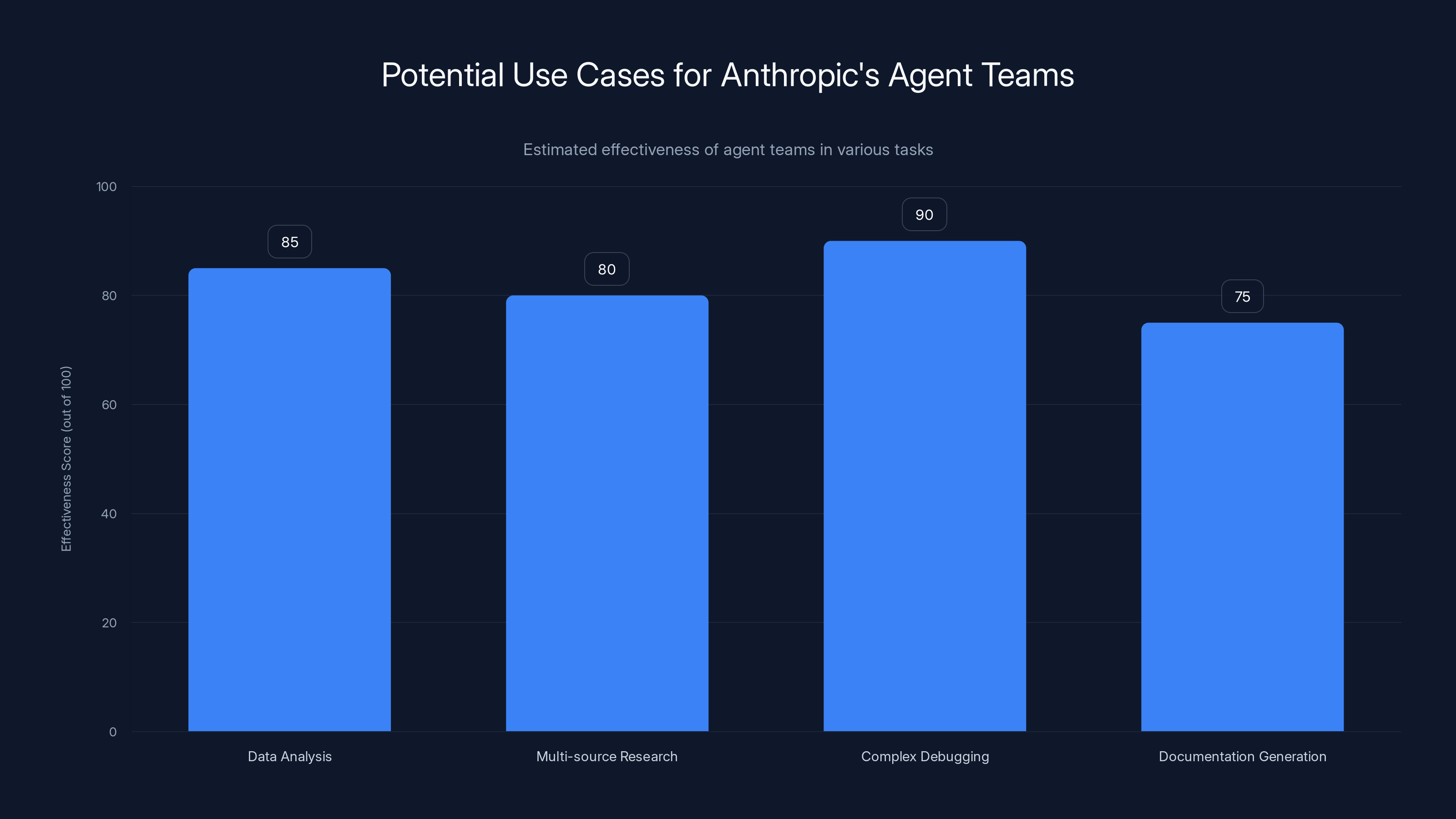
Agent teams are highly effective in tasks like complex debugging and data analysis, where parallel processing significantly enhances performance. Estimated data based on task complexity.
Anthropic's Agent Teams: The Supervisor's Interface
Anthropic's approach with Claude Opus 4.6 and the new "agent teams" feature in Claude Code feels like watching someone build the future in real time.
Here's what actually happens when you use agent teams: you break a task into independent pieces. Describe what you want done. Claude spawns multiple instances of itself, each with its own identity and context. They work on separate pieces of the task simultaneously. You watch them go, switching between agents using keyboard shortcuts. Jump into any one directly to steer it. The others keep working while you're focused elsewhere.
The interface is deliberately unsophisticated. A split-screen terminal. Shift+Up and Shift+Down to navigate between agents. Direct text input to take control of any agent. It looks almost retro compared to modern AI UIs. But that's intentional. The design assumes you're a technical person who needs control, not a casual user who wants polish.
Anthropic says it's best for "tasks that split into independent, read-heavy work like codebase reviews." That's accurate, but it undersells what's actually possible. A codebase review is just one example. You could use agent teams for:
- Data analysis across multiple datasets: One agent processes customer demographics. Another analyzes transaction patterns. A third correlates with market data. They work in parallel, reconvene with findings.
- Multi-source research: One agent researches competitor pricing. Another digs into their technology stack. A third analyzes their hiring patterns. All three build a comprehensive competitive analysis without sequential handoffs.
- Complex debugging: One agent traces API calls. Another analyzes database queries. A third reviews logs. They pinpoint problems faster than a single developer working sequentially.
- Documentation generation: Different agents extract documentation patterns from different modules, then synthesize into comprehensive docs.
The technical foundation making this work is Claude Opus 4.6's expanded capabilities. It supports a context window of up to 1 million tokens (in beta), which means each agent instance can hold massive amounts of information without losing the thread. That matters when you're working across large codebases where a single developer might lose track of context across hundreds of thousands of tokens.
On benchmarks, Anthropic demonstrated measurable advantages. On Terminal-Bench 2.0, an agentic coding test, Opus 4.6 showed strong performance. On ARC AGI 2 (a test of solving problems easy for humans but hard for AI), it scored 68.8 percent, compared to 37.6 percent from its predecessor, Opus 4.5. On MRCR v 2, a long-context retrieval benchmark at the 1 million-token variant, Opus 4.6 scored 76 percent versus 18.5 percent for Sonnet 4.5.
Those gaps matter. They're not just academic benchmarks. They directly impact whether an agent working across a massive codebase can actually find the problems buried in hundreds of thousands of tokens of code.
Pricing stayed the same as Opus 4.5:

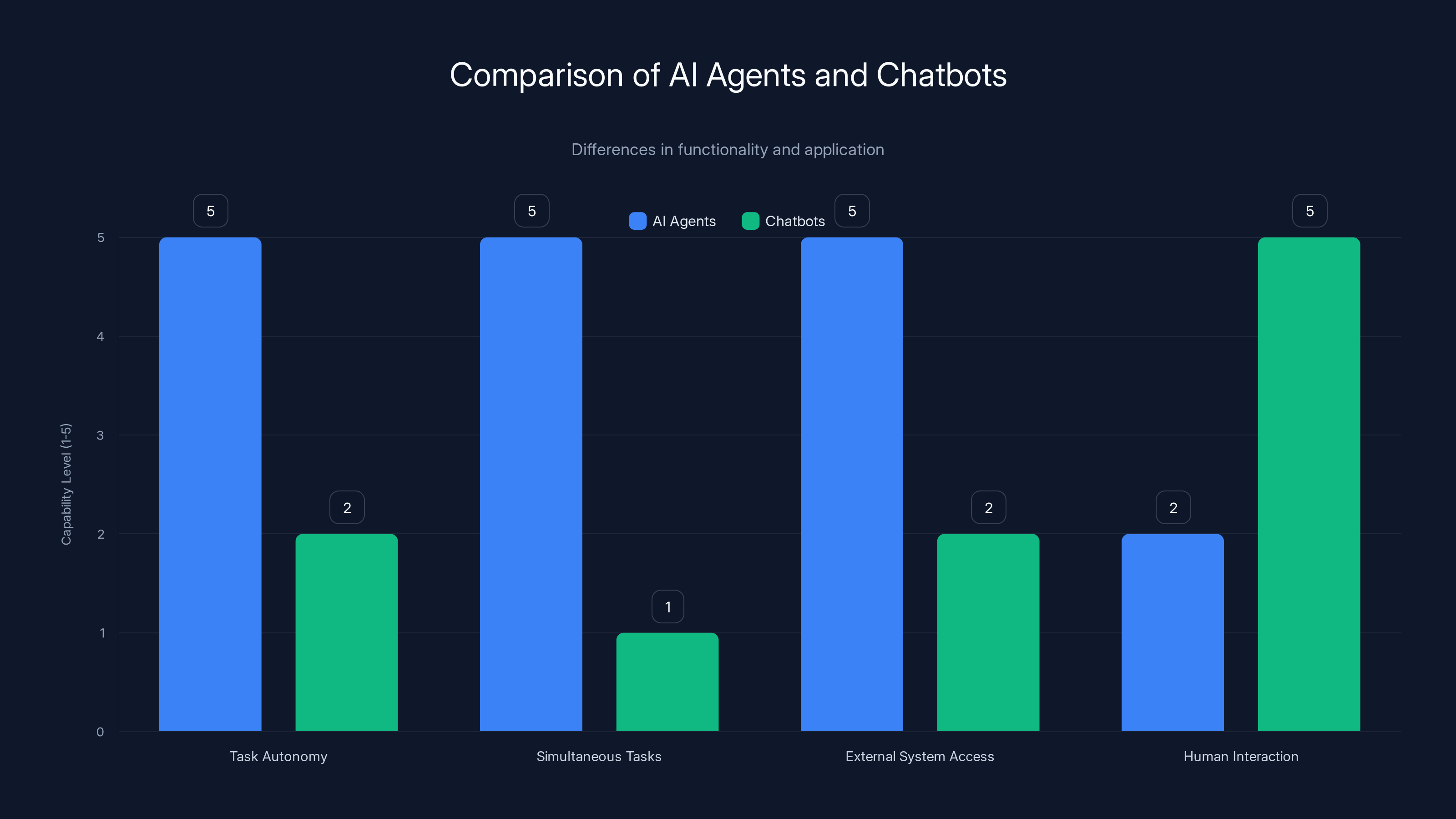
AI agents excel in autonomy and multitasking, while chatbots are more reliant on human interaction. Estimated data based on typical capabilities.
Open AI's Frontier: The Enterprise Agent Workforce
Where Anthropic emphasized the technical interface, OpenAI went full product. Frontier is positioned as a platform to "hire AI co-workers who take on many of the tasks people already do on a computer."
Notice the language. Not "AI assistants." Not "chatbots." Co-workers. It's a fundamental reframing of what AI does in an organization.
Frontier assigns each AI agent its own identity, permissions, and memory. This is crucial because it means agents can't just hallucinate their way through everything. An agent managing customer support doesn't have access to your financial systems. An agent handling HR tasks can't touch product code. The permissions structure creates safe boundaries.
It also connects to existing business systems: CRMs, ticketing tools, data warehouses, Slack integrations. Agents don't live in isolation. They hook into the actual systems humans use to work. A support agent can directly access your ticket queue. A sales agent can update your CRM in real time. A data analyst agent can query your warehouse and generate reports.
OpenAI general manager Barret Zoph told CNBC they're "fundamentally transitioning agents into true AI co-workers." The marketing is enthusiastic. The reality, based on how most organizations are actually using agents right now, is more complicated.
Here's the honest assessment: agents work best when you think of them as tools that amplify existing skills, not as autonomous replacements for humans. They can produce impressive drafts quickly. A support agent can handle a customer query, draft a response, and flag it for human approval. A data analyst agent can run five different analyses in the time a human would run one. But they need constant human course-correction.
The drafts often miss context. The analyses sometimes misinterpret what you're asking. The responses occasionally sound robotic. What makes them valuable isn't autonomy—it's speed. They reduce the time it takes to complete work from hours to minutes. But you still have to review everything.
That gap between "true AI co-workers" (the marketing) and "really capable tools that still need supervision" (the reality) is the most important thing to understand about where agents are right now.
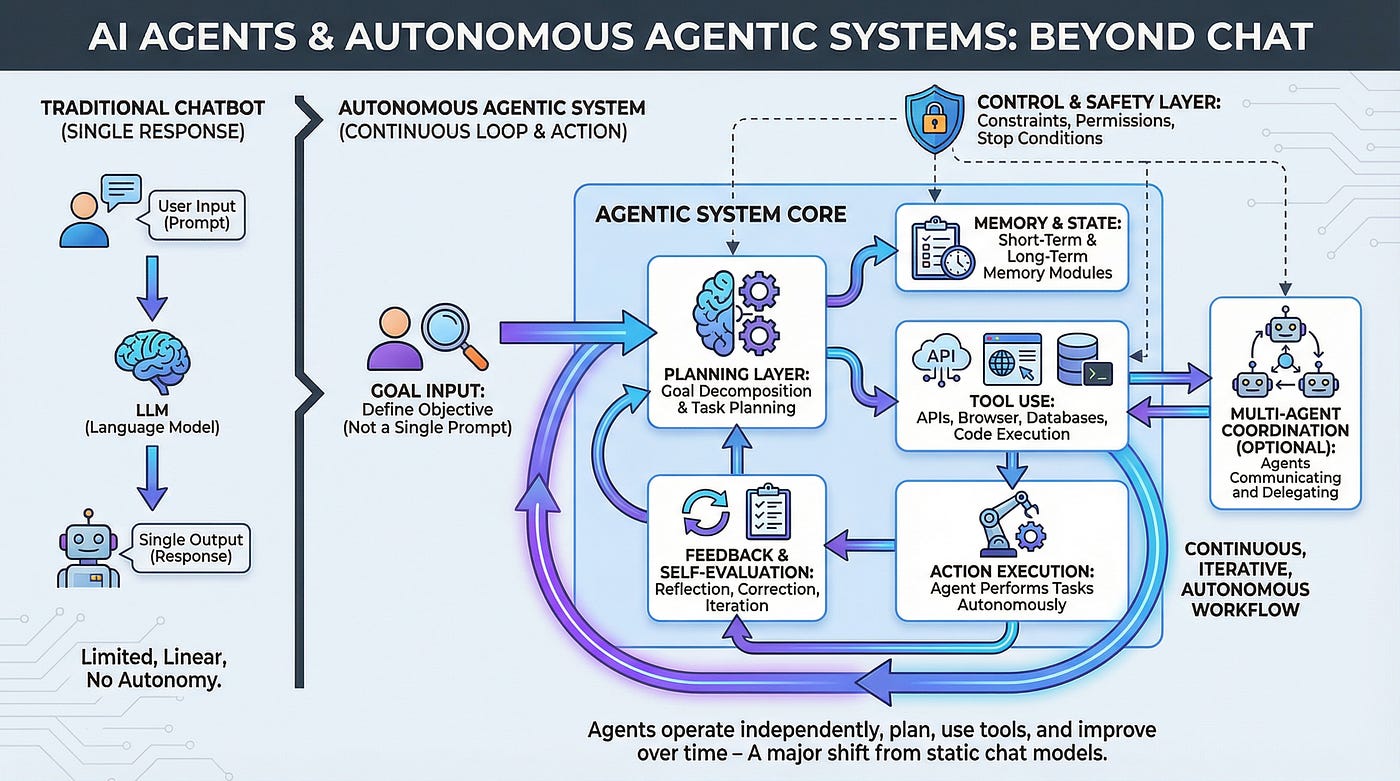
The Command Center Model: Open AI's Codex App
Three days before launching Frontier, OpenAI released a macOS desktop app for Codex, its AI coding tool. Executives described it as a "command center for agents."
The metaphor is revealing.
Codex isn't trying to be a conversation. It's trying to be a control hub. Developers can run multiple agent threads in parallel, each working on an isolated copy of the codebase via Git worktrees. You're not typing prompts back and forth. You're dispatching tasks and monitoring their progress.
OpenAI also released GPT-5.3-Codex on the same day, a new model that powers the Codex app. They claim that early versions of this model were used to debug the model's own training run, manage its deployment, and diagnose test results. That's not theoretical. That's OpenAI using agents to improve agents.
The common thread across Codex, Frontier, and agent teams is architectural. The user becomes a supervisor. You're not solving the problem yourself. You're orchestrating AIs that solve parts of it. You monitor progress. You step in when something goes wrong. You're a middle manager, but instead of managing humans, you're managing AI.
Whether that's actually a good thing is a different question entirely.
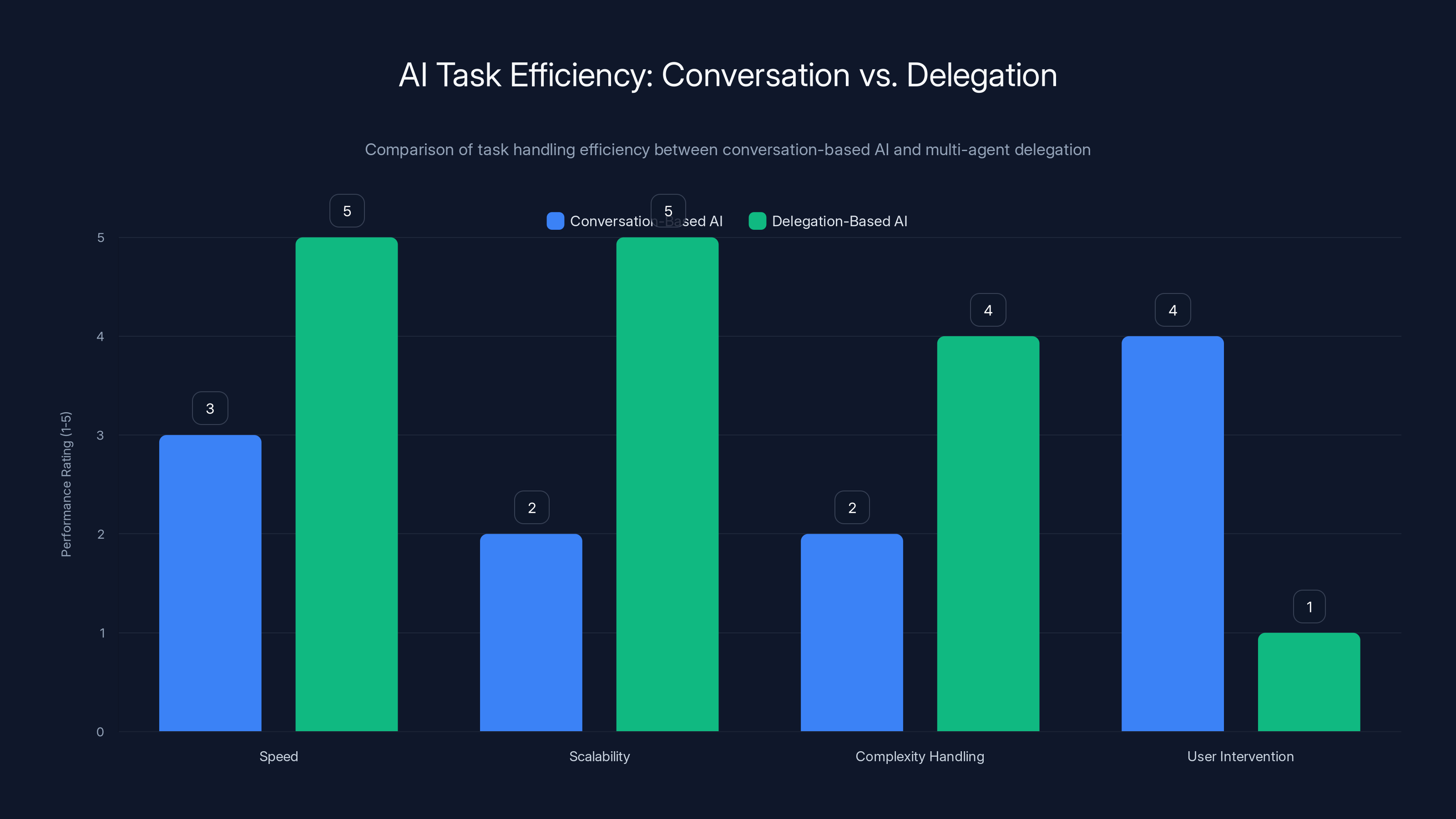
Delegation-based AI significantly outperforms conversation-based AI in speed, scalability, and complexity handling, while requiring less user intervention. (Estimated data)
The Real Problem: Hallucinations Don't Scale
Here's what nobody in the marketing materials mentions: current AI agents still require heavy human intervention to catch errors.
Why? Because hallucinations don't become less common when you run multiple agents. They multiply.
Imagine you spawn five agents to review different parts of a codebase. Each agent has maybe a 5 percent chance of hallucinating something—confidently stating a fact that's simply false. With one agent, you catch most hallucinations by reviewing the output. With five agents running in parallel, you have five different opportunities for things to go confidently wrong.
And it's worse than that. Agents don't work in complete isolation. They coordinate with each other. Agent A might report to Agent B that it found a security issue. Agent B, trusting Agent A's hallucination, builds on that false premise. Now you have cascading errors.
No independent evaluation has confirmed that multi-agent systems reliably outperform a single developer working alone on the same task. That's the research gap everyone's trying not to mention. The products exist. They're shipping. But we don't actually have solid data proving they're better than the alternative of just asking a single AI to do the whole thing.
What we do have is anecdotal evidence from early users and benchmarks on specific tasks. That's not nothing, but it's not nothing either.
This is why Anthropic and OpenAI both emphasized the supervision model. You're not trying to achieve fully autonomous agents. You're trying to amplify human capability by giving humans the ability to deploy multiple AIs and let them work in parallel. The human is still responsible for catching errors.
So the claim isn't "agents are now at human level." It's "agents can move fast enough that having a human supervisor review their work is still way faster than the human doing the work themselves."
That's a more modest claim. And probably a true one.
The Benchmark Wars: Opus 4.6 vs. GPT-5.3-Codex
Both releases came with benchmark claims. This matters because benchmarks are the only public proof we have that these systems actually do what companies claim.
Anthropic released Opus 4.6 claiming it topped OpenAI's GPT-5.2 and Google's Gemini 3 Pro across several evaluations. Then, the very same day, OpenAI released GPT-5.3-Codex, which seemingly reclaimed the lead on Terminal-Bench, the agentic coding test.
This is becoming a pattern. Every model release is immediately challenged by a competitive release. The benchmark war is intensifying precisely because conversation-level AI is getting commoditized. The real competition is moving to agent-level tasks, which are harder to measure.
Here's why benchmarks matter and why you should be skeptical of them simultaneously:
They matter because Terminal-Bench 2.0, Humanity's Last Exam, Browse Comp, ARC AGI 2, and MRCR v 2 are all measuring something real. They test genuine capabilities under controlled conditions. If Opus 4.6 scores 68.8 percent on ARC AGI 2 versus 37.6 percent for Opus 4.5, that's a real 84 percent improvement on a specific task type.
You should be skeptical because measuring AI model capabilities is still relatively new and unsettled science. Benchmarks measure narrow domains. Real-world performance rarely maps cleanly to benchmark performance. A model that dominates on Terminal-Bench might still fail at tasks not represented in the benchmark.
The long-context retrieval performance gap is more meaningful in practice. Opus 4.6 scoring 76 percent on MRCR v 2 at 1 million tokens versus 18.5 percent for Sonnet 4.5 matters because agents working across large codebases genuinely need to maintain context across massive amounts of text. That's not an abstract benchmark advantage. That's a practical difference in whether an agent loses the thread halfway through analyzing your code.

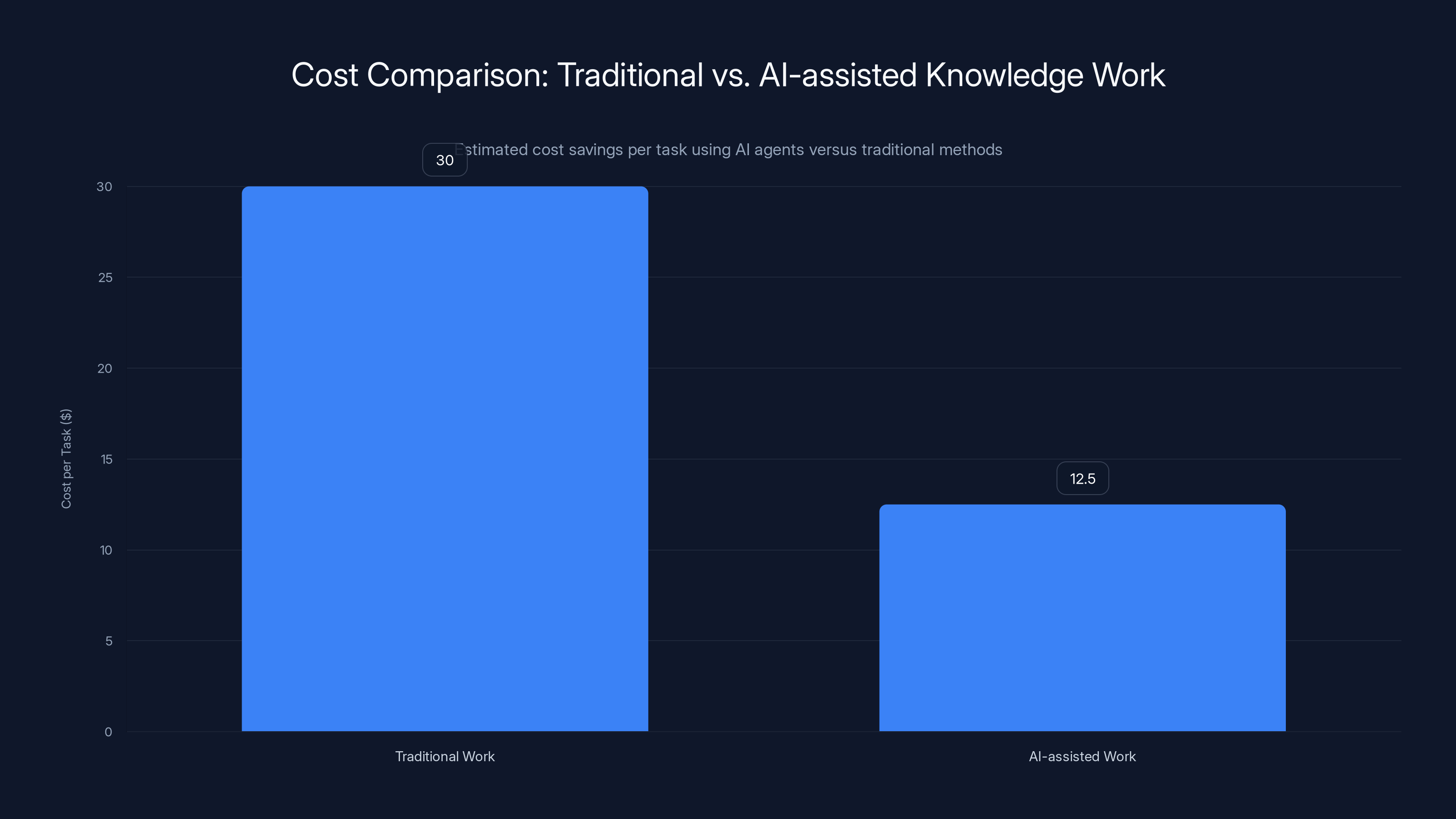
Using AI agents reduces the cost per task from
The Market Reaction: Why Software Stocks Crashed
These announcements happened during the same week that software stocks fell $285 billion.
On January 30, Anthropic released 11 open source plugins for Cowork, its agentic productivity tool that had launched two weeks earlier. OpenAI released multiple agent-focused products. Google was building competitive offerings. The entire industry was simultaneously saying: "AI agents can now do work that humans currently do."
Investors panicked.
The concern wasn't totally irrational. If AI agents can genuinely handle knowledge work autonomously, then the entire category of enterprise software built around humans doing that work becomes obsolete. Your expensive sales automation tool becomes redundant if an AI agent can just handle the work directly. Your analytics platform loses value if an AI agent can run analyses faster than a human ever could.
Software companies have built trillion-dollar businesses on the premise that humans need tools to do work. If the next decade is actually about AI agents doing the work with humans supervising, those tools become less valuable.
But here's the reality check that stabilized the markets: we're nowhere near fully autonomous agents. We're in the "amplification" phase, not the "replacement" phase. Agents still need supervision. They still make mistakes. They still need human judgment for complex decisions.
So the market crashed and then partially recovered because investors realized something: the transition to agents is going to take years, not months. And during that transition, there's massive value in companies that help humans supervise agents, integrate agents into existing systems, and catch agent mistakes.
That's a different business than "software that replaces human workers." That's "software that lets AI amplify human workers."
How Agent Supervision Works in Practice
Let's get concrete about what actually happens when you use these systems.
You're a developer reviewing a codebase. Instead of spending three days reading through code, you spawn agent teams. You tell them to review security, performance, and architectural patterns. Five agents start working. Meanwhile, you handle meetings, respond to emails, do whatever else you need to do.
After an hour, you check back. Two agents found nothing significant. One agent flagged a potential SQL injection vulnerability. One found an N+1 query problem. One identified outdated dependencies.
Now, here's where supervision matters. You don't automatically accept the findings. You:
- Verify the findings: You jump into the agent that flagged SQL injection and ask it to show you exactly where and how. You review the code together. It was real. You log a bug.
- Assess severity: The N+1 query problem is real but it's in a rarely-hit code path. You ask the agent to estimate performance impact. It runs a query analysis. You decide it's a future optimization, not a critical fix.
- Validate the dependencies: The outdated dependencies are flagged, but some are there for compatibility reasons. You ask the agent which ones are actually vulnerable. It checks the CVE database. You update two, skip three.
- Ask followup questions: You ask if there are patterns in the code that suggest the same problems exist elsewhere. The agent scans the codebase and finds three similar patterns.
In a traditional code review, this would take you three full days of deep focus. With agent supervision, it takes you three hours of tactical review. You're not doing less cognitive work—you're doing smarter cognitive work. The agents did the grunt work of reading everything. You did the judgment work of deciding what matters.
That's the value proposition in its actual form.
But notice what's not happening: the agents didn't fix the bugs automatically. You had to decide if things were actually problems. You had to validate findings. You made the final calls.
The marketing says "AI co-workers." The reality is "AI that does the boring scanning work and flags things for human judgment."

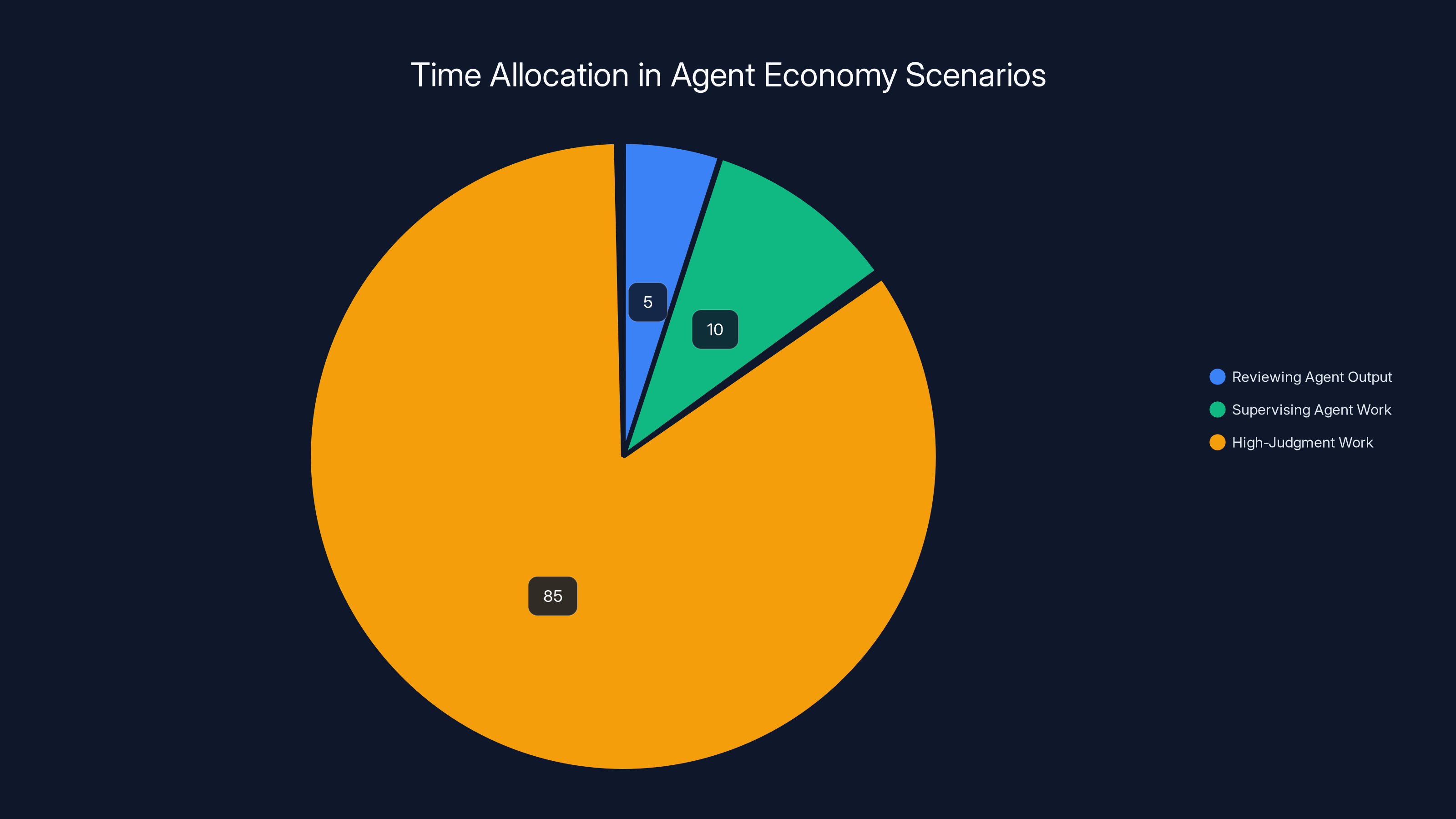
In Scenario 1, developers spend 85% of their time on high-judgment work, while in Scenario 2, supervision tasks consume 90% of their time. (Estimated data)
The Management Overhead Problem
Here's where agent systems get tricky: managing multiple agents can become its own job.
When you have one AI assistant, you just talk to it. The interface is straightforward. But when you have five agents running in parallel, suddenly you need to:
- Monitor which agents have finished and what their status is
- Understand which findings are critical versus informational
- Decide how deep to dive into agent outputs
- Know when to take over directly versus let an agent keep working
- Integrate findings from multiple agents into a coherent picture
- Manage the context each agent is working with
For simple tasks with clear outcomes, this is fine. For complex tasks with ambiguous requirements, it gets complicated fast.
Consider a data analysis task. You ask three agents to analyze customer behavior. Agent A finds that revenue per user increased 15 percent. Agent B finds that user retention dropped 8 percent. Agent C finds that the high-value users are coming from a specific channel that represents only 20 percent of traffic.
These are three different findings. They're not wrong. They're just partial truths. A human analyzing this data would synthesize them into a narrative: "We're making more money per user because high-value users from Channel X are driving disproportionate revenue, but overall retention is declining because we're not converting lower-value users effectively."
But Agent A might conclude we should focus on revenue maximization. Agent B might prioritize retention. Agent C might want to double down on the successful channel. They're not working from a coherent strategy. You have to be the person who synthesizes them into strategic judgment.
That's exhausting. That's the hidden cost of agent-based work.

Integration with Existing Systems
Frontier's big bet is that agents need to hook into existing business systems to be useful.
A standalone agent that analyzes data is interesting. An agent that analyzes data and automatically updates your CRM based on findings is transformative. That's the difference between "cool AI feature" and "system that actually changes how work happens."
OpenAI built Frontier explicitly around this. Agents get access to your CRM, your ticketing system, your data warehouse, your communication tools. When an agent finishes work, it doesn't just generate a report. It takes action: creates a ticket, updates a lead status, sends a notification.
This creates new problems and new opportunities simultaneously.
Opportunities:
- Process acceleration: Work that required manual handoffs between systems now happens automatically
- Real-time responsiveness: Agents can respond to events immediately rather than waiting for humans
- Integration of information: Agents can pull data from multiple systems to make better decisions
Problems:
- Permissions and security: You have to give agents access to sensitive systems, which requires security architecture that makes sure they can't go rogue
- Error cascading: If an agent makes a mistake and automatically updates your CRM, the mistake is now in your production system
- Audit trails: You need comprehensive logging of everything agents do so you can understand what happened if something goes wrong
- Compliance: If agents are modifying customer data, you need to make sure they're complying with regulations
Anthropic built agent teams in a more constrained way. They work within Claude Code in a development environment. You're not giving agents access to your production systems directly. You're giving them access to code, and you're responsible for what happens with that code.
OpenAI's approach is more ambitious and more risky. It's also more valuable if it works.
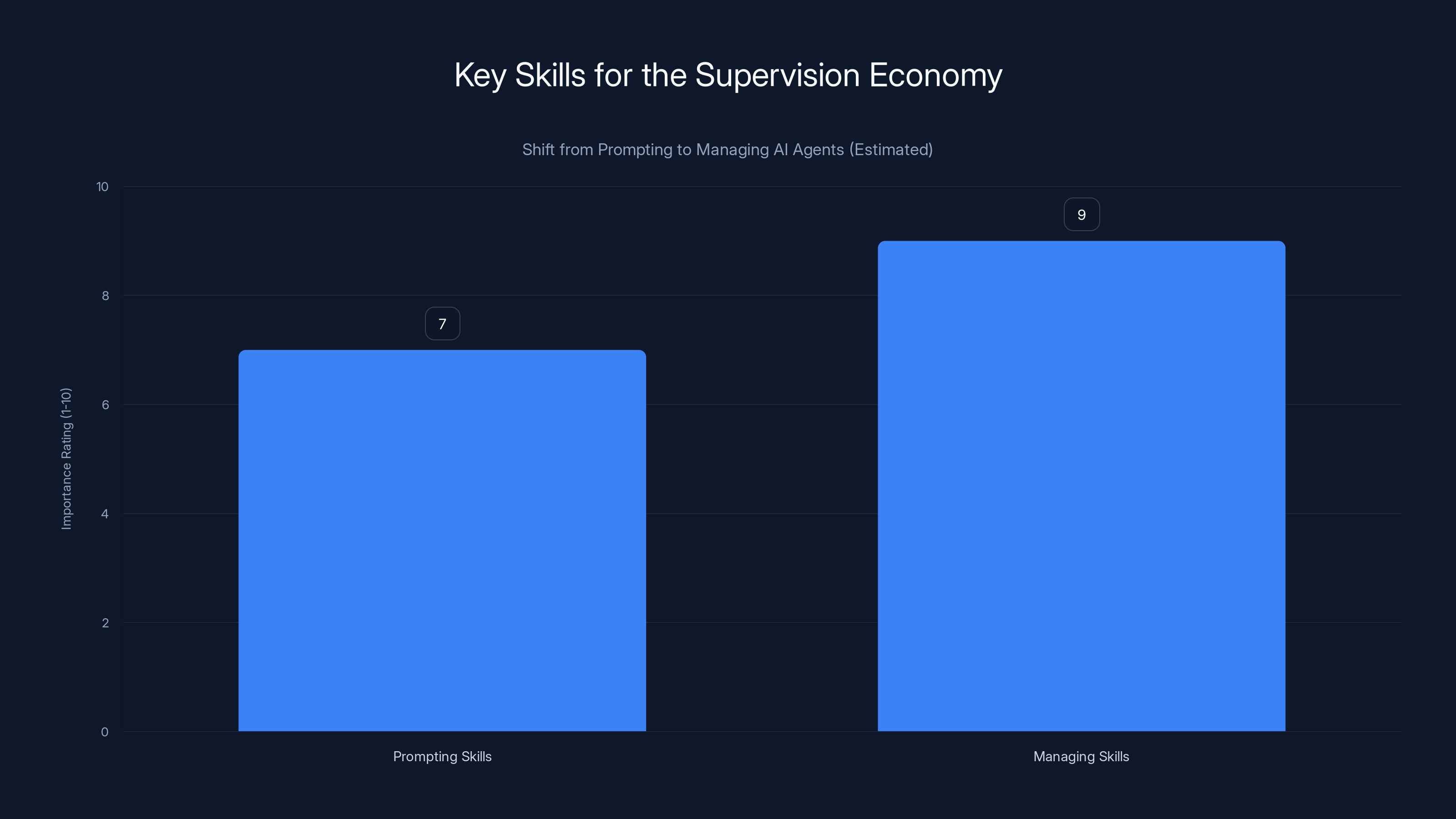
As the AI industry shifts focus, managing skills are projected to become more important than prompting skills by 2026. (Estimated data)
The Autonomous Boundary: Where Supervision Ends
One of the most important questions nobody's answered yet: how autonomous is too autonomous?
Right now, the products are positioned as "supervised autonomy." Agents work with substantial autonomy, but you're monitoring and intervening. But at some point, if agents get good enough, you'll have to decide: do I trust this agent to make decisions without my approval?
Consider a customer support scenario. An agent handles customer emails. For simple questions (tracking a package, updating an address), does it need human approval to send responses? Probably not. The risk is low. But for a customer threatening to sue? That definitely needs human approval.
So you need fine-grained rules about what agents can do autonomously and what requires approval. That's easy for simple cases and incredibly complicated for nuanced judgment calls.
We're basically trying to establish an "agent governance" framework while the agents are still early-stage. That's like trying to write employment law for a new category of worker that we don't fully understand yet.
OpenAI's permissions model is one approach. Anthropic's supervised-in-the-UI model is another. Neither is settled. Neither is perfect.
This is actually the most important problem being solved right now. Not "how do we make agents smarter." But "how do we give agents just enough autonomy to be useful without giving them so much autonomy that they break things without human oversight."
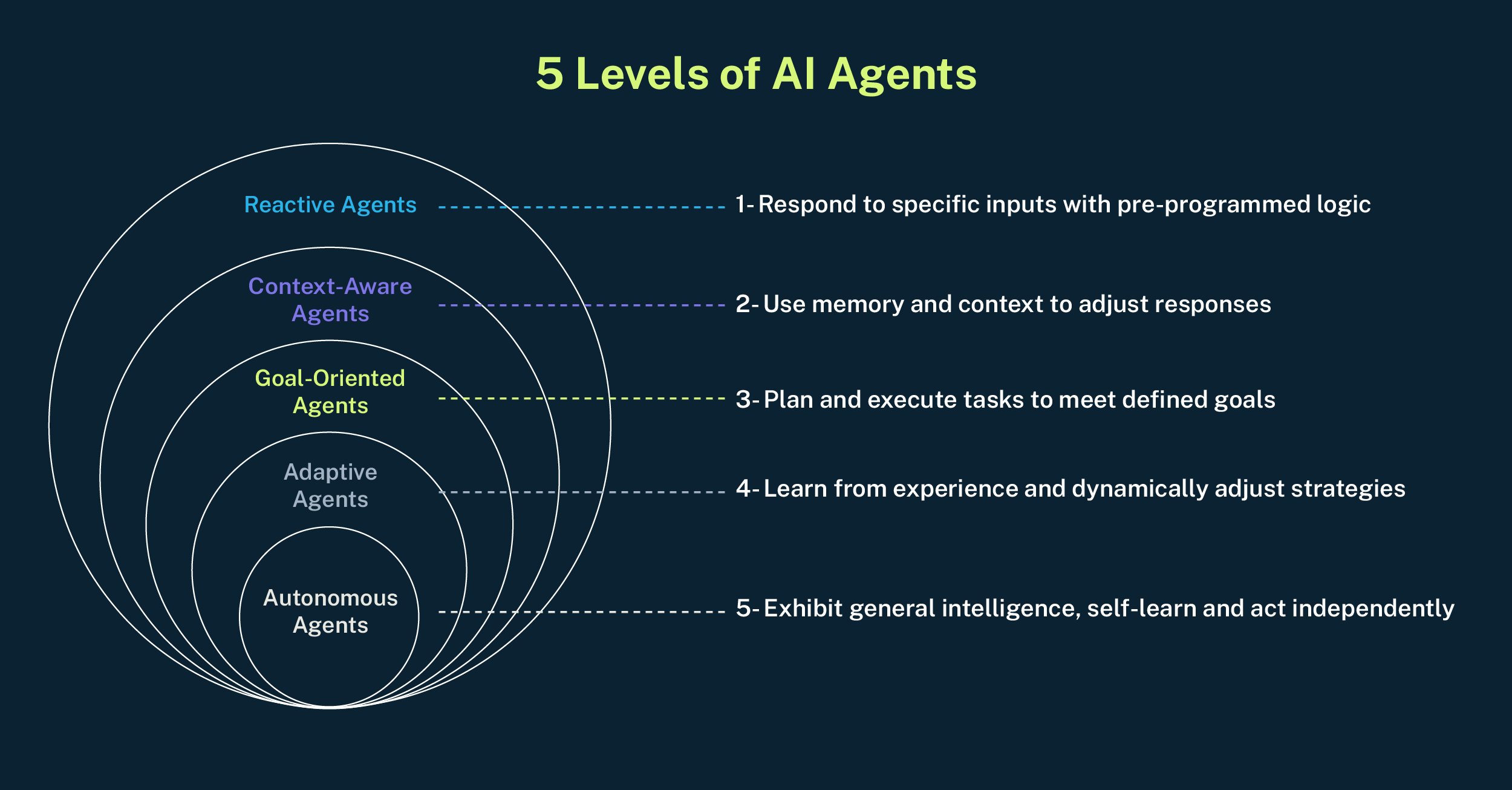
The Skills Gap: From Chatting to Managing
All of this assumes you know how to manage agents.
For the past two years, the skill you needed to use AI effectively was: write good prompts. Ask the right questions. Know how to push back when AI gives you mediocre output.
Those skills still matter, but they're no longer sufficient. Now you also need to:
- Decompose tasks: Break complex work into independent pieces that agents can work on in parallel
- Set clear metrics: Define what success looks like for each agent so they know when they're done
- Monitor and intervene: Notice when agents are off-track and steer them back
- Integrate findings: Take output from multiple agents and synthesize it into coherent action
- Debug failures: When an agent produces bad output, understand why and adjust your approach
These are management skills, not prompt-writing skills.
Some people will be great at this immediately. People who've managed teams, run projects, organized complex workflows. They already think in terms of decomposing work and monitoring progress. Agent management is just a new interface for skills they already have.
Other people will struggle. People who love direct hands-on work, who prefer doing the thing themselves to delegating it. The agent-based future requires them to become supervisors instead of doers. That's a hard transition.
There's going to be a training and education industry around "how to manage AI agents effectively." That's not a bug, that's a feature. The people who figure out agent management first will have massive advantages over people still treating AI as a conversation partner.
The Economics: Cost Per Knowledge Worker
Let's talk about money, because that's ultimately what drives adoption.
Claude Opus 4.6 pricing is
A knowledge worker costs roughly
Total cost with agents:
Scale that across an organization. A 100-person knowledge worker team doing 10 tasks per day. That's 1,000 tasks per day. At
That math is why every company is suddenly interested in agents.
But that math also assumes:
- Tasks are generic enough that agents can handle them at scale
- Supervision overhead doesn't consume savings
- Error rates don't require expensive rework
- Integration with existing systems is straightforward
None of those are guaranteed for every task or organization.
Some tasks are too nuanced for agents to handle reliably. Some organizations have so many legacy systems that integration is a nightmare. Some error rates will be unacceptably high.
But for 60-70 percent of routine knowledge work, this math probably works.
Runable's Role in Agent Management
For teams building multi-agent workflows or needing to generate content at agent scale, platforms like Runable offer practical infrastructure. Runable provides AI-powered automation for creating presentations, documents, reports, images, and videos starting at $9/month.
In an agent-management workflow, Runable becomes useful when multiple agents need to generate reports, presentations, or documentation from raw data or analysis. Rather than each agent trying to format output, Runable handles the synthesis and presentation layer. An agent analyzes data, feeds results to Runable, which generates a polished report. Another agent processes images and video, and Runable creates visual presentations automatically.
For teams transitioning from conversational AI to agent-based workflows, this reduces the overhead of managing different output formats and presentation layers across multiple agents.
Use Case: Automate report generation when data analysis agents finish their work, or synthesize multi-agent findings into executive presentations automatically.
Try Runable For Free
The Supervision Model's Hidden Assumptions
Everything about agent management assumes you have the bandwidth to supervise.
But what happens when you don't? What happens when you have 30 agents running and you can't possibly monitor all of them? You have to trust them more. You have to implement automated checks to catch obvious errors. You have to accept some level of failure.
That's actually fine for many tasks. If an agent makes a mistake analyzing historical data, you catch it in review. If an agent drafts a customer email and uses weird phrasing, you fix it before sending. Those failures aren't catastrophic.
But some failures are catastrophic. An agent accidentally grants incorrect permissions. An agent modifies financial records. An agent sends a confidential email to the wrong recipient. Suddenly you need perfect supervision, which is impossible.
This is why Anthropic kept agent teams in a sandboxed development environment. Why OpenAI built permissions models into Frontier. The supervision model only works if failure modes are contained.
As agents get more autonomy, that containment becomes harder to maintain. You end up needing systematic governance, not just human attention.
Future: The Agent Economy
If we accept that agents are real and the supervision model works at scale, what does the future look like?
Two scenarios are worth considering.
Scenario 1: Agents Become Invisible Infrastructure
Agents become like APIs. You don't think about them. They run in the background, doing routine work, flagging anything unusual. A developer spends maybe 5 percent of their time reviewing agent output and maybe 10 percent actively supervising agent work. The rest of the time they do high-judgment work that requires human intelligence.
This is the optimistic scenario. It actually happens when:
- Tasks are sufficiently standardized that agents can handle them reliably
- Error rates are low enough that supervision doesn't become its own full-time job
- Agents have clear success metrics so you know when they're done
- Integration with existing systems is smooth
If this happens, knowledge workers become more productive. Organizations need fewer people for routine work and more people for strategy and judgment. It's actually good for people who are good at strategy and judgment. Bad for people who are only good at executing tasks.
Scenario 2: Supervision Becomes Its Own Bottleneck
Agents get fast enough that having humans review everything creates a massive bottleneck. You spawn 50 agents, they finish their work, and you spend 40 hours reviewing and validating their output. You've created a new job called "AI supervisor" that consumes all the time you saved.
This happens when:
- Task decomposition is unclear, so agents work on overlapping problems
- Error rates are high enough that careful review is necessary
- Integration with existing systems is messy and requires manual validation
- Coordination between agents requires constant human mediation
If this happens, the agent economy stalls. Organizations realize that agents don't actually save time if humans have to carefully review everything. The model breaks.
The truth is probably somewhere between these scenarios. For some tasks and organizations, Scenario 1. For others, Scenario 2. The key variable is how good agents get at reliability and how well tasks can be decomposed.
Why This Matters Now
The shift from conversation to agent management isn't just a product update. It represents a fundamental assumption change about what AI is for.
Conversational AI assumes you're smart enough to do the work yourself, and you just need a better thinking partner. Agent-based AI assumes the AI should do the work, and you should supervise it.
One model makes humans the primary workers. The other makes humans the managers.
Both have implications. The conversation model led to this era where everyone can suddenly ask AI for help with their individual work. The agent model might lead to an era where organizations get exponentially more productive by deploying armies of AI systems.
Or it might lead to organizations that are constantly drowning in agent output that needs validation.
We're at an inflection point. The technology is real. The products are shipping. But whether this actually works at scale, in real organizations, on real tasks, with real error rates and real supervision overhead—we don't know yet.
What we do know is that every major AI company is betting their future on it. That alone tells you something important: they think the conversation era is over. The agent era has started.
Now we find out if they're right.

FAQ
What are AI agents and how do they differ from chatbots?
AI agents are autonomous systems that can perform tasks with minimal human intervention, making decisions and taking actions independently. Unlike chatbots, which respond to conversational prompts in real time, agents can work on multiple tasks simultaneously, coordinate with other agents, and access external systems without requiring a human to be present for each interaction. Agents decompose complex work into smaller pieces and operate in parallel, whereas chatbots handle sequential conversations one at a time.
How does the agent supervision model actually work in practice?
The agent supervision model involves spawning multiple AI instances to work on different parts of a task simultaneously while a human monitors progress and intervenes when needed. A developer or knowledge worker reviews agent outputs, validates findings, asks clarifying questions, and corrects course when agents go off track. Rather than the human doing all the work, they become a manager overseeing AI workers, focusing on judgment calls and high-level decisions while agents handle routine analysis and information gathering.
What are the main differences between Anthropic's agent teams and Open AI's Frontier platform?
Anthropic's agent teams operate within Claude Code as a development-focused tool where multiple agents review code in parallel, run in a supervised terminal interface, and require active human management. OpenAI's Frontier is an enterprise platform where agents have individual identities, permissions, and memory, with direct integration into business systems like CRMs and ticketing tools. Agent teams emphasize technical control for developers, while Frontier emphasizes business process automation across organizations.
What makes the long-context performance important for agent systems?
Long-context performance matters because agents working on large codebases or extensive documents need to maintain understanding across hundreds of thousands of tokens without losing the thread. Claude Opus 4.6's 1 million token context window allows agents to review entire projects without losing context, whereas models with shorter context windows force agents to work in smaller chunks and lose coherence. This directly impacts whether agents can reliably find problems buried deep in large codebases or comprehensive documents.
What are the biggest challenges preventing agents from becoming truly autonomous?
The main challenges are hallucinations scaling with multiple agents, lack of independent evaluation proving multi-agent systems outperform single developers, supervision overhead consuming productivity gains, error cascading when agents coordinate with each other, and integration complexity with existing business systems. Additionally, there's no standardized governance framework yet for determining which tasks agents can perform autonomously and which require human approval, particularly for mission-critical work.
How should organizations start implementing agent-based workflows?
Organizations should begin with well-defined tasks that naturally decompose into independent pieces, where error rates are low and supervision is straightforward. Start with tasks where agent failure is low-cost—like data analysis or document review—rather than mission-critical operations. Establish clear success metrics for each agent, implement permission systems to contain potential damage, build comprehensive logging to understand what agents did, and start with a single team piloting the approach before rolling out across the organization.
What skills do knowledge workers need to manage AI agents effectively?
Mastering agent management requires learning task decomposition (breaking complex work into independent pieces), setting clear metrics and success criteria, monitoring and intervening when agents drift off-track, synthesizing findings from multiple agents into coherent action, and debugging failures when agents produce poor output. These management skills are distinct from the prompt-writing skills needed for conversational AI, and will be increasingly important as organizations adopt agent-based workflows.
How do current AI agents compare on performance benchmarks?
Claude Opus 4.6 achieves strong performance on Terminal-Bench 2.0 (agentic coding), 68.8 percent on ARC AGI 2, and 76 percent on MRCR v 2 long-context retrieval, but OpenAI's GPT-5.3-Codex reclaimed the lead on Terminal-Bench released the same day. Benchmarks measure narrow domains reliably but don't always predict real-world performance. For agent work specifically, long-context retrieval benchmarks are more predictive than general conversational benchmarks, as agents need to maintain coherence across large information sets.
Conclusion: The Supervision Economy
We're watching an industry-wide pivot happen in real time. In January 2026, every major AI company simultaneously said: "The future isn't conversations. It's workers."
Anthropic released Claude Opus 4.6 with agent teams. OpenAI released Frontier and a Codex app specifically designed as a command center for agents. The timing wasn't coincidental. It was a coordinated realization that the next layer of value in AI isn't making individual conversations better. It's enabling humans to supervise multiple AI systems working in parallel.
Is this actually better than having humans do the work themselves? Sometimes. For standardized, decomposable tasks with low error rates, absolutely. For ambiguous, judgment-heavy work that requires constant coordination, maybe not.
Does this mark the end of the conversational AI era? Probably. The conversation model was useful for getting AI into people's hands quickly. But it was always a limitation. The real power is in delegation and parallelization.
What this means in practice is a fundamental skill shift. For the past two years, you needed to be good at prompting. In the next two years, you need to be good at managing. That's a different set of abilities. Some people will thrive. Others will struggle.
The organizations that figure out agent management first—that genuinely reduce supervision overhead to something sustainable, that build governance systems that contain failure modes, that integrate agents into existing workflows without breaking things—those organizations will get exponentially more productive.
The organizations that deploy agents haphazardly, that end up drowning in validation work, that give agents too much autonomy and have to clean up the mess—they'll find agents are expensive toys, not productivity multipliers.
We're not in the "agents are better than humans" era yet. We're in the "agents can amplify humans if humans manage them well" era.
How long that era lasts depends entirely on whether the supervision model actually works at the scale these companies are betting on. We'll find out soon enough.
The fact that entire software categories lost $285 billion in market cap when people realized AI agents might actually work tells you something important: the market knows this is real. The market knows this matters.
Now we just have to figure out if it actually works.
Key Takeaways
- AI companies are shifting from conversational AI to multi-agent management systems that enable humans to supervise parallel autonomous agents
- Claude Opus 4.6 with agent teams and OpenAI Frontier represent architectural changes where users become supervisors rather than conversation participants
- Agents still require heavy human intervention to catch errors and no independent evaluation has confirmed multi-agent systems reliably outperform single developers
- The economics of agent supervision show 50-60% cost reduction when agents handle routine tasks while humans focus on judgment and strategy
- The transition requires new management skills focused on task decomposition, metrics definition, progress monitoring, and finding synthesis rather than conversational prompt writing
Related Articles
- GPT-5.3-Codex vs Claude Opus: The AI Coding Wars Escalate [2025]
- Anthropic Opus 4.6 Agent Teams: Multi-Agent AI Explained [2025]
- Moltbook: The AI Agent Social Network Explained [2025]
- OpenAI Frontier: The Complete Guide to AI Agent Management [2025]
- AI Agents & Access Control: Why Traditional Security Fails [2025]
- GPT-5.3-Codex: OpenAI's Next-Gen Coding Model Explained [2025]

